本篇文章给大家谈谈mysql字符集和数据库引擎修改方法分享,以及mysql数据库字符集怎么改的知识点,同时本文还将给你拓展02|MySQL字符集和校对顺序、Liunx环境下MySQL字符集的修改方法(
本篇文章给大家谈谈mysql字符集和数据库引擎修改方法分享,以及mysql数据库字符集怎么改的知识点,同时本文还将给你拓展02 | MySQL字符集和校对顺序、Liunx环境下MySQL字符集的修改方法(1)、MySQL 如何查看及修改数据库引擎、mysql 批量修改 表字段/表/数据库 字符集和排序规则等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- mysql字符集和数据库引擎修改方法分享(mysql数据库字符集怎么改)
- 02 | MySQL字符集和校对顺序
- Liunx环境下MySQL字符集的修改方法(1)
- MySQL 如何查看及修改数据库引擎
- mysql 批量修改 表字段/表/数据库 字符集和排序规则
")
mysql字符集和数据库引擎修改方法分享(mysql数据库字符集怎么改)
MysqL字符集:cp1252 West European (latin1) ,解决乱码问题使用虚拟主机空间上的PHPmyadmin操作数据库的时候,如果看到PHPmyadmin首页上显示的MysqL 字符集为cp1252 West European (latin1),当我们导入数据时就会出现乱码,解决的方法是:
在PHPmyadmin首页的右边有个Language选项,把默认的中文 - Chinese simplified-gb2312改成 中文 - Chinese simplified,则左边的MysqL 字符集会变成UTF-8 Unicode (utf8) ,乱码问题得到解决!
PHPmyadmin 默认创建的数据库默认的数据库引擎为innodb,如果希望修改为灵活性更高的myisam
在my.ini找到default-storage-engine=innodb,修改为myisam

02 | MySQL字符集和校对顺序
全球化与本地化
本文主要介绍mysql处理不同字符语言的基础知识
字符集和校对顺序
由于不同的语言和字符集需要以不同的方式存储和检索MySQL,因此需要适应不同的字符集(不同的字母和字符),适应不同的排序和检索数据的方法。
重要术语
| 术语 | 含义 |
|---|---|
| 字符集 | 字母和符号的集合 |
| 编码 | 某个字符集成员的内部表示 |
| 校对 | 规定如何比较字符集的指令 |
使用字符集和校对顺序
查看所支持的字符集的完整列表
-- 查看所有的可支持的字符集
SHOW CHARACTER SET;
-- 查看所有可支持的校对顺序
SHOW COLLATION;
查看目前所使用的字符集和校对顺序
SHOW VARIABLES LIKE ''character%'';
SHOW VARIABLES LIKE ''collation%'';
不同的表,甚至不同的列都可能需要不同的字符集,而且两者都可以在创建表时指定
给表指定字符集和校对
CREATE TABLE mytable
(
column1 INT,
column2 VARCHAR(10)
) DEFAULT CHARACTER SET hebrew
COLLATE hebrew_general_ci;
此语句创建一个包含两列的表,并且指定一个字符集和一个校对顺序
MySQL可使用如下方式确定使用什么样的字符集和校对:
- 如果指定
CHARACTER SET和COLLATE两者,则使用这些值。 - 如果只指定
CHARACTER SET,则使用此字符集及其默认的校对(如SHOW CHARACTER SET的结果中所示)。 - 如果既不指定
CHARACTER SET,也不指定COLLATE,则使用数据库默认。
给每个列指定字符集和校对顺序
CREATE TABLE mytable(
column1 INT,
column2 VARCHAR(10),
column3 VARCHAR(10) CHARACTER SET latin1 COLLATE latin1_danish_ci
)DEFAULT CHARACTER SET hebrew
COLLATE hebrew_general_ci;
校对在对用ORDER BY子句检索出来的数据排序时起重要的作用。如果需要用与创建表时不同的校对顺序排序特定的SELECT语句,可以在SELECT语句自身中进行:
SELECT * FROM customers
ORDER BY CAST(cust_name AS ) ,cust_address COLLATE latin1_general_cs;
SELECT的其他COLLATE子句:除了这里看到的在ORDER BY子句中使用以外, COLLATE还可以用于GROUP BY、 HAVING、聚集函数、别名等。
")
Liunx环境下MySQL字符集的修改方法(1)
MySQL字符集的修改在不同的环境下有不同的方法,下面为您介绍的是在Liunx环境下MySQL字符集的修改方法,如果您对此方面感兴趣的话,不妨一看。 Liunx下修改MySQL字符集: 1.查找MySQL的cnf文件的位置 find/-iname''*.cnf''-print /usr/share/
mysql字符集的修改在不同的环境下有不同的方法,下面为您介绍的是在liunx环境下mysql字符集的修改方法,如果您对此方面感兴趣的话,不妨一看。
Liunx下修改MySQL字符集:
1.查找MySQL的cnf文件的位置
find / -iname ''*.cnf'' -print
/usr/share/mysql/my-innodb-heavy-4G.cnf
/usr/share/mysql/my-large.cnf
/usr/share/mysql/my-small.cnf
/usr/share/mysql/my-medium.cnf
/usr/share/mysql/my-huge.cnf
/usr/share/texmf/web2c/texmf.cnf
/usr/share/texmf/web2c/mktex.cnf
/usr/share/texmf/web2c/fmtutil.cnf
/usr/share/texmf/tex/xmltex/xmltexfmtutil.cnf
/usr/share/texmf/tex/jadetex/jadefmtutil.cnf
/usr/share/doc/MySQL-server-community-5.1.22/my-innodb-heavy-4G.cnf
/usr/share/doc/MySQL-server-community-5.1.22/my-large.cnf
/usr/share/doc/MySQL-server-community-5.1.22/my-small.cnf
/usr/share/doc/MySQL-server-community-5.1.22/my-medium.cnf
/usr/share/doc/MySQL-server-community-5.1.22/my-huge.cnf
2. 拷贝 small.cnf、my-medium.cnf、my-huge.cnf、my-innodb-heavy-4G.cnf其中的一个到/etc下,命名为my.cnf
cp /usr/share/mysql/my-medium.cnf /etc/my.cnf
3. 修改my.cnf
vi /etc/my.cnf
在[client]下添加
default-character-set=utf8
在[mysqld]下添加
default-character-set=utf8
4.重新启动MySQL
[root@bogon ~]# /etc/rc.d/init.d/mysql restart
Shutting down MySQL [ 确定 ]
Starting MySQL. [ 确定 ]
[root@bogon ~]# mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.1.22-rc-community-log MySQL Community Edition (GPL)
Type ''help;'' or ''\h'' for help. Type ''\c'' to clear the buffer.
5.查看MySQL字符集设置
mysql> show variables like ''collation_%'';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_general_ci |
| collation_database | utf8_general_ci |
| collation_server | utf8_general_ci |
+----------------------+-----------------+
3 rows in set (0.02 sec)
mysql> show variables like ''character_set_%'';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.02 sec)
mysql>

MySQL 如何查看及修改数据库引擎
MySQL 如何查看及修改数据库引擎
1、查看mysql支持的引擎有哪些
1 show engines结果,如图所示:
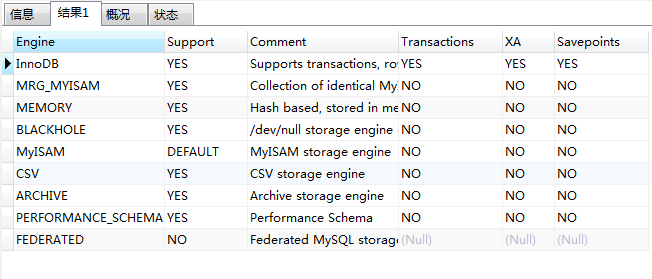
由上图可以看出,只有InnoDB是支持事务的
2、查看当前默认的引擎
1 show variables like ''default_storage_engine''如图所示,我的默认是MyISAM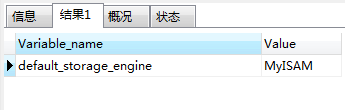
3、查看指定表当前的引擎,有2种方式
1 show table status where NAME =''xf_card'' 或
1 show create table xf_card -- 在显示结果里参数engine后面的就表示该表当前用的存储引擎4、修改指定表的引擎
1 alter table xf_card engine=innodb;5、修改mysql默认的数据库引擎
打开配置文件my.ini,将“default-storage-engine=MYISAM”改为你想设定的,然后重启即可

mysql 批量修改 表字段/表/数据库 字符集和排序规则
今天接到一个任务是需要把数据库的字符编码全部修改一下,写了以下修正用的SQL,修正顺序是 表字段 > 表 > 数据库。
表字段修复:
#改变字段数据
SELECT TABLE_SCHEMA ''数据库'',TABLE_NAME ''表'',COLUMN_NAME ''字段'',CHARACTER_SET_NAME ''原字符集'',COLLATION_NAME ''原排序规则'',CONCAT(''ALTER TABLE '', TABLE_SCHEMA,''.'',TABLE_NAME, '' MODIFY COLUMN '',COLUMN_NAME,'' '',COLUMN_TYPE,'' CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;'') ''修正SQL'' FROM information_schema.`COLUMNS` WHERE COLLATION_NAME RLIKE ''latin1'';latin1 是我demo的模糊匹配排序规则,这里需要替换为你数据库中需要替换的字段的排序规则,utf8mb4设置的是替换的字符集,utf8mb4_general_ci设置的是替换的排序规则,可以换为需要修正为什么标准,下面是SQL跑出来的样例。
把修正的SQL复制出来运行,字段标准就修复了。
ALTER TABLE scm_users.users MODIFY COLUMN password varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.contact MODIFY COLUMN address varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.contact MODIFY COLUMN country varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.contact MODIFY COLUMN postal_code varchar(6) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.contact MODIFY COLUMN contact_person varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.contact MODIFY COLUMN contact_no varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.contact MODIFY COLUMN mobile varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.contact MODIFY COLUMN email varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.contact MODIFY COLUMN remark text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.warehouse MODIFY COLUMN warehouse_no varchar(6) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.warehouse MODIFY COLUMN name varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.warehouse_category MODIFY COLUMN name varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.warehouse_op_hours MODIFY COLUMN start_time varchar(5) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER TABLE scm_warehouse.warehouse_op_hours MODIFY COLUMN end_time varchar(5) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
表修复:
#改变表
SELECT TABLE_SCHEMA ''数据库'',TABLE_NAME ''表'',TABLE_COLLATION ''原排序规则'',CONCAT(''ALTER TABLE '',TABLE_SCHEMA,''.'', TABLE_NAME, '' COLLATE=utf8mb4_general_ci;'') ''修正SQL''
FROM information_schema.`TABLES`
WHERE TABLE_COLLATION RLIKE ''latin1'';表修复只需要设置排序规则,字符集会自动设置到正确的标准,替换的话,跟上面一样,下面是SQL跑出来的样例。

同样的,把SQL复制出来运行,表就会修复了。
ALTER TABLE scm_procurement.receiving_report COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_procurement.receiving_report_detail COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_sku.sku COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_sku.sku_category COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_sku.sku_secondary_uom COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_sku.sku_sub_category COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_sku.uom COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_users.department COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_users.role COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_users.users COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_warehouse.contact COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_warehouse.warehouse COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_warehouse.warehouse_category COLLATE=utf8mb4_general_ci;
ALTER TABLE scm_warehouse.warehouse_op_hours COLLATE=utf8mb4_general_ci;
ALTER TABLE tscg.fim_data COLLATE=utf8mb4_general_ci;
数据库修复:
#修改数据库
SELECT SCHEMA_NAME ''数据库'',DEFAULT_CHARACTER_SET_NAME ''原字符集'',DEFAULT_COLLATION_NAME ''原排序规则'',CONCAT(''ALTER DATABASE '',SCHEMA_NAME,'' CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;'') ''修正SQL''
FROM information_schema.`SCHEMATA`
WHERE DEFAULT_CHARACTER_SET_NAME RLIKE ''utf8'';数据库修复,跟字段修复一样,需要设置字符集和排序规则,这里utf8是模糊匹配需要修正的数据库的字符集,也可以用DEFAULT_COLLATION_NAME 排序规则来筛选,这些都很灵活,因为我们工程是分库的,所以没有匹配数据库
如果需要选定到数据库,就用SCHEMA_NAME 匹配一下就行了,下面是SQL跑出来的样例。

一样的,SQL复制出来运行,数据库就也修复了。
ALTER DATABASE scm CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER DATABASE scm_company CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER DATABASE scm_procurement CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER DATABASE scm_sku CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER DATABASE scm_users CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER DATABASE scm_warehouse CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER DATABASE test CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
ALTER DATABASE tscg CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
如果大家有什么不解,或意见,欢迎在下方留言,楼主看到就会回复的,谢谢。
我们今天的关于mysql字符集和数据库引擎修改方法分享和mysql数据库字符集怎么改的分享就到这里,谢谢您的阅读,如果想了解更多关于02 | MySQL字符集和校对顺序、Liunx环境下MySQL字符集的修改方法(1)、MySQL 如何查看及修改数据库引擎、mysql 批量修改 表字段/表/数据库 字符集和排序规则的相关信息,可以在本站进行搜索。
本文标签:




