在本文中,我们将详细介绍mysql字符集和校对规则(Mysql校对集)的各个方面,并为您提供关于mysql字符集配置的相关解答,同时,我们也将为您带来关于02|MySQL字符集和校对顺序、innoba
在本文中,我们将详细介绍mysql字符集和校对规则(Mysql校对集)的各个方面,并为您提供关于mysql字符集配置的相关解答,同时,我们也将为您带来关于02 | MySQL字符集和校对顺序、innobackex工具备份mysql数据 mysql5.7root密码更改 mysql调优 mysql字符集调整、mysql 中一次字符集和排序规则引起的 sql 查询报错、MySQL 字符集和排序规则解析 MySQL DBA 周末学习的有用知识。
本文目录一览:- mysql字符集和校对规则(Mysql校对集)(mysql字符集配置)
- 02 | MySQL字符集和校对顺序
- innobackex工具备份mysql数据 mysql5.7root密码更改 mysql调优 mysql字符集调整
- mysql 中一次字符集和排序规则引起的 sql 查询报错
- MySQL 字符集和排序规则解析 MySQL DBA 周末学习
(mysql字符集配置)")
mysql字符集和校对规则(Mysql校对集)(mysql字符集配置)
简要说明字符集和校对规则
字符集是一套符号和编码。校对规则是在字符集内用于比较字符的一套规则。
MysqL在collation提供较强的支持,oracel在这方面没查到相应的资料。
不同字符集有不同的校对规则,命名约定:以其相关的字符集名开始,通常包括一个语言名,并且以_ci(大小写不敏感)、_cs(大小写敏感)或_bin(二元)结束
校对规则一般分为两类:
binary collation,二元法,直接比较字符的编码,可以认为是区分大小写的,因为字符集中'A'和'a'的编码显然不同。
字符集_语言名,utf8默认校对规则是utf8_general_ci
MysqL字符集和校对规则有4个级别的默认设置:服务器级、数据库级、表级和连接级。
具体来说,我们系统使用的是utf8字符集,如果使用utf8_bin校对规则执行SQL查询时区分大小写,使用utf8_general_ci 不区分大小写。不要使用utf8_unicode_ci。
如create database demo CHaraCTER SET utf8; 默认校对规则是utf8_general_ci 。
Unicode与UTF8
Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储.
UTF8字符集是存储Unicode数据的一种可选方法。MysqL同时支持另一种实现ucs2。
详细说明
字符集(charset):是一套符号和编码。
校对规则(collation):是在字符集内用于比较字符的一套规则,比如定义'A'<'B'这样的关系的规则。不同collation可以实现不同的比较规则,如'A'='a'在有的规则中成立,而有的不成立;进而说,就是有的规则区分大小写,而有的无视。
每个字符集有一个或多个校对规则,并且每个校对规则只能属于一个字符集。
binary collation,二元法,直接比较字符的编码,可以认为是区分大小写的,因为字符集中'A'和'a'的编码显然不同。除此以外,还有更加复杂的比较规则,这些规则在简单的二元法之上增加一些额外的规定,比较就更加复杂了。
MysqL5.1在字符集和校对规则的使用比其它大多数数据库管理系统超前许多,可以在任何级别进行使用和设置,为了有效地使用这些功能,你需要了解哪些字符集和 校对规则是可用的,怎样改变默认值,以及它们怎样影响字符操作符和字符串函数的行为。
校对规则一般有这些特征:
两个不同的字符集不能有相同的校对规则。
每个字符集有一个默认校对规则。例如,utf8默认校对规则是utf8_general_ci。
存在校对规则命名约定:它们以其相关的字符集名开始,通常包括一个语言名,并且以_ci(大小写不敏感)、_cs(大小写敏感)或_bin(二元)结束
确定默认字符集和校对
字符集和校对规则有4个级别的默认设置:服务器级、数据库级、表级和连接级。
数据库字符集和校对
每一个数据库有一个数据库字符集和一个数据库校对规则,它不能够为空。CREATE DATABASE和ALTER DATABASE语句有一个可选的子句来指定数据库字符集和校对规则:
例如:
CREATE DATABASE db_name DEFAULT CHaraCTER SET latin1 COLLATE latin1_swedish_ci;
MysqL这样选择数据库字符集和数据库校对规则:
・ 如果指定了CHaraCTER SET X和COLLATE Y,那么采用字符集X和校对规则Y。
・ 如果指定了CHaraCTER SET X而没有指定COLLATE Y,那么采用CHaraCTER SET X和CHaraCTER SET X的默认校对规则。
・ 否则,采用服务器字符集和服务器校对规则。
在sql语句中使用COLLATE
•使用COLLATE子句,能够为一个比较覆盖任何默认校对规则。COLLATE可以用于多种sql语句中。
使用WHERE:
select * from pro_product where product_code='ABcdefg' collate utf8_general_ci
Unicode与UTF8
Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储.Unicode码可以采用UCS-2格式直接存储.MysqL支持ucs2字符集。
UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。
UTF8字符集(转换Unicode表示)是存储Unicode数据的一种可选方法。它根据RFC 3629执行。UTF8字符集的思想是不同Unicode字符采用变长字节序列编码:
・ 基本拉丁字母、数字和标点符号使用一个字节。
・ 大多数的欧洲和中东手写字母适合两个字节序列:扩展的拉丁字母(包括发音符号、长音符号、重音符号、低音符号和其它音符)、西里尔字母、希腊语、亚美尼亚语、希伯来语、阿拉伯语、叙利亚语和其它语言。
・ 韩语、中文和日本象形文字使用三个字节序列
摘自:用梦想丈量人生,用奔跑丈量激情
校对集
MysqL5.5.8中共有字符集39,校对集195个
#显示所有的校对集
Show collation
#显示所有的字符集
show character set
所以一个字符集对应多个校对集,即同样的一个字符集有多重排序规则
比如一个utf8的字符集共有22中排序规则
Utf8字符集默认的校对集为utf8_general_ci
通过show collation like ‘utf8\_%'
即可查看

注意:
utf8_general_ci 按照普通的字母顺序,而且不区分大小写(比如:a B c D)
utf8_bin 按照二进制排序(比如:A排在a前面,B D a c)

02 | MySQL字符集和校对顺序
全球化与本地化
本文主要介绍mysql处理不同字符语言的基础知识
字符集和校对顺序
由于不同的语言和字符集需要以不同的方式存储和检索MySQL,因此需要适应不同的字符集(不同的字母和字符),适应不同的排序和检索数据的方法。
重要术语
| 术语 | 含义 |
|---|---|
| 字符集 | 字母和符号的集合 |
| 编码 | 某个字符集成员的内部表示 |
| 校对 | 规定如何比较字符集的指令 |
使用字符集和校对顺序
查看所支持的字符集的完整列表
-- 查看所有的可支持的字符集
SHOW CHARACTER SET;
-- 查看所有可支持的校对顺序
SHOW COLLATION;
查看目前所使用的字符集和校对顺序
SHOW VARIABLES LIKE ''character%'';
SHOW VARIABLES LIKE ''collation%'';
不同的表,甚至不同的列都可能需要不同的字符集,而且两者都可以在创建表时指定
给表指定字符集和校对
CREATE TABLE mytable
(
column1 INT,
column2 VARCHAR(10)
) DEFAULT CHARACTER SET hebrew
COLLATE hebrew_general_ci;
此语句创建一个包含两列的表,并且指定一个字符集和一个校对顺序
MySQL可使用如下方式确定使用什么样的字符集和校对:
- 如果指定
CHARACTER SET和COLLATE两者,则使用这些值。 - 如果只指定
CHARACTER SET,则使用此字符集及其默认的校对(如SHOW CHARACTER SET的结果中所示)。 - 如果既不指定
CHARACTER SET,也不指定COLLATE,则使用数据库默认。
给每个列指定字符集和校对顺序
CREATE TABLE mytable(
column1 INT,
column2 VARCHAR(10),
column3 VARCHAR(10) CHARACTER SET latin1 COLLATE latin1_danish_ci
)DEFAULT CHARACTER SET hebrew
COLLATE hebrew_general_ci;
校对在对用ORDER BY子句检索出来的数据排序时起重要的作用。如果需要用与创建表时不同的校对顺序排序特定的SELECT语句,可以在SELECT语句自身中进行:
SELECT * FROM customers
ORDER BY CAST(cust_name AS ) ,cust_address COLLATE latin1_general_cs;
SELECT的其他COLLATE子句:除了这里看到的在ORDER BY子句中使用以外, COLLATE还可以用于GROUP BY、 HAVING、聚集函数、别名等。

innobackex工具备份mysql数据 mysql5.7root密码更改 mysql调优 mysql字符集调整
mysql5.7root有默认密码,必须重设密码后,才能进行mysql的操作,以下是设置root密码的步骤:
一、查看默认密码
[root@localhost src]# cat /root/.mysql_secret
# The random password set for the root userat Fri Jan 10 20:00:34 2014 (local time): aJqZsA2m这里的aJqZsA2m就是生成的root随机密码啦
二、登录mysql
[root@localhost src]# mysql -u root -p
Enter password:输入上面的密码aJqZsA2m登录,如果你没有把mysql的路径加到path里,那就用绝对路径,mysql -u root -p还可以写成mysql -uroot -paJqZsA2m
三、更改密码
mysql> SET PASSWORD FOR ''root''@localhost = PASSWORD(''123456'');
Query OK, 0 rows affected (0.17 sec)至此,就成功地修改了密码。
MySQL调优
MySQL调优可以从几个方面来做:
1. 架构层:
做从库,实现读写分离;
2.系统层次:
增加内存;
给磁盘做raid0或者raid5以增加磁盘的读写速度;
可以重新挂载磁盘,并加上noatime参数,这样可以减少磁盘的i/o;
3. MySQL本身调优:
(1) 如果未配置主从同步,可以把bin-log功能关闭,减少磁盘i/o
(2) 在my.cnf中加上skip-name-resolve,这样可以避免由于解析主机名延迟造成mysql执行慢
(3) 调整几个关键的buffer和cache。调整的依据,主要根据数据库的状态来调试。如何调优可以参考5.
4. 应用层次:
查看慢查询日志,根据慢查询日志优化程序中的SQL语句,比如增加索引
5. 调整几个关键的buffer和cache
1) key_buffer_size 首先可以根据系统的内存大小设定它,大概的一个参考值:1G以下内存设定128M;2G/256M; 4G/384M;8G/1024M;16G/2048M.这个值可以通过检查状态值Key_read_requests和 Key_reads,可以知道key_buffer_size设置是否合理。比例key_reads / key_read_requests应该尽可能的低,至少是1:100,1:1000更好(上述状态值可以使用SHOW STATUS LIKE ‘key_read%’获得)。注意:该参数值设置的过大反而会是服务器整体效率降低!
2) table_open_cache 打开一个表的时候,会临时把表里面的数据放到这部分内存中,一般设置成1024就够了,它的大小我们可以通过这样的方法来衡量: 如果你发现 open_tables等于table_cache,并且opened_tables在不断增长,那么你就需要增加table_cache的值了(上述状态值可以使用SHOW STATUS LIKE ‘Open%tables’获得)。注意,不能盲目地把table_cache设置成很大的值。如果设置得太高,可能会造成文件描述符不足,从而造成性能不稳定或者连接失败。
3) sort_buffer_size 查询排序时所能使用的缓冲区大小,该参数对应的分配内存是每连接独占!如果有100个连接,那么实际分配的总共排序缓冲区大小为100 × 4 = 400MB。所以,对于内存在4GB左右的服务器推荐设置为4-8M。
4) read_buffer_size 读查询操作所能使用的缓冲区大小。和sort_buffer_size一样,该参数对应的分配内存也是每连接独享!
5) join_buffer_size 联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每连接独享!
6) myisam_sort_buffer_size 这个缓冲区主要用于修复表过程中排序索引使用的内存或者是建立索引时排序索引用到的内存大小,一般4G内存给64M即可。
7) query_cache_size MySQL查询操作缓冲区的大小,通过以下做法调整:SHOW STATUS LIKE ‘Qcache%’; 如果Qcache_lowmem_prunes该参数记录有多少条查询因为内存不足而被移除出查询缓存。通过这个值,用户可以适当的调整缓存大小。如果该值非常大,则表明经常出现缓冲不够的情况,需要增加缓存大小;Qcache_free_memory:查询缓存的内存大小,通过这个参数可以很清晰的知道当前系统的查询内存是否够用,是多了,还是不够用,我们可以根据实际情况做出调整。一般情况下4G内存设置64M足够了。
8) thread_cache_size 表示可以重新利用保存在缓存中线程的数,参考如下值:1G —> 8 2G —> 16 3G —> 32 >3G —> 64
除此之外,还有几个比较关键的参数:
9) thread_concurrency 这个值设置为cpu核数的2倍即可
10) wait_timeout 表示空闲的连接超时时间,默认是28800s,这个参数是和interactive_timeout一起使用的,也就是说要想让wait_timeout 生效,必须同时设置interactive_timeout,建议他们两个都设置为10
11) max_connect_errors 是一个MySQL中与安全有关的计数器值,它负责阻止过多尝试失败的客户端以防止暴力破解密码的情况。与性能并无太大关系。为了避免一些错误我们一般都设置比较大,比如说10000
12) max_connections 最大的连接数,根据业务请求量适当调整,设置500足够
13) max_user_connections 是指同一个账号能够同时连接到mysql服务的最大连接数。设置为0表示不限制。通常我们设置为100足够
mysql字符集调整
mysql编译安装时,指定字符集的方法:
mysql编译安装时,指定字符集的方法:
./configure --with-charset=utf8
mysql的字符集有4个级别的默认设置:服务器级、数据库级、表级和字段级。分别在不同的地方设置,作用也不相同。
1、服务器字符集设定
在mysql服务启动的时候确定,可以在my.cnf中设置:
[mysql]
### 默认字符集为utf8
default-character-set=utf8
[mysqld]
### 默认字符集为utf8
default-character-set=utf8
### (设定连接mysql数据库时使用utf8编码,以让mysql数据库为utf8运行)
init_connect=''SET NAMES utf8''
可以用show variables like ''char%'';命令查询当前服务器的字符集和校对规则。
mysql>show variables like ''char%'';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
如果增加default-character-set=utf8后,MYSQL启动报错。可以用character_set_server=utf8来取代default-character-set=utf8,就能正常启动了。这是因为MYSQL不同版本识别的问题。
2、数据库级
#创建数据库时指定字符集
mysql>CREATE DATABASE my_db default charset utf8 COLLATE utf8_general_ci;
#注意后面这句话 "COLLATE utf8_general_ci",大致意思是在排序时根据utf8编码格式来排序
#如果指定了数据库编码,那么在这个数据库下创建的所有数据表的默认字符集都会是utf8了
修改MYSQL数据库编码,如果是MYSQL数据库编码不正确,可以在MYSQL执行如下命令:
ALTER DATABASE my_db DEFAULT CHARACTER SET utf8;
以上命令就是将MYSQL的my_db数据库的编码设为utf8
3.表级
#创建表时指定字符集
mysql>create table my_table (name varchar(20) not null default '''')type=myisam default charset utf8;
#这句话就是创建一个表,指定默认字符集为utf8
修改MYSQL表的编码:
ALTER TABLE my_table DEFAULT CHARACTER SET utf8;
#以上命令就是将一个表my_table的编码改为utf8
4、 字段级
alter table test add column address varchar(110) after stu_id;
#在stu_id后增加一个字段address
alter table test add id int unsigned not Null auto_increment primary key;
#修改字段的编码:
ALTER TABLE `test` CHANGE `name` `name` VARCHAR( 45 ) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL
#以上命令就是将MYSQL数据库test表中name的字段编码改为utf8
innobackex工具备份mysql数据
xtrbackup只能用于备份innodb引擎的数据库,而innobackex 既可以备份innodb引擎的数据库,也可以备份myisam引擎的数据库。备份时也可分为全量备份和增量备份
安装innobackex
安装yum拓展源percona-release
rpm -ivh http://www.percona.com/downloads/percona-release/redhat/0.1-3/percona-release-0.1-3.noarch.rpm安装percona-xtrabackup
yum install percona-xtrabackup
全量备份mysql
创建并授权备份用户,我们可以直接授权all权限,但是不符合安全原则
mysql -uroot -pallen
> grant reload,lock tables,replication client on *.* to ''backupuser''@''localhost'' identified by ''allen'';
> flush privileges; #权限为reload,lock tables,replication client
#创建备份保存目录
mkdir /data/backup
#备份mysql
innobackupex --defaults-file=/etc/my.cnf --user=backupuser --password=''allen'' -S /tmp/mysql.sock /data/backup #–defaults-file=/etc/my.cnf指定配置文件位置是为了获得datadir位置
#备份完成后,会在指定的保存目录中生成一个时间戳目录,该时间戳目录名称也是恢复时的apply-log。
全量备份恢复
停止mysql服务
/etc/init.d/mysqld stop
ps aux |grep "mysqld"
#不允许mysql进程存在
#删除mysql原有数据
mv /data/mysql /data/mysql.bak
mkdir /data/mysql
#恢复mysql
innobackupex --use-memory=512M --apply-log /备份的时间戳目录/
# innobackupex --use-memory=512M --apply-log /data/backup/2018-12-21_10-24-06/
#–use-memory=512M指定备份时使用的内存为512M,注意单位。默认为字节
#初始化完成后,进行恢复
innobackupex --defaults-file=/etc/my.cnf --copy-back /备份的时间戳目录/
#innobackupex --defaults-file=/etc/my.cnf --copy-back /data/backup/2018-12-21_10-24-06/
#使用–copy-back参数恢复
#设置权限
chown -R mysql:mysql /data/mysql
增量备份
一段时间后重新全量备份的话,需要耗费的资源较多,这时我们就可以使用增量备份了。
增量备份是基于全量备份的,所以在增量备份操作之前我们需要先进行全量备份
进行数据库操作
#创建测试库test1_backup
mysql -uroot -pallen -e ''create database test1_backup;''
#导入数据
mysql -uroot -pallen test1_backup < /tmp/1.sql模拟数据库数据发生改变,进行增量备份
innobackupex --defaults-file=/etc/my.cnf --user=backupuser --password=''allen'' -S /tmp/mysql.sock --incremental /data/backup --incremental-basedir=/data/backup/全量备份时间戳目录/–incremental表示增量备份,–incremental-basedir指定全量备份时间戳目录,因为本次增量备份是基于全量备份。

mysql 中一次字符集和排序规则引起的 sql 查询报错
先看 sql
o.city_name AS ''城市'',
o.city_code AS ''城市编码'',
o.comp_name AS ''公司'',
o.comp_code AS ''分公司编码'',
b.brand_name AS ''品牌'',
a.account_code AS ''被处罚系统号'',
l.occur_time AS ''处罚发生日期'',
l.penalize_time AS ''处罚最终判罚日期'',
l.create_time AS ''处罚数据导入时间'',
l.violation_behavior AS ''违规行为名称'',
l.reason AS ''事件描述'',
l.ryb_category AS ''红黄线'',
l.add_score AS ''分值'',
l.credit_score_log_type AS ''类别''
FROM credit.credit_account a RIGHT JOIN credit.credit_score_log l ON l.credit_account_id = a.id
LEFT JOIN credit.org o ON o.comp_code = l.comp_code
LEFT JOIN credit.brand_comp b ON b.comp_code = o.comp_code.user_credit_score_log u ON u.user_code = a.account_code;
报错提示:[HY000][1267] Illegal mix of collations (utf8mb4_unicode_ci,IMPLICIT) and (utf8mb4_general_ci,IMPLICIT) for operation ''=''
怀疑是 字符集 或者 排序规则 对应不上,于是通过 mysql 指令排查下字符集
SHOW FULL COLUMNS FROM credit.credit_account;
SHOW FULL COLUMNS FROM credit.org;
SHOW FULL COLUMNS FROM credit.credit_score_log;
SHOW FULL COLUMNS FROM credit.brand_comp;
credit_account表,org表,credit_score_log表,brand_comp表 四张表字符集分别如下:

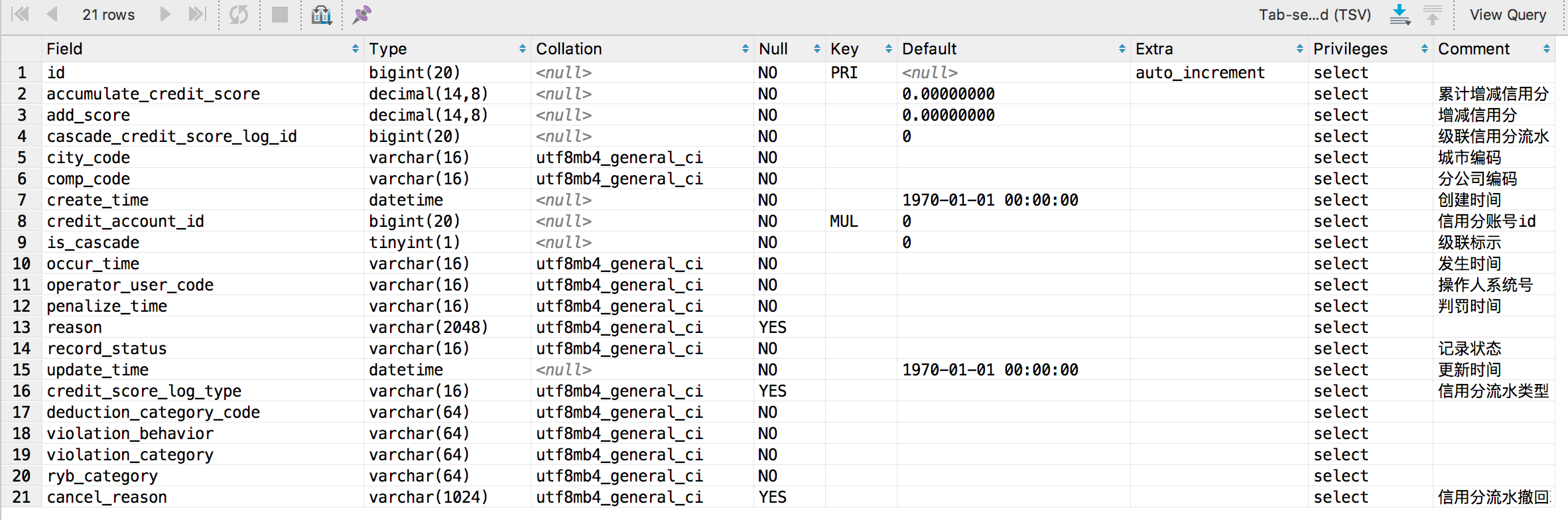

经过分析发现 最后一张表 brand_comp 的 varchar 字段 Collation 是 utf8mb4_unicode_ci,前三张表 varchar 字段段 Collation 都是 utf8mb4_general_ci
于是更改表的字符集和排序规则,命令如下
ALTER TABLE brand_comp CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;此时再查询最后一张表

排序规则更改后,再执行 sql,完美运行,问题解决!

MySQL 字符集和排序规则解析 MySQL DBA 周末学习

MySQL 提供了多种字符集和排序规则选择,其中字符集设置和数据存储以及客户端与 MySQL 实例的交互相关,排序规则和字符串的对比规则相关。
字符集的设置可以在 MySQL 实例、数据库、表、列四个级别。MySQL 设置字符集支持在 InnoDB、MyISAM、Memory 三个存储引擎。查看当前 MySQL 支持的字符集的方式有两种,一种是通过查看 information_schema.character_set 系统表,一种是通过命令 show character set 查看每个指定的字符集都会有一个或多个支持的排序规则,可以通过两种方式查看,一种是查看 information_schema.collations 表,另一种是通过 show collation 命令查看。
不同的字符集不可能有相同的排序规则,因为每个字符集都会有一个默认的排序规则。
排序规则:
每个字符集可以对应多个排序规则,但每个排序规则只能对应一个字符集。
排序规则的命令通常是以对应的字符集的名字为开头,并以自己的特定属性结尾,比如排序规则 utf8_general_ci 和 latin1_swedish_ci 就分别是对应 utf8 和 latin1 字符集的排序规则
当排序规则特指某种语言时,则中间的部分就为这种语言的名字,比如 utf8_turkish_ci 和 utf8_hungarian_ci 就代表 UTF8 字符集中的土耳其语和匈牙利语
排序规则名字的结尾字符代表是否大小写敏感,口音敏感以及是否是二进制的
当排序规则名字中没有指定_as 或者_ai 时,是否口音敏感由_ci 或者_cs 决定,当使用的是_ci,则暗指_ai,反之则暗指_as。对 Unicode 的字符集来说,对应的排序规则也可能会包含 unicode 排序算法的版本号。
互联网企业大多用的数据库是 MySQL 的,想要众多的 IT 工作者中脱颖而出,就需要拥有高深的技术,学习增值是必不可少的。学习之路,是贵在坚持的。
关于mysql字符集和校对规则(Mysql校对集)和mysql字符集配置的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于02 | MySQL字符集和校对顺序、innobackex工具备份mysql数据 mysql5.7root密码更改 mysql调优 mysql字符集调整、mysql 中一次字符集和排序规则引起的 sql 查询报错、MySQL 字符集和排序规则解析 MySQL DBA 周末学习的相关信息,请在本站寻找。
本文标签:




