如果您对java–Hadoop:配置对象时出错感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于java–Hadoop:配置对象时出错的详细内容,我们还将为您解答配置hadoo
如果您对java – Hadoop:配置对象时出错感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于java – Hadoop:配置对象时出错的详细内容,我们还将为您解答配置hadoop时,java_home包含配置文件的相关问题,并且为您提供关于008-004 配置 java api hadoop fs client 操作,hadoop 客户端 文件命令的maven配置、Hadoop (1)--- 运行 Hadoop 自带的 wordcount 出错问题。、Hadoop-02 基于Hadoop的JavaEE数据可视化简易案例、Hadoop2.6编译java类出错的有价值信息。
本文目录一览:- java – Hadoop:配置对象时出错(配置hadoop时,java_home包含配置文件)
- 008-004 配置 java api hadoop fs client 操作,hadoop 客户端 文件命令的maven配置
- Hadoop (1)--- 运行 Hadoop 自带的 wordcount 出错问题。
- Hadoop-02 基于Hadoop的JavaEE数据可视化简易案例
- Hadoop2.6编译java类出错
")
java – Hadoop:配置对象时出错(配置hadoop时,java_home包含配置文件)
java.lang.RuntimeException: Error in configuring object
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:93)
at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:64)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:117)
at org.apache.hadoop.mapred.MapTask$OldOutputCollector.<init>(MapTask.java:573)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:435)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:371)
at org.apache.hadoop.mapred.Child$4.run(Child.java:259)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupinformation.doAs(UserGroupinformation.java:1059)
at org.apache.hadoop.mapred.Child.main(Child.java:253)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:88)
... 10 more
Caused by: java.lang.IllegalArgumentException: can't read paritions file
at org.apache.hadoop.examples.terasort.teraSort$TotalOrderPartitioner.configure(teraSort.java:213)
... 15 more
Caused by: java.io.FileNotFoundException: File _partition.lst does not exist.
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:371)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:245)
at org.apache.hadoop.fs.FileSystem.getLength(FileSystem.java:720)
at org.apache.hadoop.io.SequenceFile$Reader.<init>(SequenceFile.java:1417)
at org.apache.hadoop.io.SequenceFile$Reader.<init>(SequenceFile.java:1412)
at org.apache.hadoop.examples.terasort.teraSort$TotalOrderPartitioner.readPartitions(teraSort.java:153)
at org.apache.hadoop.examples.terasort.teraSort$TotalOrderPartitioner.configure(teraSort.java:210)
... 15 more
teraGen命令运行正常,并为teraSort创建了输入文件.这是我的输入目录的列表:
bin/hadoop fs -ls /user/hadoop/terasort-input/Warning: Maximum heap size rounded up to 1024 MB Found 5 items -rw-r--r-- 1 sqatest supergroup 0 2012-01-23 14:13 /user/hadoop/terasort-input/_SUCCESS drwxr-xr-x - sqatest supergroup 0 2012-01-23 13:30 /user/hadoop/terasort-input/_logs -rw-r--r-- 1 sqatest supergroup 129 2012-01-23 15:49 /user/hadoop/terasort-input/_partition.lst -rw-r--r-- 1 sqatest supergroup 50000000000 2012-01-23 13:30 /user/hadoop/terasort-input/part-00000 -rw-r--r-- 1 sqatest supergroup 50000000000 2012-01-23 13:30 /user/hadoop/terasort-input/part-00001
这是我运行terasort的命令:
bin/hadoop jar hadoop-examples-0.20.203.0.jar terasort -libjars hadoop-examples-0.20.203.0.jar /user/hadoop/terasort-input /user/hadoop/terasort-output
我在输入目录中看到文件_partition.lst,我不明白为什么我得到FileNotFoundException.
我按照http://www.michael-noll.com/blog/2011/04/09/benchmarking-and-stress-testing-an-hadoop-cluster-with-terasort-testdfsio-nnbench-mrbench/提供的设置详细信息进行操作
解决方法
我从我的hadoop基目录运行本地模式,hadoop-1.0.0下面有一个输入子目录,我得到了同样的错误.
我编辑了失败的java文件,让它记录路径而不是文件名,重建它(“ant binary”),然后重新编写它.它正在我运行的目录中查找该文件.我不知道它是在查看hadoop基础目录还是执行目录.
…所以我在运行terasort的目录中创建了一个符号链接,指向输入目录中的真实文件.
这是一个廉价的黑客,但它的工作原理.
- Tim.

008-004 配置 java api hadoop fs client 操作,hadoop 客户端 文件命令的maven配置
<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>C:/Program Files/Java/jdk1.8.0_162/lib/tools.jar</systemPath> </dependency> </dependencies>
--- 运行 Hadoop 自带的 wordcount 出错问题。")
Hadoop (1)--- 运行 Hadoop 自带的 wordcount 出错问题。
在 hadoop2.9.0 版本中,对 namenode、yarn 做了 ha,随后在某一台 namenode 节点上运行自带的 wordcount 程序出现偶发性的错误(有时成功,有时失败),错误信息如下:
18/08/16 17:02:42 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
18/08/16 17:02:42 INFO input.FileInputFormat: Total input files to process : 1
18/08/16 17:02:42 INFO mapreduce.JobSubmitter: number of splits:1
18/08/16 17:02:42 INFO Configuration.deprecation: yarn.resourcemanager.zk-address is deprecated. Instead, use hadoop.zk.address
18/08/16 17:02:42 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/08/16 17:02:42 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1534406793739_0005
18/08/16 17:02:42 INFO impl.YarnClientImpl: Submitted application application_1534406793739_0005
18/08/16 17:02:43 INFO mapreduce.Job: The url to track the job: http://HLJRslog2:8088/proxy/application_1534406793739_0005/
18/08/16 17:02:43 INFO mapreduce.Job: Running job: job_1534406793739_0005
18/08/16 17:02:54 INFO mapreduce.Job: Job job_1534406793739_0005 running in uber mode : false
18/08/16 17:02:54 INFO mapreduce.Job: map 0% reduce 0%
18/08/16 17:02:54 INFO mapreduce.Job: Job job_1534406793739_0005 failed with state FAILED due to: Application application_1534406793739_0005 failed 2 times due to AM Container for appattempt_1534406793739_0005_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2018-08-16 17:02:48.561]Exception from container-launch.
Container id: container_e27_1534406793739_0005_02_000001
Exit code: 1
[2018-08-16 17:02:48.562]
[2018-08-16 17:02:48.574]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
log4j:WARN No appenders could be found for logger (org.apache.hadoop.mapreduce.v2.app.MRAppMaster).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
[2018-08-16 17:02:48.575]
[2018-08-16 17:02:48.575]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
log4j:WARN No appenders could be found for logger (org.apache.hadoop.mapreduce.v2.app.MRAppMaster).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.分析与解决:
网上对类似问题解决办法,主要就是添加对应的 classpath,测试了一遍,都不好使,说明上诉问题并不是 classpath 造成的,出错的时候也查看了 classpath,都有对应的值,这里贴一下添加 classpath 的方法。
1、# yarn classpath 注:查看对应的 classpath 的值
/data1/hadoop/hadoop/etc/hadoop:/data1/hadoop/hadoop/etc/hadoop:/data1/hadoop/hadoop/etc/hadoop:/data1/hadoop/hadoop/share/hadoop/common/lib/*:/data1/hadoop/hadoop/share/hadoop/common/*:/data1/hadoop/hadoop/share/hadoop/hdfs:/data1/hadoop/hadoop/share/hadoop/hdfs/lib/*:/data1/hadoop/hadoop/share/hadoop/hdfs/*:/data1/hadoop/hadoop/share/hadoop/yarn:/data1/hadoop/hadoop/share/hadoop/yarn/lib/*:/data1/hadoop/hadoop/share/hadoop/yarn/*:/data1/hadoop/hadoop/share/hadoop/mapreduce/lib/*:/data1/hadoop/hadoop/share/hadoop/mapreduce/*:/data1/hadoop/hadoop/contrib/capacity-scheduler/*.jar:/data1/hadoop/hadoop/share/hadoop/yarn/*:/data1/hadoop/hadoop/share/hadoop/yarn/lib/*如果是上述类变量为空,可以通过下面三个步骤添加 classpath。
2. 修改 mapred.site.xml
添加:
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
3.yarn.site.xml
添加:
<property>
<name>yarn.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
4. 修改环境变量
#vim ~/.bashrc
在文件最后添加下述环境变量:
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native5. source ~/.bashrc
解决报错问题:
从日志可以看出,发现是由于跑 AM 的 container 退出了,并没有为任务去 RM 获取资源,怀疑是 AM 和 RM 通信有问题;一台是备 RM, 一台活动的 RM,在 yarn 内部,当 MR 去活动的 RM 为任务获取资源的时候当然没问题,但是去备 RM 获取时就会出现这个问题了。
修改 vim yarn-site.xml
<property>
<!-- 客户端通过该地址向RM提交对应用程序操作 -->
<name>yarn.resourcemanager.address.rm1</name>
<value>master:8032</value>
</property>
<property>
<!--ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。 -->
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>master:8030</value>
</property>
<property>
<!-- RM HTTP访问地址,查看集群信息-->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master:8088</value>
</property>
<property>
<!-- NodeManager通过该地址交换信息 -->
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>master:8031</value>
</property>
<property>
<!--管理员通过该地址向RM发送管理命令 -->
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>master:23142</value>
</property>
<!--
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>slave1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>slave1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>slave1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>slave1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>slave1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>slave1:23142</value>
</property>
-->注:标红的地方就是 AM 向 RM 申请资源的 rpc 端口,出错问题就在这里。
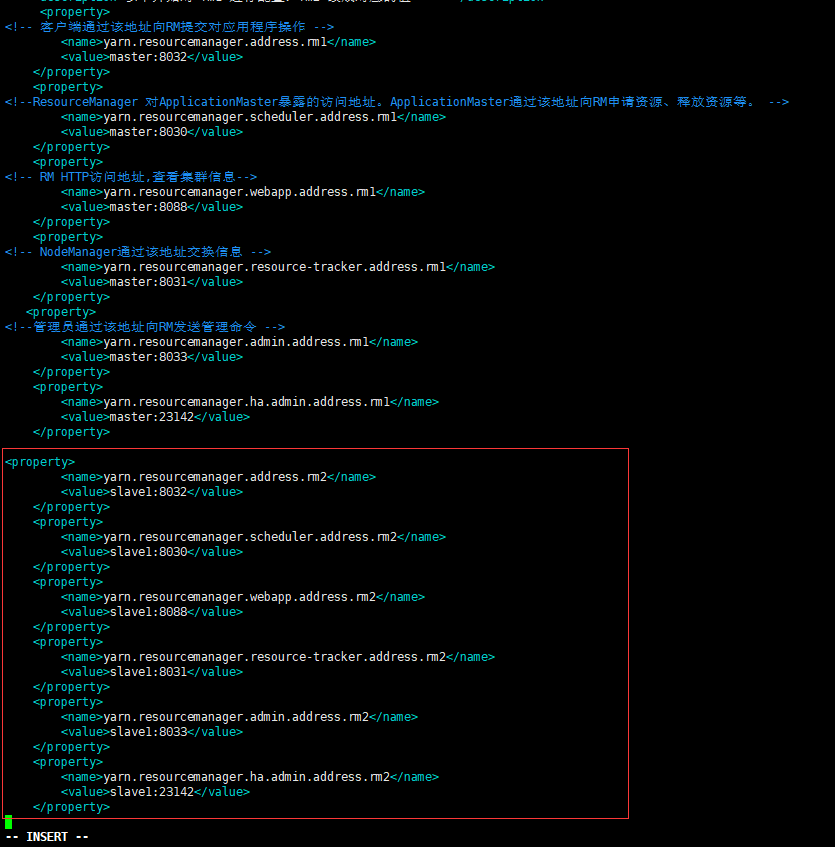
红框里面是我在 rm1 机器(也就是 master)上的 yarn 文件添加的;当然,如果是在 slave1 里面添加的话就是添加红框上面以.rm1 结尾的那几行,其实,说白点,就是要在 yarn-site.xml 这个配置文件里面添加所有 resourcemanager 机器的通信主机与端口。然后拷贝到其他机器,重新启动 yarn。最后在跑 wordcount 或者其他程序没在出错。其实这就是由于 MR 与 RM 通信的问题,所以在配置 yarn-site.xml 文件的时候,最好把主备的通信端口都配置到改文件,防止出错。

Hadoop-02 基于Hadoop的JavaEE数据可视化简易案例
需求
1.统计音乐点播次数
2.使用echarts柱状图显示每首音乐的点播次数
项目结构
创建JavaEE项目
统计播放次数Job关键代码
package com.etc.mc;
import java.io.IOException;
import java.util.HashMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/** 歌曲点播统计 */
public class MusicCount {
//定义保存统计数据结果的map集合
public static HashMap<String, Integer> map=new HashMap<String, Integer>();
public static class MusicMapper extends Mapper<Object, Text, Text, IntWritable> {
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
IntWritable valueOut = new IntWritable(1);
String keyInStr = value.toString();
String[] keyInStrArr = keyInStr.split("\t");// 使用\t将输入 文本行转换为字符串
String keyOut = keyInStrArr[0];// 获取歌曲名称
context.write(new Text(keyOut), valueOut);
}
}
public static class MusicReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);//统计数据保存到hdfs文件
map.put(key.toString(), sum);//将统计结果保存到map集合
}
}
public static HashMap<String, Integer> main() throws Exception {
Configuration conf = new Configuration();
conf.addResource("core-site.xml");// 读取项目中hdfs配置信息
conf.addResource("mapred-site.xml");// 读取项目中mapreduce配置信息
// 实例化作业
Job job = Job.getInstance(conf, "music_count");
// 指定jar的class
job.setJarByClass(MusicCount.class);
// 指定Mapper
job.setMapperClass(MusicMapper.class);
// 压缩数据
job.setCombinerClass(MusicReducer.class);// 减少datanode,TaskTracker之间数据传输
// 指定reducer
job.setReducerClass(MusicReducer.class);
// 设置输出key数据类型
job.setOutputKeyClass(Text.class);
// 设置输出Value数据类型
job.setOutputValueClass(IntWritable.class);
// 设置输入文件路径
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.137.131:9000/music/music1.txt"));
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.137.131:9000/music/music2.txt"));
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.137.131:9000/music/music3.txt"));
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.137.131:9000/music/music4.txt"));
//设置输出文件路径
FileSystem fs=FileSystem.get(conf);
Path path=new Path("hdfs://192.168.137.131:9000/musicout");
if(fs.exists(path)) {
fs.delete(path,true);
}
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.137.131:9000/musicout"));
if(job.waitForCompletion(true)) {
return map;
}else {
return null;
}
}
}
Servlet关键代码
package com.etc.action;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.HashMap;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.alibaba.fastjson.JSON;
import com.etc.mc.MusicCount;
/**向客户端提供json数据*/
@WebServlet("/CountServlet")
public class CountServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//post乱码处理
request.setCharacterEncoding("utf-8");
// 设置响应数据类型
response.setContentType("text/html");
// 设置响应编码格式
response.setCharacterEncoding("utf-8");
// 获取out对象
PrintWriter out = response.getWriter();
//组织json数据
HashMap<String, Integer> map=null;
try {
map=MusicCount.main();
} catch (Exception e) {
System.out.println("获取数据出错");
}
//通过构建map集合转换为嵌套json格式数据
HashMap jsonmap = new HashMap();
jsonmap.put("mytitle","歌词播放统计");
jsonmap.put("mylegend", "点播");
jsonmap.put("prolist", map);
String str =JSON.toJSONString(jsonmap);
out.print(str);
out.flush();
out.close();
}
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
视图index.jsp关键代码
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>金融大数据解析</title>
<!-- 引入 echarts.js -->
<script src="script/echarts.min.js"></script>
<!-- 引入 jquery.js -->
<script src="script/jquery-1.8.3.min.js"></script>
</head>
<body>
<!-- 为ECharts准备一个具备大小(宽高)的Dom -->
<div id="main"></div>
<script type="text/javascript">
//显示柱状图函数
function showdata(mytitle, mylegend, xdata, ydata) {
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById(''main''));
// 指定图表的配置项和数据
var option = {
title : {
text : mytitle
},
tooltip : {},
legend : {
data : mylegend
},
xAxis : {
data : xdata
},
yAxis : {},
series : [ {
name : ''点播'',
type : ''bar'',
data : ydata
} ]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
}
$(function() {
var mytitle;
var mylegend;
var xdata=new Array();
var ydata=new Array();
$.getJSON("CountServlet", function(data) {
mytitle = data.mytitle;
mylegend = data.mylegend;
//获取x轴数据
$.each(data.prolist, function(i, n) {
xdata.push(i);
});
//获取y轴数据
$.each(data.prolist, function(i, n) {
ydata.push(n);
});
//执行函数
showdata(mytitle, [ mylegend ], xdata, ydata);
});
});
</script>
</body>
</html>
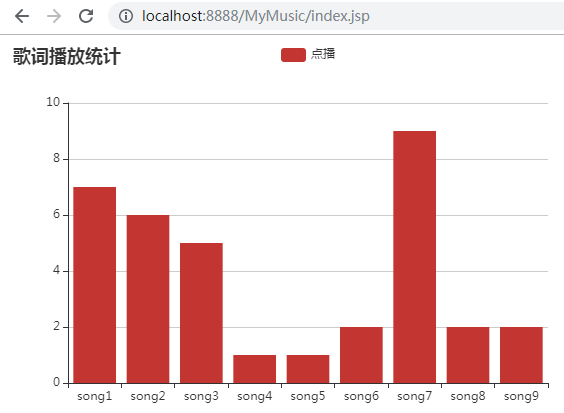
运行结果
项目所需jar列表
总结
1.该案例的缺点是什么?每次访问数据需要提交job到hadoop集群运行,性能低。
2.数据分析结果保存在HDFS和集合中,不适合分析结果为大数据集合。
3.如何改进?使用HBase存储解析后的数据集,构建离线分析和即时查询大数据分析平台。

Hadoop2.6编译java类出错
环境:Ubuntu14.4 Hadoop2.6
安装在/usr/local/hadoop
Hadoop已经安装好了hadoop fs -ls **..之类的指令也能运行,试了下streaming也没有问题
但是再看《hadoop权威指南》时尝试了里面的java编写的例子:在编译时出错
URLCat.java: 错误:程序包org.apache.hadoop不存在
后面都是类似各种找不到。。。。
求解决
今天的关于java – Hadoop:配置对象时出错和配置hadoop时,java_home包含配置文件的分享已经结束,谢谢您的关注,如果想了解更多关于008-004 配置 java api hadoop fs client 操作,hadoop 客户端 文件命令的maven配置、Hadoop (1)--- 运行 Hadoop 自带的 wordcount 出错问题。、Hadoop-02 基于Hadoop的JavaEE数据可视化简易案例、Hadoop2.6编译java类出错的相关知识,请在本站进行查询。
本文标签:




