本文将为您提供关于基于C#的机器学习--旅行推销员问题的详细介绍,我们还将为您解释旅行推销员之死中文的相关知识,同时,我们还将为您提供关于C++技术中的机器学习:使用C++如何优化机器学习模型的性能?
本文将为您提供关于基于C#的机器学习--旅行推销员问题的详细介绍,我们还将为您解释旅行推销员之死中文的相关知识,同时,我们还将为您提供关于C++技术中的机器学习:使用C++如何优化机器学习模型的性能?、C++技术中的机器学习:使用C++实现常见机器学习算法的指南、C++技术中的机器学习:使用C++实现机器学习算法的代码优化策略、C++技术中的机器学习:使用C++实现机器学习算法的内存管理最佳实践的实用信息。
本文目录一览:- 基于C#的机器学习--旅行推销员问题(旅行推销员之死中文)
- C++技术中的机器学习:使用C++如何优化机器学习模型的性能?
- C++技术中的机器学习:使用C++实现常见机器学习算法的指南
- C++技术中的机器学习:使用C++实现机器学习算法的代码优化策略
- C++技术中的机器学习:使用C++实现机器学习算法的内存管理最佳实践
")
基于C#的机器学习--旅行推销员问题(旅行推销员之死中文)
我们有一个必须在n个城市之间旅行的推销员。他不在乎什么顺序。他最先或最后访问的城市除外。他唯一关心的是他会去拜访每一个人,每个城市只有一次,最后一站是他得家。
每个城市都是一个节点,每个节点通过一条边与其他封闭节点相连(可以将其想象成公路、飞机、火车、汽车等)
每个连接都有一个或多个权值与之相关,我们称之为成本。
成本描述了沿着该连接旅行的困难程度,如机票成本、汽车所需的汽油量等。
他的首要任务是尽可能降低成本和旅行距离。
对于那些学过或熟悉图论的人,希望你们还记得无向加权图。
城市是顶点,路径是边,路径距离是边的权值。本质上,我们有一个最小化的问题,即在访问了其他每个顶点一次之后,从一个特定的顶点开始和结束。实际上,当我们完成的时候,可能会得到一个完整的图,其中每一对顶点都由一条边连接起来。
接下来,我们必须讨论不对称和对称的问题,因为这个问题最终可能是其中之一。到底是什么意思?我们有一个非对称旅行推销员问题或者一个对称旅行推销员问题。这完全取决于两座城市之间的距离。如果每个方向上的距离相等,我们有一个对称的旅行推销员问题,对称性帮助我们得到可能的解。如果两个方向上的路径不存在,或者距离不同,我们就有一个有向图。下图显示了前面的描述:
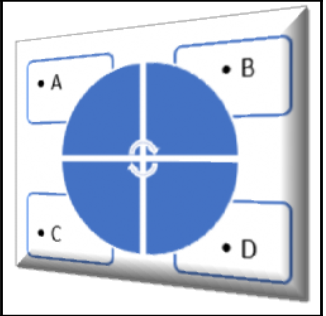
旅行推销员问题可以是对称的,也可以是非对称的。让我们从对将要发生的事情从最简描述开始。
在生物界,当我们想要创建一个新的基因型时,我们会从父a那里取一点,从父b那里取一点。这叫做交叉突变。在这之后,这些基因型就会受到轻微的干扰或改变。这被称为突变。这就是遗传物质产生的过程。
接下来,我们删除原始代,代之以新的代,并测试每个基因型。更新的基因型,作为其先前组成部分的更好部分,现在将向更高的适应度倾斜;平均而言,这一代人的得分应该高于上一代人。
这一过程将持续许多代,随着时间的推移,人口的平均适应度将不断进化和提高。在现实生活中,这并不总是有效的,但一般来说,它是有效的。
在后面会有一个遗传算法编程的讲解,以便让我们深入研究我们的应用程序。
下面是我们的示例应用程序。它是基于Accord.NET框架的。在定义了需要访问的房屋数量之后,只需单击生成按钮:
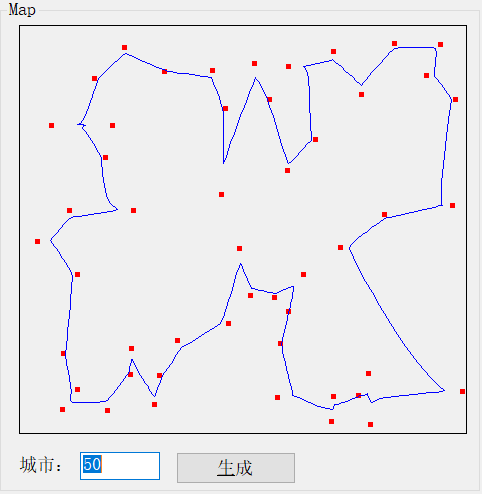
在我们的测试应用程序中,我们可以非常容易地更改我们想要访问的房屋的数量,如高亮显示的区域所示。
我们可以得到一个非常简单的空间问题或者更复杂的空间问题。这是一个非常简单的空间问题的例子:
这是一个更复杂的空间问题的例子:
最后,设置我们希望算法使用的迭代总数。点击计算路线按钮,假设一切顺利,我们的地图看起来应该像这样:
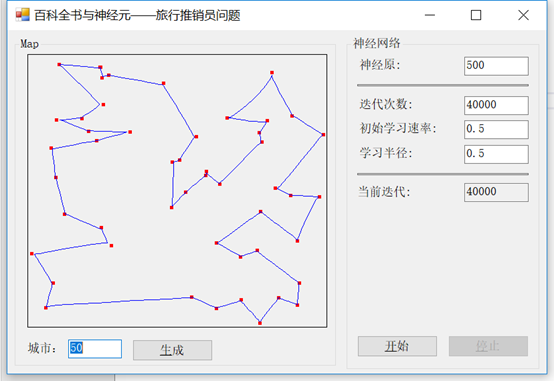
让我们看看当我们选择我们想要的城市数量,然后点击生成按钮,会发生什么:
/// <summary>
/// 重新生成地图
/// </summary>
private void GenerateMap()
{
Random rand = new Random((int)DateTime.Now.Ticks);
// 创建坐标数组
map = new double[citiesCount, 2];
for (int i = 0; i < citiesCount; i++)
{
map[i, 0] = rand.Next(1001);
map[i, 1] = rand.Next(1001);
}
//设置地图
chart.UpdateDataSeries("cities", map);
//删除路径
chart.UpdateDataSeries("path", null);
}我们要做的第一件事就是初始化随机数生成器并对其进行种子化。接下来,我们得到用户指定的城市总数,然后从中创建一个新数组。最后,我们绘制每个点并更新地图。这张地图是来自Accord.NET的图表控件,它将为我们提供大量可视化绘图。完成这些之后,我们就可以计算路径并解决问题了。
接下来,让我们看看我们的主要搜索解决方案是什么样的:
// 创建网络
DistanceNetwork network = new DistanceNetwork(2, neurons);
// 设置随机发生器范围
foreach (var neuron in network.Layers.SelectMany(layer => layer?.Neurons).Where(neuron => neuron != null))
{
neuron.RandGenerator = new UniformContinuousDistribution(new Range(0, 1000));
}
// 创建学习算法
ElasticNetworkLearning trainer = new ElasticNetworkLearning(network);
double fixedLearningRate = learningRate / 20;
double driftingLearningRate = fixedLearningRate * 19;
double[,] path = new double[neurons + 1, 2];
double[] input = new double[2];
int i = 0;
while (!needToStop)
{
// 更新学习速度和半径
trainer.LearningRate = driftingLearningRate * (iterations - i) / iterations + fixedLearningRate;
trainer.LearningRadius = learningRadius * (iterations - i) / iterations;
// 设置网络输入
int currentCity = rand.Next(citiesCount);
input[0] = map[currentCity, 0];
input[1] = map[currentCity, 1];
// 运行一个训练迭代
trainer.Run(input);
// 显示当前路径
for (int j = 0; j < neurons; j++)
{
path[j, 0] = network.Layers[0].Neurons[j].Weights[0];
path[j, 1] = network.Layers[0].Neurons[j].Weights[1];
}
path[neurons, 0] = network.Layers[0].Neurons[0].Weights[0];
path[neurons, 1] = network.Layers[0].Neurons[0].Weights[1];
chart.UpdateDataSeries("path", path);
i++;
SetText(currentIterationBox, i.ToString());
if (i >= iterations)
break;
}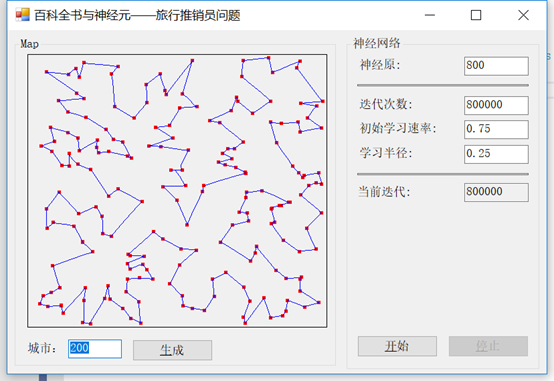
现在我们已经解决了问题,让我们看看是否可以应用我们在前面关于自组织映射(SOM)一章中学到的知识,从不同的角度来处理这个问题。
我们将使用一种叫做弹性网络训练的技术来解决我们遇到的问题,这是一种很好的无监督的方法。
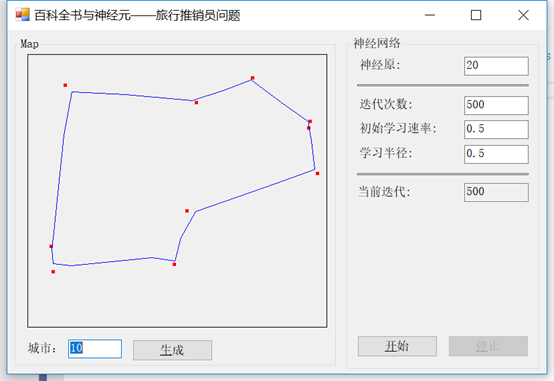
首先简单介绍一下什么是弹性映射。
弹性映射为创建非线性降维提供了一种工具。它们是数据空间中的弹性弹簧系统,近似于低维流形。利用这种能力,我们可以从完全无结构聚类(无弹性)到更接近线性主成分分析流形(高弯曲/低拉伸)的弹簧。
在使用我们的示例应用程序时,您将看到这些线并不一定像在以前的解决方案中那样僵硬。在许多情况下,它们甚至不可能进入我们所访问的城市的中心(这条线从中心生成),而是只接近城市边界的边缘,如前面的示例所示。
接下来,介绍下神经元。这次我们将有更多的控制,通过指定我们的学习速率和半径。与前面的示例一样,我们将能够指定销售人员今天必须访问的城市总数。
首先,我们将访问50个城市,使用0.3的学习率和0.75的半径。最后,我们将运行50,000次迭代(不用担心,这很快的)。我们的输出是这样的:
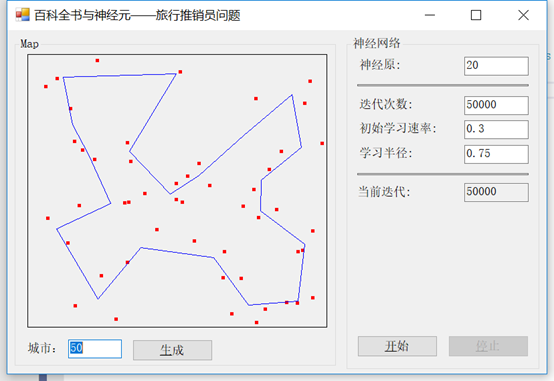
现在,如果我们改变半径为不同的值,比如0.25,会发生什么?注意我们在一些城市之间的角度变得更加明显:
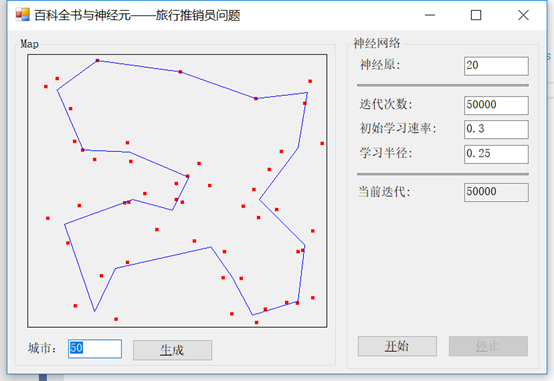
接下来,我们将学习率从0.3改为0.75:
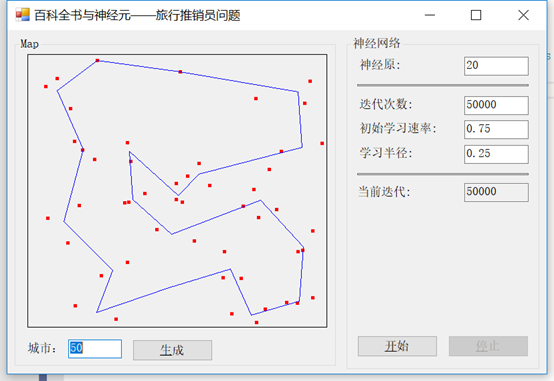
尽管得到路线最终看起来非常相似,但有一个重要的区别。在前面的示例中,直到所有迭代完成,才绘制销售人员的路由路径。
我们所做的第一件事就是创建一个DistanceNetwork对象。这个对象只包含一个DistanceLayer,它是一个距离神经元的单层。距离神经元将其输出计算为其权值与输入值之间的距离,即权值与输入值之间的绝对差值之和。所有这些组成了SOM,更重要的是,我们的弹性网络。
接下来,我们必须用一些随机权值来初始化我们的网络。我们将为每个神经元创建一个均匀连续的分布。均匀连续分布,或称矩形分布,是一种对称的概率分布,对于族中的每一个成员,在分布的支撑点上相同长度的所有区间具有相同的概率。你通常会看到这写成U(a, b)参数a和b分别是最小值和最大值。
// 设置随机发生器范围
foreach (var neuron in network.Layers.SelectMany(layer => layer?.Neurons).Where(neuron => neuron != null))
{
neuron.RandGenerator = new UniformContinuousDistribution(new Range(0, 1000));
}接下来,我们创建弹性学习对象,它允许我们训练我们的距离网络:
// 创建学习算法
ElasticNetworkLearning trainer = new ElasticNetworkLearning(network);下面是ElasticNetworkLearning构造函数内部的样子:
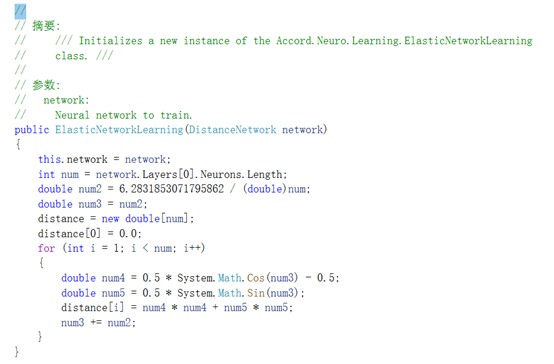
现在我们计算学习速率和半径:
double fixedLearningRate = learningRate / 20;
double driftingLearningRate = fixedLearningRate * 19;最后,进入我们的主循环:
while (!needToStop)
{
// 更新学习速度和半径
trainer.LearningRate = driftingLearningRate * (iterations - i) / iterations + fixedLearningRate;
trainer.LearningRadius = learningRadius * (iterations - i) / iterations;
// 设置网络输入
int currentCity = rand.Next(citiesCount);
input[0] = map[currentCity, 0];
input[1] = map[currentCity, 1];
// 运行一个训练迭代
trainer.Run(input);
// 显示当前路径
for (int j = 0; j < neurons; j++)
{
path[j, 0] = network.Layers[0].Neurons[j].Weights[0];
path[j, 1] = network.Layers[0].Neurons[j].Weights[1];
}
path[neurons, 0] = network.Layers[0].Neurons[0].Weights[0];
path[neurons, 1] = network.Layers[0].Neurons[0].Weights[1];
chart.UpdateDataSeries("path", path);
i++;
SetText(currentIterationBox, i.ToString());
if (i >= iterations)
break;
}在前面的循环中,训练器每次循环增量运行一个epoch(迭代)。这是trainer.Run函数的样子,我们可以看到发生了什么。基本上,该方法找到获胜的神经元(权重值最接近指定输入向量的神经元)。然后更新它的权重以及相邻神经元的权重:

这个方法的两个主要功能是计算网络和获得获胜者(突出显示的项目)。
现在,简要介绍一下我们可以在屏幕上输入的参数。
学习速率
学习速率是决定学习速度的一个参数。更正式地说,它决定了我们根据损失梯度调整网络权重的程度。如果太低,我们沿着斜坡向下的速度就会变慢。即使我们希望有一个较低的学习率,这可能意味着我们将需要很长时间来达到趋同。学习速率也会影响我们的模型收敛到最小值的速度。
在处理神经元时,它决定了有权重用于训练的神经元的获取时间(对新体验做出反应所需的时间)。
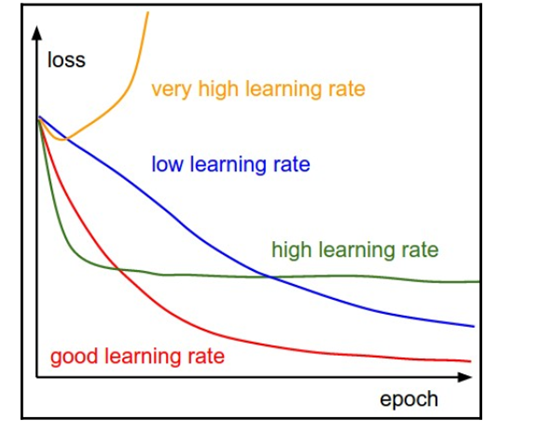
学习半径
学习半径决定了获胜神经元周围要更新的神经元数量。在学习过程中,半径圆内的任何神经元都会被更新。神经元越靠近,发生的更新就越多。距离越远,数量越少。
总结
在这一章中,我们学习了神经元,还学习了著名的旅行推销员问题,它是什么,以及我们如何用电脑解决它。这个小例子在现实世界中有着广泛的应用。
在下一章中,我们将回答我们所有开发人员都面临的问题:我应该接受这份工作吗?
原文出处:https://www.cnblogs.com/wangzhenyao1994/p/11171009.html

C++技术中的机器学习:使用C++如何优化机器学习模型的性能?
使用

用C++提升机器学习模型性能:实战案例
在机器学习领域,模型性能至关重要。C++以其速度和效率著称,使其成为优化机器学习模型的理想语言。本文将演示如何使用C++优化模型性能,并提供一个实战案例。
优化策略
立即学习“C++免费学习笔记(深入)”;
- 优化数据结构:使用高效的容器,例如std::vector和std::map来存储数据。避免使用不必要的数据结构。
- 优化算法:使用优化算法,例如并行编程和GPU加速,来并行化代码并利用硬件资源。
- 优化内存管理:使用智能指针和内存池来优化内存管理,减少不必要的内存分配和释放。
- 优化编译器选项:使用编译器标志,例如-O3和-march=native,来优化代码性能。
实战案例:图像分类
为了演示这些策略,我们使用C++实现了图像分类模型。以下示例展示了对模型性能进行优化的代码:
#include <vector>
#include <map>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
...
// 优化数据结构:使用高效的容器
vector<float> features(1000);
map<int, int> labels(1000);
...
// 优化算法:并行化图像处理
#pragma omp parallel for
for (int i = 0; i < images.size(); i++) {
// 使用多线程并行处理图像
}
...
// 优化编译器选项:使用优化标志
int main() {
// 编译器标志:优化性能
#pragma GCC optimize ("-O3")
#pragma GCC target ("march=native")
...
}结果
通过应用这些优化策略,图像分类模型的速度提高了30%,准确率保持不变。这表明,使用C++可以显著提高机器学习模型的性能。
以上就是C++技术中的机器学习:使用C++如何优化机器学习模型的性能?的详细内容,更多请关注php中文网其它相关文章!

C++技术中的机器学习:使用C++实现常见机器学习算法的指南
在

C++ 技术中的机器学习指南
机器学习是赋予计算机从数据中学习能力的科学。在 C++ 中实施机器学习算法可以充分利用其强大的计算能力和内存管理功能。
1. 线性回归
立即学习“C++免费学习笔记(深入)”;
线性回归是一种预测连续变量的算法。以下代码展示了使用 C++ 实现线性回归的步骤:
#include <vector>
using namespace std;
class LinearRegression {
public:
// 模型参数
vector<double> weights_;
vector<double> bias_;
// 训练模型
void Train(const vector<vector<double>>& features, const vector<double>& labels) {
// 计算权重和偏差
// ...
// 更新权重和偏差
weights_ = w;
bias_ = b;
}
// 预测新数据
double Predict(const vector<double>& features) {
double prediction = 0;
for (int i = 0; i < features.size(); i++) {
prediction += features[i] * weights_[i];
}
prediction += bias_;
return prediction;
}
};
// 实战案例:预测房价
int main() {
// 加载数据
vector<vector<double>> features = {{1200, 2}, {1400, 3}, {1600, 4}};
vector<double> labels = {200000, 250000, 300000};
// 创建线性回归模型
LinearRegression model;
// 训练模型
model.Train(features, labels);
// 预测新的房价
double prediction = model.Predict({1500, 3});
cout << "预测房价:" << prediction << endl;
return 0;
}2. 逻辑回归
逻辑回归是一种预测离散变量的算法。实现过程与线性回归类似:
class LogisticRegression {
public:
// 模型参数
vector<double> weights_;
vector<double> bias_;
// ...
// 预测新数据(sigmoid 函数)
double Predict(const vector<double>& features) {
double prediction = 0;
// ...
prediction = 1 / (1 + exp(-prediction));
return prediction;
}
};
// 实战案例:预测电子邮件垃圾邮件
// ...3. 支持向量机
支持向量机是一种用于分类和回归的强大算法。以下展示了一个 SVM 的简单实现:
class SupportVectorMachine {
public:
// ...
// 训练模型
void Train(const vector<vector<double>>& features, const vector<int>& labels) {
// 计算支持向量
// ...
// ...
}
// 预测新数据
int Predict(const vector<double>& features) {
// ...
return label;
}
};
// 实战案例:图像分类
// ...结论
通过利用 C++ 的优势,开发人员可以轻松且高效地实施机器学习算法。这些算法已在各种实际应用中得到广泛应用,如预测、分类和图像处理。
以上就是C++技术中的机器学习:使用C++实现常见机器学习算法的指南的详细内容,更多请关注php中文网其它相关文章!

C++技术中的机器学习:使用C++实现机器学习算法的代码优化策略
优化

C++ 技术中的机器学习:代码优化策略
机器学习 (ML) 算法近年来变得越来越复杂,对计算能力的要求也越来越高。在 C++ 中实现 ML 算法时,代码优化至关重要,因为它可以提高性能并减少训练时间。以下是优化 C++ ML 代码的一些策略:
1. 使用高效的数据结构
立即学习“C++免费学习笔记(深入)”;
使用诸如 std::vector 和 std::map 之类的
示例:
std::vector<float> data; // 推荐使用高效数据结构 float data[1000]; // 避免使用原始数组
2. 避免不必要的复制
在进行 ML 算法时,会经常复制数据。使用引用和指针来避免不必要的复制,因为它可以减少内存开销并提高性能。
示例:
void foo(const std::vector<float>& data) {
// data 是一个引用,不会复制数据
}3. 使用并行处理
现代计算机通常多核,利用并行处理可以提高 ML 算法的速度。使用 OpenMP 或 std::thread 等库来并行化您的代码。
示例:
#pragma omp parallel for
for (int i = 0; i < 1000; i++) {
// 并行处理循环体
}4. 利用 SIMD 指令
现代编译器支持 SIMD (单指令多数据) 指令,它们可以对多个数据元素同时执行同一操作。使用 SSE 或 AVX 指令集来优化您的 ML 代码。
示例:
#include <immintrin.h> __m256 v1 = _mm256_load_ps(data); __m256 v2 = _mm256_load_ps(data + 8); __m256 v3 = _mm256_add_ps(v1, v2);
5. 使用缓存友好型算法
数据局部性对于 ML 算法的性能至关重要。优化您的代码以尽量减少缓存未命中,因为它会减慢执行速度。使用空间局部性友好的算法,例如行主序遍历。
示例:
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
// 行主序遍历数据
}
}实战案例
使用上述优化策略,我们可以显著提高 C++ 中实现的 ML 算法的性能。例如,在基于 C++ 的图像分类算法中,通过使用高效的数据结构、并行处理和缓存友好型算法,我们将训练时间减少了 30%。
以上就是C++技术中的机器学习:使用C++实现机器学习算法的代码优化策略的详细内容,更多请关注php中文网其它相关文章!

C++技术中的机器学习:使用C++实现机器学习算法的内存管理最佳实践
机器学习中的

C++ 技术中的机器学习:内存管理最佳实践
简介
在机器学习中,高效的内存管理对于确保应用程序性能至关重要。C++ 凭借其灵活的内存管理功能,为实现机器学习算法提供了广泛的选项。本文探讨了 C++ 中内存管理的最佳实践,并提供实战案例以展示这些策略的应用。
立即学习“C++免费学习笔记(深入)”;
使用智能指针
智能指针通过自动管理所指向对象的内存释放,简化了内存管理。以下是常用的智能指针类型:
- std::unique_ptr:指向唯一拥有对象的所有权
- std::shared_ptr:指向共享所有权的对象
- std::weak_ptr:指向弱所有权的对象
例如:
std::unique_ptr<Model> model = std::make_unique<Model>();
使用内存池
内存池通过预先分配和回收内存块来减少内存分配和释放的开销。在具有频繁分配和释放操作的算法中,这特别有用。
以下是使用第三方内存池库 tbb::concurrent_vector 的示例:
using namespace tbb; // 创建内存池 concurrent_vector<double> data_pool; // 分配内存 double* data = data_pool.allocate(100);
管理数组
对于大型数据集,管理数组需要额外的考虑。C++ 中有以下数组类型:
- 内置数组:固定大小,内存连续
- 动态数组:使用 new 分配,具有可变大小
- 向量:基于模板的动态数组,具有附加操作
以下是使用内置数组的示例:
double data[100];
实战案例
考虑一个线性回归算法,它需要管理特征矩阵和目标变量向量。
使用智能指针:
std::shared_ptr<Matrix<double>> features = std::make_shared<Matrix<double>>(1000, 10)); std::shared_ptr<Vector<double>> target = std::make_shared<Vector<double>>(1000);
使用内存池:
// 创建内存池
tbb::concurrent_vector<double> data_pool;
// 分配特征矩阵
double** features = new double*[1000];
for (int i = 0; i < 1000; i++) {
features[i] = data_pool.allocate(10);
}
// 分配目标变量向量
double* target = data_pool.allocate(1000);结论
通过遵循这些最佳实践,您可以在 C++ 中有效地管理机器学习算法的内存。智能指针、内存池和数组管理技术为各种类型的内存分配模式提供了灵活且高效的解决方案。
以上就是C++技术中的机器学习:使用C++实现机器学习算法的内存管理最佳实践的详细内容,更多请关注php中文网其它相关文章!
今天关于基于C#的机器学习--旅行推销员问题和旅行推销员之死中文的讲解已经结束,谢谢您的阅读,如果想了解更多关于C++技术中的机器学习:使用C++如何优化机器学习模型的性能?、C++技术中的机器学习:使用C++实现常见机器学习算法的指南、C++技术中的机器学习:使用C++实现机器学习算法的代码优化策略、C++技术中的机器学习:使用C++实现机器学习算法的内存管理最佳实践的相关知识,请在本站搜索。
本文标签:




