本文将介绍基本功|Litho的使用及原理剖析的详细情况,特别是关于lithologic的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于(八)Thre
本文将介绍基本功 | Litho的使用及原理剖析的详细情况,特别是关于lithologic的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于(八)ThreadLocal的使用及原理分析、003. 线程池应用及实现原理剖析、20210404 7. 玩转 Elasticsearch 之深度应用及原理剖析 - 拉勾教育、@MapperScan的使用及原理的知识。
本文目录一览:- 基本功 | Litho的使用及原理剖析(lithologic)
- (八)ThreadLocal的使用及原理分析
- 003. 线程池应用及实现原理剖析
- 20210404 7. 玩转 Elasticsearch 之深度应用及原理剖析 - 拉勾教育
- @MapperScan的使用及原理
")
基本功 | Litho的使用及原理剖析(lithologic)
1. 什么是Litho?
Litho是Facebook推出的一套高效构建Android UI的声明式框架,主要目的是提升RecyclerView复杂列表的滑动性能和降低内存占用。下面是Litho官网的介绍:
Litho is a declarative framework for building efficient user interfaces (UI) on Android. It allows you to write highly-optimized Android views through a simple functional API based on Java annotations. It was primarily built to implement complex scrollable UIs based on RecyclerView.
With Litho, you build your UI in terms of components instead of interacting directly with Traditional Android views. A component is essentially a function that takes immutable inputs, called props, and returns a component hierarchy describing your user interface.
Litho是高效构建Android UI的声明式框架,通过注解API创建高优的Android视图,非常适用于基于Recyclerview的复杂滚动列表。Litho使用一系列组件构建视图,代替了Android传统视图交互方式。组件本质上是一个函数,它接受名为Props的不可变输入,并返回描述用户界面的组件层次结构。
Litho是一套完全不同于传统Android的UI框架,它继承了Facebook一向大胆创新的风格,突破性地在Android上实现了React风格的UI框架。架构图如下:

应用层:上层Android应用接入层。
规范层(API):允许用户使用声明式的API(注解)来构建符合FlexBox规范的布局。
布局层:Litho使用可挂载组件、布局组件和FlexBox组件来构建布局,其中可挂载组件和布局组件允许用户使用规范来定义,各个组件的具体用法下面的组件规范中会详细介绍。在Litho中每一个组件都是一个独立的功能模块。Litho的组件和React的组件相类似,也具有属性和状态的概念,通过状态的变更来控制组件的展示样式。
布局测量:Litho使用Yoga来完成组件布局的异步或同步(可根据场景定制)测量和计算,实现了布局的扁平化。
布局渲染:Litho不仅支持使用View来渲染视图,还可以使用更轻量的Drawable来渲染视图。Litho实现了大量使用Drawable来渲染的基础组件,可以进一步拍平布局。
除了上面提到的扁平化布局,Litho还实现了布局的细粒度复用和异步计算布局的能力,对于这些功能的实现在Litho的特性及原理剖析中详细介绍。下面先介绍一下大家比较关心的Litho使用方法。
2. Litho的使用
Litho的使用方式相比于传统的Android来说有些另类,它抛弃了通过XML定义布局的方式,采用声明式的组件在Java中构建布局。
2.1 Litho和原生Android在使用上的区别
Android传统布局:首先在资源文件res/layout目录下定义布局文件xx.xml,然后在Activity或Fragment中引用布局文件生成视图,示例如下:
<?xml version="1.0" encoding="utf-8"?>
<TextView xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="Hello World"
android:textAlignment="center"
android:textColor="#666666"
android:textSize="40dp" />
public class MainActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.helloworld);
}
}
Litho布局:Litho抛弃了Android原生的布局方式,通过组件方式构建布局生成视图,示例如下:
public class MainActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
ComponentContext context = new ComponentContext(this);
final Text.Builder builder = Text.create(context);
final Component = builder.text("Hello World")
.textSizeDip(40)
.textColor(Color.parseColor("#666666"))
.textAlignment(Layout.Alignment.ALIGN_CENTER)
.build();
LithoView view = LithoView.create(context, component);
setContentView(view);
}
}
2.2 Litho自定义视图
Litho中的视图单元叫做Component,可以直观的翻译为“组件”,它的设计理念来自于React组件化的思想。每个组件持有描述一个视图单元所必须的属性和状态,用于视图布局的计算工作。视图最终的绘制工作是由组件指定的绘制单元(View或者Drawable)来完成的。
Litho组件的创建方式也和原生View的创建方式有着很大的区别。Litho使用注解定义了一系列的规范,我们需要使用Litho的注解来定义自己的组件生成规则,最终由Litho在编译期自动编译生成真正的组件。
2.2.1 组件规范
Litho提供了两种类型的组件规范,分别是Layout Spec规范和Mount Spec规范。下面分别介绍两种规范的使用方式:
Layout Spec规范:用于生成布局类型组件的规范,布局组件在逻辑上等同于Android中的ViewGroup,用于组织其他组件构成一个布局。它要求我们必须使用@LayoutSpec注解来注明,并实现一个标注了@OnCreateLayout注解的方法。示例如下:
@LayoutSpec
class HelloComponentSpec {
@OnCreateLayout
static Component onCreateLayout(ComponentContext c, @Prop String name) {
return Column.create(c)
.child(Text.create(c)
.text("Hello, " + name)
.textSizeRes(R.dimen.my_text_size)
.textColor(Color.BLACK)
.paddingDip(ALL, 10)
.build())
.child(Image.create(c)
.drawableRes(R.drawable.welcome)
.scaleType(ImageView.ScaleType.CENTER_CROP)
.build())
.build();
}
}
最终Litho会在编译时生成一个名为HelloComponent的组件。
public final class HelloComponent extends Component {
@Prop(resType = ResType.NONE,optional = false) String name;
private HelloComponent() {
super();
}
@Override
protected Component onCreateLayout(ComponentContext c) {
return (Component) HelloComponentSpec.onCreateLayout((ComponentContext) c, (String) name);
}
...
public static Builder create(ComponentContext context, int defStyleAttr, int defStyleRes) {
Builder builder = sBuilderPool.acquire();
if (builder == null) {
builder = new Builder();
}
HelloComponent instance = new HelloComponent();
builder.init(context, defStyleAttr, defStyleRes, instance);
return builder;
}
public static class Builder extends Component.Builder<Builder> {
private static final String[] required_PROPS_NAMES = new String[] {"name"};
private static final int required_PROPS_COUNT = 1;
HelloComponent mHelloComponent;
...
public Builder name(String name) {
this.mHelloComponent.name = name;
mrequired.set(0);
return this;
}
@Override
public HelloComponent build() {
checkArgs(required_PROPS_COUNT, mrequired, required_PROPS_NAMES);
HelloComponent helloComponentRef = mHelloComponent;
release();
return helloComponentRef;
}
}
}
Mount Spec规范:用来生成可挂载类型组件的规范,用来生成渲染具体View或者Drawable的组件。同样,它必须使用@MountSpec注解来标注,并至少实现一个标注了@onCreateMountContent的方法。Mount Spec相比于Layout Spec更复杂一些,它拥有自己的生命周期:
- @OnPrepare,准备阶段,进行一些初始化操作。
- @OnMeasure,负责布局的计算。
- @OnBoundsDefined,在布局计算完成后挂载视图前做一些操作。
- @OnCreateMountContent,创建需要挂载的视图。
- @OnMount,挂载视图,完成布局相关的设置。
- @OnBind,绑定视图,完成数据和视图的绑定。
- @OnUnBind,解绑视图,主要用于重置视图的数据相关的属性,防止出现复用问题。
- @OnUnmount,卸载视图,主要用于重置视图的布局相关的属性,防止出现复用问题。

除了上述两种组件类型,Litho中还有一种特殊的组件——Layout,它不能使用规范来生成。Layout是Litho中的容器组件,类似于Android中的ViewGroup,但是只能使用FlexBox的规范。它可以包含子组件节点,是Litho各组件连接的纽带。Layout组件只是Yoga在Litho中的代理,组件的所有布局相关的属性都会直接设置给Yoga,并由Yoga完成布局的计算。Litho实现了两个Layout组件Row和Column,分别对应FlexBox中的行和列。
2.2.2 Litho的属性
在Litho中属性分为两种,不可变属性称为Props,可变属性称为State,下面分别介绍一下两种属性:
Props属性:组件中使用@Prop注解标注的参数集合,具有单向性和不可变性。下面通过一个简单的例子了解一下如何在组件中定义和使用Props属性:
@MountSpec
class MyComponentSpec {
@OnPrepare
static void onPrepare(
ComponentContext c,
@Prop(optional = true) String prop1) {
...
}
@OnMount
static void onMount(
ComponentContext c,
SomeDrawable convertDrawable,
@Prop(optional = true) String prop1,
@Prop int prop2) {
if (prop1 != null) {
...
}
}
}
在上面的代码中,共使用了三次Prop注解,分别标注prop1和prop2两个变量,即定义了prop1和prop2两个属性。Litho会在自动编译生成的MyComponent类的Builder类中生成这两个属性的同名方法。按照如下代码,便可以去使用上面定义的属性:
MyComponent.create(c)
.prop1("My prop 1")
.prop2(256)
.build();
State属性:意为“状态”属性,State属性虽然可变,但是其变化由组件内部控制,例如:输入框、CheckBox等都是由组件内部去感知用户行为,并更新组件的State属性。所以一个组件一旦创建,我们便无法通过任何外部设置去更改它的属性。组件的State属性虽然不允许像Props属性那样去显式设置,但是我们可以定义一个单独的Props属性来当做某个State属性的初始值。
3. Litho的特性及原理剖析
Litho官网首页通过4个段落重点介绍了Litho的4个特性。
3.1 声明式组件
Litho采用声明式的API来定义UI组件,组件通过一组不可变的属性来描述UI。这种组件化的思想灵感来源于React,关于声明式组件的用法上面已经详细介绍过了。
传统Android布局因为UI与逻辑分离,所以开发工具都有强大的预览功能,方便开发者调整布局。而Litho采用React组件化的思想,通过组件连接了逻辑与布局UI,虽然Litho也提供了对Stetho的支持,借助于Chrome开发者工具对界面进行调试,不过使用起来并没有那么方便。
3.2 异步布局
Android系统在绘制时为了防止页面错乱,页面所有View的测量(Measure)、布局(Layout)以及绘制(Draw)都是在UI线程中完成的。当页面UI非常复杂、视图层级较深时,难免Measure和Layout的时间会过长,从而导致页面渲染时候丢帧出现卡顿情况。Litho为解决该问题,提出了异步布局的思想,利用cpu的闲置时间提前在异步线程中完成Measure和Layout的过程,仅在UI线程中完成绘制工作。当然,Litho只是提供了异步布局的能力,它主要使用在RecyclerView等可以提前知道下一个视图长什么样子的场景。
3.2.1 异步布局原理剖析
针对RecyclerView等滑动列表,由于可以提前知道接下来要展示的一个甚至多个条目的视图样式,所以只要提前创建好下一个或多个条目的视图,就可以提前完成视图的布局工作。
那么Android原生为什么不支持异步布局呢?主要有以下两个原因:
-
View的属性是可变的,只要属性发生变化就可能导致布局变化,因此需要重新计算布局,那么提前计算布局的意义就不大了。而Litho组件的属性是不可变的,所以对于一个组件来说,它的布局计算结果是唯一且不变的。
-
提前异步布局就意味着要提前创建好接下来要用到的一个或者多个条目的视图,而Android原生的View作为视图单元,不仅包含一个视图的所有属性,而且还负责视图的绘制工作。如果要在绘制前提前去计算布局,就需要预先去持有大量未展示的View实例,大大增加内存占用。反观Litho的组件则没有这个问题,Litho的组件只是视图属性的一个集合,仅负责计算布局,绘制工作由指定的绘制单元来完成,相比与传统的View显然Litho的组件要轻量的多。所以在Litho中,提前创建好接下来要用到的多个条目的组件,并不会带来性能问题,甚至还可以直接把组件当成滑动列表的数据源。如下图所示:

3.3 扁平化的视图
使用Litho布局,我们可以得到一个极致扁平的视图效果。它可以减少渲染时的递归调用,加快渲染速度。
下面是同一个视图在Android和Litho实现下的视图层级效果对比。可以看到,同样的样式,使用Litho实现的布局要比使用Android原生实现的布局更加扁平。

3.3.1 扁平化视图原理剖析
Litho使用FlexBox来创建布局,最终生成带有层级结构的组件树。然后Litho对布局层级进行了两次优化。
-
使用了Yoga来进行布局计算,Yoga会将FlexBox的相对布局转成绝对布局。经过Yoga处理后的布局没有了原来的布局层级,变成了只有一层。虽然不能解决过度绘制的问题,但是可以有效地减少渲染时的递归调用。
-
前面介绍过Litho的视图渲染由绘制单元来完成,绘制单元可以是View或者更加轻量的Drawable,Litho自己实现了一系列挂载Drawable的基本视图组件。通过使用Drawable可以减少内存占用,同时相比于View,Android无法检查出Drawable的视图层级,这样可以使视图效果看起来更加扁平。
原理如下图所示,Litho会先把组件树拍平成没有层级的列表,然后使用Drawable来绘制对应的视图单元。

Litho使用Drawable代替View能带来多少好处呢?Drawable和View的区别在于前者不能和用户交互,只能展示,因此Drawable不会像View那样持有很多变量和引用,所以Drawable比View从内存上看要轻量很多。举个例子:50个同样展示“Hello world”的TextView和TextDrawable在内存占比上,前者几乎是后者的8倍。对比图如下,Shallow Size表示对象自身占用的内存大小。

3.3.2 绘制单元的降级策略
由于Drawable不具有交互能力,所以对于使用Drawable无法实现的交互场景,Litho会自动降级成View。主要有以下几种场景:
- 有监听点击事件。
- 限制子视图绘出父布局。
- 有监听焦点变化。
- 有设置Tag。
- 有监听触摸事件。
- 有光影效果。
对于以上场景的使用请仔细考虑,过多的使用会导致Litho的层级优化效果变差。
3.3.3 对比Android的约束布局
为了解决布局嵌套问题,Android推出了约束布局(ConstraintLayout),使用约束布局也可以达到扁平化视图的目的,那么使用Litho的好处是什么呢?
Litho可以更好地实现复杂布局。约束布局虽然可以实现扁平效果,但是它使用了大量的约束来固定视图的位置。随着布局复杂程度的增加,约束条件变得越来越多,可读性也变得越来越差。而Litho则是对FlexBox布局进行的扁平化处理,所以实际使用的还是FlexBox布局,对于复杂的布局FlexBox布局可读性更高。
3.4 细粒度的复用
Litho中的所有组件都可以被回收,并在任何位置进行复用。这种细粒度的复用方式可以极大地提高内存使用率,尤其适用于复杂滑动列表,内存优化非常明显。
3.4.1 原生RecyclerView复用原理剖析
原生的RecyclerView视图按模板类型进行存储并复用,也就是说模板类型越多,所需存储的模板种类也就越多,导致内存占用越来越大。原理如下图。滑出屏幕的itemType1和itemType2都会在Recycler缓存池保存,等待后面滑进屏幕的条目的复用。

3.4.2 细粒度复用优化内存原理剖析
在Litho中,item在回收前,会把LithoView中挂载的各个绘制单元拆分出来(解绑),由Litho自己的缓存池去分类回收,在展示前由LithoView按照组件树的样式组装(挂载)各个绘制单元,这样就达到了细粒度复用的目的。原理如下图。滑出屏幕的itemType1会被拆分成一个个的视图单元。LithoView容器由Recycler缓存池回收,其他视图单元由Litho的缓存池分类回收。

使用细粒度复用的RecyclerView的缓存池不再需要区分模板类型来缓存大量的视图模板,只需要缓存LithoView容器。细粒度回收的视图单元数量要远远小于原来缓存在各个视图模板中的视图单元数量。
4. 实践
美团对Litho进行了二次开发,在美团的MTFlexBox动态化实现方案(简称动态布局)中把Litho作为底层UI渲染引擎来使用。通过动态布局的预览工具,为Litho提供实时预览能力,同时可以有效发挥Litho的性能优化效果。
目前Litho+动态布局的实现方案已经应用在了美团App中,给美团App带来了不错的性能提升。后续博主会详细介绍Litho+动态布局在美团性能优化的实践方案。

4.1 内存数据
由于Litho中使用了大量Drawable替换View,并且实现了视图单元的细粒度复用,因此复杂列表滑动时内存优化比较明显。美团首页内存占用随滑动页数变化走势图如下。随着一页一页地滑动,内存优化了30M以上。(数据采集自Vivo x20手机内存占用情况)

4.2 FPS数据
FPS的提升主要得益于Litho的异步布局能力,提前计算布局可以减少滑动时的帧率波动,所以滑动过程较平稳,不会有高低起伏的卡顿感。(数据采集自魅蓝2手机一段时间内连续fps的波动情况)

5. 总结
Litho相对于传统Android是颠覆式的,它采用了React的思路,使用声明式的API来编写UI。相比于传统Android,确实在性能优化上有很大的进步,但是如果完全使用Litho开发一款应用,需要自己实现很多组件,而Litho的组件需要在编译时生成,实时预览方面也有所欠缺。相对于直接使用Litho的高成本,把Litho封装成FlexBox布局的底层渲染引擎是个不错的选择。
6. 参考资料
- Litho官网
- 说一说 Facebook 开源的 Litho
- React官网
- Yoga官网
7. 作者简介
- 何少宽,美团Android开发工程师,2015年加入美团,负责美团平台终端业务研发工作。
- 张颖,美团Android开发工程师,2017年加入美团,负责美团平台终端业务研发工作。

ThreadLocal的使用及原理分析")
(八)ThreadLocal的使用及原理分析
什么是ThreadLocal
ThreadLocal,简单翻译过来就是本地线程,但是直接这么翻译很难理解ThreadLocal的作用,如果换一种说法,可以称为线程本地存储。简单来说,就是ThreadLocal为共享变量在每个线程中都创建一个副本,每个线程可以访问自己内部的副本变量。这样做的好处是可以保证共享变量在多线程环境下访问的线程安全性
ThreadLocal的使用
没有使用ThreadLocal时
通过一个简单的例子来演示一下ThreadLocal的作用,这段代码是定义了一个静态的成员变量num,然后通过构造5个线程对这个num做递增
public class ThreadLocalDemo {
private static Integer num=0;
public static void main(String[] args) {
Thread[] threads=new Thread[5];
for(int i=0;i<5;i++){
threads[i]=new Thread(()->{
num+=5;
System.out.println(Thread.currentThread().getName()+" : "+num);
},"Thread-"+i);
}
for(Thread thread:threads){
thread.start();
}
}
}运行结果
Thread-0 : 5
Thread-1 : 10
Thread-2 : 15
Thread-3 : 20
Thread-4 : 25每个线程都会对这个成员变量做递增,如果线程的执行顺序不确定,那么意味着每个线程获得的结果也是不一样的。
使用了ThreadLocal以后
通过ThreadLocal对上面的代码做一个改动
public class ThreadLocalDemo {
private static final ThreadLocal<Integer> local=new ThreadLocal<Integer>(){
protected Integer initialValue(){
return 0; //通过initialValue方法设置默认值
}
};
public static void main(String[] args) {
Thread[] threads=new Thread[5];
for(int i=0;i<5;i++){
threads[i]=new Thread(()->{
int num=local.get().intValue();
num+=5;
System.out.println(Thread.currentThread().getName()+" : "+num);
},"Thread-"+i);
}
for(Thread thread:threads){
thread.start();
}
}
}运行结果
Thread-0 : 5
Thread-4 : 5
Thread-2 : 5
Thread-1 : 5
Thread-3 : 5从结果可以看到,每个线程的值都是5,意味着各个线程之间都是独立的变量副本,彼此不相互影响.
ThreadLocal会给定一个初始值,也就是initialValue()方法,而每个线程都会从ThreadLocal中获得这个初始化的值的副本,这样可以使得每个线程都拥有一个副本拷贝
看到这里,估计有很多人都会和我一样有一些疑问
- 每个线程的变量副本是怎么存储的?
- ThreadLocal是如何实现多线程场景下的共享变量副本隔离?
带着疑问,来看一下ThreadLocal这个类的定义(默认情况下,JDK的源码都是基于1.8版本)

从ThreadLocal的方法定义来看,还是挺简单的。就几个方法
- get: 获取ThreadLocal中当前线程对应的线程局部变量
- set:设置当前线程的线程局部变量的值
- remove:将当前线程局部变量的值删除
另外,还有一个initialValue()方法,在前面的代码中有演示,作用是返回当前线程局部变量的初始值,这个方法是一个protected方法,主要是在构造ThreadLocal时用于设置默认的初始值
set方法的实现
set方法是设置一个线程的局部变量的值,相当于当前线程通过set设置的局部变量的值,只对当前线程可见。
public void set(T value) {
Thread t = Thread.currentThread();//获取当前执行的线程
ThreadLocalMap map = getMap(t); //获得当前线程的ThreadLocalMap实例
if (map != null)//如果map不为空,说明当前线程已经有了一个ThreadLocalMap实例
map.set(this, value);//直接将当前value设置到ThreadLocalMap中
else
createMap(t, value); //说明当前线程是第一次使用线程本地变量,构造map
}-
Thread.currentThread获取当前执行的线程 -
getMap(t),根据当前线程得到当前线程的ThreadLocalMap对象,这个对象具体是做什么的?稍后分析 - 如果map不为空,说明当前线程已经构造过ThreadLocalMap,直接将值存储到map中
- 如果map为空,说明是第一次使用,调用
createMap构造
ThreadLocalMap是什么?
我们来分析一下这句话,ThreadLocalMap map=getMap(t)获得一个ThreadLocalMap对象,那这个对象是干嘛的呢?
其实不用分析,基本上也能猜测出来,Map是一个集合,集合用来存储数据,那么在ThreadLocal中,应该就是用来存储线程的局部变量的。ThreadLocalMap这个类很关键。
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}t.threadLocals实际上就是访问Thread类中的ThreadLocalMap这个成员变量
public
class Thread implements Runnable {
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
...
}从上面的代码发现每一个线程都有自己单独的ThreadLocalMap实例,而对应这个线程的所有本地变量都会保存到这个map内
ThreadLocalMap是在哪里构造?
在set方法中,有一行代码createmap(t,value);,这个方法就是用来构造ThreadLocalMap,从传入的参数来看,它的实现逻辑基本也能猜出出几分吧
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}Thread t 是通过Thread.currentThread()来获取的表示当前线程,然后直接通过new ThreadLocalMap将当前线程中的threadLocals做了初始化
ThreadLocalMap是一个静态内部类,内部定义了一个Entry对象用来真正存储数据
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
//构造一个Entry数组,并设置初始大小
table = new Entry[INITIAL_CAPACITY];
//计算Entry数据下标
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
//将`firstValue`存入到指定的table下标中
table[i] = new Entry(firstKey, firstValue);
size = 1;//设置节点长度为1
setThreshold(INITIAL_CAPACITY); //设置扩容的阈值
}
//...省略部分代码
}分析到这里,基本知道了ThreadLocalMap长啥样了,也知道它是如何构造的?那么我看到这里的时候仍然有疑问
- Entry集成了
WeakReference,这个表示什么意思? - 在构造ThreadLocalMap的时候
new ThreadLocalMap(this, firstValue);,key其实是this,this表示当前对象的引用,在当前的案例中,this指的是ThreadLocal<Integer> local。那么多个线程对应同一个ThreadLocal实例,怎么对每一个ThreadLocal对象做区分呢?
解惑WeakReference
weakReference表示弱引用,在Java中有四种引用类型,强引用、弱引用、软引用、虚引用。
使用弱引用的对象,不会阻止它所指向的对象被垃圾回收器回收。
在Java语言中, 当一个对象o被创建时, 它被放在Heap里. 当GC运行的时候, 如果发现没有任何引用指向o, o就会被回收以腾出内存空间. 也就是说, 一个对象被回收, 必须满足两个条件:
- 没有任何引用指向它
- GC被运行.
这段代码中,构造了两个对象a,b,a是对象DemoA的引用,b是对象DemoB的引用,对象DemoB同时还依赖对象DemoA,那么这个时候我们认为从对象DemoB是可以到达对象DemoA的。这种称为强可达(strongly reachable)
DemoA a=new DemoA();
DemoB b=new DemoB(a);如果我们增加一行代码来将a对象的引用设置为null,当一个对象不再被其他对象引用的时候,是会被GC回收的,但是对于这个场景来说,即时是a=null,也不可能被回收,因为DemoB依赖DemoA,这个时候是可能造成内存泄漏的
DemoA a=new DemoA();
DemoB b=new DemoB(a);
a=null;通过弱引用,有两个方法可以避免这样的问题
//方法1
DemoA a=new DemoA();
DemoB b=new DemoB(a);
a=null;
b=null;
//方法2
DemoA a=new DemoA();
WeakReference b=new WeakReference(a);
a=null;对于方法2来说,DemoA只是被弱引用依赖,假设垃圾收集器在某个时间点决定一个对象是弱可达的(weakly reachable)(也就是说当前指向它的全都是弱引用),这时垃圾收集器会清除所有指向该对象的弱引用,然后把这个弱可达对象标记为可终结(finalizable)的,这样它随后就会被回收。
试想一下如果这里没有使用弱引用,意味着ThreadLocal的生命周期和线程是强绑定,只要线程没有销毁,那么ThreadLocal一直无法回收。而使用弱引用以后,当ThreadLocal被回收时,由于Entry的key是弱引用,不会影响ThreadLocal的回收防止内存泄漏,同时,在后续的源码分析中会看到,ThreadLocalMap本身的垃圾清理会用到这一个好处,方便对无效的Entry进行回收
解惑ThreadLocalMap以this作为key
在构造ThreadLocalMap时,使用this作为key来存储,那么对于同一个ThreadLocal对象,如果同一个Thread中存储了多个值,是如何来区分存储的呢?
答案就在firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1)
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
关键点就在threadLocalHashCode,它相当于一个ThreadLocal的ID,实现的逻辑如下
private final int threadLocalHashCode = nextHashCode();
private static AtomicInteger nextHashCode =
new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}这里用到了一个非常完美的散列算法,可以简单理解为,对于同一个ThreadLocal下的多个线程来说,当任意线程调用set方法存入一个数据到Entry中的时候,其实会根据threadLocalHashCode生成一个唯一的id标识对应这个数据,存储在Entry数据下标中。
-
threadLocalHashCode是通过nextHashCode.getAndAdd(HASH_INCREMENT)来实现的
i*HASH_INCREMENT+HASH_INCREMENT,每次新增一个元素(ThreadLocal)到Entry[],都会自增0x61c88647,目的为了让哈希码能均匀的分布在2的N次方的数组里
- Entry[i]= hashCode & (length-1)
魔数0x61c88647
从上面的分析可以看出,它是在上一个被构造出的ThreadLocal的threadLocalHashCode的基础上加上一个魔数0x61c88647。我们来做一个实验,看看这个散列算法的运算结果
private static final int HASH_INCREMENT = 0x61c88647;
public static void main(String[] args) {
magicHash(16); //初始大小16
magicHash(32); //扩容一倍
}
private static void magicHash(int size){
int hashCode = 0;
for(int i=0;i<size;i++){
hashCode = i*HASH_INCREMENT+HASH_INCREMENT;
System.out.print((hashCode & (size-1))+" ");
}
System.out.println();
}输出结果
7 14 5 12 3 10 1 8 15 6 13 4 11 2 9 0
7 14 21 28 3 10 17 24 31 6 13 20 27 2 9 16 23 30 5 12 19 26 1 8 15 22 29 4 11 18 25 0 根据运行结果,这个算法在长度为2的N次方的数组上,确实可以完美散列,没有任何冲突, 是不是很神奇。
魔数0x61c88647的选取和斐波那契散列有关,0x61c88647对应的十进制为1640531527。而斐波那契散列的乘数可以用(long) ((1L << 31) * (Math.sqrt(5) - 1));如果把这个值给转为带符号的int,则会得到-1640531527。也就是说(long) ((1L << 31) * (Math.sqrt(5) - 1));得到的结果就是1640531527,也就是魔数0x61c88647
//(根号5-1)*2的31次方=(根号5-1)/2 *2的32次方=黄金分割数*2的32次方
long l1 = (long) ((1L << 31) * (Math.sqrt(5) - 1));
System.out.println("32位无符号整数: " + l1);
int i1 = (int) l1;
System.out.println("32位有符号整数: " + i1);总结,我们用0x61c88647作为魔数累加为每个ThreadLocal分配各自的ID也就是threadLocalHashCode再与2的幂取模,得到的结果分布很均匀。
图形分析
为了更直观的体现set方法的实现,通过一个图形表示如下

set剩余源码分析
前面分析了set方法第一次初始化ThreadLocalMap的过程,也对ThreadLocalMap的结构有了一个全面的了解。那么接下来看一下map不为空时的执行逻辑
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
// 根据哈希码和数组长度求元素放置的位置,即数组下标
int i = key.threadLocalHashCode & (len-1);
//从i开始往后一直遍历到数组最后一个Entry(线性探索)
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
//如果key相等,覆盖value
if (k == key) {
e.value = value;
return;
}
//如果key为null,用新key、value覆盖,同时清理历史key=null的陈旧数据
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
//如果超过阀值,就需要扩容了
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}主要逻辑
- 根据key的散列哈希计算Entry的数组下标
- 通过线性探索探测从i开始往后一直遍历到数组的最后一个Entry
- 如果map中的key和传入的key相等,表示该数据已经存在,直接覆盖
- 如果map中的key为空,则用新的key、value覆盖,并清理key=null的数据
- rehash扩容
replaceStaleEntry
由于Entry的key为弱引用,如果key为空,说明ThreadLocal这个对象被GC回收了。replaceStaleEntry的作用就是把陈旧的Entry进行替换
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
//向前扫描,查找最前一个无效的slot
int slotToExpunge = staleSlot;
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
//通过循环遍历,可以定位到最前面一个无效的slot
slotToExpunge = i;
//从i开始往后一直遍历到数组最后一个Entry(线性探索)
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
//找到匹配的key以后
if (k == key) {
e.value = value;//更新对应slot的value值
//与无效的sloat进行交换
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
//如果最早的一个无效的slot和当前的staleSlot相等,则从i作为清理的起点
if (slotToExpunge == staleSlot)
slotToExpunge = i;
//从slotToExpunge开始做一次连续的清理
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
//如果当前的slot已经无效,并且向前扫描过程中没有无效slot,则更新slotToExpunge为当前位置
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
//如果key对应的value在entry中不存在,则直接放一个新的entry
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
//如果有任何一个无效的slot,则做一次清理
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}cleanSomeSlots
这个函数有两处地方会被调用,用于清理无效的Entry
- 插入的时候可能会被调用
- 替换无效slot的时候可能会被调用
区别是前者传入的n为元素个数,后者为table的容量
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
// i在任何情况下自己都不会是一个无效slot,所以从下一个开始判断
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;// 扩大扫描控制因子
removed = true;
i = expungeStaleEntry(i); // 清理一个连续段
}
} while ( (n >>>= 1) != 0);
return removed;
}
expungeStaleEntry
执行一次全量清理
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// expunge entry at staleSlot
tab[staleSlot].value = null;//删除value
tab[staleSlot] = null;//删除entry
size--; //map的size递减
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len);// 遍历指定删除节点,所有后续节点
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {//key为null,执行删除操作
e.value = null;
tab[i] = null;
size--;
} else {//key不为null,重新计算下标
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {//如果不在同一个位置
tab[i] = null;//把老位置的entry置null(删除)
// 从h开始往后遍历,一直到找到空为止,插入
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}get操作
set的逻辑分析完成以后,get的源码分析就很简单了
public T get() {
Thread t = Thread.currentThread();
//从当前线程中获取ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null) {
//查询当前ThreadLocal变量实例对应的Entry
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {//获取成功,直接返回
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
//如果map为null,即还没有初始化,走初始化方法
return setInitialValue();
}setInitialValue
根据initialValue()的value初始化ThreadLocalMap
private T setInitialValue() {
T value = initialValue();//protected方法,用户可以重写
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
//如果map不为null,把初始化value设置进去
map.set(this, value);
else
//如果map为null,则new一个map,并把初始化value设置进去
createMap(t, value);
return value;
}- 从当前线程中获取ThreadLocalMap,查询当前ThreadLocal变量实例对应的Entry,如果不为null,获取value,返回
- 如果map为null,即还没有初始化,走初始化方法
remove方法
remove的方法比较简单,从Entry[]中删除指定的key就行
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();//调用Entry的clear方法
expungeStaleEntry(i);//清除陈旧数据
return;
}
}
}应用场景
ThreadLocal的实际应用场景:
- 比如在线程级别,维护session,维护用户登录信息userID(登陆时插入,多个地方获取)
- 数据库的链接对象
Connection,可以通过ThreadLocal来做隔离避免线程安全问题
问题
ThreadLocal的内存泄漏
ThreadLocalMap中Entry的key使用的是ThreadLocal的弱引用,如果一个ThreadLocal没有外部强引用,当系统执行GC时,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现一个key为null的Entry,而这个key=null的Entry是无法访问的,当这个线程一直没有结束的话,那么就会存在一条强引用链

Thread Ref - > Thread -> ThreadLocalMap - > Entry -> value 永远无法回收而造成内存泄漏
其实我们从源码分析可以看到,ThreadLocalMap是做了防护措施的
- 首先从ThreadLocal的直接索引位置(通过ThreadLocal.threadLocalHashCode & (len-1)运算得到)获取Entry e,如果e不为null并且key相同则返回e
- 如果e为null或者key不一致则向下一个位置查询,如果下一个位置的key和当前需要查询的key相等,则返回对应的Entry,否则,如果key值为null,则擦除该位置的Entry,否则继续向下一个位置查询
在这个过程中遇到的key为null的Entry都会被擦除,那么Entry内的value也就没有强引用链,自然会被回收。仔细研究代码可以发现,set操作也有类似的思想,将key为null的这些Entry都删除,防止内存泄露。
但是这个设计一来与一个前提条件,就是调用get或者set方法,但是不是所有场景都会满足这个场景的,所以为了避免这类的问题,我们可以在合适的位置手动调用ThreadLocal的remove函数删除不需要的ThreadLocal,防止出现内存泄漏
所以建议的使用方法是
- 将ThreadLocal变量定义成private static的,这样的话ThreadLocal的生命周期就更长,由于一直存在ThreadLocal的强引用,所以ThreadLocal也就不会被回收,也就能保证任何时候都能根据ThreadLocal的弱引用访问到Entry的value值,然后remove它,防止内存泄露
- 每次使用完ThreadLocal,都调用它的remove()方法,清除数据。


003. 线程池应用及实现原理剖析
1. 为什么使用线程池?线程池是不是越多越好?
-
线程在 java 中是一个对象,更是操作系统的资源,线程创建、销毁需要时间。如果创建时间+销毁时间>执行任务时间就很不合算了。
-
Java 对象占用堆内存,操作系统线程占用系统内存,根据 jvm 规范,一个线程默认最大栈大小 1 M,这个栈空间是需要从系统内存中分配的。线程过多,会消耗很多的内存。
-
操作系统需要频繁切换线程上下文(大家都想被运行),影响性能。
-
线程池的推出,就是为了方便控制线程数量。
2. 线程池原理 - 概念
- 线程池管理器:用于创建并管理线程池,包括创建线程池,销毁线程池,添加新任务。
- 工作线程:线程池中线程,在没有任务时处于等待状态,可以循环地执行任务。
- 任务接口:每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等。
- 任务队列:用于存放没有处理的任务。提供一种缓冲机制。

3. 线程池 API - 接口定义和实现类
| 类型 | 名称 | 描述 |
|---|---|---|
| 接口 | Executor | 最上层的接口,定义了执行任务的方法 execute |
| 接口 | ExecutorService | 继承了 Executor 接口,扩展了 Callable、Future、关闭方法 |
| 接口 | ScheduledExecutorService | 继承了 ExecutorService,增加了定时任务相关的方法 |
| 实现类 | ThreadPoolExecutor | 基础、标准的线程池实现 |
| 实现类 | ScheduledThreadPoolExecutor | 继承了 ThreadPoolExecutor,实现了 ScheduledExecutorService 中相关定时任务的方法 |
4. 线程池 API - 方法定义
ExecutorService

ScheduledExecutorService

5. 线程池 API - Executors 工具类
- 你可以自己实例化线程池,也可以用 Executors 创建线程池的工厂类,常用方法如下:
| 方法 | 描述 |
|---|---|
| newFixedThreadPool(int nThreads) | 创建一个固定大小、任务队列容量无界的线程池。核心线程数=最大线程数。 |
| newCachedThreadPool() | 创建的是一个大小无界的缓冲线程池。它的任务队列是一个同步队列。任务加入到池中,如果池中有空闲线程,则用空闲线程执行,如无则创建新线程执行。池中的线程空闲超过60秒,将被销毁释放。线程数随任务的多少变化。适用于执行耗时较小的异步任务。池的核心线程数=0,最大线程数=Integer.MAX_VALUE。 |
| newSingleThreadExecutor() | 只有一个线程来执行无界任务队列的单一线程池。该线程池确保任务按加入的顺序一个一个依次执行。当唯一的线程因任务异常中止时,将创建一个新的线程来继续执行后续的任务。与 newFixedThreadPool(1) 的却别在于,单一线程池的池大小在 newSingleThreadExecutor 方法中硬编码,不能再改变的。 |
| newScheduledThreadPool(int corePoolSize) | 能定时执行任务的线程池。该池的核心线程数由参数指定,最大线程数=Integer.MAX_VALUE。 |
6. 线程池原理 - 任务 execute 过程
- 是否达到核心线程数量?没达到,创建一个工作线程来执行任务。
- 工作队列是否已满?没满,则将新提交的任务存储到工作队列里。
- 是否达到线程池最大数量?没达到,创建一个新的工作线程来执行任务。
- 最后,执行拒绝策略来处理这个任务。

7. 线程数量
如何确定合适数量的线程?
-
计算型任务:cpu 数量的 1-2 倍。
-
IO 型任务:相对比计算型任务,需多一些线程,要根据具体的 IO 阻塞时常进行考量决定。如 tomcat 中默认的最大线程数 为200。也可考虑根据需要在一个最小数量和最大数量间进行自动增减线程数。
8. 代码演示
package com.study.hc.thread.chapter1.thread;
import sun.nio.ch.ThreadPool;
import java.util.List;
import java.util.concurrent.*;
/**
* 线程池的使用
*/
public class Demo9 {
/**
* 测试,提交15个执行时间需要3秒的任务,看线程池的状况
* @param threadPoolExecutor 传入不同的线程池,看不同的结果
* @throws Exception
*/
private void testCommon(ThreadPoolExecutor threadPoolExecutor) throws Exception {
// 测试,提交15个执行时间需要3秒的任务,看超过大小的2个,对应的处理情况
for (int i = 0; i < 15; i ++) {
int n = i;
threadPoolExecutor.submit(() -> {
try {
System.out.println("开始执行:" + n);
Thread.sleep(3000);
System.out.println("执行结束:" + n);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println("任务提交成功:" + n);
}
// 查看线程数量,查看队列等待数量
Thread.sleep(500);
System.out.println("当前线程池线程数量为:" + threadPoolExecutor.getPoolSize());
System.out.println("当前线程池等待的数量为:" + threadPoolExecutor.getQueue().size());
// 等待15秒,查看线程数量和等待数量(理论上,超出核心线程数量的线程自动销毁)
Thread.sleep(15000);
System.out.println("当前线程池线程数量为:" + threadPoolExecutor.getPoolSize());
System.out.println("当前线程池等待的数量为:" + threadPoolExecutor.getQueue().size());
}
/**
* 1. 线程池信息:核心线程数量5,最大数量10,无界队列,超出核心线程数量的线程存活时间为:5秒,指定拒绝策略
* @throws Exception
*/
private void threadPoolExecutorTest1() throws Exception {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5, 10,
5, TimeUnit.SECONDS, new LinkedBlockingQueue<>());
testCommon(threadPoolExecutor);
// 预计结果:线程池线程数量为5,超出数量的任务,其他的进入队列中等待被执行
}
/**
* 2. 线程池信息:核心线程数量5,最大数量10,队列大小3,超出核心线程数量的线程存活时间为:5秒,指定拒绝策略
* @throws Exception
*/
private void threadPoolExecutorTest2() throws Exception {
// 创建一个 核心线程数量5,最大数量10,等待队列最大是3的线程池,也就是最大容纳13个任务
// 默认的策略是抛出 RejectedExecutionException 异常,java.util.concurrent.ThreadPoolExecutor.AbortPolicy
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5, 10, 5, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3), (r, executor) -> System.out.println("有任务被拒绝执行了"));
testCommon(threadPoolExecutor);
// 预计结果:
// 1. 5个任务直接分配线程开始执行
// 2. 3个任务进入等待队列
// 3. 队列不够用,临时加开5个线程来执行任务(5秒没活干就销毁)
// 4. 队列和线程池都满了,剩下2个任务,没资源了,被拒绝执行
// 5. 任务执行,5秒后,如果无任务可执行,销毁临时创建的5个线程
}
/**
* 3. 线程池信息:核心线程数量5,最大数量5,无界队列,超出核心线程数量的线程存活时间:0秒
* @throws Exception
*/
private void threadPoolExecutorTest3() throws Exception {
// 和 Executors.newFixedThreadPool(int nThreads) 一样的
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5, 5, 0, TimeUnit.SECONDS,
new LinkedBlockingQueue<>());
testCommon(threadPoolExecutor);
// 预计结果:线程池线程数量为5,超出数量的任务,其他的进入队列中等待被执行
}
/**
* 4. 线程池信息:核心线程数量0,最大数量 Integer.MAX_VALUE,SynchronousQueue 队列,超出核心线程数量的线程存活时间:60秒
* @throws Exception
*/
private void threadPoolExecutorTest4() throws Exception {
/*
SynchronousQueue,实际上它不是一个真正的队列,因为它不会为队列中元素维护存储空间,与其他队列不同的是,它维护一组线程,这些线程在等待着把元素加入或移出队列
在使用 SynchronousQueue 作为工作队列的前提下,客户端代码向线程池提交任务时,
而线程中又没有空闲的线程能够从 SynchronousQueue 队列中取出一个任务
那么相应的 offer 方法调用就会失败(即任务没有被存入工作队列)
此时,ThreadPoolExecutor 会新建一个新的工作线程用于对这个入队列失败的任务进行处理(假设此时线程池大小还未达到其最大线程池大小 maximumPoolSize)
*/
// 和 Executors.newCachedThreadPool() 一样的
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<>());
testCommon(threadPoolExecutor);
// 预计结果:
// 1. 线程池线程数量为15,超出数量的任务,其他的进入队列中等待被执行
// 2. 所有任务执行结束,60秒后,如果无任务可执行,所有线程全部被销毁,池的大小恢复为0
Thread.sleep(60000);
System.out.println("60秒后,再看看线程池中的数量:" + threadPoolExecutor.getPoolSize());
}
/**
* 5. 定时执行线程池信息:3秒后执行,一次性任务,到点就执行
* 核心线程数量是5,最大数量 Integer.MAX_VALUE,DelayedWorkQueue 延时队列,超出核心线程数量的线程存活时间:0秒
*/
private void threadPoolExecutorTest5() {
ScheduledThreadPoolExecutor scheduledThreadPoolExecutor = new ScheduledThreadPoolExecutor(5);
scheduledThreadPoolExecutor.schedule(() -> {
System.out.println("任务被执行,现在时间:" + System.currentTimeMillis());
}, 3, TimeUnit.SECONDS);
System.out.println("定时任务,提交成功,时间是:" + System.currentTimeMillis() + ",当前线程池数量:" + scheduledThreadPoolExecutor.getPoolSize());
// 预计结果:任务在3秒后被执行一次
}
/**
* 6. 定时执行线程池信息:线程固定数量5
* 核心线程数量5,最大数量 Integer.MAX_VALUE,DelayedWorkQueue 延时队列,超出核心线程数量的线程存活时间:0秒
*/
private void threadPoolExecutorTest6() {
ScheduledThreadPoolExecutor threadPoolExecutor = new ScheduledThreadPoolExecutor(5);
// 周期性执行一个任务,线程池提供了两周调度方式
// 测试场景:提交的任务需要3秒才能执行完毕
// 效果1:提交后,2秒后开始第一次执行,之后每隔一秒,固定执行一次(如果发现上次执行还未完毕,则等待完毕,完毕后立刻执行)
// 也就是说,这个代码中,3秒执行一次(计算方式:每次执行3秒,间隔时间1秒,执行结束后马上开始下一次执行,无需等待)
threadPoolExecutor.scheduleAtFixedRate(() -> {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("任务-1被执行,现在时间:" + System.currentTimeMillis());
}, 2000, 1000, TimeUnit.MILLISECONDS);
// 效果2:提交后,2秒后开始第一次执行,之后每隔1秒,固定执行一次(如果发现上次执行还未完毕,则等待完毕,等上一次执行完毕后再开始计时,等待1秒)
// 也就是说这个代码的效果看到的是:4秒执行一次(计算方式:每次执行3秒,间隔时间1秒,执行完以后再等待1秒,所以是3+1)
threadPoolExecutor.scheduleWithFixedDelay(() -> {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("任务-2被执行,现在时间:" + System.currentTimeMillis());
}, 2000, 1000, TimeUnit.MILLISECONDS);
}
/**
* 7. 终止线程:线程池信息:核心线程数量5,最大数量10,队列大小3,超出核心线程数量的线程存活时间:5秒,指定拒绝策略的
*/
private void threadPoolExecutorTest7() throws InterruptedException {
// 创建一个 核心线程数量5,最大数量10,等待队列最大是3的线程池,也就是最大容纳13个任务
// 默认的策略是抛出 RejectedExecutionException 异常,java.util.concurrent.ThreadPoolExecutor.AbortPolicy
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5, 10, 5, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3), (r, executor) -> {
System.out.println("有任务被拒绝执行了");
});
// 测试:提交15个执行时间需要3秒的任务,看超过大小的2个,对应的处理情况
for (int i = 0; i < 15; i ++) {
int n = i;
threadPoolExecutor.submit(() -> {
try {
System.out.println("开始执行:" + n);
Thread.sleep(3000);
System.out.println("执行结束: " + n);
} catch (InterruptedException e) {
System.out.println("异常:" + e.getMessage());
}
});
System.out.println("任务提交成功:" + n);
}
// 1秒后终止线程池
Thread.sleep(1000);
threadPoolExecutor.shutdown();
// 再次提交提示失败
threadPoolExecutor.submit(() -> {
System.out.println("追加一个任务");
});
// 结果分析:
// 1. 10个任务被执行,3个任务进入等待队列,2个任务被拒绝执行
// 2. 调用 shutdown 后,不接收新的任务,等待13任务执行结束
// 3. 追加的任务在线程池关闭后,无法再提交,会被拒绝执行
}
/**
* 8. 立即终止线程:线程池信息:核心线程数量5,最大数量10,队列大小3,超出核心线程数量的线程存活时间:5秒,指定拒绝策略的
* @throws InterruptedException
*/
private void threadPoolExecutorTest8() throws InterruptedException {
// 创建一个 核心线程数量5,最大数量10,等待队列最大是3的线程池,也就是最大容纳13个任务
// 默认的策略是抛出 RejectedExecutionException 异常,java.util.concurrent.ThreadPoolExecutor.AbortPolicy
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5, 10, 5, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3), (r, executor) -> {
System.out.println("有任务被拒绝执行了");
});
// 测试:提交15个执行时间需要3秒的任务,看超过大小的2个,对应的处理情况
for (int i = 0; i < 15; i++) {
int n = i;
threadPoolExecutor.submit(() -> {
try {
System.out.println("开始执行:" + n);
Thread.sleep(3000);
System.out.println("执行结束: " + n);
} catch (InterruptedException e) {
System.out.println("异常:" + e.getMessage());
}
});
System.out.println("任务提交成功:" + n);
}
// 1秒后终止线程池
Thread.sleep(1000);
List<Runnable> shutdownNow = threadPoolExecutor.shutdownNow();
// 再次提交提示失败
threadPoolExecutor.submit(() -> {
System.out.println("追加一个任务");
});
System.out.println("未结束的任务有:" + shutdownNow.size());
// 结果分析:
// 1. 10个任务被执行,3个任务进入等待队列,2个任务被拒绝执行
// 2. 调用 shutdownNow 后,队列中的三个线程不再执行,10个线程被终止
}
public static void main(String[] args) throws Exception {
// new Demo9().threadPoolExecutorTest1();
// new Demo9().threadPoolExecutorTest2();
// new Demo9().threadPoolExecutorTest3();
// new Demo9().threadPoolExecutorTest4();
// new Demo9().threadPoolExecutorTest5();
// new Demo9().threadPoolExecutorTest6();
// new Demo9().threadPoolExecutorTest7();
new Demo9().threadPoolExecutorTest8();
}
}

20210404 7. 玩转 Elasticsearch 之深度应用及原理剖析 - 拉勾教育

转:
20210404 7. 玩转 Elasticsearch 之深度应用及原理剖析 - 拉勾教育
玩转 Elasticsearch 之深度应用及原理剖析
索引文档写入和近实时搜索原理
基本概念
Segments in Lucene
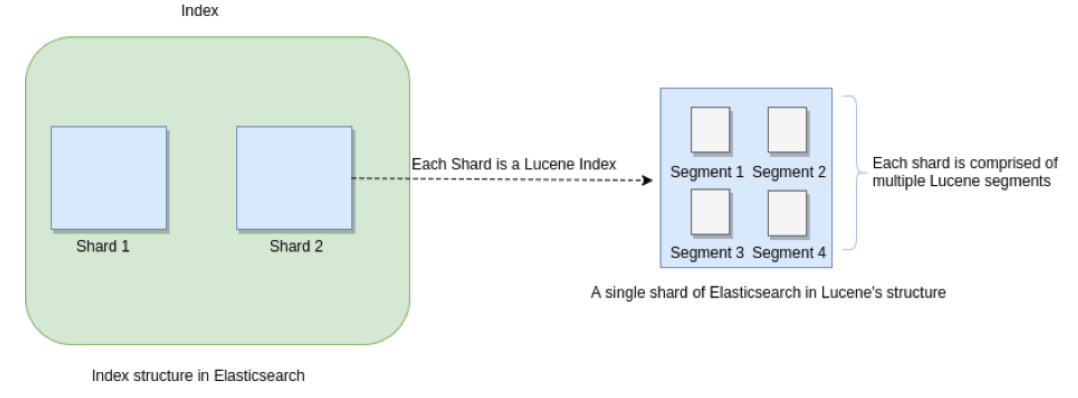
众所周知,Elasticsearch 存储的基本单元是 shard , ES 中一个 Index 可能分为多个 shard, 事实上每个 shard 都是一个 Lucence 的 Index,并且每个 Lucence Index 由多个 Segment 组成, 每个 Segment 事实上是一些倒排索引的集合, 每次创建一个新的 Document , 都会归属于一个新的 Segment, 而不会去修改原来的 Segment 。且每次的文档删除操作,会仅仅标记 Segment 中该文档为删除状态, 而不会真正的立马物理删除, 所以说 ES 的 index 可以理解为一个抽象的概念。 就像下图所示:
Commits in Lucene
Commit 操作意味着将 Segment 合并,并写入磁盘。保证内存数据尽量不丢。但刷盘是很重的 IO 操作, 所以为了机器性能和近实时搜索, 并不会刷盘那么及时。
Translog
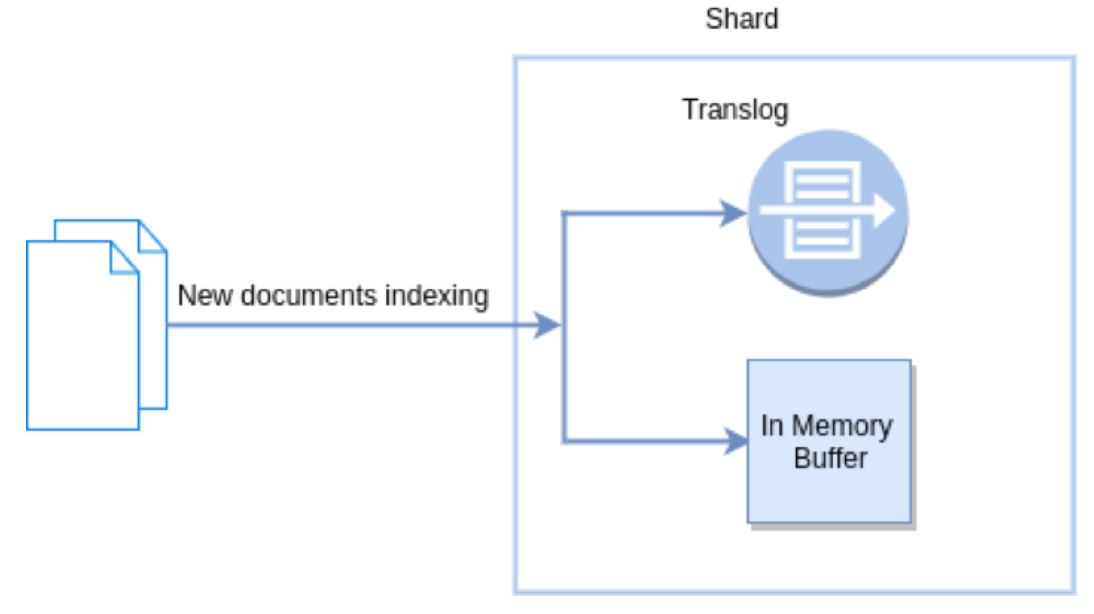
新文档被索引意味着文档会被首先写入内存 buffer 和 translog 文件。每个 shard 都对应一个 translog 文件
Refresh in Elasticsearch
在 Elasticsearch 中, _refresh 操作默认每秒执行一次, 意味着将内存 buffer 的数据写入到一个新的 Segment 中,这个时候索引变成了可被检索的。写入新 Segment 后会清空内存 buffer 。

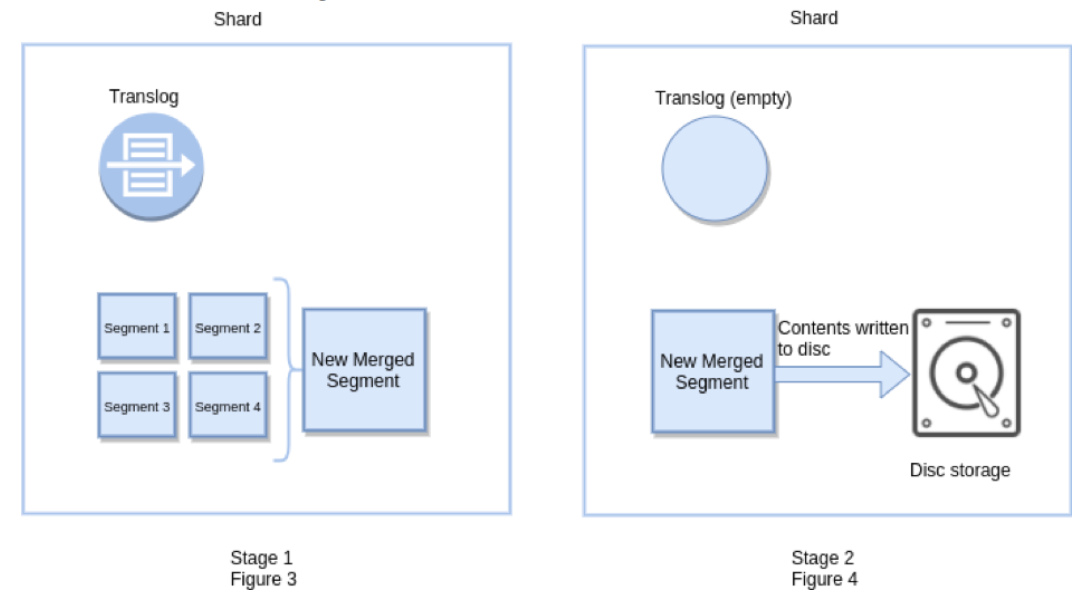
Flush in Elasticsearch
Flush 操作意味着将内存 buffer 的数据全都写入新的 Segments 中, 并将内存中所有的 Segments 全部刷盘, 并且清空 translog 日志的过程。
近实时搜索
提交(Commiting)一个新的段到磁盘需要一个 fsync 来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。 但是 fsync 操作代价很大;如果每次索引一个文档都去执行一次的话会造成很大的性能问题。
我们需要的是一个更轻量的方式来使一个文档可被搜索,这意味着 fsync 要从整个过程中被移除。
在 Elasticsearch 和磁盘之间是 文件系统缓存 。 像之前描述的一样, 在内存索引缓冲区中的文档会被写入到一个新的段中。 但是这里新段会被先写入到文件系统缓存(这一步代价会比较低),稍后再被刷新到磁盘(这一步代价比较高)。不过只要文件已经在系统缓存中, 就可以像其它文件一样被打开和读取了。
在内存缓冲区中包含了新文档的 Lucene 索引:
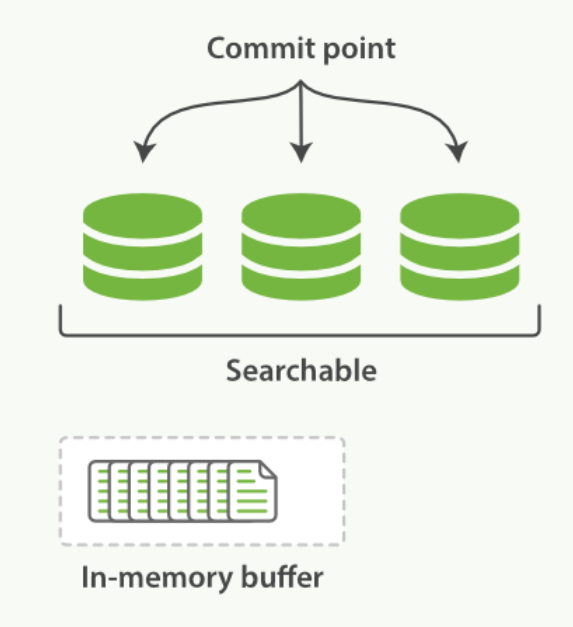
Lucene 允许新段被写入和打开,使其包含的文档在未进行一次完整提交时便对搜索可见。 这种方式比进行一次提交代价要小得多,并且在不影响性能的前提下可以被频繁地执行。
缓冲区的内容已经被写入一个可被搜索的段中,但还没有进行提交:
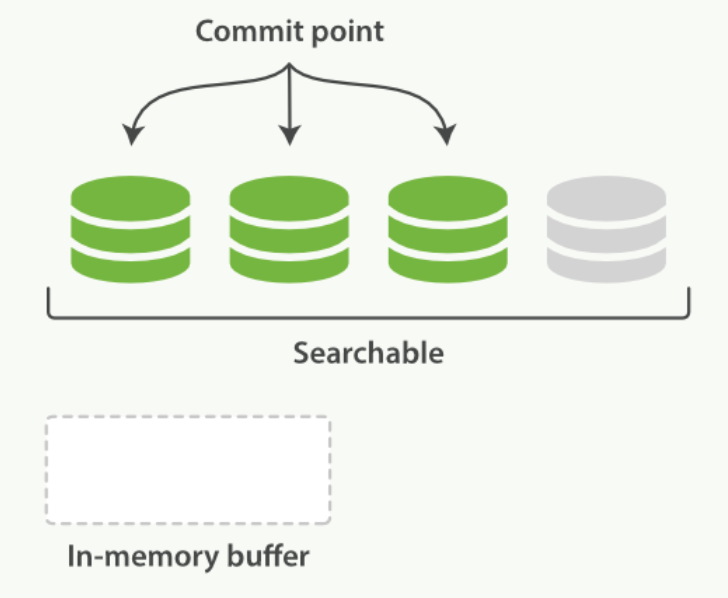
原理
下图表示是 es 写操作流程,当一个写请求发送到 es 后,es 将数据写入 memory buffer 中,并添加事务日志( translog )。如果每次一条数据写入内存后立即写到硬盘文件上,由于写入的数据肯定是离散的,因此写入硬盘的操作也就是随机写入了。硬盘随机写入的效率相当低,会严重降低 es 的性能。
因此 es 在设计时在 memory buffer 和硬盘间加入了 Linux 的高速缓存( File system cache )来提高 es 的写效率。
当写请求发送到 es 后,es 将数据暂时写入 memory buffer 中,此时写入的数据还不能被查询到。默认设置下,es 每 1 秒钟将 memory buffer 中的数据 refresh 到 Linux 的 File system cache ,并清空 memory buffer ,此时写入的数据就可以被查询到了。
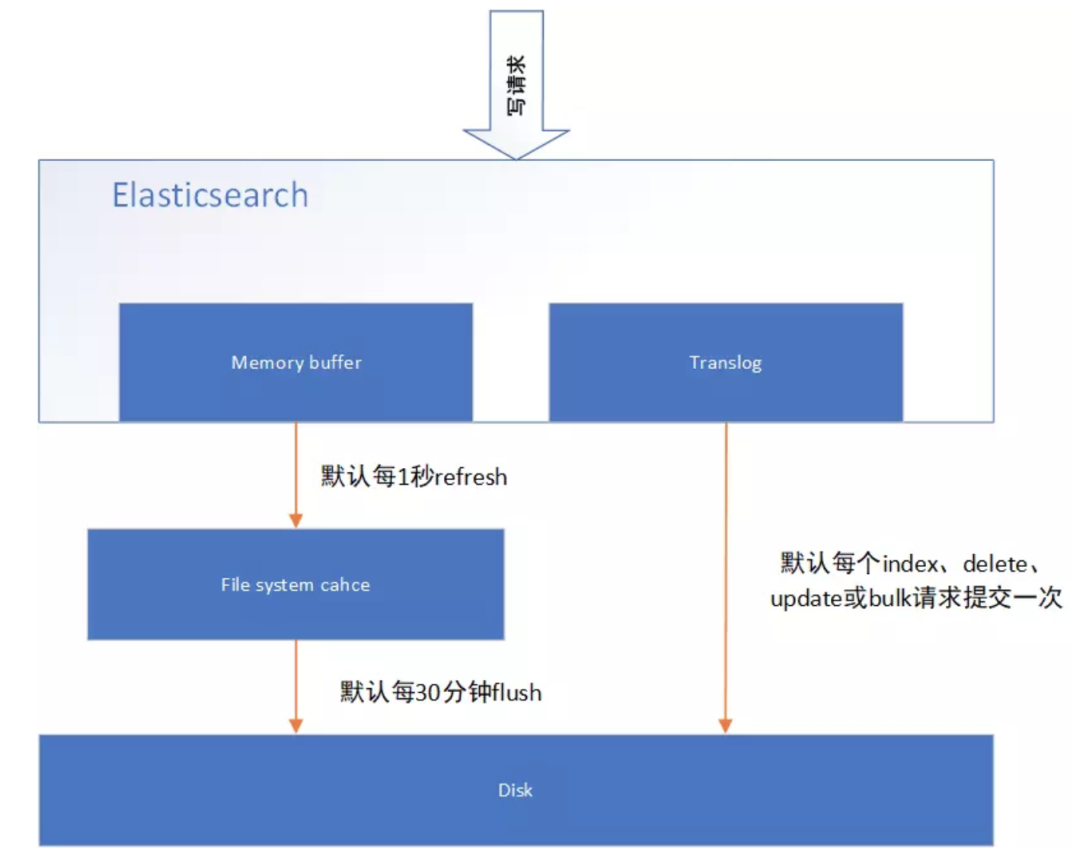
refresh API
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是 近实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
这些行为可能会对新用户造成困惑: 他们索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是用 refresh API 执行一次手动刷新:
# 刷新(Refresh)所有的索引
POST /_refresh
# 只刷新(Refresh) blogs 索引
POST /my_blogs/_refresh
# 只刷新 文档
PUT /my_blogs/_doc/1?refresh
{"test": "test"}
PUT /test/_doc/2?refresh=true
{"test": "test"}
并不是所有的情况都需要每秒刷新。可能你正在使用 Elasticsearch 索引大量的日志文件, 你可能想优化索引速度而不是近实时搜索, 可以通过设置 refresh_interval , 降低每个索引的刷新频率
PUT /my_logs
{
"settings": {
"refresh_interval": "30s"
}
}
refresh_interval 可以在既存索引上进行动态更新。 在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来:
PUT /my_logs/_settings
{
"refresh_interval": -1
}
PUT /my_logs/_settings
{
"refresh_interval": "1s"
}
持久化变更
原理
如果没有用 fsync 把数据从文件系统缓存刷(flush)到硬盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证 Elasticsearch 的可靠性,需要确保数据变化被持久化到磁盘。
在动态更新索引时,我们说一次完整的提交会将段刷到磁盘,并写入一个包含所有段列表的提交点。Elasticsearch 在启动或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片。
即使通过每秒刷新(refresh)实现了近实时搜索,我们仍然需要经常进行完整提交来确保能从失败中恢复。但在两次提交之间发生变化的文档怎么办?我们也不希望丢失掉这些数据。
Elasticsearch 增加了一个 translog ,或者叫事务日志,在每一次对 Elasticsearch 进行操作时均进行了日志记录。通过 translog ,整个流程看起来是下面这样:
-
一个文档被索引之后,就会被添加到内存缓冲区,并且 追加到了 translog ,正如下图描述的一样:
新的文档被添加到内存缓冲区并且被追加到了事务日志
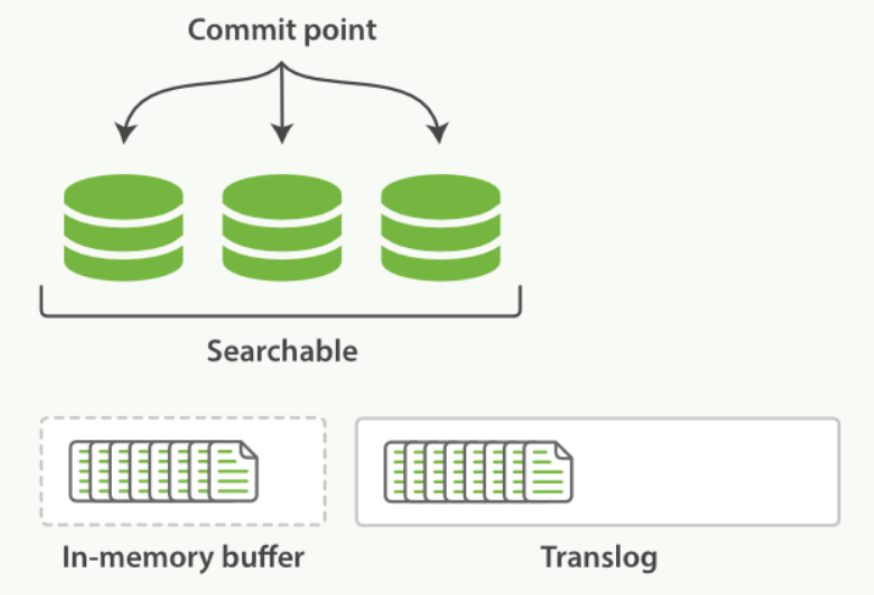
-
刷新(refresh)使分片处于下图描述的状态,分片每秒被刷新(refresh)一次:
- 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行
fsync操作。 - 这个段被打开,使其可被搜索。
- 内存缓冲区被清空。
刷新(refresh)完成后, 缓存被清空但是事务日志不会:
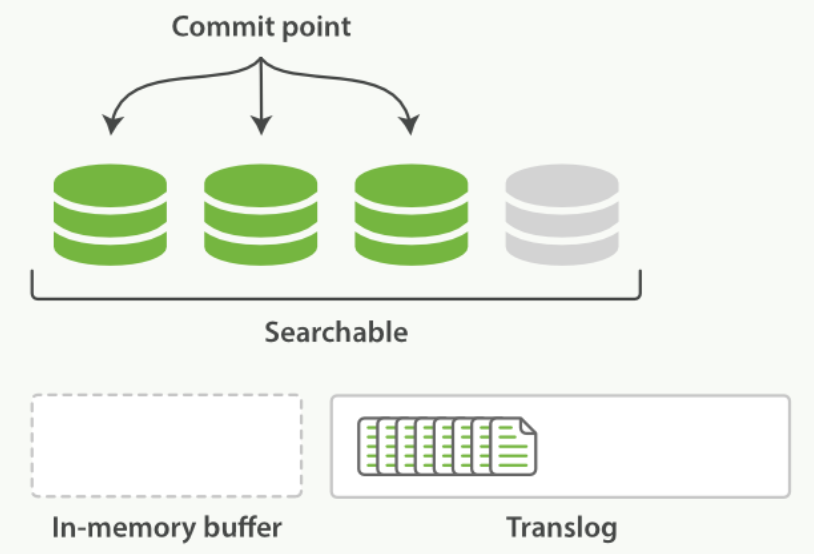
- 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行
-
这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志
事务日志不断积累文档
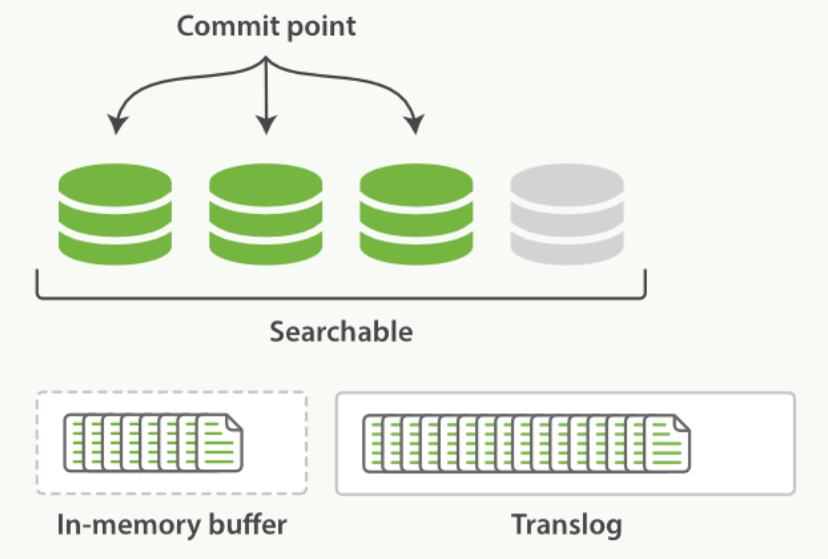
-
每隔一段时间 -- 例如 translog 变得越来越大 -- 索引被刷新(flush);一个新的 translog 被创建,并且一个全量提交被执行(见下图):
- 所有在内存缓冲区的文档都被写入一个新的段。
- 缓冲区被清空。
- 一个提交点被写入硬盘。
- 文件系统缓存通过
fsync被刷新(flush)。 - 老的 translog 被删除。
translog 提供所有还没有被刷到磁盘的操作的一个持久化纪录。当 Elasticsearch 启动的时候, 它会从磁盘中使用最后一个提交点去恢复已知的段,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时 CRUD 。当你试着通过 ID 查询、更新、删除一个文档,它会在尝试从相应的段中检索之前, 首先检查 translog 任何最近的变更。这意味着它总是能够实时地获取到文档的最新版本。
在刷新(flush)之后,段被全量提交,并且事务日志被清空:
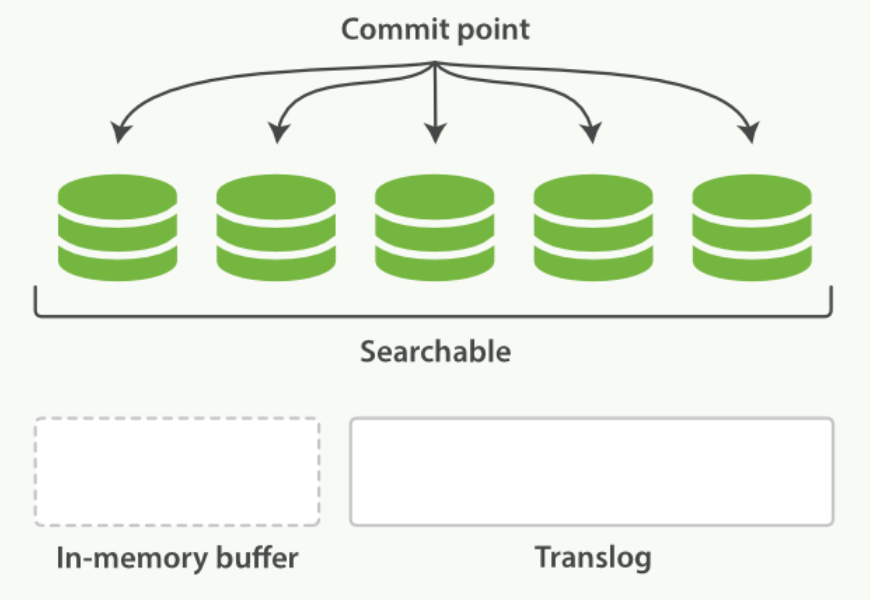
flush API
这个执行一个提交并且截断 translog 的行为在 Elasticsearch 被称作一次 flush 。 分片每 30 分钟被自动刷新(flush),或者在 translog 太大的时候也会刷新。
flush API 可以 被用来执行一个手工的刷新(flush):
# 刷新(flush) blogs 索引。
POST /blogs/_flush
# 刷新(flush)所有的索引并且等待所有刷新在返回前完成。
POST /_flush?wait_for_ongoin
我们很少需要自己手动执行一个的 flush 操作;通常情况下,自动刷新就足够了。
这就是说,在重启节点或关闭索引之前执行 flush 有益于你的索引。当 Elasticsearch 尝试恢复或重新打开一个索引, 它需要重放 translog 中所有的操作,所以如果日志越短,恢复越快
Translog 有多安全?
translog 的目的是保证操作不会丢失。这引出了这个问题: Translog 有多安全?
在文件被 fsync 到磁盘前,被写入的文件在重启之后就会丢失。默认 translog 是每 5 秒被 fsync 刷新到硬盘, 或者在每次写请求完成之后执行 (e.g. index, delete, update, bulk)。这个过程在主分片和复制分片都会发生。最终, 基本上,这意味着在整个请求被 fsync 到主分片和复制分片的 translog 之前,你的客户端不会得到一个 200 OK 响应。
在每次写请求后都执行一个 fsync 会带来一些性能损失,尽管实践表明这种损失相对较小(特别是 bulk 导入,它在一次请求中平摊了大量文档的开销)。
但是对于一些大容量的偶尔丢失几秒数据问题也并不严重的集群,使用异步的 fsync 还是比较有
益的。比如,写入的数据被缓存到内存中,再每 5 秒执行一次 fsync 。
这个行为可以通过设置 durability 参数为 async 来启用:
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}
这个选项可以针对索引单独设置,并且可以动态进行修改。如果你决定使用异步 translog 的话,你需
要保证在发生 crash 时,丢失掉 sync_interval 时间段的数据也无所谓。请在决定前知晓这个特性。
如果你不确定这个行为的后果,最好是使用默认的参数( "index.translog.durability": "request" )来避免数据丢失。
索引文档存储段合并机制( segment merge 、 policy 、 optimize )
段合并机制
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和 CPU 运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
Elasticsearch 通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。段合并的时候会将那些旧的已删除文档 从文件系统中清除。 被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。
启动段合并在进行索引和搜索时会自动进行。这个流程像在下图中提到的一样工作:
-
当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
-
合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索。
两个提交了的段和一个未提交的段正在被合并到一个更大的段:
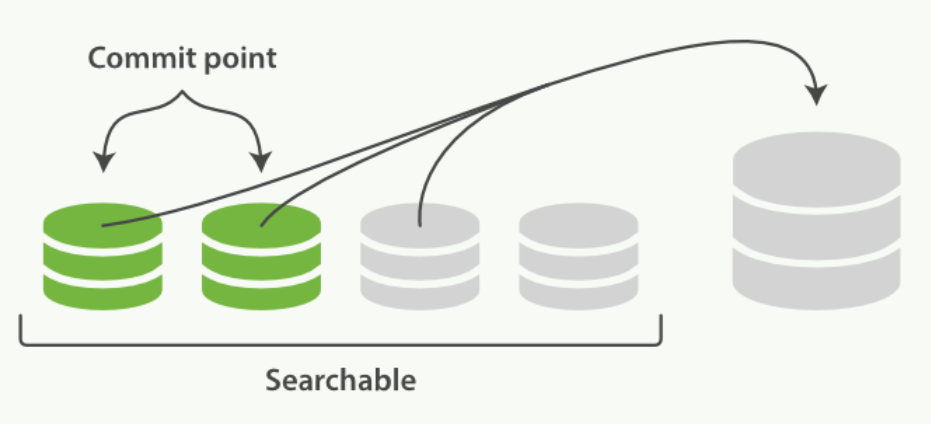
-
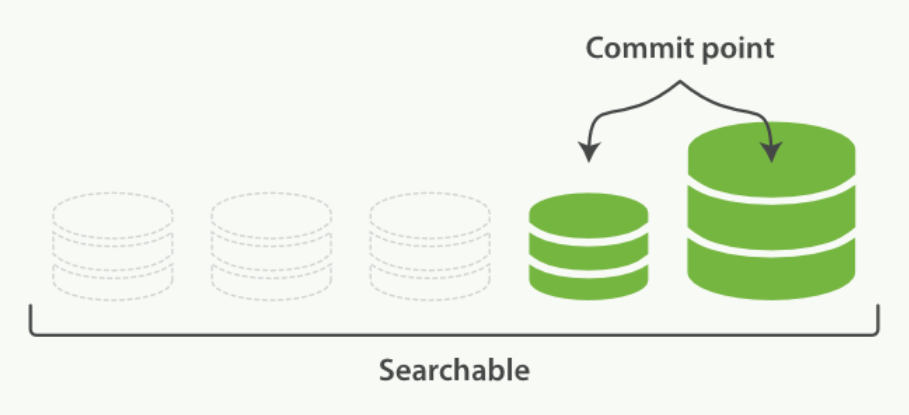
合并完成时的活动:
- 新的段被刷新(flush)到了磁盘。 写入一个包含新段且排除旧的和较小的段的新提交点。
- 新的段被打开用来搜索。
- 老的段被删除。
一旦合并结束,老的段被删除
合并大的段需要消耗大量的 I/O 和 CPU 资源,如果任其发展会影响搜索性能。 Elasticsearch 在默认情况下会对合并流程进行资源限制,所以搜索仍然 有足够的资源很好地执行。默认情况下,归并线程的限速配置
indices.store.throttle.max_bytes_per_sec是20MB。对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器来说,这个限速是明显过低的。对于 ELK Stack 应用,建议可以适当调大到 100MB 或者更高。PUT /_cluster/settings { "persistent": { "indices.store.throttle.max_bytes_per_sec": "100mb" } }用于控制归并线程的数目,推荐设置为 CPU 核心数的一半。 如果觉得自己磁盘性能跟不上,可以降低配置,免得 I/O 情况瓶颈。
index.merge.scheduler.max_thread_count
归并策略 policy
归并线程是按照一定的运行策略来挑选 segment 进行归并的。主要有以下几条:
| 策略 | 描述 |
|---|---|
index.merge.policy.floor_segment |
默认 2MB,小于这个大小的 segment,优先被归并 |
index.merge.policy.max_merge_at_once |
默认一次最多归并 10 个 segment |
index.merge.policy.max_merge_at_once_explicit |
默认 optimize 时一次最多归并 30 个 segment |
index.merge.policy.max_merged_segment |
默认 5 GB,大于这个大小的 segment,不用参与归并。optimize 除外。 |
optimize API
optimize API 大可看做是 强制合并 API。它会将一个分片强制合并到 max_num_segments 参数指定大小的段数目。 这样做的意图是减少段的数量(通常减少到一个),来提升搜索性能。
在特定情况下,使用 optimize API 颇有益处。例如在日志这种用例下,每天、每周、每月的日志被存储在一个索引中。 老的索引实质上是只读的;它们也并不太可能会发生变化。在这种情况下,使用 optimize 优化老的索引,将每一个分片合并为一个单独的段就很有用了;这样既可以节省资源,也可以使搜索更加快速:
POST /logstash-2014-10/_optimize?max_num_segments=1
forceMergeRequest.maxNumSegments(1)
并发冲突处理机制剖析
详解并发冲突
在电商场景下,工作流程为:
- 读取商品信息,包括库存数量
- 用户下单购买
- 更新商品信息,将库存数减一
如果是多线程操作,就可能有多个线程并发的去执行上述的 3 步骤流程,假如此时有两个人都来读取商品数据,两个线程并发的服务于两个人,同时在进行商品库存数据的修改。假设库存为 100 件 正确的情况:线程 A 将库存 -1 ,设置为 99 件,线程 B 接着读取 99 件,再 -1 ,变为 98 件。如果 A , B 线程都读取的为 100 件, A 处理完之后修改为 99 件, B 处理完之后再次修改为 99 件,此时结果就出错了。
解决方案
悲观锁
顾名思义,就是很悲观,每次去拿数据的时候都认为被人会修改,所以每次拿数据的时候都会加锁,以防别人修改,直到操作完成后,才会被别人执行。常见的关系型数据库,就用到了很多这样的机制,如行锁,表锁,写锁,都是在操作之前加锁。
悲观锁的优点:方便,直接加锁,对外透明,不需要额外的操作。
悲观锁的缺点:并发能力低,同一时间只能有一个操作。
乐观锁
乐观锁不加锁,每个线程都可以任意操作。比如每条文档中有一个 version 字段,新建文档后为 1 ,修改一次累加,线程 A , B 同时读取到数据, version = 1 , A 处理完之后库存为 99 ,在写入 es 的时候会跟 es 中的版本号比较,都是 1 ,则写入成功, version = 2 , B 处理完之后也为 99 ,存入 es 时与 es 中的数据的版本号 version = 2 相比,明显不同,此时不会用 99 去更新,而是重新读取最新的数据,再减一,变为 98 ,执行上述操作写入。
Elasticsearch 的乐观锁
Elasticsearch 的后台都是多线程异步的,多个请求之间是乱序的,可能后修改的先到,先修改的后到。
Elasticsearch 的多线程异步并发修改是基于自己的 _version 版本号进行乐观锁并发控制的。
在后修改的先到时,比较版本号,版本号相同修改可以成功,而当先修改的后到时,也会比较一下 _version 版本号,如果不相等就再次读取新的数据修改。这样结果会就会保存为一个正确状态
删除操作也会对这条数据的版本号加 1
在删除一个 document 之后,可以从一个侧面证明,它不是立即物理删除掉的,因为它的一些版本号等信息还是保留着的。先删除一条 document ,再重新创建这条 document ,其实会在 delete version 基础之上,再把 version 号加 1
es 的乐观锁并发控制示例
-
先新建一条数据
PUT /test_index/_doc/4 { "test_field": "test" } -
模拟两个客户端,都获取到了同一条数据
GET /test_index/_doc/4 // 返回结果 { "_index" : "test_index", "_type" : "_doc", "_id" : "4", "_version" : 1, "_seq_no" : 0, "_primary_term" : 1, "found" : true, "_source" : { "test_field" : "test" } } -
其中一个客户端,先更新了一下这个数据, 同时带上数据的版本号。这是为了确保 es 中的数据的版本号和客户端中的数据的版本号(
_seq_no)是相同的,才能修改PUT /test_index/_doc/4?if_seq_no=0&if_primary_term=1 { "test_field": "client1 changed" } // 返回结果 { "_index" : "test_index", "_type" : "_doc", "_id" : "4", "_version" : 2, "result" : "updated", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 1 } -
另一个客户端执行相同的更新,更新失败报错
{ "error" : { "root_cause" : [ { "type" : "version_conflict_engine_exception", "reason" : "[4]: version conflict, required seqNo [0], primary term [1]. current document has seqNo [1] and primary term [1]", "index_uuid" : "BASrMZZ9SNepBS67_0vlhg", "shard" : "0", "index" : "test_index" } ], "type" : "version_conflict_engine_exception", "reason" : "[4]: version conflict, required seqNo [0], primary term [1]. current document has seqNo [1] and primary term [1]", "index_uuid" : "BASrMZZ9SNepBS67_0vlhg", "shard" : "0", "index" : "test_index" }, "status" : 409 }乐观锁就成功阻止并发问题
-
在乐观锁成功阻止并发问题之后,尝试正确的完成更新
重新进行 GET 请求,得到 version
GET /test_index/_doc/4 // 返回结果 { "_index" : "test_index", "_type" : "_doc", "_id" : "4", "_version" : 2, "_seq_no" : 1, "_primary_term" : 1, "found" : true, "_source" : { "test_field" : "client1 changed" } }基于最新的数据和版本号(以前是
version现在是if_seq_no和if_primary_term),去进行修改,修改后,带上最新的版本号,可能这个步骤会需要反复执行好几次,才能成功,特别是在多线程并发更新同一条数据很频繁的情况下PUT /test_index/_doc/4?if_seq_no=1&if_primary_term=1 { "test_field": "client2 changed" } // 返回结果 { "_index" : "test_index", "_type" : "_doc", "_id" : "4", "_version" : 3, "result" : "updated", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 2, "_primary_term" : 1 }成功更新
基于 external version 进行乐观锁并发控制
es 提供了一个 feature ,就是说,你可以不用它提供的内部 _version 版本号来进行并发控制,可以基于你自己维护的一个版本号来进行并发控制。
?version=1&version_type=external
区别在于,_version 方式,只有当你提供的 version 与 es 中的 _version 一模一样的时候,才可以进行修改,只要不一样,就报错;当 version_type=external 的时候,只有当你提供的 version 比 es 中的 _version 大的时候,才能完成修改
if_seq_no=0&if_primary_term=1和文档中的值相等才能更新成功?version>1&version_type=external,大于才能成功,比如说?version=2&version_type=external
代码示例:
-
先创建一条数据
PUT /test_index/_doc/5 { "test_field": "external test" } -
模拟两个客户端同时查询到这条数据
GET /test_index/_doc/5 // 返回结果 { "_index" : "test_index", "_type" : "_doc", "_id" : "5", "_version" : 1, "_seq_no" : 3, "_primary_term" : 1, "found" : true, "_source" : { "test_field" : "external test" } } -
第一个客户端先进行修改,此时客户端程序是在自己的数据库中获取到了这条数据的最新版本号,比如说是 2
PUT /test_index/_doc/5?version=2&version_type=external { "test_field": "external client1 changed" } // 返回结果 { "_index" : "test_index", "_type" : "_doc", "_id" : "5", "_version" : 2, "result" : "updated", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 4, "_primary_term" : 1 } -
模拟第二个客户端,同时拿到了自己数据库中维护的那个版本号,也是 2 ,同时基于
version=2发起了修改// 返回错误 { "error" : { "root_cause" : [ { "type" : "version_conflict_engine_exception", "reason" : "[5]: version conflict, current version [2] is higher or equal to the one provided [2]", "index_uuid" : "BASrMZZ9SNepBS67_0vlhg", "shard" : "0", "index" : "test_index" } ], "type" : "version_conflict_engine_exception", "reason" : "[5]: version conflict, current version [2] is higher or equal to the one provided [2]", "index_uuid" : "BASrMZZ9SNepBS67_0vlhg", "shard" : "0", "index" : "test_index" }, "status" : 409 } -
在并发控制成功后,重新基于最新的版本号发起更新
GET /test_index/_doc/5 // 更新成功,_version 被更新成 5 PUT /test_index/_doc/5?version=5&version_type=external { "test_field": "external client1 changed" }
分布式数据一致性如何保证?quorum 及 timeout 机制的原理
在分布式环境下,一致性指的是多个数据副本是否能保持一致的特性。
在一致性的条件下,系统在执行数据更新操作之后能够从一致性状态转移到另一个一致性状态。
对系统的一个数据更新成功之后,如果所有用户都能够读取到最新的值,该系统就被认为具有强一致性。
ES5.0 以前的一致性
consistency,one(primary shard),all(all shard),quorum(default)
我们在发送任何一个增删改操作的时候,比如 PUT /index/indextype/id ,都可以带上一个 consistency 参数,指明我们想要的写一致性是什么?
PUT /index/indextype/id?consistency=quorum
one:要求我们这个写操作,只要有一个 primary shard 是active状态,就可以执行。all:要求我们这个写操作,必须所有的 primary shard 和 replica shard 都是活跃的,才可以执行这个写操作。quorum:默认值,要求所有的 shard 中,必须是quorum个数的 shard 都是活跃的,可用的,才可以执行这个写操作。
quorum 机制
写之前必须确保法定数 shard 可用
公式
int((primary shard + number_of_replicas) / 2) + 1
当number_of_replicas > 1时才生效。
3 primary shard + 1 = 6 shard ---> 3
举例
比如:1 个 primary shard , 3 个 replica 。那么 quorum=((1 + 3) / 2) + 1 = 3 ,要求 3 个 primary shard + 1 个 replica shard = 4 个 shard 中必须有 3 个 shard 是要处于 active 状态,若这时候只有两台机器的话,会出现什么情况?
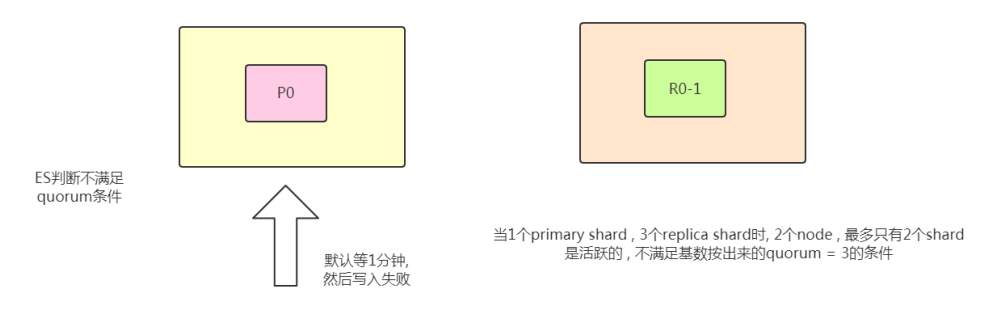
timeout 机制
quorum 不齐全时,会 wait(等待)1 分钟
默认 1 分钟,可以设置 timeout 手动去调,默认单位毫秒。
等待期间,期望活跃的 shard 数量可以增加,最后无法满足 shard 数量就会 timeout ,我们其实可以在写操作的时候,加一个 timeout 参数,比如说 PUT /index/_doc/id?timeout=30s ,这个就是说自己去设定 quorum 不齐全的时候, ES 的 timeout 时长。默认是毫秒,加个 s 代表秒
ElasticSearch 5.0 以及以后的版本
从 ES 5.0 后,原先执行 PUT 带 consistency=all/quorum 参数的,都报错了,提示语法错误。
原因是 consistency 检查是在 PUT 之前做的。然而,虽然检查的时候, shard 满足 quorum ,但是真正从 primary shard 写到 replica 之前,仍会出现 shard 挂掉,但 Update API 会返回 succeed 。因此,这个检查并不能保证 replica 成功写入,甚至这个 primary shard 是否能成功写入也未必能保证。
因此,修改了语法,用了 下面的 wait_for_active_shards,因为这个更能清楚表述,而没有歧义。
PUT /test_index/_doc/1?wait_for_active_shards=4&timeout=10s
{
"name": "xiao mi"
}
Query 文档搜索机制剖析
Elasticsearch 的搜索类型( SearchType 类型)
- 2.0 之前四种:
QUERY_AND_FETCHDFS_QUERY_AND_FETCH,QUERY_THEN_FETCH,DFS_QUERY_THEN_FETCH - 2.0 版本之后只有两种:
QUERY_THEN_FETCH,DFS_QUERY_THEN_FETCH
public enum SearchType {
DFS_QUERY_THEN_FETCH((byte)0), QUERY_THEN_FETCH((byte)1);
public static final SearchType DEFAULT = QUERY_THEN_FETCH;
public static final SearchType[] CURRENTLY_SUPPORTED = new SearchType[]{QUERY_THEN_FETCH, DFS_QUERY_THEN_FETCH};
}
可以通过 Java 的 API 设置:
SearchRequest searchRequest = new SearchRequest(POSITION_INDEX);
searchRequest.setSearchType(SearchType.DFS_QUERY_THEN_FETCH)
query and fetch
向索引的所有分片 ( shard )都发出查询请求, 各分片返回的时候把元素文档 ( document )和计算后的排名信息一起返回。
这种搜索方式是最快的。 因为相比下面的几种搜索方式, 这种查询方法只需要去 shard 查询一次。 但是各个 shard 返回的结果的数量之和可能是用户要求的 size 的 n 倍。
- 优点:这种搜索方式是最快的。因为相比后面的几种 es 的搜索方式,这种查询方法只需要去 shard 查询一次。
- 缺点:返回的数据量不准确, 可能返回( N * 分片数量)的数据并且数据排名也不准确,同时各个 shard 返回的结果的数量之和可能是用户要求的 size 的 n 倍。
DFS query and fetch
这个 D 是 Distributed , F 是 frequency 的缩写,至于 S 是 Scatter 的缩写,整个 DFS 是分布式词频率和文档频率散发的缩写。 DFS 其实就是在进行真正的查询之前, 先把各个分片的词频率和文档频率收集一下, 然后进行词搜索的时候, 各分片依据全局的词频率和文档频率进行搜索和排名。这种方式比第一种方式多了一个 DFS 步骤(初始化散发( initial scatter )),可以更精确控制搜索打分和排名。也就是在进行查询之前,先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块,再执行后面的操作。
- 优点:数据排名准确
- 缺点:
- 性能一般
- 返回的数据量不准确, 可能返回 (N * 分片数量) 的数据
query then fetch(es 默认的搜索方式)
如果你搜索时, 没有指定搜索方式, 就是使用的这种搜索方式。 这种搜索方式, 大概分两个步骤:
- 第一步, 先向所有的 shard 发出请求, 各分片只返回文档 id (注意, 不包括文档 document )和排名相关的信息(也就是文档对应的分值), 然后按照各分片返回的文档的分数进行重新排序和排名, 取前 size 个文档。
- 第二步, 根据文档 id 去相关的 shard 取 document 。 这种方式返回的 document 数量与用户要求的大小是相等的。
详细过程:
- 发送查询到每个 shard
- 找到所有匹配的文档,并使用本地的 Term/Document Frequency 信息进行打分
- 对结果构建一个优先队列(排序,标页等)
- 返回关于结果的元数据到请求节点。注意,实际文档还没有发送,只是分数
- 来自所有 shard 的分数合并起来,并在请求节点上进行排序,文档被按照查询要求进行选择
- 最终,实际文档从他们各自所在的独立的 shard 上检索出来
- 结果被返回给用户
- 优点:返回的数据量是准确的。
- 缺点:性能一般,并且数据排名不准确
DFS query then fetch
比第 3 种方式多了一个 DFS 步骤。
也就是在进行查询之前, 先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块, 再执行后面的操作
详细步骤:
- 预查询每个 shard ,询问 Term 和 Document frequency
- 发送查询到每个 shard
- 找到所有匹配的文档,并使用全局的 Term/Document Frequency 信息进行打分
- 对结果构建一个优先队列(排序,标页等)
- 返回关于结果的元数据到请求节点。注意,实际文档还没有发送,只是分数
- 来自所有 shard 的分数合并起来,并在请求节点上进行排序,文档被按照查询要求进行选择
- 最终,实际文档从他们各自所在的独立的 shard 上检索出来
- 结果被返回给用户
- 优点:
- 返回的数据量是准确的
- 数据排名准确
- 缺点:
- 性能最差【 这个最差只是表示在这四种查询方式中性能最慢, 也不至于不能忍受,如果对查询性能要求不是非常高, 而对查询准确度要求比较高的时候可以考虑这个】
文档增删改和搜索请求过程
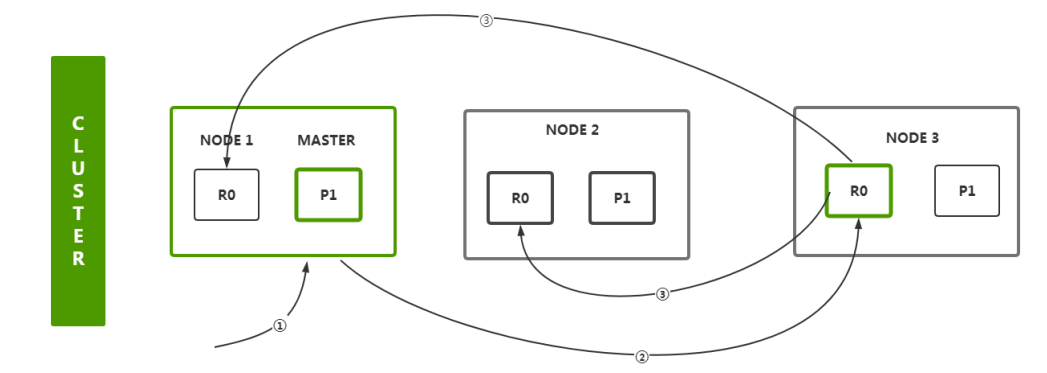
增删改流程
- 客户端首先会选择一个节点 node 发送请求过去,这个节点 node 可能是协调节点 coordinatingnode
- 协调节点 coordinating node 会对 document 数据进行路由,将请求转发给对应的 node (含有 primary shard )
- 实际上 node 的 primary shard 会处理请求,然后将数据同步到对应的含有 replica shard 的 node
- 协调节点 coordinating node 如果发现含有 primary shard 的 node 和所有的含有 replica shard 的 node 符合要求的数量之后,就会返回响应结果给客户端
search 流程
- 客户端首先会选择一个节点 node 发送请求过去,这个节点 node 可能是协调节点 coordinating node
- 协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard ,都可以
- query phase :每个 shard 将自己的搜索结果的元数据到请求节点(其实就是一些 doc id 和 打分信息等返回给协调节点),由协调节点进行数据的合并、排序、分页等操作,产出最终结果
- fetch phase :接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端
相关性评分算法 BM25
BM25 算法
BM25 ( Best Match25 )是在信息检索系统中根据提出的 query 对 document 进行评分的算法。
TF-IDF 算法是一个可用的算法,但并不太完美。而 BM25 算法则是在此之上做出改进之后的算法:
- 当两篇描述【人工智能】的文档 A 和 B ,其中 A 出现【人工智能】100 次, B 出现【人工智能】200 次。两篇文章的单词数量都是 10000 ,那么按照 TF-IDF 算法, A 的 tf 得分是: 0.01 , B 的 tf 得分是 0.02 。得分上 B 比 A 多了一倍,但是两篇文章都是再说人工智能, tf 分数不应该相差这么多。可见单纯统计的 tf 算法在文本内容多的时候是不可靠的
- 多篇文档内容的长度长短不同,对 tf 算法的结果也影响很大,所以需要将文本的平均长度也考虑到算法当中去。
基于上面两点,BM25 算法做出了改进:
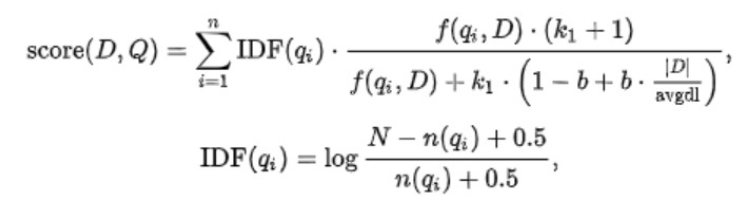
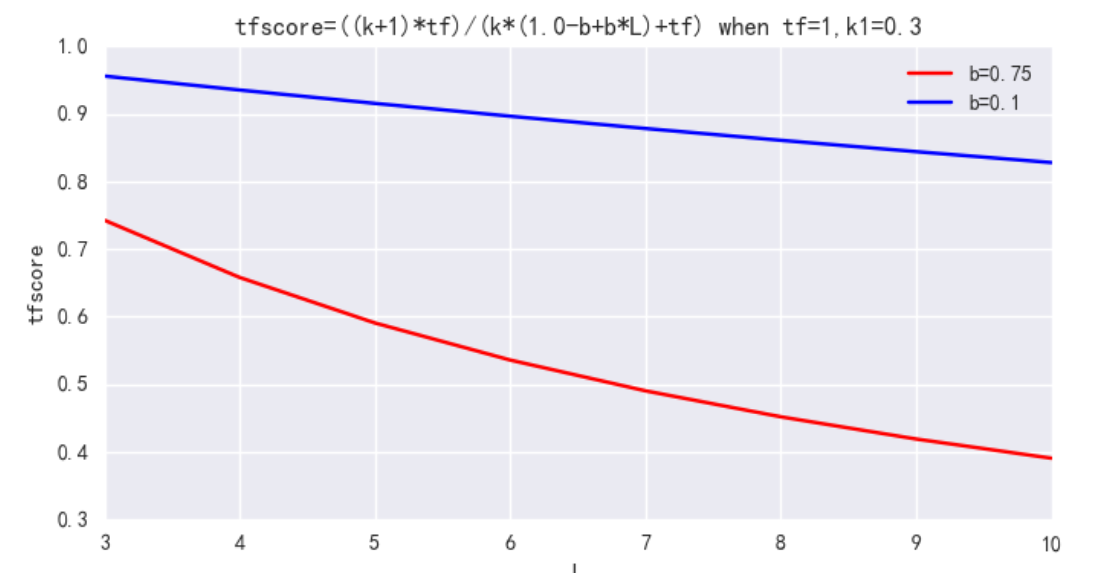
k1:词语频率饱和度( term frequency saturation )它用于调节饱和度变化的速率。它的值一般介于 1.2 到 2.0 之间。数值越低则饱和的过程越快速。(意味着两个上面 A 、 B 两个文档有相同的分数,因为他们都包含大量的【人工智能】这个词语都达到饱和程度)。在 ES 应用中为 1.2b:字段长度归约,将文档的长度归约化到全部文档的平均长度,它的值在 0 和 1 之间, 1 意味着全部归约化, 0 则不进行归约化。在 ES 的应用中为 0.75 。
k1 用来控制公式对词项频率 tf 的敏感程度。((k1 + 1) * tf) / (k1 + tf) 的上限是 (k1+1),也即饱和值。当 k1=0 时,不管 tf 如何变化,BM25 后一项都是 1;随着 k1 不断增大,虽然上限值依然是 (k1+1) ,但到达饱和的 tf 值也会越大;当 k1 无限大时,BM25 后一项就是原始的词项频率。一句话,k1 就是衡量高频 term 所在文档和低频 term 所在文档的相关性差异,在我们的场景下,term 频次并不重要,该值可以设小。ES 中默认 k1=1.2,可调整为 k1=0.3。
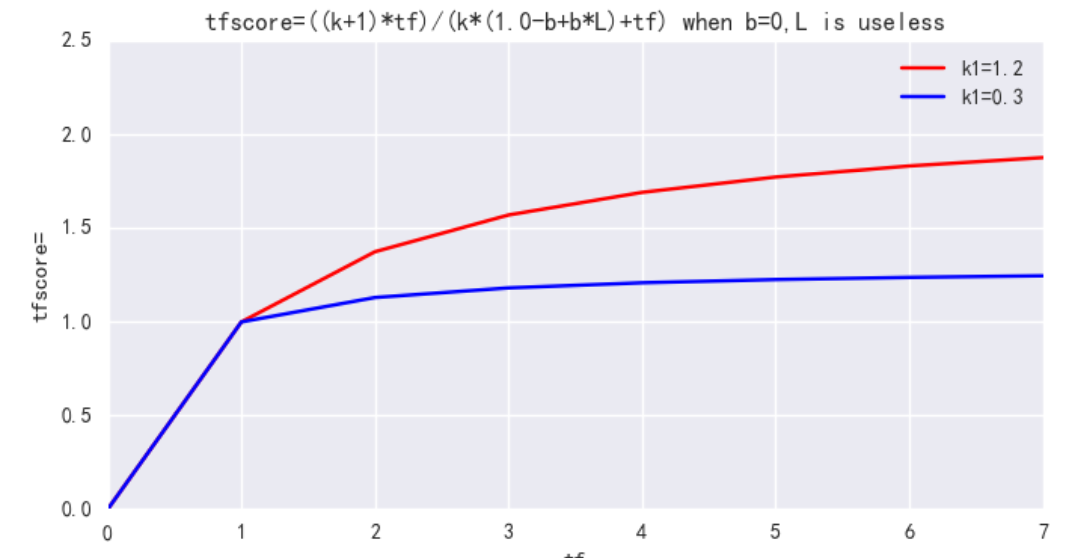
b : 单个文档长度对相关性的影响力与它和平均长度的比值有关系,用来控制文档长度 L 对权值的惩罚程度。b=0,则文档长度对权值无影响,b=1,则文档长度对权值达到完全的惩罚作用。ES 中默认 b=0.75,可调整为 b=0.1。
ES 中调整 BM25
DELETE /my_index
# ES 7 执行报错
PUT /my_index
{
"settings": {
"similarity": {
"my_bm25": {
"type": "BM25",
"b": 0.1,
"k1": 0.3
}
}
},
"mappings": {
"doc": {
"properties": {
"title": {
"type": "text",
"similarity": "my_bm25"
}
}
}
}
}
# ES7
PUT /my_index
{
"settings": {
"similarity": {
"my_bm25": {
"type": "BM25",
"b": 0.1,
"k1": 0.3
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"similarity": "my_bm25"
}
}
}
}
GET /my_index
排序那点事之内核级 DocValues 机制大揭秘
为什么要有 Doc Values
我们都知道 ElasticSearch 之所以搜索这么快速,归功于他的 倒排索引 的设计,然而它也不是万能的,倒排索引的检索性能是非常快的,但是在字段值排序时却不是理想的结构。下面是一个简单的 倒排索引 的结构
Term Doc_1 Doc_2
-------------------------
quick | | X
the | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
summer | | X
the | X |
----------------------
如上表便可以看出,他只有词对应的 doc ,但是并不知道每一个 doc 中的内容,那么如果想要排序的
话每一个 doc 都去获取一次文档内容岂不非常耗时? DocValues 的出现使得这个问题迎刃而解。
字段的 doc_values 属性有两个值, true、false。默认为 true ,即开启。
当 doc_values 为 fasle 时,无法基于该字段排序、聚合、在脚本中访问字段值。
当 doc_values 为 true 时,ES 会增加一个相应的正排索引,这增加的磁盘占用,也会导致索引数据速度慢一些
DELETE /person
PUT /person
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"doc_values": true
},
"age": {
"type": "integer",
"doc_values": false
}
}
}
}
POST _bulk
{"index":{"_index":"person","_id":"1"}}
{"name":"明明","age":22}
{"index":{"_index":"person","_id":"2"}}
{"name":"丽丽","age":18}
{"index":{"_index":"person","_id":"3"}}
{"name":"媛媛","age":19}
POST /person/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"name": {
"order": "desc"
}
}
]
}
# 报错
POST /person/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
# 报错
POST /person/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
Doc Values 是什么
Docvalues 通过转置倒排索引和正排索引两者间的关系来解决这个问题。倒排索引将词项映射到包含它们的文档, Docvalues 将文档映射到它们包含的词项:
Doc Terms
-----------------------------------------------------------------
Doc_1 | brown, dog, fox, jumped, lazy, over, quick, the
Doc_2 | brown, dogs, foxes, in, lazy, leap, over, quick, summer
Doc_3 | dog, dogs, fox, jumped, over, quick, the
当数据被转置之后,想要收集到每个文档行,获取所有的词项就非常简单了。所以搜索使用倒排索引查找文档,聚合操作收集和聚合 DocValues 里的数据,这就是 ElasticSearch 。
深入理解 ElasticSearch Doc Values
DocValues 是在索引时与倒排索引同时生成。也就是说 DocValues 和 倒排索引 一样,基于 Segement 生成并且是不可变的。同时 DocValues 和 倒排索引 一样序列化到磁盘,这样对性能和扩展性有很大帮助。
DocValues 通过序列化把数据结构持久化到磁盘,我们可以充分利用操作系统的内存,而不是 JVM 的 Heap 。 当 workingset 远小于系统的可用内存,系统会自动将 DocValues 保存在内存中,使得其读写十分高速; 不过,当其远大于可用内存时,操作系统会自动把 DocValues 写入磁盘。很显然,这样性能会比在内存中差很多,但是它的大小就不再局限于服务器的内存了。如果是使用 JVM 的 Heap 来实现是因为容易 OutOfMemory 导致程序崩溃了。
Doc Values 压缩
从广义来说, DocValues 本质上是一个序列化的 列式存储,这个结构非常适用于聚合、排序、脚本等操作。而且,这种存储方式也非常便于压缩,特别是数字类型。这样可以减少磁盘空间并且提高访问速度。下面来看一组数字类型的 DocValues :
Doc Terms
-----------------------------------------------------------------
Doc_1 | 100
Doc_2 | 1000
Doc_3 | 1500
Doc_4 | 1200
Doc_5 | 300
Doc_6 | 1900
Doc_7 | 4200
--------------------
你会注意到这里每个数字都是 100 的倍数, DocValues 会检测一个段里面的所有数值,并使用一个最大公约数 ,方便做进一步的数据压缩。我们可以对每个数字都除以 100,然后得到:[1,10,15,12,3,19,42] 。现在这些数字变小了,只需要很少的位就可以存储下,也减少了磁盘存放的大小。
DocValues 在压缩过程中使用如下技巧。它会按依次检测以下压缩模式:
- 如果所有的数值各不相同(或缺失),设置一个标记并记录这些值
- 如果这些值小于 256,将使用一个简单的编码表
- 如果这些值大于 256,检测是否存在一个最大公约数
- 如果没有存在最大公约数,从最小的数值开始,统一计算偏移量进行编码
当然如果存储 String 类型,其一样可以通过顺序表对 String 类型进行数字编码,然后再把数字类型构建 DocValues 。
禁用 Doc Values
DocValues 默认对所有字段启用,除了 analyzed strings 。也就是说所有的数字、地理坐标、日期、IP 和不分析( not_analyzed )字符类型都会默认开启。
analyzed strings 暂时还不能使用 DocValues ,是因为经过分析以后的文本会生成大量的 Token ,这样非常影响性能。
虽然 DocValues 非常好用,但是如果你存储的数据确实不需要这个特性,就不如禁用他,这样不仅节省磁盘空间,也许会提升索引的速度。
要禁用 DocValues ,在字段的映射(mapping)设置 doc_values:false 即可。例如,这里我们创建了一个新的索引,字段 session_id 禁用了 DocValues :
DELETE /my_index
PUT my_index
{
"mappings": {
"properties": {
"session_id": {
"type": "keyword",
"doc_values": false
}
}
}
}
通过设置 doc_values:false ,这个字段将不能被用于聚合、排序以及脚本操作
Filter 过滤机制剖析( bitset 机制与 caching 机制)
在倒排索引中查找搜索串,获取 document list
以 date 举例:倒排索引列表,过滤 date 为 2020-02-02 ( filter: 2020-02-02 )。
去倒排索引中查找,发现 2020-02-02 对应的 document list 是 doc2 、 doc3 。
| word | doc1 | doc2 | doc3 |
|---|---|---|---|
| 2020-01-01 | * | * | |
| 2020-02-02 | * | * | |
| 2020-03-03 | * | * | * |
Filter 为 每个在倒排索引中搜索到的结果,构建一个 bitset,[0, 0, 0, 1, 0, 1](非常重要)
- 使用找到的 document list ,构建一个 bitset (二进制数组,用来表示一个 document 对应一个 filter 条件是否匹配;匹配为 1 ,不匹配为 0 )。
- 为什么使用 bitset :尽可能用简单的数据结构去实现复杂的功能,可以节省内存空间、提升性能。
- 由上步的 document list 可以得出该 filter 条件对应的 bitset 为:
[0, 1, 1];代表着 doc1 不匹配 filter , doc2 、 doc3 匹配 filter 。
多个过滤条件时,遍历每个过滤条件对应的 bitset,优先从最稀疏的开始搜索,查找满足所有条件的 document
-
多个 filter 组合查询时,每个 filter 条件都会对应一个 bitset 。
-
稀疏、密集的判断是通过匹配的多少(即 bitset 中元素为 1 的个数),[0, 0, 0, 1, 0, 0] 比较稀疏、[0,1, 0, 1, 0, 1] 比较密集 。
-
先过滤稀疏的 bitset ,就可以先过滤掉尽可能多的数据。
-
遍历所有的 bitset 、找到匹配所有 filter 条件的 doc 。
请求:
filter: postDate=2017-01-01,userID=1postDate: [0, 0, 1, 1, 0, 0]userID: [0, 1, 0, 1, 0, 1]遍历完两个 bitset 之后,找到的匹配所有条件的 doc ,就是 doc4 。
-
将得到的 document 作为结果返回给 client 。
caching bitset ,跟踪 query ,在最近 256 个 query 中超过一定次数的过滤条件,缓存其 bitset 。对于小 segment (< 1000 或 < 3% ),不缓存 bitset
- 比如
postDate=2020-01-01, [0, 0, 1, 1, 0, 0]可以缓存在内存中,这样下次如果再有该条件查询时,就不用重新扫描倒排索引,反复生成 bitset ,可以大幅提升性能。 - 在最近 256 个 filter 中,有某个 filter 超过一定次数,次数不固定,就会自动缓存该 filter 对应的 bitset 。
- filter 针对小 segment 获取的结果,可以不缓存, segment 记录数 <1000 ,或者 segment 大小 < index 总大小的 3% ( segment 数据量很小,此时哪怕是扫描也很快, segment 会在后台自动合并,小 segment 很快就会跟其他小 segment 合并成大 segment ,此时缓存没有多大意义,因为 segment 很快就会消失)。
- filter 比 query 的好处就在于有 caching 机制, filter bitset 缓存起来便于下次不用扫描倒排索引。以后只要是由相同的 filter 条件的,会直接使用该过滤条件对应的 cached bitset 比如
postDate=2020-01-01, [0, 0, 1, 1, 0, 0]可以缓存在内存中,这样下次如果再有该条件查询时,就不用重新扫描倒排索引,反复生成 bitset ,可以大幅提升性能。
如果 document 有新增或修改,那么 cached bitset 会被自动更新
postDate=2020-01-01, filter:[0, 0, 1, 0]
- 新增 document,
id=5, postDate=2020-01-01;会自动更新到postDate=2020-01-01这个 filter 的 bitset 中,缓存要会进行相应的更新。postDate=2020-01-01的 bitset :[0, 0, 1, 0, 1]。 - 修改 document ,
id=1, postDate=2019-01-31,修改为postDate=2020-01-01,此时也会自动更新 bitset :[1, 0, 1, 0, 1]。
filter 大部分情况下,在 query 之前执行,先尽量过滤尽可能多的数据
- query :要计算 doc 对搜索条件的 relevance score ,还会根据这个 score 排序。
- filter :只是简单过滤出想要的数据,不计算 relevance score ,也不排序。
控制搜索精准度 - 基于 boost 的细粒度搜索的条件权重控制
boost ,搜索条件权重。可以将某个搜索条件的权重加大,此时匹配这个搜索条件的 document ,在计算 relevance score 时,权重更大的搜索条件的 document 对应的 relevance score 会更高,当然也就会优先被返回回来。默认情况下,搜索条件的权重都是 1 。
DELETE /article
POST /article/_bulk
{"create":{"_id":"1"}}
{"title":"elasticsearch"}
{"create":{"_id":"2"}}
{"title":"java"}
{"create":{"_id":"3"}}
{"title":"elasticsearch"}
{"create":{"_id":"4"}}
{"title":"hadoop"}
{"create":{"_id":"5"}}
{"title":"spark"}
GET /article/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": {
"value": "java"
}
}
},
{
"term": {
"title": {
"value": "spark"
}
}
},
{
"term": {
"title": {
"value": "hadoop"
}
}
},
{
"term": {
"title": {
"value": "elasticsearch"
}
}
}
]
}
}
}
搜索帖子,如果标题包含 Hadoop 或 Java 或 Spark 或 Elasticsearch ,就优先输出包含 Java 的,再输出 Spark 的,再输出 Hadoop 的,最后输出 Elasticsearch 的。
GET /article/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": {
"value": "java",
"boost": 5
}
}
},
{
"term": {
"title": {
"value": "spark",
"boost": 4
}
}
},
{
"term": {
"title": {
"value": "hadoop",
"boost": 3
}
}
},
{
"term": {
"title": {
"value": "elasticsearch"
}
}
}
]
}
}
}
控制搜索精准度 - 基于 dis_max 实现 best fields 策略
为帖子数据增加 content 字段
POST /article/_bulk
{"update":{"_id":"1"}}
{"doc":{"content":"i like to write best elasticsearch article"}}
{"update":{"_id":"2"}}
{"doc":{"content":"i think java is the best programming language"}}
{"update":{"_id":"3"}}
{"doc":{"content":"i am only an elasticsearch beginner"}}
{"update":{"_id":"4"}}
{ "doc" : {"content" : "elasticsearch and hadoop are all very good solution, i am a beginner"} }
{"update":{"_id":"5"}}
{ "doc" : {"content" : "spark is best big data solution based on scala ,an programming language similar to java"} }
搜索 title 或 content 中包含 Java 或 solution 的帖子
下面这个就是 multi-field 搜索,多字段搜索
GET /article/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "java solution"
}
},
{
"match": {
"content": "java solution"
}
}
]
}
}
}
结果分析
期望的是 doc5 排在了前面,结果是 doc2 排在了前面
算一下 doc2 的分数:
{ "match": { "title": "java solution" }},针对 doc2,是有一个分数的{ "match": { "content": "java solution" }},针对 doc2,也是有一个分数的
所以是两个分数加起来,比如说,1.0 + 1.3 = 2.3
算一下 doc5 的分数:
{ "match": { "title": "java solution" }},针对 doc5 ,是没有分数的{ "match": { "content": "java solution" }},针对 doc5 ,是有一个分数的
所以说,只有一个 query 是有分数的,比如 1.4
best fields 策略,dis_max
如果不是简单将每个字段的评分结果加在一起,而是将 最佳匹配 字段的评分作为查询的整体评分,结果会怎样?这样返回的结果可能是: 同时 包含 java 和 solution 的单个字段比反复出现相同词语的多个不同字段有更高的相关度。
- best fields 策略,就是说,搜索到的结果,应该是某一个 field 中匹配到了尽可能多的关键词,被排在前面;而不是尽可能多的 field 匹配到了少数的关键词,排在了前面
- dis_max 语法,直接取多个 query 中,分数最高的那一个 query 的分数即可
{ "match": { "title": "java solution" }} ,针对 doc2 ,是有一个分数的,1.0
{ "match": { "content": "java solution" }} ,针对 doc2 ,也是有一个分数的,1.3
取最大分数,1.3
{ "match": { "title": "java solution" }} ,针对 doc5,是没有分数的
{ "match": { "content": "java solution" }} ,针对 doc5,是有一个分数的,1.4
取最大分数,1.4
然后 doc2 的分数 = 1.3 < doc5 的分数 = 1.4,所以 doc5 就可以排在更前面的地方,符合我们的需要
GET /article/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": "java solution"
}
},
{
"match": {
"content": "java solution"
}
}
]
}
}
}
控制搜索精准度 - 基于 function_score 自定义相关度分数算法
Function score 查询
Elasticsearch Guide [7.3] » Query DSL » Compound queries » Function score query
在使用 ES 进行全文搜索时,搜索结果默认会以文档的相关度进行排序,而这个 "文档的相关度",是可以通过 function_score 自己定义的,也就是说我们可以通过使用 function_score ,来控制 "怎样的文档相关度得分更高" 这件事。
GET /book/_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"boost": "5",
"random_score": {}
}
}
}
比如对 book 进行随机打分 如果没有给函数提供过滤,则等效于指定 "match_all":{} ,要排除不符合特定分数阈值的文档,可以将 min_score 参数设置为所需分数阈值。
为了使 min_score 正常工作,需要对查询返回的所有文档进行评分,然后逐一过滤掉。
function_score 查询提供了几种类型的得分函数:
script_scoreweightrandom_scorefield_value_factordecay functions: gauss, linear, exp
Field Value factor
field_value_factor 函数可以使用文档中的字段来影响得分。与使用 script_score 函数类似,但是它避免了脚本编写的开销。如果用于多值字段,则在计算中仅使用该字段的第一个值。
GET /book/_search
{
"query": {
"function_score": {
"field_value_factor": {
"field": "price",
"factor": 1.2,
"modifier": "sqrt"
}
}
}
}
得分公式:sqrt(1.2 * doc[''price''].value)
field_value_factor 函数有许多选项:
| 属性 | 说明 |
|---|---|
| field | 要从文档中提取的字段 |
| factor | 字段值乘以的值,默认为 1 |
| modifier | 应用于字段值的修饰符可以是以下之一: none , log , log1p , log2p , ln , ln1p , ln2p , square , sqrt , or reciprocal 。默认为无 |
modifier 的取值
| Modifier | 说明 |
|---|---|
| none | 不要对字段值应用任何乘数 |
| log | 取字段值的常用对数。因为此函数将返回负值并在 0 到 1 之间的值上使用时导致错 误,所以建议改用 log1p |
| log1p | 将字段值上加 1 并取对数 |
| log2p | 将字段值上加 2 并取对数 |
| ln | 取字段值的自然对数。因为此函数将返回负值并在 0 到 1 之间的值上使用时引起错 误,所以建议改用 ln1p |
| ln1p | 将 1 加到字段值上并取自然对数 |
| ln2p | 将 2 加到字段值上并取自然对数 |
| square | 对字段值求平方(乘以它本身) |
| sqrt | 取字段值的平方根 |
| reciprocal | 交换字段值,与 1 /x 相同,其中 x 是字段的值 |
field_value_score 函数产生的分数必须为非负数,否则将引发错误。如果在 0 到 1 之间的值上使用 log 和 ln 修饰符将产生负值。请确保使用范围过滤器限制该字段的值以避免这种情况,或者使用 log1p 和 ln1p
Decay functions
衰减函数对文档进行评分,该函数的衰减取决于文档的数字字段值与用户给定原点的距离。这类似于范围查询,但具有平滑的边缘而不是框。
要在具有数字字段的查询上使用距离计分,用户必须为每个字段定义 origin 和 scale 。需要 origin 来定义从中间计算距离的 “中心点”,并需要 scale 来定义衰减率。衰减函数指定为
"DECAY_FUNCTION": {
"FIELD_NAME": {
"origin": "11, 12",
"scale": "2km",
"offset": "0km",
"decay": 0.33
}
}
DECAY_FUNCTION 必须是 linear , exp , gauss 其中一个,指定的字段必须是数字,日期或地理点字段
在上面的例子中,该字段是 geo_point ,可以以地理格式提供起点。在这种情况下,必须使用 scale 和 offset 。如果您的字段是日期字段,则可以将比例和偏移量设置为天,周等。如下:
GET /_search
{
"query": {
"function_score": {
"gauss": {
"date": {
"origin": "2013-09-17",
"scale": "10d",
"offset": "5d",
"decay": 0.5
}
}
}
}
}
原点的日期格式取决于映射中定义的格式。如果未定义原点,则使用当前时间 offset 和 decay 参数是可选的
| 属性 | 说明 |
|---|---|
| origin | 用于计算距离的原点。对于数字字段,必须指定为数字;对于日期字段,必须指定为 日期;对于地理字段,必须指定为地理点。地理位置和数字字段必填。对于日期字 段,默认值为现在。原始日期支持日期数学(例如 now-1h ) |
| scale | 所有类型都必需。定义到原点的距离 + 偏移,计算出的分数将等于衰减参数。对于地 理字段:可以定义为数字 + 单位(1m,12km,…)。默认单位是米。对于日期字 段:可以定义为数字 + 单位(“1h”,“ 10d”,…。)。默认单位是毫秒。对于数字字 段:任何数字 |
| offset | 如果定义了偏移量,则衰减函数将仅计算距离大于定义的偏移量的文档的衰减函数。 默认值为 0 |
| decay | 衰减参数定义了如何按比例给定的距离对文档进行评分。如果未定义衰减,则距离尺 度的文档将获得 0.5 分 |
在第一个示例中,您的文档可能代表酒店,并且包含地理位置字段。您要根据酒店距指定位置的距离来计算衰减函数。 您可能不会立即看到为高斯功能选择哪种比例,但是您可以说:“在距所需位置 2 公里的距离处,分数应降低到 0.33 。” 然后将自动调整参数 “规模”,以确保得分功能为距离期望位置 2 公里的酒店计算出高于 0.33 的得分。
在第二个示例中,字段值在 2013-09-12 和 2013-09-22 之 间的文档的权重为 1.0 ,从该日期起 15 天的文档的权重为 0.5 。
支持的衰减函数:
gauss:正常衰减exp:指数衰减linear:线性衰减
如果文档中缺少数字字段,该函数将返回 1
bulk 操作的 api json 格式与底层性能优化的关系?
之前我们有讲过 bulk 的 json 格式很奇葩,不能换行,两行为一组(除删除外),如下:
{"action" : {"metadata"}}
{"data"}
POST /_bulk
{"delete":{"_index":"book","_id":"1"}}
{"create":{"_index":"book","_id":"5"}}
{"name":"test14","price":100.99}
{"update":{"_index":"book","_id":"2"}}
{"doc":{"name":"test"}}
bulk 中的每个操作都可能要转发到不同 node 的 shard 上执行
如果采用比较良好的 json 数组格式
首先,整个可读性非常棒,读起来很爽,ES 拿到那种标准格式的 JSON 串以后,要按照下述流程去进行处理
- 将 JSON 数组解析为 JSONArray 对象,这个时候,整个数据,就会在内存中出现一份一模一样的拷贝,一份数据是 JSON 文本,一份数据是 JSONArray 对象。
- 解析 JSON 数组里的每个 JSON ,对每个请求中的 document 进行路由
- 为路由到同一个 shard 上的多个请求,创建一个请求数组。
- 将这个请求数组序列化
- 将序列化后的请求数组发送到对应的节点上去
现在这种丑陋两行格式的 JSON
{"action" : {"meta"}}
{"data"}
{"action" : {"meta"}}
{"data"}
- 不用将其转换为 JSON 对象,不会出现内存中的相同数据的拷贝,直接按照换行符切割 JSON
- 对每两个一组的 JSON ,读取 meta ,进行 document 路由
- 直接将对应的 JSON 发送到 node 上去
两种格式对比,为什么 ES 选择丑陋的格式?
-
优雅格式:
耗费更多的内存,更多的 JVM GC 开销。我们之前提到过 bulk size 最佳大小的问题,一般建议说在几千条那样,然后大小在 10MB 左右,所以说,可怕的事情来了,假设说现在 100 个 bulk 请求发送到了一个节点上去,然后每个请求是 10MB , 100 个请求就是 1000MB = 1GB 。然后每个请求的 JSON 都 copy 一份为 JSONArray 对象,此时内存中的占用就会翻倍,就会占用 2GB 内存,甚至还不止,因为弄成 JSONArray 后,还可能会多搞一些其他的数据结构, 2GB+ 的内存占用。占用更多的内存可能就会积压其他请求的内存使用量,比如说最重要的搜索请求,分析请求,等等,此时就可能会导致其他请求的性能急速下降另外的话,占用内存更多,就会导致 ES 的 Java 虚拟机的垃圾回收次数更多,更频繁,每次要回收的垃圾对象更多,耗费的时间更多,导致 ES 的 Java 虚拟机停止工作线程的时间更多。
-
丑陋的 JSON 格式:
最大的优势在于,不需要将 JSON 数组解析为一个 JSONArray 对象,形成一份大数据的拷贝,浪费内存空间,尽可能的保证性能。
deep paging 性能问题 和 解决方案
深度分页问题
ES 默认采用的分页方式是 from + size 的形式,类似于 mysql 的分页 limit。当请求数据量比较大时,Elasticsearch 会对分页做出限制,因为此时性能消耗会很大。举个例子,一个索引 分 10 个 shards,然
后,一个搜索请求,from=990,size=10,这时候,会带来严重的性能问题:
- CPU
- 内存
- IO
- 网络带宽
CPU 、内存和 IO 消耗容易理解,网络带宽问题稍难理解一点。在 query 阶段,每个 shard 需要返回 1000 条数据给 coordinating node ,而 coordinating node 需要接收 10 * 1000 条数据,即使每条数据只有 _doc、_id 和 _score ,这数据量也很大了,而且,这才一个查询请求,那如果再乘以 100 呢?
es 中有个设置 index.max_result_window ,默认是 10000 条数据,如果分页的数据超过第 1 万条,就拒绝返回结果了。如果你觉得自己的集群还算可以,可以适当的放大这个参数,比如 100 万。
我们意识到,有时这种深度分页的请求并不合理,因为我们是很少人为的看很后面的请求的,在很多的业务场景中,都直接限制分页,比如只能看前 100 页。
不过,这种深度分页确实存在,比如有 1 千万粉丝的微信大 V ,要给所有粉丝群发消息,或者给某省粉丝群发,这时候就需要取得所有符合条件的粉丝,而最容易想到的就是利用 from + size 来实现,但这是不现实的,我们需要使用下面的解决方案。
深度分页解决方案
利用 scroll 遍历方式
scroll 分为初始化和遍历两步,初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照,在遍历时,从这个快照里取数据,也就是说,在初始化后对索引插入、删除、更新数据都不会影响遍历结果。因此,scroll 并不适合用来做实时搜索,而更适用于后台批处理任务,比如群发。
初始化
POST /article/_search?scroll=1m&size=2
{
"query": {
"match_all": {}
}
}
初始化时需要像普通 search 一样,指明 index 和 type (当然,search 是可以不指明 index 和 type
的),然后,加上参数 scroll,表示暂存搜索结果的时间,其它就像一个普通的 search 请求一样。
初始化返回一个 _scroll_id,_scroll_id 用来下次取数据用。
遍历
GET /_search/scroll
{
"scroll": "1m",
"scroll_id": "步骤1中查询出来的 _scroll_id"
}
这里的 _scroll_id 即 上一次遍历取回的 _scroll_id 或者是初始化返回的 _scroll_id ,同样的,需要带 scroll 参数。 重复这一步骤,直到返回的数据为空,即遍历完成。注意,每次都要传参数 scroll ,刷新搜索结果的缓存时间。另外,不需要指定 index 和 type 。设置 scroll 的时候,需要使搜索结果缓存到下一次遍历完成,同时,也不能太长,毕竟空间有限。
search after 方式
满足实时获取下一页的文档信息, search_after 分页的方式是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改,这些变更也会实时的反映到游标上,这种方式是在 ES 5.X 之后才提供的。为了找到每一页最后一条数据,每个文档的排序字段必须有一个全局唯一值 使用 _id 就可以了。
GET /book/_search
{
"query": {
"match_all": {}
},
"size": 2,
"sort": [
{
"_id": "desc"
}
]
}
GET /book/_search
{
"query": {
"match_all": {}
},
"size": 2,
"search_after": [
3
],
"sort": [
{
"_id": "desc"
}
]
}
下一页的数据依赖上一页的最后一条的信息 所以不能跳页。
三种分页方式比较
| 分页方式 | 性 能 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较 小,能容忍深 度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反映数据的实时性(快 照版本) 维护成本高,需 要维护一个 scroll_id | 海量数据的导 出 需要查询海 量结果集的数 据 |
| search_after | 高 | 性能最好 不存在深 度分页问题 能够反 映数据的实时变更 | 实现连续分页的实现会比较 复杂,因为每一次查询都需 要上次查询的结果 | 海量数据的分 页 |
转:
20210404 7. 玩转 Elasticsearch 之深度应用及原理剖析 - 拉勾教育
--Posted from Rpc

@MapperScan的使用及原理
以前写都是直接在Mapper类上添加注解@Mapper,这种方式要求每一个mapper类都需要添加这个注解。
通过使用@MapperScan可以指定要Mapper类的包路径。
比如:https://blog.csdn.net/u013059432/article/details/80239075
我们今天的关于基本功 | Litho的使用及原理剖析和lithologic的分享就到这里,谢谢您的阅读,如果想了解更多关于(八)ThreadLocal的使用及原理分析、003. 线程池应用及实现原理剖析、20210404 7. 玩转 Elasticsearch 之深度应用及原理剖析 - 拉勾教育、@MapperScan的使用及原理的相关信息,可以在本站进行搜索。
本文标签:




