在本文中,我们将带你了解网站sitemap的知识点有哪些在这篇文章中,我们将为您详细介绍网站sitemap的知识点有哪些的方方面面,并解答网站sitemap生成常见的疑惑,同时我们还将给您一些技巧,以
在本文中,我们将带你了解网站sitemap的知识点有哪些在这篇文章中,我们将为您详细介绍网站sitemap的知识点有哪些的方方面面,并解答网站sitemap生成常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的Apache HBase内核知识点有哪些、Appium框架的知识点有哪些、C++内存模型与名称空间的知识点有哪些、django知识点有哪些。
本文目录一览:")
网站sitemap的知识点有哪些(网站sitemap生成)
sitemap可方便网站管理员通知搜索引擎他们网站上有哪些可供抓取的网页。大多数搜索引擎都支持文本格式和xml格式的形式的地图,站点可以根据站点的需求随便选择一种。但是不推荐大家使用文本格式的sitemap方式提交,而是推荐使用xml格式的网站地图。
xml网站地图可以实现更强大的功能,可以标记页面的性质、抓取频次、在站点的权重以及页面的更新频率,可以帮助搜索引擎蜘蛛更好抓取站点内容。
sitemap优化步骤:
1、我们需要为每一个页面链接设计一段简短的文字介绍,这样可以提示这部分内容是关于哪方面的。
2、要为谷歌、百度这样的搜索引擎提供一条"绿色的通道"为蜘蛛提供可以浏览整个网站的链接,使搜索引擎能迅速收录网站的主要的网页,例如首页,详细页及帮助等页面。
3、如果用户已经在你网站上搜索过某些文章或信息,此时就需要有一个关于已经查看过的页面或列表。如果没有这些程序,那么你需要做一个文字链接到某个页面,并且这个页面是可以得到所有想查询的内容链接,以便告诉用户如何去查找他们需要查找的信息。
4、如果网站的链接因为某些原因无法访问,例如链接失效后无法获得链接内容的话,此时你就需要做一个错误页面的转向,这个错误的转向页面你也可以充分发挥你的想象力以便做的更加漂亮。
5、你可以在网站地图的文本和超链接里提到你要优化的主要的关键词,以便帮助搜索引擎来识别。
6、间接的帮助搜索引擎能够轻轻松松索引到一些动态的页面,建议此时的动态页面你将其设计成伪静态化,当然还是尽量选择静态化网页,因为搜索引擎更喜欢静态化的页面。
sitemap注意事项
1、需要注意的是sitemap文档应该放在网站根目录下,并且不能有访问权限限制,同时值得注意的一点,sitemap的路径需要复杂点,目的就是保护sitemap文档被他人访问或恶意爬虫的抓取。
2、蜘蛛抓取内容爬行是自上而下,所以我们通常把网站内重要参数的URL放置在页面上方,而网站地图数据放置在下方,这样更易让蜘蛛抓取网站重点,突出体现网站的主要内容,而不会浪费蜘蛛抓取内容的机会。
网站sitemap的知识点有哪些
sitemap可方便网站管理员通知搜索引擎他们网站上有哪些可供抓取的网页。大多数搜索引擎都支持文本格式和xml格式的形式的地图,站点可以根据站点的需求随便选择一种。但是不推荐大...
如何利用sitemap,促进网站收录?
今做seo的难度是历史性最高时刻,为什么这么说呢?以前做seo讨论怎么才能有权重,后来谈论怎么才能有更好的排名而现在谈论的大多是如何收录,一个网站页面都不收录,还谈什么获取流量...
网站推广之网站地图(sitemap)制作的6个点
不要低估网站地图在企业网站建设中的重要性,因为网站地图的功能对于网站建设的辅助功能非常重要,尤其是对于新网站的建设。换言之,无论是什么样的企业,都应该建立一个网站。然而,不同的...
延伸阅读

Apache HBase内核知识点有哪些
这篇文章主要讲解了“Apache HBase内核知识点有哪些”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Apache HBase内核知识点有哪些”吧!
HBase相关算法与数据结构基础知识
跳跃表
暂时先不说跳跃表是什么,在Java里面有一个Map叫:concurrentskiplistmap,通过对HBase的源码跟踪,我们发现这些地方使用了它:

简单的列了几个,但是观察这几个类所在的模块就可以发现,HBase从客户端,到请求处理,到元数据再到文件存储贯穿HBase的整个生命周期中的各个重要环节,都能看到它的身影,Map那么多,为何偏偏HBase选择了这个?接下来我们仔细分析下。
在算法概念里面有一种数据结构叫跳跃表,顾名思义,之所以叫跳跃表就是因为在查找的时候可以快速的跳过部分列表,用来提升查找效率,跳跃表的查找效率可以和二叉树相比为O(log(N)),这个算法的实现在Java中的concurrentskiplistmap就是实现跳跃表的相关算法。
首先我们看一个有序的全量表:

假设我们要从中找出 可以发现需要比较的次数(比较次数不是循环次数)为<3,5,8>共计16次,可以看到对这样一个有序链表进行查找比较的次数会非常多,那么有没有办法对这种查找做优化。当然是有的,对于这种查找耳熟能详从数据结构的基础课程开始大家就知道二叉树,折半查找,值查找都属于解决这类问题的方法,自然跳跃表也是解决这类问题的方法之一。
跳跃表的思路和如今大部分大数据组件像kylin对海量数据下的快速查找的解决思路非常相似,都是通过某种逻辑提前将部分数据做预处理,然后查找的时候进行快速匹配,典型的空间换时间,那么对于跳跃表来说,它的预处理的方式如下:

可以看到,跳跃表是按照层次构造的,最底层是一个全量有序链表,依次向上都是它的精简版,而在上层链表中节点的后续下一步的节点是以随机化的方式进行的,因此在上层链表中可以跳过部分列表,也叫跳跃表,特点如下:
链表层从上往下查找
跳跃表由很多层组成
每一层都是一个有序链表
最底层是全量有序链表
如果一个元素出现在上层的某个节点那么它一定会出现在下层的链表
每一个元素都有两个指针,一个指向当前链表的下一个元素,一个指向下一层链表的相同节点
假设根据前面的图表我们要查询G这个字母,那么在上面的跳跃表中经过的路径如下:

其中红色代表查找所走过的路径。
LSM树
前面讲到了跳跃表的原理,在HBase中较大规模的使用了跳跃表,就是为了增快其查找效率,除了跳跃表之外HBase还使用到了LSM树,LSM树本质上和B+相似,是一种存储在磁盘上的数据的索引格式,但是差异点在于LSM对写入非常高效,实现来说就是无论什么样的写入LSM都是当成一次顺序写入,这一点和HDFS的优点正好契合,HDFS不支持随机写,支持顺序写。LSM数据存储在两个地方,一个是磁盘上一个是内存中,内存中同样使用的跳跃表,内存中是多个有序的文件。

HBase对LSM的应用采用了如上的结构方式,对于HBase具体的存储文件的分析,在后面专门针对HBase的存储部分进行深入的分析。
布隆过滤器
布隆过滤器解决的问题是,如何快速的发现一个元素是否存在于某个集合里面,最简单的办法就是在集合或者链表上查找一遍,但是考虑到在大数据场景下,数据量非常大,即便不考虑性能,也不见得会有足够多的机器来加载对应的集合。所以需要一种新的思路去解决此类问题,那么布隆过滤器就是一种,它的思想为:
由一个长度为N的数组构成,每一个元素为0或者1,默认都为0
对集合的每个元素做K次哈希,到第i次的时候对N取一个模,会得到一个index
将数组中的array[index]变为1

上图是长度为18,进行3次哈希得到的结果,那么在HBase中是如何利用布隆过滤器的呢,首先从操作来说,HBase的Get就经过布隆过滤器,同时HBase支持度对不同的列设置不同的布隆过滤器。

可以看到对HBase来讲可以启用或者禁用过滤器,对于不同的过滤器的实现分别在不同的类中,在查询的时候分别根据不同的过滤器采用不同的实现类:

所以可以通过如上的代码找到对应的过滤器实现,甚至可以新增自己的过滤器。
HBase读写操作
前面提到HBase的相关算法,现在我们讲一下HBase的整个操作的读写流程。首先,摆出HBase的架构图,如下所示:

从这个图可以看到,HBase的一个写操作,大的流程会经过三个地方:1. 客户端,2. RegionServer 3. Memstore刷新到磁盘。也就是说对于HBase的一次写入操作来讲,数据落到Memstore就算写入完成,那么必然需要考虑一个问题,那就是没有落盘的数据,万一机器发生故障,这部分数据如何保障不丢失。解析来我们逐步分解一下这三个部分。
客户端:HBase的客户端和服务器并不是单一的链接,而是在封装完数据后,通过请求HMaster获取该次写入对应的RegionServer的地址,然后直接链接RegionServer,进行写入操作,对于客户端的数据封装来讲,HBase支持在客户端设置本地缓存,也就是批量提交还是实时提交。因为HBase的hbase:Meta表中记录了RegionServer的信息,HBase的数据均衡是根据rowkey进行分配,因此客户端会根据rowkey查找到对应的RegionServer,定义在Connection中:

而实现在:AsyncRegionLocator

RegionServer写入:当客户端拿到对应的RegionServer后,便和HMaster没有关系了,开始了直接的数据传输,我们前面提到一个问题,那就是HBase如何防止数据丢失,毕竟HBase的写入是到内存,一次请求就返回了,解决这个问题是通过WAL日志文件来解决的,任何一次写入操作,首先写入的是WAL,这类日志存储格式和Kafka类似的顺序追加,但是具有时效性,也就是当数据落盘成功,并且经过检查无误之后,这部分日志会清楚,以保障HBase具有一个较好的性能,当写完日志文件后,再写入Memstore。
那么在RegionServer的写入阶段会发生什么呢?首先我们知道,HBase是具有锁的能力的,也就是行锁能力,对于HBase来讲,HBase使用行锁保障对同一行的数据的更新要么都成功要么都失败,所以在RegionServer阶段,会经过以下步骤:
申请行锁,用来保障本次写入的事务性
更新LATEST_TIMESTAMP字段,HBase默认会保留历史的所有版本,但是查询过滤的时候始终只显示最新的数据,然后进行写入前提条件的检查:

以上相关操作的代码都在HRegion,RegionAsTable中,可以以此作为入口去查看,所以这里就不贴大部分的代码了。
写入WAL日志文件,在WALProvider中定义了两个方法:

append用来对每一次的写入操作进行日志追踪,因为有事物机制,所以HBase会将一次操作中的所有的key value变成一条日志信息写入日志文件,aync用来同步将该日志文件落盘到HDFS的文件系统,入场中间发生失败,则立即回滚。
4. 写入Memstore,释放锁,本次写入成功。
所以可以看到对于HBase来讲写入通过日志文件再加Memstore进行配合,最后HBase自身再通过对数据落盘,通过这样一系列的机制来保障了写入的一套动作。
讲完了HBase的写入操作,再来看看HBase的读取流程。
对于读来讲,客户端的流程和写一样,HBase的数据不会经过Master进行转发,客户端通过Master查找到元信息,再根据元信息拿到Meta表,找到对应的Region Sever直接取数据。对于读操作来讲,HBase内部归纳下来有两种操作,一种是GET,一种是SCAN。GET为根据rowkey直接获取一条记录,而SCAN则是根据某个条件进行扫描,然后返回多条数据的过程。可以看到GET经过一系列的判断,例如检查是否有coprocessor hook后,直接返回了存储数据集的List:

那么我们再看SCAN就不那么一样了,可以看到,对于SCAN的操作来讲并不是一次的返回所有数据,而是返回了一个Scanner,也就是说在HBase里面,对于Scan操作,将其分成了多个RPC操作,类似于数据的ResultSet,通过next来获取下一行数据。

HBase文件格式
前面讲了HBase的操作流程,现在我们看下HBase的存储机制,首先HBase使用的HDFS存储,也就是在文件系统方面没有自身的文件管理系统,所以HBase仅仅需要设计的是文件格式,在HBase里面,最终的数据都是存储在HFile里面,HFile的实现借鉴了BigTable的sstable和Hadoop的TFile,一张图先展示HFile的逻辑结构:

可以看到HFie主要由四个部分构成:
Scanned block section: 顾名思义,表示顺序扫描HFile时所有的数据块将会被读取,包括Leaf Index Block和Bloom Block。
Non-scanned block section: 表示在HFile顺序扫描的时候数据不会被读取,主要包括Meta Block和* Intermediate Level Data Index Blocks两部分。
Load-on-open-section: 这部分数据在HBase的region server启动时,需要加载到内存中。包括FileInfo、Bloom filter block、data block index和Meta block index。
Trailer: 这部分主要记录了HFile的基本信息、各个部分的偏移值和寻址信息。
对于一个HFile文件来讲,最终落盘到磁盘上的时候会将一个大的HFile拆分成多个小文件,每一个叫做block块,和HDFS的块相似,每一个都可以自己重新设定大小,在HBase里面默认为64KB,对于较大的块,在SCAN的时候可以在连续的地址上读取数据,因此对于顺序SCAN的查询会非常高效,对于小块来讲则更有利于随机的查询,所以块大小的设置,也是HBase的调参的一个挑战,相关的定义在源码里面使用的HFileBlock类中,HFileBlock的结构如下所示:

每一个block块支持两种类型,一种是支持Checksum的,一种是不支持Checksum的,通过参数usesHBaseChecksum在创建block的时候进行设置:

HFileBlock主要包含两个部分,一个是Header一个是Data,如下图所示:

(HFileBlock结构,来自网络)
BlockHeader主要存储block元数据,BlockData用来存储具体数据。前面提到一个大的HFile会被切分成多个小的block,每一个block的header都相同,但是data不相同,主要是通过BlockType字段来进行区分,也就是HFile把文件按照不同使用类型,分成多个小的block文件,具体定义在BlockType中,定义了支持的Type类型:

下面我们仔细分解一下HBase的Data部分的存储,HBase是一个K-V的数据库,并且每条记录都会默认保留,通过时间戳进行筛选,所以HBase的K-V的格式在磁盘的逻辑架构如下所示:

每个keyvalue都由4个部分构成,而Key又是一个复杂的结构,首先是rowkey的长度,接着是rowkey,然后是ColumnFamily的长度,再是ColumnFamily,之后是ColumnQualifier,最后是时间戳和KeyType(keytype有四种类型,分别是Put、Delete、 DeleteColumn和DeleteFamily),而value相对简单,是一串纯粹的二进制数据。
最开始的时候我们介绍了布隆过滤器,布隆过滤器会根据条件减少和跳过部分文件,以增加查询速度:

每一个HFile有自己的布隆过滤器的数组,但是我们也会发现,这样的一个数组,如果HBase的块数足够多,那么这个数组会更加的长,也就意味着资源消耗会更多,为了解决这个问题,在HFile里面又定义了布隆过滤器的块,用来检索对应的Key需要使用哪个数组:

一次get请求进来,首先会根据key在所有的索引条目中进行二分查找,查找到对应的Bloom Index Entry,就可以定位到该key对应的位数组,加载到内存进行过滤判断。
HBase RegionServer
聊完了HBase的流程和存储格式,现在我们来看一下HBase的RegionServer,RegionServer是HBase响应用户读写操作的服务器,内部结构如下所示:

一个RegionServer由一个HLog,一个BlockCache和多个Region组成,HLog保障数据写入的可靠性,BlockCache缓存查询的热点数据提升效率,每一个Region是HBase中的数据表的一个分片,一个RegionServer会承担多个Region的读写,而每一个Region又由多个store组成。store中存储着列簇的数据。例如一个表包含两个列簇的话,这个表的所有Region都会包含两个Store,每个Store又包含Mem和Hfile两部分,写入的时候先写入Mem,根据条件再落盘成Hfile。
RegionServer管理的HLog的文件格式如下所示:

HLog的日志文件存放在HDFS中,hbase集群默认会在hdfs上创建hbase文件夹,在该文件夹下有一个WAL目录,其中存放着所有相关的HLog,HLog并不会永久存在,在整个HBase总HLog会经历如下过程:
HLog构建: 任何写入操作都会先记录到HLog,因此在发生写入操作的时候会先构建HLog。
HLog滚动: 因为HLog会不断追加,所以整个文件会越来越大,因此需要支持滚动日志文件存储,所以HBase后台每间隔一段时间(默认一小时)会产生一个新的HLog文件,历史HLog标记为历史文件。
HLog失效: 一旦数据进入到磁盘,形成HFile后,HLog中的数据就没有存在必要了,因为HFile存储在HDFS中,HDFS文件系统保障了其可靠性,因此当该HLog中的数据都落地成磁盘后,该HLog会变为失效状态,对应的操作是将该文件从WAL移动到oldWAl目录,此时文件依旧存在,并未进行删除。
HLog删除: hbase有一个后台进程,默认每间隔一分钟会对失效日志文件进行判断,如果没有任何引用操作,那么此时的文件会被彻底的从物理删除。
对于RegionServer来讲,每一个RegionServer都是一个独立的读写请求服务,因此HBase可以水平增加多个RegionServer来达到水平扩展的效果,但是多个RegionServer之间并不存在信息共享,也就是如果一个海量任务计算失败的时候,客户端重试后,链接新的RegionServer后,整个计算会重新开始。
HBase怎么用
虽然HBase目前使用非常广泛,并且默认情况下,只要机器配置到位,不需要特别多的操作,HBase就可以满足大部分情况下的海量数据处理,再配合第三方工具像phoenix,可以直接利用HBase构建一套OLAP系统,但是我们还是要认识到HBase的客观影响,知道其对应的细节差异,大概来说如果我们使用HBase,有以下点需要关心一下:
因为HBase在RegionServer对写入的检查机制,会导致客户端在符合条件的情况下出现重试的情况,所以对于较为频繁的写入操作,或者较大数据量的写入操作,推荐使用直接产生HFlie然后load到HBase中的方式,不建议直接使用HBase的自身的Put API。
从使用来讲如果业务场景导致HBase中存储的列簇对应的数据量差异巨大,那么不建议创建过多的列簇,因为HBase的存储机制会导致不同列簇的数据存储在同一个HBase的HFile中,但是split机制在数据量增加较大的情况下,会发生拆分,则会导致小数据量的列簇被频繁的split,反而降低了查询性能。
RegionServer是相互独立的,所以如果想要让集群更加的稳定高效,例如如果想实现RegionServer集群,达到信息共享,任务增量计算,需要自己修改RegionServer的代码。
对于HBase来讲,很多场景下,像如果Region正在Split,或者Mem正在Dump,则无法进行对应的操作,此时错误信息会被以异常的形式返回到客户端,再由客户端进行重试,因此在使用过程中,需要结合我们的应用场景,考虑如何设置类似于buffer大小的参数,以尽可能少的降低因为内部操作引起的客户端重试,特别是在使用类似opentsdb的这类集成hhbase的数据的情况下。
感谢各位的阅读,以上就是“Apache HBase内核知识点有哪些”的内容了,经过本文的学习后,相信大家对Apache HBase内核知识点有哪些这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是小编,小编将为大家推送更多相关知识点的文章,欢迎关注!

Appium框架的知识点有哪些
1、测试对象
Appium是一个开源工具,用于自动化iOS、Android设备和Windows桌面平台上的原生、移动Web和混合应用。
"原生应用"指那些用iOS、Android或者WindowsSDK编写的应用。
"移动web应用"是用移动端浏览器访问的应用(Appium支持iOS上的Safari、Chrome和Android上的内置浏览器)。
"混合应用"带有一个"webview"的包装器——用来和Web内容交互的原生控件。
重要的是:Appium是跨平台的:它允许你用同样的API对多平台写测试,做到在iOS、Android和Windows测试套件之间复用代码。
2、支持平台及语言
● appium是跨平台的,支持OSX,Windows以及Linux系统。它允许测试人员在不同的平台(iOS,Android)使用同一套API来写自动化测试脚本,这样大大增加了iOS和Android测试套件间代码的复用性
● appium支持多语言,采用C/S设计模式,只要满足client能够发送http请求给server即可
3、工作原理
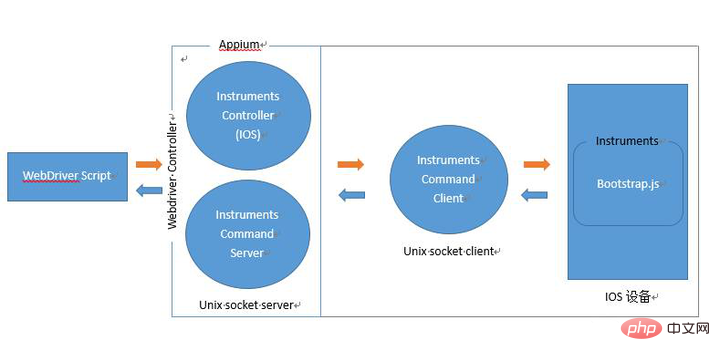
APPIUM IOS端工作原理
下面我们通过一张图来看下IOS端APPIUM全过程工作原理:
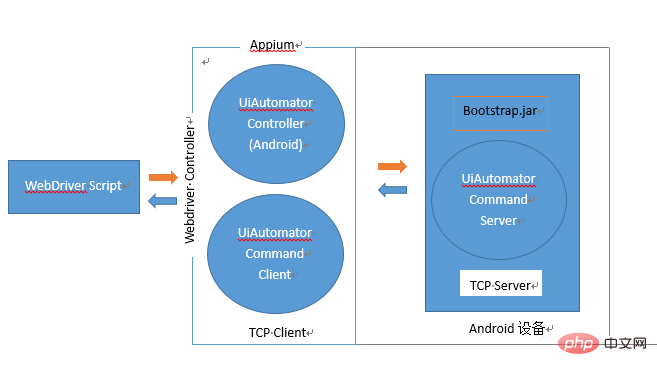
APPIUM Android端工作原理
下面我们通过一张图来看下android端APPIUM全过程工作原理:
解释:
整个箭头指向为一个完成的指令循环
webdriver script需要自动化测试人员自己编写对应的测试脚本
建议大家去了解下JSON wire protocol、instruments、UiAutomator
4、安装工具
● 测试语言,如python
● appium客户端
● appium服务端
● 移动设备,若使用虚拟机则需进行安装
5、环境搭建
(一)安装Android SDK
1、Android SDK(Software Development Kit,软件开发工具包)提供了 Android API 库和开发工具构建,测试和调试应用程序,可以看做用于开发和运行Android应用的一个软件
2、提供小工具,比如adb、aapt、uiautomatorview
3、测试设备使用安卓模拟器,这一步决不能跳过
(二)安装 appium Server
1、appium官网:https://pium.app/downloads/
2、下载appium安装包(AppiumForWindows.zip,appium.dmg)
3、安装,并配置appium环境变量
(三)安装 python-client
1、先安装编程语言,比如python语言
2、安装Appium-Client,python的话可使用pip安装:pip install Appium-Python-Client
6、应用及操作
①调用appium过程
1、配置手机设备参数,告诉server端我想调起的是哪一台手机设备
2、抓取手机上应用的控件,指定对应的控件来进行操作
3、对抓取到的控件进行操作,比如点击、填写参数等
第一步,配置手机设备参数
Appium 的 Desired Capabilities 基本配置如下:
#Android environment
import unittest
from appium import webdriver
desired_caps = {}
desired_caps[''platformName''] = ''Android''
desired_caps[''platformVersion''] = ''4.2''
desired_caps[''deviceName''] = ''Android Emulator''
desired_caps[''app''] = PATH(''../../../apps/selendroid-test-app.apk'')
desired_caps[''appPackage''] = package
desired_caps[''appActivity''] = activity
self.driver = webdriver.Remote(''http://localhost:4723/wd/hub'', desired_caps)
常见参数解释:
● deviceName:指定启动设备,比如Android Emulator、iPhone Simulator等
● automationName:指定自动化引擎,默认appium
● platformName:指定移动平台,Android或者iOS
● platformVersion:指定平台的系统版本。例如指定Android系统版本为4.2
● appActivity:待测试app的Activity,注意,原生app的话要在activity前加个"."
● appPackage:待测试app的包名(package)信息
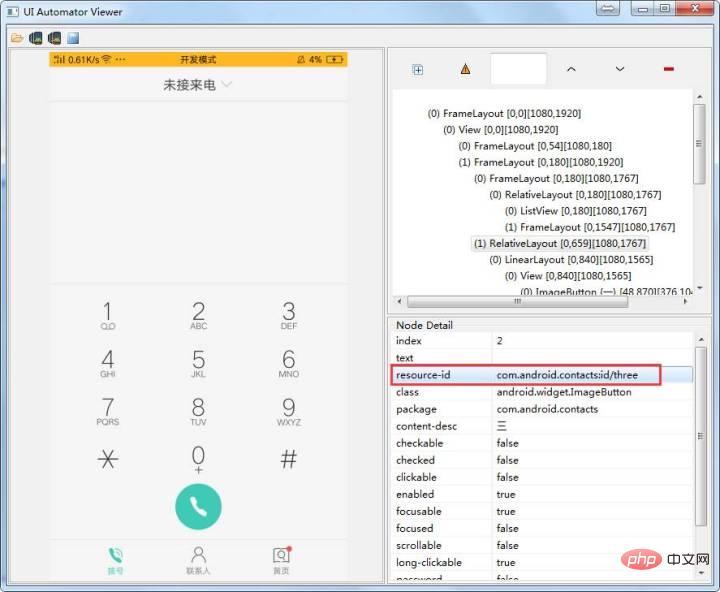
第二步,抓取手机上应用的控件
通过Android SDK内置工具uiautomatorviewer.bat来查看手机应用的控件参数(该工具位于 /tools/bin/ 目录下)
1、id定位
使用方法:
driver.find_element_by_id(''com.android.contacts:id/three'')
2、name定位
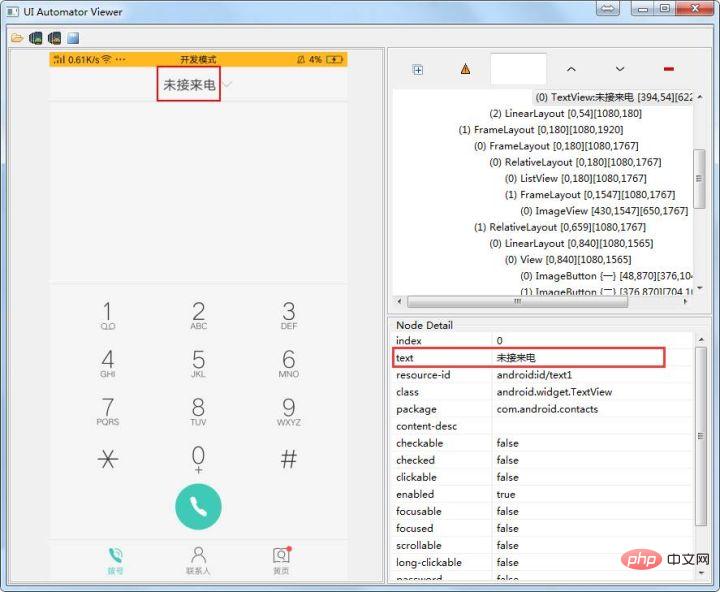
使用方法:
el = self.driver.find_element_by_name(''未接来电'') el = self.driver.find_elements_by_name(''未接来电'')
3、class name 定位
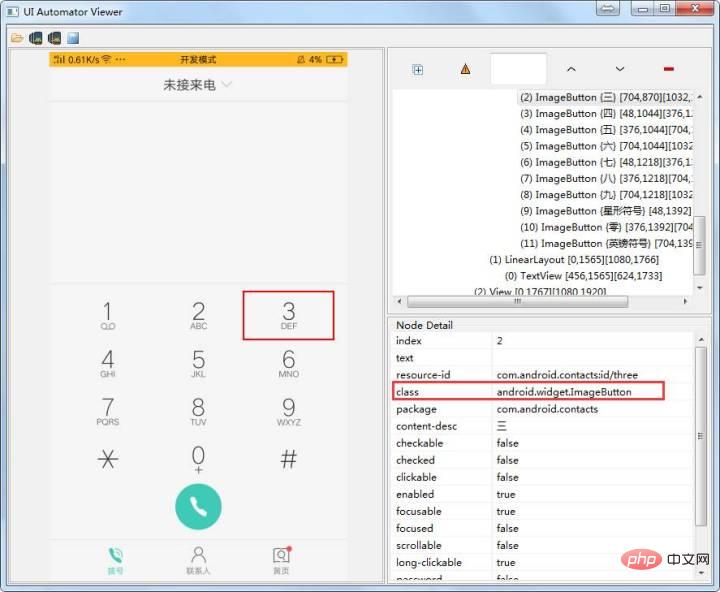
使用方法:
els = self.driver.find_element_by_class_name(''android.widget.ImageButton'') els = self.driver.find_elements_by_class_name(''android.widget.ImageButton'')
4、Accessibility ID定位
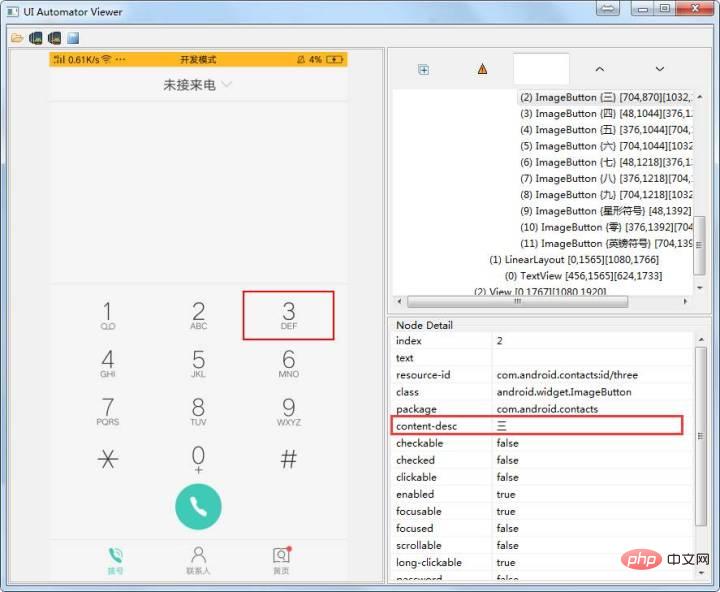
使用方法:
el = self.driver.find_element_by_accessibility_id(''三'') el = self.driver.find_elements_by_accessibility_id(''三'')
5、android uiautomator定位
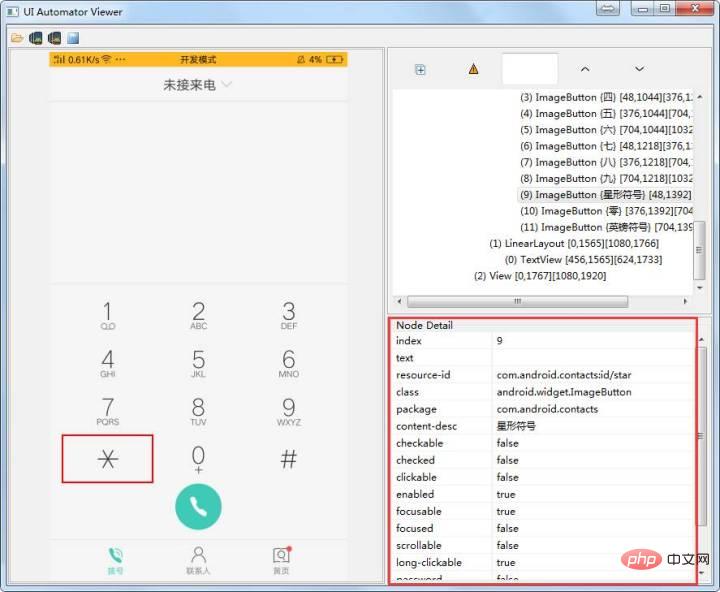
使用方法:
el=self.driver.find_element_by_android_uiautomator(''new UiSelector().description(星形符号")'')
els=self.driver.find_elements_by_android_uiautomator(''new UiSelector().clickable(false)'')
第三步,操作控件
1.scroll
scroll(self, origin_el, destination_el):
从元素origin_el滚动至元素destination_el
举例:driver.scroll(el1, el2)
用法:driver.scroll(el1,el2)
2.tap
tap(self, positions, duration=None):
模拟手指点击(最多五个手指),可设置按住时间长度(毫秒)
举例:driver.tap([(100, 20), (100, 60), (100, 100)], 500)
用法:driver.tap([(x,y),(x1,y1)],500)
3. swipe
swipe(self, start_x, start_y, end_x, end_y, duration=None):
从A点滑动至B点,滑动时间为毫秒
举例:driver.swipe(100, 100, 100, 400)
用法:driver.swipe(x1,y1,x2,y2,500)
4. keyevent
keyevent(self, keycode, metastate=None):
发送按键码(安卓仅有),按键码可以上网址中找到
用法:driver.keyevent(''4'')
5. press_keycode
press_keycode(self, keycode, metastate=None):
发送按键码(安卓仅有),按键码可以上网址中找到
用法:driver.press_ keycode(''4'')
6.text
text(self):
返回元素的文本值
用法:element.text
7.click
click(self):
点击元素
用法:element.click()
8.get_attribute
get_attribute(self, name):
获取某元素的相关值
用法:element.get_attribute("name")
9.size
size(self):
获取元素的大小(高和宽)
用法 driver.element.size
10. page_source
page_source(self):
获取当前页面的源
用法:driver.page_source
11.quit
quit(self):
退出脚本运行并关闭每个相关的窗口连接
举例:driver.quit()
执行结果判断
在用例执行完毕,需要判断是否通过时,需要和你预期的结果进行对比,一般可以选择断言查找某个标志位是否出现,或者某个元素的text值是否和预期相等,还可以截图后跟参照图片做对比等等。
以上就是Appium框架的知识点有哪些的详细内容,更多请关注php中文网其它相关文章!

C++内存模型与名称空间的知识点有哪些
这篇文章主要介绍“C++内存模型与名称空间的知识点有哪些”,在日常操作中,相信很多人在C++内存模型与名称空间的知识点有哪些问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”C++内存模型与名称空间的知识点有哪些”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
程序可分为三部分:
头文件:包含结构声明和使用这些结构的函数的原型
源代码文件:包含与结构有关的函数的代码
源代码文件:包含调用与结构相关的函数代码。
头文件中常包含的内容:
函数原型、使用#define或const定义的符号常量、结构声明、类声明、模板声明、内联函数。
文件在编译时可以解释为翻译单元。
1、存储持续性与作用域及链接性
存储类别如何影响信息在文件间的共享呢?C++使用三种不同的方案来存储数据,这些方案的区别在于数据保留在内存中的时间:
自动存储特性:在函数定义中声明的变量(包括函数参数)的存储持续性为自动的,他们在程序开始执行其所属的函数或代码块时被创建,在执行完函数或代码块时,他们使用的内存被释放
静态存储特性:在函数定义外定义的变量和使用关键字static定义的变量的存储持续性都为静态,他们在程序整个运行过程中都存在
线程存储持续性:如果变量使用关键字thread_local声明,其声明周期和所属线程一样长
动态存储特性:用new运算符分配的内存将一直存在,直到使用delete运算符释放或者程序结束。
2、作用域和链接
作用域描述了名称在文件(翻译单元)的多大范围内可见。链接性描述了名称如何在不同单元间共享,链接性为外部的名称可在文件间共享,链接性为内部的名称只能由一个文件中的函数共享,自动变量的名称没有链接性,因为他们不能共享。
3、静态持续变量
静态存储持续性变量有三种链接性:外部、内部和无链接性,这三种链接性都在整个程序执行期间存在,它们的寿命更长,编译器将分配固定的内存。另外如果没有显式初始化静态变量,编译器将把它设置为0。
int global = 100; // 外部链接
static int one_file = 10; // 内部链接
extern double up = 0; // 外部链接
int func(int n)
{
static int cnt = 0; // 无链接,只在代码块内使用
return 0;
}
4、静态持续性和外部链接性
链接性为外部的变量称为外部变量,他们的存储性为静态,作用域为整个文件。
C++提供有两种变量声明,一种是定义声明,它给变量分配存储空间;另一种是引用声明,它不给变量分配存储空间,而是引用已有的变量。
double d; // 定义 extern int a; // 引用声明 extern char c = 'a'; 定义声明
如果要在多个文件中使用外部变量,只需要在一个文件中包含该变量的定义,在使用该变量的其他所有文件中,都必须使用关键字extern声明它。
// a.h
#pragma once
int getGlobalNum()
// a.cpp
#include "a.h"
extern int global;
int getGlobalNum()
{
return global;
}
// b.cpp
#include "a.h";
int global = 100;
int main()
{
cout << getGlobalNum() << endl; // 100
getchar();
}
定义与全局变量同名的局部变量后,局部变量将隐藏全局变量。C++中提供了作用域解析运算符(::),放在变量名前面是,该运算符表示使用变量的全局版本。
// a.cpp
#include "a.h"
extern int global;
int getGlobalNum()
{
int global = 10;
return ::global;
}
// b.cpp
#include "a.h";
int global = 100;
int main()
{
cout << getGlobalNum() << endl; // 100
getchar();
}
5、静态持续性与内部链接性
将static限定符用于作用域为整个文件的变量时,该变量的链接性为内部的,链接性为内部的变量只能在其所属的文件中使用。
常规外部变量具有外部链接性,即可以在其他文件中使用,如果要在其他文件中使用相同的名称来表示其他变量,需要使用static。(如果在两个文件中有两个相同名称的外部变量,那么第三个文件引用时就不能确定引用哪一个)
// a.cpp extern int a = 10; // b.cpp extern int a = 30; // error static int a = 30; // OK
6、静态存储性与无链接性
在代码块中使用static时,将导致局部变量的存储持续性为静态的,该变量在代码块不在活动时仍存在。两次函数调用之间,静态局部变量的值将保持不变。初始化了静态局部变量,程序只在启动时进行一次初始化,以后再调用时将不会再被初始化。
void add2()
{
static int value = 0;
cout << value++ << " "; // 0 1 2
}
for (size_t i = 0; i < 3; i++)
add2();
7、const
默认情况下全局变量的链接性为外部的,但是const全局变量的链接性为内部的,也就是说C++中全局const定义就像使用了static说明符一样。因为有该特性,const修饰的常量可以放在头文件中,并且可以在多个文件中使用该头文件(如果const声明是外部的,根据单定义规则将出错,即只有一个文件可以使用const声明,其他需要用extern来提供引用声明)。
extern const int a = 10; // 外部声明的常量 const int b = 10; // 内部声明的常量
如果希望某个常量的链接性是外部的,可以使用extern来覆盖默认的内部链接性。
8、函数和链接性
C++不允许在一个函数中定义另一个函数,所以所有的函数的存储持续性都自动为静态的,即整个程序执行期间都存在。
默认情况下,函数的链接性为外部的,可以使用extern来指出函数实在另一个文件中定义的(而不用去加头文件);
extern int pub();
可以使用static将函数的链接性设置为内部的,使之只能在一个文件中使用,必须同时在原型和定义中使用该关键字。
static int private();
static int private()
{
}
使用static修饰函数并不仅意味着该函数只在当前文件中可见,还意味着可以在其他文件中定义同名的函数。
// a.cpp
int pub()
{
return 0;
}
// b.cpp
int pub() // error
{
return 0;
}
static int pub() // OK
{
return 0;
}
在定义静态函数的文件中,静态函数将覆盖外部定义。
对于每个非内联函数,程序只能包含一个定义(如果两个文件中包含相同名称的外部函数,那么第三个文件使用外部函数时将不能确定使用哪个定义)
内联函数不会受到单定义规则约束,所以可以放在头文件中,这样包含有头文件的每个文件都有内联函数的定义。C++要求同一个函数的所有内联定义都必须相同。
9、语言的链接性
链接程序要求每个不同的函数都有不同的符号名。C语言中一个名称只能对应一个函数,这很容易实现,C语言编译器可能将spiff翻译为_spiff。但是在C++中,同一个名称可能对应多个函数,必须将这些函数翻译为不同的符号名称,可能将spiff(int)翻译为_spiff_i,将spiff(double)翻译为_spiff_d。
链接程序寻找与C++函数调用匹配的函数时,使用的方法与C语言不同,要在C++程序中使用C库中预编译的函数可以在声明时指定链接性说明符,比如下面第一种指定用C语言的链接方式去链接spiff方法
extern "C" void spiff(int); // 使用C语言链接性 extern void spoff(int); // 默认使用C++链接性 extern "C++" void spaff(int); // 显式指定C++链接性
假设有一个C库libC,里面有一个函数spiff,如果我们在C++程序中直接引用头文件,并且调用函数,那么会出现找不到函数定义的情况。这时候我们可以用extern "C"将头文件包裹起来,表示用C语言的连接方式去链接方法:
extern "C" {
#include "a.h"
}
10、命名空间
一个命名空间中的名称不会与另一个命名空间中的相同名称发生冲突,命名空间可以是全局的,也可以位于另一个命名空间中,但不能位于代码中。默认情况下,命名空间中声明的名称的链接性为外部的。
除了用户定义的命名空间外,还有一个全局命名空间,它对应于文件及声明区域,因此前面所说的全局变量现在被描述为位于全局名称中间中。
namespace A
{
int a = 10;
void printk()
{
}
}
namespace B {
int a = 20;
void printk()
{
}
}
名称空间是开放的,可以把名称加入到已有的名称空间中:
namespace B
{
void printkk();
}
C++提供using声明和using编译两种机制来简化对名称空间中名称的使用:
using声明使特定的标识符可用,在函数外使用using声明,可以把名称添加到全局名称空间中
using B::printkk;
int main()
{
using B::printk;
printk();
}
using编译指令使整个名称空间可用,在全局声明区域中使用using编译指令,使得该名称空间中的名称全局可用:
using namespace B;
int main()
{
// using namespace B;
printk();
}
如果名称空间和声明区域定义了相同的名称,如果使用using声明来导入,则两个名称会发生冲突:
namespace B {
int a = 20;
}
int main()
{
using B::a;
// int a = 10; // error
cout << a;
getchar();
return 0;
}
如果用using编译指令将名称空间的名称导入,则局部版本将隐藏名称空间版本:
namespace B {
int a = 20;
}
int a = 100;
int main()
{
using namespace B;
int a = 10;
cout << a << " " << ::a << " " << B::a << endl; // 10 100 20
}
一般来说,使用using声明比使用using编译指令更安全,如果名称和局部名称发生冲突,编译器将发出指示。using编译导入所有名称可能包括不需要的名称。
命名空间的声明可以进行嵌套:
namespace element {
namespace fire {
}
}
using namespace element::fire;
可以在名称空间中使用using编译指令和using声明:
namespace spaceA {
int a = 10;
}
namespace spaceB {
using namespace A;
}
可以给命名空间创建别名,来简化嵌套命名空间的使用:
namespace spaceA {
namespace B {
int a = 10;
}
}
namespace spaceX = spaceA::spaceB;
spaceX::a = 100;
命名空间的使用指导原则:
使用在已命名的名称空间中声明的变量,而不是使用外部全局变量;
使用在已命名的名称空间中声明的变量,而不是使用静态全局变量;
如果开发了一个函数库或者一个类库,将其放在一个命名空间中;
不要在头文件中使用using编译指令,如果非要使用将其放在所有预处理指令之后;
导入名称时,首选使用作用域解析运算符或using声明的方法;
对于using声明,首选将其作用域设置为局部而不是全局。
到此,关于“C++内存模型与名称空间的知识点有哪些”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注小编网站,小编会继续努力为大家带来更多实用的文章!

django知识点有哪些
小编给大家分享一下django知识点有哪些,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
一、视图函数:
请求对象-----------request:
1、HttpRequest.body: 请求原数据
2、HttpRequest.path: 一个字符串,表示请求的路径组件(不含域名)
3、HttpRequest.method
4、HttpRequest.GET
5、HttpRequest.POST
6、HttpRequest.FILES
7、HttpResquest.user: 一个AUTH_USER_MODEL 类型的对象
响应对象:
return HttpResponse("") 返回字符串实例
return render(request,"template",{"":""}) 返回字符串实例
return rredirect("/index/") 重定向
二、 模板语言
首先在views视图函数里写函数,返回一个渲染页面:
views:
def foo (request):
name="li"
l=[111,2222,3333]
d={"info":[obj1,obj2...]}
return render(request,"index.html",locals())
1、变量:{{name}}
-------深度查询 句点符. 如:{{d.info.0.name}}
-------过滤器{{name|date:"Y-m-d"}}
2.标签:
for循环
{%for i in l%}
{{i}}
{%empty%}
<p>没有符合的条件</p>
{%endfor%}
if判断语句
{%if name="li"%}
<p> Yes</p>
{%elif%}
{%endif....%}
3、模板语法
(1)在母版中base.html: {%block con%}{%endblock%}
(2)继承母版 index.html:
{%extends "base.html"%} 继承
{%block con%}
{%endblock%}
三、ORM之models模型
1、 映射关系:
sql中表名-----------Python的类名
sql中的字段---------Python的类属性
sql中的记录---------Python的类对象
2、单表操作
class Article(models.Model):
nid = models.BigAutoField(primary_key=True)
title = models.CharField(max_length=50, verbose_name='文章标题')
read_count = models.IntegerField(default=0)
(1)添加操作
views:
复制代码
#方法1:
article_obj=models.Article.objects.create(nid=1,title="yuan",read_count=12) # create方法返回的是当前创建的文章对象
#方法2:
article_obj=models.Article(nid=1,title="yuan",read_count=12)
article_obj.save()
删除:
models.Article.objects.filter(title="python").delete() # 默认级联删除
修改:
models.Article.objects.filter(title="python").update(read_count=F("read_count")+10)
查询API:
<1> all(): 查询所有结果 #QuerySet
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 #QuerySet
<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,
如果符合筛选条件的对象超过一个或者没有都会抛出错误。# model对象
<5> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 #QuerySet
<4> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列
model的实例化对象,而是一个可迭代的字典序列 #QuerySet
<9> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 #QuerySet
<6> order_by(*field): 对查询结果排序 #QuerySet
<7> reverse(): 对查询结果反向排序 #QuerySet
<8> distinct(): 从返回结果中剔除重复纪录 #QuerySet
<10> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 # int
<11> first(): 返回第一条记录 # model对象
<12> last(): 返回最后一条记录 # model对象
<13> exists(): 如果QuerySet包含数据,就返回True,否则返回False
querySet支持链式操作:
models.Article.objects.all().filter().values().distinct().count()
QuerySet数据类型:
1、可切片,可迭代 [obj,....]
2、惰性查询:
articles_list=models.Article.objects.all()
使用articles_list,比如if articles_list,这时转换sql语句
3、缓存机制
articles_list=models.Article.objects.all()
for i in articles_list:
print(i.title) # hit the database
for i in articles_list:
print(i.title) # not hit the database
==============================================
for i in models.Article.objects.all():
print(i.title) # hit the database
for i in models.Article.objects.all():
print(i.title) # hit the database
4、优化查询
articles_list=models.Article.objects.all().iterator()
for i in articles_list:
print(i.title) # hit the database
for i in articles_list:
print(i.title) # 无结果
连表操作:
表关系:
class UserInfo(AbstractUser): # settings: AUTH_USER_MODEL = "blog.UserInfo"
"""
用户信息
"""
nid = models.BigAutoField(primary_key=True)
nickname = models.CharField(verbose_name='昵称', max_length=32,null=True)
telephone = models.CharField(max_length=11, blank=True, null=True, unique=True, verbose_name='手机号码')
avatar = models.FileField(verbose_name='头像', upload_to='avatar', default="avatar/default.png")
create_time = models.DateTimeField(verbose_name='创建时间', auto_Now_add=True)
class Blog(models.Model):
"""
站点信息
"""
nid = models.BigAutoField(primary_key=True)
title = models.CharField(verbose_name='个人博客标题', max_length=64)
site = models.CharField(verbose_name='个人博客后缀', max_length=32, unique=True)
theme = models.CharField(verbose_name='博客主题', max_length=32)
user = models.OnetoOneField(to='UserInfo', to_field='nid')
class Category(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField(verbose_name='分类标题', max_length=32)
blog = models.ForeignKey(verbose_name='所属博客', to='Blog', to_field='nid')
class Article(models.Model):
nid = models.BigAutoField(primary_key=True)
title = models.CharField(max_length=50, verbose_name='文章标题')
desc = models.CharField(max_length=255, verbose_name='文章描述')
# category字段: 与Article对象关联的category对象
category = models.ForeignKey(verbose_name='文章类型', to='Category', to_field='nid', null=True)
# user字段:与Article对象关联的user字段
user = models.ForeignKey(verbose_name='所属用户', to='UserInfo', to_field='nid')
tags = models.ManyToManyField(
to="Tag",
through='Article2Tag',
through_fields=('article', 'tag'),
)
class ArticleDetail(models.Model):
nid = models.AutoField(primary_key=True)
content = models.TextField(verbose_name='文章内容', )
article = models.OnetoOneField(verbose_name='所属文章', to='Article', to_field='nid')
class Article2Tag(models.Model):
nid = models.AutoField(primary_key=True)
article = models.ForeignKey(verbose_name='文章', to="Article", to_field='nid')
tag = models.ForeignKey(verbose_name='标签', to="Tag", to_field='nid')
class Tag(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField(verbose_name='标签名称', max_length=32)
blog = models.ForeignKey(verbose_name='所属博客', to='Blog', to_field='nid'
关联表的添加记录操作:
1、创建一篇文章对象:
user_obj=models.UserInfo.objects.get(nid=1)
category_obj=models.Category.objects.get(nid=2)
#################一对多关系绑定#########################
# 方式1:
article_obj=models.Article.objects.create(nid=5,title="朝花夕拾"....,user=user_obj,category=category_obj)
# 方式2:
article_obj=models.Article.objects.create(nid=5,title="朝花夕拾"....,user_id=1,category_id=2)
'''
Article:
nid title user_id category_id
5 朝花夕拾 1 2
'''
############################多对多关系绑定#########################
if 没有中介模型:
tags = models.ManyToManyField("Tag")
'''
ORM创建的第三张表:
Article2tags:
nid article_id tag_id
1 5 1
2 5 2
'''
实例:给article_obj绑定kw1,kw2的标签
tag1=Tag.objects.filter(title=kw1).first()
tag2=Tag.objects.filter(title=kw2).first()
article_obj.tags.add(tag1,tag2) #
article_obj.tags.add(*[tag1,tag2])
article_obj.tags.add(1,2)
article_obj.tags.add(*[1,2])
解除关系:
article_obj.tags.remove(tag1,tag2)
article_obj.tags.clear()
重置关系:
article_obj.tags.clear()
article_obj.tags.add(tag1,tag2)
=====
article_obj.tags.set(tag1,tag2)
if 有中介模型:
tags = models.ManyToManyField(
to="Tag",
through='Article2Tag',
through_fields=('article', 'tag'),
)
class Article2Tag(models.Model): # 中介模型
nid = models.AutoField(primary_key=True)
article = models.ForeignKey(verbose_name='文章', to="Article", to_field='nid')
tag = models.ForeignKey(verbose_name='标签', to="Tag", to_field='nid')
绑定多对多的关系,有中介模型,不能再使用article_obj.tags.add(),remove()等方法;
只能用Article2Tag表进行实例对象。
实例:给article_obj绑定kw1,kw2的标签:
models.Article2Tag.objects.create(tag_id=1,article_id=5)
models.Article2Tag.objects.create(tag_id=2,article_id=5)
复制代码
连表操作(基于对象查询):
复制代码
一对多的查询:
实例1:查询主键为4的文章的分类名称(正向查询,按字段)
article_obj=models.Article.objects.get(nid=4)
print(article_obj.category.title)
SELECT * FROM "blog_article" WHERE "blog_article"."nid" = 4; // category_id=2
SELECT * FROM "blog_category" WHERE "blog_category"."nid" = 2;
实例2:查询用户yuan发表过的所有的文章(反向查询,表名_set)
yuan=models.UserInfo.objects.get(username="yuan")
book_list=yuan.article_set.all() # QuerySet
多对多的查询:
实例3:查询主键为4的文章的标签名称(正向查询,按字段)
article_obj=models.Article.objects.get(nid=4)
tag_list=article_obj.tags.all() # 是通过Article2Tag找到tag表中关联的tag记录
for i in tag_list:
print(i.title)
实例4:查询web开发的这个标签对应的所有的文章(反向查询,按表名_set)
tag_obj=models.Tag.objects.get(title="web开发")
article_list=tag_obj.article_set.all()
for i in article_list:
print(i.title)
实例5:查询web开发的这个标签对应的所有的文章对应的作者名字
tag_obj=models.Tag.objects.get(title="web开发")
article_list=tag_obj.article_set.all()
for article in article_list:
print(article.user.username)
基于QuerySet跨表查询 ( 正向查询,按字段 ;反向查询,按表名)
一对多的查询:
实例1:查询主键为4的文章的分类名称
models.Article.objects.filter(nid=4).values("category__title")
models.Category.objects.filter(article__nid=4).values("title")
实例2:查询用户yuan发表过的所有的文章
models.UserInfo.objects.filter(username="yuan").values(article__title)
models.Article.objects.filter(user__username="yuan").values("title")
多对多的查询:
实例3:查询主键为4的文章的标签名称(正向查询,按字段)
models.Article.objects.filter(nid=4).values("tags__title")
models.Tag.objects.filter(article__nid=4).values("title")
实例4:查询web开发的这个标签对应的所有的文章(反向查询,按表名_set)
models.Article.objects.filter(tags__title="web开发").values("title")
models.Tag.objects.filter(title="web开发").values("article__title")
实例5:查询web开发的这个标签对应的所有的文章对应的作者名字
models.Tag.objects.filter(title="web开发").values("article__user__username")
models.UserInfo.objects.filter(article__tags__title="web开发").values("username")
以上是“django知识点有哪些”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注小编行业资讯频道!
今天关于网站sitemap的知识点有哪些和网站sitemap生成的介绍到此结束,谢谢您的阅读,有关Apache HBase内核知识点有哪些、Appium框架的知识点有哪些、C++内存模型与名称空间的知识点有哪些、django知识点有哪些等更多相关知识的信息可以在本站进行查询。
本文标签:




