本文将带您了解关于SqlServer无法解决equalto运算中排序规则冲突的新内容,同时我们还将为您解释sql排序规则冲突解决方法的相关知识,另外,我们还将为您提供关于04-SQLServer的排序
本文将带您了解关于SqlServer无法解决 equal to 运算中排序规则冲突的新内容,同时我们还将为您解释sql排序规则冲突解决方法的相关知识,另外,我们还将为您提供关于04-SQLServer的排序规则(字符集编码)、BOS打开单据的时候出现:无法解决 equal to 运算中 "Chinese_PRC_CS_AS" 和 "Chinese_PRC_CI_AS" 之间的排序规则冲突、SQL Server 2008排序规则冲突-如何解决?、SQL Server 与MySQL中排序规则与字符集相关知识的一点总结的实用信息。
本文目录一览:- SqlServer无法解决 equal to 运算中排序规则冲突(sql排序规则冲突解决方法)
- 04-SQLServer的排序规则(字符集编码)
- BOS打开单据的时候出现:无法解决 equal to 运算中 "Chinese_PRC_CS_AS" 和 "Chinese_PRC_CI_AS" 之间的排序规则冲突
- SQL Server 2008排序规则冲突-如何解决?
- SQL Server 与MySQL中排序规则与字符集相关知识的一点总结
")
SqlServer无法解决 equal to 运算中排序规则冲突(sql排序规则冲突解决方法)
无法解决 equal to 运算中 "Chinese_PRC_CI_AS" 和 "SQL_Latin1_General_CP1_CI_AS" 之间的排序规则冲突。
网上找了好多,试了好多解决不了问题,还是MSDN给力,直接看事例:
CREATE TABLE MyTable
(PrimaryKey int PRIMARY KEY,
CharCol varchar(10) COLLATE french_CI_AS NOT NULL
)
GO
ALTER TABLE MyTable ALTER COLUMN CharCol
varchar(10)COLLATE latin1_General_CI_AS NOT NULL
GO
.
修改冲突列的排序规则,ok,完美解决
")
04-SQLServer的排序规则(字符集编码)
一、总结
1.SQLServer中的排序规则就是其他关系型数据库里所说的字符集编码;
2.SQLServer中的排序规则可以在3处设置,如下:
服务器级别(实例):instances ----->安装数据库的时候设置
数据库级别:database
表列级别:columns
所以在使用SQLServer的排序规则的时候,只需要保证这三处一致,就是正确的使用方式;
3.SQLServer的排序规则不仅影响记录行的sort顺序,还影响中文显示是否乱码;
4.创建数据库时,若我们未指定排序规则,数据库就会使用实例默认的排序规则;
5.SQLServer的排序规则只影响字符型的列,例如:char,varchar,text,nchar,nvarchar,ntext,因此在查询视图sys.columns中非字符型的字段的排序规则显示是NULL;
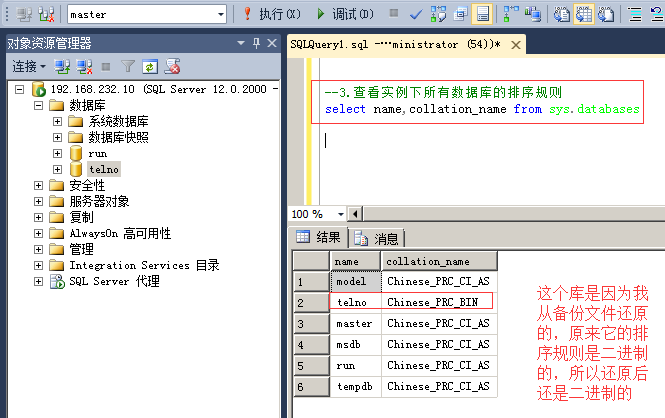
6.需要注意的是,虽然数据库的排序规则可以改,但是是有问题的,因为即使把数据库的排序规则改了,库里的表的字段的排序规则可能还是原来的,没有改,这在使用的时候,就可能会存在问题,所以数据库的排序规则尽力不要随意改动。
7.排序规则中,二进制排序的速度是最快的,因为SQLServer不用做任何调整即可使用快速、简单的排序算法。
二、查询语句
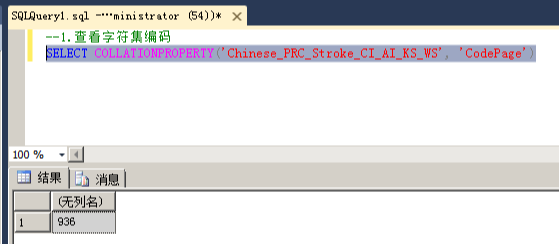
1.查询字符集编码
命令:SELECT COLLATIONPROPERTY(''Chinese_PRC_Stroke_CI_AI_KS_WS'', ''CodePage'')
注:
(1).该数据库实例的排序规则是Chinese_PRC_CI_AS
(2).查出结果对应的字符集编码
936 :简体中文GBK
950 :繁体中文BIG5
437 :美国/加拿大英语
932 :日文
949 :韩文
866 :俄文
65001 :unicode UTF-8
2.查看实例的排序规则
命令:select serverproperty(N''Collation'')

3.查看实例下所有数据库的排序规则
命令:select name,collation_name from sys.databases
4.修改现有数据库的排序规则
命令:alter database telno collate Chinese_PRC_BIN
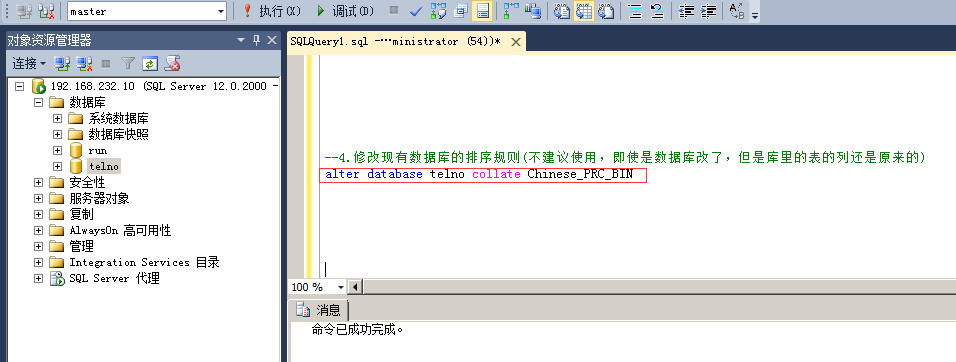
注:不建议使用,即使是数据库改了,但是库里的表的列还是原来的。
5.查询列的排序规则
命令:select name,collation_name from telno.sys.columns where collation_name is not null
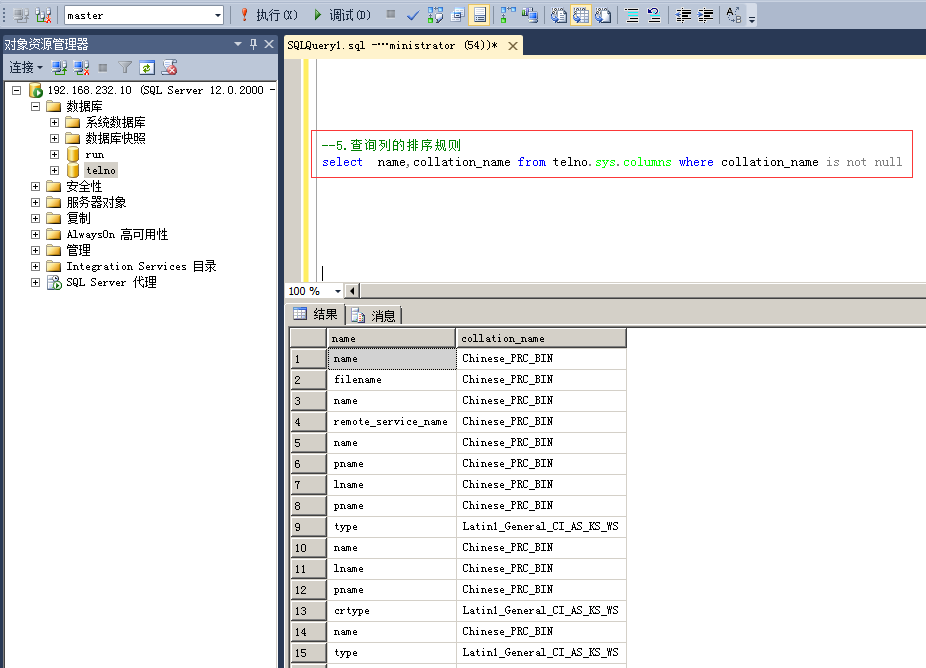
注:非字符型的字段的排序规则显示为NULL,所以要把NULL的结果过滤掉。
6.查看当前SQLServer版本支持的排序规则
命令:
select * from ::fn_helpcollations()
select * from fn_helpcollations()
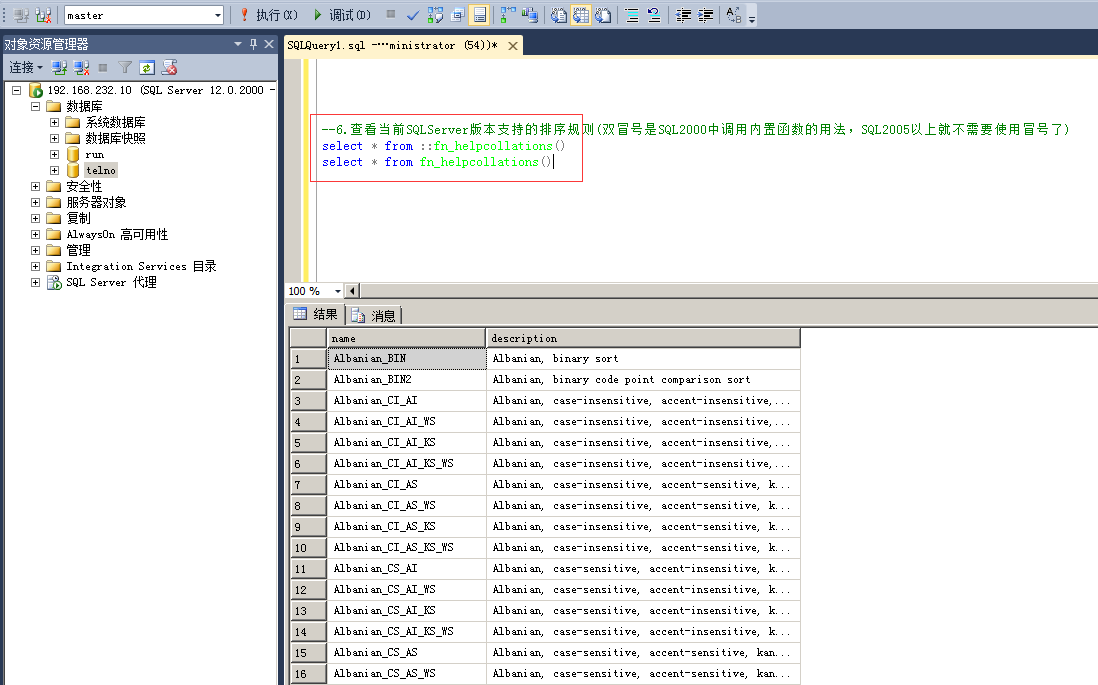
注:
(1)双冒号是SQL2000中调用内置函数的用法,SQL2005以上不需要使用冒号也能使用内置函数了;
(2)排序规则代表的意思详解
Chinese_PRC_ :指针对大陆简体字Unicode字符集的排序规则
后半部分的含义:
_BIN :二进制排序
C : case,大小写;
A :accent,重音;
I :Insensitive,不敏感,不区分;
S :sensitive,敏感,区分;
W :width,宽度
K :kanatype,假名
eg:
_CI :不区分大小写
_AS :区分重音
原文出处:https://www.cnblogs.com/jialanyu/p/11550367.html

BOS打开单据的时候出现:无法解决 equal to 运算中 "Chinese_PRC_CS_AS" 和 "Chinese_PRC_CI_AS" 之间的排序规则冲突
alter table t_ap_otherbill alter COLUMN CFXiangmuID varchar(44) collate Chinese_PRC_CS_AS
这个问题只有sql,server才有 因为BOS里面一个排序规则 与sqlserver里面的排序规则给冲突了。 修改一下就行了。

SQL Server 2008排序规则冲突-如何解决?
为了简化POC,我使用字符类型的列进行以下查询:
select AH_NAME1 from GGIMAIN.SYSADM.BW_AUFTR_KOPFunionselect AH_NAME1 from GGI2014.SYSADM.BW_AUFTR_KOPF我收到以下错误:
消息468,级别16,状态9,第2
行在UNION操作中无法解决“ SQL_Latin1_General_CP1_CI_AS”和“
Latin1_General_CS_AS”之间的排序规则冲突。
GGI2014确实是由归类创建的SQL_Latin1_General_CP1_CI_AS。这已在SMS中更改,实例也已在SMS中重新启动。
当我查看短信以及查询时:
select name, collation_name from sys.databases所有迹象都表明,这两个GGIMAIN并GGI2014进行整理Latin1_General_CS_AS。
有人对其他需要完成的工作有任何建议吗?
谢谢,
马特
答案1
小编典典select AH_NAME1 COLLATE DATABASE_DEFAULT from GGIMAIN.SYSADM.BW_AUFTR_KOPFunionselect AH_NAME1 COLLATE DATABASE_DEFAULT from GGI2014.SYSADM.BW_AUFTR_KOPF除非我没有记错,否则更改数据库的排序规则不会更改已经存在的对象的排序规则。只有新对象会受到影响

SQL Server 与MySQL中排序规则与字符集相关知识的一点总结
字符集&&排序规则
字符集是针对不同语言的字符编码的集合,比如UTF-8字符集,GBK字符集,GB2312字符集等等,不同的字符集使用不同的规则给字符进行编码
排序规则则是在特定字符集的基础上特定的字符排序方式,排序规则是基于字符集的,是对字符集在排序方式维度上的一个划分。
排序规则是依赖于字符集的,一种字符集可以有多种排序规则,但是一种排序规则只能基于某一种字符集的
比如中文字符集,也即汉字,可以按照“拼音排序”、“按姓氏笔划排序”等等。
而对于英语,就没有“拼音”和“姓氏笔画”,但是可以分为区分大小写、不区分大小写等等
而其他语言下面也有自己特定的排序规则。
在SQL Server中,任何一种字符集的数据库,都能存储任何一种语言的字符。
并不是说拉丁(Latin)字符集的数据就存储不了中文,中文(Chinese)字符集的数据库就存储不了蒙古语(只要操作系统本身支持)
sqlserver中,不管哪种字符集(实际上是排序规则)的数据库(或者字段),都是可以使用nvarchar(或者nchar),而nvarchar(或者nchar)是可以存储任意非Unicode字符的
至于排序规则,那是根据不同的字符集所支持的不同的排序规则人为定义的。
SQL Server中的字符集和排序规则
排序规则只不过是指定了存储的数据的排序(比较)规则而已,换句话说就是,排序规则中已经包含了字符集的信息。
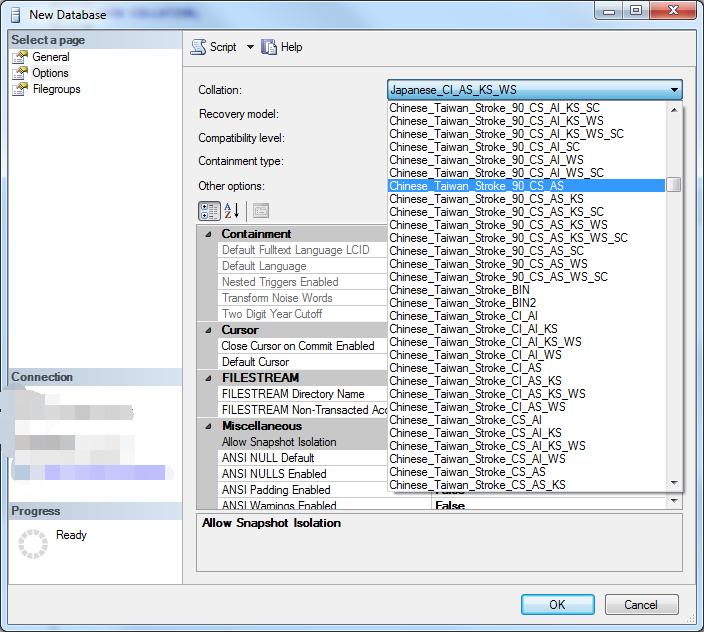
因此在sqlserver中 ,不需要关心字符集,只需要关心排序规则,sqlserver中在创建只能指定排序规则(不能直接指定字符集),
如截图,只能指定collation,也就是字符集
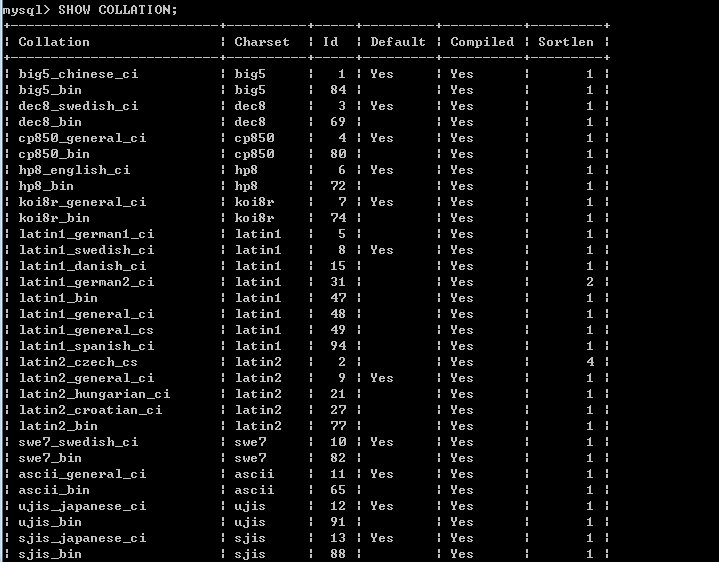
在MySQL中的字符集和排序规则
上面说了,排序规则是依赖于字符集的,一种字符集可以有多种排序规则,但是一种排序规则只能基于某一种字符集的。
如下是MySQL中排序规则和字符集的对应关系。
MySQL的建库语法比较扯,可以指定字符集和排序规则,
如果指定的排序规则在字符集的下面,则是没有问题的,如果指定的排序规则不在字符集下面,则会报错。
比如下面这一句,排序规则utf8_bin是属于字符集utf8下面的一种排序规则,这个语句执行是没有问题的
create database test_database2 charset utf8 collate utf8_bin;
再比如下面这一句,排序规则latin1_bin不是属于字符集utf8下面的一种排序规则,这个语句执行是会报错的
create database test_database2 charset utf8 collate latin1_bin;

以上是字符集和排序规则在sqlserver和MySQL中的一些基本应用,再说说常用的排序规则的区别
***_genera_ci & ***_genera_cs & ***_bin 常见排序规则的特点
以上是某种字符集下常用的三种排序规则,下面以常见的utf8为例说明
utf8_genera_ci不区分大小写,ci为case insensitive的缩写,即大小写不敏感,
utf8_general_cs区分大小写,cs为case sensitive的缩写,即大小写敏感,但是目前MySQL版本中已经不支持类似于***_genera_cs的排序规则,直接使用utf8_bin替代。
utf8_bin将字符串中的每一个字符用二进制数据存储,区分大小写。
那么,同样是区分大小写,utf8_general_cs和utf8_bin有什么区别?
cs为case sensitive的缩写,即大小写敏感;bin的意思是二进制,也就是二进制编码比较。
utf8_general_cs排序规则下,即便是区分了大小写,但是某些西欧的字符和拉丁字符是不区分的,比如ä=a,但是有时并不需要ä=a,所以才有utf8_bin
utf8_bin的特点在于使用字符的二进制的编码进行运算,任何不同的二进制编码都是不同的,因此在utf8_bin排序规则下:ä<>a
在utf8_genera_ci的情况下A=a,ä=a
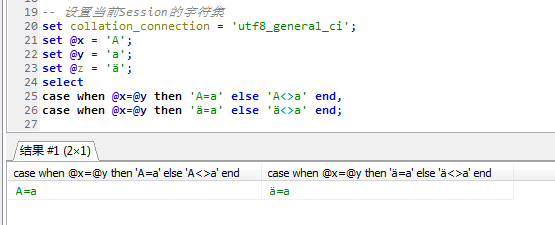
在utf8_bin排序规则下,A<>a,ä<>a
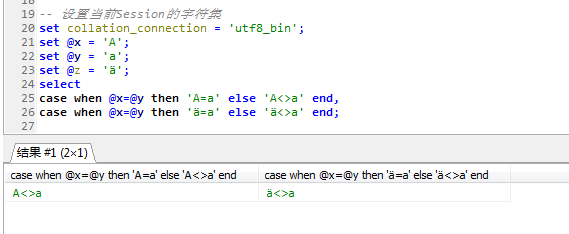
所以要想区分大小写,有没有特殊需求,就直接使用utf8_bin(实际上***_general_cs在MySQL中本身就不支持,在SQL Server中支持)
以上字符集的特点以及使用情况在SQL Server中表现为类似。
以上。
我们今天的关于SqlServer无法解决 equal to 运算中排序规则冲突和sql排序规则冲突解决方法的分享已经告一段落,感谢您的关注,如果您想了解更多关于04-SQLServer的排序规则(字符集编码)、BOS打开单据的时候出现:无法解决 equal to 运算中 "Chinese_PRC_CS_AS" 和 "Chinese_PRC_CI_AS" 之间的排序规则冲突、SQL Server 2008排序规则冲突-如何解决?、SQL Server 与MySQL中排序规则与字符集相关知识的一点总结的相关信息,请在本站查询。
本文标签:




