本篇文章给大家谈谈jsdom,以及江苏迪欧姆股份有限公司的知识点,同时本文还将给你拓展DOM,SAX,JDOM,DOM4J解析比较(二)、DOM4J、DOM、JDOM和SAX之间的比较、DOMJS高级
本篇文章给大家谈谈js dom,以及江苏迪欧姆股份有限公司的知识点,同时本文还将给你拓展DOM,SAX,JDOM,DOM4J 解析比较 (二)、DOM4J、DOM、JDOM和SAX之间的比较、DOMJS高级程序设计笔记——DOM2和DOM3、dom渲染流程(cssdom和dom)等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- js dom(江苏迪欧姆股份有限公司)
- DOM,SAX,JDOM,DOM4J 解析比较 (二)
- DOM4J、DOM、JDOM和SAX之间的比较
- DOMJS高级程序设计笔记——DOM2和DOM3
- dom渲染流程(cssdom和dom)
")
js dom(江苏迪欧姆股份有限公司)
一:DOM
DOM(Document Object Model)是一套对文档的内容进行抽象和概念化的方法。
当网页被加载时,浏览器会创建页面的文档对象模型(Document Object Model)。
HTML DOM 模型被构造为对象的树。
html dom树:
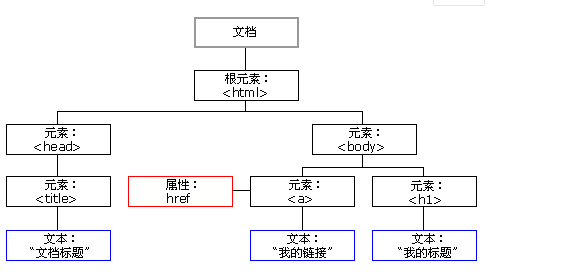
DOM标准规定HTML文档中的每个成分都是一个节点(node):
- 文档节点(document对象):代表整个文档
- 元素节点(element 对象):代表一个元素(标签)
- 文本节点(text对象):代表元素(标签)中的文本
- 属性节点(attribute对象):代表一个属性,元素(标签)才有属性
- 注释是注释节点(comment对象)
JavaScript 可以通过DOM创建动态的 HTML:
- JavaScript 能够改变页面中的所有 HTML 元素
- JavaScript 能够改变页面中的所有 HTML 属性
- JavaScript 能够改变页面中的所有 CSS 样式
- JavaScript 能够对页面中的所有事件做出反应
查找标签
直接查找
document.getElementById 根据ID获取一个标签 document.getElementsByClassName 根据class属性获取 document.getElementsByTagName 根据标签名获取标签合集
注意:
涉及到DOM操作的JS代码应该放在文档的哪个位置。
例子:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div id="d1">id=1</div>
<div>c1</div>
<script>
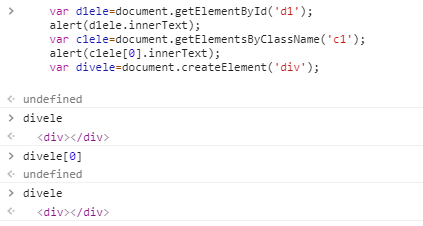
id名
var d1ele=document.getElementById(''d1'');
alert(d1ele.innerText)
类名
var c1ele=document.getElementsByClassName(''c1'');
alert(c1ele【0】.innerText)
标签名
var divele=document.createElement(''div'');
divele
</script> </body> </html>
运行结果:弹出id=1和undentify
注意:获取类名的时候一定要从索引里面找【0】
然后就是获取标签名直接输入标签名就可以了。最好是解释器运行。不要在pycharm运行。
dom节点操作:

间接查找
parentElement 父节点标签元素 children 所有子标签 firstElementChild 第一个子标签元素 lastElementChild 最后一个子标签元素 nextElementSibling 下一个兄弟标签元素 previousElementSibling 上一个兄弟标签元素
节点操作
创建节点
语法:
createElement(标签名)
示例:
var divEle = document.createElement("div");
添加节点
语法:
追加一个子节点(作为最后的子节点)
somenode.appendChild(newnode);
把增加的节点放到某个节点的前边。
somenode.insertBefore(newnode,某个节点);
示例:
var imgEle=document.createElement("img");
imgEle.setAttribute("src", "http://image11.m1905.cn/uploadfile/s2010/0205/20100205083613178.jpg");
var d1Ele = document.getElementById("d1");
d1Ele.appendChild(imgEle);
删除节点:
语法:
获得要删除的元素,通过父元素调用删除。
removeChild(要删除的节点)
替换节点:
语法:
somenode.replaceChild(newnode, 某个节点);
属性节点
获取文本节点的值:
var divEle = document.getElementById("d1")
divEle.innerText
divEle.innerHTML
设置文本节点的值:
var divEle = document.getElementById("d1")
divEle.innerText="1"
divEle.innerHTML="<p>2</p>"
attribute操作
var divEle = document.getElementById("d1");
divEle.setAttribute("age","18")
divEle.getAttribute("age")
divEle.removeAttribute("age")
// 自带的属性还可以直接.属性名来获取和设置
imgEle.src
imgEle.src="..."
获取值操作
语法:
elementNode.value
适用于以下标签:
- .input
- .select
- .textarea
var iEle = document.getElementById("i1");
console.log(iEle.value);
var sEle = document.getElementById("s1");
console.log(sEle.value);
var tEle = document.getElementById("t1");
console.log(tEle.value);
class的操作
className 获取所有样式类名(字符串) classList.remove(cls) 删除指定类 classList.add(cls) 添加类 classList.contains(cls) 存在返回true,否则返回false classList.toggle(cls) 存在就删除,否则添加
指定CSS操作
obj.style.backgroundColor="red"
JS操作CSS属性的规律:
1.对于没有中横线的CSS属性一般直接使用style.属性名即可。如:
obj.style.margin obj.style.width obj.style.left obj.style.position
2.对含有中横线的CSS属性,将中横线后面的第一个字母换成大写即可。如:
obj.style.marginTop obj.style.borderLeftWidth obj.style.zIndex obj.style.fontFamily
事件
HTML 4.0 的新特性之一是有能力使 HTML 事件触发浏览器中的动作(action),比如当用户点击某个 HTML 元素时启动一段 JavaScript。下面是一个属性列表,这些属性可插入 HTML 标签来定义事件动作。
常用事件
onclick 当用户点击某个对象时调用的事件句柄。 ondblclick 当用户双击某个对象时调用的事件句柄。 onfocus 元素获得焦点。 // 练习:输入框 onblur 元素失去焦点。 应用场景:用于表单验证,用户离开某个输入框时,代表已经输入完了,我们可以对它进行验证. onchange 域的内容被改变。 应用场景:通常用于表单元素,当元素内容被改变时触发.(select联动) onkeydown 某个键盘按键被按下。 应用场景: 当用户在最后一个输入框按下回车按键时,表单提交. onkeypress 某个键盘按键被按下并松开。 onkeyup 某个键盘按键被松开。 onload 一张页面或一幅图像完成加载。 onmousedown 鼠标按钮被按下。 onmousemove 鼠标被移动。 onmouseout 鼠标从某元素移开。 onmouseover 鼠标移到某元素之上。 onselect 在文本框中的文本被选中时发生。 onsubmit 确认按钮被点击,使用的对象是form。
绑定方式:
方式一:
<div id="d1" onclick="changeColor(this);">点我</div>
<script>
function changeColor(ths) {
ths.style.backgroundColor="green";
}
</script>
注意:
this是实参,表示触发事件的当前元素。
函数定义过程中的ths为形参。
方式二:
<div id="d2">点我</div>
<script>
var divEle2 = document.getElementById("d2");
divEle2.onclick=function () {
this.innerText="呵呵";
}
</script>
事件示例:
搜索框示例
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>搜索框示例</title>
</head>
<body>
<input id="d1" type="text" value="请输入关键字" onblur="blur()" onfocus="focus()">
<script>
function focus(){
var inputEle=document.getElementById("d1");
if (inputEle.value==="请输入关键字"){
inputEle.value="";
}
}
function blur(){
var inputEle=document.getElementById("d1");
var val=inputEle.value;
if(!val.trim()){
inputEle.value="请输入关键字";
}
}
</script>
</body>
</html>
select联动
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="x-ua-compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>select联动</title>
</head>
<body>
<select id="province">
<option>请选择省:</option>
</select>
<select id="city">
<option>请选择市:</option>
</select>
<script>
data = {"河北省": ["廊坊", "邯郸"], "北京": ["朝阳区", "海淀区"], "山东": ["威海市", "烟台市"]};
var p = document.getElementById("province");
var c = document.getElementById("city");
for (var i in data) {
var optionP = document.createElement("option");
optionP.innerHTML = i;
p.appendChild(optionP);
}
p.onchange = function () {
var pro = (this.options[this.selectedIndex]).innerHTML;
var citys = data[pro];
// 清空option
c.innerHTML = "";
for (var i=0;i<citys.length;i++) {
var option_city = document.createElement("option");
option_city.innerHTML = citys[i];
c.appendChild(option_city);
}
}
</script>
</body>
</html>")
DOM,SAX,JDOM,DOM4J 解析比较 (二)

公有部分:
books.xml
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book id="1">
<name>西游记</name>
<author>吴承恩</author>
<year>19XX</year>
</book>
<book id="2">
<name>冰与火之歌</name>
<year>2014</year>
<author>乔治马丁</author>
<price>11</price>
</book>
</bookstore>Book 类:
public class Book {
private String id;
private String name;
private String author;
private String year;
private String price;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getYear() {
return year;
}
public void setYear(String year) {
this.year = year;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
}DOM 解析:
public class DOMTest {
public static void main(String[] args) {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder db = dbf.newDocumentBuilder();
Document document = db.parse("books.xml");
NodeList bookList = document.getElementsByTagName("book");
System.out.println("一共有" + bookList.getLength() + "本书");
for (int i = 0; i < bookList.getLength(); i++) {
System.out.println("=================下面开始遍历第" + (i + 1)
+ "本书的内容=================");
// 解析属性值
/*for (int k = 0; k < bookList.getLength(); k++) {
Node book = bookList.item(k);
NamedNodeMap attrs = book.getAttributes();
for (int j = 0; j < attrs.getLength(); j++) {
Node attr = attrs.item(j);
System.out.print("属性名:" + attr.getNodeName());
System.out.println("--属性值" + attr.getNodeValue());
}
}*/
// 解析属性值
Element book = (Element) bookList.item(i);
String attrValue = book.getAttribute("id");
System.out.println("id属性的属性值为" + attrValue);
NodeList childNodes = book.getChildNodes();
for (int k = 0; k < childNodes.getLength(); k++) {
if (childNodes.item(k).getNodeType() == Node.ELEMENT_NODE) {
System.out.print("节点名:"
+ childNodes.item(k).getNodeName());
/**
* 请注意,这里还使用了一个getFirstChild()方法来获得message下面的第一个子Node对象。虽然在message标签下面除了文本外并没有其它子标签或者属性,
* 但是我们坚持在这里使用getFirseChild()方法,这主要和W3C对DOM的定义有关。W3C把标签内的文本部分也定义成一个Node,所以先要得到代表文本的那个Node,
* 我们才能够使用getNodeValue()来获取文本的内容。
*/
System.out.println("--节点值是:"
+ childNodes.item(k).getFirstChild()
.getNodeValue());
/* System.out.println("--节点值是:" +
childNodes.item(k).getTextContent());*/
}
}
System.out.println("======================结束遍历第" + (i + 1)
+ "本书的内容=================");
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}结果:
一共有 2 本书
================= 下面开始遍历第 1 本书的内容 =================
id 属性的属性值为 1
节点名:name-- 节点值是:西游记
节点名:author-- 节点值是:吴承恩
节点名:year-- 节点值是:19XX
====================== 结束遍历第 1 本书的内容 =================
================= 下面开始遍历第 2 本书的内容 =================
id 属性的属性值为 2
节点名:name-- 节点值是:冰与火之歌
节点名:year-- 节点值是:2014
节点名:author-- 节点值是:乔治马丁
节点名:price-- 节点值是:11
====================== 结束遍历第 2 本书的内容 =================
SAX 解析:
public class SAXParserHandler extends DefaultHandler {
String value = null;
Book book;
private ArrayList<Book> bookList = new ArrayList<Book>();
public ArrayList<Book> getBookList() {
return bookList;
}
// 遍历xml文件的开始标签
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// TODO Auto-generated method stub
super.startElement(uri, localName, qName, attributes);
// 解析book元素
if (qName.equals("book")) {
// 已知book属性的名称
/*
* String value = attributes.getValue("id");
* System.out.println("book属性值:" + value);
*/
book = new Book();
int num = attributes.getLength();
for (int i = 0; i < num; i++) {
System.out.println("属性名:" + attributes.getQName(i));
System.out.println("属性值:" + attributes.getValue(i));
if(attributes.getQName(i).equals("id")){
book.setId(attributes.getValue(i));
}
}
}else if (!qName.equals("bookstore")) {
System.out.print("节点名是:" + qName + "---");
}
}
// 遍历xml文件的结束标签
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
// TODO Auto-generated method stub
super.endElement(uri, localName, qName);
//判断结束节点
if(qName.equals("book")){
bookList.add(book);
System.out.println("结束遍历");
}else if(qName.equals("name")){
book.setName(value);
}else if(qName.equals("author")){
book.setAuthor(value);
}else if(qName.equals("year")){
book.setYear(value);
}else if(qName.equals("price")){
book.setPrice(value);
}
}
// 标示解析开始
@Override
public void startDocument() throws SAXException {
// TODO Auto-generated method stub
super.startDocument();
System.out.println("解析开始");
}
// 标示解析结束
@Override
public void endDocument() throws SAXException {
// TODO Auto-generated method stub
super.endDocument();
System.out.println("解析结束");
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
// TODO Auto-generated method stub
super.characters(ch, start, length);
value = new String(ch,start,length);
if(!value.trim().equals("")){
System.out.println(value.trim());
}
}public class SAXTest {
public static void main(String[] args) throws ParserConfigurationException, SAXException {
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
SAXParser saxParser = saxParserFactory.newSAXParser();
SAXParserHandler handler = new SAXParserHandler();
try {
saxParser.parse("books.xml", handler);
System.out.println(handler.getBookList().size() + "本书");
for(int i=0;i<handler.getBookList().size();i++){
System.out.println("第"+i+"本书");
System.out.println(handler.getBookList().get(i).getId());
System.out.println(handler.getBookList().get(i).getAuthor());
System.out.println(handler.getBookList().get(i).getName());
System.out.println(handler.getBookList().get(i).getPrice());
System.out.println(handler.getBookList().get(i).getYear());
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}结果:
解析开始
属性名:id
属性值:1
节点名是:name--- 西游记
节点名是:author--- 吴承恩
节点名是:year---19XX
结束遍历
属性名:id
属性值:2
节点名是:name--- 冰与火之歌
节点名是:year---2014
节点名是:author--- 乔治马丁
节点名是:price---11
结束遍历
解析结束
2 本书
第 0 本书
1
吴承恩
西游记
null
19XX
第 1 本书
2
乔治马丁
冰与火之歌
11
2014
JDOM 解析:
public class JDOMTest {
public static void main(String[] args) {
SAXBuilder saxBuilder = new SAXBuilder();
InputStream inputStream;
try {
ArrayList<Book> arrayList = new ArrayList<Book>();
inputStream = new FileInputStream("books.xml");
Document document = saxBuilder.build(inputStream);
// 得到根节点
Element element = document.getRootElement();
List<Element> list = element.getChildren();
for (Element book : list) {
Book jdom_book = new Book();
System.out.println("第" + list.indexOf(book) + "本书");
List<Attribute> attributes = book.getAttributes();
for (Attribute attribute : attributes) {
System.out.print("属性名:" + attribute.getName() + " ");
System.out.println("属性值:" + attribute.getValue() + " ");
if (attribute.getName().equals("id")) {
jdom_book.setId(attribute.getName());
}
}
List<Element> boolChilds = book.getChildren();
for (Element element2 : boolChilds) {
System.out.print("节点名:" + element2.getName() + " ");
System.out.println("节点值:" + element2.getValue() + " ");
if (element2.getName().equals("name")) {
jdom_book.setName(element2.getName());
}
if (element2.getName().equals("author")) {
jdom_book.setAuthor(element2.getName());
}
if (element2.getName().equals("year")) {
jdom_book.setYear(element2.getName());
}
if (element2.getName().equals("price")) {
jdom_book.setPrice(element2.getName());
}
}
arrayList.add(jdom_book);
}
System.out.println(arrayList.size());
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}结果:
第 0 本书
属性名:id 属性值:1
节点名:name 节点值:西游记
节点名:author 节点值:吴承恩
节点名:year 节点值:19XX
第 1 本书
属性名:id 属性值:2
节点名:name 节点值:冰与火之歌
节点名:year 节点值:2014
节点名:author 节点值:乔治马丁
节点名:price 节点值:11
2
DOM4J 解析:
public class DOM4JTest {
public static void main(String[] args) {
SAXReader reader = new SAXReader();
try {
Document document = reader.read("books.xml");
Element element_root = document.getRootElement();
Iterator iterator = element_root.elementIterator();
while (iterator.hasNext()) {
Element book = (Element) iterator.next();
List<Attribute> list = book.attributes();
for (Attribute attribute : list) {
System.out.print("节点名:" + attribute.getName() + " ");
System.out.println("节点值:" + attribute.getValue() + " ");
}
Iterator itt = book.elementIterator();
while (itt.hasNext()) {
Element element = (Element) itt.next();
System.out.print("节点名:" + element.getName() + " ");
System.out.println("节点值:" + element.getStringValue());
}
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}结果:
节点名:id 节点值:1
节点名:name 节点值:西游记
节点名:author 节点值:吴承恩
节点名:year 节点值:19XX
节点名:id 节点值:2
节点名:name 节点值:冰与火之歌
节点名:year 节点值:2014
节点名:author 节点值:乔治马丁
节点名:price 节点值:11
总结:
DOM 解析:
形成树结构,直观好理解,代码更易编写
解析过程中树结构保留在内存中,方便修改
当 xml 文件较大的时候,对内存消耗比较大,容易影响解析性能并造成内存溢出
SAX 解析:
一行一行地解析 触发事件。。 调用不同的方法
对内存消耗比较小
适用于只需要处理 xml 中数据时候
不易编码
很难同时访问同一个 xml 中多处不同的数据
JDOM 解析:
仅使用具体类而不是用接口
API 大量使用 Collections 类
DOM4J:
现在比较流行的一种解析 xml 文件的方式
jdom 的一种智能分支,他合并了许多超出基本 xml 表示的功能
dom4j 使用接口和抽象类方法,是一种优秀的 JavaxmlAPI
具有性能优异、灵活性号、功能强大和极易用和使用的特点
是一种开源代码的软件

DOM4J、DOM、JDOM和SAX之间的比较
DOM4J是四个中性能最好的,连Sun的JAXM用的都是DOM4J。很多开源项目中也大量采用DOM4J,例如大名鼎鼎的Hibernate也用DOM4J来读取XML配置文件。若忽略可移植性,可以采用DOM4J.
JDOM和DOM在性能测试中相对较弱,在测试10M文档的时候存在内存溢出的问题,但可移植。在小文档情况下还值得考虑使用DOM和JDOM.虽然JDOM的开发者已经说明他们期望在正式发行版前专注性能问题,但是从性能观点来看,它确实没有值得推荐之处。另外,DOM仍是一个非常好的选择。DOM实现广泛应用于多种编程语言。它还是许多其它与XML相关的标准的基础,因为它正式获得W3C推荐(与基于非标准的Java模型相对),所以在某些类型的项目中可能也需要它(如在JavaScript中使用DOM)。
SAX表现较好,这要依赖于它特定的解析方式-事件驱动。一个SAX检测即将到来的XML流,但并没有载入到内存(当然当XML流被读入时,会有部分文档暂时隐藏在内存中)。
如果XML文档较大且不考虑移植性问题建议采用DOM4J;如果XML文档较小则建议采用JDOM;如果需要及时处理而不需要保存数据则考虑SAX。但无论如何,还是那句话:适合自己的才是最好的,如果时间允许,建议大家将这四种方法都尝试一遍然后选择一种适合自己的即可。

DOMJS高级程序设计笔记——DOM2和DOM3
DOM1级主要定义了HTML和XML文档的底层结构,DOM2和DOM3则在DOM1的基础上引入了更多的交互功能,支持了更高级的XML特性。DOM2和DOM3分为许多模块(模块之间具有某种联系),这些模块如下:
DOM2级核心:在1级核心基础上,为节点添加了更多方法和属性。
DOM2级视图:为文档定义了基于样式信息的不同视图
DOM2级HTML:在1级HTML基础上构建,添加了更多属性、方法和新接口
DOM2级样式:定义了如何以编程方式来访问和改变CSS样式信息
DOM2级遍历和范围:引入了遍历DOM文档和选择其特定部分的新接口
DOM2级事件:说明了如何以编程方式来访问和改变CSS样式
DOM3级XPath
DOM3级加载与保存
一、DOM的变化
(一)针对xml命名空间的变化
有了XML命名空间,不同XML文档的元素就可以混合在一起,共同构成格式良好的文档,而不必担心发生命名冲突。从技术上说,HTML不支持XML命名空间,但XHTML支持XML命名空间。
在此,先不讨论针对xml命名空间的变化,后续有需要再进行更新。
(二)其他方面的变化
其他方面的变化与XML命名空间无关,这些变化是为了确保API的可靠性及完整性
1、DocumentType类型的变化
DocumentType类型新增了3个属性(在网页中很少需要使用以下三个属性访问此类信息):
publicId
systemId
internalSubset
2、Document类型的变化
3、Node类型的变化
4、框架的变化
二、样式
(一)访问元素的样式
1、DOM style属性的属性和方法
DOM2级样式规范为style对象定义了一些属性和方法:
cssText:返回style属性中的CSS代码
length:HTML元素的style属性中包含的CSS属性的个数
item(index):
getPropertyValue(propertyName)
getPropertyCSSValue(propertyName):返回一个CSSValue(实际开发中用得很少)
getPropertyPriority(propertyName):若属性使用了!important设置,则返回"!important";否则,返回空字符串
removeProperty(propertyName)
setProperty(propertyName,value,priority):参数priority的取值为"!important"或空字符串
parentRule:表示CSS信息的CSSRule对象
2、计算的样式
元素的style对象只包含通过style属性设置的样式信息,不包含其他样式表中的信息。为了得到应用在当前元素的所有样式,DOM2级增加了document.defaultView属性,并为该属性提供了getComputedStyle()方法。
语法:document.default.getComputedStyle(要取得样式的元素, 伪元素字符串)(伪元素字符串如:":after",若不需要伪元素信息,则该参数为null)
getComputedStyle()返回一个CSSStyleDeclaration对象,包含应用在当前元素的所有样式。
var div = document.getElementById("#myDiv");
var computedStyle = document.defaultView.getComputedSytle(div,null);IE不支持getComputedStyle(),但它为每个支持style属性的元素指定了currentStyle属性,这个属性返回一个CSSStyleDeclaration对象。
var div = document.getElementById("#myDiv");
var computedStyle = div.currentStyle;(二)操作样式表
可以用CSSStyleSheet类型来表示样式表,它包括<link>元素包含的样式表和<style>元素中定义的样式表。
DOM2级定义了获取样式表的属性,返回CSSStyleSheet对象,该对象是一套只读的接口。
document.styleSheets返回的是应用于文档的所有样式表的对象集合
-
还可以通过<link>或<style>元素直接获取CSSStyleSheet对象,获取的方式是使用sheet属性(非IE),或styleSheet属性(IE)
function getStyleSheet(element){ return element.sheet || element.styleSheet; } //获取第一<link>元素引入的样式表 var link = document.getElementsByTagName("link")[0] var sheet = getStyleSheet(link);
1、CSS规则
CSSRule表示样式表中的每一条规则。其实,CSSRule是一个供其他多种类型继承的基类型,其中最常见的是CSSStyleRule,表示样式信息。CSSStyleRule对象包含下列属性:
(1) cssText:返回整条规则对应的文本(包括CSS选择符和花括号)
(2)selectorText:返回当前规则的选择符
(3)style:一个CSSStyleDeclaration对象(style.cssText返回规则中所有的CSS样式)
(4)parentRule:
(5)parentStyleSheet:当前规则所属的样式表
(6)type:表示规则类型的常量值。
上述属性中,前三个常用。
2、创建规则
使用insertRule()可以向现有样式表中添加新规则
-
语法:sheet.insertRule(规则文本,插入规则的位置)
sheet.insertRule("body{background-color:silver;}",0); -
IE8及更早版本支持一个类似的方法:addRule(选择符文本,CSS样式信息,插入规则的位置)
sheet.addRule("body","background-color:silver",0); 若要添加的规则非常多,请使用动态加载样式表的技术
3、删除规则
若要删除某天规则,请使用deleteRule(index)
sheet.deleteRule(0) //IE之外的浏览器
sheet.removeRule(0) //IE
//跨浏览器删除规则的函数
function deleteRule(sheet, index){
if(sheet.deleteRule){
sheet.deleteRule(index);
}
else if(sheet.removeRule){
sheet.removeRule(index);
}
}请慎用删除规则的方法
(三)元素的大小
下面介绍的属性和方法并不属于“DOM2级样式”规范,但却与HTML元素的样式息息相关。
1、偏移量
元素的偏移量涉及4个属性(这些偏移量属性都是只读的,每次访问都会重新计算):
offsetHeight:包含可见的垂直滚动条高度
offsetWidth:包含可见的垂直滚动条宽度
offsetLeft
offsetTop
下图反映了上述4个属性的表示范围:

2、客户区大小
客户区大小指的是,元素内容及其内边距所占据的空间大小(不包括滚动条及边框)
与客户区大小有关的属性有两个:
clientWidth
clientHeight
下图反映了上述两个属性的表示范围:

三、范围
DOM2级为Document类型定义了createRange()方法,该方法可以创建范围:
var range = document.createRange();每一个范围由一个Range类型的实例表示,该实例拥有很多属性和方法,下列属性提供了当前范围在文档中的位置信息:
startContainer:选区中第一个节点的父节点
startOffset:范围中第一个子节点的索引
endContainer:选区中最后一个节点的父节点
endOffset:范围中最后一个子节点的索引
commonAncestorContainer
(一)用范围实现简单选择
以下方法可以实现选择文档中的一部分:
selectNode(DOM节点):选择整个DOM节点
selectNodeContents(DOM节点):只选择节点的子节点
setStartBefore(redNode):将范围的七点设置在refNode之前
setStartAfter(refNode):将范围的起点设置在refNode之后
setEndBefore(refNode):将范围的终点设置在refNode之前
setEndAfter(refNode):将范围的终点设置在refNode之后
(二)用DOM范围实现复杂选择
DOM2级创建的范围,不仅能够选择节点,还能够选择节点的一部分,使用下面两个方法可以完成这种操作:
setStart(参照节点,偏移量)
setEnd(参照节点,偏移量)
例如有如下HTML代码:
<!DOCTYPE html>
<html lang="en">
<body>
<p id="p1"><b>Hello</b> world!</p>
</body>
</html>我们想从“Hello world!”中选取“llo wo”,代码如下:
var p1 = document.getElementById("p1");
var helloNode = p1.firstChild.firstChid;
var worldNode = p1.lastChid;
var range = document.createRange();
range.setStart(helloNode, 2);
range.setEnd(worldNode, 3);利用范围选择了文档的某一部分,接下来便可以对选择的部分进行操作。
(三)操作DOM范围中的内容
在上述的例子中,范围会自动为自身添加相应的HTML标签,上例创建范围完成后的HTML代码如下:
<p><b>He</b><b>llo</b> world!</p>这样创建范围后,就可以使用各种方法对范围的内容进行操作了
1、deleteContents():从文档中删除范围包含的内容
var p1 = document.getElementById("p1");
var helloNode = p1.firstChild.firstChid;
var worldNode = p1.lastChid;
var range = document.createRange();
range.setStart(helloNode, 2);
range.setEnd(worldNode, 3);
range.deleteContents();运行上述代码后输出结果:

2、extractContents():从文档中移除范围选区,并返回范围的文档片段
var p1 = document.getElementById("p1");
var helloNode = p1.firstChild.firstChid;
var worldNode = p1.lastChid;
var range = document.createRange();
range.setStart(helloNode, 2);
range.setEnd(worldNode, 3);
var fragement = range.extractContents();
p1.parentNode.appendChild(fragement);运行上述代码后输出结果:

3、cloneContents():创建范围对象的一个副本
var p1 = document.getElementById("p1");
var helloNode = p1.firstChild.firstChid;
var worldNode = p1.lastChid;
var range = document.createRange();
range.setStart(helloNode, 2);
range.setEnd(worldNode, 3);
var fragement = range.cloneContents();
p1.parentNode.appendChild(fragement);运行上述代码后输出结果:

(四)向范围中插入内容
1、insertNode():向范围选区的开始处插入一个节点
假设向前面例子中的范围前插入以下HTML代码:
<span>Inserted text</span>则js代码如下:
var p1 = document.getElementById("p1");
var helloNode = p1.firstChild.firstChid;
var worldNode = p1.lastChid;
var range = document.createRange();
range.setStart(helloNode, 2);
range.setEnd(worldNode, 3);
var span = document.creatElement("span");
span.style.color = "red";
span.appendChild(document.createTextNode("Inserted text"));
range.insertNode(span);运行上述代码后输出结果:

2、surroundContents(环绕范围内容的节点):环绕范围插入内容
利用该方法可以突出显示网页中的某些词句,代码如下:
var p1 = document.getElementById("p1");
var helloNode = p1.firstChild.firstChid;
var worldNode = p1.lastChid;
var range = document.createRange();
range.selectNode(helloNode);
var span = document.createElement("span");
span.style.backgroundColor = "yellow";
range.surroundContents(span);代码运行的结果如下:

(五)折叠范围
折叠范围,就是指范围中未选择文档的任何部分。
-
collapse()方法可以折叠范围,该方法接受一个布尔值的参数:
参数取值为true:折叠到范围的起点
参数取值为false:折叠到范围的终点
collapse属性可以检测范围是否处于折叠状态
(六)比较范围
compareBoundaryPoints()方法可以比较多个范围的起点(或终点)
-
该方法接受两个参数:
-
表示比较方式的常量(有以下四个取值)
Range.START_TO_START:比较第一个范围和第二个范围的起点
Range.START_TO_END
Range.END_TO_END
Range.END_TO_START
要比较的范围
-
-
该方法有三个可能的返回值:
返回-1:第一个范围中的点位于第二个范围中的点之前
返回0:两个点相等
返回1:第一个范围中的点位于第二个范围中的点之后
(七)复制范围
cloneRange()方法可以复制范围
var newRange = range.cloneRange();以上代码创建了一个range的副本,newRange与range有相同的属性,修改newRange不会影响原来的范围。
(八)清理范围
在使用完范围后,最好是从创建范围的文档中分离出该范围,从而可以让垃圾回收机制回收其内存。
range.detach(); //从文档中分离
range = null; //解除引用推荐在使用完范围后再执行上述两个步骤。
")
dom渲染流程(cssdom和dom)
渲染引擎——webkit和Gecko
Firefox使用Geoko——Mozilla自主研发的渲染引擎
Safari和Chrome都使用webkit,Webkit是一款开源渲染引擎
dom渲染流程:
1、浏览器解析html源码,然后创建一个DOM树。
在DOM树中,每一个HTML标签都有一个对应的节点(元素节点),并且每一个文本也都有一个对应的节点(文本节点)。DOM树的根节点就是documentElement,对应的是html标签。
2、浏览器解析CSS代码,计算出最终的样式数据。
对CSS代码中非法的语法它会直接忽略掉。解析CSS的时候会按照如下顺序来定义优先级:浏览器默认设置,用户设置,外联样式,内联样式,html中的style(嵌在标签中的行间样式)。
3、创建完DOM树并得到最终的样式数据之后,构建一个渲染树。
渲染树和DOM树有点像,但是有区别。DOM树完全和html标签一一对应,而渲染树会忽略不需要渲染的元素(head、display:none的元素)。渲染树中每一个节点都存储着对应的CSS属性。
4、当渲染树创建完成之后,浏览器就可以根据渲染树直接把页面绘制到屏幕上。
渲染树和Dom树的关系
渲染对象和Dom元素相对应,但这种对应关系不是一对一的,不可见的Dom元素不会被插入渲染树,例如head元素。另外,display属性为none的元素也不会在渲染树中出现(visibility属性为hidden的元素将出现在渲染树中)。
还有一些Dom元素对应几个可见对象,它们一般是一些具有复杂结构的元素,无法用一个矩形来描述。例如,select元素有三个渲染对象——一个显示区域、一个下拉列表及一个按钮。同样,当文本因为宽度不够而折行时,新行将作为额外的渲染元素被添加。另一个多个渲染对象的例子是不规范的html,根据css规范,一个行内元素只能仅包含行内元素或仅包含块状元素,在存在混合内容时,将会创建匿名的块状渲染对象包裹住行内元素。
一些渲染对象和所对应的Dom节点不在树上相同的位置,例如,浮动和绝对定位的元素在文本流之外,在两棵树上的位置不同,渲染树上标识出真实的结构,并用一个占位结构标识出它们原来的位置。
我们今天的关于js dom和江苏迪欧姆股份有限公司的分享已经告一段落,感谢您的关注,如果您想了解更多关于DOM,SAX,JDOM,DOM4J 解析比较 (二)、DOM4J、DOM、JDOM和SAX之间的比较、DOMJS高级程序设计笔记——DOM2和DOM3、dom渲染流程(cssdom和dom)的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

