本篇文章给大家谈谈mssqlserver存储过程里,bulkinserttablefrom'路径+文件',路径固定,文件名不固定的实现方法,同时本文还将给你拓展BULKCOLLECT(成批聚合类型)和
本篇文章给大家谈谈mssql server 存储过程里,bulk insert table from '路径+文件',路径固定,文件名不固定的实现方法,同时本文还将给你拓展BULK COLLECT(成批聚合类型)和数组集合type类型is table of 表%rowtype index by binary_integer、Bulk Insert 命令详细、BULK INSERT 如何将大量数据高效地导入 SQL Server、bulk.insert(doc) 默认值无法插入 MongoDB nodejs等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- mssql server 存储过程里,bulk insert table from '路径+文件',路径固定,文件名不固定的实现方法
- BULK COLLECT(成批聚合类型)和数组集合type类型is table of 表%rowtype index by binary_integer
- Bulk Insert 命令详细
- BULK INSERT 如何将大量数据高效地导入 SQL Server
- bulk.insert(doc) 默认值无法插入 MongoDB nodejs

mssql server 存储过程里,bulk insert table from '路径+文件',路径固定,文件名不固定的实现方法
动态语句, bulk insert的from 子句只能使用常量.CREATE proc test
@fn varchar(50)
as
declare @path varchar(100)
set @path= ''d:\''
exec(''
bulk INSERT table FROM ''''''+@path+@fn+''''''
WITH
(
FIELDTERMINATOR = '''','''',
ROWTERMINATOR = ''''\n''''
)'')
摘自CSDN
- SQL Server Bulk Insert 只需要部分字段时的方法
- 使用BULK INSERT大批量导入数据 SQLSERVER
- sql server Bulk Insert命令详细
和数组集合type类型is table of 表%rowtype index by binary_integer")
BULK COLLECT(成批聚合类型)和数组集合type类型is table of 表%rowtype index by binary_integer

Bulk Insert 命令详细
Bulk Insert 命令详细
BULK INSERT 以用户指定的格式复制一个数据文件至数据库表或视图中。 语法: Sql 代码 BULK INSERT [[ ''database_name''.][ ''owner'' ].]{ ''table_name'' FROM ''data_file'' }
WITH (
[ BATCHSIZE [ = batch_size ] ],
[ CHECK_CONSTRAINTS ],
[ CODEPAGE [ = ''ACP'' | ''OEM'' | ''RAW'' | ''code_page'' ] ],
[ DATAFILETYPE [ = ''char'' | ''native''| ''widechar'' | ''widenative'' ] ],
[ FIELDTERMINATOR [ = ''field_terminator'' ] ],
[ FIRSTROW [ = first_row ] ],
[ FIRE_TRIGGERS ],
[ FORMATFILE = ''format_file_path'' ],
[ KEEPIDENTITY ],
[ KEEPNULLS ],
[ KILOBYTES_PER_BATCH [ = kilobytes_per_batch ] ],
[ LASTROW [ = last_row ] ],
[ MAXERRORS [ = max_errors ] ],
[ ORDER ( { column [ ASC | DESC ] } [ ,...n ] ) ],
[ ROWS_PER_BATCH [ = rows_per_batch ] ],
[ ROWTERMINATOR [ = ''row_terminator'' ] ],
[ TABLOCK ],
)
[SQL] view plaincopy BULK INSERT [ [ ''database_name''.][ ''owner'' ].]{ ''table_name'' FROM ''data_file'' }
WITH (
[ BATCHSIZE [ = batch_size ] ],
[ CHECK_CONSTRAINTS ],
[ CODEPAGE [ = ''ACP'' | ''OEM'' | ''RAW'' | ''code_page'' ] ],
[ DATAFILETYPE [ = ''char'' | ''native''| ''widechar'' | ''widenative'' ] ],
[ FIELDTERMINATOR [ = ''field_terminator'' ] ],
[ FIRSTROW [ = first_row ] ],
[ FIRE_TRIGGERS ],
[ FORMATFILE = ''format_file_path'' ],
[ KEEPIDENTITY ],
[ KEEPNULLS ],
[ KILOBYTES_PER_BATCH [ = kilobytes_per_batch ] ],
[ LASTROW [ = last_row ] ],
[ MAXERRORS [ = max_errors ] ],
[ ORDER ( { column [ ASC | DESC ] } [ ,...n ] ) ],
[ ROWS_PER_BATCH [ = rows_per_batch ] ],
[ ROWTERMINATOR [ = ''row_terminator'' ] ],
[ TABLOCK ],
)
参数: ''database_name'' 是包含指定表或视图的数据库的名称。如果未指定,则系统默认为当前数据库。
''owner'' 是表或视图所有者的名称。当执行大容量复制操作的用户拥有指定的表或视图时,owner 是可选项。如果没有指定 owner 并且执行大容量复制操作的用户不拥有指定的表或视图,则 Microsoft® SQL Server? 将返回错误信息并取消大容量复制操作。
''table_name'' 是大容量复制数据于其中的表或视图的名称。只能使用那些所有的列引用相同基表所在的视图。有关向视图中复制数据的限制的更多信息,请参见 INSERT。
''data_file'' 是数据文件的完整路径,该数据文件包含要复制到指定表或视图的数据。BULK INSERT 从磁盘复制数据(包括网络、软盘、硬盘等)。 data_file 必须从运行 SQL Server 的服务器指定有效路径。如果 data_file 是远程文件,则请指定通用命名规则 (UNC) 名称。
BATCHSIZE [= batch_size] 指定批处理中的行数。每个批处理作为一个事务复制至服务器。SQL Server 提交或回滚(在失败时)每个批处理的事务。默认情况下,指定数据文件中的所有数据是一个批处理。
CHECK_CONSTRAINTS 指定在大容量复制操作中检查 table_name 的任何约束。默认情况下,将会忽略约束。
CODEPAGE [= ''ACP'' | ''OEM'' | ''RAW'' | ''code_page''] 指定该数据文件中数据的代码页。仅当数据含有字符值大于 127 或小于 32 的 char、varchar 或 text 列时,CODEPAGE 才是适用的。CODEPAGE 值 描述 ACP char、varchar 或 text 数据类型的列从 ANSI/Microsoft Windows® 代码页 ISO 1252 转换为 SQL Server 代码页。 OEM(默认值) char、varchar 或 text 数据类型的列被从系统 OEM 代码页转换为 SQL Server 代码页。 RAW 并不进行从一个代码页到另一个代码页的转换;这是最快的选项。 code_page 特定的代码页号码,例如 850。
DATAFILETYPE [= {''char'' | ''native'' | ''widechar'' | ''widenative''} ] 指定 BULK INSERT 使用指定的默认值执行复制操作。DATAFILETYPE 值 描述 char(默认值) 从含有字符数据的数据文件执行大容量复制操作。 native 使用 native(数据库)数据类型执行大容量复制操作。要装载的数据文件由大容量复制数据创建,该复制是用 bcp 实用工具从 SQL Server 进行的。 widechar 从含有 Unicode 字符的数据文件中执行大容量复制操作。 widenative 执行与 native 相同的大容量复制操作,不同之处是 char、varchar 和 text 列在数据文件中存储为 Unicode。要装载的数据文件由大容量复制数据创建,该复制是用 bcp 实用工具从 SQL Server 进行的。该选项是对 widechar 选项的一个更高性能的替代,并且它用于使用数据文件从一个运行 SQL Server 的计算机向另一个计算机传送数据。当传送含有 ANSI 扩展字符的数据时,使用该选项以便利用 native 模式的性能。
FIELDTERMINATOR [= ''field_terminator''] 指定用于 char 和 widechar 数据文件的字段终止符。默认的字段终止符是 /t(制表符)。
FIRSTROW [= first_row] 指定要复制的第一行的行号。默认值是 1,表示在指定数据文件的第一行。
FIRE_TRIGGERS 指定目的表中定义的任何插入触发器将在大容量复制操作过程中执行。如果没有指定 FIRE_TRIGGERS,将不执行任何插入触发器。
FORMATFILE [= ''format_file_path''] 指定一个格式文件的完整路径。格式文件描述了含有存储响应的数据文件,这些存储响应是使用 bcp 实用工具在相同的表或视图中创建的。格式文件应该用于以下情况: 数据文件含有比表或视图更多或更少的列。列使用不同的顺序。列分割符发生变化。数据格式有其它的改变。通常,格式文件通过 bcp 实用工具创建并且根据需要用文本编辑器修改。有关更多信息,请参见 bcp 实用工具。
KEEPIDENTITY 指定标识列的值存在于导入文件中。如果没有指定 KEEPIDENTITY,在导入的数据文件中此列的标识值将被忽略,并且 SQL Server 将根据表创建时指定的种子值和增量值自动赋给一个唯一的值。假如数据文件不含该表或视图中的标识列,使用一个格式文件来指定在导入数据时,表或视图中的标识列应被忽略;SQL Server 自动为此列赋予唯一的值。有关详细信息,请参见 DBCC CHECKIDENT。
KEEPNULLS 指定在大容量复制操作中空列应保留一个空值,而不是对插入的列赋予默认值。
KILOBYTES_PER_BATCH [= kilobytes_per_batch] 指定每个批处理中数据的近似千字节数(KB)。默认情况下,KILOBYTES_PER_BATCH 未知。
LASTROW [= last_row] 指定要复制的最后一行的行号。默认值是 0,表示指定数据文件中的最后一行。
MAXERRORS [= max_errors] 指定在大容量复制操作取消之前可能产生的错误的最大数目。不能被大容量复制操作导入的每一行将被忽略并且被计为一次错误。如果没有指定 max_errors,默认值为 0。
ORDER ({ column [ ASC | DESC] } [ ,...n ] ) 指定数据文件中的数据如何排序。如果装载的数据根据表中的聚集索引进行排序,则可以提高大容量复制操作的性能。如果数据文件基于不同的顺序排序,或表中没有聚集索引,ORDER 子句将被忽略。给出的列名必须是目的表中有效的列。默认情况下,大容量插入操作假设数据文件未排序。n 是表示可以指定多列的占位符。
ROWS_PER_BATCH [= rows_per_batch] 指定每一批处理数据的行数(即 rows_per_bacth)。当没有指定 BATCHSIZE 时使用,导致整个数据文件作为单个事务发送给服务器。服务器根据 rows_per_batch 优化大容量装载。默认情况下,ROWS_PER_BATCH 未知。
ROWTERMINATOR [= ''row_terminator''] 指定对于 char 和 widechar 数据文件要使用的行终止符。默认值是 /n(换行符)。
TABLOCK 指定对于大容量复制操作期间获取一个表级锁。如果表没有索引并且指定了 TABLOCK,则该表可以同时由多个客户端装载。默认情况下,锁定行为是由表选项 table lock on bulk load 决定的。只在大容量复制操作期间控制锁会减少表上的锁争夺,极大地提高性能。注释 BULK INSERT 语句能在用户定义事务中执行。对于一个用 BULK INSERT 语句和 BATCHSIZE 子句将数据装载到使用多个批处理的表或视图中的用户定义事务来说,回滚它将回滚所有发送给 SQL Server 的批处理。权限只有 sysadmin 和 bulkadmin 固定服务器角色成员才能执行 BULK INSERT。
示例本例从指定的数据文件中导入订单详细信息,该文件使用竖杠 (|) 字符作为字段终止符,使用 |/n 作为行终止符。 Sql 代码 BULK INSERT Northwind.dbo.[Order Details] FROM ''f:/orders/lineitem.tbl''
WITH (
FIELDTERMINATOR = ''|'',
ROWTERMINATOR = ''|/n''
)
[SQL] view plaincopy BULK INSERT Northwind.dbo.[Order Details] FROM ''f:/orders/lineitem.tbl''
WITH (
FIELDTERMINATOR = ''|'',
ROWTERMINATOR = ''|/n''
)
本例指定 FIRE_TRIGGERS 参数。 Sql 代码 BULK INSERT Northwind.dbo.[Order Details] FROM ''f:/orders/lineitem.tbl''
WITH (
FIELDTERMINATOR = ''|'',
ROWTERMINATOR = '':/n'',
FIRE_TRIGGERS
)
BULK INSERT
[ database_name . [ schema_name ] . | schema_name . ] [ table_name | view_name ]
FROM ''data_file''
[ WITH
(
[[ ,] BATCHSIZE = batch_size ] --BATCHSIZE 指令来设置在单个事务中可以插入到表中的记录的数量
[[ ,] CHECK_CONSTRAINTS ] -- 指定在大容量导入操作期间,必须检查所有对目标表或视图的约束。若没有 CHECK_CONSTRAINTS 选项,则所有 CHECK 和 FOREIGN KEY 约束都将被忽略,并且在此操作之后表的约束将标记为不可信。
[[ ,] CODEPAGE = { ''ACP'' | ''OEM'' | ''RAW'' | ''code_page'' } ] -- 指定该数据文件中数据的代码页
[ [ , ] DATAFILETYPE =
{''char'' | ''native''| ''widechar'' | ''widenative''} ] -- 指定 BULK INSERT 使用指定的数据文件类型值执行导入操作。
[[ ,] FIELDTERMINATOR = ''field_terminator'' ] -- 标识分隔内容的符号
[[ ,] FIRSTROW = first_row ] -- 指定要加载的第一行的行号。默认值是指定数据文件中的第一行
[[ ,] FIRE_TRIGGERS ] -- 是否启动触发器
[ [ , ] FORMATFILE = ''format_file_path'' ]
[[ ,] KEEPIDENTITY ] -- 指定导入数据文件中的标识值用于标识列
[[ ,] KEEPNULLS ] -- 指定在大容量导入操作期间空列应保留一个空值,而不插入用于列的任何默认值
[ [ , ] KILOBYTES_PER_BATCH = kilobytes_per_batch ]
[[ ,] LASTROW = last_row ] -- 指定要加载的最后一行的行号
[[ ,] MAXERRORS = max_errors ] -- 指定允许在数据中出现的最多语法错误数,超过该数量后将取消大容量导入操作。
[[ ,] ORDER ( { column [ ASC | DESC ] } [ ,...n ] ) ] -- 指定数据文件中的数据如何排序
[ [ , ] ROWS_PER_BATCH = rows_per_batch ]
[[ ,] ROWTERMINATOR = ''row_terminator'' ] -- 标识分隔行的符号
[[ ,] TABLOCK ] -- 指定为大容量导入操作持续时间获取一个表级锁
[[ ,] ERRORFILE = ''file_name'' ] -- 指定用于收集格式有误且不能转换为 OLE DB 行集的行的文件。
)]
[SQL] view plaincopy BULK INSERT Northwind.dbo.[Order Details] FROM ''f:/orders/lineitem.tbl''
WITH (
FIELDTERMINATOR = ''|'',
ROWTERMINATOR = '':/n'',
FIRE_TRIGGERS
)
BULK INSERT
[ database_name . [ schema_name ] . | schema_name . ] [ table_name | view_name ]
FROM ''data_file''
[ WITH
(
[[ ,] BATCHSIZE = batch_size ] --BATCHSIZE 指令来设置在单个事务中可以插入到表中的记录的数量
[[ ,] CHECK_CONSTRAINTS ] -- 指定在大容量导入操作期间,必须检查所有对目标表或视图的约束。若没有 CHECK_CONSTRAINTS 选项,则所有 CHECK 和 FOREIGN KEY 约束都将被忽略,并且在此操作之后表的约束将标记为不可信。
[[ ,] CODEPAGE = { ''ACP'' | ''OEM'' | ''RAW'' | ''code_page'' } ] -- 指定该数据文件中数据的代码页
[ [ , ] DATAFILETYPE =
{''char'' | ''native''| ''widechar'' | ''widenative''} ] -- 指定 BULK INSERT 使用指定的数据文件类型值执行导入操作。
[[ ,] FIELDTERMINATOR = ''field_terminator'' ] -- 标识分隔内容的符号
[[ ,] FIRSTROW = first_row ] -- 指定要加载的第一行的行号。默认值是指定数据文件中的第一行
[[ ,] FIRE_TRIGGERS ] -- 是否启动触发器
[ [ , ] FORMATFILE = ''format_file_path'' ]
[[ ,] KEEPIDENTITY ] -- 指定导入数据文件中的标识值用于标识列
[[ ,] KEEPNULLS ] -- 指定在大容量导入操作期间空列应保留一个空值,而不插入用于列的任何默认值
[ [ , ] KILOBYTES_PER_BATCH = kilobytes_per_batch ]
[[ ,] LASTROW = last_row ] -- 指定要加载的最后一行的行号
[[ ,] MAXERRORS = max_errors ] -- 指定允许在数据中出现的最多语法错误数,超过该数量后将取消大容量导入操作。
[[ ,] ORDER ( { column [ ASC | DESC ] } [ ,...n ] ) ] -- 指定数据文件中的数据如何排序
[ [ , ] ROWS_PER_BATCH = rows_per_batch ]
[[ ,] ROWTERMINATOR = ''row_terminator'' ] -- 标识分隔行的符号
[[ ,] TABLOCK ] -- 指定为大容量导入操作持续时间获取一个表级锁
[[ ,] ERRORFILE = ''file_name'' ] -- 指定用于收集格式有误且不能转换为 OLE DB 行集的行的文件。
)]
下面写个个简单的应用例子 Sql 代码 bulk insert xsxt.dbo.tabletest from ''c:/data.txt''
with(
FIELDTERMINATOR='','',
ROWTERMINATOR=''/n''
)

BULK INSERT 如何将大量数据高效地导入 SQL Server
在实际的工作需要中,我们有时候需将大量的数据导入到数据库中。这时候我们不得不考虑的就是效率问题。本文我们就介绍了一种将大量数据高效地导入 SQL Server 数据库的方法,该方法是使用 BULK INSERT 来实现的,接下来就让我们来一起了解一下这部分内容。
源数据 (文本文件)
下载了大量的股票历史数据,都是文本格式的:
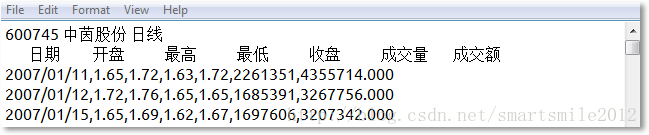
每个文件第一行包含股票代码,股票名称,数据类型。第二行是数据列的名称:
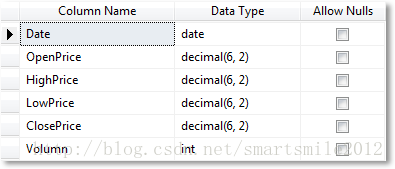
数据表
在数据库中新建了一个数据表 TestStock,并设置以下字段,但没有关于 "成交额" 的字段,因为以后的计算不会用到这个数据。另外这里关于价格的字段没有使用 money 数据类型,decimal 足矣。
编写格式化文件
当前数据的格式化文件为:
<?xml version="1.0"?>
<BCPFORMAT xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload/format" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<RECORD>
<FIELDID FIELDID="1" xsi:type="CharTerm" TERMINATOR=","/>
<FIELDID FIELDID="2" xsi:type="CharTerm" TERMINATOR=","/>
<FIELDID FIELDID="3" xsi:type="CharTerm" TERMINATOR=","/>
<FIELDID FIELDID="4" xsi:type="CharTerm" TERMINATOR=","/>
<FIELDID FIELDID="5" xsi:type="CharTerm" TERMINATOR=","/>
<FIELDID FIELDID="6" xsi:type="CharTerm" TERMINATOR=","/>
<FIELDI DFIELDID="7" xsi:type="CharTerm" TERMINATOR="\r\n"/>
</RECORD>
<ROW>
<COLUMNSOURCE COLUMNSOURCE="1" NAME="Date" xsi:type="SQLDATE"/>
<COLUMNSOURCE COLUMNSOURCE="2" NAME="OpenPrice" xsi:type="SQLDECIMAL" PRECISION="6" SCALE="2"/>
<COLUMNSOURCE COLUMNSOURCE="3" NAME="HighPrice" xsi:type="SQLDECIMAL" PRECISION="6" SCALE="2"/>
<COLUMNSOURCE COLUMNSOURCE="4" NAME="LowPrice" xsi:type="SQLDECIMAL" PRECISION="6" SCALE="2"/>
<COLUMNSOURCE COLUMNSOURCE="5" NAME="ClosePrice" xsi:type="SQLDECIMAL" PRECISION="6" SCALE="2"/>
<COLUMNSOURCE COLUMNSOURCE="6" NAME="Volumn" xsi:type="SQLINT"/>
</ROW>
</BCPFORMAT>暂且先保存在 C 盘目录下吧,文件名叫 BCPFORMAT.xml
编写 BULKINSERT 语句:
BULKINSERTTestStock FROM''C:\SH600475.txt'' WITH( FORMATFILE=''C:\BCPFORMAT.xml'', FIELDTERMINATOR='','', ROWTERMINATOR=''\r\n'')执行 BULKINSERT 的速度很快,结果如下:
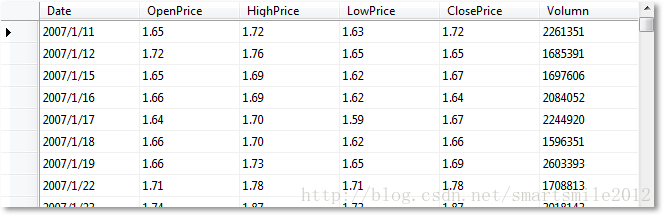
同样的效果,如果从文本中读一行记录,执行一次 INSERTINTO 语句的话,需要 10 秒左右,由此可见 BULKINSERT 的高效。
 默认值无法插入 MongoDB nodejs")
bulk.insert(doc) 默认值无法插入 MongoDB nodejs
如何解决bulk.insert(doc) 默认值无法插入 MongoDB nodejs
我已经插入了 100k 条记录,我已经成功地批量上传了记录。但是,如果我使用 bulk.insert(doc),则不会使用 mongoose 和 Nodejs 插入默认值。像 createdAt 和 updatedAt 字段作为未插入的默认值。我试图添加选项 setDefaultsOnInsert: true bulk.insert 没有选项来添加值。目前,我添加了我的代码。请帮我提前。
代码
let data = req.body;
var bulk = calldispositionModel.collection.initializeOrderedBulkOp();
var counter=0
data.forEach(doc1 => {
bulk.insert(doc1);
if (counter % 5000 == 0) {
bulk.execute();
bulk = calldispositionModel.collection.initializeUnorderedBulkOp();
counter = 0;
}
counter++
})
if (counter > 0) {
bulk.execute(function(err,result) {
if(err){
console.log(`err `,err)
}else{
console.log(`result `,result)
return res.send({success: true,message:''data uploaded successfully'')
}
});
}
架构或模型
let dispositionSchema = new mongoose.Schema({
name : {type: String,default: null},mobile : {type : String,remarks : {type: String,default:null},duration: {type : String,amount : {type : Number,default: 0},date : {type : String,time : {type : String,createdAt: {type: Date,default: Date.Now },updatedAt: {type: Date,default: Date.Now }
});
const disposition = mongoose.model(''disposition'',dispositionSchema);
export default disposition;
数据
在mongodb中插入数据
{
"_id" : ObjectId("6098e6d007e2804b9c1f8317"),"name" : "senthil","amount" : 0
}
{
"_id" : ObjectId("6098e6d007e2804b9c1f8316"),"name" : "periyas","amount" : 0
}
但是,我已经预料到了输出
预期数据
{
"_id" : ObjectId("6098e6d007e2804b9c1f8317"),"amount" : 0,"mobile" : null,"remarks" : null,"createdAt": "2021-05-07T13:55:34.233Z"
},{
"_id" : ObjectId("6098e6d007e2804b9c1f8316"),"createdAt": "2021-05-07T13:55:34.233Z"
}
解决方法
有一个批量插入支持request in mongoose github,由版主阅读comment之一:
initializeUnorderedBulkOp() 和 initializeOrderedBulkOp() api 方法,已被 mongodb “软弃用”。它已被 bulkWrite() API 取代,后者是 MongoDB 核心 CRUD 规范的一部分,因此得到了更广泛的实现。特别是,从 4.9.0 开始,mongoose 有一个 Model.bulkWrite() 函数,它具有验证、强制转换、promise 和 ref depopulating 功能。
您可以使用 bulkWrite() 类似的东西:
let data = req.body;
let bulk = [];
data.forEach((doc1) => {
bulk.push({ "insertOne": { "document": doc1 } });
if (bulk.length === 5000) {
callDispositionModel.bulkWrite(bulk).then((result) => {});
bulk = [];
}
})
if (bulk.length > 0) {
callDispositionModel.bulkWrite(bulk).then((res) => {
console.log(res.insertedCount);
return res.send({success: true,message: ''all data uploaded successfully''})
});
}
改变
let dispositionSchema = new mongoose.Schema({
name : {type: String,default: null},mobile : {type : String,remarks : {type: String,default:null},duration: {type : String,amount : {type : Number,default: 0},date : {type : String,time : {type : String,createdAt: {type: Date,default: Date.now },updatedAt: {type: Date,default: Date.now }
});
到
let dispositionSchema = new mongoose.Schema({
name : {type: String,default: Date.now }
},{ timestamps: { createdAt: ''createdAt'',updatedAt: ''updatedAt''} });
More detail here
,您现在可以在 Schema 上设置时间戳选项,让 Mongoose 为您处理:
var dispositionSchema = new Schema({..},{ timestamps: true });
关于mssql server 存储过程里,bulk insert table from '路径+文件',路径固定,文件名不固定的实现方法的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于BULK COLLECT(成批聚合类型)和数组集合type类型is table of 表%rowtype index by binary_integer、Bulk Insert 命令详细、BULK INSERT 如何将大量数据高效地导入 SQL Server、bulk.insert(doc) 默认值无法插入 MongoDB nodejs的相关知识,请在本站寻找。
本文标签:




