以上就是给各位分享mysql复制一个库,其中也会对mysql复制一个库的所有表结构,并做成新的库进行解释,同时本文还将给你拓展mysql-PHP的一个库,求详细信息。、MySQL18、如何快速复制一个
以上就是给各位分享mysql 复制一个库,其中也会对mysql复制一个库的所有表结构,并做成新的库进行解释,同时本文还将给你拓展mysql - PHP的一个库,求详细信息。、MySQL 18、如何快速复制一个表 grant之后要跟着flushprivileges吗、mysql 5.6.14主从复制(也称mysql AB复制)环境配置方法、MySQL 5.7并发复制和mysqldump相互阻塞引起的复制延迟等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- mysql 复制一个库(mysql复制一个库的所有表结构,并做成新的库)
- mysql - PHP的一个库,求详细信息。
- MySQL 18、如何快速复制一个表 grant之后要跟着flushprivileges吗
- mysql 5.6.14主从复制(也称mysql AB复制)环境配置方法
- MySQL 5.7并发复制和mysqldump相互阻塞引起的复制延迟
")
mysql 复制一个库(mysql复制一个库的所有表结构,并做成新的库)
首先创建一个库 new_db
然后使用MysqLdump工具把老的库数据复制到新库
打开黑框
MysqLdump old_db -uroot -p'12345' --add-drop-table | MysqL new_db -u root -p'12345'
root 是用户名 12345是密码
如果不在一个服务器上
MysqLdump old_db -u 账户 -p密码 | MysqL -h 主机IP -P 端口 new_db -u 账户 -p密码
需要增加 -h 然后把主机ip和端口加上

mysql - PHP的一个库,求详细信息。
经常性闭门造车,对php其他的事了解甚少。
今天在研究typeche的时候又遇到了类似:
a:2:{s:7:"logoUrl";N;s:12:"sidebarBlock";a:5:{i:0;s:15:"ShowRecentPosts";i:1;s:18:"ShowRecentComments";i:2;s:12:"ShowCategory";i:3;s:11:"ShowArchive";i:4;s:9:"ShowOther";}}<?php exit;//a:4:{i:4;a:1:{i:0;a:3:{s:6:"tagurl";s:18:"%E4%B8%8D%E7%9D%A1";s:7:"tagname";s:6:"不睡";s:3:"tid";i:2;}}i:3;a:1:{i:0;a:3:{s:6:"tagurl";s:18:"%E6%B0%B4%E6%B0%B4";s:7:"tagname";s:6:"水水";s:3:"tid";i:1;}}i:2;a:0:{}i:1;a:0:{}}的数据库配置,想知道这个格式的配置的相关信息,百度也不好百度,今天跟踪代码也没找到,求各位大大指点一下。
回复内容:
经常性闭门造车,对php其他的事了解甚少。
今天在研究typeche的时候又遇到了类似:
a:2:{s:7:"logoUrl";N;s:12:"sidebarBlock";a:5:{i:0;s:15:"ShowRecentPosts";i:1;s:18:"ShowRecentComments";i:2;s:12:"ShowCategory";i:3;s:11:"ShowArchive";i:4;s:9:"ShowOther";}}<?php exit;//a:4:{i:4;a:1:{i:0;a:3:{s:6:"tagurl";s:18:"%E4%B8%8D%E7%9D%A1";s:7:"tagname";s:6:"不睡";s:3:"tid";i:2;}}i:3;a:1:{i:0;a:3:{s:6:"tagurl";s:18:"%E6%B0%B4%E6%B0%B4";s:7:"tagname";s:6:"水水";s:3:"tid";i:1;}}i:2;a:0:{}i:1;a:0:{}}的数据库配置,想知道这个格式的配置的相关信息,百度也不好百度,今天跟踪代码也没找到,求各位大大指点一下。
php序列化的结果
通过unserialize可以将这个字符串转为php变量。
立即学习“PHP免费学习笔记(深入)”;
今天强行想找如下格式的储存文件是由啥生成的:
a:4:{i:4;a:1:{i:0;a:3:{s:6:"tagurl";s:18:"%E4%B8%8D%E7%9D%A1";s:7:"tagname";s:6:"不睡";s:3:"tid";i:2;}}i:3;a:1:{i:0;a:3:{s:6:"tagurl";s:18:"%E6%B0%B4%E6%B0%B4";s:7:"tagname";s:6:"水水";s:3:"tid";i:1;}}i:2;a:0:{}i:1;a:0:{}}妈的智障,先是在Typecho中找了3个小时,使出浑身解数还是没发现。。。。。。
吐血的是,联想到Emlog这个PHP程序的缓存就是这种格式的,MDZZ的我稍微一跟踪就看到了代码:
$cacheData = serialize($tag_cache); $this->cacheWrite($cacheData, ''tags'');
一切水落石出了,MDZZ。。。。亏我花了3小时,太他妈浪费时间了!
function MDZZ()
{
$array=[''name''=>''DXKite'',''type''=>''智障''];
$str=serialize($array);
var_dump($str);
var_dump(unserialize($str));
}输出:
string(54) "a:2:{s:4:"name";s:6:"DXKite";s:4:"type";s:6:"智障";}" array(2) { ["name"]=> string(6) "DXKite" ["type"]=> string(6) "智障" }php语言里,数组内容想要直接保存至数据库中,经常会用到serialize,但是呢,serialize经常会出现一些莫名其妙的错误,encode编码效率不如json_encode,且生成编码量比json_encode多。
建议使用json_encode。
做缓存经常用到serialize

MySQL 18、如何快速复制一个表 grant之后要跟着flushprivileges吗
怎么在两张表中拷贝数据。
当然,为了避免对源表加读锁,更稳妥的方案是先将数据写到外部文本文件,然后再写回目标表。这时,有两种常用的方法。接下来的内容,我会和你详细展开一下这两种方法。
为了便于说明,我还是先创建一个表db1.t,并插入1000行数据,同时创建一个相同结构的表db2.t。
create database db1;
use db1;
create table t(id int primary key, a int, b int, index(a))engine=innodb;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=1000)do
insert into t values(i,i,i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
create database db2;
create table db2.t like db1.t
假设,我们要把db1.t里面a>900的数据行导出来,插入到db2.t中。
mysqldump方法
一种方法是,使用mysqldump命令将数据导出成一组INSERT语句。你可以使用下面的命令:
mysqldump -h$host -P$port -u$user --add-locks --no-create-info --single-transaction --set-gtid-purged=OFF db1 t --where="a>900" --result-file=/client_tmp/t.sql
把结果输出到临时文件。
这条命令中,主要参数含义如下:
-
–single-transaction的作用是,在导出数据的时候不需要对表db1.t加表锁,而是使用START TRANSACTION WITH CONSISTENT SNAPSHOT的方法;
-
–add-locks设置为0,表示在输出的文件结果里,不增加" LOCK TABLES
tWRITE;" ; -
–no-create-info的意思是,不需要导出表结构;
-
–set-gtid-purged=off表示的是,不输出跟GTID相关的信息;
-
–result-file指定了输出文件的路径,其中client表示生成的文件是在客户端机器上的。
通过这条mysqldump命令生成的t.sql文件中就包含了如图1所示的INSERT语句。

图1 mysqldump输出文件的部分结果
可以看到,一条INSERT语句里面会包含多个value对,这是为了后续用这个文件来写入数据的时候,执行速度可以更快。
如果你希望生成的文件中一条INSERT语句只插入一行数据的话,可以在执行mysqldump命令时,加上参数–skip-extended-insert。
然后,你可以通过下面这条命令,将这些INSERT语句放到db2库里去执行。
mysql -h127.0.0.1 -P13000 -uroot db2 -e "source /client_tmp/t.sql"
需要说明的是,source并不是一条SQL语句,而是一个客户端命令。mysql客户端执行这个命令的流程是这样的:
-
打开文件,默认以分号为结尾读取一条条的SQL语句;
-
将SQL语句发送到服务端执行。
也就是说,服务端执行的并不是这个“source t.sql"语句,而是INSERT语句。所以,不论是在慢查询日志(slow log),还是在binlog,记录的都是这些要被真正执行的INSERT语句。
导出CSV文件
另一种方法是直接将结果导出成.csv文件。MySQL提供了下面的语法,用来将查询结果导出到服务端本地目录:
select * from db1.t where a>900 into outfile ''/server_tmp/t.csv'';
我们在使用这条语句时,需要注意如下几点。
-
这条语句会将结果保存在服务端。如果你执行命令的客户端和MySQL服务端不在同一个机器上,客户端机器的临时目录下是不会生成t.csv文件的。
-
into outfile指定了文件的生成位置(/server_tmp/),这个位置必须受参数secure_file_priv的限制。参数secure_file_priv的可选值和作用分别是:
- 如果设置为empty,表示不限制文件生成的位置,这是不安全的设置;
- 如果设置为一个表示路径的字符串,就要求生成的文件只能放在这个指定的目录,或者它的子目录;
- 如果设置为NULL,就表示禁止在这个MySQL实例上执行select … into outfile 操作。
-
这条命令不会帮你覆盖文件,因此你需要确保/server_tmp/t.csv这个文件不存在,否则执行语句时就会因为有同名文件的存在而报错。
-
这条命令生成的文本文件中,原则上一个数据行对应文本文件的一行。但是,如果字段中包含换行符,在生成的文本中也会有换行符。不过类似换行符、制表符这类符号,前面都会跟上“\”这个转义符,这样就可以跟字段之间、数据行之间的分隔符区分开。
得到.csv导出文件后,你就可以用下面的load data命令将数据导入到目标表db2.t中。
load data infile ''/server_tmp/t.csv'' into table db2.t;
这条语句的执行流程如下所示。
-
打开文件/server_tmp/t.csv,以制表符(\t)作为字段间的分隔符,以换行符(\n)作为记录之间的分隔符,进行数据读取;
-
启动事务。
-
判断每一行的字段数与表db2.t是否相同:
- 若不相同,则直接报错,事务回滚;
- 若相同,则构造成一行,调用InnoDB引擎接口,写入到表中。
-
重复步骤3,直到/server_tmp/t.csv整个文件读入完成,提交事务。
你可能有一个疑问,如果binlog_format=statement,这个load语句记录到binlog里以后,怎么在备库重放呢?
由于/server_tmp/t.csv文件只保存在主库所在的主机上,如果只是把这条语句原文写到binlog中,在备库执行的时候,备库的本地机器上没有这个文件,就会导致主备同步停止。
所以,这条语句执行的完整流程,其实是下面这样的。
-
主库执行完成后,将/server_tmp/t.csv文件的内容直接写到binlog文件中。
-
往binlog文件中写入语句load data local infile ‘/tmp/SQL_LOAD_MB-1-0’ INTO TABLE `db2`.`t`。
-
把这个binlog日志传到备库。
-
备库的apply线程在执行这个事务日志时:
a. 先将binlog中t.csv文件的内容读出来,写入到本地临时目录/tmp/SQL_LOAD_MB-1-0 中;
b. 再执行load data语句,往备库的db2.t表中插入跟主库相同的数据。
执行流程如图2所示:
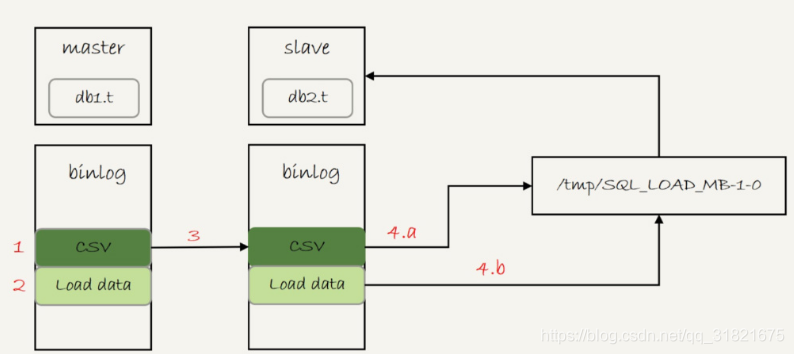
图2 load data的同步流程
注意,这里备库执行的load data语句里面,多了一个“local”。它的意思是“将执行这条命令的客户端所在机器的本地文件/tmp/SQL_LOAD_MB-1-0的内容,加载到目标表db2.t中”。
也就是说,load data命令有两种用法:
-
不加“local”,是读取服务端的文件,这个文件必须在secure_file_priv指定的目录或子目录下;
-
加上“local”,读取的是客户端的文件,只要mysql客户端有访问这个文件的权限即可。这时候,MySQL客户端会先把本地文件传给服务端,然后执行上述的load data流程。
另外需要注意的是,select …into outfile方法不会生成表结构文件, 所以我们导数据时还需要单独的命令得到表结构定义。mysqldump提供了一个–tab参数,可以同时导出表结构定义文件和csv数据文件。这条命令的使用方法如下:
mysqldump -h$host -P$port -u$user ---single-transaction --set-gtid-purged=OFF db1 t --where="a>900" --tab=$secure_file_priv
这条命令会在$secure_file_priv定义的目录下,创建一个t.sql文件保存建表语句,同时创建一个t.txt文件保存CSV数据。
物理拷贝方法
前面我们提到的mysqldump方法和导出CSV文件的方法,都是逻辑导数据的方法,也就是将数据从表db1.t中读出来,生成文本,然后再写入目标表db2.t中。
你可能会问,有物理导数据的方法吗?比如,直接把db1.t表的.frm文件和.ibd文件拷贝到db2目录下,是否可行呢?
答案是不行的。
因为,一个InnoDB表,除了包含这两个物理文件外,还需要在数据字典中注册。直接拷贝这两个文件的话,因为数据字典中没有db2.t这个表,系统是不会识别和接受它们的。
不过,在MySQL 5.6版本引入了可传输表空间(transportable tablespace)的方法,可以通过导出+导入表空间的方式,实现物理拷贝表的功能。
假设我们现在的目标是在db1库下,复制一个跟表t相同的表r,具体的执行步骤如下:
-
执行 create table r like t,创建一个相同表结构的空表;
-
执行alter table r discard tablespace,这时候r.ibd文件会被删除;
-
执行flush table t for export,这时候db1目录下会生成一个t.cfg文件;
-
在db1目录下执行cp t.cfg r.cfg; cp t.ibd r.ibd;这两个命令;
-
执行unlock tables,这时候t.cfg文件会被删除;
-
执行alter table r import tablespace,将这个r.ibd文件作为表r的新的表空间,由于这个文件的数据内容和t.ibd是相同的,所以表r中就有了和表t相同的数据。
至此,拷贝表数据的操作就完成了。这个流程的执行过程图如下:
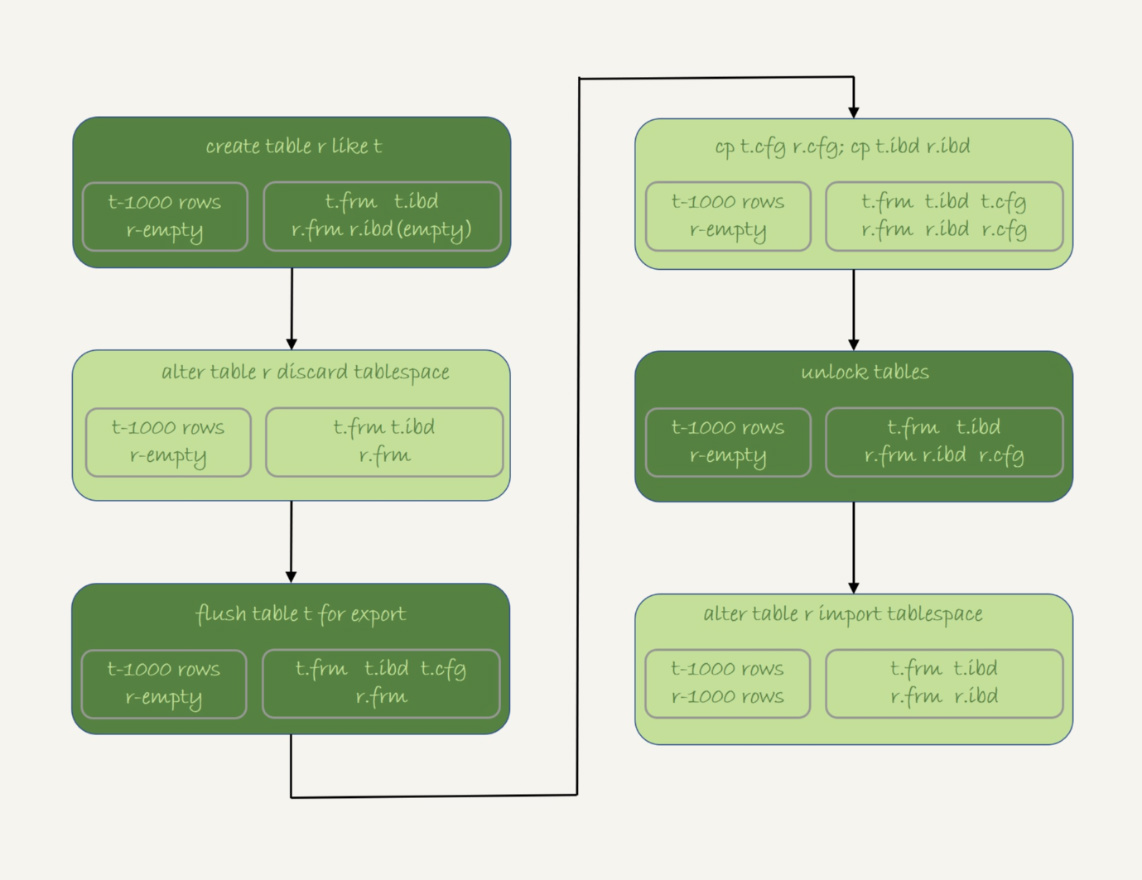
图3 物理拷贝表
关于拷贝表的这个流程,有以下几个注意点:
-
在第3步执行完flsuh table命令之后,db1.t整个表处于只读状态,直到执行unlock tables命令后才释放读锁;
-
在执行import tablespace的时候,为了让文件里的表空间id和数据字典中的一致,会修改t.ibd的表空间id。而这个表空间id存在于每一个数据页中。因此,如果是一个很大的文件(比如TB级别),每个数据页都需要修改,所以你会看到这个import语句的执行是需要一些时间的。当然,如果是相比于逻辑导入的方法,import语句的耗时是非常短的。
小结
今天这篇文章,我和你介绍了三种将一个表的数据导入到另外一个表中的方法。
我们来对比一下这三种方法的优缺点。
-
物理拷贝的方式速度最快,尤其对于大表拷贝来说是最快的方法。如果出现误删表的情况,用备份恢复出误删之前的临时库,然后再把临时库中的表拷贝到生产库上,是恢复数据最快的方法。但是,这种方法的使用也有一定的局限性:
- 必须是全表拷贝,不能只拷贝部分数据;
- 需要到服务器上拷贝数据,在用户无法登录数据库主机的场景下无法使用;
- 由于是通过拷贝物理文件实现的,源表和目标表都是使用InnoDB引擎时才能使用。
-
用mysqldump生成包含INSERT语句文件的方法,可以在where参数增加过滤条件,来实现只导出部分数据。这个方式的不足之一是,不能使用join这种比较复杂的where条件写法。
-
用select … into outfile的方法是最灵活的,支持所有的SQL写法。但,这个方法的缺点之一就是,每次只能导出一张表的数据,而且表结构也需要另外的语句单独备份。
后两种方式都是逻辑备份方式,是可以跨引擎使用的。
我们前面介绍binlog_format=statement的时候,binlog记录的load data命令是带local的。既然这条命令是发送到备库去执行的,那么备库执行的时候也是本地执行,为什么需要这个local呢?如果写到binlog中的命令不带local,又会出现什么问题呢?
这样做的一个原因是,为了确保备库应用binlog正常。因为备库可能配置了secure_file_priv=null,所以如果不用local的话,可能会导入失败,造成主备同步延迟。
另一种应用场景是使用mysqlbinlog工具解析binlog文件,并应用到目标库的情况。你可以使用下面这条命令 :
mysqlbinlog $binlog_file | mysql -h$host -P$port -u$user -p$pwd
把日志直接解析出来发给目标库执行。增加local,就能让这个方法支持非本地的$host。
grant之后要跟着flushprivileges吗
在MySQL里面,grant语句是用来给用户赋权的。不知道你有没有见过一些操作文档里面提到,grant之后要马上跟着执行一个flush privileges命令,才能使赋权语句生效。我最开始使用MySQL的时候,就是照着一个操作文档的说明按照这个顺序操作的。
那么,grant之后真的需要执行flush privileges吗?如果没有执行这个flush命令的话,赋权语句真的不能生效吗?
接下来,我就先和你介绍一下grant语句和flush privileges语句分别做了什么事情,然后再一起来分析这个问题。
为了便于说明,我先创建一个用户:
create user ''ua''@''%'' identified by ''pa'';
这条语句的逻辑是创建一个用户’ua’@’%’,密码是pa。注意,在MySQL里面,用户名(user)+地址(host)才表示一个用户,因此 ua@ip1 和 ua@ip2代表的是两个不同的用户。
这条命令做了两个动作:
-
磁盘上,往mysql.user表里插入一行,由于没有指定权限,所以这行数据上所有表示权限的字段的值都是N;
-
内存里,往数组acl_users里插入一个acl_user对象,这个对象的access字段值为0。
图1就是这个时刻用户ua在user表中的状态。
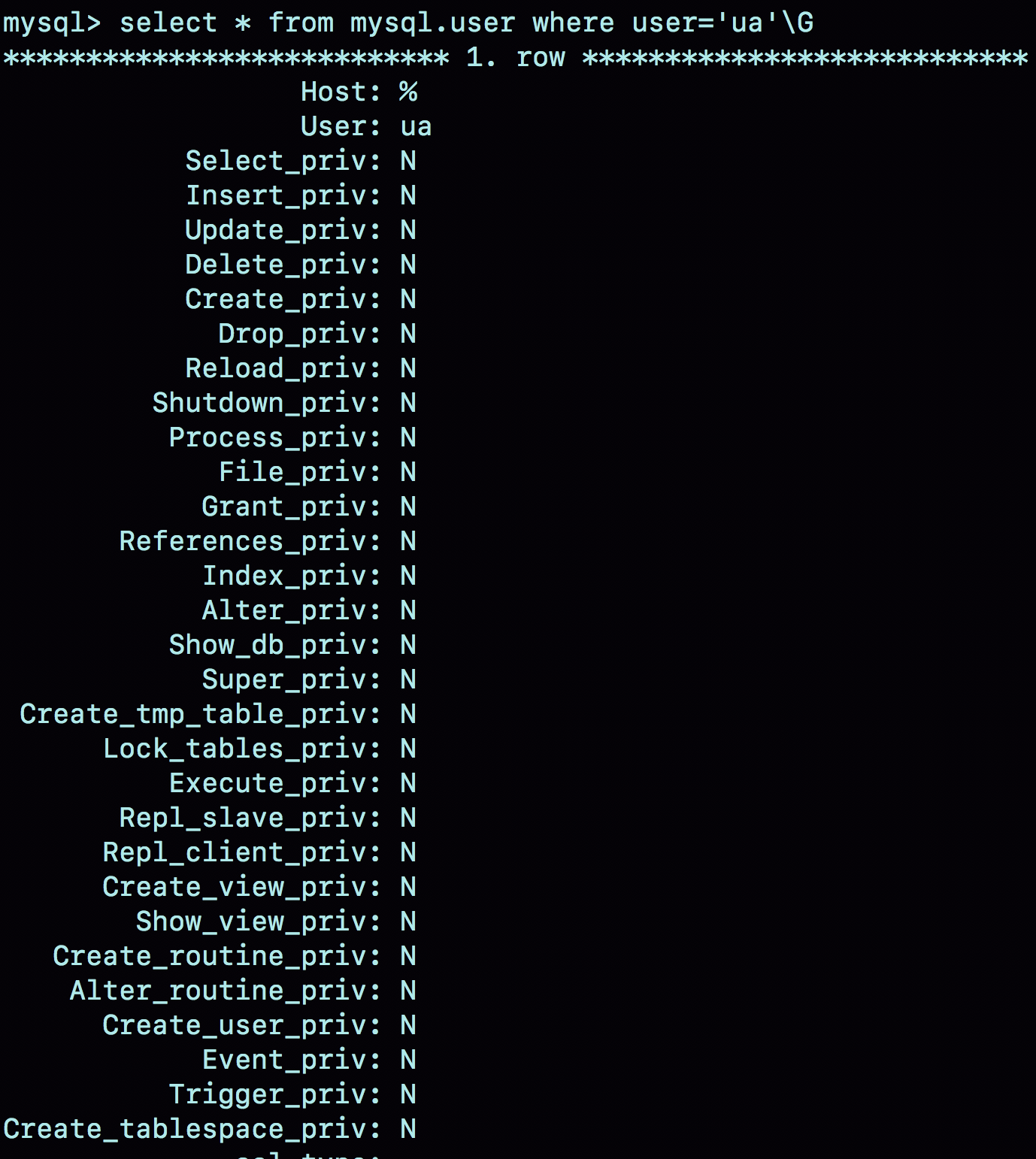
图1 mysql.user 数据行
在MySQL中,用户权限是有不同的范围的。接下来,我就按照用户权限范围从大到小的顺序依次和你说明。
全局权限
全局权限,作用于整个MySQL实例,这些权限信息保存在mysql库的user表里。如果我要给用户ua赋一个最高权限的话,语句是这么写的:
grant all privileges on *.* to ''ua''@''%'' with grant option;
这个grant命令做了两个动作:
-
磁盘上,将mysql.user表里,用户’ua’@’%''这一行的所有表示权限的字段的值都修改为‘Y’;
-
内存里,从数组acl_users中找到这个用户对应的对象,将access值(权限位)修改为二进制的“全1”。
在这个grant命令执行完成后,如果有新的客户端使用用户名ua登录成功,MySQL会为新连接维护一个线程对象,然后从acl_users数组里查到这个用户的权限,并将权限值拷贝到这个线程对象中。之后在这个连接中执行的语句,所有关于全局权限的判断,都直接使用线程对象内部保存的权限位。
基于上面的分析我们可以知道:
-
grant 命令对于全局权限,同时更新了磁盘和内存。命令完成后即时生效,接下来新创建的连接会使用新的权限。
-
对于一个已经存在的连接,它的全局权限不受grant命令的影响。
需要说明的是,一般在生产环境上要合理控制用户权限的范围。我们上面用到的这个grant语句就是一个典型的错误示范。如果一个用户有所有权限,一般就不应该设置为所有IP地址都可以访问。
如果要回收上面的grant语句赋予的权限,你可以使用下面这条命令:
revoke all privileges on *.* from ''ua''@''%'';
这条revoke命令的用法与grant类似,做了如下两个动作:
-
磁盘上,将mysql.user表里,用户’ua’@’%''这一行的所有表示权限的字段的值都修改为“N”;
-
内存里,从数组acl_users中找到这个用户对应的对象,将access的值修改为0。
db权限
除了全局权限,MySQL也支持库级别的权限定义。如果要让用户ua拥有库db1的所有权限,可以执行下面这条命令:
grant all privileges on db1.* to ''ua''@''%'' with grant option;
基于库的权限记录保存在mysql.db表中,在内存里则保存在数组acl_dbs中。这条grant命令做了如下两个动作:
-
磁盘上,往mysql.db表中插入了一行记录,所有权限位字段设置为“Y”;
-
内存里,增加一个对象到数组acl_dbs中,这个对象的权限位为“全1”。
图2就是这个时刻用户ua在db表中的状态。
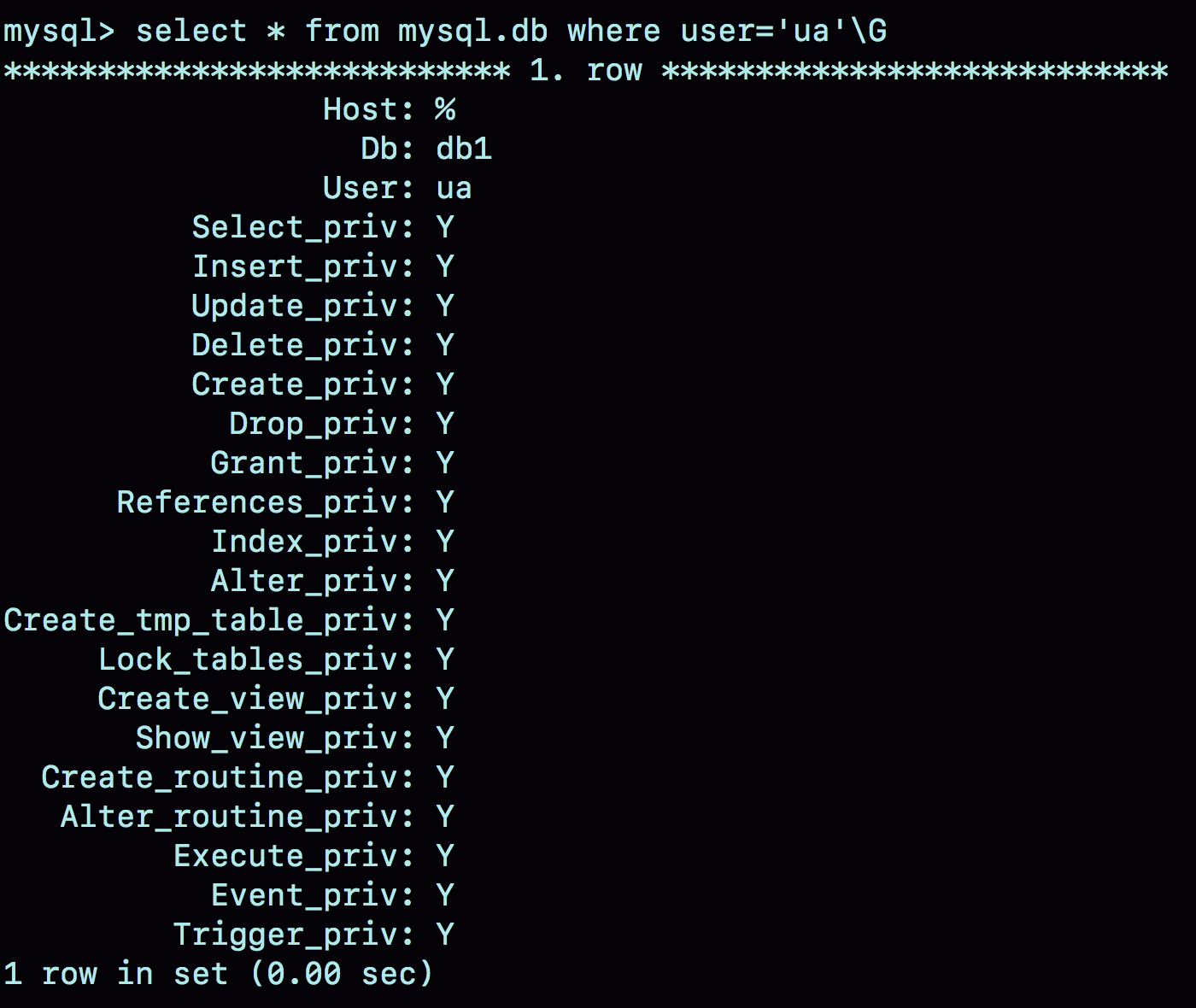
图2 mysql.db 数据行
每次需要判断一个用户对一个数据库读写权限的时候,都需要遍历一次acl_dbs数组,根据user、host和db找到匹配的对象,然后根据对象的权限位来判断。
也就是说,grant修改db权限的时候,是同时对磁盘和内存生效的。
grant操作对于已经存在的连接的影响,在全局权限和基于db的权限效果是不同的。接下来,我们做一个对照试验来分别看一下。
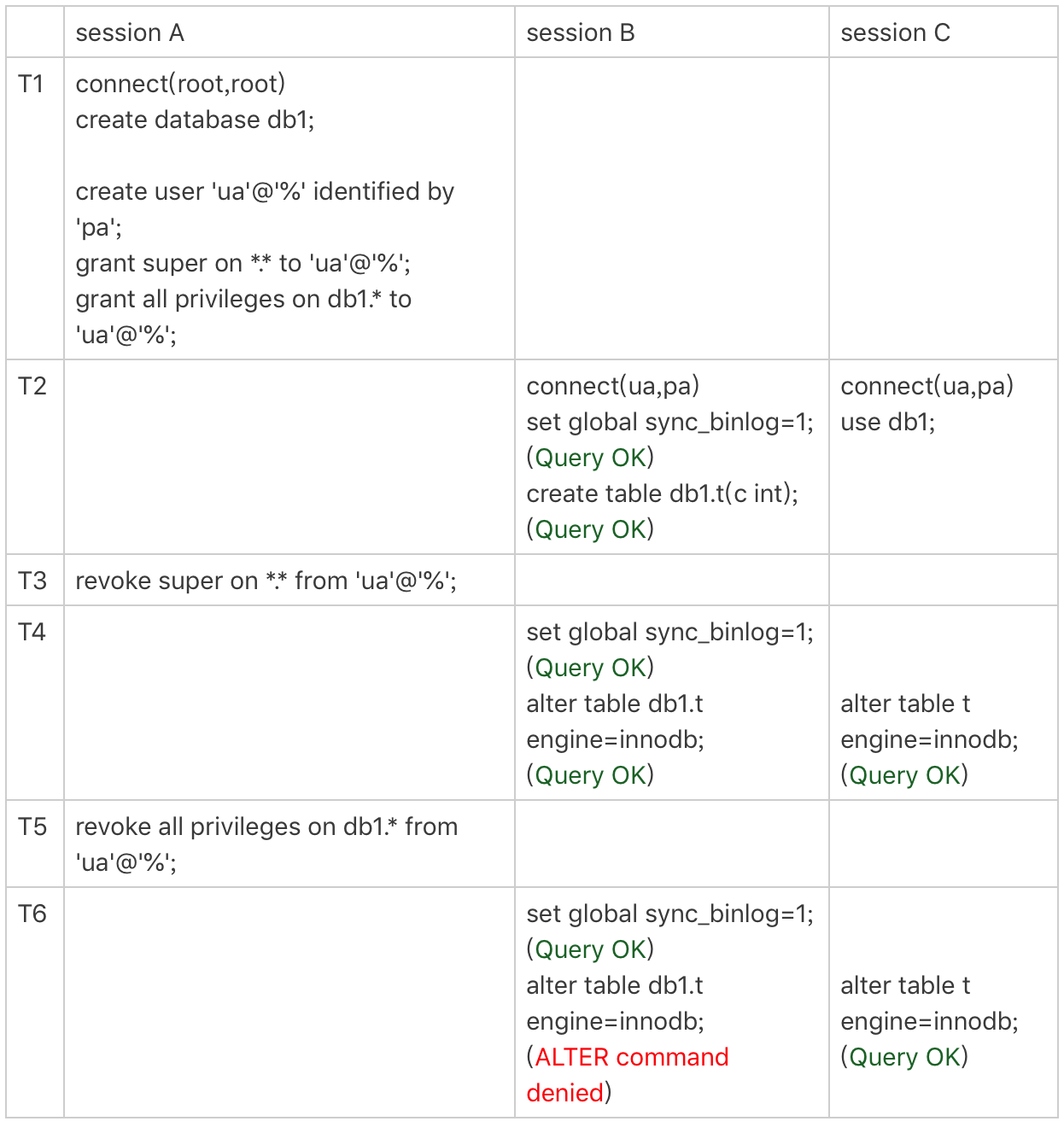
图3 权限操作效果
需要说明的是,图中set global sync_binlog这个操作是需要super权限的。sync_binlog = 1表示 SQL每次提交事务之前会将二进制同步到磁盘上
可以看到,虽然用户ua的super权限在T3时刻已经通过revoke语句回收了,但是在T4时刻执行set global的时候,权限验证还是通过了。这是因为super是全局权限,这个权限信息在线程对象中,而revoke操作影响不到这个线程对象。
而在T5时刻去掉ua对db1库的所有权限后,在T6时刻session B再操作db1库的表,就会报错“权限不足”。这是因为acl_dbs是一个全局数组,所有线程判断db权限都用这个数组,这样revoke操作马上就会影响到session B。
这里在代码实现上有一个特别的逻辑,如果当前会话已经处于某一个db里面,之前use这个库的时候拿到的库权限会保存在会话变量中。
你可以看到在T6时刻,session C和session B对表t的操作逻辑是一样的。但是session B报错,而session C可以执行成功。这是因为session C在T2 时刻执行的use db1,拿到了这个库的权限,在切换出db1库之前,session C对这个库就一直有权限。
表权限和列权限
除了db级别的权限外,MySQL支持更细粒度的表权限和列权限。其中,表权限定义存放在表mysql.tables_priv中,列权限定义存放在表mysql.columns_priv中。这两类权限,组合起来存放在内存的hash结构column_priv_hash中。
这两类权限的赋权命令如下:
create table db1.t1(id int, a int);
grant all privileges on db1.t1 to ''ua''@''%'' with grant option;
GRANT SELECT(id), INSERT (id,a) ON mydb.mytbl TO ''ua''@''%'' with grant option;
跟db权限类似,这两个权限每次grant的时候都会修改数据表,也会同步修改内存中的hash结构。因此,对这两类权限的操作,也会马上影响到已经存在的连接。
看到这里,你一定会问,看来grant语句都是即时生效的,那这么看应该就不需要执行flush privileges语句了呀。
答案也确实是这样的。
flush privileges命令会清空acl_users数组,然后从mysql.user表中读取数据重新加载,重新构造一个acl_users数组。也就是说,以数据表中的数据为准,会将全局权限内存数组重新加载一遍。
同样地,对于db权限、表权限和列权限,MySQL也做了这样的处理。
也就是说,如果内存的权限数据和磁盘数据表相同的话,不需要执行flush privileges。而如果我们都是用grant/revoke语句来执行的话,内存和数据表本来就是保持同步更新的。
因此,正常情况下,grant命令之后,没有必要跟着执行flush privileges命令。
flush privileges使用场景
那么,flush privileges是在什么时候使用呢?显然,当数据表中的权限数据跟内存中的权限数据不一致的时候,flush privileges语句可以用来重建内存数据,达到一致状态。
这种不一致往往是由不规范的操作导致的,比如直接用DML语句操作系统权限表。我们来看一下下面这个场景:

图4 使用flush privileges
可以看到,T3时刻虽然已经用delete语句删除了用户ua,但是在T4时刻,仍然可以用ua连接成功。原因就是,这时候内存中acl_users数组中还有这个用户,因此系统判断时认为用户还正常存在。
在T5时刻执行过flush命令后,内存更新,T6时刻再要用ua来登录的话,就会报错“无法访问”了。
直接操作系统表是不规范的操作,这个不一致状态也会导致一些更“诡异”的现象发生。比如,前面这个通过delete语句删除用户的例子,就会出现下面的情况:
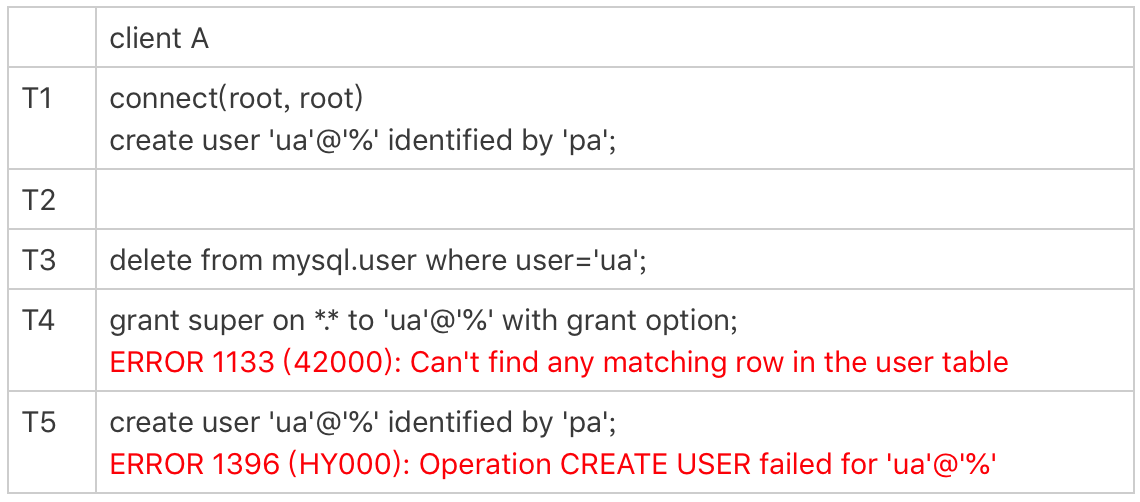
图5 不规范权限操作导致的异常
可以看到,由于在T3时刻直接删除了数据表的记录,而内存的数据还存在。这就导致了:
-
T4时刻给用户ua赋权限失败,因为mysql.user表中找不到这行记录;
-
而T5时刻要重新创建这个用户也不行,因为在做内存判断的时候,会认为这个用户还存在。
-
drop才会同时从内存和磁盘删除用户信息,但是delete只是从磁盘删除 。
小结
今天这篇文章,我和你介绍了MySQL用户权限在数据表和内存中的存在形式,以及grant和revoke命令的执行逻辑。
grant语句会同时修改数据表和内存,判断权限的时候使用的是内存数据。因此,规范地使用grant和revoke语句,是不需要随后加上flush privileges语句的。
flush privileges语句本身会用数据表的数据重建一份内存权限数据,所以在权限数据可能存在不一致的情况下再使用。而这种不一致往往是由于直接用DML语句操作系统权限表导致的,所以我们尽量不要使用这类语句。
另外,在使用grant语句赋权时,你可能还会看到这样的写法:
grant super on *.* to ''ua''@''%'' identified by ''pa'';
这条命令加了identified by ‘密码’, 语句的逻辑里面除了赋权外,还包含了:
-
如果用户’ua’@’%''不存在,就创建这个用户,密码是pa;
-
如果用户ua已经存在,就将密码修改成pa。
这也是一种不建议的写法,因为这种写法很容易就会不慎把密码给改了。

要不要使用分区策略
我经常被问到这样一个问题:分区表有什么问题,为什么公司规范不让使用分区表呢?今天,我们就来聊聊分区表的使用行为,然后再一起回答这个问题。
分区表是什么?
为了说明分区表的组织形式,我先创建一个表t:
CREATE TABLE `t` (
`ftime` datetime NOT NULL,
`c` int(11) DEFAULT NULL,
KEY (`ftime`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
PARTITION BY RANGE (YEAR(ftime))
(PARTITION p_2017 VALUES LESS THAN (2017) ENGINE = InnoDB,
PARTITION p_2018 VALUES LESS THAN (2018) ENGINE = InnoDB,
PARTITION p_2019 VALUES LESS THAN (2019) ENGINE = InnoDB,
PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE = InnoDB);
insert into t values(''2017-4-1'',1),(''2018-4-1'',1);

图1 表t的磁盘文件
我在表t中初始化插入了两行记录,按照定义的分区规则,这两行记录分别落在p_2018和p_2019这两个分区上。
可以看到,这个表包含了一个.frm文件和4个.ibd文件,每个分区对应一个.ibd文件。也就是说:
- 对于引擎层来说,这是4个表;
- 对于Server层来说,这是1个表。
你可能会觉得这两句都是废话。其实不然,这两句话非常重要,可以帮我们理解分区表的执行逻辑。
分区表的引擎层行为
我先给你举个在分区表加间隙锁的例子,目的是说明对于InnoDB来说,这是4个表。
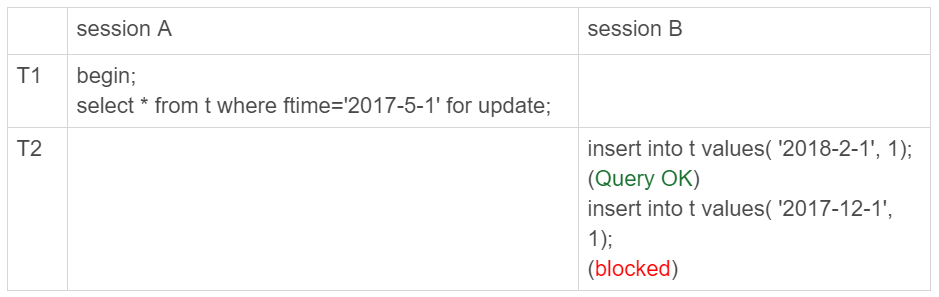
图2 分区表间隙锁示例
这里顺便复习一下间隙锁加锁规则。
我们初始化表t的时候,只插入了两行数据, ftime的值分别是,‘2017-4-1’ 和’2018-4-1’ 。session A的select语句对索引ftime上这两个记录之间的间隙加了锁。如果是一个普通表的话,那么T1时刻,在表t的ftime索引上,间隙和加锁状态应该是图3这样的。
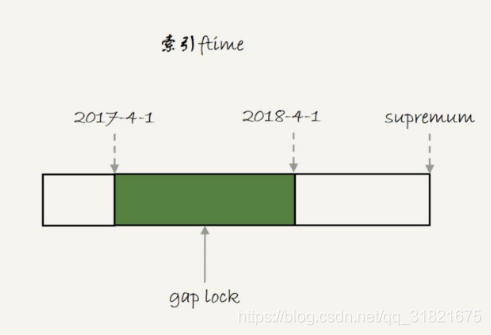
图3 普通表的加锁范围
也就是说,‘2017-4-1’ 和’2018-4-1’ 这两个记录之间的间隙是会被锁住的。那么,sesion B的两条插入语句应该都要进入锁等待状态。
但是,从上面的实验效果可以看出,session B的第一个insert语句是可以执行成功的。这是因为,对于引擎来说,p_2018和p_2019是两个不同的表,也就是说2017-4-1的下一个记录并不是2018-4-1,而是p_2018分区的supremum。所以T1时刻,在表t的ftime索引上,间隙和加锁的状态其实是图4这样的:
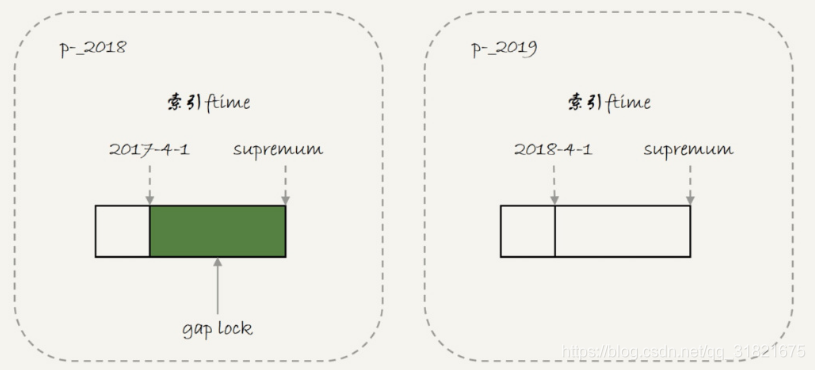
图4 分区表t的加锁范围
由于分区表的规则,session A的select语句其实只操作了分区p_2018,因此加锁范围就是图4中深绿色的部分。
所以,session B要写入一行ftime是2018-2-1的时候是可以成功的,而要写入2017-12-1这个记录,就要等session A的间隙锁。
图5就是这时候的show engine innodb status的部分结果。

图5 session B被锁住信息
看完InnoDB引擎的例子,我们再来一个MyISAM分区表的例子。
我首先用alter table t engine=myisam,把表t改成MyISAM表;然后,我再用下面这个例子说明,对于MyISAM引擎来说,这是4个表。
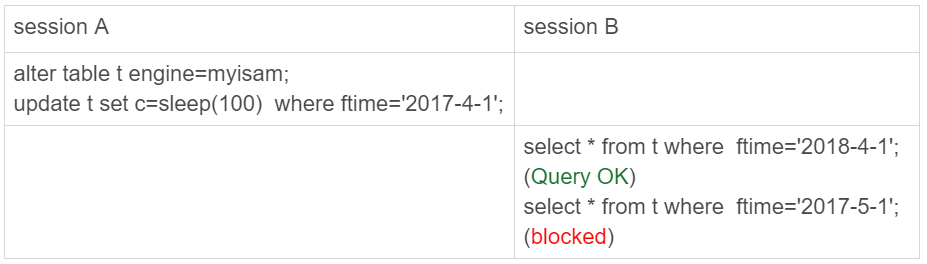
图6 用MyISAM表锁验证
在session A里面,我用sleep(100)将这条语句的执行时间设置为100秒。由于MyISAM引擎只支持表锁,所以这条update语句会锁住整个表t上的读。
但我们看到的结果是,session B的第一条查询语句是可以正常执行的,第二条语句才进入锁等待状态。
这正是因为MyISAM的表锁是在引擎层实现的,session A加的表锁,其实是锁在分区p_2018上。因此,只会堵住在这个分区上执行的查询,落到其他分区的查询是不受影响的。
看到这里,你可能会说,分区表看来还不错嘛,为什么不让用呢?我们使用分区表的一个重要原因就是单表过大。那么,如果不使用分区表的话,我们就是要使用手动分表的方式。
接下来,我们一起看看手动分表和分区表有什么区别。
比如,按照年份来划分,我们就分别创建普通表t_2017、t_2018、t_2019等等。手工分表的逻辑,也是找到需要更新的所有分表,然后依次执行更新。在性能上,这和分区表并没有实质的差别。
分区表和手工分表,一个是由server层来决定使用哪个分区,一个是由应用层代码来决定使用哪个分表。因此,从引擎层看,这两种方式也是没有差别的。
其实这两个方案的区别,主要是在server层上。从server层看,我们就不得不提到分区表一个被广为诟病的问题:打开表的行为。
分区策略
每当第一次访问一个分区表的时候,MySQL需要把所有的分区都访问一遍。一个典型的报错情况是这样的:如果一个分区表的分区很多,比如超过了1000个,而MySQL启动的时候,open_files_limit参数使用的是默认值1024,那么就会在访问这个表的时候,由于需要打开所有的文件,导致打开表文件的个数超过了上限而报错。
下图就是我创建的一个包含了很多分区的表t_myisam,执行一条插入语句后报错的情况。

图 7 insert 语句报错
可以看到,这条insert语句,明显只需要访问一个分区,但语句却无法执行。
这时,你一定从表名猜到了,这个表我用的是MyISAM引擎。是的,因为使用InnoDB引擎的话,并不会出现这个问题。
MyISAM分区表使用的分区策略,我们称为通用分区策略(generic partitioning),每次访问分区都由server层控制。通用分区策略,是MySQL一开始支持分区表的时候就存在的代码,在文件管理、表管理的实现上很粗糙,因此有比较严重的性能问题。
从MySQL 5.7.9开始,InnoDB引擎引入了本地分区策略(native partitioning)。这个策略是在InnoDB内部自己管理打开分区的行为。
MySQL从5.7.17开始,将MyISAM分区表标记为即将弃用(deprecated),意思是“从这个版本开始不建议这么使用,请使用替代方案。在将来的版本中会废弃这个功能”。
从MySQL 8.0版本开始,就不允许创建MyISAM分区表了,只允许创建已经实现了本地分区策略的引擎。目前来看,只有InnoDB和NDB这两个引擎支持了本地分区策略。
接下来,我们再看一下分区表在server层的行为。
分区表的server层行为
如果从server层看的话,一个分区表就只是一个表。
这句话是什么意思呢?接下来,我就用下面这个例子来和你说明。如图8和图9所示,分别是这个例子的操作序列和执行结果图。
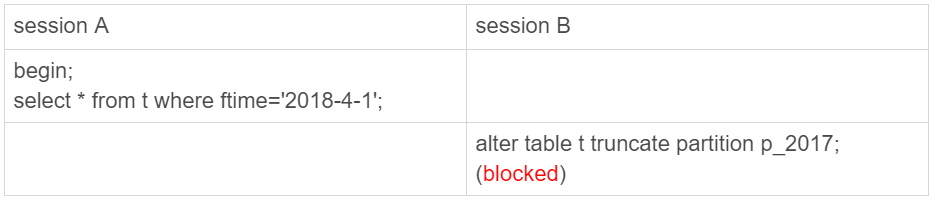
图8 分区表的MDL锁

图9 show processlist结果
可以看到,虽然session B只需要操作p_2107这个分区,但是由于session A持有整个表t的MDL锁,就导致了session B的alter语句被堵住。
这也是DBA同学经常说的,分区表,在做DDL的时候,影响会更大。如果你使用的是普通分表,那么当你在truncate一个分表的时候,肯定不会跟另外一个分表上的查询语句,出现MDL锁冲突。
到这里我们小结一下:
-
MySQL在第一次打开分区表的时候,需要访问所有的分区;
-
在server层,认为这是同一张表,因此所有分区共用同一个MDL锁;
-
在引擎层,认为这是不同的表,因此MDL锁之后的执行过程,会根据分区表规则,只访问必要的分区。
而关于“必要的分区”的判断,就是根据SQL语句中的where条件,结合分区规则来实现的。比如我们上面的例子中,where ftime=‘2018-4-1’,根据分区规则year函数算出来的值是2018,那么就会落在p_2019这个分区。
但是,如果这个where 条件改成 where ftime>=‘2018-4-1’,虽然查询结果相同,但是这时候根据where条件,就要访问p_2019和p_others这两个分区。
如果查询语句的where条件中没有分区key,那就只能访问所有分区了。当然,这并不是分区表的问题。即使是使用业务分表的方式,where条件中没有使用分表的key,也必须访问所有的分表。
我们已经理解了分区表的概念,那么什么场景下适合使用分区表呢?
分区表的应用场景
分区表的一个显而易见的优势是对业务透明,相对于用户分表来说,使用分区表的业务代码更简洁。还有,分区表可以很方便的清理历史数据。
如果一项业务跑的时间足够长,往往就会有根据时间删除历史数据的需求。这时候,按照时间分区的分区表,就可以直接通过alter table t drop partition …这个语法删掉分区,从而删掉过期的历史数据。
这个alter table t drop partition …操作是直接删除分区文件,效果跟drop普通表类似。与使用delete语句删除数据相比,优势是速度快、对系统影响小。
小结
这篇文章,我主要和你介绍的是server层和引擎层对分区表的处理方式。我希望通过这些介绍,你能够对是否选择使用分区表,有更清晰的想法。
需要注意的是,我是以范围分区(range)为例和你介绍的。实际上,MySQL还支持hash分区、list分区等分区方法。你可以在需要用到的时候,再翻翻手册。
实际使用时,分区表跟用户分表比起来,有两个绕不开的问题:一个是第一次访问的时候需要访问所有分区,另一个是共用MDL锁。
因此,如果要使用分区表,就不要创建太多的分区。我见过一个用户做了按天分区策略,然后预先创建了10年的分区。这种情况下,访问分区表的性能自然是不好的。这里有两个问题需要注意:
-
分区并不是越细越好。实际上,单表或者单分区的数据一千万行,只要没有特别大的索引,对于现在的硬件能力来说都已经是小表了。
-
分区也不要提前预留太多,在使用之前预先创建即可。比如,如果是按月分区,每年年底时再把下一年度的12个新分区创建上即可。对于没有数据的历史分区,要及时的drop掉。
至于分区表的其他问题,比如查询需要跨多个分区取数据,查询性能就会比较慢,基本上就不是分区表本身的问题,而是数据量的问题或者说是使用方式的问题了。
当然,如果你的团队已经维护了成熟的分库分表中间件,用业务分表,对业务开发同学没有额外的复杂性,对DBA也更直观,自然是更好的。
最后,我给你留下一个思考题吧。
我们举例的表中没有用到自增主键,假设现在要创建一个自增字段id。MySQL要求分区表中的主键必须包含分区字段。如果要在表t的基础上做修改,你会怎么定义这个表的主键呢?为什么这么定义呢?
本文同步分享在 博客“SoWhat1412”(CSDN)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
环境配置方法")
mysql 5.6.14主从复制(也称mysql AB复制)环境配置方法
一、MysqL主(称master)从(称slave)复制的原理:
(1).master将数据改变记录到二进制日志(binary log)中,也即是配置文件log-bin指定的文件(这些记录叫做二进制日志事件,binary log events)
(2).slave将master的binary log events拷贝到它的中继日志(relay log)
(3).slave重做中继日志中的事件,将改变反映它自己的数据(数据重演)
附简要原理图:

二、MysqL主从复制支持的类型:
(1).基于语句的复制:在主服务器上执行的sql语句,在从服务器上执行同样的语句.MysqL默认采用基于语句的复制,效率比较高
word-spacing: 0px"> (2).基于行的复制:把改变的内容直接复制过去,而不关心到底改变该内容是由哪条语句引发的 . 从MysqL5.0开始支持
word-spacing: 0px"> (3).混合类型的复制: 默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制.
三、主从配置需要注意的地方:
(1).主DB server和从DB server数据库的版本一致
(2).主DB server和从DB server数据库数据一致[ 这里就会可以把主的备份在从上还原,也可以直接将主的数据目录拷贝到从的相应数据目录]
(3).主DB server开启二进制日志,主DB server和从DB server的server_id都必须唯一
四、主从配置的简要步骤:
附简要示意图:

1.主DB SERVER上的配置
(1).安装数据库
(2).修改数据库配置文件,指明server_id,开启二进制日志(log-bin)
(3).启动数据库,查看当前是哪个日志,position号是多少
(4).登陆数据库,授权用户[ip地址为从机IP地址,如果是双向主从,这里的还需要授权本机的IP地址(此时自己的IP地址就是从IP地址)]
(5).备份数据库[记得加锁和解锁]
(6).传送备份到从DB server上
(7).启动数据库
以下步骤,为单向主从搭建成功,想搭建双向主从需要的步骤:
(1).登陆数据库,指定主DB server的地址,用户,密码等信息[此步仅双向主从时,需要]
(2).开启同步,查看状态
2.从DB SERVER上的配置
(1).安装数据库
(2).修改数据库配置文件,指明server_id[如果是搭建双向主从的话,也要开启二进制日志(log-bin)]
(3).启动数据库,还原备份
(4).查看当前是哪个日志,position号是多少[单向主从此步不需要,双向主从需要]
(5).指定主DB server的地址,密码等信息
(6).开启同步,查看状态
五、单向主从环境[也称 MysqL A/B复制]的搭建案例:
1.主DB server和从DB server都安装相应版本的数据库,我的两台DB server都已经安装好(5.6.14版本),都会是双实例,这里就不演示安装,可以参考MysqL源码编译安装和MysqL多实例配置两篇文章
注:两台机器的的selinux都是disable(永久关闭selinux,请修改/etc/selinux/config,将SELINUX改为disabled),防火墙可以选择关闭,开启的话也行[不行的话,添加防火墙策略]
2.修改主DB server的配置文件(/etc/my.cnf),开启日志功能,设置server_id值,保证唯一[client102为主DB server]
[root@client102 scripts]# vim /etc/my.cnf # 修改配置文件里,下面两个参数: # 设置server_id,一般建议设置为IP,或者再加一些数字 server_id =102 # 开启二进制日志功能,可以随便取,最好有含义 log-bin=MysqL3306-bin
3.启动数据库服务器,并登陆数据库,授予相应的用户用于同步
# 我这里是多实例MysqL,所以启动是这样的,如果大家是单实例的,就直接启动就可以[/etc/init.d/MysqLd start] [root@client102 scripts]# MysqLd_multi start 3306 # 登陆MysqL 服务器 [root@client102 scripts]# MysqL -uroot -S /usr/local/MysqL/MysqLd3306.sock -p # 授予用户权限用于主从同步 MysqL> grant replication slave on *.* to 'kongzhong'@'192.168.1.100' identified by 'kongzhong'; Query OK,0 rows affected (0.00 sec) # 刷新授权表信息 MysqL> flush privileges; Query OK,0 rows affected (0.00 sec) # 查看position 号,记下position 号(很重要,从机上需要这个position号和现在的日志文件,我这里是414和MysqL3306-bin.000001) MysqL> show master status; +----------------------+----------+--------------+------------------+-------------------+ | File | Position | binlog_Do_DB | binlog_Ignore_DB | Executed_Gtid_Set | +----------------------+----------+--------------+------------------+-------------------+ | MysqL3306-bin.000001 | 414 | | | | +----------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec)
4.为保证主DB server和从DB server的数据一致,这里采用主备份,从还原来实现初始数据一致
# 临时锁表
MysqL> flush tables with read lock;
# 我这里实行的全库备份,在实际中,我们可能只同步某一个库,可以只备份一个库
# 新开一个终端,执行如下操作
[root@client102 data]# MysqLdump -p3306 -uroot -p -S /usr/local/MysqL/MysqLd3306.sock --all-databases > /tmp/MysqL.sql
# 解锁
MysqL> unlock tables;
# 将备份的数据传送到从机上,用于恢复
[root@client102 data]# scp /tmp/MysqL.sql root@192.168.1.100:/tmp
5.从DB server配置文件只需修改一项,其余用命令行做
[root@client100 ~]# vim /etc/my.cnf
# 设置server_id,或者再加一些数字
server_id =100