本文将带您了解关于java–ApacheCommons数学优化的新内容,同时我们还将为您解释java优化算法的相关知识,另外,我们还将为您提供关于java.lang.NoClassDefFoundEr
本文将带您了解关于java – Apache Commons数学优化的新内容,同时我们还将为您解释java优化算法的相关知识,另外,我们还将为您提供关于 java.lang.NoClassDefFoundError: org/apache/spark/api/java/function/Function、An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)、Apache HTTP 服务器和 Apache Tomcat 之间的区别?、Apache HttpComponents:org.apache.http.client.ClientProtocolException的实用信息。
本文目录一览:- java – Apache Commons数学优化(java优化算法)
- java.lang.NoClassDefFoundError: org/apache/spark/api/java/function/Function
- An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)
- Apache HTTP 服务器和 Apache Tomcat 之间的区别?
- Apache HttpComponents:org.apache.http.client.ClientProtocolException
")
java – Apache Commons数学优化(java优化算法)
解决方法
但是,如果您有更多信息,例如渐变,则应考虑使用更“明智”的算法,例如BFGS.它也适用于分析梯度(使用有限差分). R默认使用BFGS,我认为……
SuanShu已经实现了10个Java optimization算法,您可以根据自己的需要选择这些算法.希望这可以帮助.

java.lang.NoClassDefFoundError: org/apache/spark/api/java/function/Function
java.lang.NoClassDefFoundError: org/apache/spark/api/java/function/Function
at com.test.utils.test.TestSpark.main(TestSpark.java:26)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.api.java.function.Function
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
... 1 more
")
An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)
01 Mar 2018 Piotr Nowojski (@PiotrNowojski) & Mike Winters (@wints)
This post is an adaptation of Piotr Nowojski’s presentation from Flink Forward Berlin 2017. You can find the slides and a recording of the presentation on the Flink Forward Berlin website.
Apache Flink 1.4.0, released in December 2017, introduced a significant milestone for stream processing with Flink: a new feature called TwoPhaseCommitSinkFunction (relevant Jira here) that extracts the common logic of the two-phase commit protocol and makes it possible to build end-to-end exactly-once applications with Flink and a selection of data sources and sinks, including Apache Kafka versions 0.11 and beyond. It provides a layer of abstraction and requires a user to implement only a handful of methods to achieve end-to-end exactly-once semantics.
If that’s all you need to hear, let us point you to the relevant place in the Flink documentation, where you can read about how to put TwoPhaseCommitSinkFunction to use.
But if you’d like to learn more, in this post, we’ll share an in-depth overview of the new feature and what is happening behind the scenes in Flink.
Throughout the rest of this post, we’ll:
- Describe the role of Flink’s checkpoints for guaranteeing exactly-once results within a Flink application.
- Show how Flink interacts with data sources and data sinks via the two-phase commit protocol to deliver end-to-end exactly-once guarantees.
- Walk through a simple example on how to use
TwoPhaseCommitSinkFunctionto implement an exactly-once file sink.
Exactly-once Semantics Within an Apache Flink Application
When we say “exactly-once semantics”, what we mean is that each incoming event affects the final results exactly once. Even in case of a machine or software failure, there’s no duplicate data and no data that goes unprocessed.
Flink has long provided exactly-once semantics within a Flink application. Over the past few years, we’ve written in depth about Flink’s checkpointing, which is at the core of Flink’s ability to provide exactly-once semantics. The Flink documentation also provides a thorough overview of the feature.
Before we continue, here’s a quick summary of the checkpointing algorithm because understanding checkpoints is necessary for understanding this broader topic.
A checkpoint in Flink is a consistent snapshot of:
- The current state of an application
- The position in an input stream
Flink generates checkpoints on a regular, configurable interval and then writes the checkpoint to a persistent storage system, such as S3 or HDFS. Writing the checkpoint data to the persistent storage happens asynchronously, which means that a Flink application continues to process data during the checkpointing process.
In the event of a machine or software failure and upon restart, a Flink application resumes processing from the most recent successfully-completed checkpoint; Flink restores application state and rolls back to the correct position in the input stream from a checkpoint before processing starts again. This means that Flink computes results as though the failure never occurred.
Before Flink 1.4.0, exactly-once semantics were limited to the scope of a Flink application only and did not extend to most of the external systems to which Flink sends data after processing.
But Flink applications operate in conjunction with a wide range of data sinks, and developers should be able to maintain exactly-once semantics beyond the context of one component.
To provide end-to-end exactly-once semantics–that is, semantics that also apply to the external systems that Flink writes to in addition to the state of the Flink application–these external systems must provide a means to commit or roll back writes that coordinate with Flink’s checkpoints.
One common approach for coordinating commits and rollbacks in a distributed system is the two-phase commit protocol. In the next section, we’ll go behind the scenes and discuss how Flink’s TwoPhaseCommitSinkFunction utilizes the two-phase commit protocol to provide end-to-end exactly-once semantics.
End-to-end Exactly Once Applications with Apache Flink
We’ll walk through the two-phase commit protocol and how it enables end-to-end exactly-once semantics in a sample Flink application that reads from and writes to Kafka. Kafka is a popular messaging system to use along with Flink, and Kafka recently added support for transactions with its 0.11 release. This means that Flink now has the necessary mechanism to provide end-to-end exactly-once semantics in applications when receiving data from and writing data to Kafka.
Flink’s support for end-to-end exactly-once semantics is not limited to Kafka and you can use it with any source / sink that provides the necessary coordination mechanism. For example, Pravega, an open-source streaming storage system from Dell/EMC, also supports end-to-end exactly-once semantics with Flink via the TwoPhaseCommitSinkFunction.
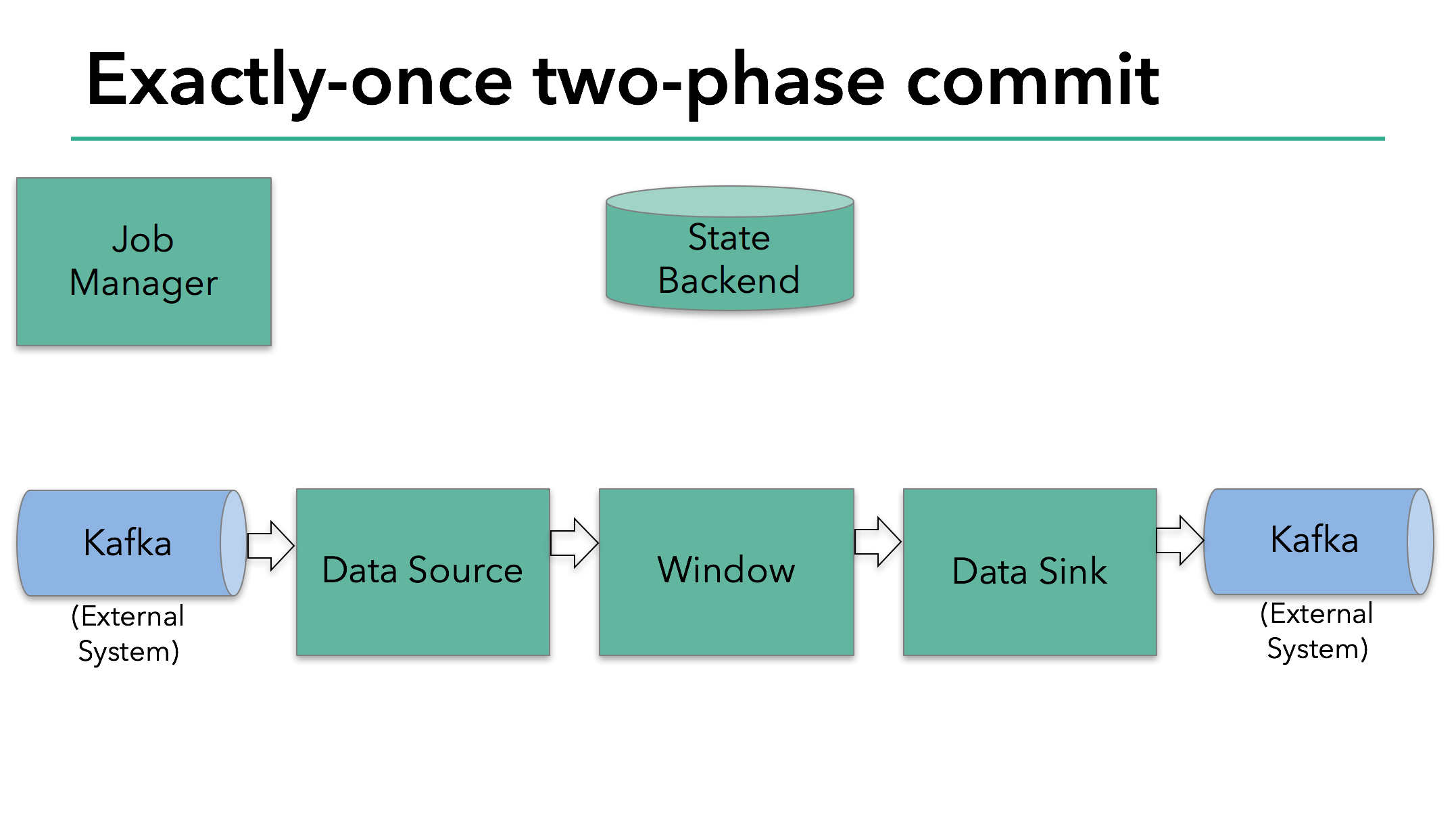
In the sample Flink application that we’ll discuss today, we have:
- A data source that reads from Kafka (in Flink, a KafkaConsumer)
- A windowed aggregation
- A data sink that writes data back to Kafka (in Flink, a KafkaProducer)
For the data sink to provide exactly-once guarantees, it must write all data to Kafka within the scope of a transaction. A commit bundles all writes between two checkpoints.
This ensures that writes are rolled back in case of a failure.
However, in a distributed system with multiple, concurrently-running sink tasks, a simple commit or rollback is not sufficient, because all of the components must “agree” together on committing or rolling back to ensure a consistent result. Flink uses the two-phase commit protocol and its pre-commit phase to address this challenge.
The starting of a checkpoint represents the “pre-commit” phase of our two-phase commit protocol. When a checkpoint starts, the Flink JobManager injects a checkpoint barrier (which separates the records in the data stream into the set that goes into the current checkpoint vs. the set that goes into the next checkpoint) into the data stream.
The barrier is passed from operator to operator. For every operator, it triggers the operator’s state backend to take a snapshot of its state.
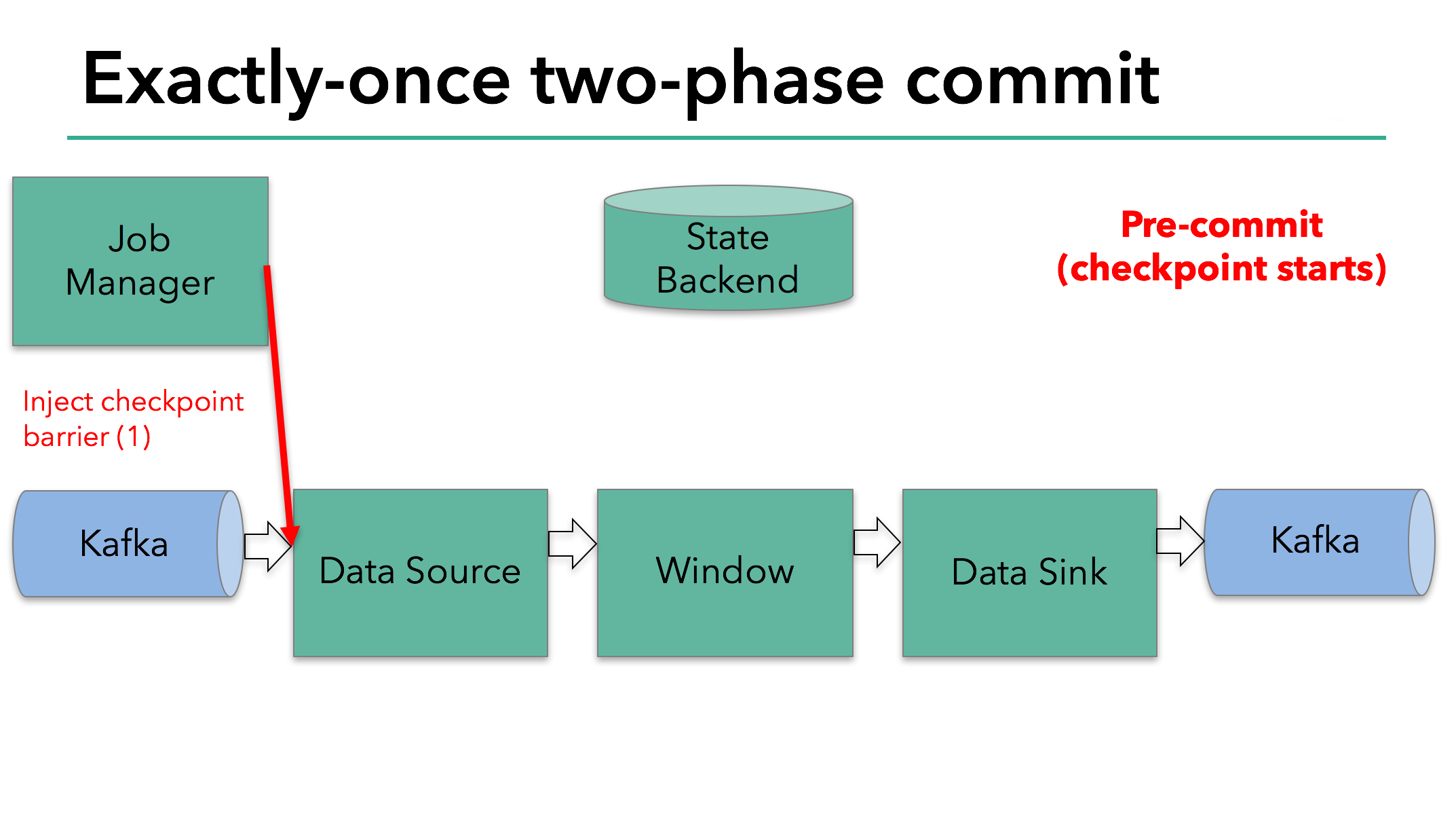
The data source stores its Kafka offsets, and after completing this, it passes the checkpoint barrier to the next operator.
This approach works if an operator has internal state only. Internal state is everything that is stored and managed by Flink’s state backends - for example, the windowed sums in the second operator. When a process has only internal state, there is no need to perform any additional action during pre-commit aside from updating the data in the state backends before it is checkpointed. Flink takes care of correctly committing those writes in case of checkpoint success or aborting them in case of failure.
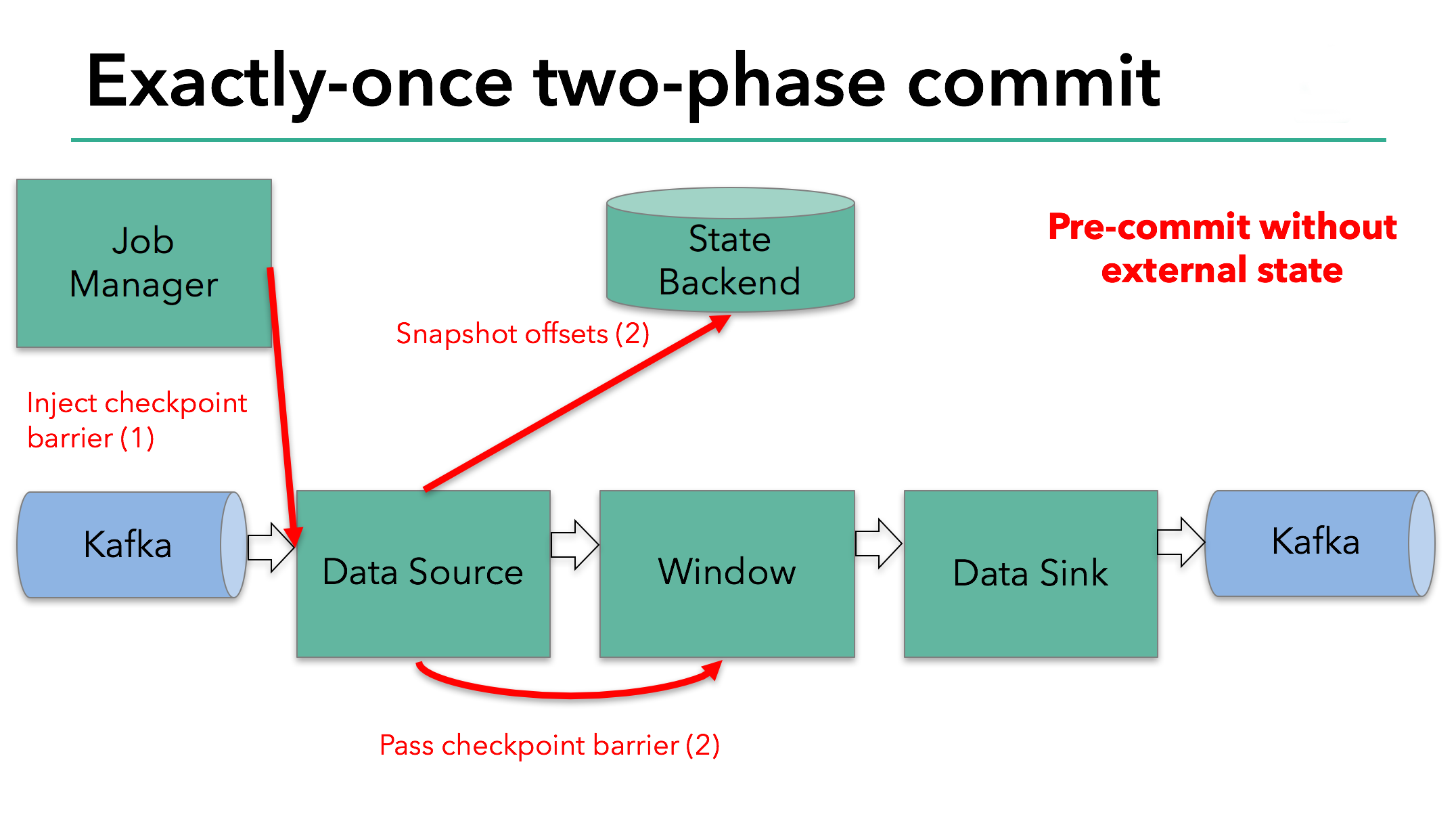
However, when a process has external state, this state must be handled a bit differently. External state usually comes in the form of writes to an external system such as Kafka. In that case, to provide exactly-once guarantees, the external system must provide support for transactions that integrates with a two-phase commit protocol.
We know that the data sink in our example has such external state because it’s writing data to Kafka. In this case, in the pre-commit phase, the data sink must pre-commit its external transaction in addition to writing its state to the state backend.
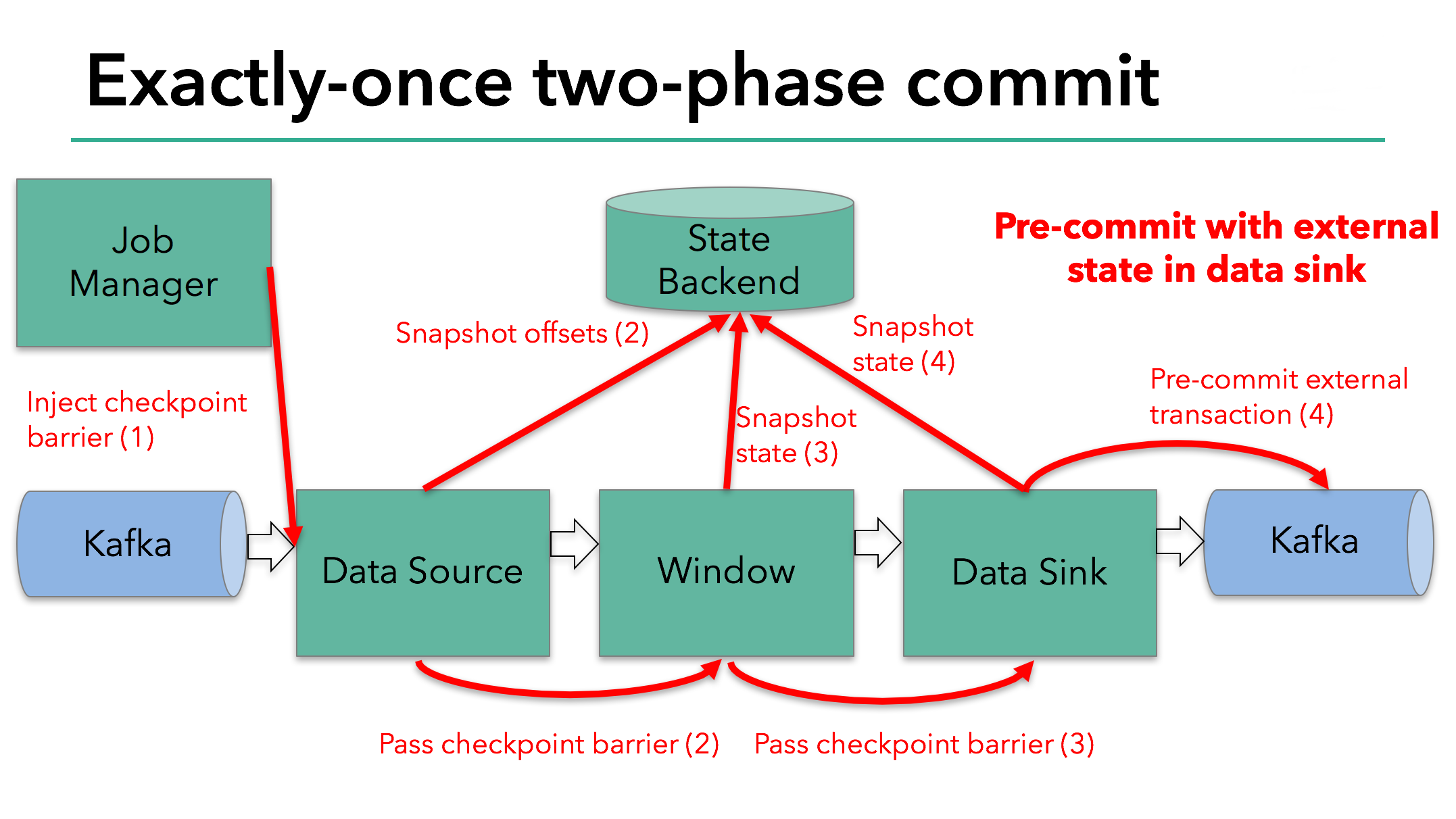
The pre-commit phase finishes when the checkpoint barrier passes through all of the operators and the triggered snapshot callbacks complete. At this point the checkpoint completed successfully and consists of the state of the entire application, including pre-committed external state. In case of a failure, we would re-initialize the application from this checkpoint.
The next step is to notify all operators that the checkpoint has succeeded. This is the commit phase of the two-phase commit protocol and the JobManager issues checkpoint-completed callbacks for every operator in the application. The data source and window operator have no external state, and so in the commit phase, these operators don’t have to take any action. The data sink does have external state, though, and commits the transaction with the external writes.
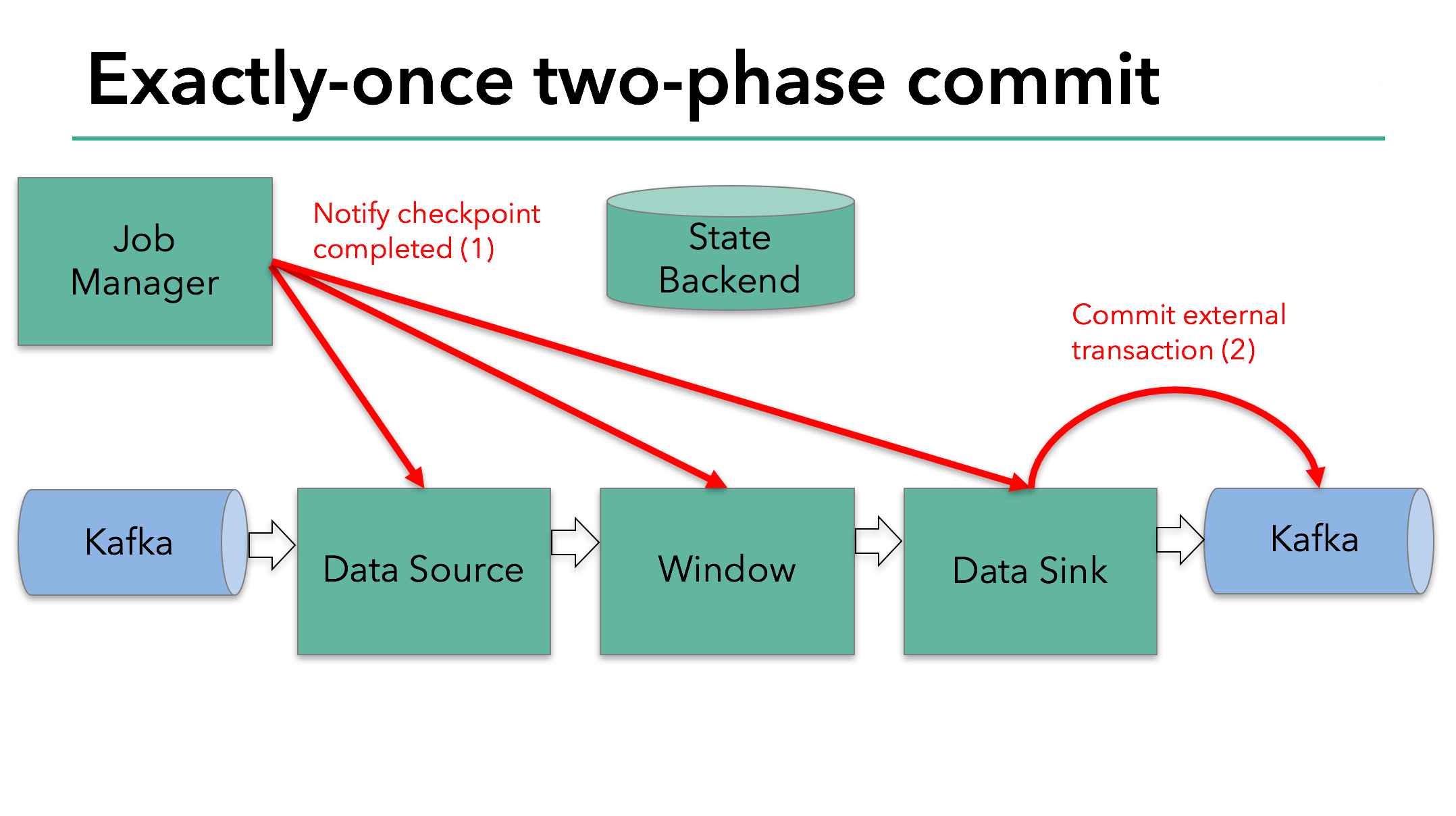
So let’s put all of these different pieces together:
- Once all of the operators complete their pre-commit, they issue a commit.
- If at least one pre-commit fails, all others are aborted, and we roll back to the previous successfully-completed checkpoint.
- After a successful pre-commit, the commit must be guaranteed to eventually succeed – both our operators and our external system need to make this guarantee. If a commit fails (for example, due to an intermittent network issue), the entire Flink application fails, restarts according to the user’s restart strategy, and there is another commit attempt. This process is critical because if the commit does not eventually succeed, data loss occurs.
Therefore, we can be sure that all operators agree on the final outcome of the checkpoint: all operators agree that the data is either committed or that the commit is aborted and rolled back.
Implementing the Two-Phase Commit Operator in Flink
All the logic required to put a two-phase commit protocol together can be a little bit complicated and that’s why Flink extracts the common logic of the two-phase commit protocol into the abstract TwoPhaseCommitSinkFunction class.
Let’s discuss how to extend a TwoPhaseCommitSinkFunction on a simple file-based example. We need to implement only four methods and present their implementations for an exactly-once file sink:
beginTransaction -to begin the transaction, we create a temporary file in a temporary directory on our destination file system. Subsequently, we can write data to this file as we process it.preCommit -on pre-commit, we flush the file, close it, and never write to it again. We’ll also start a new transaction for any subsequent writes that belong to the next checkpoint.commit -on commit, we atomically move the pre-committed file to the actual destination directory. Please note that this increases the latency in the visibility of the output data.abort -on abort, we delete the temporary file.
As we know, if there’s any failure, Flink restores the state of the application to the latest successful checkpoint. One potential catch is in a rare case when the failure occurs after a successful pre-commit but before notification of that fact (a commit) reaches our operator. In that case, Flink restores our operator to the state that has already been pre-committed but not yet committed.
We must save enough information about pre-committed transactions in checkpointed state to be able to either abort or commit transactions after a restart. In our example, this would be the path to the temporary file and target directory.
The TwoPhaseCommitSinkFunction takes this scenario into account, and it always issues a preemptive commit when restoring state from a checkpoint. It is our responsibility to implement a commit in an idempotent way. Generally, this shouldn’t be an issue. In our example, we can recognize such a situation: the temporary file is not in the temporary directory, but has already been moved to the target directory.
There are a handful of other edge cases that TwoPhaseCommitSinkFunction takes into account, too. Learn more in the Flink documentation.
Wrapping Up
If you’ve made it this far, thanks for staying with us through a detailed post. Here are some key points that we covered:
- Flink’s checkpointing system serves as Flink’s basis for supporting a two-phase commit protocol and providing end-to-end exactly-once semantics.
- An advantage of this approach is that Flink does not materialize data in transit the way that some other systems do–there’s no need to write every stage of the computation to disk as is the case is most batch processing.
- Flink’s new
TwoPhaseCommitSinkFunctionextracts the common logic of the two-phase commit protocol and makes it possible to build end-to-end exactly-once applications with Flink and external systems that support transactions - Starting with Flink 1.4.0, both the Pravega and Kafka 0.11 producers provide exactly-once semantics; Kafka introduced transactions for the first time in Kafka 0.11, which is what made the Kafka exactly-once producer possible in Flink.
- The Kafka 0.11 producer is implemented on top of the
TwoPhaseCommitSinkFunction, and it offers very low overhead compared to the at-least-once Kafka producer.
We’re very excited about what this new feature enables, and we look forward to being able to support additional producers with the TwoPhaseCommitSinkFunction in the future.
This post first appeared on the data Artisans blog and was contributed to Apache Flink and the Flink blog by the original authors Piotr Nowojski and Mike Winters.

Apache HTTP 服务器和 Apache Tomcat 之间的区别?
Apache HTTP Server 和 Apache Tomcat 在功能方面有什么区别?
我知道 Tomcat 是用 Java 编写的,HTTP Server 是用 C 编写的,但除此之外,我真的不知道它们是如何区分的。它们有不同的功能吗?
答案1
小编典典Apache Tomcat 用于部署 Java Servlet 和 JSP。因此,在您的 Java 项目中,您可以构建您的 WAR(Web ARchive
的缩写)文件,然后将其放入 Tomcat 的部署目录中。
所以基本上 Apache 是一个 HTTP 服务器,服务于 HTTP。Tomcat 是一个服务于 Java 技术的 Servlet 和 JSP 服务器。
Tomcat 包括 Catalina,它是一个 servlet 容器。最后,servlet 是一个 Java 类。JSP 文件(类似于 PHP 和较旧的
ASP 文件)生成为 Java 代码(HttpServlet),然后由服务器编译为 .class 文件并由 Java 虚拟机执行。

Apache HttpComponents:org.apache.http.client.ClientProtocolException
因此,我使用apache
HttpComponents处理Java中的http请求。现在,我想重用DefaultHttpClient,根据此示例,应该可以:http
://wiki.apache.org/HttpComponents/QuickStart
。该示例本身给出了ssl错误,因此我对其进行了简化和简化。现在我总是得到一个org.apache.http.client.ClientProtocolException
这是我的示例程序,基本上我只是使用相同的请求两个网页DefaultHttpClient。
import java.io.ByteArrayOutputStream;import java.io.IOException;import java.io.InputStream;import org.apache.http.HttpEntity;import org.apache.http.HttpResponse;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.DefaultHttpClient;public class ClientFormLogin { public static void main(String[] args) throws Exception { DefaultHttpClient httpclient = new DefaultHttpClient(); //Handle first request. HttpGet httpget = new HttpGet("http://tweakers.net/nieuws/82969/amazon-nederland-opent-digitale-deuren-in-september.html"); HttpResponse response = httpclient.execute(httpget); System.out.println("Execute finished"); HttpEntity entity = response.getEntity(); String page = readInput(entity.getContent()); System.out.println("Request one finished without problems!"); //Handle second request HttpGet httpost = new HttpGet("http://gathering.tweakers.net/forum/list_messages/1506977/last"); response = httpclient.execute(httpost); entity = response.getEntity(); page = readInput(entity.getContent()); System.out.println("Request two finished without problems!"); } private static String readInput(InputStream in) throws IOException { ByteArrayOutputStream out = new ByteArrayOutputStream(); byte bytes[] = new byte[1024]; int n = in.read(bytes); while (n != -1) { out.write(bytes, 0, n); n = in.read(bytes); } return new String(out.toString()); }}在运行我的示例时,出现以下错误
Request one finished without problems!Exception in thread "main" org.apache.http.client.ClientProtocolException at org.apache.http.impl.client.AbstractHttpClient.execute(AbstractHttpClient.java:909) at org.apache.http.impl.client.AbstractHttpClient.execute(AbstractHttpClient.java:805) at org.apache.http.impl.client.AbstractHttpClient.execute(AbstractHttpClient.java:784) at ClientFormLogin.main(ClientFormLogin.java:29)Caused by: org.apache.http.HttpException: Unable to establish route: planned = {}->http://gathering.tweakers.net; current = {}->http://tweakers.net at org.apache.http.impl.client.DefaultRequestDirector.establishRoute(DefaultRequestDirector.java:842) at org.apache.http.impl.client.DefaultRequestDirector.tryConnect(DefaultRequestDirector.java:645) at org.apache.http.impl.client.DefaultRequestDirector.execute(DefaultRequestDirector.java:480) at org.apache.http.impl.client.AbstractHttpClient.execute(AbstractHttpClient.java:906) ... 3 more任何人都可以给我一些指示,指出如何解决这个问题,但DefaultHttpClient对于每个请求都使用一个新的指示符。
编辑
我只是发现如果我留在同一个域中就没有问题,所以:
page1: ''http://tweakers.net/nieuws/82969/amazon-nederland-opent-digitale-deuren-in-september.html''page2: ''http://tweakers.net/nieuws/82973/website-nujij-belandt-op-zwarte-lijst-google-door-malware.html''如果我要:
page1: ''http://tweakers.net/nieuws/82969/amazon-nederland-opent-digitale-deuren-in-september.html''page2: ''http://gathering.tweakers.net/forum/list_messages/1506076/last''我得到了错误。
我在发布问题后一分钟就看到了Ofc。除非有人可以告诉我我如何可以同时使用2个独立域名,否则DefaultHttpClient我的问题已得到解答。
答案1
小编典典这可能是由于v4.2
BasicClientConnectionManager中的最新错误影响了跨站点重定向。参见http://issues.apache.org/jira/browse/HTTPCLIENT-1193。
根据维护者的说法,一种临时的解决方法是使用SingleClientConnManager或PoolingClientConnectionManager。也许是这样的:
ClientConnectionManager connManager = new PoolingClientConnectionManager();DefaultHttpClient httpclient = new DefaultHttpClient(connManager);...我们今天的关于java – Apache Commons数学优化和java优化算法的分享就到这里,谢谢您的阅读,如果想了解更多关于 java.lang.NoClassDefFoundError: org/apache/spark/api/java/function/Function、An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)、Apache HTTP 服务器和 Apache Tomcat 之间的区别?、Apache HttpComponents:org.apache.http.client.ClientProtocolException的相关信息,可以在本站进行搜索。
本文标签:




