dedecms采集过滤规则及替换规则(dedecms采集怎么用)
9
本文将介绍dedecms采集过滤规则及替换规则的详细情况,特别是关于dedecms采集怎么用的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于dede
本文将介绍dedecms采集过滤规则及替换规则的详细情况,特别是关于dedecms采集怎么用的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于dede3.1分页文字采集过滤规则详说(图文教程)、dede3.1分页文字采集过滤规则详说(图文教程)_php技巧、dede3.1分页文字采集过滤规则详说(图文教程)续二、dede3.1分页文字采集过滤规则详说(图文教程)续二_php技巧的知识。
本文目录一览:")
dedecms采集过滤规则及替换规则(dedecms采集怎么用)
采集过滤规则 及替换规则
{dede:trim replace=''}<a([^>]*)>(.*)</a>{/dede:trim}
{dede:trim replace=''}<script([^>]*)>(.*)</script>{/dede:trim}
{dede:trim replace=''}<!--(.*)-->{/dede:trim}
{dede:trim replace=''}<table([^>]*)>(.*)</table>{/dede:trim}
{dede:trim replace=''}<style([^>]*)>(.*)</style>{/dede:trim}
{dede:trim replace=''}<img([^>]*)>{/dede:trim}
{dede:trim replace=''}<object([^>]*)>(.*)</object>{/dede:trim}
{dede:trim replace=''}<embed([^>]*)>(.*)</embed>{/dede:trim}
{dede:trim replace=''}<iframe([^>]*)>(.*)</iframe>{/dede:trim}
{dede:trim replace=''}<param([^>]*)>(.*)</param>{/dede:trim}
{dede:trim replace=''}<div([^.]*)>{/dede:trim}
{dede:trim replace=''}</div>{/dede:trim}
如果新闻中的字段 想替换的话
{dede:trim replace='替换内容'}原内容{/dede:trim}
本文章网址:http://www.ppssdd.com/code/12685.html。转载请保留出处,谢谢合作!
")
dede3.1分页文字采集过滤规则详说(图文教程)
本文旨在以一个有代表性的文字分页的取样规则和过滤规则为蓝本,通过简单的变通和改动,解决一般性文字分页的采集问题一、范例部分
范例分页区域代码:
范例分页区域代码:

范例分页区域取样代码:
分页区域取样(匹配):
 范例分页内容过滤规则:
范例分页内容过滤规则:
分页内容过滤规则:

范例采集内容预览:
范例采集内容预览:
 范例全代码(说明:此代码为在原基础上进行更改后的代码,原代码版本不同,直接导入后无效,因此在dede论坛中有许多朋友说过‘直接导入人家的代码都不能用',确实如此):
范例全代码(说明:此代码为在原基础上进行更改后的代码,原代码版本不同,直接导入后无效,因此在dede论坛中有许多朋友说过‘直接导入人家的代码都不能用',确实如此):
输出结果:http://wen.soudata.net/html/guizeceshi/caijibiji/20070327/2044_2.html
与原文比较下吧:http://www.xiaocao.com/text/class1/class1/200609/text_28623.html
这是全部的代码,可导入试下:
代码如下: {!--节点基本信息--} {dede:itemname='论坛范例_工作总结_成功(改)'
imgurl='/upimg'imgdir='../upimg'language='gb2312'typeid='1'macthtype='string'}
{/dede:item} {!--采集列表获取规则--} {dede:listsource='var'sourcetype='archives'
varstart=''varend=''}
{dede:urlvalue='http://www.xiaocao.com/text/class1/class1/200609/text_28623.html'}{/dede:url}
{dede:need}{/dede:need}
{dede:cannot}{/dede:cannot}
{dede:linkarea}[var:区域]{/dede:linkarea}
{/dede:list} {!--网页内容获取规则--} {dede:art}
{dede:sppagesptype='full'}[1][var:分页区域]{/dede:sppage} {dede:notefield='dede_archives.title'value='[var:内容]'comment='文章标题'
isunit=''isdown=''} {dede:match}[var:<a href="https://www.jb51.cc/tag/neirong/" target="_blank">内容</a>]{/dede:match} {dede:function}{/dede:function} {/dede:note} {dede:notefield='dede_archives.sortrank'value='[var:内容]'comment='排序级别'
isunit=''isdown=''} {dede:match}{/dede:match} {dede:function}@me=time();{/dede:function} {/dede:note} {dede:notefield='dede_archives.writer'value='[var:内容]'comment='文章作者'
isunit=''isdown=''} {dede:match}{/dede:match} {dede:function}{/dede:function} {/dede:note} {dede:notefield='dede_archives.litpic'value='[var:内容]'comment='缩略图'
isunit=''isdown=''} {dede:match}{/dede:match} {dede:function}@me=@litpic;{/dede:function} {/dede:note} {dede:notefield='dede_archives.pubdate'value='[var:内容]'comment='发布时间'
isunit=''isdown=''} {dede:match}{/dede:match} {dede:function}if(@me!="")@me=GetMkTime(@me);
else@me=time();{/dede:function} {/dede:note} {dede:notefield='dede_archives.senddate'value='[var:内容]'comment='录入时间'
isunit=''isdown=''} {dede:match}{/dede:match} {dede:function}@me=time();{/dede:function} {/dede:note} {dede:notefield='dede_addonarticle.body'value='[var:内容]'comment='文章内容'
isunit='1'isdown=''} {dede:match}[var:内容]{/dede:match}
{dede:trim}(.*){/dede:trim} {dede:function}{/dede:function} {/dede:note} {dede:notefield='dede_archives.source'value='[var:内容]'comment='文章来源'
isunit=''isdown=''} {dede:match}{/dede:match} {dede:function}{/dede:function} {/dede:note}
{/dede:art}
_php技巧")
dede3.1分页文字采集过滤规则详说(图文教程)_php技巧
本文旨在以一个有代表性的文字分页的取样规则和过滤规则为蓝本,通过简单的变通和改动,解决一般性文字分页的采集问题
一、范例部分
范例分页区域代码:
范例分页区域代码:

范例分页区域取样代码:
分页区域取样(匹配):
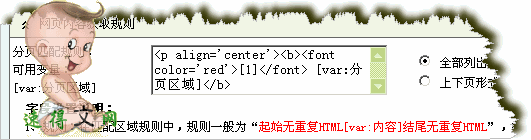
范例分页内容过滤规则:
分页内容过滤规则:
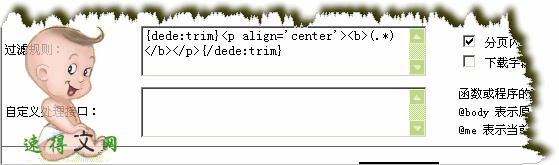
范例采集内容预览:
范例采集内容预览:

范例全代码(说明:此代码为在原基础上进行更改后的代码,原代码版本不同,直接导入后无效,因此在dede论坛中有许多朋友说过‘直接导入人家的代码都不能用'',确实如此):
输出结果:http://wen.soudata.net/html/guizeceshi/caijibiji/20070327/2044_2.html
与原文比较下吧:http://www.xiaocao.com/text/class1/class1/200609/text_28623.html
这是全部的代码,可导入试下:
{!-- 节点基本信息 --}
{dede:item name=''论坛范例_工作总结_成功(改)''
imgurl=''/upimg'' imgdir=''../upimg'' language=''gb2312'' typeid=''1'' macthtype=''string''}
{/dede:item}
{!-- 采集列表获取规则 --}
{dede:list source=''var'' sourcetype=''archives''
varstart='''' varend=''''}
{dede:url value=''http://www.xiaocao.com/text/class1/class1/200609/text_28623.html''}{/dede:url}
{dede:need}{/dede:need}
{dede:cannot}{/dede:cannot}
{dede:linkarea}[var:区域]{/dede:linkarea}
{/dede:list}
{!-- 网页内容获取规则 --}
{dede:art}
{dede:sppage sptype=''full''}[1][var:分页区域]{/dede:sppage}
{dede:note field=''dede_archives.title'' value=''[var:内容]'' comment=''文章标题''
isunit='''' isdown=''''}
{dede:match}
[var:内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:note}
{dede:note field=''dede_archives.sortrank'' value=''[var:内容]'' comment=''排序级别''
isunit='''' isdown=''''}
{dede:match}{/dede:match}
{dede:function}@me = time();{/dede:function}
{/dede:note}
{dede:note field=''dede_archives.writer'' value=''[var:内容]'' comment=''文章作者''
isunit='''' isdown=''''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:note}
{dede:note field=''dede_archives.litpic'' value=''[var:内容]'' comment=''缩略图''
isunit='''' isdown=''''}
{dede:match}{/dede:match}
{dede:function}@me = @litpic;{/dede:function}
{/dede:note}
{dede:note field=''dede_archives.pubdate'' value=''[var:内容]'' comment=''发布时间''
isunit='''' isdown=''''}
{dede:match}{/dede:match}
{dede:function}if(@me!="") @me = GetMkTime(@me);
else @me = time();{/dede:function}
{/dede:note}
{dede:note field=''dede_archives.senddate'' value=''[var:内容]'' comment=''录入时间''
isunit='''' isdown=''''}
{dede:match}{/dede:match}
{dede:function}@me = time();{/dede:function}
{/dede:note}
{dede:note field=''dede_addonarticle.body'' value=''[var:内容]'' comment=''文章内容''
isunit=''1'' isdown=''''}
{dede:match}<script></script>[var:内容]
{/dede:match}
{dede:trim}(.*)
{/dede:trim}
{dede:function}{/dede:function}
{/dede:note}
{dede:note field=''dede_archives.source'' value=''[var:内容]'' comment=''文章来源''
isunit='''' isdown=''''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:note}
{/dede:art}
续二")
dede3.1分页文字采集过滤规则详说(图文教程)续二
稍微了解dede采集规则的朋友上篇内容完全可以略过,下面看看如何以静制动、以不变就万变地解决分页采集问题。
二、采集新目标目标地址:
1、http://www.tiansou.net/Html/Y_CYFW/R_Gzzj/F_Gzjh/index.html
2、http://www.tiansou.net/Html/Y_CYFW/R_Gzzj/F_Gzjh/2007-2/9/20070209110903558.html
之所以选取两个目标页面,是因为以上的两个页面一个有分页,而另一个没有,并且在分页和全文取样部分有较大的差别。以下的说明是在为采集目标地址(首页)全部链接的基础上改动的,个别地方会显得蛇足,只为说明的方便。目标文字部分头部代码1:

目标文字部分头部代码2:
 通过比较不难发现,两个文字部分的开始采集部分能确定下来为描黑部分,开头部分好说,代码如下:
通过比较不难发现,两个文字部分的开始采集部分能确定下来为描黑部分,开头部分好说,代码如下:
<div><adata="65362"id="copybut65362" onclick="doCopy('code65362')"> 代码如下:
续二_php技巧")
dede3.1分页文字采集过滤规则详说(图文教程)续二_php技巧
稍微了解dede采集规则的朋友上篇内容完全可以略过,下面看看如何以静制动、以不变就万变地解决分页采集问题。
二、采集新目标
目标地址:
1、http://www.tiansou.net/Html/Y_CYFW/R_Gzzj/F_Gzjh/index.html
2、http://www.tiansou.net/Html/Y_CYFW/R_Gzzj/F_Gzjh/2007-2/9/20070209110903558.html
之所以选取两个目标页面,是因为以上的两个页面一个有分页,而另一个没有,并且在分页和全文取样部分有较大的差别。以下的说明是在为采集目标地址(首页)全部链接的基础上改动的,个别地方会显得蛇足,只为说明的方便。
目标文字部分头部代码1:
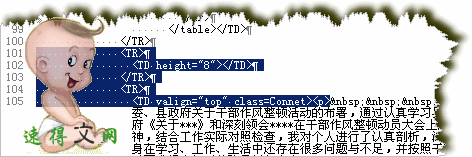
目标文字部分头部代码2:
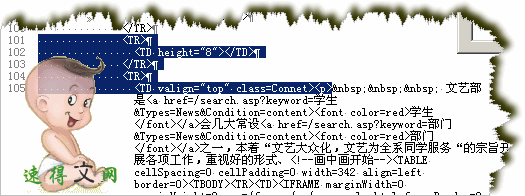
通过比较不难发现,两个文字部分的开始采集部分能确定下来为描黑部分,开头部分好说,代码如下:
目标文尾及分页区域代码1:
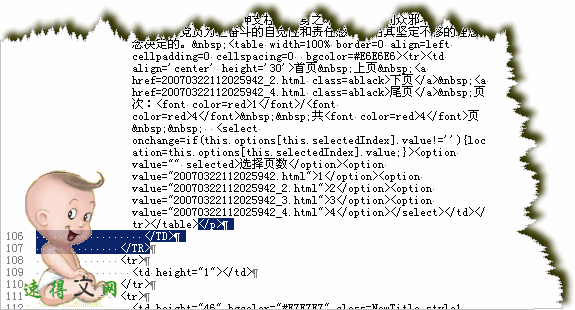
目标文尾及分页区域代码2:

比较一下两个结尾,尽管想把第一个的结尾再往前提一点,但没法子,要考虑到全部链接的共同部分,就只好取描黑的部分了,这也给今后确定过滤规则添了点麻烦,这是后话。先把结尾部分确定了吧:




