对于想了解java+selenium网易云音乐刷累计听歌数的方法的读者,本文将是一篇不可错过的文章,我们将详细介绍网易云代码刷听歌量,并且为您提供关于curl实例1:登录落网获取累计听歌数、pytho
对于想了解java+selenium 网易云音乐刷累计听歌数的方法的读者,本文将是一篇不可错过的文章,我们将详细介绍网易云代码刷听歌量,并且为您提供关于curl实例1:登录落网获取累计听歌数、python+selenium 下载网易云音乐 支持批量下载、selenium实战-同步网易云音乐歌单到qq音乐、【java+selenium】网易云音乐刷累计听歌数的有价值信息。
本文目录一览:- java+selenium 网易云音乐刷累计听歌数的方法(网易云代码刷听歌量)
- curl实例1:登录落网获取累计听歌数
- python+selenium 下载网易云音乐 支持批量下载
- selenium实战-同步网易云音乐歌单到qq音乐
- 【java+selenium】网易云音乐刷累计听歌数
")
java+selenium 网易云音乐刷累计听歌数的方法(网易云代码刷听歌量)
这篇文章主要介绍了java+selenium 网易云音乐刷累计听歌数的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
背景
应该是在去年的时候,刷知乎看到一个问题,大概是说怎么刷网易云音乐个人累计听歌数,然后有一个高赞回答,贴了一段js代码,直接在浏览器console执行就可以了。当时试了下,直接一下子刷了有好几万。悲剧的是,第二天又回到原来的样子了,很明显这种方式被网易云音乐发现封掉了。而且后续网易云还针对累计听歌数加了一些限制,每天最多增加300首。今天带来一种通过java+selenium的方式,自动播放歌曲,来达到刷累计听歌数的效果。另外借助这个demo,对selenium的使用更加熟悉,也算是爬虫应用中一些有趣的东西了。
思路
登录,有以下两种方式可以选择:
a. 模拟web端的登录过程。优点:这种方式更加通用,便于动态切换账号。缺点:比直接使用cookie稍微麻烦一些,并且有一定几率会出现图形验证码,需要考虑这种情况。
b. 设置cookie。优点:不用处理登录过程,比较简单方便,在cookie的过期时间比较长情况下还是比较方便的,不用频繁切换。缺点:切换账号比较麻烦,不能达到自动化。我这里选择的该方式。
播放:上一个步骤中登录成功后,直接打开歌单列表页面。如下图

,在歌单列表页面可以看到。有3个地方是可以点击播放的,我最先想到是最下面一个播放按钮,然后一直保持底部播放组件的显示,实时获取播放的动态。尝试通过模拟点击播放按钮,始终不成功,最终点击最上面的播放按钮可以播放的。
获取播放动态:为了确定播放是否在正常进行,可以通过实时获取个人home页面的累计听歌数相关信息,用于监控,由于已经有一个页面在播放歌曲了,为了不影响原有播放歌曲的页面,可以打开一个新的tab页来获取个人home页面,打开新的table页,这里采用js的方式window.open('about:blank')。
最终都会看到如下类似如下格式日志,那就说明成功了:
2019-03-26 09:25:10,406 INFO [,main] - [com.github.wycm.Music163] - 伊犁河畔-00:00 / 00:00---当前播放第1首歌曲, 累计听歌:20572 2019-03-26 09:25:16,817 INFO [,main] - [com.github.wycm.Music163] - 伊犁河畔-01:00 / 07:19---当前播放第1首歌曲, 累计听歌:20572 2019-03-26 09:25:23,157 INFO [,main] - [com.github.wycm.Music163] - 伊犁河畔-01:06 / 07:19---当前播放第1首歌曲, 累计听歌:20572 2019-03-26 09:25:29,394 INFO [,main] - [com.github.wycm.Music163] - 伊犁河畔-01:13 / 07:19---当前播放第1首歌曲, 累计听歌:20572 2019-03-26 09:25:35,592 INFO [,main] - [com.github.wycm.Music163] - 伊犁河畔-01:19 / 07:19---当前播放第1首歌曲, 累计听歌:20572 2019-03-26 09:25:41,974 INFO [,main] - [com.github.wycm.Music163] - 伊犁河畔-01:25 / 07:19---当前播放第1首歌曲, 累计听歌:20572
完整代码
package com.github.wycm; import org.openqa.selenium.*; import org.openqa.selenium.chrome.ChromeDriver; import org.openqa.selenium.chrome.ChromeOptions; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.*; import java.util.concurrent.TimeUnit; import java.util.regex.Matcher; import java.util.regex.Pattern; /** * Created by wycm */ public class Music163 { private static Logger logger = LoggerFactory.getLogger(Music163.class); //拷贝登录成功的浏览器原始cookie private final static String RAW_COOKIES = "cookie1=value1; cookie2=value2"; private final static String CHROME_DRIVER_PATH = "/Users/wangyang/Downloads/chromedriver"; //歌曲列表id private static String startId = "22336453"; private static String userId = null; private static Set playListSet = new HashSet(); private static Pattern pattern = Pattern.compile("(.*?)(.*?)"); private static Pattern songName = Pattern.compile("title="(.*?)""); private static ChromeOptions chromeOptions = new ChromeOptions(); private static WebDriver driver = null; static { System.setProperty("webdriver.chrome.driver", CHROME_DRIVER_PATH); chromeOptions.addArguments("--no-sandBox"); } public static void main(String[] args) throws InterruptedException { while (true){ try { driver = new ChromeDriver(chromeOptions); playListSet.add(startId); invoke(); } catch (Exception e){ logger.error(e.getMessage(), e); } finally { driver.quit(); } Thread.sleep(1000 * 10); } } /** * 初始化cookies */ private static void initCookies(){ Arrays.stream(RAW_COOKIES.split("; ")).forEach(rawCookie -> { String[] ss = rawCookie.split("="); Cookie cookie = new Cookie.Builder(ss[0], ss[1]).domain(".163.com").build(); driver.manage().addCookie(cookie); }); } private static void invoke() throws InterruptedException { driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS); driver.manage().timeouts().pageLoadTimeout(15, TimeUnit.SECONDS); String s = null; driver.get("http://music.163.com/"); initCookies(); driver.get("http://music.163.com/"); s = driver.getPageSource(); userId = group(s, "userId:(\d+)", 1); driver.get("https://music.163.com/#/playlist?id=" + startId); driver.switchTo().frame("contentFrame"); WebElement element = driver.findElement(By.cssSelector("[id=content-operation]>a:first-child")); element.click(); ((JavascriptExecutor) driver).executeScript("window.open('about:blank')"); ArrayList tabs = new ArrayList(driver.getwindowHandles()); driver.switchTo().window(tabs.get(0)); driver.switchTo().defaultContent(); int i = 0; String lastSongName = ""; int count = 0; while (true){ if(i > Integer.MAX_VALUE - 2){ break; } i++; s = driver.getPageSource(); driver.switchTo().window(tabs.get(1)); //switches to new tab String songs = null; try{ driver.get("https://music.163.com/user/home?id=" + userId); driver.switchTo().frame("contentFrame"); songs = group(driver.getPageSource(), "累积听歌(\d+)首", 1); } catch (TimeoutException e){ logger.error(e.getMessage(), e); } driver.switchTo().window(tabs.get(0)); Matcher matcher = pattern.matcher(s); Matcher songNameMatcher = songName.matcher(s); if (matcher.find() && songNameMatcher.find()){ String songNameStr = songNameMatcher.group(1); if (!songNameStr.equals(lastSongName)){ count++; lastSongName = songNameStr; } logger.info(songNameStr + "-" + matcher.group(1) + matcher.group(2) + "---当前播放第" + count + "首歌曲, 累计听歌:" + songs); } else { logger.info("解析歌曲播放记录或歌曲名失败"); } Thread.sleep(1000 * 30); } } public static String group(String str, String regex, int index) { Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(str); return matcher.find() ? matcher.group(index) : ""; } }
运行注意事项
修改自己相关chromedriver路径配置
登录自己的web端网易云音乐:https://music.163.com/
复制自己登录成功的原始cookies,至代码中的RAW_COOKIES字段
切换歌单,如果默认的歌单播放完成后,可以搜索一些没有播放过的歌单,类似https://music.163.com/#/playlist?id=22336453的url,提取出id,直接替换代码中的startId字段。
总结
大家可能会有疑问,我想把这个任务放到自己的服务器上直接后台运行。这就是服务器上搭建selenium运行环境的问题了,可以参考我上一篇文章。阿里云和腾讯云最低配的服务器都能够跑起来的。
另外这里为啥采用selenium的方式,有没有其他更简单的方式,直接通过简单的Http请求的方式达到刷的效果。我个人尝试过像通过纯http 请求的方式,找到增加个人累计听歌数的请求,由于网银云的请求都做了加密,最终没有找到。所以就用selenium的方式来代替。
最后
完整工程代码见:https://github.com/wycm/crawler-set/tree/master/music163
版权声明
出处:https://my.oschina.net/wycm/blog/3023967
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小编。

curl实例1:登录落网获取累计听歌数
脚本curl_luoo.sh内容如下:
#!/bin/bash
# login luoo
luoo_url="http://www.luoo.net/login/"
name="你的账号"
password="你的密码"
# create cookie
curl -v -c cookies.luoo -X POST -d "name=${name}&password=${password}" ${luoo_url}
# get msg
curl -v -b cookies.luoo -X GET -H "Accept-Encoding: gzip" http://www.luoo.net/message/latest | gunzip | jsonpp > ./$(date +%Y%m%d%H%M).msg
# count
curl -b cookies.luoo -X GET http://www.luoo.net/user/12549 | grep "<span class=\"playcnt\">.*</span>" | awk -F"[<|>]" ''{print ''"\"$(date +%Y%m%d%H%M%S)\""''"\t\t"$3}'' >> count.txtps:脚本中-X指定的方法,-d指定的参数,及url地址,以chrome-F12跟踪到的为准
脚本执行结果:
# cat count.txt
20170723104356 已经在落网上累计听过 5022 首音乐。
20170723105351 已经在落网上累计听过 5024 首音乐。

python+selenium 下载网易云音乐 支持批量下载
import os
import re
import requests
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
class Wy_music():
def __init__(self, name):
self.option=webdriver.ChromeOptions()
self.option.add_argument(''disable-infobars'')
self.driver = webdriver.Chrome(options=self.option)
self.i_list = []
self.id_list = []
self.name_list = []
self.music_name = name
def get_id_name(self):
aim_url=''https://music.163.com/#/search/m/?s=''+self.music_name+''&type=1'' #目标歌曲的 url
self.driver.get(aim_url)
self.driver.switch_to.frame (''contentFrame'') #切换到 frame 中,不然会定位失败
div_list =self.driver.find_elements_by_xpath(''.//div[@]/div'')
print(len(div_list))
for div in div_list:
#try 语句先是尝试查询一边 name url singer 如果不存在再尝试 except 中的内容
#因为不同的出现两种不同的 xpath, 应该是后来修改过 html
try:
name = div.find_element_by_xpath(''.//div[@]//b'').text
url = div.find_element_by_xpath(''.//div[@]//a'').get_attribute(''href'')
singer = div.find_element_by_xpath(''.//div[@]//a'').text
except NoSuchElementException:
name = div.find_element_by_xpath(''.//div[@]//b'').text
url = div.find_element_by_xpath(''.//div[@]//a'').get_attribute(''href'')
singer = div.find_element_by_xpath(''.//div[@]/div'').text
id = re.search(r''id=(\d+)'', url).group(1)
i = div_list.index(div)
self.i_list.append(i)
self.id_list.append(id)
self.name_list.append(name+"_"+singer)
print(i,name,singer)
name_list = list(zip(self.id_list, self.name_list))
print(''id_name'',name_list)
song_dict = dict(zip(self.i_list, name_list))
print ('' 最终 id_歌曲 '',song_dict)
return song_dict
def download_music(self, url, song_name):
print (''{} 正在下载 ''.format ((song_name)))
headers = {''User-Agent'': ''Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0''}
response = requests.get(url,headers=headers)
full_songname = song_name + ''.mp3''
with open(''{}''.format(full_songname), ''wb'') as f:
f.write(response.content)
print (''{} 下载完成 ''.format (song_name))
def choose_musicid(self, song_dict):
num_str = input ('' 请输入你需要下载歌曲的编号,以空格隔开: '')
num_list = num_str.split('' '')
for num in num_list:
try:
num = int(num)
except Exception as e:
print (e, '' 请输入整数 '')
if num > len(song_dict):
print ('' 请输入有效数字 '')
url =''https://music.163.com/song/media/outer/url?id={}''.format(song_dict[num][0])
print(url)
song_name = song_dict[num][1]
# print ('' 歌曲名 —— 歌手名 '',song_name)
yield url,song_name
if __name__ == ''__main__'':
name = input ('' 请输入你要搜索的歌名或歌手:'')
wy = Wy_music(name)
song_dict = wy.get_id_name()
for url, song_name in wy.choose_musicid(song_dict):
wy.download_music(url, song_name)
目前未解决的小问题,再创建文件时,有多个歌手时,会有 “/” 隔开,这会导致创建文件失败

selenium实战-同步网易云音乐歌单到qq音乐
本文主要介绍selenium在爬虫脚本的实际应用。适合刚接触python,没使用过selenium的童鞋。(如果你是老司机路过的话,帮忙点个star吧)
项目地址
https://github.com/Denon/sync...
selenium介绍
selenium官网. 直接引用官网的话
Selenium automates browsers. That''s it! What you do with that power is entirely up to you. Primarily, it is for automating web applications for testing purposes, but is certainly not limited to just that. Boring web-based administration tasks can (and should!) also be automated as well.
简单翻译下
selenium是一个自动化的浏览器, 主要使用来做web应用的自动化测试。
个人认为用selenium主要的好处是: 可以解析js渲染的页面。对于这次的爬虫来说, 由于网易云音乐以及qq音乐网页中大部分元素都是使用js渲染生成的, 因此选择使用selenium来完成这次的脚本。
环境准备
python 2.7
selenium
phantomjs / Chromium
selenium 运行需要额外的浏览器支持. 其中phantomjs可以在这里下载, Chromium可以在这里下载。 前期debug阶段建议使用 Chromium 。
详细的包依赖请查看github项目
流程
初始化selenium
从网易云音乐歌单网页中获取歌曲列表
登录qq音乐
搜索音乐
添加到qq音乐的歌单中
初始化selenium
from selenium import webdriver
# 这里是使用PhantomJs, 如果使用chromium则使用webdriver.Chrome(),
# 并替换对应的驱动路径即可
phantomjs_driver = phantomjs_driver_path
opts = Options()
opts.add_argument("user-agent={}".format(headers["User-Agent"]))
browser = webdriver.PhantomJS(phantomjs_driver)从网易云音乐中获取音乐
对于一般爬虫来说, 如果能用手机端网页爬取那就无脑选网页端爬取。可以发现网易云音乐的手机版歌单地址是: http://music.163.com/m/playli... 。 这个地址么一看就知道, 后面那串id就是歌单id。chrome浏览器打开调试工具, 可以看到所有的歌曲都在<span>...</span>里面。 那么直接用requests + beautifulsoup 爬取元素就好。 这里就不深入讨论了。 具体的代码请参考项目
登录qq音乐
一般来说,爬虫做登录有两种选择。一种是抓包,分析登录请求体,直接模拟登录,这种稳定性较好,只要解析出请求体后,登录一般都能成功。一种是模拟正常登录操作,在输入框中输入账号密码,然后点击登录按钮来登录,这种稳定性较差,有可能会有各种意外的情况,比如验证码之类的。这里当然要使用第二种来做(不然就跑题了)。
首先打开qq音乐网站, 发现qq登录的按钮在

这里介绍selenium第一个函数find_element_by_xpath,这个函数就是根据element的xpath来获取元素的。
browser.find_element_by_xpath("/html/body/div[1]/div/div[2]/span/a[2]").click()点击完后, 页面应该会弹出一个登录框, 不过默认应该是扫码登录, 这个时候就要点击下“帐号密码登录”来切换。可以发现, 这个切换按钮的id是switcher_plogin. 那么使用selenium的 find_element_by_id 函数:
browser.find_element_by_id("switcher_plogin").click()按理来说这段代码应该能运行成功,但是如无意外的话,我们只能获得一个报错
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"id","selector":"switcher_plogin"}这是什么情况???
细心点观察可以发现,这个弹出来的登录框是在一个iframe里面。这个时候需要使用到另外一个函数switch_to.frame,
# 切换iframe
browser.switch_to.frame("frame_tips")
browser.find_element_by_id("switcher_plogin").click()
# 输入账号密码, 用到send_keys函数
user_input = browser.find_element_by_id("u")
user_input.send_keys("qq_account")
pwd_input = self.browser.find_element_by_id("p")
pwd_input.send_keys("qq_password")
# 最后要切换回来
browser.switch_to.default_content()可以发现ok了,然后账号密码等输入框直接用上面介绍过的函数直接获取就行。
搜索歌曲
在浏览器中打开qq音乐实际搜索一下,发现搜索的url是 https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E6%B5%AE%E5%A4%B8,可以看到搜索的关键词在 w 这个参数里面,并且中文字是被url encode过的。那么这里使用python内置的urllib2包即可
from urllib2 import quote
url_sw = quote(search_word.encode(''utf8''))由于python2坑爹的编码问题, 一般把字符存储成unicode, 在需要使用的时候再转换对应编码比较合适。
添加到歌单
人工添加歌单的操作实际分为三步:
鼠标移动到歌曲上
点击 + 号
点击对应的歌单
观察html元素可以发现,搜索出来的歌曲都在<div>...</div>里面。这里使用find_elements_by_class_name这个函数
all_song = browser.find_elements_by_class_name("songlist__list")点击完以后,可以看到歌单的html元素都在<li>里面。
all_playlist = browser.find_elements_by_class_name("operate_menu__item")而其中每个歌单是以data-dirid这个属性来区分的,这里介绍另外一个元素选择函数find_element_by_css_selector
browser.find_element_by_css_selector("a[data-dirid=''{}'']").click()那么就这样结束了么?
当然不是! 实际运行中发现,这里面大部分元素都是js渲染生成的,直接使用selenium函数去获取这些元素,很大可能会报错
selenium.common.exceptions.ElementNotVisibleException: Message: element not visible碰到这种情况,最好的解决办法是,用selenium直接执行js脚本来调用元素,selenium执行js脚本的函数为execute_script
browser.execute_script("document.getElementsByClassName(''songlist__list'')[0].firstElementChild.getElementsByClassName(''list_menu__add'')[0].click()"而js代码是可以直接在浏览器上debug的,一般现在浏览器上执行成功在复制回来。
其他一些辅助方法
在实际操作中,虽然使用的方法是正确的,但会出现很多意外的情况导致本次操作是失败的,这时候就需要来一次重试来解决问题(如果一次重试解决不了问题,那就来两次)。这里使用一个装饰器来写
def retry(retry_times=0, exc_class=Exception, notice_message=None, print_exc=False):
''''''retry_times: 重试次数
exc_class: 捕捉的异常
notice_message: 提示信息
print_exc: 是否打印错误信息
''''''
def wrapper(f):
@functools.wraps(f)
def inner_wrapper(*args, **kwargs):
current = 0
while True:
try:
return f(*args, **kwargs)
except exc_class as e:
if print_exc:
traceback.print_exc()
if current >= retry_times:
raise RetryException()
if notice_message:
print notice_message
current += 1
return inner_wrapper
return wrapper总结
介绍了selenium获取元素的各种用法,更多的请参考文档
解决使用selenium可能会碰到的一些坑。
最后在安利一次github项目, https://github.com/Denon/sync...。欢迎点赞以及提issue。现在已经支持网易云音乐与qq音乐歌单的互相同步。

【java+selenium】网易云音乐刷累计听歌数
背景
应该是在去年的时候,刷知乎看到一个问题,大概是说怎么刷网易云音乐个人累计听歌数,然后有一个高赞回答,贴了一段js代码,直接在浏览器console执行就可以了。当时试了下,直接一下子刷了有好几万。悲剧的是,第二天又回到原来的样子了,很明显这种方式被网易云音乐发现封掉了。而且后续网易云还针对累计听歌数加了一些限制,每天最多增加300首。今天带来一种通过java+selenium的方式,自动播放歌曲,来达到刷累计听歌数的效果。另外借助这个demo,对selenium的使用更加熟悉,也算是爬虫应用中一些有趣的东西了。
思路
-
登录,有以下两种方式可以选择: a. 模拟web端的登录过程。优点:这种方式更加通用,便于动态切换账号。缺点:比直接使用cookie稍微麻烦一些,并且有一定几率会出现图形验证码,需要考虑这种情况。 b. 设置cookie。优点:不用处理登录过程,比较简单方便,在cookie的过期时间比较长情况下还是比较方便的,不用频繁切换。缺点:切换账号比较麻烦,不能达到自动化。我这里选择的该方式。
-
播放:上一个步骤中登录成功后,直接打开歌单列表页面。如下图
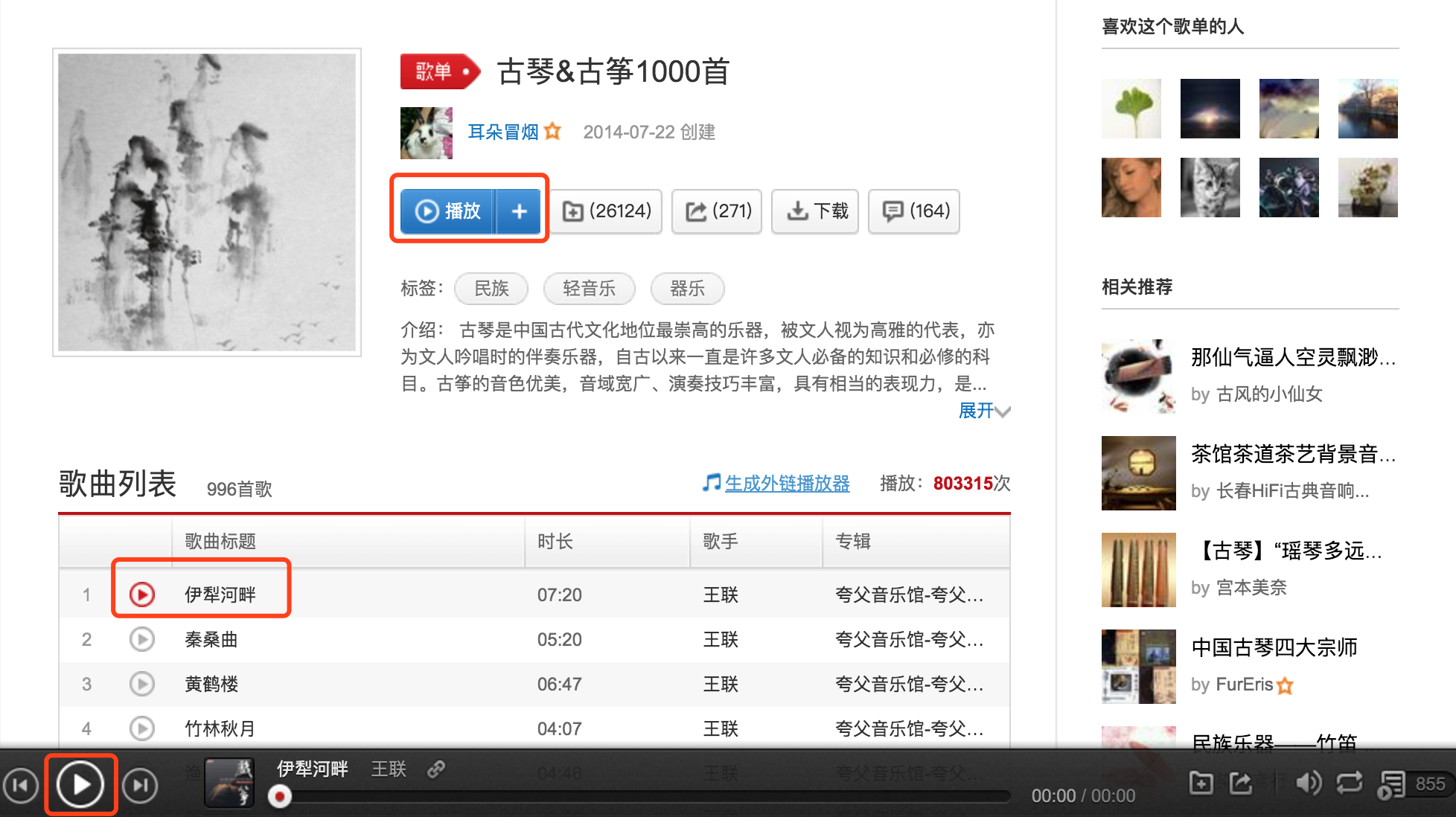 ,在歌单列表页面可以看到。有3个地方是可以点击播放的,我最先想到是最下面一个播放按钮,然后一直保持底部播放组件的显示,实时获取播放的动态。尝试通过模拟点击播放按钮,始终不成功,最终点击最上面的播放按钮可以播放的。
,在歌单列表页面可以看到。有3个地方是可以点击播放的,我最先想到是最下面一个播放按钮,然后一直保持底部播放组件的显示,实时获取播放的动态。尝试通过模拟点击播放按钮,始终不成功,最终点击最上面的播放按钮可以播放的。 -
获取播放动态:为了确定播放是否在正常进行,可以通过实时获取个人home页面的累计听歌数相关信息,用于监控,由于已经有一个页面在播放歌曲了,为了不影响原有播放歌曲的页面,可以打开一个新的tab页来获取个人home页面,打开新的table页,这里采用js的方式
window.open(''about:blank'')。最终都会看到如下类似如下格式日志,那就说明成功了:
2019-03-26 09:25:10,406 INFO [,main] - [com.github.wycm.Music163] - 伊犁河畔-00:00 / 00:00---当前播放第1首歌曲, 累计听歌:20572
2019-03-26 09:25:16,817 INFO [,main] - [com.github.wycm.Music163] - 伊犁河畔-01:00 / 07:19---当前播放第1首歌曲, 累计听歌:20572
2019-03-26 09:25:23,157 INFO [,main] - [com.github.wycm.Music163] - 伊犁河畔-01:06 / 07:19---当前播放第1首歌曲, 累计听歌:20572
2019-03-26 09:25:29,394 INFO [,main] - [com.github.wycm.Music163] - 伊犁河畔-01:13 / 07:19---当前播放第1首歌曲, 累计听歌:20572
2019-03-26 09:25:35,592 INFO [,main] - [com.github.wycm.Music163] - 伊犁河畔-01:19 / 07:19---当前播放第1首歌曲, 累计听歌:20572
2019-03-26 09:25:41,974 INFO [,main] - [com.github.wycm.Music163] - 伊犁河畔-01:25 / 07:19---当前播放第1首歌曲, 累计听歌:20572
完整代码
package com.github.wycm;
import org.openqa.selenium.*;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.*;
import java.util.concurrent.TimeUnit;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Created by wycm
*/
public class Music163 {
private static Logger logger = LoggerFactory.getLogger(Music163.class);
//拷贝登录成功的浏览器原始cookie
private final static String RAW_COOKIES = "cookie1=value1; cookie2=value2";
private final static String CHROME_DRIVER_PATH = "/Users/wangyang/Downloads/chromedriver";
//歌曲列表id
private static String startId = "22336453";
private static String userId = null;
private static Set<String> playListSet = new HashSet<>();
private static Pattern pattern = Pattern.compile("<span class=\"j-flag time\"><em>(.*?)</em>(.*?)</span>");
private static Pattern songName = Pattern.compile("class=\"f-thide name fc1 f-fl\" title=\"(.*?)\"");
private static ChromeOptions chromeOptions = new ChromeOptions();
private static WebDriver driver = null;
static {
System.setProperty("webdriver.chrome.driver", CHROME_DRIVER_PATH);
chromeOptions.addArguments("--no-sandbox");
}
public static void main(String[] args) throws InterruptedException {
while (true){
try {
driver = new ChromeDriver(chromeOptions);
playListSet.add(startId);
invoke();
} catch (Exception e){
logger.error(e.getMessage(), e);
} finally {
driver.quit();
}
Thread.sleep(1000 * 10);
}
}
/**
* 初始化cookies
*/
private static void initCookies(){
Arrays.stream(RAW_COOKIES.split("; ")).forEach(rawCookie -> {
String[] ss = rawCookie.split("=");
Cookie cookie = new Cookie.Builder(ss[0], ss[1]).domain(".163.com").build();
driver.manage().addCookie(cookie);
});
}
private static void invoke() throws InterruptedException {
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
driver.manage().timeouts().pageLoadTimeout(15, TimeUnit.SECONDS);
String s = null;
driver.get("http://music.163.com/");
initCookies();
driver.get("http://music.163.com/");
s = driver.getPageSource();
userId = group(s, "userId:(\\d+)", 1);
driver.get("https://music.163.com/#/playlist?id=" + startId);
driver.switchTo().frame("contentFrame");
WebElement element = driver.findElement(By.cssSelector("[id=content-operation]>a:first-child"));
element.click();
((JavascriptExecutor) driver).executeScript("window.open(''about:blank'')");
ArrayList<String> tabs = new ArrayList<String>(driver.getWindowHandles());
driver.switchTo().window(tabs.get(0));
driver.switchTo().defaultContent();
int i = 0;
String lastSongName = "";
int count = 0;
while (true){
if(i > Integer.MAX_VALUE - 2){
break;
}
i++;
s = driver.getPageSource();
driver.switchTo().window(tabs.get(1)); //switches to new tab
String songs = null;
try{
driver.get("https://music.163.com/user/home?id=" + userId);
driver.switchTo().frame("contentFrame");
songs = group(driver.getPageSource(), "累积听歌(\\d+)首", 1);
} catch (TimeoutException e){
logger.error(e.getMessage(), e);
}
driver.switchTo().window(tabs.get(0));
Matcher matcher = pattern.matcher(s);
Matcher songNameMatcher = songName.matcher(s);
if (matcher.find() && songNameMatcher.find()){
String songNameStr = songNameMatcher.group(1);
if (!songNameStr.equals(lastSongName)){
count++;
lastSongName = songNameStr;
}
logger.info(songNameStr + "-" + matcher.group(1) + matcher.group(2) + "---当前播放第" + count + "首歌曲, 累计听歌:" + songs);
} else {
logger.info("解析歌曲播放记录或歌曲名失败");
}
Thread.sleep(1000 * 30);
}
}
public static String group(String str, String regex, int index) {
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(str);
return matcher.find() ? matcher.group(index) : "";
}
}
运行注意事项
- 修改自己相关chromedriver路径配置
- 登录自己的web端网易云音乐:https://music.163.com/
- 复制自己登录成功的原始cookies,至代码中的RAW_COOKIES字段
- 切换歌单,如果默认的歌单播放完成后,可以搜索一些没有播放过的歌单,类似
https://music.163.com/#/playlist?id=22336453的url,提取出id,直接替换代码中的startId字段。
总结
- 大家可能会有疑问,我想把这个任务放到自己的服务器上直接后台运行。这就是服务器上搭建selenium运行环境的问题了,可以参考我上一篇文章。阿里云和腾讯云最低配的服务器都能够跑起来的。
- 另外这里为啥采用selenium的方式,有没有其他更简单的方式,直接通过简单的Http请求的方式达到刷的效果。我个人尝试过像通过纯http 请求的方式,找到增加个人累计听歌数的请求,由于网银云的请求都做了加密,最终没有找到。所以就用selenium的方式来代替。
最后
- 完整工程代码见https://github.com/wycm/crawler-set/tree/master/music163
版权声明 作者:wycm
出处:https://my.oschina.net/wycm/blog/3028366
您的支持是对博主最大的鼓励,感谢您的认真阅读。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

今天的关于java+selenium 网易云音乐刷累计听歌数的方法和网易云代码刷听歌量的分享已经结束,谢谢您的关注,如果想了解更多关于curl实例1:登录落网获取累计听歌数、python+selenium 下载网易云音乐 支持批量下载、selenium实战-同步网易云音乐歌单到qq音乐、【java+selenium】网易云音乐刷累计听歌数的相关知识,请在本站进行查询。
本文标签:




