如果您想了解MySQL:对GROUP_CONCAT值进行排序的相关知识,那么本文是一篇不可错过的文章,我们将对mysqlgroupby排序进行全面详尽的解释,并且为您提供关于GROUP_CONCAT3
如果您想了解MySQL:对 GROUP_CONCAT 值进行排序的相关知识,那么本文是一篇不可错过的文章,我们将对mysql group by排序进行全面详尽的解释,并且为您提供关于GROUP_CONCAT 3 个表 php mysql、MySQL GROUP BY 和GROUP_CONCAT的一些用法、MySQL group_concat、MySQL group_concat 介绍的有价值的信息。
本文目录一览:- MySQL:对 GROUP_CONCAT 值进行排序(mysql group by排序)
- GROUP_CONCAT 3 个表 php mysql
- MySQL GROUP BY 和GROUP_CONCAT的一些用法
- MySQL group_concat
- MySQL group_concat 介绍
")
MySQL:对 GROUP_CONCAT 值进行排序(mysql group by排序)
简而言之:有没有办法对 GROUP_CONCAT 语句中的值进行排序?
询问:
GROUP_CONCAT((SELECT GROUP_CONCAT(parent.name SEPARATOR " » ") FROM test_competence AS node, test_competence AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.id = l.competence AND parent.id != 1 ORDER BY parent.lft) SEPARATOR "<br />\n") AS competences我得到这一行:
Crafts » Joinery
Administration » Organization
我想要这样:
Administration » Organization
Crafts » Joinery
答案1
小编典典当然,请参阅http://dev.mysql.com/doc/refman/...tions.html#function_group-
concat:
SELECT student_name, GROUP_CONCAT(DISTINCT test_score ORDER BY test_score DESC SEPARATOR '' '') FROM student GROUP BY student_name;
GROUP_CONCAT 3 个表 php mysql
如何解决GROUP_CONCAT 3 个表 php mysql?
我有一个叫做问题的表格,每个问题都有 id,question_body
还有一个叫做answers的表,每个答案都有id、answer_body、right、question_id
还有一个叫做hint_imgs,每一行都有id、img_url、question_id
这些图片是关于桌子的
问题:

答案:

hint_imgs:

我想返回这样的大数组:
[
{
"question_id": "","question_body": "","answers": [{"answer_id": "","answer_body": "","right": "","question_id": ""}],"hint_imgs": [{"hint_id": "","img_url": "","question_id": ""}]
},{
"question_id": "","question_id": ""}]
}
]
怎么做???????
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

MySQL GROUP BY 和GROUP_CONCAT的一些用法
1) 作用:GROUP BY 语句根据一个或多个列对结果集进行分组。
所谓的分组就是根据GROUP BY中的分组标记,将一个“数据集”划分成若干个“小区域”,每个分组标记相同的值,会划分在同一个"小区域中",最终查询出的结果只会显示"小区域"中一条记录。
2)GROUP BY 语句中的GROUP_CONCAT()函数
因为GROUP BY默认只显示了组中一条记录,如果想看组内的所有信息,就需要用到GROUP_CONCAT()函数
3)COUNT()函数:统计记录总数
COUNT(*)会统计我们表中的NULL值,如果不想统计NULL值,请写COUNT(字段名)
4)聚合函数[‘SUM()求和函数’,’MAX()函数:求最大值’,’MIN()函数:求最小值’,’AVG()函数:求平均值
在GROUP BY的过程中,如果碰到聚合函数,会进行聚合操作
MYSQL测试:
假设有数据表结构如下:
CREATE TABLE `user_info` (
`id` INT(11) NOT NULL AUTO_INCREMENT COMMENT ''主键id'',
`user_id` VARCHAR(50) NOT NULL DEFAULT '''' COMMENT ''用户编号'',
`grade` VARCHAR(50) NOT NULL DEFAULT '''' COMMENT ''年级'',
`class` VARCHAR(50) NOT NULL DEFAULT '''' COMMENT ''班级'',
PRIMARY KEY (`id`),
UNIQUE INDEX `uniq_user_id` (`user_id`)
)
ENGINE=InnoDB插入记录:
INSERT INTO `user_info` (`id`, `user_id`, `grade`, `class`) VALUES (10, ''10230'', ''C'', ''B'');
INSERT INTO `user_info` (`id`, `user_id`, `grade`, `class`) VALUES (9, ''10229'', ''C'', ''a'');
INSERT INTO `user_info` (`id`, `user_id`, `grade`, `class`) VALUES (8, ''10228'', ''B'', ''b'');
INSERT INTO `user_info` (`id`, `user_id`, `grade`, `class`) VALUES (7, ''10227'', ''B'', ''b'');
INSERT INTO `user_info` (`id`, `user_id`, `grade`, `class`) VALUES (6, ''10226'', ''B'', ''a'');
INSERT INTO `user_info` (`id`, `user_id`, `grade`, `class`) VALUES (5, ''10225'', ''B'', ''a'');
INSERT INTO `user_info` (`id`, `user_id`, `grade`, `class`) VALUES (4, ''10224'', ''A'', ''b'');
INSERT INTO `user_info` (`id`, `user_id`, `grade`, `class`) VALUES (3, ''10223'', ''A'', ''b'');
INSERT INTO `user_info` (`id`, `user_id`, `grade`, `class`) VALUES (2, ''10222'', ''A'', ''a'');
INSERT INTO `user_info` (`id`, `user_id`, `grade`, `class`) VALUES (1, ''10221'', ''A'', ''a'');所有记录查询结果:
查询grade,和user_id的所有记录
mysql> SELECT user_id,grade FROM user_info;
+---------+-------+
| user_id | grade |
+---------+-------+
| 10221 | A |
| 10222 | A |
| 10223 | A |
| 10224 | A |
| 10225 | B |
| 10226 | B |
| 10227 | B |
| 10228 | B |
| 10229 | C |
| 10230 | C |
+---------+-------+
group by的常规用法
1.以grade分组,并且查看user_id信息
mysql> SELECT user_id,grade FROM user_info GROUP BY grade ;
+---------+-------+
| user_id | grade |
+---------+-------+
| 10221 | A |
| 10225 | B |
| 10229 | C |
+---------+-------+
由结果可知:使用GROUP BY分组之后,每个分组标记相同的记录只会出现第一条,其他的相同的分组标记的记录会舍弃
2.利用GROUP_CONCAT查看user_id的详细信息
mysql> SELECT GROUP_CONCAT(user_id),grade FROM user_info GROUP BY grade ;
+-------------------------+-------+
| GROUP_CONCAT(user_id) | grade |
+-------------------------+-------+
| 10221,10222,10223,10224 | A |
| 10228,10227,10226,10225 | B |
| 10229,10230 | C |
+-------------------------+-------+
3.聚合函数max
mysql> select max(user_id),grade from user_info group by grade ;
+--------------+-------+
| max(user_id) | grade |
+--------------+-------+
| 10224 | A |
| 10228 | B |
| 10230 | C |
+--------------+-------+
4.having条件进一步过滤
mysql> select max(user_id),grade from user_info group by grade having grade>''A'';
+--------------+-------+
| max(user_id) | grade |
+--------------+-------+
| 10228 | B |
| 10230 | C |
+--------------+-------+
group by的非常规用法
1.查询的列中除了聚合列,分组列标识还有其他常规列,常规列如何取值?
mysql> select max(user_id),id,grade from user_info group by grade;
+--------------+----+-------+
| max(user_id) | id | grade |
+--------------+----+-------+
| 10224 | 1 | A |
| 10228 | 5 | B |
| 10230 | 9 | C |
+--------------+----+-------+
sql的结果就值得讨论了,与上述例子不同的是,查询条件多了id一列。数据按照grade分组后,grade一列是相同的,max(user_id)按照数据进行计算也是唯一的,id一列是如何取值的?看上述的数据结果,
推论:id是物理内存的第一个匹配项
2.修改id按照上述数据结果,将id=1,改为id=99,执行相同SQL:
mysql> select max(user_id),id,grade from user_info group by grade;
+--------------+----+-------+
| max(user_id) | id | grade |
+--------------+----+-------+
| 10224 | 2 | A |
| 10228 | 5 | B |
| 10230 | 9 | C |
+--------------+----+-------+
推论:第一条数据id变成了99,查出的结果第一条数据的id从1变成了2。表明,id这个非聚合条件字段的取值与数据写入的时间无关,因为id=1的记录是先于id=2存在的,修改的数据不过是修改了这条数据的内容。结合mysql的数据存储理论,由于id是主键,所以数据在检索是是按照主键排序后进行过滤的,因此
推论:id字段的选取是按照mysql存储的检索数据匹配的第一条。
3.聚合函数和常量在一起做运算
mysql> SELECT GROUP_CONCAT(user_id),grade,SUM(user_id)+9,SUM(user_id) FROM user_info GROUP BY grade ;
+-------------------------+-------+----------------+--------------+
| GROUP_CONCAT(user_id) | grade | SUM(user_id)+9 | SUM(user_id) |
+-------------------------+-------+----------------+--------------+
| 10222,10221,10224,10223 | A | 40899 | 40890 |
| 10225,10226,10228,10227 | B | 40915 | 40906 |
| 10229,10230 | C | 20468 | 20459 |
+-------------------------+-------+----------------+--------------+
当GROUP BY 碰到聚合函数和常量在一起的时候,聚合函数会正常发挥作用,但是常量只会计算一次,即在聚合完成之后,再和常量运算,而不是user_id和常量一起累加
注意:这种常量有可能是变量,例如多表查询的时候
SELECT COALESCE(SUM(t2.SUMS),0)+(SELECT COALESCE(SUM(t3.SUMS),0) FROM table3 t3 WHERE t3.UID=t2.uid) FROM table1 t1 LEFT JOIN table2 t2 ON ..... GROUP BY t2.uid其中COALESCE(SUM(t2.SUMS),0)是聚合函数,在group by的时候每次都会累加求和
而(SELECT COALESCE(SUM(t3.SUMS),0) FROM table3 t3 WHERE t3.UID=t2.uid)作为一个常量,总共只会加入一次,但是每一行记录的这个值可能是不同的,
如果想要查看每次累加具体的值,可以使用GROUP_CONCAT((SELECT COALESCE(SUM(t3.SUMS),0) FROM table3 t3 WHERE t3.UID=t2.uid)),注意GROUP_CONCAT中也要去除聚合函数:
SELECT
GROUP_CONCAT(t2.SUMS),
GROUP_CONCAT(SELECT COALESCE(SUM(t3.SUMS),0) FROM table3 t3 WHERE t3.UID=t2.uid),
(SELECT COALESCE(SUM(t3.SUMS),0) FROM table3 t3 WHERE t3.UID=t2.uid) FROM table1 t1 LEFT JOIN table2 t2 ON .....也可以先不使用分组,把分组条件去掉,同时也要去除聚合函数(聚合函数如果不分组整个表只会返回一条记录;如果分组,则返回不同的分组标记中的一条记录):
SELECT t2.SUMS,(SELECT COALESCE(SUM(t3.SUMS),0) FROM table3 t3 WHERE t3.UID=t2.uid) FROM table1 t1 LEFT JOIN table2 t2 ON .....
示例: 还是在user_info表,根据grade分组,查询每个分组中user_id之和加上ID总和的数值(模拟两个表来统计每个部门的user_id之和和另外一个表的字段的ID总和)
mysql> SELECT SUM(user_id),SUM(user_id)+id,GROUP_CONCAT(user_id),GROUP_CONCAT(id) grade FROM user_info GROUP BY grade;
+--------------+-----------------+-------------------------+----------+
| SUM(user_id) | SUM(user_id)+id | GROUP_CONCAT(user_id) | grade |
+--------------+-----------------+-------------------------+----------+
| 40890 | 40892 | 10222,10221,10224,10223 | 2,99,4,3 |
| 40906 | 40911 | 10225,10226,10228,10227 | 5,6,8,7 |
| 20459 | 20468 | 10229,10230 | 9,10 |
+--------------+-----------------+-------------------------+----------+
上述结果可以看出:SUM(user_id)+id中的id作为常量,在分组的时候,只计算了一次(2,99,4,3中只把2累加进去了,其他值舍弃,即如果不为聚合函数,只会参与一次)
想全部计算可以这样:
SELECT SUM(user_id),SUM(user_id)+(SELECT SUM(ID) FROM user_info),GROUP_CONCAT(user_id),GROUP_CONCAT(id), grade FROM user_info GROUP BY grade;上面是模仿多表,如果只有一个表,可以这样:
SELECT SUM(user_id),SUM(user_id+id),GROUP_CONCAT(user_id),GROUP_CONCAT(id), grade FROM user_info GROUP BY grade;结果:
mysql> SELECT SUM(user_id),SUM(user_id)+(SELECT SUM(ID) FROM user_info),GROUP_CONCAT(user_id),GROUP_CONCAT(id), grade FROM user_info GROUP BY grade;
+--------------+----------------------------------------------+-------------------------+------------------+-------+
| SUM(user_id) | SUM(user_id)+(SELECT SUM(ID) FROM user_info) | GROUP_CONCAT(user_id) | GROUP_CONCAT(id) | grade |
+--------------+----------------------------------------------+-------------------------+------------------+-------+
| 40890 | 41043 | 10222,10221,10224,10223 | 2,99,4,3 | A |
| 40906 | 41059 | 10225,10226,10228,10227 | 5,6,8,7 | B |
| 20459 | 20612 | 10229,10230 | 9,10 | C |
+--------------+----------------------------------------------+-------------------------+------------------+-------+
结论
- 当group by 与聚合函数配合使用时,功能为分组后计算
- 当group by 与having配合使用时,功能为分组后过滤
- 当group by 与聚合函数,同时非聚合字段同时使用时,非聚合字段的取值是第一个匹配到的字段内容,即id小的条目对应的字段内容。

MySQL group_concat
一、concat
CONCAT(str1,str2,…)
例如:在使用mybatis的时候我们要使用模糊查询的时候就会用到:
select id,name from tableName like concat(#{name},%)
注意:concat函数在连接字符串的时候,只要其中一个是NULL,那么将返回NULL
二、concat_ws
CONCAT_WS(separator,str1,str2,…)
concat_ws可以看做是concat分隔符版本。ws就是with separator的缩写。
例如:我们查询名字的时候:
select concat_ws(" ",first_name,last_name)
concat函数不同的是, concat_ws函数在执行的时候,不会因为NULL值而返回NULL
三、group_concat
先看一下group_concat的语法:
group_concat([DISTINCT] col [Order BY ASC/DESC 排序字段] [Separator ''分隔符''])
考虑下面的一个场景:我们有一个公用的文章标签表,简化像下面的样子:

一个文章可以用多个标签,有一个文章标签关联表简化大概如下:

在前端我们希望展示位 "时事新闻 | 娱乐轶事"这样的样式,怎么处理?查询列表然后应用层去拼接?当然可以,这里是有group_concat的玩法。SQL如下:
SELECT
AID,
GROUP_CONCAT(
DISTINCT LABEL
ORDER BY
LABEL DESC SEPARATOR ''|''
) AS LABELS
FROM
article_label al
JOIN article_label_relation alr ON al.ID = alr.LABEL_ID
GROUP BY
AID
结果就像下面的样子:

又可以少些代码了是不是感觉美滋滋。后面有结构数据的转储SQL,感兴趣可以导入数据库玩一下。
四、结构数据转储SQL
SET FOREIGN_KEY_CHECKS=0;
DROP TABLE IF EXISTS `article_label`;
CREATE TABLE `article_label` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`LABEL` varchar(20) NOT NULL DEFAULT '''' COMMENT ''标签名称'',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
INSERT INTO `article_label` VALUES (''1'', ''时事新闻'');
INSERT INTO `article_label` VALUES (''2'', ''娱乐轶事'');
INSERT INTO `article_label` VALUES (''3'', ''明星八卦'');
INSERT INTO `article_label` VALUES (''4'', ''科技博览'');
INSERT INTO `article_label` VALUES (''5'', ''1'');
INSERT INTO `article_label` VALUES (''6'', ''2'');
DROP TABLE IF EXISTS `article_label_relation`;
CREATE TABLE `article_label_relation` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`AID` int(11) NOT NULL DEFAULT ''0'' COMMENT ''文章id'',
`LABEL_ID` int(11) NOT NULL DEFAULT ''0'' COMMENT ''标签id'',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
INSERT INTO `article_label_relation` VALUES (''1'', ''2'', ''1'');
INSERT INTO `article_label_relation` VALUES (''2'', ''2'', ''6'');
INSERT INTO `article_label_relation` VALUES (''3'', ''2'', ''5'');
INSERT INTO `article_label_relation` VALUES (''4'', ''2'', ''4'');
INSERT INTO `article_label_relation` VALUES (''5'', ''3'', ''2'');
INSERT INTO `article_label_relation` VALUES (''6'', ''3'', ''3'');
INSERT INTO `article_label_relation` VALUES (''7'', ''3'', ''3'');
五、数据处理
5.1 生成指定格式的id集合
有没有经常需要根据id修改数据的,例如:
update tableName set status = 0 where id in()
当然可以用子查询,但是有时候需要检查这些id或者不在一个数据库中,就可以使用group_concat来获取id集合了。例如:
select status,group_concat(id) from tableName group by status
status就是要修改的字段。
5.2 生成insert语句
有比如说想把一个查询中的结果导入到另一个库的表中:
SELECT
GROUP_CONCAT(
CONCAT(
"VALUES(",
CONCAT_WS(
",",
t1.id,
t1.name,
t2.lable
),
")"
) SEPARATOR ","
) AS insert_sql
FROM
tableName1 t1
JOIN tableName2 t2 an ON t1.id = t2.tid
group_concat concat,concat_ws 结合,完美,老板再也不用担心我导数据了。
六、总结
我们可以把concat想象为连接行,而group_concat想象为连接列。

MySQL group_concat 介绍
在做数据初始化的时候,由于需要修改满足条件的全部订单的状态,因此,想使用 group_concat 函数提取满足条件的所有订单 id,以方便写回滚脚本。测试数据取自表 test1,表结构和相关 insert 脚本见《常用 SQL 之日期格式化和查询重复数据》。
使用方法
select t.`name`,group_concat(t.id) AS result from test1 t group by t.`name`;
执行后,结果集如下图所示:
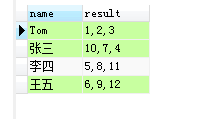
查询结果 result 默认使用英文逗号连接,可以使用 separator 关键字指定连接符:
select t.`name`,group_concat(t.id separator '';'') AS result from test1 t group by t.`name`;执行后,结果集如下图所示:

使用关键字 order by 可以指定被合并数据的排序,
select t.`name`,group_concat(t.id order by t.id desc) AS result from test1 t group by t.`name`;
执行后,结果集如下图所示:

温馨提示,关键字 separator 和 order by 不可以同时使用。
踩过的坑
在应用过程中,发现 group_concat 会漏掉部分数据,究其原因是因为这个函数有默认长度限制,默认是 1024。可以通过如下脚本查询数据库的当前限制
show variables like ''group_concat_max_len'';在客户端设置当前 session 的 group_concat 长度,其它 session 连接不受影响
SET SESSION group_concat_max_len = 10240;设置全局 group_concat 长度
SET GLOBAL group_concat_max_len = 10240;该语句在执行后,MySQL 重启前一直有作用,但一旦重启 MySQL,则会恢复默认的设置值。
今天关于MySQL:对 GROUP_CONCAT 值进行排序和mysql group by排序的讲解已经结束,谢谢您的阅读,如果想了解更多关于GROUP_CONCAT 3 个表 php mysql、MySQL GROUP BY 和GROUP_CONCAT的一些用法、MySQL group_concat、MySQL group_concat 介绍的相关知识,请在本站搜索。
本文标签:




