如果您想了解Node.js中的一股清流:理解Stream的相关知识,那么本文是一篇不可错过的文章,我们将对流的基本概念进行全面详尽的解释,并且为您提供关于flutter异步编程-事件循环、Isolat
如果您想了解Node.js 中的一股清流:理解 Stream的相关知识,那么本文是一篇不可错过的文章,我们将对流的基本概念进行全面详尽的解释,并且为您提供关于flutter异步编程-事件循环、Isolate、Stream(流)、Gstreamer的一些基本概念与A/V同步分析、Java 8 中 Stream(流)的转换、Java Stream的基本概念以及创建方法的有价值的信息。
本文目录一览:- Node.js 中的一股清流:理解 Stream(流)的基本概念(node stream(流)有哪些?)
- flutter异步编程-事件循环、Isolate、Stream(流)
- Gstreamer的一些基本概念与A/V同步分析
- Java 8 中 Stream(流)的转换
- Java Stream的基本概念以及创建方法
的基本概念(node stream(流)有哪些?)")
Node.js 中的一股清流:理解 Stream(流)的基本概念(node stream(流)有哪些?)
这是1024译站的第 36 篇文章
接触过 Node.js 的开发人员可能知道,流(Stream)这个概念比较难理解,也不太好处理。
这篇文章就来帮你理解流的概念,以及如何使用它。别担心,一定会搞懂的。
流(Stream)是什么?
流(Stream)是驱动 Node.js 应用的基础概念之一。它是数据处理方法,用于按顺序将输入读写到输出中。
流是一种处理读写文件、网络通信或任何端到端信息交换的有效方式。
流的独特之处在于,它不像传统的程序那样一次将一个文件读入内存,而是逐块读取数据、处理其内容,而不是将其全部保存在内存中。
这使得流在处理大量数据时非常强大,例如,文件可能大于你的空闲内存,不可能将整个文件读入内存来处理,这时候流就发挥作用了。
我们以 YouTube 或 Netflix 等流媒体服务为例:这些服务不会让你立即下载完整的视频和音频,而是浏览器将视频作为连续流的数据块,可以做到用户立即收看。
然而,流并不仅仅用来处理媒体或大数据,它还赋予了代码的“可组合性”。在设计时考虑到可组合性意味着几个组件可以以某种方式组合以产生相同类型的结果。在 Node.js 中,通过使用流将数据从其他更小的代码段中导入或导出,可以组成功能强大的代码段。
为什么要用流
与其他数据处理方法相比,流有两个主要优势:
内存效率:不需要加载大量的数据到内存就可以处理
时间效率:一旦有了数据就开始处理,而不必等待传输完所有数据
Node.js 中的 4 种流(Stream)
可写流: 可写入数据的流。例如
fs.createWriteStream()可以使用流将数据写入文件。可读流: 可读取数据的流。例如
fs.createReadStream()可以从文件读取内容。双工流: 既可读又可写的流。例如
net.Socket。转换流: 可以在数据写入和读取时修改或转换数据的流。例如,在文件压缩操作中,可以向文件写入压缩数据,并从文件中读取解压数据。
如果你用过 Node.js,可能已经遇到过流了。例如,在基于 Node.js 的 HTTP 服务器中,request 是可读流,response 是可写流。还有fs 模块,能同时处理可读和可写文件流。只要你用 Express,就是在使用流与客户端进行交互,流也被用于各种数据库连接驱动程序中,因为 TCP 套接字、TLS 堆栈和其他连接都是基于 Node.js 流的。
如何创建可读流
引入模块并初始化:
const Stream = require(''stream'')const readableStream = new Stream.Readable()
初始化后就可以给它发送数据了:
readableStream.push(''ping!'')readableStream.push(''pong!'')
异步迭代器(async iterator)
强烈建议在处理流时使用异步迭代器。异步迭代是一种异步检索数据容器内容的协议,意味着当前的“任务”可能在检索数据项之前暂停。另外,值得一提的是,流的异步迭代器的内部实现使用了 readable事件。
当从可读的流读取数据时,可以使用 async iterator:
import * as fs from ''fs'';
async function logChunks(readable) {
for await (const chunk of readable) {
console.log(chunk);
}
}
const readable = fs.createReadStream(
''tmp/test.txt'', {encoding: ''utf8''});
logChunks(readable);
// Output:
// ''This is a test!\n''
也可以在字符串中收集可读流的内容:
import { Readable } from ''stream'';
async function readableToString2(readable) {
let result = '''';
for await (const chunk of readable) {
result += chunk;
}
return result;
}
const readable = Readable.from(''Good morning!'', { encoding: ''utf8'' });
assert.equal(await readableToString2(readable), ''Good morning!'');
注意,在本例中,我们必须使用异步函数,因为我们希望返回一个 Promise。
记得不要将异步函数与 EventEmitter 搞混了,因为目前无法捕获从事件处理程序中发出的 rejection,从而导致难以跟踪 bug 和内存泄漏。当前的最佳实践是始终将异步函数的内容封装在 try/catch 块中并处理错误,但这很容易出错。这个 pull request就是为了解决这个问题,如果能加入到 Node 核心代码的话。
Readable.from(): 从 iterables 创建可读流
stream.Readable.from(iterable, [options]) 是一个实用方法,用于从迭代器创建可读流,其中的 iterable 包含了数据。iterable 可以是同步迭代的,也可以是异步迭代的。options 是可选的,可以用于指定文本编码。
const { Readable } = require(''stream'');
async function * generate() {
yield ''hello'';
yield ''streams'';
}
const readable = Readable.from(generate());
readable.on(''data'', (chunk) => {
console.log(chunk);
});
两种读取模式
根据 Streams API,可读流有两种操作模式: flowing 和 paused。无论流是处于流模式还是暂停模式,可读流都可以用对象模式或非对象模式。
在 flowing 模式中,数据从底层系统自动读取,并通过
EventEmitter接口以尽可能快的速度使用事件提供给应用程序。在 paused 模式中,必须显式地调用
stream.read()方法来从流中读取数据块。
在 flowing 模式中,要从流中读取数据,可以监听 data 事件并绑定回调。当数据块可用时,可读流发出 data 事件并执行回调。代码如下:
var fs = require("fs");var data = '''';
var readerStream = fs.createReadStream(''file.txt''); //Create a readable stream
readerStream.setEncoding(''UTF8''); // Set the encoding to be utf8\.
// 处理 stream 事件 --> data, end, 和 error
readerStream.on(''data'', function(chunk) {
data += chunk;
});
readerStream.on(''end'',function() {
console.log(data);
});
readerStream.on(''error'', function(err) {
console.log(err.stack);
});
console.log("Program Ended");
函数调用 fs.createReadStream() 提供了一个可读流。一开始,流处于静止状态。只要监听 data 事件并绑定回调,它就开始流动。然后,读取数据块并将其传递给回调。流的实现者可以决定 data 事件发出的频率。例如,HTTP 请求可以在每读取几 KB 数据时发出一个 data 事件。当你从文件中读取数据时,你可能会采取每读取一行就发出 data 事件。
当没有更多的数据要读取(到达尾部)时,流就会发出 end 事件。在上面的代码中,我们监听了这个事件,以便在结束时得到通知。
另外,如果出现错误,流将发出错误并通知。
在 paused 模式下,你只需要反复调用流实例上的 read(),直到每一块数据都被读取,如下所示:
var fs = require(''fs'');var readableStream = fs.createReadStream(''file.txt'');
var data = '''';
var chunk;
readableStream.on(''readable'', function() {
while ((chunk=readableStream.read()) != null) {
data += chunk;
}
});
readableStream.on(''end'', function() {
console.log(data)
});
read() 函数从内部缓冲区读取一些数据并返回。当没有要读取的内容时,它返回 null。因此,在while循环中,我们检查null并终止循环。请注意,readable事件是在可以从流中读取数据块时发出的。
所有Readable数据流都以 paused 模式开始,但可以通过以下方式切换到 flowing 模式:
添加
data事件处理器调用
stream.resume()方法调用
stream.pipe()方法发送数据到一个Writable
Readable可以使用以下几种方式切换回 paused 模式:
如果没有管道(pipe)目标,调用
stream.pause()方法如果有管道(pipe)目标,删除所有管道目标。可以通过调用
stream.unpipe()方法来删除多个管道目标。
要记住的重要概念是,除非提供了一种用于消费或忽略该数据的机制,否则Readable 将不会生成数据。如果消费机制被禁用或取消,Readable将尝试停止生成数据。添加一个readable 事件处理程序会自动使流停止流动,并通过readable.read()消费数据。如果删除了readable事件处理程序,那么如果存在data事件处理程序,则流就会再次开始流动。
如何创建可写流
要将数据写入可写流,你需要在流实例上调用write()。如下所示:
var fs = require(''fs'');var readableStream = fs.createReadStream(''file1.txt'');
var writableStream = fs.createWriteStream(''file2.txt'');
readableStream.setEncoding(''utf8'');
readableStream.on(''data'', function(chunk) {
writableStream.write(chunk);
});
上面的代码简单直白。它只是简单地从输入流中读取数据块,并使用write()写入目标位置。该函数返回一个布尔值,表明操作是否成功。如果为true,则写入成功,你可以继续写入更多数据。如果返回 false,则表示出了点问题,目前无法写入任何内容。可写流将通过发出drain事件来通知你何时可以开始写入更多数据。
调用writable.end()方法表明没有更多数据将被写入Writable。如果提供可选的回调函数,将作为finish事件的监听器函数。
// 写入 ''hello, '' 然后以 ''world!'' 结束const fs = require(''fs'');
const file = fs.createWriteStream(''example.txt'');
file.write(''hello, '');
file.end(''world!'');
// 不允许写更多内容!
使用可写流,你可以从可读流中读取数据:
const Stream = require(''stream'')
const readableStream = new Stream.Readable()
const writableStream = new Stream.Writable()
writableStream._write = (chunk, encoding, next) => {
console.log(chunk.toString())
next()
}
readableStream.pipe(writableStream)
readableStream.push(''ping!'')
readableStream.push(''pong!'')
writableStream.end()
你还可以使用异步迭代器写入可写流,这也是建议的做法:
import * as util from ''util'';import * as stream from ''stream'';
import * as fs from ''fs'';
import {once} from ''events'';
const finished = util.promisify(stream.finished); // (A)
async function writeIterableToFile(iterable, filePath) {
const writable = fs.createWriteStream(filePath, {encoding: ''utf8''});
for await (const chunk of iterable) {
if (!writable.write(chunk)) { // (B)
// 处理反压
await once(writable, ''drain'');
}
}
writable.end(); // (C)
// 等待完成,如果有错误则抛出
await finished(writable);
}
await writeIterableToFile(
[''One'', '' line of text.\n''], ''tmp/log.txt'');
assert.equal(
fs.readFileSync(''tmp/log.txt'', {encoding: ''utf8''}),
''One line of text.\n'');
stream.finished()的默认版本是基于回调的,但是可以通过util.promisify()转换为基于 Promise 的版本(A行)。
在此示例中,使用了以下两种模式:
写入可写流,同时处理反压(短时负载高峰导致系统接收数据的速率远高于它处理数据的速率)(B行):
if (!writable.write(chunk)) {await once(writable, ''drain'');
}
关闭可写流,并等待写入完成(C行):
writable.end();await finished(writable);
pipeline()
管道是一种机制,是将一个流的输出作为另一流的输入。它通常用于从一个流中获取数据并将该流的输出传递到另外的流。管道操作没有限制,换句话说,管道用于分步骤处理流数据。
Node 10.x 引入了stream.pipeline()。这是一种模块方法,用于在流之间进行管道传输,转发错误信息和数据清理,并在管道完成后提供回调。
下面是使用 pipeline 的一个例子:
const { pipeline } = require(''stream'');const fs = require(''fs'');
const zlib = require(''zlib'');
// 使用 pipeline API 轻松管理多个管道流,并且在管道全部完成时得到通知
// 一个用来高效压缩超大视频文件的管道
pipeline(
fs.createReadStream(''The.Matrix.1080p.mkv''),
zlib.createGzip(),
fs.createWriteStream(''The.Matrix.1080p.mkv.gz''),
(err) => {
if (err) {
console.error(''Pipeline failed'', err);
} else {
console.log(''Pipeline succeeded'');
}
}
);
应该使用pipeline 而不是 pipe,因为pipe是不安全的。
Stream 模块
Node.js stream 模块 是构建所有流 API 的基础。
Stream 模块是 Node.js 中默认提供的内建模块。Stream 是 EventEmitter 类的实例,该类在Node 中用于异步处理事件。因此,流本质上是基于事件的。
使用stream模块只需:
const stream = require(''stream'');
stream 模块对于创建新型流实例非常有用。通常没有必要使用stream模块来消费流。
基于流的 Node.js API
由于它们的优点,Node.js 许多核心模块提供了原生流处理功能,最值得注意的是这些:
net.Socket基于流的主要 node api,是以下大部分 API 的基础process.stdin返回连接到 stdin 的流process.stdout返回连接到 stdout 的流process.stderr返回连接到 stderr 的流fs.createReadStream()创建一个文件可读流fs.createWriteStream()创建一个文件可写流net.connect()初始化一个基于流的连接http.request()返回http.ClientRequest类的一个实例,是一个可写流zlib.createGzip()用 gzip (一种压缩算法)将数据压缩到流zlib.createGunzip()解压 gzip 流zlib.createDeflate()用 deflate (一种压缩算法)将数据压缩到流zlib.createInflate()解压 deflate 流
Streams 备忘录
| 类型 | 功能 |
|---|---|
Readable |
数据提供者 |
Writable |
数据接收者 |
Transform |
提供者和接收者 |
Duplex |
提供者和接收者(独立的) |
更多内容请查阅文档: https://nodejs.org/api/stream.html#stream_stream
Streams
const Readable = require(''stream'').Readableconst Writable = require(''stream'').Writable
const Transform = require(''stream'').Transform
管道 Piping
clock() // 可读流.pipe(xformer()) // 转换流
.pipe(renderer()) // 可写流
方法
stream.push(/*...*/) // Emit a chunkstream.emit(''error'', error) // Raise an error
stream.push(null) // Close a stream
事件
const st = source() // 假设 source() 是可读流st.on(''data'', (data) => { console.log(''<-'', data) })
st.on(''error'', (err) => { console.log(''!'', err.message) })
st.on(''close'', () => { console.log(''** bye'') })
st.on(''finish'', () => { console.log(''** bye'') })
Flowing 模式
// 开启和关闭 flowing 模式st.resume()
st.pause()
// 自动开启 flowing 模式
st.on(''data'', /*...*/)
可读流
function clock () {const stream = new Readable({
objectMode: true,
read() {} // 自己实现 read() 方法,如果要按需读取
})
setInterval(() => {
stream.push({ time: new Date() })
}, 1000)
return stream
}
可读流是数据生成器,用
stream.push()写入数据。
转换流
function xformer () {let count = 0
return new Transform({
objectMode: true,
transform: (data, _, done) => {
done(null, { ...data, index: count++ })
}
})
}
将转换后的数据块传给
done(null, chunk).
可写流
function renderer () {return new Writable({
objectMode: true,
write: (data, _, done) => {
console.log(''<-'', data)
done()
}
})
}
全部串起来
clock() // 可读流.pipe(xformer()) // 转换流
.pipe(renderer()) // 可写流
以下是与可写流相关的一些重要事件:
error– 在写入/管道操作发生了错误时发送pipeline– 当将可读流传递到可写流中时,可写流会发出此事件。unpipe– 当你在可读流上调用unpipe并停止将其输送到目标流中时发出。
总结
这就是所有关于流的基础知识。流、管道和链式操作是 Node.js 的核心和最强大的功能。有了流的帮助,操作 I/O 的代码会变得更简洁和高效。
你可能还想看:
Node.js多线程完全指南
手把手教你写一个 Node.js CLI
构建你的第一个 Node.js 微服务
顺手点“在看”,今天早下班;转发加关注,共奔小康路~
本文分享自微信公众号 - 1024译站(trans1024)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
")
flutter异步编程-事件循环、Isolate、Stream(流)
事件循环、Isolate
开始前我们需要明白 Dart 是单线程的并且 Flutter 依赖于 Dart
如果你知道js 中的event loop 将很好理解dart的整个异步过程
先看一段代码
import ''dart:async'';
Future eventLoop() async{
print(''A'');
Future((){
print(''F'');
scheduleMicrotask((){print(''H'');});
Future((){
print(''M'');
}).then((_){
print(''N'');
});
}).then((_){
print(''G'');
});
Future((){
print(''I'');
}).then((_){
print(''J'');
});
scheduleMicrotask(text1);
scheduleMicrotask((){print(''D'');});
print(''B'');
}
void text1() {
print(''C'');
scheduleMicrotask((){print(''E'');});
Future((){
print(''K'');
}).then((_){
print(''L'');
});
}
你只到输出结果吗
正确的输出顺序是: A B C D E F G H I J K L M N
eventLoop
1、MicroTask 队列
微任务队列,一般使用scheduleMicroTask方法向队列中添加
这是大多数时候你不必使用的东西。比如,在整个 Flutter 源代码中 scheduleMicroTask() 方法仅被引用了 7 次, 所以最好优先考虑使用 Event 队列
2、Event 队列
I/O、手势、绘图、计时器、流、futures等等异步操作都将进入event队列
尽量使用事件队列可以使微任务队列更短,降低事件队列卡死的可能性
代码执行顺序
首先我们知道dart是单线程的,所以dart的代码执行顺序是:
- 同步代码依次执行
- 碰到异步代码先进对应的队列中,然后继续执行下面的代码
- 当同步代码执行完毕,先去看MicroTask 队列中的任务,将MicroTask队列中的任务依次执行完毕
- MicroTask中的任务执行完毕后,再去看Event 队列中的任务,event队列出一个任务 然后执行 , 然后回到第三步 循环 直到所有队列都清空
Isolate
Isolate 是 Dart 中的 线程, Flutter的代码都是默认跑在root isolate上的
「Isolate」在 Flutter 中并不共享内存。不同「Isolate」之间通过「消息」进行通信。
import ''dart:async'';
import ''dart:io'';
import ''dart:isolate'';
import ''package:flutter/foundation.dart'';
import ''package:flutter/material.dart'';
//一个普普通通的Flutter应用的入口
//main函数这里有async关键字,是因为创建的isolate是异步的
void main() async{
runApp(MyApp());
//asyncFibonacci函数里会创建一个isolate,并返回运行结果
print(await asyncFibonacci(20));
}
//这里以计算斐波那契数列为例,返回的值是Future,因为是异步的
Future<dynamic> asyncFibonacci(int n) async{
//首先创建一个ReceivePort,为什么要创建这个?
//因为创建isolate所需的参数,必须要有SendPort,SendPort需要ReceivePort来创建
final response = new ReceivePort();
//开始创建isolate,Isolate.spawn函数是isolate.dart里的代码,_isolate是我们自己实现的函数
//_isolate是创建isolate必须要的参数。
await Isolate.spawn(_isolate,response.sendPort);
//获取sendPort来发送数据
final sendPort = await response.first as SendPort;
//接收消息的ReceivePort
final answer = new ReceivePort();
//发送数据
sendPort.send([n,answer.sendPort]);
//获得数据并返回
return answer.first;
}
//创建isolate必须要的参数
void _isolate(SendPort initialReplyTo){
final port = new ReceivePort();
//绑定
initialReplyTo.send(port.sendPort);
//监听
port.listen((message){
//获取数据并解析
final data = message[0] as int;
final send = message[1] as SendPort;
//返回结果
send.send(syncFibonacci(data));
});
}
int syncFibonacci(int n){
return n < 2 ? n : syncFibonacci(n-2) + syncFibonacci(n-1);
}
因为Root isolate会负责渲染,还有UI交互,如果我们有一个很耗时的操作呢?前面知道isolate里是一个event loop(事件循环),如果一个很耗时的task一直在运行,那么后面的UI操作都被阻塞了,所以如果我们有耗时的操作,就应该放在isolate里!
Stream(流)
什么是流?

- 这个大机器就是StreamController,它是创建流的方式之一。
- StreamController有一个入口,叫做sink
- sink可以使用add方法放东西进来,放进去以后就不再关心了。
- 当有东西从sink进来以后,我们的机器就开始工作
- StreamController有一个出口,叫做stream
- 机器处理完毕后就会把产品从出口丢出来,但是我们并不知道什么时候会出来,所以我们需要使用listen方法一直监听这个出口
- 而且当多个物品被放进来了之后,它不会打乱顺序,而是先入先出
使用Stream
StreamController controller = StreamController();
//监听这个流的出口,当有data流出时,打印这个data
StreamSubscription subscription =
controller.stream.listen((data)=>print("$data"));
controller.sink.add(123);
// 输出: 123
你需要将一个方法交给stream的listen函数,这个方法入参(data)是我们的StreamController处理完毕后产生的结果,我们监听出口,并获得了这个结果(data)。这里可以使用lambda表达式,也可以是其他任何函数
transform
如果你需要更多的控制转换,那么请使用transform()方法。他需要配合StreamTransformer进行使用。
StreamController<int> controller = StreamController<int>();
final transformer = StreamTransformer<int,String>.fromHandlers(
handleData:(value, sink){
if(value==100){
sink.add("你猜对了");
}
else{ sink.addError(''还没猜中,再试一次吧'');
}
});
controller.stream
.transform(transformer)
.listen(
(data) => print(data),
onError:(err) => print(err));
controller.sink.add(23);
//controller.sink.add(100);
// 输出: 还没猜中,再试一次吧
StreamTransformer<S,T>是我们stream的检查员,他负责接收stream通过的信息,然后进行处理返回一条新的流。
- S代表之前的流的输入类型,我们这里是输入一个数字,所以是int。
- T代表转化后流的输入类型,我们这里add进去的是一串字符串,所以是String。
- handleData接收一个value并创建一条新的流并暴露sink,我们可以在这里对流进行转化
Stream的种类
- "Single-subscription" streams 单订阅流
- "broadcast" streams 多订阅流
单订阅流
StreamController controller = StreamController();
controller.stream.listen((data)=> print(data));
controller.stream.listen((data)=> print(data));
controller.sink.add(123);
// 输出: Bad state: Stream has already been listened to. 单订阅流不能有多个收听者。
单个订阅流在流的整个生命周期内仅允许有一个listener
多订阅流
StreamController controller = StreamController();
//将单订阅流转化为广播流
Stream stream = controller.stream.asBroadcastStream();
stream.listen((data)=> print(data));
stream.listen((data)=> print(data));
controller.sink.add(123);
// 输出: 123 123
广播流允许任意数量的收听者,且无论是否有收听者,他都能产生事件。所以中途进来的收听者将不会收到之前的消息。
参考深入了解isolate
永久原文地址flutter异步编程

Gstreamer的一些基本概念与A/V同步分析
(Original: http://blog.csdn.net/shenbin1430/article/details/4291963)
一、媒体流(streams)
流线程中包含事件和缓存如下:
-events
-NEW_SEGMENT (NS)
-EOS (EOS)*
-TAG (T)
-buffers (B) *
其中标*号的需要同时钟进行同步。
典型的流如图1所示:
图1媒体流组成图
(1)NEW_SEGMENT,rate,start/stop,time
包括了有效的时间戳范围(start/stop);stream_time;需要的回放率以及已经应用的回放率。
(2)Buffers
只有处于NEW_SEGMENT的start和stop之间的buffers是可以被显示的,否则将被丢弃或者裁剪。
running_time的计算:
if(NS.rate > 0.0)
running_time= (B.timestamp - NS.start) / NS.abs_rate + NS.accum
else
running_time= (NS.stop - B.timestamp) / NS.abs_rate + NS.accum
stream_time的计算:
stream_time= (B.timestamp - NS.start) * NS.abs_applied_rate + NS.time
(3)EOS
数据的结束。
二、几个时钟概念
1、clock time(absolute_time): 管道维护的一个全局时钟,是一个以纳秒为单位单调递增的时钟时间。可以通过gst_clock_get_time()函数获取。如果管道中没有元素提供时钟,则使用该系统时钟。
2、base time: 媒体从0开始时全局的时间值。可以通过_get_time()函数获取。
3、Running time: 媒体处于PLAYING状态时流逝的时间。
4、stream time: 媒体播放的位置(在整个媒体流中)。
如图2所示。
图2 Gstreamer时钟和变量图(引自Gstreamer文档)
由此可以得出:
running_time = clock_time - base_time;
如果媒体流按照同一频率从开始到结束运行,那么running_time == stream_time;
Running time的详细计算:
running_time是基于管道所选的时钟的,它代表了媒体处于PLAYING状态的总时间,如表1所示。
表1 running_time的计算表
管道状态
running_time
NULL/READY
undefined
PAUSED
暂停时的时间
PLAYING
absolute_time - base_time
Flushing seek
0
三、时钟的提供与同步原理
clock providers:
由于媒体播放的频率与全局时钟的频率不一定相一致,需要元素提供一个时间,使得按照其需要的频率进行播放。主要负责保证时钟与当前媒体时间相一致。需要维护播放延迟、缓冲时间管理等,影响A/V同步等。
clock slaves:
负责从包含他们的管道中获得分配一个时钟。常常需要调用gst_clock_id_wait()来等待播放他们当前的sample,或者丢弃。
当一个时钟被标记为GST_CLOCK_FLAG_CAN_SET_MASTER时,它可以通过设置从属于另一个时钟,随后通过不断地校正使得它与从属的 主时钟进行同步。主要用于当组件提供一个内部时钟,而此时管道又分配了一个时钟时,通过不断地校正从而使得它们之间同步。 在主从时钟的机制中又引入了内部时间和外部时间的概念:
内部时间:时钟自己提供的时间,未做调整的时间;
外部时间:在内部时间基础上,经过校正的时间。
在clock中保存着internal_calibration, external_calibration, rate_numerator, rate_denominator属性,并利用这些值校正出外部时间,校正公式为
external = (internal – cinternal) * cnum / cdenom + cexternal;
其中external,internal,cinternal,cnum,cdenom,cexternal分别表示外部时间,内部时间,clock中保存的内部校正值,校正率分子,校正率分母,外部校正值。
主从同步可以同过一下三个属性来调整:
1、timeout:定义了从时钟对主时钟进行采样的时间间隔;
2、window-size:定义了校正时需要采样的数量;
3、window-threshold:定义了校正时最少需要的采样数量。
为了同步不同的元素,管道需要负责为管道中的所有元素选择和发布一个全局的时钟。
时钟发布的时机包括:
1、管道进入PLAYING状态;
2、添加一个可以提供时钟的元素;
发送一个GST_MESSAGE_CLOCK_PROVIDE消息——>bus——>通知父bin——>选择一个clock——>发送一个NEW_CLOCK消息——>bus
3、移除一个提供时钟的元素;
发送一个CLOCK_LOST消息——>PAUSED——>PLAYING
时钟选择的算法:
1、从媒体流的最上(most upstream)开始选择一个可以提供时钟的元素;
2、如果管道中所有元素都不能提供时钟,则采用系统时钟。
管道的同步通过如下三个方面实现:
1、GstClock
管道从所有提供时钟的元素中选取一个时钟,然后发布给管道中的所有元素。
2、Timestamps of GstBuffer
3、NEW_SEGMENT event preceding the buffers
正如前面所提到的,running_time有两种计算方式:
1、用全局时钟和元素的base_time计算
running_time = absolute_time – base_time;
2、用buffer的时间戳和NEWSEGMENT事件计算(假设rate为正值)
running_time = (B.timestamp - NS.start) / NS.abs_rate + NS.accum
同步主要是保证上述两个时间计算值的相同。即
absolute_time – base_time = (B.timestamp - NS.start) / NS.abs_rate + NS.accum
而absolute_time也就是Buffer的同步时间(B.sync_time == absolute_time),因此
B.sync_time = (B.timestamp - NS.start) / NS.abs_rate + NS.accum + base_time
在render之前需要等待,直到时钟到达sync_time;对于多个流,则是具有相同running_time的将会同时播放;解复用器 (demuxer)则需要保证需要同时播放的Buffers具有相同的running_time,因此会给Buffers附上相同的时间戳以保证同步。
四、延迟(latency)的计算与实现
1、延迟的引入
管道中元素与时钟的同步仅仅发生在各个sink中,如果其他元素对buffer没有延迟的话,那么延迟就为0。延迟的引入主要是基于这样的考 虑,buffer从source推送到sink会花费一定的时间,从而可能导致buffer被丢弃。这个问题一般发生在活动管道,sink被设置为 PLAYING并且buffer没有被预送(preroll)至sink。
2、延迟的实现
一般的解决方案是在被预送(preroll)之前所有的sink都不能设置为PLAYING状态。为了达到这样的目的,管道需要跟踪所有需要预送的元素 (就是在状态改变后返回ASYNC的元素),这些元素发送一个ASYNC_START消息,当元素进行预送,便把状态设置为PAUSED,同时发送一个 ASYNC_DONE消息,该消息恰好与之前的ASYNC_START相对应。当管道收集了所有的与ASYNC_START消息对应的 ASYNC_DONE消息以后便可以开始计算全局延迟了。
3、延迟的计算
延迟的计算方法如图3所示。
图3 延迟的计算
管道通过发送一个LATENCY事件给管道中的所有sink来给管道设置延迟,该事件为sinks配置总的延迟,延迟对所有的sink来说都是相同的,这样sink在提交数据时可以保持相对的同步。
五、服务质量(QoS)
服务质量是关于衡量和调整管道的实时性能的。实时性能的衡量主要在于管道的时钟,通常发生在sink中buffer的同步。
QoS一般用于视频的buffer中,原因有两个,其一,相对于视频来说,丢弃音频是会带来更大的麻烦,这是基于人的生理特征的考虑;其二,视频比音频需要更多更复杂的处理,因此会消耗更多的时间。
服务质量问题的来源:
1、cpu负载;
2、网络问题;
3、磁盘负载、内存瓶颈等。
衡量的目的是调整元素中的数据传输率,主要有两种类型的调整:
1、在sink中检测到的短时间紧急调整;
2、在sink中检测到的长期调整(传输率的调整),对整个趋势的检测。
服务质量事件:
服务质量事件由元素收集,包括以下属性:
1、timestamp
2、jitter
timestamps与当前时钟的差值,负值表示及时到达(实际上是提前到达的时间值),正值表示晚的时间值。
3、proportion
为了得到优化的质量相对于普通数据处理率的一个理想处理率的预测。
服务质量主要在GstBaseSink中实现,每次在对到达sink的buffers进行一次render处理后都会触发一个服务质量事件,该事件通过把 计算好的一些信息发送给upstream element,来通知upstream element进行相应调整以保证服务质量(主要是音频和视频的同步)。而这其中的一个关键信息则是处理率,对处理率的计算如下:
先了解各AVG值的计算:
next_avg = (current_vale + (size – 1) * current_avg) / size
这其中的size一般为8 ,处理率平均值的计算例外(4或16)。
jitter是由buffer的时间戳和当前时间来计算的。
jitter = current_time – timestamps;
jitter < 0 说明buffer提前到达sink;
jitter > 0 说明buffer迟了jitter长的时间到达sink;
jitter = 0 说明正好。
下面逐步说明处理率rate的计算过程:
start = sink->priv->current_rstart;
stop = sink->priv->current_rstop;
duration = stop – start;
如果jitter < 0,则 entered = start + jitter; left = start;
如果jitter > 0,则 entered = left = start + jitter;
其中entered表示buffer到达sink的时间,left表示buffer被render出去的时间。
pt = entered – sink->priv->last_left;
根据上述计算平均值的公式计算出avg_pt和avg_duration;
rate = avg_pt / avg_duration;
如果0 < rate < 1,说明upstream element生产速度比较快,导致sink来不及处理,会产生flood的情况;
如果 rate = 1, perfect;
如果 rate > 1,说明upstream element不能提供足够的buffer给sink,会导致starvation的情况。
随后通过发送QoS message的方式将当前buffer的timestamp,jitter和rate发送给upstream elements,告知他们作相应的处理,比如丢弃一些buffer。并且可以对下一次可以及时render的buffer进行估计。
六、同步的实现
gstreamer的同步主要在sink中实现,在render之前进行,因此一般在函数GstBaseSink::render中具体实现。同步指的是 buffer在进入到每个sink,render之前与时钟的同步。媒体流在解复用后,在其多个流(比如音频流和视频流)的buffers中附加了时间 戳,因此在sink进行输出之前分别与时钟进行同步,即可达到A/V的同步输出。
在gstreamer-0.10.3之前,同步在GstBaseSink的函数gst_base_sink_render_object()中实现(如图 4所示),子类对其进行覆盖的很少。在之后版本中,在某些具体的sink子类中进行了覆盖,使得同步的效果达到了最佳。比如在 GstBaseAudioSink的函数gst_base_audio_sink_render()中对Audio的同步进行了覆盖。然而对于视频的同步 并没有进行覆盖,仍然在基类中进行实现。因此A/V同步的实现主要看gst_base_sink_render_object()和 gst_base_audio_sink_render()两个方法。
gst_base_sink_render_object()处理流程如图4所示。其中sync object的流程如图5所示。
图4render object处理流程
图5sync object流程图
在对音频的处理中,引入了ringbuffer的概念,仅用于音频中,类名为GstRingBuffer,下面对ringbuffer的设计做一个简单的介绍:
ringbuffer由若干连续的segment组成,它有一个播放位置,并且播放位置总是以segment为单位的,该位置是设备当前从缓冲区中读sample的位置。如图6所示。
处于播放状态时,samples被写入设备,在每次写入一个segment后,ringbuffer将会调用其配置好的回调函数,并且播放位置向后移动。
图6ringbuffer示意图
普通的buffer用GstBuffer表示,而ringbuffer相当于在音频中对buffer又一次进行了封装,从而使得它又具有了一些特性,比如有状态(STOPPED,PAUSED,STARTED)等。
在音频中对render的重构主要在函数gst_base_audio_sink_render()中实现,在往设备写入之前,根据设置情况也可能需要进行同步和对输出数据的裁剪过程,流程如图7所示。
图7audio render流程图 七、调试分析 (1)根据调试,得到结果及其分析,可以发现在正常情况下,在往设备上写是按照先audio,后video的顺序进行的,一般每次写8-9个audio的 segment,6-7个video的segment。每次写完后都会等待其他流都写完后才进行下一轮写入。 (2)举例:音频用pulsesink,视频用ximagesink为例,讲述从同步到输出的处理过程,如下过程中从上到下分别为音频和视频的处理函数/过程。 音频(pulsesink) 视频(ximagesink) gst_base_sink_render_object gst_base_sink_render_object gst_base_sink_do_sync gst_base_sink_do_sync gst_base_sink_get_sync_times gst_base_sink_get_sync_times *gst_base_audio_sink_get_times==-1 *gst_ximagesink_get_times!=-1 @gst_base_audio_sink_render gst_base_sink_adjust_time 一系列同步过程 gst_base_sink_wait_clock gst_ring_buffer_commit_full @gst_ximagesink_show_frame gst_ximagesink_ximage_put 从上述过程可以看到,音频的同步过程在gst_base_audio_sink_render中实现,而视频的同步则在 gst_base_sink_render_object中实现,并且在get_times方法后进行区分。打“*”的表示在音频和视频的子类中对 get_times的实现,打“@”的表示在音频和视频的子类中对render的实现。
的转换")
Java 8 中 Stream(流)的转换
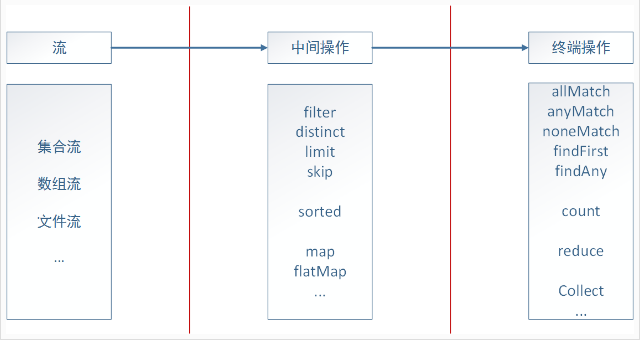
1 Stream stream1 = Stream.of("It''s ", "a ", "wonderful ", "day ", "for ", "pie!");
2 Stream stream2 = Stream.of(3.14159, 2.718, 1.618);
3 Stream stream3 = Stream.of(new ArrayList());
4 Integer[] integers = {1,2,3};
5 Stream stream4 = Stream.of(integers);
1 List<Long> longList = new ArrayList();
2 Stream stream = longList.stream();
1 Random rand = new Random(47);
2 Stream stream = rand.ints().boxed();
1 // import static java.util.stream.IntStream.*;
2 // 传统方法:
3 int result = 0;
4 for (int i = 10; i < 20; i++){
5 result += i;
6 }
7 System.out.println(result);
8 // for-in 循环:
9 result = 0;
10 for (int i : range(10, 20).toArray()){
11 result += i;
12 }
1 // streams/FileToWordsBuilder.java
2 import java.io.*;
3 import java.nio.file.*;
4 import java.util.stream.*;
5
6 public class FileToWordsBuilder {
7 Stream.Builder<String> builder = Stream.builder();
8
9 public FileToWordsBuilder(String filePath) throws Exception {
10 Files.lines(Paths.get(filePath))
11 .skip(1) // 略过开头的注释行
12 .forEach(line -> {
13 for (String w : line.split("[ .?,]+"))
14 builder.add(w);
15 });
16 }
17
18 Stream<String> stream() {
19 return builder.build();
20 }
21
22 public static void main(String[] args) throws Exception {
23 new FileToWordsBuilder("Cheese.dat")
24 .stream()
25 .limit(7)
26 .map(w -> w + " ")
27 .forEach(System.out::print);
28 }
29 }

Java Stream的基本概念以及创建方法
这篇文章主要介绍了Java Stream的基本概念以及创建方法,帮助大家更好的理解和学习Java,感兴趣的朋友可以了解下
前言
相信很多人(包括我自己),在很长一段时间内虽然使用了 JDK 1.8 ,却从来没有使用过自1.8开始增加的 Stream 这一强大使用的新特性,本文则将先从如何创建 Stream 开始,逐步去学会 Stream 的使用。本文不会涉及对流中数据的操作,而只讨论创建流的几种方法,以及一些基础概念,关于流的实用操作将会在后续文章中一一介绍。
Stream 与 Collection 的区别
1.用途与关注点不同
Collection 主要关注于对象的存储方面,通过使用 List 、 Map、Set等等数据结构,让数据被更好的组织起来,以便于使用。而 Stream 则关注于对象的操作方面,包含reduce、map、filter等等实用的操作。
2.流是懒搜索(Laziness-seeking)的
先看一个例子,考虑一下代码:
Random random = new Random(29); random.ints() .filter(v -> v > 5 && v
代码首先创建了一个随机整数流,然后过滤得到其中在(5, 31)范围内的数,最终得到其中的3个数并输出,这里创建的流就是3中所说的无限流,而流在执行的过程中一旦得到一个满足条件的整数就会加到结果序列中,并且开始进行下一轮的搜索,直到找到3个满足的整数为止。流只会完成所给任务(找到3个满足指定范围的整数并输出),不会有额外的操作。
3.流的大小可以是无限的
尽管 Collection 的数据量也可以动态扩展改变,但由于计算机内存是有限的,所以其数据量大小始终可以看成只能为有限的大小。但 Stream 则不同,由于流是懒加载的,所以当使用limit类似的短路操作时,就可以利用特性2的原因去接收一个无限流。
4.流操作不存在副作用
和 Collection 中的某些操作,例如remove会删除集合中的元素不同,流不会修改生成流的原有集合中的数据,例如使用filter时,会产生一个经过元素过滤后的新流,而不会修改原集合中的数据。
5.流属于消耗品(Consumable)
不同与 Collection 没有访问次数与使用的限制,一个流在其生命周期中只能被执行一次,当执行了终端操作(terminal operation,在之后的文章中会具体介绍)后,即使没有将流关闭,例如上述代码中的forEach,也无法再次访问了(类似迭代器),如下代码所示,想要再操作,必须重新创建一个流。
IntStream stream = new Random(29).ints(); stream.filter(v -> v > 5 && v
创建流
流可以通过很多种方式被创建,下面进行一一介绍:
1.Collection 家族创建的方式
对于实现了Collection 接口的类,都可以通过stream()和parallelStream()创建对应流,如下代码所示:
List list = new ArrayList(Arrays.asList(1, 2, 3, 4, 5)); // 创建一个普通的流 Stream stream = list.stream(); // 创建一个并行流 Stream parallelStream = list.parallelStream();
2.数组家族创建的方式
对于数组类型的元素,都可以使用Arrays类的stream()创建对应的流,如果想获得并行流则需要使用parallel()方法,如下所示:
IntStream stream = Arrays.stream(new int[]{1, 2, 3}); // 生成流对应的并行流 IntStream parallelStream = stream.parallel();
3.Stream家族的工厂方法
通过工厂方法来创建流的方式比较多,可以通过empty、of、concat、generate、iterate、range、rangeClosed以及builder等方法创建流,下面就通过代码样例来一一介绍:
// 产生一个不包含任何元素的流 Stream stream1 = Stream.empty(); // 由给定元素所生成的流 Stream stream2 = Stream.of(1, 2, 3); // 合并两个流产生一个新的流 Stream stream3 = Stream.concat(stream1, stream2); // 创建一个,流中的数据是通过调用所传函数产生的 Stream stream4 = Stream.generate(Math::random); // 创建一个,流中的数据由第一个参数、将 // 第一个参数作为函数参数调用产生的值以及不断将 // 函数调用得到的值作为参数继续调用所组成, // 例如下面会生成1,2,3....的整数流 Stream stream5 = Stream.iterate(1, v -> v + 1); // 创建范围为[1, 5)组成的整数流 IntStream stream6 = IntStream.range(1, 5); // 创建范围为[1, 5]组成的整数流 IntStream stream7 = IntStream.rangeClosed(1, 5); // 通过流的建造者模式创建流 Stream.Builder builder = Stream.builder(); for (int i = 0; i stream8 = builder.build();
4.IO/NIO家族中的方法
除了两种获取lines生成的流外,其它几种方式都很少使用,这一部分了解即可。
try { String dir = System.getProperty("user.dir"); // 以下两种方法均是获取文件中行数据组成的流 Stream stream1 = new BufferedReader(new FileReader(dir + "\demo.txt")).lines(); Stream stream2 = Files.lines(Paths.get(dir + "\demo.txt")); // 获取指定路径下所有文件/文件夹的路径组成的流 Stream stream3 = Files.list(Paths.get("d:\temp")); // 获取指定路径下以及指定最深文件层级内(在这里为2)且满足函数条件的所有文件/文件夹的路径组成的流 Stream stream4 = Files.find( Paths.get("d:\temp"), 1, (path, basicFileAttributes) -> path.isAbsolute()); // 获取指定路径下以及指定最深文件层级内(在这里为2)所有文件/文件夹的路径组成的流 Stream stream5 = Files.walk(Paths.get("d:\temp"), 2); } catch (IOException e) { e.printstacktrace(); }
5.Random 获取流的方式
由于直接使用 Random 类生成随机数无限流,均为基本数据类型组成的流,因此通常还需要使用Boxed方法进行装箱(以前凡是生成的为IntStream,DoubleStream,LongStream均同此),以便可以使用更加丰富的特性。
Random random = new Random(); // 以下三种方式得到的均是随机数组成的 IntStream stream1 = random.ints(); DoubleStream stream2 = random.doubles(); LongStream stream3 = random.longs(); Stream BoxedStream = stream1.Boxed();
下面就先举一个具体的实用的例子,在之后的文章中会详细介绍一些实用操作,这里可以先做了解:
// 对数组元素进行倒序排序 // 如果不进行装箱(Boxed)处理,则只能使用默认的升序排序方法 // 通过装箱,则可以通过自定义比较器,实现更加多样的排序 int[] arr = {1, 5, 4, 6, 3, 9, 4, 5, 6, 4}; int[] reverseArr = Arrays.stream(arr) .Boxed() .sorted(Comparator.reverSEOrder()) .mapToInt(Integer::valueOf) .toArray(); // output: [9, 6, 6, 5, 5, 4, 4, 4, 3, 1] System.out.println(Arrays.toString(reverseArr));
6.其它可以生成流的类
除了以上介绍的几个主要可以生成流的类之外,还有一些其它不太常见的可以流的类,下面是部分代码展示:
String s = "1,2,3,4,5,6,7"; // 由分割后的字符串组成的流 // 在这里就是"1", "2", "3", "4", "5", "6", "7"组成的流 Stream stream1 = Pattern.compile(",").splitAsstream(s); BitSet bitSet = new BitSet(); for (int i = 0; i stream3 = jarFile.stream(); } catch (IOException e) { e.printstacktrace(); }
此外还可以通过 StreamSupport工具类进行产生和操作流,由于本文包括之后的文章主要是为了入门和先简单上手,所以这里不做详细讨论,感兴趣的可以自己进行查阅资料。
总结
本文简单介绍了 Stream 这个自1.8开始引入的新特性,然后简单介绍了一些基本概念和流的创建方式,在接下来的文章中还会介绍流的一些实用操作,希望能和大家一起学会使用 Stream 这个实用的特性,当然本文也难免有错误之处,希望得到各位的指正。
以上就是Java Stream的基本概念以及创建方法的详细内容,更多关于JAVA Stream的资料请关注小编其它相关文章!
关于Node.js 中的一股清流:理解 Stream和流的基本概念的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于flutter异步编程-事件循环、Isolate、Stream(流)、Gstreamer的一些基本概念与A/V同步分析、Java 8 中 Stream(流)的转换、Java Stream的基本概念以及创建方法的相关信息,请在本站寻找。
本文标签:




