在本文中,我们将带你了解MySql在这篇文章中,我们将为您详细介绍MySql的方方面面,并解答二常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的8.19MySQL(二)、Django连接My
在本文中,我们将带你了解MySql在这篇文章中,我们将为您详细介绍MySql的方方面面,并解答二常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的8.19MySQL(二)、Django连接MySQL(二)、Django:模型 model 和数据库 mysql(二)、Go 操作 Mysql(二)。
本文目录一览:(mysql二级考试真题)")
MySql(二)(mysql二级考试真题)
MySQL查询
基本数据查询
全表查询
select * from tableName;

查询部分字段
select Field from tableName;

计数1
select count(*) from tableName;

计数2
select count(1) from tableName;

条件过滤
and (并且)
select * from tableName where 条件1 and 条件2;

or(或者)
select * from tableName where 条件1 or 条件2;

in(包含)
select * from tableName where Field in(value1,value2);

between ··· and ···(范围检查)
select * from tableName where Field between a and b;

not (否定结果)
select * from tableName where Field not in(value1,value2);

select * from tableName where Field not between a and b;

%(匹配任意字符)
select * from tableName where Field like "要匹配的字符%";

^(匹配以···开头的字符)
select * from tableName where Field rlike "^要匹配的字符";

$(匹配以···结尾的字符)
select * from tableName where Field rlike "要匹配的字符$";

")
8.19MySQL(二)
一、存储引擎
不同的数据应该有不同的处理机制
1.mysql存储引擎
Innodb:默认的存储引擎,查询速度较myisam慢,但是更安全
myisam:mysql老版本用的存储引擎
memory:内存引擎(数据全部存在内存中)
blackhole:无论存什么,都立马消失(黑洞)
2.查看所有的存储引擎
show engines;
3.研究一下每个存储引擎存取数据的特点
(1)Innodb:两个文件,一个是表结构文件,一个是真实数据文件

(2)myisam:三个文件,表结构文件,真实数据文件,索引文件(目录)

(3)memory:一个文件,表结构文件

(4)blackhole:一个文件,表结构文件

二、创建表的完整性约束
1.创建表的完整语法
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);注意:
(1)字段名和字段类型是必须的 中括号内的参数都是可选参数
(2)同一张表中字段名不能重复
(3)最后一个字段后面不能加逗号,例如:
create table t6(
id int,
name char,
); # 错误宽度:
(1)使用数据库的准则:能尽量让它少干活就尽量少干活
(2)对存储数据的限制:char(1),只能存一个字符
1.如果超了,mysql会自动帮你截取
2.会直接报错(mysql严格模式)
类型和中括号内的约束条件有什么区别:
类型约束的是数据的存储类型
而约束条件是基于类型之上的额外限制
2.约束条件:如何限制一个字段不能插空
alter table t5 modify name char not null;
not null 约束条件,该字段不能插空
三、严格模式
我们刚刚在上面设置了char,tinyint,存储数据时超过它们的最大存储长度,发现数据也能正常存储进去,只是mysql帮我们自动截取了最大长度。但在实际情况下,我们应该尽量减少数据库的操作,缓解数据库的压力,让它仅仅只管理数据即可,这样的情况下就需要设置安全模式
1.模糊匹配
like
%匹配任意多个字符
_匹配任意一个字符
show variables like "%mode%"; # 查看数据库配置中变量名包含mode的配置参数
2.修改严格模式
set session:临时有效,只在你当前操作的窗口有效
set global:全局有效,终生有效
set global sql_mode = ''STRICT_TRANS_TABLES'';
修改完之后退出当前客户端重新登陆即可
四、字段类型
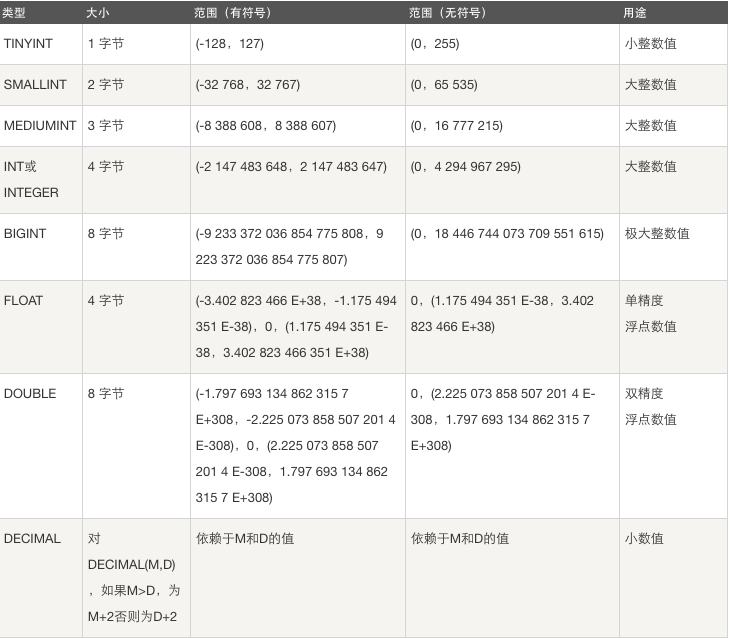
1.整型
SMALLINT、TINYINT、INT、BIGINT
TINYINT
create table t6(id TINYINT);
默认是带有符号的(-128,127)
超出之后只会存最大值或者最小值
怎样改成无符号
alter table t6 modify id TINYINT unsigned;
就改成无符号的(0,255)
INT
也是默认带有符号的
超出之后只会存最大值或者最小值
改成无符号与上方法一致
括号内的数字
char后面的数字是用来限制存储数据的长度的
特例:
只有整型后面的数字不是用来限制存储数据的长度,而是用来控制展示的数据的位数
int(8):够/超8位有几位存几位,不够8位空格填充
zerofill:修改约束条件,不够8位的情况下,用0填充
强调:
***对于整型来说,数据类型后的宽度并不是存储限制,而是显示限制,所以在创建表时,如果字段采用的是整型类型,完全无需指定显示宽度, 默认的显示宽度,足够显示完整当初存放的数据
只要是整型,都不需要指定宽度,因为有默认的宽度,足够显示对应的数据
约束条件:
not null 不能为空
unsigned 无正负符号
zerofill 0填充多余的位数
2.浮点型
float(255,30):总共255位,小数部分占30位
double(255,30):总共255位,小数部分占30位
decimal(65,30):总共65位,小数部分占30位
前一位表示所有的位数,后一位表示小数个数
精确度
验证
create table t12(id FLOAT(255,30));
create table t13(id DOUBLE(255,30));
create table t14(id DECIMAL(65,30));
insert into t12 values(1.111111111111111111111111111111);
insert into t13 values(1.111111111111111111111111111111);
insert into t14 values(1.111111111111111111111111111111);精确度:float < double < decimal
3.字符类型
char(4):最大只能存四个字符,超出来会直接报错,如果少了,会自动用空格填充
varchar(4):最大只能存四个字符,超出来会直接报错,如果少了,有几个存几个
create table t15(name char(4));
create table t16(name varchar(4));char_length():获取一个字符的长度
mysql在存储char类型字段的时候,硬盘上确确实实存的是固定长度的数据,但是在取出来的那一瞬间,mysql会自动将填充的空格去除
可以通过严格模式,来修改该机制,然后退出客户端重新登陆,这样mysql就不做自动去除末尾空格的操作,
set global sql_mode="strict_trans_tables,PAD_CHAR_TO_FULL_LENGTH";char与varchar的使用区别
name char(5):char定长
优点:存取速度都快
缺点:浪费空间
name varchar(5):varchar变长
优点:节省空间
缺点:存取速度慢(较于char比较慢)
存的时候,需要给数据讲一个记录长度的报头
取的时候,需要先读取报头才能读取真实数据
4.日期类型
date:2019-05-01 年月日
datetime: 2019-01-02 11:11:11 年月日时分秒
time:11:11:11 时分秒
year:2019 年
测试:
create table student(
id int,
name char(16),
born_year year,
birth date,
study_time time,
reg_time datetime
);
insert into student values(1,''egon'',''2019'',''2019-05-09'',''11:11:00'',''2019-11-11 11:11:11'');5.枚举与集合类型
分类
枚举enum:多选一
集合set:多选多
测试
create table user(
id int,
name char(16),
gender enum(''male'',''female'',''others'')
);
insert into user values(1,''jason'',''xxx'') # 报错
insert into user values(2,''egon'',''female'') # 正确!
create table teacher(
id int,
name char(16),
gender enum(''male'',''female'',''others''),
hobby set(''read'',''sleep'',''sanna'',''dbj'')
);
insert into teacher values(1,''egon'',''male'',''read,sleep,dbj'') # 集合也可以只存一个五、约束条件
1.not null:不能为空
2.default:给某个字段设置默认值(当用户写了的时候用用户的,当用户没有写就用默认值)
create table t17(id int,name char(16) default ''jason'');
往表中插入数据的时候,可以指定字段进行插入,不需要全部都插入
insert into t17(name,id) values(''egon'',2);
3.unique:唯一
单列唯一:限制某一个字段是唯一的
create table user1(
id int unique,
name char(16)
);
insert into user1 values(1,''jason''),(1,''egon'') # 报错
insert into user1 values(1,''jason''),(2,''egon'') # 成功联合唯一:在语句的最后,用括号的形式,表示哪几个字段组合的结果是唯一的
create table server(
id int,
ip char(16),
port int,
unique(ip,port)
)
insert into server values(1,''127.0.0.1'',8080);
insert into server values(2,''127.0.0.1'',8080); # 报错
insert into server values(1,''127.0.0.1'',8081);4.primary key:主键
限制效果跟 not null + unique 组合效果一致,非空且唯一
create table t11(id int primary key);
desc t11;
insert into t11 values(1),(1); # 报错
insert into t11 values(1),(2);primary key也是innodb引擎查询必备的索引
innodb引擎在创建表的时候,必须要有一个主键
当你没有指定主键的时候
1.会将非空且唯一的字段自动升级成主键
2.当你的表中没有任何的约束条件,innodb会采用自己内部默认的一个主键字段
该主键字段你在查询时候是无法使用的
查询数据的速度就会很慢
类似于一页一页的翻书
create table t12(
id int,
name char(16),
age int not null unique,
addr char(16) not null unique
);主键字段到底该设置给谁
通常每张表里面都应该有一个id字段
并且应该将id设置为表的主键字段
联合主键
***多个字段联合起来作为表的一个主键,本质还是一个主键***
***PS:innodb引擎中一张表有且只有一个主键***
主键字段应该具备自动递增的特点:primary key auto_increment
主键id作为数据的编号,每次最好能自动递增
每次添加数据,不需要用户手动输入
auto_increment:自动递增
create table t13(
id int primary key auto_increment,
name char(16)
);
insert into t13(''jason''),(''jason''),(''jason''); # id字段自动从1开始递增
# 注意:auto_increment通常都是加在主键上,并且只能给设置为key的字段加补充:
delete from t21; 仅仅是删除数据,不会重置主键
这条命令确实可以将表里的所有记录都删掉,但不会将id重置为0,所以收该条命令根本不是用来清空表的,delete是用来删除表中某一些符合条件的记录
truncate t21; 初始化表,会重置主键
将整张表重置,id重新从0开始记录
")
Django连接MySQL(二)
1.首先我们需要创建好项目
2.安装MySQL数据库
3.setting中修改database设置
DATABASES = {
''default'': {
''ENGINE'': ''django.db.backends.mysql'',
''NAME'': ''CRM'',
''USER'':''root'',
''PASSWORD'':''admin'',
''HOST'':''localhost'',
''PORT'':''3306'',
}
}4.init中写入2行代码。不输入会当成未安装MySQLclient
告诉django用pymysql替换它默认mysqldb模块连接数据库

import pymysql
pymysql.install_as_MySQLdb()5.models.py中创建一个表
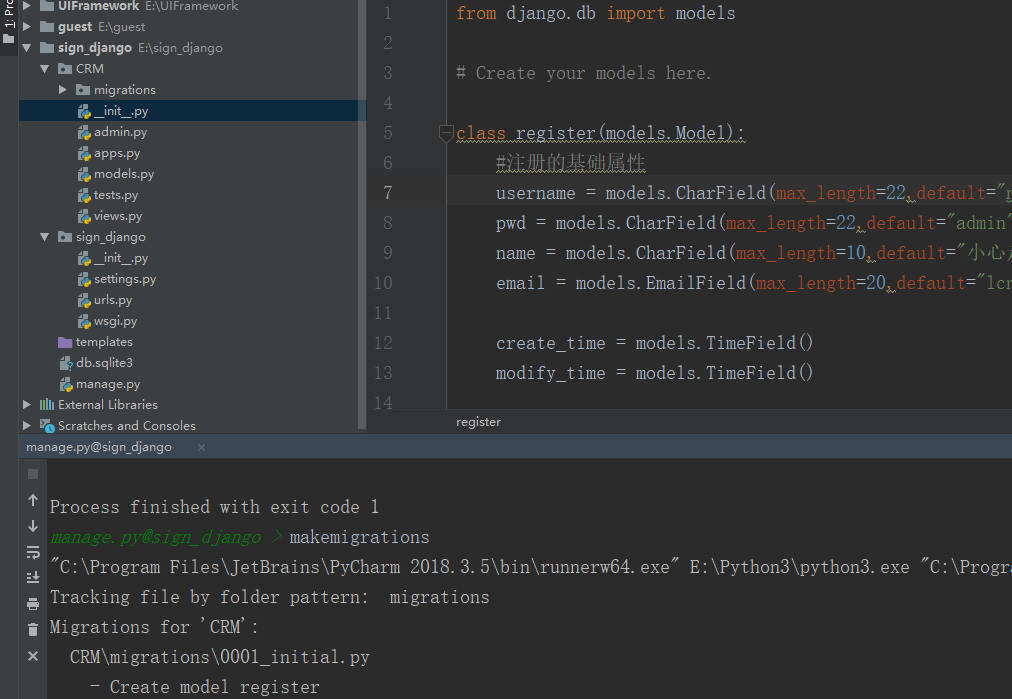
6.使用python manage.py makemifrations同步数据库
7.使用python manage.py migrate同步数据表
问题一。

解决办法:注释if version < (1,3,13): ...
问题二、未创建crm数据库

解决办法:create database crm
问题三、
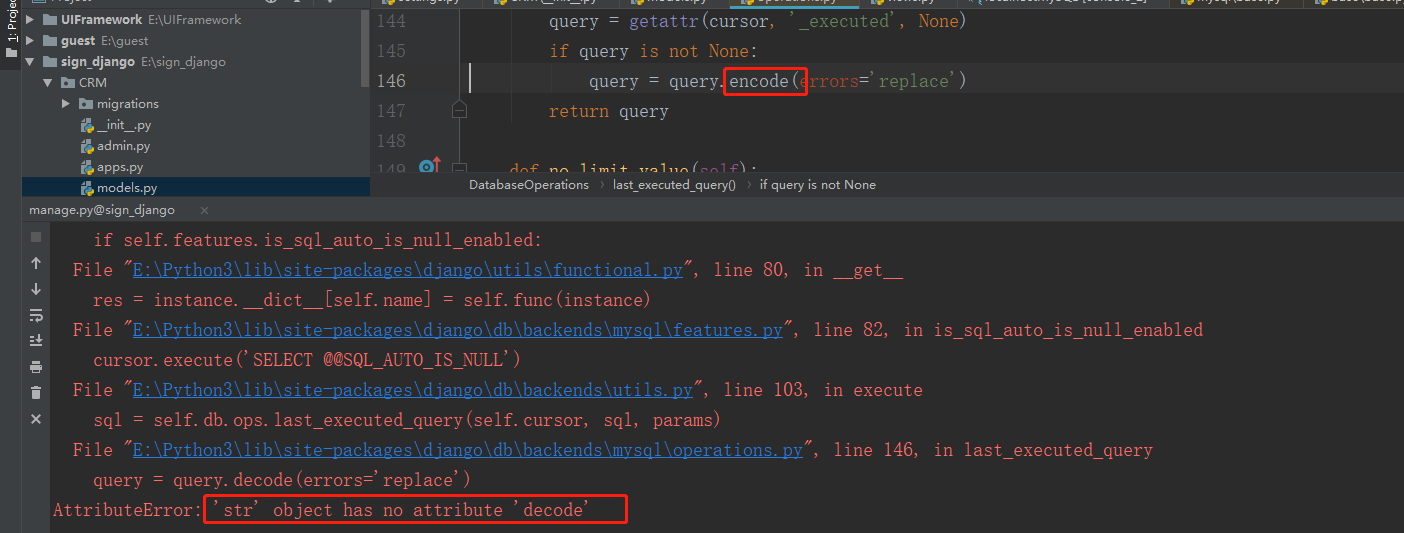
解决方法:decode修改为encode
")
Django:模型 model 和数据库 mysql(二)
上一篇把简单的模型与数据库的搭建写了一遍,但模型中有很多深入好用的写法补充一下。
同样的栗子,建立新的模型与数据库来写一写
1、依然是搭建环境
>>>django-admin startproject django2
>>>cd django2配置数据库、语言、地区
django2/settings.py
DATABASES = {
''default'': {
''ENGINE'': ''django.db.backends.mysql'',
''NAME'': ''django2'',
''USER'': ''root'',
''PASSWORD'': ''123456'',
''HOST'': ''localhost'',
''PORT'': ''3306''
}
}
LANGUAGE_CODE = ''zh-hans''
TIME_ZONE = ''Asia/Shanghai''# 创建应用
>>>python manage.py startapp booktest把该应用添加到 settings 中
django2/settings.py
INSTALLED_APPS = (
''django.contrib.admin'',
''django.contrib.auth'',
''django.contrib.contenttypes'',
''django.contrib.sessions'',
''django.contrib.messages'',
''django.contrib.staticfiles'',
''booktest''
)2、定义模型
booktest/models.py
class BookInfo(models.Model):
btitle = models.CharField(max_length = 20)
bpub_date = models.DateTimeField(db_column = ''pub_date'') # db_column指定在数据库中呈现的字段名称
bread = models.IntegerField(default = 0) # default指定默认值
bcomment = models.IntegerField(null = False) # null指示该字段是否为空 True可以为空 False不能为空
isDelete = models.BooleanField(default = False)
class Meta:
db_table = ''bookinfo'' # 指定数据库中生成的表明(默认是 应用名_模型类名 booktest_bookinfo)
def __str__(self):
return self.btitleclass HeroInfo(models.Model):
hname = models.CharField(max_length = 10)
hgender = models.BooleanField(default = True) # True:男 False:女
hcontent = models.CharField(max_length = 1000)
isDelete = models.BooleanField(default = False)
book = models.ForeignKey(BookInfo, on_delete = models.CASCADE)
def __str__(self):
return self.hname创建数据库 Django2 后
# 制作迁移
>>>python manage.py makemigrations
# 生成迁移
>>>python manage.py migrate自定义管理器场景一:修改默认查询集
booktest/models.py
class BookInfo(models.Model):
btitle = models.CharField(max_length = 20)
bpub_date = models.DateTimeField(db_column = ''pub_date'') # db_column指定在数据库中呈现的字段名称
bread = models.IntegerField(default = 0) # default指定默认值
bcomment = models.IntegerField(null = False) # null指示该字段是否为空 True可以为空 False不能为空
isDelete = models.BooleanField(default = False)
class Meta:
db_table = ''bookinfo'' # 指定数据库中生成的表明(默认是 应用名_模型类名 booktest_bookinfo)
def __str__(self):
return self.btitle
book1 = models.Manager() # 指定book1为模型类的管理器对象
book2 = BookInfoManager() # 用来下面写筛选
class HeroInfo(models.Model):
hname = models.CharField(max_length = 10)
hgender = models.BooleanField(default = True) # True:男 False:女
hcontent = models.CharField(max_length = 1000)
isDelete = models.BooleanField(default = False)
book = models.ForeignKey(BookInfo, on_delete = models.CASCADE)
def __str__(self):
return self.hname在 manage.py shell 中,通过命令
>>>from booktest.models import BookInfo, HeroInfo
# 导入模块
>>> BookInfo.book1.all()
# 查看所有的书的信息
# 注意:这样写了以后,默认的管理器objects就不存在了自定义管理器的场景二:添加创建的方法。
# 之前的写法
b = BookInfo()
b.btitle = ''射雕英雄传''
b.bpub_date = datetime(year = 2018, month = 8, day = 11)
b.save()现在提供一个 create() 方法,只需要传入参数,即可创建对象
这个 create() 方法可以写在 BookInfo 中,也可以写在 BookInfoManager 中。官方推荐写在 BookInfoManager 中。
class BookInfoManager(models.Manager):
def get_queryset(self):
return super(BookInfoManager,self).get_queryset().filter(isDelete = False)
def create(self, btitle, bpub_date):
b = BookInfo()
b.btitle = btitle
b.bpub_date = bpub_date
b.bread = 0
b.bcomment = 0
b.isDelete = False
return b# 注意python manage.py shell需要退出并重新进入。
# 测试代码:
from booktest.models import *
from datetime import datetime
b = BookInfo.book2.create(''程序员的自我修炼'',datetime(2018,9,12))
b.save()运行后,留意数据库的 bookinfo 表多了程序员的自我修炼一行
3、模型查询
''''''
返回查询集合的方法,称为过滤器
all():获取所有的数据
filter():获取满足条件的数据
exclude():获取不满足条件的是数据
''''''
# 注意:如果使用and与操作同时过滤两个条件,可以使用如下两种方法之一
>>>BookInfo.book1.filter(bread__gt=22, bcomment__lt=50)
>>>BookInfo.book1.filter(bread__gt=22).filter(bcomment__lt=50)
# order_by():排序
>>>BookInfo.book1.all().order_by("bread")
# values():把一个对象构建成一个字典。最后返回一个列表
>>>BookInfo.book1.values()
''''''
返回单个值的方法:
get():返回单个满足条件的对象
如果返回多个数,会抛出MultipleObjectsReturned异常
如果未找到,会抛出DoesNotExist异常
''''''
>>>BookInfo.book1.get(btitle=''雪山飞狐'')
#count():返回当前查询的总条数(返回一个整数)
>>>BookInfo.book1.all().count()
# first():返回第一个对象
# last():返回最后一个对象
>>>BookInfo.book1.all().first()
>>>BookInfo.book1.all().last()
# exists():判断查询集中是否有数据,如果有返回True
>>>BookInfo.book1.filter(bread__gt=20).exists()
''''''
方法filter()、exclude()、get()……可以添加子查询运算符
比较运算符。格式为:
属性名_ _比较运算符 = 值
''''''
# exact:表示判断相等。如果没有写比较运算符,默认则是exact。
# 所以下面两句是等效的
>>>BookInfo.book1.filter(bread__exact=20)
>>>BookInfo.book1.filter(bread=20)
# contains:是否包含
>>>BookInfo.book1.filter(btitle__contains=''传'')
#startswith:以某个子串开头
# endswith:以某个子串结尾
>>>BookInfo.book1.filter(btitle__startswith=''传'')
>>>BookInfo.book1.filter(btitle__endswith=''传'')
# isnull:为空
#i snotnull:不为空
>>>BookInfo.book1.filter(btitle__isnull=False)
# 注意:前面的操作都是区分大小写的。如果不区分大小写,可以在前面加上i。比如iexact、icontains、istartswith、iendswith等
# in:是否包含在范围内
>>>BookInfo.book1.filter(pk__in=[1,2,3])
>>>BookInfo.book1.filter(id__in=[1,2,3])
''''''
gt:大于(Greater Than)
gte:大于等于(Greater Than or Equal)
lt:小于(Little Than)
lte:小于等于(Little Than or Equal)
''''''
>>>BookInfo.book1.filter(bread__gte=20)
# 注意:这些操作也可以对日期进行判断。包括year month day week_day hour minute second
>>>from datetime import date
>>>BookInfo.book1.filter(bpub_date__gt=date(1985,12,31))
# 跨表查询
# 语法:模型类名_ _属性名_ _比较
>>>BookInfo.book1.filter(heroinfo__hcontent__contains=''八'')
")
Go 操作 Mysql(二)
查询数据方法回顾整理
上一篇博客中,主要是快速过了一遍 demo 代码和 DB 类型对象中方法的使用
在整理查询数据方法的时候,使用了 Query() 方法,其实 sqlx 还提供了 QueryRow() 方法,查询单行记录,以及 Queryx() 和 QueryRowx() 方法,将查询的结果保存到结构体
所以我们通过 DB 查询数据的方法一共就有三对:
- Query() 和 QueryRow() 分别返回 sql.Rows 和 sql.Row 类型
- Queryx() 和 QueryRowx() 分别返回 sql.Rows 和 sql.Row 类型,支持将查询记录保存到结构体
- Get() 和 Select() 将查询记录保存到结构体 和 结构体切片中
Query() 方法
func (db *DB) Query(query string, args ...interface{}) (*Rows, error)使用场景:查询字段较少的情况下使用,比如 select uid, username from userinfo; 这样的语句,如果是 select * from userinfo,就使用 Get() 或 Select() 好了
Query() 返回的结果集是 sql.Rows 类型,它有一个 Next() 方法,可以迭代数据库的游标,进而获取下一条记录,结果集使用完毕之后需要调用 rows.Close() 手动关闭连接
其实通过 for 循环迭代数据的时候,当迭代到最后一行记录时,会发出一个 io.EOF(与读文件类似),引发一个错误,同时 Go 会自动调用 rows.Close() 方法释放连接,然后返回 false,此时循环结束退出
通常情况下,会正常迭代完数据然后退出循环,可是如果因为循环语句中的其它错误导致退出了循环,此时 rows.Next() 处理结果集的过程并没有完成,归属于 rows 的数据库连接不会释放回到连接池,因此十分有必要正确的处理 rows 的连接,如果没有关闭 rows 连接,将导致大量的连接并且不会被其它方法重用,就像溢出了一样,最终导致数据库无法使用(提示数据库有过多的连接)
rows.Next循环迭代的时候,因为触发了io.EOF而退出循环。为了检查是否是迭代正常退出还是异常退出,需要检查rows.Err
package main
import (
"fmt"
_ "github.com/go-sql-driver/mysql"
"github.com/jmoiron/sqlx"
)
var (
userName string = "root"
password string = "seemmo"
ipAddrees string = "10.10.4.80"
port int = 3306
dbName string = "golang_db"
charset string = "utf8"
)
func connectMysql() *sqlx.DB {
dsn := fmt.Sprintf("%s:%s@tcp(%s:%d)/%s?charset=%s", userName, password, ipAddrees, port, dbName, charset)
Db, err := sqlx.Open("mysql", dsn)
if err != nil {
fmt.Printf("mysql connect failed, detail is [%v]", err.Error())
}
return Db
}
func queryData(Db *sqlx.DB) {
rows, err := Db.Query("select uid, username, create_time from userinfo")
if err != nil {
fmt.Printf("query data failed, error is [%v]", err.Error())
return
}
for rows.Next() {
var uid int
var userName, createTime string
err := rows.Scan(&uid, &userName, &createTime)
if err != nil {
fmt.Printf("scan data failed, error is [%v]", err.Error())
return
}
fmt.Println(uid, userName, createTime)
}
err = rows.Close()
if err != nil {
fmt.Println(err.Error())
}
}
func main (){
var Db *sqlx.DB = connectMysql()
defer Db.Close()
queryData(Db)
}
//运行结果:
//1 johny 2019-07-08 10:43:21
//2 anson 2019-07-08 10:52:46
QueryRow() 方法
func (db *DB) QueryRow(query string, args ...interface{}) *RowQuery() 方法是查询多行结果集的(sqlx.Rows),QueryRow() 方法用来查询单行结果集(sqlx.Row),不需要通过 Next() 方法迭代
QueryRow() 方法的返回值与 Query() 不同,它要么返回一个 sqlx.Row 类型,要么返回一个 error 类型,如果是发生了 error,则会延迟到 Scan() 方法调用结束后返回,如果没有错误,则 Scan 正常执行,只有当查询结果为空的时候,会触发一个 sqlx.ErrNoRows 错误,你可以先调用 Scan() 方法再检查错误(也可以先检查错误再调用 Scan() 方法)
在没有过滤条件的情况下,默认返回第一条数据,不用调用 Close() 方法释放连接(因为只有一条记录)
package main
import (
"fmt"
_ "github.com/go-sql-driver/mysql"
"github.com/jmoiron/sqlx"
"time"
)
var (
userName string = "root"
password string = "seemmo"
ipAddrees string = "10.10.4.80"
port int = 3306
dbName string = "golang_db"
charset string = "utf8"
)
func connectMysql() *sqlx.DB {
dsn := fmt.Sprintf("%s:%s@tcp(%s:%d)/%s?charset=%s", userName, password, ipAddrees, port, dbName, charset)
Db, err := sqlx.Open("mysql", dsn)
if err != nil {
fmt.Printf("mysql connect failed, detail is [%v]", err.Error())
}
return Db
}
func queryRow(Db *sqlx.DB) {
row := Db.QueryRow("select uid, username, create_time from userinfo")
var uid int
var userName, createTime string
err := row.Scan(&uid, &userName, &createTime)
if err != nil {
fmt.Printf("scan data failed, error is [%v]", err.Error())
return
}
fmt.Println(uid, userName, createTime)
}
func main (){
var Db *sqlx.DB = connectMysql()
defer Db.Close()
queryRow(Db)
}
运行结果:
1 johny 2019-07-08 10:43:21
查询方法补充
Queryx() 和 QueryRowx(),不仅支持 Scan() 方法,同时可将数据与结构体进行转换
1)Queryx()
func (db *DB) Queryx(query string, args ...interface{}) (*Rows, error)代码示例
func queryx(Db *sqlx.DB) {
//定义结构体保存数据
type userinfo struct {
Uid int `db:"uid"`
UserName string `db:"username"`
CreateTime string `db:"create_time"`
}
var userData userinfo
rows, err := Db.Queryx("select uid, username, create_time from userinfo")
if err != nil {
fmt.Printf("query data failed, error is [%v]", err.Error())
return
}
var userDataSlice []userinfo
for rows.Next() {
err := rows.StructScan(&userData)
if err != nil {
fmt.Printf("scan data failed, error is [%v]", err.Error())
return
}
userDataSlice = append(userDataSlice, userData)
}
fmt.Println(userDataSlice)
err = rows.Close()
if err != nil {
fmt.Println(err.Error())
}
}
运行结果:
[{1 johny 2019-07-08 14:05:40} {2 anson 2019-07-08 16:33:19}]
2)QueryRowx()
func (db *DB) QueryRowx(query string, args ...interface{}) *Row
代码示例
func queryRowx(Db *sqlx.DB) {
//定义结构体保存数据
type userinfo struct {
Uid int `db:"uid"`
UserName string `db:"username"`
CreateTime string `db:"create_time"`
}
var userData *userinfo = new(userinfo)
row := Db.QueryRowx("select uid, username, create_time from userinfo where uid = 1")
err := row.StructScan(userData)
if err != nil {
fmt.Printf("scan data failed, error is [%v]", err.Error())
}
fmt.Println(userData.Uid, userData.UserName, userData.CreateTime)
}
运行结果:
1 johny 2019-07-08 14:05:40
说了这么多,Query(),QueryRow() 不如 Get(),Select() 方法简洁
空值处理
Scan() 方法处理数据库中的 null
1)使用标准库中的数据类型
数据库中有一个特殊的类型,null 空值,可是 null 不能通过 scan 直接给变量赋值,也不能将 null 赋值给 nil,对于 null 必须指定特殊的类型,这些类型定义在 sqlx 扩展库中,例如 sql.NullFloat64,sql.NullString,sql.NullBool,sql.NullInt64,如果在扩展库中找不到匹配的值,可以尝试在驱动中寻找,下面的 demo,当数据表中 create_time 字段为 null 时,如果直接这样查询,会提示错误:
sql: Scan error on column index 2, name "create_time": unsupported Scan, storing driver.Value type <nil> into type *string所以需要将代码改为:
func queryRow(Db *sqlx.DB) {
row := Db.QueryRow("select uid, username, create_time from userinfo")
var uid int
var userName string
var createTime sql.NullString
err := row.Scan(&uid, &userName, &createTime)
if err != nil {
fmt.Printf("scan data failed, error is [%v]", err.Error())
return
}
fmt.Println(uid, userName, createTime)
}
运行结果:
1 johny { false}
上面的运行结果中 { false},其实是 空字符串 与 string 类型的判断结果
在查询数据之前,查询结果有两种情况,null 与 非null,所以是需要验证的,如果值为 null,则会输出 NullString 的默认值,否则输出查询的值,demo 如下:
func queryRow(Db *sqlx.DB) {
row := Db.QueryRow("select uid, username, create_time from userinfo")
var uid int
var userName string
var createTime sql.NullString
err := row.Scan(&uid, &userName, &createTime)
if err != nil {
fmt.Printf("scan data failed, error is [%v]", err.Error())
return
}
fmt.Printf("%d %s\n", uid, userName)
fmt.Printf("createTime.String: ''%v''\n", createTime.String)
fmt.Printf("createTime.Valid: %v\n", createTime.Valid)
}
运行结果:
//null值的情况
1 johny
createTime.String: ''''
createTime.Valid: false
//值存在的情况
1 johny
createTime.String: ''2019-07-08 12:53:18''
createTime.Valid: true
2)使用 []byte 接收数据
如果我们不关心查询的字段数据是不是 null 的时候,只是想把它当做空字符串处理就行,可以定义 []byte 接收数据,这样处理后,如果有值就获取值([]byte),如果没有则获取的为空字符串,demo 如下:
func queryRow(Db *sqlx.DB) {
row := Db.QueryRow("select uid, username, create_time from userinfo")
var uid []byte
var userName []byte
var createTime []byte
err := row.Scan(&uid, &userName, &createTime)
if err != nil {
fmt.Printf("scan data failed, error is [%v]", err.Error())
return
}
fmt.Printf("%s %s\n", uid, userName)
fmt.Printf("createTime.String: ''%s''\n", createTime)
}
运行结果:
//有值的情况
1 johny
createTime.String: ''2019-07-08 12:53:18''
//null值的情况
1 johny
createTime.String: ''''
自动匹配字段数据
竟然所有的数据都能通过 []byte 进行接收,而字段名都是 string 类型,那么可以就可以把查询的数据放到 map 中保存,然后根据 key 进行取值,这样就方便多了
demo:
package main
import (
"fmt"
_ "github.com/go-sql-driver/mysql"
"github.com/jmoiron/sqlx"
)
var (
userName string = "root"
password string = "seemmo"
ipAddrees string = "10.10.4.80"
port int = 3306
dbName string = "golang_db"
charset string = "utf8"
)
func connectMysql() *sqlx.DB {
dsn := fmt.Sprintf("%s:%s@tcp(%s:%d)/%s?charset=%s", userName, password, ipAddrees, port, dbName, charset)
Db, err := sqlx.Open("mysql", dsn)
if err != nil {
fmt.Printf("mysql connect failed, detail is [%v]", err.Error())
}
return Db
}
func queryData(Db *sqlx.DB) {
rows, err := Db.Query("select uid, username, create_time from userinfo")
if err != nil {
fmt.Printf("query data failed, error is [%v]", err.Error())
return
}
cols, err := rows.Columns()
if err != nil {
fmt.Errorf("get rows columns failed, error is [%v]", err.Error())
}
var vals = make([][]byte, len(cols)) //用来存放查询数据
var scanSlice = make([]interface{}, len(cols)) //用来当做参数,Scan 接收接口类型的参数
////将 []byte 放入接口
for i := range cols {
scanSlice[i] = &vals[i]
}
var sliceMapData = make([]map[string]string, 0)
for rows.Next() {
err := rows.Scan(scanSlice...)
if err != nil {
fmt.Printf("scan data failed, error is [%v]", err.Error())
return
}
var mapData = make(map[string]string)
//这里遍历的是 字节切片
for i, value := range vals {
mapData[cols[i]] = string(value)
}
fmt.Println(mapData)
sliceMapData = append(sliceMapData, mapData)
}
fmt.Println(sliceMapData)
err = rows.Close()
if err != nil {
fmt.Println(err.Error())
}
}
func main (){
var Db *sqlx.DB = connectMysql()
defer Db.Close()
queryData(Db)
}
运行结果:
map[create_time:2019-07-08 14:05:40 uid:1 username:johny]
map[create_time: uid:2 username:anson]
[map[create_time:2019-07-08 14:05:40 uid:1 username:johny] map[create_time: uid:2 username:anson]]查询的是全部字段的数据,使用 rows.Columns() 方法可以获取到字段数据的切片([]string)
然后创建一个切片 vals,用来存放所取出来的数据结果
接下来又定义一个切片 scanSlice,在 Scan() 中使用,因为Scan() 方法接收的数据是接口类型,将数据库的查询结果复制给到它
vals 则得到了 scanSlice 复制给它的值,因为是 byte 切片,因此在循环一次,将其转换成 string,最后添加到 map 类型中
参考链接:https://www.cnblogs.com/zhaof/p/8509164.html
ending ~
今天关于MySql和二的讲解已经结束,谢谢您的阅读,如果想了解更多关于8.19MySQL(二)、Django连接MySQL(二)、Django:模型 model 和数据库 mysql(二)、Go 操作 Mysql(二)的相关知识,请在本站搜索。
本文标签:




