在这篇文章中,我们将为您详细介绍Java8中的简易并发的内容,并且讨论关于java并发编程设计原则与模式的相关问题。此外,我们还会涉及一些关于Java8中的Lambda表达式教程、Java8中的def
在这篇文章中,我们将为您详细介绍Java8中的简易并发的内容,并且讨论关于java并发编程设计原则与模式的相关问题。此外,我们还会涉及一些关于Java8中的 Lambda表达式教程、Java8中的default方法详解、java8中的HashMap的putVal方法、java8中的Lambda表达式的知识,以帮助您更全面地了解这个主题。
本文目录一览:- Java8中的简易并发(java并发编程设计原则与模式)
- Java8中的 Lambda表达式教程
- Java8中的default方法详解
- java8中的HashMap的putVal方法
- java8中的Lambda表达式
")
Java8中的简易并发(java并发编程设计原则与模式)
Java8中的简易并发
分享到: 5
本文由 ImportNew - kingviker 翻译自 jaxenter。欢迎加入Java小组。转载请参见文章末尾的要求。
有人曾经说过(很抱歉,我们找不到原句了):
初级程序员认为并发很难。
中级程序员认为并发很简单。
高级程序员认为并发很难。
这说的很对。但是从好的方面来看,Java8为我们带来了转机,通过lambda表达式和改进的API可以使得编写并发代码更容易。让我们来具体的看看Java8的改进吧:
Java8对JDK 1.0 API的改进
java.lang.Thread早在JDK 1.0版本中就已经存在。在java8中被注解为功能性接口的java.lang.Runnable也是。
从现在起,几乎不需要动大脑我们就可以提交Runnables给一个线程。让我们假设我们有一个很耗时的操作:
public static int longOperation() {
System.out.println("Running on thread #"
+ Thread.currentThread().getId());
// [...]
return 42;
}
我们可以用多种方法把这个操作传递给线程,例如:
Thread[] threads = {
// Pass a lambda to a thread
new Thread(() -> {
longOperation();
}),
// Pass a method reference to a thread
new Thread(ThreadGoodies::longOperation)
};
// Start all threads
Arrays.stream(threads).forEach(Thread::start);
// Join all threads
Arrays.stream(threads).forEach(t -> {
try { t.join(); }
catch (InterruptedException ignore) {}
});
就像我们在之前的博文里提到的一样,lambda表达式没有一个简洁的方式来处理被检查异常实在是一大憾事。在java.util.function包中新增的功能性接口都不会抛出被检查异常,把这项工作留给了调用端。
在上一篇博文中,我们已经因此而发布了jOOλ(also jOOL,jOO-Lambda)包,该包包装了JDK中的每一个功能性接口,具有相同功能而且也允许抛出被检异常。这在使用老的JDK API时特别有用,例如JDBC,或者上面提到的Thread API。使用jOOλ,我们可以这么写:
// Join all threads
Arrays.stream(threads).forEach(Unchecked.consumer(
t -> t.join()
));
Java8中改进的Java5 API
Java的多线程功能一直没有什么起色,直到Java5的ExecutorService的发布。管理多线程是一个负担,人们需要额外的库或者一个J2EE/JEE容器来管理线程池。这些用Java5来处理已经容易了很多。我们现在可以提交一个Runnable对象或者一个Callable对象到ExcutorService,它管理自己的线程池。
下面是一个我们如何在Java8中利用这些Java5的并发API的例子:
ExecutorService service = Executors
.newFixedThreadPool(5);
Future[] answers = {
service.submit(() -> longOperation()),
service.submit(ThreadGoodies::longOperation)
};
Arrays.stream(answers).forEach(Unchecked.consumer(
f -> System.out.println(f.get())
));
注意看,我们是如何再次使用jOOλ中的UncheckedConsumer来包装在运行期调用get()方法抛出的被检异常。
Java8中的并行和ForkJoinPool
现在,Java8的Streams API在并发和并行方面有了很大改进。
在Java8中你可以写出如下的代码:
Arrays.stream(new int[]{ 1, 2, 3, 4, 5, 6 })
.parallel()
.max()
.ifPresent(System.out::println);
虽然在这个特殊的例子中不是很必要,但还是挺有意思的,你仅仅调用了parallel()就运行IntStream.max()来启用ForkJoinPool,而你不必担心包含的ForkJoinTasks。这是非常有用的,因为不是每个人都能够接受JDK7中引进的复杂的JorkJoin API。

Java8中的 Lambda表达式教程
这篇文章主要介绍了 Java8中的 Lambda表达式教程,需要的朋友可以参考下
1. 什么是λ表达式
λ表达式本质上是一个匿名方法。让我们来看下面这个例子:
public int add(int x, int y) { return x + y; }
转成λ表达式后是这个样子:
(int x, int y) -> x + y;
参数类型也可以省略,Java编译器会根据上下文推断出来:
(x, y) -> x + y; //返回两数之和
或者
(x, y) -> { return x + y; } //显式指明返回值
可见λ表达式有三部分组成:参数列表,箭头(->),以及一个表达式或语句块。
下面这个例子里的λ表达式没有参数,也没有返回值(相当于一个方法接受0个参数,返回void,其实就是Runnable里run方法的一个实现):
() -> { System.out.println("Hello Lambda!"); }
如果只有一个参数且可以被Java推断出类型,那么参数列表的括号也可以省略:
c -> { return c.size(); }
2. λ表达式的类型(它是Object吗?)
λ表达式可以被当做是一个Object(注意措辞)。λ表达式的类型,叫做“目标类型(target type)”。λ表达式的目标类型是“函数接口(functional interface)”,这是Java8新引入的概念。它的定义是:一个接口,如果只有一个显式声明的抽象方法,那么它就是一个函数接口。一般用@FunctionalInterface标注出来(也可以不标)。举例如下:
@FunctionalInterface public interface Runnable { void run(); } public interface Callable { V call() throws Exception; } public interface ActionListener { void actionPerformed(ActionEvent e); } public interface Comparator { int compare(T o1, T o2); boolean equals(Object obj); }
注意最后这个Comparator接口。它里面声明了两个方法,貌似不符合函数接口的定义,但它的确是函数接口。这是因为equals方法是Object的,所有的接口都会声明Object的public方法――虽然大多是隐式的。所以,Comparator显式的声明了equals不影响它依然是个函数接口。
你可以用一个λ表达式为一个函数接口赋值:
Runnable r1 = () -> {System.out.println("Hello Lambda!");};
然后再赋值给一个Object:
Object obj = r1;
但却不能这样干:
Object obj = () -> {System.out.println("Hello Lambda!");}; // ERROR! Object is not a functional interface!
必须显式的转型成一个函数接口才可以:
Object o = (Runnable) () -> { System.out.println("hi"); }; // correct
一个λ表达式只有在转型成一个函数接口后才能被当做Object使用。所以下面这句也不能编译:
System.out.println( () -> {} ); //错误! 目标类型不明
必须先转型:
System.out.println( (Runnable)() -> {} ); // 正确
假设你自己写了一个函数接口,长的跟Runnable一模一样:
@FunctionalInterface public interface MyRunnable { public void run(); }
那么
Runnable r1 = () -> {System.out.println("Hello Lambda!");}; MyRunnable2 r2 = () -> {System.out.println("Hello Lambda!");};
都是正确的写法。这说明一个λ表达式可以有多个目标类型(函数接口),只要函数匹配成功即可。
但需注意一个λ表达式必须至少有一个目标类型。
JDK预定义了很多函数接口以避免用户重复定义。最典型的是Function:
@FunctionalInterface public interface Function { R apply(T t); }
这个接口代表一个函数,接受一个T类型的参数,并返回一个R类型的返回值。
另一个预定义函数接口叫做Consumer,跟Function的唯一不同是它没有返回值。
@FunctionalInterface public interface Consumer { void accept(T t); }
还有一个Predicate,用来判断某项条件是否满足。经常用来进行筛滤操作:
@FunctionalInterface public interface Predicate { boolean test(T t); }
综上所述,一个λ表达式其实就是定义了一个匿名方法,只不过这个方法必须符合至少一个函数接口。
3. λ表达式的使用
3.1 λ表达式用在何处
λ表达式主要用于替换以前广泛使用的内部匿名类,各种回调,比如事件响应器、传入Thread类的Runnable等。看下面的例子:
Thread oldSchool = new Thread( new Runnable () { @Override public void run() { System.out.println("This is from an anonymous class."); } } ); Thread gaoDuanDaQiShangDangCi = new Thread( () -> { System.out.println("This is from an anonymous method (lambda exp)."); } );
注意第二个线程里的λ表达式,你并不需要显式地把它转成一个Runnable,因为Java能根据上下文自动推断出来:一个Thread的构造函数接受一个Runnable参数,而传入的λ表达式正好符合其run()函数,所以Java编译器推断它为Runnable。
从形式上看,λ表达式只是为你节省了几行代码。但将λ表达式引入Java的动机并不仅仅为此。Java8有一个短期目标和一个长期目标。短期目标是:配合“集合类批处理操作”的内部迭代和并行处理(下面将要讲到);长期目标是将Java向函数式编程语言这个方向引导(并不是要完全变成一门函数式编程语言,只是让它有更多的函数式编程语言的特性),也正是由于这个原因,Oracle并没有简单地使用内部类去实现λ表达式,而是使用了一种更动态、更灵活、易于将来扩展和改变的策略(invokedynamic)。
3.2 λ表达式与集合类批处理操作(或者叫块操作)
上文提到了集合类的批处理操作。这是Java8的另一个重要特性,它与λ表达式的配合使用乃是Java8的最主要特性。集合类的批处理操作API的目的是实现集合类的“内部迭代”,并期望充分利用现代多核cpu进行并行计算。
Java8之前集合类的迭代(Iteration)都是外部的,即客户代码。而内部迭代意味着改由java类库来进行迭代,而不是客户代码。例如:
for(Object o: list) { // 外部迭代 System.out.println(o); }
可以写成:
list.forEach(o -> {System.out.println(o);}); //forEach函数实现内部迭代
集合类(包括List)现在都有一个forEach方法,对元素进行迭代(遍历),所以我们不需要再写for循环了。forEach方法接受一个函数接口Consumer做参数,所以可以使用λ表达式。
这种内部迭代方法广泛存在于各种语言,如C++的STL算法库、Python、ruby、Scala等。
Java8为集合类引入了另一个重要概念:流(stream)。一个流通常以一个集合类实例为其数据源,然后在其上定义各种操作。流的API设计使用了管道(pipelines)模式。对流的一次操作会返回另一个流。如同IO的API或者StringBuffer的append方法那样,从而多个不同的操作可以在一个语句里串起来。看下面的例子:
List shapes = ... shapes.stream() .filter(s -> s.getColor() == BLUE) .forEach(s -> s.setColor(RED));
首先调用stream方法,以集合类对象shapes里面的元素为数据源,生成一个流。然后在这个流上调用filter方法,挑出蓝色的,返回另一个流。最后调用forEach方法将这些蓝色的物体喷成红色。(forEach方法不再返回流,而是一个终端方法,类似于StringBuffer在调用若干append之后的那个toString)
filter方法的参数是Predicate类型,forEach方法的参数是Consumer类型,它们都是函数接口,所以可以使用λ表达式。
还有一个方法叫parallelStream(),顾名思义它和stream()一样,只不过指明要并行处理,以期充分利用现代cpu的多核特性。
shapes.parallelStream(); // 或shapes.stream().parallel()
来看更多的例子。下面是典型的大数据处理方法,Filter-Map-Reduce:
//给出一个String类型的数组,找出其中所有不重复的素数 public void distinctPrimary(String... numbers) { List l = Arrays.asList(numbers); List r = l.stream() .map(e -> new Integer(e)) .filter(e -> Primes.isPrime(e)) .distinct() .collect(Collectors.toList()); System.out.println("distinctPrimary result is: " + r); }
第一步:传入一系列String(假设都是合法的数字),转成一个List,然后调用stream()方法生成流。
第二步:调用流的map方法把每个元素由String转成Integer,得到一个新的流。map方法接受一个Function类型的参数,上面介绍了,Function是个函数接口,所以这里用λ表达式。
第三步:调用流的filter方法,过滤那些不是素数的数字,并得到一个新流。filter方法接受一个Predicate类型的参数,上面介绍了,Predicate是个函数接口,所以这里用λ表达式。
第四步:调用流的distinct方法,去掉重复,并得到一个新流。这本质上是另一个filter操作。
第五步:用collect方法将最终结果收集到一个List里面去。collect方法接受一个Collector类型的参数,这个参数指明如何收集最终结果。在这个例子中,结果简单地收集到一个List中。我们也可以用Collectors.toMap(e->e, e->e)把结果收集到一个Map中,它的意思是:把结果收到一个Map,用这些素数自身既作为键又作为值。toMap方法接受两个Function类型的参数,分别用以生成键和值,Function是个函数接口,所以这里都用λ表达式。
你可能会觉得在这个例子里,List l被迭代了好多次,map,filter,distinct都分别是一次循环,效率会不好。实际并非如此。这些返回另一个Stream的方法都是“懒(lazy)”的,而最后返回最终结果的collect方法则是“急(eager)”的。在遇到eager方法之前,lazy的方法不会执行。
当遇到eager方法时,前面的lazy方法才会被依次执行。而且是管道贯通式执行。这意味着每一个元素依次通过这些管道。例如有个元素“3”,首先它被map成整数型3;然后通过filter,发现是素数,被保留下来;又通过distinct,如果已经有一个3了,那么就直接丢弃,如果还没有则保留。这样,3个操作其实只经过了一次循环。
除collect外其它的eager操作还有forEach,toArray,reduce等。
下面来看一下也许是最常用的收集器方法,groupingBy:
//给出一个String类型的数组,找出其中各个素数,并统计其出现次数 public void primaryOccurrence(String... numbers) { List l = Arrays.asList(numbers); Map r = l.stream() .map(e -> new Integer(e)) .filter(e -> Primes.isPrime(e)) .collect( Collectors.groupingBy(p->p, Collectors.summingInt(p->1)) ); System.out.println("primaryOccurrence result is: " + r); }
注意这一行:
Collectors.groupingBy(p->p, Collectors.summingInt(p->1))
它的意思是:把结果收集到一个Map中,用统计到的各个素数自身作为键,其出现次数作为值。
下面是一个reduce的例子:
//给出一个String类型的数组,求其中所有不重复素数的和 public void distinctPrimarySum(String... numbers) { List l = Arrays.asList(numbers); int sum = l.stream() .map(e -> new Integer(e)) .filter(e -> Primes.isPrime(e)) .distinct() .reduce(0, (x,y) -> x+y); // equivalent to .sum() System.out.println("distinctPrimarySum result is: " + sum); }
reduce方法用来产生单一的一个最终结果。
流有很多预定义的reduce操作,如sum(),max(),min()等。
再举个现实世界里的栗子比如:
// 统计年龄在25-35岁的男女人数、比例 public void boysAndGirls(List persons) { Map result = persons.parallelStream().filter(p -> p.getAge()>=25 && p.getAge()p.getSex(), Collectors.summingInt(p->1)) ); System.out.print("boysAndGirls result is " + result); System.out.println(", ratio (male : female) is " + (float)result.get(Person.MALE)/result.get(Person.FEMALE)); }
3.3 λ表达式的更多用法
// 嵌套的λ表达式 Callable c1 = () -> () -> { System.out.println("nested lambda"); }; c1.call().run(); // 用在条件表达式中 Callable c2 = true ? (() -> 42) : (() -> 24); System.out.println(c2.call()); // 定义一个递归函数,注意须用this限定 protected UnaryOperator factorial = i -> i == 0 ? 1 : i * this.factorial.apply( i - 1 ); ... System.out.println(factorial.apply(3));
在Java中,随声明随调用的方式是不行的,比如下面这样,声明了一个λ表达式(x, y) -> x + y,同时企图通过传入实参(2, 3)来调用它:
int five = ( (x, y) -> x + y ) (2, 3); // ERROR! try to call a lambda in-place
这在C++中是可以的,但Java中不行。Java的λ表达式只能用作赋值、传参、返回值等。
4. 其它相关概念
4.1 捕获(Capture)
捕获的概念在于解决在λ表达式中我们可以使用哪些外部变量(即除了它自己的参数和内部定义的本地变量)的问题。
答案是:与内部类非常相似,但有不同点。不同点在于内部类总是持有一个其外部类对象的引用。而λ表达式呢,除非在它内部用到了其外部类(包围类)对象的方法或者成员,否则它就不持有这个对象的引用。
在Java8以前,如果要在内部类访问外部对象的一个本地变量,那么这个变量必须声明为final才行。在Java8中,这种限制被去掉了,代之以一个新的概念,“effectively final”。它的意思是你可以声明为final,也可以不声明final但是按照final来用,也就是一次赋值永不改变。换句话说,保证它加上final前缀后不会出编译错误。
在Java8中,内部类和λ表达式都可以访问effectively final的本地变量。λ表达式的例子如下:
... int tmp1 = 1; //包围类的成员变量 static int tmp2 = 2; //包围类的静态成员变量 public void testCapture() { int tmp3 = 3; //没有声明为final,但是effectively final的本地变量 final int tmp4 = 4; //声明为final的本地变量 int tmp5 = 5; //普通本地变量 Function f1 = i -> i + tmp1; Function f2 = i -> i + tmp2; Function f3 = i -> i + tmp3; Function f4 = i -> i + tmp4; Function f5 = i -> { tmp5 += i; // 编译错!对tmp5赋值导致它不是effectively final的 return tmp5; }; ... tmp5 = 9; // 编译错!对tmp5赋值导致它不是effectively final的 } ...
Java要求本地变量final或者effectively final的原因是多线程并发问题。内部类、λ表达式都有可能在不同的线程中执行,允许多个线程同时修改一个本地变量不符合Java的设计理念。
4.2 方法引用(Method reference)
任何一个λ表达式都可以代表某个函数接口的唯一方法的匿名描述符。我们也可以使用某个类的某个具体方法来代表这个描述符,叫做方法引用。例如:
Integer::parseInt //静态方法引用 System.out::print //实例方法引用 Person::new //构造器引用
下面是一组例子,教你使用方法引用代替λ表达式:
//c1 与 c2 是一样的(静态方法引用) Comparator c2 = (x, y) -> Integer.compare(x, y); Comparator c1 = Integer::compare; //下面两句是一样的(实例方法引用1) persons.forEach(e -> System.out.println(e)); persons.forEach(System.out::println); //下面两句是一样的(实例方法引用2) persons.forEach(person -> person.eat()); persons.forEach(Person::eat); //下面两句是一样的(构造器引用) strList.stream().map(s -> new Integer(s)); strList.stream().map(Integer::new);
使用方法引用,你的程序会变得更短些。现在distinctPrimarySum方法可以改写如下:
public void distinctPrimarySum(String... numbers) { List l = Arrays.asList(numbers); int sum = l.stream().map(Integer::new).filter(Primes::isPrime).distinct().sum(); System.out.println("distinctPrimarySum result is: " + sum); }
还有一些其它的方法引用:
super::toString //引用某个对象的父类方法 String[]::new //引用一个数组的构造器
4.3 默认方法(Default method)
Java8中,接口声明里可以有方法实现了,叫做默认方法。在此之前,接口里的方法全部是抽象方法。
public interface MyInterf { String m1(); default String m2() { return "Hello default method!"; } }
这实际上混淆了接口和抽象类,但一个类仍然可以实现多个接口,而只能继承一个抽象类。
这么做的原因是:由于Collection库需要为批处理操作添加新的方法,如forEach(),stream()等,但是不能修改现有的Collection接口――如果那样做的话所有的实现类都要进行修改,包括很多客户自制的实现类。所以只好使用这种妥协的办法。
如此一来,我们就面临一种类似多继承的问题。如果类Sub继承了两个接口,Base1和Base2,而这两个接口恰好具有完全相同的两个默认方法,那么就会产生冲突。这时Sub类就必须通过重载来显式指明自己要使用哪一个接口的实现(或者提供自己的实现):
public class Sub implements Base1, Base2 { public void hello() { Base1.super.hello(); //使用Base1的实现 } }
除了默认方法,Java8的接口也可以有静态方法的实现:
public interface MyInterf { String m1(); default String m2() { return "Hello default method!"; } static String m3() { return "Hello static method in Interface!"; } }
4.4 生成器函数(Generator function)
有时候一个流的数据源不一定是一个已存在的集合对象,也可能是个“生成器函数”。一个生成器函数会产生一系列元素,供给一个流。Stream.generate(supplier s)就是一个生成器函数。其中参数supplier是一个函数接口,里面有唯一的抽象方法 get()。
下面这个例子生成并打印5个随机数:
Stream.generate(Math::random).limit(5).forEach(System.out::println);
注意这个limit(5),如果没有这个调用,那么这条语句会永远地执行下去。也就是说这个生成器是无穷的。这种调用叫做终结操作,或者短路(short-circuiting)操作。
参考资料:
http://openjdk.java.net/projects/lambda/
http://docs.oracle.com/javase/tutorial/java/javaOO/lambdaexpressions.html
以上所述是小编给大家介绍的Java8中的 Lambda表达式教程,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对小编网站的支持!

Java8中的default方法详解
这篇文章主要介绍了Java8中的default方法详解,Java 8新增了default方法,它可以在接口添加新功能特性,而且还不影响接口的实现类,需要的朋友可以参考下
Java 8新增了default方法,它可以在接口添加新功能特性,而且还不影响接口的实现类。下面我们通过例子来说明这一点。
复制代码 代码如下:
public class MyClass implements InterfaceA {
public static void main(String[] args){
}
@Override
public void saySomething() {
// Todo Auto-generated method stub
}
}interface InterfaceA{
public void saySomething();
}
上一篇:Java使用反射创建对象示例下一篇:CentOS安装solr 4.10.3详细教程 热门搜索:
default方法
方法详解
详细解决方法
java8,对集合中方法有变动的类
java8对集合中方法有变动的类
相关文章

Java8中的default方法详解
2021-10-18阅读(3266)评论(0)推荐()这篇文章主要介绍了Java8中的default方法详解,Java 8新增了default方法,它可以在接口添加新功能特性,而且还不影响接口的实现类,需要的朋友可...

Java8新特性之默认方法(default)浅析
2021-10-12阅读(3545)评论(0)推荐()这篇文章主要介绍了Java8新特性之默认方法(default)浅析,默认方法也称为虚拟扩展方法或防护方法,可以让我们修改接口而不破坏原来的实现类的结构,需要的朋...

详解Java8新特性之interface中的static方法和default方法
2021-10-06阅读(6717)评论(0)推荐()这篇文章主要介绍了Java8新特性之interface中的static方法和default方法,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下

Java8默认方法Default Methods原理及实例详解
2021-10-08阅读(8554)评论(0)推荐()这篇文章主要介绍了Java8默认方法Default Methods原理及实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需...

Java 8中default方法能做什么?不能做什么?
2021-09-19阅读(7446)评论(0)推荐()这篇文章主要给大家介绍了关于Java 8中default方法能做什么?不能做什么?文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需...

java8新特性之接口的static和default的使用
2021-10-06阅读(8700)评论(0)推荐()这篇文章主要介绍了java8新特性之接口的static和default的使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的...

default怎么修饰接口中的方法详解
2021-11-05阅读(6078)评论(0)推荐()今天给各位小伙伴们总结一下default怎么修饰接口中的方法,文中有非常详细的图文解说.对正在学习java的小伙伴们很有帮助,需要的朋友可以参考下

取消
有人回复时邮件通知我
提交评论

java8中的HashMap的putVal方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}【4】【5】如果原始的节点数组为空或者节点数目=0,则重置数组大小为默认值(resize方法)
【6】(n-1)&hash查找hash表中的数组索引,保证查找的位置不会大于数组长度,类似于求余查询索引
【6】【7】通过计算的索引在数组中位置数据为null,则在该索引位置创建新的节点
【9-35】获取已存在的节点
【9-11】要查询的节点位于数组或者说链表的第一个
【13-14】如果是红黑树,则调用红黑树中的put方法获取要查询的节点
【16-27】链表查询节点
【19-20】如果某一个链表的节点数>=TREEIFY_THRESHOLD-1,则改为红黑树存储
总结:
hashmap的数据结构为hash表,具体结构如下:
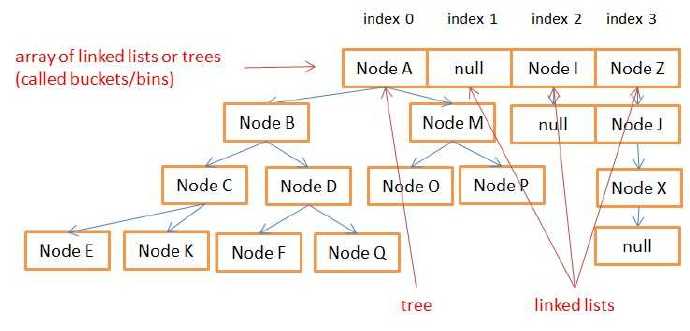
第一行为数组,通过求hash值与数组的大小的位运算求得索引定位数据;添加数据的时候,检查每个桶的数据大小,如果超过8(默认)个,则将链表修改为红黑树存储;添加完数据检查数组大小,如有必要,重置数组大小(resize())

java8中的Lambda表达式
lambad表达式是一个匿名函数,既没有函数名的函数。在lambda表达式出现之前,java中更多使用的是匿名内部类所以有些刚刚接触lambda表达式的人会把lambda表达式误认为就是匿名内部类的简写。这里需要注意lambada表达式并不能简写所有的匿名内部类,准确的说lambda表达式表示的是一个函数式接口的实现,而函数式接口其实就是仅有一个需要实现的方法的接口。
在介绍lambda表达式之前我想先说一下什么是面向接口编程。面向接口编程可以实现程序间的解耦,提高代码的灵活性和复用性。有时我们的方法的参数就是一个接口,这里我们并不是想要这个接口而是需要这个接口实现的代码,可是代码没有办法做为接口的参数传递,例如:File的String[] list(FilenameFilter filter)方法,里面需要传入一个FilenameFilter类型的参数,这里我们需要的其实就只是FilenameFilter这个接口的实现代码,所以有时接口常被用于传递代码,理解了这个思想lambda表达式就已经学会了一半了。
java8提供了一种更为紧凑的传递代码的方法也就是lambda表达式。在介绍lambda表达式之前我们先来回顾一下java中使用匿名内部类来创建java多线程,代码如下:
public class TestLambda1 {
public static void main(String[] args) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("当前线程的名字是:"+Thread.currentThread().getName());
}
});
t.start();
}
}这里我们通过了一个匿名内部类创建了一个线程。但是在java8之后,上面的代码可以简写成:
Thread lambdaThread = new Thread(
()->{System.out.println("当前线程的名字是:"+Thread.currentThread().getName());
});
lambdaThread.start();可以看出,lambda表达式相比于内部类代码更加的简约易读,把接口和方法的名字都省略了,传递的代码更加的直观。lambda表达式是由方法的参数列表和方法体组成的,其中方法的参数类型可以省略,jvm会自动的判断参数的类型。当lambda表达式的函数体只有一句代码时,可以省略括号,这时主体的代码就是一个表达式,表达式的值就是函数的返回值。例如:
List<String> list = new ArrayList<String>();
list.sort((s1,s2)->s1.length()-s2.length());在lambda表达式中可以访问定义在lambda式之外的变量,但是在访问定义在方法中的局部变量时要求方法中的局部变量是不可变的,例如:
public class TestLambda1 {
public static void main(String[] args) {
String selfTest = "selfTest";
selfTest="changeTest";
Thread t = new Thread(()->{
System.out.println(selfTest);
});
t.start();
}
}上面的代码会报错,因为selfTest是局部变量并且被重新赋值了。
关于Java8中的简易并发和java并发编程设计原则与模式的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于Java8中的 Lambda表达式教程、Java8中的default方法详解、java8中的HashMap的putVal方法、java8中的Lambda表达式等相关知识的信息别忘了在本站进行查找喔。
本文标签:




