在这里,我们将给大家分享关于《Node.js设计模式》基于回调的异步控制流的知识,让您更了解nodejs回调的本质,同时也会涉及到如何更有效地Android学习笔记基于回调的事件处理、iOS设计模式-
在这里,我们将给大家分享关于《Node.js设计模式》基于回调的异步控制流的知识,让您更了解nodejs 回调的本质,同时也会涉及到如何更有效地Android学习笔记基于回调的事件处理、iOS设计模式--备忘录设计模式与命令设计模式、Java基于回调的观察者模式详解、mybatis设计模式之builder设计模式的内容。
本文目录一览:- 《Node.js设计模式》基于回调的异步控制流(nodejs 回调)
- Android学习笔记基于回调的事件处理
- iOS设计模式--备忘录设计模式与命令设计模式
- Java基于回调的观察者模式详解
- mybatis设计模式之builder设计模式
")
《Node.js设计模式》基于回调的异步控制流(nodejs 回调)
本系列文章为《Node.js Design Patterns Second Edition》的原文翻译和读书笔记,在GitHub连载更新,同步翻译版链接。
欢迎关注我的专栏,之后的博文将在专栏同步:
- Encounter的掘金专栏
- 知乎专栏 Encounter的编程思考
- segmentfault专栏 前端小站
Asynchronous Control Flow Patterns with Callbacks
Node.js这类语言习惯于同步的编程风格,其cps风格和异步特性的API是其标准,对于新手来说可能难以理解。编写异步代码可能是一种不同的体验,尤其是对异步控制流而言。异步代码可能让我们难以预测在Node.js中执行语句的顺序。例如读取一组文件,执行一串任务,或者等待一组操作完成,都需要开发人员采用新的方法和技术,以避免最终编写出效率低下和不可维护的代码。一个常见的错误是回调地狱,代码量急剧上升又不可读,使得简单的程序也难以阅读和维护。在本章中,我们将看到如何通过使用一些规则和一些模式来避免回调,并编写干净、可管理的异步代码。我们将看到控制流库,如async,可以极大地简化我们的问题,提升我们的代码可读性,更易于维护。
异步编程的困难
JavaScript中异步代码的顺序错乱无疑是很容易的。闭包和对匿名函数的定义可以使开发人员有更好的编程体验,而并不需要开发人员手动对异步操作进行管理和跳转。这是符合KISS原则的。简单且能保持异步代码控制流,让它在更短的时间内工作。但不幸的是,回调嵌套是以牺牲诸如模块性、可重用性和可维护性,增大整个函数的大小,导致糟糕的代码结构为代价的。大多数情况下,创建闭包在功能上是不需要的,但这更多是一种约束,而不是与异步编程相关的问题。认识到回调嵌套会使得我们的代码变得笨拙,然后根据最适合的解决方案采取相应的方法解决回调地狱,这是新手与专家的区别。
创建一个简单的Web爬虫
为了解释上述问题,我们创建了一个简单的Web爬虫,一个命令行应用,其接受一个URL为输入,然后可以把其内容下载到一个文件中。在下列代码中,我们会依赖以下两个npm库。
此外,我们还将引用一个叫做./utilities的本地模块。
我们的应用程序的核心功能包含在一个名为spider.js的模块中。如下所示,首先加载我们所需要的依赖包:
const request = require('request');
const fs = require('fs');
const mkdirp = require('mkdirp');
const path = require('path');
const utilities = require('./utilities');
接下来,我们将创建一个名为spider()的新函数,该函数接受URL为参数,并在下载过程完成时调用一个回调函数。
function spider(url,callback) {
const filename = utilities.urlToFilename(url);
fs.exists(filename,exists => {
if (!exists) {
console.log(`Downloading ${url}`);
request(url,(err,response,body) => {
if (err) {
callback(err);
} else {
mkdirp(path.dirname(filename),err => {
if (err) {
callback(err);
} else {
fs.writeFile(filename,body,err => {
if (err) {
callback(err);
} else {
callback(null,filename,true);
}
});
}
});
}
});
} else {
callback(null,false);
}
});
}
上述函数执行以下任务:
- 检查该
URL的文件是否已经下载过,即验证相应文件是否已经被创建:
fs.exists(filename,exists => ...
- 如果文件还没有被下载,则执行下列代码进行下载操作:
request(url,body) => ...
- 然后,我们需要确定目录下是否已经包含了该文件:
mkdirp(path.dirname(filename),err => ...
- 最后,我们把
HTTP请求返回的报文主体写入文件系统:
mkdirp(path.dirname(filename),err => ...
要完成我们的Web爬虫应用程序,只需提供一个URL作为输入(在我们的例子中,我们从命令行参数中读取它),我们只需调用spider()函数即可。
spider(process.argv[2],downloaded) => {
if (err) {
console.log(err);
} else if (downloaded) {
console.log(`Completed the download of "${filename}"`);
} else {
console.log(`"${filename}" was already downloaded`);
}
});
现在,我们开始尝试运行Web爬虫应用程序,但是首先,确保已有utilities.js模块和package.json中的所有依赖包已经安装到你的项目中:
npm install
之后,我们执行我们这个爬虫模块来下载一个网页,使用以下命令:
node spider http://www.example.com
我们的Web爬虫应用程序要求在我们提供的URL中总是包含协议类型(例如,http://)。另外,不要期望HTML链接被重新编写,也不要期望下载像图片这样的资源,因为这只是一个简单的例子来演示异步编程是如何工作的。

回调地狱
看看我们的spider()函数,我们可以发现,尽管我们实现的算法非常简单,但是生成的代码有几个级别的缩进,而且很难读懂。使用阻塞式的同步API实现类似的功能是很简单的,而且很少有机会让它看起来如此错误。然而,使用异步cps是另一回事,使用闭包可能会导致出现难以阅读的代码。
大量闭包和回调将代码转换成不可读的、难以管理的情况称为回调地狱。它是Node.js中最受认可和最严重的反模式之一。一般来说,对于JavaScript而言。受此问题影响的代码的典型结构如下:
asyncFoo(err => {
asyncBar(err => {
asyncFooBar(err => {
//...
});
});
});
我们可以看到,用这种方式编写的代码是如何形成金字塔形状的,由于深嵌的原因导致的难以阅读,称为“末日金字塔”。
像前面的代码片段这样的代码最明显的问题是可读性差。由于嵌套太深,几乎不可能跟踪回调函数的结束位置和另一个回调函数开始的位置。
另一个问题是由每个作用域中使用的变量名的重叠引起的。通常,我们必须使用类似甚至相同的名称来描述变量的内容。最好的例子是每个回调接收到的错误参数。有些人经常尝试使用相同名称的变体来区分每个范围内的对象,例如,error、err、err1、err2等等。另一些人则倾向于隐藏在范围中定义的变量,总是使用相同的名称。例如,err。这两种选择都远非完美,而且会造成混淆,并增加导致bug的可能性。
此外,我们必须记住,虽然闭包在性能和内存消耗方面的代价很小。此外,它们还可以创建不易识别的内存泄漏,因为我们不应该忘记,由闭包引用的任何上下文变量都不会被垃圾收集所保留。
关于对于V8的闭包工作原理,可以参考Vyacheslav Egorov的博客文章。
如果我们看一下我们的spider()函数,我们会清楚地注意到它便是一个典型的回调地狱的场景,并且在这个函数中有我们刚才描述的所有问题。这正是我们将在本章中学习的模式和技巧所要解决的问题。
使用简单的JavaScript
既然我们已经遇到了第一个回调地狱的例子,我们知道我们应该避免什么。然而,在编写异步代码时,这并不是惟一的关注点。事实上,有几种情况下,控制一组异步任务的流需要使用特定的模式和技术,特别是如果我们只使用普通的JavaScript而没有任何外部库的帮助的情况下。例如,通过按顺序应用异步操作来遍历集合并不像在数组中调用forEach()那样简单,但实际上它需要一种类似于递归的技术。
在本节中,我们将学习如何避免回调地狱,以及如何使用简单的JavaScript实现一些最常见的控制流模式。
回调函数的准则
在编写异步代码时,要记住的第一个规则是在定义回调时不要滥用闭包。滥用闭包一时很爽,因为它不需要对诸如模块化和可重用性这样的问题进行额外的思考。但是,我们已经看到,这种做法弊大于利。大多数情况下,修复回调地狱问题并不需要任何库、花哨的技术或范式的改变,只是一些常识。
以下是一些基本原则,可以帮助我们更少的嵌套,并改进我们的代码的组织:
- 尽可能退出外层函数。根据上下文,使用
return、continue或break,以便立即退出当前代码块,而不是使用if...else代码块。其他语句。这将有助于优化我们的代码结构。 - 为回调创建命名函数,避免使用闭包,并将中间结果作为参数传递。命名函数也会使它们在堆栈跟踪中更优雅。
- 代码尽可能模块化。并尽可能将代码分成更小的、可重用的函数。
回调调用的准则
为了展示上述原则,我们通过重构Web爬虫应用程序来说明。
对于第一步,我们可以通过删除else语句来重构我们的错误检查方式。这是在我们收到错误后立即从函数中返回。因此,看以下代码:
if (err) {
callback(err);
} else {
// 如果没有错误,执行该代码块
}
我们可以通过编写下面的代码来改进我们的代码结构:
if (err) {
return callback(err);
}
// 如果没有错误,执行该代码块
有了这个简单的技巧,我们立即减少了函数的嵌套级别,它很简单,不需要任何复杂的重构。
在执行我们刚才描述的优化时,一个常见的错误是在调用回调函数之后忘记终止函数,即return。对于错误处理场景,以下代码是bug的典型来源:
if (err) {
callback(err);
}
// 如果没有错误,执行该代码块
在这个例子中,即使在调用回调之后,函数的执行也会继续。那么避免这种情况的出现,return语句是十分必要的。还要注意,函数返回的输出是什么并不重要,实际结果(或错误)是异步生成的,并传递给回调。异步函数的返回值通常被忽略。该属性允许我们编写如下的代码:
return callback(...);
否则我们必须拆成两条语句来写:
callback(...); return;
接下来我们继续重构我们的spider()函数,我们可以尝试识别可复用的代码片段。例如,将给定字符串写入文件的功能可以很容易地分解为一个单独的函数:
function saveFile(filename,contents,callback) {
mkdirp(path.dirname(filename),err => {
if (err) {
return callback(err);
}
fs.writeFile(filename,callback);
});
}
遵循同样的原则,我们可以创建一个名为download()的通用函数,它将URL和文件名作为输入,并将URL的内容下载到给定的文件中。在内部,我们可以使用前面创建的saveFile()函数。
function download(url,callback) {
console.log(`Downloading ${url}`);
request(url,body) => {
if (err) {
return callback(err);
}
saveFile(filename,err => {
if (err) {
return callback(err);
}
console.log(`Downloaded and saved: ${url}`);
callback(null,body);
});
});
}
最后,修改我们的spider()函数:
function spider(url,exists => {
if (exists) {
return callback(null,false);
}
download(url,err => {
if (err) {
return callback(err);
}
callback(null,true);
})
});
}
spider()函数的功能和接口仍然是完全相同的,改变的仅仅是代码的组织方式。通过应用上述基本原则,我们能够极大地减少代码的嵌套,同时增加了它的可重用性和可测试性。实际上,我们可以考虑导出saveFile()和download(),这样我们就可以在其他模块中重用它们。这也使我们能够更容易地测试他们的功能。
我们在这一节中进行的重构清楚地表明,大多数时候,我们所需要的只是一些规则,并确保我们不滥用闭包和匿名函数。它的工作非常出色,只需最少的工作量,并且只使用原始的JavaScript。
顺序执行
现在开始探寻异步控制流的执行顺序,我们会通过开始分析一串异步代码来探寻其控制流。
按顺序执行一组任务意味着一次一个接一个地运行它们。执行顺序很重要,必须保证其正确性,因为列表中一个任务的结果可能会影响下一个任务的执行。下图说明了这个概念:

上述异步控制流有一些不同的变化:
- 按顺序执行一组已知任务,无需链接或传递执行结果
- 使用任务的输出作为下一个输入(也称为
chain,pipeline,或者waterfall) - 在每个元素上运行异步任务时迭代一个集合,一个元素接一个元素
对于顺序执行而言,尽管在使用直接样式阻塞API实现很简单,但通常情况下使用异步cps时会导致回调地狱问题。
按顺序执行一组已知的任务
在上一节中实现spider()函数时,我们已经遇到了顺序执行的问题。通过研究如下方式,我们可以更好地控制异步代码。以该代码为准则,我们可以用以下模式来解决上述问题:
function task1(callback) {
asyncoperation(() => {
task2(callback);
});
}
function task2(callback) {
asyncoperation(result() => {
task3(callback);
});
}
function task3(callback) {
asyncoperation(() => {
callback(); //finally executes the callback
});
}
task1(() => {
//executed when task1,task2 and task3 are completed
console.log('tasks 1,2 and 3 executed');
});
上述模式显示了在完成一个异步操作后,再调用下一个异步操作。该模式强调任务的模块化,并且避免在处理异步代码使用闭包。
顺序迭代
我们前面描述的模式如果我们预先知道要执行什么和有多少个任务,这些模式是完美的。这使我们能够对序列中下一个任务的调用进行硬编码,但是如果要对集合中的每个项目执行异步操作,会发生什么?在这种情况下,我们不能对任务序列进行硬编码。相反的是,我们必须动态构建它。
Web爬虫版本2
为了显示顺序迭代的例子,让我们为Web爬虫应用程序引入一个新功能。我们现在想要递归地下载网页中的所有链接。要做到这一点,我们将从页面中提取所有链接,然后按顺序逐个地触发我们的Web爬虫应用程序。
第一步是修改我们的spider()函数,以便通过调用一个名为spiderLinks()的函数触发页面所有链接的递归下载。
此外,我们现在尝试读取文件,而不是检查文件是否已经存在,并开始爬取其链接。这样,我们就可以恢复中断的下载。最后还有一个变化是,我们确保我们传递的参数是最新的,还要限制递归深度。结果代码如下:
function spider(url,nesting,callback) {
const filename = utilities.urlToFilename(url);
fs.readFile(filename,'utf8',body) => {
if (err) {
if (err.code! == 'ENOENT') {
return callback(err);
}
return download(url,body) => {
if (err) {
return callback(err);
}
spiderLinks(url,callback);
});
}
spiderLinks(url,callback);
});
}
爬取链接
现在我们可以创建这个新版本的Web爬虫应用程序的核心,即spiderLinks()函数,它使用顺序异步迭代算法下载HTML页面的所有链接。注意我们在下面的代码块中定义的方式:
function spiderLinks(currentUrl,callback) {
if(nesting === 0) {
return process.nextTick(callback);
}
let links = utilities.getPageLinks(currentUrl,body); //[1]
function iterate(index) { //[2]
if(index === links.length) {
return callback();
}
spider(links[index],nesting - 1,function(err) { //[3]
if(err) {
return callback(err);
}
iterate(index + 1);
});
}
iterate(0); //[4]
}
从这个新功能中的重要步骤如下:
- 我们使用
utilities.getPageLinks()函数获取页面中包含的所有链接的列表。此函数仅返回指向相同主机名的链接。 - 我们使用一个称为
iterate()的本地函数来遍历链接,该函数需要下一个链接的索引进行分析。在这个函数中,我们首先要检查索引是否等于链接数组的长度,如果等于则是迭代完成,在这种情况下我们立即调用callback()函数,因为这意味着我们处理了所有的项目。 - 这时,处理链接已准备就绪。我们通过递归调用
spider()函数。 - 作为
spiderLinks()函数的最后一步也是最重要的一步,我们通过调用iterate(0)来开始迭代。
我们刚刚提出的算法允许我们通过顺序执行异步操作来迭代数组,在我们的例子中是spider()函数。
我们现在可以尝试这个新版本的Web爬虫应用程序,并观看它一个接一个地递归地下载网页的所有链接。要中断这个过程,如果有很多链接可能需要一段时间,请记住我们可以随时使用Ctrl + C。如果我们决定恢复它,我们可以通过启动Web爬虫应用程序并提供与上次结束时相同的URL来恢复执行。
现在我们的网络Web爬虫应用程序可能会触发整个网站的下载,请仔细考虑使用它。例如,不要设置高嵌套级别或离开爬虫运行超过几秒钟。用数千个请求重载服务器是不道德的。在某些情况下,这也被认为是非法的。需要考虑后果!
迭代模式
我们之前展示的spiderLinks()函数的代码是一个清楚的例子,说明了如何在应用异步操作时迭代集合。我们还可以注意到,这是一种可以适应任何其他情况的模式,我们需要在集合的元素或通常的任务列表上按顺序异步迭代。该模式可以推广如下:
function iterate(index) {
if (index === tasks.length) {
return finish();
}
const task = tasks[index];
task(function() {
iterate(index + 1);
});
}
function finish() {
// 迭代完成的操作
}
iterate(0);
注意到,如果task()是同步操作,这些类型的算法变得真正递归。在这种情况下,可能造成调用栈的溢出。
我们刚刚提出的模式是非常强大的,因为它可以适应几种情况。例如,我们可以映射数组的值,或者我们可以将迭代的结果传递给迭代中的下一个,以实现一个reduce算法,如果满足特定的条件,我们可以提前退出循环,或者甚至可以迭代无限数量的元素。
我们还可以选择将解决方案进一步推广:
iterateSeries(collection,iteratorCallback,finalCallback);
通过创建一个名为iterator的函数来执行任务列表,该函数调用集合中的下一个可执行的任务,并确保在当前任务完成时调用迭代器结束的回调函数。
并行
在某些情况下,一组异步任务的执行顺序并不重要,我们只需要在所有这些运行的任务完成时通知我们。使用并行执行流更好地处理这种情况,如下图所示:

如果我们认为Node.js是单线程的话,这可能听起来很奇怪,但是如果我们记住我们在第一章中讨论过的内容,我们意识到即使我们只有一个线程,我们仍然可以实现并发,由于Node.js的非阻塞性质。实际上,在这种情况下,并行字不正确地使用,因为这并不意味着任务同时运行,而是它们的执行由底层的非阻塞API执行,并由事件循环进行交织。
我们知道,当一个任务允许事件循环执行另一个任务时,或者是说一个任务允许控制回到事件循环。这种工作流的名称为并发,但为了简单起见,我们仍然会使用并行。
下图显示了两个异步任务可以在Node.js程序中并行运行:

通过上图,我们有一个Main函数执行两个异步任务:
-
Main函数触发Task 1和Task 2的执行。由于这些触发异步操作,这两个函数会立即返回,并将控制权返还给主函数,之后等到事件循环完成再通知主线程。 - 当
Task 1的异步操作完成时,事件循环给与其线程控制权。当Task 1同步操作完成时,它通知Main函数。 - 当
Task 2的异步操作完成时,事件循环给与其线程控制权。当Task 2同步操作完成时,它再次通知Main函数。在这一点上,Main函数知晓Task 1和Task 2都已经执行完毕,所以它可以继续执行其后操作或将操作的结果返回给另一个回调函数。
简而言之,这意味着在Node.js中,我们只能执行并行异步操作,因为它们的并发性由非阻塞API在内部处理。在Node.js中,同步阻塞操作不能同时运行,除非它们的执行与异步操作交错,或者通过setTimeout()或setImmediate()延迟。我们将在第九章中更详细地看到这一点。
Web爬虫版本3
上边的Web爬虫在并行异步操作上似乎也算表现得很完美。到目前为止,应用程序正在递归地执行链接页面的下载。但性能不是最佳的,想要提升这个应用的性能很容易。
要做到这一点,我们只需要修改spiderLinks()函数,确保spider()任务只执行一次,当所有任务都执行完毕后,调用最后的回调,所以我们对spiderLinks()做如下修改:
function spiderLinks(currentUrl,callback) {
if (nesting === 0) {
return process.nextTick(callback);
}
const links = utilities.getPageLinks(currentUrl,body);
if (links.length === 0) {
return process.nextTick(callback);
}
let completed = 0,hasErrors = false;
function done(err) {
if (err) {
hasErrors = true;
return callback(err);
}
if (++completed === links.length && !hasErrors) {
return callback();
}
}
links.forEach(link => {
spider(link,done);
});
}
上述代码有何变化?,现在spider()函数的任务全部同步启动。可以通过简单地遍历链接数组和启动每个任务,我们不必等待前一个任务完成再进行下一个任务:
links.forEach(link => {
spider(link,done);
});
然后,使我们的应用程序知晓所有任务完成的方法是为spider()函数提供一个特殊的回调函数,我们称之为done()。当爬虫任务完成时,done()函数设定一个计数器。当完成的下载次数达到链接数组的大小时,调用最终回调:
function done(err) {
if (err) {
hasErrors = true;
return callback(err);
}
if (++completed === links.length && !hasErrors) {
callback();
}
}
通过上述变化,如果我们现在试图对网页运行我们的爬虫,我们将注意到整个过程的速度有很大的改进,因为每次下载都是并行执行的,而不必等待之前的链接被处理。
模式
此外,对于并行执行流程,我们可以提取我们方案,以便适应于不同的情况提高代码的可复用性。我们可以使用以下代码来表示模式的通用版本:
const tasks = [ /* ... */ ];
let completed = 0;
tasks.forEach(task => {
task(() => {
if (++completed === tasks.length) {
finish();
}
});
});
function finish() {
// 所有任务执行完成后调用
}
通过小的修改,我们可以调整模式,将每个任务的结果累积到一个list中,以便过滤或映射数组的元素,或者一旦完成了一个或一定数量的任务即可调用finish()回调。
注意:如果是没有限制的情况下,并行执行的一组异步任务,然后等待所有异步任务完成后执行回调这种方式,其方法是计算它们的执行完成的数目。
用并发任务修复竞争条件
当使用阻塞I/O与多线程组合的方式时,并行运行一组任务可能会导致一些问题。但是,我们刚刚看到,在Node.js中却不一样,并行运行多个异步任务实际上在资源方面消耗较低。这是Node.js最重要的优点之一,因此在Node.js中并行化成为一种常见的做法,而且这并是多么复杂的技术。
Node.js的并发模型的另一个重要特征是我们处理任务同步和竞争条件的方式。在多线程编程中,这通常使用诸如锁,互斥条件,信号量和观察器之类的构造来实现,这些是多线程语言并行化的最复杂的方面之一,对性能也有很大的影响。在Node.js中,我们通常不需要一个花哨的同步机制,因为所有运行在单个线程上!但是,这并不意味着我们没有竞争条件。相反,他们可以相当普遍。问题的根源在于异步操作的调用与其结果通知之间的延迟。举一个具体的例子,我们可以再次参考我们的Web爬虫应用程序,特别是我们创建的最后一个版本,其实际上包含一个竞争条件。
问题在于在开始下载相应的URL的文档之前,检查文件是否已经存在的spider()函数:
function spider(url,callback) {
if(spidering.has(url)) {
return process.nextTick(callback);
}
spidering.set(url,true);
const filename = utilities.urlToFilename(url);
fs.readFile(filename,function(err,body) {
if(err) {
if(err.code !== 'ENOENT') {
return callback(err);
}
return download(url,body) {
if(err) {
return callback(err);
}
spiderLinks(url,callback);
});
}
spiderLinks(url,callback);
});
}
现在的问题是,在同一个URL上操作的两个爬虫任务可能会在两个任务之一完成下载并创建一个文件,导致第二个任务开始下载之前,在同一个文件上调用fs.readFile()的结果不对,致使下载两次。这种情况如下图所示:

上图显示了Task 1和Task 2如何在Node.js的单个线程中交错执行,以及异步操作如何实际引入竞争条件。在我们的情况下,两个爬虫任务最终会下载相同的文件。
我们如何解决这个问题?答案比我们想象的要简单得多。实际上,我们所需要的只是一个变量(互斥变量),可以相互排除运行在同一个URL上的多个spider()任务。这可以通过以下代码来实现:
const spidering = new Map();
function spider(url,callback) {
if (spidering.has(url)) {
return process.nextTick(callback);
}
spidering.set(url,true);
// ...
}
并行执行频率限制
通常,如果不控制并行任务频率,并行任务就会导致过载。想象一下,有数千个文件要读取,访问的URL或数据库查询并行运行。在这种情况下,常见的问题是系统资源不足,例如,当尝试一次打开太多文件时,利用可用于应用程序的所有文件描述符。在Web应用程序中,它还可能会创建一个利用拒绝服务(DoS)攻击的漏洞。在所有这种情况下,最好限制同时运行的任务数量。这样,我们可以为服务器的负载增加一些可预测性,并确保我们的应用程序不会耗尽资源。下图描述了一个情况,我们将五个任务并行运行并发限制为两段:

从上图可以清楚我们的算法如何工作:
- 我们可以执行尽可能多的任务,而不超过并发限制。
- 每当任务完成时,我们再执行一个或多个任务,同时确保任务数量达不到限制。
并发限制
我们现在提出一种模式,以有限的并发性并行执行一组给定的任务:
const tasks = ...
let concurrency = 2,running = 0,completed = 0,index = 0;
function next() {
while (running < concurrency && index < tasks.length) {
task = tasks[index++];
task(() => {
if (completed === tasks.length) {
return finish();
}
completed++,running--;
next();
});
running++;
}
}
next();
function finish() {
// 所有任务执行完成
}
该算法可以被认为是顺序执行和并行执行之间的混合。事实上,我们可能会注意到我们之前介绍的两种模式的相似之处:
- 我们有一个迭代器函数,我们称之为
next(),有一个内部循环,并行执行尽可能多的任务,同时保持并发限制。 - 我们传递给每个任务的回调检查是否完成了列表中的所有任务。如果还有任务要运行,它会调用
next()来执行下一个任务。
全局并发限制
我们的Web爬虫应用程序非常适合应用我们所学到的限制一组任务的并发性。事实上,为了避免同时爬上数千个链接的情况,我们可以通过在并发下载数量上增加一些措施来限制并发量。
0.11之前的Node.js版本已经将每个主机的并发HTTP连接数限制为5.然而,这可以改变以适应我们的需要。请查看官方文档http://nodejs.org/docs/v0.10.... axsockets中的更多内容。从Node.js 0.11开始,并发连接数没有默认限制。
我们可以将我们刚刚学到的模式应用到我们的spiderLinks()函数,但是我们将获得的只是限制一个页面中的一组链接的并发性。如果我们选择了并发量为2,我们最多可以为每个页面并行下载两个链接。然而,由于我们可以一次下载多个链接,因此每个页面都会产生另外两个下载,这样递归下去,其实也没有完全做到并发量的限制。
使用队列
我们真正想要的是限制我们可以并行运行的全局下载操作数量。我们可以略微修改之前展示的模式,但是我们宁愿把它作为一个练习,因为我们想借此机会引入另一个机制,它利用队列来限制多个任务的并发性。让我们看看这是如何工作的。
我们现在要实现一个名为TaskQueue类,它将队列与我们之前提到的算法相结合。我们创建一个名为taskQueue.js的新模块:
class TaskQueue {
constructor(concurrency) {
this.concurrency = concurrency;
this.running = 0;
this.queue = [];
}
pushTask(task) {
this.queue.push(task);
this.next();
}
next() {
while (this.running < this.concurrency && this.queue.length) {
const task = this.queue.shift();
task(() => {
this.running--;
this.next();
});
this.running++;
}
}
};
上述类的构造函数只作为输入的并发限制,但除此之外,它初始化运行和队列的变量。前一个变量是用于跟踪所有正在运行的任务的计数器,而后者是将用作队列以存储待处理任务的数组。
pushTask()方法简单地将新任务添加到队列中,然后通过调用this.next()来引导任务的执行。
next()方法从队列中生成一组任务,确保它不超过并发限制。
我们可能会注意到,这种方法与限制我们前面提到的并发性的模式有一些相似之处。它基本上从队列开始尽可能多的任务,而不超过并发限制。当每个任务完成时,它会更新运行任务的计数,然后再次调用next()来启动另一轮任务。 TaskQueue类的有趣属性是它允许我们动态地将新的项目添加到队列中。另一个优点是,现在我们有一个中央实体负责限制我们任务的并发性,这可以在函数执行的所有实例中共享。在我们的例子中,它是spider()函数,我们将在稍后看到。
Web爬虫版本4
现在我们有一个通用的队列来执行有限的并行流程中的任务,我们可以在我们的Web爬虫应用程序中直接使用它。我们首先加载新的依赖关系并通过将并发限制设置为2来创建TaskQueue类的新实例:
const TaskQueue = require('./taskQueue');
const downloadQueue = new TaskQueue(2);
接下来,我们使用新创建的downloadQueue更新spiderLinks()函数:
function spiderLinks(currentUrl,hasErrors = false;
links.forEach(link => {
downloadQueue.pushTask(done => {
spider(link,err => {
if (err) {
hasErrors = true;
return callback(err);
}
if (++completed === links.length && !hasErrors) {
callback();
}
done();
});
});
});
}
这个函数的这种新的实现是非常容易的,它与这本章前面提到的无限并行执行的算法非常相似。这是因为我们将并发控制委托给TaskQueue对象,我们唯一要做的就是检查所有任务是否完成。看上述代码中如何定义我们的任务:
- 我们通过提供自定义回调来运行
spider()函数。 - 在回调中,我们检查与
spiderLinks()函数执行相关的所有任务是否完成。当这个条件为真时,我们调用spiderLinks()函数的最后回调。 - 在我们的任务结束时,我们调用了
done()回调,以便队列可以继续执行。
在我们进行这些小的变化之后,我们现在可以尝试再次运行Web爬虫应用程序。这一次,我们应该注意到,同时不会有两个以上的下载。
async库
如果我们到目前为止我们分析的每一个控制流程模式看一下,我们可以看到它们可以用作构建可重用和更通用的解决方案的基础。例如,我们可以将无限制的并行执行算法包装到一个接受任务列表的函数中,并行运行它们,并且当它们都完成时调用给定的回调函数。将控制流算法转化为可重用功能的这种方式可以导致更具声明性和表达性的方式来定义异步控制流,这正是async所做的。async库是一个非常流行的解决方案,在Node.js和JavaScript中来说,用于处理异步代码。它提供了一组功能,可以大大简化不同配置中一组任务的执行,并为异步处理集合提供了有用的帮助。即使有其他几个具有相似目标的库,由于它的受欢迎程度,因此async是Node.js中的一个事实上的标准。
顺序执行
async库可以在实现复杂的异步控制流程时大大帮助我们,但是一个难题就是选择正确的库来解决问题。例如,对于顺序执行,有大约20个不同的函数可供选择,包括eachSeries(),mapSeries(),filterSeries(),rejectSeries(),reduce(),reduceRight(),detectSeries(),concatSeries(),series(),whilst(),doWhilst(),until(),doUntil(),forever(),waterfall(),compose(),seq(),applyEachSeries(),iterator(),和timesSeries()
。
选择正确的函数是编写更稳固和可读的代码的重要一步,但这也需要一些经验和实践。在我们的例子中,我们将仅介绍其中的一些情况,但它们仍将为理解和有效地使用库的其余部分提供坚实的基础。
下面,通过例子说明async库如何工作,我们将用于我们的Web爬虫应用程序。我们直接从版本2开始,按顺序递归地下载所有的链接。
但是,首先我们确保将async库安装到我们当前的项目中:
npm install async
然后我们需要从spider.js模块加载新的依赖项:
const async = require('async');
已知一组任务的顺序执行
我们先修改download()函数。如下所示,它依次做了以下三件事:
- 下载
URL的内容。 - 创建一个新目录(如果尚不存在)。
- 将
URL的内容保存到文件中。
async.series()可以实现顺序执行一组任务:
async.series(tasks,[callback])
async.series()接受一个任务列表和一个在所有任务完成后调用的回调函数作为参数。每个任务只是一个接受回调函数的函数,当任务完成执行时,这个回调函数被调用:
function task(callback) {}
async的优势是它使用与Node.js相同的回调约定,它会自动处理错误传播。所以,如果任何一个任务调用它的回调并且产生了一个错误,async将跳过列表中剩余的任务,直接跳转到最后的回调。
考虑到这一点,让我们看看如何通过使用async来修改上述的download()函数:
function download(url,callback) {
console.log(`Downloading ${url}`);
let body;
async.series([
callback => {
request(url,resBody) => {
if (err) {
return callback(err);
}
body = resBody;
callback();
});
},mkdirp.bind(null,path.dirname(filename)),callback => {
fs.writeFile(filename,callback);
}
],err => {
if (err) {
return callback(err);
}
console.log(`Downloaded and saved: ${url}`);
callback(null,body);
});
}
对比起这段代码的回调地狱版本,使用async方式使我们能够更好地组织我们的异步任务。并且不会嵌套回调,因为我们只需要提供一个的任务列表,通常对于用于每个异步操作,然后异步任务将依次执行:
- 首先是下载
URL的内容。我们将响应体保存到一个闭包变量(body)中,以便它可以与其他任务共享。 - 创建并保存下载的页面的目录。我们通过执行
mkdirp()函数实现,并和创建的目录路径绑定。这样,我们可以节省几行代码并增加其可读性。 - 最后,我们将下载的
URL的内容写入文件。在这种情况下,我们无法执行部分应用程序(就像我们在第二个任务中所做的那样),因为变量body只在系列中的下载任务完成后才可用。但是,通过将任务的回调直接传递到fs.writeFile()函数,我们仍然可以通过利用异步的自动错误管理来保存一些代码行。
4.完成所有任务后,将调用async.series()的最后回调。在我们的例子中,我们只是做一些错误管理,然后返回body变量来回调download()函数。
对于上述情况,async.series()的一个可替代的方法是async.waterfall(),它仍然按顺序执行任务,但另外还提供每个任务的输出作为下一个输入。在我们的情况下,我们可以使用这个特征来传播body变量直到序列结束。
顺序迭代
在前面讲了如何按顺序执行一组任务。上面的例子async.series()来做到这一点。可以使用相同的功能来实现Web爬虫版本2的spiderLinks()函数。然而,async为特定的情况提供了一个更合适的API,遍历一个集合,这个API是async.eachSeries()。我们来使用它来重新实现我们的spiderLinks()函数(版本2,串行下载),如下所示:
function spiderLinks(currentUrl,body);
if (links.length === 0) {
return process.nextTick(callback);
}
async.eachSeries(links,(link,callback) => {
spider(link,callback);
},callback);
}
如果我们将使用async的上述代码与使用纯JavaScript模式实现的相同功能的代码进行比较,我们将注意到async在代码组织和可读性方面给我们带来的巨大优势。
并行执行
async不具有处理并行流的功能,其中可以找到each(),map(),filter(),reject(),detect(),some(),every(),concat(),parallel(),applyEach()和times()。它们遵循与我们已经看到的用于顺序执行的功能相同的逻辑,区别在于所提供的任务是并行执行的。
为了证明这一点,我们可以尝试应用上述功能之一来实现我们的Web爬虫应用程序的第三版,即使用无限制的并行流程来执行下载。
如果我们记住我们之前使用的代码来实现spiderLinks()函数的顺序版本,那么调整它使其并行工作就比较简单:
function spiderLinks(currentUrl,callback) {
// ...
async.each(links,callback);
}
这个函数与我们用于顺序下载的功能完全相同,但是使用的是async.each()而非async.eachSeries()。这清楚地表明了使用库(例如async)抽象异步流的功能。代码不再绑定到特定的执行流程了,没有专门为此写的代码。大多数只是应用逻辑。
限制并行执行
如果你想知道async还可以用来限制并行任务的并发性,答案是肯定的。我们有一些我们可以使用的函数,即eachLimit(),mapLimit(),parallelLimit(),queue()和cargo()。
我们试图利用其中的一个来实现Web爬虫应用程序的第4版,以有限的并发性并行执行链接的下载。幸运的是,async有async.queue(),它的工作方式与本章前面创建的TaskQueue类似。 async.queue()函数创建一个新的队列,它使用一个worker()函数来执行一组具有指定并发限制的任务:
const q = async.queue(worker,concurrency);
worker()函数作为输入接收要运行的任务和一个回调函数作为参数,当任务完成时执行回调:
function worker(task,callback);
我们应该注意到在这个例子中 task 可以是任何类型,而不仅仅只能是函数。实际上, worker有责任以最适当的方式处理任务。新建任务,可以通过q.push(task,callback)将任务添加到队列中。一个任务处理完后,关联一个任务的回调函数必须被worker调用。
现在,我们再次修改我们的代码实现一个全面并行的有并发限制的执行流,利用async.queue(),首先,我们需要创建一个队列:
const downloadQueue = async.queue((taskData,callback) => {
spider(taskData.link,taskData.nesting - 1,callback);
},2);
代码很简单。我们正在创建一个并发限制为2的新队列,让一个工作人员只需使用与任务关联的数据调用我们的spider()函数。接下来,我们实现spiderLinks()函数:
function spiderLinks(currentUrl,body);
if (links.length === 0) {
return process.nextTick(callback);
}
const completed = 0,hasErrors = false;
links.forEach(function(link) {
const taskData = {
link: link,nesting: nesting
};
downloadQueue.push(taskData,err => {
if (err) {
hasErrors = true;
return callback(err);
}
if (++completed === links.length && !hasErrors) {
callback();
}
});
});
}
前面的代码应该看起来非常熟悉,因为它几乎和使用TaskQueue对象来实现相同流程的代码相同。此外,在这种情况下,要分析的重要部分是将新任务推入队列的位置。在这一点上,我们确保我们传递一个回调,使我们能够检查当前页面的所有下载任务是否完成,并最终调用最终回调。
辛亏有async.queue(),我们可以轻松地复制我们的TaskQueue对象的功能,再次证明了通过async,我们可以避免从头开始编写异步控制流模式,减少我们的工作量,代码量更加简洁。
总结
在本章开始的时候,我们说Node.js的编程可能很难因为它的异步性,特别是对于以前在其他平台上开发的人而言。然而,在本章中,我们展示了异步API如何可以从简单原生JavaScript开始,从而为我们分析更复杂的技术奠定了基础。然后我们看到,除了为每一种口味提供编程风格,我们所掌握的工具确实是多样化的,并为我们大部分的问题提供了很好的解决方案。例如,我们可以选择async库来简化最常见的流程。
还有更为先进的技术,如Promise和Generator函数,这将是下一章的重点。当了解所有这些技术时,能够根据需求选择最佳解决方案,或者在同一个项目中使用多种技术。

Android学习笔记基于回调的事件处理
流程:

常见的回调方法:

代码示例:
@Override
public boolean onTouchEvent(MotionEvent event) {
Toast.makeText(getApplicationContext(),"触摸",Toast.LENGTH_SHORT).show();
return super.onTouchEvent(event);
}
@Override
public boolean onKeyDown(int keyCode, KeyEvent event) {
Toast.makeText(getApplicationContext(),"按下",Toast.LENGTH_SHORT).show();
return super.onKeyDown(keyCode, event);
}
@Override
public boolean onKeyUp(int keyCode, KeyEvent event) {
Toast.makeText(getApplicationContext(),"抬起",Toast.LENGTH_SHORT).show();
return super.onKeyUp(keyCode, event);
}

iOS设计模式--备忘录设计模式与命令设计模式
何为备忘录模式?
在响应某些事件时,应用程序需要保存自身的状态,比如当用户保存文档或程序退出时。例如,游戏退出之前,可能需要保存当前会话的状态,如游戏等级、敌人数量、可用武器的种类等。游戏再次打开时,玩家可以从离开的地方接着玩。很多时候,保存程序的状态真的不需要什么特别巧妙的方法。任何简单有效的方法都可以,但是同时,保存信息应该只对原始程序有意义。原始程序应该是能够解码它所保存文档中的信息的唯一实体。这就是备忘录模式应用于游戏、文字处理等程序的软件设计中的方式,这些程序需要保存当前上下文的复杂状态的快照并在以后恢复。
备忘录模式:在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到原先的保存状态。
何时使用备忘录模式?
当同时满足以下两个条件时,应当考虑使用这一模式:
@:需要保存一个对象(或某部分)在某一个时刻的状态,这样以后就可以恢复到先前的状态。
@:用于获取状态的接口会暴漏实现的细节,需要将其隐藏起来。
Cocoa Touch框架中的备忘录模式
Cocoa Touch框架在归档、属性列表序列化和核心数据中采用了备忘录模式。Cocoa的归档是对对象及其属性还有同其他对象间的关系进行编码,形成一个文档,该文档既可以保存于文件系统,也可以在进程或网络间传送。对象与其他对象的关系被看做对象图的网络。归档过程把对象保存为一种与架构无关的字节流,保持对象的标识以及对象之间的关系。对象的类型也同数据一起保存。从字节流解码出来的对象通常用与对象编码时相同的类型进行实例化。
如果想归档一个对象,很多时候我们是考虑保存程序的状态。在模型-视图-控制器范式中,程序的状态通常由模型对象来进行维护。我们把模型对象编码到文档,然后再对其解码读回来。在运行时使用NSCoder对象进行编码与解码操作。NSCoder本身是个抽象类。苹果公司建议通过NSCoder的具体类NSKeyArchiver和NSKeyedUnarchiver,使用基于键的归档技术。被编码与解码的对象必须遵守NSCoding协议并实现以下方法:
- (void)encodeWithCoder:(NSCoder *)aCoder;
- (id)initWithCoder:(NSCoder *)aDecoder;何为命令模式?
命令对象封装了如何对目标执行命令的信息,因此客户端或调用者不必了解目标的任何细节,却仍可以对它执行任何已有的操作。通过把请求封装成对象,客户端可以把参数化并置入队列或日志中,也能够支持可撤销的操作。命令对象将一个或多个动作绑定到特定的接收器。命令模式消除了作为对象的动作和执行它的接收器之间的绑定。
命令模式:将请求封装为一个对象,从而可用不同的请求对客户进行参数化,对请求队列或记录请求日志,以及支持可撤销的操作。
何时使用命令模式?
在以下情形,自然会考虑使用这一模式。
@:想让应用程序支持撤销与恢复。
@:想用对象参数化一个动作以执行操作,并用不同的命令对象来代替回调函数。
@:想要在不同时刻对请求进行指定、排列和执行。
@:想记录修改日志,这样在系统故障时,这些修改可以在后来重做一遍。
@:想让系统支持事务,事务封装了对数据的一系列修改,事务可以建模为命令对象。
在Cocoa Touch框架中使用命令模式:
NSInvocation、NSUndoManage和Target-Action机制是框架中对这个模式的典型引用。
如何使用备忘录模式与命令模式,详见下面这篇文章:
http://blog.jobbole.com/48179/ (译文) http://www.raywenderlich.com/46988/ios-design-patterns (原文)
本篇文章的demo链接地址:
https://guoshimeihua@github.com/guoshimeihua/MemoryAndCommandDemo.git
本篇文章备忘录模式与命令模式就写到这里了。

Java基于回调的观察者模式详解
本文由“言念小文”原创,转载请说明文章出处
一、前言
什么是回调?回调如何使用?如何优雅的使用?
本文将首先详解回调的原理,然后介绍回调的基本使用方法,最后介绍基于回调的“观察者模式”实现,演示
如何优化回调使用方法。
二、什么是回调
案例1
现有一农场需要向气象局订阅天气预报信息。农场向气象局发出订阅请求,气象局接受农场的订阅请求后,
每天都会向农场推送后一天的天气信息。农场每天接受到天气预报信息,将做对应的生产安排,具体安排
如下:如果气温在0~10℃,播种小麦,如果气温在11~15℃播种大豆,如果气温在16~20℃播种棉花,否则
维护农场设备。
我们从“案例1”中可以提取回调的概念。
首先,农场向气象局订阅天气预报信息,气象局会在当天向农场发送次日的天气预报。这里有两个异步条件:
a.农场订阅天气预报后,气象局不可能立即回复此后每一天天气预报信息;
b.农场并不知道气象局会在前一天具体哪一个精确时间点将天气预报发送给自己。
因此“农场-气象局”之间信息传递是异步的。
其次,农场接收到天气预报信息后,才会进行“工作安排”,由于农场不知道天气预报信息返回的精确时间,因此进行
“工作安排”的时机实际是由气象局决定的。自然地,我们想到将“工作安排”用一个函数(func())来实现,并且该函数的
具体实现由农场(Farm类)来实施,而函数的调用位置及调用时机由气象局(MeteorologicalBureau类)来决定。这就是一个典型的回调场景,
而func()函数被称之为回调函数。下面我们给出回调的通俗描述:
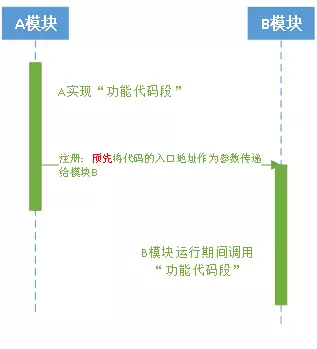
程序中某一模块A(类/库/其他)中通过一段代码(类/函数)实现某一功能(模块A定义该功能实现的具体细节),但该段代码
执行并不取决于模块A,而是由模块B(类/库/其他)决定,这时通常预先将该段代码的入口地址作为参数传递
给模块B,由模块B在程序的运行期间根据具体情况来选择何时何地调用这段代码。这一过程便称作回调。
通过下图直观理解回调
三、如何使用回调
我们通过实现“案例1”来演示如何使用回调
第一步,创建一个关于气象局的监听接口MeteorologicalBureauListener,该接口中声明气象局相关行为的函数,
这里声明了天气信息发布函数onRelease()。
public interface MeteorologicalBureauListener {
/**
* 天气信息发布
* @param description 天气预报信息描述
* @param minTemperature 最低气温
* @param maxTemperature 最高气温
* @param minWindscale 最低风力
* @param maxWindscale 最高风力
*/
void onRelease(String description,
int minTemperature,
int maxTemperature,
int minWindscale,
int maxWindscale);
}第二步,创建气象局类MeteorologicalBureau,该类负责接受天气预报信息的订阅和发布天气预报信息
/**
* 气象局(天气预报信息发布者)
* @author WenYong
*
*/
public class MeteorologicalBureau {
private MeteorologicalBureauListener mListener;
/**
* 注册对"气象局"类监听
* @param listener
*/
public void register(MeteorologicalBureauListener listener){
if(null == listener){
return;
}
mListener = listener;
}
/**
* 取消注册对"气象局"类监听
* @param listener
*/
public void unregister(MeteorologicalBureauListener listener){
if(null == listener){
return;
}
if(mListener.equals(listener)){
mListener = null;
}
}
/**
* 天气信息预测
*/
public void predict(){
new Thread(new Runnable() {
public void run() {
try {
// 模拟耗时操作
Thread.sleep(9000);
} catch (InterruptedException e) {
e.printStackTrace();
}
mListener.onRelease("明日渝北区气温8~10℃,风力5~8级", 8, 10, 5, 8);
}
}).start();
}
}第三步,创建农场类,该类订阅天气预报信息,并在接收到天气预报信息后做对应工作安排
/**
* 农场(天气预报信息订阅者)
* @author WenYong
*
*/
public class Farm {
private MeteorologicalBureau mBureau;
private MeteorologicalBureauListener mBureauListener;
public Farm(MeteorologicalBureau bureau){
mBureau = bureau;
}
/**
* 订阅天气信息
*/
public void subscribe(){
System.out.println(TestUtils.getTimeStamp() + "," + "农场订阅天气预报信息");
mBureauListener = new MeteorologicalBureauListener() {
public void onRelease(String description, int minTemperature,
int maxTemperature, int minWindscale, int maxWindscale) {
System.out.println(TestUtils.getTimeStamp() + ","
+ "农场接收到天气信息:" + description);
doAfterReceiveWheatherInfo(minTemperature, maxTemperature);
}
};
mBureau.register(mBureauListener);
}
/**
* 取消订阅天气信息
*/
public void unsubscribe(){
mBureau.unregister(mBureauListener);
}
/**
* 接收到气象局发布的天气信息后,农场做对应的工作安排
* @param minTemperature 明日最低气温
* @param maxTemperature 明日最高气温
*/
private void doAfterReceiveWheatherInfo(int minTemperature, int maxTemperature){
String timeStamp = TestUtils.getTimeStamp();
if(minTemperature >= 0 && minTemperature <= 10){
System.out.println(timeStamp + "," + "农场明日工作安排:播种小麦");
}else if(minTemperature >= 11 && minTemperature <= 15){
System.out.println(timeStamp + "," + "农场明日工作安排:播种大豆");
}else if(minTemperature >= 16 && minTemperature <= 20){
System.out.println(timeStamp + "," + "农场明日工作安排:播种棉花");
}else{
System.out.println(timeStamp + "," + "农场明日工作安排:维护设备");
}
}
}第四步,编写测试类,首先new一个农场对象并订阅天气预报信息,然后气象局调用predict()函数预测天气并发布预报
public class Test {
public static void main(String[] args) {
MeteorologicalBureau bureau = new MeteorologicalBureau();
// 农场订阅天气信息
new Farm(bureau).subscribe();
// 气象局进行天气信息预测
bureau.predict();
}
}第五步,运行,结果如下:
2019-02-06 21-54-59,农场订阅天气预报信息
2019-02-06 21-55-08,农场接收到天气信息:明日渝北区气温8~10℃,风力5~8级
2019-02-06 21-55-08,农场明日工作安排:播种小麦
从结果不难看出,农场向气象局订阅天气预报后,9s后气象局向农场发布了天气预报信息,然后农场根据天气预报信息
做出了对应工作安排。
原理分析:
好了,看到了结果之后,我们来分析如何实现回调的。第一步在气象局的监听接口MeteorologicalBureauListener中声明
了天气信息发布接口onRelease()。然后第二步在农场类Farm的天气订阅方法subscribe()中,以内部类对象的方式实现MeteorologicalBureauListener
接口并重写onRelease()方法,然后通过mBureau.register(mBureauListener)将内部类对象传递给气象局对象,这样实际就将Farm对象中实现的onRelease()方法
传递给了气象局对象。从而气象局对象就可以根据具体情况来调用该方法了。再看测试类Test中,首先农场订阅天气信息的过程,就将
Farm对象中定义的接口方法onRelease()传递给了气象局对象,然后气象局对象调用predict(),该方法先模拟耗时9s,然后便执行了onRelease()方法,这样
相当于便将天气信息发布给了Farm对象,由于农场对象事先已定义好接收到天气预报信息后的工作安排doAfterReceiveWheatherInfo(),故而当onRelease()被
气象局回调后,紧接着便执行了农场的工作安排。
四、回调进阶(基于回调的“观察者模式”实现)
在学会了回调的基本使用方法后,我们将案例1稍加修改,增加一个天气预报订阅者
案例2
现有一农场和一机场需要向气象局订阅天气预报信息。农场和机场向气象局发出订阅请求,气象局接受订阅请求后,
每天都会向农场和机场推送后一天的天气信息。农场每天接受到天气预报信息,将做对应的生产安排,具体安排
如下:如果气温在0~10℃,播种小麦,如果气温在11~15℃播种大豆,如果气温在16~20℃播种棉花,否则
维护农场设备;机场接收到天气预报信息,将采取对应的运营管理措施,具体如下:如果风力小于5级,不做预警正常起飞,
如果风力5~8级,预警起飞,如果风力大于8级,暂停起飞。
案例2中看一看出,气象局发布信息是一对多的关系,如下图:
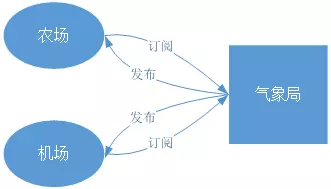
这便是我们开发中经常遇到的观察者模式(设计模式中的观察者模式在此不多做介绍),农场和机场作为“观察者”向气象局订阅天气预报信息,气象局作为信息发布者
每天以一对多的方式,向农场和机场“广播”信息。那么如何通过回调实现”一对多“的信息发布呢?
第一步,创建一个关于气象局的监听接口MeteorologicalBureauListener,该接口中声明气象局相关行为的函数,
这里声明了天气信息发布函数onRelease()。
public interface MeteorologicalBureauListener {
/**
* 天气信息发布
* @param description 天气预报信息描述
* @param minTemperature 最低气温
* @param maxTemperature 最高气温
* @param minWindscale 最低风力
* @param maxWindscale 最高风力
*/
void onRelease(String description,
int minTemperature,
int maxTemperature,
int minWindscale,
int maxWindscale);
}第二步,创建气象局类MeteorologicalBureau,该类负责接受天气预报信息的订阅和发布天气预报信息。需要注意
这里使用了一个并发队列来存储机场和农场传递过来的MeteorologicalBureauListener实现对象的引用。之所以使用ConcurrentLinkedQueue
是为了防止在后面遍历的时候出现多线程问题:遍历的同时被修改,从而导致软件闪退。
/**
* 气象局(天气预报信息发布者)
* @author WenYong
*
*/
public class MeteorologicalBureau {
private ConcurrentLinkedQueue<MeteorologicalBureauListener> mListenerQueue;
public MeteorologicalBureau(){
mListenerQueue = new ConcurrentLinkedQueue<>();
}
/**
* 注册对"气象局"类监听
* @param listener
*/
public void register(MeteorologicalBureauListener listener){
if(null == listener){
return;
}
if(mListenerQueue.contains(listener)){
return;
}
mListenerQueue.add(listener);
}
/**
* 取消注册对"气象局"类监听
* @param listener
*/
public void unregister(MeteorologicalBureauListener listener){
if(null == listener){
return;
}
if(!mListenerQueue.contains(listener)){
return;
}
mListenerQueue.remove(listener);
}
/**
* 天气信息预测
*/
public void predict(){
new Thread(new Runnable() {
public void run() {
try {
// 模拟耗时操作
Thread.sleep(9000);
} catch (InterruptedException e) {
e.printStackTrace();
}
release(mListenerQueue, "明日渝北区气温8~10℃,风力5~8级", 8, 10, 5, 8);
}
}).start();
}
/**
* 天气预报信息发布
* @param queue 监听队列
* @param description 天气预报描述
* @param minTemperature 最低气温
* @param maxTemperature 最高气温
* @param minWindscale 最低风力
* @param maxWindscale 最高风力
*/
private void release(ConcurrentLinkedQueue<MeteorologicalBureauListener> queue,
String description,
int minTemperature,
int maxTemperature,
int minWindscale,
int maxWindscale){
if(null == queue || queue.isEmpty()){
return;
}
Iterator<MeteorologicalBureauListener> it = queue.iterator();
while(it.hasNext()){
it.next().onRelease(description, minTemperature,
maxTemperature, minWindscale, maxWindscale);
}
}
}第三步,创建农场类(农场类代码和案例1相同这里不再重复贴出)和机场类
/**
* 机场(天气预报信息订阅者)
* @author WenYong
*
*/
public class Airport {
private MeteorologicalBureau mBureau;
private MeteorologicalBureauListener mBureauListener;
public Airport(MeteorologicalBureau bureau){
mBureau = bureau;
}
/**
* 订阅天气信息
*/
public void subscribe(){
System.out.println(TestUtils.getTimeStamp() + "," + "机场订阅天气预报信息");
mBureauListener = new MeteorologicalBureauListener() {
public void onRelease(String description, int minTemperature,
int maxTemperature, int minWindscale, int maxWindscale) {
System.out.println(TestUtils.getTimeStamp() + ","
+ "机场接收到天气信息:" + description);
doAfterReceiveWheatherInfo(minWindscale, maxWindscale);
}
};
mBureau.register(mBureauListener);
}
/**
* 取消订阅天气信息
*/
public void unsubscribe(){
mBureau.unregister(mBureauListener);
}
/**
* 接收到气象局发布的天气信息后,机场做对应的运营管理措施
* @param minWindscale
* @param maxWindscale
*/
private void doAfterReceiveWheatherInfo(int minWindscale, int maxWindscale){
String timeStamp = TestUtils.getTimeStamp();
if(maxWindscale < 5){
System.out.println(timeStamp + "," + "机场明日运营管理措施:不做预警正常起飞");
}else if(minWindscale >= 5 && maxWindscale <= 8){
System.out.println(timeStamp + "," + "机场明日运营管理措施:预警起飞");
}else{
System.out.println(timeStamp + "," + "机场明日运营管理措施:暂停起飞");
}
}
}第四步,编写测试类,首先分别new一个农场对象和机场对象,并订阅天气预报信息,然后气象局调用predict()函数预测天气并发布预报
public class Test {
public static void main(String[] args) {
MeteorologicalBureau bureau = new MeteorologicalBureau();
// 农场订阅天气信息
new Farm(bureau).subscribe();
// 机场订阅天气信息
new Airport(bureau).subscribe();
// 气象局进行天气信息预测
bureau.predict();
}
}第五步,运行,结果如下:
2019-02-07 10-35-54,农场订阅天气预报信息
2019-02-07 10-35-54,机场订阅天气预报信息
2019-02-07 10-36-03,农场接收到天气信息:明日渝北区气温8~10℃,风力5~8级
2019-02-07 10-36-03,农场明日工作安排:播种小麦
2019-02-07 10-36-03,机场接收到天气信息:明日渝北区气温8~10℃,风力5~8级
2019-02-07 10-36-03,机场明日运营管理措施:预警起飞
从结果可以看出,农场和机场分别向气象局订阅了天气预报信息,9s模拟耗时后,气象局向它们发布了天气预报信息,二者并根据对应
天气信息作了对应工作安排和运营管理。
原理分析:
案例2中回调的实现原理与案例1中相同,在此不再赘述。不同点在于案例2如何实现“一对多”的回调。气象局类MeteorologicalBureau中使用
并发队列mListenerQueue来存储机场和农场传递过来的MeteorologicalBureauListener实现对象的引用,这样气象局就可以调用二者中实现的onRelease()方法。
MeteorologicalBureau中调用私有的release()来对mListenerQueue中对象实现遍历,从而遍历各订阅对象中onRelease()方法。
五、结语
回调是我们日常开发工作中使用最为基础最为频繁的技术手段,不论是同步调用还是异步调用场景(特别是异步调用使用尤其多)有大量应用。
如果您也是跟我当初一样是初入行的小白,希望本文对您有用,另外在java开发中经常用到判null处理,本文代码中经常使用在判null时,大量
使用return处理,个人觉得这是一个好习惯,多使用return以减少逻辑判断的嵌套,使代码更容易阅读。

mybatis设计模式之builder设计模式
builder设计模式很好的体现在了 MappedStatement对象的创建上,MappedStatement对象有非常多的成员变量,这些成员的变量的初始化,可以通过定义一个一个Builder 来进行构建初始化,来简化初始化的过程。
相关代码如下:
public final class MappedStatement {
private String resource;
private Configuration configuration;
private String id;
private Integer fetchSize;
private Integer timeout;
private StatementType statementType;
private ResultSetType resultSetType;
private SqlSource sqlSource;
private Cache cache;
private ParameterMap parameterMap;
private List<ResultMap> resultMaps;
private boolean flushCacheRequired;
private boolean useCache;
private boolean resultOrdered;
private SqlCommandType sqlCommandType;
private KeyGenerator keyGenerator;
private String[] keyProperties;
private String[] keyColumns;
private boolean hasNestedResultMaps;
private String databaseId;
private Log statementLog;
private LanguageDriver lang;
private String[] resultSets;
private MappedStatement() {
// constructor disabled
}
public static class Builder {
private MappedStatement mappedStatement = new MappedStatement();
public Builder(Configuration configuration, String id, SqlSource sqlSource, SqlCommandType sqlCommandType) {
mappedStatement.configuration = configuration;
mappedStatement.id = id;
mappedStatement.sqlSource = sqlSource;
mappedStatement.statementType = StatementType.PREPARED;
mappedStatement.parameterMap = new ParameterMap.Builder(configuration, "defaultParameterMap", null, new ArrayList<ParameterMapping>()).build();
mappedStatement.resultMaps = new ArrayList<ResultMap>();
mappedStatement.timeout = configuration.getDefaultStatementTimeout();
mappedStatement.sqlCommandType = sqlCommandType;
mappedStatement.keyGenerator = configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType) ? new Jdbc3KeyGenerator() : new NoKeyGenerator();
String logId = id;
if (configuration.getLogPrefix() != null) logId = configuration.getLogPrefix() + id;
mappedStatement.statementLog = LogFactory.getLog(logId);
mappedStatement.lang = configuration.getDefaultScriptingLanuageInstance();
}
public Builder resource(String resource) {
mappedStatement.resource = resource;
return this;
}
public String id() {
return mappedStatement.id;
}
public Builder parameterMap(ParameterMap parameterMap) {
mappedStatement.parameterMap = parameterMap;
return this;
}
public Builder resultMaps(List<ResultMap> resultMaps) {
mappedStatement.resultMaps = resultMaps;
for (ResultMap resultMap : resultMaps) {
mappedStatement.hasNestedResultMaps = mappedStatement.hasNestedResultMaps || resultMap.hasNestedResultMaps();
}
return this;
}
public Builder fetchSize(Integer fetchSize) {
mappedStatement.fetchSize = fetchSize;
return this;
}
public Builder timeout(Integer timeout) {
mappedStatement.timeout = timeout;
return this;
}
public Builder statementType(StatementType statementType) {
mappedStatement.statementType = statementType;
return this;
}
public Builder resultSetType(ResultSetType resultSetType) {
mappedStatement.resultSetType = resultSetType;
return this;
}
public Builder cache(Cache cache) {
mappedStatement.cache = cache;
return this;
}
public Builder flushCacheRequired(boolean flushCacheRequired) {
mappedStatement.flushCacheRequired = flushCacheRequired;
return this;
}
public Builder useCache(boolean useCache) {
mappedStatement.useCache = useCache;
return this;
}
public Builder resultOrdered(boolean resultOrdered) {
mappedStatement.resultOrdered = resultOrdered;
return this;
}
public Builder keyGenerator(KeyGenerator keyGenerator) {
mappedStatement.keyGenerator = keyGenerator;
return this;
}
public Builder keyProperty(String keyProperty) {
mappedStatement.keyProperties = delimitedStringtoArray(keyProperty);
return this;
}
public Builder keyColumn(String keyColumn) {
mappedStatement.keyColumns = delimitedStringtoArray(keyColumn);
return this;
}
public Builder databaseId(String databaseId) {
mappedStatement.databaseId = databaseId;
return this;
}
public Builder lang(LanguageDriver driver) {
mappedStatement.lang = driver;
return this;
}
public Builder resulSets(String resultSet) {
mappedStatement.resultSets = delimitedStringtoArray(resultSet);
return this;
}
public MappedStatement build() {
assert mappedStatement.configuration != null;
assert mappedStatement.id != null;
assert mappedStatement.sqlSource != null;
assert mappedStatement.lang != null;
mappedStatement.resultMaps = Collections.unmodifiableList(mappedStatement.resultMaps);
return mappedStatement;
}
}我们今天的关于《Node.js设计模式》基于回调的异步控制流和nodejs 回调的分享就到这里,谢谢您的阅读,如果想了解更多关于Android学习笔记基于回调的事件处理、iOS设计模式--备忘录设计模式与命令设计模式、Java基于回调的观察者模式详解、mybatis设计模式之builder设计模式的相关信息,可以在本站进行搜索。
本文标签:




