本文将带您了解关于sqlserver中分区函数partitionby的用法的新内容,同时我们还将为您解释sql分区语句的相关知识,另外,我们还将为您提供关于hive中简单介绍分区表(partition
本文将带您了解关于sqlserver中分区函数 partition by的用法的新内容,同时我们还将为您解释sql分区语句的相关知识,另外,我们还将为您提供关于hive 中简单介绍分区表 (partition table)—— 动态分区 (dynamic partition)、静态分区 (static partition)、Hive 窗口函数之 lead() over(partition by ) 和 lag() over(partition by )、MS-SQLServer over partition by的使用、MYSQL - 实现 sqlserver- row_number () over (partition by order by) 分组排序功能的实用信息。
本文目录一览:- sqlserver中分区函数 partition by的用法(sql分区语句)
- hive 中简单介绍分区表 (partition table)—— 动态分区 (dynamic partition)、静态分区 (static partition)
- Hive 窗口函数之 lead() over(partition by ) 和 lag() over(partition by )
- MS-SQLServer over partition by的使用
- MYSQL - 实现 sqlserver- row_number () over (partition by order by) 分组排序功能
")
sqlserver中分区函数 partition by的用法(sql分区语句)
partition by关键字是分析性函数的一部分,它和聚合函数(如group by)不同的地方在于它能返回一个分组中的多条记录,而聚合函数一般只有一条反映统计值的记录,
partition by用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组。
partition by 与group by不同之处在于前者返回的是分组里的每一条数据,并且可以对分组数据进行排序操作。后者只能返回聚合之后的组的数据统计值的记录。
Demo
数据库表结构 学生成绩表 UserGrade
Id int Checked 主键Id
Name varchar(50) Checked 学生名
Course varchar(50) Checked 课程名
score int Checked 分数
01、把每个人学生的成绩按照升序排名 (思路:根据学生姓名分组 根据每个人成绩排序)
sql语句
select *,ROW_NUMBER() over( partition by Name order by score )排名
from UserGrade
查询结果
Id Name Course score 排名
1004 李四 数学 60 1
1005 李四 语文 80 2
1001 李四 英语 100 3
1007 王五 数学 30 1
1006 王五 语文 50 2
1003 王五 英语 50 3
1008 张三 英语 60 1
1000 张三 语文 80 2
1002 张三 数学 90 3
02、把每个学科的成绩分别进行排名 (思路:根据学科分组 根据成绩排序)
sql语句
from UserGrade
Id Name Course score 排名 1002 张三 数学 90 1 1004 李四 数学 60 2 1007 王五 数学 30 3 1001 李四 英语 100 1 1008 张三 英语 60 2 1003 王五 英语 50 3 1000 张三 语文 80 1 1005 李四 语文 80 2 1006 王五 语文 50 3
—— 动态分区 (dynamic partition)、静态分区 (static partition)")
hive 中简单介绍分区表 (partition table)—— 动态分区 (dynamic partition)、静态分区 (static partition)

一、基本概念
hive 中分区表分为:范围分区、列表分区、hash 分区、混合分区等。
分区列:分区列不是表中的一个实际的字段,而是一个或者多个伪列。翻译一下是:“在表的数据文件中实际上并不保存分区列的信息与数据”,这个概念十分重要,要记住,后面是经常用到。
1.1 创建数据表
下面的语句创建了一个简单的分区表:

create table partition_test( member_id string, name string ) partitioned by ( stat_date string, province string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '','';
1.2 创建分区
这个例子中创建了 stat_date 和 province 两个字段作为分区列。如果要添加数据,通常情况下我们需要先创建好分区,然后才能使用该分区,例如:
alter table partition_test add partition (stat_date=''20141113'',province=''jilin'');
这样就创建好了一个分区。这时我们会看到 hive 在 HDFS 存储中创建了一个相应的文件夹:
hive> dfs -ls /user/ticketdev/hive/warehouse/partition_test/stat_date=20141113; Found 1 items drwxr-xr-x - ticketdev ticketdev 0 2014-11-13 17:50 /user/ticketdev/hive/warehouse/partition_test/stat_date=20141113/province=jilin h
每一个分区都会有一个独立的文件夹,在这个例子中 stat_date 是主文件夹,province 是子文件夹,如:
hive> alter table partition_test add partition (stat_date=''20141113'',province=''beijing''); OK Time taken: 0.119 seconds hive> dfs -ls /user/ticketdev/hive/warehouse/partition_test/stat_date=20141113/; Found 2 items drwxr-xr-x - ticketdev ticketdev 0 2014-11-13 18:06 /user/ticketdev/hive/warehouse/partition_test/stat_date=20141113/province=beijing drwxr-xr-x - ticketdev ticketdev 0 2014-11-13 17:50 /user/ticketdev/hive/warehouse/partition_test/stat_date=20141113/province=jilin
二、静态分区
2.1 数据准备
基本知识介绍到这里,下面开始插入数据。我使用一个辅助的非分区表 partition_test_input 准备向 partition_test 中插入数据:
hive> desc partition_test_input; OK stat_date string member_id string name string province string hive> select * from partition_test_input; OK 20110526 1 liujiannan liaoning 20110526 2 wangchaoqun hubei 20110728 3 xuhongxing sichuan 20110728 4 zhudaoyong henan 20110728 5 zhouchengyu heilongjiang
2.2 添加数据
然后我向 partition_test 的分区中插入数据:
hive> insert overwrite table partition_test partition(stat_date=''20110728'',province=''henan'') select member_id,name from partition_test_input where stat_date=''20141113'' and province=''beijing''; Total MapReduce jobs = 2 ... 1 Rows loaded to partition_test OK
还可以同时向多个分区插入数据:
hive> > from partition_test_input > insert overwrite table partition_test partition (stat_date=''20110526'',province=''liaoning'') > select member_id,name where stat_date=''20110526'' and province=''liaoning'' > insert overwrite table partition_test partition (stat_date=''20110728'',province=''sichuan'') > select member_id,name where stat_date=''20110728'' and province=''sichuan'' > insert overwrite table partition_test partition (stat_date=''20110728'',province=''heilongjiang'') > select member_id,name where stat_date=''20110728'' and province=''heilongjiang''; Total MapReduce jobs = 4 ... 3 Rows loaded to partition_test OK
特别要注意,在其他数据库中,一般向分区表中插入数据时系统会校验数据是否符合该分区,如果不符合会报错。而在 hive 中,向某个分区中插入什么样的数据完全是由人来控制的,因为分区键是伪列,不实际存储在文件中,如:
hive> insert overwrite table partition_test partition(stat_date=''20110527'',province=''liaoning'') select member_id,name from partition_test_input; Total MapReduce jobs = 2 ... 5 Rows loaded to partition_test OK hive> select * from partition_test where stat_date=''20110527'' and province=''liaoning''; OK 1 liujiannan 20110527 liaoning 2 wangchaoqun 20110527 liaoning 3 xuhongxing 20110527 liaoning 4 zhudaoyong 20110527 liaoning 5 zhouchengyu 20110527 liaoning
可以看到在 partition_test_input 中的 5 条数据有着不同的 stat_date 和 province,但是在插入到 partition (stat_date=''20110527'',province=''liaoning'') 这个分区后,5 条数据的 stat_date 和 province 都变成相同的了,因为这两列的数据是根据文件夹的名字读取来的,而不是实际从数据文件中读取来的:
$ hadoop fs -cat /user/hive/warehouse/partition_test/stat_date=20110527/province=liaoning/000000_0 1,liujiannan 2,wangchaoqun 3,xuhongxing 4,zhudaoyong 5,zhouchengyu
三、动态分区
下面介绍一下动态分区,因为按照上面的方法向分区表中插入数据,如果源数据量很大,那么针对一个分区就要写一个 insert,非常麻烦。况且在之前的版本中,必须先手动创建好所有的分区后才能插入,这就更麻烦了,你必须先要知道源数据中都有什么样的数据才能创建分区。
使用动态分区可以很好的解决上述问题。动态分区可以根据查询得到的数据自动匹配到相应的分区中去。
使用动态分区要先设置 hive.exec.dynamic.partition 参数值为 true,默认值为 false,即不允许使用:
hive> set hive.exec.dynamic.partition; hive.exec.dynamic.partition=false hive> set hive.exec.dynamic.partition=true; hive> set hive.exec.dynamic.partition; hive.exec.dynamic.partition=true
动态分区的使用方法很简单,假设我想向 stat_date=''20110728'' 这个分区下面插入数据,至于 province 插入到哪个子分区下面让数据库自己来判断,那可以这样写:
hive> insert overwrite table partition_test partition(stat_date=''20110728'',province) > select member_id,name,province from partition_test_input where stat_date=''20110728''; Total MapReduce jobs = 2 ... 3 Rows loaded to partition_test OK
stat_date 叫做静态分区列,province 叫做动态分区列。select 子句中需要把动态分区列按照分区的顺序写出来,静态分区列不用写出来。这样 stat_date=''20110728'' 的所有数据,会根据 province 的不同分别插入到 /user/hive/warehouse/partition_test/stat_date=20110728 / 下面的不同的子文件夹下,如果源数据对应的 province 子分区不存在,则会自动创建,非常方便,而且避免了人工控制插入数据与分区的映射关系存在的潜在风险。
注意,动态分区不允许主分区采用动态列而副分区采用静态列,这样将导致所有的主分区都要创建副分区静态列所定义的分区:
hive> insert overwrite table partition_test partition(stat_date,province=''liaoning'') > select member_id,name,province from partition_test_input where province=''liaoning''; FAILED: Error in semantic analysis: Line 1:48 Dynamic partition cannot be the parent of a static partition ''liaoning''
动态分区可以允许所有的分区列都是动态分区列,但是要首先设置一个参数 hive.exec.dynamic.partition.mode :
hive> set hive.exec.dynamic.partition.mode; hive.exec.dynamic.partition.mode=strict
它的默认值是 strick,即不允许分区列全部是动态的,这是为了防止用户有可能原意是只在子分区内进行动态建分区,但是由于疏忽忘记为主分区列指定值了,这将导致一个 dml 语句在短时间内创建大量的新的分区(对应大量新的文件夹),对系统性能带来影响。所以我们要设置:
hive> set hive.exec.dynamic.partition.mode=nostrick;
再介绍 3 个参数:
- hive.exec.max.dynamic.partitions.pernode (缺省值 100):每一个 mapreduce job 允许创建的分区的最大数量,如果超过了这个数量就会报错
- hive.exec.max.dynamic.partitions (缺省值 1000):一个 dml 语句允许创建的所有分区的最大数量
- hive.exec.max.created.files (缺省值 100000):所有的 mapreduce job 允许创建的文件的最大数量
 over(partition by ) 和 lag() over(partition by )")
Hive 窗口函数之 lead() over(partition by ) 和 lag() over(partition by )
lead函数用于提取当前行前某行的数据
lag函数用于提取当前行后某行的数据
语法如下:
lead(expression,offset,default) over(partition by ... order by ...)
lag(expression,offset,default) over(partition by ... order by ... )
例如提取前一周和后一周的数据,如下:
select
year,week,sale,
lead(sale,1,NULL) over(--前一周sale partition by product,country,region order by year,week) lead_week_sale,
lag(sale,1,NULL) over(--后一周sale partition by product,country,region order by year,week) lag_week_sale
from sales_fact a
where a.country=''country1'' and a.product=''product1'' and region=''region1''
order by product,country,year,week
实例2:
SELECT
created_at create_time,
operator,
bridge_duration,
lead(created_at, 1) OVER (PARTITION BY operator ORDER BY created_at ASC) next_create_time
FROM ods.ods_call_ctob_auction_call_recording
WHERE substr(created_at,1,10)= ''${date_y_m_d}''
————————————————
版权声明:本文为CSDN博主「hongyd」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hongyd/article/details/83056194

MS-SQLServer over partition by的使用
临下班时一个朋友问我一个问题,他想实现一个分组后统计的功能,比如一Class列为GroupBy对象,检索之后希望能对这个分组结果再来个统计,知道一下输入各个Class的Record各有多少条,如下图所示(环境:MSsql-2008):
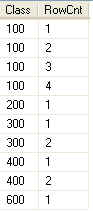
坦白的说,以前真没搞过这样的示例,但想到用ROW_NUMBER函数,别的不太了解,就自己查资料试了试,还真给弄出来了。今天有闲,把这个记下来。
sql语句:
Select Top 10
b.Class,RowCnt = ROW_NUMBER() OVER(PARTITION BY b.Class ORDER BY Id ASC)
From Info a,Candidate b
Where a.Id = b.Id
这个sql没什么好解释的,唯一想提醒的是PARTITION BY的对象是想分组的那列。
注释:
row_number() over(partition by ... order by ...) :分组排序功能
 over (partition by order by) 分组排序功能")
MYSQL - 实现 sqlserver- row_number () over (partition by order by) 分组排序功能
sqlserver:
with Result as
(
select SUM(F_DayValue) AS F_Value,F_ZZ_ttBuildID,F_EnergyItemCode
from T_EC_EnergyItemDayResult
where F_EnergyItemCode like ''%000''
and F_StartDay>=@ldStartDate and F_StartDay<=@ldEndDate
and F_ZZ_ttBuildID IN (select F_BuildID from T_BD_BuildBaseInfo)
group by F_ZZ_ttBuildID,F_EnergyItemCode
)
select a.F_Value,a.F_ZZ_ttBuildID,b.F_BuildName,a.F_EnergyItemCode,
ROW_NUMBER() over(partition by a.F_EnergyItemCode order by a.F_Value desc) as nsort
from Result a
left join T_BD_BuildBaseInfo b on a.F_ZZ_ttBuildID=b.F_BuildID
mysql:
CREATE TEMPORARY TABLE IF NOT EXISTS Result
(
select SUM(F_DayValue) AS F_Value,F_ZZ_ttBuildID,F_EnergyItemCode
from T_EC_EnergyItemDayResult
where F_EnergyItemCode like ''%000''
and F_StartDay>=V_ldStartDate and F_StartDay<=V_ldEndDate
and F_ZZ_ttBuildID IN (select F_BuildID from T_BD_BuildBaseInfo)
group by F_ZZ_ttBuildID,F_EnergyItemCode
);
CREATE TEMPORARY TABLE IF NOT EXISTS TMP01
(
select a.F_Value,a.F_ZZ_ttBuildID,b.F_BuildName,a.F_EnergyItemCode
from Result a
left join T_BD_BuildBaseInfo b on a.F_ZZ_ttBuildID=b.F_BuildID
);
select F_Value,F_ZZ_ttBuildID,F_BuildName,F_EnergyItemCode,nsort from (
select heyf_tmp.F_Value,heyf_tmp.F_ZZ_ttBuildID,heyf_tmp.F_BuildName,heyf_tmp.F_EnergyItemCode,@rownum
:=@rownum+1 ,
if(@pdept=heyf_tmp.F_EnergyItemCode,@rank:=@rank+1,@rank:=1) as nsort,
@pdept:=heyf_tmp.F_EnergyItemCode
from (
select F_Value,F_ZZ_ttBuildID,F_BuildName,F_EnergyItemCode from TMP01 order by F_EnergyItemCode ASC
,F_Value desc
) heyf_tmp ,(select @rownum :=0 , @pdept := null ,@rank:=0) a) T;
我们今天的关于sqlserver中分区函数 partition by的用法和sql分区语句的分享就到这里,谢谢您的阅读,如果想了解更多关于hive 中简单介绍分区表 (partition table)—— 动态分区 (dynamic partition)、静态分区 (static partition)、Hive 窗口函数之 lead() over(partition by ) 和 lag() over(partition by )、MS-SQLServer over partition by的使用、MYSQL - 实现 sqlserver- row_number () over (partition by order by) 分组排序功能的相关信息,可以在本站进行搜索。
本文标签:




