如果您想了解Java-Zipkin:Zipkin介绍的相关知识,那么本文是一篇不可错过的文章,我们将对javazip包进行全面详尽的解释,并且为您提供关于Dubbo+Zipkin+Brave实现全链路
如果您想了解Java-Zipkin:Zipkin 介绍的相关知识,那么本文是一篇不可错过的文章,我们将对java zip包进行全面详尽的解释,并且为您提供关于Dubbo + Zipkin + Brave实现全链路追踪、GO微服务实战第三十一节 案例:如何在微服务中集成 Zipkin 组件?、java B2B2C社交电子商务平台分析-----Spring Cloud Zipkin、Java JNDI 与其他 Java 技术的协作:揭秘 Java JNDI 与 Java EE 等技术的融合的有价值的信息。
本文目录一览:- Java-Zipkin:Zipkin 介绍(java zip包)
- Dubbo + Zipkin + Brave实现全链路追踪
- GO微服务实战第三十一节 案例:如何在微服务中集成 Zipkin 组件?
- java B2B2C社交电子商务平台分析-----Spring Cloud Zipkin
- Java JNDI 与其他 Java 技术的协作:揭秘 Java JNDI 与 Java EE 等技术的融合
")
Java-Zipkin:Zipkin 介绍(java zip包)
| ylbtech-Java-Zipkin:Zipkin 介绍 |
介绍
Zipkin 是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper 的论文设计而来,由 Twitter公司开发贡献。其主要功能是聚集来自各个异构系统的实时监控数据,用来追踪微服务架构下的系统延时问题。应用系统需要进行装备(instrument)以向 Zipkin 报告数据。Zipkin 的用户界面可以呈现一幅关联图表,以显示有多少被追踪的请求通过了每一层应用。Zipkin 以 Trace 结构表示对一次请求的追踪,又把每个 Trace 拆分为若干个有依赖关系的 Span。在微服务架构中,一次用户请求可能会由后台若干个服务负责处理,那么每个处理请求的服务就可以理解为一个 Span(可以包括 API 服务,缓存服务,数据库服务以及报表服务等)。当然这个服务也可能继续请求其他的服务,因此 Span 是一个树形结构,以体现服务之间的调用关系。Zipkin 的用户界面除了可以查看 Span 的依赖关系之外,还以瀑布图的形式显示了每个 Span 的耗时情况,可以一目了然的看到各个服务的性能状况。打开每个 Span,还有更详细的数据以键值对的形式呈现,而且这些数据可以在装备应用的时候自行添加。
架构
zipkin结构
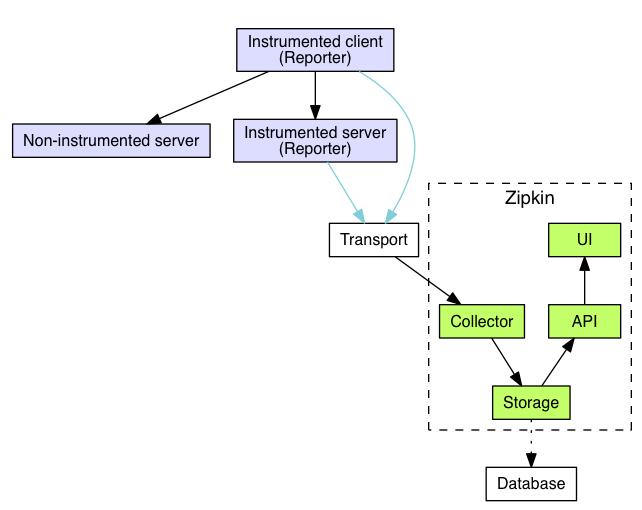
可以看到zipkin内部主要分为四部分:collector、storage、api、ui
collector:负责将各系统报告过来的追踪数据进行接收
storage:默认使用Cassandra存储数据,也可以替换为其他存储,例如mysql5.6-5.7,ElasticSearch 2.x和5.x,还有一些第三方的存储
api:查询服务用来向其他服务提供数据查询的能力,是以json api格式提供
ui:Web服务是官方默认提供的一个图形用户界面
transport
transport负责从运输从service收集来的spans,并把这些spans转化为zipkin的通用span,并将其传递到存储层,这种方法是模块化的,允许任何生产者接收任何类型的数据,zipkin配有HTTP、kafka、scribe三种类型的transport。instrumentations负责和transport进行交互。
instrumentations
官方维护
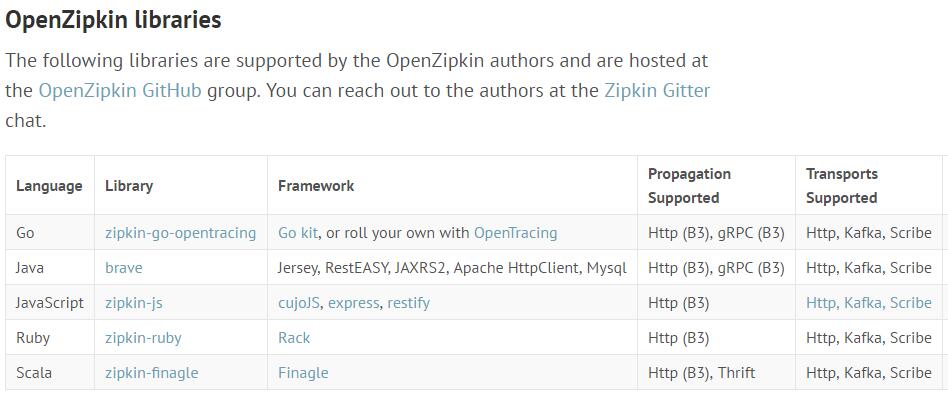
ps:支持go、scala,这个不错
第三方维护

ps:支持python,我就可以自己玩了,同时支持了四个Python库,最基础的是py_zipkin模块,pyramid_zipkin、swagger_zipkin、flask_zipkin三个都是基于py_zipkin再次封装的。
核心数据结构
traceId:全局跟踪ID,用它来标记一次完整服务调用,所以和一次服务调用相关的span中的traceId都是相同的,Zipkin将具有相同traceId的span组装成跟踪树来直观的将调用链路图展现在我们面前。
id:span的id,理论上来说,span的id只要做到一个traceId下唯一就可以
parentId:父span的id,调用有层级关系,所以span作为调用节点的存储结构,也有层级关系,就像图3所示,跟踪链是采用跟踪树的形式来展现的,树的根节点就是调用调用的顶点,从开发者的角度来说,顶级span是从接入了Zipkin的应用中最先接触到服务调用的应用中采集的。所以,顶级span是没有parentId字段的
name:span的名称,主要用于在界面上展示,一般是接口方法名,name的作用是让人知道它是哪里采集的span,不然某个span耗时高我都不知道是哪个服务节点耗时高
timestamp:span创建时的时间戳,用来记录采集的时刻。
duration:持续时间,即span的创建到span完成最终的采集所经历的时间,除去span自己逻辑处理的时间,该时间段可以理解成对于该跟踪埋点来说服务调用的总耗时
annotations:基本标注列表,一个标注可以理解成span生命周期中重要时刻的数据快照,比如一个标注中一般包含发生时刻(timestamp)、事件类型(value)、端点(endpoint)等信息
事件类型
cs:客户端/消费者发起请求
cr:客户端/消费者接收到应答
sr:服务端/生产者接收到请求
ss:服务端/生产者发送应答
PS:这四种事件类型的统计都应该是Zipkin提供客户端来做的,因为这些事件和业务无关,这也是为什么跟踪数据的采集适合放到中间件或者公共库来做的原因。
binaryAnnotations:业务标注列表,如果某些跟踪埋点需要带上部分业务数据(比如url地址、返回码和异常信息等),可以将需要的数据以键值对的形式放入到这个字段中。
参考
zipkin官网
分布式跟踪系统(一):Zipkin的背景和设计
分布式跟踪系统(二):Zipkin的Span模型
出处:http://ylbtech.cnblogs.com/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

Dubbo + Zipkin + Brave实现全链路追踪
Dubbo + Zipkin + Brave实现全链路追踪
最近写了一个链路追踪Demo分享下,实现了链路追踪过程中数据的记录,还有能扩展的地方,后期再继续补充。
原理参考上面文章 《Dubbo链路追踪——生成全局ID(traceId)》
源码地址
实现链路追踪的目的
- 服务调用的流程信息,定位服务调用链
- 记录调用入参及返回值信息,方便问题重现
- 记录调用时间线,代码重构及调优处理
- 调用信息统计
分布式跟踪系统还有其他比较成熟的实现,例如:Naver的Pinpoint、Apache的HTrace、阿里的鹰眼Tracing、京东的Hydra、新浪的Watchman,美团点评的CAT,skywalking等。 本次主要利用Dubbo数据传播特性扩展Filter接口来实现链路追踪的目的
重点主要是zipkin及brave使用及特性,当前brave版本为 5.2.0 为 2018年8月份发布的release版本 , zipkin版本为2.2.1 所需JDK为1.8
快速启动zipkin
下载最新的zipkin并启动
wget -O zipkin.jar ''https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec''
java -jar zipkin.jar
输入 http://localhost:9411/zipkin/ 进入WebUI界面如下 
核心源码
代码的初步版本:方便描述
import brave.Span;
import brave.Tracer;
import brave.Tracing;
import brave.propagation.*;
import brave.sampler.Sampler;
import com.alibaba.dubbo.common.Constants;
import com.alibaba.dubbo.common.extension.Activate;
import com.alibaba.dubbo.common.json.JSON;
import com.alibaba.dubbo.common.logger.Logger;
import com.alibaba.dubbo.common.logger.LoggerFactory;
import com.alibaba.dubbo.remoting.exchange.ResponseCallback;
import com.alibaba.dubbo.rpc.*;
import com.alibaba.dubbo.rpc.protocol.dubbo.FutureAdapter;
import com.alibaba.dubbo.rpc.support.RpcUtils;
import zipkin2.codec.SpanBytesEncoder;
import zipkin2.reporter.AsyncReporter;
import zipkin2.reporter.Sender;
import zipkin2.reporter.okhttp3.OkHttpSender;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.util.Map;
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
/**
* Created with IntelliJ IDEA.
*
* @author: bakerZhu
* @description:
* @modifytime:
*/
@Activate(group = {Constants.PROVIDER, Constants.CONSUMER})
public class TracingFilter implements Filter {
private static final Logger log = LoggerFactory.getLogger(TracingFilter.class);
private static Tracing tracing;
private static Tracer tracer;
private static TraceContext.Extractor<Map<String, String>> extractor;
private static TraceContext.Injector<Map<String, String>> injector;
static final Propagation.Getter<Map<String, String>, String> GETTER =
new Propagation.Getter<Map<String, String>, String>() {
@Override
public String get(Map<String, String> carrier, String key) {
return carrier.get(key);
}
@Override
public String toString() {
return "Map::get";
}
};
static final Propagation.Setter<Map<String, String>, String> SETTER =
new Propagation.Setter<Map<String, String>, String>() {
@Override
public void put(Map<String, String> carrier, String key, String value) {
carrier.put(key, value);
}
@Override
public String toString() {
return "Map::set";
}
};
static {
// 1
Sender sender = OkHttpSender.create("http://localhost:9411/api/v2/spans");
// 2
AsyncReporter asyncReporter = AsyncReporter.builder(sender)
.closeTimeout(500, TimeUnit.MILLISECONDS)
.build(SpanBytesEncoder.JSON_V2);
// 3
tracing = Tracing.newBuilder()
.localServiceName("tracer-client")
.spanReporter(asyncReporter)
.sampler(Sampler.ALWAYS_SAMPLE)
.propagationFactory(ExtraFieldPropagation.newFactory(B3Propagation.FACTORY, "user-name"))
.build();
tracer = tracing.tracer();
// 4
// 4.1
extractor = tracing.propagation().extractor(GETTER);
// 4.2
injector = tracing.propagation().injector(SETTER);
}
public TracingFilter() {
}
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
RpcContext rpcContext = RpcContext.getContext();
// 5
Span.Kind kind = rpcContext.isProviderSide() ? Span.Kind.SERVER : Span.Kind.CLIENT;
final Span span;
if (kind.equals(Span.Kind.CLIENT)) {
//6
span = tracer.nextSpan();
//7
injector.inject(span.context(), invocation.getAttachments());
} else {
//8
TraceContextOrSamplingFlags extracted = extractor.extract(invocation.getAttachments());
//9
span = extracted.context() != null ? tracer.joinSpan(extracted.context()) : tracer.nextSpan(extracted);
}
if (!span.isNoop()) {
span.kind(kind).start();
//10
String service = invoker.getInterface().getSimpleName();
String method = RpcUtils.getMethodName(invocation);
span.kind(kind);
span.name(service + "/" + method);
InetSocketAddress remoteAddress = rpcContext.getRemoteAddress();
span.remoteIpAndPort(
remoteAddress.getAddress() != null ? remoteAddress.getAddress().getHostAddress() : remoteAddress.getHostName(),remoteAddress.getPort());
}
boolean isOneway = false, deferFinish = false;
try (Tracer.SpanInScope scope = tracer.withSpanInScope(span)){
//11
collectArguments(invocation, span, kind);
Result result = invoker.invoke(invocation);
if (result.hasException()) {
onError(result.getException(), span);
}
// 12
isOneway = RpcUtils.isOneway(invoker.getUrl(), invocation);
// 13
Future<Object> future = rpcContext.getFuture();
if (future instanceof FutureAdapter) {
deferFinish = true;
((FutureAdapter) future).getFuture().setCallback(new FinishSpanCallback(span));// 14
}
return result;
} catch (Error | RuntimeException e) {
onError(e, span);
throw e;
} finally {
if (isOneway) { // 15
span.flush();
} else if (!deferFinish) { // 16
span.finish();
}
}
}
static void onError(Throwable error, Span span) {
span.error(error);
if (error instanceof RpcException) {
span.tag("dubbo.error_msg", RpcExceptionEnum.getMsgByCode(((RpcException) error).getCode()));
}
}
static void collectArguments(Invocation invocation, Span span, Span.Kind kind) {
if (kind == Span.Kind.CLIENT) {
StringBuilder fqcn = new StringBuilder();
Object[] args = invocation.getArguments();
if (args != null && args.length > 0) {
try {
fqcn.append(JSON.json(args));
} catch (IOException e) {
log.warn(e.getMessage(), e);
}
}
span.tag("args", fqcn.toString());
}
}
static final class FinishSpanCallback implements ResponseCallback {
final Span span;
FinishSpanCallback(Span span) {
this.span = span;
}
@Override
public void done(Object response) {
span.finish();
}
@Override
public void caught(Throwable exception) {
onError(exception, span);
span.finish();
}
}
// 17
private enum RpcExceptionEnum {
UNKNOWN_EXCEPTION(0, "unknown exception"),
NETWORK_EXCEPTION(1, "network exception"),
TIMEOUT_EXCEPTION(2, "timeout exception"),
BIZ_EXCEPTION(3, "biz exception"),
FORBIDDEN_EXCEPTION(4, "forbidden exception"),
SERIALIZATION_EXCEPTION(5, "serialization exception"),;
private int code;
private String msg;
RpcExceptionEnum(int code, String msg) {
this.code = code;
this.msg = msg;
}
public static String getMsgByCode(int code) {
for (RpcExceptionEnum error : RpcExceptionEnum.values()) {
if (code == error.code) {
return error.msg;
}
}
return null;
}
}
}
- 构建客户端发送工具
- 构建异步reporter
- 构建tracing上下文
- 初始化injector 和 Extractor [tab]4.1 extractor 指数据提取对象,用于在carrier中提取TraceContext相关信息或者采样标记信息到TraceContextOrSamplingFlags 中 -4.2 injector 用于将TraceContext中的各种数据注入到carrier中,其中carrier一半是指数据传输中的载体,类似于Dubbo中Invocation中的attachment(附件集合)
- 判断此次调用是作为服务端还是客户端
- rpc客户端调用会从ThreadLocal中获取parent的 TraceContext ,为新生成的Span指定traceId及 parentId如果没有parent traceContext 则生成的Span为 root span
- 将Span绑定的TraceContext中 属性信息 Copy 到 Invocation中达到远程参数传递的作用
- rpc服务提供端 , 从invocation中提取TraceContext相关信息及采样数据信息
- 生成span , 兼容初次服务端调用
- 记录接口信息及远程IP Port
- 将创建的Span 作为当前Span (可以通过Tracer.currentSpan 访问到它) 并设置查询范围
- oneway调用即只请求不接受结果
- 如果future不为空则为 async 调用 在回调中finish span
- 设置异步回调,回调代码执行span finish() .
- oneway调用 因为不需等待返回值 即没有 cr (Client Receive) 需手动flush()
- 同步调用 业务代码执行完毕后需手动finish()
- 设置枚举类 与 Dubbo中RpcException保持对应
测试项
- Dubbo sync async oneway 测试
- RPC异常测试
- 普通业务异常测试
- 并发测试
配置方式
POM依赖添加
<dependency>
<groupId>com.github.baker</groupId>
<artifactId>Tracing</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
资源目录根路径下添加tracing.properties文件  一次调用信息
一次调用信息  调用链
调用链  调用成功失败汇总
调用成功失败汇总  zipkinHost 指定zipkin服务器IP:PORT 默认为localhost:9411 serviceName 指定应用名称 默认为trace-default
zipkinHost 指定zipkin服务器IP:PORT 默认为localhost:9411 serviceName 指定应用名称 默认为trace-default
调用链: 
待扩展项
- 抽象数据传输(扩展Kafka数据传输)
- 调用返回值数据打印
- 更灵活的配置方式
源码地址
赞赏支持


GO微服务实战第三十一节 案例:如何在微服务中集成 Zipkin 组件?
这一课时我们就来进行案例实战,选择当前流行的链路追踪组件 Zipkin 作为示例,演示如何在 Go 微服务中集成 Zipkin。对于很多使用了 Go 微服务框架的用户来说,其框架本身就拥有 Trace 模块,如 Go-kit。所以本课时我们就在 Go-kit 微服务的案例中集成 Zipkin。
Zipkin 社区提供了诸如 zipkin-go、zipkin-go-opentracing、go-zipkin 等 Go 客户端库,后面我们会介绍如何将其中的 zipkin-go-opentracing(组件地址参见 https://github.com/openzipkin-contrib/zipkin-go-opentracing)集成到微服务中并加以应用。
Go-kit 微服务框架的 tracing 包为服务提供了 Dapper 样式的请求追踪。Go-kit 支持 OpenTracing API,并使用 opentracing-go 包为其服务器和客户端提供追踪中间件。Zipkin、LightStep 和 AppDash 是已支持的追踪组件,通过 OpenTracing API 与 Go-kit 一起使用。
应用架构图
本课时将会介绍如何在 Go-kit 中集成 Zipkin 进行链路调用的追踪,包括HTTP 和 gRPC 两种调用方式。在具体介绍这两种调用方式之前,我们先来看一下 Go-kit 集成 Zipkin 的应用架构,如下图所示:

Go-kit 集成 Zipkin 的应用架构图
从架构图中可以看到:我们构建了一个服务网关,通过 API 网关调用具体的微服务,所有的服务都注册到 Consul 上;当客户端的请求到来之时,网关作为服务端的门户,会根据配置的规则,从 Consul 中获取对应服务的信息,并将请求反向代理到指定的服务实例。
涉及的业务服务与组件包含以下 4 个:
-
Consul,本地安装并启动;
-
Zipkin,本地安装并启动;
-
API Gateway,微服务网关;
-
String Service,字符串服务,是基于 Kit 构建的,提供基本的字符串操作。
HTTP 调用方式的链路追踪
关于 HTTP 调用方式的链路追踪,下面我们将依次构建微服务网关、业务服务,并进行结果验证。
1. API 网关构建
在网关(gateway)中增加链路追踪的采集逻辑,同时在反向代理中增加追踪(tracer)设置。
Go-kit 在 tracing 包中默认添加了 Zipkin 的支持,所以集成工作会比较轻松。在开始之前,需要下载以下依赖:
# zipkin 官方库
go get github.com/openzipkin/zipkin-go
下面三个包都是依赖,按需下载
git clone https://github.com/googleapis/googleapis.git [your GOPATH]/ src/google.golang.org/genproto
git clone https://github.com/grpc/grpc-go.git [your GOPATH]/src/google. golang.org/grpc
git clone https://github.com/golang/text.git [your GOPATH]/src/golang. org/text
作为链路追踪的“第一站”和“最后一站”,网关会将客户端的请求转发给对应的业务服务,并将响应的结果返回给客户端。我们需要截获到达网关的所有请求,记录追踪信息。在下面这个示例中,网关是作为外部请求的服务端,同时作为字符串服务的客户端(反向代理内部实现),其代码实现如下:
// 创建环境变量
var (
// consul 环境变量省略
zipkinURL = flag.String("zipkin.url", "HTTP://localhost:9411/api/ v2/spans", "Zipkin server url")
)
flag.Parse()
var zipkinTracer *zipkin.Tracer
{
var (
err error
hostPort = “localhost:9090”
serviceName = “gateway-service”
useNoopTracer = (*zipkinURL == “”)
reporter = zipkinHTTP.NewReporter(*zipkinURL)
) // zipkin 相关的配置变量
defer reporter.Close()
zEP, _ := zipkin.NewEndpoint(serviceName, hostPort)
// 构建 zipkinTracer
zipkinTracer, err = zipkin.NewTracer(
reporter, zipkin.WithLocalEndpoint(zEP), zipkin.WithNoopTracer (useNoopTracer),
)
if err != nil {
logger.Log(“err”, err)
os.Exit(1)
}
if !useNoopTracer {
logger.Log(“tracer”, “Zipkin”, “type”, “Native”, “URL”, *zipkinURL)
}
}
我们使用的传输方式为 HTTP,可以使用 zipkin-go 提供的 middleware/HTTP 包,它采用装饰者模式把我们的 HTTP.Handler 进行封装,然后启动 HTTP 监听,代码如下所示:
//创建反向代理
proxy := NewReverseProxy(consulClient, zipkinTracer, logger)
tags := map[string]string{
“component”: “gateway_server”,
}
handler := zipkinHTTPsvr.NewServerMiddleware(
zipkinTracer,
zipkinHTTPsvr.SpanName(“gateway”),
zipkinHTTPsvr.TagResponseSize(true),
zipkinHTTPsvr.ServerTags(tags),
)(proxy)
网关接收请求后,会创建一个 Span,其中的 traceId 将作为本次请求的唯一编号,网关必须把这个 traceID 传递给字符串服务,字符串服务才能为该请求持续记录追踪信息。在 ReverseProxy 中能够完成这一任务的就是 Transport,我们可以使用 zipkin-go 的 middleware/HTTP 包提供的 NewTransport 替换系统默认的 HTTP.DefaultTransport。代码如下所示:
// NewReverseProxy 创建反向代理处理方法 func NewReverseProxy(client *api.Client, zikkinTracer *zipkin.Tracer, logger log.Logger) *HTTPutil.ReverseProxy {<span>//创建 Director</span> <span>director</span> := func(req *HTTP.Request) { <span>//省略</span> } <span>// 为反向代理增加追踪逻辑,使用如下 roundtrip 代替默认 Transport</span> roundtrip, <span>_</span> := zipkinHTTPsvr.NewTransport(zikkinTracer, zipkinHTTPsvr.TransportTrace(<spanhttps://www.jb51.cc/tag/tera/" target="_blank">teral">true</span>)) <span>return</span> &HTTPutil.ReverseProxy{ <span>Director</span>: director, <span>Transport</span>: roundtrip, }
}
至此,API 网关服务的搭建就完成了。
2. 业务服务构建
创建追踪器与网关的处理方式一样,我们就不再描述。字符串服务对外提供了两个接口:字符串操作(/op/{type}/{a}/{b})和健康检查(/health)。定义如下:
endpoint := MakeStringEndpoint(svc)
//添加追踪,设置 span 的名称为 string-endpoint
endpoint = Kitzipkin.TraceEndpoint(zipkinTracer, "string-endpoint") (endpoint)
//创建健康检查的 Endpoint
healthEndpoint := MakeHealthCheckEndpoint(svc)
//添加追踪,设置 span 的名称为 health-endpoint
healthEndpoint = Kitzipkin.TraceEndpoint(zipkinTracer, “health-endpoint”) (healthEndpoint)
Go-kit 提供了对 zipkin-go 的封装,上面的实现中,直接调用中间件 TraceEndpoint 对字符串服务的两个 Endpoint 进行设置。
除了 Endpoint,还需要追踪 Transport。可以修改 transports.go 的 MakeHTTPHandler 方法,增加参数 zipkinTracer,然后在 ServerOption 中设置追踪参数。代码如下:
// MakeHTTPHandler make HTTP handler use mux func MakeHTTPHandler(ctx context.Context, endpoints ArithmeticEndpoints, zipkinTracer *gozipkin.Tracer, logger log.Logger) HTTP.Handler { r := mux.NewRouter()<span>zipkinServer</span> := zipkin.HTTPServerTrace(zipkinTracer, zipkin.Name (<span>"HTTP-transport"</span>)) <span>options</span> := []KitHTTP.ServerOption{ KitHTTP.ServerErrorLogger(logger), KitHTTP.ServerErrorEncoder(KitHTTP.DefaultErrorEncoder), zipkinServer, } <span>// ...</span> <span>return</span> r
}
至此,所有的代码修改工作已经完成,下一步就是启动测试、对结果验证了。
3. 结果验证
我们可以访问 http://localhost:9090/string-service/op/Diff/abc/bcd,查看字符串服务的请求结果,如下图所示:

结果验证截图
可以看到,通过网关,我们可以正常访问字符串服务提供的接口。下面我们通过 Zipkin UI 来查看本次链路调用的信息,如下图所示:

Zipkin UI 查看链路调用的信息截图
在浏览器请求之后,可以在 Zipkin UI 中看到发送的请求记录(单击上方“Try Lens UI”切换成了 Lens UI,效果还不错),点击查看详细的链路调用情况,如下图所示:

Lens UI 截图
从调用链中可以看到,本次请求涉及两个服务:gateway-service 和 string-service。
整个链路有 3 个 Span:gateway、HTTP-transport 和 string-endpoint,确实如我们所定义的一样。这里我们主要看一下网关中的 Gateway Span 详情,如下图所示:

Gateway Span 详情截图
Gateway 访问字符串服务的时候,其实是作为一个客户端建立连接并发起调用,然后等待 Server 写回响应结果,最后结束客户端的调用。通过上图的展开,我们清楚地了解这次调用(Span)打的标签(tag),包括 method、path 等。
gRPC 调用方式的链路追踪
上面我们分析了微服务中 HTTP 调用方式的链路追踪,Go-kit 中的 transport 层可以方便地切换 RPC 调用方式,所以下面我们就来介绍下基于 gRPC 调用方式的链路追踪。本案例的实现是在前面HTTP 调用的代码基础上进行修改,并增加测试的调用客户端。
1. 定义 protobuf 文件
我们首先来定义 protobuf 文件及生成对应的 Go 文件。
Syntax = "proto3";
package pb;
service StringService{
rpc Diff(StringRequest) returns (StringResponse){}
}
message StringRequest {
string request_type = 1;
string a = 2;
string b = 3;
}
message StringResponse {
string result = 1;
string err = 2;
}
这里提供了字符串服务中的 Diff 方法,客户端通过 gRPC 调用字符串服务。使用 proto 工具生成对应的 Go 语言文件:
protoc string.proto --go_out=plugins=grpc:.
生成的 string.pb.go 可以参见源码,此处不再展开。
2. 定义 gRPC Server
在字符串服务中增加 gRPC server 的实现,并织入 gRPC 链路追踪的相关代码。
//grpc server go func() { fmt.Println("grpc Server start at port" + *grpcAddr) listener, err := net.Listen("tcp", *grpcAddr) if err != nil { errChan <- err return } serverTracer := kitzipkin.GRPCServerTrace(zipkinTracer, kitzipkin.Name("string-grpc-transport"))<span>handler</span> := NewGRPCServer(ctx, endpts, serverTracer) <span>gRPCServer</span> := grpc.NewServer() pb.RegisterStringServiceServer(gRPCServer, handler) errChan <- gRPCServer.Serve(listener) }()
要增加 Trace 的中间件,其实就是在 gRPC 的 ServerOption 中追加 GRPCServerTrace。我们增加的通用 Span 名为:string-grpc-transport。接下来就是在 endpoint 中,增加暴露接口的 gRPC 实现,代码如下:
func (se StringEndpoints) Diff(ctx context.Context, a, b string) (string, error) {
resp, err := se.StringEndpoint(ctx, StringRequest{
RequestType: "Diff",
A: a,
B: b,
})
response := resp.(StringResponse)
return response.Result, err
}
在构造 StringRequest 时,我们根据调用的 Diff 方法,指定了请求参数为“Diff”,下面即可定义 RPC 调用的客户端。
3. 定义服务 gRPC 调用的客户端
字符串服务提供对外的客户端调用,定义方法名为 StringDiff,返回 StringEndpoint,代码如下:
import (
grpctransport "github.com/go-kit/kit/transport/grpc"
kitgrpc "github.com/go-kit/kit/transport/grpc"
"github.com/longjoy/micro-go-course/section35/zipkin-kit/pb"
endpts "github.com/longjoy/micro-go-course/section35/zipkin-kit/string-service/endpoint"
"github.com/longjoy/micro-go-course/section35/zipkin-kit/string-service/service"
"google.golang.org/grpc"
)
func StringDiff(conn *grpc.ClientConn, clientTracer kitgrpc.ClientOption) service.Service {
<span>var</span> ep = grpctransport.NewClient(conn,
<span>"pb.StringService"</span>,
<span>"Diff"</span>,
EncodeGRPCStringRequest, <span>// 请求的编码</span>
DecodeGRPCStringResponse, <span>// 响应的解码</span>
pb.StringResponse{}, <span>//定义返回的对象</span>
clientTracer, <span>//客户端的 GRPcclientTrace</span>
).Endpoint()
<span>StringEp</span> := endpts.StringEndpoints{
<span>StringEndpoint</span>: ep,
}
<span>return</span> StringEp
}
从客户端调用的定义可以看到,传入的是 grpc 连接和客户端的 trace 上下文。这里需要注意的是 GRPcclientTrace 的初始化,测试 gRPC 调用的客户端时将会传入该参数。
4. 测试 gRPC 调用的客户端
编写 client_test.go,调用我们在前面已经定义的 client.StringDiff 方法,代码如下:
//... zipkinTracer 的构造省略 tr := zipkinTracer // 设定根 Span 的名称 parentSpan := tr.StartSpan("test") defer parentSpan.Flush() // 写入上下文<span>ctx</span> := zipkin.NewContext(context.Background(), parentSpan) <span>//初始化 GRPcclientTrace</span> <span>clientTracer</span> := kitzipkin.GRPcclientTrace(tr) conn, <span>err</span> := grpc.Dial(*grpcAddr, grpc.WithInsecure(), grpc.WithTimeout (<span>1</span>*time.Second)) <span>if</span> err != nil { fmt.Println(<span>"gRPC dial err:"</span>, err) } defer conn.Close() <span>// 获取 rpc 调用的 endpoint,发起调用</span> <span>svr</span> := client.StringDiff(conn, clientTracer) result, <span>err</span> := svr.Diff(ctx, <span>"Add"</span>, <span>"ppsdd"</span>) <span>if</span> err != nil { fmt.Println(<span>"Diff error"</span>, err.Error()) } fmt.Println(<span>"result ="</span>, result)
客户端在调用之前,我们构建了要传入的 GRPcclientTrace,作为获取 rpc 调用的 endpoint 的参数,设定调用的父 Span 名称,这个上下文信息会传入 Zipkin 服务端。调用输出的结果如下:
ts=2020-9-24T15:27:06.817056Z caller=client_test.go:51 tracer=Zipkin type=Native URL=http://localhost:9411/api/v2/spans
result = dd
测试用例的调用结果正确,我们来看一下 Zipkin 中记录的调用链信息。点击查看详情,可以看到本次请求涉及两个服务:test-service 和 string-service。如图所示:

精选评论

java B2B2C社交电子商务平台分析-----Spring Cloud Zipkin
Zipkin是什么
Zipkin分布式跟踪系统;它可以帮助收集时间数据,解决在microservice架构下的延迟问题;它管理这些数据的收集和查找;Zipkin的设计是基于谷歌的Google Dapper论文。电子商务社交平台源码请加企鹅求求:三五三六二四七二五九
每个应用程序向Zipkin报告定时数据,Zipkin UI呈现了一个依赖图表来展示多少跟踪请求经过了每个应用程序;如果想解决延迟问题,可以过滤或者排序所有的跟踪请求,并且可以查看每个跟踪请求占总跟踪时间的百分比。
为什么使用Zipkin
随着业务越来越复杂,系统也随之进行各种拆分,特别是随着微服务架构和容器技术的兴起,看似简单的一个应用,后台可能有几十个甚至几百个服务在支撑;一个前端的请求可能需要多次的服务调用最后才能完成;当请求变慢或者不可用时,我们无法得知是哪个后台服务引起的,这时就需要解决如何快速定位服务故障点,Zipkin分布式跟踪系统就能很好的解决这样的问题。
Zipkin原理
针对服务化应用全链路追踪的问题,Google发表了Dapper论文,介绍了他们如何进行服务追踪分析。其基本思路是在服务调用的请求和响应中加入ID,标明上下游请求的关系。利用这些信息,可以可视化地分析服务调用链路和服务间的依赖关系。
对应Dpper的开源实现是Zipkin,支持多种语言包括JavaScript,Python,Java, Scala, Ruby, C#, Go等。其中Java由多种不同的库来支持
Spring Cloud Sleuth是对Zipkin的一个封装,对于Span、Trace等信息的生成、接入HTTP Request,以及向Zipkin Server发送采集信息等全部自动完成。Spring Cloud Sleuth的概念图见上图。
Zipkin架构
跟踪器(Tracer)位于你的应用程序中,并记录发生的操作的时间和元数据,提供了相应的类库,对用户的使用来说是透明的,收集的跟踪数据称为Span;将数据发送到Zipkin的仪器化应用程序中的组件称为Reporter,Reporter通过几种传输方式之一将追踪数据发送到Zipkin收集器(collector),然后将跟踪数据进行存储(storage),由API查询存储以向UI提供数据。
架构图如下:

1.Trace
Zipkin使用Trace结构表示对一次请求的跟踪,一次请求可能由后台的若干服务负责处理,每个服务的处理是一个Span,Span之间有依赖关系,Trace就是树结构的Span集合;
2.Span
每个服务的处理跟踪是一个Span,可以理解为一个基本的工作单元,包含了一些描述信息:id,parentId,name,timestamp,duration,annotations等。
3.Transport
收集的Spans必须从被追踪的服务运输到Zipkin collector,有三个主要的传输方式:HTTP, Kafka和Scribe;
4.Components
有4个组件组成Zipkin:collector,storage,search,web UI
collector:一旦跟踪数据到达Zipkin collector守护进程,它将被验证,存储和索引,以供Zipkin收集器查找;
storage:Zipkin最初数据存储在Cassandra上,因为Cassandra是可扩展的,具有灵活的模式,并在Twitter中大量使用;但是这个组件可插入,除了Cassandra之外,还支持ElasticSearch和MySQL; 存储,zipkin默认的存储方式为in-memory,即不会进行持久化操作。如果想进行收集数据的持久化,可以存储数据在Cassandra,因为Cassandra是可扩展的,有一个灵活的模式,并且在Twitter中被大量使用,我们使这个组件可插入。除了Cassandra,我们原生支持ElasticSearch和MySQL。其他后端可能作为第三方扩展提供。
search:一旦数据被存储和索引,我们需要一种方法来提取它。查询守护进程提供了一个简单的JSON API来查找和检索跟踪,主要给Web UI使用;
web UI:创建了一个GUI,为查看痕迹提供了一个很好的界面;Web UI提供了一种基于服务,时间和注释查看跟踪的方法。
java版spring cloud电子商务社交平台源码请加企鹅求求:三五三六二四七二五九

Java JNDI 与其他 Java 技术的协作:揭秘 Java JNDI 与 Java EE 等技术的融合

Java JNDI 简介
Java JNDI(Java Naming and Directory Interface)是Java中用于访问命名和目录服务的API,与Java EE等技术的协作至关重要。在实际开发中,Java JNDI可以与Java EE框架无缝融合,为应用程序提供更灵活的资源访问方式。本文将深入探讨Java JNDI与其他Java技术的协作,揭示它们之间的关联与互补,帮助开发者更好地理解和应用这些技术。
Java JNDI 与 Java EE 的协作
Java JNDI与Java EE有着密切的协作,在Java EE应用程序中扮演着重要的角色。Java EE规范中定义了JNDI作为标准的命名和目录服务API,Java EE应用程序可以通过JNDI来访问各种命名和目录服务中的数据。
JNDI在Java EE中的应用
在Java EE应用程序中,JNDI主要用于以下几个方面:
- 资源查找: Java EE应用程序可以使用JNDI来查找各种资源,如数据源、消息队列、EJB组件等。这些资源通常由应用程序服务器管理,Java EE应用程序可以通过JNDI来访问这些资源,而无需关心资源的具体位置和访问方式。
- 服务发现: Java EE应用程序可以使用JNDI来发现其他服务,如WEB服务、EJB组件等。这些服务通常由应用程序服务器注册,Java EE应用程序可以通过JNDI来查找这些服务,并与之通信。
- 命名空间管理: Java EE应用程序可以使用JNDI来管理命名空间,如全局JNDI命名空间和Web应用程序JNDI命名空间等。Java EE应用程序可以通过JNDI来创建、修改和删除命名空间中的对象,并访问命名空间中的对象。
Java JNDI与Java EE的集成
Java JNDI与Java EE的集成主要通过以下几个方面来实现:
立即学习“Java免费学习笔记(深入)”;
- Java EE应用程序服务器: Java EE应用程序服务器通常提供了一个JNDI服务,用于管理命名空间和资源。Java EE应用程序可以通过JNDI服务来查找资源和服务。
- Java EE规范: Java EE规范中定义了JNDI作为标准的命名和目录服务API。Java EE应用程序可以使用JNDI来访问各种命名和目录服务中的数据。
- JNDI API: Java JNDI API提供了一组丰富的类和接口,用于访问命名和目录服务中的数据。Java EE应用程序可以通过JNDI API来实现资源查找、服务发现和命名空间管理等功能。
Java JNDI 与其他 Java 技术的协作
除了Java EE之外,Java JNDI还与其他Java技术有着密切的协作,如Java RMI、Java CORBA、Java Servlet等。
Java JNDI与Java RMI的协作
Java JNDI与Java RMI(Remote Method Invocation)协作,使Java程序能够通过网络调用远程对象的方法。Java RMI中,远程对象可以注册到JNDI命名空间中,其他Java程序可以通过JNDI来查找远程对象,并调用远程对象的方法。
Java JNDI 与 Java CORBA 的协作
Java JNDI 与 Java CORBA(Common Object Request Broker Architecture)协作,使Java程序能够与其他语言(如c++、C#等)编写的 CORBA 对象进行通信。Java CORBA 对象可以注册到 JNDI 命名空间中,其他 Java 程序或其他语言编写的 CORBA 程序可以通过 JNDI 来查找 CORBA 对象,并调用 CORBA 对象的方法。
Java JNDI 与 Java Servlet 的协作
Java JNDI 与 Java Servlet 协作,使 Servlet 能够访问各种资源,如数据源、消息队列等。Servlet 可以通过 JNDI 来查找资源,并使用这些资源。
总结
Java JNDI 作为 Java 平台上通用的命名和目录服务 API,不仅与 Java EE 有着密切的协作,还与其他 Java 技术(如 Java RMI、Java CORBA、Java Servlet 等)有着密切的协作。在项目开发中,Java JNDI 发挥着重要的作用,帮助 Java 程序员轻松地访问和操纵命名和目录服务中的数据,实现资源查找、服务发现和命名空间管理等功能。
以上就是Java JNDI 与其他 Java 技术的协作:揭秘 Java JNDI 与 Java EE 等技术的融合的详细内容,更多请关注php中文网其它相关文章!
今天关于Java-Zipkin:Zipkin 介绍和java zip包的讲解已经结束,谢谢您的阅读,如果想了解更多关于Dubbo + Zipkin + Brave实现全链路追踪、GO微服务实战第三十一节 案例:如何在微服务中集成 Zipkin 组件?、java B2B2C社交电子商务平台分析-----Spring Cloud Zipkin、Java JNDI 与其他 Java 技术的协作:揭秘 Java JNDI 与 Java EE 等技术的融合的相关知识,请在本站搜索。
本文标签:




