本文将分享基于聚合函数的InfluxQL过滤的详细内容,并且还将对通过聚合函数的结果来过滤查询结果集进行详尽解释,此外,我们还将为大家带来关于10.InfluxDB-InfluxQL基础语法教程--O
本文将分享基于聚合函数的InfluxQL过滤的详细内容,并且还将对通过聚合函数的结果来过滤查询结果集进行详尽解释,此外,我们还将为大家带来关于10.InfluxDB-InfluxQL基础语法教程--OFFSET 和SOFFSET子句、2.InfluxDB-InfluxQL基础语法教程--目录、4.InfluxDB-InfluxQL基础语法教程--基本select语句、5.InfluxDB-InfluxQL基础语法教程--WHERE子句的相关知识,希望对你有所帮助。
本文目录一览:- 基于聚合函数的InfluxQL过滤(通过聚合函数的结果来过滤查询结果集)
- 10.InfluxDB-InfluxQL基础语法教程--OFFSET 和SOFFSET子句
- 2.InfluxDB-InfluxQL基础语法教程--目录
- 4.InfluxDB-InfluxQL基础语法教程--基本select语句
- 5.InfluxDB-InfluxQL基础语法教程--WHERE子句
")
基于聚合函数的InfluxQL过滤(通过聚合函数的结果来过滤查询结果集)
如何解决基于聚合函数的InfluxQL过滤?
我有大量传感器数据存储在涌入中,在过滤掉传感器故障的异常值之后,我想对其进行汇总。数据带有会话ID标记,我将“故障”定义为在会话期间的任何时候每秒感测到的值每秒变化超过N个单位。
我很希望能够编写类似SELECT sum("value") FROM "data" WHERE max(derivative("value")) > N GROUP BY "session_id"的查询,但是InfluxQL不允许使用WHERE子句中的函数来链接函数,也不允许混合聚合字段和非聚合字段。
相反,我有如下内容:
SELECT derivative("value"),difference("value") INTO "data_derivative" FROM "data" GROUP BY "session_id"
SELECT max("derivative"),cumulative_sum("value") INTO "data_derivative_max" FROM "data_derivative" GROUP BY "session_id"
SELECT sum("cumulative_sum") FROM "data_derivative_max" WHERE "max" < N
这感觉完全是疯了,肯定有更好的方法吗?
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

10.InfluxDB-InfluxQL基础语法教程--OFFSET 和SOFFSET子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/)
OFFSET 和SOFFSET对返回的points和series进行分页。
一、OFFSET子句
OFFSET <N> 将从查询结果的第N个points开始进行分页。
语法:
SELECT_clause [INTO_clause] FROM_clause
[WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause]
LIMIT_clause OFFSET <N>
[SLIMIT_clause]
OFFSET<N>中的N表示从查询结果的第N个points开始进行分页。注意OFFSET必须和LIMIT搭配使用,如果只有OFFSET而没有LIMIT,将会导致不一致的查询结果。
OFFSET示例sql
- 示例1
为了对比效果更明显,我们先看下面的sql
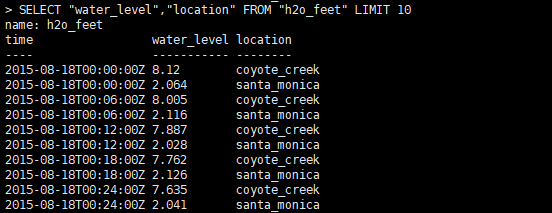
上面的sql查询除了measurement的前10行
接下来看下面的sql
SELECT "water_level","location" FROM "h2o_feet"
LIMIT 3 OFFSET 4
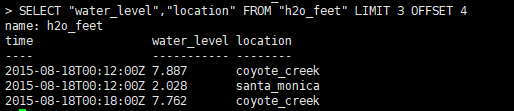 可以看到,LIMIT 3 OFFSET 4将查询结果的从下标4开始的第5、6、7行总共3行显示了出来。
可以看到,LIMIT 3 OFFSET 4将查询结果的从下标4开始的第5、6、7行总共3行显示了出来。
- 示例2 Sql
SELECT MEAN("water_level") FROM "h2o_feet"
WHERE time >= ''2015-08-18T00:00:00Z''
AND time <= ''2015-08-18T00:42:00Z''
GROUP BY *,time(12m)
ORDER BY time DESC
LIMIT 2 OFFSET 2 SLIMIT 1
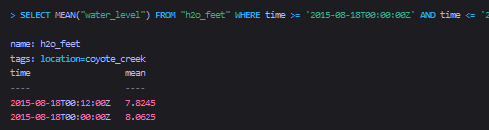 这个例子非常复杂,下面是逐条分解:
这个例子非常复杂,下面是逐条分解:
- The SELECT clause specifies an InfluxQL function.
- The FROM clause specifies a single measurement.
- The WHERE clause specifies the time range for the query.
- The GROUP BY clause groups results by all tags (*) and into 12-minute intervals.
- The ORDER BY time DESC clause returns results in descending timestamp order.
- The LIMIT 2 clause limits the number of points returned to two.
- The OFFSET 2 clause excludes the first two averages from the query results.
- The SLIMIT 1 clause limits the number of series returned to one.
- The SOFFSET 1 clause paginates the series returned.
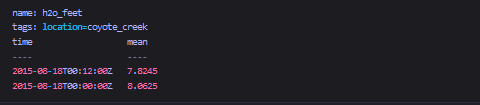
如果上面的sql中没有SOFFSET 2,则会查询到不同的series:
二、SOFFSET子句
SOFFSET <N> 将从查询结果的第N个series开始进行分页。
语法:
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause]
GROUP BY *[,time(time_interval)]
[ORDER_BY_clause]
[LIMIT_clause] [OFFSET_clause]
SLIMIT_clause SOFFSET <N>
SOFFSET <N>中的N指定了开始分页的地方,SOFFSET要跟SLIMIT子句一同搭配使用。如果只使用SOFFSET而没有SLIMIT子句,则可能会导致不一致的查询结果。
SOFFSET示例sql
- 示例1
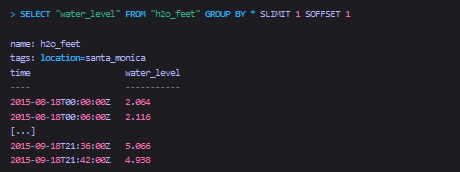 上面的sql将h2o_feet表中tag的 location = santa_monica的所有数据。如果没有SOFFSET 1子句,查询结果将会变成是location = coyote_creek的数据。为了更好的说明这个问题,依次看下面的示例。
上面的sql将h2o_feet表中tag的 location = santa_monica的所有数据。如果没有SOFFSET 1子句,查询结果将会变成是location = coyote_creek的数据。为了更好的说明这个问题,依次看下面的示例。
SELECT count("water_level") FROM "h2o_feet" GROUP BY *
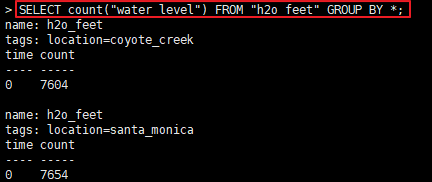 可以看到,上面的sql查询出每个tag的water_level字段个数。 让我们在上面sql的基础上,加上SLIMIT 1:
可以看到,上面的sql查询出每个tag的water_level字段个数。 让我们在上面sql的基础上,加上SLIMIT 1:
 因为加上了SLIMIT 1,所以查询结果只展示了第一个tag的结果。
因为加上了SLIMIT 1,所以查询结果只展示了第一个tag的结果。
再在上面sql的基础上加上SOFFSET 1:

可见,因为加上了SOFFSET 1,所以查询结果从第二个series开始展示(下标是从0开始的)。
- 示例2 接下来看一个更复杂的sql
SELECT MEAN("water_level") FROM "h2o_feet"
WHERE time >= ''2015-08-18T00:00:00Z''
AND time <= ''2015-08-18T00:42:00Z''
GROUP BY *,time(12m)
ORDER BY time DESC
LIMIT 2 OFFSET 2
SLIMIT 1 SOFFSET 1
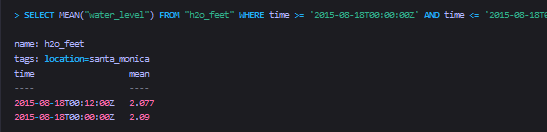
示例sql相对比较复杂,下面将逐个子句的进行分析(挺简单的,不翻译了):
- The SELECT clause specifies an InfluxQL function.
- The FROM clause specifies a single measurement.
- The WHERE clause specifies the time range for the query.
- The GROUP BY clause groups results by all tags (*) and into 12-minute intervals.
- The ORDER BY time DESC clause returns results in descending timestamp order.
- The LIMIT 2 clause limits the number of points returned to two.
- The OFFSET 2 clause excludes the first two averages from the query results.
- The SLIMIT 1 clause limits the number of series returned to one.
- The SOFFSET 1 clause paginates the series returned.
如果没有SOFFSET 1,查询结果将会是: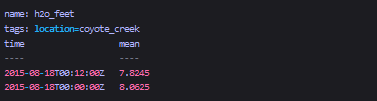
可以看到,查询到的是另一个series的数据。

2.InfluxDB-InfluxQL基础语法教程--目录
本文翻译自官网,官方文档地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/)
<kbd>InfluxQL</kbd>是用于在InfluxDB中进行数据探索的类似于SQL的查询语法。下面将详细介绍在InfluxDB中使用select语句的情形。
接下来介绍的语法如下面的表格所示。
| The Basics | Configure Query Results | General Tips on Query Syntax |
|---|---|---|
| The SELECT statement | ORDER BY time DESC | Time Syntax |
| The WHERE clause | The LIMIT and SLIMIT clauses | Regular Expressions |
| The GROUP BY clause | The OFFSET and SOFFSET clauses | Data types and cast operations |
| The INTO clause | The Time Zone clause | Merge behavior |
| Multiple statements | ||
| Subqueries |
目录
- InfluxDB-InfluxQL基础语法教程--数据说明
- InfluxDB-InfluxQL基础语法教程--基本select语句
- InfluxDB-InfluxQL基础语法教程--WHERE子句
- InfluxDB-InfluxQL基础语法教程--GROUP BY子句
- InfluxDB-InfluxQL基础语法教程--INTO子句
- InfluxDB-InfluxQL基础语法教程--ORDER BY子句
- InfluxDB-InfluxQL基础语法教程--LIMIT and SLIMIT 子句
- InfluxDB-InfluxQL基础语法教程--OFFSET 和SOFFSET子句

4.InfluxDB-InfluxQL基础语法教程--基本select语句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/)
基本语法如下:
SELECT <field_key>[,<field_key>,<tag_key>] FROM <measurement_name>[,<measurement_name>]
可见,select语句是由SELECT子句和FROM子句组成的。
一、SELECT子句
在SELECT字句中,有如下几种形式,分别用于查询各种指定的数据:
| 语法 | 意思 |
|---|---|
| SELECT * | 查询measurement中所有的fields和 tags。示例sql:<kbd>select * from h2o_feet;</kbd> |
| SELECT "<field_key>" | 查询指定的一个field。示例sql:<kbd>select water_level from h2o_feet;</kbd> |
| SELECT "<field_key>","<field_key>" | 查询多个field。示例sql:<kbd>select "level description", "water_level" from h2o_feet;</kbd> |
| SELECT "<field_key>","<tag_key>" | 查询指定的field和tag。示例sql:<kbd>select water_level,location from h2o_feet;</kbd> 注:在SELECT子句中,如果包含了tag,那么此时就必须指定至少一个field。比如如下的sql就是错误的,因为它只select了一个tag,而没有field:<kbd>select location from h2o_feet;</kbd> |
| SELECT "<field_key>"::field,"<tag_key>"::tag | 跟上面一样,也是查询指定的field和tag。 ::[field | tag]语法用来指定标识符的类型,因为有时候tag和field有可能同名,因此用 ::[field | tag]语法来加以区分。 |
在SELECT子句中,还包含数学运算、聚合函数、基本的类型转换、正则表达式等。
二、FROM子句
FROM子句用于指定要查询的measurement,支持的语法如下:
| 语法 | 意思 |
|---|---|
| FROM <measurement_name> | 从指定measurement中查询数据。这种方式会从当前DB、默认retention policy的measurement中查询数据。 |
| FROM <measurement_name>,<measurement_name> | 从多个measurement中查询数据 |
| FROM <database_name>.<retention_policy_name>.<measurement_name> | 从指定DB、指定retention policy的measurement中查询数据 |
| FROM <database_name>..<measurement_name> | 从指定DB、默认retention policy的measurement 中查询数据 |
FROM子句中还支持正则表达式。
关于引号
如果measurement、tag、field等的标识符除了[A-z,0-9,_]之外,还有其他字符,或者标识符是keyword关键字,那么在引用的时候必须加上双引号。比如在表 h2o_feet 中,"level description"就是一个带有空格的field,如此一来在查询到的时候,就必须加上双引号了。如下图,在查询level description时若不加双引号,则会报错。
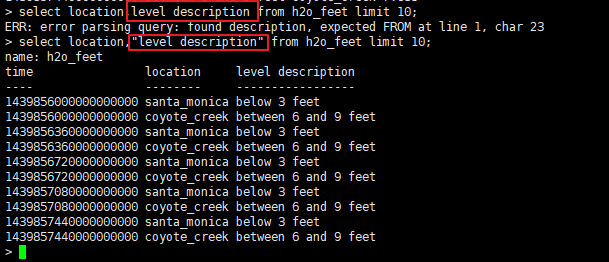
<font color=DarkRed size=4>官方推荐,虽然有些标识符不是必须使用双引号,但是推荐对所有标识符使用双引号!</font>
示例sql
-
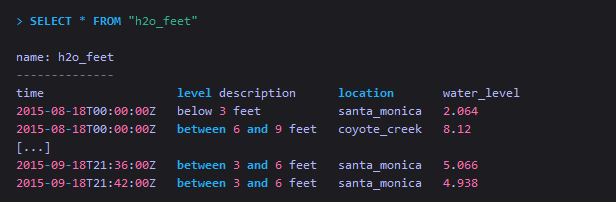
从单个measurement中查询该measurement所有的tag和field
-
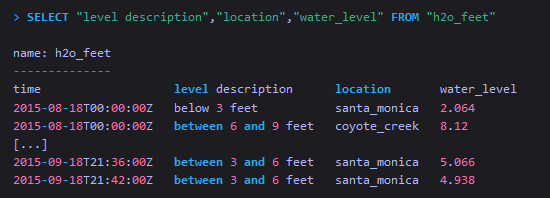
从单个measurement中查询指定的tag和field
-
从单个measurement中查询指定的tag和field,并指定它们的标识类型
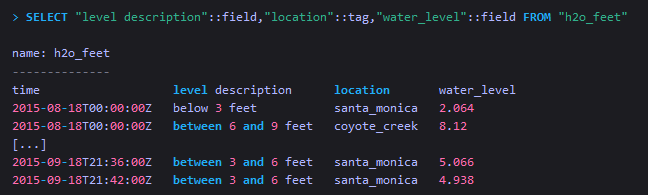
这种方式一般使用较少。 -
从measurement中查询所有的field
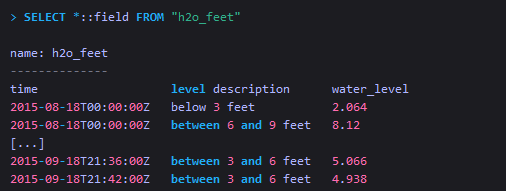
The SELECT clause supports combining the * syntax with the :: syntax. -
在查询时进行基本的数学运算
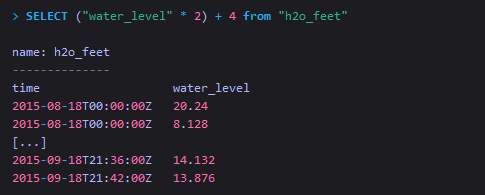
InfluxDB遵循标准的四则运算规则。更多操作详见Mathematical Operators。 -
同时从多个measurement中查询它们的所有数据
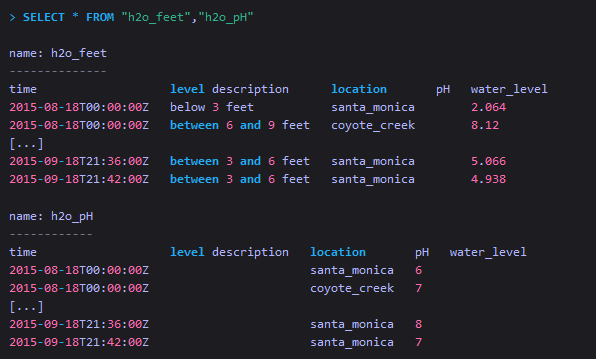
-
从一个全路径的measurement中查询数据
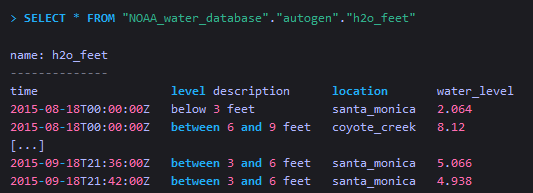
可见,所谓的全路径,其实就是指在FROM子句中,指定了measurement所在的DB,以及要查询数据所在的retention policy。 -
查询指定数据库中的measurement的数据
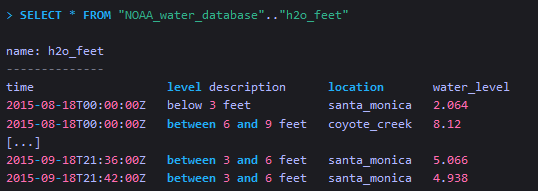
The query selects data in the NOAA_water_database, the DEFAULT retention policy, and the h2o_feet measurement. The .. indicates the DEFAULT retention policy for the specified database.
关于SELECT语句的常见疑问
在SELECT 子句中,必须要有至少一个field key!如果在SELECT子句中只有一个或多个tag key,那么该查询会返回空。这是由InfluxDB底层存储数据的方式所导致的结果。
示例:

上面的查询结果返回为空,是因为在它的SELECT子句中,只查询了location这个tag key。
如果想要查询跟location这个tag key有关的任何数据,则在SELECT字句中必须至少要包含一个field key,如下: 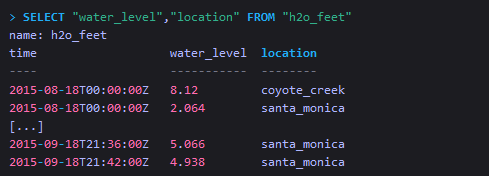

5.InfluxDB-InfluxQL基础语法教程--WHERE子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/)
WHERE子句
语法:
SELECT_clause FROM_clause WHERE <conditional_expression> [(AND|OR) <conditional_expression> [...]]
注:在WHERE子句中,支持在fields, tags, and timestamps上进行条件表达式的运算。
注:在InfluxDB的WHERE子句中,不支持使用 OR 来指定不同的time区间,如下面的sql将会返回空:
SELECT * FROM "absolutismus" WHERE time = ''2016-07-31T20:07:00Z'' OR time = ''2016-07-31T23:07:17Z''
Fields
语法如下:
field_key <operator> [''string'' | boolean | float | integer]
在WHERE子句中,支持对string, boolean, float 和 integer类型的field values进行比较。
注意 :<font color=Red size=3>在WHERE子句中,如果是string类型的field value,一定要用单引号括起来。如果不适用引号括起来,或者使用的是双引号,将不会返回任何数据,有时甚至都不报错! </font>
WHERE支持的运算符如下:
| Operator | Meaning |
|---|---|
| = | equal to |
| <> | not equal to |
| != | not equal to |
| > | greater than |
| >= | greater than or equal to |
| < | less than |
| <= | less than or equal to |
支持的更多运算符详见: Arithmetic Operations, Regular Expressions
Tags
语法如下:
tag_key <operator> [''tag_value'']
<font color=Red size=3>对于在WHERE子句中的tag values,也要用单引号括起来。如果不用引号括起来,或者使用双引号,则查询不会返回任务数据。甚至不会报错。</font>
Tag支持的运算符如下:
| Operator | Meaning |
|---|---|
| = | equal to |
| <> | not equal to |
| != | not equal to |
还支持正则运算: Regular Expressions
Timestamps
对于大部分的SELECT 语句来说,默认的时间区间是1677-09-21 00:12:43.145224194 到 2262-04-11T23:47:16.854775806Z UTC. 对于有GROUP BY time() 的SELECT 语句,默认的时间区间是1677-09-21 00:12:43.145224194 UTC 到 now()。
在 Time Syntax 小节将会介绍如何在WHERE子句中指定时间 区间。
WHERE示例sql
-
Select data that have specific field key-values
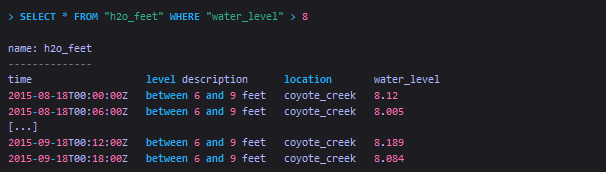
-
Select data that have a specific string field key-value
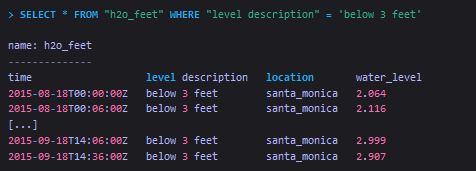 InfluxQL requires single quotes around string field values in the WHERE clause.
InfluxQL requires single quotes around string field values in the WHERE clause. -
Select data that have a specific field key-value and perform basic arithmetic
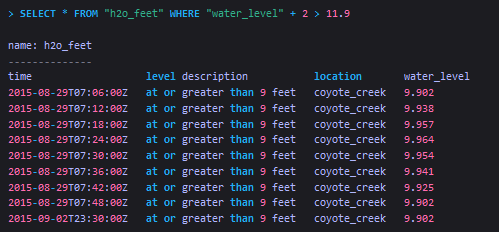
-
Select data that have a specific tag key-value
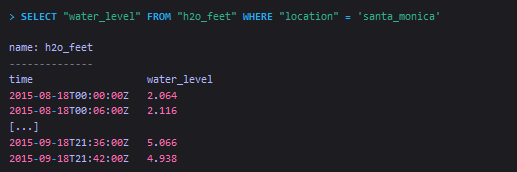 InfluxQL requires single quotes around tag values in the WHERE clause.
InfluxQL requires single quotes around tag values in the WHERE clause. -
Select data that have specific field key-values and tag key-values
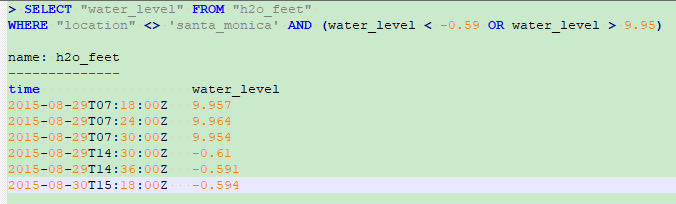 The WHERE clause supports the operators AND and OR, and supports separating logic with parentheses.
The WHERE clause supports the operators AND and OR, and supports separating logic with parentheses.
- Select data that have specific timestamps
该sql将查询h2o_feet中在7天以内的所有数据
关于WHERE语句的常见疑问
问题 :where子句查询意外地未返回任何数据。
答 :通常情况,出现该问题是因为在WHERE子句中没有对tag values或string类型的field values使用单引号括起来的缘故。对于WHERE子句中的tag values或string类型的field values,如果没有用引号括起来,或者是用的双引号,这种时候,查询不会返回任何结果,有时甚至也不会报错。
在下面的示例sql中,对tag value的引号使用做说明。第一个sql没有对tag value使用引号,第二个sql对tag value使用了双引号,第三个sql则对tag value使用了单引号。可以看到,第一和第二个sql都没有返回任何查询结果,而第三个sql返回了预期中的结果。
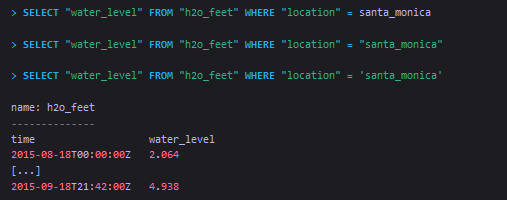
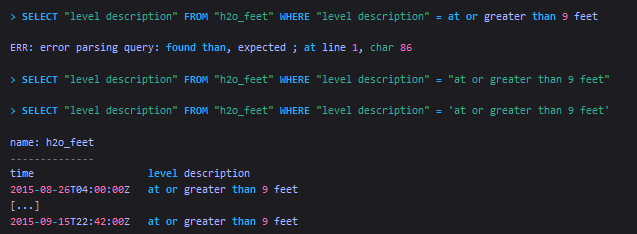
在下面的sql对string类型的field value的引号情况做说明,其中field value为“at or greater than 9 feet”。第一个sql没有对field value使用引号,第二个sql对field value使用了双引号,第三个sql则对field value使用了单引号。可以看到,第一个sql报错了,因为field valus中包含了空格。第二个sql虽然没报错,但是查询结果为空。第三个sql返回了预期中的结果。
我们今天的关于基于聚合函数的InfluxQL过滤和通过聚合函数的结果来过滤查询结果集的分享就到这里,谢谢您的阅读,如果想了解更多关于10.InfluxDB-InfluxQL基础语法教程--OFFSET 和SOFFSET子句、2.InfluxDB-InfluxQL基础语法教程--目录、4.InfluxDB-InfluxQL基础语法教程--基本select语句、5.InfluxDB-InfluxQL基础语法教程--WHERE子句的相关信息,可以在本站进行搜索。
本文标签:




