本文的目的是介绍如何使用GROUPBY子句将查询移植到PostgreSQL?的详细情况,我们将通过专业的研究、有关数据的分析等多种方式,同时也不会遗漏关于javassh项目oracle移植到postg
本文的目的是介绍如何使用GROUP BY子句将查询移植到PostgreSQL?的详细情况,我们将通过专业的研究、有关数据的分析等多种方式,同时也不会遗漏关于java ssh 项目oracle移植到postgresql、Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句、Postgres SQL:列必须出现在 GROUP BY 子句中或用于聚合函数中、PostgreSQL -must出现在GROUP BY子句中,或者在聚合函数中使用的知识。
本文目录一览:- 如何使用GROUP BY子句将查询移植到PostgreSQL?
- java ssh 项目oracle移植到postgresql
- Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句
- Postgres SQL:列必须出现在 GROUP BY 子句中或用于聚合函数中
- PostgreSQL -must出现在GROUP BY子句中,或者在聚合函数中使用

如何使用GROUP BY子句将查询移植到PostgreSQL?
我正在将一个简单的费用数据库移植到Postgres,并被困在使用GROUPBY和多个JOIN子句的视图上。我认为Postgres希望我使用GROUP BY子句中的所有表。
表定义在最后。需要注意的是列account_id,receiving_account_id并place可能NULL和operation可以有0个标签。
原始CREATE声明
CREATE VIEW details AS SELECT op.id, op.name, c.name, CASE --amountsign WHEN op.receiving_account_id IS NOT NULL THEN CASE WHEN op.account_id IS NULL THEN ''+'' ELSE ''='' END ELSE ''-'' END || '' '' || printf("%.2f", op.amount) || '' z艂'' AS amount, CASE --account WHEN op.receiving_account_id IS NOT NULL THEN CASE WHEN op.account_id IS NULL THEN ac2.name ELSE ac.name || '' -> '' || ac2.name END ELSE ac.name END AS account, t.name AS type, CASE --date WHEN op.time IS NOT NULL THEN op.date || '' '' || op.time ELSE op.date END AS date, p.name AS place, GROUP_CONCAT(tag.name, '', '') AS tagsFROM operation opLEFT JOIN category c ON op.category_id = c.idLEFT JOIN type t ON op.type_id = t.idLEFT JOIN account ac ON op.account_id = ac.idLEFT JOIN account ac2 ON op.receiving_account_id = ac2.idLEFT JOIN place p ON op.place_id = p.idLEFT JOIN operation_tag ot ON op.id = ot.operation_idLEFT JOIN tag ON ot.tag_id = tag.idGROUP BY IFNULL (ot.operation_id, op.id)ORDER BY date DESCPostgres中的当前查询
我进行了一些更新,目前的说法是:
BEGIN TRANSACTION;CREATE VIEW details AS SELECT op.id, op.name, c.name, CASE --amountsign WHEN op.receiving_account_id IS NOT NULL THEN CASE WHEN op.account_id IS NULL THEN ''+'' ELSE ''='' END ELSE ''-'' END || '' '' || op.amount || '' z艂'' AS amount, CASE --account WHEN op.receiving_account_id IS NOT NULL THEN CASE WHEN op.account_id IS NULL THEN ac2.name ELSE ac.name || '' -> '' || ac2.name END ELSE ac.name END AS account, t.name AS type, CASE --date WHEN op.time IS NOT NULL THEN to_char(op.date, ''DD.MM.YY'') || '' '' || op.time ELSE to_char(op.date, ''DD.MM.YY'') END AS date, p.name AS place, STRING_AGG(tag.name, '', '') AS tagsFROM operation opLEFT JOIN category c ON op.category_id = c.idLEFT JOIN type t ON op.type_id = t.idLEFT JOIN account ac ON op.account_id = ac.idLEFT JOIN account ac2 ON op.receiving_account_id = ac2.idLEFT JOIN place p ON op.place_id = p.idLEFT JOIN operation_tag ot ON op.id = ot.operation_idLEFT JOIN tag ON ot.tag_id = tag.idGROUP BY COALESCE (ot.operation_id, op.id)ORDER BY date DESC;COMMIT;在Column ''x'' must appear in GROUP BY clause添加列出的错误时,我在这里遇到错误:
GROUP BY COALESCE(ot.operation_id, op.id), op.id, c.name, ac2.name, ac.name, t.name, p.name当我添加p.name列时,我Column ''p.name'' is defined more than once error.如何解决该问题?
表定义
CREATE TABLE operation ( id integer NOT NULL PRIMARY KEY, name character varying(64) NOT NULL, category_id integer NOT NULL, type_id integer NOT NULL, amount numeric(8,2) NOT NULL, date date NOT NULL, "time" time without time zone NOT NULL, place_id integer, account_id integer, receiving_account_id integer, CONSTRAINT categories_transactions FOREIGN KEY (category_id) REFERENCES category (id) MATCH SIMPLE ON UPDATE NO ACTION ON DELETE NO ACTION, CONSTRAINT transactions_accounts FOREIGN KEY (account_id) REFERENCES account (id) MATCH SIMPLE ON UPDATE NO ACTION ON DELETE NO ACTION, CONSTRAINT transactions_accounts_second FOREIGN KEY (receiving_account_id) REFERENCES account (id) MATCH SIMPLE ON UPDATE NO ACTION ON DELETE NO ACTION, CONSTRAINT transactions_places FOREIGN KEY (place_id) REFERENCES place (id) MATCH SIMPLE ON UPDATE NO ACTION ON DELETE NO ACTION, CONSTRAINT transactions_transaction_types FOREIGN KEY (type_id) REFERENCES type (id) MATCH SIMPLE ON UPDATE NO ACTION ON DELETE NO ACTION);答案1
就像已经提供的@Andomar一样:大多数RDBMS要求按未聚合的每一列进行分组-
查询中的其他任何位置(包括SELECT列表,还包括WHERE子句等)。
因此op.id覆盖了整个表格,这应该适用于您当前的查询:
GROUP BY op.id, c.name, 5, t.name, p.name5作为一个 位置参考 的SELECT列表,这也允许在Postgres的。这只是重复长表达的简写形式:
CASE WHEN op.receiving_account_id IS NOT NULL THEN CASE WHEN op.account_id IS NULL THEN ac2.name ELSE ac.name || '' -> '' || ac2.name END ELSE ac.nameEND我从您的名字得出,您与之间有一个:m关系,operation并通过tag实现operation_tag。所有其他联接似乎都没有将行相乘,因此单独聚合标签会更有效-
就像@Andomar暗示的那样,只需弄清楚逻辑即可。
这应该工作:
SELECT op.id , op.name , c.name , CASE -- amountsign WHEN op.receiving_account_id IS NOT NULL THEN CASE WHEN op.account_id IS NULL THEN ''+'' ELSE ''='' END ELSE ''-'' END || '' '' || op.amount || '' z艂'' AS amount , CASE -- account WHEN op.receiving_account_id IS NOT NULL THEN CASE WHEN op.account_id IS NULL THEN ac2.name ELSE ac.name || '' -> '' || ac2.name END ELSE ac.name END AS account , t.name AS type , **to_char(op.date, ''DD.MM.YY'') || '' '' || op.time AS date** -- see below , p.name AS place , ot.tagsFROM operation opLEFT JOIN category c ON op.category_id = c.idLEFT JOIN type t ON op.type_id = t.idLEFT JOIN account ac ON op.account_id = ac.idLEFT JOIN account ac2 ON op.receiving_account_id = ac2.idLEFT JOIN place p ON op.place_id = p.id**LEFT JOIN ( SELECT operation_id, string_agg(t.name, '', '') AS tags FROM operation_tag ot LEFT JOIN tag t ON t.id = ot.tag_id GROUP BY 1 ) ot ON op.id = ot.operation_id****ORDER BY op.date DESC, op.time DESC** ;阿西德斯
您可以替换:
CASE --date WHEN op.time IS NOT NULL THEN to_char(op.date, ''DD.MM.YY'') || '' '' || op.time ELSE to_char(op.date, ''DD.MM.YY'')END AS date具有以下较短的等效项:
concat_ws('' '', to_char(op.date, ''DD.MM.YY''), op.time) AS date但是,由于这两个列均已定义NOT NULL,因此您可以进一步简化为:
to_char(op.date, ''DD.MM.YY'') || '' '' || op.time AS date小心一点,您ORDER BY至少有一个输入列也称为date。如果使用非限定名称,它将引用 输出 列-这就是您想要的名称(如注释中所阐明)。
但是 ,按文本表示进行排序将无法正确地根据您的时间轴进行排序。按原始值排序,而不是上面我的查询中所建议的。

java ssh 项目oracle移植到postgresql
原来一使用ssh开发的项目,因实际需要,要从oracle迁移到postgresql。
理想
1.postgresql中创建相关表,把数据从oracle导到postgresql中
2.复制postgresql的jdbc包到项目中
3.配置jdbc参数,及方言
4.大功告成
现实
1,2,3顺利完成
但并没有大功告成
分析
主要的错误为两类:
1. 不支持 connect by ... start with语法
2. 不支持 a.id=b.id(+) 语法
原项目中大量使用了上述两种语句,在postgresql中要相应修改
解决
1. 递归查询
postgresql 支持两种递归查询语法,本人倾向于使用 with recursive 语法,如:
with recursive rec as (
select p_id, id, code, name
from t_menu
where id=[start with value]
union all
select m.p_id, m.id, m.code, m.name
from t_menu m, rec r
where r.id = m.p_id /* connect by part*/
)
select * from rec
2. 外连接
改用 left outer join [table] on a.[field]=b.[field] 语法,如:
select a.* from a, b where a.id=b.id(+) and a.type=?
更改为:
select a.* from a left outer join b on a.id=b.id where a.type = ?
3. 比较庆幸原项目没有使用存储过程、函数及其他oracle专有功能,如:序列、同义词、物化视图、job等,否则迁移起来更麻烦。
最后
留一个外连接的题目,看看大家能否正确的转换成postgresql语句
select a.a_id, b.b_id, c.c_id from a, b, c where a.b_id = b.b_id(+) and b.c_id = c.c_id(+)

Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句
Mysql的各个查询语句
一、where子句
语法:select *|字段列表 from 表名 where 表达式。where子句后面往往配合MySQL运算符一起使用(做条件判断)
作用:通过限定的表达式的条件对数据进行过滤,得到我们想要的结果。
1.MYSQL运算符:
MySQL支持以下的运算符:
关系运算符
< >
<= >=
= !=(<>)
注意:这里的等于是一个等号
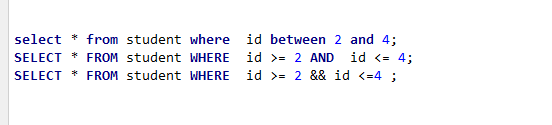
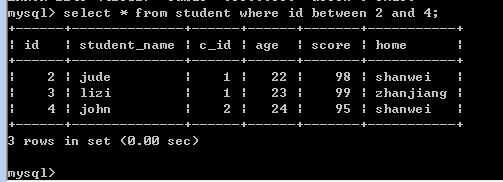
between and
做数值范围限定,相当于数学上的闭区间!
比如:
between A and B相当于 [A,B]
in和not in
语法形式:in|not in(集合)
表示某个值出现或没出现在一个集合之中!

逻辑运算符
&& and
|| or
! not

where子句的其他形式
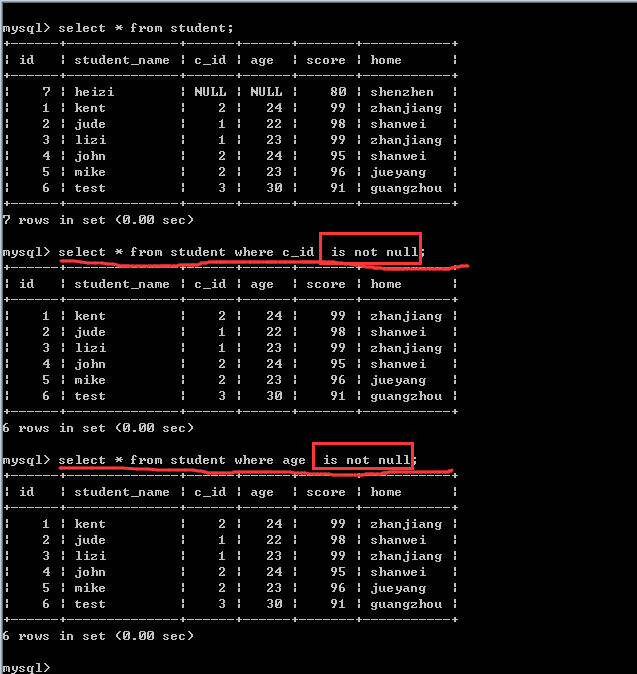
空值查询
select *|字段列表 from 表名 where 字段名 is [not] null
模糊查询
也就是带有like关键字的查询,常见的语法形式是:
select *|字段列表from 表名 where 字段名 [not] like ‘通配符字符串’;
所谓的通配符字符串,就是含有通配符的字符串!
MySQL中的通配符有两个:
_ :代表任意的单个字符
% :代表任意的字符
案例一:
查找student表中student_name字段以“j”开头的学生信息!

案例二:
查找student表中student_name字段以“j”开头以“n”结尾的学生信息!
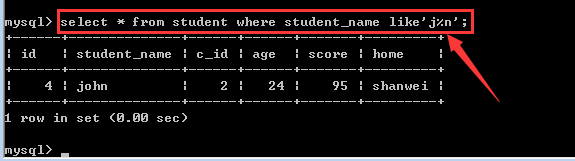
案例三:
查找student表中student_name字段含有“n”字的学生信息
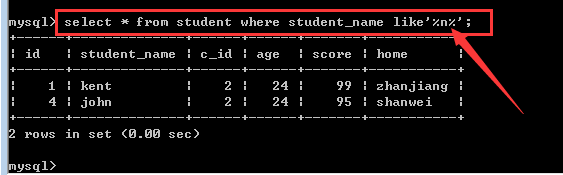
案例四:
查找student表中student_name以“j”开头含有四个字母的名字的学生信息

案例五:
查找student表中stu_name含有_或含有%的学生信息
由于%和_都具有特殊的含义,所以如果确实想查询某个字段中含有%或_的记录,需要对它们进行转义!
也就是查找 \_ 和 \%

二、group by子句
也叫作分组统计查询语句!
语法
group by 字段1[,字段2]……
从形式上看,就是通过表内的某个或某些字段进行分组:
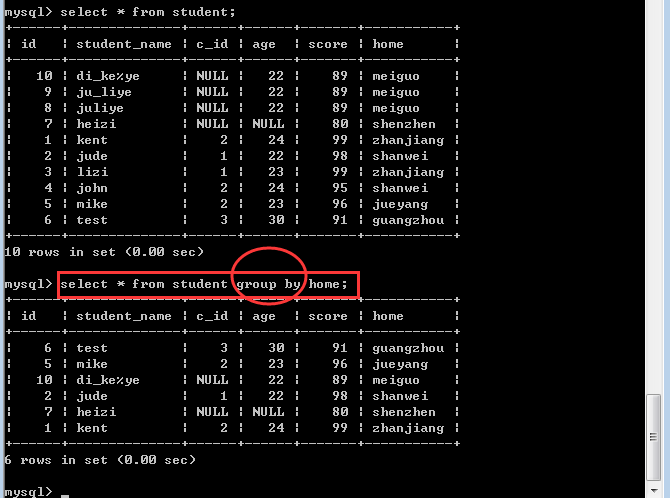
所以,分组之后,只会从每一个组内取出第一条记录,这种查询结果毫无意义!
因为分组统计查询的主要作用不是分组,而是统计!或者说分组的目的就是针对每一个分组进行相关的统计!
此时,就需要使用系统中的一些统计函数!
统计函数(聚合函数)
sum():求和,就是将某个分组内的某个字段的值全部相加

等于做了以前的两件事情:
1, 先按home字段对整个的表进行分组!(分成了4组)
2, 再把每一个组内的所有记录的age字段的值全部相加

max():求某个组内某个字段的最大值
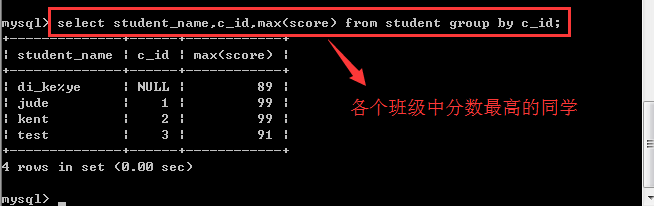
min():求某个组内某个字段的最小值

avg():求某个组内某个字段的平均值
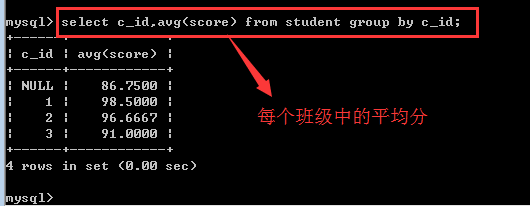
count():统计某个组内非null记录的个数,通常就是用count(*)来表示!


注意:
统计函数都是可以单独的使用的!但是,只要使用统计函数,系统默认的就是需要分组,如果没有group by子句,默认的就是把整个表中的数据当成一组!
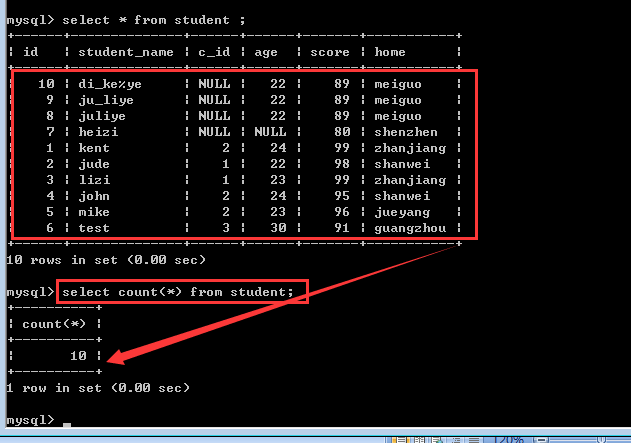
多字段分组
group by 字段1[,字段2]……
作用是:先根据字段1进行分组,然后再根据字段2进行分组!

所以,多字段分组的结果就是分组变多了!
回溯(su)统计
回溯统计就是向上统计!
在进行分组统计的时候,往往需要做上级统计!
比如,先统计各个班的总人数,然后各个班的总人数再相加,就可以得到一个年级的总人数!
再比如,先统计各个班的最高分,然后各个班的最高分再进行比较,就可以得到一个年级的最高分!
如何实现?
答:在MySQL中,其实就是在语句的后面加上with rollup即可!

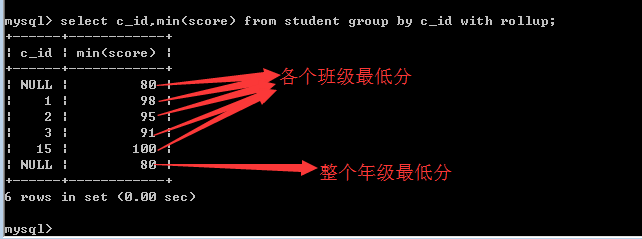

注意:
既然group by子句出现在where子句之后,说明了,我们可以先将整个数据源进行筛选,然后再进行分组统计!
三、having子句
having子句和where子句一样,也是用来筛选数据的,通常是对group by之后的统计结果再次进行筛选!

那么,having子句和where子句到底有什么区别呢?
二者的比较:
1, 如果语句中只有having子句或只有where子句的时候,此时,它们的作用基本是一样的!
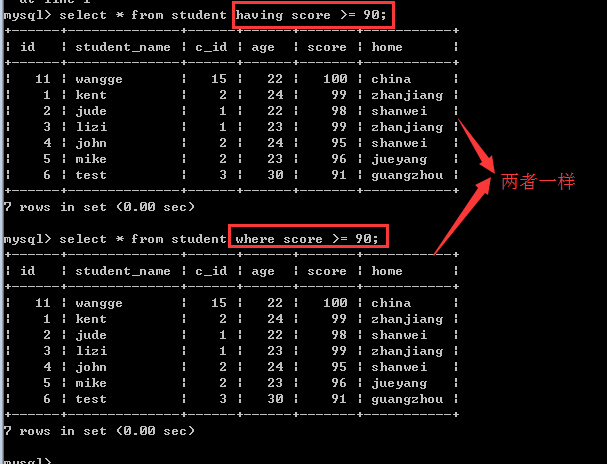
2, 二者的本质区别是:where子句是把磁盘上的数据筛选到内存上,而having子句是把内存中的数据再次进行筛选!
3, where子句的后面不能使用统计函数,而having子句可以!因为只有在内存中的数据才可以进行运算统计!

四、order by子句
语法
根据某个字段进行排序,有升序和降序!
语法形式为:
order by 字段1[asc|desc]
默认的是asc,也就是升序!如果要降序排序,需要加上desc!
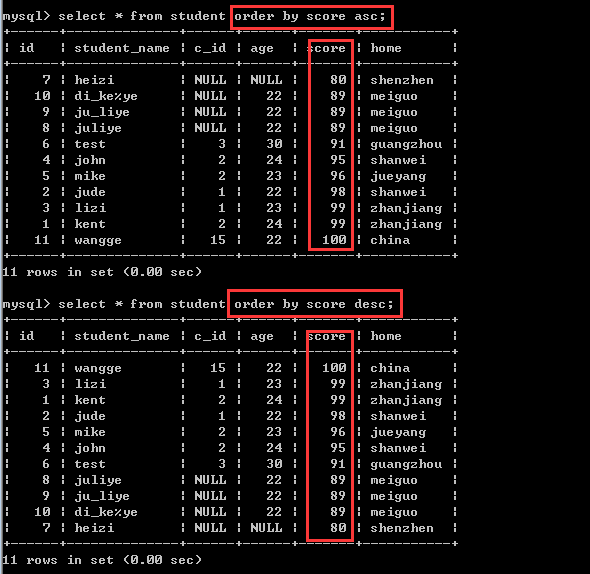
①根据id排序

②根据成绩排序
思考:
假如现在有若干个学生的成绩score是一样的,怎么办?
此时,可以使用多字段排序!
多字段排序
order by 字段1[asc|desc],字段2[asc|desc]……
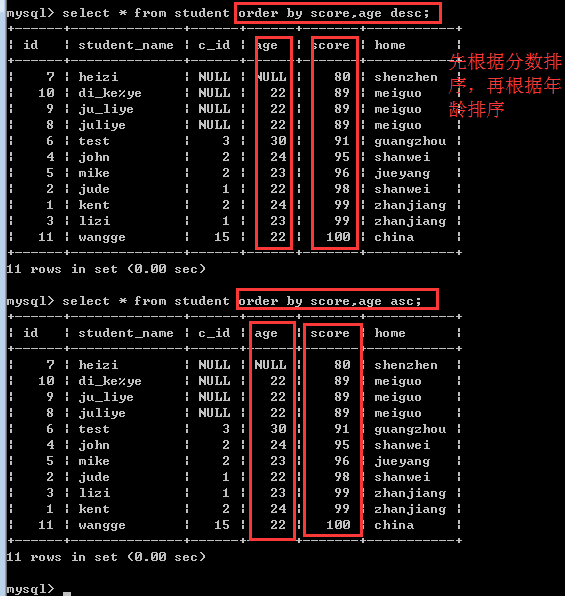
比如:order by score asc,age desc
也就是说,先按分数进行升序排序,如果分数一样的时候,再按年龄进行降序排序!
五、limit子句
limit就是限制的意思,所以,limit子句的作用就是限制查询记录的条数!
语法
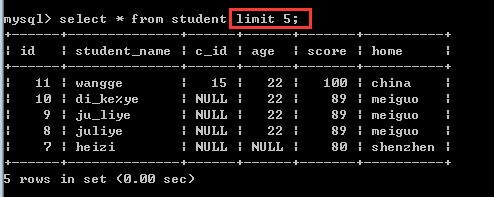
limit offset,length
其中,offset是指偏移量,默认为0,而length是指需要显示的记录数!
思考:
limit子句为什么排在最后?
因为前面所有的限制条件都处理完了,只剩下需要显示多少条记录的问题了!
思考:
假如现在想显示记录的第4条到第8条,limit子句应该怎么写?
limit 3,5;

注意:这里的偏移量offset可以省略的!缺省值就代表0!
分页原理
假如在项目中,需要使用分页的效果,就应该使用limit子句!
比如,每页显示10条记录:
第1页:limit 0,10
第2页:limit 10,10
第3页:limit 20,10
如果用$pageNum代表第多少页,用$rowsPerPage代表每页显示的长度
limit ($pageNum - 1)*$rowsPerPage, $rowsPerPage

Postgres SQL:列必须出现在 GROUP BY 子句中或用于聚合函数中
作为一般规则,未在 GROUP BY 子句中列出的任何列都应聚合显示在 SELECT 列表中。
例如,s.name 应显示为 max(s.name) 或 min(s.name),因为它不存在于 GROUP BY 列表中。但是,PostgreSQL 为 GROUP BY 子句实现了函数依赖(SQL 标准特性),并检测到 s.name 在 s.id 列中是依赖的(这可能是一个PK);简而言之,每个 s.name 都有一个可能的值 s.id。因此,PostgreSQL 中不需要聚合此列(可以,但不需要)。
另一方面,对于 lookupStudyType.description,PostgreSQL 无法确定它是否在功能上依赖于 s.id。您需要将其聚合为 max(lookupStudyType.description) 或 min(lookupStudyType.description),或任何其他聚合表达式。
顺便说一句,我很少看到在其他数据库中实现了函数依赖。 PostgreSQL 不是很棒吗? (我与 PostgreSQL 没有任何关系)。

PostgreSQL -must出现在GROUP BY子句中,或者在聚合函数中使用
ActiveRecord::StatementInvalid in ManagementController#index
PG::Error: ERROR: column "estates.id" must appear in the GROUP BY clause or be used in an aggregate function
LINE 1: SELECT "estates".* FROM "estates" WHERE "estates"."Mgmt" = ...
^
: SELECT "estates".* FROM "estates" WHERE "estates"."Mgmt" = 'Mazzey' GROUP BY user_id
@myestate = Estate.where(:Mgmt => current_user.Company).group(:user_id).all
如果user_id既不是唯一的,也不是所讨论的’estates’关系的主键,那么这个查询没有什么意义,因为Postgresql无法知道为每个共享相同列的每个列的列返回哪个值用户名。您必须使用表达您想要的集合函数,如min,max,avg,string_agg,array_agg等,或者添加GROUP BY感兴趣的列。
或者,您可以重新使用查询以使用disTINCT ON和ORDER BY,如果您确实想要选择一个有点任意的行,但我真的怀疑可以通过ActiveRecord来表达。
一些数据库(包括sqlite和MysqL)只会选择任意一行。 Postgresql团队认为这是错误的和不安全的,所以Postgresql遵循sql标准,并将这些查询视为错误。
如果你有:
col1 col2 fred 42 bob 9 fred 44 fred 99
你做:
SELECT col1,col2 FROM mytable GROUP BY col1;
那么很明显你应该得到这个行:
bob 9
但是fred的结果呢?没有一个正确的答案选择,所以数据库将拒绝执行这样的不安全的查询。如果您想要任何col1最大的col2,您将使用最大聚合:
SELECT col1,max(col2) AS max_col2 FROM mytable GROUP BY col1;
我们今天的关于如何使用GROUP BY子句将查询移植到PostgreSQL?的分享就到这里,谢谢您的阅读,如果想了解更多关于java ssh 项目oracle移植到postgresql、Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句、Postgres SQL:列必须出现在 GROUP BY 子句中或用于聚合函数中、PostgreSQL -must出现在GROUP BY子句中,或者在聚合函数中使用的相关信息,可以在本站进行搜索。
本文标签:




