对于想了解android–Xamarin.IOS错误–无法解析参考:C:/ProgramFiles(x86)/../Xamarin.iOS/v1.0/Facades/System.Private.Co
对于想了解android – Xamarin.IOS错误 – 无法解析参考:C:/ Program Files(x86)/../ Xamarin.iOS / v1.0 / Facades / System.Private.CoreLib.InteropServices.dll的读者,本文将是一篇不可错过的文章,并且为您提供关于2018 ACM-ICPC, Syrian Collegiate Programming Contest F - Pretests SOS dp、3——Building Microservices: Inter-Process Communication in a Microservices Architecture、ACM International Collegiate Programming Contest, Damascus University Collegiate Programming Cont...、Android Camera 原理之 camera service 与 camera provider session 会话与 capture request 轮转的有价值信息。
本文目录一览:- android – Xamarin.IOS错误 – 无法解析参考:C:/ Program Files(x86)/../ Xamarin.iOS / v1.0 / Facades / System.Private.CoreLib.InteropServices.dll
- 2018 ACM-ICPC, Syrian Collegiate Programming Contest F - Pretests SOS dp
- 3——Building Microservices: Inter-Process Communication in a Microservices Architecture
- ACM International Collegiate Programming Contest, Damascus University Collegiate Programming Cont...
- Android Camera 原理之 camera service 与 camera provider session 会话与 capture request 轮转
/../ Xamarin.iOS / v1.0 / Facades / System.Private.CoreLib.InteropServices.dll")
android – Xamarin.IOS错误 – 无法解析参考:C:/ Program Files(x86)/../ Xamarin.iOS / v1.0 / Facades / System.Private.CoreLib.InteropServices.dll
我正在使用Visual Studio 2015和Window 10操作系统来制作xamarin项目.我已经在MAC PC上安装了Xamarin工作室来运行IOS项目.
我的IOS和android项目成功运行,但是当我更新MAC PC中的Xamarin工作室时,它会在ios项目中出现错误:
无法解析参考:C:/ Program Files(x86)/ Reference Assemblies / Microsoft / Framework / Xamarin.iOS / v1.0 / Facades / System.Private.CoreLib.InteropServices.dll
请建议我如何解决这个错误.
提前致谢
解决方法

2018 ACM-ICPC, Syrian Collegiate Programming Contest F - Pretests SOS dp
#include<bits/stdc++.h>
#define LL long long
#define fi first
#define se second
#define mk make_pair
#define PLL pair<LL, LL>
#define PLI pair<LL, int>
#define PII pair<int, int>
#define SZ(x) ((int)x.size())
#define ull unsigned long long
using namespace std;
const int N = 2e5 + 7;
const int inf = 0x3f3f3f3f;
const LL INF = 0x3f3f3f3f3f3f3f3f;
const int mod = 1e9 + 7;
const double eps = 1e-3;
const double PI = acos(-1);
int T, m, n, up, dp2[1<<20], dp[1<<20], pre[1<<20];
char s[100];
vector<int> ans;
int main() {
// freopen("tests.in", "r", stdin);
scanf("%d", &T);
while(T--) {
ans.clear();
scanf("%d%d", &m, &n);
up = 1 << m;
for(int i = 0; i < up; i++) dp2[i] = 0, dp[i] = inf;
for(int i = 0; i < n; i++) {
scanf("%s", s); int x = 0;
for(int j = 0; j < m; j++)
if(s[j] == ''1'') x += 1 << j;
dp2[x]++;
}
for(int i = 0; i < m; i++)
for(int s = 0; s < up; s++)
if(s>>i&1) dp2[s^(1<<i)] += dp2[s];
dp[0] = 0;
for(int s = 0; s < up; s++) {
for(int i = 0; i < m; i++) {
if(s>>i&1) continue;
int nexs = s | (1<<i);
if(dp[s]+dp2[s] < dp[nexs]) {
dp[nexs] = dp[s]+dp2[s];
pre[nexs] = s;
}
}
}
int nows = up-1, nexs;
while(nows) {
nexs = pre[nows];
int xo = nexs ^ nows;
for(int i = 0; i < m; i++) {
if(1<<i == xo) {
ans.push_back(i+1);
break;
}
}
nows = nexs;
}
reverse(ans.begin(), ans.end());
printf("%d\n", dp[up-1]);
for(int t : ans) printf("%d ", t);
puts("");
}
return 0;
}
/*
*/

3——Building Microservices: Inter-Process Communication in a Microservices Architecture
https://www.nginx.com/blog/building-microservices-inter-process-communication/
This is the third article in our series about building applications with a microservices architecture. The first article introduces the Microservices Architecture pattern, compares it with the Monolithic Architecture pattern, and discusses the benefits and drawbacks of using microservices. The second article describes how clients of an application communicate with the microservices via an intermediary known as an API Gateway. In this article, we take a look at how the services within a system communicate with one another. The fourth article explores the closely related problem of service discovery.
Editor’s note – This seven-part series of articles is now complete:
- Introduction to Microservices
- Building Microservices: Using an API Gateway
- Building Microservices: Inter-Process Communication in a Microservices Architecture (this article)
- Service Discovery in a Microservices Architecture
- Event-Driven Data Management for Microservices
- Choosing a Microservices Deployment Strategy
- Refactoring a Monolith into Microservices
Introduction
In a monolithic application, components invoke one another via language-level method or function calls. In contrast, a microservices-based application is a distributed system running on multiple machines. Each service instance is typically a process. Consequently, as the following diagram shows, services must interact using an inter-process communication (IPC) mechanism.
Later on we will look at specific IPC technologies, but first let’s explore various design issues.
Interaction Styles
When selecting an IPC mechanism for a service, it is useful to think first about how services interact. There are a variety of client⇔service interaction styles. They can be categorized along two dimensions. The first dimension is whether the interaction is one-to-one or one-to-many:
- One-to-one – Each client request is processed by exactly one service instance.
- One-to-many – Each request is processed by multiple service instances.
The second dimension is whether the interaction is synchronous or asynchronous:
- Synchronous – The client expects a timely response from the service and might even block while it waits.
- Asynchronous – The client doesn’t block while waiting for a response, and the response, if any, isn’t necessarily sent immediately.
The following table shows the various interaction styles.
| One-to-One | One-to-Many | |
| Synchronous | Request/response | — |
| Asynchronous | Notification | Publish/subscribe |
| Request/async response | Publish/async responses |
There are the following kinds of one-to-one interactions:
- Request/response – A client makes a request to a service and waits for a response. The client expects the response to arrive in a timely fashion. In a thread-based application, the thread that makes the request might even block while waiting.
- Notification (a.k.a. a one-way request) – A client sends a request to a service but no reply is expected or sent.
- Request/async response – A client sends a request to a service, which replies asynchronously. The client does not block while waiting and is designed with the assumption that the response might not arrive for a while.
There are the following kinds of one-to-many interactions:
- Publish/subscribe – A client publishes a notification message, which is consumed by zero or more interested services.
- Publish/async responses – A client publishes a request message, and then waits a certain amount of time for responses from interested services.
Each service typically uses a combination of these interaction styles. For some services, a single IPC mechanism is sufficient. Other services might need to use a combination of IPC mechanisms. The following diagram shows how services in a taxi-hailing application might interact when the user requests a trip.
The services use a combination of notifications, request/response, and publish/subscribe. For example, the passenger’s smartphone sends a notification to the Trip Management service to request a pickup. The Trip Management service verifies that the passenger’s account is active by using request/response to invoke the Passenger Service. The Trip Management service then creates the trip and uses publish/subscribe to notify other services including the Dispatcher, which locates an available driver.
Now that we have looked at interaction styles, let’s take a look at how to define APIs.
Defining APIs
A service’s API is a contract between the service and its clients. Regardless of your choice of IPC mechanism, it’s important to precisely define a service’s API using some kind of interface definition language (IDL). There are even good arguments for using an API‑first approach to defining services. You begin the development of a service by writing the interface definition and reviewing it with the client developers. It is only after iterating on the API definition that you implement the service. Doing this design up front increases your chances of building a service that meets the needs of its clients.
As you will see later in this article, the nature of the API definition depends on which IPC mechanism you are using. If you are using messaging, the API consists of the message channels and the message types. If you are using HTTP, the API consists of the URLs and the request and response formats. Later on we will describe some IDLs in more detail.
Evolving APIs
A service’s API invariably changes over time. In a monolithic application it is usually straightforward to change the API and update all the callers. In a microservices-based application it is a lot more difficult, even if all of the consumers of your API are other services in the same application. You usually cannot force all clients to upgrade in lockstep with the service. Also, you will probably incrementally deploy new versions of a service such that both old and new versions of a service will be running simultaneously. It is important to have a strategy for dealing with these issues.
How you handle an API change depends on the size of the change. Some changes are minor and backward compatible with the previous version. You might, for example, add attributes to requests or responses. It makes sense to design clients and services so that they observe the robustness principle. Clients that use an older API should continue to work with the new version of the service. The service provides default values for the missing request attributes and the clients ignore any extra response attributes. It is important to use an IPC mechanism and a messaging format that enable you to easily evolve your APIs..
Sometimes, however, you must make major, incompatible changes to an API. Since you can’t force clients to upgrade immediately, a service must support older versions of the API for some period of time. If you are using an HTTP-based mechanism such as REST, one approach is to embed the version number in the URL. Each service instance might handle multiple versions simultaneously. Alternatively, you could deploy different instances that each handle a particular version.
Handling Partial Failure
As mentioned in the previous article about the API Gateway, in a distributed system there is the ever-present risk of partial failure. Since clients and services are separate processes, a service might not be able to respond in a timely way to a client’s request. A service might be down because of a failure or for maintenance. Or the service might be overloaded and responding extremely slowly to requests.
Consider, for example, the Product details scenario from that article. Let’s imagine that the Recommendation Service is unresponsive. A naive implementation of a client might block indefinitely waiting for a response. Not only would that result in a poor user experience, but in many applications it would consume a precious resource such as a thread. Eventually the runtime would run out of threads and become unresponsive as shown in the following figure.
To prevent this problem, it is essential that you design your services to handle partial failures.
A good to approach to follow is the one described by Netflix. The strategies for dealing with partial failures include:
- Network timeouts – Never block indefinitely and always use timeouts when waiting for a response. Using timeouts ensures that resources are never tied up indefinitely.
- Limiting the number of outstanding requests – Impose an upper bound on the number of outstanding requests that a client can have with a particular service. If the limit has been reached, it is probably pointless to make additional requests, and those attempts need to fail immediately.
- Circuit breaker pattern – Track the number of successful and failed requests. If the error rate exceeds a configured threshold, trip the circuit breaker so that further attempts fail immediately. If a large number of requests are failing, that suggests the service is unavailable and that sending requests is pointless. After a timeout period, the client should try again and, if successful, close the circuit breaker.
- Provide fallbacks – Perform fallback logic when a request fails. For example, return cached data or a default value such as empty set of recommendations.
Netflix Hystrix is an open source library that implements these and other patterns. If you are using the JVM you should definitely consider using Hystrix. And, if you are running in a non-JVM environment you should use an equivalent library.
IPC Technologies
There are lots of different IPC technologies to choose from. Services can use synchronous request/response-based communication mechanisms such as HTTP-based REST or Thrift. Alternatively, they can use asynchronous, message-based communication mechanisms such as AMQP or STOMP. There are also a variety of different message formats. Services can use human readable, text-based formats such as JSON or XML. Alternatively, they can use a binary format (which is more efficient) such as Avro or Protocol Buffers. Later on we will look at synchronous IPC mechanisms, but first let’s discuss asynchronous IPC mechanisms.
Asynchronous, Message-Based Communication
When using messaging, processes communicate by asynchronously exchanging messages. A client makes a request to a service by sending it a message. If the service is expected to reply, it does so by sending a separate message back to the client. Since the communication is asynchronous, the client does not block waiting for a reply. Instead, the client is written assuming that the reply will not be received immediately.
A message consists of headers (metadata such as the sender) and a message body. Messages are exchanged over channels. Any number of producers can send messages to a channel. Similarly, any number of consumers can receive messages from a channel. There are two kinds of channels, point‑to‑point and publish‑subscribe. A point‑to‑point channel delivers a message to exactly one of the consumers that is reading from the channel. Services use point‑to‑point channels for the one‑to‑one interaction styles described earlier. A publish‑subscribe channel delivers each message to all of the attached consumers. Services use publish‑subscribe channels for the one‑to‑many interaction styles described above.
The following diagram shows how the taxi-hailing application might use publish‑subscribe channels.
The Trip Management service notifies interested services such as the Dispatcher about a new Trip by writing a Trip Created message to a publish‑subscribe channel. The Dispatcher finds an available driver and notifies other services by writing a Driver Proposed message to a publish‑subscribe channel.
There are many messaging systems to chose from. You should pick one that supports a variety of programming languages. Some messaging systems support standard protocols such as AMQP and STOMP. Other messaging systems have proprietary but documented protocols. There are a large number of open source messaging systems to choose from, including RabbitMQ, Apache Kafka, Apache ActiveMQ, and NSQ. At a high level, they all support some form of messages and channels. They all strive to be reliable, high-performance, and scalable. However, there are significant differences in the details of each broker’s messaging model.
There are many advantages to using messaging:
- Decouples the client from the service – A client makes a request simply by sending a message to the appropriate channel. The client is completely unaware of the service instances. It does not need to use a discovery mechanism to determine the location of a service instance.
- Message buffering – With a synchronous request/response protocol, such as a HTTP, both the client and service must be available for the duration of the exchange. In contrast, a message broker queues up the messages written to a channel until they can be processed by the consumer. This means, for example, that an online store can accept orders from customers even when the order fulfillment system is slow or unavailable. The order messages simply queue up.
- Flexible client-service interactions – Messaging supports all of the interaction styles described earlier.
- Explicit inter-process communication – RPC-based mechanisms attempt to make invoking a remote service look the same as calling a local service. However, because of the laws of physics and the possibility of partial failure, they are in fact quite different. Messaging makes these differences very explicit so developers are not lulled into a false sense of security.
There are, however, some downsides to using messaging:
- Additional operational complexity – The messaging system is yet another system component that must be installed, configured, and operated. It’s essential that the message broker be highly available, otherwise system reliability is impacted.
- Complexity of implementing request/response-based interaction – Request/response-style interaction requires some work to implement. Each request message must contain a reply channel identifier and a correlation identifier. The service writes a response message containing the correlation ID to the reply channel. The client uses the correlation ID to match the response with the request. It is often easier to use an IPC mechanism that directly supports request/response.
Now that we have looked at using messaging-based IPC, let’s examine request/response-based IPC.
Synchronous, Request/Response IPC
When using a synchronous, request/response-based IPC mechanism, a client sends a request to a service. The service processes the request and sends back a response. In many clients, the thread that makes the request blocks while waiting for a response. Other clients might use asynchronous, event-driven client code that is perhaps encapsulated by Futures or Rx Observables. However, unlike when using messaging, the client assumes that the response will arrive in a timely fashion. There are numerous protocols to choose from. Two popular protocols are REST and Thrift. Let’s first take a look at REST.
REST
Today it is fashionable to develop APIs in the RESTful style. REST is an IPC mechanism that (almost always) uses HTTP. A key concept in REST is a resource, which typically represents a business object such as a Customer or Product, or a collection of business objects. REST uses the HTTP verbs for manipulating resources, which are referenced using a URL. For example, a GET request returns the representation of a resource, which might be in the form of an XML document or JSON object. A POST request creates a new resource and a PUT request updates a resource. To quote Roy Fielding, the creator of REST:
“REST provides a set of architectural constraints that, when applied as a whole, emphasizes scalability of component interactions, generality of interfaces, independent deployment of components, and intermediary components to reduce interaction latency, enforce security, and encapsulate legacy systems.”
—Fielding, Architectural Styles and the Design of Network-based Software Architectures
The following diagram shows one of the ways that the taxi-hailing application might use REST.
The passenger’s smartphone requests a trip by make a POST request to the /trips resource of the Trip Management service. This service handles the request by sending a GET request for information about the passenger to the Passenger Management service. After verifying that the passenger is authorized to create a trip, the Trip Management service creates the trip and returns a 201 response to the smartphone.
Many developers claim their HTTP-based APIs are RESTful. However, as Fielding describes in this blog post, not all of them actually are. Leonard Richardson (no relation) defines a very useful maturity model for REST that consists of the following levels.
- Level 0 – Clients of a level 0 API invoke the service by making HTTP
POSTrequests to its sole URL endpoint. Each request specifies the action to perform, the target of the action (e.g. the business object), and any parameters. - Level 1 – A level 1 API supports the idea of resources. To perform an action on a resource, a client makes a
POSTrequest that specifies the action to perform and any parameters. - Level 2 – A level 2 API uses HTTP verbs to perform actions:
GETto retrieve,POSTto create, andPUTto update. The request query parameters and body, if any, specify the action’s parameters. This enables services to leverage web infrastructure such as caching forGETrequests. - Level 3 – The design of a level 3 API is based on the terribly named HATEOAS (Hypertext As The Engine Of Application State) principle. The basic idea is that the representation of a resource returned by a
GETrequest contains links for performing the allowable actions on that resource. For example, a client can cancel an order using a link in the Order representation returned in response to theGETrequest sent to retrieve the order. Benefits of HATEOAS include no longer having to hardwire URLs into client code. Another benefit is that because the representation of a resource contains links for the allowable actions, the client doesn’t have to guess what actions can be performed on a resource in its current state.
There are numerous benefits to using a protocol that is based on HTTP:
- HTTP is simple and familiar.
- You can test an HTTP API from within a browser using an extension such as Postman or from the command line using
curl(assuming JSON or some other text format is used). - It directly supports request/response-style communication.
- HTTP is, of course, firewall-friendly.
- It doesn’t require an intermediate broker, which simplifies the system’s architecture.
There are some drawbacks to using HTTP:
- It only directly supports the request/response style of interaction. You can use HTTP for notifications but the server must always send an HTTP response.
- Because the client and service communicate directly (without an intermediary to buffer messages), they must both be running for the duration of the exchange.
- The client must know the location (i.e., the URL) of each service instance. As described in the previous article about the API Gateway, this is a non-trivial problem in a modern application. Clients must use a service discovery mechanism to locate service instances.
The developer community has recently rediscovered the value of an interface definition language for RESTful APIs. There are a few options, including RAML and Swagger. Some IDLs such as Swagger allow you to define the format of request and response messages. Others such as RAML require you to use a separate specification such as JSON Schema. As well as describing APIs, IDLs typically have tools that generate client stubs and server skeletons from an interface definition.
Thrift
Apache Thrift is an interesting alternative to REST. It is a framework for writing cross-language RPC clients and servers. Thrift provides a C-style IDL for defining your APIs. You use the Thrift compiler to generate client-side stubs and server-side skeletons. The compiler generates code for a variety of languages including C++, Java, Python, PHP, Ruby, Erlang, and Node.js.
A Thrift interface consists of one or more services. A service definition is analogous to a Java interface. It is a collection of strongly typed methods. Thrift methods can either return a (possibly void) value or they can be defined as one-way. Methods that return a value implement the request/response style of interaction. The client waits for a response and might throw an exception. One-way methods correspond to the notification style of interaction. The server does not send a response.
Thrift supports various message formats: JSON, binary, and compact binary. Binary is more efficient than JSON because it is faster to decode. And, as the name suggests, compact binary is a space-efficient format. JSON is, of course, human and browser friendly. Thrift also gives you a choice of transport protocols including raw TCP and HTTP. Raw TCP is likely to be more efficient than HTTP. However, HTTP is firewall, browser, and human friendly.
Message Formats
Now that we have looked at HTTP and Thrift, let’s examine the issue of message formats. If you are using a messaging system or REST, you get to pick your message format. Other IPC mechanisms such as Thrift might support only a small number of message formats, perhaps only one. In either case, it’s important to use a cross-language message format. Even if you are writing your microservices in a single language today, it’s likely that you will use other languages in the future.
There are two main kinds of message formats: text and binary. Examples of text-based formats include JSON and XML. An advantage of these formats is that not only are they human-readable, they are self-describing. In JSON, the attributes of an object are represented by a collection of name-value pairs. Similarly, in XML the attributes are represented by named elements and values. This enables a consumer of a message to pick out the values that it is interested in and ignore the rest. Consequently, minor changes to the message format can be easily backward compatible.
The structure of XML documents is specified by an XML schema. Over time the developer community has come to realize that JSON also needs a similar mechanism. One option is to use JSON Schema, either stand-alone or as part of an IDL such as Swagger.
A downside of using a text-based message format is that the messages tend to be verbose, especially XML. Because the messages are self-describing, every message contains the name of the attributes in addition to their values. Another drawback is the overhead of parsing text. Consequently, you might want to consider using a binary format.
There are several binary formats to choose from. If you are using Thrift RPC, you can use binary Thrift. If you get to pick the message format, popular options include Protocol Buffers and Apache Avro. Both of these formats provide a typed IDL for defining the structure of your messages. One difference, however, is that Protocol Buffers uses tagged fields, whereas an Avro consumer needs to know the schema in order to interpret messages. As a result, API evolution is easier with Protocol Buffers than with Avro. This blog post is an excellent comparison of Thrift, Protocol Buffers, and Avro.
Summary
Microservices must communicate using an inter-process communication mechanism. When designing how your services will communicate, you need to consider various issues: how services interact, how to specify the API for each service, how to evolve the APIs, and how to handle partial failure. There are two kinds of IPC mechanisms that microservices can use, asynchronous messaging and synchronous request/response. In the next article in the series, we will look the problem of service discovery in a microservices architecture.
Editor’s note – This seven-part series of articles is now complete:
- Introduction to Microservices
- Building Microservices: Using an API Gateway
- Building Microservices: Inter-Process Communication in a Microservices Architecture (this article)
- Service Discovery in a Microservices Architecture
- Event-Driven Data Management for Microservices
- Choosing a Microservices Deployment Strategy
- Refactoring a Monolith into Microservices
Guest blogger Chris Richardson is the founder of the original CloudFoundry.com, an early Java PaaS (Platform as a Service) for Amazon EC2. He now consults with organizations to improve how they develop and deploy applications. He also blogs regularly about microservices at http://microservices.io.

ACM International Collegiate Programming Contest, Damascus University Collegiate Programming Cont...
签到题
A
4min 1Y
C
45min 3Y
题意
给两个串,要把第一个串变成第二个串。每次选择一个半径r,然后以第一个串的中心为中心,r为半径,左右翻转。问最少几次操作?
题解
细节有点多。
- 先是输出
-1的情况。这个很好考虑 - 然后遍历s1串,对于位置
i,如果需要翻转(s1[i]=s2[n+1-i]),则打上标记1,不需要翻转(s1[i]=s2[i]).则打上标记0,如果翻不翻转都可以(s1[i]=s1[n+1-i]),打上标记2。 - 遍历
[1,n/2],对于打上标记2的位置,我们要决定是翻还是不翻,根据贪心,我们可以怠惰一点!对于打上标记2的位置,和前一个位置保持一致即可。
F
25min 1Y
题解
统计一下每个数字出现了多少次,出现了x次,对答案的贡献则为x!,相乘即为答案。
J
42min 2Y
题解
按题意模拟。
冷静分析一下开局
- 开场看了C觉得很基本,然后过了A,开始写C。
- C细节没考虑清楚,用了
10min,WA on test 2!
#include <iostream>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 100000 + 10;
int T;
char s1[N], s2[N], s3[N];
bool ok[N];
int main() {
scanf("%d", &T);
while (T --) {
scanf("%s %s", s1+1, s2+1);
int n = strlen(s1+1);
int mid = (n+1)/2;
if (s1[mid] != s2[mid]) {
printf("-1\n"); continue;
}
bool gg = 0;
for (int i=1;i<mid;i++) {
if (s1[i]==s2[i] && s1[n-i+1]==s2[n-i+1])
ok[i] = 1;
else if (s1[i]==s2[n-i+1] && s1[n-i+1]==s2[i])
ok[i] = 0;
else
gg = 1;
}
if (gg) {
printf("-1\n"); continue;
}
int ans = 0;
ok[0] = 1;
for(int i=1;i<mid;i++) {
if (ok[i] != ok[i-1])
ans ++;
}
printf("%d\n", ans);
}
}
完全没有考虑s1[i]=s1[n+1-i]的情况。
用了6分钟fix了一下。s1[i]=s1[n+1-i]
int ans = 0;
ok[0] = 1;
for(int i=1;i<mid;i++) {
if (ok[i] != ok[i-1] && ok[i] != 2)
ans ++;
}
printf("%d\n", ans);
然后喵了个呜,又一次WA2
- 我逃跑,用了5min时间过了F
- 用了10min的时间J题
WA2 - 用了5min的时间fix了一下,人调换方向那个地方写得意识有点模糊。
- 用了2min时间fix了一下C,很沙比的错误,比如说
n = 7,前3位,标记为0 2 0的情况就智障掉了。
前期比较容易细节没考虑清楚就上去写代码。C,J这两个模拟题都是这个原因吧。开始写代码之间,大概是抱着“随便搞搞就好”的想法。这种态度很沙比的啊。
- 我在求什么?
- 在模拟的过程,变量会如何变化?
这两个问题都考虑得不清楚吧!
中档题
B
Hash的做法很容易看出。然后就unlimited WA TLE MLE
搞Hash的经验严重不足?
边的种数不会超过n种,因此我们放n个桶。每个桶记录这种边出现的次数。
然后就是对一个XXX进制下,n位数的hash了【双hash保平安】
#include <iostream>
#include <algorithm>
#include <vector>
#include <unordered_map>
using namespace std;
typedef long long LL;
const int N = 10000008;
const LL MOD1 = 100000007;
const LL MOD2 = 923439347;
int T;
int n, x, y;
int val[N]; vector<int> v;
LL k1[N], k2[N];
unordered_map< LL, int > mp;
int main() {
scanf("%d", &T);
k1[0] = k2[0] = 1;
for(int i=1;i<N;i++) {
k1[i]=k1[i-1]*10007LL%MOD1;
k2[i]=k2[i-1]*20007LL%MOD2;
}
while (T --) {
scanf("%d", &n);
v.clear();
for (int i = 1; i <= n; i ++) {
scanf("%d %d", &x, &y);
if (x > y) swap(x, y);
val[i] = (2*n+1)*x + y;
v.push_back(val[i]);
}
sort(v.begin(), v.end());
v.erase(unique(v.begin(), v.end()), v.end());
for(int i=1;i<=n;i++) {
val[i] = lower_bound(v.begin(), v.end(), val[i])-v.begin()+1;
}
mp.clear();
LL sum1, sum2;
LL ans=0;
for (int i=1;i<=n;i++) {
sum1 = 0, sum2 = 0;
for(int j=1;j<=n;j++) {
sum1 += k1[val[j]];
sum1 %= MOD1;
sum2 += k2[val[j]];
sum2 %= MOD2;
}
mp[sum1*MOD2 + sum2] ++;
for(int j=i+1;j<=n;j++) {
sum1 += k1[val[j]]-k1[val[j-i]];
sum1 = (sum1%MOD1+MOD1)%MOD1;
sum2 += k2[val[j]]-k2[val[j-i]];
sum2 = (sum2%MOD2+MOD2)%MOD2;
mp[sum1*MOD2+sum2] ++;
}
for (auto x: mp) {
LL v = x.second;
ans += v * (v - 1) / 2;
}
mp.clear();
}
printf("%lld\n", ans);
}
}
G
题意
修改最少的元素,使得序列的GCD为x,LCM为y。
题解
先判-1(一番激烈的讨论)
如果a[i]%x!=0 or y%a[i]!=0,那么i就是个卜。
直觉告诉我们把一个数字变成x,另一个数字变成y,只要其它的数字不卜,生活就有保障了。
- 如果卜的个数>=2,那么答案就是卜的个数了。
- 否则答案可能是1,可能是2,可能是0
- 答案是0,很简单。
- 答案是1,很不简单。我们枚举一下每个数字,看他是否能力挽狂澜,我们把枚举的数字放逐掉,求出其它数字的GCD&LCM(先预处理前缀后缀GCD&LCM),然后看一看世界末日前怎么办?来得及拯救吗?【具体怎么做,留给读者思考。】
- 答案是2,很简单,加个else
I
题意
n堆石头,两种操作,两人轮流操作。
- 可以从一堆石头中拿走一个石头。
- 如果每堆石子都至少有1个,可以从每堆石头中拿走一个石头。
先手胜?后手胜?
题解
冷静分析一下
- n%2=1. 易证,留给读者思考【读者似乎就我一个人。】
- n%2=0. 这个得冷静分析一下。
- min=1, 先手可以把后手气死。类似于chomp Game的模型。
- min=2, 第一种操作肯定不可以施展的!不然会被气死。既然只能施展第二种操作,胜负显而易见了吧。
- min=3, 先手可以把后手气死。类似于chomp Game的模型。
- min=4, .......
博弈在模型的直觉很重要的吖!这题意识到了chomp Game就很简单了吧。
K
题意
n个点,n条边,多组查询,求两点间最短路。
题解
先去掉一条边edge,那么这个图就是一颗树了。
枚举,u到v是否要经过edge即可。
冷静分析一下中期
- 先用了10min施展G,施展了一大半,然后咕咕咕了。
- 先用了10min施展B题。没考虑清楚自己在hash什么东西,耽误了一段时间,然后
WA11。 - 用了13min过了K。
- 用了3min过了G的样例,
WA2 - 开始unlimited Fix G,中间用了很长一段时间次饭去了。但调G的时间至少有1小时。
- Bug1:没读完就输出结果,WA
- Bug2:复杂度
nsqrt(n).【不错,有创意】 - Bug3:
n=1的特判不到位,搞得后面越界了。一大波RE。
- 用了一个小时Fix B题的Hash,好不容易开始双hash然后MLE。枚举长度后清空,解决了问题。
- 用了半个小时搞I
emmmm....大部分时间都在Fix辣鸡。。。
考虑清楚再写啊······
羊肉粉丝汤弱鸡啊。
感觉30min 4题,2h30min8题是比较合理的。

Android Camera 原理之 camera service 与 camera provider session 会话与 capture request 轮转
上层调用 CameraManager.openCamera 的时候,会触发底层的一系列反应,之前我们分享过 camera framework 到 camera service 之间的调用,但是光看这一块还不够深入,接下来我们讨论一下 camera service 与 camera provider 之间在 openCamera 调用的时候做了什么事情。
status_t Camera3Device::initialize(sp<CameraProviderManager> manager, const String8& monitorTags) {
sp<ICameraDeviceSession> session;
status_t res = manager->openSession(mId.string(), this,
/*out*/ &session);
//......
res = manager->getCameraCharacteristics(mId.string(), &mDeviceInfo);
//......
std::shared_ptr<RequestMetadataQueue> queue;
auto requestQueueRet = session->getCaptureRequestMetadataQueue(
[&queue](const auto& descriptor) {
queue = std::make_shared<RequestMetadataQueue>(descriptor);
if (!queue->isValid() || queue->availableToWrite() <= 0) {
ALOGE("HAL returns empty request metadata fmq, not use it");
queue = nullptr;
// don''t use the queue onwards.
}
});
//......
std::unique_ptr<ResultMetadataQueue>& resQueue = mResultMetadataQueue;
auto resultQueueRet = session->getCaptureResultMetadataQueue(
[&resQueue](const auto& descriptor) {
resQueue = std::make_unique<ResultMetadataQueue>(descriptor);
if (!resQueue->isValid() || resQueue->availableToWrite() <= 0) {
ALOGE("HAL returns empty result metadata fmq, not use it");
resQueue = nullptr;
// Don''t use the resQueue onwards.
}
});
//......
mInterface = new HalInterface(session, queue);
std::string providerType;
mVendorTagId = manager->getProviderTagIdLocked(mId.string());
mTagMonitor.initialize(mVendorTagId);
if (!monitorTags.isEmpty()) {
mTagMonitor.parseTagsToMonitor(String8(monitorTags));
}
return initializeCommonLocked();
}
上面 camera service 中执行 openCamera 中的核心步骤,可以看出,第一步执行的就是 manager->openSession (mId.string (), this, /out/ &session);
本文就是通过剖析 openSession 的执行流程来 还原 camera service 与 camera provider 的执行过程。
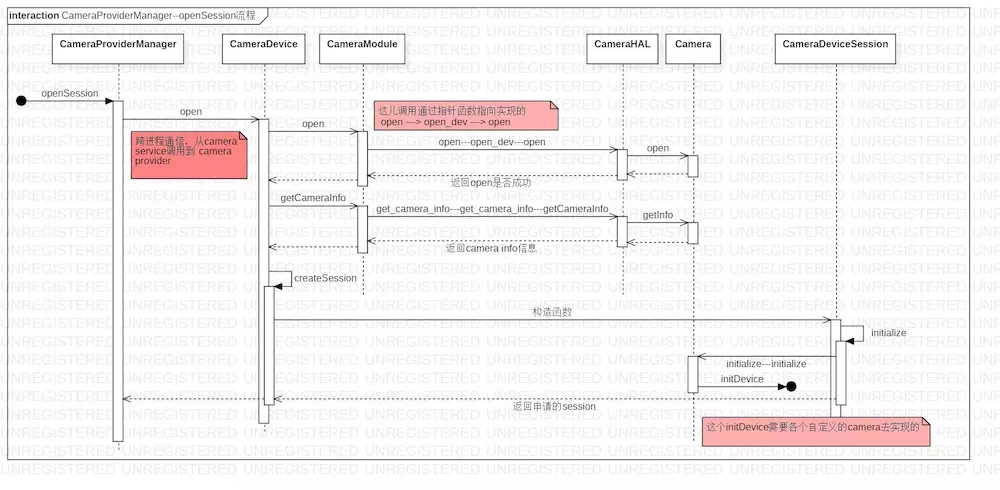
CameraProviderManager--openSession 流程.jpg
为了让大家看得更加清楚,列出各个文件的位置:
CameraProviderManager : frameworks/av/services/camera/libcameraservice/common/CameraServiceProvider.cpp
CameraDevice : hardware/interfaces/camera/device/3.2/default/CameraDevice.cpp
CameraModule : hardware/interfaces/camera/common/1.0/default/CameraModule.cpp
CameraHAL : hardware/libhardware/modules/camera/3_0/CameraHAL.cpp
Camera : hardware/libhardware/modules/camera/3_0/Camera.cpp
CameraDeviceSession : hardware/interfaces/camera/device/3.2/default/CameraDeviceSession.cpp
中间涉及到一些指针函数的映射,如果看不明白,可以参考:《Android Camera 原理之底层数据结构总结》,具体的调用流程就不说了,按照上面的时序图走,都能看明白的。
一些回调关系还是值得说下的。我们看下 CameraProviderManager::openSession 调用的地方:
status_t CameraProviderManager::openSession(const std::string &id,
const sp<hardware::camera::device::V3_2::ICameraDeviceCallback>& callback,
/*out*/
sp<hardware::camera::device::V3_2::ICameraDeviceSession> *session) {
std::lock_guard<std::mutex> lock(mInterfaceMutex);
auto deviceInfo = findDeviceInfoLocked(id,
/*minVersion*/ {3,0}, /*maxVersion*/ {4,0});
if (deviceInfo == nullptr) return NAME_NOT_FOUND;
auto *deviceInfo3 = static_cast<ProviderInfo::DeviceInfo3*>(deviceInfo);
Status status;
hardware::Return<void> ret;
ret = deviceInfo3->mInterface->open(callback, [&status, &session]
(Status s, const sp<device::V3_2::ICameraDeviceSession>& cameraSession) {
status = s;
if (status == Status::OK) {
*session = cameraSession;
}
});
if (!ret.isOk()) {
ALOGE("%s: Transaction error opening a session for camera device %s: %s",
__FUNCTION__, id.c_str(), ret.description().c_str());
return DEAD_OBJECT;
}
return mapToStatusT(status);
}
我们看下 IPC 调用的地方:
ret = deviceInfo3->mInterface->open(callback, [&status, &session]
(Status s, const sp<device::V3_2::ICameraDeviceSession>& cameraSession) {
status = s;
if (status == Status::OK) {
*session = cameraSession;
}
});
传入两个参数,一个是 const sp<hardware::camera::device::V3_2::ICameraDeviceCallback>& callback, 另一个是 open_cb _hidl_cb
callback 提供了 camera HAL 层到 camera service 的回调。
open_cb _hidl_cb 是硬件抽象层提供了一种 IPC 间回传数据的方式。就本段代码而言,需要传回两个数据,一个 status:表示当前 openSession 是否成功;另一个是 session:表示 camera session 会话创建成功之后返回的 session 数据。
CameraDevice::open (...) 函数
{
session = createSession(
device, info.static_camera_characteristics, callback);
if (session == nullptr) {
ALOGE("%s: camera device session allocation failed", __FUNCTION__);
mLock.unlock();
_hidl_cb(Status::INTERNAL_ERROR, nullptr);
return Void();
}
if (session->isInitFailed()) {
ALOGE("%s: camera device session init failed", __FUNCTION__);
session = nullptr;
mLock.unlock();
_hidl_cb(Status::INTERNAL_ERROR, nullptr);
return Void();
}
mSession = session;
IF_ALOGV() {
session->getInterface()->interfaceChain([](
::android::hardware::hidl_vec<::android::hardware::hidl_string> interfaceChain) {
ALOGV("Session interface chain:");
for (auto iface : interfaceChain) {
ALOGV(" %s", iface.c_str());
}
});
}
mLock.unlock();
}
_hidl_cb(status, session->getInterface());
最后执行的代码 _hidl_cb (status, session→getInterface ()); 当前 session 创建成功之后,回调到 camera service 中。
const sp<hardware::camera::device::V3_2::ICameraDeviceCallback>& callback 设置到什么地方?这个问题非常重要的,camera 上层很依赖底层的回调,所以我们要搞清楚底层的回调被设置到什么地方,然后在搞清楚在合适的时机触发这些回调。
执行 CameraDeviceSession 构造函数的时候,传入了这个 callback。
CameraDeviceSession::CameraDeviceSession(
camera3_device_t* device,
const camera_metadata_t* deviceInfo,
const sp<ICameraDeviceCallback>& callback) :
camera3_callback_ops({&sProcessCaptureResult, &sNotify}),
mDevice(device),
mDeviceVersion(device->common.version),
mIsAELockAvailable(false),
mDerivePostRawSensKey(false),
mNumPartialResults(1),
mResultBatcher(callback) {
mDeviceInfo = deviceInfo;
camera_metadata_entry partialResultsCount =
mDeviceInfo.find(ANDROID_REQUEST_PARTIAL_RESULT_COUNT);
if (partialResultsCount.count > 0) {
mNumPartialResults = partialResultsCount.data.i32[0];
}
mResultBatcher.setNumPartialResults(mNumPartialResults);
camera_metadata_entry aeLockAvailableEntry = mDeviceInfo.find(
ANDROID_CONTROL_AE_LOCK_AVAILABLE);
if (aeLockAvailableEntry.count > 0) {
mIsAELockAvailable = (aeLockAvailableEntry.data.u8[0] ==
ANDROID_CONTROL_AE_LOCK_AVAILABLE_TRUE);
}
// Determine whether we need to derive sensitivity boost values for older devices.
// If post-RAW sensitivity boost range is listed, so should post-raw sensitivity control
// be listed (as the default value 100)
if (mDeviceInfo.exists(ANDROID_CONTROL_POST_RAW_SENSITIVITY_BOOST_RANGE)) {
mDerivePostRawSensKey = true;
}
mInitFail = initialize();
}
CameraDeviceSession 中的 mResultBatcher 类构造中传入了这个 callback,现在由 CameraDeviceSession::ResultBatcher 来持有 callback 了。看下 ResultBatcher 全局代码,在 CameraDeviceSession.h 中。
那以后底层要回调到上层必定要经过 CameraDeviceSession::ResultBatcher 的 mCallback 来完成了。
class ResultBatcher {
public:
ResultBatcher(const sp<ICameraDeviceCallback>& callback);
void setNumPartialResults(uint32_t n);
void setBatchedStreams(const std::vector<int>& streamsToBatch);
void setResultMetadataQueue(std::shared_ptr<ResultMetadataQueue> q);
void registerBatch(uint32_t frameNumber, uint32_t batchSize);
void notify(NotifyMsg& msg);
void processCaptureResult(CaptureResult& result);
protected:
struct InflightBatch {
// Protect access to entire struct. Acquire this lock before read/write any data or
// calling any methods. processCaptureResult and notify will compete for this lock
// HIDL IPCs might be issued while the lock is held
Mutex mLock;
bool allDelivered() const;
uint32_t mFirstFrame;
uint32_t mLastFrame;
uint32_t mBatchSize;
bool mShutterDelivered = false;
std::vector<NotifyMsg> mShutterMsgs;
struct BufferBatch {
BufferBatch(uint32_t batchSize) {
mBuffers.reserve(batchSize);
}
bool mDelivered = false;
// This currently assumes every batched request will output to the batched stream
// and since HAL must always send buffers in order, no frameNumber tracking is
// needed
std::vector<StreamBuffer> mBuffers;
};
// Stream ID -> VideoBatch
std::unordered_map<int, BufferBatch> mBatchBufs;
struct MetadataBatch {
// (frameNumber, metadata)
std::vector<std::pair<uint32_t, CameraMetadata>> mMds;
};
// Partial result IDs that has been delivered to framework
uint32_t mNumPartialResults;
uint32_t mPartialResultProgress = 0;
// partialResult -> MetadataBatch
std::map<uint32_t, MetadataBatch> mResultMds;
// Set to true when batch is removed from mInflightBatches
// processCaptureResult and notify must check this flag after acquiring mLock to make
// sure this batch isn''t removed while waiting for mLock
bool mRemoved = false;
};
// Get the batch index and pointer to InflightBatch (nullptrt if the frame is not batched)
// Caller must acquire the InflightBatch::mLock before accessing the InflightBatch
// It''s possible that the InflightBatch is removed from mInflightBatches before the
// InflightBatch::mLock is acquired (most likely caused by an error notification), so
// caller must check InflightBatch::mRemoved flag after the lock is acquried.
// This method will hold ResultBatcher::mLock briefly
std::pair<int, std::shared_ptr<InflightBatch>> getBatch(uint32_t frameNumber);
static const int NOT_BATCHED = -1;
// move/push function avoids "hidl_handle& operator=(hidl_handle&)", which clones native
// handle
void moveStreamBuffer(StreamBuffer&& src, StreamBuffer& dst);
void pushStreamBuffer(StreamBuffer&& src, std::vector<StreamBuffer>& dst);
void sendBatchMetadataLocked(
std::shared_ptr<InflightBatch> batch, uint32_t lastPartialResultIdx);
// Check if the first batch in mInflightBatches is ready to be removed, and remove it if so
// This method will hold ResultBatcher::mLock briefly
void checkAndRemoveFirstBatch();
// The following sendXXXX methods must be called while the InflightBatch::mLock is locked
// HIDL IPC methods will be called during these methods.
void sendBatchShutterCbsLocked(std::shared_ptr<InflightBatch> batch);
// send buffers for all batched streams
void sendBatchBuffersLocked(std::shared_ptr<InflightBatch> batch);
// send buffers for specified streams
void sendBatchBuffersLocked(
std::shared_ptr<InflightBatch> batch, const std::vector<int>& streams);
// End of sendXXXX methods
// helper methods
void freeReleaseFences(hidl_vec<CaptureResult>&);
void notifySingleMsg(NotifyMsg& msg);
void processOneCaptureResult(CaptureResult& result);
void invokeProcessCaptureResultCallback(hidl_vec<CaptureResult> &results, bool tryWriteFmq);
// Protect access to mInflightBatches, mNumPartialResults and mStreamsToBatch
// processCaptureRequest, processCaptureResult, notify will compete for this lock
// Do NOT issue HIDL IPCs while holding this lock (except when HAL reports error)
mutable Mutex mLock;
std::deque<std::shared_ptr<InflightBatch>> mInflightBatches;
uint32_t mNumPartialResults;
std::vector<int> mStreamsToBatch;
const sp<ICameraDeviceCallback> mCallback;
std::shared_ptr<ResultMetadataQueue> mResultMetadataQueue;
// Protect against invokeProcessCaptureResultCallback()
Mutex mProcessCaptureResultLock;
} mResultBatcher;
到这里,openSession 工作就完成了,这个主要是设置了上层的回调到底层,并且底层返回可用的 camera session 到上层来,实现底层和上层的交互通信。
1. 获取的 session 是什么?为什么这个重要?
此 session 是 ICameraDeviceSession 对象,这个对象是指为了操作 camera device,camera provider 与 camera service 之间建立的一个会话机制,可以保证 camera service IPC 调用到 camera provider 进程中的代码。
1.1. 获取 session 当前请求原数组队列
auto requestQueueRet = session->getCaptureRequestMetadataQueue(
[&queue](const auto& descriptor) {
queue = std::make_shared<RequestMetadataQueue>(descriptor);
if (!queue->isValid() || queue->availableToWrite() <= 0) {
ALOGE("HAL returns empty request metadata fmq, not use it");
queue = nullptr;
// don''t use the queue onwards.
}
});
到 HAL 层的 CameraDeviceSession.cpp 中调用 getCaptureRequestMetadataQueue
Return<void> CameraDeviceSession::getCaptureRequestMetadataQueue(
ICameraDeviceSession::getCaptureRequestMetadataQueue_cb _hidl_cb) {
_hidl_cb(*mRequestMetadataQueue->getDesc());
return Void();
}
这个 mRequestMetadataQueue 是在 CameraDeviceSession::initialize 执行的时候初始化的。
int32_t reqFMQSize = property_get_int32("ro.camera.req.fmq.size", /*default*/-1);
if (reqFMQSize < 0) {
reqFMQSize = CAMERA_REQUEST_METADATA_QUEUE_SIZE;
} else {
ALOGV("%s: request FMQ size overridden to %d", __FUNCTION__, reqFMQSize);
}
mRequestMetadataQueue = std::make_unique<RequestMetadataQueue>(
static_cast<size_t>(reqFMQSize),
false /* non blocking */);
if (!mRequestMetadataQueue->isValid()) {
ALOGE("%s: invalid request fmq", __FUNCTION__);
return true;
}
首先读取 ro.camera.req.fmq.size 属性,如果没有找到,则直接赋给一个 1M 大小的 请求原数组队列。这个队列很重要,后续的 camera capture 请求都是通过这个队列处理的。
1.2. 获取 session 当前结果原数组队列
这个和 请求原数组队列相似,不过结果原数组中保留的是 camera capture 的结果数据。大家可以看下源码,这儿就不贴源码了
2. 开始运转 capture request 线程
camera service 与 camera provider 建立 session 会话之后,开始运转 capture request 请求线程,之后发送的 capture request 都会到这个线程中执行,这就是熟知的 capture request 轮转。
在 Camera3Device::initializeCommonLocked 中执行了 capture request 轮转。
/** Start up request queue thread */
mRequestThread = new RequestThread(this, mStatusTracker, mInterface, sessionParamKeys);
res = mRequestThread->run(String8::format("C3Dev-%s-ReqQueue", mId.string()).string());
if (res != OK) {
SET_ERR_L("Unable to start request queue thread: %s (%d)",
strerror(-res), res);
mInterface->close();
mRequestThread.clear();
return res;
}
开始启动当前的 capture request 队列,放在 RequestThread 线程中执行,这个线程会一直执行,当有新的 capture request 发过来,会将 capture request 放进当前会话的请求队列中,继续执行。这个轮转很重要,这是 camera 能正常工作的前提。
轮转的主要工作在 Camera3Device::RequestThread::threadLoop 函数中完成,这是 native 中定义的一个 线程执行函数块。
bool Camera3Device::RequestThread::threadLoop() {
ATRACE_CALL();
status_t res;
// Handle paused state.
if (waitIfPaused()) {
return true;
}
// Wait for the next batch of requests.
waitForNextRequestBatch();
if (mNextRequests.size() == 0) {
return true;
}
//......
// Prepare a batch of HAL requests and output buffers.
res = prepareHalRequests();
if (res == TIMED_OUT) {
// Not a fatal error if getting output buffers time out.
cleanUpFailedRequests(/*sendRequestError*/ true);
// Check if any stream is abandoned.
checkAndStopRepeatingRequest();
return true;
} else if (res != OK) {
cleanUpFailedRequests(/*sendRequestError*/ false);
return false;
}
// Inform waitUntilRequestProcessed thread of a new request ID
{
Mutex::Autolock al(mLatestRequestMutex);
mLatestRequestId = latestRequestId;
mLatestRequestSignal.signal();
}
//......
bool submitRequestSuccess = false;
nsecs_t tRequestStart = systemTime(SYSTEM_TIME_MONOTONIC);
if (mInterface->supportBatchRequest()) {
submitRequestSuccess = sendRequestsBatch();
} else {
submitRequestSuccess = sendRequestsOneByOne();
}
//......
return submitRequestSuccess;
}
waitForNextRequestBatch () 不断去轮训底层是否有 InputBuffer 数据,获取的 inputBuffer 数据放在 request 中,这些数据会在之后被消费。
这儿先列个调用过程:对照着代码看一下,camera 的 producer 与 consumer 模型之后还会详细讲解的。
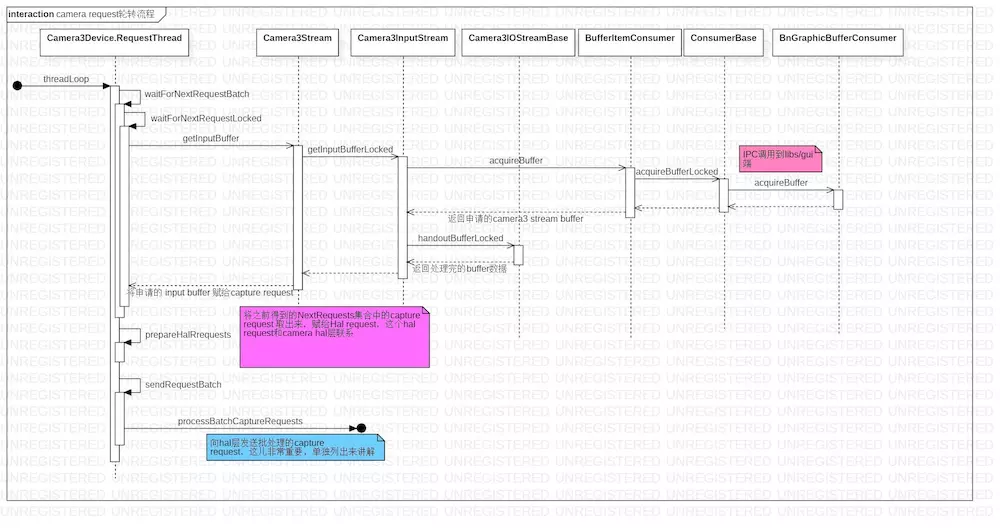
camera request 轮转流程.jpg
这儿也为了大家快速进入代码,也列出来代码的对应位置:
Camera3Device::RequestThread : frameworks/av/services/camera/libcameraservice/device3/Camera3Device.cpp 中有内部类 RequestThread,这是一个线程类。
Camera3Stream : frameworks/av/services/camera/libcameraservice/device3/Camera3Stream.cpp
Camera3InputStream : frameworks/av/services/camera/libcameraservice/device3/Camera3InputStream.cpp
Camera3IOStreamBase : frameworks/av/services/camera/libcameraservice/device3/Camera3IOStreamBase.cpp
BufferItemConsumer : frameworks/native/libs/gui/BufferItemConsumer.cpp
ConsumerBase : frameworks/native/libs/gui/ConsumerBase.cpp
BnGraphicBufferConsumer : frameworks/native/libs/gui/IGraphicBufferConsumer.cpp
上层发过来来的 capture request,手下到底层申请 Consumer buffer,这个 buffer 数据存储在 capture request 缓存中,后期这些 buffer 数据会被复用,不断地生产数据,也不断地被消费。
capture request 开启之后,camera hal 层也会受到 capture request 批处理请求,让 camera hal 做好准备,开始和 camera driver 层交互。hal 层的请求下一章讲解。
小礼物走一走,来简书关注我
关于android – Xamarin.IOS错误 – 无法解析参考:C:/ Program Files(x86)/../ Xamarin.iOS / v1.0 / Facades / System.Private.CoreLib.InteropServices.dll的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于2018 ACM-ICPC, Syrian Collegiate Programming Contest F - Pretests SOS dp、3——Building Microservices: Inter-Process Communication in a Microservices Architecture、ACM International Collegiate Programming Contest, Damascus University Collegiate Programming Cont...、Android Camera 原理之 camera service 与 camera provider session 会话与 capture request 轮转等相关内容,可以在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

