如果您对Django自定义权限及用户分组和django自定义权限感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解Django自定义权限及用户分组的各种细节,并对django自定义权限进行深入的分
如果您对Django自定义权限及用户分组和django 自定义权限感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解Django自定义权限及用户分组的各种细节,并对django 自定义权限进行深入的分析,此外还有关于$ Django 调API的几种方式,django自定义错误响应、25 Jun 18 Django,Cookie,Session,分页(自定义,Django自带)、django – 如何仅使用syncdb同步自定义权限?、Django自定义Action的实用技巧。
本文目录一览:- Django自定义权限及用户分组(django 自定义权限)
- $ Django 调API的几种方式,django自定义错误响应
- 25 Jun 18 Django,Cookie,Session,分页(自定义,Django自带)
- django – 如何仅使用syncdb同步自定义权限?
- Django自定义Action
")
Django自定义权限及用户分组(django 自定义权限)
登录、注销和登录限制:
登录
在使用authenticate进行验证后,如果验证通过了。那么会返回一个user对象,拿到user对象后,可以使用django.contrib.auth.login进行登录。示例代码如下:
user = authenticate(username=username, password=password)
if user is not None:
if user.is_active:
login(request, user)注销:
注销,或者说退出登录。我们可以通过django.contrib.auth.logout来实现。他会清理掉这个用户的session数据。
登录限制:
有时候,某个视图函数是需要经过登录后才能访问的。那么我们可以通过django.contrib.auth.decorators.login_required装饰器来实现。示例代码如下:
from django.contrib.auth.decorators import login_required
# 在验证失败后,会跳转到/accounts/login/这个url页面
@login_required(login_url=''/accounts/login/'')
def my_view(request):
pass权限:
Django中内置了权限的功能。他的权限都是针对表或者说是模型级别的。比如对某个模型上的数据是否可以进行增删改查操作。他不能针对数据级别的,比如对某个表中的某条数据能否进行增删改查操作(如果要实现数据级别的,考虑使用django-guardian)。创建完一个模型后,针对这个模型默认就有三种权限,分别是增/删/改/。可以在执行完migrate命令后,查看数据库中的auth_permission表中的所有权限。
其中的codename表示的是权限的名字。name表示的是这个权限的作用。
通过定义模型添加权限:
如果我们想要增加新的权限,比如查看某个模型的权限,那么我们可以在定义模型的时候在Meta中定义好。示例代码如下:
class Article(models.Model):
title = models.CharField(max_length=100)
content = models.TextField()
author = models.ForeignKey(get_user_model(),on_delete=models.CASCADE)
class Meta:
permissions = (
(''view_article'',''can view article''),
)通过代码添加权限:
权限都是django.contrib.auth.Permission的实例。这个模型包含三个字段,name、codename以及content_type,其中的content_type表示这个permission是属于哪个app下的哪个models。用Permission模型创建权限的代码如下:
from django.contrib.auth.models import Permission,ContentType from .models import Article content_type = ContentType.objects.get_for_model(Article) permission = Permission.objects.create(name=''可以编辑的权限'',codename=''edit_article'',content_type=content_type)
用户与权限管理:
权限本身只是一个数据,必须和用户进行绑定,才能起到作用。User模型和权限之间的管理,可以通过以下几种方式来管理:
- myuser.user_permissions.set(permission_list):直接给定一个权限的列表。
- myuser.user_permissions.add(permission,permission,...):一个个添加权限。
- myuser.user_permissions.remove(permission,permission,...):一个个删除权限。
- myuser.user_permissions.clear():清除权限。
- myuser.has_perm(''<app_name>.<codename>''):判断是否拥有某个权限。权限参数是一个字符串,格式是app_name.codename。
- myuser.get_all_permissons():获取所有的权限。
权限限定装饰器:
使用django.contrib.auth.decorators.permission_required可以非常方便的检查用户是否拥有这个权限,如果拥有,那么就可以进入到指定的视图函数中,如果不拥有,那么就会报一个400错误。示例代码如下:
from django.contrib.auth.decorators import permission_required
@permission_required(''front.view_article'')
def my_view(request):
...分组:
权限有很多,一个模型就有最少三个权限,如果一些用户拥有相同的权限,那么每次都要重复添加。这时候分组就可以帮我们解决这种问题了,我们可以把一些权限归类,然后添加到某个分组中,之后再把和把需要赋予这些权限的用户添加到这个分组中,就比较好管理了。分组我们使用的是django.contrib.auth.models.Group模型, 每个用户组拥有id和name两个字段,该模型在数据库被映射为auth_group数据表。
分组操作:
Group.object.create(group_name):创建分组。
group.permissions:某个分组上的权限。多对多的关系。
- group.permissions.add:添加权限。
- group.permissions.remove:移除权限。
- group.permissions.clear:清除所有权限。
- user.get_group_permissions():获取用户所属组的权限。
user.groups:某个用户上的所有分组。多对多的关系。
在模板中使用权限:
在settings.TEMPLATES.OPTIONS.context_processors下,因为添加了django.contrib.auth.context_processors.auth上下文处理器,因此在模板中可以直接通过perms来获取用户的所有权限。示例代码如下:
{% if perms.front.add_article %}
<a href=''/article/add/''>添加文章</a>
{% endif %}以上就是Django登录权限及分组模板使用权限的详细内容,更多关于Django权限分组的资料请关注其它相关文章!
- 对Django中的权限和分组管理实例讲解
- Django自定义User模型、认证、权限控制的操作
- Django权限控制的使用
- Django 权限管理(permissions)与用户组(group)详解
- Django权限设置及验证方式
- django自带的权限管理Permission用法说明

$ Django 调API的几种方式,django自定义错误响应
django自定义错误响应
前提:settings.py
#debug为true时要配置网站的allowed_hosts域名
# 简单就为"*"
DEBUG = False
ALLOWED_HOSTS = [''127.0.0.1'']

直接templates下书写404.htm,400.html,403.html,500.html

#第一步:总的urls.py 重写handler函数,(注意要加项目app名 要写在上面)
from django.conf.urls import url
from django.contrib import admin
from app01 import views
# handler404="app01.views.erro"
# handler400="app01.views.erro"
# handler403="app01.views.erro"
# handler500="app01.views.erro"
urlpatterns = [
url(r''^admin/'', admin.site.urls),
url(r''^download/'', views.Download),#下载
url(r''^file/'', views.File.as_view()),#播放
url(r''^tes/'', views.tes),#test
url(r''^data/'', views.date),#test
]
#第二步:views.py写错误调的视图
from django.http import HttpResponseNotFound
def erro(request):
return HttpResponseNotFound("NOT FOUND!")API调用方式
下面是python中会用到的库。
urllib2
httplib2
pycurl
requests
urllib2
#request
import requests, json
github_url = ”
data = json.dumps({‘name’:’test’, ‘description’:’some test repo’})
r = requests.post(github_url, data, auth=(‘user’, ‘*‘))
print r.json
#以上几种方式都可以调用API来执行动作,但requests这种方式代码最简洁,最清晰,建议采用。#urllib2, urllib
import urllib2, urllib
github_url = ‘https://api.github.com/user/repos’
password_manager = urllib2.HTTPPasswordMgrWithDefaultRealm()
password_manager.add_password(None, github_url, ‘user’, ‘*‘)
auth = urllib2.HTTPBasicAuthHandler(password_manager) # create an authentication handler
opener = urllib2.build_opener(auth) # create an opener with the authentication handler
urllib2.install_opener(opener) # install the opener…
request = urllib2.Request(github_url, urllib.urlencode({‘name’:’Test repo’, ‘description’: ‘Some test repository’})) # Manual encoding required
handler = urllib2.urlopen(request)
print handler.read()#httplib2
import urllib, httplib2
github_url = ’
h = httplib2.Http(“.cache”)
h.add_credentials(“user”, “**“, ”
data = urllib.urlencode({“name”:”test”})
resp, content = h.request(github_url, “POST”, data)
print content#pycurl
import pycurl, json
github_url = ”
user_pwd = “user:*”
data = json.dumps({“name”: “test_repo”, “description”: “Some test repo”})
c = pycurl.Curl()
c.setopt(pycurl.URL, github_url)
c.setopt(pycurl.USERPWD, user_pwd)
c.setopt(pycurl.POST, 1)
c.setopt(pycurl.POSTFIELDS, data)
c.perform()
")
25 Jun 18 Django,Cookie,Session,分页(自定义,Django自带)
25 Jun 18
https://www.cnblogs.com/liwenzhou/p/8343243.html
一、分页
# 利用URL携带参数page,views.py中通过request.GET来获取page参数
# utils: 放常用工具
- 在工具包utils中自定义mypage,并用其完成分页显示(推荐使用)
book_list.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Book_list</title>
<link rel="stylesheet" href="/static/bootstrap-3.3.7/css/bootstrap.min.css">
</head>
<body>
<h1>Book List</h1>
<div>
<table>
<thead>
<tr>
<th>#</th>
<th>Title</th>
<th>Publish Date</th>
</tr>
</thead>
<tbody>
{% for book in book_list %}
<tr>
<td>{{ forloop.counter }}</td>
<td>{{ book.title }}</td>
<td>{{ book.publish_date|date:''Y-m-d''}}</td> # 格式化输出日期
</tr>
{% endfor %}
</tbody>
</table>
</div>
<nav aria-label="Page navigation">
<ul>
{{ page_html|safe}} # 取消浏览器自动转译功能
</ul>
</nav>
<script src="/static/jquery-3.3.1.min.js"></script>
<script src="/static/bootstrap-3.3.7/js/bootstrap.min.js"></script>
</body>
</html>
views.py
from django.shortcuts import render
from app01 import models
from utils import mypage
# 用工具包utils中的自定义mypage,完成分页显示
def book_list(request):
data = models.Book.objects.all()
total_num = data.count()
current_page = request.GET.get(''page'')
page_obj=mypage.Page(total_num, current_page, ''book_list'',per_page=20)
book_list = data[page_obj.data_start:page_obj.data_end]
page_html = page_obj.page_html()
return render(request, "book_List.html", {''book_list'':book_list, ''page_html'':page_html})
utils -> mypage.py. (小工具,可反复使用)
class Page(object):
"""
这是一个自定义分页类
可以实现Django ORM数据的分页展示
使用说明:
from utils import mypage
page_obj = mypage.Page(total_num, current_page, ''publisher_list'')
publisher_list = data[page_obj.data_start:page_obj.data_end]
page_html = page_obj.page_html()
为了显示效果,show_page_num最好使用奇数 #当前页面highlight,左右对称排列
"""
def __init__(self, total_num, current_page, url_prefix, per_page=10, show_page_num=11):
"""
:param total_num: 数据的总条数
:param current_page: 当前访问的页码
:param url_prefix: 分页代码里a标签的前缀
:param per_page: 每一页显示多少条数据
:param show_page_num: 页面上最多显示多少个页码
"""
self.total_num = total_num
self.url_prefix = url_prefix
self.per_page = per_page
self.show_page_num = show_page_num
self.half_show_page_num = self.show_page_num // 2
total_page, more = divmod(self.total_num, self.per_page) # divmod()得到商和余数的小元组
if more:
total_page += 1
self.total_page = total_page
try:
current_page = int(current_page) # GET得到的current_page是字符串,必须要转成int才能进行后续运算操作
except Exception as e:
current_page = 1
if current_page > self.total_page:
current_page = self.total_page
if current_page < 1:
current_page = 1
self.current_page = current_page
if self.current_page - self.half_show_page_num <= 1:
page_start = 1
page_end = self.show_page_num
elif self.current_page + self.half_show_page_num >= self.total_page:
page_end = self.total_page
page_start = self.total_page - self.show_page_num + 1
else:
page_start = self.current_page - self.half_show_page_num
page_end = self.current_page + self.half_show_page_num
self.page_start = page_start
self.page_end = page_end
@property # 将方法装饰成数据属性
def data_start(self):
return (self.current_page-1)*self.per_page
@property
def data_end(self):
return (self.current_page)*self.per_page
def page_html(self):
li_list = []
li_list.append(''<li><a href="/{}/?page=1">首页</a></li>''.format(self.url_prefix))
if self.current_page <= 1:
prev_html = ''<li ><a aria-label="Previous"><span aria-hidden="true">«</span></a></li>'' # disabled,当在第一页时不能选前一页
else:
prev_html = ''<li><a href="/{}/?page={}" aria_label="Previous"><span aria-hidden="true">«</span></a></li>''.format(
self.url_prefix,self.current_page - 1)
li_list.append(prev_html)
for i in range(self.page_start, self.page_end + 1):
if i == self.current_page:
tmp = ''<li ><a href="/{0}/?page={1}">{1}</a></li>''.format(self.url_prefix,i)# active,当前页highlight
else:
tmp = ''<li><a href="/{0}/?page={1}">{1}</a></li>''.format(self.url_prefix,i)
li_list.append(tmp)
if self.current_page >= self.total_page:
next_html = ''<li><a aria-label="Previous"><span aria-hidden="true">»</span></a></li>''
else:
next_html = ''<li><a href="/{}/?page={}" aria_label="Previous"><span aria-hidden="true">»</span></a></li>''.format(
self.url_prefix, self.current_page + 1)
li_list.append(next_html)
li_list.append(''<li><a href="/{}/?page={}">尾页</a></li>''.format(self.url_prefix,self.total_page))
page_html = "".join(li_list) # 连成一个大的字符串,传至前段,方便后续操作
return page_html
- 用Django中的分页,完成显示
views.py
# 用django中的工具,完成分页显示;功能单薄,一般不用
from django.core.paginator import Paginator,EmptyPage,PageNotAnInteger
def publisher_list(request):
data = models.Publisher.objects.all()
current_page = request.GET.get(''page'')
page_obj = Paginator(data,10)
try:
publisher_list = page_obj.page(current_page)
# has_next 是否有下一页
# next_page_number 下一页页码
# has_previous 是否有上一页
# previous_page_number 上一页页码
# object_list 分页之后的数据列表
# number 当前页
# paginator paginator对象
except PageNotAnInteger:
publisher_list= page_obj.page(1)
except EmptyPage:
publisher_list = page_obj.page(page_obj.num_pages)
return render(request,''publisher_list.html'',{''publisher_list'':publisher_list})
publisher_list.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Publisher_list</title>
<link rel="stylesheet" href="/static/bootstrap-3.3.7/css/bootstrap.min.css">
</head>
<body>
<h1>Publisher List</h1>
<div>
<table>
<thead>
<tr>
<th>#</th>
<th>Publish Name</th>
</tr>
</thead>
<tbody>
{% for publisher in publisher_list %}
<tr>
<td>{{ forloop.counter }}</td>
<td>{{ publisher.name }}</td>
</tr>
{% endfor %}
</tbody>
</table>
<nav aria-label="Page navigation">
<ul>
{% if publisher_list.has_previous%}
<li>
<a href="/publisher_list/?page={{ publisher_list.previous_page_number}}" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
{% else %}
<li>
<a aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
{% endif %}
<li><a href="#">{{ publisher_list.number }}</a></li>
{% if publisher_list.has_next%}
<li>
<a href="/publisher_list/?page={{ publisher_list.next_page_number}}" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
{% else %}
<li>
<a aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
{% endif %}
</ul>
</nav>
</div>
<script src="/static/jquery-3.3.1.min.js"></script>
<script src="/static/bootstrap-3.3.7/js/bootstrap.min.js"></script>
</body>
二、Cookie
HTTP无状态-> Cookie
Cookie:服务端在返回响应的时候设置的,保存在浏览器上的键值对。
复习:
print(request.path_info) # 获得路径
print(request.get_full_path()) # 获得路径+参数
login.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Title</title>
</head>
<body>
<form action="{{ request.get_full_path }}" method="post">
{% csrf_token %}
<p>Username: <input type="text" name = "username"></p>
<p>Password: <input type="password" name="pwd"></p>
<p><input type="submit" value="Login"></p>
</form>
</body>
</html>
views.py
from django.shortcuts import render
from django.shortcuts import HttpResponse,render,redirect
from app01 import models
from utils import mypage
# 定义一个检测是否登陆的装饰器
def check_login(func):
def wrapper(request,*args,**kwargs):
login_flag = request.get_signed_cookie("login",default="",salt="shanghais1hao") # 获取Cookie,加盐版的盐要一致
# login_flag = request.COOKIES.get("login", "")
#获取Cookie,非加盐版
# default: 默认值
# salt: 加密盐
# max_age: 后台控制过期时间
if login_flag.upper() == ''OK'':
return func(request,*args,**kwargs)
else:
url = request.path_info # 获取跳转源路径
return redirect("/login/?next={}".format(url)) # 如果是从其他页面跳转来,记录下该页面,完成验证后跳转回去
return wrapper
# 用工具包utils中的自定义mypage,完成分页显示
@check_login
def book_list(request):
data = models.Book.objects.all()
total_num = data.count()
current_page = request.GET.get(''page'')
page_obj=mypage.Page(total_num, current_page, ''book_list'',per_page=20)
book_list = data[page_obj.data_start:page_obj.data_end]
page_html = page_obj.page_html()
return render(request, "book_List.html", {''book_list'':book_list, ''page_html'':page_html})
def login(request):
if request.method == ''POST'':
username = request.POST.get(''username'')
pwd = request.POST.get(''pwd'')
if username == ''alex'' and pwd ==''alex'':
url = request.GET.get(''next'') # 如果是从其他页面跳转来,跳转至该页面
if not url:
url = ''/publisher_list/'' # 若非从其他页面跳转来的,跳转到默认页面
rep = redirect(url)
rep.set_signed_cookie("login","ok",salt="shanghais1hao")
# 给响应设置Cookie,加密盐版
# rep.set_cookie("login", "ok")
# 给响应设置Cookie
# key, 键
# value = '''', 值
# max_age = None, 超时时间
# expires = None, 超时时间(IE requires expires, so set it if hasn''t been already.)
# path = ''/'', Cookie生效的路径,/ 表示根路径,特殊的:根路径的cookie可以被任何url的页面访问
# domain = None, Cookie生效的域名
# secure = False, https传输
# httponly = False 只能http协议传输,无法被JavaScript获取(不是绝对,底层抓包可以获取到也可以被覆盖)
return rep
return render(request,"login.html")
def logout(request):
rep = redirect(''/login/'')
rep.delete_cookie(''login'') # 删除用户浏览器上之前设置的cookie值
return rep
三、Session
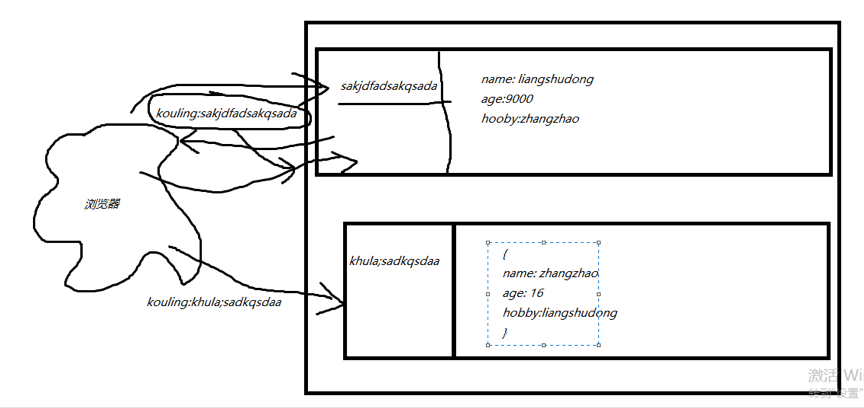
Cookie虽然在一定程度上解决了“保持状态”的需求,但是由于Cookie本身最大支持4096字节,以及Cookie本身保存在客户端,可能被拦截或窃取,因此就需要有一种新的东西,它能支持更多的字节,并且他保存在服务器,有较高的安全性。这就是Session。
# 用session前要现有一个数据库(一定要执行makemigrations, migrate两条命令,即使models无变化)
1. 浏览器请求来了之后,服务端给你分配一个序号(口令)(程序级别完成)
2. 浏览器收到响应之后,把得到的口令保存在cookie (浏览器自带)
3. 浏览器携带着刚才得到的口令,再次发送请求 (浏览器自带)
4. 服务端拿到口令,去后端根据口令找对应的数据(大字典)(程序级别完成)
views.py
def login(request):
err_msg = ""
if request.method == ''POST'':
username = request.POST.get(''username'')
pwd = request.POST.get(''pwd'')
is_exist = models.User.objects.filter(name=username,pwd=pwd)
if is_exist:
# 登陆成功
# 1. 生成随机字符串(口令),给浏览器返回
# 2. 在服务端开辟一块空间,用来保存对应的session数据(大字典)
# 3. 在服务端开辟的空间中保存需要保存的键值对数据
request.session[''login''] = ''OK''
request.session[''user''] = username # 可以插入不只一条数据
request.session.set_expiry(60*60*24*14) # 两周,python支持上述写法
return redirect(''/index/'')
else:
err_msg = ''invalid username or password''
return render(request,''login.html'',{''err_msg'':err_msg})
def index(request):
# 1. 判断请求中是否携带了我下发的随机字符串(口令)
# 2. 拿着口令去后端找对应的session数据
# 3. 根据固定的key去取固定的值
login_flag = request.session.get(''login'')
if login_flag == ''OK'':
return render(request,''index.html'')
else:
return redirect(''/login/'')
def logout(request):
request.session.flush() # 删除当前的会话数据并删除会话的Cookie
return redirect(''/login/'')
总结:
# 获取、设置、删除Session中数据
request.session[''k1'']
request.session.get(''k1'',None)
request.session[''k1''] = 123
request.session.setdefault(''k1'',123) # 存在则不设置
del request.session[''k1'']
# 所有 键、值、键值对
request.session.keys()
request.session.values()
request.session.items()
request.session.iterkeys()
request.session.itervalues()
request.session.iteritems()
# 会话session的key
request.session.session_key
# 将所有Session失效日期小于当前日期的数据删除
request.session.clear_expired() # session数据库中的数据不会自动清除,需手动删除
# 检查会话session的key在数据库中是否存在
request.session.exists("session_key")
# 删除当前会话的所有Session数据
request.session.delete()
# 删除当前的会话数据并删除会话的Cookie。
request.session.flush() # 推荐使用
这用于确保前面的会话数据不可以再次被用户的浏览器访问
例如,django.contrib.auth.logout() 函数中就会调用它。
# 设置会话Session和Cookie的超时时间
request.session.set_expiry(value)
* 如果value是个整数,session会在些秒数后失效。
* 如果value是个datatime或timedelta,session就会在这个时间后失效。
* 如果value是0,用户关闭浏览器session就会失效。
* 如果value是None,session会依赖全局session失效策略。
四、CBV中加装饰器(Django内置的把函数装饰器转换成方法装饰器)
方式一:加载CBV视图的get或post方法上
views.py
from django import views
from django.utils.decorators import method_decorator
class Home(views.View):
@method_decorator(check_login)
def get(self, request):
return render(request, "home.html")
def post(self):
pass
urls.py
urlpatterns = [
url(r''^home/'',views.Home.as_view()),
]
方式二:加载dispatch方法上
# 因为CBV中首先执行的就是dispatch方法,所以这么写相当于给get和post方法都加上了登录校验。
from django.utils.decorators import method_decorator
class HomeView(View):
@method_decorator(check_login)
def dispatch(self, request, *args, **kwargs):
return super(HomeView, self).dispatch(request, *args, **kwargs)
def get(self, request):
return render(request, "home.html")
def post(self, request):
print("Home View POST method...")
return redirect("/index/")
方式三:直接加在视图类上,但method_decorator必须传name 关键字参数
from django.utils.decorators import method_decorator
@method_decorator(check_login, name="get")
@method_decorator(check_login, name="post")
class HomeView(View):
def dispatch(self, request, *args, **kwargs):
return super(HomeView, self).dispatch(request, *args, **kwargs)
def get(self, request):
return render(request, "home.html")
def post(self, request):
print("Home View POST method...")
return redirect("/index/")
五、CSRF Token相关装饰器(csrf_exempt,csrf_protect)
CSRF Token相关装饰器在CBV只能加到dispatch方法上
csrf_protect:为当前函数强制设置防跨站请求伪造功能,即便settings没设置全局中间件。
csrf_exempt,取消当前函数防跨站请求伪造功能,即便settings中设置了全局中间件。
views.py
from django.views.decorators.csrf import csrf_exempt, csrf_protect
@csrf_exempt
def login(request):
err_msg = ""
if request.method == ''POST'':
username = request.POST.get(''username'')
pwd = request.POST.get(''pwd'')
is_exist = models.User.objects.filter(name=username,pwd=pwd)
if is_exist:
# 登陆成功
# 1. 生成随机字符串(口令),给浏览器返回
# 2. 在服务端开辟一块空间,用来保存对应的session数据(大字典)
# 3. 在服务端开辟的空间中保存需要保存的键值对数据
request.session[''login''] = ''OK''
request.session[''user''] = username # 可以插入不只一条数据
request.session.set_expiry(60*60*24*14) # 两周,python支持上述写法
return redirect(''/index/'')
else:
err_msg = ''invalid username or password''
return render(request,''login.html'',{''err_msg'':err_msg})
logins.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Title</title>
</head>
<body>
<form action="{{ request.get_full_path }}" method="post">
{# {% csrf_token %}#}
<p>Username: <input type="text" name = "username"></p>
<p>Password: <input type="password" name="pwd"></p>
<p><input type="submit" value="Login"></p>
<p>{{ err_msg }}</p>
</form>
</body>
</html>
六、其他
[链接]2018年不容错过的Django全栈项目YaDjangoBlog
https://zhuanlan.zhihu.com/p/33903527
七、补充


django – 如何仅使用syncdb同步自定义权限?
class Meta:
permissions = (
("admin","Can create/edit/delete projects"),("user","Can view projects"),)
谢谢!
解决方法
>手动插入auth_permission表;
>添加命令this snippet.
添加命令非常简单.只需在您的某个应用中的management.commands包中创建一个模块sync_perms.py(带有代码段代码)(here the official documentation).
然后运行:
python manage.py sync_perms
Etvoilà!

Django自定义Action
上次安装了Django之后,自己摸索玩了一段时间,没想到最近因为需要接下了一个使用Django的工作,感觉个人真的是按需折腾啊。
接手的工作中,Django的框架大致搭好,在测试中发现,admin管理界面本身挺方便的,但是默认的界面总感觉缺点什么,首先看图:

模型原始的管理界面如上,模型代码 model.py:


1 # coding:utf-8
2 from django.db import models
3 from blast_service.models import DiskInfo
4 # Create your models here.
5 class GenomicsFileInfo(models.Model):
6 COMPUTE_STATE = (
7 (0, ''computing''),
8 (1, ''computed''),
9 (2, ''idle''),
10 )
11 ACHIVE_STATUS = (
12 (0, ''Not archive''),
13 (1, ''Archive failed''),
14 (2, ''Archive success''),
15 (3, ''Ignore''),
16 (4, ''Archiving'')
17 )
18
19 SEND_STATUS = (
20 (0, ''idle''),
21 (1, ''sended''),
22 )
23 userid = models.CharField(max_length=32,blank=True)
24 cluster_account = models.CharField(max_length=32)
25 filename = models.CharField(max_length=100)
26 md5 = models.CharField(max_length=32, blank=True)
27 file_path = models.CharField(max_length=500)
28 updatetime = models.DateTimeField(auto_now_add=True)
29 diskinfo = models.ForeignKey(DiskInfo, on_delete=models.CASCADE,)
30 size = models.BigIntegerField(blank=True)
31 compute_state = models.IntegerField(choices=COMPUTE_STATE, default=2)
32 achive_status = models.IntegerField(choices=ACHIVE_STATUS, default=0)
33 achive_path = models.CharField(max_length=500, blank=True)
34 is_deleted = models.BooleanField(default=False, verbose_name=u''delete tag'')
35 class Meta:
36 unique_together = (''userid'', ''file_path'',''filename'')
37 db_table = ''GenomicsFileInfo''
38 def __unicode__(self):
39 return self.file_pathadmin.py是原始未改动:


1 from django.contrib import admin
2
3 # Register your models here.
4 from models import GenomicsFileInfo
5
6 admin.site.register(GenomicsFileInfo)本以为这样也挺好的,随着测试的进行,数据库中保存的记录也越多,对接做前端系统的同事某一天问我:“我上传了一个文件,一直没有计算完成,我在管理界面中找不到它啊,为啥没找到你们的搜索栏呢?”我一愣,赶紧上去一看,对啊,我没有搜索栏我咋找数据库的记录呢?
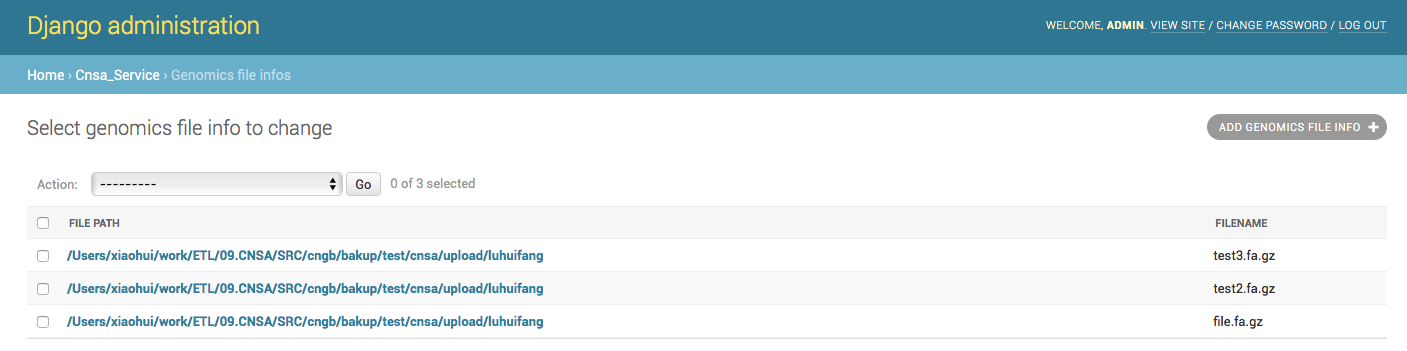
网上一顿搜索,原来admin有很多很方便的组件都没有用上,我一想,现在管理界面上只显示了文件路径,我将文件名也显示上来,不就可以直接 control+f 来搜索了。
修改admin.py:


1 from django.contrib import admin
2
3 # Register your models here.
4 from models import GenomicsFileInfo
5
6 class GenomicsFileInfoAdmin(admin.ModelAdmin): # 添加一个对模型的管理类
7 list_display = (''file_path'',''filename'') #添加一个显示的组件,显示文件路径和文件名
8
9 admin.site.register(GenomicsFileInfo, GenomicsFileInfoAdmin) #将管理类注册到admin中修改完成后界面如下:
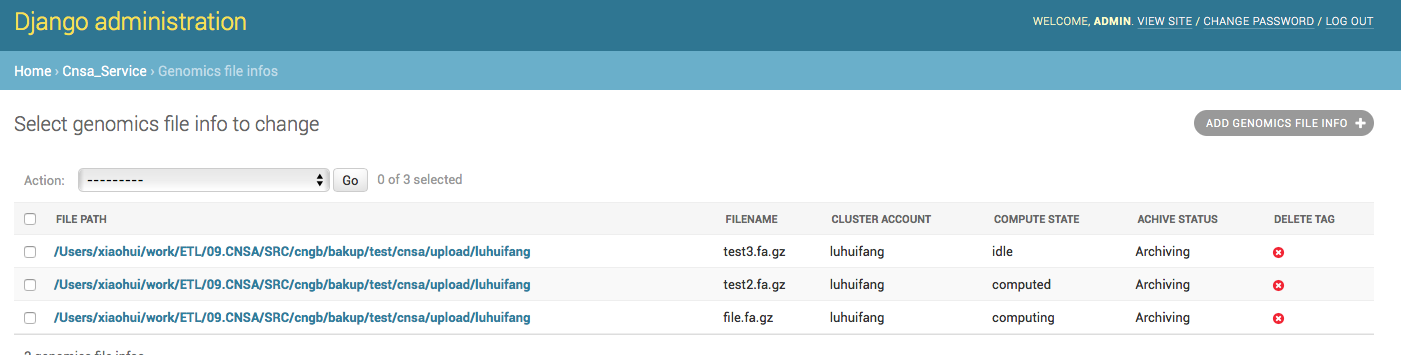
确实将文件名也显示出来了,我一想,我还有计算的状态,归档的状态等,都可以列出来呢,那就一起吧,修改admin.py:


1 from django.contrib import admin
2
3 # Register your models here.
4 from models import GenomicsFileInfo
5
6 class GenomicsFileInfoAdmin(admin.ModelAdmin):
7 list_display = (''file_path'',''filename'',''cluster_account'',''compute_state'',''achive_status'',''is_deleted'') #需要展示在页面上的字段都可以列在这里
8
9 admin.site.register(GenomicsFileInfo, GenomicsFileInfoAdmin)效果如下:
随之而来的问题是,control+f 在少量记录是还可以使用,多条记录分页之后,完全不可行啊,而且我只想显示某个文件名的记录,或者某种状态的记录的话,这完全就是废的。因此,我们必须用上admin的search组件和filter组件。
1. 其中search就是搜索栏,由于Django中的模型就是数据库中的表,所以搜索可以类似于数据库中的 ''select ''语句,这个组件指定搜索的字段,类似于sql中 where colname like ''%搜索的内容%'';
2. filter组件就是过滤,指定字段,其效果相当于sql中的 where colname = ''某个内容'',这个组件比较适用于值域确定的字段。
来看一起修改后但admin.py:


1 from django.contrib import admin
2
3 # Register your models here.
4 from models import GenomicsFileInfo
5
6 class GenomicsFileInfoAdmin(admin.ModelAdmin):
7 list_display = (''file_path'',''filename'',''cluster_account'',''compute_state'',''achive_status'',''is_deleted'')
8 search_fields = (''file_path'',''filename'',''md5'',''userid'') #search组件,指定输入搜索内容后,只在文件路径,文件名,md5和用户id这几个字段搜索
9 list_filter = (''compute_state'',''achive_status'',''is_deleted'') #filter组件,由于我但表中这个几个字段有确定的值域,所以filter就列这几个字段
10
11 admin.site.register(GenomicsFileInfo, GenomicsFileInfoAdmin)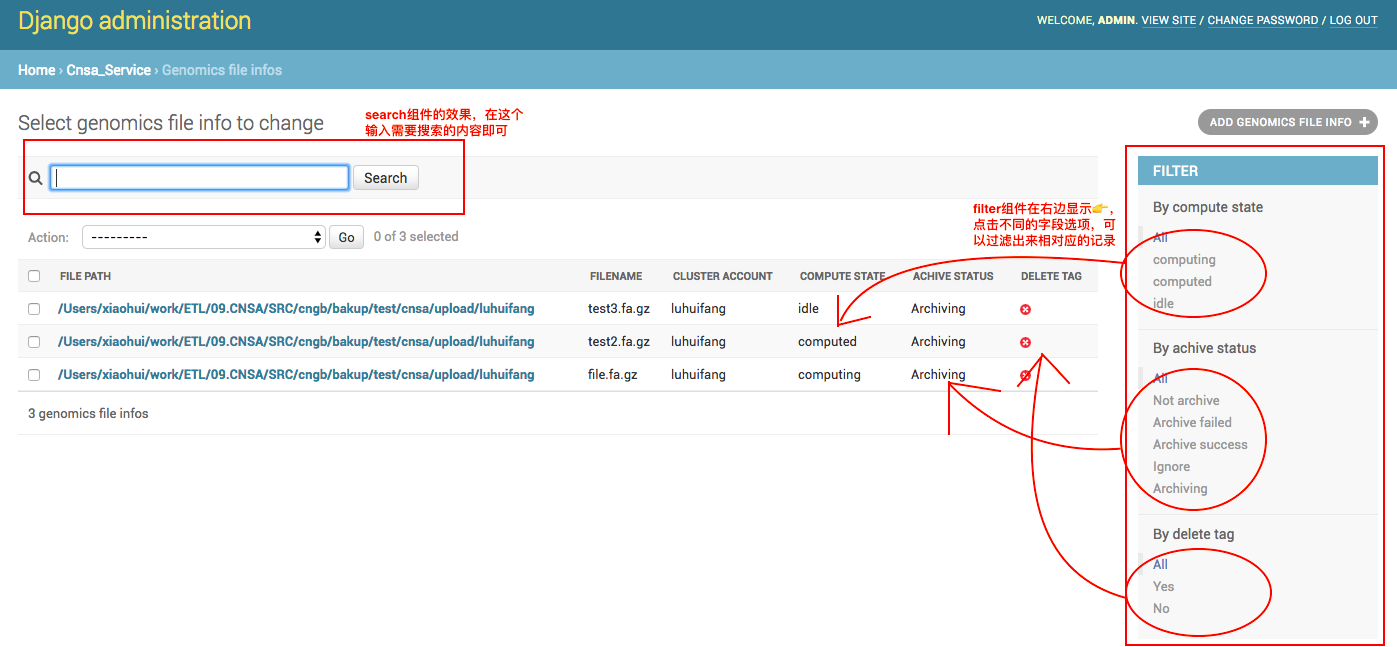
这样看起来界面完整多了,可又出现了麻烦的事,我搜索(过滤)到了想要的记录,然后希望批量修改他们的状态或者字段值,总不能一条一条记录点进去改吧?如果10000条记录,那我一天的工作就交代了(苦笑)。
其实Django的admin管理工具中只有一个默认的操作,就是批量删除选中的记录(见第一张图☝️的Action部分),所以我们需要自定义(手动)添加我们需要的Action。
假设我们的需求是,将选中的记录中compute_state修改为computed(1),这种需求,其实网上很多篇博文都有写到,直接上代码,admin.py:


1 from django.contrib import admin
2
3 # Register your models here.
4 from models import GenomicsFileInfo
5
6 compute_state = {0:''computing'', 1:''computed'', 2:''idle''} #计算状态的字典
7
8 def change2computed(modeladmin, request, queryset): #新建一个批量操作的函数,其中有三个参数:
9 #第一个参数是模型管理类,第二个request是请求,第三个queryset表示你选中的所有记录,这个函数里面会处理所有选中的queryset,所以要在操作之前用搜索或者过滤来选出需要修改的记录
10 queryset.update(compute_state=1) #改变数据库表中,选中的记录的状态
11 change2computed.short_description = ''Change compute state to computed'' #这个是在界面显示的描述信息
12
13
14 class GenomicsFileInfoAdmin(admin.ModelAdmin):
15 list_display = (''file_path'',''filename'',''cluster_account'',''compute_state'',''achive_status'',''is_deleted'')
16 search_fields = (''file_path'',''filename'',''md5'',''userid'')
17 list_filter = (''compute_state'',''achive_status'',''is_deleted'')
18 actions = [change2computed,] #添加actions的列表,表示要在页面上显示的操作
19
20 admin.site.register(GenomicsFileInfo, GenomicsFileInfoAdmin)效果如下图:
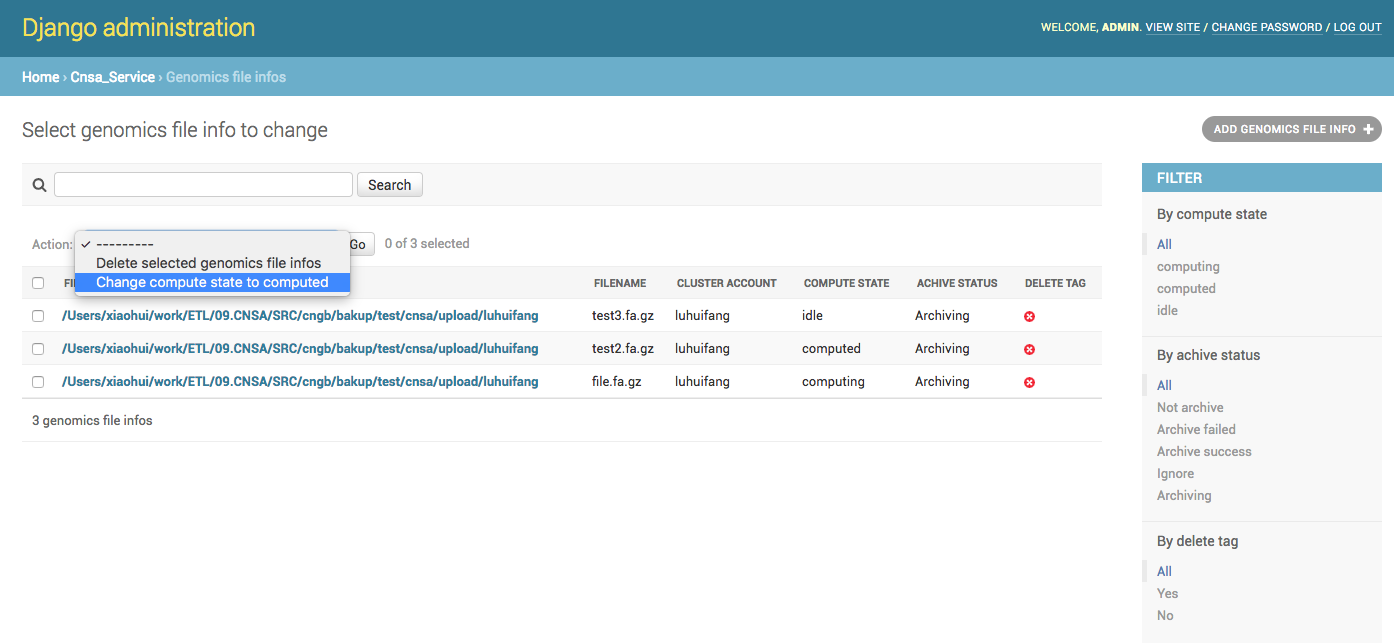
在Action中除了默认的操作,还多了一个我们自定义的操作。这种自定义的方式是最简单的方式,随之而来的问题是,如果我操作的状态有 computing,computed,idle,根据归档状态又有5种,那我就要写8个函数,再添加到actions中,而且每次新加之后又要重新启动,就会很麻烦。而Django的管理类有一个get_action的函数,可以根据规则获取actions,网上也有少许资料,我直接用代码解释,修改admin.py:


1 import collections #导入模块后续要用到
2
3 from django.contrib import admin
4 # Register your models here.
5 from models import GenomicsFileInfo
6
7 ##字段的状态
8 compute_state = {0:''computing'', 1:''computed'', 2:''idle''}
9 achive_status = {0:''Not archive'', 1:''Archive failed'', 2:''Archive success'', 3:''Ignore'', 4:''Arching''}
10
11 ## 将刚刚简单的函数注释掉
12 ''''''
13 def change2computed(modeladmin, request, queryset):
14 queryset.update(compute_state=1)
15 change2computed.short_description = ''Change compute state to computed''
16 ''''''
17
18 ## 下面新建一个闭包
19 def _change_state(state, typename): ## 新建一个函数,参数是需要修改成的状态值,和指定字段的标记符
20 if typename == ''compute'': # 如果标记符是compute
21 fileds_name = ''compute_state'' #那么需要修改的字段是 compete_state
22 show = compute_state[state] #这个主要用作显示名称
23 elif typename == ''archive'': # 如果标记符是 archive
24 fileds_name = ''archive_status'' #那么需要修改的字段是 archive_status
25 show = achive_status[state]
26 else:
27 return None #其他的返回None
28
29 def set_selected(modeladmin,request, queryset): ##主要修改数据库的函数,根据之前的字段和值进行修改,和刚刚简单的那个函数功能一致
30 kwargs = {}
31 kwargs[fileds_name] = state
32 return queryset.update(**kwargs)
33
34 set_selected.short_description = ''Change selected to {0}''.format(show) # 管理界面显示的名称
35 set_selected.__name__ = ''change_to_{0}''.format(show) # 同一个字段可以有多种状态进行修改,每种状态赋一个不同的函数名用以指定不同的操作
36 return set_selected ##返回修改数据库的函数
37
38
39 class GenomicsFileInfoAdmin(admin.ModelAdmin):
40 list_display = (''file_path'',''filename'',''cluster_account'',''compute_state'',''achive_status'',''is_deleted'')
41 search_fields = (''file_path'',''filename'',''md5'',''userid'')
42 list_filter = (''compute_state'',''achive_status'',''is_deleted'')
43 #actions = [change2computed,] #将刚刚的语句注释掉
44
45 def get_actions(self, request): #使用get_actions函数来自动获取actions
46 action = super(GenomicsFileInfoAdmin, self).get_actions(request) #这一步主要是要保留原有的批量删除操作和其他已经定义过的操作
47 fns = [_change_state(i, ''compute'') for i in compute_state] #调用闭包获取到所有操作的函数名
48 fns += [_change_state(i, ''archive'') for i in achive_status]
49 actions = [ self.get_action(fn) for fn in fns ] #使用管理类的函数来获取每个操作
50 ## 下面这一步很关键,actions表面是一个列表,但是实际上是一个字典,每个函数名都要对应上其功能函数,函数名以及对应的描述,所以最后要将其转换为字典形式
51 actions = collections.OrderedDict(
52 (name, (func, name, desc))
53 for func, name, desc in actions
54 )
55
56 actions = dict(action, **actions) ##这一步是合并字典,是将最开始获取到的默认操作添加到最终的actions中
57 return actions # 返回最终的actions
58
59
60 admin.site.register(GenomicsFileInfo, GenomicsFileInfoAdmin)最终的显示效果如下:
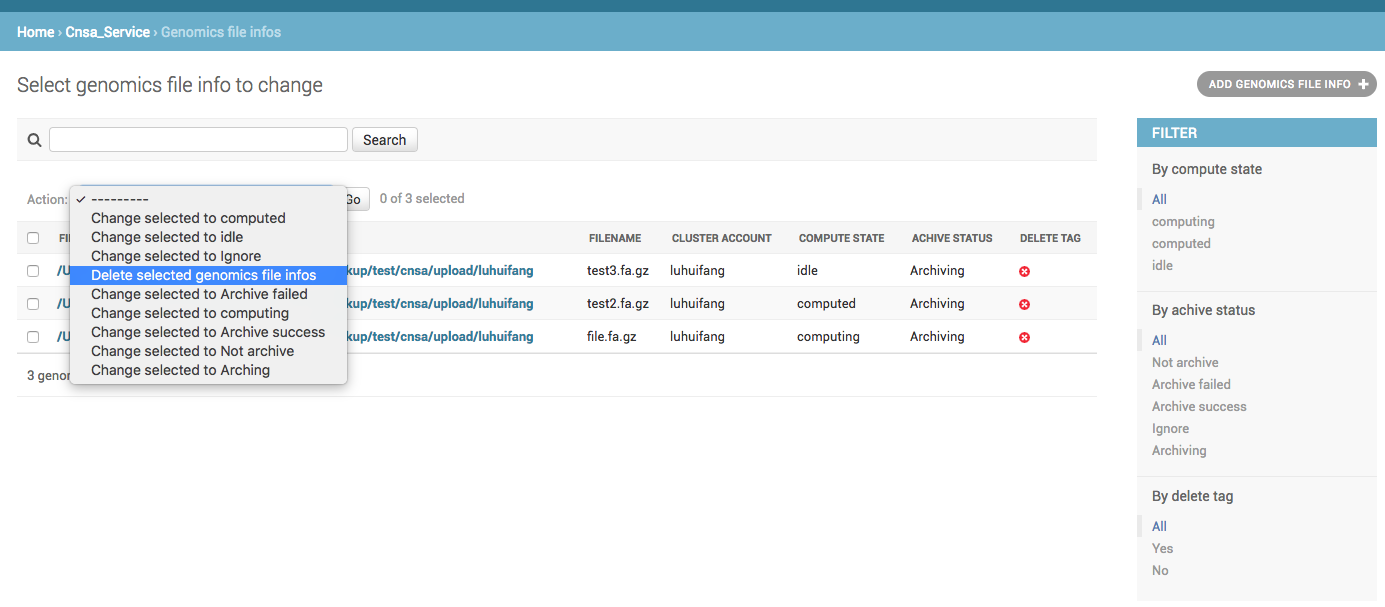
有我们自定义的操作与其默认的操作。使用get_actions函数的另一个好处是,当我修改admin.py代码,在其函数中添加新的操作时,不用重启Django,之需要刷新页面即可。
OK,最终的效果如上,如若后续有修改会继续更博~
我们今天的关于Django自定义权限及用户分组和django 自定义权限的分享已经告一段落,感谢您的关注,如果您想了解更多关于$ Django 调API的几种方式,django自定义错误响应、25 Jun 18 Django,Cookie,Session,分页(自定义,Django自带)、django – 如何仅使用syncdb同步自定义权限?、Django自定义Action的相关信息,请在本站查询。
本文标签:




