在本文中,我们将详细介绍Django系列博客的各个方面,并为您提供关于十的相关解答,同时,我们也将为您带来关于Anaconda+django写出第一个webapp(十)、Django博客开发教程3-创
在本文中,我们将详细介绍Django 系列博客的各个方面,并为您提供关于十的相关解答,同时,我们也将为您带来关于Anaconda+django写出第一个web app(十)、Django 博客开发教程 3 - 创建 Django 博客的数据库模型、Django 博客开发教程 5 - Django 博客首页视图、Django 博客开发教程 6 - 真正的 Django 博客首页视图的有用知识。
本文目录一览:- Django 系列博客(十)(django blog)
- Anaconda+django写出第一个web app(十)
- Django 博客开发教程 3 - 创建 Django 博客的数据库模型
- Django 博客开发教程 5 - Django 博客首页视图
- Django 博客开发教程 6 - 真正的 Django 博客首页视图
(django blog)")
Django 系列博客(十)(django blog)
<h1 id="django-系列博客十">Django 系列博客(十)
<h2 id="前言">前言
本篇博客介绍在 Django 中如何对数据库进行增删查改,主要为对单表进行操作。
查询数据层次图解:如果操作 MysqL,ORM 是在 pyMysqL 之上又进行了一层封装。

- MVC 或者 MTV 框架中包括一个重要的部分,就是 ORM,它实现了数据模型与数据库的解耦合,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,极大地减轻了工作量,不需要面对因数据变更而导致的无效劳动。
- ORM 是‘’对象-关系-映射‘’的简称

通过 ORM 可以简化甚至不需要在写 sql 语句,通过操作与数据库中对应的表的类来进行增删查改。
创建表:
CREATE TABLE employee(
id INT PRIMARY KEY auto_increment,name VARCHAR (20),gender BIT default 1,birthday DATA,department VARCHAR (20),salary DECIMAL (8,2) unsigned,);sql中的表纪录
添加一条表纪录:
INSERT employee (name,gender,birthday,salary,department)
VALUES ("alex",1,"1985-12-12",8000,"保洁部"); 查询一条表纪录:
SELECT * FROM employee WHERE age=24; 更新一条表纪录:
UPDATE employee SET birthday="1989-10-24" WHERE id=1; 删除一条表纪录:
DELETE FROM employee WHERE name="alex" python的类
class Employee(models.Model):
id=models.AutoField(primary_key=True)
name=models.CharField(max_length=32)
gender=models.BooleanField()
birthday=models.DateField()
department=models.CharField(max_length=32)
salary=models.DecimalField(max_digits=8,decimal_places=2)
python的类对象
#<a href="https://www.jb51.cc/tag/tianjia/" target="_blank">添加</a>一条表纪录:
emp=Employee(name="alex",gender=True,birthday="1985-12-12",epartment="保洁部")
emp.save()
#<a href="https://www.jb51.cc/tag/chaxun/" target="_blank">查询</a>一条表纪录:
Employee.objects.filter(age=24)
#更新一条表纪录:
Employee.objects.filter(id=1).update(birthday="1989-10-24")
#<a href="https://www.jb51.cc/tag/shanchu/" target="_blank">删除</a>一条表纪录:
Employee.objects.filter(name="alex").delete()</code></pre><h2 id="单表操作">单表操作
<h3 id="创建表">创建表
- 首先在 settings.py中配置好 MysqL参数。
**注意:NAME 即数据库的名字,在 MysqL 连接前该数据库必须已经创建,而上面的 sqlite 数据库下的db.sqlite3则是项目自动 创建 USER 和 PASSWORD 分别是数据库的用户名和密码。设置完后,再启动我们的 django 项目前,我们需要激活 MysqL。然后,启动项目会报错:no module named MysqLdb 。这是因为django默认你导入的驱动是MysqLdb,可是MysqLdb 对于py3有很大问题,所以我们需要的驱动是PyMysqL 所以,我们只需要找到项目名文件下的__init__,在里面写入下面的代码:**
- 在一个模块中设置 MysqL 引擎
pyMysqL.installasMysqLdb()
- 在 models.py中创建数据模型
Create your models here.
class Book(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=64)
pub_data = models.DateField()
price = models.DecimalField(max_digits=5,decimal_places=2)
publish = models.CharField(max_length=12)
def str(self):
return self.name
- 数据迁移
- 想打印 ORM 转换过程中的 sql,在 settings.py中进行如下设置:
- 增加删除字段
删除,直接注释掉字段,重新执行数据库迁移命令即可;
新增字段,在类里直接新增字段,直接执行数据库迁移命令会提示输入默认值,此时需要在字段里面设置:
注意:
1. 数据库迁移记录都在 application 下面的 migrations 里面的 py 文件中;
2. 使用 showmigrations 命令可以查看没有执行 migrate 的文件;
3. makemigrations 是生成一个创建表的记录,migrate 是将更改提交到数据库。
- 在 python 中调用 Django 环境
from app01 import models
books = models.Book.objects.all()
print(books)</code></pre><h3 id="更多字段和参数">更多字段和参数
每个字段有一些特有的参数,例如,CharField 需要 max_length参数来指定 VARCHAR 数据库字段的大小。还有一些适用于所有字段的通用参数。这些参数在文档中有详细定义,这里简单介绍一些常用字段含义:
AutoField(Field):int自增列,必须填入参数
primary_key=True-
BigAutoField(AutoField):bigint 自增列,必须填入参数
primary_key=True注:当 model 中没有自增列,则自动会创建一个列名为 id 的字段
SmallIntegerField(IntegerField):小整数,-32768 ~ 32767
PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin,IntegerField):正小整数 0 ~ 32767
IntegerField(Field):整数列(有符号)-2147483648 ~ 2147483647
PositiveIntegerField(PositiveIntegerRelDbTypeMixin,IntegerField):正整数 0 ~ 2147483647
BigIntegerField(IntegerField):长整型(有符号)-9223372036854775808 ~ 9223372036854775807
自定义无符号整数字段
- BooleanField(Field):布尔值类型
- NullBooleanField(Field):可以为空的布尔值
- CharField(Field):字符类型。必须设置 max_length参数,表示字符长度
- TextField(Field):文本类型
- EmailField(CharField):字符串类型,Django admin 以及 ModelForm 中提供验证机制
- IPAddressField(Field):字符串类型,Django Admin 以及 ModelForm 中提供验证 IPV4机制
- GenericIPAddressField(Field):字符串类型,Django Admin 以及 ModelFOrm 中提供验证 IPV4和 IPV6,参数:protocol,用于指定 IPV4或 IPV6,
- URLField(CharField):字符串类型,Django Admin 以及ModelForm 中提供验证 URL
- SlugField(CharField):字符串类型,Django Admin 以及 ModelForm 中提供验证支持字母、数字、下划线、连接符(减号)
- CommaSeparatedIntegerField(CharField):字符串类型,格式必须为逗号分隔的数字
- UUIDField(Field):字符串类型,Django Admin 以及 ModelForm 中提供对 UUID 格式的验证
- FilePathField(Field):字符串,Django Admin 以及 ModelFOrm 中提供读取文件夹下文件的功能,参数:path:文件夹路径,match=None:正则匹配,recursive=False:递归下面的文件夹,allow_files=True:允许文件,allow_folders=False:允许文件夹
- FileField(Field):字符串,路径保存在数据库,文件上传到指定目录,参数:upload_to='''':上传文件的保存路径,storage=None:存储组件,默认 django.core.files.storage.FileSystemStorage
- ImageField(FileFiled):字符串,路径保存在数据库,文件上传到指定目录,参数:upload_to='''':上传文件的保存路径,storage=None:存储组件,默认django.core.files.storage.FileSystemStorage,width_field=None:上传图片的高度保存的数据库字段名(字符串),height_field=None:上传图片的宽度保存的数据库字段名(字符串)
- DateTimeField(DateField):日期+时间格式:YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ]
- DateField(DateTimeCheckMixin,Field):日期格式:YYYY-MM-DD
- TimeField(DateTimeCheckMixin,Field):时间格式:HH:MM[:ss[.uuuuuu]]
- DurationField(Field):长整数,时间间隔,数据库中按照 bigint 存储,ORM 中获取的值为 datetime.timedelta类型
- FloatField(Field):浮点型
- DecimalField(Field):10进制小数,参数:max_digits:小数点总长度,decimal_places:小数位长度
- BinaryField(Field):二进制类型
(1)null
如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False.
(1)blank
如果为True,该字段允许不填。默认为False。
要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。
如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。
(2)default
字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。
(3)primary_key
如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True,
Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为,
否则没必要设置任何一个字段的primary_key=True。
(4)unique
如果该值设置为 True,这个数据字段的值在整张表中必须是唯一的
(5)choices
由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,默认的表单将是一个选择框而不是标准的文本框,
而且这个选择框的选项就是choices 中的选项。
<h3 id="返回值为字段在数据库中的属性-django-字段默认的值">返回值为字段在数据库中的属性, Django 字段默认的值:
(1)null
如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False.
(1)blank
如果为True,该字段允许不填。默认为False。
要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。
如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。
(2)default
字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。
(3)primary_key
如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True,
Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为,
否则没必要设置任何一个字段的primary_key=True。
(4)unique
如果该值设置为 True,这个数据字段的值在整张表中必须是唯一的
(5)choices
由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,默认的表单将是一个选择框而不是标准的文本框,
而且这个选择框的选项就是choices 中的选项。
<pre>
'AutoField': 'integer AUTO_INCREMENT','BigAutoField': 'bigint AUTO_INCREMENT','BinaryField': 'longblob','BooleanField': 'bool','CharField': 'varchar(%(max_length)s)','CommaSeparatedIntegerField': 'varchar(%(max_length)s)','DateField': 'date','DateTimeField': 'datetime','DecimalField': 'numeric(%(max_digits)s,%(decimal_places)s)','DurationField': 'bigint','FileField': 'varchar(%(max_length)s)','FilePathField': 'varchar(%(max_length)s)','FloatField': 'double precision','IntegerField': 'integer','BigIntegerField': 'bigint','IPAddressField': 'char(15)','GenericIPAddressField': 'char(39)','NullBooleanField': 'bool','OnetoOneField': 'integer','PositiveIntegerField': 'integer UNSIGNED','PositiveSmallIntegerField': 'smallint UNSIGNED','SlugField': 'varchar(%(max_length)s)','SmallIntegerField': 'smallint','TextField': 'longtext','TimeField': 'time','UUIDField': 'char(32)',<h2 id="单表增删查改">单表增删查改
<h3 id="添加表记录">添加表记录
- 第一种方法
- 第二种方法
查询表记录
查询
删除表记录
删除方法就是 delete(),它运行时立即删除对象而不返回任何值。例如:
你也可以一次性删除多个对象。每个 QuerySet 都有一个 delete() 方法,它一次性删除 QuerySet 中所有的对象。
例如,下面的代码将删除 pub_date 是2005年的 Entry 对象:
在 Django 删除对象时,会模仿 sql 约束 ON DELETE CASCADE 的行为,换句话说,删除一个对象时也会删除与它相关联的外键对象。例如:
要注意的是: delete() 方法是 QuerySet 上的方法,但并不适用于 Manager 本身。这是一种保护机制,是为了避免意外地调用 Entry.objects.delete() 方法导致 所有的 记录被误删除。如果你确认要删除所有的对象,那么你必须显式地调用:
如果不要级联删除,可以设置为:
修改表记录
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录 update()方法会返回一个整型数值,表示受影响的记录条数。
")
Anaconda+django写出第一个web app(十)
今天继续学习外键的使用。
当我们有了category、series和很多tutorials时,我们查看某个tutorial,可能需要这样的路径http://127.0.0.1:8000/category/series/tutorial,这样看上去十分的繁琐,我们希望无论是在category下还是在series、tutorials下,都只有一级路径。
那么如何做呢?首先在views.py中,我们定义一个single_slug函数:
def single_slug(request, single_slug):
categories = [c.category_slug for c in TutorialCategory.objects.all()]
if single_slug in categories:
matching_series = TutorialSeries.objects.filter(tutorial_category__category_slug=single_slug)
series_urls = {}
for m in matching_series.all():
part_one = Tutorial.objects.filter(tutorial_series__tutorial_series=m.tutorial_series).earliest(''tutorial_published'')
series_urls[m] = part_one.tutorial_slug
return render(request=request,
template_name=''main/category.html'',
context={''tutorial_series'':matching_series, ''part_ones'': series_urls})
tutorials = [t.tutorial_slug for t in Tutorial.objects.all()]
if single_slug in tutorials:
return HttpResponse(f"{single_slug} is a tutorial.")这里我们还定义了一个字典series_urls,字典的键为series,字典的值为该series下的第一个tutorial(也就是发布时间最早的tutorial)。然后我们指向了一个新的网页category.html,内容如下:
{% extends ''main/header.html'' %}
{% block content %}
<div class="row">
{% for t, partone in part_ones.items %}
<div class="col s12 m6 l4">
<a href="{{partone}}" style="color:#000">
<div class="card hoverable">
<div class="card-content">
<div class="card-title blue-text"><strong>{{ t.tutorial_series }}</strong></div>
<p>{{ t.series_summary }}</p>
</div>
</div>
</a>
</div>
{% endfor %}
</div>
{% endblock %}我们显示了这个该category下的某个series的标题和摘要。
为了能够访问这个html,我们还需要定义main文件夹下的urls.py,来指向这个路径:
from django.urls import path
from . import views
app_name = ''main'' #此处为了urls的命名空间
urlpatterns = [
path('''', views.homepage, name=''homepage''),
path(''register/'', views.register, name=''register''),
path(''logout/'', views.logout_request, name=''logout_request''),
path(''login/'', views.login_request, name=''login_request''),
path(''<single_slug>'', views.single_slug, name=''single_slug''),
]我们可以在admin下自己先定义几个category和几个series,我定义了两个category,分别为Web Development和Data Analysis,定义了两个Series,分别为Django和Machine Learning,然后到浏览器http://127.0.0.1:8000/,刷新页面:
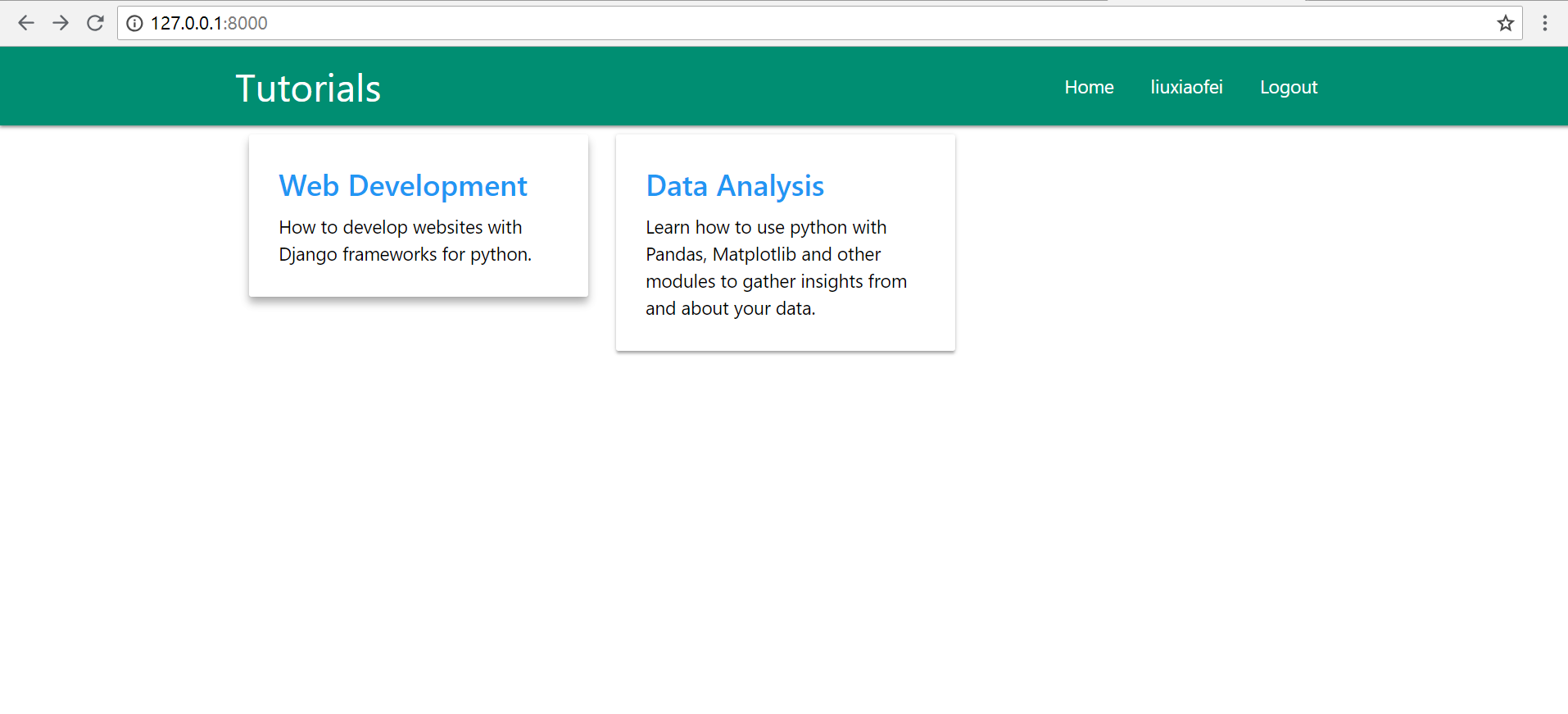
随便点击某一个卡片,我这里点击第一个Web Development,看到如下界面:
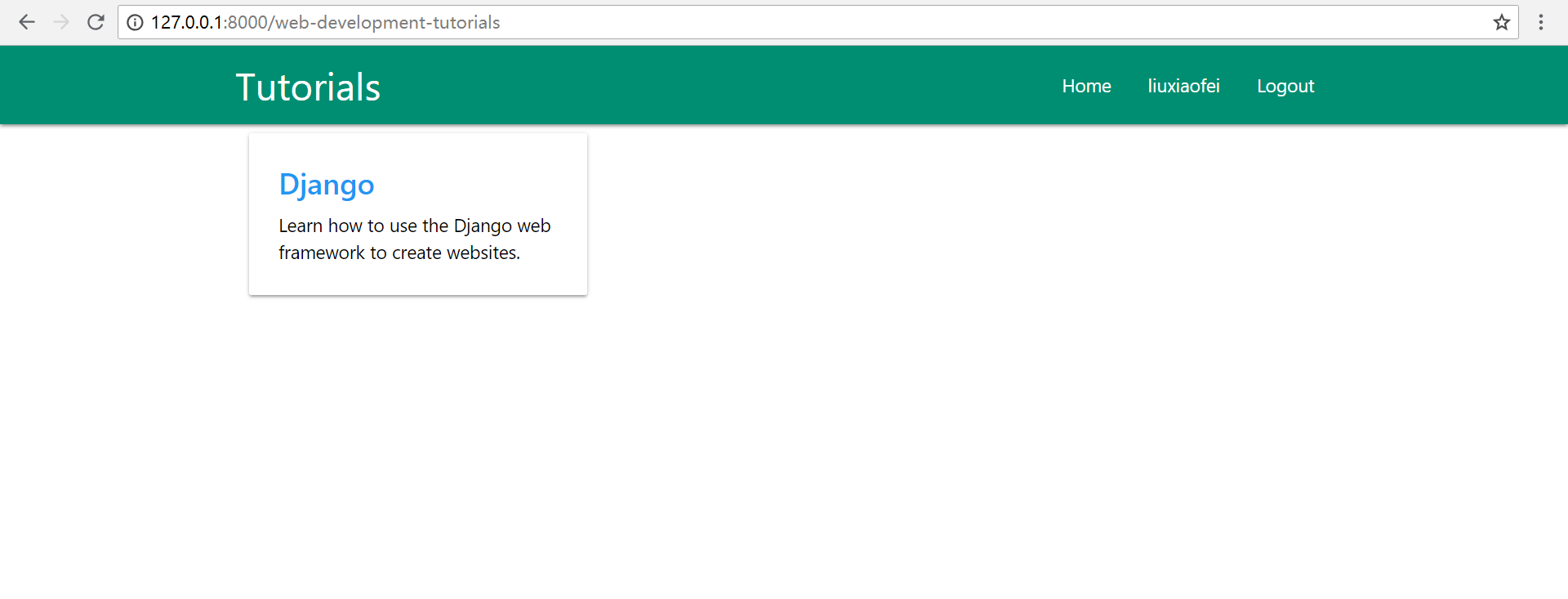
继续点击,我们看到路径仍然只有一级:

下一节,我们需要继续定义tutorial这个路径下显示的内容,也就是第一个tutorial以及一个滑动条来显示所有的tutorials,而不是只显示这么一行字。
参考链接:
[1] https://pythonprogramming.net/working-foreign-keys-django-tutorial/

Django 博客开发教程 3 - 创建 Django 博客的数据库模型
设计博客的数据库表结构
博客最主要的功能就是展示我们写的文章,它需要从某个地方获取博客文章数据才能把文章展示出来,通常来说这个地方就是数据库。我们把写好的文章永久地保存在数据库里,当用户访问我们的博客时,Django 就去数据库里把这些数据取出来展现给用户。
博客的文章应该含有标题、正文、作者、发表时间等数据。一个更加现代化的博客文章还希望它有分类、标签、评论等。为了更好地存储这些数据,我们需要合理地组织数据库的表结构。
我们的博客初级版本主要包含博客文章,文章会有分类以及标签。一篇文章只能有一个分类,但可以打上很多标签。
数据库存储的数据其实就是表格的形式,例如存储博客文章的数据库表长这个样子:
| 文章 id | 标题 | 正文 | 发表时间 | 分类 | 标签 |
|---|---|---|---|---|---|
| 1 | title 1 | text 1 | 2016-12-23 | Django | Django 学习 |
| 2 | title 2 | text 2 | 2016-12-24 | Django | Django 学习 |
| 3 | title 3 | text 3 | 2016-12-26 | Python | Python 学习 |
其中文章 ID 是一个数字,唯一对应着一篇文章。当然还可以有更多的列以存储更多相关数据,这只是一个最基本的示例。
数据库表设计成这样其实已经可以了,但是稍微分析一下我们就会发现一个问题,这 3 篇文章的分类和标签都是相同的,这会产生很多重复数据,当数据量很大时就浪费了存储空间。
不同的文章可能它们对应的分类或者标签是相同的,所以我们把分类和标签提取出来,做成单独的数据库表,再把文章和分类、标签关联起来。下面分别是分类和标签的数据库表:
| 分类 id | 分类名 |
|---|---|
| 1 | Django |
| 2 | Python |
| 标签 id | 标签名 |
|---|---|
| 1 | Django 学习 |
| 2 | Python 学习 |
编写博客模型代码
以上是自然语言描述的表格,数据库也和编程语言一样,有它自己的一套规定的语法来生成上述的表结构,这样我们才能把数据存进去。一般来说这时候我们应该先去学习数据库创建表格的语法,再回来写我们的 Django 博客代码了。但是 Django 告诉我们不用这么麻烦,它已经帮我们做了一些事情。Django 把那一套数据库的语法转换成了 Python 的语法形式,我们只要写 Python 代码就可以了,Django 会把 Python 代码翻译成对应的数据库操作语言。用更加专业一点的说法,就是 Django 为我们提供了一套 ORM(Object Relational Mapping)系统。
例如我们的分类数据库表,Django 只要求我们这样写:
blog/models.py
from django.db import models
class Category(models.Model):
name = models.CharField(max_length=100)Category 就是一个标准的 Python 类,它继承了 models.Model 类,类名为 Category 。Category 类有一个属性 name,它是 models.CharField 的一个实例。
这样,Django 就可以把这个类翻译成数据库的操作语言,在数据库里创建一个名为 category 的表格,这个表格的一个列名为 name。还有一个列 id,Django 则会自动创建。可以看出从 Python 代码翻译成数据库语言时其规则就是一个 Python 类对应一个数据库表格,类名即表名,类的属性对应着表格的列,属性名即列名。
我们需要 3 个表格:文章(Post)、分类(Category)以及标签(Tag),下面就来分别编写它们对应的 Python 类。模型的代码通常写在相关应用的 models.py 文件里。已经在代码中做了详细的注释,说明每一句代码的含义。但如果你在移动端下阅读不便的话,也可以跳到代码后面看正文的里的讲解。
注意:代码中含有中文注释,如果你直接 copy 代码到你的文本编辑器且使用了 Python 2 开发环境的话,会得到一个编码错误。因此请在文件最开始处加入编码声明:# coding: utf-8。
blog/models.py
from django.db import models
from django.contrib.auth.models import User
class Category(models.Model):
"""
Django 要求模型必须继承 models.Model 类。
Category 只需要一个简单的分类名 name 就可以了。
CharField 指定了分类名 name 的数据类型,CharField 是字符型,
CharField 的 max_length 参数指定其最大长度,超过这个长度的分类名就不能被存入数据库。
当然 Django 还为我们提供了多种其它的数据类型,如日期时间类型 DateTimeField、整数类型 IntegerField 等等。
Django 内置的全部类型可查看文档:
https://docs.djangoproject.com/en/1.10/ref/models/fields/#field-types
"""
name = models.CharField(max_length=100)
class Tag(models.Model):
"""
标签 Tag 也比较简单,和 Category 一样。
再次强调一定要继承 models.Model 类!
"""
name = models.CharField(max_length=100)
class Post(models.Model):
"""
文章的数据库表稍微复杂一点,主要是涉及的字段更多。
"""
# 文章标题
title = models.CharField(max_length=70)
# 文章正文,我们使用了 TextField。
# 存储比较短的字符串可以使用 CharField,但对于文章的正文来说可能会是一大段文本,因此使用 TextField 来存储大段文本。
body = models.TextField()
# 这两个列分别表示文章的创建时间和最后一次修改时间,存储时间的字段用 DateTimeField 类型。
created_time = models.DateTimeField()
modified_time = models.DateTimeField()
# 文章摘要,可以没有文章摘要,但默认情况下 CharField 要求我们必须存入数据,否则就会报错。
# 指定 CharField 的 blank=True 参数值后就可以允许空值了。
excerpt = models.CharField(max_length=200, blank=True)
# 这是分类与标签,分类与标签的模型我们已经定义在上面。
# 我们在这里把文章对应的数据库表和分类、标签对应的数据库表关联了起来,但是关联形式稍微有点不同。
# 我们规定一篇文章只能对应一个分类,但是一个分类下可以有多篇文章,所以我们使用的是 ForeignKey,即一对多的关联关系。
# 而对于标签来说,一篇文章可以有多个标签,同一个标签下也可能有多篇文章,所以我们使用 ManyToManyField,表明这是多对多的关联关系。
# 同时我们规定文章可以没有标签,因此为标签 tags 指定了 blank=True。
# 如果你对 ForeignKey、ManyToManyField 不了解,请看教程中的解释,亦可参考官方文档:
# https://docs.djangoproject.com/en/1.10/topics/db/models/#relationships
category = models.ForeignKey(Category)
tags = models.ManyToManyField(Tag, blank=True)
# 文章作者,这里 User 是从 django.contrib.auth.models 导入的。
# django.contrib.auth 是 Django 内置的应用,专门用于处理网站用户的注册、登录等流程,User 是 Django 为我们已经写好的用户模型。
# 这里我们通过 ForeignKey 把文章和 User 关联了起来。
# 因为我们规定一篇文章只能有一个作者,而一个作者可能会写多篇文章,因此这是一对多的关联关系,和 Category 类似。
author = models.ForeignKey(User)博客模型代码代码详解
首先是 Category 和 Tag 类,它们均继承自 model.Model 类,这是 Django 规定的。Category 和 Tag 类均有一个 name 属性,用来存储它们的名称。由于分类名和标签名一般都是用字符串表示,因此我们使用了 CharField 来指定 name 的数据类型,同时 max_length 参数则指定 name 允许的最大长度,超过该长度的字符串将不允许存入数据库。除了 CharField ,Django 还为我们提供了更多内置的数据类型,比如时间类型 DateTimeField、整数类型 IntegerField 等等。
在本教程中我们会教你这些类型的使用方法,但以后你开发自己的项目时,你就需要通过阅读Django 官方文档 关于字段类型的介绍 来了解有哪些数据类型可以使用以及如何使用它们。
Post 类也一样,必须继承自 model.Model 类。文章的数据库表稍微复杂一点,主要是列更多,我们指定了这些列:
title。这是文章的标题,数据类型是CharField,允许的最大长度max_length = 70。body。文章正文,我们使用了TextField。比较短的字符串存储可以使用CharField,但对于文章的正文来说可能会是一大段文本,因此使用TextField来存储大段文本。created_time、modified_time。这两个列分别表示文章的创建时间和最后一次修改时间,存储时间的列用DateTimeField数据类型。excerpt。文章摘要,可以没有文章摘要,但默认情况下CharField要求我们必须存入数据,否则就会报错。指定CharField的blank=True参数值后就可以允许空值了。category和tags。这是分类与标签,分类与标签的模型我们已经定义在上面。我们把文章对应的数据库表和分类、标签对应的数据库表关联了起来,但是关联形式稍微有点不同。我们规定一篇文章只能对应一个分类,但是一个分类下可以有多篇文章,所以我们使用的是ForeignKey,即一对多的关联关系。而对于标签来说,一篇文章可以有多个标签,同一个标签下也可能有多篇文章,所以我们使用ManyToManyField,表明这是多对多的关联关系。同时我们规定文章可以没有标签,因此为标签 tags 指定了blank=True。author。文章作者,这里User是从 django.contrib.auth.models 导入的。django.contrib.auth 是 Django 内置的应用,专门用于处理网站用户的注册、登录等流程。其中User是 Django 为我们已经写好的用户模型,和我们自己编写的Category等类是一样的。这里我们通过ForeignKey把文章和User关联了起来,因为我们规定一篇文章只能有一个作者,而一个作者可能会写多篇文章,因此这是一对多的关联关系,和Category类似。
理解多对一和多对多两种关联关系
我们分别使用了两种关联数据库表的形式:ForeignKey 和 ManyToManyField。
ForeignKey
ForeignKey 表明一种一对多的关联关系。比如这里我们的文章和分类的关系,一篇文章只能对应一个分类,而一个分类下可以有多篇文章。反应到数据库表格中,它们的实际存储情况是这样的:
| 文章 ID | 标题 | 正文 | 分类 ID |
|---|---|---|---|
| 1 | title 1 | body 1 | 1 |
| 2 | title 2 | body 2 | 1 |
| 3 | title 3 | body 3 | 1 |
| 4 | title 4 | body 4 | 2 |
| 分类 ID | 分类名 | |
|---|---|---|
| 1 | Django | |
| 2 | Python |
可以看到文章和分类实际上是通过文章数据库表中 分类 ID 这一列关联的。当要查询文章属于哪一个分类时,只需要查看其对应的分类 ID 是多少,然后根据这个分类 ID 就可以从分类数据库表中找到该分类的数据。例如这里文章 1、2、3 对应的分类 ID 均为 1,而分类 ID 为 1 的分类名为 Django,所以文章 1、2、3 属于分类 Django。同理文章 4 属于分类 Python。
反之,要查询某个分类下有哪些文章,只需要查看对应该分类 ID 的文章有哪些即可。例如这里 Django 的分类 ID 为 1,而对应分类 ID 为 1 的文章有文章 1、2、3,所以分类 Django 下有 3 篇文章。
希望这个例子能帮助你加深对多对一关系,以及它们在数据库中是如何被关联的理解,更多的例子请看文末给出的 Django 官方参考资料。
ManyToManyField
ManyToManyField 表明一种多对多的关联关系,比如这里的文章和标签,一篇文章可以有多个标签,而一个标签下也可以有多篇文章。反应到数据库表格中,它们的实际存储情况是这样的:
| 文章 ID | 标题 | 正文 |
|---|---|---|
| 1 | title 1 | body 1 |
| 2 | title 2 | body 2 |
| 3 | title 3 | body 3 |
| 4 | title 4 | body 4 |
| 标签 ID | 标签名 |
|---|---|
| 1 | Django 学习 |
| 2 | Python 学习 |
| 文章 ID | 标签 ID |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 1 |
| 3 | 2 |
多对多的关系无法再像一对多的关系中的例子一样在文章数据库表加一列 分类 ID 来关联了,因此需要额外建一张表来记录文章和标签之间的关联。例如文章 ID 为 1 的文章,既对应着 标签 ID 为 1 的标签,也对应着 标签 ID 为 2 的标签,即文章 1 既属于标签 1:Django 学习,也属于标签 2:Python 学习。
反之,标签 ID 为 1 的标签,既对应着 文章 ID 为 1 的文章,也对应着 文章 ID 为 2 的文章,即标签 1:Django 学习下有两篇文章。
希望这个例子能帮助你加深对多对多关系,以及它们在数据库中是如何被关联的理解,更多的例子请看文末给出的 Django 官方参考资料。
假如你对多对一关系和多对多关系还存在一些困惑,强烈建议阅读官方文档对这两种关系的说明以及更多官方的例子以加深理解:
Django ForeignKey 简介
Django ForeignKey 详细示例
Django ManyToManyField 简介
Django ManyToManyField 详细示例
总结
本章节的代码位于:Step3: blog models。
如果遇到问题,请通过下面的方式寻求帮助。
在 创建 Django 博客的数据库模型 - 追梦人物的博客 的评论区留言。
将问题的详细描述通过邮件发送到 djangostudyteam@163.com,一般会在 24 小时内回复。
更多Django 教程,请访问 追梦人物的博客。

Django 博客开发教程 5 - Django 博客首页视图
Django 处理 HTTP 请求
Web 应用的交互过程其实就是 HTTP 请求与响应的过程。无论是在 PC 端还是移动端,我们通常使用浏览器来上网,上网流程大致来说是这样的:
我们打开浏览器,在地址栏输入想访问的网址,比如 http://zmrenwu.com/(当然你也可能从收藏夹里直接打开网站,但本质上都是一样的)。
浏览器知道我们想要访问哪个网址后,它在后台帮我们做了很多事情。主要就是把我们的访问意图包装成一个 HTTP 请求,发给我们想要访问的网址所对应的服务器。通俗点说就是浏览器帮我们通知网站的服务器,说有人来访问你啦,访问的请求都写在 HTTP 里了,你按照要求处理后告诉我,我再帮你回应他!
服务器处理了HTTP 请求,然后生成一段 HTTP 响应给浏览器。浏览器解读这个响应,把相关的内容在浏览器里显示出来,于是我们就看到了网站的内容。比如你访问了我的博客主页 http://zmrenwu.com/,服务器接收到这个请求后就知道用户访问的是首页,首页显示的是全部文章列表,于是它从数据库里把文章数据取出来,生成一个写着这些数据的 HTML 文档,包装到 HTTP 响应里发给浏览器,浏览器解读这个响应,把 HTML 文档显示出来,我们就看到了文章列表的内容。
因此,Django 作为一个 Web 框架,它的使命就是处理流程中的第二步。即接收浏览器发来的 HTTP 请求,返回相应的 HTTP 响应。于是引出这么几个问题:
Django 如何接收 HTTP 请求?
Django 如何处理这个 HTTP 请求?
Django 如何生成 HTTP 响应?
对于如何处理这些问题,Django 有其一套规定的机制。我们按照 Django 的规定,就能开发出所需的功能。
Hello 视图函数
我们先以一个最简单的 Hello World 为例来看看 Django 处理上述问题的机制是怎么样的。
绑定 URL 与视图函数
首先 Django 需要知道当用户访问不同的网址时,应该如何处理这些不同的网址(即所说的路由)。Django 的做法是把不同的网址对应的处理函数写在一个 urls.py 文件里,当用户访问某个网址时,Django 就去会这个文件里找,如果找到这个网址,就会调用和它绑定在一起的处理函数(叫做视图函数)。
下面是具体的做法,首先在 blog 应用的目录下创建一个 urls.py 文件,这时你的目录看起来是这样:
blog\
__init__.py
admin.py
apps.py
migrations\
0001_initial.py
__init__.py
models.py
tests.py
views.py
urls.py在 blogurls.py 中写入这些代码:
blog/urls.py
from django.conf.urls import url
from . import views
urlpatterns = [
url(r''^$'', views.index, name=''index''),
]我们首先从 django.conf.urls 导入了 url 函数,又从当前目录下导入了 views 模块。然后我们把网址和处理函数的关系写在了 urlpatterns 列表里。
绑定关系的写法是把网址和对应的处理函数作为参数传给 url 函数(第一个参数是网址,第二个参数是处理函数),另外我们还传递了另外一个参数 name,这个参数的值将作为处理函数 index 的别名,这在以后会用到。
注意这里我们的网址是用正则表达式写的,Django 会用这个正则表达式去匹配用户实际输入的网址,如果匹配成功,就会调用其后面的视图函数做相应的处理。
比如说我们本地开发服务器的域名是 http://127.0.0.1:8000,那么当用户输入网址 http://127.0.0.1:8000 后,Django 首先会把协议 http、域名 127.0.0.1 和端口号 8000 去掉,此时只剩下一个空字符串,而 r''^$'' 的模式正是匹配一个空字符串(这个正则表达式的意思是以空字符串开头且以空字符串结尾),于是二者匹配,Django 便会调用其对应的 views.index 函数。
注意:在项目根目录的 blogproject 目录下(即 settings.py 所在的目录),原本就有一个 urls.py 文件,这是整个工程项目的 URL 配置文件。而我们这里新建了一个 urls.py 文件,且位于 blog 应用下。这个文件将用于 blog 应用相关的 URL 配置。不要把两个文件搞混了。
编写视图函数
第二步就是要实际编写我们的 views.index 视图函数了,按照惯例视图函数定义在 views.py 文件里:
blog/views.py
from django.http import HttpResponse
def index(request):
return HttpResponse("欢迎访问我的博客首页!")我们前面说过,Web 服务器的作用就是接收来自用户的 HTTP 请求,根据请求内容作出相应的处理,并把处理结果包装成 HTTP 响应返回给用户。
这个两行的函数体现了这个过程。它首先接受了一个名为 request 的参数,这个 request 就是 Django 为我们封装好的 HTTP 请求,它是类 HttpRequest 的一个实例。然后我们便直接返回了一个 HTTP 响应给用户,这个 HTTP 响应也是 Django 帮我们封装好的,它是类 HttpResponse 的一个实例,只是我们给它传了一个自定义的字符串参数。
浏览器接收到这个响应后就会在页面上显示出我们传递的内容 :欢迎访问我的博客首页!
配置项目 URL
还差最后一步了,我们前面建立了一个 urls.py 文件,并且绑定了 URL 和视图函数 index,但是 Django 并不知道。Django 匹配 URL 模式是在 blogproject 目录(即 settings.py 文件所在的目录)的 urls.py 下的,所以我们要把 blog 应用下的 urls.py 文件包含到 blogprojecturls.py 里去,打开这个文件看到如下内容:
blogproject/urls.py
"""
一大段注释
"""
from django.conf.urls import url
from django.contrib import admin
urlpatterns = [
url(r''^admin/'', admin.site.urls),
]修改成如下的形式:
- from django.conf.urls import url
+ from django.conf.urls import url, include
from django.contrib import admin
urlpatterns = [
url(r''^admin/'', admin.site.urls),
+ url(r'''', include(''blog.urls'')),
]这里 - 表示删掉这一行,+ 表示添加这一行。
我们这里导入了一个 include 函数,然后利用这个函数把 blog 应用下的 urls.py 文件包含了进来。此外 include 前还有一个 r'''',这是一个空字符串。这里也可以写其它字符串,Django 会把这个字符串和后面 include 的 urls.py 文件中的 URL 拼接。比如说如果我们这里把 r'''' 改成 r''blog/'',而我们在 blog.urls 中写的 URL 是 r''^$'',即一个空字符串。那么 Django 最终匹配的就是 blog/ 加上一个空字符串,即 blog/。
运行结果
激活虚拟环境,运行 python manage.py runserver 打开开发服务器,在浏览器输入开发服务器的地址 http://127.0.0.1:8000/,可以看到 Django 返回的内容了。
欢迎访问我的博客首页!
使用 Django 模板系统
这基本上就上 Django 的开发流程了,写好处理 HTTP 请求和返回 HTTP 响应的视图函数,然后把视图函数绑定到相应的 URL 上。
但是等一等!我们看到在视图函数里返回的是一个 HttpResponse 类的实例,我们给它传入了一个希望显示在用户浏览器上的字符串。但是我们的博客不可能只显示这么一句话,它有可能会显示很长很长的内容。比如我们发布的博客文章列表,或者一大段的博客文章。我们不能每次都把这些大段大段的内容传给 HttpResponse。
Django 对这个问题给我们提供了一个很好的解决方案,叫做模板系统。Django 要我们把大段的文本写到一个文件里,然后 Django 自己会去读取这个文件,再把读取到的内容传给 HttpResponse。让我们用模板系统来改造一下上面的例子。
首先在我们的项目根目录(即 manage.py 文件所在目录)下建立一个名为 templates 的文件夹,用来存放我们的模板。然后在 templates 目录下建立一个名为 blog 的文件夹,用来存放和 blog 应用相关的模板。
当然模板存放在哪里是无关紧要的,只要 Django 能够找到的就好。但是我们建立这样的文件夹结构的目的是把不同应用用到的模板隔离开来,这样方便以后维护。我们在 templatesblog 目录下建立一个名为 index.html 的文件,此时你的目录结构应该是这样的:
blogproject\
manage.py
blogproject\
__init__.py
settings.py
...
blog\
__init__.py
models.py
,,,
templates\
blog\
index.html再一次强调 templates 目录位于项目根目录,而 index.html 位于 templatesblog 目录下,而不是 blog 应用下,如果弄错了你可能会得到一个TemplateDoesNotExist 异常。如果遇到这个异常,请回来检查一下模板目录结构是否正确。
在 templatesblogindex.html 文件里写入下面的代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{{ title }}</title>
</head>
<body>
<h1>{{ welcome }}</h1>
</body>
</html>这是一个标准的 HTML 文档,只是里面有两个比较奇怪的地方:{{ title }},{{ welcome }}。这是 Django 规定的语法。用 {{ }} 包起来的变量叫做模板变量。Django 在渲染这个模板的时候会根据我们传递给模板的变量替换掉这些变量。最终在模板中显示的将会是我们传递的值。
注意:index.html 必须以 UTF-8 的编码格式保存,且小心不要往里面添加一些特殊字符,否则极有可能得到一个 UnicodeDecodeError 这样的错误。
模板写好了,还得告诉 Django 去哪里找模板,在 settings.py 文件里设置一下模板文件所在的路径。在 settings.py 找到 TEMPLATES 选项,它的内容是这样的:
blogproject/settings.py
TEMPLATES = [
{
''BACKEND'': ''django.template.backends.django.DjangoTemplates'',
''DIRS'': [],
''APP_DIRS'': True,
''OPTIONS'': {
''context_processors'': [
''django.template.context_processors.debug'',
''django.template.context_processors.request'',
''django.contrib.auth.context_processors.auth'',
''django.contrib.messages.context_processors.messages'',
],
},
},
]其中 DIRS 就是设置模板的路径,在 [] 中写入 os.path.join(BASE_DIR, ''templates''),即像下面这样:
blogproject/settings.py
TEMPLATES = [
{
...
''DIRS'': [os.path.join(BASE_DIR, ''templates'')],
...
},
]这里 BASE_DIR 是 settings.py 在配置开头前面定义的变量,记录的是工程根目录 blogproject 的值(注意是最外层的 blogproject 目录)。在这个目录下有模板文件所在的目录 templates,于是利用os.path.join 把这两个路径连起来,构成完整的模板路径,Django 就知道去这个路径下面找我们的模板了。
视图函数可以改一下了:
blog/views.py
from django.http import HttpResponse
from django.shortcuts import render
def index(request):
return render(request, ''blog/index.html'', context={
''title'': ''我的博客首页'',
''welcome'': ''欢迎访问我的博客首页''
})这里我们不再是直接把字符串传给 HttpResponse 了,而是调用 Django 提供的 render 函数。这个函数根据我们传入的参数来构造 HttpResponse。
我们首先把 HTTP 请求传了进去,然后 render 根据第二个参数的值 blog/index.html 找到这个模板文件并读取模板中的内容。之后 render 根据我们传入的 context 参数的值把模板中的变量替换为我们传递的变量的值,{{ title }} 被替换成了 context 字典中 title 对应的值,同理 {{ welcome }} 也被替换成相应的值。
最终,我们的 HTML 模板中的内容字符串被传递给 HttpResponse 对象并返回给浏览器(Django 在 render 函数里隐式地帮我们完成了这个过程),这样用户的浏览器上便显示出了我们写的 HTML 模板的内容。
总结
本章节的代码位于:Step5: blog index view。
如果遇到问题,请通过下面的方式寻求帮助。
在 Django 博客首页视图 - 追梦人物的博客 的评论区留言。
将问题的详细描述通过邮件发送到 djangostudyteam@163.com,一般会在 24 小时内回复。
更多Django 教程,请访问 追梦人物的博客。

Django 博客开发教程 6 - 真正的 Django 博客首页视图
在此之前我们已经编写了 Blog 的首页视图,并且配置了 URL 和模板,让 Django 能够正确地处理 HTTP 请求并返回合适的 HTTP 响应。不过我们仅仅在首页返回了一句话:欢迎访问我的博客。这是个 Hello World 级别的视图函数,我们需要编写真正的首页视图函数,当用户访问我们的博客首页时,他将看到我们发表的博客文章列表,就像 演示项目 里展示的这样。
首页视图函数
上一节我们阐明了 Django 的开发流程。即首先配置 URL,把 URL 和相应的视图函数绑定,一般写在 urls.py 文件里,然后在工程的 urls.py 文件引入。其次是编写视图函数,视图中需要渲染模板,我们也在 settings.py 中进行了模板相关的配置,让 Django 能够找到需要渲染的模板。最后把渲染完成的 HTTP 响应返回就可以了。相关的配置和准备工作都在之前完成了,这里我们只需专心编写视图函数,让它实现我们想要的功能即可。
首页的视图函数其实很简单,代码像这样:
blog/views.py
from django.shortcuts import render
from .models import Post
def index(request):
post_list = Post.objects.all().order_by(''-created_time'')
return render(request, ''blog/index.html'', context={''post_list'': post_list})我们曾经在前面的章节讲解过模型管理器 objects 的使用。这里我们使用 all() 方法从数据库里获取了全部的文章,存在了 post_list 变量里。all 方法返回的是一个 QuerySet(可以理解成一个类似于列表的数据结构),由于通常来说博客文章列表是按文章发表时间倒序排列的,即最新的文章排在最前面,所以我们紧接着调用了 order_by 方法对这个返回的 queryset 进行排序。排序依据的字段是 created_time,即文章的创建时间。- 号表示逆序,如果不加 - 则是正序。 接着如之前所做,我们渲染了 blogindex.html 模板文件,并且把包含文章列表数据的 post_list 变量传给了模板。
处理静态文件
我们的项目使用了从网上下载的一套博客模板(点击这里下载全套模板)。这里面除了 HTML 文档外,还包含了一些 CSS 文件和 JavaScript 文件以让网页呈现出我们现在看到的样式。同样我们需要对 Django 做一些必要的配置,才能让 Django 知道如何在开发服务器中引入这些 CSS 和 JavaScript 文件,这样才能让博客页面的 CSS 样式生效。
按照惯例,我们把 CSS 和 JavaScript 文件放在 blog 应用的 static 目录下。因此,先在 blog 应用下建立一个 static 文件夹。同时,为了避免和其它应用中的 CSS 和 JavaScript 文件命名冲突(别的应用下也可能有和 blog 应用下同名的 CSS 、JavaScript 文件),我们再在 static 目录下建立一个 blog 文件夹,把下载的博客模板中的 css 和 js 文件夹连同里面的全部文件一同拷贝进这个目录。最终我们的 blog 应用目录结构应该是这样的:
blog\
__init__.py
static\
blog\
css\
.css 文件...
js\
.js 文件...
admin.py
apps.py
migrations\
__init__.py
models.py
tests.py
views.py用下载的博客模板中的 index.html 文件替换掉之前我们自己写的 index.html 文件。如果你好奇,现在就可以运行开发服务器,看看首页是什么样子。

如图所示,你会看到首页显示的样式非常混乱,原因是浏览器无法正确加载 CSS 等样式文件。需要以 Django 的方式来正确地处理 CSS 和 JavaScript 等静态文件的加载路径。CSS 样式文件通常在 HTML 文档的 head 标签里引入,打开 index.html 文件,在文件的开始处找到 head 标签包裹的内容,大概像这样:
templates/blog/index.html
<!DOCTYPE html>
<html>
<head>
<title>Black & White</title>
<!-- meta -->
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- css -->
<link rel="stylesheet" href="css/bootstrap.min.css">
<link rel="stylesheet" href="http://code.ionicframework.com/ionicons/2.0.1/css/ionicons.min.css">
<link rel="stylesheet" href="css/pace.css">
<link rel="stylesheet" href="css/custom.css">
<!-- js -->
<script src="js/jquery-2.1.3.min.js"></script>
<script src="js/bootstrap.min.js"></script>
<script src="js/pace.min.js"></script>
<script src="js/modernizr.custom.js"></script>
</head>
<body>
<!-- 其它内容 -->
<script src="js/script.js"></script>
</body>
</html>CSS 样式文件的路径在 link 标签的 href 属性里,而 JavaScript 文件的路径在 script 标签的 src 属性里。可以看到诸如 `href="css/bootstrap.min.css" 或者 src="js/jquery-2.1.3.min.js" 这样的引用,由于引用文件的路径不对,所以浏览器引入这些文件失败。我们需要把它们改成正确的路径。把代码改成下面样子,正确地引入 static 文件下的 CSS 和 JavaScript 文件:
templates/blog/index.html
+ {% load staticfiles %}
<!DOCTYPE html>
<html>
<head>
<title>Black & White</title>
<!-- meta -->
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- css -->
- <link rel="stylesheet" href="css/bootstrap.min.css">
<link rel="stylesheet" href="http://code.ionicframework.com/ionicons/2.0.1/css/ionicons.min.css">
- <link rel="stylesheet" href="css/pace.css">
- <link rel="stylesheet" href="css/custom.css">
+ <link rel="stylesheet" href="{% static ''blog/css/bootstrap.min.css'' %}">
+ <link rel="stylesheet" href="{% static ''blog/css/pace.css'' %}">
+ <link rel="stylesheet" href="{% static ''blog/css/custom.css'' %}">
<!-- js -->
- <script src="js/jquery-2.1.3.min.js"></script>
- <script src="js/bootstrap.min.js"></script>
- <script src="js/pace.min.js"></script>
- <script src="js/modernizr.custom.js"></script>
+ <script src="{% static ''blog/js/jquery-2.1.3.min.js'' %}"></script>
+ <script src="{% static ''blog/js/bootstrap.min.js'' %}"></script>
+ <script src="{% static ''blog/js/pace.min.js'' %}"></script>
+ <script src="{% static ''blog/js/modernizr.custom.js'' %}"></script>
</head>
<body>
<!-- 其它内容 -->
- <script src="js/script.js'' %}"></script>
+ <script src="{% static ''blog/js/script.js'' %}"></script>
</body>
</html>这里 - 表示删掉这一行,而 + 表示增加这一行。
我们把引用路径放在了一个奇怪的符号里,例如:href="{% static ''blog/css/bootstrap.min.css'' %}"。用 {% %} 包裹起来的叫做模板标签。我们前面说过用 {{ }} 包裹起来的叫做模板变量,其作用是在最终渲染的模板里显示由视图函数传过来的变量值。而这里我们使用的模板标签的功能则类似于函数,例如这里的 static 模板标签,它把跟在后面的字符串 ''css/bootstrap.min.css'' 转换成正确的文件引入路径。这样 css 和 js 文件才能被正确加载,样式才能正常显示。
为了能在模板中使用 {% static %} 模板标签,别忘了在最顶部 {% load staticfiles %} 。static 模板标签位于 staticfiles 模块中,只有通过 load 模板标签将该模块引入后,才能在模板中使用 {% static %} 标签。
替换完成后你可以刷新页面并看看网页的源代码,看一看 {% static %} 模板标签在页面渲染后究竟被替换成了什么样的值。例如我们可以看到
<link rel="stylesheet" href="{% static ''blog/css/pace.css'' %}">这一部分最终在浏览器中显示的是:
<link rel="stylesheet" href="/static/blog/css/pace.css">这正是 pace.css 文件所在的路径,其它的文件路径也被类似替换。可以看到 {% static %} 标签的作用实际就是把后面的字符串加了一个 /static/ 前缀,比如 {% static ''blog/css/pace.css'' %} 最终渲染的值是 /static/blog/css/pace.css。而 /static/ 前缀是我们在 settings.py 文件中通过 STATIC_URL = ''/static/'' 指定的。事实上,如果我们直接把引用路径写成 /static/blog/css/pace.css 也是可以的,那么为什么要使用 {% static %} 标签呢?想一下,目前 URL 的前缀是 /static/,如果哪一天因为某些原因,我们需要把 /static/ 改成 /resource/,如果你是直接写的引用路劲而没有使用 static 模板标签,那么你可能需要改 N 个地方。如果你使用了 static 模板标签,那么只要在 settings.py 处改一个地方就可以了,即把 STATIC_URL = ''/static/'' 改成 STATIC_URL = ''/resource/''。
有时候按 F5 刷新后页面还是很乱,这可能是因为浏览器缓存了之前的结果。按 Shift + F5(有些浏览器可能是 Ctrl + F5)强制刷新浏览器页面即可。
注意这里有一个 CSS 文件的引入
<link rel="stylesheet" href="http://code.ionicframework.com/ionicons/2.0.1/css/ionicons.min.css">我们没有使用模板标签,因为这里的引用的文件是一个外部文件,不是我们项目里 staticblogcss 目录下的文件,因此无需使用模板标签。
正确引入了静态文件后样式显示正常了。

修改模板
目前我们看到的只是模板中预先填充的一些数据,我们得让它显示从数据库中获取的文章数据。下面来稍微改造一下模板:
在模板 index.html 中你会找到一系列 article 标签:
templates/blog/index.html
...
<article>
...
</article>
<article>
...
</article>
<article>
...
</article>
...这里面包裹的内容显示的就是文章数据了。我们前面在视图函数 index 里给模板传了一个 post_list 变量,它里面包含着从数据库中取出的文章列表数据。就像 Python 一样,我们可以在模板中循环这个列表,把文章一篇篇循环出来,然后一篇篇显示文章的数据。要在模板中使用循环,需要使用到前面提到的模板标签,这次使用 {% for %} 模板标签。将 index.html 中多余的 article 标签删掉,只留下一个 article 标签,然后写上下列代码:
templates/blog/index.html
...
{% for post in post_list %}
<article>
...
</article>
{% empty %}
<div>暂时还没有发布的文章!</div>
{% endfor %}
...可以看到语法和 Python 的 for 循环类似,只是被 {% %} 这样一个模板标签符号包裹着。{% empty %} 的作用是当 post_list 为空,即数据库里没有文章时显示 {% empty %} 下面的内容,最后我们用 {% endfor %} 告诉 Django 循环在这里结束了。
你可能不太理解模板中的 post 和 post_list 是什么。post_list 是一个 QuerySet(类似于一个列表的数据结构),其中每一项都是之前定义在 blogmodels.py 中的 Post 类的实例,且每个实例分别对应着数据库中每篇文章的记录。因此我们循环遍历 post_list ,每一次遍历的结果都保存在 post 变量里。所以我们使用模板变量来显示 post 的属性值。例如这里的 {{ post.pk }}(pk 是 primary key 的缩写,即 post 对应于数据库中记录的 id 值,该属性尽管我们没有显示定义,但是 Django 会自动为我们添加)。
现在我们可以在循环体内通过 post 变量访问单篇文章的数据了。分析 article 标签里面的 HTML 内容,h1 显示的是文章的标题,
<h1>
<a href="single.html">Adaptive Vs. Responsive Layouts And Optimal Text Readability</a>
</h1>我们把标题替换成 post 的 title 属性值。注意要把它包裹在模板变量里,因为它最终要被替换成实际的 title 值。
<h1>
<a href="single.html">{{ post.title }}</a>
</h1>下面这 5 个 span 标签里分别显示了分类(category)、文章发布时间、文章作者、评论数、阅读量。
<div>
<span><a href="#">Django 博客教程</a></span>
<span><a href="#"><timedatetime="2012-11-09T23:15:57+00:00">2017年5月11日</time></a></span>
<span><a href="#">追梦人物</a></span>
<span><a href="#">4 评论</a></span>
<span><a href="#">588 阅读</a></span>
</div>再次替换掉一些数据,由于评论数和阅读量暂时没法替换,因此先留着,我们在之后实现了这些功能后再来修改它,目前只替换分类、文章发布时间、文章作者:
<div>
<span><a href="#">{{ post.category.name }}</a></span>
<span><a href="#"><timedatetime="{{ post.created_time }}">{{ post.created_time }}</time></a></span>
<span><a href="#">{{ post.author }}</a></span>
<span><a href="#">4 评论</a></span>
<span><a href="#">588 阅读</a></span>
</div>这里 p 标签里显示的是摘要
<div>
<p>免费、中文、零基础,完整的项目,基于最新版 Django 1.10 和 Python 3.5。带你从零开始一步步开发属于自己的博客网站,帮助你以最快的速度掌握 Django
开发的技巧...</p>
<div>
<a href="#">继续阅读 <span>→</span></a>
</div>
</div>替换成 post 的摘要:
<div>
<p>{{ post.excerpt }}</p>
<div>
<a href="#">继续阅读 <span>→</span></a>
</div>
</div>再次访问首页,它显示:暂时还没有发布的文章!好吧,做了这么多工作,但是数据库中其实还没有任何数据呀!接下来我们就实际写几篇文章保存到数据库里,看看显示的效果究竟如何。
总结
本章节的代码位于:Step6: real blog index view。
如果遇到问题,请通过下面的方式寻求帮助。
在 真正的 Django 博客首页视图 - 追梦人物的博客 的评论区留言。
将问题的详细描述通过邮件发送到 djangostudyteam@163.com,一般会在 24 小时内回复。
更多Django 教程,请访问 追梦人物的博客。
今天的关于Django 系列博客和十的分享已经结束,谢谢您的关注,如果想了解更多关于Anaconda+django写出第一个web app(十)、Django 博客开发教程 3 - 创建 Django 博客的数据库模型、Django 博客开发教程 5 - Django 博客首页视图、Django 博客开发教程 6 - 真正的 Django 博客首页视图的相关知识,请在本站进行查询。
本文标签:




