在本文中,我们将给您介绍关于在sqljoin中使用列而不将其添加到groupby子句的详细内容,并且为您解答sql语句不在某个集合没的相关问题,此外,我们还将为您提供关于GROUPBY子句中的SQLG
在本文中,我们将给您介绍关于在sql join中使用列而不将其添加到group by子句的详细内容,并且为您解答sql语句不在某个集合没的相关问题,此外,我们还将为您提供关于GROUP BY子句中的SQL Geography数据类型列、Left Join 必须出现在 GROUP BY 子句中还是在聚合中使用?、mysql 函数之与GROUP BY子句同时使用的函数、Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句的知识。
本文目录一览:- 在sql join中使用列而不将其添加到group by子句(sql语句不在某个集合没)
- GROUP BY子句中的SQL Geography数据类型列
- Left Join 必须出现在 GROUP BY 子句中还是在聚合中使用?
- mysql 函数之与GROUP BY子句同时使用的函数
- Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句
")
在sql join中使用列而不将其添加到group by子句(sql语句不在某个集合没)
我的实际表结构要复杂得多,但是下面是两个简化的表定义:
桌子 invoice
CREATE TABLE invoice ( id integer NOT NULL, create_datetime timestamp with time zone NOT NULL, total numeric(22,10) NOT NULL);id create_datetime total ----------------------------100 2014-05-08 1000桌子 payment_invoice
CREATE TABLE payment_invoice ( invoice_id integer, amount numeric(22,10));invoice_id amount-------------------100 100100 200100 150我想通过连接上述2个表来选择数据,并且所选数据应如下所示:-
month total_invoice_count outstanding_balance05/2014 1 550我正在使用的查询:
selectto_char(date_trunc(''month'', i.create_datetime), ''MM/YYYY'') as month,count(i.id) as total_invoice_count,(sum(i.total) - sum(pi.amount)) as outstanding_balancefrom invoice ijoin payment_invoice pi on i.id=pi.invoice_idgroup by date_trunc(''month'', i.create_datetime)order by date_trunc(''month'', i.create_datetime);上面的查询给我错误的结果作为sum(i.total) - sum(pi.amount)回报(1000 + 1000 + 1000)-(100 + 200
+ 150)= 2550 。
我希望它返回(1000)-(100 + 200 + 150)= 550
而且我无法将其更改为i.total - sum(pi.amount),因为这样我被迫将i.total列添加到group by子句中,而我不想这样做。
答案1
小编典典每个发票只需要一行,因此payment_invoice请先汇总-最好在加入之前。
选择整个表格后,通常最先进行汇总然后再_进行合并 的最快方法是:
SELECT to_char(date_trunc(''month'', i.create_datetime), ''MM/YYYY'') AS month , count(*) AS total_invoice_count , (sum(i.total) - COALESCE(sum(pi.paid), 0)) AS outstanding_balanceFROM invoice iLEFT JOIN ( SELECT invoice_id AS id, sum(amount) AS paid FROM payment_invoice pi GROUP BY 1 ) pi USING (id)GROUP BY date_trunc(''month'', i.create_datetime)ORDER BY date_trunc(''month'', i.create_datetime);LEFT JOIN
在这里至关重要。您不希望丢失payment_invoice尚未在其中存在相应行的发票,而这会在Plain上发生JOIN。
相应地,将其COALESCE()用于付款总和,该总和可能为NULL。
SQL Fiddle 具有改进的测试用例。

GROUP BY子句中的SQL Geography数据类型列
我正在使用SQL Server并创建一个脚本,该脚本将从我的数据库中获取工作人员的地理位置。该脚本如下。
SELECT w.display_name, w.geo_locationFROM jobs j WITH(NOLOCK)INNER JOIN workers w WITH(NOLOCK) ON w.worker_id = j.worker_idWHERE .....问题是我要添加GROUP BY w.display_name, w.geo_location到脚本,因为显示了重复的记录。向group
by子句添加数据类型为geography的列会导致引发错误。
当我添加此错误时抛出的错误是:
类型“地理”是不可比较的。不能在GROUP BY子句中使用它。
有没有解决的办法?我无法转换w.geo_location为VARCHAR地理位置数据类型所需的。
答案1
小编典典您可以使用row_number()类似这样的东西。
declare @g geography;set @g = geography::STGeomFromText(''LINESTRING(-122.360 47.656, -122.343 47.656)'', 4326);declare @T table(display_name varchar(10), geo_location geography)insert into @T values (''1'', @g)insert into @T values (''1'', @g)insert into @T values (''1'', @g)insert into @T values (''2'', @g)insert into @T values (''2'', @g)select display_name, geo_locationfrom ( select *, row_number() over(partition by display_name, geo_location.ToString() order by (select 0)) as rn from @T ) as Twhere rn = 1结果:
display_name geo_location------------ --------------------------------------------------------------------------------1 0xE610000001148716D9CEF7D34740D7A3703D0A975EC08716D9CEF7D34740CBA145B6F3955EC02 0xE610000001148716D9CEF7D34740D7A3703D0A975EC08716D9CEF7D34740CBA145B6F3955EC0
Left Join 必须出现在 GROUP BY 子句中还是在聚合中使用?
如何解决Left Join 必须出现在 GROUP BY 子句中还是在聚合中使用??
我刚开始使用 sql,所以我认为这可能是一个简单的问题。我正在尝试使用 2 个不同的子查询创建查询。输出应该是来自 1 个子查询的一列、来自另一个子查询的 1 列和作为其他 2 列之间的操作的第三列。
前 2 个 subs 工作正常,但是当我尝试加入它们时,出现以下错误
“运行查询时出错:列“r.revenue”必须出现在 GROUP BY 子句中或用于聚合函数 LINE 17:,r.revenue ^”
with d as (
select date_trunc(''month'',created_date - interval ''3 hour'') as month,sum(amount_foreign) filter (where type in (''OUTBOUND_FOREX'',''OUTBOUND_INVESTMENTS'',''INBOUND_FOREX'',''INBOUND_INVESTMENTS'')) as Remitted_Volume
from remittance.transfers t
where status = ''COMPLETED''
group by 1
),r as (
select date_trunc(''month'',event_date - interval ''3 hour'') as month,sum(report.all_customer_revenues.net_value) as revenue
from report.all_customer_revenues
where bu = ''REMIT''
GROUP BY 1
order by month
)
select d.remitted_volume,r.revenue,sum(r.revenue/d.Remitted_Volume)*100 as avg_spread,r.month
from d
left join r
on r.month = d.month
group by 1
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

mysql 函数之与GROUP BY子句同时使用的函数
本章论述了用于一组数值操作的 group (集合)函数。除非另作说明, group 函数会忽略 null 值。
假如你在一个不包含 ROUP BY子句的语句中使用一个 group函数 ,它相当于对所有行进行分组。
AVG([DISTINCT] expr)
返回expr 的平均值。 DISTINCT 选项可用于返回 expr的不同值的平均值。
若找不到匹配的行,则AVG()返回 NULL 。
mysql> SELECT student_name, AVG(test_score) -> FROM student -> GROUP BY student_name;
BIT_AND(expr)
返回expr中所有比特的 bitwise AND 。计算执行的精确度为64比特(BIGINT) 。
若找不到匹配的行,则这个函数返回 18446744073709551615 。(这是无符号 BIGINT 值,所有比特被设置为 1)。
BIT_OR(expr)
返回expr 中所有比特的bitwise OR。计算执行的精确度为64比特(BIGINT) 。
若找不到匹配的行,则函数返回 0 。
BIT_XOR(expr)
返回expr 中所有比特的bitwise XOR。计算执行的精确度为64比特(BIGINT) 。
若找不到匹配的行,则函数返回 0 。
COUNT(expr)
返回SELECT语句检索到的行中非NULL值的数目。
若找不到匹配的行,则COUNT() 返回 0 。
mysql> SELECT student.student_name,COUNT(*)-> FROM student,course-> WHERE student.student_id=course.student_id-> GROUP BY student_name;
COUNT(*) 的稍微不同之处在于,它返回检索行的数目, 不论其是否包含 NULL值。
SELECT 从一个表中检索,而不检索其它的列,并且没有 WHERE子句时, COUNT(*)被优化到最快的返回速度。例如:
mysql> SELECT COUNT(*) FROM student;
这个优化仅适用于 MyISAM表, 原因是这些表类型会储存一个函数返回记录的精确数量,而且非常容易访问。对于事务型的存储引擎(InnoDB, BDB), 存储一个精确行数的问题比较多,原因是可能会发生多重事物处理, 而每个都可能会对行数产生影响。
COUNT(DISTINCT expr,[expr...])
返回不同的非NULL值数目。
若找不到匹配的项,则COUNT(DISTINCT)返回 0 。
mysql> SELECT COUNT(DISTINCT results) FROM student;
在MySQL中, 你通过给定一个表达式列表而获取不包含NULL 不同表达式组合的数目。在标准 SQL中,你将必须在COUNT(DISTINCT ...)中连接所有表达式。
GROUP_CONCAT(expr)
该函数返回带有来自一个组的连接的非NULL值的字符串结果。其完整的语法如下所示:
GROUP_CONCAT([DISTINCT] expr [,expr ...]
[ORDER BY {unsigned_integer | col_name | expr}
[ASC | DESC] [,col_name ...]]
[SEPARATOR str_val])
mysql> SELECT student_name,-> GROUP_CONCAT(test_score)-> FROM student-> GROUP BY student_name;
Or:
mysql> SELECT student_name,-> GROUP_CONCAT(DISTINCT test_score-> ORDER BY test_score DESC SEPARATOR ' ')-> FROM student-> GROUP BY student_name;在MySQL中,你可以获取表达式组合的连接值。你可以使用DISTINCT删去重复值。假若你希望多结果值进行排序,则应该使用 ORDER BY子句。若要按相反顺序排列,将 DESC (递减) 关键词添加到你要用ORDER BY 子句进行排序的列名称中。默认顺序为升序;可使用ASC将其明确指定。 SEPARATOR 后面跟随应该被插入结果的值中间的字符串值。默认为逗号 (‘,’)。通过指定SEPARATOR '''' ,你可以删除所有分隔符。
使用group_concat_max_len系统变量,你可以设置允许的最大长度。 程序中进行这项操作的语法如下,其中 val 是一个无符号整数:
SET [SESSION | GLOBAL] group_concat_max_len = val;
若已经设置了最大长度, 则结果被截至这个最大长度。
MIN([DISTINCT] expr), MAX([DISTINCT] expr)
返回expr 的最小值和最大值。 MIN() 和 MAX() 的取值可以是一个字符串参数;在这些情况下, 它们返回最小或最大字符串值。DISTINCT关键词可以被用来查找expr 的不同值的最小或最大值,然而,这产生的结果与省略DISTINCT 的结果相同。
若找不到匹配的行,MIN()和MAX()返回 NULL 。
mysql> SELECT student_name, MIN(test_score), MAX(test_score)-> FROM student-> GROUP BY student_name;
对于MIN()、 MAX()和其它集合函数, MySQL当前按照它们的字符串值而非字符串在集合中的相关位置比较 ENUM和SET 列。这同ORDER BY比较二者的方式有所不同。这一点应该在MySQL的未来版本中得到改善。
STD(expr) STDDEV(expr)
返回expr 的总体标准偏差。这是标准 SQL 的延伸。这个函数的STDDEV() 形式用来提供和Oracle 的兼容性。可使用标准SQL函数 STDDEV_POP() 进行代替。
若找不到匹配的行,则这些函数返回 NULL 。
STDDEV_POP(expr)
返回expr 的总体标准偏差(VAR_POP()的平方根)。你也可以使用 STD() 或STDDEV(), 它们具有相同的意义,然而不是标准的 SQL。
若找不到匹配的行,则STDDEV_POP()返回 NULL。
STDDEV_SAMP(expr)
返回expr 的样本标准差 ( VAR_SAMP()的平方根)。
若找不到匹配的行,则STDDEV_SAMP() 返回 NULL 。
SUM([DISTINCT] expr)
返回expr 的总数。 若返回集合中无任何行,则 SUM() 返回NULL。DISTINCT 关键词可用于 MySQL 5.1 中,求得expr不同值的总和。
若找不到匹配的行,则SUM()返回 NULL。
VAR_POP(expr)
返回expr 总体标准方差。它将行视为总体,而不是一个样本, 所以它将行数作为分母。你也可以使用 VARIANCE(),它具有相同的意义然而不是 标准的 SQL。
若找不到匹配的项,则VAR_POP()返回NULL。
VAR_SAMP(expr)
返回expr 的样本方差。更确切的说,分母的数字是行数减去1。
若找不到匹配的行,则VAR_SAMP()返回NULL。
VARIANCE(expr)
返回expr 的总体标准方差。这是标准SQL 的延伸。可使用标准SQL 函数 VAR_POP() 进行代替。
若找不到匹配的项,则VARIANCE()返回NULL。
2. GROUP BY修改程序
GROUP BY子句允许一个将额外行添加到简略输出端 WITH ROLLUP 修饰符。这些行代表高层(或高聚集)简略操作。ROLLUP 因而允许你在多层分析的角度回答有关问询的问题。例如,它可以用来向OLAP (联机分析处理) 操作提供支持。
设想一个名为sales 的表具有年份、国家、产品及记录销售利润的利润列:
CREATE TABLE sales
(
year INT NOT NULL,
country VARCHAR(20) NOT NULL,
product VARCHAR(32) NOT NULL,
profit INT
);可以使用这样的简单GROUP BY,每年对表的内容做一次总结:
mysql> SELECT year, SUM(profit) FROM sales GROUP BY year;+------+-------------+ | year | SUM(profit) | +------+-------------+ | 2000 | 4525 | | 2001 | 3010 | +------+-------------+
这个输出结果显示了每年的总利润, 但如果你也想确定所有年份的总利润,你必须自己累加每年的单个值或运行一个加法询问。
或者你可以使用 ROLLUP, 它能用一个问询提供双层分析。将一个 WITH ROLLUP修饰符添加到GROUP BY 语句,使询问产生另一行结果,该行显示了所有年份的总价值:
mysql> SELECT year, SUM(profit) FROM sales GROUP BY year WITH ROLLUP;+------+-------------+ | year | SUM(profit) | +------+-------------+ | 2000 | 4525 | | 2001 | 3010 | | NULL | 7535 | +------+-------------+
总计高聚集行被年份列中的NULL值标出。
当有多重 GROUP BY 列时,ROLLUP产生的效果更加复杂。这时,每次在除了最后一个分类列之外的任何列出现一个 “break” (值的改变) ,则问讯会产生一个高聚集累计行。
例如,在没有 ROLLUP的情况下,一个以年、国家和产品为基础的关于 sales 表的一览表可能如下所示:
mysql> SELECT year, country, product, SUM(profit)-> FROM sales-> GROUP BY year, country, product;+------+---------+------------+-------------+ | year | country | product | SUM(profit) | +------+---------+------------+-------------+ | 2000 | Finland | Computer | 1500 | | 2000 | Finland | Phone | 100 | | 2000 | India | Calculator | 150 | | 2000 | India | Computer | 1200 | | 2000 | USA | Calculator | 75 | | 2000 | USA | Computer | 1500 | | 2001 | Finland | Phone | 10 | | 2001 | USA | Calculator | 50 | | 2001 | USA | Computer | 2700 | | 2001 | USA | TV | 250 | +------+---------+------------+-------------+
表示总值的输出结果仅位于年/国家/产品的分析级别。当添加了 ROLLUP后, 问询会产生一些额外的行:
mysql> SELECT year, country, product, SUM(profit)
-> FROM sales
-> GROUP BY year, country, product WITH ROLLUP;+------+---------+------------+-------------+
| year | country | product | SUM(profit) |
+------+---------+------------+-------------+
| 2000 | Finland | Computer | 1500 |
| 2000 | Finland | Phone | 100 |
| 2000 | Finland | NULL | 1600 |
| 2000 | India | Calculator | 150 |
| 2000 | India | Computer | 1200 |
| 2000 | India | NULL | 1350 |
| 2000 | USA | Calculator | 75 |
| 2000 | USA | Computer | 1500 |
| 2000 | USA | NULL | 1575 |
| 2000 | NULL | NULL | 4525 |
| 2001 | Finland | Phone | 10 |
| 2001 | Finland | NULL | 10 |
| 2001 | USA | Calculator | 50 |
| 2001 | USA | Computer | 2700 |
| 2001 | USA | TV | 250 |
| 2001 | USA | NULL | 3000 |
| 2001 | NULL | NULL | 3010 |
| NULL | NULL | NULL | 7535 |
+------+---------+------------+-------------+对于这个问询, 添加ROLLUP 子句使村输出结果包含了四层分析的简略信息,而不只是一个下面是怎样解释 ROLLUP输出:
一组给定的年份和国家的每组产品行后面, 会产生一个额外的总计行, 显示所有产品的总值。这些行将产品列设置为 NULL。
一组给定年份的行后面,会产生一个额外的总计行,显示所有国家和产品的总值。这些行将国家和产品列设置为 NULL。
最后, 在所有其它行后面,会产生一个额外的总计列,显示所有年份、国家及产品的总值。 这一行将年份、国家和产品列设置为 NULL。
使用ROLLUP 时的其它注意事项
以下各项列出了一些MySQL执行ROLLUP的特殊状态:
当你使用 ROLLUP时, 你不能同时使用 ORDER BY子句进行结果排序。换言之, ROLLUP 和ORDER BY 是互相排斥的。然而,你仍可以对排序进行一些控制。在 MySQL中, GROUP BY 可以对结果进行排序,而且你可以在GROUP BY列表指定的列中使用明确的 ASC和DESC关键词,从而对个别列进行排序。 (不论如何排序被ROLLUP添加的较高级别的总计行仍出现在它们被计算出的行后面)。
LIMIT可用来限制返回客户端的行数。LIMIT 用在 ROLLUP后面, 因此这个限制 会取消被ROLLUP添加的行。例如:
mysql> SELECT year, country, product, SUM(profit)
-> FROM sales
-> GROUP BY year, country, product WITH ROLLUP
-> LIMIT 5;+------+---------+------------+-------------+
| year | country | product | SUM(profit) |
+------+---------+------------+-------------+
| 2000 | Finland | Computer | 1500 |
| 2000 | Finland | Phone | 100 |
| 2000 | Finland | NULL | 1600 |
| 2000 | India | Calculator | 150 |
| 2000 | India | Computer | 1200 |
+------+---------+------------+-------------+将ROLLUP同 LIMIT一起使用可能会产生更加难以解释的结果,原因是对于理解高聚集行,你所掌握的上下文较少。
在每个高聚集行中的NULL 指示符会在该行被送至客户端时产生。服务器会查看最左边的改变值后面的GROUP BY子句指定的列。对于任何结果集合中的,有一个词匹配这些名字的列, 其值被设为 NULL。(若你使用列数字指定了分组列,则服务器会通过数字确定将哪个列设置为 NULL)。
由于在高聚集行中的 NULL值在问询处理阶段被放入结果集合中,你无法将它们在问询本身中作为NULL值检验。例如,你无法将 HAVING product IS NULL 添加到问询中,从而在输出结果中删去除了高聚集行以外的部分。
另一方面, NULL值在客户端不以 NULL 的形式出现, 因而可以使用任何MySQL客户端编程接口进行检验。
3. 具有隐含字段的GROUP BY
MySQL 扩展了 GROUP BY的用途,因此你可以使用SELECT 列表中不出现在GROUP BY语句中的列或运算。这代表 “对该组的任何可能值 ”。你可以通过避免排序和对不必要项分组的办法得到它更好的性能。例如,在下列问询中,你无须对customer.name 进行分组:
mysql> SELECT order.custid, customer.name, MAX(payments)
-> FROM order,customer
-> WHERE order.custid = customer.custid
-> GROUP BY order.custid;在标准SQL中, 你必须将 customer.name添加到 GROUP BY子句中。在MySQL中, 假如你不在ANSI模式中运行,则这个名字就是多余的。
假如你从 GROUP BY 部分省略的列在该组中不是唯一的,那么不要使用这个功能! 你会得到非预测性结果。
在有些情况下,你可以使用MIN()和MAX() 获取一个特殊的列值,即使他不是唯一的。下面给出了来自包含排序列中最小值的列中的值:
SUBSTR(MIN(CONCAT(RPAD(sort,6,'' ''),column)),7)
注意,假如你正在尝试遵循标准 SQL, 你不能使用GROUP BY或 ORDER BY子句中的表达式。你可以通过使用表达式的别名绕过这一限制:
mysql> SELECT id,FLOOR(value/100) AS val
-> FROM tbl_name
-> GROUP BY id, val ORDER BY val;然而, MySQL允许你使用GROUP BY 及 ORDER BY 子句中的表达式。例如:

Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句
Mysql的各个查询语句
一、where子句
语法:select *|字段列表 from 表名 where 表达式。where子句后面往往配合MySQL运算符一起使用(做条件判断)
作用:通过限定的表达式的条件对数据进行过滤,得到我们想要的结果。
1.MYSQL运算符:
MySQL支持以下的运算符:
关系运算符
< >
<= >=
= !=(<>)
注意:这里的等于是一个等号
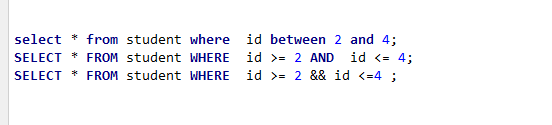
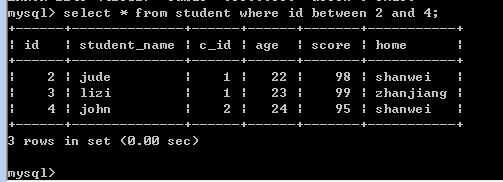
between and
做数值范围限定,相当于数学上的闭区间!
比如:
between A and B相当于 [A,B]
in和not in
语法形式:in|not in(集合)
表示某个值出现或没出现在一个集合之中!

逻辑运算符
&& and
|| or
! not

where子句的其他形式
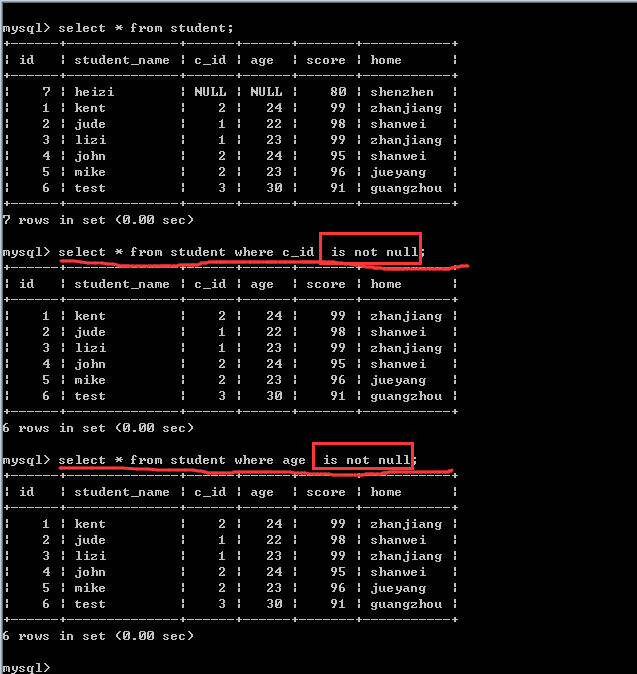
空值查询
select *|字段列表 from 表名 where 字段名 is [not] null
模糊查询
也就是带有like关键字的查询,常见的语法形式是:
select *|字段列表from 表名 where 字段名 [not] like ‘通配符字符串’;
所谓的通配符字符串,就是含有通配符的字符串!
MySQL中的通配符有两个:
_ :代表任意的单个字符
% :代表任意的字符
案例一:
查找student表中student_name字段以“j”开头的学生信息!

案例二:
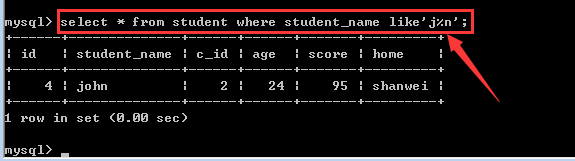
查找student表中student_name字段以“j”开头以“n”结尾的学生信息!
案例三:
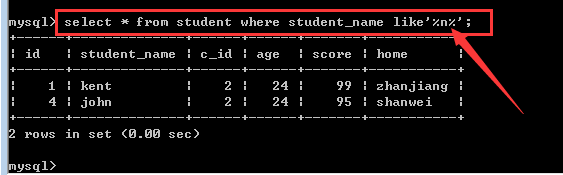
查找student表中student_name字段含有“n”字的学生信息
案例四:
查找student表中student_name以“j”开头含有四个字母的名字的学生信息

案例五:
查找student表中stu_name含有_或含有%的学生信息
由于%和_都具有特殊的含义,所以如果确实想查询某个字段中含有%或_的记录,需要对它们进行转义!
也就是查找 \_ 和 \%

二、group by子句
也叫作分组统计查询语句!
语法
group by 字段1[,字段2]……
从形式上看,就是通过表内的某个或某些字段进行分组:
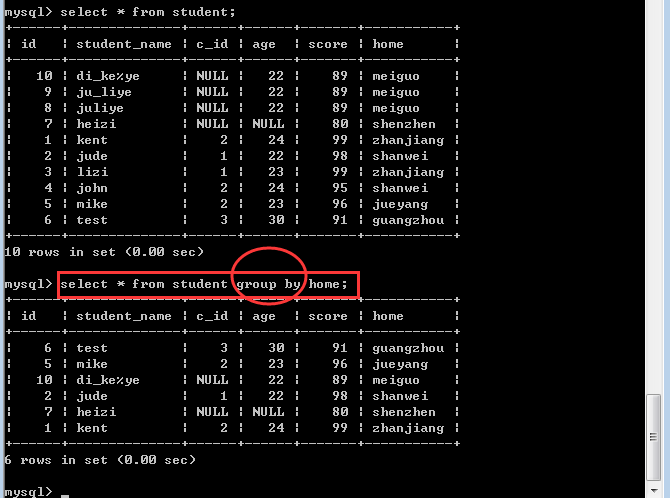
所以,分组之后,只会从每一个组内取出第一条记录,这种查询结果毫无意义!
因为分组统计查询的主要作用不是分组,而是统计!或者说分组的目的就是针对每一个分组进行相关的统计!
此时,就需要使用系统中的一些统计函数!
统计函数(聚合函数)
sum():求和,就是将某个分组内的某个字段的值全部相加

等于做了以前的两件事情:
1, 先按home字段对整个的表进行分组!(分成了4组)
2, 再把每一个组内的所有记录的age字段的值全部相加

max():求某个组内某个字段的最大值
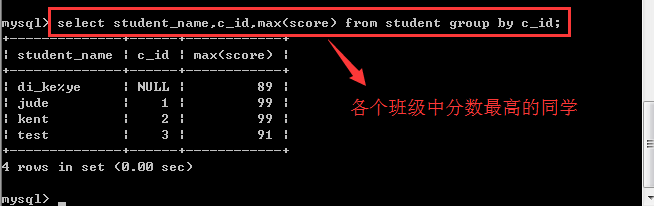
min():求某个组内某个字段的最小值

avg():求某个组内某个字段的平均值
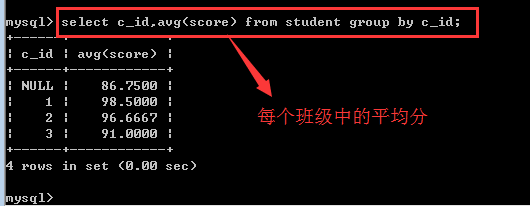
count():统计某个组内非null记录的个数,通常就是用count(*)来表示!


注意:
统计函数都是可以单独的使用的!但是,只要使用统计函数,系统默认的就是需要分组,如果没有group by子句,默认的就是把整个表中的数据当成一组!
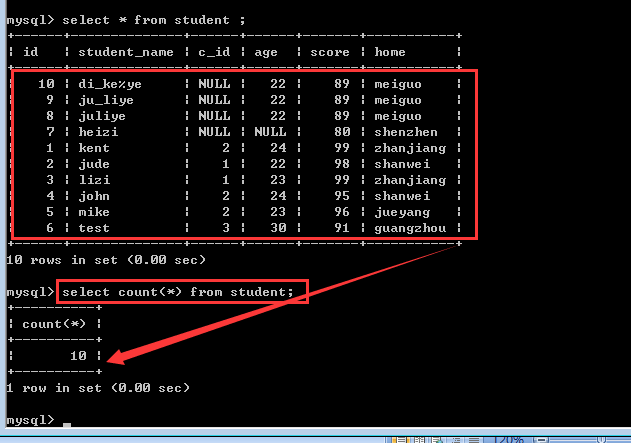
多字段分组
group by 字段1[,字段2]……
作用是:先根据字段1进行分组,然后再根据字段2进行分组!

所以,多字段分组的结果就是分组变多了!
回溯(su)统计
回溯统计就是向上统计!
在进行分组统计的时候,往往需要做上级统计!
比如,先统计各个班的总人数,然后各个班的总人数再相加,就可以得到一个年级的总人数!
再比如,先统计各个班的最高分,然后各个班的最高分再进行比较,就可以得到一个年级的最高分!
如何实现?
答:在MySQL中,其实就是在语句的后面加上with rollup即可!

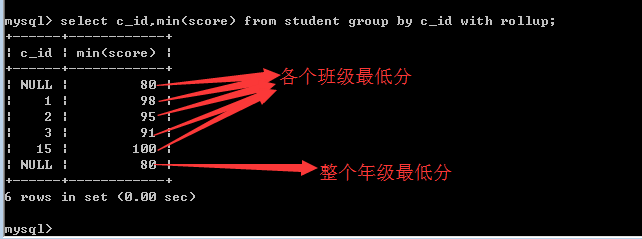

注意:
既然group by子句出现在where子句之后,说明了,我们可以先将整个数据源进行筛选,然后再进行分组统计!
三、having子句
having子句和where子句一样,也是用来筛选数据的,通常是对group by之后的统计结果再次进行筛选!

那么,having子句和where子句到底有什么区别呢?
二者的比较:
1, 如果语句中只有having子句或只有where子句的时候,此时,它们的作用基本是一样的!
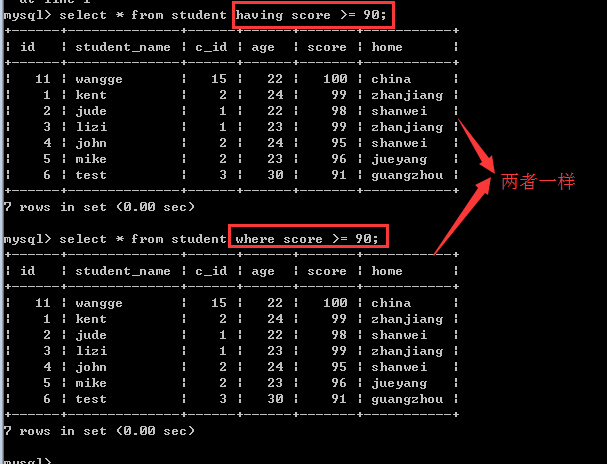
2, 二者的本质区别是:where子句是把磁盘上的数据筛选到内存上,而having子句是把内存中的数据再次进行筛选!
3, where子句的后面不能使用统计函数,而having子句可以!因为只有在内存中的数据才可以进行运算统计!

四、order by子句
语法
根据某个字段进行排序,有升序和降序!
语法形式为:
order by 字段1[asc|desc]
默认的是asc,也就是升序!如果要降序排序,需要加上desc!
①根据id排序

②根据成绩排序
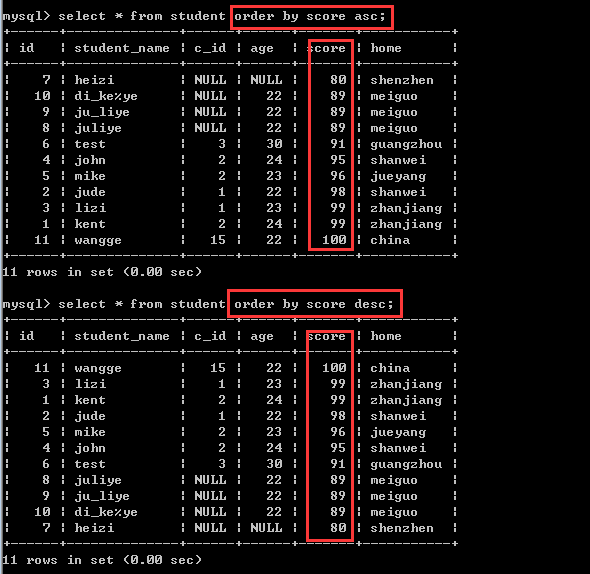
思考:
假如现在有若干个学生的成绩score是一样的,怎么办?
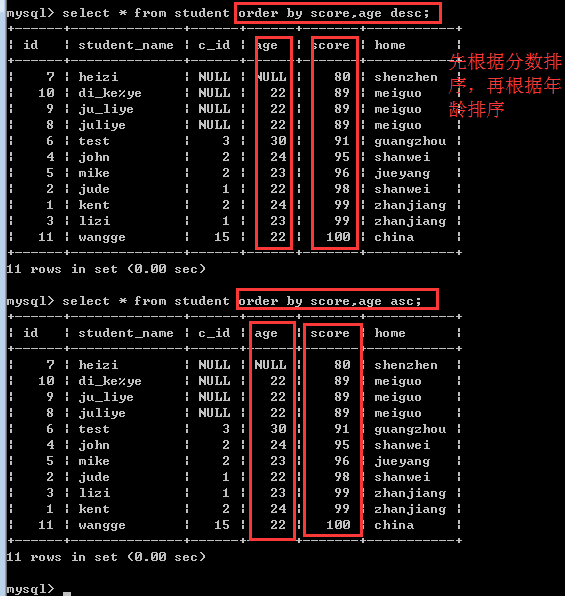
此时,可以使用多字段排序!
多字段排序
order by 字段1[asc|desc],字段2[asc|desc]……
比如:order by score asc,age desc
也就是说,先按分数进行升序排序,如果分数一样的时候,再按年龄进行降序排序!
五、limit子句
limit就是限制的意思,所以,limit子句的作用就是限制查询记录的条数!
语法
limit offset,length
其中,offset是指偏移量,默认为0,而length是指需要显示的记录数!
思考:
limit子句为什么排在最后?
因为前面所有的限制条件都处理完了,只剩下需要显示多少条记录的问题了!
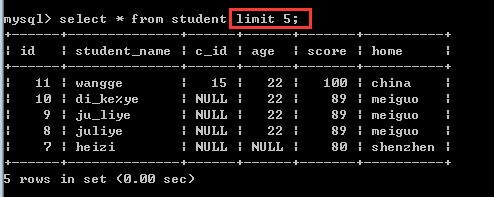
思考:
假如现在想显示记录的第4条到第8条,limit子句应该怎么写?
limit 3,5;

注意:这里的偏移量offset可以省略的!缺省值就代表0!
分页原理
假如在项目中,需要使用分页的效果,就应该使用limit子句!
比如,每页显示10条记录:
第1页:limit 0,10
第2页:limit 10,10
第3页:limit 20,10
如果用$pageNum代表第多少页,用$rowsPerPage代表每页显示的长度
limit ($pageNum - 1)*$rowsPerPage, $rowsPerPage
今天关于在sql join中使用列而不将其添加到group by子句和sql语句不在某个集合没的介绍到此结束,谢谢您的阅读,有关GROUP BY子句中的SQL Geography数据类型列、Left Join 必须出现在 GROUP BY 子句中还是在聚合中使用?、mysql 函数之与GROUP BY子句同时使用的函数、Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句等更多相关知识的信息可以在本站进行查询。
本文标签:




