在本文中,您将会了解到关于一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)的新资讯,同时我们还将为您解释idea开发hadoop的相关在本文中,我们将带你探
在本文中,您将会了解到关于一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)的新资讯,同时我们还将为您解释idea开发hadoop的相关在本文中,我们将带你探索一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)的奥秘,分析idea开发hadoop的特点,并给出一些关于bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar、Eclipse下Hadoop的MapReduce开发之MapReduce编写、Eclipse中使用Hadoop插件编写Map/Reduce程序、Hadoop 6、第一个 mapreduce 程序 WordCount的实用技巧。
本文目录一览:- 一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)(idea开发hadoop)
- bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar
- Eclipse下Hadoop的MapReduce开发之MapReduce编写
- Eclipse中使用Hadoop插件编写Map/Reduce程序
- Hadoop 6、第一个 mapreduce 程序 WordCount
(idea开发hadoop)")
一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)(idea开发hadoop)
上一篇我们学习了MapReduce的原理,今天我们使用代码来加深对MapReduce原理的理解。
wordcount是Hadoop入门的经典例子,我们也不能免俗,也使用这个例子作为学习Hadoop的第一个程序。本文将介绍使用java和python编写第一个MapReduce程序。
本文使用Idea2018开发工具开发第一个Hadoop程序。使用的编程语言是Java。
打开idea,新建一个工程,如下图所示:
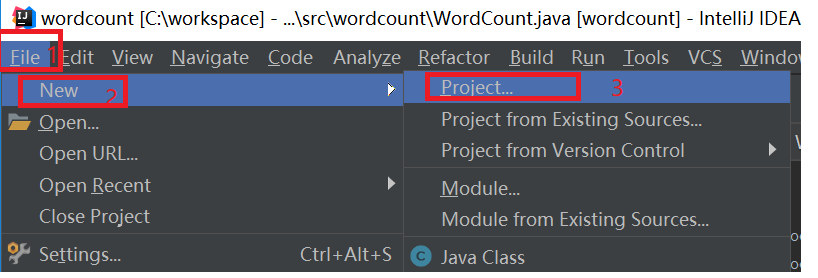
在弹出新建工程的界面选择Java,接着选择SDK,一般默认即可,点击“Next”按钮,如下图:
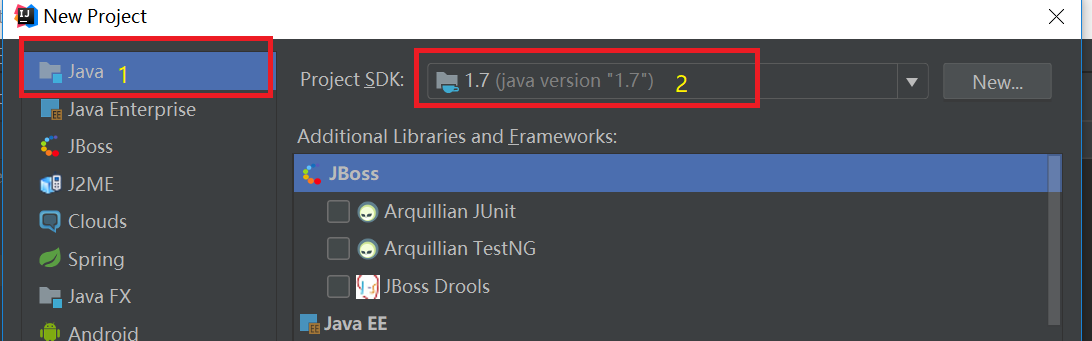
在弹出的选择创建项目的模板页面,不做任何操作,直接点击“Next”按钮。
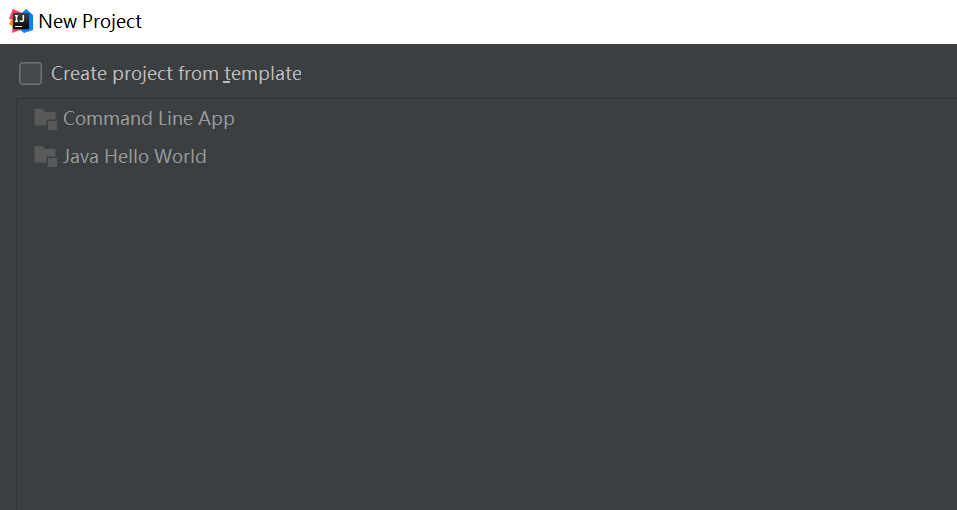
输入项目名称,点击Finish,就完成了创建新项目的工作,我们的项目名称为:WordCount。如下图所示:
添加依赖jar包,和Eclipse一样,要给项目添加相关依赖包,否则会出错。
点击Idea的File菜单,然后点击“Project Structure”菜单,如下图所示:
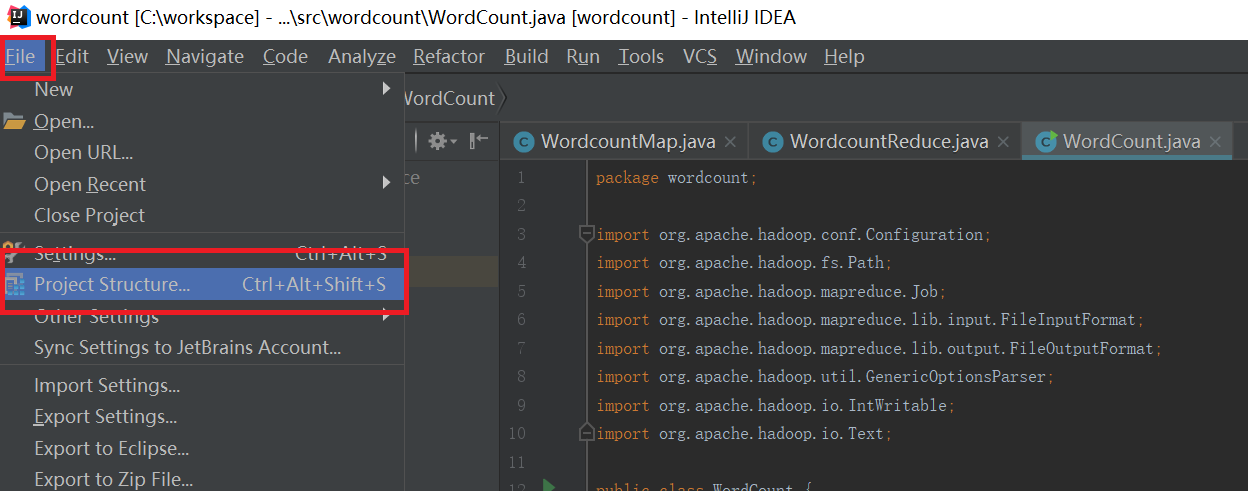
依次点击Modules和Dependencies,然后选择“+”的符号,如下图所示:
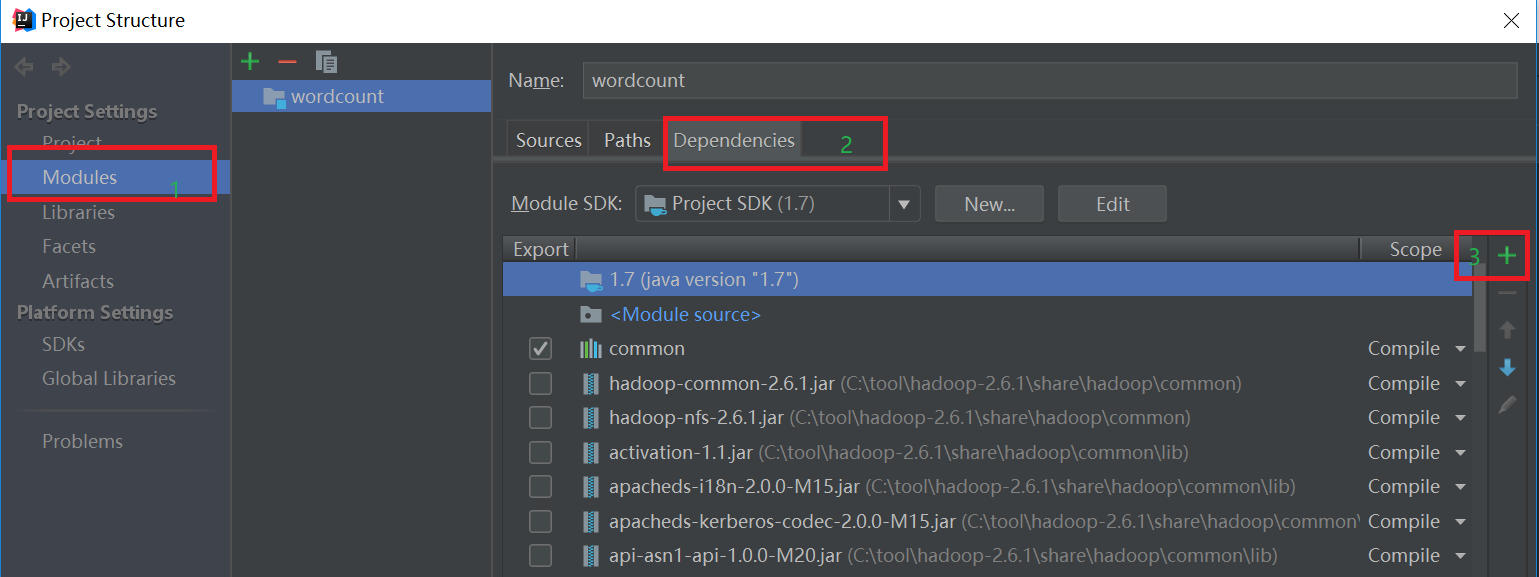
选择hadoop的包,我用得是hadoop2.6.1。把下面的依赖包都加入到工程中,否则会出现某个类找不到的错误。
(1)”/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-2.6.1.jar和haoop-nfs-2.6.1.jar;
(2)/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的haoop-hdfs-2.6.1.jar和haoop-hdfs-nfs-2.7.1.jar;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
工程已经创建好,我们开始编写Map类、Reduce类和运行MapReduce的入口类:
JAVA编写MarReduce代码
Map类如下:
1 import org.apache.hadoop.io.IntWritable;
2
3 import org.apache.hadoop.io.LongWritable;
4
5 import org.apache.hadoop.io.Text;
6
7 import org.apache.hadoop.mapreduce.Mapper;
8
9 import java.io.IOException;
10
11
12 public class WordcountMap extends Mapper<LongWritable,Text,Text,IntWritable> {
13 public void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException{
14
15 String line = value.toString();//读取一行数据
16
17 String str[] = line.split("");//因为英文字母是以“ ”为间隔的,因此使用“ ”分隔符将一行数据切成多个单词并存在数组中
18
19 for(String s :str){//循环迭代字符串,将一个单词变成<key,value>形式,及<"hello",1>
20 context.write(new Text(s),new IntWritable(1));
21 }
22 }
23 }
Reudce类:
1 import org.apache.hadoop.io.IntWritable;
2 import org.apache.hadoop.mapreduce.Reducer;
3 import org.apache.hadoop.io.Text;
4 import java.io.IOException;
5
6 public class WordcountReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
7 public void reduce(Text key, Iterable<IntWritable> values,Context context)throws IOException,InterruptedException{
8 int count = 0;
9 for(IntWritable value: values) {
10 count++;
11 }
12 context.write(key,new IntWritable(count));
13 }
14 }
入口类 :
1 import org.apache.hadoop.conf.Configuration;
2 import org.apache.hadoop.fs.Path;
3 import org.apache.hadoop.mapreduce.Job;
4 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
5 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
6 import org.apache.hadoop.util.GenericOptionsParser;
7 import org.apache.hadoop.io.IntWritable;
8 import org.apache.hadoop.io.Text;
9
10 public class WordCount {
11
12 public static void main(String[] args)throws Exception{
13 Configuration conf = new Configuration();
14 //获取运行时输入的参数,一般是通过shell脚本文件传进来。
15 String [] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
16 if(otherArgs.length < 2){
17 System.err.println("必须输入读取文件路径和输出路径");
18 System.exit(2);
19 }
20 Job job = new Job();
21 job.setJarByClass(WordCount.class);
22 job.setJobName("wordcount app");
23
24 //设置读取文件的路径,都是从HDFS中读取。读取文件路径从脚本文件中传进来
25 FileInputFormat.addInputPath(job,new Path(args[0]));
26 //设置mapreduce程序的输出路径,MapReduce的结果都是输入到文件中
27 FileOutputFormat.setOutputPath(job,new Path(args[1]));
28
29 //设置实现了map函数的类
30 job.setMapperClass(WordcountMap.class);
31 //设置实现了reduce函数的类
32 job.setReducerClass(WordcountReduce.class);
33
34 //设置reduce函数的key值
35 job.setOutputKeyClass(Text.class);
36 //设置reduce函数的value值
37 job.setOutputValueClass(IntWritable.class);
38 System.exit(job.waitForCompletion(true) ? 0 :1);
39 }
40 }
代码写好之后,开始jar包,按照下图打包。点击“File”,然后点击“Project Structure”,弹出如下的界面,
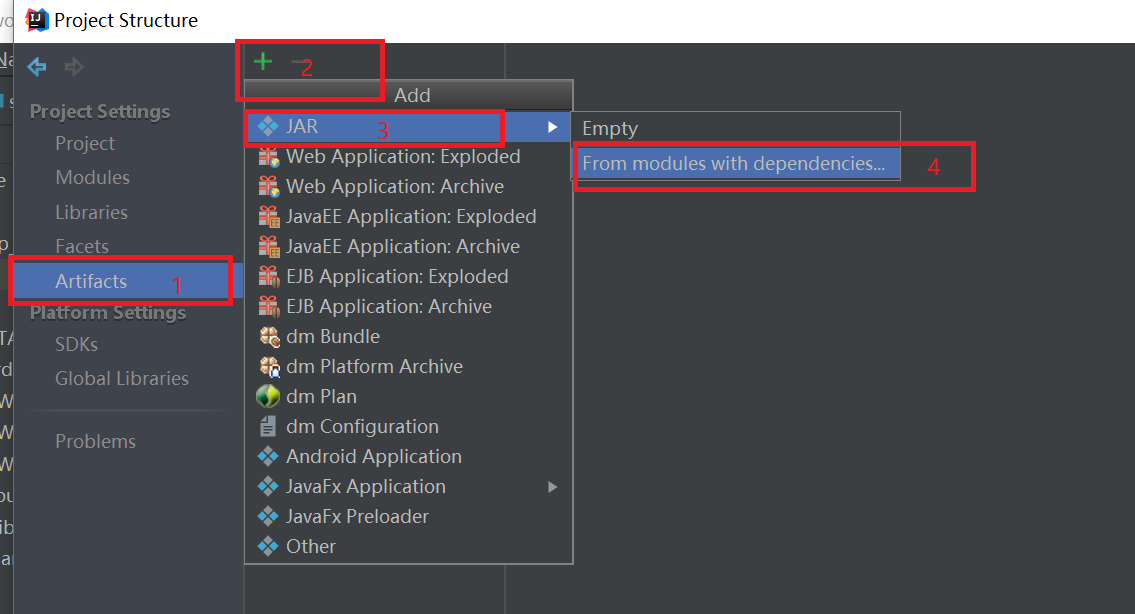
依次点击"Artifacts" -> "+" -> "JAR" -> "From modules with dependencies",然后弹出一个选择入口类的界面,选择刚刚写好的WordCount类,如下图:
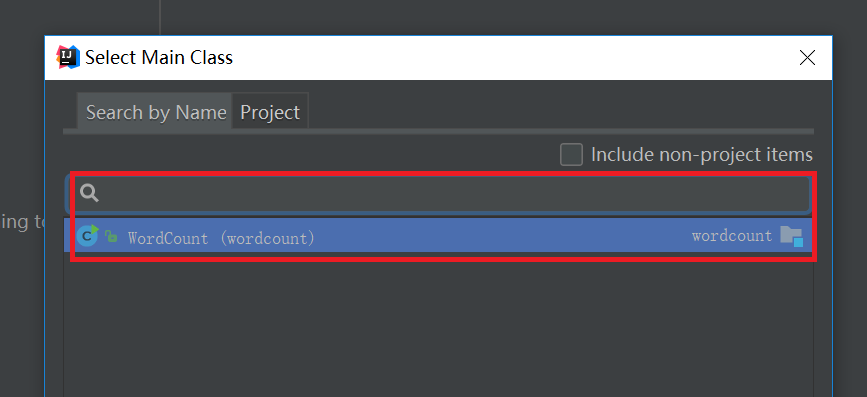
按照上面设置好之后,就开始打jar包,如下图:
点击上图的“Build”之后就会生成一个jar包。jar的位置看下图,依次点击File->Project Structure->Artifacts就会看到如下的界面:
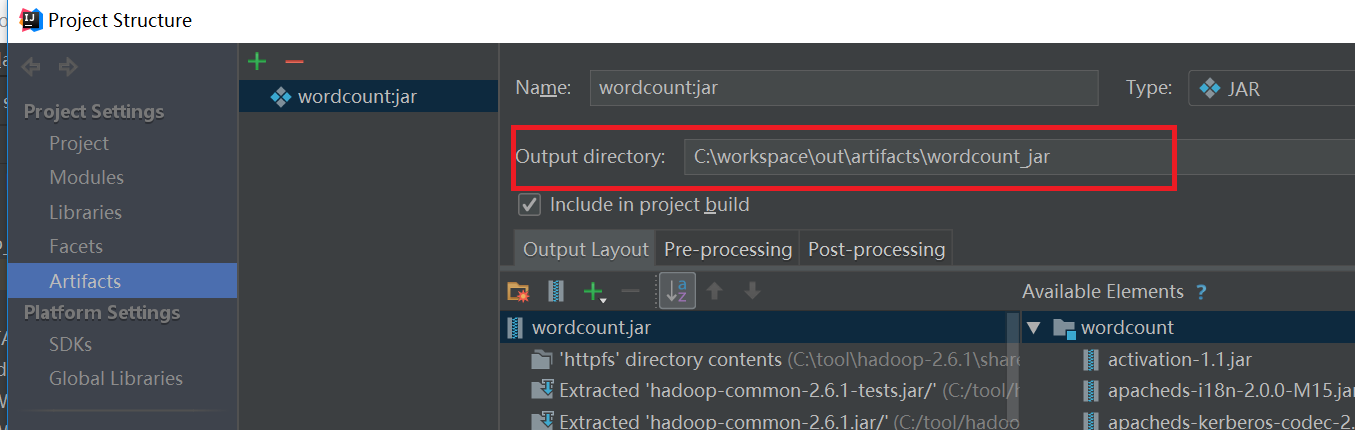
将打好包的wordcount.jar文件上传到装有hadoop集群的机器中,然后创建shell文件,shell文件内容如下,/usr/local/src/hadoop-2.6.1是hadoop集群中hadoop的安装位置,
1 /usr/local/src/hadoop-2.6.1/bin/hadoop jar wordcount.jar \ #执行jar文件的命令以及jar文件名,
2
3 hdfs://hadoop-master:8020/data/english.txt \ #输入路径
4
5 hdfs://hadoop-master:8020/wordcount_output #输出路径
执行shell文件之后,会看到如下的信息,
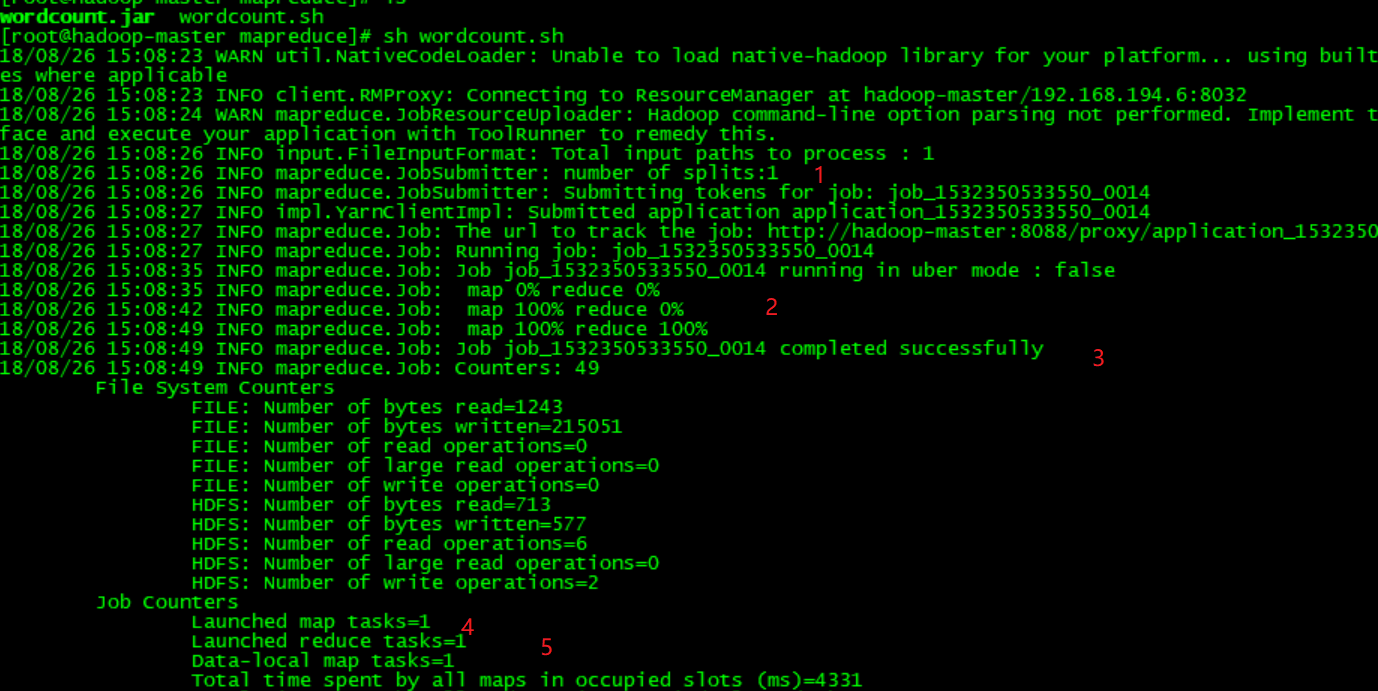
上图中数字1表示输入分片split的数量,数字2表示map和reduce的进度,数字3表示mapreduce执行成功,数字4表示启动多少个map任务,数字5表示启动多少个reduce任务。
自行成功后在hadoop集群中的hdfs文件系统中会看到一个wordcount_output的文件夹。使用“hadoop fs -ls /”命令查看:

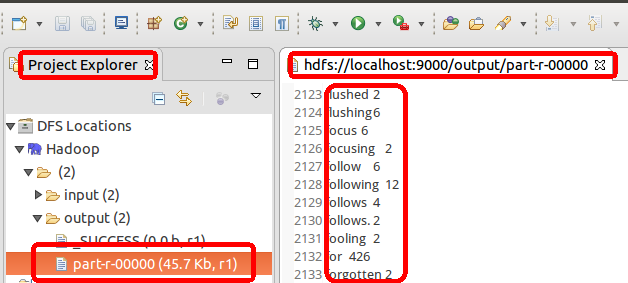
在wordcount_output文件夹中有两个文件,分别是_SUCCESS和part-r-00000,part-r-00000记录着mapreduce的执行结果,使用hadoop fs -cat /wordcount_output/part-r-00000查看part-r-00000的内容:
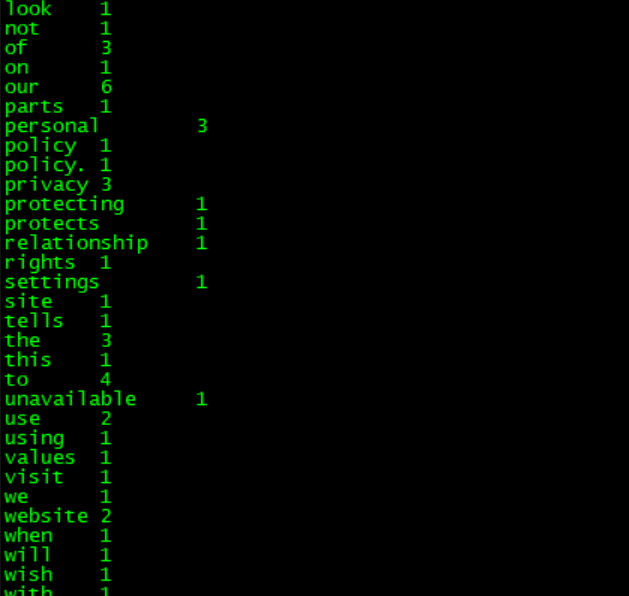
可以每个英文单词出现的次数。
至此,借助idea 2018工具开发第一个使用java语言编写的mapreduce程序已经成功执行。下面介绍使用python语言编写的第一个mapreduce程序,相对于java,python编写mapreduce会简单很多,因为hadoop提供streaming,streaming是使用Unix标准流作为Hadoop和应用程序之间的接口,所以可以使用任何语言通过标准输入输出来写MapReduce程序。
Python编写MapReduce程序
看代码:
实现了map函数的python程序,命名为map.py:
1 #!/usr/local/bin/python
2
3 import sys #导入sys包
4
5 for line in sys.stdin: #从标准输入中读取数据
6 ss = line.strip().split('' '')#读取每一行数据,strip()函数过滤掉空格换行的字符,split('' '')分隔出每个额单词并存放在数组ss中
7
8 for s in ss: #读取数组ss中的每个单词
9 if s.strip() != "":
10 print "%s\t%s" % (s, 1)#构造以单词为key,1为value的键值对,并写入到标准输出中。
实现了reduce函数的python程序,命名为reduce.py:
1 import sys
2 cur_word = None
3 sum = 0
4 for line in sys.stdin:
5 ss = line.strip().split(''\t'')#从标准输入中读取数据。
6 if len(ss) != 2:
7 continue
8 word,cnt = ss
9 if cur_word == None:
10 cur_word = word
11 #因为从map流转到reduce的数据时按照key排好序的,cur_word记录的是上一个单词,word记 #录的是当前读取的单词,如果两个单词一致,则将sum+1,否则将word和sum值组成一个键值对,##写入到标准输出,同时sum赋值为0,并且将word赋值给cur_word变量。
12 if cur_word != word:
13 print ''\t''.join([cur_word,str(sum)])
14 cur_word = word
15 sum = 0
16 sum += int(cnt)
17 print ''\t''.join([cur_word,str(sum)])
map和reduce程序已经编写完毕,下面编写shell脚本文件:
1 HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop"
2 STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar "
3
4 INPUT_FILE_PATH_1="/data/english.txt"#输入路径
5 OUTPUT_PATH="/wordcount_output"#输出路径
6 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH#每次执行时都删除输出路径,否则会出错
7
8 $HADOOP_CMD jar $STREAM_JAR_PATH \
9 -input $INPUT_FILE_PATH_1 \#指定输入路径
10 -output $OUTPUT_PATH \#指定输出路径
11 -mapper "python map.py" \#指定要执行的map程序
12 -reducer "python reduce.py" \#指定要执行reduce程序
13 -file ./map.py \#指定map程序所在的位置
14 -file ./reduce.py#指定reduce程序所在的位置到此Java和Python编写第一个MapReduce程序已经完成。

bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar
[root@master hadoop-3.1.1]# bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.

Eclipse下Hadoop的MapReduce开发之MapReduce编写
hadoop安装部署及Eclipse安装集成,这里不赘述了。
先说下业务需求吧,有个系统日志文件,记录系统的运行信息,其中包含DEBUG、INFO、WARN、ERROR四个级别的日志,现在想要看到所有级别各有多少条记录。
创建一个map/reduce项目,项目名为mapreducetest。在src下建立一个名为mapreducetest的包,然后建一个类名叫MapReduceTest,下面是代码。
package mapreducetest;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MapReduceTest extends Configuration implements Tool{
/**
* 配置
*/
private Configuration configuration;
/**
* 获取配置
*/
@Override
public Configuration getConf() {
return this.configuration;
}
/**
* 设置配置
*/
@Override
public void setConf(Configuration arg0) {
this.configuration=arg0;
}
/**
*
* @ClassName: Counter
* @Description: TODO(计数器)
* @author scc
* @date 2015年5月27日 下午2:54:39
*
*/
enum Counter{
TIMER
}
/**
*
* @ClassName: Map
* @Description: map实现,所有的map业务都在这里进行Mapper后的四个参数分别为,输入key类型,输入value类型,输出key类型,输出value类型
* @author scc
* @date 2015年5月27日 下午2:30:06
* @
*/
public static class Map extends Mapper<LongWritable, Text, Text, Text>{
/**
* key:输入key
* value:输入value
* context:map上下文对象
* 说明,hdfs生成的所有键值对都会调用此方法
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
try{
//得到日志每一行数据
String mapvalue=value.toString();
//日志具有固定格式,通过空格切分可以获得固定打下的string数组
String[] infos=mapvalue.split(" ");
//时间在数组的第一列,日志级别在数据的第九列,
String info=infos[10];
//调整数据格式(第一个参数为key,第二个参数为value),这里key和value都设置为日志级别
context.write(new Text(info), new Text(info));
}catch(Exception e){
//遇到错误是记录错误
context.getCounter(Counter.TIMER).increment(1);
return;
}
}
}
/**
*
* @ClassName: Reduce
* @Description: reduce处理类 ,Reducer四个参数,前两个是输入key和value的类型,必须和map一样,后两个是输出的key和value的类型
* @author scc
* @date 2015年5月27日 下午3:33:06
*
*/
public static class Reduce extends Reducer<Text, Text, Text, Text>{
/**
* 第一个参数输入的value,第二个参数是该key对应的所有的value集合,第三个是reducer的上下文
* 说明:与map不同的这里是对map处理后的数据进行的调用,当map处理后的key有重复时,这里传进来的key会是去重后的key,比方说在map里放进10个键值对,
* 其中有五个key是key1,有五个是key2,那么在reduce的时候只会调用两次reduce,分别是key1和key2
*/
@Override
protected void reduce(Text key, Iterable<Text> values,Context arg2) throws IOException, InterruptedException {
//获取当前遍历的key
String info=key.toString();
//计数器
int count=0;
//当值和key相同时计数器加1
for (Text text : values) {
if(info.equals(text.toString()))
count=count+1;
}
//将级别和对应的数据写出去
arg2.write(key, new Text(String.valueOf(count)));
}
}
/**
* run方法是一个入口
*/
@Override
public int run(String[] arg0) throws Exception {
//建立一个job,并指定job的名称
Job job=Job.getInstance(getConf(), "maptest");
//指定job的类
job.setJarByClass(MapReduceTest.class);
//设置日志文件路径(hdfs路径)
FileInputFormat.setInputPaths(job, new Path(arg0[0]));
//设置结果输出路径(hdfs路径)
FileOutputFormat.setOutputPath(job, new Path(arg0[1]));
//设置map处理类的class
job.setMapperClass(Map.class);
//设置reduce的class
job.setReducerClass(Reduce.class);
//设置输出格式化的类的class
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出key的类型
job.setOutputKeyClass(Text.class);
//设置输出value的类型
job.setOutputValueClass(Text.class);
//设置等待job完成
job.waitForCompletion(true);
return job.isSuccessful()?0:1;
}
public static void main(String[] args) throws Exception {
String[] args2=new String[2];
args2[0]="hdfs://192.168.1.55:9000/test2-in/singlemaptest.log";
args2[1]="hdfs://192.168.1.55:9000/test2-out";
int res=ToolRunner.run(new Configuration(), new MapReduceTest(), args2);
System.exit(res);
}
}下面是生成的结果:
INFO 3800
WARN 55有兴趣的大佬大神可以关注下小弟的微信公共号,一起学习交流,扫描以下二维码关注即可。


Eclipse中使用Hadoop插件编写Map/Reduce程序
纯转自 使用Eclipse搭建Hadoop编程环境
在eclipse中使用hadoop插件编程,在网上找了不少帖子,最终该贴解决了在eclipse中直接run on hadoop,而不用打jar,上传到hadoop主机,然后在hadoop jar xxx.jar。
在帖子中间补充了两点:
1.如果hadoop是搭建在虚拟机中,如何连接并运行程序
2.增加了log4j.properties配置
注:使用eclipse开发时,将workspace的默认字符集设置为utf-8
在前人的基础上,进行总结学习,发现bug,修改bug。
系统平台:Ubuntu14.04TLS(64位)
Hadoop环境:Hadoop2.7.1
Eclipse:Neon.2 Release(4.6.2)
Eclipse插件:hadoop-eclipse-plugin-2.7.1.jar
一.编译环境搭建
1.在eclipse上安装Hadoop插件
把下载好的hadoop-eclipse-plugin-2.7.1.jar文件拷贝到eclipse安装目录中的plugins文件夹内。如下图:
2.继续配置hadoop编译环境(方便配置,确保已经开启了 Hadoop)
启动 Eclipse 后就可以在左侧的Project Explorer中看到DFS Locations。
3.插件的配置
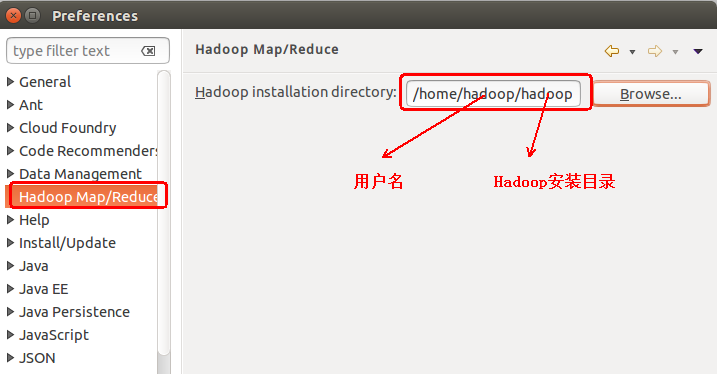
第一步:选择 Window 菜单下的 Preference。
此时会弹出一个窗体,点击选择 Hadoop Map/Reduce 选项,选择 Hadoop 的安装目录(例如:/home/hadoop/hadoop)。
第二步:切换 Map/Reduce 开发视图
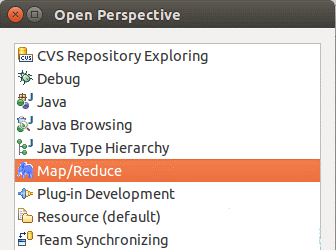
选择Window 菜单下选择 Open Perspective -> Other,弹出一个窗体,从中选择Map/Reduce 选项即可进行切换。
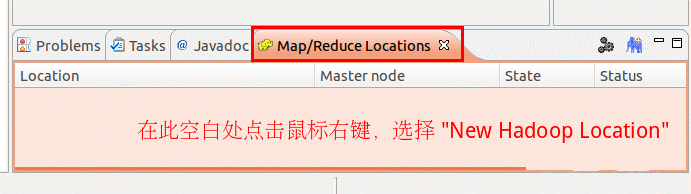
第三步:建立与 Hadoop 集群的连接
点击Eclipse软件右下角的Map/Reduce Locations 面板,在面板中单击右键,选择New Hadoop Location。
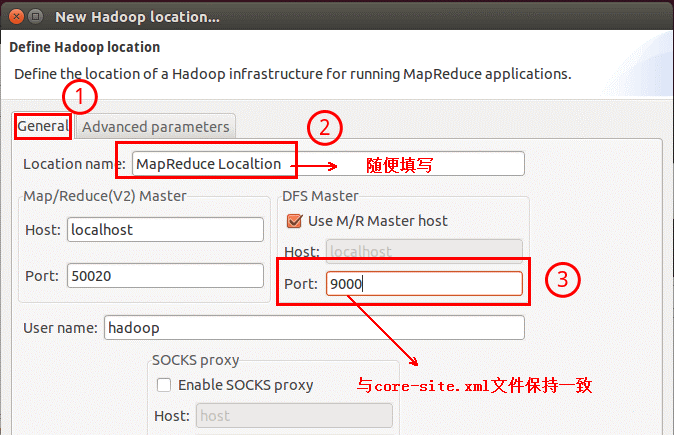
在弹出来的General选项面板中,General 的设置要与 Hadoop 的配置一致。一般两个 Host值是一样的。
如果是在本机搭建hadoop伪分布式,填写 localhost 即可,这里使用的是Hadoop伪分布,设置fs.defaultFS 为 hdfs://localhost:9000,则 DFS Master 的 Port 改为 9000。Map/Reduce(V2) Master 的 Port 用默认的即可,Location Name 随意填写。
如果你是在虚拟机中搭建的hadoop伪分布模式,那么图中的Host应该填ip地址或者hostname,建议在这里填写hostname,然后去windows的hosts文件中添加一行
192.168.245.141 hadoop01(hostname可以自定义)
Advanced parameters 选项面板是对 Hadoop 参数进行配置,就是填写 Hadoop 的配置项(/home/hadoop/hadoop/etc/hadoop中的配置文件),如果配置了 hadoop.tmp.dir,就要进行相应的修改。但修改起来会比较繁琐,可以通过复制配置文件的方式解决。只要配置General 就行了,点击 finish,Map/Reduce Location 就创建完成。
二.在 Eclipse 中操作 HDFS 中的文件
配置好后,点击左侧Project Explorer 中的 MapReduce Location 就能直接查看 HDFS 中的文件列表了(HDFS 中要有文件,如下图是 WordCount的输出结果),双击可以查看内容,右键点击可以上传、下载、删除 HDFS 中的文件。
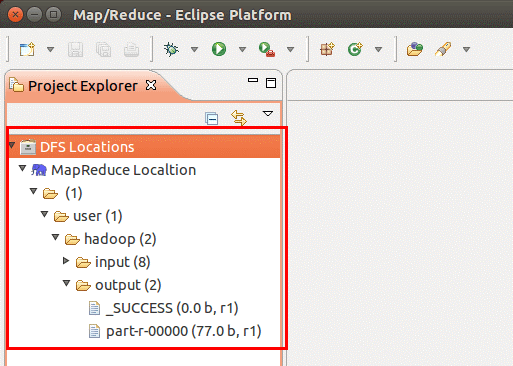
如果无法查看,可右键点击Location 尝试 Reconnect 或重启 Eclipse。HDFS 中的内容更新后Eclipse 不会同步刷新,需要右键点击 Project Explorer中的MapReduce Location,选择Refresh,(文件比较大的情况下eclipse可能死掉,重启eclipse就行)才能看到更新后的文件。
三.在 Eclipse 中创建 MapReduce 项目
点击 File 菜单,选择 New -> Project...:
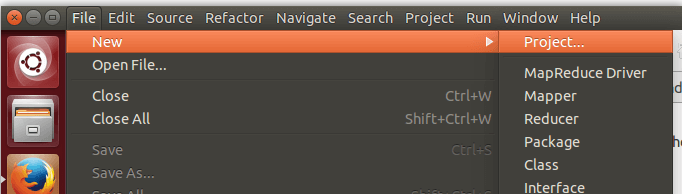
选择Map/Reduce Project,点击Next。
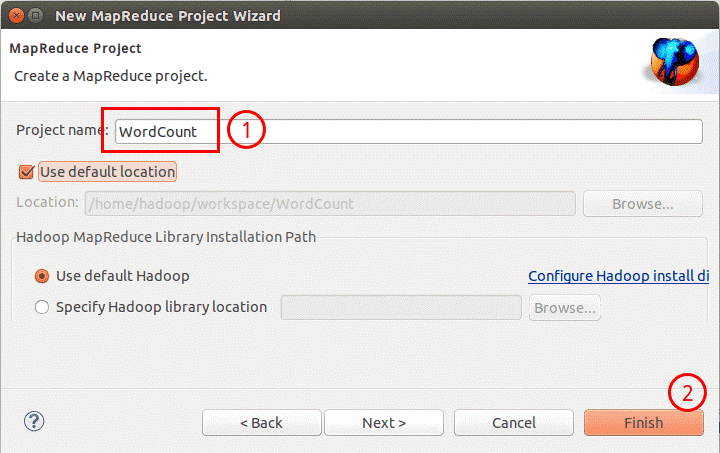
填写 Projectname 为 WordCount 即可,点击Finish就创建好了项目。
然后在左侧的Project Explorer 可以看到刚才建立的项目。
接着右键点击刚创建的WordCount 项目,选择 New -> Class
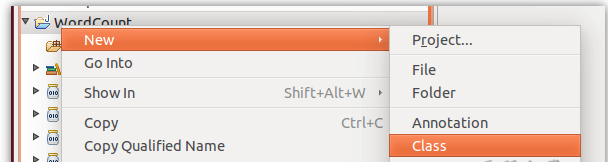
需要填写两个地方:在Package 处填写 org.apache.hadoop.examples;在Name 处填写WordCount。(包名、类名可以随意起)
创建 Class 完成后,在 Project 的src中可以看到 WordCount.java 这个文件。将如下 WordCount的代码拷贝到该文件中。
package com.jv.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.log4j.Logger;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Logger logger = Logger.getLogger(WordCountMapper.class);
Text k = new Text();
IntWritable v = new IntWritable(1);
/*
* 知识点
* 1.map方法的key是输入key,是每行的行首偏移量
* 2.map方法的value是输入value,是每行内容
* 3.Writable机制是Hadoop自身的序列化机制,
* 比如:LongWritable IntWritable NullWritable Text(String)等
* 4.context是MR的上下文件对象,此对象的作用:①可以输出结果 ②获取其他环境对象,比如文件的切片信息等
* 5.继承Mapper时,需要制定4个泛型类型
* ①泛型类型对应的是:Mapper输入key的类型
* ②泛型类型对应的是:Mapper输入value的类型
* 初学时,记住:① ②的类型是固定的
* ③泛型类型对应的是:Mapper的输出key类型
* ④泛型类型对应的是:Mapper的输出value类型
* 注:输出key和输出value是程序员自己决定.所以③ ④类型不固定,取决业务
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
logger.info("-----------" + key.get());
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}package com.jv.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
int sum;
IntWritable v = new IntWritable();
/*
* 知识点
* 1.reducer组件会接受Mapper组件的输出结果,所以reducer组件不能单独存在,但是Mapper组件可以
* 2.reducer会把Mapper的输出key,按相同的key做聚合(合并)
* 3.合并的形式:key it(迭代器) 通过reduce方法传给开发者.
* 其中 迭代器存储的是 key对应的value的集合
* 4.继承Reducer组件时的四个泛型
* ①泛型对应的Mapper输出key
* ②泛型对应的Mapper输出value
* ③泛型对应的Reducer的输出key
* ④泛型对应的Reducer的输出value
* 5.如果引入reducer组件后,最后的输出结果文件的结果是Reducer的输出key 和输出value
* 6.reduce方法会被调用多次,取决于有多少个不同的key
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> value, Context context)
throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : value) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key, v);
}
}package com.jv.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置 jar 加载路径
job.setJarByClass(WordcountDriver.class);
// 3 设置 map 和 reduce 类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置 map 输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置 Reduce 输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.245.141:9000/park03"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.245.141:9000/park03/result"));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
四.通过eclipse运行mapreduce
运行 MapReduce 程序前,务必将 /home/hadoop/hadoop/etc/hadoop 中将有修改过的配置文件(如伪分布式需要core-site.xml 和 hdfs-site.xml),以及log4j.properties复制到WordCount 项目下的 src文件夹(~/workspace/WordCount/src)中。
原因:
在使用 Eclipse 运行 MapReduce 程序时,会读取 Hadoop-Eclipse-Plugin 的Advanced parameters作为 Hadoop 运行参数,如果未进行修改,则默认的参数其实就是单机(非分布式)参数,因此程序运行时是读取本地目录而不是HDFS 目录,就会提示Input 路径不存在。
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: file:/home/hadoop/workspace/WordCountProject/input所以需要将配置文件拷贝到项目中的 src 目录,来覆盖这些参数。让程序能够正确运行。log4j用于记录程序的输出日记,需要log4j.properties 这个配置文件,如果没有拷贝该文件到项目中,运行程序后在Console 面板中会出现警告提示:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
这种情况不影响程序的正确运行的,但程序运行时无法看到任何提示消息,只能看到出错信息。
或者将如下内容复制到log4j.properties中
log4j.rootLogger=INFO,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n拷贝完成后,右键点击 WordCount 选择 refresh 进行刷新(不会自动刷新,需要手动刷新),可以看到文件结构如下所示:
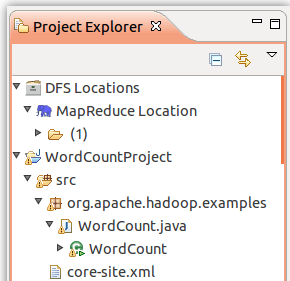
将Hadoop安装目录\bin\hadoop.dll复制到c:\windows\system32目录下
在windows环境变量中增加HADOOP_HOME=d:\hadoop-2.7.1
点击工具栏中的 Run 图标,或者右键点击 Project Explorer 中的 WordCount.java,选择 Run As -> Run on Hadoop,就可以运行 MapReduce 程序了。不过由于没有指定参数,运行时会提示 "Usage: wordcount ",需要通过Eclipse设定一下运行参数。
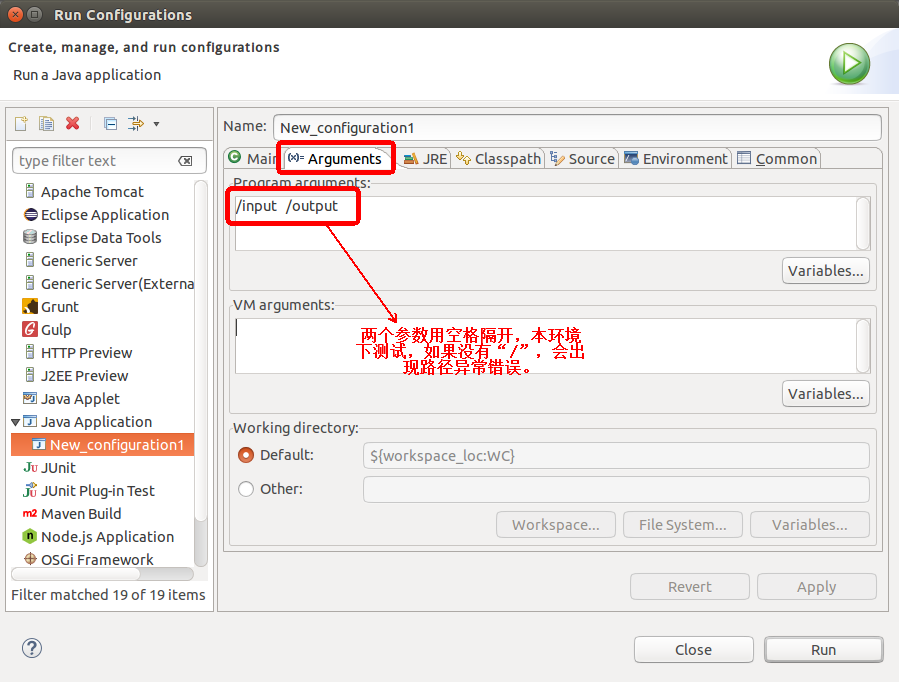
右键点击刚创建的 WordCount.java,选择 Run As -> Run Configurations,在此处可以设置运行时的相关参数(如果 Java Application 下面没有 WordCount,那么需要先双击 Java Application)。切换到 "Arguments"栏,在Program arguments 处填写参数 "/input /output"。
注意:在环境下测试,如果没有"/",会提示如下错误信息:
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: hdfs://localhost:9000/user/hadoop/input
也可以直接在代码中设置好输入参数。可将代码 main() 函数的 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); 改为(没有测试):
// String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
String[] otherArgs=new String[]{"input","output"}; /* 直接设置输入参数 */
设定参数后,运行程序,可以看到运行成功的提示,刷新DFS Location后也能看到输出的 output 文件夹。
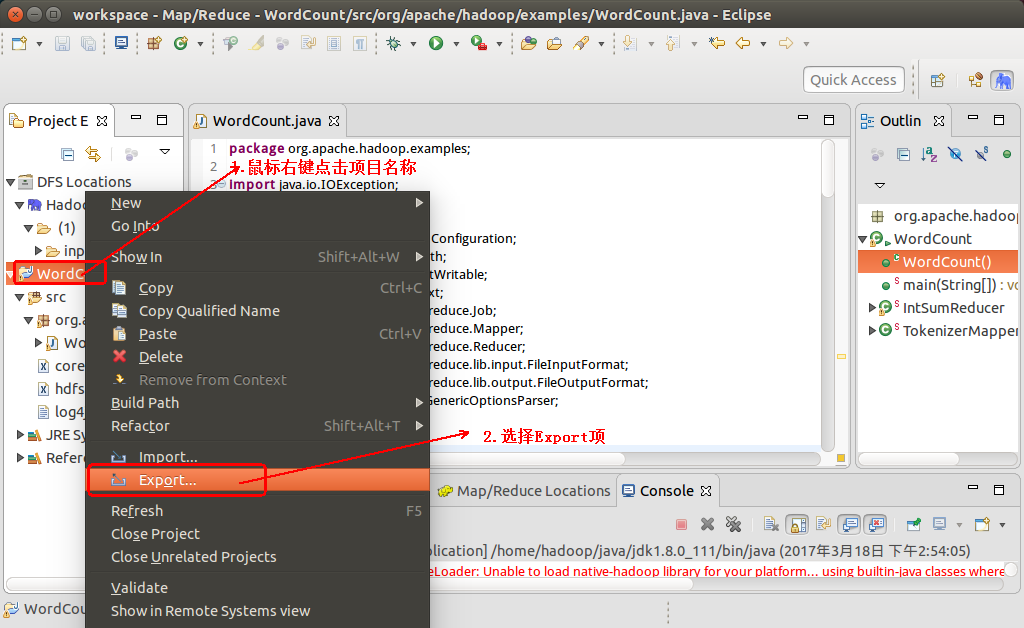
五.在eclipse中导出可运行的jar包
1. 鼠标右键点击项目名称,并选择Export项
2. 选择Java--> Runnable JAR file
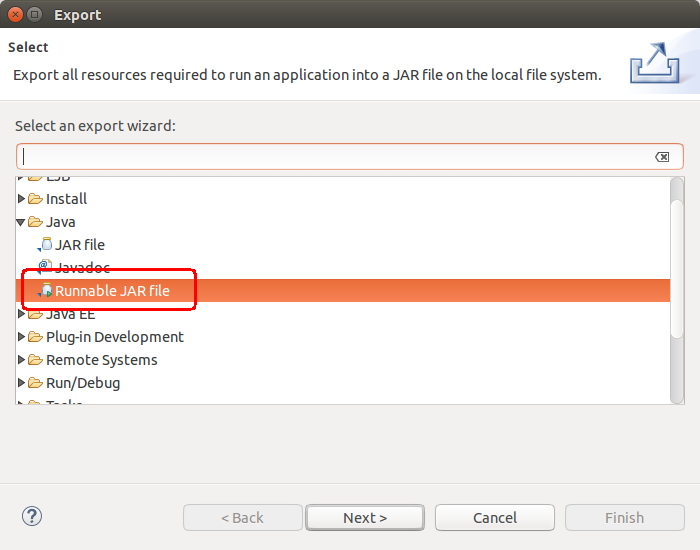
3. 选择正确的项目配置信息,和输出路径以及重命名jar包
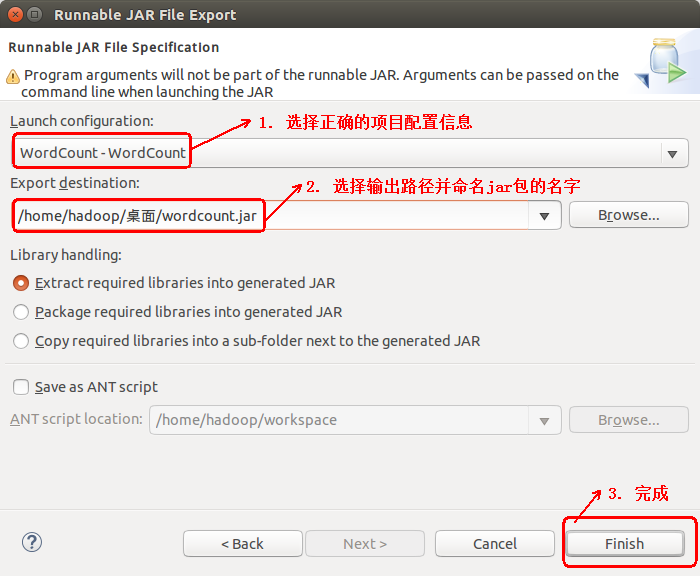
4. 点击OK完成导出可运行jar(测试方法与运行Hadoop自带的Wordcount方法一样,不在赘述)
六、在hadoop的浏览器控制台查看日志
有很多朋友喜欢用System.out.println输出日志,那么可以使用浏览器控制台查看日志
前提:如果按照上面的步骤配置了log4j.properties,那这一节就忽略掉,因为日志不会输出到hadoop主机所在的日志文件中了。如果没有配置log4j.properties,则可以使用控制台查看日志输出
进入自己网址:http://192.168.245.141:50070/logs/userlogs/
下面列出的最后一条就是你最新运行mr程序的日志
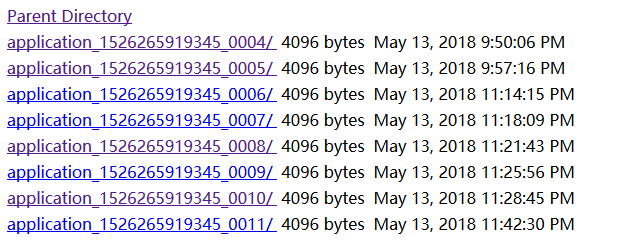
点开最后一条

三个目录应该分别是mapper、reduce、driver的日志输出

Hadoop 6、第一个 mapreduce 程序 WordCount
1、程序代码
Map:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String[] words = StringUtils.split(value.toString(), '' '');
for(String word : words){
context.write(new Text(word), new IntWritable(1));
}
}
}Reduce:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
public class wordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text arg0, Iterable<IntWritable> arg1,Context arg2)
throws IOException, InterruptedException {
int sum = 0;
for(IntWritable i : arg1){
sum += i.get();
}
arg2.write(arg0, new IntWritable(sum));
}
}Main:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class RunJob {
public static void main(String[] args) {
Configuration config = new Configuration();
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("wordCount");
job.setJarByClass(RunJob.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(wordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/usr/input/"));
Path outPath = new Path("/usr/output/wc/");
if(fs.exists(outPath)){
fs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
Boolean result = job.waitForCompletion(true);
if(result){
System.out.println("Job is complete!");
}else{
System.out.println("Job is fail!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
2、打包程序
将 Java 程序打成 Jar 包,并上传到 Hadoop 服务器上(任何一台在启动的 NameNode 节点即可)
3、数据源
数据源是如下:
hadoop java text hdfs
tom jack java text
job hadoop abc lusi
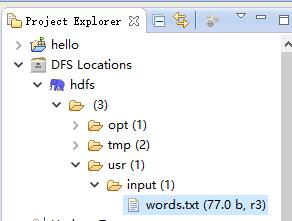
hdfs tom text将该内容放到 txt 文件中,并放到 HDFS 的 /usr/input (是 HDFS 下不是 Linux 下),可以使用 Eclipse 插件上传:
4、执行 Jar 包
# hadoop jar jar路径 类的全限定名(Hadoop需要配置环境变量)
$ hadoop jar wc.jar com.raphael.wc.RunJob执行完成以后会在 HDFS 的 /usr 下新创建一个 output 目录:
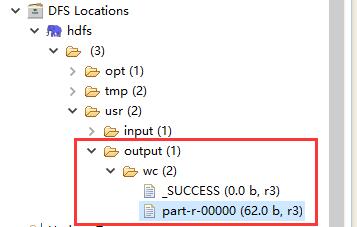
查看执行结果:
abc 1
hadoop 2
hdfs 2
jack 1
java 2
job 1
lusi 1
text 3
tom 2完成了单词个数的统计。
今天关于一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)和idea开发hadoop的介绍到此结束,谢谢您的阅读,有关bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar、Eclipse下Hadoop的MapReduce开发之MapReduce编写、Eclipse中使用Hadoop插件编写Map/Reduce程序、Hadoop 6、第一个 mapreduce 程序 WordCount等更多相关知识的信息可以在本站进行查询。
本文标签:




