最近很多小伙伴都在问MSSQL-最佳实践-如何监控备份还原进度和备份的sql怎么还原这两个问题,那么本篇文章就来给大家详细解答一下,同时本文还将给你拓展1.7、BootstrapV4自学之路-----
最近很多小伙伴都在问MSSQL-最佳实践-如何监控备份还原进度和备份的sql怎么还原这两个问题,那么本篇文章就来给大家详细解答一下,同时本文还将给你拓展1.7、Bootstrap V4自学之路------起步---最佳实践、10 条 oracle sql 最佳实践、Core Bluetooth框架之三:最佳实践、DB2 最佳实践: 编写并调优查询语句以优化性能最佳实践等相关知识,下面开始了哦!
本文目录一览:- MSSQL-最佳实践-如何监控备份还原进度(备份的sql怎么还原)
- 1.7、Bootstrap V4自学之路------起步---最佳实践
- 10 条 oracle sql 最佳实践
- Core Bluetooth框架之三:最佳实践
- DB2 最佳实践: 编写并调优查询语句以优化性能最佳实践
")
MSSQL-最佳实践-如何监控备份还原进度(备份的sql怎么还原)
title: MSSQL · 最佳实践 · 如何监控备份还原进度
author: 风移
摘要
本期月报是SQL Server备份还原专题分享系列的第六期,打算分享给大家如何监控SQL Server备份还原进度。
场景引入
由于SQL Server备份还原操作是重I/O读写操作,尤其是当数据库或数据库备份文件比较大的到时候。那么,我们就有强烈的需求去监控备份还原的过程,时时刻刻把握备份还原的进度,以获取备份还原操作完成时间的心理预期以及对系统的影响。本期月报分享如何监控SQL Server备份还原进度。
监控备份还原进度
在SQL Server数据库中,监控数据库备份还原进度方法主要有以下三种:
利用SSMS的备份、还原进度百分比
利用T-SQL的stats关键字展示百分比
利用动态视图监控备份、还原完成百分比
利用SSMS
监控数据库备份进度
在SSMS中,右键点击你需要备份的数据库 => Tasks => Back Up...
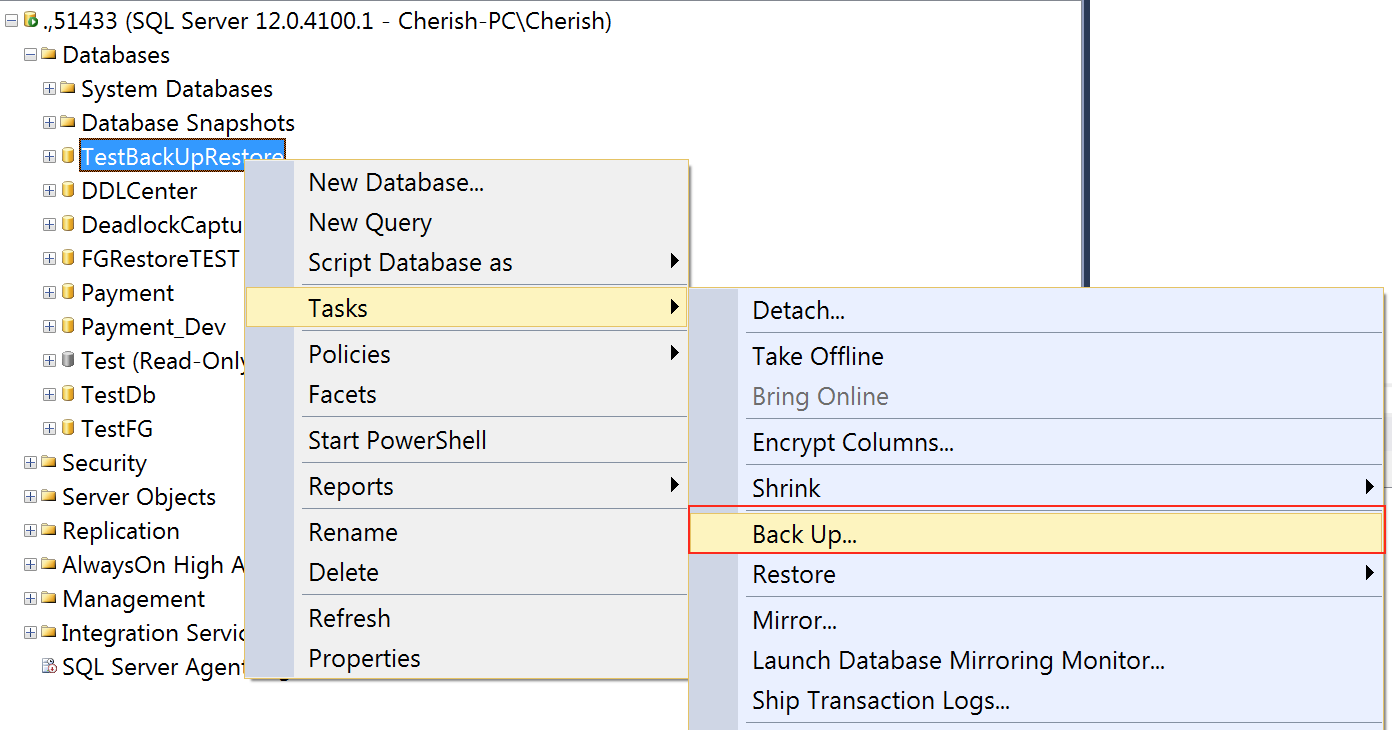
在Destination中选择Disk => Add... => 选择备份文件本地存储路径 => OK
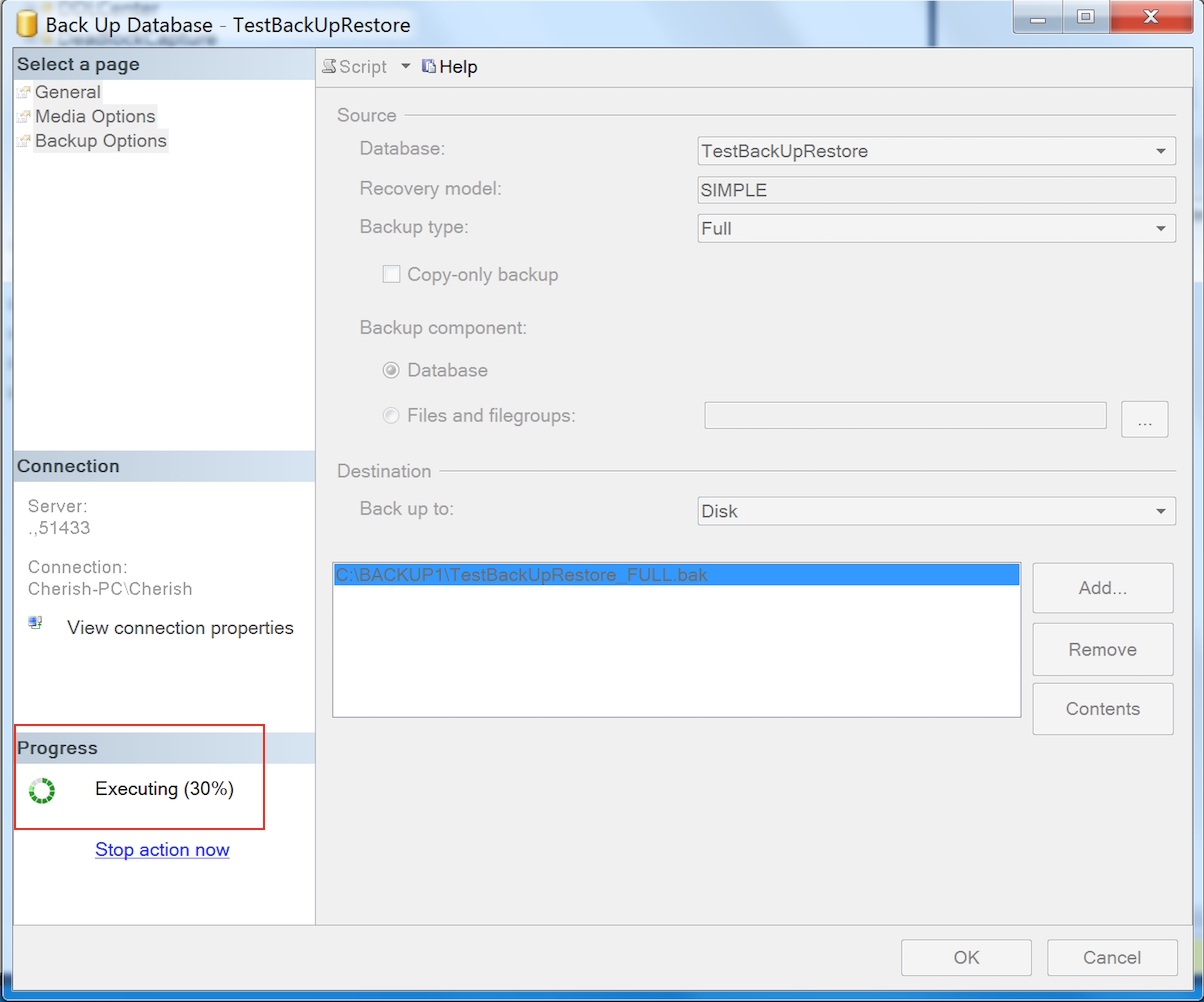
在该窗口的左下角部分,会有Process的进度展示,比如截图中的进度表示数据库已经备份完成了30%。
这种方法可以看到数据库备份进程进度的百分比,但是没有更多的详细信息。

1.7、Bootstrap V4自学之路------起步---最佳实践
最佳实践
我们已经将Bootstrap开发设计成能够在很多环境下工作了。下面有一些最佳实践案例,这些都是我们从多年的研究和使用它的基础上收集的。
小心,这个副本是一个进行中的作品。
大纲
使用CSS
使用Sass
创建新的CSS组件
在Salck中询问
这章可能还在进行中,可能是放一个例子之类的实例吧。
但目前还是空白的。

10 条 oracle sql 最佳实践
原文: 10 条 oracle sql 最佳实践
1. 使用 ANSI Joins 而不是 Oracle Joins
- 在大型查询中,很容易忘记添加 WHERE 子句来连接表,从而导致不必要的笛卡尔联接和不正确的结果;
- WHERE 子句应用于过滤记录,而不是用于将表连接在一起。一个微妙的区别,但它使查询更容易理解;
ANSI Joins更容易阅读,因为您可以看到哪些部分用于联接,哪些部分用于筛选数据;
2. 避免带函数的 WHERE 子句
- 如果在查询中应用了函数,则不会使用在列本身上创建的
任何索引,这会大大降低查询的速度。 - 如果确实需要在 WHERE 子句中的列上使用函数,请考虑在该列上创建一个基于函数的索引。这是一种根据应用于列的函数的结果创建的索引类型,可以在此查询中使用。
3. 使用 CASE 代替 Multiple Unions
SELECT id, product_name
FROM product
WHERE status = ‘X’ AND created_date < TO_DATE(‘2017-01-01’, ‘YYYY-MM-DD’)
UNION ALL
SELECT id, product_name
FROM product
WHERE status = ‘A’ AND product_series = ‘WXT’;
改进:
SELECT id, product_name
FROM (
SELECT id, product_name,
CASE
WHEN status = ‘X’ AND created_date < TO_DATE(‘2017-01-01’, ‘YYYY-MM-DD’) THEN 1
WHEN status = ‘A’ AND product_series = ‘WXT’ THEN 1
ELSE 0 END AS prodcheck
FROM product
) sub
WHERE prodcheck = 1;
- 显示正确记录的逻辑在 case 语句中。有几行,每组标准一行,如果找到匹配,则返回 1。此逻辑都在子查询中,外部查询筛选器只显示该情况为 1 的记录。
- 编写 case 语句有几种不同的方法,但其思想是只使用 CASE 语句中的主查询和几个条件,而不是单独的查询。但是,请确保测试两个版本的查询以提高性能,因为可能会有与 UNION 查询一起使用的索引,而这些索引不会与 CASE 查询一起运行。
4. 尽量减少使用 DISTION
添加一个不同的关键字以确保不会得到重复的记录是很有诱惑力的。但是,添加一个单独的关键字可能会导致对查询执行昂贵的操作,从而减慢其速度。它会给你需要的结果,但它掩盖了其他地方的问题。它可能来自一个不完整的联接,或者表中的不正确数据,或者是一些你没有考虑的标准,这导致了重复的行。解决查询或数据中的问题是正确的解决方案。
5. 重新设计数据值列表以使用表
SELECT *
FROM product
WHERE status IN (‘A’, ‘P’, ‘C’, ‘S’);
- 此查询可能会给出所需的结果。如果状态值在将来的某个时候发生了变化,或者业务规则发生了变化,这意味着您需要调整这个列表,那么会发生什么呢?如果将此列表编码到查询中,则需要调整查询。这可能会导致应用程序代码和部署过程的更改。
- 另一种方法是将值存储在单独的表中并连接到此表。例如,您可以有一个 Status_lookup 表,其中包含值和类别,其中类别定义了所需的数据。
SELECT product.*
FROM product
INNER JOIN status_lookup ON product.status = status_lookup.status
WHERE status_lookup.category = ‘ACTIVE’;
6. UNION ALL 代替 UNION [集合运算符]
- 他们之间有一些细微的差别。UNION All 显示两个结果集中的所有记录,而 UNION 显示不包括重复的所有记录。简单而言:UNION 移除重复项,UNIONALL 不删除。
- 这意味着,在 Oracle 中,当使用 UNION 在合并后从结果集中删除所有重复行时,将执行额外的步骤, 它与执行 DISTINCT 类似。
7. 使用表别名
8. 仅对聚合函数使用 HAVING
- Oracle SQL 中的 HAVING 子句用于过滤结果集中的记录,它与 WHERE 子句非常相似。但是,WHERE 子句在应用聚合函数之前过滤行,HAVING 子句在应用聚合函数之后过滤行。如果您正在使用聚合函数,那么将 HAVING 用于所有内容可能很诱人,但它们会在您的查询中执行不同的操作。
- 确保仅对聚合函数使用 HAVING,并在聚合之前对要限制的结果使用 WHERE。
9. 始终在 INSERT 语句中指定列
- 一个很好的习惯是在 INSERT 语句中指定列。这有几个好处。首先,它可以防止错误或数据进入错误的列。如果不指定列,就无法保证将这些列插入到哪个顺序中。这可能导致出现错误,或在错误的列中插入带有值的数据。
- 可以清楚地看到哪些列代表哪些值。当您查看一个没有列的语句时,您将不得不猜测值是什么。如果添加列,则准确地知道每个列的值。
10. 避免使用空格的对象名称
- 使用带有空格的表名可能更容易阅读。然而,它可能会引起几个问题。Oracle 中的表名以大写形式存储,或者如果它们有引号,则在输入它们时存储它们。这意味着每当您引用此表时,都需要使用引号并在编写时指定它。这对您和其他开发人员都不方便。
- 另一个原因是在查询中很难引用此表。您必须用引号指定它,并且可能需要使用表别名来确保查询是正确的。最好指定没有空格的对象名称。您可以使用下划线代替

Core Bluetooth框架之三:最佳实践
在iOS设备中使用BLE时,无论是将其作为central端还是peripheral端,其在通信时都会使用设备自身的无线电来发送信号。考虑到其它形式的无线通信也需要使用无线电,因此开发程序时应该尽量少使用无线电。另外,这对于设备电池的寿命及程序的性能也有所帮助。以此为出发点,我们将介绍一些使用BLE时的最佳实践,希望有所帮助。
与Peripheral设备交互的最佳实践
Core Bluetooth框架让程序的大部分Central端交互变得透明。即程序能够控制且有责任实现大部分Central端的操作,如设备搜索及连接,解析并与远程peripheral数据交互。下面我们将介绍一些Central端的最佳实践。
留意无线电的使用及电量消耗
只有当需要时才扫描设备
当调用CBCentralManager类的scanForPeripheralsWithServices:options:方法来搜索正在广告服务的peripheral设备时,central设备使用无线电来监听广告的设备,直到我们显示停止它。除非需要搜索更多的设备,否则当发现想要连接的设备时就停止扫描操作。此时可以调用CBCentralManager实例的stopScan方法来处理。
只有当需要时才指定CBCentralManagerScanOptionAllowDuplicatesKey选项
远程peripheral设备可能每秒发送多个广告包来声明它们的存在。当我们使用scanForPeripheralsWithServices:options:方法扫描设备时,该方法的默认行为是将多个搜索到的广告peripheral事件归集为一个事件—即central管理器在只有在每次发现新的peripheral时都调用其代理对象的centralManager:didDiscoverPeripheral:advertisementData:RSSI:,而不管它收到多少个广告包。central管理器在已发现的peripheral改变广告的数据时也会调用这个代理方法。
如果想要改变默认行为,可以指定CBCentralManagerScanOptionAllowDuplicatesKey作为扫描选项。此时,central管理器会在每次收到peripheral端的广告包时都触发一个事件。在某些情况下关闭默认行为很有用处,但记住指定CBCentralManagerScanOptionAllowDuplicatesKey扫描选项不利于电池的寿命及程序性能。因此,只在需要的时候使用这个选项以完成特定的任务。
解析peripheral数据
一个peripheral设备可能有多个服务和特性,但在我们的应用中,可能只对其中一些感兴趣。搜索peripheral设备的所有服务和特性可能不利于电池的寿命及程序性能。因此,我们只去搜索那些与我们的的应用相关的服务和特性。
例如,假设我们正在连接一个有很多可用服务的peripheral设备,但是我们的程序只需要访问其中两个。我们可以只查找这两个服务,即在调用CBPeripheral对象的discoverServices:方法时传入感兴趣服务的UUID的数组即可。如下代码所示:
[peripheral discoverServices:@[firstServiceUUID, secondServiceUUID]];在搜索到这两个感兴趣的服务后,我们可以用类似的方法去搜索我们感兴趣的服务中的特性。此时调用CBPeripheral实例的discoverCharacteristics:forService:方法并传入特性UUID的数组。
订阅经常改变的特性值
我们可以通过两种方式获取特性的值:
在我们每次需要值时调用readValueForCharacteristic:方法来显示的轮循特性的值
调用setNotifyValue:forCharacteristic:方法来订阅特性的值,这样当值改变时我们可以收到来自于peripheral的通知。
通常最好是去订阅特性的值,特别是特性值经常改变时。
当获取到所有需要的数据时断开到设备的连接
当连接不再需要时,我们可以断开连接,以减少无线电的使用。在下面两种情况下,我们应该断开连接:
所有订阅的特性值已经停止发送通知(我们可以访问特性的isNotifying属性来查看属性值是否正在被通知)
我们已以获取来来自peripheral设备的全部值。
两种情况下,取自我们有的所有订阅并断开连接。我们通过调用setNotifyValue:forCharacteristic:方法并设置第一个参数为NO来取消订阅。同时调用CBCentralManager实例的cancelPeripheralConnection:方法来断开连接。注意这个cancelPeripheralConnection:方法是非阻塞的,如果我们尝试断开连接的peripheral设备仍然挂起,则CBPeripheral实例的命令可能完成执行,也可能没有。因为其它程序可能也连接着那个peripheral设备。取消一个本地连接不能保证底层物理链接会立即断开。
重新链接Peripheral
使用Core Bluetooth框架,有三种方式来重新连接peripheral设备:
使用retrievePeripheralsWithIdentifiers:方法获取已知peripheral设备的列表,这些设备是我们已经搜索并连接过的设备。如果我们查找的peripheral在列表中,则尝试重新连接。
使用retrieveConnectedPeripheralsWithServices:方法获取当前连接到系统的peripheral设备的列表。如果我们查找的peripheral设备在列表中,则连接它。
使用scanForPeripheralsWithServices:options:方法扫描并搜索peripheral设备。如果找到,则连接它。
根据使用的场景,我们可能不希望每次重新连接设备时,都去扫描并搜索设备。相反,我们可能想首先使用其它方式来重新连接。如下图所示,一个可能的重新连接操作流是按照上面列出来的方式去重新连接:
获取已知peripheral设备的列表
我们第一次发现一个peripheral设备时,系统生成一个标识符(NSUUID对象)来标识peripheral设备。我们可以存储这些设备,后续我们可以使用CBCentralManager实例的retrievePeripheralsWithIdentifiers:方法来重新连接这个peripheral设备。
当我们启动程序时,调用retrievePeripheralsWithIdentifiers:方法,传递一个我们先前搜索并连接过的peripheral设备的标识符的数组,如下代码所示:
knownPeripherals = [myCentralManager retrievePeripheralsWithIdentifiers:savedIdentifiers];central管理器尝试在这个列表中匹配我们提供的标识符,并返回一个CBPeripheral对象的数组。如果没找到,则返回的数组为空,那么我们需要尝试另外两种方法。如果返回的数组不为空,则让用户选择连接哪一个peripheral设备。当用户选择后,调用CBCentralManager实例的connectPeripheral:options:方法来尝试连接。如果peripheral设备仍然可以连接,则central管理器调用代理对象的centralManager:didConnectPeripheral:方法,且成功连接上peripheral设备。
获取已连接peripheral设备的列表
另一种重新连接peripheral设备的方法是查看我们正在查找的设备是否正由系统连接着(如被其它程序连接着)。我们可以调用CBCentralManager实例的retrieveConnectedPeripheralsWithServices:方法,它返回一个表示当前系统正在连接着的peripheral设备的CBPeripheral对象的数组。
因为可以有多于一个peripheral设备正在连接着系统,我们可以传递一个CBUUID对象的数组来获取只包含指定UUID所标识服务的设备。如果当前系统没有连接任何peripheral设备,则返回数组为空,我们应该尝试其它两种方法。如果返回数组不为空,则让用户选择连接哪个设备。
假设用户找到并选择了需要的peripheral设备,则调用CBCentralManager实例的connectPeripheral:options:方法来连接它(即使系统已经连接了它,我们的程序仍然需要连接它以开始解析并交互数据)。当连接建立后,central管理器调用代理对象的centralManager:didConnectPeripheral:方法,然后成功连接peripheral设备。
将本地设备设置为peripheral设备的最佳实践
广告注意事项
在设置本地设备作为peripheral端时,广告peripheral数据是非常重要的一部分。我们下面将介绍一下如何以适当的方式来实现这一功能。
我们广告peripheral数据时,是将其放在一个字典中传递给CBPeripheralManager对象的startAdvertising:方法中。当创建一个广告字典时,需要知道我们可以广告什么及能广告多少数据。
虽然广告数据包通常可以放置关于peripheral设备的多种信息,但建议只放置设备的本地名及我们需要广告的服务的UUID。即,当创建广告字典时,可能只指定下面两个键:CBAdvertisementDataLocalNameKey和CBAdvertisementDataServiceUUIDsKey。如果指定其它键,则会收到一个错误。
同样,广告数据时也限定了可以使用多少空间。当程序在前台时,可广告的数据对于上述两个key值的任意组合来说,初始值不能超过28个字节。如果这个空间用完了,在扫描响应时可以有额外的10个字节的空间,但这只能用于本地名。任何超出的数据都会被放到一个指定的“溢出”区域;它们只能被显示扫描它们的iOS设备发现。当程序在后台时,本地名不能被广告,且所有的服务UUID都被放在溢出区域。
为了符合这此限制条件,我们需要将广告的服务UUID限制在主要服务的标识上。
另外,因为广告peripheral数据使用本地设备的无线电,所以只在需要其它设备连接的时候广告数据。一旦连接后,这些设备可以直接解析并交互数据,而不需要任何广告包。因此,为了减少无线电的使用、提高程序的性能及节省电量,当不再需要任何试图进行BLE交易时可以停止广告。为了停止本地peripheral,可以调用CBPeripheralManager对象的stopAdvertising方法,如下所示:
[myPeripheralManager stopAdvertising];通常,只有用户才知道什么时候广告数据。例如,当我们知道没有任何BLE设备在附近时,在我们的设备上广告服务没有任何意义。因为我们的程序通常不知道是否有其它设备在附近,所以提供一个界面让用户来决定什么时候广告数据。
配置特性
当创建一个可变的特性时,我们设置它的属性、值和权限。这些设置决定了如何连接central访问及交互特性值。虽然我们可能基于程序的需求来配置特性的属性和权限,但当执行下面两种任务时,我们还是有章可循的
允许连接的central订阅属性
保护敏感特性值,不让其被未配对的central访问
对于这两种情况,首先我们配置特性以支持通知。通常建议central去订阅那些经常改变的特性值。当我们创建一个可变特性时,可以通过使用CBCharacteristicPropertyNotify常量来设置特性属性以支持订阅,如下所示:
myCharacteristic = [[CBMutableCharacteristic alloc] initWithType:myCharacteristicUUID properties:CBCharacteristicPropertyRead | CBCharacteristicPropertyNotify value:nil permissions:CBAttributePermissionsReadable];在这个例子中,特性值是可读的,且可以被连接的central端订阅。
其它,要求配对的连接才能访问敏感数据。根据场景的不同,我们可能想要提供一个服务,这个服务有一个或多个需要加密值的特性。例如,假设我们想要提供一个社交媒体配置文件服务。这个服务有一些特性,它们的值表示成员的配置信息,如姓名、电子邮件地址。更可能的是,我们只允许受信任的设备来获取成员的电子邮件地址。
我们可以设置合适的特性属性及权限来确保只有受信任的设备可以访问敏感的特性值。继续上面的例子,为了只允许受信任的设备来获取成员的邮箱地址,可以如下设置合适的特性属性与权限:
emailCharacteristic = [[CBMutableCharacteristic alloc] initWithType:emailCharacteristicUUID properties:CBCharacteristicPropertyRead | CBCharacteristicPropertyNotifyEncryptionRequired value:nil permissions:CBAttributePermissionsReadEncryptionRequired];在这个例子中,特性配置为只有受信任的设备才可以读取或订阅它的值。当一个连接的central尝试读取或订阅特性值时,Core Bluetooth尝试配对本地peripheral和central端来创建安全连接。
例如,如果central和peripheral都是iOS设备,两端都接收一个提示显示对方想要配对。central设备上的提示包含包含一个确认码,这个确认码必须在peripheral设备提示框的输入域中输入,来完成配对操作。
在配对成功后,peripheral认为配对的central是一个受信任的设备且允许central访问它的加密特性值。
小结
在使用BLE时,基于以下几点,程序开发过程中我们合理地使用蓝牙
程序性能
电池电量消耗
与其它通信方法争抢无线电资源
通常我们只在需要时才使用BLE,尽量减少设备扫描搜索操作。
参考
Core Bluetooth Programming Guide

DB2 最佳实践: 编写并调优查询语句以优化性能最佳实践
内容提要
通过 “IBM DB2 for Linux, UNIX, and Windows 最佳实践”专题,获得最常用的 DB2 9 产品配置实践指南,并使用这些知识提高 DB2 数据服务器的价值。
这些最佳实践文章给出了最优化方法的建议,使您能使用 DB2 满足关键的业务数据处理需求。每篇最佳实践文章都为最常用的 DB2 产品配置提供了实践指南。通过应用这些建议,您可以提高 DB2 数据服务器的价值,并且能够始终把握 IBM 在 DB2 方面的技术方向。
- IBM DB2 for Linux, UNIX, and Windows 最佳实践
本文描述了在 DB2 数据库性能方面最小化 SQL 语句的影响的最佳实践。有几种将影响减到最小的方法:
- 通过编写可以很容易被 DB2 优化器优化的语句。 DB2 优化器可以高效的运行不包含连接谓词的 SQL 语句、连接列数据类型不匹配、多余的外连接和其他复杂搜索条件。
- 通过改正配置 DB2 数据库将从 DB2 优化功能得到好处。如果你有精确的编目统计信息并为你的工作负载选择了最好的优化级别 DB2 优化器可以选择最优的查询计划。
- 通过使用 DB2 explain 功能来查看可能的插叙计划并判断如何调整查询以达到最佳性能。
本文包括最佳实践对适用于、一般的工作负载、数据仓库工作负载和 SAP 工作负载,包括特定 SAP 商业智能(BI)应用程序。
这里有很多方法来处理应用程序编写后特定的查询性能问题。但是,本文专注于良好的基础编写和调优练习,这能更广泛的提高 DB2 数据库性能。
如果你遵循了本文讨论的建议后仍然碰到性能低下的问题,这也有很多技术可以让你理解为什么会性能低下。“性能调优和问题诊断最佳实践” 最佳实践文章描述了很多技术来定位性能问题和进行系统配置来防止它们。“物理数据库设计最佳实践”最佳实践文章中描述了如何使用 DB2 数据库系统功能,想多位集群(MDC),物化查询表(MQTs)和 DB2 Design Advisor 来达到优化查询性能的目的。后面的最佳实践文章将描述分析特定查询性能问题的技术。
对于提高 XQuery 性能的建议,参见“使用 DB2 pureXML 管理 XML 数据的最佳实践”。
回页首
介绍
查询性能不能只考虑某一次的问题,而应该贯穿于应用程序开发的整个生命周期,在设计、开发、生产各个阶段中都要考虑它。
SQL 是一个非常灵活的语言,也就是说有很多途径同样可以获得正确的结果。这种灵活性也意味着利用 DB2 优化器具有优势,一些查询会优于其他的查询。
在查询运行的过程中,DB2 优化器会为每个 SQL 语句选择一个查询计划。优化器模拟不同的访问计划的运行成本,并选择其中一个成本最低的访问计划。如果一个查询包括很多复杂的搜索条件,DB2 优化器在某些情况下可以重写谓词,不过在某些一些情况下却不能。
对于一些比较复杂的查询,一个 SQL 语句的准备或编译的时间可能会比较长,尤其是 BI 应用程序中使用的 SQL 语句。你可以通过调整设计和你的数据库配置来帮助缩短语句编辑时间。这包括选择正确的优化级别并正确设置其他注册变量。
优化器也需要精确输入以获得精确的查询计划。这意味着你需要收集精确的统计信息,并潜在的使用高级统计功能,比如统计视图和列组统计信息。
你也可以使用 DB2 工具(尤其是 DB2 explain 工具)来调优查询。 DB2 编译器可以抓取动态或静态语句关于访问计划和环境的信息。利用抓取的信息来理解单个语句的运行,所以你可以调整它们以及你的数据库管理器配置来提高性能。
回页首
编写 SQL 语句
SQL 是很强大的语言,它允许你指定语法不同而语义相同的关系型描述。不过,一些语义相同的变化比起其他的更容易优化。虽然 DB2 优化器有很强的查询重写能力,但也并不总是可以把一个 SQL 语句重写成最优的形式。某些 SQL 结构也可能会限制优化器对访问计划考虑。下面的章节描述了需要避免的某些 SQL 结构,并对如何替换或避免它们提出了建议。
在搜索条件中避免复杂的描述
在搜索条件中避免复杂的描述,这样的描述阻止了优化器使用编目统计信息来评估一个精确的选择。这个描述也可能会限制选择可以应用这些谓词的访问计划。在优化的查询语句的重写阶段,优化器可以重写一批描述以允许优化器评估一个精确的选择;不过它不能处理所有可能性。
在描述中避免使用连接谓词
在描述中使用连接谓词把连接方法限制为了嵌套循环。另外,对基数的评估可能不准确。下面是一些连接描述的例子:
|
避免对本地谓词有过多的列描述
使用相反的描述来替代应用中的一个在本地谓词上有太多列的描述。考虑下面的例子:
|
你可把它们语句重写为:
|
应用多列的描述将妨碍索引开始和结束键的使用,从而导致不准确的可选评估,并需要在查询运行时花费额外的时间来处理。这些描述同样会阻止对查询的重写优化,比如在列相等时的识别、使用常量来替换各列并且对只有一行返回的情况进行识别。在这之后的进一步的优化也可能会被阻止,因此会失去更多的优化机会。考虑下面的查询:
|
你也可以用下面的语句:
|
如果在 CUST_ID 上有一个唯一索引,重写的查询版本让查询优化器注意到最多一行记录将被返回。这避免了引入一个没有必要的排序操作。这也让 CUST_ID 和 CUST_CODE 列被 1234 和‘ 56 ’替代,从而避免了从数据页或索引页复制数据。最终,使得在 CUST_ID 上的谓词应用成一个索引开始或结束键。
当一个描述在谓词中时,它可能不是总这么明显。这种情况经常发生在涉及视图的查询中,尤其当视图列是通过描述定义的时候。比如,考虑下面视图定义和查询:
|
查询优化器把查询和视图定义合并了,产生下面的查询:
这是前面例子中有问题的谓词。你可以通过使用 explain 功能显示优化后的 SQL 语句来观察视图合并的结果。
如果相反的功能很难表达,考虑使用一个生成列。例如,如果你想找到一个满足 LASTNAME IN (''Woo'', ''woo'', ''WOO'', ''WOo'', and so on) 描述标准的姓氏,你可以创建一个生成列 UCASE(LASTNAME) = ''WOO'' ,如下 :
|
避免连接列上的数据类型不匹配
在某些情况下,数据类型不匹配将妨碍使用哈希连接。哈希连接在连接谓词上比其他连接方法要多一些约束。特别是连接列的数据类型必须完全相同。例如,如果一个连接列是 FLOAT 另外一个是 REAL,哈希连接将不支持。另外,如果连接列数据类型是 CHAR、GRAPHIC、DECIMAL 或 DECFLOAT 则长度必须一样。
在谓词中不要使用 no-op 描述来更改优化器评估
一个“ no-op ” coalesce() 谓词以“ COALESCE(X, X) = X ”会引入一个评估错误到使用它的所有查询的计划中。现在 DB2 查询编译器没有能力不去选则那个谓词并确定是否所有的行具体满足它。作为结果,这个谓词减少了对来自于部分查询计划的评估的行数。这个更小的行估计通常为后面的查询计划减少了行数和评估成本,而有时选择不同计划的结果是因为不同候选计划之间的相关评估条件改变了。
为什么这个什么都不做的谓词有时候却会提高查询性能?增加谓词“ no-op ” coalesce() 引入了一个错误掩盖了一些东西,要不然就是阻止了性能优化。
一些性能增强工具做了什么是一个强力测试:工具一再引入谓词到一个查询的不同位置,操作不同的列,通过引入一个错误来尝试找到一种情况,这个错误出现在哪里影响了一个更好的查询计划。这也是一个真正的查询语句开发人员在一个查询中手动。编写“ no-op ”谓词。通常,开发人员会得到一些对数据的了解来指导这个谓词的放置。
使用这个方法来提高查询性能是一个短期的解决方案,它并没有定位根本原因而且会有以下影响:
- 性能提升的潜力被掩盖了。
- 不能保证这个 workaround 会提供永久的性能提高,就像 DB2 查询编译器可能最终更好的处理这个谓词或者其他随机因素可能影响了它。
- 或许会有其他语句受到相同的原因影响而且对系统性能的影响通常会由你的系统承受。
避免不相等的连接谓词
连接谓词使用比较操作,除了相等其他都应该避免。因为不相等连接方法就会限制为嵌套循环。而且,优化器或许不能为连接谓词计算一个精确的可选评估。然而不等连接谓词不能永远规避。当它们是必须的时候,确保一个谓词索引存在于任何一个表中,因为连接谓词将应用嵌套内部连接。
不等连接谓词的一个简单例子是,为了精确反映维度数据在不同的时间点的状态,一个星型模式中的维度数据必须版本化。这常常作为一个‘慢慢改变的维度’来被参考。一类慢慢改变的维度包括每个维度行的有效的开始和结束日期。为了连接维度的主键,一个在事实表和维度表之间的连接需要检查和事实表相关的数据,包括维度的开始和结束日期。这常常作为一个‘第 6 类慢慢改变的维度’被参考。范围连接回到事实表通过一些实际事务日期以进一步限定维度版本,成本会很高。例如:
|
在这个情况下,需要确保有一个索引在(F.PROD_KEY, F.SALE_DATE)列上
可以考虑创建一个统计视图来帮助优化器计算一个更好的可选评估。例如
|
指定星型模式连接,比如索引 ANDing 星型连接,并且如果在查询块中有任何不等连接谓词,集中连接不被考虑。(参见“如果你使用星型模式连接,确保你的查询和必须匹配在 12 页中的标准”)
避免出现多个 DISTINCT 关键字
避免使用在同一个 subselect 中运行多个 DISTINCT 集合的查询,它的运行成本非常高。考虑下面的例子:
|
为了判断 DISTINCT REBATE 值和 DISTINCT COUNT 值,来自 PROD_KEY 表的输入流需要进行两次排序。这个查询语句的查询计划就像这样 :
优化器重写了最初的查询语句,分成两个单独的集合,每个指定 DISTINCT 关键字,然后把多个集合用 UNION 关键字连接起来。内部重写的语句是:
|
如果你不能避免多个 DISTINCT 集合的话,就考虑使用带 ENHANCED_MUTIPLE_DISTINCT 选项的 DB2_EXTENDED_OPTIMIZATION 注册表变量。 这个选项将使到多个 DISTICT 集合的输入流被读取一次然后被 UNION 的每一个分支重复使用。这个选项可以在数据库分区的处理器比率较低的时(例如,比率小于或等于 1)提高这类查询的性能。这个设置应该对没有对称的多处理器的 DPF(Database Partitioning Feature)环境(SMPs)很有用。这个优化扩展不能在所有环境中提高查询性能。应该进行测试来判断单个查询性能的提高。
避免多余的谓词
某些查询的语义需要外连接(不管左、右或全连接)。然而,如果查询语义不需要一个外连接并被用于处理不一致数据,那么最好是处理不一致数据的根本原因。例如,在一个数据集市中有一个星型模式,事实表可能包含事务数据,不过因为数据不一致的问题,造成与父维度行的一些维度不匹配。这是可能发生的,因为抽取、转换和装载(ETL)过程出于某些原因不与商业键不兼容。在这种情况下,事实表的行与维度左连接可以确保它们即使在没有父表的情况下得到返回。例如:
|
左外连接会阻止一些优化,也包括使用指定的星型模式连接访问方法。然而,在某些情况下左外连接可以自动被查询优化器重写成一个内部连接。在这个例子中,在 CUSTOMER 和 DAILY_SALES 之间的左外连接可以被转换成一个内部连接,因为 C.CUST_NAME= ’ SMITH ’谓词将排除这一列中所有 NULL 值的行,使得一个左外连接语义变得没有必要。所以由于外连接的出现导致那些优化损失可能并不会对所有查询产生负面影响。然而,注意到这些限制并避免外连接非常重要,除非它们是绝对必须的。
把 FETCH FIRST N ROWS ONLY 子句和 OPTIMIZE FOR N ROWS 子句放在一起使用
OPTIMIZE FOR N ROWS 子句表明对于优化器应用程序打算只获取 N 行,不过查询将返回完整的结果集。 FETCH FIRST N ROWS ONLY 子句显示查询只需返回 N 行。
DB2 数据服务器不会在为外部子查询指定了 FETCH FIRST N ROWS ONLY 而自动假设 OPTIMIZE FOR N ROWS 。尝试与 FETCH FIRST N ROWS ONLY 一起指定 OPTIMIZE FOR N ROWS 来鼓励查询计划直接从引用的表返回行,而不执行一个缓冲操作,比如插入一个临时表、排序或插入一个哈希连接的哈希表。
应用程序指定 OPTIMIZE FOR N ROWS 来鼓励查询计划避免缓冲操作,也不获取整个结果集,它们可能导致性能低下。这是因为快速返回前 N 行的查询计划可能不是对于获取整个结果集的查询计划。
如果你正在使用星型模式的连接,请确保你的查询满足需要的标准
优化器为星型模式考虑两个特殊的连接方法,叫做一个星型连接或集中连接,它们可以明显的提高性能。如果查询必须满足以下标准。
- 对每个查询块
- 最少 3 个不同的表被连接
- 所有连接谓词必须相等
- 没有子查询存在
- 在表与表之间或者查询块之间不存在相关性或依赖性
- 另外,对于索引 ANDing,必须没有不确定的函数,因为为方便 semi-joins 事实表的谓词必须通过索引来应用
- 事实表
- 是查询块中最大的表
- 少于 10000 行
- 被视为只有一个表
- 必须连接到至少两个维度表或叫做 snowflakes 的组。
- 维度表
- 不是事实表
- 可以单据连接到实施表或在 snowflakes 中
- 一个维度表或者一个 snowflake 。
- 必须过滤实施表(基于优化器的评估结果来过滤)
- 必须有一个连接谓词到实施表,它使用了实施表索引中主要的列。这个规范必须满足,不管是考虑星型连接或集中连接,即使集中连接将至需要使用一个单独的事实表索引。
一个查询块表现一个左外部链接或右外部连接,可以只涉及两个表,所以不符合一个星型模式的连接
不需要为优化器能发现一个星型模式连接而显示的声明参考完整性。
避免多余的谓词
避免多余的谓词,尤其是当他们发生在不同的表的时候。在某些情况下,优化器并不能判断多余的谓词。这可能导致基数被低估。
例如,在 SAP BI 应用程序中雪花模式和实施表以及维度表被作为一个查询优化数据结构被用到。在一些情况下会有多余的时间特征列(对于月的“ SID_0CALMONTH ”或对于年的 "SID_0FISCPER")定义在事实表和维度表中。
SAP BI OLAP 处理器在维度和事实表的时间特征列上会产生多余的谓词。
这些多余的谓词可能产生很长的运行时间。
下面提供了一个例子,在一个 SAP BI 查询中有两个多余的谓词被定义在 WHERE 条件里。相同的位谓词定义在时间维度(DT)和事实(F)表。
|
DB2 优化器没有注意到相同的谓词,并对它们分别处理。这导致低估了谓词、生成不是最优的访问计划以及更长的查询运行时间。
处于这个原因多余的谓词从 DB2 数据库具体平台软件层面去掉了。
以上谓词转换成下面这一个。只有事实表“ SID_0CALMONTH ”列上的谓词被保留:
|
应用 SAP 957070 和 1144883 备忘录来去掉多余的谓词。
回页首
设计并配置你的数据库
有很多数据库设计和配置选项可以影响查询性能。对数据库设计的更多建议参考“ Planning your Physical Database Design ”最佳实践文章。
使用约束来提高查询优化
考虑定义的唯一性,检查并参考一致性约束。这些约束提供了语义信息,允许 DB2 优化器重写查询来评估连接,通过连接来降低聚合和 FETCH FIRST N ROWS,去掉不必要的 DISTINCT 选项被和一些其它的优化。当应用程序可以保证它自己的关系时,信息约束也可以被用来检查并参考一致性约束。相同的优化也是可以的。当更新(插入或删除)行的时候,来自数据库管理器的强制约束可能导致很高的系统开销,尤其在更新很多有一致性约束的行的时候。如果一个应用程序在更新一行之前已经验证的信息,这样使用信息约束比起正常的约束更有效
例如,考虑 2 个表 DAILY_SALES 和 CUSTOMER 。在 CUSTOMER 表中的每一行都有一个唯一的客户键值(CUST_KEY)。 DAILY_SALES 包含一个 CUST_KEY 列并且每一行都引用一个 CUSTOMER 表中的客户键。可以创建一个参考一致性约束来防止在 CUSTOMER 和 DAILY_SALES 之间发生 1:N 的关系。如果应用程序要强制约束这个关系,可以创建一个信息化的约束。那么下面的查询避免了在 CUSTOMER 和 DAILY_SALES 之间进行连接,因为没有从 CUSTOMER 获取任何列,而且来自于 DAILY_SALES 的每一行都可以在 CUSTOMER 里面找到与之匹配的行,所以查询优化器将自动删除连接
|
应用程序必须执行信息约束,否则查询可能返回不正确的结果。在上面的例子中,如果行存在于 DAILY_SALES 中,在 CUSTOMER 表中却找不到相应的客户键,那么上面的查询返回的行可能不正确。
在复杂查询中使用 REOPT 绑定选项和输入变量
在一个在线事务处理(OLTP)环境的中输入变量有较好的语句准备时间是关键,在这样的环境中语句往往比较简单而且查询计划选择也很简单。使用不同的输入变量多次运行相同的语句可以复用在动态语句高速缓存中编译了的访问片段,避免了由于随时更改输入值而造成昂贵的 SQL 语句编译开销。
然而,输入变量对复杂的查询负载也会造成问题,它们的查询计划选择非常复杂,因此优化器需要更多的信息来做出好的决定。而且,语句编译时间通常是总运行时间中的一个很小组成部分。因为 BI 查询通常不会重复,所以并没有从动态语句高速缓存上得到好处。
如果在一个复杂查询工作负载中需要使用输入变量,请考虑使用 REOPT(ALWAYS) BIND 选项。当输入变量值是已知的,REOPT BIND 选项从 PREPARE 到 OPEN 或执行过程中推迟了语句编译。变量值被传递到 SQL 编译器中,这样优化器可以使用这些便利来计算一个更精确的选择评估。 REOPT(ALWAYS) 表示所有执行语句都应该被预编译。 REOPT(ALWAYS) 也可以被用于涉及特殊寄存器的复杂查询,比如 "WHERE TRANS_DATE = CURRENT DATE - 30 DAYS" 。如果输入变量对 OLTP 工作负载造成较差的访问计划选择,并且 REOPT(ALWAYS) 选项因为语句编译造成过多的开销,那么考虑对挑选过的查询使用 REOPT(ONCE) 。 REOPT(ONCE) 推迟语句的编译直到首个数据变量被绑定。使用这个首个输入变量值编译并优化 SQL 语句。后续使用不同的值来运行的语句将重用基于第一个输入编译的查询片段。这是一个好方法 , 如果首个输入变量代表了后续的输入值,并且在输入值未知的情况下比起优化器使用不同的值进行评估,它提供个了一个更好的查询访问计划 .
有很多方法来指定 REOPT:
- 对 C/C++ 应用程序中的嵌入式 SQL,使用 REOPT BIND 选项。这个 BIND 选项影响静态和动态 SQL 的再优化行为。
- 对 CLP 包,用 REOPT 绑定参数重新绑定 CLP 包。例如,使用 CS 隔离级别和 REOPT ALWAYS 来重新绑定 CLP 包,详细命令:
rebind nullid.SQLC2G13 reopt always;
- 对使用传统 JDBC 驱动的 CLI 应用程序或 JDBC 应用程序,在 db2cli.ini 中设置 REOPT 关键字。选项的值是:
- 2 - NONE
- 3 - ONCE
- 4 - ALWAYS
- 对于使用 JCC 通用驱动的 JDBC 应用程序,使用下面的方法之一:
- 使用 SQLATTR_REOPT 连接或语句属性。
- 使用 SQL_ATTR_CURRENT_PACKAGE_SET 连接或语句属性来制定 NULLID、NULLIDR1 或 NULLIDRA 包集合。 NULLIDR1 和 NULLIDRA 是保留的包集合名称。一旦使用就分别隐含了 REOPT ONCE 和 REOPT ALWAYS 。这些包集合需要于那个下面命令显示的创建:
db2 bind db2clipk.bnd collection NULLIDR1; db2 bind db2clipk.bnd collection NULLIDRA;
- 对 SQL PL 存储过程使用下面的方法之一:
- 使用 SET_ROUTINE_OPTS 存储过程来为在当前会话中创建 SQL PL 存储过程设置绑定选项,例如调用 sysproc.set_routine_opts( ‘ reopt always ’ )
- 使用 DB2_SQLROUTINE_PREPOPTS 注册表变量在实例级别设置 SQL PL 存储过程选项。值设置为使用 SET_ROUTINE_OPTS 存储过程将覆盖 DB2_SQLROUTINE_PREPOPTS 指定的值
你可也能使用优化配置来为静态语句和动态语句设置 REOPT,如下面例子显示的:
|
为你的工作负载选择最佳的优化级别
设置优化级别可以获得显式指定优化技术的好处,尤其出于下面的原因:
- 为了管理非常小的数据库或者非常简单的查询语句
- 为了在你的数据库服务器编译时进行内存限制
- 为了减少查询编译时间,比如 PREPARE
大多数语句可以通过使用第 5 级优化得到充分的优化和合理的资源,这也是默认的查询优化级别。在一个给定的优化级别,查询编译时间和资源消耗是主要受查询复杂度的影响,尤其是连接以及子查询的数目。不过,编译时间和资源的使用同样受到执行优化的影响。
查询优化级别 1,2,3,5 和 7 适用于一般用途。只有你需要进一步减少查询优化时间而且在你知道 SQL 语句非常简单的情况下才考虑级别 0 。
Tip:要分析一个运行很长时间的查询,对查询运行 db2batch 来找出花了多少时间在编译上在运行上花费了多少时间。如果编译需要更多的时间,降低优化级别。如果执行需要更多的时间那么就考虑更高的优化级别
当你选择了一个优化级别,考虑下面的一般准则:
- 从使用默认查询优化级别开始,级别 5
- 要使用默认级别之外的级别,首先尝试级别 1,2 或 3 。级别 0,1 和 2 使用贪婪连接枚举运算法则。
- 如果你有很多表以及在同一列上有大量的连接谓词,在关心编译时间的情况下使用优化级别 1 或 2 。
- 对只有不到一秒的运行时间的查询使用一个低的优化级别(0 或 1)。比如查询往往有下面的特点:
- 只访问一个或很少的表
- 只获取一行或者几行
- 使用完全唯一的索引
在线事务处理(OLTP)事务是这种类型访问的很好例子
- 对长时间运行(超过 30 秒)的语句使用高一些的优化级别(3,5 或 7)。
优化级别 3 及其以上使用动态编程连接枚举算法。这个算法考虑更多的可选计划,并且可能招致比 0,1,和 2 更多的编译时间,尤其在表的数目增加后。
- 只有在你对一个查询有特别的优化需求时才使用优化级别 9 。
复杂查询需要不同数量的优化来选择最佳访问计划。对有下面特征的查询,请考虑使用更高的优化级别:
- 访问一个大表
- 谓词数目很多
- 大量的子查询
- 很多连接
- 很多集合操作,比如 UNION 和 INTERSECT
- 很多匹配的行
- 有 GROUP BY 何 HAVING 操作
- 嵌套表描述
- 大量的视图
决策支持查询或月底报告查询对于数据库是一个很常见的复杂查询的很好例子,对于这类查询优化级别至少应该使用默认值。
使用更高的查询优化级别的 SQL 语句是由查询生成器产生的。很多查询生成器创建效率低下的查询。写得很拙劣的查询,包括那些有查询生成器产生的查询,需要额外的优化以选择一个好的访问计划。使用查询优化级别 2 和更高的级别可以提高那些 SQL 查询。
对于 SAP 应用程序,总是使用优化级别 5 。这个优化级别启用了很多为 SAP 优化过的 DB2 功能,比如设置 DB2_REDUCED_OPTIMIZATION 注册表变量。
使用参数标记来减少动态语句的编辑时间
DB2 数据服务器可以通过在动态语句高速缓存中保存访问片段和语句文本来避免重复预编译一个前面运行过的动态 SQL 语句。对这个语句的一个后续 PREPARE 请求将尝试在动态语句高速缓存中查找访问片段来避免编译。然而,只要谓词在字面上有一点不同,这个语句高速缓存中的片段就不一致。例如,下面两个语句就在动态语句高速缓存中被看作不同的语句。
|
如果它们运行得太频繁,相关 SQL 语句的编译甚至会造成额外的系统 CPU 负担。在“ Monitoring and Tuning the System ”最佳实践文章中描述了 如何检测这性能问题。如果你的系统遇到这类性能问题,应该考虑把应用程序改成使用参数标记来把谓词的值传递给 DB2 编译器,而不要显式的在 SQL 语句中包含它。不过,对于复杂的查询如果使用参数标记那么得到的访问计划可能不是最优的。更多信息请参见“在复杂查询中使用 REOPT 绑定选项和输入变量”。
设置 DB2_REDUCED_OPTIMIZATION 注册表变量
如果对你的应用程序设置的优化级别不能充分的减少编译时间,那么就尝试设置 DB2_REDUCED_OPTIMIZATION 注册变量。这个注册变量在优化器查找空间上比设置优化级别提供了更多控制。这个注册变量让你可以请求在指定的优化级别中减少优化功能或者严格使用优化功能。如果你减少了使用优化技术的数目,你同样减少了时间和优化过程中使用的资源。
注意:虽然优化时间和资源使用可能会减少,这也增加了产生的查询计划不是最优的风险。
首先,尝试设置注册表变量为 YES 。如果优化级别是 5(默认值)或更低,优化器将不会使用某些需要花费大量准备时间和资源的优化技术,但是通常也不会产生更好的查询计划。如果优化级别是 5,优化器会减少或取消一些额外的技术,这可能进一步减少优化时间和使用的资源,不过同样进一步增加了得到的查询计划不是最优的风险。对于低于 5 的优化级别,它们的一些技术可能在任何情况下都无效。
如果设置 YES 没能充分缩短编译时间,可以尝试设置这个注册变量为一个数字。效果是和 YES 一样,对于在级别 5 上的动态准备查询优化有后续的附加行为。如果在任何查询块中连接的总数目超过了这个设置,那么优化器就切换到一个贪婪连接枚举算法而不是取消额外的优化技术。这样的效果是查询将在一个类似优化级别 2 的级别上被优化。
对 SAP 应用程序设置 DB2_WORKLOAD 注册变量
对于 SAP 应用程序,总是会为 SAP 设 DB2_WORKLOAD 注册变量。这会触发一批其他的对 SAP 应用程序有特殊好处的 DB2 注册表变量设置。下面是在这些便利中和 DB2 优化器相关的注册变量设置
- DB2_MINIMIZE_LIST_PREFETCH=YES
- DB2_INLIST_TO_NLJN=YES
- DB2_ANTIJOIN=EXTEND
- DB2_REDUCED_OPTIMIZATION=<specific heuristics for SAP workloads>
- DB2_VIEW_REOPT_VALUES=YES
DB2_REDUCED_OPTIMIZATION 的设置是专门针对 SAP 工作负载的。不要在其他应用程序下使用除非是 DB2 技术支持推荐的。
- DB2_MINIMIZE_LIST_PREFETCH=YES 如没有足够可用信息来判断是否这个访问方法对查询有好处,将会阻止优化器考虑列出预取表访问方法。如果谓词包含参数标记,这可能对实例就是这种情况。在 SAP 应用程序中,参数标记在大多数应用程序中都有使用,除了 SAP NetWeaver BIreport 查询。
- DB2_INLIST_TO_NLJN=YES 使优化器支持包含列表谓词 IN 的查询使用嵌套循环连接。 IN 列表被转换进一个表并像外部表的 NLJN 和通过索引访问的内部表使用。在 SAP 应用程序中经常有 IN 列表的查询,例如当使用 SAP 的 F4 帮助功能来从一个可能的值的列表中选择一个范围或一批不同的值。
即使在指定了 REOPT(ONCE) 的情况下,DB2_MINIMIZE_LIST_PREFETCH=YES 和 DB2_INLIST_TO_NLJOIN=YES 将依然保持活动。
- DB2_ANTIJOIN=EXTEND 让优化器去寻找把 NOT IN 和 NOT EXISTS 子查询转换成 anti-joins 的机会。
- DB2_VIEW_REOPT_VALUES=YES 让所有 SAP 用户去存储一个当语句被解释的时候在 EXPLAIN_PREDICATE 表中重新优化过的 SQL 语句的缓存的值。所有 SAP 用户使用相同的具有所需权限的数据库连接用户。
收集正确的编目信息,包括高级统计功能
精确的数据库统计信息是查询优化的关键。在所有对查询性能来说非常关键的表上有规律的运行 RUNSTATS 。如果一个应用程序直接查询这些表并且有大量的动态编目更新比如 DDL 语句,你可能也希望搜集系统编目表的信息。可以启用自动搜集统计信息功能来允许 DB2 数据服务器自动运行 RUNSTATS 。可以启用实时收集统计信息,通过立刻收集这些信息来让 DB2 数据服务器在优化查询之前能提供更及时的统计信息。
如果手动运行 RUNSTATS 来收集统计信息,你应该至少使用下面的选项。
|
分发统计信息可以让优化器知道是否有数据倾斜。当使用特定索引访问表时,详细的索引统计信息提供更多的 I/O 需求细节来预取数据页。然而对大表收集详细的索引统计信息会消耗很多的 CPU 和内存。 SAMPLED 选项提供了详细索引统计信息和相同的精确性,却只需要一小部分 CPU 和内存。当并没有对一个表提供一个统计配置文件时,这些默认值同样会被自动收集统计信息使用。
为了提高查询性能,考虑收集更多更高级的统计信息,比如列组的统计信息,LIKE 统计信息或创建统计信息视图。
列组统计信息
如果你的查询不止一个连接谓词来连接两个表,在选择一个执行计划来运行查询之前 DB2 优化器将计算如何选择每个谓词。
例如,考虑以供厂商,他用有很多颜色的原料生产产品,弹性和品质。产品最后页是和原料一样的颜色。这个厂商执行了以下查询:
|
这个查询返回了所有产品的名字和原材料品质。在这里有两个连接谓词:
|
优化器会假定这两个谓词是独立的,也就是说所有弹性对颜色的变化没有关系。然后通过建立每个表关于弹性等级数和不同的颜色数目的编目信息评估谓词的总的可选组合,并基于这个评估。例如,比起合并连接它可能更倾向于选择一个嵌套循环连接,反之亦然。
然而,这两个谓词可能并不独立。例如比较高的弹性材料可能只有几种颜色,而且弹性差的材料也可能不同于弹性好的材料只有剩下的其他颜色。然后组合这些谓词的选择消除一些行,所以查询将返回更多的行。没有这些信息,优化器也许不会选择最佳的计划。
为了在 PRODUCT.COLOR 和 PRODUCT.ELASTICITY 上收集列组统计信息 , 运行下面 RUNSTATS 命令:
|
优化器使用这些统计信息来检测相关性,并动态调整相关的谓词选项组合,因此得到对连接的尺度和开销更精确的评估。
当一个查询需要数据以一个具体的方式(使用 GROUP BY 或 DISTINCT 关键字)编组时列组统计信息也会非常有用,因为优化器需要计算明确分组的数目。
考虑下面查询:
|
没有任何索引或列组统计信息,优化器评估分组的数目(也包括在这种情况下返回的行数目)是 DEPTNO、MGR 和 YEAR_HIRED 的不同值的结果。这个评估假设分组键列是独立的。然而,如果每个管理员管理一个确定的部门,这个假设就可能是错误的。同样,不大可能每个部门每年都雇用新员工。因此,不同 DEPTNO、MGR 和 YEAR_HIRED 值得结果可能是对具体组的数目过高评估。
在 DEPTNO、MGR 和 YEAR_HIRED 上收集的列组统计信息将为上面的查询提供给优化器和有确定数目的分组:
|
为了 JOIN 谓词关系,优化器也管理简单等价谓词,比如
|
在上面的 EMPLOYEE 表,在 DEPTNO 谓词上很可能与在 YEAR 上的谓词毫无关系。然而在 DEPTNO 和 MGR 上的谓词却肯定相关,因为每个单独的部门可能经常在一段时间受到同一个经理的管理。优化器使用列的统计信息来判断不同之的组合数目并对这两列的关系调整选择或计数评估。
子元素统计
如果你在模式结尾之外的任何位置对指定的 LIKE 谓词使用 % 通配符,你都应该搜集关于子元素结构的基本信息。
以及向通配符 LIKE 谓词(例如,SELECT .... FROM DOCUMENTS WHERE KEYWORDS LIKE ''%simulation%''),这列以及查询必须满足某些标准来从子元素统计信息中获利。
表列应该包括由空格分开的子域或者子元素。例如,一个四行的 DOCUMENTS 表出于文本检索的目的有一个 KEWORDS 列和一系列相关的关键字。 KEYWORDS 的值是:
|
在这个例子中,每列的值有 5 个子元素组成,每个都是一个词(关键词),通过空格和其他关键词分隔开。
查询应该在 WHERE 子句中参考这些列。
优化器会评估每个谓词匹配多少行。对于这些通配符 LIKE 谓词,优化器假设 COLUMN 匹配了一系列彼此连接的元素,并且它基于字符串的长度来估算每个元素的长度,除了 % 开头或结尾的字符。如果你收集子元素的统计信息,优化器将有关于每个子元素和分隔符的长度信息。它可以使用这些额外的信息来更精确的评估可能有多少行匹配这个谓词。
为了连接子元素统计信息,运行有 LIKE STATISTICS 子句的 RUNSTATS 。
统计视图
DB2 基于成本的优化器把一个基于访问计划处理器处理的行数 – 或基数的评估作为这个操作的精确成本。这个基数评估是优化器成本唯一最重要的输入,而且它的精确度很大程度上取决于 RUNSTATS 实用工具从数据库收集的统计信息。对于计算一个精确的基数评估来说上面描述的统计信息是最重要的,然而有一些环境却需要非常成熟的统计信息。尤其是想要体现越复杂的关系就更需要成熟的统计信息,比如涉及比较的描述(例如,price > MSRP + Dealer_markup),关系跨了多个表(例如,product.name = ''Alloy wheels'' and product.key = sales.product_key),或者其他谓词除了涉及独立属性以及简单比较操作的谓词。统计视图可以防止这些复杂关系类型,因为统计信息是在这个视图返回值的基础上收集的,而不是从这个视图相关的基础表上。
当一个查询被编译时,优化器把这个查询和可用的统计视图进行匹配。当优化器计算基数估算中间结果集时,它使用来自视图的统计信息来计算一个更好的评估。
查询不必因为优化器使用视图就直接参考统计视图。优化器可以使用和物化查询表(MQTs)相同的匹配机制来匹配到统计视图的查询。出于这个考虑,除了他们不被永久储存,统计视图和 MQTs 非常相似,因此它们也不消耗磁盘空间也不需要维护。
一个统计视图在第一次创建一个视图并使用 ALTER VIEW 语句允许优化。然后在这个统计视图上运行 RUNSTATS,用这个视图的统计信息填入系统编目表中。例如为了创建一个统计视图来表现在时间在一个星型模式中维度表和实施表之间的连接,执行下面语句:
|
统计视图可以被用于对查询提高基数评估,以及访问计划和查询性能,例如:
|
没有统计视图,优化器假设所有事实表 TIME_KEY 的值对应一个特定的时间维度 YEAR_MON 值在事实表中是统一的。然而可能销售在 12 月特别强劲,产生比其他月份强劲多很多的交易。
在很多情况下,统计视图可以提高查询性能,并且有一些简单的最佳实践可以帮助判断需要创建哪些统计视图。请参考“更多阅读”章节。
自动收集统计信息当前不能用于统计视图。无论什么时候统计视图的基础表数据有了显著的改动都要收集统计视图的统计信息。
最小化 RUNSTAS 的影响
进一步改善 RUNSTATS 的时机:
- 通过 COLUMNS 子句来限制要收集统计信息的列。在查询工作负载中经常会有一些列永远都不会被谓词涉及到,因此它们不需要被统计。
- 如果倾向于一致的数据就限制搜集分布统计信息的列数。收集分布统计信息需要比收集基础列统计花费更多的 CPU 和内存。不过,要判断一列的值是否相同需要现有的统计信息或者对数据进行查询。因为表会发生改变,这个方法同样基于数据将保持一致的假设。
- 通过制定 TABLESAMPLE SYSTEM 或 BERNOULLI 子句使用页面或行级别的取样来显示处理的行数和页面的数目。从 10% 级别的样本开始例如 TABLESAMPLE SYSTEM(10) 。检查统计信息的精确性以及系统性能是否因为更改访问计划而有所下降。如果是的话,就尝试用 10% 行级别的样本来替换,比如 TABLESAMPLE BERNOULLI(10) 。如果统计信息精度不够,则增加取样数量。当使用 RUNSTATS 页面或行级别的取样,对进行连接的表使用相同样本率。这和确保连接列统计信息有相同级别的精度。
对一个配置了数据库分区功能(DPF)的数据服务器,RUNSTATS 从单个数据库分区搜集统计信息。如果 RUNSTATS 运行在表所在的这个数据库分区上,统计信息将在这里收集。如果不是,统计信息将从第这个表所在分区组的一个数据库分区上收集。为了保持一致的统计信息,就要确保进行连接的表的统计信息从相同的数据库分区搜集。
避免手动更新编目统计信息
DB2 数据服务器支持通过对 SYSSTAT 模式下的视图发起 UPDATE 语句手动来更新编目统计信息。这个功能对在测试系统中模拟一个生产数据库来检查查询计划,或许非常有用。为了在其他系统上重放,db2look 工具对抓取 DDL 和 UPDATE SYSSTAT 语句方面很有帮助。
然而,要避免手动更新统计信息 - 意味着为了强制执行一个特定的查询计划通过提供不正确的统计信息影响查询优化器。这个实践可能造成某些查询的性能提升,也可能导致其他的性能下降。在最终使用这个办法之前,请考虑其它之前考虑过的调优方法。如果不得不使用这个方法,在这种情况下一定要记录原始的统计信息,如果更新统计信息造成了性能下降就需要恢复它们。
对 SAP 应用程序,使用自动统计信息收集
在 SAP 安装过程中,自动和实施统计信息是默认打开的。这就是说你不需要手动发起 RUNSTATS 。
很多 SAP 使用情况是在第一步以及通过一个复杂的 SAP 文本查询来访问修改表内容。不要改变下面提到的默认设置 :
|
使用有不均匀数据的 SAP BI 表的统计视图
在 SAP BI snowflake 模式的表中不均匀的分布数据可能导致并不优化的查询访问计划并增加查询时间。大多数这样的问题是通过设置 SAP 工作负载变量 =SAP 来解决的。但是在一些例外的情况下,当很多表互相连接时,统计视图可以被创建来为 DB2 优化器提供更多关于值分布的信息。
下面的例子中,事实表和客户、请求、时间以及产品维度表进行连接。
大多数交易是跟 Customer #10200 完成的。因此,事实表的绝大多数行在 Dim C 列的值是 2 。这造成了在事实表的 Dim C 列上的不均匀的数据分布。
DB2 优化器可能会在对在客户维度有约束的查询时候估算出错误的基数
可以在维度和事实表上定义统计视图生成额外的统计信息,DB2 优化器利用这些信息来增强基数评估并减少查询运行时间。
在上面的例子中,下面在客户和事实表维度上的统计视图可能解决错误基数统计问题并减少查询响应时间:
|
如果这个统计视图的一个基本表发生了改动,就需要在统计视图上更新数据库统计信息。统计视图不支持 DB2 自动统计信息搜集。
使用 SAP BI 聚集
SAP BI 实施了它们自己的物化查询表,叫做 SAP BI 聚集。使用 SAP 聚集在 SAP BI 应用程序中替代一般的 DB2 物化查询表。
如果其他调优选项不能产生可以接受的效果那么使用优化配置文件
如果你已经遵循了本文推荐的最佳实践,而你相信仍然没有达到最优的性能的话,你就可以向 DB2 优化器提供一个明确的优化指南。
优化指南包含在一个叫做优化配置文件的 XML 文档中。配置文件定义 SQL 语句和他们相关的优化指南。
如果你广泛的使用了优化配置文件,它们需要你付出很多的努力来维护。更重要的是,你只能使用优化配置文件来对现有 SQL 语句提高性能。下面的最佳实践对所有的查询持续稳定的提高查询性能,包括未来的某些查询。
回页首
使用解释工具来调优 SQL 语句
解释工具是用来显示被查询优化器用来运行一个 SQL 语句的查询访问计划。它包含了用于运行 SQL 语句关于相关操作非常广泛的信息,比如计划操作去、它们的 arguments、执行顺序和成本。因为查询访问计划是查询性能中最重要的因素之一,为了能诊断查询性能问题,能够理解解释工具的输出非常重要。
解释信息通常用于:
- 理解为什么应用程序性能发生了变化
- 评估性能调优的效果
分析性能变化
为了帮助你理解查询性能变化的原因,需要调优前后的解释信息,你可以通过执行下面步骤得到它们:
- 在你做任何更改之前,抓取查询的解释信息并保存解释表。另外,也可以保存 db2exfmt 解释工具的输出。然而,为了更成熟的分析,把解释信息保存在解释表中可以更方便用 SQL 查询,又提供了把数据保存在关系型 DBMS 中在维护上明显的优势。此外 db2exfmt 工具可以在任何时间运行。
- 如果你不想、或不能访问 Visual Explain 来查看这些信息,就保存或打印当前编目统计信息。你也可以使用 db2look 生产力工具来帮助执行这个任务。另外,如果是你用 DB2 9.5,在语句被解释的同时搜集解释快照。 Db2exfmt 工具将自动格式化包含在快照中的信息。这在使用自动或是统计信息收集的时候尤其重要,因为查询优化器使用的统计信息可能还没有存入系统编目表中,或者他们可能在语句从系统编目表中获取信息到被解释的过程中被更改了。
- 保存或打印数据定义语言(DDL)语句,包括这那些 CREATE TABLE、CREATE VIEW、CREATE INDEX、CREATE TABLESPACE 。 Db2look 同样可以执行这个任务。
通过这个方法收集的信息,为将来的分析提供了一个参考点。对动态 SQL 语句来说,当你第一次运行你的应用程序时,你可以搜集这个信息。对于静态语句,也可以在绑定的时候搜集这个信息。在一个主要系统更改之前搜集这个信息非常重要,比如安装一个新的服务级别或 DB2 版本或者一个很大的配置改动,比如增加或删除数据库分区和分布数据。这是因为这类系统更改可能造成访问计划的不利更改。虽然访问计划退步应该很少发生,但是有这些可用信息将允许更快的你解决性能退步的问题。要分析一个性能变化,把之前的信息和现在你开始分析的时候收集到的关于查询和环境的信息进行比较。
一个简单的例子,你的分析可能显示索引不再作为访问计划的一部分被用到。使用 Visual Explain 或 db2exfmt 显示的编目统计信息,你可能注意到 index 级别数远远高于查询第一次绑定到数据库的时候的值。然后你可以选择执行下面的某个操作:
- 重组索引
- 为你的表和索引搜集新的统计信息
- 在重新绑定的时候搜集解释信息。
在你执行其中某个操作之后,再检查一下查询计划。如果索引再一次被使用了,这个查询的性能可能不再是个问题。重复这些步骤直到问题被解决。
评估性能调整效果
你可以进行一系列的操作来帮助提高查询性能,比如校对配置参数、添加容器、和搜集刷新编目统计信息。
在你这些方面进行了更改,如果在被访问计划选择到的方面有更改的话,你可以使用解释工具来判断影响。例如,如果你基于索引指南添加一个索引或物化查询表(MQT),解释数据可以帮助你判断是否索引或物化查询表最终如你所期望的被用到了。
虽然解释输出提供了让你判断选中的访问计划的信息和成本,对一个查询来说精确测量性能提高的唯一方法是使用基准的是技术。
今天关于MSSQL-最佳实践-如何监控备份还原进度和备份的sql怎么还原的分享就到这里,希望大家有所收获,若想了解更多关于1.7、Bootstrap V4自学之路------起步---最佳实践、10 条 oracle sql 最佳实践、Core Bluetooth框架之三:最佳实践、DB2 最佳实践: 编写并调优查询语句以优化性能最佳实践等相关知识,可以在本站进行查询。
本文标签:




