在本文中,我们将带你了解android–达到数据库的编译SQL语句高速缓存的MAX大小在这篇文章中,我们将为您详细介绍android–达到数据库的编译SQL语句高速缓存的MAX大小的方方面面,并解答s
在本文中,我们将带你了解android – 达到数据库的编译SQL语句高速缓存的MAX大小在这篇文章中,我们将为您详细介绍android – 达到数据库的编译SQL语句高速缓存的MAX大小的方方面面,并解答sql语句超过缓冲区长度常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的8.5 高速缓存的工作原理、8.6 高速缓存的设计要点、Android App使用SQLite数据库的一些要点总结、android ndk 编译so动态库的问题。
本文目录一览:- android – 达到数据库的编译SQL语句高速缓存的MAX大小(sql语句超过缓冲区长度)
- 8.5 高速缓存的工作原理
- 8.6 高速缓存的设计要点
- Android App使用SQLite数据库的一些要点总结
- android ndk 编译so动态库的问题
")
android – 达到数据库的编译SQL语句高速缓存的MAX大小(sql语句超过缓冲区长度)
ContentValues values;
values = new ContentValues();
values.put(sqlHelper.EMPLOYEE_LPN,jsObj.getString("lpn"));
db.update(sqlHelper.EMPLOYEE_TABLE,values,"EMPLOYEE_LPN ='" + jsObj.getString("lpn") + "'",null);
Log Cat中显示警告
08-31 15:19:45.297: WARN/Database(2868): Reached MAX size for compiled-sql statement cache for database /data/data/org.sipdroid.sipua/databases/test.db; i.e.,NO space for this sql statement in cache: SELECT EMPLOYEE_NAME FROM eyemployee WHERE EMPLOYEE_LPN ='1169162'. Please change your sql statements to use '?' for bindargs,instead of using actual values
如何解决请帮忙
解决方法
例8-3.使用更新方法
/**
* Update a job in the database.
* @param job_id The job id of the existing job
* @param employer_id The employer offering the job
* @param title The job title
* @param description The job description
*/
public void editJob(long job_id,long employer_id,String title,String description) {
ContentValues map = new ContentValues();
map.put("employer_id",employer_id);
map.put("title",title);
map.put("description",description);
String[] whereArgs = new String[]{Long.toString(job_id)};
try{
getWritableDatabase().update("jobs",map,"_id=?",whereArgs);
} catch (sqlException e) {
Log.e("Error writing new job",e.toString());
}
}
以下是示例8-3中的代码的一些亮点:
例8-4显示了如何使用execsql方法.
例8-4.使用execsql方法
/**
* Update a job in the database.
* @param job_id The job id of the existing job
* @param employer_id The employer offering the job
* @param title The job title
* @param description The job description
*/
public void editJob(long job_id,String description) {
String sql =
"UPDATE jobs " +
"SET employer_id = ?,"+
" title = ?,"+
" description = ? "+
"WHERE _id = ? ";
Object[] bindArgs = new Object[]{employer_id,title,description,job_id};
try{
getWritableDatabase().execsql(sql,bindArgs);
} catch (sqlException e) {
Log.e("Error writing new job",e.toString());
}
}
该消息是要求您使用sql变量而不是sql文字的参数.
解析每个SQL查询,生成计划,并存储在sql语句缓存中.
从缓存中提取具有相同文本的查询.
--One query SELECT * FROM Customers WHERE Id = @1 (@1 = 3) SELECT * FROM Customers WHERE Id = @1 (@1 = 4) SELECT * FROM Customers WHERE Id = @1 (@1 = 5)
在缓存中找不到具有不同文本(包括文字)的查询,并且(无用地)添加了它.
--Three Queries. SELECT * FROM Customers WHERE Id = 3 SELECT * FROM Customers WHERE Id = 4 SELECT * FROM Customers WHERE Id = 5

8.5 高速缓存的工作原理
计算机组成
8 存储层次结构
8.5 高速缓存的工作原理

因为CPU的速度和内存的速度差距越来越大,计算机整体系统的性能,就受到了巨大的影响。而高速缓存技术的出现,则挽救了这个局面。
那在这一节,我们就来看一看高速缓存是如何工作的。
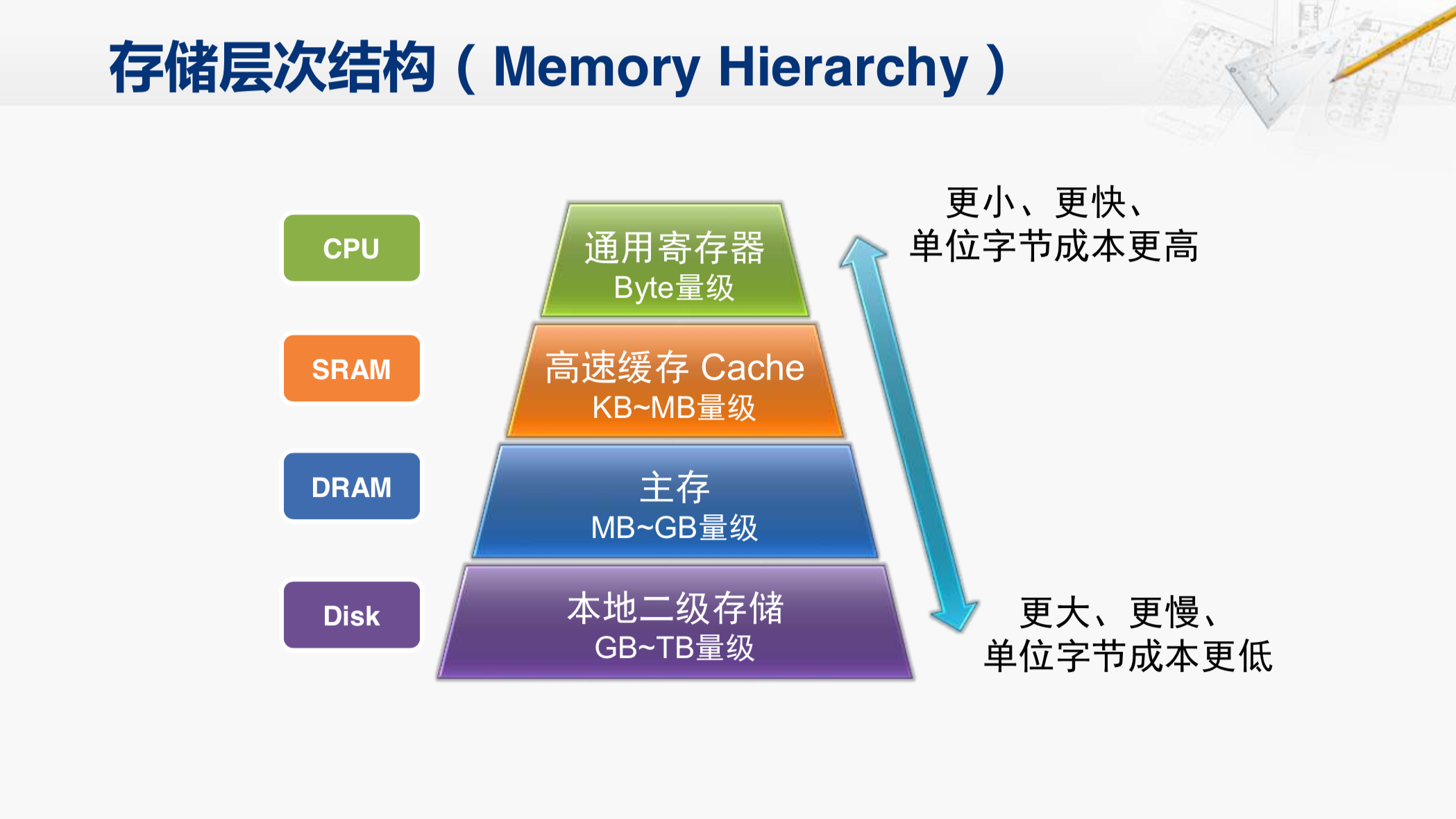
这是计算机的存储层次结构。高速缓存,也就是Cache位于CPU和主存之间。相比于主存,它的容量要小的多,但是速度也快很多。
为什么在CPU和主存之间,增加这么一个速度很快,但是容量很小的存储部件,就可以提升整个计算机系统的性能呢?这就要得益于计算机中运行程序的一个特点,这个特点被称为程序的局部性原理。
我们通过一个例子来进行说明。
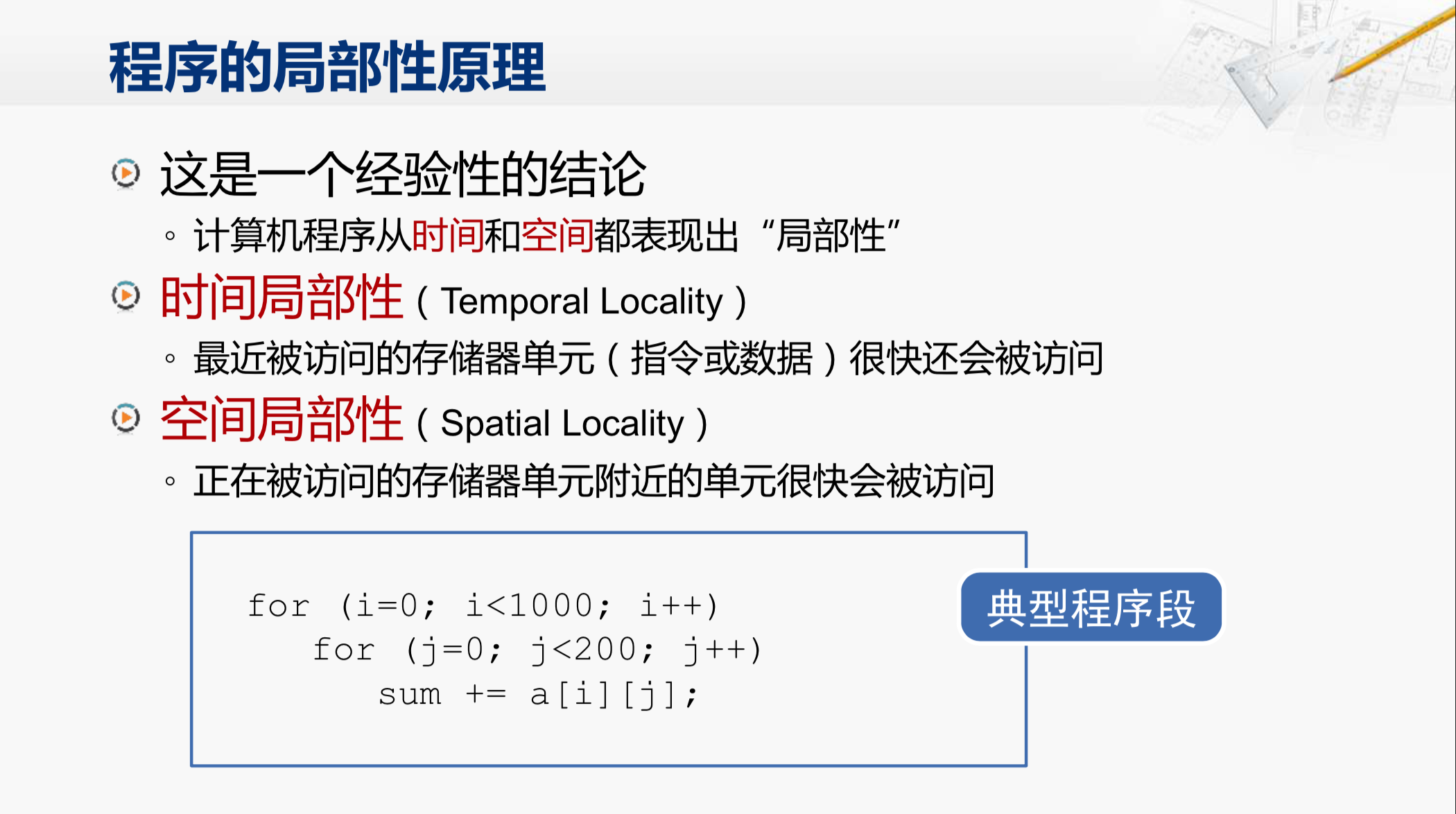
这是一段很常见的程序,有两层循环。对一个二维数组进行累加,如果sum这个变量是保存在内存中的,那它所在的这个存储单元就会不断的被访问,这就称为时间局部性。这些对循环变量进行判断和对循环变量进行递增的指令,也都会被反复执行。而另一点,叫作空间局部性,指的是正在被访问的存储器单元附近的那些数据,也很快会被访问到。
那么就来看这个数组。它在内存当中是连续存放的,从 $a_{[0][0]}$ $a_{[0][1]}$ $a_{[0][2]}$ $a_{[0][3]}$ ... ... 这样一个接一个的存放下去。那么在这段循环访问它的时候,访问了 $a_{[0][0]}$ 之后,很快就会访问 $a_{[0][1]}$,然后很快会访问 $a_{[0][2]}$,这样的特征就被称为空间局部性。
Cache就是利用了程序的局部性原理,而设计出来的。
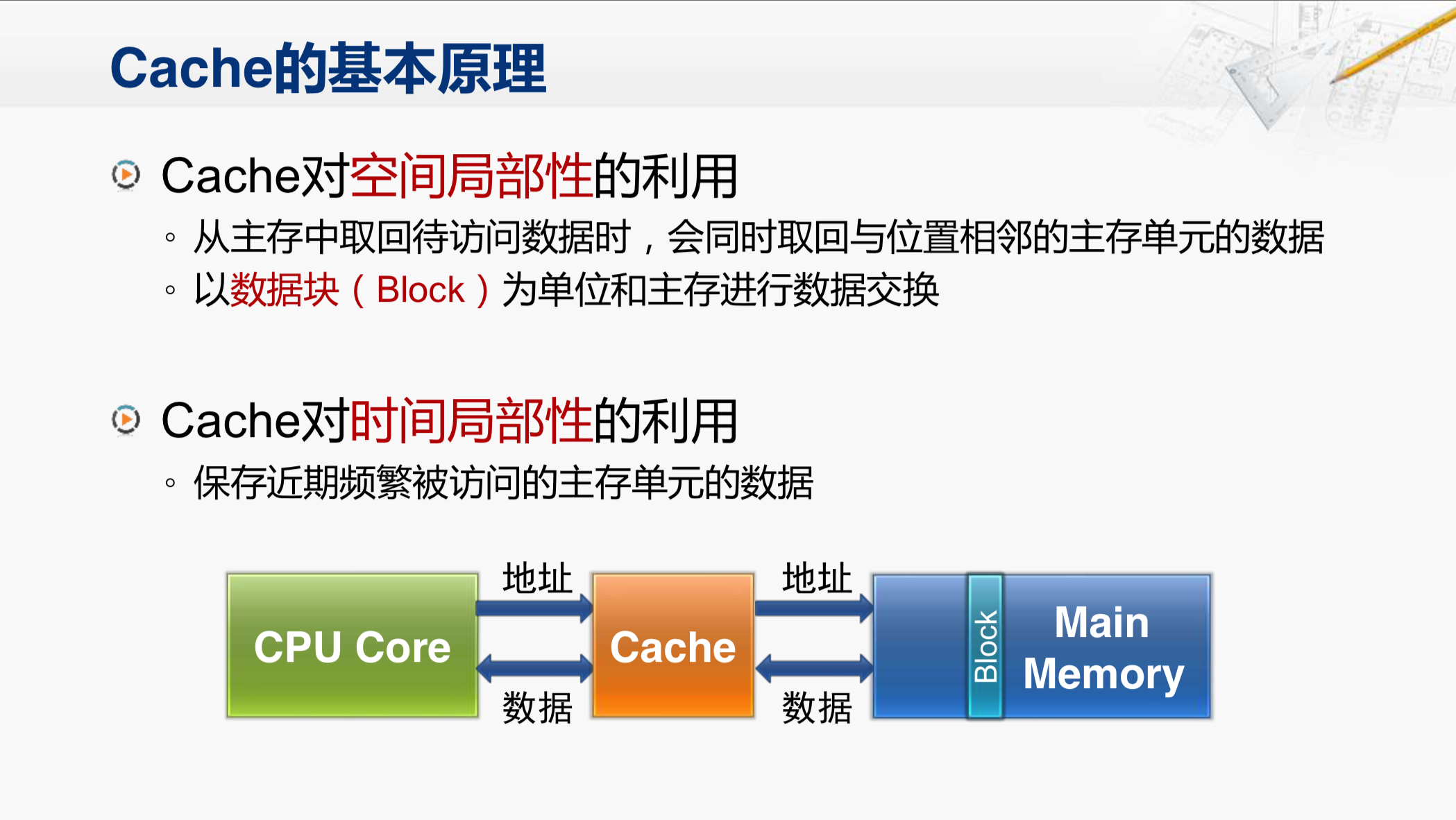
首先,我们来看Cache对空间局部性的利用。当CPU要访问主存时,实际上是把地址发给了Cache,最开始,Cache里面是没有数据的。所以,Cache会把地址再发给主存,然后从主存中取得对应的数据,但Cache并不会只取回CPU当前需要的那个数据,而是会把与这个数据位置相邻的主存单元里的数据一并取回来,这些数据就称为一个数据块。那么Cache会从主存里,取回这么一个数据块,存放在自己内部。然后,再选出CPU需要的那个数据送出去,那过一会儿,CPU很可能就会需要刚才那个数据附近的其它数据,这时候,这些数据已经在Cache当中了,就可以很快的返回,从而提升了访存的性能。第二种情况,是Cache对时间局部性的利用。因为这个数据块暂时会保存在Cache当中,CPU如果要再次用到刚才用过的那个存储单元,Cache也可以很快的提供这个单元的数据,这就是Cache对程序局部性的利用。
我们要注意,这些操作都是由硬件完成的。对于软件编程人员来说,他编写的程序代码当中,只是访问了主存当中的某个地址,而并不知道这个地址对应的存储单元到底是放在主存当中,还是在Cache当中。
如果这个不太好理解的话,那我来打个比方。我们可以把主存看作一个图书馆,里面可能有几千万册的藏书。CPU就像一个来借书的人,他给出了一个书号,希望借到这本书。管理员可能要花几个小时,才能找到这本书,拿出来交给借书的人。过一会儿,借书的人把这本书还了以后,管理员又把它放回到仓库当中去。再过一会儿,这个人又要借这本书,管理人员又要花几个小时,从仓库里再找到这本书拿出来。后来,管理员发现这样的工作实在是太低效了,于是就在这个仓库的外面,借阅的柜台旁边准备了一个柜子,把刚才借过的书暂时先存放在这个柜子里。有些书在很短的时间内会被多次借阅。所以,这本书放在这个临时柜子里的时候,经常就会被借阅到,那管理员就可以很快的把这本书交给借阅的人,而不用去大库里面,花几个小时去寻找。与此同时,管理员还发现了另一个现象,那就是有一个人来借了一本明朝的故事,然后过一会儿,就会再来借清朝的故事,再过一会儿,可能又来借宋朝的故事。而这些书在仓库里面都是紧挨着排放的。所以,他干脆这么做,当要从仓库里取出一本书的时候,就把和这个书在同一层书架上的所有的书都一次性拿出来。这样并不会比取一本书多花多少时间,而对于借书的人来说,他并不会知道管理员做了这件事情。对他来说,还是给出了一个书号,然后过一会儿得到这本书。他只会发现借书的速度变快了。这个类比差不多就是Cache所做的事情。
那我们再来整理一下Cache的访问过程。
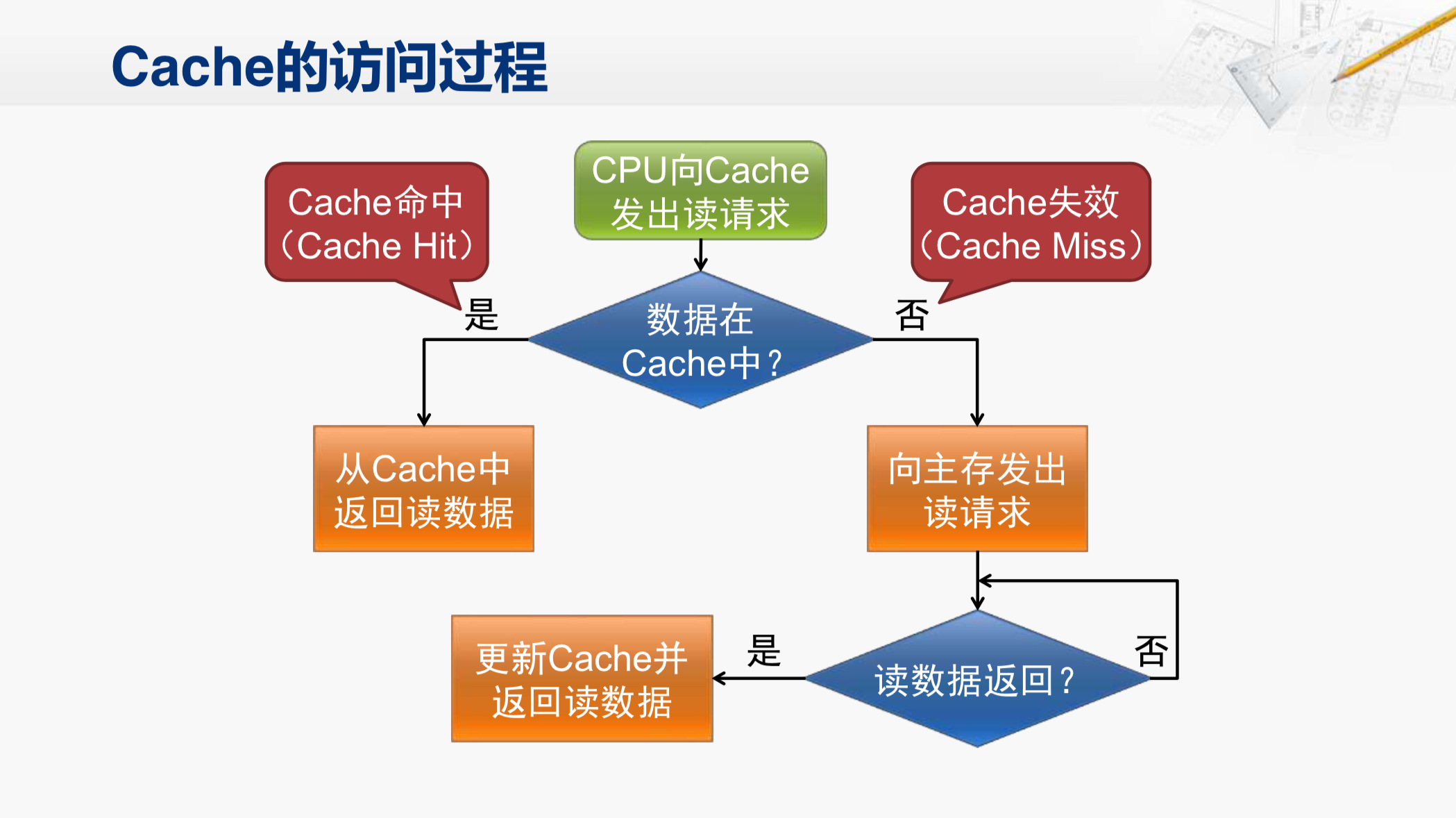
那现在CPU发出读请求,都是直接发给Cache了。然后,Cache这个硬件的部件,会检查这个数据是否在Cache当中。如果是,就称为Cache命中,然后从Cache当中取出对应的数据,返回给CPU就可以了。但是如果这个数不在Cache中,我们就称为Cache失效,这时候,就要由Cache这个部件,向主存发起读请求,这个过程CPU是不知情的,它仍然是在等待Cache返回数据。Cache向主存发出读请求之后,就会等待主存将数据返回,这个过程会很长。那么当包含这个数据的一整个数据块返回之后,Cache就会更新自己内部的内容,并将CPU需要的那个数据返回给CPU。这样就完成了一次Cache读的操作。
那么Cache这个部件内部是如何组织的呢?
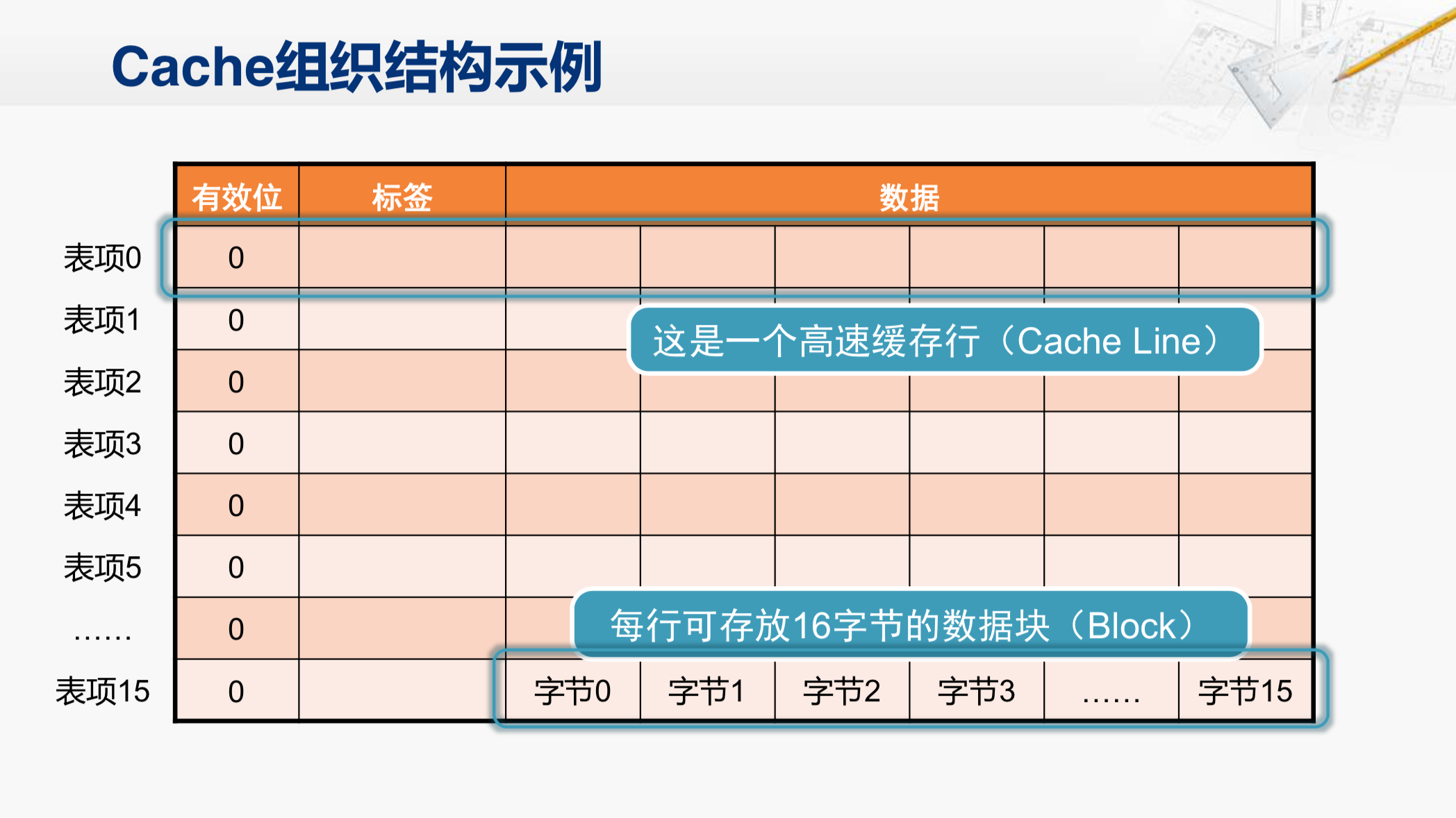
Cache主要组成部分是一块SRAM,当然还有配套的一些控制逻辑电路。
这个SRAM的组织形式就像这个表格,它会分为很多行。那么在这个示例的结构当中,一共有16行。每一行当中有一个比特,是有效位,还有若干个比特是标签,然后其它的位置都是用来存放从内存取回来的数据块。在这个例子当中,一个数据块是16个字节。
那么还是通过一个例子,来看一看这个Cache是如何运行的。
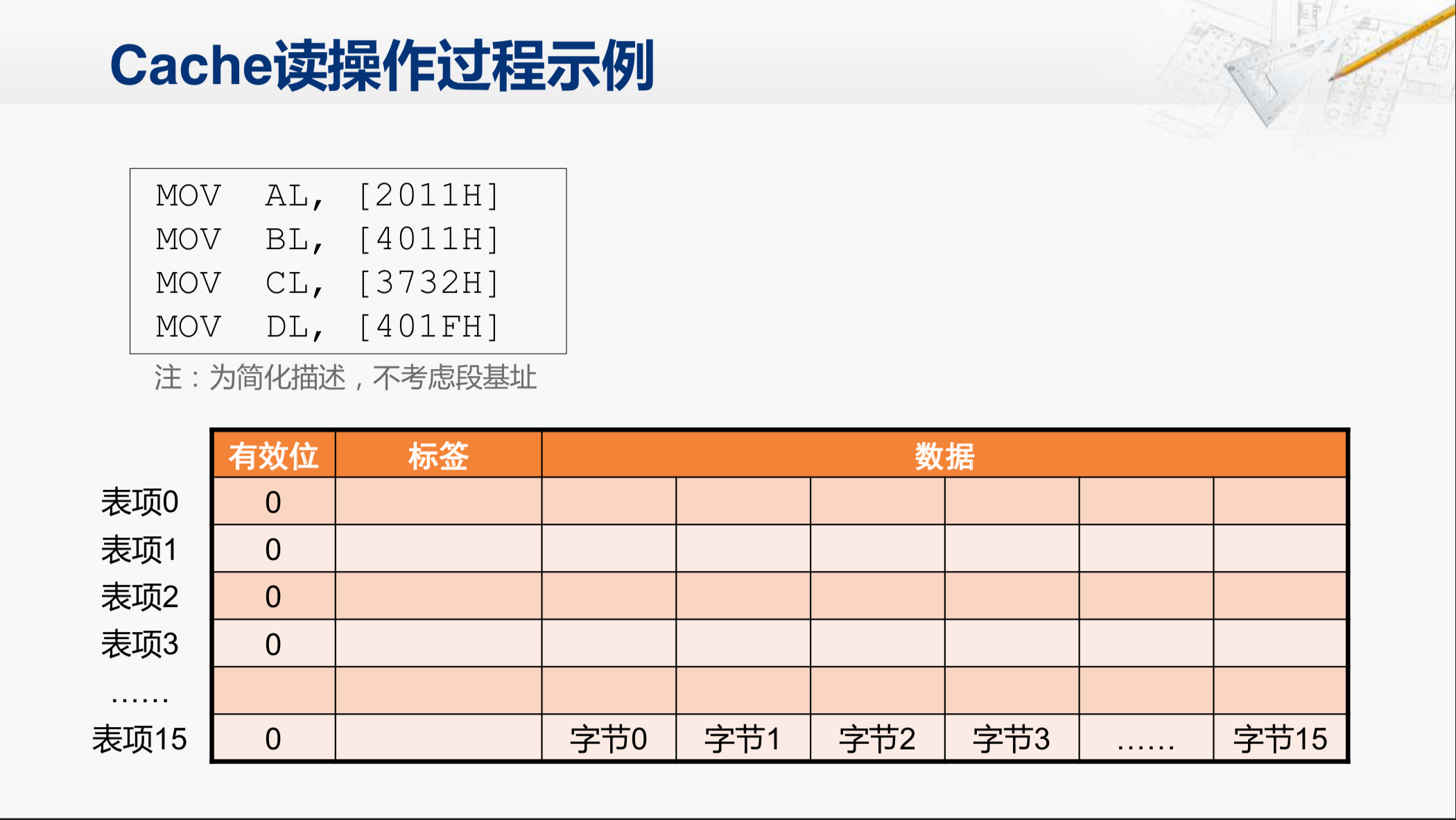
我们就用这个表格来代表Cache。假设现在这个Cache里面全是空的,有效位为0,代表它对应的这一行没有数据。
那么现在来执行这四条指令。
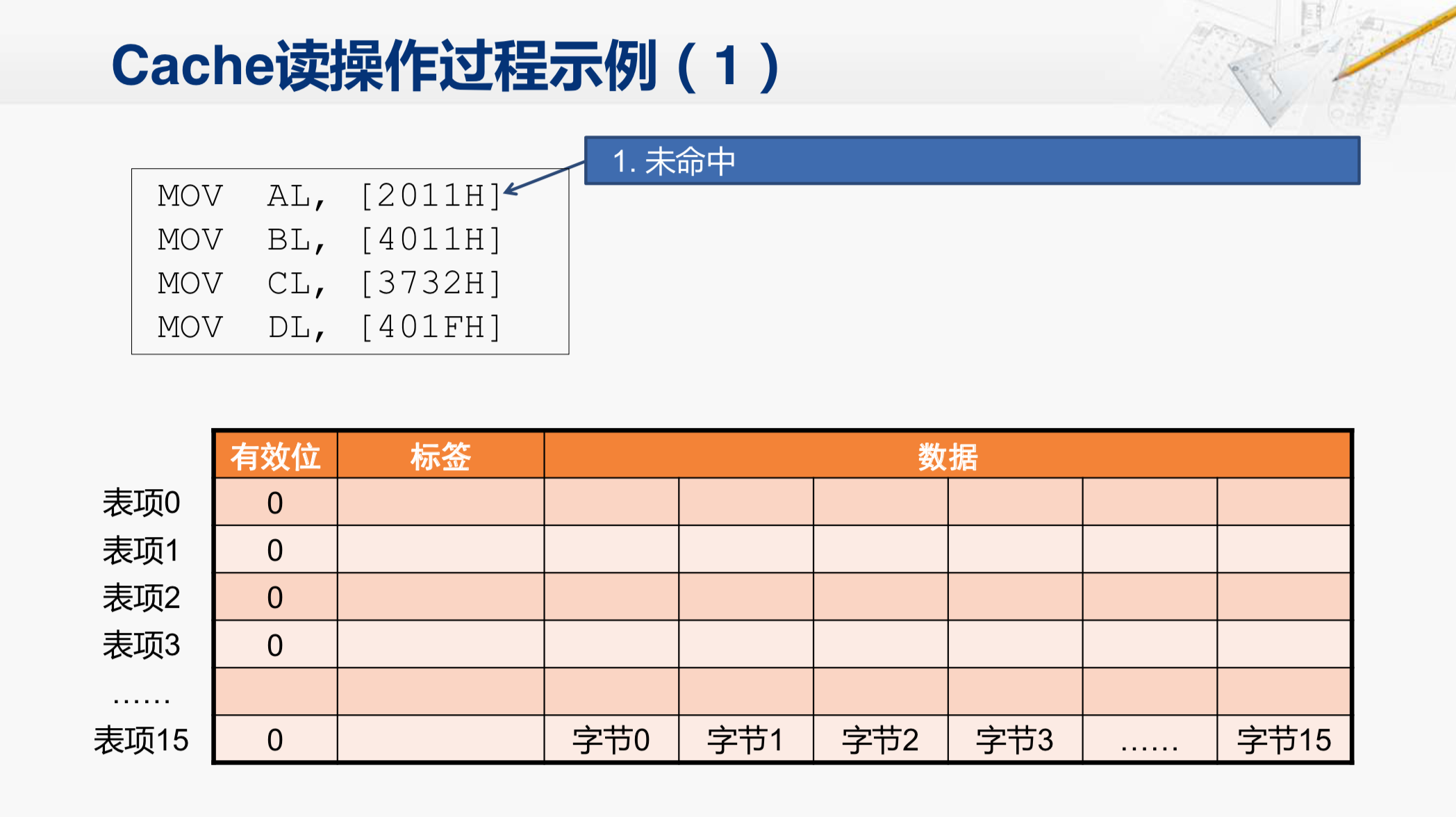
第一步,我们要访问2011H这个内存地址,并取出对应的字节,放在AL寄存器当中去。那CPU就会把这个地址发给Cache,因为现在Cache全是空的,所以,显然没有命中,Cache就会向内存发起一次读操作的请求。
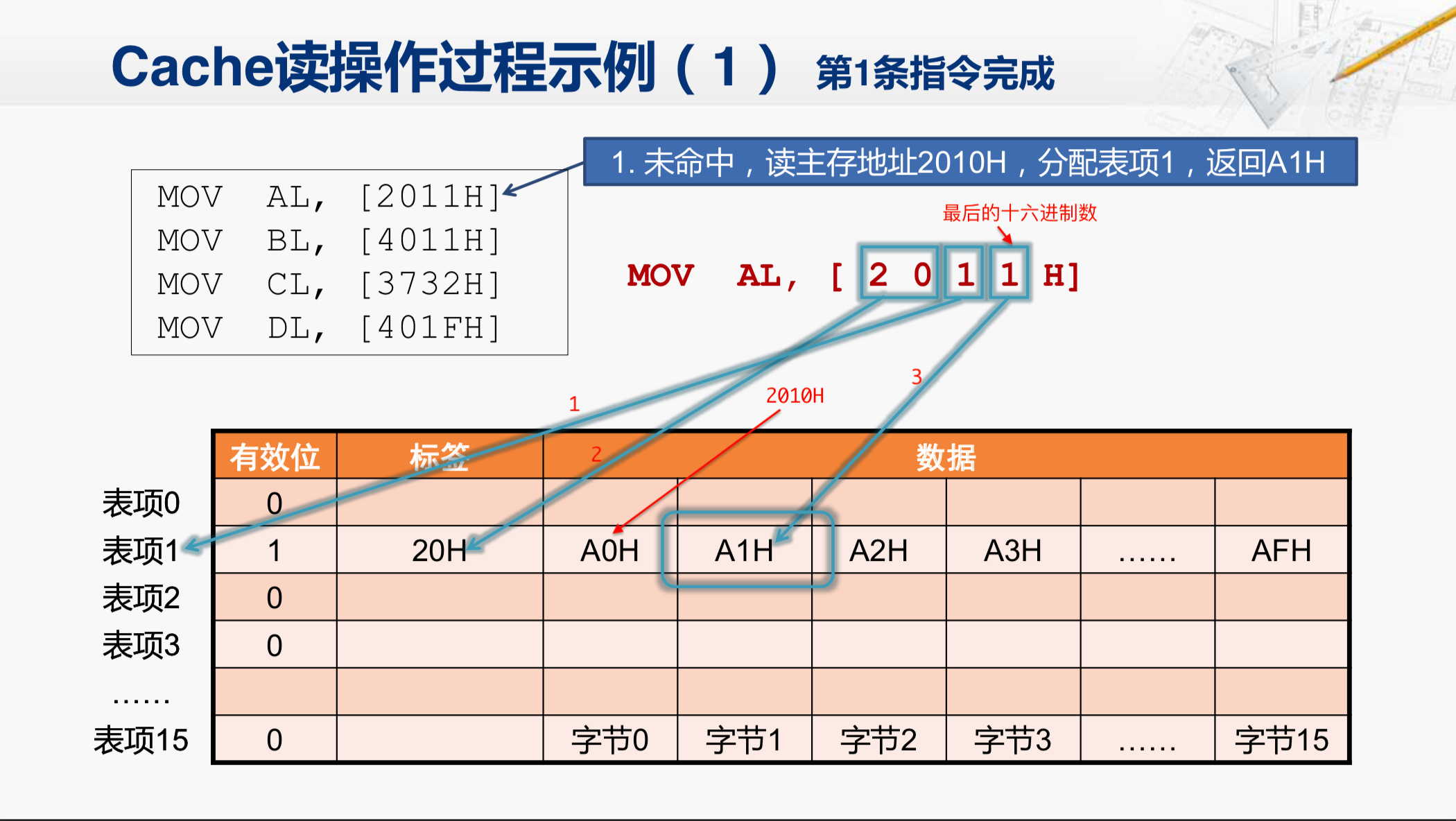
但我们要注意,因为Cache一次要从内存中读出一个数据块。而现在这个Cache的结构,一个数据块是16个字节。所以,它发出的地址都是16个字节对齐的。所以,这时Cache向主存发出的地址是2010H这个地址,是16个字节对齐的,而且从它开始的16个字节的这个数据块当中,包含了2011H这个地址单元。当Cache把这个数据块读回来之后,会分配到表项1中。那么在这个表项(表项1)当中,这个字节(字节0)就是2010所对应的数据;这个字节(字节1)就是2011所对应的数据。所以,Cache会将这个字节返回给CPU。
但是Cache为什么要把这个数据块放在了表项1当中呢?我们详细来看一看。CPU在执行 MOV AL,[2011H] 这条指令的时候,Cache收到的地址实际上是2011H,因为现在一个数据块当中,包括16个字节,最后的这个16进制数,正好用来指定这16个字节当中的哪一个字节是当前所需的。因此,我们取回的这个数据块,要放在哪一个表项当中,就要靠前面的一个地址来决定。那么在现在的Cache设计当中,一般来说,都是用剩下的这些地址当中,最低的那几位来决定到底把这个数据块放在哪一个Cache行中,那我们现在有16个表项,所以也需要4位的地址来决定,那因此,现在剩下的最低的4位地址,就正好是这个16进制数了(红色标号1处),这个数是1。所以,Cache就决定把这个数据块放在表项1的Cache行里。那现在还剩下8位的地址(红色标号2处),我们也必须记录下来,不然以后就搞不清楚这个Cache行里存放的数据到底是对应哪一个地址的。所以,剩下的地址不管有多少都要存放在标签这个域当中。当然,在把数据块取回之后,还需要把有效位置为1。
这样,我们通过这个表格,就可以明确的知道当前的这个数据块是从2010这个地址读出来的。在这个Cache行中的第一个字节(字节1),就是CPU现在所需要的那个字节了,把这个字节取出来,交给CPU,这条指令对应的读操作就完成了。
然后,我们再来看第二条指令。
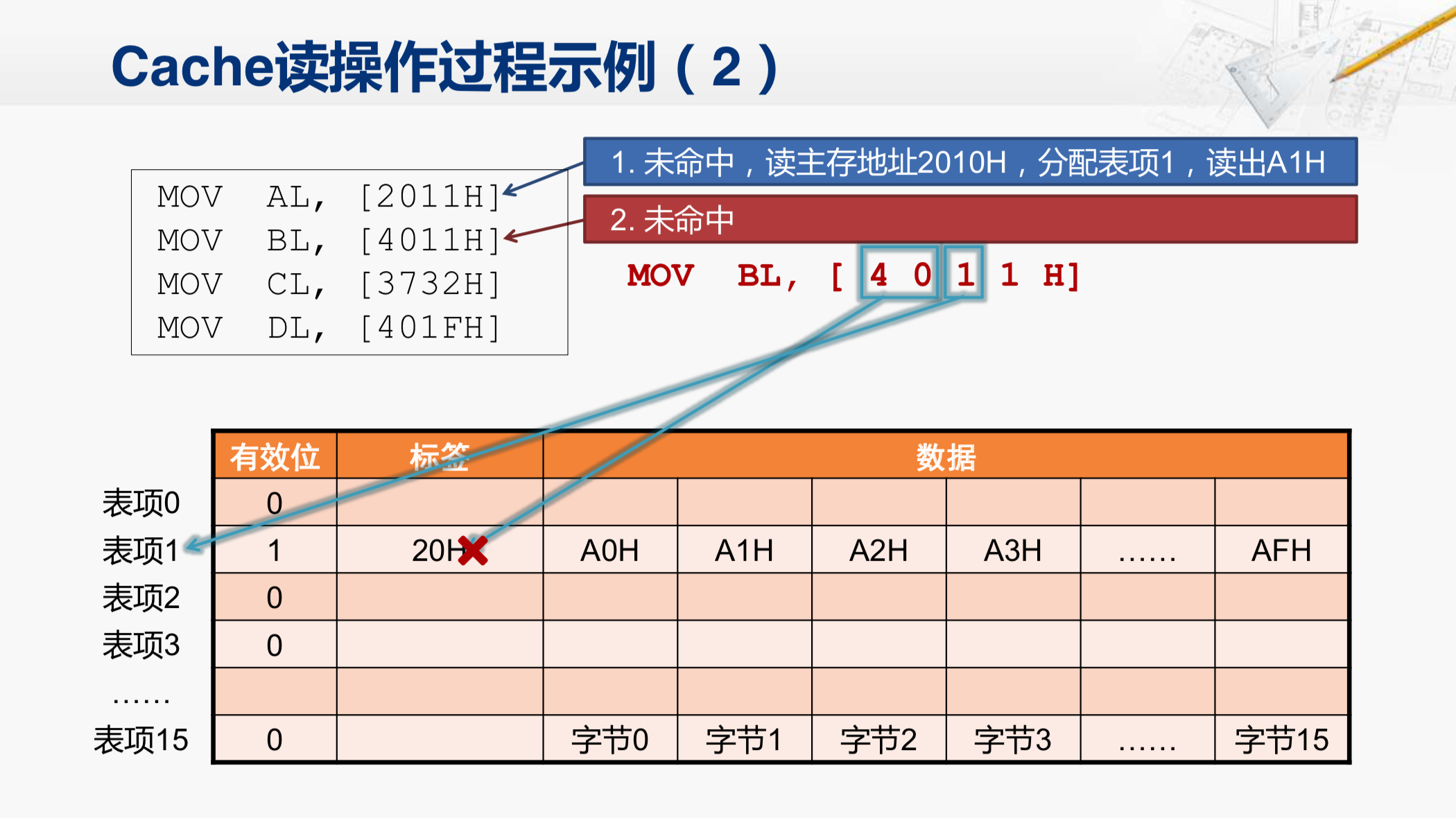
这条指令要读取4011H这个地址。这次我们就来看一看,Cache在收到这个地址后,会做哪些操作。
开始收到4011这个地址后,首先应该找到这个地址对应的Cache行在哪里。它会用这一部分的地址(第二个小蓝矩形中的1)来索引行。所以,找到的还是表项1。然后,检查有效位是1,代表这一行当中的数据是有效的。但这并不能说明它所需要的数据就在这一行里面,接下来还需要比较标签位,把地址当中的高位40H和这个标签位进行比较,结果发现不相等,那就说明这行当中的数据不是4011对应的那个数据块。因此,Cache还是需要向主存发出访存请求。发出的访存地址应该是什么呢?你先考虑一下。
还有一点要注意的就是等会儿取回的这个数据块,也还是需要放在这个表项1当中。所以,会覆盖现在Cache当中的这个数据块,而且等会儿还会把这个标签位也改成40H。
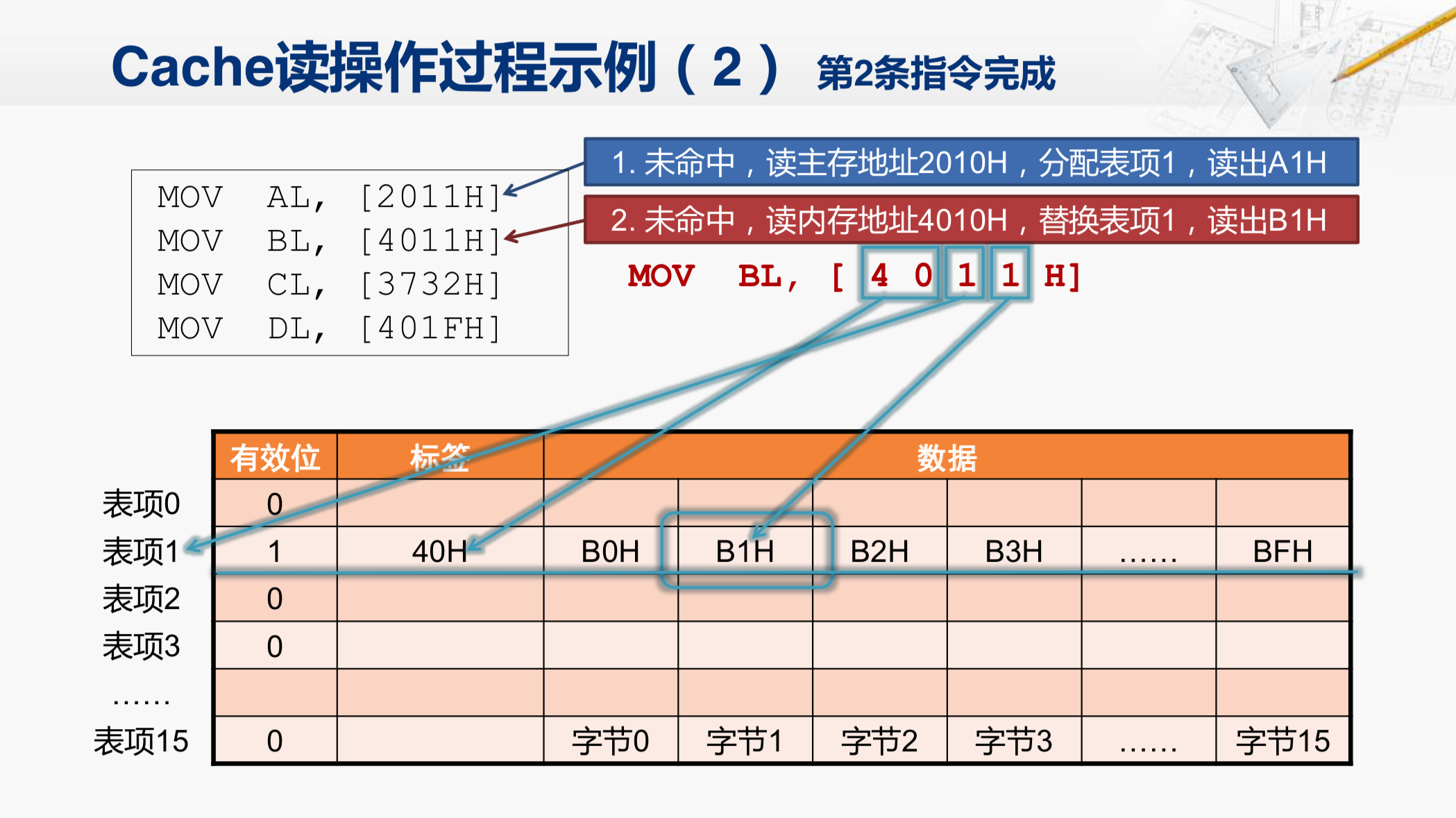
那假设现在Cache已经把对应的数据块从储存当中读回来了,并且完成了对这个Cache行的替换操作。那之后Cache就可以根据地址当中的最低四位找到对应的字节,现在还是第一个字节,把这个字节B1H返回给CPU就完成了这条指令的读操作了。
然后我们再来看第三条指令。
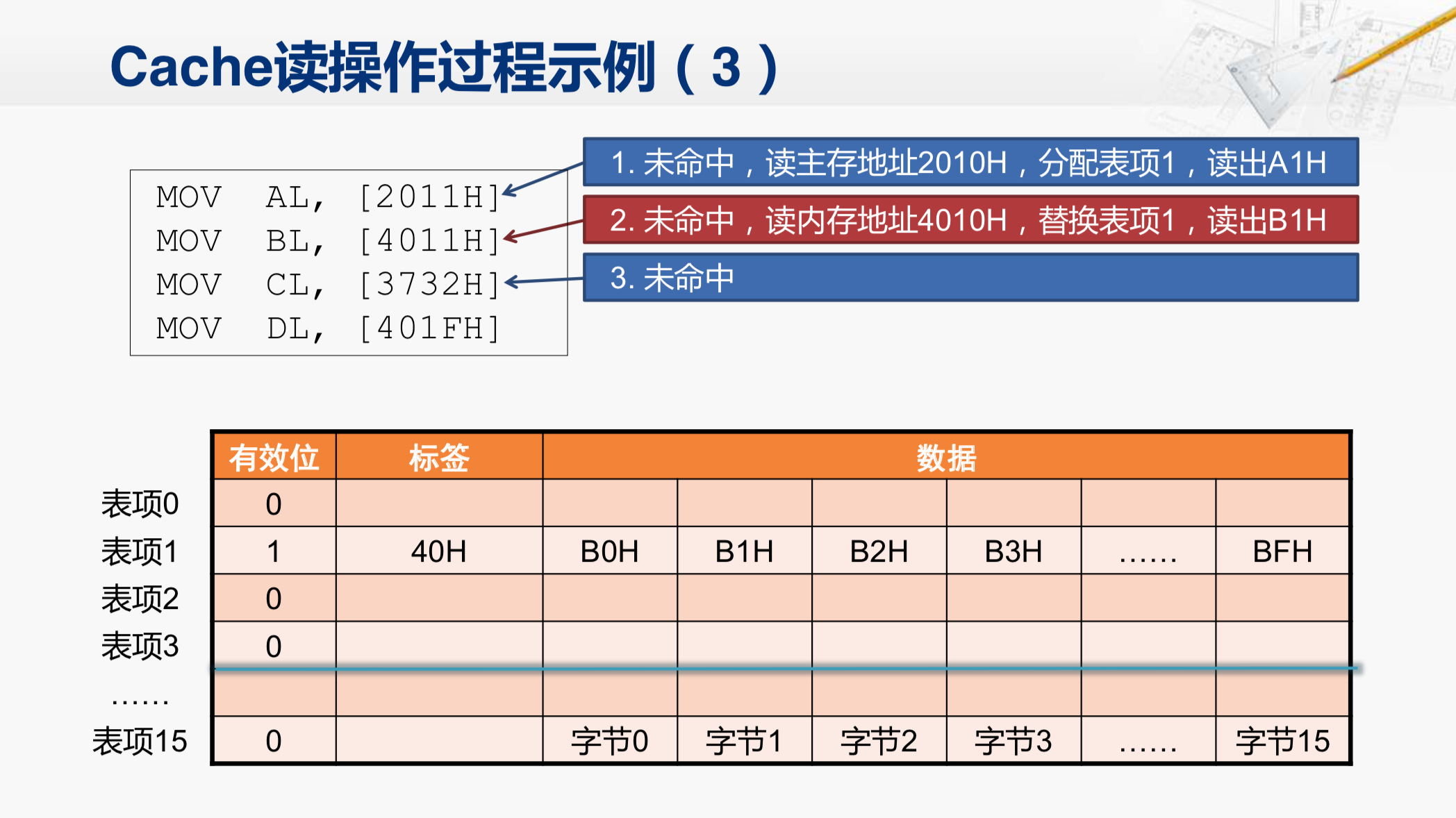
那请先想一想访问这个地址的时候,Cache会去检查哪一个表项,又会进行什么样的操作呢?请先思考一下。然后,我会快速地给出结果,就不再详细地解释了。其实这一次会访问表项3,然后是不命中的。
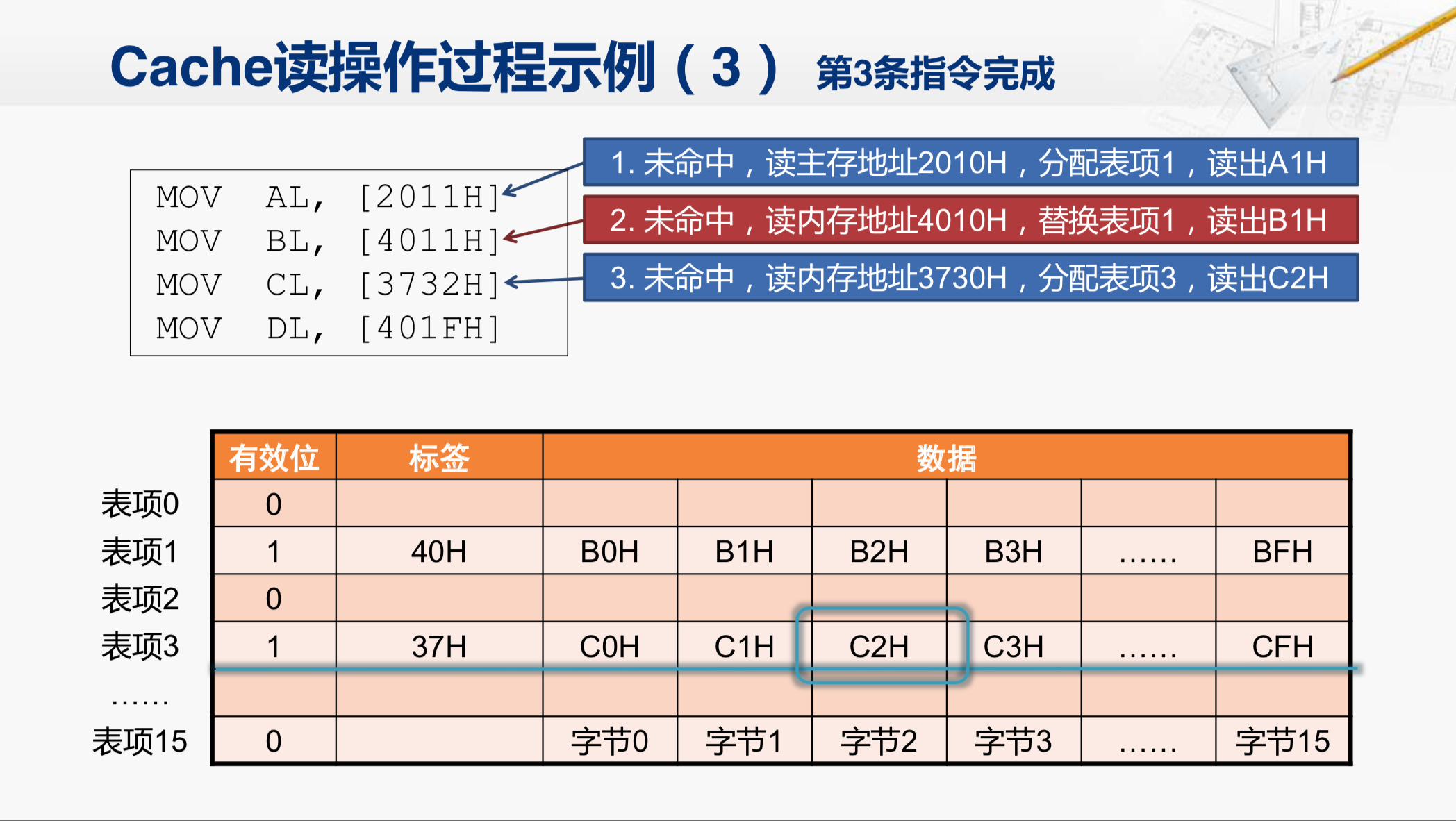
然后读取内存地址3730的数据块,并填到表项3中。然后,返回其中第二个字节C2H给CPU。这样就完成了第三条指令。
然后我们再来看第四条指令。
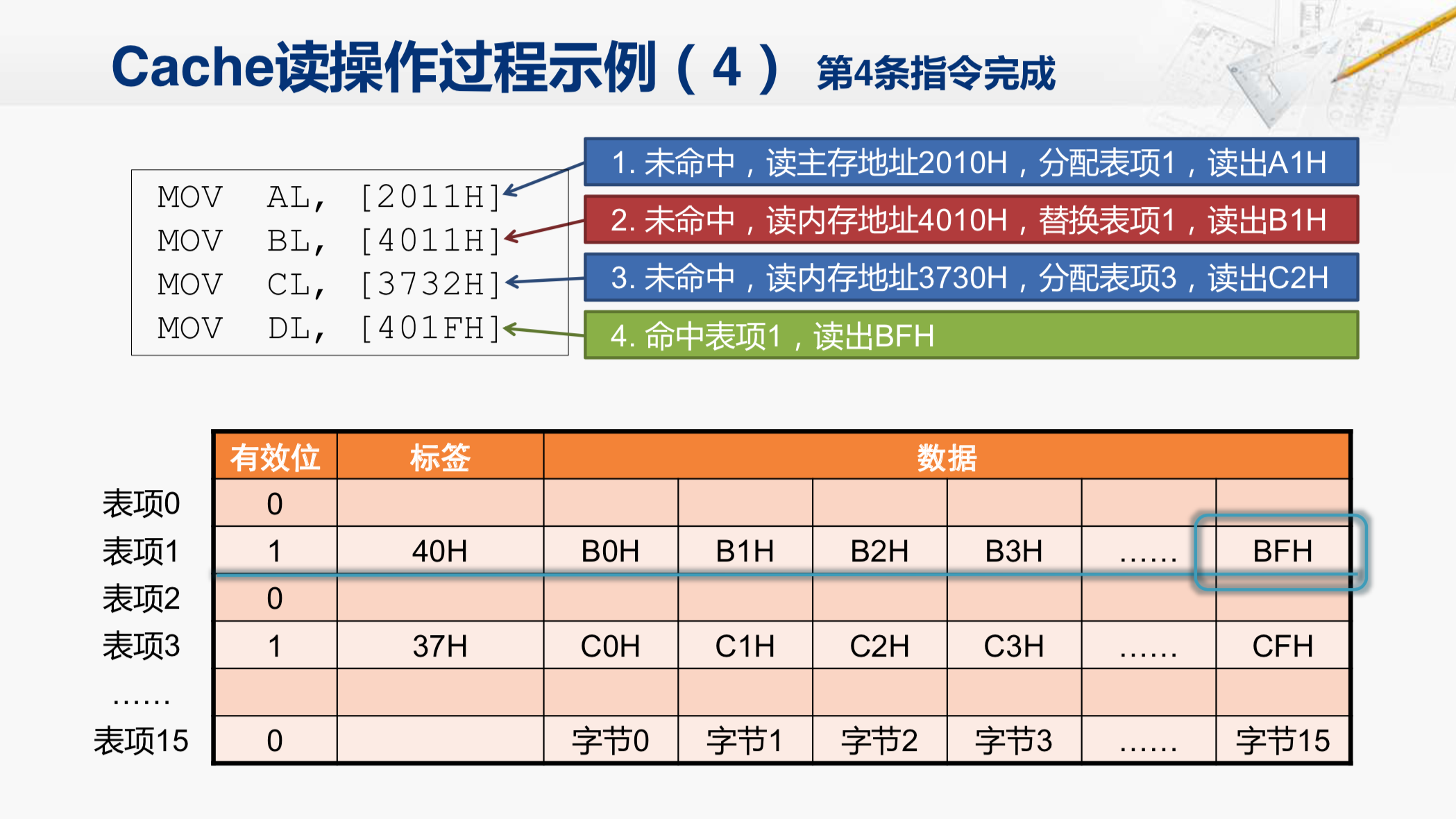
这条指令的地址是401F,那么Cache会首先找到对应的行,因为这部分地址(十六进制数401F第三位)是1。所以,索引到的还是表项1。然后,查看有效位,确定这一行的数据是有效的。下一步是比较标签,那么都是40。所以,标签也是匹配的。这样就可以确认这个地址对应的数据就在这个Cache行当中,那我们就称为Cache命中。最后再根据地址的最低几位(对应十六进制最低位),找到对应的字节,那这个BFH就是CPU需要的这个数据了,把这个数据返回之后,这条指令也就完成了。
那现在我们就了解了Cache读操作的几种典型的情况。一种是没有命中,而且对应的表项是空的时候;第二是没有命中,但是对应的表项已经被占用的情况;还有就是命中了的情况。
那看完了读,我们再来看一看写的情况。

当CPU要写一个数据的时候,也会先送到Cache。这时也会有命中和失效两种情况。
如果Cache命中。我们可以采用一种叫写穿透的策略,把这个数据写入Cache中命中的那一行的同时,也写入主存当中对应的单元。这样就保证了Cache中的数据和主存中的数据始终是一致的。但是因为访问主存比较慢,这样的操作效率是比较低的。所以,我们还可以用另一种策略叫做写返回,这时只需要把数据写到Cache当中,而不写回主存,只有当这个数据块被替换的时候,才把数据写回主存。那这样做的性能显然会好一些,因为有可能会对同一个单元连续进行多次的写,这样只用将最后一次写的结果在替换时,写回主存就可以了,大大减少了访问主存的次数。但是要完成这样的功能,Cache这个部件就会变得复杂得多。
那同样地,在Cache失效的时候,也有两种写策略。一种叫做写不分配。因为Cache失效,所以,要写的那个存储单元不在Cache当中。写不分配的策略就是直接将这个数据写到对应的主存单元里;而另一种策略叫写分配,那就是先将这个数据所在的数据块读到Cache里以后,再将数据写到Cache里。写不分配的策略实现起来是很简单的,但是性能并不太好;而写分配的策略,虽然第一次写的时候操作复杂一些——还是要将这个块读到Cache里以后再写入,看起来比写不分配要慢一点。但是根据局部性的原理,现在写过的这个数据块过一会很可能会被使用。所以,提前把它分配到Cache当中后,会让后续的访存性能大大提升。因此,在现代的Cache设计当中,写穿透和写不分配这两种比较简单的策略往往是配套使用的,用于那些对性能要求不高,但是希望设计比较简单的系统;而大多数希望性能比较好的Cache,都会采用写返回和写分配这一套组合的策略。
那除此之外,在对Cache进行写的过程中,如何去查找分配和替换Cache中的表项,都是和刚才介绍过的读操作的情形是一样的,就不再重复描述了。

高速缓存的基本原理并不复杂,现在我们就可以构造出能够正常工作的高速缓存了。但是如果希望高速缓存能够高效地工作,真正提升计算机的性能,就还需要解决很多的细节问题,之后我们一一探索。

8.6 高速缓存的设计要点
计算机组成
8 存储层次结构
8.6 高速缓存的设计要点

高速缓存是一个非常精细的部件,想让它高效地工作,就得在设计时,进行仔细地权衡。想要设计出一个优秀的高速缓存部件,我们就得从几个基本概念开始入手。
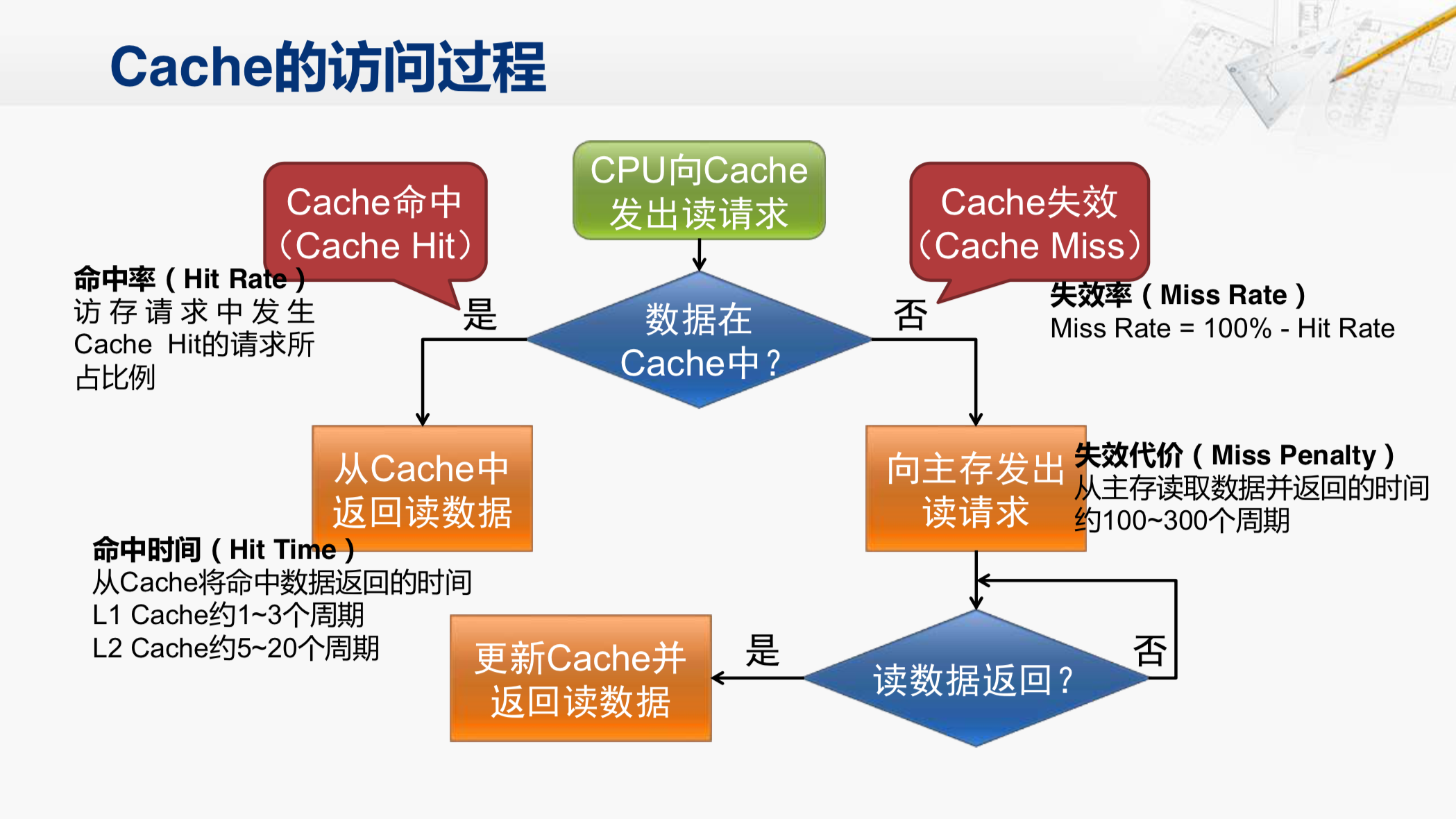
我们再来看一看Cache的访问过程。如果CPU向Cache发出了读请求,Cache就会检查对应的数据是否在自己内部。
如果在,我们就称为Cache命中。有项性能指标就叫做命中率,这说的是CPU所有访存请求中发生了Cache命中的请求所占的比例。如果命中就从Cache内部向CPU返回数据。从Cache中将命中的数据返回的时间,就称为命中时间,这也是一个重要的性能参数。现在的CPU当中,一级开始的命中时间大约是1到3个周期,二级Cache的命中时间大约是5到20个周期。
如果数据不在Cache里,我们就称为Cache失效,对应的就是失效率。失效率和命中率加在一起肯定是百分之一百。在失效之后,Cache会向主存发起读请求,那么等待从主存中返回读数据的这个时间,我们就称为失效代价。现在通常需要在100到300个时钟周期之后,才能得到读的数据。

那要评价访存的性能,我们经常会用到平均访存时间这个指标,这个指标就是用刚才介绍的那几个参数推算出来的。平均访存时间就等于命中时间,加上失效代价乘以失效率。想要提高访存的性能,我们就得降低平均访存时间,要做的就是分别降低这三个参数,这就是提高访存性能的主要途径。
其中想要降低命中时间,就要尽量将Cache的容量做得小一些,Cache的结构也不要做得太复杂。但是小容量的结构简单的Cache,又很容易发生失效,这样就会增加平均访存时间。其中如果要减少失效代价, 要么是提升主存的性能,要么是在当前的高速缓存和主存之间再增加一级高速缓存。那在新增的那级高速缓存当中,也需要面临这些问题。所以,这三个途径并不是独立的,它们是交织在一起相互影响。那我们先重点来看一看命中率这个因素。
如果有一个Cache的命中率是97%,我们假设命中时间是3个周期,失效代价是300个周期。那么平均访存时间就是12个周期。那如果我们有一个方法可以在不影响命中时间和失效代价的情况下,将命中率提高到99%,这时候的平均访存时间就降低到了6个周期。所以,虽然命中率只提高了2%,看起来并不起眼,但是访存性能却提高了一倍,这是非常大幅度的提升。所以,对于现在的Cache来说,能够提高一点点命中率,都可以带来很好的性能提升。
那哪些因素会影响命中率呢?

或者我们反过来看,Cache失效会由哪些原因造成?
有一种叫做义务失效。从来没有访问过的数据块,肯定就不在Cache里。所以,第一次访问这个数据块所发生的失效,就称为义务失效。义务失效是很难避免的。
第二种失效原因称为容量失效。如果这个程序现在所需的数据块已经超过了这个Cache容量的总和,这样不管我们怎么去精巧地设计这个Cache,总会发生失效。当然容量失效可以通过扩大Cache来缓解,但是增加了Cache容量之后,一方面会增加成本,另一方面可能也会影响到命中时间。所以,也需要综合地考虑。
第三种失效称为冲突失效。也就是在Cache并没有满的情况下,因为我们将多个存储器的位置映射到了同一个Cache行,导致位置上的冲突而带来的失效。我们重点就来看一看如何解决这个问题。这个问题就称为Cache的映射策略。
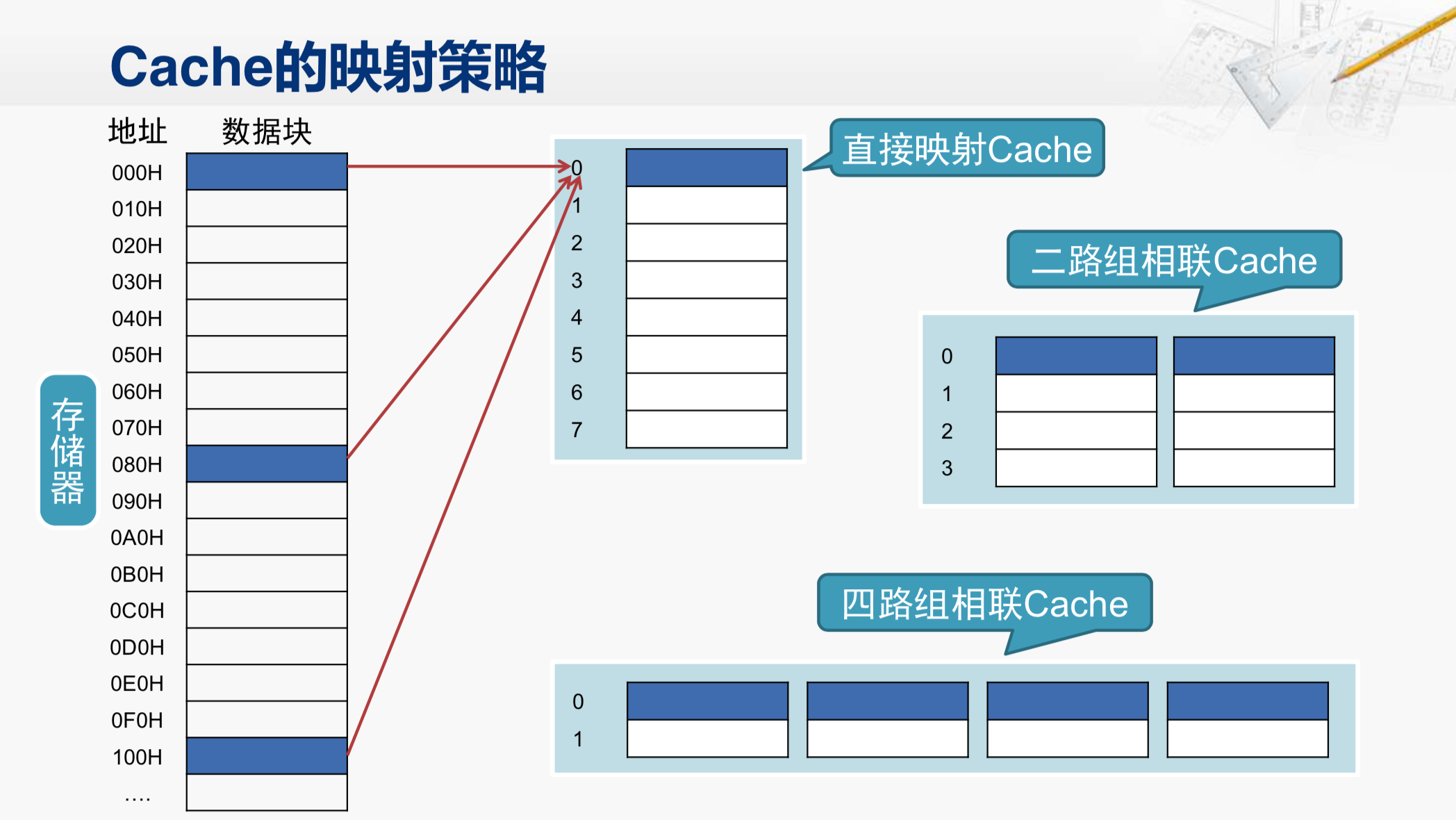
那这是一块存储器的区域,我们还是按照**每16个字节一个数据块(十六进制地址最低位为0)**的形式把这块存储器的区域画出来。所以,地址这一列标记的是各个数据块的起始地址,每个地址之间正好相差16。那如果我们有一个8表项的Cache,那么就采用我们之前介绍过的那种存放方法。地址为0的数据块是要放在表项0当中;而地址为080的数据块,也得放在表项0当中;同样地址为100的数据块,也要存放在这个表项中。这其实就是把内存分成每8个数据块为一组,任何一组当中的第0个数据块,都会被放在表项0,第一个数据块都会被放在表项1,这样的Cache的映射策略就叫做直接映射。它的优点在于硬件结构非常简单,我们只要根据地址就可以知道对应的数据块应该放在哪个表项,但是,它的问题也很明显。如果我们在程序当中正好要交替地不断访问两个数据,不妨称为数据A和数据B。如果数据A在地址为0的这个数据块当中,而数据B在地址080的这个数据块当中,那在访问到数据A时,会把地址0的这个数据块调到Cache当中来,然后把对应的数据A交给CPU;然后CPU又需要访问数据B,其后开始发现,数据B不在Cache当中,所以又要把080对应的这个数据块调进来,替换掉原有的表项0当中的数据,然后再将数据B交给CPU。然后,接下来CPU又访问到数据A,那Cache又要把地址为000H的这个数据块调进来,再次覆盖表项0。那如果CPU不断地在交替访问数据A和数据B,这段时间的Cache访问每一次都是不命中的,这样的访存性能还不如没有Cache,而这时Cache当中其他的行都还是空着的,根本没有发挥作用。所以,这就是这个映射策略上的问题。
为了解决这个问题,我们可以做一些改进,在不增加Cache总的容量情况下,我们可以将这8个Cache行分为两组,这就是二路组相联的Cache。这样刚才那种交替地访问数据A和数据B的情况,就不会有问题了,因为CPU访问数据A时,就会把地址0对应的数据块放在这里,而接下来在访问数据B时,就会把地址080对应的数据块放在这里。然后,再反复地访问数据A和数据B,都会在Cache中命中,这样访存的性能就会非常好。当然如果CPU在交替地访问这三个数据(000H,080H,100H)块当中的数据,那么二路组相联的Cache又会出现连续不命中的情况。所以,我们还可以对它进一步切分。这就是一个四路组相联的Cache。
我们是不是可以无限制地切分下去呢?这倒是可以的。如果这个Cache总共只有8行,而我们把它分成八路组相联,那也就是说,内存当中任一个数据块都可以放到这个Cache当中的任何一个行中,而不用通过地址的特征来约定固定放在哪一个行,这样结构的Cache就叫做全相联的Cache。这样的设计灵活性显然是最高的,但是它的控制逻辑也会变得非常的复杂。我们假设CPU发了一个地址,Cache要判断这个地址是否在自己内部,它就需要把可能包含这个地址的Cache行当中的标签取出来进行比较。对于直接映射的Cache,只需要取一个标签来比较就行;二路组相联的时候,就需要取两个标签同时进行比较;四路组相联的时候就需要取出四个标签来比较;而在全相联的情况下,那就需要把所有行当中的标签都取出来比较。
这样的比较需要选用大量的硬件电路,既增加了延迟,又增加了功耗。如果划分的路数太多,虽然有可能降低了失效率,但是却增加了命中时间,这样就得不偿失了。而且话又说回来,增加了路数,还不一定能够降低失效率。

因为在多路组相联的Cache当中,同一个数据块可以放在不同的地方。如果这些地方都已经被占用了,就需要去选择一行替换出去,这个替换算法设计得好不好,就对性能有很大的影响。如果这个Cache选择替换出去的行,恰恰总是过一会就要使用到的那个数据块,那这样性能的表现就会很差。
现在常见的Cache替换算法有这几种。最简单的是随机替换,这个性能显然不会很好。然后还有轮转替换,也就是按照事先设定好的顺序依次地进行替换,如果是四路组相联,上一次替换了第0路,这一次就替换第1路,下一次就替换第2路,再下一次就替换第3路。这个从硬件设计设计上来说比较简单,但是性能也一般。性能比较好的替换算法,是最近最少使用的替换算法,简称为LRU,它需要额外的硬件来记录访问的历史信息,在替换的时候,选择距离现在最长时间没有被访问的那个Cache行进行替换。在使用中,这种方法的性能表现比较好,但是其硬件的设计也相当的复杂。所以,映射策略和替换算法都需要在性能和实现代价之间进行权衡。
那我们再来看看一些Cache设计的实例。
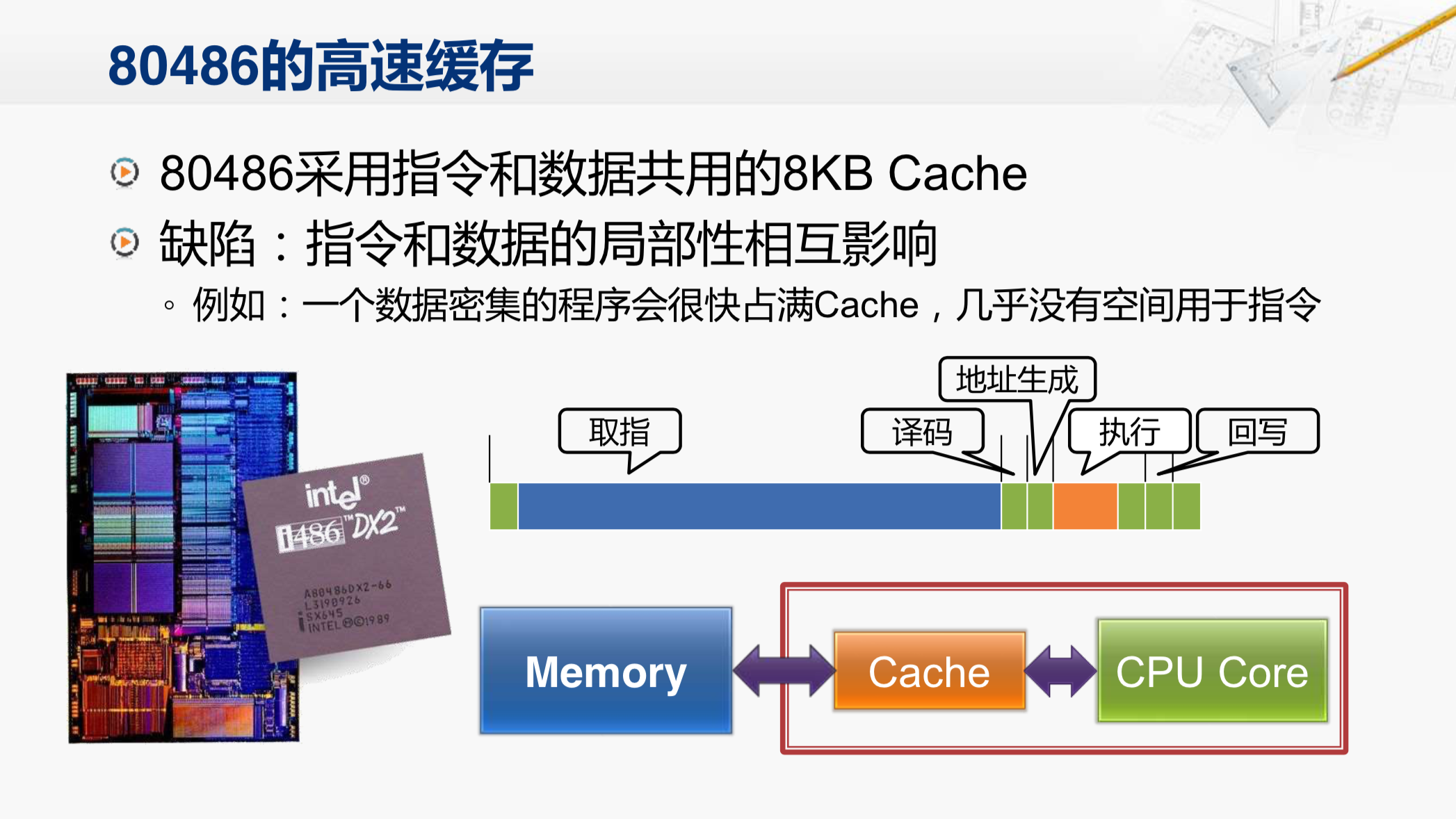
在X86系列CPU当中,486是最早在CPU芯片内部集成了Cache的,但它使用的是一个指令和数据共用的Cache。这个Cache有一个很明显的缺点,那就是指令和数据的局部性会互相影响。因为指令和数据一般是存放在内存中的不同区域,所以它们各自具有局部性。利用在执行一个要操作大量数据的程序,这些数据就会很快地占满Cache,把其中的指令都挤出去了,在这个时候,执行一条指令,取指的阶段很可能是Cache不命中,需要等待访问存储器,那就需要花很长的时间。而在执行阶段,去取操作数时,却往往会命中Cache,虽然这段时间比较短,但是整个指令执行的时间还是很长。
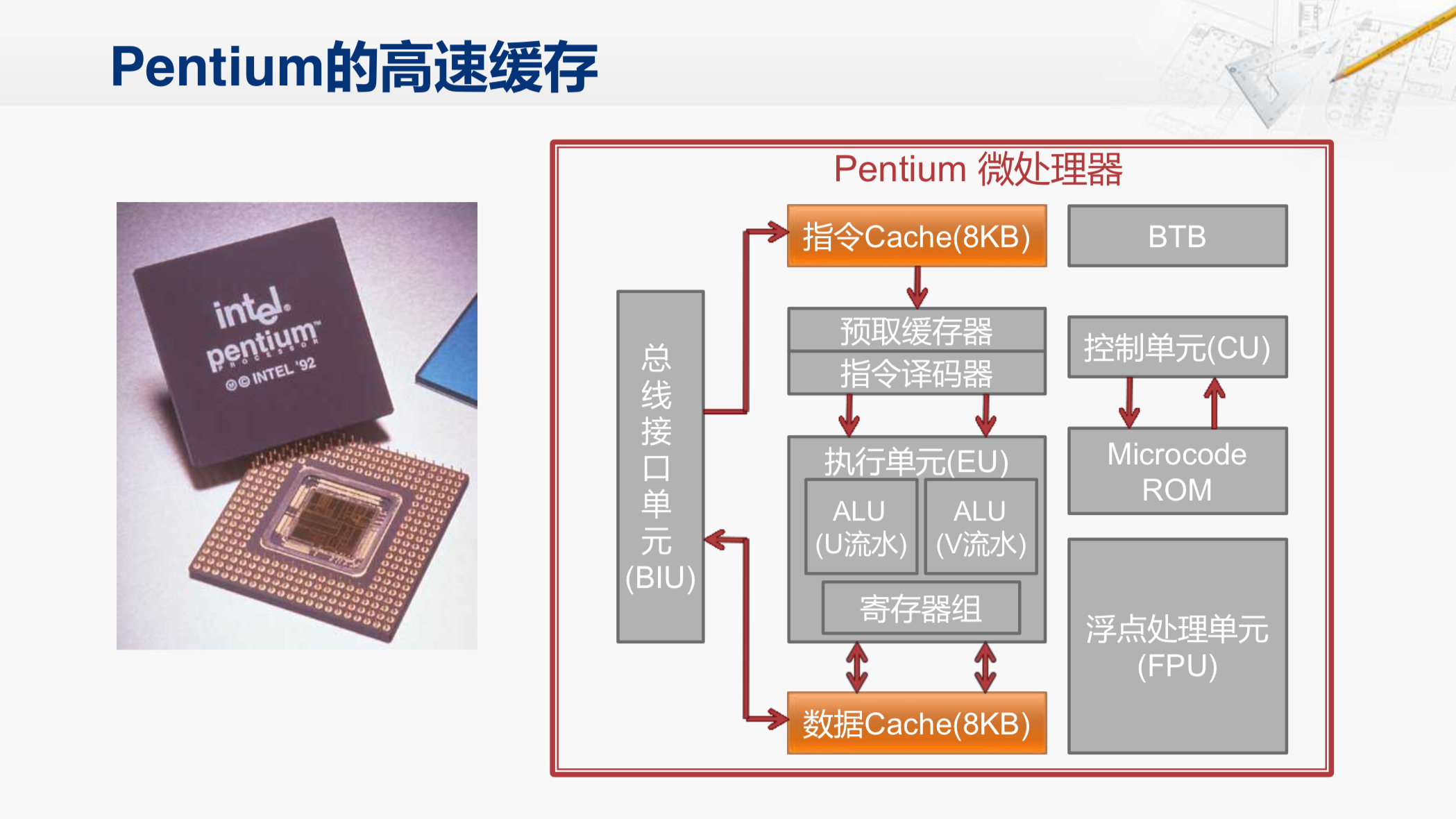
所以到了后来的奔腾,就把指令和数据分成了两个独立的Cache,这样它们各自的局部性就不会相互影响了。
现在大多数CPU的一级Cache都会采用这样的形式。

这个是现在比较先进的Core i7。它内部采用了多级Cache的结构,其中一级Cache是指令和数据分离的各32K个Byte,采用了8路组相联的形式,命中时间是4个周期。所以,在CPU的流水线当中,访问Cache也需要占多个流水级。
那么在这个4核的i7当中,每个处理器核还有自己独享的二级Cache。二级Cache就不再分成指令和数据两个部分了,因为它的容量比较大,指令和数据之间的相互影响就不那么明显。但是二级Cache的命中时间也比较长,需要11个周期,Core i7 CPU的流水线总共也就16级左右,肯定是没有办法和二级Cache直接协同工作的。这也是为什么一级Cache不能做得很大的一个重要原因(做大了需要花费多个流水级)。
在二级Cache之下,还有一个三级Cache。这是由四个核共享的,总共8兆个字节。三级Cache采用了16路组相联的结构,而且容量也很大,达到了8兆个字节,这又导致它的命中时间很长,需要30到40个周期,但它这样的结构命中率会很高,这样就很少需要去访问主存了。
我们可以看到这三级的Cache,它的命中时间从4个周期、11个周期到40个周期,我们再考虑到主存的100到300个周期,就可以看出这个多级Cache + 主存的结构就拉开了明显的层次,在各自的设计时就可以有不同的侧重,相互配合来提升整个系统的性能。

高速缓存的研究已经持续了很长时间,直到今天仍然是一个研究的热点。只不过之前的研究对象是CPU和主存之间的这一级高速缓存,而现在的研究对象则是由多级高速缓存组成的这么一个多层次的结构。不管怎么样,高速缓存技术的研究给我们带来了在可控成本之下,尽可能高的系统性能。

Android App使用SQLite数据库的一些要点总结
/DATA/data/包名/databases是该程序存放数据的目录,DATA是Environment.getDataDirectory() 方法返回的路径。找到数据库之后可以选中user.db 执行导出。
用真机调试,data目录如果打不开,说明你的手机没有root,改用模拟器就OK了。
1.获取sqliteDatabase对象:
sqliteDatabase db = openorCreateDatabase(File file,sqliteDatabase.Cursor,Factory factor);
2.sqliteDatabase提供了如下方法:
db.execsql(sql) //执行任何sql语句 db.insert(table,nullColumnHack,value) //(增) db.delete(table,whereClause,whereArgs) //(删) db.updata(table,values,whereArgs) //(改) db.query(table,columns,whereArgs,groupBy,having,orderBy) //(查) db.rawQuery(sql,selectionArgs) //可以使用sql语句直接查询
3.执行query和rawQuery操作,返回一个Cursor游标对象,它可以遍历整个查询处的内容,Cursor提供了如下方法来移动游标:
c.move( int offset) //游标向上或向下移动指定行数,正数向下,负数向上 c.movetoFirst() //移动到第一行,返回布尔值 c.movetoLast() c.movetoNext() c.movetoPostion(int postion) //移动到指定行,返回布尔值 c.movetoPrevIoUs() //移动到上一行 c.isFirst(); //是否指向第一条 c.isLast(); //是否指向最后一条 c.isBeforeFirst(); //是否指向第一条之前 c.isAfterLast(); //是否指向最后一条之后 c.isNull(int columnIndex); //指定列是否为空(列基数为0) c.isClosed(); //游标是否已关闭 c.getCount(); //总数据项数 c.getPosition(); //返回当前游标所指向的行数 c.getColumnIndex(String columnName); //返回某列名对应的列索引值 c.getString(int columnIndex); //返回当前行指定列的值
下面是一个创建一个sqliteDatabase对象,只用sql语句进行查询的实例
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
//每个程序都有自己的数据库,而且互不干扰
//创建一个数据库,并且打开,这个方法返回的是一个sqliteDadabase对象(如果没有就创建,有就直接打开)
//这个数据库的名字叫user.db,这样取名是为了以后导出到电脑上后方便第三方软件打开,第二个参数是一个常量,此例表示私有别的数据库无法访问
sqliteDatabase db = openorCreateDatabase("user.db",MODE_PRIVATE,null);
//创建一张表 usertb ,主键名字建议写成_id,1个主键,3列,加上_id总共4列
db.execsql("create table if not exists usertb(_id integer primary key autoincrement,name text not null,age integer not null,sex text not null)");
//往这张表usertb中加3条数据,分别3列,3个对应的值
db.execsql("insert into usertb(name,age,sex) values('Jack','18','男')");
db.execsql("insert into usertb(name,sex) values('Hellen','19','女')");
db.execsql("insert into usertb(name,sex) values('Mike','20','男')");
//查询数据,第一个参数还是一条语句,查询方法,指定如何查找查询条件, 第二个参数是查询条件,默认把数据全部查询出来
//这里的返回值是Cursor,是查询数据后得到的管理集合的一个类,可以理解为list(游标接口)
Cursor c = db.rawQuery("select * from usertb",null);
if (c!= null){ //如果能查询到数据
c.movetoFirst(); //如果没有处理过数据,这条可以省略,默认光标第一行
while(c.movetoNext()){ //每次只能查询到一条数据,判断是否能查询到下一行(重点:每次光标到达一行后,下面的语句依次打印那一行中的数据,再循环,打印下面一行数据)
Log.i ("info"," "+ c.getInt(c.getColumnIndex("_id"))); //第一个字段int型, 需要转成String型才能用Log打印(找到这一条数据中字段角标为0的integer型数据)
Log.i("info",c.getString(c.getColumnIndex("name"))); //第二个字段是text型
Log.i("info"," "+c.getInt(c.getColumnIndex("age")));
Log.i("info",c.getString(c.getColumnIndex("sex")));
Log.i("info","~~~~~~~~"); //测试一次循环有多少数据被打印
}
c.close(); //查询完,游标一定要释放
}
db.close();
}
4.增删查改的相关参数:
table:查询数据的表名
columns: 要查询出来的列名
whereClause: 查询条件子句,允许使用占位符"?"
whereArgs: 用于为占位符传入参数值
groupBy:用于控制分组
having:用于对分组进行过滤
orderBy:用于对记录进行排序
ContentValues是对key/value的一个包装,使用它可以将要插入或者要修改的数据以key/value的形式进行封装,在使用相应增改方法的时候直接使用。
它有两个存入和取出两个方法:
put(String key,Xxx); getAsXxx(String Key);
下面一个实例,使用内置函数操作数据库增删改查:
sqliteDatabase db = openorCreateDatabase("user.db",null);
db.execsql("create table if not exists usertb(_id integer primary key autoincrement,sex integer not null) ");
//在执行增、改方法之前,先创建insert方法中的一个ContentValues对象,再对这个对象存入数据,存完后把values插入
ContentValues values = new ContentValues();
//增
values.put("name","张三");
values.put("age",18);
values.put("sex","男");
db.insert("usertb",null,values); //插入方法的返回值是一个long,表示新添记录的行号
values.clear(); //在插入下一条数据前需要把values清空,再对values存入新数据
values.put("name","李四");
values.put("age",19);
values.put("sex",values);
values.clear();
values.put("name","王五");
values.put("age",20);
values.put("sex",values);
values.clear();
//改 (将id大于的性别改成女
values.put("sex","女");
db.update("usertb","_id >?",new String[]{"2"});
//删 (将名字里带三的人删除)
db.delete("uesrtb","name like ?",new String [] {"%三%"});
//查 (查询usertb这张表,所有行都差,_id >0的数据都查,查询出的数据按照name排序)
Cursor c = db.query("usertb","_id > ?",new String[]{"0"},"name");
c.close();
//关闭当前数据库
db.close();
//删除user.db数据库(注意不是表名table)
deleteDatabase("user.db");
5.sqliteOpenHelper :
sqliteOpenHelper是一个帮助类,通过继承它并实现onCreate方法和Upgrade方法,来管理我们的数据库。
sqliteDatabase db = helper.getWritableDatabase(); sqliteDatabase db = helper.getReadableDatabase();
下面一个实例,新建一个类继承sqliteOpenHelper
public class DBOpenHelper extends sqliteOpenHelper{
public DBOpenHelper(Context context,String name) {
super(context,name,1);
}
public DBOpenHelper(Context context,String name,CursorFactory factory,int version) {
super(context,factory,version);
}
@Override//首次创建数据库的时候调用 一般可以把建库 建表的操作
public void onCreate(sqliteDatabase db) {
db.execsql("create table if not exists stutb(_id integer primary key autoincrement,sex text not null,age integer not null)");
db.execsql("insert into stutb(name,sex,age)values('张三','女',18)");
}
@Override//当数据库的版本发生变化的时候 会自动执行
public void onUpgrade(sqliteDatabase db,int oldVersion,int newVersion) {
}
}
然后在主activity中就可以创建这个子类的对象,通过这个类的get方法得到sqliteDatabase对象
DBOpenHelper helper =new DBOpenHelper(MainActivity.this,"stu.db"); sqliteDatabase db = helper.getWritableDatabase();

android ndk 编译so动态库的问题
为什么我用ndk的ndk-build编译动态so库的时候,生成的so文件会很大有40kb,同样的c文件和mk文件,我让别人编译了一下才1kb多,而且两个库都可以正常使用。
求大神解答。
关于android – 达到数据库的编译SQL语句高速缓存的MAX大小和sql语句超过缓冲区长度的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于8.5 高速缓存的工作原理、8.6 高速缓存的设计要点、Android App使用SQLite数据库的一些要点总结、android ndk 编译so动态库的问题的相关知识,请在本站寻找。
本文标签:




