本文的目的是介绍对Node.js事件驱动模型的深入理解的详细情况,特别关注对node.js事件驱动模型的深入理解是什么的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解
本文的目的是介绍对Node.js事件驱动模型的深入理解的详细情况,特别关注对node.js事件驱动模型的深入理解是什么的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解对Node.js事件驱动模型的深入理解的机会,同时也不会遗漏关于C中的事件驱动模型、JS事件深入理解、JUnit 5中扩展模型的深入理解、libuv的事件驱动模型的知识。
本文目录一览:")
对Node.js事件驱动模型的深入理解(对node.js事件驱动模型的深入理解是什么)
本文主要讨论以下问题:
1.Node.js的事件驱动模型分析
2.Node.js如何处理高并发请求?
3.Node.js的缺点介绍
先简单介绍一下Node.js,Node.js是基于事件驱动、非阻塞I/O模型的服务器端JavaScript运行环境,是基于Google的V8引擎在服务器端运行的单线程、高性能的JavaScript语言。
一、Node.js事件驱动模型分析
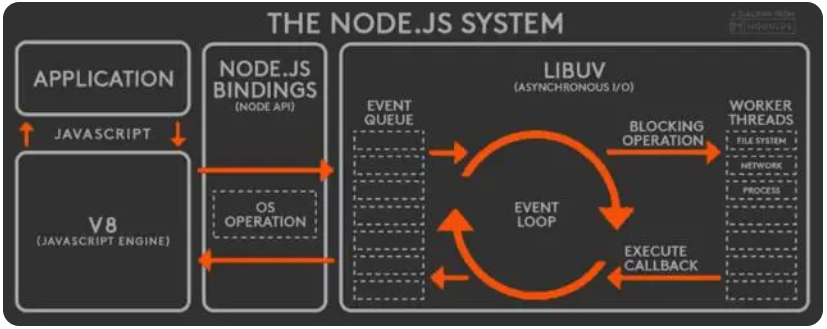
看懂上图之后,你就明白Node.js的事件驱动模型了,从上图中我们可以看到以下几个部分:
Application应用层,也就是JavaScript交互层,是Node.js的常用模块,比如http,fs等。
V8是V8引擎层,主要用于解析JavaScript,与应用层和NodeApi层交互。
NodeApi为上层模块提供系统调用,并与操作系统交互。
Libuv是一个跨平台的底层包,实现了线程池、事件循环、文件操作等。实现异步是Node.js的核心。
Libuv层维护一个事件队列的事件队列。当请求到来时,Node.js的应用层和NodeApi层将请求作为事件放入事件队列,设置回调事件函数,然后继续接受新的请求。
在Libuv层的Event Loop事件循环中,事件队列中的事件被连续读取。在读取事件的过程中,如果遇到非阻塞事件,就自己处理,处理完后调用回调函数将结果返回给下一层。对于阻塞事件,会委托给后台线程池来处理。当这些阻塞操作完成后,执行结果将和提供的回调函数一起放入事件队列。当事件循环再次读取该事件时,将再次执行放置在队列中的事件回调函数,最后将结果返回给上级。详情请参考下图:
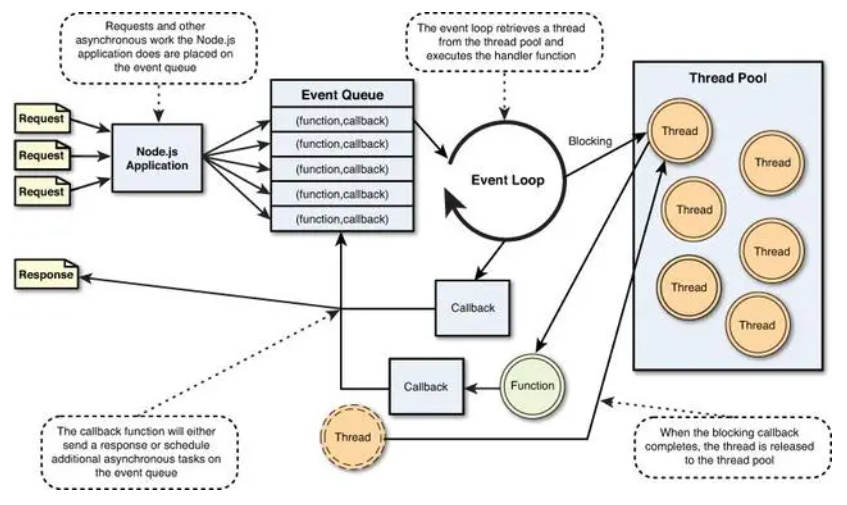
二、Node.js如何处理高并发请求?
如果你理解了最后一个问题,就好理解了。如果要总结的话,就是异步无阻塞编程的思想。当遇到耗时的操作时,会以异步非阻塞的方式进入事件队列,不会影响后续请求的执行。循环将读取这个耗时的请求,并将其交给线程池进行处理。当这些耗时的操作被处理后,会再次进入事件队列,请求结果通过事件循环和回调返回给上层应用,最终返回给客户端。以上方式减少了高并发的等待时间,让高并发可以从容应对。
三、Node.js的缺点介绍
通过上面的介绍,我们知道了Node.js的事件驱动模型,下面我们将介绍Node.js的不足之处。
Node.js最大的缺点是一次只能服务一个请求。目前大部分服务器都是多核CPU,导致CPU利用率非常低,资源浪费。
Node.js的主线程Event Loop按照事件队列的顺序执行事件队列中的事件。在其中一个任务完成之前,回调和监听器等其他函数都没有机会运行,因为被阻塞的事件循环没有机会处理它们。如果发生这种情况,程序执行速度将会变慢。点此下载完整附件

C中的事件驱动模型
我对C中的事件驱动编程非常感兴趣,特别是使用套接字,所以我将花一些时间来做我的研究。
假设我想用一个客户机/服务器应用程序构build一个具有大量文件和networkingI / O的程序,基本上第一个问题是这个模型背后的哲学是什么。 在正常的编程中,我会产生新的进程,一个进程怎么能够实际上服务于许多其他的请求。 例如,有一些Web服务器可以处理连接,而无需创build线程或其他进程,只需要一个主进程。
我知道这很复杂,但至less知道这种编程的基础设施是多么的好。
事件驱动和asynchronous之间有什么区别? 在epoll和AIO之间?
Twisted:目录中新文件的事件
我想等待一个文件描述符和一个互斥量,推荐的方法是什么?
Win32事件驱动编程是如何实现的?
您一定要阅读以下内容: http : //www.kegel.com/c10k.html 。 该页面是事件驱动和异步技术的完美概述。
但是,一个快速和肮脏的答案 :事件驱动既不是非阻塞的,也不是异步的。
事件驱动意味着进程将监视其文件描述符(和套接字),并且只在某些描述符(事件是:收到数据,错误,变为可写,…)发生某些事件时才动作。
BSD套接字具有“select()”功能。 被调用时,操作系统将监视描述符,并在其中一个描述符上发生某些事件时立即返回进程。
不过,上面的网站有更好的描述(和不同的API的细节)。
“这个模型背后的哲学是什么”
事件驱动意味着没有“监控”,但事件本身启动行动。
通常这是由中断引发的,中断是从外部设备向系统发出的信号,或者(在软件中断的情况下)异步过程。
https://en.wikipedia.org/wiki/Interrupt
进一步阅读似乎在这里:
https://docs.oracle.com/cd/E19455-01/806-1017/6jab5di2m/index.html#sockets-40 – “中断驱动的套接字I / O”
另外http://cs.baylor.edu/~donahoo/practical/CSockets/textcode.html有一些中断驱动套接字的例子,以及其他的套接字编程例子。
事件驱动的编程基于事件循环。 循环只是等待一个新事件,调度处理事件的代码,然后循环等待下一个事件。 在套接字的情况下,你在谈论“异步网络编程”。 这涉及select ()或其他一些选项,如Kqueue ()等待事件循环中的事件。 套接字将需要设置为非阻塞 ,以便在读取()或写入()时,代码不会等待I / O完成。
异步网络编程可能非常复杂,而且很难正确。 看看这里和这里的几个介绍。 我强烈建议使用像libevent或liboop这样的库来获得这个权利。
这种TCP服务器/客户端可以通过使用select(2)调用和非阻塞套接字来实现。
使用非阻塞套接字比阻塞套接字更为棘手。
例:
connect调用通常立即返回-1,并在使用非阻塞套接字时设置errno EINPROGRESS 。 在这种情况下,您应该使用select在连接打开或失败时等待。 connect也可能会返回0.如果您创建连接到本地主机,可能会发生这种情况。 这样你可以服务其他套接字,而一个套接字打开TCP连接。
这实际上是非常平台具体如何工作。
如果你在linux系统上运行,那真的不难,你只需要用'fork'来产生一个你的进程的副本就可以了:
#include <sys/types.h> #include <sys/socket.h> #include <stdio.h> #include <netinet.h> #include <signal.h> #include <unistd.h> int main() { int server_sockfd,client_sockfd; int server_len,client_len; struct sockaddr_in server_address; struct sockaddr_in client_address; server_sockfd = socket(AF_INET,SOCK_STREAM,0); server_address.sin_family = AF_INET; server_address.sin_addr.s_addr = htonl(INADDR_ANY); server_Address.sin_port = htons(1234); server_len = sizeof(server_address); bind(server_sockfd,(struct sockaddr *)&server_address,server_len); listen(server_sockfd,5); signal(SIGCHLD,SIG_IGN); while(1) { char ch; printf("server Waitingn"); client_len = sizeof(client_address); client_sockfd = accept(server_sockfd,(struct sockaddr *)&client_address,&client_len) // Here's where we do the forking,if you've forked already then this will be the child running,if not then your still the parent task. if(fork() == 0) { // Do what ever the child needs to do with the connected client read(client_sockfd,&ch,1); sleep(5); // just for show :-) ch++; write(client_sockfd,1); close(client_sockfd); exit(0); } else { // Parent code here,close and loop for next connection close(client_sockfd); } } }
你可能不得不用那个代码来做一些测试,我现在不在Linux附近做一个测试编译,而且我几乎从内存中输入了这个代码。
然而,使用fork是在基于Linux / Unix的系统下在C中执行此操作的标准方法。
在Windows下,这是一个非常不同的故事,而我不能完全记住所有需要的代码(我习惯于在C#中编写代码),但是设置套接字几乎是一样的,除了需要使用'Winsock'API更好的兼容性。
你可以(我相信)仍然使用窗口下的标准berkley套接字,但它充满了陷阱和漏洞,对于Windows winsock这是一个很好的开始:
http://tangentsoft.net/wskfaq/
据我所知,如果你使用Winsock,它有东西来帮助产卵和多客户端,但是我个人通常只是分离出一个单独的线程,然后复制socket连接,然后返回到循环听我的服务器。

JS事件深入理解
学习目标:
| 节数 | 知识点 | 要求 |
|---|---|---|
| 第一节 表单文档事件 | 获取焦点事件 | 了解 |
| 失去焦点事件 | 了解 | |
| 第二节 键盘事件 | 键盘事件的种类 | 了解 |
| 键盘属性 | 了解 | |
| 第三节 滚动事件 | 回到页面顶部 | 掌握 |
| 滚动事件 | 掌握 | |
| 滚动事件的属性 | 掌握 | |
| 第四节 手机触摸事件 | 手机触摸事件 | 掌握 |
| 第五节 表单注册案例 | 表单注册案例 | 掌握 |
一、表单文档事件
焦点:js当前正在和用户发生交互的节点称为焦点。可以类比为人类目光汇聚的地方。
语法:获得焦点和失去焦点事件既可以使用DOM1绑定也可以使用DOM2绑定
八哥总结说明:
这两个事件均不支持事件冒泡。
1.1获得焦点事件



i2.onfocus = function () {console.log("i2获得了焦点")};
i1.addEventListener(''focus'', function () {console.log(''i1捕获事件'');}, true);
1.2 失去焦点事件
i1.addEventListener(''blur'', function () {console.log(''i1捕获事件'');}, true);
i2.onblur = function () {console.log("i2失去了焦点")};
1.3 oninput事件和onchange事件
onchange:元素发生变化的时候,就会触发。
oninput:当给元素输入内容的时候,就会触发。
区别:
onchange:当失去焦点的时候才会触发此事件。
oninput:当输入内容的时候,会立即触发。
二、键盘事件
2.1键盘事件种类
键盘事件是指当用户在操作键盘的时候会自动被触发的事件,通常有以下三种:
(1) onkeydown:用户按下任意键都可以触发这个事件。如果按住不放,事件会被连续触发。
(2) onkeypress:用户按下任意键都可以触发这个事件(功能键除外)。如果按住不放,事件会被连续触发
(3) onkeyup: 用户释放按键时触发
ps:键盘事件一般绑定在需要用户输入的元素上(例如input),但是由于键盘事件默认采用事件冒泡机制,因此将键盘事件直接绑定在body之上也是允许的。
2.2键盘属性
key和keyCode属性
Key:具体是哪一个键
keyCode:返回keydown何keyup事件发生的时候按键的代码,以及keypress 事件的Unicode字符(ascii码值)。
A:65,a:97,0:48,空格键:32.

JUnit 5中扩展模型的深入理解
几乎所有的Java 开发人员都会使用JUnit 来做测试,但其实很多自动化测试人员也会使用Junit 。下面这篇文章主要给大家介绍了关于JUnit 5中扩展模型的相关资料,文中通过示例代码介绍的非常详细,需要的朋友可以参考下
什么是junit5 ?
先看来个公式:
JUnit 5 = JUnit Platform + JUnit Jupiter + JUnit Vintage
这看上去比Junit4 复杂,实际上在导入包时也会复杂一些。
JUnit Platform是在JVM上启动测试框架的基础。
JUnit Jupiter是junit5扩展的新的编程模型和扩展模型,用来编写测试用例。Jupiter子项目为在平台上运行Jupiter的测试提供了一个TestEngine (测试引擎)。
JUnit Vintage提供了一个在平台上运行JUnit 3和JUnit 4的TestEngine 。
关键要点
JUnit 5是一个模块化和可扩展的测试框架,支持Java 8及更高版本。
JUnit 5由三个部分组成――一个基础平台、一个新的编程和扩展模型Jupiter,以及一个名为Vintage的向后兼容的测试引擎。
JUnit 5 Jupiter的扩展模型可用于向JUnit中添加自定义功能。
扩展模型API测试生命周期提供了钩子和注入自定义参数的方法(即依赖注入)。
JUnit是最受欢迎的基于JVM的测试框架,在第5个主要版本中进行了彻底的改造。JUnit 5提供了丰富的功能――从改进的注解、标签和过滤器到条件执行和对断言消息的惰性求值。这让基于TDD编写单元测试变得轻而易举。新框架还带来了一个强大的扩展模型。扩展开发人员可以使用这个新模型向JUnit 5中添加自定义功能。本文将指导你完成自定义扩展的设计和实现。这种自定义扩展机制为Java程序员提供了一种创建和执行故事和行为(即BDD规范测试)的方法。
我们首先使用JUnit 5和我们的自定义扩展(称为“StoryExtension”)来编写一个示例故事和行为(测试方法)。这个示例使用了两个新的自定义注解“@Story”和“@Scenario”,以及“Scene”类,用以支持我们的自定义StoryExtension:
import org.junit.jupiter.api.extension.ExtendWith; import ud.junit.bdd.ext.Scenario; import ud.junit.bdd.ext.Scene; import ud.junit.bdd.ext.Story; import ud.junit.bdd.ext.StoryExtension; @ExtendWith(StoryExtension.class) @Story(name=“Returns go back to the stockpile”, description=“...“) public class StoreFrontTest { @Scenario(“refunded items should be returned to the stockpile”) public void refundedItemsShouldBeRestocked(Scene scene) { scene .given(“customer bought a blue sweater”, () -> buySweater(scene, “blue”)) .and(“I have three blue sweaters in stock”, () -> assertEquals(3, sweaterCount(scene, “blue”), “Store should carry 3 blue sweaters”)) .when(“the customer returns the blue sweater for a refund”, () -> refund(scene, 1, “blue”)) .then(“I should have four blue sweaters in stock”, () -> assertEquals(4, sweaterCount(scene, “blue”), “Store should carry 4 blue sweaters”)) .run(); } }
从代码片段中我们可以看到,Jupiter的扩展模型非常强大。我们还可以看到,我们的自定义扩展及其相应的注解为测试用例编写者提供了简单而干净的方法来编写BDD规范。
作为额外的奖励,当使用我们的自定义扩展程序执行测试时,会生成如下所示的文本报告:
STORY: Returns go back to the stockpile
As a store owner, in order to keep track of stock, I want to add items back to stock when they're returned.
SCENARIO: refunded items should be returned to stock
GIVEN that a customer prevIoUsly bought a blue sweater from me
AND I have three blue sweaters in stock
WHEN the customer returns the blue sweater for a refund
THEN I should have four blue sweaters in stock
这些报告可以作为应用程序功能集的文档。
自定义扩展StoryExtension能够借助以下核心概念来支持和执行故事和行为:
用于装饰测试类和测试方法的注解
JUnit 5 Jupiter的生命周期回调
动态参数解析
注解
示例中的“@ExtendWith”注解是由Jupiter提供的标记接口。这是在测试类或方法上注册自定义扩展的方法,目的是让Jupiter测试引擎调用给定类或方法的自定义扩展。或者,测试用例编写者可以通过编程的方式注册自定义扩展,或者通过服务加载器机制进行自动注册。
我们的自定义扩展需要一种识别故事的方法。为此,我们定义了一个名为“Story”的自定义注解类,如下所示:
import org.junit.platform.commons.annotation.Testable; @Testable public @interface Story {...}
测试用例编写者应该使用这个自定义注解将测试类标记为故事。请注意,这个注解本身使用了JUnit 5内置的“@Testable”注解。这个注解为IDE和其他工具提供了一种识别可测试的类和方法的方式――也就是说,带有这个注解的类或方法可以通过JUnit 5 Jupiter测试引擎来执行。
我们的自定义扩展还需要一种方法来识别故事中的行为或场景。为此,我们定义一个名为“Scenario”的自定义注解类,看起来像这样:
import org.junit.jupiter.api.Test; @Test public @interface Scenario {...}
测试用例编写者应使用这个自定义注解将测试方法标记为场景。这个注解本身使用了JUnit 5 Jupiter的内置“@Test”注解。当IDE和测试引擎扫描给定的一组测试类并在公共实例方法上找到@Scenario注解时,就会将这些方法标记为可执行的测试方法。
请注意,与JUnit 4的@Test注解不同,Jupiter的@Test注解不支持可选的“预期”异常和“超时”参数。Jupiter的@Test注解是从头开始设计的,并考虑到了可扩展性。
生命周期
JUnit 5 Jupiter提供了扩展回调,可用于访问测试生命周期事件。扩展模型提供了几个接口,用于在测试执行生命周期的各个时间点对测试进行扩展:

扩展开发者可以自由地实现所有或部分生命周期接口。
“BeforeAllCallback”接口提供了一种方法用于初始化扩展并在调用JUnit测试容器中的测试用例之前添加自定义逻辑。我们的StoryExtension类将实现这个接口,以确保给定的测试类使用了“@Story”注解。
import org.junit.jupiter.api.extension.BeforeAllCallback; public class StoryExtension implements BeforeAllCallback { @Override public void beforeAll(ExtensionContext context) throws Exception { if (!AnnotationSupport .isAnnotated(context.getrequiredTestClass(), Story.class)) { throw new Exception(“Use @Story annotation...“); } } }
Jupiter引擎将提供一个用于运行扩展的执行上下文。我们使用这个上下文来确定正在执行的测试类是否使用了“@Story”注解。我们使用JUnit平台提供的AnnotationSupport辅助类来检查是否存在这个注解。
回想一下,我们的自定义扩展在执行测试后会生成BDD报告。这些报告的某些部分是从“@Store”注解的元素中提取的。我们使用beforeAll回调来保存这些字符串。稍后,在执行生命周期结束时,再基于这些字符串生成报告。我们使用了一个简单的POJO。我们将这个类命名为“StoryDetails”。以下代码片段演示了创建这个类实例的过程,并将注解元素保存到实例中:
public class StoryExtension implements BeforeAllCallback { @Override public void beforeAll(ExtensionContext context) throws Exception { Class> clazz = context.getrequiredTestClass(); Story story = clazz.getAnnotation(Story.class); StoryDetails storyDetails = new StoryDetails() .setName(story.name()) .setDescription(story.description()) .setClassName(clazz.getName()); context.getStore(NAMESPACE).put(clazz.getName(), storyDetails); } }
我们需要解释一下方法的最后一个语句。我们实际上是从执行上下文中获取一个带有名字的存储,并将新创建的“StoryDetails”实例保存到这个存储中。
自定义扩展可以使用存储来保存和获取任意数据――基本上就是一个存在于内存中的map。为了避免多个扩展之间出现意外的key冲突,JUnit引入了命名空间的概念。命名空间是一种对不同扩展保存的数据进行隔离的方法。用于隔离扩展数据的一种常用方法是使用自定义扩展类名:
private static final Namespace NAMESPACE = Namespace .create(StoryExtension.class);
我们的扩展需要用到的另一个自定义注解是“@Scenario”注解。这个注解用于将测试方法标记为故事中的场景或行为。我们的扩展将解析这些场景,以便将它们作为JUnit测试用例来执行并生成报告。回想一下我们之前看到的生命周期图中的“BeforeEachCallback”接口,在调用每个测试方法之前,我们将使用回调来添加附加逻辑:
import org.junit.jupiter.api.extension.BeforeEachCallback; public class StoryExtension implements BeforeEachCallback { @Override public void beforeEach(ExtensionContext context) throws Exception { if (!AnnotationSupport. isAnnotated(context.getrequiredTestMethod(), Scenario.class)) { throw new Exception(“Use @Scenario annotation...“); } } }
如前所述,Jupiter引擎将提供一个用于运行扩展的执行上下文。我们使用上下文来确定正在执行的测试方法是否使用了“@Scenario”注解。
回到本文的开头,我们提供了一个故事的示例代码,我们的自定义扩展负责将“Scene”类的实例注入到每个测试方法中。Scene类让测试用例编写者能够使用“given”、“then”和“when”等步骤来定义场景(行为)。Scene类是我们自定义扩展的中心单元,它包含了特定于测试方法的状态信息。状态信息可以在场景的各个步骤之间传递。我们使用“BeforeEachCallback”接口在调用测试方法之前准备一个Scene实例:如前所述,Jupiter引擎将提供一个用于运行扩展执行上下文。我们使用上下文来确定正在执行的测试方法是否使用了“@Scenario”注解。
public class StoryExtension implements BeforeEachCallback { @Override public void beforeEach(ExtensionContext context) throws Exception { Scene scene = new Scene() .setDescription(getValue(context, Scenario.class)); Class> clazz = context.getrequiredTestClass(); StoryDetails details = context.getStore(NAMESPACE) .get(clazz.getName(), StoryDetails.class); details.put(scene.getmethodName(), scene); } }
上面的代码与我们在“BeforeAllCallback”接口方法中所做的非常相似。
动态参数解析
现在我们还缺少一个东西,即如何将场景实例注入到测试方法中。Jupiter的扩展模型为我们提供了一个“ParameterResolver”接口。这个接口为测试引擎提供了一种方法,用于识别希望在测试执行期间动态注入参数的扩展。我们需要实现这个接口的两个方法,以便注入我们的场景实例:
import org.junit.jupiter.api.extension.ParameterResolver; public class StoryExtension implements ParameterResolver { @Override public boolean supportsParameter(ParameterContext parameterContext, ExtensionContext extensionContext) { Parameter parameter = parameterContext.getParameter(); return Scene.class.equals(parameter.getType()); } @Override public Object resolveParameter(ParameterContext parameterContext, ExtensionContext extensionContext) { Class> clazz = extensionContext.getrequiredTestClass(); StoryDetails details = extensionContext.getStore(NAMESPACE) .get(clazz.getName(), StoryDetails.class); return details.get(extensionContext .getrequiredTestMethod().getName()); } }
上面的第一个方法告诉Jupiter我们的自定义扩展是否可以注入测试方法所需的参数。
在第二个方法“resolveParameter()”中,我们从执行上下文的存储中获取StoryDetails实例,然后从StoryDetails实例中获取先前为给定测试方法创建的场景实例,并将其传给测试引擎。测试引擎将这个场景实例注入到测试方法中并执行测试。请注意,仅当“supportsParameter()”方法返回true值时才会调用“resolveParameter()”方法。
最后,为了在执行完所有故事和场景后生成报告,自定义扩展实现了“AfterallCallback”接口:
import org.junit.jupiter.api.extension.AfterallCallback; public class StoryExtension implements AfterallCallback { @Override public void afterall(ExtensionContext context) throws Exception { new StoryWriter(getStoryDetails(context)).write(); } }
“StoryWriter”是一个自定义类,可生成报告并将其保存到JSON或文本文件中。
现在,让我们看看如何使用这个自定义扩展来编写BDD风格的测试用例。Gradle 4.6及更高版本支持使用JUnit 5运行单元测试。你可以使用build.gradle文件来配置JUnit 5。
dependencies { testCompile group: “ud.junit.bdd”, name: “bdd-junit”, version: “0.0.1-SNAPSHOT” testCompile group: “org.junit.jupiter”, name: “junit-jupiter-api”, version: “5.2.0" testRuntime group: “org.junit.jupiter”, name: “junit-jupiter-engine”, version: “5.2.0” } test { useJUnitPlatform() }
如你所见,我们通过“useJUnitPlatform()”方法要求gradle使用JUnit 5。然后我们就可以使用StoryExtension类来编写测试用例。这是本文开头给出的示例:
import org.junit.jupiter.api.extension.ExtendWith; import ud.junit.bdd.ext.Scenario; import ud.junit.bdd.ext.Story; import ud.junit.bdd.ext.StoryExtension; @ExtendWith(StoryExtension.class) @Story(name=“Returns go back to the stockpile”, description=“...“) public class StoreFrontTest { @Scenario(“refunded items should be returned to the stockpile”) public void refundedItemsShouldBeRestocked(Scene scene) { scene .given(“customer bought a blue sweater”, () -> buySweater(scene, “blue”)) .and(“I have three blue sweaters in stock”, () -> assertEquals(3, sweaterCount(scene, “blue”), “Store should carry 3 blue sweaters”)) .when(“the customer returns the blue sweater for a refund”, () -> refund(scene, 1, “blue”)) .then(“I should have four blue sweaters in stock”, () -> assertEquals(4, sweaterCount(scene, “blue”), “Store should carry 4 blue sweaters”)) .run(); } }
我们可以通过“gradle testClasses”来运行测试,或者使用其他支持JUnit 5的IDE。除了常规的测试报告外,自定义扩展还为所有测试类生成BDD文档。
结论
我们描述了JUnit 5扩展模型以及如何利用它来创建自定义扩展。我们设计并实现了一个自定义扩展,测试用例编写者可以使用它来创建和执行故事。读者可以从GitHub上获取代码,并研究如何使用Jupiter扩展模型及其API来实现自定义扩展。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对小编的支持。

libuv的事件驱动模型
libuv非常高效, 它利用事件驱动/异步IO, 实现线程的高度复用; 比如定时器, 网络传输等, 都可以使用同一个线程来执行. 本文是以unix/core.c为例.
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
int ran_pending;
r = uv__loop_alive(loop);
if (!r)
uv__update_time(loop);
//主循环
while (r != 0 && loop->stop_flag == 0) {
//获取当前系统时间, linux上调用系统的clock_gettime
uv__update_time(loop);
//检查定时器是否达到触发条件, 如果需要触发, 将执行timer的回调函数
uv__run_timers(loop);
//执行其它的待处理的任务, 比如网络事件, uv__io_poll触发网络事件时, 会将触发的socket存入poll_fds
ran_pending = uv__run_pending(loop);
//uv__run_idle和uv__run_prepare是用宏定义出来的, IDE没办法直接找到它的定义;
//见loop-watcher.c中的#define UV_LOOP_WATCHER_DEFINE(name, type)
//监听idle事件和prepare事件, 它们的本质是一样的; 如果设置了这样的事件, 则本循环将一直循环, 不会停顿;
uv__run_idle(loop);
uv__run_prepare(loop);
//计算下一次需要定时的时间; 如果设置了idle或者是prepare事件, 这个值为0, 否则就是timer中最短的那个超时时间
timeout = 0;
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
timeout = uv_backend_timeout(loop);
//linux调用epoll来监听网络事件, 并利用它实现定时
uv__io_poll(loop, timeout);
//与uv__run_idle, uv__run_prepare一样的机制, 用的少
uv__run_check(loop);
//close的相关操作也可以是异步的.
uv__run_closing_handles(loop);
if (mode == UV_RUN_ONCE) {
/* UV_RUN_ONCE implies forward progress: at least one callback must have
* been invoked when it returns. uv__io_poll() can return without doing
* I/O (meaning: no callbacks) when its timeout expires - which means we
* have pending timers that satisfy the forward progress constraint.
*
* UV_RUN_NOWAIT makes no guarantees about progress so it''s omitted from
* the check.
*/
uv__update_time(loop);
uv__run_timers(loop);
}
r = uv__loop_alive(loop);
if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)
break;
}
/* The if statement lets gcc compile it to a conditional store. Avoids
* dirtying a cache line.
*/
if (loop->stop_flag != 0)
loop->stop_flag = 0;
return r;
}
在由loop调用的各种回调函数中, 添加或删除定时器, 或创建/销毁新的网络连接, 是安全的. 但是如果在其它的线程中, 直接调用loop的接口, 不是线程安全的, 非常危险. 所以libuv通常的例子是这样的:
int main() {
loop = uv_default_loop();
//在loop循环之前, 先把各种定时或网络任务设置好.
uv_timer_init(loop, &gc_req);
uv_unref((uv_handle_t*) &gc_req);
uv_timer_start(&gc_req, gc, 0, 2000);
// could actually be a TCP download or something
uv_timer_init(loop, &fake_job_req);
uv_timer_start(&fake_job_req, fake_job, 9000, 0);
//各种定时任务初始化完成之后, 再执行loop循环
return uv_run(loop, UV_RUN_DEFAULT);
}
我们今天的关于对Node.js事件驱动模型的深入理解和对node.js事件驱动模型的深入理解是什么的分享就到这里,谢谢您的阅读,如果想了解更多关于C中的事件驱动模型、JS事件深入理解、JUnit 5中扩展模型的深入理解、libuv的事件驱动模型的相关信息,可以在本站进行搜索。
本文标签:




