在本文中,我们将带你了解spring数据jpasaveandflush方法在这篇文章中,我们将为您详细介绍spring数据jpasaveandflush方法的方方面面,并解答spring.jpa.sh
在本文中,我们将带你了解spring数据jpa saveandflush方法在这篇文章中,我们将为您详细介绍spring数据jpa saveandflush方法的方方面面,并解答spring.jpa.show-sql常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的ES spring数据JPA&spring data elasticsearch;找不到类型的属性索引、java – Spring数据jpa repo,为什么需要接口服务和服务实现、java – Spring数据jpa.如果没有结果返回默认值,则查找max、java – Spring数据jpa分离实体。
本文目录一览:- spring数据jpa saveandflush方法(spring.jpa.show-sql)
- ES spring数据JPA&spring data elasticsearch;找不到类型的属性索引
- java – Spring数据jpa repo,为什么需要接口服务和服务实现
- java – Spring数据jpa.如果没有结果返回默认值,则查找max
- java – Spring数据jpa分离实体
")
spring数据jpa saveandflush方法(spring.jpa.show-sql)
您的测试场景的问题在于 JPA 总是在执行本机查询之前刷新持久性上下文(这也是 JPQL 查询的默认行为,尽管它可以被覆盖)。其基本原理是查询应报告反映当前工作单元中已经进行的更改的状态。
要查看 save/saveAndFlush 之间的区别,您可以改用以下测试用例:
@Repository
public interface ClassRepository extends JpaRepository<ClassA,Long> {
@Query("SELECT COUNT(c.id) FROM ClassA c")
@QueryHints({
@QueryHint(name = org.hibernate.annotations.QueryHints.FLUSH_MODE,value = "COMMIT")
})
int countClassAEntities();
}
@Test
@Transactional
void saveAndUpdate() {
int initialCount = classRepository.countClassAEntities();
ClassA classA = ClassA.builder().className("Test").employeeId("S0810").build();
classRepository.save(classA);
int finalCount = classRepository.countClassAEntities();
assertEquals(initialCount,finalCount);
}
@Test
@Transactional
void saveAndUpdateWithFlush() {
int initialCount = classRepository.countClassAEntities();
ClassA classA = ClassA.builder().className("Test").employeeId("S0810").build();
classRepository.saveAndFlush(classA);
int finalCount = classRepository.countClassAEntities();
assertEquals(initialCount + 1,finalCount);
}
在上面的设置中,计数查询的刷新模式设置为 COMMIT,这意味着执行查询不会触发刷新。如果您改用默认的 repository.count() 方法,第一个测试用例将失败,因为默认情况下,刷新模式设置为 AUTO。

ES spring数据JPA&spring data elasticsearch;找不到类型的属性索引
我不确定为什么会这样!我有一个由
spring data elasticsearch和spring data jpa使用的类,但是当我尝试运行我的应用程序时,我得到一个错误.
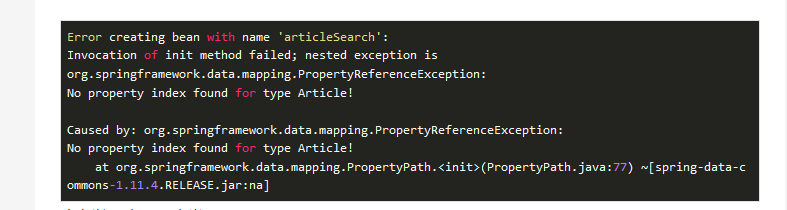
我有以下应用程序类:

以下的elasticsearch配置:

这就是我设置模型类的方法:

然后我得到了一个扩展elasticsearchrepository的包搜索,如下所示:

我试图在另一个导致错误发生的服务中自动装入articlesearch类:

我在这里想念的是什么?!我想在尝试使用data-jpa data-elasticsearch时会有点复杂.
最佳答案 我发现了为什么会这样.我不知道为什么,但是Spring似乎没有拿起我的ElasticSearchConfiguration配置类!
所以我只是移动了所有内容并将其转储到我的主应用程序类中(其他所有配置都是).
我还删除了组件扫描&将enablejparepository enableelasticsearchrepository注释添加到我的主类.这是现在的样子:


java – Spring数据jpa repo,为什么需要接口服务和服务实现
public interface userRepository extends JpaRepository<User,String>{
}
然后从控制器,我可以轻松调用userRepository.findAll()来获取数据.
但是,当我查看一些教程时,他们在调用findAll()之前还有几个步骤.看看下面:
public interface userService{
Iterator findAll();
}
public class userServiceImpl implements userService{
@Autowired
UserRepository userRepository
@Override
Iterator findAll(){
return userRepository.findAll();
}
}
像这样的事情,我可以直接从userRepository查询数据,只要@Autowired注入userRepository.
在一些示例中,它们在上面执行相同的结构.任何人都可以在调用数据之前解释为什么我们需要service和serviceImpl.
解决方法
如果您只需要调用数据库并返回该数据,则可以安全地跳过“服务”调用/类.另一方面,如果你正在“在现实生活中”做一些事情,你将最终使用这些“服务”类,因为大多数操作(阅读:业务逻辑)将会存在,所以你会想要将所有这些行为隔离在一个地方 – 否则你将在任何地方注入豆子而不遵循任何“项目组织”等.有时它有点乏味,但另一方面,无论何时需要改变某些东西,你都知道在哪里寻找.在大中型项目中,这非常重要;如果你有几个人修改相同的代码库,甚至更多.
提示:保持小班级.在“服务”类上注入大量的bean(存储库,服务和什么不是)是糟糕的设计,可能会导致其他非感官.

java – Spring数据jpa.如果没有结果返回默认值,则查找max
@Query("SELECT max(ch.id) FROM MyEntity ch")
Long getMaxId();
如果db不为空,它可以正常工作.如果我使用测试配置启动我的环境(使用H2DB) – 一开始就没有数据. getMaxId()返回的结果为null.我想在这里0.
是否可以修改我的* JpaRepository以获得0结果?如果是,应该如何修改?
解决方法
@Query("SELECT coalesce(max(ch.id),0) FROM MyEntity ch")
Long getMaxId();
如果没有数据,它将返回0而不是null.

java – Spring数据jpa分离实体
此关系在User类中定义如下:
@ManyToMany(fetch = FetchType.EAGER,cascade = CascadeType.ALL)
@JoinTable(name="user_role",joinColumns = {@JoinColumn(name="user_id")},inverseJoinColumns = {@JoinColumn(name="role_id")})
private Set<UserRole> roles;
我用以下方法创建角色
@Transactional
private void generateSeedRoles() {
UserRole adminRole = new UserRole(RoleEnum.ADMIN.toString());
userRoleRepository.save(adminRole);
UserRole userRole = new UserRole(RoleEnum.USER.toString());
userRoleRepository.save(userRole);
}
之后为用户分配角色失败:
@Transactional
private void generateSeedUsers() {
UserRole adminRole = userRoleRepository.findUserRoleByRoleName("ADMIN");
User user = User.createuser("user1","user1@user.com","pass");
user.setRoles(new HashSet<UserRole>(Arrays.asList(adminRole)));
userRepository.save(user);
}
抛出以下异常(为便于阅读而格式化):
org.springframework.dao.InvalidDataAccessApiUsageException: detached entity passed to persist: co.feeb.models.UserRole; nested exception is org.hibernate.PersistentObjectException: detached entity passed to persist: co.feeb.models.UserRole
但是,如果在创建关系之前保存用户,则它可以正常工作:
@Transactional
private void generateSeedUsers() {
UserRole adminRole = userRoleRepository.findUserRoleByRoleName("ADMIN");
User user = User.createuser("user1","pass");
//Save user
userRepository.save(user);
//Build relationship and update user
user.setRoles(new HashSet<UserRole>(Arrays.asList(adminRole)));
userRepository.save(user);
}
必须保存/更新用户两次对我来说似乎有些不合理.有没有办法将收到的角色分配给新用户而不先保存用户?
解决方法
由于您已经使用Cascade.ALL定义了User与UserRole的关系,因此来自User的任何持久/合并也将级联到UserRole.
鉴于Spring如何实现保存以及上面级联的行为,以下是一些需要考虑的方案:
>如果User和UserRole都是新的 – 你在保存用户时会得到一个持久的动作,并且一个级联的持久存在UserRole,因为UserRole是新的,所以工作正常.
>如果User是新的但UserRole已经存在 – 再次保存User时会得到一个持久动作,并且级联持续存在UserRole,这会导致错误,因为UserRole已经存在!
如果您可以保证添加到用户关系的任何UserRole始终存在,您只需从级联选项中删除Cascade.Persist即可.否则,我相信在上述两种情况下保存用户时,您必须使用合并 – 通过自定义存储库和entityManager.
关于你使用Cascade.ALL,在这种情况下可能没有意义,因为你有一个@ManyToMany关系,从用户到UserRole级联ALL可能会产生一些不良影响(例如Cascade.Remove会每次删除UserRole用户被删除).
关于spring数据jpa saveandflush方法和spring.jpa.show-sql的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于ES spring数据JPA&spring data elasticsearch;找不到类型的属性索引、java – Spring数据jpa repo,为什么需要接口服务和服务实现、java – Spring数据jpa.如果没有结果返回默认值,则查找max、java – Spring数据jpa分离实体的相关知识,请在本站寻找。
本文标签:




