以上就是给各位分享JSON的使用场景及注意事项介绍,其中也会对json的使用场景及注意事项介绍图片进行解释,同时本文还将给你拓展c#事务的使用、示例及注意事项、DispatchSourceTimer的
以上就是给各位分享JSON的使用场景及注意事项介绍,其中也会对json的使用场景及注意事项介绍图片进行解释,同时本文还将给你拓展c#事务的使用、示例及注意事项、Dispatch Source Timer的使用及注意事项介绍、Docker的使用及注意事项、Go中defer使用场景及注意事项等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- JSON的使用场景及注意事项介绍(json的使用场景及注意事项介绍图片)
- c#事务的使用、示例及注意事项
- Dispatch Source Timer的使用及注意事项介绍
- Docker的使用及注意事项
- Go中defer使用场景及注意事项
")
JSON的使用场景及注意事项介绍(json的使用场景及注意事项介绍图片)
上篇我们讲解了JSON的诞生原因是因为XML整合到HTML中各个浏览器实现的细节不尽相同,所以道格拉斯·克罗克福特(Douglas Crockford) 和 奇普·莫宁斯达(Chip Morningstar)一起从JS的数据类型中提取了一个子集,作为新的数据交换格式,因为主流的浏览器使用了通用的JavaScript引擎组件,所以在解析这种新数据格式时就不存在兼容性问题,于是他们将这种数据格式命名为 “JavaScript Object Notation”,缩写为 JSON,由此JSON便诞生了!
今天我们来学习一下JSON的结构形式、数据类型、使用场景以及注意事项吧!
一、JSON格式
上面我们知道JSON是从JavaScript的数据类型中提取出来的子集,那JSON有几种结构形式呢?又有哪些数据类型呢?他们又分别对应着JavaScript中的哪些数据类型呢?
1.JSON的2种结构形式
1、键值对形式
上期我们举了一个JSON的实例,就是键值对形式的,如下:
{
"person": {
"name": "pig",
"age": "18",
"sex": "man",
"hometown": {
"province": "江西省",
"city": "抚州市",
"county": "崇仁县"
}
}
}
这种结构的JSON数据规则是:一个无序的“‘名称/值’对”集合。一个对象以 {左括号 开始, }右括号 结束。每个“名称”后跟一个 :冒号 ;“‘名称/值’ 对”之间使用 ,逗号 分隔,。 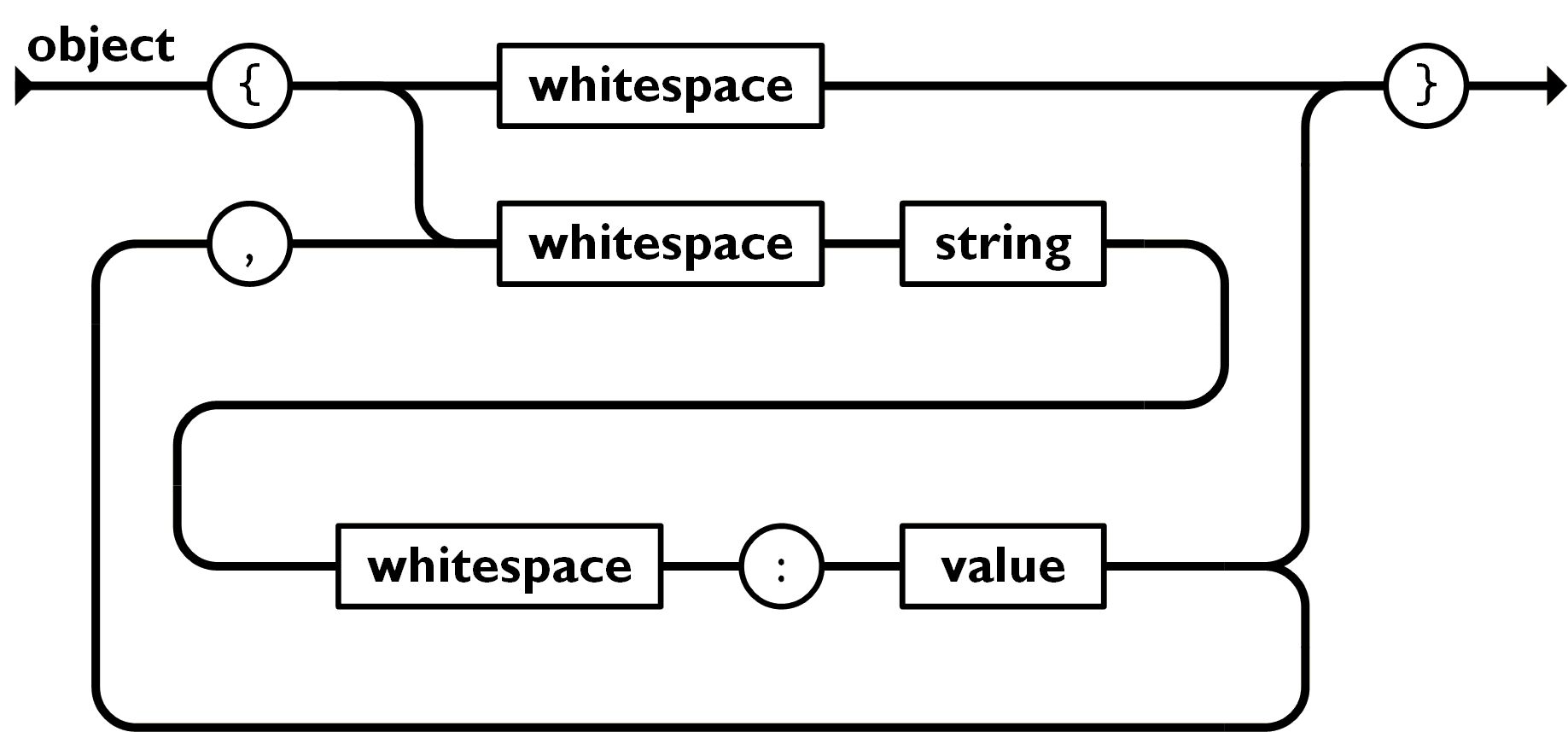 2、数组形式 因为大多数时候大家用的JSON可能都是上面那种key-value形式,所以很多人在讲解JSON的时候总是会忽略数组形式,这一点是需要注意的。
2、数组形式 因为大多数时候大家用的JSON可能都是上面那种key-value形式,所以很多人在讲解JSON的时候总是会忽略数组形式,这一点是需要注意的。
那JSON的数组形式是怎么样的呢?猪哥也举一个实例吧!
["pig", 18, "man", "江西省抚州市崇仁县"]
数组形式的JSON数据就是值(value)的有序集合。一个数组以 [左中括号 开始, ]右中括号 结束。值之间使用 ,逗号 分隔。 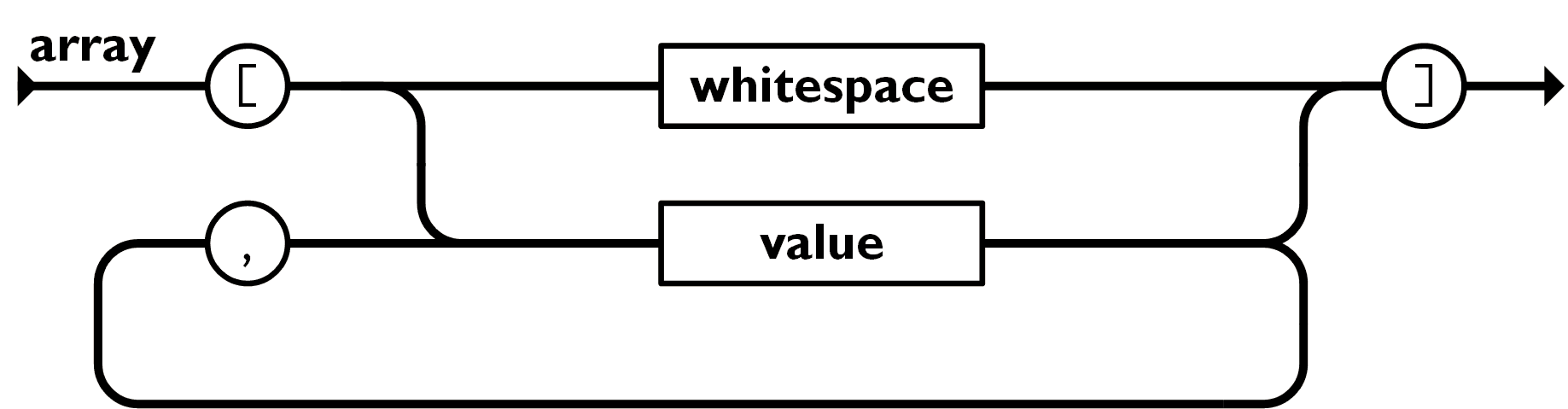
2.JOSN的6种数据类型
上面两种JSON形式内部都是包含value的,那JSON的value到底有哪些类型,而且上期我们说JSON其实就是从Js数据格式中提取了一个子集,那具体有哪几种数据类型呢?
- string:字符串,必须要用双引号引起来。
- number:数值,与JavaScript的number一致,整数(不使用小数点或指数计数法)最多为 15 位。小数的最大位数是 17。
- object:JavaScript的对象形式,{ key:value }表示方式,可嵌套。
- array:数组,JavaScript的Array表示方式[ value ],可嵌套。
- true/false:布尔类型,JavaScript的boolean类型。
- null:空值,JavaScript的null。
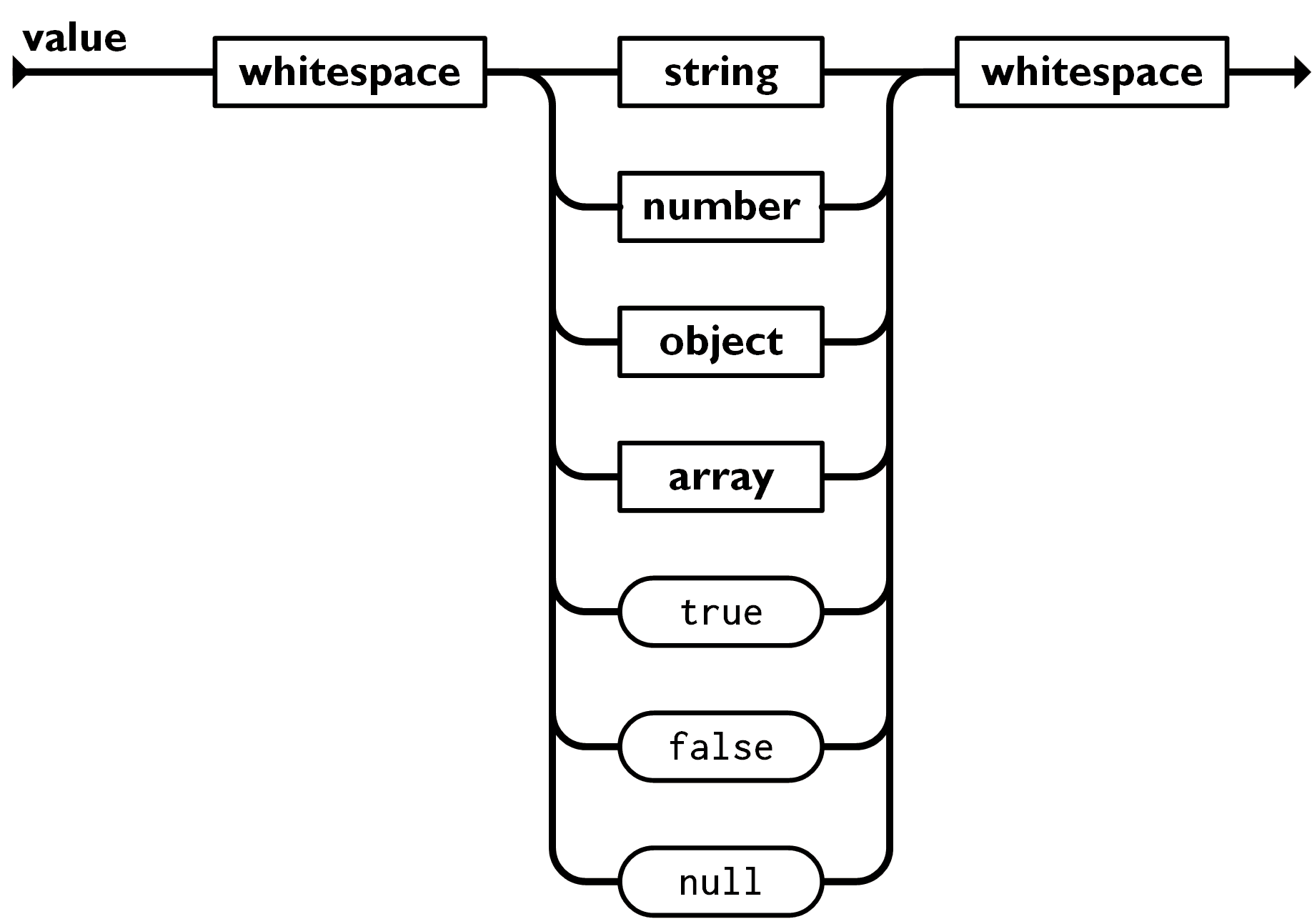 以上数据形式图片来源JSON官方文档:http://www.json.org/json-zh.html
以上数据形式图片来源JSON官方文档:http://www.json.org/json-zh.html
二、JSON使用场景
介绍完JSON的数据格式,那我们来看看JSON在企业中使用的比较多的场景。
1.接口返回数据
JSON用的最多的地方莫过于Web了,现在的数据接口基本上都是返回的JSON,具体细化的场景有:
- Ajxa异步访问数据
- RPC远程调用
- 前后端分离后端返回的数据
- 开放API,如百度、高德等一些开放接口
- 企业间合作接口
这种API接口一般都会提供一个接口文档,说明接口的入参、出参等, 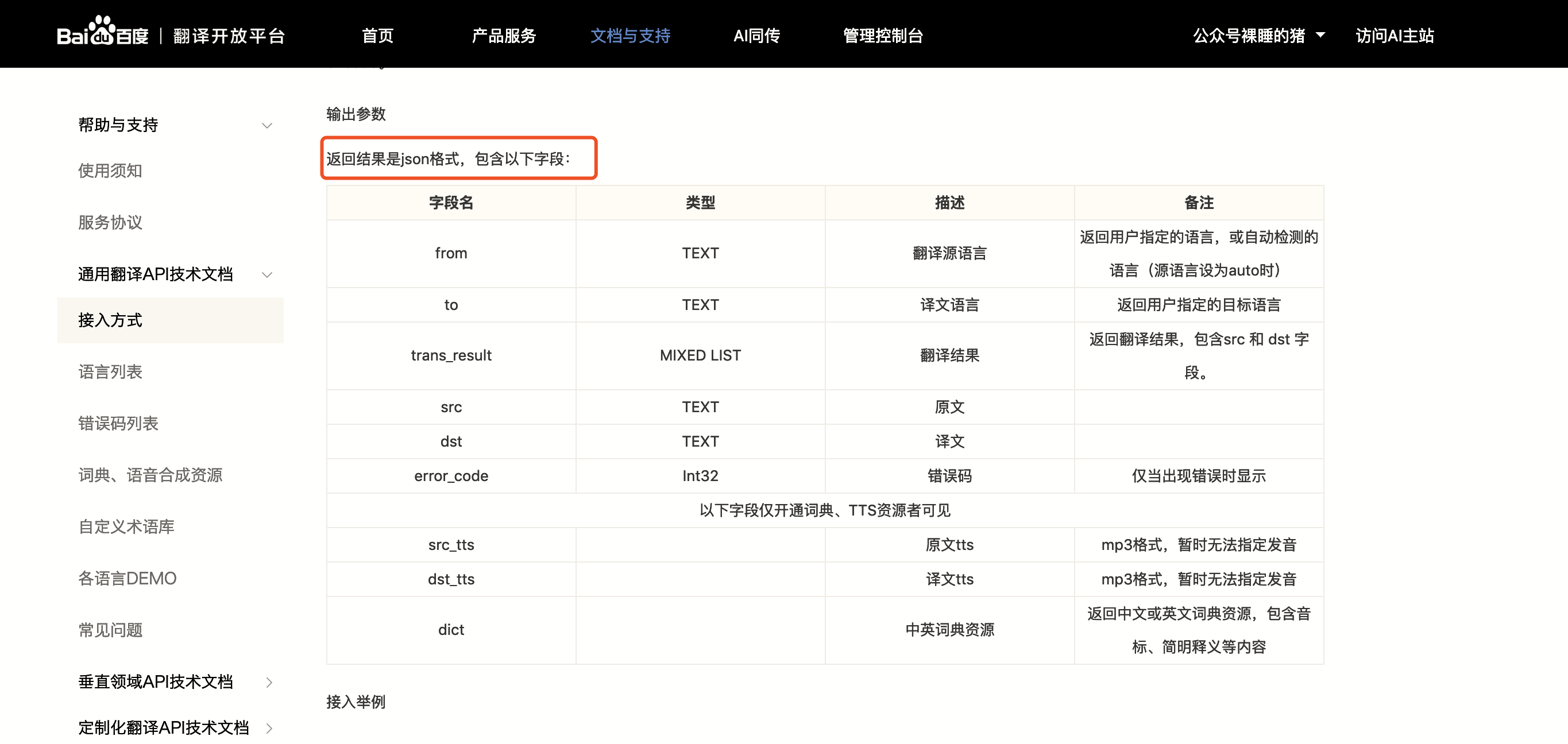 一般的接口返回数据都会封装成JSON格式,比如类似下面这种
一般的接口返回数据都会封装成JSON格式,比如类似下面这种
{
"code": 1,
"msg": "success",
"data": {
"name": "pig",
"age": "18",
"sex": "man",
"hometown": {
"province": "江西省",
"city": "抚州市",
"county": "崇仁县"
}
}
}
2.序列化
程序在运行时所有的变量都是保存在内存当中的,如果出现程序重启或者机器宕机的情况,那这些数据就丢失了。一般情况运行时变量并不是那么重要丢了就丢了,但有些内存中的数据是需要保存起来供下次程序或者其他程序使用。
保存内存中的数据要么保存在数据库,要么保存直接到文件中,而将内存中的数据变成可保存或可传输的数据的过程叫做序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
正常的序列化是将编程语言中的对象直接转成可保存或可传输的,这样会保存对象的类型信息,而JSON序列化则不会保留对象类型!
为了让大家更直观的感受区别,猪哥用代码做一个测试,大家一目了然 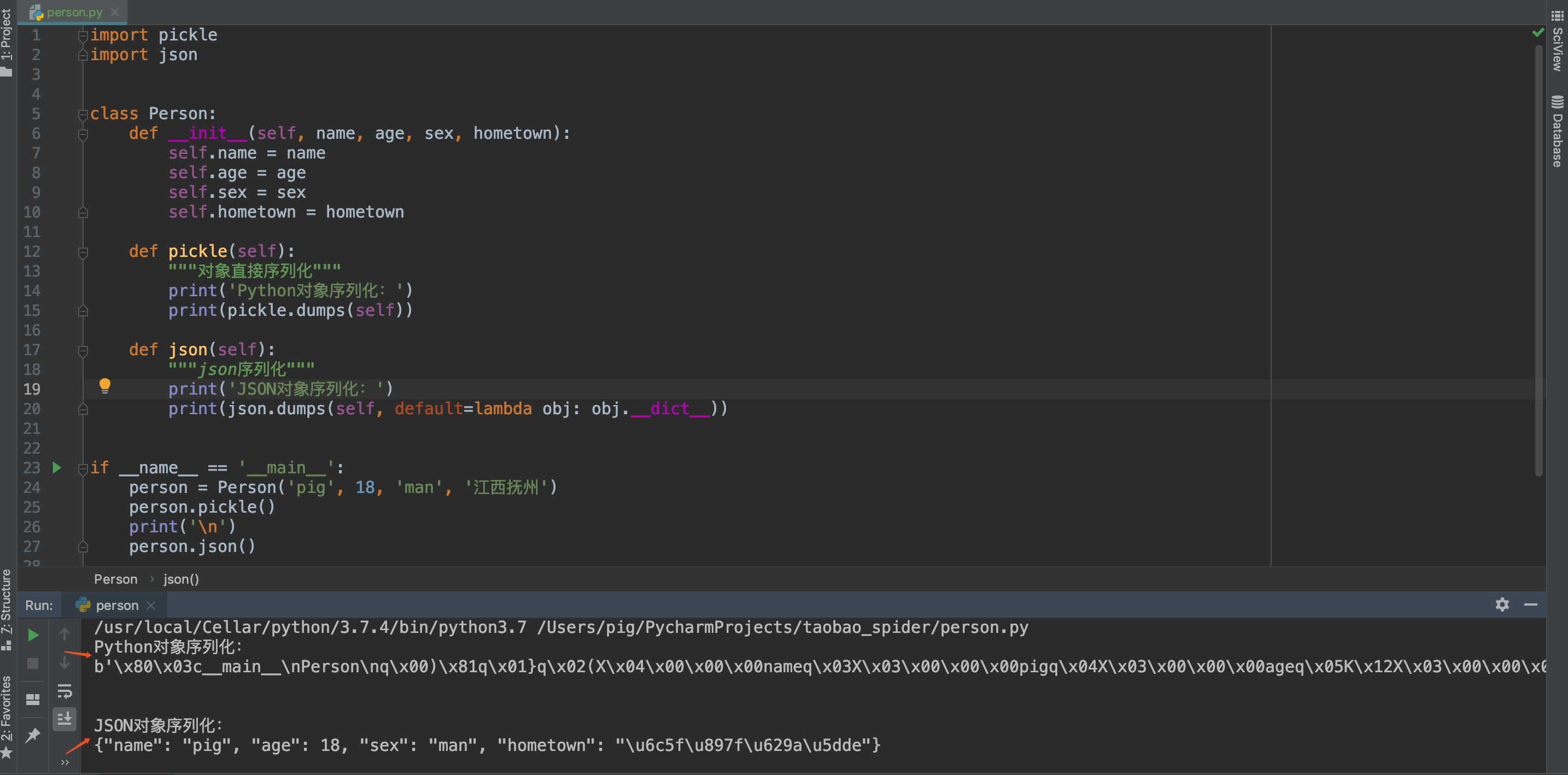
- Python对象直接序列化会保存class信息,下次使用loads加载到内存时直接变成Python对象。
- JSON对象序列化只保存属性数据,不保留class信息,下次使用loads加载到内存可以直接转成dict对象,当然也可以转为Person对象,但是需要写辅助方法。
对于JSON序列化不能保存class信息的特点,那JSON序列化还有什么用?答案是当然游有用,对于不同编程语言序列化读取有用,比如:我用Python爬取数据然后转成对象,现在我需要将它序列化磁盘,然后使用Java语言读取这份数据,这个时候由于跨语言数据类型不同,所以就需要用到JSON序列化。
存在即合理,两种序列化可根据需求自行选择!
3.生成Token
首先声明Token的形式多种多样,有JSON、字符串、数字等等,只要能满足需求即可,没有规定用哪种形式。
JSON格式的Token最有代表性的莫过于JWT(JSON Web Tokens)。  随着技术的发展,分布式web应用的普及,通过Session管理用户登录状态成本越来越高,因此慢慢发展成为Token的方式做登录身份校验,然后通过Token去取Redis中的缓存的用户信息,随着之后JWT的出现,校验方式更加简单便捷化,无需通过Redis缓存,而是直接根据Token取出保存的用户信息,以及对Token可用性校验,单点登录更为简单。
随着技术的发展,分布式web应用的普及,通过Session管理用户登录状态成本越来越高,因此慢慢发展成为Token的方式做登录身份校验,然后通过Token去取Redis中的缓存的用户信息,随着之后JWT的出现,校验方式更加简单便捷化,无需通过Redis缓存,而是直接根据Token取出保存的用户信息,以及对Token可用性校验,单点登录更为简单。 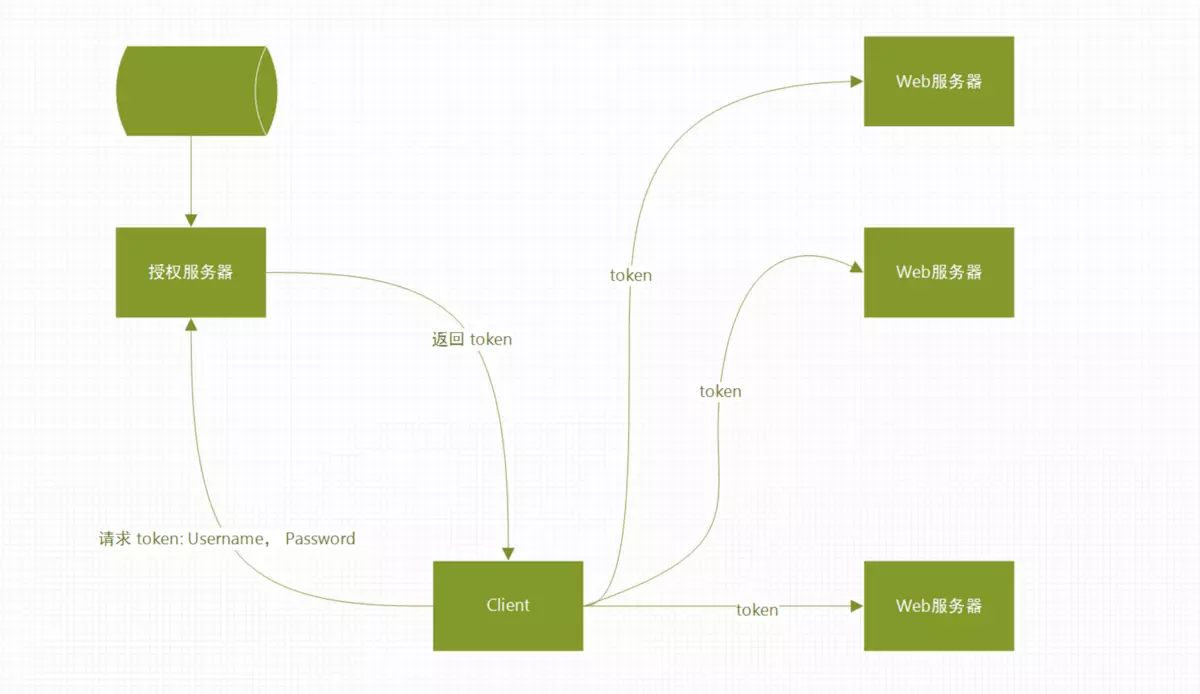 猪哥也曾经使用JWT做过app的登录系统,大概的流程就是:
猪哥也曾经使用JWT做过app的登录系统,大概的流程就是:
- 用户输入用户名密码
- app请求登录中心验证用户名密码
- 如果验证通过则生成一个Token,其中Token中包含:用户的uid、Token过期时间、过期延期时间等,然后返回给app
- app获得Token,保存在cookie中,下次请求其他服务则带上
- 其他服务获取到Token之后调用登录中心接口验证
- 验证通过则响应
JWT登录认证有哪些优势:
- 性能好:服务器不需要保存大量的session
- 单点登录(登录一个应用,同一个企业的其他应用都可以访问):使用JWT做一个登录中心基本搞定,很容易实现。
- 兼容性好:支持移动设备,支持跨程序调用,Cookie 是不允许垮域访问的,而 Token 则不存在这个问题。
- 安全性好:因为有签名,所以JWT可以防止被篡改。
更多JWT相关知识自行在网上学习,本文不过多介绍!
4.配置文件
说实话JSON作为配置文件使用场景并不多,最具代表性的就是npm的package.json包管理配置文件了,下面就是一个npm的package.json配置文件内容。
{
"name": "server", //项目名称
"version": "0.0.0",
"private": true,
"main": "server.js", //项目入口地址,即执行npm后会执行的项目
"scripts": {
"start": "node ./bin/www" ///scripts指定了运行脚本命令的npm命令行缩写
},
"dependencies": {
"cookie-parser": "~1.4.3", //指定项目开发所需的模块
"debug": "~2.6.9",
"express": "~4.16.0",
"http-errors": "~1.6.2",
"jade": "~1.11.0",
"morgan": "~1.9.0"
}
}
但其实JSON并不合适做配置文件,因为它不能写注释、作为配置文件的可读性差等原因。
配置文件的格式有很多种如:toml、yaml、xml、ini等,目前很多地方开始使用yaml作为配置文件。
三、JSON在Python中的使用
最后我们来看看Python中操作JSON的方法有哪些,在Python中操作JSON时需要引入json标准库。
import json
1.类型转换
1、Python类型转JSON:json.dump()
# 1、Python的dict类型转JSON
person_dict = {''name'': ''pig'', ''age'': 18, ''sex'': ''man'', ''hometown'': ''江西抚州''}
# indent参数为缩进空格数
person_dict_json = json.dumps(person_dict, indent=4)
print(person_dict_json, ''\n'')
# 2、Python的列表类型转JSON
person_list = [''pig'', 18, ''man'', ''江西抚州'']
person_list_json = json.dumps(person_list)
print(person_list_json, ''\n'')
# 3、Python的对象类型转JSON
person_obj = Person(''pig'', 18, ''man'', ''江西抚州'')
# 中间的匿名函数是获得对象所有属性的字典形式
person_obj_json = json.dumps(person_obj, default=lambda obj: obj.__dict__, indent=4)
print(person_obj_json, ''\n'')
执行结果: 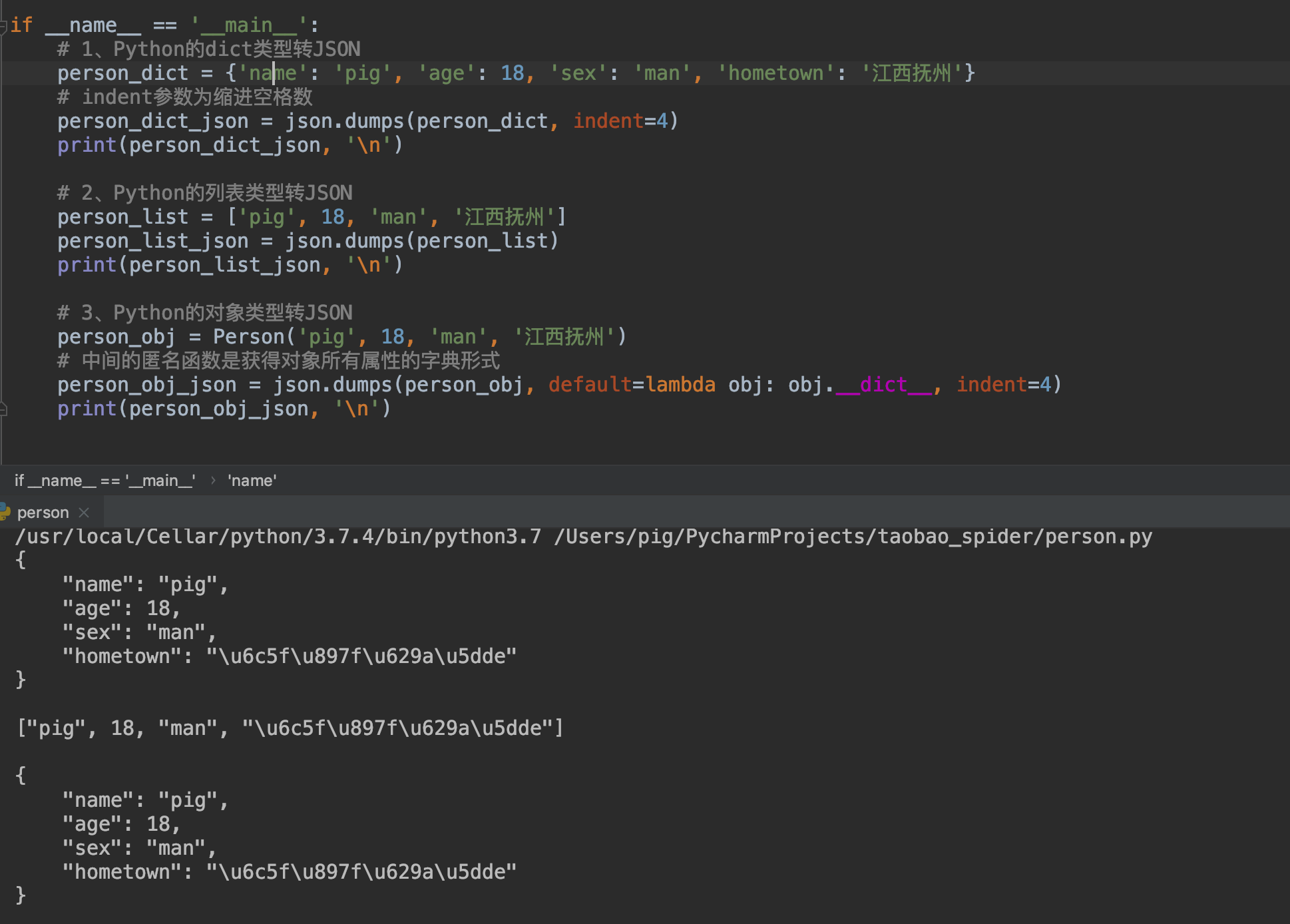
2、JSON转Python类型:json.loads()
# 4、JSON转Python的dict类型
person_json = ''{ "name": "pig","age": 18, "sex": "man", "hometown": "江西抚州"}''
person_json_dict = json.loads(person_json)
print(type(person_json_dict), ''\n'')
# 5、JSON转Python的列表类型
person_json2 = ''["pig", 18, "man", "江西抚州"]''
person_json_list = json.loads(person_json2)
print(type(person_json_list), ''\n'')
# 6、JSON转Python的自定义对象类型
person_json = ''{ "name": "pig","age": 18, "sex": "man", "hometown": "江西抚州"}''
# object_hook参数是将dict对象转成自定义对象
person_json_obj = json.loads(person_json, object_hook=lambda d: Person(d[''name''], d[''age''], d[''sex''], d[''hometown'']))
print(type(person_json_obj), ''\n'')
执行结果如下: 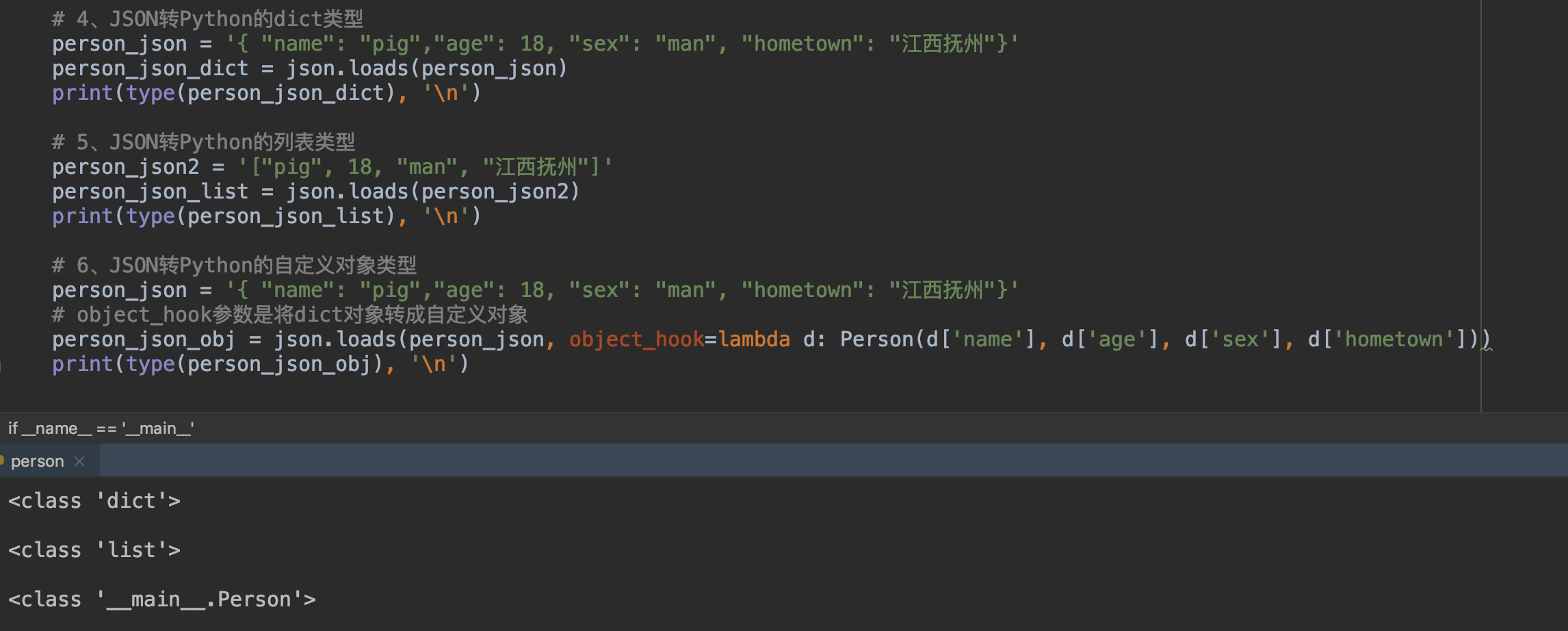
2.对应的数据类型
上面我们演示了Python类型与JSON的相互转换,最开始的时候我们讲过JSON有6种数据类型,那这6种数据类型分别对应Python中的哪些数据类型呢? 
3.需要注意的点
- JSON的键名和字符串都必须使用双引号引起来,而Python中单引号也可以表示为字符串,所以这是个比较容易犯的错误!
- Python类型与JSON相互转换的时候到底是用
load/dump还是用loads\dumps?他们之间有什么区别?什么时候该加s什么时候不该加s?这个我们可以通过查看源码找到答案:不加s的方法入参多了一个fp表示filepath,最后多了一个写入文件的操作。所以我们在记忆的时候可以这样记忆:加s表示转成字符串(str),不加s表示转成文件。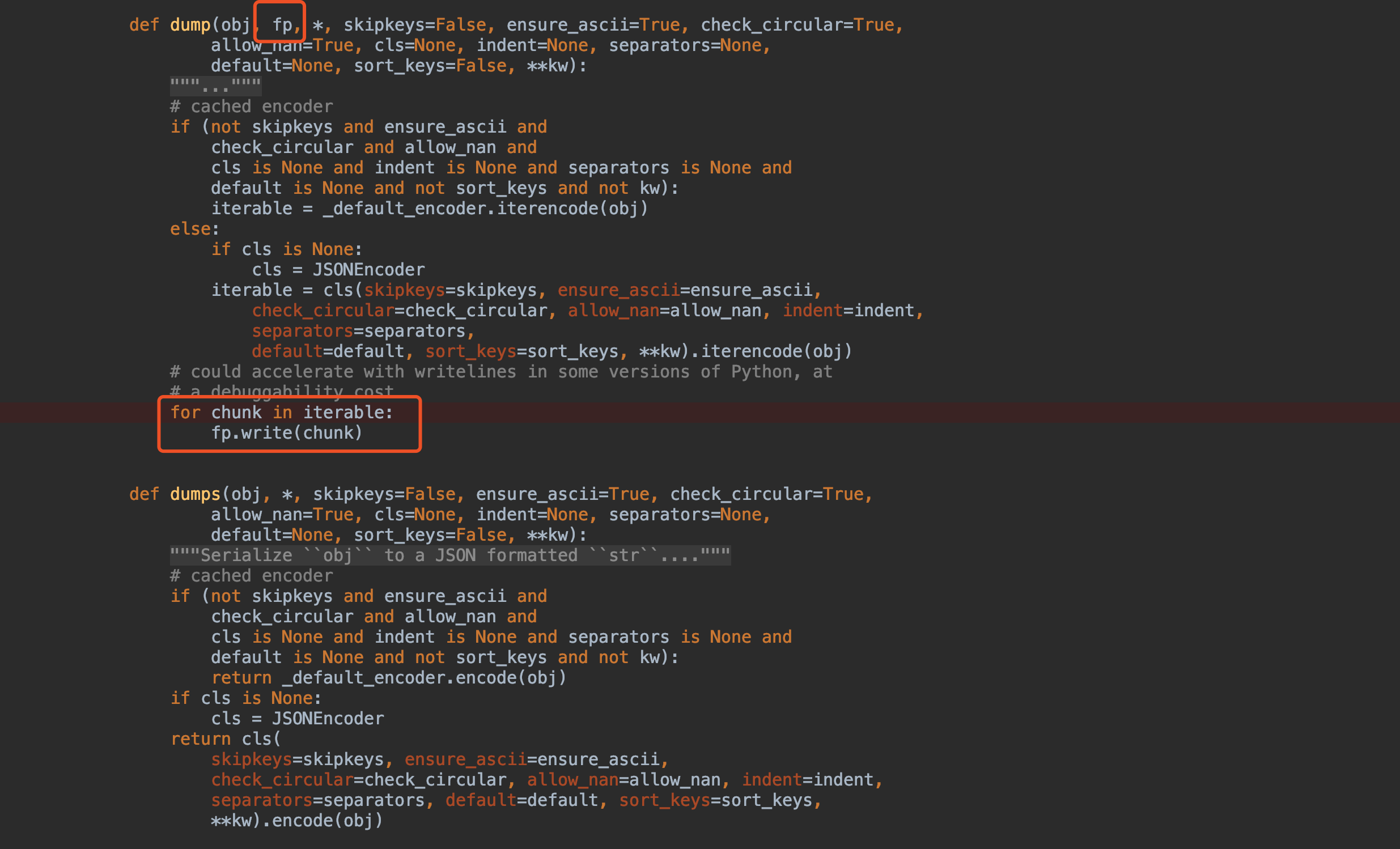
- Python自定义对象与JSON相互转换的时候需要辅助方法来指明属性与键名的对应关系,如果不指定一个方法则会抛出异常!
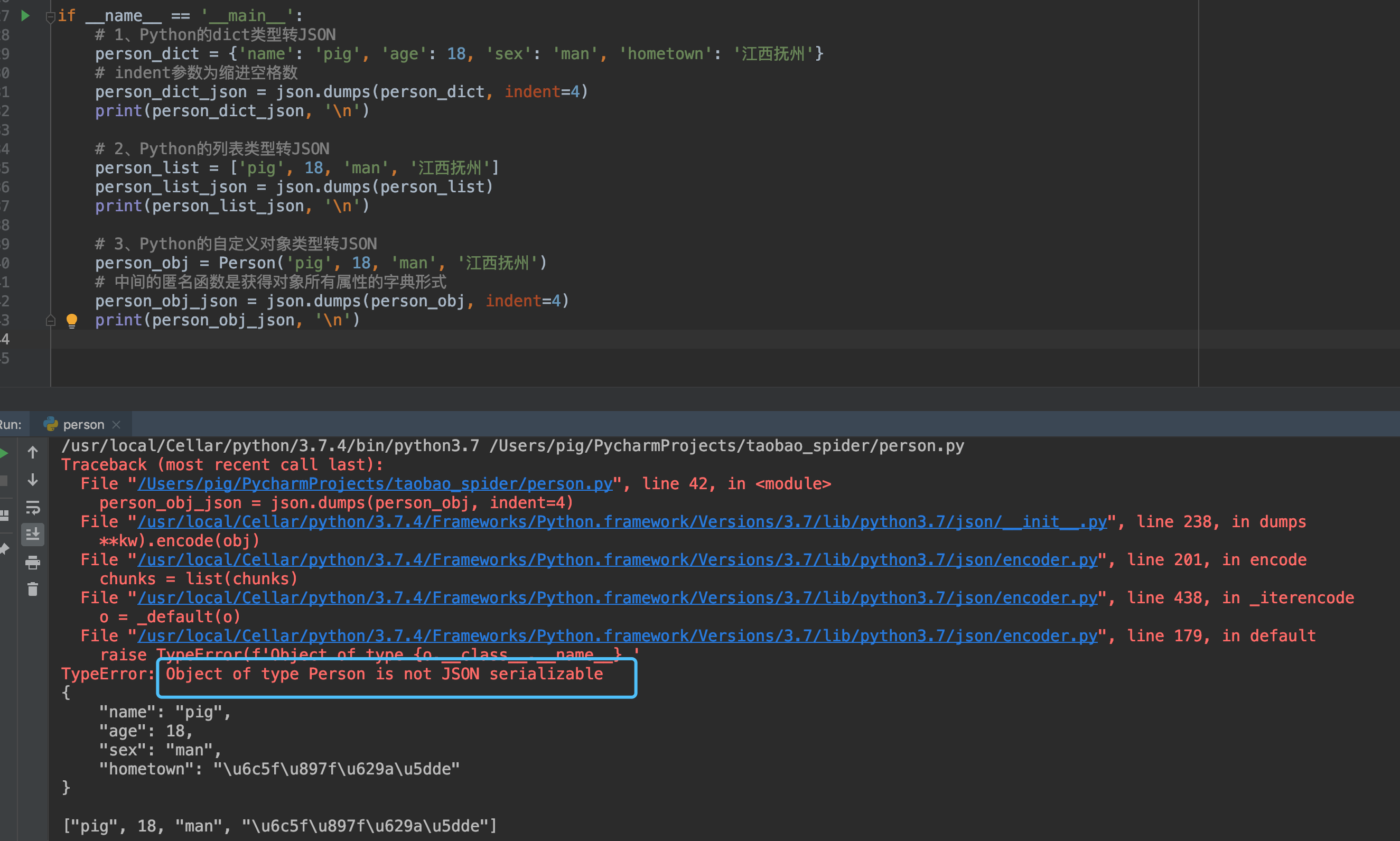
- 相信有些看的仔细的同学会好奇上面猪哥使用json.dumps方法将Python类型转JSON的时候,如果出现中文,则会出现:\u6c5f\u897f\u629a\u5dde这种东西,这是为什么呢?原因是:Python 3中的json在做dumps操作时,会将中文转换成unicode编码,并以16进制方式存储,而并不是UTF-8格式!
四、总结
今天我们学习了JSON的2种形式,切记JSON还有[...]这种形式的。
学习了JSON的6种数据类型他们分别对于Python中的哪些类型。
了解了JSON的一些使用场景以及实际的例子。
还学习了在Python中如何使用JSON以及需要注意的事项。
结合上期的JSON的诞生与发展介绍,我们JSON相关的知识基本就介绍的差不多,后面会出一些爬虫实际案例来教大家如何解析返回JSON数据。
一个JSON知识点却分两篇长文(近万字)来讲,其重要性不言而喻。因为不管你是做爬虫、还是做数据分析、web、甚至前端、测试、运维,JSON都是你必须要掌握的一个知识点!
原文出处:https://www.cnblogs.com/pig66/p/11959035.html

c#事务的使用、示例及注意事项
什么是数据库事务
数据库事务是指作为单个逻辑工作单元执行的一系列操作。
设想网上购物的一次交易,其付款过程至少包括以下几步数据库操作:
· 更新客户所购商品的库存信息
· 保存客户付款信息--可能包括与银行系统的交互
· 生成订单并且保存到数据库中
· 更新用户相关信息,例如购物数量等等
正常的情况下,这些操作将顺利进行,最终交易成功,与交易相关的所有数据库信息也成功地更新。但是,如果在这一系列过程中任何一个环节出了差错,例如在更新商品库存信息时发生异常、该顾客银行帐户存款不足等,都将导致交易失败。一旦交易失败,数据库中所有信息都必须保持交易前的状态不变,比如最后一步更新用户信息时失败而导致交易失败,那么必须保证这笔失败的交易不影响数据库的状态--库存信息没有被更新、用户也没有付款,订单也没有生成。否则,数据库的信息将会一片混乱而不可预测。
数据库事务正是用来保证这种情况下交易的平稳性和可预测性的技术。
数据库事务的ACID属性
事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据的资源。通过将一组相关操作组合为一个要么全部成功要么全部失败的单元,可以简化错误恢复并使应用程序更加可靠。一个逻辑工作单元要成为事务,必须满足所谓的ACID(原子性、一致性、隔离性和持久性)属性:
· 原子性
事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。通常,与某个事务关联的操作具有共同的目标,并且是相互依赖的。如果系统只执行这些操作的一个子集,则可能会破坏事务的总体目标。原子性消除了系统处理操作子集的可能性。
· 一致性
事务在完成时,必须使所有的数据都保持一致状态。在相关数据库中,所有规则都必须应用于事务的修改,以保持所有数据的完整性。事务结束时,所有的内部数据结构(如 B 树索引或双向链表)都必须是正确的。某些维护一致性的责任由应用程序开发人员承担,他们必须确保应用程序已强制所有已知的完整性约束。例如,当开发用于转帐的应用程序时,应避免在转帐过程中任意移动小数点。
· 隔离性
由并发事务所作的修改必须与任何其它并发事务所作的修改隔离。事务查看数据时数据所处的状态,要么是另一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看中间状态的数据。这称为可串行性,因为它能够重新装载起始数据,并且重播一系列事务,以使数据结束时的状态与原始事务执行的状态相同。当事务可序列化时将获得最高的隔离级别。在此级别上,从一组可并行执行的事务获得的结果与通过连续运行每个事务所获得的结果相同。由于高度隔离会限制可并行执行的事务数,所以一些应用程序降低隔离级别以换取更大的吞吐量。
· 持久性
事务完成之后,它对于系统的影响是永久性的。该修改即使出现致命的系统故障也将一直保持。
DBMS的责任和我们的任务
企业级的数据库管理系统(DBMS)都有责任提供一种保证事务的物理完整性的机制。就常用的SQL Server2000系统而言,它具备锁定设备隔离事务、记录设备保证事务持久性等机制。因此,我们不必关心数据库事务的物理完整性,而应该关注在什么情况下使用数据库事务、事务对性能的影响,如何使用事务等等。
本文将涉及到在.net框架下使用C#语言操纵数据库事务的各个方面。
体验SQL语言的事务机制
作为大型的企业级数据库,SQL Server2000对事务提供了很好的支持。我们可以使用SQL语句来定义、提交以及回滚一个事务。
如下所示的SQL代码定义了一个事务,并且命名为"MyTransaction"(限于篇幅,本文并不讨论如何编写SQL语言程序,请读者自行参考相关书籍):
DECLARE @TranName VARCHAR(20)
SELECT @TranName = ''MyTransaction''
BEGIN TRANSACTION @TranNameGOUSE pubs
GO
UPDATE roysched
SET royalty = royalty * 1.10
WHERE title_id LIKE ''Pc%''
GO
COMMIT TRANSACTION MyTransaction
GO
这里用到了SQL Server2000自带的示例数据库pubs,提交事务后,将为所有畅销计算机书籍支付的版税增加 10%。
打开SQL Server2000的查询分析器,选择pubs数据库,然后运行这段程序,结果显而易见。
可是如何在C#程序中运行呢?我们记得在普通的SQL查询中,一般需要把查询语句赋值给SalCommand.CommandText属性,这里也就像普通的SQL查询语句一样,将这些语句赋给SqlCommand.CommandText属性即可。要注意的一点是,其中的"GO"语句标志着SQL批处理的结束,编写SQL脚本是需要的,但是在这里是不必要的。我们可以编写如下的程序来验证这个想法:
//TranSql.csusing System;
using System.Data;
using System.Data.SqlClient;
namespace Aspcn
{
public class DbTranSql
{
file://将事务放到SQL Server中执行
public void DoTran()
{
file://建立连接并打开
SqlConnection myConn=GetConn();myConn.Open();
SqlCommand myComm=new SqlCommand();
try
{
myComm.Connection=myConn;
myComm.CommandText="DECLARE @TranName VARCHAR(20) ";
myComm.CommandText+="SELECT @TranName = ''MyTransaction'' ";
myComm.CommandText+="BEGIN TRANSACTION @TranName ";
myComm.CommandText+="USE pubs ";
myComm.CommandText+="UPDATE roysched SET royalty = royalty * 1.10 WHERE title_id LIKE ''Pc%'' ";
myComm.CommandText+="COMMIT TRANSACTION MyTransaction ";
myComm.ExecuteNonQuery();
}
catch(Exception err)
{
throw new ApplicationException("事务操作出错,系统信息:"+err.Message);
}
finally
{
myConn.Close();
}
}
file://获取数据连接
private SqlConnection GetConn()
{
string strSql="Data Source=localhost;Integrated Security=SSPI;user id=sa;password=";
SqlConnection myConn=new SqlConnection(strSql);
return myConn;
}
}
public class Test
{
public static void Main()
{
DbTranSql tranTest=new DbTranSql();
tranTest.DoTran();
Console.WriteLine("事务处理已经成功完成。");
Console.ReadLine();
}
}
}
注意到其中的SqlCommand对象myComm,它的CommandText属性仅仅是前面SQL代码字符串连接起来即可,当然,其中的"GO"语句已经全部去掉了。这个语句就像普通的查询一样,程序将SQL文本事实上提交给DBMS去处理了,然后接收返回的结果(如果有结果返回的话)。
很自然,我们最后看到了输出"事务处理已经成功完成",再用企业管理器查看pubs数据库的roysched表,所有title_id字段以"PC"开头的书籍的royalty字段的值都增加了0.1倍。
这里,我们并没有使用ADO.net的事务处理机制,而是简单地将执行事务的SQL语句当作普通的查询来执行,因此,事实上该事务完全没有用到.net的相关特性。
了解.net中的事务机制
如你所知,在.net框架中主要有两个命名空间(namespace)用于应用程序同数据库系统的交互:System.Data.SqlClient和System.Data.OleDb。前者专门用于连接Microsoft公司自己的SQL Server数据库,而后者可以适应多种不同的数据库。这两个命名空间中都包含有专门用于管理数据库事务的类,分别是System.Data.SqlClient.SqlTranscation类和System.Data.OleDb.OleDbTranscation类。
就像它们的名字一样,这两个类大部分功能是一样的,二者之间的主要差别在于它们的连接机制,前者提供一组直接调用 SQL Server 的对象,而后者使用本机 OLE DB 启用数据访问。事实上,ADO.net 事务完全在数据库的内部处理,且不受 Microsoft 分布式事务处理协调器 (DTC) 或任何其他事务性机制的支持。本文将主要介绍System.Data.SqlClient.SqlTranscation类,下面的段落中,除了特别注明,都将使用System.Data.SqlClient.SqlTranscation类。
事务的开启和提交
现在我们对事务的概念和原理都了然于心了,并且作为已经有一些基础的C#开发者,我们已经熟知编写数据库交互程序的一些要点,即使用SqlConnection类的对象的Open()方法建立与数据库服务器的连接,然后将该连接赋给SqlCommand对象的Connection属性,将欲执行的SQL语句赋给它的CommandText属性,于是就可以通过SqlCommand对象进行数据库操作了。对于我们将要编写的事务处理程序,当然还需要定义一个SqlTransaction类型的对象。并且看到SqlCommand对象的Transcation属性,我们很容易想到新建的SqlTransaction对象应该与它关联起来。
基于以上认识,下面我们就开始动手写我们的第一个事务处理程序。我们可以很熟练地写出下面这一段程序:
//DoTran.csusing System;
using System.Data;
using System.Data.SqlClient;
namespace Aspcn
{
public class DbTran
{
file://执行事务处理
public void DoTran()
{
file://建立连接并打开
SqlConnection myConn=GetConn();
myConn.Open();
SqlCommand myComm=new SqlCommand();
SqlTransaction myTran=new SqlTransaction();
try
{
myComm.Connection=myConn;
myComm.Transaction=myTran;
file://定位到pubs数据库
myComm.CommandText="USE pubs";
myComm.ExecuteNonQuery();
file://更新数据
file://将所有的计算机类图书
myComm.CommandText="UPDATE roysched SET royalty = royalty * 1.10 WHERE title_id LIKE ''Pc%''";
myComm.ExecuteNonQuery();//提交事务
myTran.Commit();
}
catch(Exception err)
{
throw new ApplicationException("事务操作出错,系统信息:"+err.Message);
}
finally
{
myConn.Close();
}
}
file://获取数据连接
private SqlConnection GetConn()
{
string strSql="Data Source=localhost;Integrated Security=SSPI;user id=sa;password=";
SqlConnection myConn=new SqlConnection(strSql);
return myConn;
}
}
public class Test{public static void Main()
{
DbTran tranTest=new DbTran();
tranTest.DoTran();
Console.WriteLine("事务处理已经成功完成。");
Console.ReadLine();
}
}
}
显然,这个程序非常简单,我们非常自信地编译它,但是,出乎意料的结果使我们的成就感顿时烟消云散:
error CS1501: 重载"SqlTransaction"方法未获取"0"参数
是什么原因呢?注意到我们初始化的代码:
SqlTransaction myTran=new SqlTransaction();
显然,问题出在这里,事实上,SqlTransaction类并没有公共的构造函数,我们不能这样新建一个SqlTrancaction类型的变量。在事务处理之前确实需要有一个SqlTransaction类型的变量,将该变量关联到SqlCommand类的Transcation属性也是必要的,但是初始化方法却比较特别一点。在初始化SqlTransaction类时,你需要使用SqlConnection类的BeginTranscation()方法:
SqlTransaction myTran; myTran=myConn.BeginTransaction();
该方法返回一个SqlTransaction类型的变量。在调用BeginTransaction()方法以后,所有基于该数据连接对象的SQL语句执行动作都将被认为是事务MyTran的一部分。同时,你也可以在该方法的参数中指定事务隔离级别和事务名称,如:
SqlTransaction myTran;
myTran=myConn.BeginTransaction(IsolationLevel.ReadCommitted,"SampleTransaction");
关于隔离级别的概念我们将在随后的内容中探讨,在这里我们只需牢记一个事务是如何被启动,并且关联到特定的数据链接的。
先不要急着去搞懂我们的事务都干了些什么,看到这一行:
myTran.Commit();
是的,这就是事务的提交方式。该语句执行后,事务的所有数据库操作将生效,并且为数据库事务的持久性机制所保持--即使系统在这以后发生致命错误,该事务对数据库的影响也不会消失。
对上面的程序做了修改之后我们可以得到如下代码(为了节约篇幅,重复之处已省略,请参照前文):
//DoTran.cs……}
file://执行事务处理
public void DoTran()
{
file://建立连接并打开
SqlConnection myConn=GetConn();
myConn.Open();
SqlCommand myComm=new SqlCommand();
file://SqlTransaction myTran=new SqlTransaction();
file://注意,SqlTransaction类无公开的构造函数
SqlTransaction myTran;
file://创建一个事务
myTran=myConn.BeginTransaction();
try
{
file://从此开始,基于该连接的数据操作都被认为是事务的一部分
file://下面绑定连接和事务对象
myComm.Connection=myConn;
myComm.Transaction=myTran; file://定位到pubs数据库
myComm.CommandText="USE pubs";
myComm.ExecuteNonQuery();//更新数据
file://将所有的计算机类图书
myComm.CommandText="UPDATE roysched SET royalty = royalty * 1.10 WHERE title_id LIKE ''Pc%''";
myComm.ExecuteNonQuery();
file://提交事务
myTran.Commit();
}
catch(Exception err)
{
throw new ApplicationException("事务操作出错,系统信息:"+err.Message);
}
finally
{
myConn.Close();
}
}
……
到此为止,我们仅仅掌握了如何开始和提交事务。下一步我们必须考虑的是在事务中可以干什么和不可以干什么。
另一个走向极端的错误
满怀信心的新手们可能为自己所掌握的部分知识陶醉不已,刚接触数据库库事务处理的准开发者们也一样,踌躇满志地准备将事务机制应用到他的数据处理程序的每一个模块每一条语句中去。的确,事务机制看起来是如此的诱人——简洁、美妙而又实用,我当然想用它来避免一切可能出现的错误——我甚至想用事务把我的数据操作从头到尾包裹起来。
看着吧,下面我要从创建一个数据库开始:
using System;
using System.Data;
using System.Data.SqlClient;
namespace Aspcn
{
public class DbTran
{
file://执行事务处理
public void DoTran()
{
file://建立连接并打开
SqlConnection myConn=GetConn();
myConn.Open();
SqlCommand myComm=new SqlCommand();
SqlTransaction myTran;
myTran=myConn.BeginTransaction();
file://下面绑定连接和事务对象
myComm.Connection=myConn;
myComm.Transaction=myTran;
file://试图创建数据库TestDB
myComm.CommandText="CREATE database TestDB";
myComm.ExecuteNonQuery();
file://提交事务
myTran.Commit();
}
file://获取数据连接
private SqlConnection GetConn()
{
string strSql="Data Source=localhost;Integrated Security=SSPI;user id=sa;password=";
SqlConnection myConn=new SqlConnection(strSql);
return myConn;
}
}
public class Test
{
public static void Main()
{
DbTran tranTest=new DbTran();
tranTest.DoTran();
Console.WriteLine("事务处理已经成功完成。");
Console.ReadLine();
}
}
}
//---------------
未处理的异常: System.Data.SqlClient.SqlException: 在多语句事务内不允许使用 CREATE DATABASE 语句。
at System.Data.SqlClient.SqlCommand.ExecuteNonQuery()
at Aspcn.DbTran.DoTran()
at Aspcn.Test.Main()
注意,如下的SQL语句不允许出现在事务中:
ALTER DATABASE
修改数据库
BACKUP LOG
备份日志
CREATE DATABASE
创建数据库
DISK INIT
创建数据库或事务日志设备
DROP DATABASE
删除数据库
DUMP TRANSACTION
转储事务日志
LOAD DATABASE
装载数据库备份复本
LOAD TRANSACTION
装载事务日志备份复本
RECONFIGURE
更新使用 sp_configure 系统存储过程更改的配置选项的当前配置(sp_configure 结果集中的 config_value 列)值。
RESTORE DATABASE
还原使用BACKUP命令所作的数据库备份
RESTORE LOG
还原使用BACKUP命令所作的日志备份
UPDATE STATISTICS
在指定的表或索引视图中,对一个或多个统计组(集合)有关键值分发的信息进行更新
除了这些语句以外,你可以在你的数据库事务中使用任何合法的SQL语句。
事务回滚
事务的四个特性之一是原子性,其含义是指对于特定操作序列组成的事务,要么全部完成,要么就一件也不做。如果在事务处理的过程中,发生未知的不可预料的错误,如何保证事务的原子性呢?当事务中止时,必须执行回滚操作,以便消除已经执行的操作对数据库的影响。
一般的情况下,在异常处理中使用回滚动作是比较好的想法。前面,我们已经得到了一个更新数据库的程序,并且验证了它的正确性,稍微修改一下,可以得到:
//RollBack.cs
using System;
using System.Data;
using System.Data.SqlClient;
namespace Aspcn
{
public class DbTran
{
file://执行事务处理
public void DoTran()
{
file://建立连接并打开
SqlConnection myConn=GetConn();
myConn.Open();
SqlCommand myComm=new SqlCommand();
SqlTransaction myTran;
file://创建一个事务
myTran=myConn.BeginTransaction();
file://从此开始,基于该连接的数据操作都被认为是事务的一部分
file://下面绑定连接和事务对象
myComm.Connection=myConn;
myComm.Transaction=myTran;
try
{
file://定位到pubs数据库
myComm.CommandText="USE pubs";
myComm.ExecuteNonQuery();
myComm.CommandText="UPDATE roysched SET royalty = royalty * 1.10 WHERE title_id LIKE ''Pc%''";
myComm.ExecuteNonQuery();
file://下面使用创建数据库的语句制造一个错误
myComm.CommandText="Create database testdb";
myComm.ExecuteNonQuery();
myComm.CommandText="UPDATE roysched SET royalty = royalty * 1.20 WHERE title_id LIKE ''Ps%''";
myComm.ExecuteNonQuery();
file://提交事务
myTran.Commit();
}
catch(Exception err)
{
myTran.Rollback();
Console.Write("事务操作出错,已回滚。系统信息:"+err.Message);
}
}
file://获取数据连接
private SqlConnection GetConn()
{
string strSql="Data Source=localhost;Integrated Security=SSPI;user id=sa;password=";
SqlConnection myConn=new SqlConnection(strSql);
return myConn;
}
}
public class Test
{
public static void Main()
{
DbTran tranTest=new DbTran();
tranTest.DoTran();
Console.WriteLine("事务处理已经成功完成。");
Console.ReadLine();
}
}
}
首先,我们在中间人为地制造了一个错误——使用前面讲过的Create database语句。然后,在异常处理的catch块中有如下语句:
myTran.Rollback();
当异常发生时,程序执行流跳转到catch块中,首先执行的就是这条语句,它将当前事务回滚。在这段程序可以看出,在Create database之前,已经有了一个更新数据库的操作——将pubs数据库的roysched表中的所有title_id字段以“PC”开头的书籍的royalty字段的值都增加0.1倍。但是,由于异常发生而导致的回滚使得对于数据库来说什么都没有发生。由此可见,Rollback()方法维护了数据库的一致性及事务的原子性。
使用存储点
事务只是一种最坏情况下的保障措施,事实上,平时系统的运行可靠性都是相当高的,错误很少发生,因此,在每次事务执行之前都检查其有效性显得代价太高——绝大多数的情况下这种耗时的检查是不必要的。我们不得不想另外一种办法来提高效率。
事务存储点提供了一种机制,用于回滚部分事务。因此,我们可以不必在更新之前检查更新的有效性,而是预设一个存储点,在更新之后,如果没有出现错误,就继续执行,否则回滚到更新之前的存储点。存储点的作用就在于此。要注意的是,更新和回滚代价很大,只有在遇到错误的可能性很小,而且预先检查更新的有效性的代价相对很高的情况下,使用存储点才会非常有效。
使用.net框架编程时,你可以非常简单地定义事务存储点和回滚到特定的存储点。下面的语句定义了一个存储点“NoUpdate”:
myTran.Save("NoUpdate");
当你在程序中创建同名的存储点时,新创建的存储点将替代原有的存储点。
在回滚事务时,只需使用Rollback()方法的一个重载函数即可:
myTran.Rollback("NoUpdate");
下面这段程序说明了回滚到存储点的方法和时机:
using System;
using System.Data;
using System.Data.SqlClient;
namespace Aspcn
{
public class DbTran
{
file://执行事务处理
public void DoTran()
{
file://建立连接并打开
SqlConnection myConn=GetConn();
myConn.Open();
SqlCommand myComm=new SqlCommand();
SqlTransaction myTran;
file://创建一个事务
myTran=myConn.BeginTransaction();
file://从此开始,基于该连接的数据操作都被认为是事务的一部分
file://下面绑定连接和事务对象
myComm.Connection=myConn;
myComm.Transaction=myTran;
try
{
myComm.CommandText="use pubs";
myComm.ExecuteNonQuery();
myTran.Save("NoUpdate");
myComm.CommandText="UPDATE roysched SET royalty = royalty * 1.10 WHERE title_id LIKE ''Pc%''";
myComm.ExecuteNonQuery();
file://提交事务
myTran.Commit();
}
catch(Exception err)
{
file://更新错误,回滚到指定存储点
myTran.Rollback("NoUpdate");
throw new ApplicationException("事务操作出错,系统信息:"+err.Message);
}
}
file://获取数据连接
private SqlConnection GetConn()
{
string strSql="Data Source=localhost;Integrated Security=SSPI;user id=sa;password=";
SqlConnection myConn=new SqlConnection(strSql);
return myConn;
}
}
public class Test
{
public static void Main()
{
DbTran tranTest=new DbTran();
tranTest.DoTran();
Console.WriteLine("事务处理已经成功完成。");
Console.ReadLine();
}
}
}
很明显,在这个程序中,更新无效的几率是非常小的,而且在更新前验证其有效性的代价相当高,因此我们无须在更新之前验证其有效性,而是结合事务的存储点机制,提供了数据完整性的保证。
隔离级别的概念
企业级的数据库每一秒钟都可能应付成千上万的并发访问,因而带来了并发控制的问题。由数据库理论可知,由于并发访问,在不可预料的时刻可能引发如下几个可以预料的问题:
脏读:包含未提交数据的读取。例如,事务1 更改了某行。事务2 在事务1 提交更改之前读取已更改的行。如果事务1 回滚更改,则事务2 便读取了逻辑上从未存在过的行。
不可重复读取:当某个事务不止一次读取同一行,并且一个单独的事务在两次(或多次)读取之间修改该行时,因为在同一个事务内的多次读取之间修改了该行,所以每次读取都生成不同值,从而引发不一致问题。
幻象:通过一个任务,在以前由另一个尚未提交其事务的任务读取的行的范围中插入新行或删除现有行。带有未提交事务的任务由于该范围中行数的更改而无法重复其原始读取。
如你所想,这些情况发生的根本原因都是因为在并发访问的时候,没有一个机制避免交叉存取所造成的。而隔离级别的设置,正是为了避免这些情况的发生。事务准备接受不一致数据的级别称为隔离级别。隔离级别是一个事务必须与其它事务进行隔离的程度。较低的隔离级别可以增加并发,但代价是降低数据的正确性。相反,较高的隔离级别可以确保数据的正确性,但可能对并发产生负面影响。
根据隔离级别的不同,DBMS为并行访问提供不同的互斥保证。在SQL Server数据库中,提供四种隔离级别:未提交读、提交读、可重复读、可串行读。这四种隔离级别可以不同程度地保证并发的数据完整性:
隔离级别
脏读
不可重复读取
幻像
未提交读
是
是
是
提交读
否
是
是
可重复读
否
否
是
可串行读
否
否
否
可以看出,“可串行读”提供了最高级别的隔离,这时并发事务的执行结果将与串行执行的完全一致。如前所述,最高级别的隔离也就意味着最低程度的并发,因此,在此隔离级别下,数据库的服务效率事实上是比较低的。尽管可串行性对于事务确保数据库中的数据在所有时间内的正确性相当重要,然而许多事务并不总是要求完全的隔离。例如,多个作者工作于同一本书的不同章节。新章节可以在任意时候提交到项目中。但是,对于已经编辑过的章节,没有编辑人员的批准,作者不能对此章节进行任何更改。这样,尽管有未编辑的新章节,但编辑人员仍可以确保在任意时间该书籍项目的正确性。编辑人员可以查看以前编辑的章节以及最近提交的章节。这样,其它的几种隔离级别也有其存在的意义。
在.net框架中,事务的隔离级别是由枚举System.Data.IsolationLevel所定义的:
[Flags]
[Serializable]
public enum IsolationLevel
其成员及相应的含义如下:
成员
含义
Chaos
无法改写隔离级别更高的事务中的挂起的更改。
ReadCommitted
在正在读取数据时保持共享锁,以避免脏读,但是在事务结束之前可以更改数据,从而导致不可重复的读取或幻像数据。
ReadUncommitted
可以进行脏读,意思是说,不发布共享锁,也不接受独占锁。
RepeatableRead
在查询中使用的所有数据上放置锁,以防止其他用户更新这些数据。防止不可重复的读取,但是仍可以有幻像行。
Serializable
在DataSet上放置范围锁,以防止在事务完成之前由其他用户更新行或向数据集中插入行。
Unspecified
正在使用与指定隔离级别不同的隔离级别,但是无法确定该级别。
显而意见,数据库的四个隔离级别在这里都有映射。
默认的情况下,SQL Server使用ReadCommitted(提交读)隔离级别。
关于隔离级别的最后一点就是如果你在事务执行的过程中改变了隔离级别,那么后面的命名都在最新的隔离级别下执行——隔离级别的改变是立即生效的。有了这一点,你可以在你的事务中更灵活地使用隔离级别从而达到更高的效率和并发安全性。

Dispatch Source Timer的使用及注意事项介绍
前言
Dispatch Source Timer 是一种与 Dispatch Queue 结合使用的定时器。当需要在后台 queue 中定期执行任务的时候,使用 Dispatch Source Timer 要比使用 NSTimer 更加自然,也更加高效(无需在 main queue 和后台 queue 之前切换)。下面将详细给大家介绍关于Dispatch Source Timer的使用和一些注意事项,话不多说了,来一起看看详细的介绍吧。
创建 Timer
Dispatch Source Timer 首先其实是 Dispatch Source 的一种,关于 Dispatch Source 的内容在这里就不再赘述了。下面是苹果官方文档里给出的创建 Dispatch Timer 的代码:
dispatch_source_t CreateDispatchTimer(uint64_t interval,
uint64_t leeway,
dispatch_queue_t queue,
dispatch_block_t block)
{
dispatch_source_t timer = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER,
0, 0, queue);
if (timer)
{
dispatch_source_set_timer(timer, dispatch_walltime(NULL, 0), interval, leeway);
dispatch_source_set_event_handler(timer, block);
dispatch_resume(timer);
}
return timer;
}
有几个地方需要注意:
- Dispatch Source Timer 是间隔定时器,也就是说每隔一段时间间隔定时器就会触发。在 NSTimer 中要做到同样的效果需要手动把 repeats 设置为 YES。
- dispatch_source_set_timer 中第二个参数,当我们使用dispatch_time 或者 DISPATCH_TIME_NOW 时,系统会使用默认时钟来进行计时。然而当系统休眠的时候,默认时钟是不走的,也就会导致计时器停止。使用 dispatch_walltime 可以让计时器按照真实时间间隔进行计时。
- dispatch_source_set_timer 的第四个参数 leeway 指的是一个期望的容忍时间,将它设置为 1 秒,意味着系统有可能在定时器时间到达的前 1 秒或者后 1 秒才真正触发定时器。在调用时推荐设置一个合理的 leeway 值。需要注意,就算指定 leeway 值为 0,系统也无法保证完全精确的触发时间,只是会尽可能满足这个需求。
- event handler block 中的代码会在指定的 queue 中执行。当 queue 是后台线程的时候,dispatch timer 相比 NSTimer 就好操作一些了。因为 NSTimer 是需要 Runloop 支持的,如果要在后台 dispatch queue 中使用,则需要手动添加 Runloop。使用 dispatch timer 就简单很多了。
- dispatch_source_set_event_handler 这个函数在执行完之后,block 会立马执行一遍,后面隔一定时间间隔再执行一次。而 NSTimer 第一次执行是到计时器触发之后。这也是和 NSTimer 之间的一个显著区别。
停止 Timer
停止 Dispatch Timer 有两种方法,一种是使用 dispatch_suspend,另外一种是使用 dispatch_source_cancel。
dispatch_suspend 严格上只是把 Timer 暂时挂起,它和 dispatch_resume 是一个平衡调用,两者分别会减少和增加 dispatch 对象的挂起计数。当这个计数大于 0 的时候,Timer 就会执行。在挂起期间,产生的事件会积累起来,等到 resume 的时候会融合为一个事件发送。
需要注意的是:dispatch source 并没有提供用于检测 source 本身的挂起计数的 API,也就是说外部不能得知一个 source 当前是不是挂起状态,在设计代码逻辑时需要考虑到这一点。
dispatch_source_cancel 则是真正意义上的取消 Timer。被取消之后如果想再次执行 Timer,只能重新创建新的 Timer。这个过程类似于对 NSTimer 执行 invalidate。
关于取消 Timer,另外一个很重要的注意事项:dispatch_suspend 之后的 Timer,是不能被释放的!下面的代码会引起崩溃:
- (void)stopTimer
{
dispatch_suspend(_timer);
_timer = nil; // EXC_BAD_INSTRUCTION 崩溃
}
因此使用 dispatch_suspend 时,Timer 本身的实例需要一直保持。使用 dispatch_source_cancel 则没有这个限制:
- (void)stopTimer
{
dispatch_source_cancel(_timer);
_timer = nil; // OK
}
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对的支持。

Docker的使用及注意事项
docker从国内拉取镜像
docker pull hub.c.163.com/library/tomcat:latest
执行启动命令: systemctl start docker ,报下面错误:
Error starting daemon: SELinux is not supported with the overlay2 graph driver on this kernel. Either boot into a newer kernel or disable selinux in docker (--selinux-enabled=false)
# /etc/sysconfig/docker
# Modify these options if you want to change the way the docker daemon runs
OPTIONS=''--selinux-enabled=false --log-driver=journald --signature-verification=false''
if [ -z "${DOCKER_CERT_PATH}" ]; then
DOCKER_CERT_PATH=/etc/docker
fi
:wq
systemctl restart docker
docker 中mysql初始化及关闭后再次启动
docker 实例化mysql后后台运行
docker run -di --name=tensquare_mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 centos/mysql-57-centos7
刚关闭或者mysql显示exited时采用如下方法启动
mysql启动正常。
启动方式主要有以下三种:
1、使用systemctl 启动 systemctl start mysqld (docker start + dockerId)
2、使用脚本启动 /etc/inint.d/mysqld start
3、使用safe_mysqld或mysqld --user=mysql启动
关闭方式也有以下三种:
1、使用systemctl 关闭 systemctl stop mysqld
2、使用脚本关闭 /etc/inint.d/mysqld stop
3、mysqladmin shutdown
注意:使用safe_mysqld或mysqld --user=mysql启动的服务,只能通过mysqladmin shutdown关闭,不能通过systemctl 或脚本关闭。
mysqladmin shutdown可关闭以上三种服务。脚本可关闭systemctl开启的服务,同样systemctl也可关闭脚本开启的服务。

Go中defer使用场景及注意事项
1. 简介
defer 会在当前函数返回前执行传入的函数,它会经常被用于关闭文件描述符、关闭数据库连接以及解锁资源。
理解这句话主要在三个方面:
- 当前函数
- 返回前执行,当然函数可能没有返回值
- 传入的函数,即 defer 关键值后面跟的是一个函数,包括普通函数如(fmt.Println), 也可以是匿名函数 func()
1.1 使用场景
使用 defer 的最常见场景是在函数调用结束后完成一些收尾工作,例如在 defer 中回滚数据库的事务:
func createPost(db *gorm.DB) error {
tx := db.Begin()
// 用来回滚数据库事件
defer tx.Rollback()
if err := tx.Create(&Post{Author: "Draveness"}).Error; err != nil {
return err
}
return tx.Commit().Error
}
在使用数据库事务时,我们可以使用上面的代码在创建事务后就立刻调用 Rollback 保证事务一定会回滚。哪怕事务真的执行成功了,那么调用 tx.Commit() 之后再执行 tx.Rollback() 也不会影响已经提交的事务。
1.2 注意事项
使用defer时会遇到两个常见问题,这里会介绍具体的场景并分析这两个现象背后的设计原理:
defer 关键字的调用时机以及多次调用 defer 时执行顺序是如何确定的defer 关键字使用传值的方式传递参数时会进行预计算,导致不符合预期的结果
作用域
向 defer 关键字传入的函数会在函数返回之前运行。
假设我们在 for 循环中多次调用 defer 关键字:
package main
import "fmt"
func main() {
for i := 0; i < 5; i++ {
// FILO, 先进后出, 先出现的关键字defer会被压入栈底,会最后取出执行
defer fmt.Println(i)
}
}
#运行
$ go run main.go
4
3
2
1
0
运行上述代码会倒序执行传入 defer 关键字的所有表达式,因为最后一次调用 defer 时传入了 fmt.Println(4),所以这段代码会优先打印 4。我们可以通过下面这个简单例子强化对 defer 执行时机的理解:
package main
import "fmt"
func main() {
// 代码块
{
defer fmt.Println("defer runs")
fmt.Println("block ends")
}
fmt.Println("main ends")
}
# 输出
$ go run main.go
block ends
main ends
defer runs
从上述代码的输出我们会发现,defer 传入的函数不是在退出代码块的作用域时执行的,它只会在当前函数和方法返回之前被调用。
预计算参数
Go 语言中所有的函数调用都是传值的.
虽然 defer 是关键字,但是也继承了这个特性。假设我们想要计算 main 函数运行的时间,可能会写出以下的代码:
package main
import (
"fmt"
"time"
)
func main() {
startedAt := time.Now()
// 这里误以为:startedAt是在time.Sleep之后才会将参数传递给defer所在语句的函数中
defer fmt.Println(time.Since(startedAt))
time.Sleep(time.Second)
}
# 输出
$ go run main.go
0s
上述代码的运行结果并不符合我们的预期,这个现象背后的原因是什么呢?
经过分析(或者使用debug方式),我们会发现:
调用 defer 关键字会立刻拷贝函数中引用的外部参数
所以 time.Since(startedAt) 的结果不是在 main 函数退出之前计算的,而是在 defer 关键字调用时计算的,最终导致上述代码输出 0s。
想要解决这个问题的方法非常简单,我们只需要向 defer 关键字传入匿名函数:
package main
import (
"fmt"
"time"
)
func main() {
startedAt := time.Now()
// 使用匿名函数,传递的是函数的指针
defer func() {
fmt.Println(time.Since(startedAt))
}()
time.Sleep(time.Second)
}
#输出
$ go run main.go
$ 1.0056135s
2. defer 数据结构
defer 关键字在 Go 语言源代码中对应的数据结构:
type _defer struct {
siz int32
started bool
openDefer bool
sp uintptr
pc uintptr
fn *funcval
_panic *_panic
link *_defer
}
简单介绍一下 runtime._defer 结构体中的几个字段:
- siz 是参数和结果的内存大小;
- sp 和 pc 分别代表栈指针和调用方的程序计数器;
- fn 是 defer 关键字中传入的函数;
- _panic 是触发延迟调用的结构体,可能为空;
- openDefer 表示当前 defer 是否经过开放编码的优化;
除了上述的这些字段之外,runtime._defer 中还包含一些垃圾回收机制使用的字段, 这里不做过多的说明
3. 执行机制
堆分配、栈分配和开放编码是处理 defer 关键字的三种方法。
- 早期的 Go 语言会在堆上分配, 不过性能较差
- Go 语言在 1.13 中引入栈上分配的结构体,减少了 30% 的额外开销
- 在1.14 中引入了基于开放编码的 defer,使得该关键字的额外开销可以忽略不计
堆上分配暂时不做过多的说明
3.1 栈上分配
在 1.13 中对 defer 关键字进行了优化,当该关键字在函数体中最多执行一次时,会将结构体分配到栈上并调用。
除了分配位置的不同,栈上分配和堆上分配的 runtime._defer 并没有本质的不同,而该方法可以适用于绝大多数的场景,与堆上分配的 runtime._defer 相比,该方法可以将 defer 关键字的额外开销降低 ~30%。
3.2 开放编码
在 1.14 中通过开放编码(Open Coded)实现 defer 关键字,该设计使用代码内联优化 defer 关键的额外开销并引入函数数据 funcdata 管理 panic 的调用3,该优化可以将 defer 的调用开销从 1.13 版本的~35ns 降低至 ~6ns 左右:
然而开放编码作为一种优化 defer 关键字的方法,它不是在所有的场景下都会开启的,开放编码只会在满足以下的条件时启用:
- 函数的 defer 数量小于或等于8个;
- 函数的 defer 关键字不能再循环中执行
- 函数的 return 语句 与 defer 语句个数的成绩小于或者等于15个。
4. 参考
https://draveness.me/golang/docs/part2-foundation/ch05-keyword/golang-defer/
到此这篇关于Go中defer使用注意事项的文章就介绍到这了,更多相关Go中defer使用内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- Go程序员踩过的defer坑错误处理
- GO语言中err接口及defer延迟异常处理分析
- Go基础教程系列之defer、panic和recover详解
- Go defer 原理和源码剖析(推荐)
- Go语言使用defer+recover解决panic导致程序崩溃的问题
- Go语言defer的一些神奇规则示例详解
我们今天的关于JSON的使用场景及注意事项介绍和json的使用场景及注意事项介绍图片的分享就到这里,谢谢您的阅读,如果想了解更多关于c#事务的使用、示例及注意事项、Dispatch Source Timer的使用及注意事项介绍、Docker的使用及注意事项、Go中defer使用场景及注意事项的相关信息,可以在本站进行搜索。
本文标签:




