本文将带您了解关于mysql分表分库的应用场景和设计方式的新内容,同时我们还将为您解释mysql分表分库技术实现的相关知识,另外,我们还将为您提供关于mysql分表分库策略、mysql主从不同步如何做
本文将带您了解关于mysql分表分库的应用场景和设计方式的新内容,同时我们还将为您解释mysql分表分库技术 实现的相关知识,另外,我们还将为您提供关于mysql 分表分库策略、mysql主从不同步如何做,mysql 主主,mysql一主多从,cobar实现mysql分库分表、mysql分库 分表、mysql分库分区分表的实用信息。
本文目录一览:- mysql分表分库的应用场景和设计方式(mysql分表分库技术 实现)
- mysql 分表分库策略
- mysql主从不同步如何做,mysql 主主,mysql一主多从,cobar实现mysql分库分表
- mysql分库 分表
- mysql分库分区分表
")
mysql分表分库的应用场景和设计方式(mysql分表分库技术 实现)
很多朋友在论坛和留言区域问MysqL在什么情况下才需要进行分库分表,以及采用何种设计方式才是最优的选择,根据这些问题,小编为大家整理了关于MysqL分库分表的应用场景和最优的设计方式举例。
一. 分表
场景:对于大型的互联网应用来说,数据库单表的记录行数可能达到千万级甚至是亿级,并且数据库面临着极高的并发访问。采用Master-Slave复制模式的MysqL架构,
只能够对数据库的读进行扩展,而对数据库的写入操作还是集中在Master上,并且单个Master挂载的Slave也不可能无限制多,Slave的数量受到Master能力和负载的限制。
因此,需要对数据库的吞吐能力进行进一步的扩展,以满足高并发访问与海量数据存储的需要!
对于访问极为频繁且数据量巨大的单表来说,我们首先要做的就是减少单表的记录条数,以便减少数据查询所需要的时间,提高数据库的吞吐,这就是所谓的分表!
在分表之前,首先需要选择适当的分表策略,使得数据能够较为均衡地分不到多张表中,并且不影响正常的查询!
对于互联网企业来说,大部分数据都是与用户关联的,因此,用户id是最常用的分表字段。因为大部分查询都需要带上用户id,这样既不影响查询,又能够使数据较为均衡地
分布到各个表中(当然,有的场景也可能会出现冷热数据分布不均衡的情况),如下图:

假设有一张表记录用户购买信息的订单表order,由于order表记录条数太多,将被拆分成256张表。
拆分的记录根据user_id%256取得对应的表进行存储,前台应用则根据对应的user_id%256,找到对应订单存储的表进行访问。
这样一来,user_id便成为一个必需的查询条件,否则将会由于无法定位数据存储的表而无法对数据进行访问。
注:拆分后表的数量一般为2的n次方,就是上面拆分成256张表的由来!
假设order表结构如下:
create table order_( order_id bigint(20) primary key auto_increment,user_id bigint(20),user_nick varchar(50),auction_id bigint(20),auction_title bigint(20),price bigint(20),auction_cat varchar(200),seller_id bigint(20),seller_nick varchar(50) )
那么分表以后,假设user_id = 257,并且auction_id = 100,需要根据auction_id来查询对应的订单信息,则对应的sql语句如下:
select * from order_1 where user_id=257 and auction_id = 100;
其中,order_1是根据257%256计算得出,表示分表之后的第一张order表。
二. 分库
场景:分表能够解决单表数据量过大带来的查询效率下降的问题,但是,却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,当数据库master
服务器无法承载写操作压力时,不管如何扩展slave服务器,此时都没有意义了。
因此,我们必须换一种思路,对数据库进行拆分,从而提高数据库写入能力,这就是所谓的分库!
与分表策略相似,分库可以采用通过一个关键字取模的方式,来对数据访问进行路由,如下图所示:

还是之前的订单表,假设user_id 字段的值为258,将原有的单库分为256个库,那么应用程序对数据库的访问请求将被路由到第二个库(258%256 = 2)。
三. 分库分表
场景:有时数据库可能既面临着高并发访问的压力,又需要面对海量数据的存储问题,这时需要对数据库既采用分表策略,又采用分库策略,以便同时扩展系统的
并发处理能力,以及提升单表的查询性能,这就是所谓的分库分表。
分库分表的策略比前面的仅分库或者仅分表的策略要更为复杂,一种分库分表的路由策略如下:
1. 中间变量 = user_id % (分库数量 * 每个库的表数量)
2. 库 = 取整数 (中间变量 / 每个库的表数量)
3. 表 = 中间变量 % 每个库的表数量
同样采用user_id作为路由字段,首先使用user_id 对库数量*每个库表的数量取模,得到一个中间变量;然后使用中间变量除以每个库表的数量,取整,便得到
对应的库;而中间变量对每个库表的数量取模,即得到对应的表。
分库分表策略详细过程如下:
假设将原来的单库单表order拆分成256个库,每个库包含1024个表,那么按照前面所提到的路由策略,对于user_id=262145 的访问,路由的计算过程如下:
1. 中间变量 = 262145 % (256 * 1024) = 1
2. 库 = 取整 (1/1024) = 0
3. 表 = 1 % 1024 = 1
这就意味着,对于user_id=262145 的订单记录的查询和修改,将被路由到第0个库的第1个order_1表中执行!!!

mysql 分表分库策略
唯一ID的生成
下面列举几种常见的唯一ID生成方案,需要满足两大核心需求:1.全局唯一 2趋势有序
1. 用数据库的auto_increment(自增ID)来生成,每次通过写入数据库一条记录,利用数据库ID自增的特性获取唯一,有序的ID。
优点:使用数据库原有的功能,相对简单;能够保证唯一;能够保证递增性;ID之间的步长是固定且可以自定义的
缺点:可用性难以保证,当生成ID的那台服务器宕机,系统就玩不转了;由于写入是单点的,所以扩展性差,性能上限取决于数据库的写性能。
2. 用UUID
优点:简单方便;全球唯一,在遇见数据迁移、合并或者变更时可以从容应对;
缺点:没有递增性;UUID是很长的字符串,作为主键对存储空间有一定要求,查询效率也较低。
3. 使用Redis生成ID,主要利用Redis是单线程的,所以也可以用来生成唯一ID。当使用的是Redis集群的时候,比如集群中有5台Redis,初始化每台Redis的值为1,2,3,4,5,设置步长为5,并且确定一个不随机的负载均衡策略,能够保证有序,唯一。
优点:不依赖数据库,灵活,且性能相对于数据库有一定提高;使用Redis集群策略还能排除单点故障问题;ID天然有序
缺点:如果系统中没有Redis,还需要引入新的组件;编码和配置工作量大
4. 使用Twitter的snowflake算法;其核心思想是一个64位long型ID,使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。具体实现的代码可以参看https://github.com/twitter/snowflake。可以根据自身需求进行一定的修改。
优点:不依赖数据库,灵活方便,性能优于数据库;ID按照时间在单机上是递增的
缺点:单机上递增,但是当分布式环境下每台机器的时钟不可能完全同步,有时并不能做做全局递增。
5. 使用zookeeper生成唯一ID,主要通过znode数据版本来生成序列号,可以生成32为和64为的数据版本号。很少使用,因为是多步调用API,并发情况下还需要考虑分布式锁,不是很理想。
6. MongoDB的ObjectID,和snowflake算法类似。4字节Unix时间戳,3字节机器编码,2字节进程编码,3字节随机数
1 单表分表策略
a.当数据比较大的时候,对数据进行分表操作,首先要确定需要将数据平均分配到多少张表中,也就是:表容量。
这里假设有100张表进行存储,则我们在进行存储数据的时候,首先对用户ID进行取模操作,根据 user_id % 100获取对应的表进行存储查询操作.
user_id % 100 = 0 user_id % 100 = 1 user_id % 100 = 2
2 分表分库策略
a.
1、中间变量 = user_id%(库数量*每个库的表数量);
2、库序号 = 取整(中间变量/每个库的表数量);
3、表序号 = 中间变量%每个库的表数量;
例如:数据库有256 个,每一个库中有1024个数据表,用户的user_id=262145,按照上述的路由策略,可得:
1、中间变量 = 262145%(256*1024)= 1;
2、库序号 = 取整(1/1024)= 0;
3、表序号 = 1%1024 = 1;
这样的话,对于user_id=262145,将被路由到第0个数据库的第1个表中

mysql主从不同步如何做,mysql 主主,mysql一主多从,cobar实现mysql分库分表
mysql主从不同步如何做
先上Master库:
mysql>show processlist; 查看下进程是否Sleep太多。发现很正常。
show master status; 也正常。
mysql> show master status;
+-------------------+----------+--------------+-------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+-------------------------------+
| mysqld-bin.000001 | 3260 | | mysql,test,information_schema |
+-------------------+----------+--------------+-------------------------------+
1 row in set (0.00 sec)
再到Slave上查看
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: No
可见是Slave不同步
下面介绍两种解决方法:
方法一:忽略错误后,继续同步
该方法适用于主从库数据相差不大,或者要求数据可以不完全统一的情况,数据要求不严格的情况
解决:
stop slave;
#表示跳过一步错误,后面的数字可变
set global sql_slave_skip_counter =1;
start slave;
之后再用mysql> show slave status\G 查看:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
ok,现在主从同步状态正常了。。。
方式二:重新做主从,完全同步
该方法适用于主从库数据相差较大,或者要求数据完全统一的情况
解决步骤如下:
1.先进入主库,进行锁表,防止数据写入
使用命令:
mysql> flush tables with read lock;
注意:该处是锁定为只读状态,语句不区分大小写
2.进行数据备份
#把数据备份到mysql.bak.sql文件
[root@server01 mysql]#mysqldump -uroot -p -hlocalhost > mysql.bak.sql
这里注意一点:数据库备份一定要定期进行,可以用shell脚本或者python脚本,都比较方便,确保数据
万无一失
3.查看master 状态
mysql> show master status;
+-------------------+----------+--------------+-------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+-------------------------------+
| mysqld-bin.000001 | 3260 | | mysql,test,information_schema |
+-------------------+----------+--------------+-------------------------------+
1 row in set (0.00 sec)
4.把mysql备份文件传到从库机器,进行数据恢复
#使用scp命令
[root@server01 mysql]# scp mysql.bak.sql root@192.168.128.101:/tmp/
5.停止从库的状态
mysql> stop slave;
6.然后到从库执行mysql命令,导入数据备份
mysql> source /tmp/mysql.bak.sql
7.设置从库同步,注意该处的同步点,就是主库show master status信息里的| File| Position两项
change master to master_host = ''192.168.128.100'', master_user = ''rsync'', master_port=3306,
master_password='''', master_log_file = ''mysqld-bin.000001'', master_log_pos=3260;
8.重新开启从同步
mysql> stop slave;
9.查看同步状态
mysql> show slave status\G 查看:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
好了,同步完成啦。
出处:http://www.jb51.net/article/33052.htm
mysql 主主
MySQL双主(主主)架构方案思路是:
1.两台mysql都可读写,互为主备,默认只使用一台(masterA)负责数据的写入,另一台(masterB)备用;
2.masterA是masterB的主库,masterB又是masterA的主库,它们互为主从;
3.两台主库之间做高可用,可以采用keepalived等方案(使用VIP对外提供服务);
4.所有提供服务的从服务器与masterB进行主从同步(双主多从);
5.建议采用高可用策略的时候,masterA或masterB均不因宕机恢复后而抢占VIP(非抢占模式);
这样做可以在一定程度上保证主库的高可用,在一台主库down掉之后,可以在极短的时间内切换到另一台主库上(尽可能减少主库宕机对业务造成的影响),减少了主从同步给线上主库带来的压力;
但是也有几个不足的地方:
1.masterB可能会一直处于空闲状态(可以用它当从库,负责部分查询);
2.主库后面提供服务的从库要等masterB先同步完了数据后才能去masterB上去同步数据,这样可能会造成一定程度的同步延时;
架构的简易图如下:
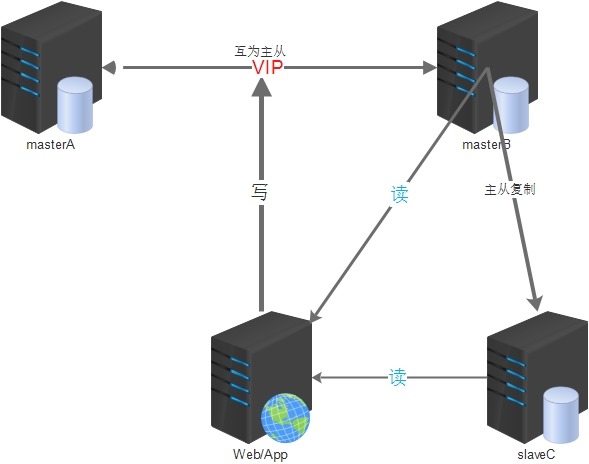
主主环境(这里只介绍2台主的配置方案):
1.CentOS 7 64位 2台:masterA(192.168.10.11),masterB(192.168.10.12)
2.官方Mysql5.6版本
搭建过程:
1.安装MySQL服务(建议源码安装)
1.1 yum安装依赖包
yum -y install make gcc gcc-c++ ncurses-devel bison openssl-devel
1.2 添加MySQL所需要的用户和组
groupadd -g 27 mysql adduser -u 27 -g mysql -s /sbin/nologin mysql
1.3 下载MySQL源码包
mkdir -p /data/packages/src cd /data/packages/ wget http://distfiles.macports.org/cmake/cmake-3.2.3.tar.gz wget http://dev.mysql.com/get/Downloads/MySQL-5.6/mysql-5.6.34.tar.gz
1.4 创建mysql数据目录
mkdir -p /usr/local/mysql/data
1.5 解压编译安装cmake、MySQL
cd /data/packages/src
tar -zxvf ../cmake-3.2.3.tar.gz
cd cmake-3.2.3/
./bootstrap
gmake
make install
cd ../
tar xf mysql-5.6.34.tar.gz
cd mysql-5.6.34
cmake . -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DSYSCONFDIR=/etc \
-DWITH_SSL=bundled -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci \
-DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_MYISAM_STORAGE_ENGINE=1 \
-DMYSQL_TCP_PORT=3306 -DMYSQL_UNIX_ADDR=/tmp/mysql.sock \
-DMYSQL_DATADIR=/usr/local/mysql/data
make && make install1.6 添加开机启动脚本
cp support-files/mysql.server /etc/rc.d/init.d/mysqld
1.7 添加masterA配置文件/etc/my.cnf
[client]
port = 3306
socket = /tmp/mysql.sock
[mysqld]
basedir = /usr/local/mysql
port = 3306
socket = /tmp/mysql.sock
datadir = /usr/local/mysql/data
pid-file = /usr/local/mysql/data/mysql.pid
log-error = /usr/local/mysql/data/mysql.err
server-id = 1
auto_increment_offset = 1
auto_increment_increment = 2 #奇数ID
log-bin = mysql-bin #打开二进制功能,MASTER主服务器必须打开此项
binlog-format=ROW
binlog-row-p_w_picpath=minimal
log-slave-updates=true
gtid-mode=on
enforce-gtid-consistency=true
master-info-repository=TABLE
relay-log-info-repository=TABLE
sync-master-info=1
slave-parallel-workers=0
sync_binlog=0
binlog-checksum=CRC32
master-verify-checksum=1
slave-sql-verify-checksum=1
binlog-rows-query-log_events=1
#expire_logs_days=5
max_binlog_size=1024M #binlog单文件最大值
replicate-ignore-db = mysql #忽略不同步主从的数据库
replicate-ignore-db = information_schema
replicate-ignore-db = performance_schema
replicate-ignore-db = test
replicate-ignore-db = zabbix
max_connections = 3000
max_connect_errors = 30
skip-character-set-client-handshake #忽略应用程序想要设置的其他字符集
init-connect=''SET NAMES utf8'' #连接时执行的SQL
character-set-server=utf8 #服务端默认字符集
wait_timeout=1800 #请求的最大连接时间
interactive_timeout=1800 #和上一参数同时修改才会生效
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES #sql模式
max_allowed_packet = 10M
bulk_insert_buffer_size = 8M
query_cache_type = 1
query_cache_size = 128M
query_cache_limit = 4M
key_buffer_size = 256M
read_buffer_size = 16K
skip-name-resolve
slow_query_log=1
long_query_time = 6
slow_query_log_file=slow-query.log
innodb_flush_log_at_trx_commit = 2
innodb_log_buffer_size = 16M
[mysql]
no-auto-rehash
[myisamchk]
key_buffer_size = 20M
sort_buffer_size = 20M
read_buffer = 2M
write_buffer = 2M
[mysqlhotcopy]
interactive-timeout
[mysqldump]
quick
max_allowed_packet = 16M
[mysqld_safe]1.8 特别参数说明
log-slave-updates = true #将复制事件写入binlog,一台服务器既做主库又做从库此选项必须要开启
#masterA自增长ID
auto_increment_offset = 1
auto_increment_increment = 2 #奇数ID
#masterB自增加ID
auto_increment_offset = 2
auto_increment_increment = 2 #偶数ID1.9 添加masterB配置文件/etc/my.cnf
[client]
port = 3306
socket = /tmp/mysql.sock
[mysqld]
basedir = /usr/local/mysql
port = 3306
socket = /tmp/mysql.sock
datadir = /usr/local/mysql/data
pid-file = /usr/local/mysql/data/mysql.pid
log-error = /usr/local/mysql/data/mysql.err
server-id = 2
auto_increment_offset = 2
auto_increment_increment = 2 #偶数ID
log-bin = mysql-bin #打开二进制功能,MASTER主服务器必须打开此项
binlog-format=ROW
binlog-row-p_w_picpath=minimal
log-slave-updates=true
gtid-mode=on
enforce-gtid-consistency=true
master-info-repository=TABLE
relay-log-info-repository=TABLE
sync-master-info=1
slave-parallel-workers=0
sync_binlog=0
binlog-checksum=CRC32
master-verify-checksum=1
slave-sql-verify-checksum=1
binlog-rows-query-log_events=1
#expire_logs_days=5
max_binlog_size=1024M #binlog单文件最大值
replicate-ignore-db = mysql #忽略不同步主从的数据库
replicate-ignore-db = information_schema
replicate-ignore-db = performance_schema
replicate-ignore-db = test
replicate-ignore-db = zabbix
max_connections = 3000
max_connect_errors = 30
skip-character-set-client-handshake #忽略应用程序想要设置的其他字符集
init-connect=''SET NAMES utf8'' #连接时执行的SQL
character-set-server=utf8 #服务端默认字符集
wait_timeout=1800 #请求的最大连接时间
interactive_timeout=1800 #和上一参数同时修改才会生效
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES #sql模式
max_allowed_packet = 10M
bulk_insert_buffer_size = 8M
query_cache_type = 1
query_cache_size = 128M
query_cache_limit = 4M
key_buffer_size = 256M
read_buffer_size = 16K
skip-name-resolve
slow_query_log=1
long_query_time = 6
slow_query_log_file=slow-query.log
innodb_flush_log_at_trx_commit = 2
innodb_log_buffer_size = 16M
[mysql]
no-auto-rehash
[myisamchk]
key_buffer_size = 20M
sort_buffer_size = 20M
read_buffer = 2M
write_buffer = 2M
[mysqlhotcopy]
interactive-timeout
[mysqldump]
quick
max_allowed_packet = 16M
[mysqld_safe]1.10 初始化MySQL
cd /usr/local/mysql scripts/mysql_install_db --user=mysql
1.11 为启动脚本赋予可执行权限并启动MySQL
chmod +x /etc/rc.d/init.d/mysqld /etc/init.d/mysqld start
2. 配置主从同步
2.1 添加主从同步账户
masterA上:
mysql> grant replication slave on *.* to ''repl''@''192.168.10.12'' identified by ''123456''; mysql> flush privileges;
masterB上:
mysql> grant replication slave on *.* to ''repl''@''192.168.10.11'' identified by ''123456''; mysql> flush privileges;
2.2 查看主库的状态
masterA上:
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000003 | 120 | | | |
+------------------+----------+--------------+------------------+-------------------+
row in set (0.00 sec)masterB上
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000003 | 437 | | | |
+------------------+----------+--------------+------------------+-------------------+
row in set (0.00 sec)2.3 配置同步信息:
masterA上:
mysql> change master to master_host=''192.168.10.12'',master_port=3306,master_user=''repl'',master_password=''123456'',master_log_file=''mysql-bin.000003'',master_log_pos=437; mysql> start slave; mysql> show slave status\G;
显示有如下状态则正常:
Slave_IO_Running: Yes Slave_SQL_Running: Yes
masterB上:
#本人是测试环境,可以保证没数据写入,否则需要的步骤是:先masterA锁表-->masterA备份数据-->masterA解锁表 -->masterB导入数据-->masterB设置主从-->查看主从
mysql> change master to master_host=''192.168.10.11'',master_port=3306,master_user=''repl'',master_password=''123456'',master_log_file=''mysql-bin.000003'',master_log_pos=120; start slave; mysql> show slave status\G;
显示有如下状态则正常:
Slave_IO_Running: Yes Slave_SQL_Running: Yes
3.测试主从同步
3.1 在masterA上创建一个数据库测试同步效果
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
rows in set (0.00 sec)
mysql> create database test01;
Query OK, 1 row affected (0.00 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
| test01 |
+--------------------+
rows in set (0.00 sec)
mysql> quit
Bye
[root@masterA data]#3.2 到masterB查看是否已经同步创建数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
| test01 |
+--------------------+
rows in set (0.00 sec)
mysql> quit
Bye
[root@masterB data]#4. 开启MySQL5.6的GTID功能
mysql> stop slave;
Query OK, 0 rows affected (0.00 sec)
mysql> change master to MASTER_AUTO_POSITION=1;
Query OK, 0 rows affected (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)5. 遇到的问题
一种主从报错:
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ''Could not open log file''
后面修改主从同步相关参数,确认原因是my.cnf增加了如下参数:
log-bin = mysql-bin
relay-log = mysql-bin
出处:http://ygqygq2.cnblogs.com>
mysql一主多从
一主多从的测试,其实和一主一从是一样的原理
一、环境
master:192.168.101
MYSQL版本:5.1.48-community-log
slave1:192.168.2.182
MYSQL版本:5.1.48-community-log
slave2:192.168.2.111
MYSQL版本:5.1.48-community-log
so...1 vs 2。
二、master和 slave上的相关配置
3台上都一样:
在/etc目录下可能无my.cnf文件,从/user/share/mysql目录中拷贝my-medium.cnf 到/etc并修改成my.cnf
[root@localhost etc]# cp /usr/share/mysql/my-medium.cnf my.cnfmaster 上:
1.修改master上的配置文件my.cnf。
[root@mysql101 ~]# vi /etc/my.cnf
在[mysqld]下添加如下字段:
server-id = 1
log-bin=mysql-bin
binlog-do-db=YYY //需要同步的数据库
binlog-ignore-db=mysql //被忽略的数据库
binlog-ignore-db=information-schema //被忽略的数据库添加一个同步账号
mysql> grant replication slave on *.* to ''affairlog''@''192.168.2.182'' identified by ''pwd123'';
//在slave1上登陆成功
mysql> grant replication slave on *.* to ''affairlog''@''192.168.2.111'' identified by ''pwd123'';
//在slave2上登陆成功
保存后,重启master的mysql服务:
service mysql restart;
用show master status命令查看日志情况
mysql> show master status\G;
*************************** 1. row ***************************
File: mysql-bin.000087
Position: 106
Binlog_Do_DB: YYY
Binlog_Ignore_DB: mysql,information-schema
1 row in set (0.00 sec)2.修改slave1上的配置文件my.cnf。
在[mysqld]下添加如下字段
[root@mysql182 ~]# vi /etc/my.cnf
server-id=182
master-host=192.168.3.101
master-user= affairlog
master-password=pwd123
master-port=3306
master-connect-retry=60
replicate-do-db=YYY //同步的数据库
replicate-ignore-db=mysql //被忽略的数据库
replicate-ignore-db=information-schema //被忽略的数据库
保存后,重启slave的mysql服务:
service mysql restart;修改slave2上的配置文件my.cnf,和上面类似,只是把server-id改下,为了方便,我都用了相应的ip某位,
so,slave2上我设置的server-id是111。
再进入两个slave机中的mysql。
mysql>start slave;
mysql>show slave status\G;
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
如果两个slave中的Slave_IO_Running、Slave_SQL_Running状态均为Yes则表明设置成功。
三、可能遇到的问题:
错误一:Slave_IO_Running: No或者Slave_SQL_Running: No
1.停掉slave服务
mysql> slave stop;
Query OK, 0 rows affected (2.01 sec)2.解决办法
a.在master上查看。
mysql> show master status\G;
*************************** 1. row ***************************
File: mysql-bin.000087
Position: 1845
Binlog_Do_DB: YYY
Binlog_Ignore_DB: mysql,information-schema
1 row in set (0.00 sec)
b.到slave上手动同步。
mysql>change master to
>master_host=''192.168.3.101'',
>master_user=''affairlog'',
>master_password=''pwd123'',
>master_log_file=''mysql-bin.000087'',
>master_log_pos=1845;
Query OK, 0 rows affected (0.00 sec)3.启动slave服务
mysql> slave start;4.再次查看Slave_IO_Running、Slave_SQL_Running状态,为Yes则表明设置成功。
错误二:ERROR 1198 (HY000): This operation cannot be performed with a running slave; run STOP SLAVE first
解决方法:
1.停掉slave服务
mysql> slave stop;
Query OK, 0 rows affected (2.01 sec)2.重置slave服务
mysql> reset stop;
Query OK, 0 rows affected (2.01 sec)3.再执行一次change命令
mysql>change master to
>master_host=''192.168.3.101'',
>master_user=''affairlog'',
>master_password=''pwd123'',
>master_log_file=''mysql-bin.000087'',
>master_log_pos=1845;
Query OK, 0 rows affected (0.00 sec)4.启动slave服务
mysql> slave start;5.再次查看Slave_IO_Running、Slave_SQL_Running状态,为Yes则表明设置成功。
出处:http://blog.sina.com.cn/s/blog_4c197d4201017qjs.html
cobar实现mysql分库分表
参考文章

mysql分库 分表
原文链接:http://www.jianshu.com/p/89311703b320
传统的分库分表
传统的分库分表都是通过应用层逻辑实现的,对于数据库层面来说,都是普通的表和库。
分库
分库的原因
首先,在单台数据库服务器性能足够的情况下,分库对于数据库性能是没有影响的。在数据库存储上,database只起到一个namespace的作用。database中的表文件存储在一个以database名命名的文件夹中。比如下面的employees数据库:
mysql> show tables in employees;
+---------------------+
| Tables_in_employees |
+---------------------+
| departments |
| dept_emp |
| dept_manager |
| employees |
| salaries |
| titles |
+---------------------+
在操作系统中看是这样的:
ls /usr/local/var/mysql/employees
db.opt dept_emp.frm dept_manager.ibd salaries.frm titles.ibd
departments.frm dept_emp.ibd employees.frm salaries.ibd
departments.ibd dept_manager.frm employees.ibd titles.frm
database不是文件,只起到namespace的作用,所以MySQL对database大小当然也是没有限制的,而且对里面的表数量也没有限制
所以,为什么要分库呢?
答案是为了解决单台服务器的性能问题,当单台数据库服务器无法支撑当前的数据量时,就需要根据业务逻辑紧密程度把表分成几撮,分别放在不同的数据库服务器中以降低单台服务器的负载。
分库一般考虑的是垂直切分,除非在垂直切分后,数据量仍然多到单台服务器无法负载,才继续水平切分。
比如一个论坛系统的数据库因当前服务器性能无法满足需要进行分库。先垂直切分,按业务逻辑把用户相关数据表比如用户信息、积分、用户间私信等放入user数据库;论坛相关数据表比如板块,帖子,回复等放入forum数据库,两个数据库放在不同服务器上。
拆分后表往往不可能完全无关联,比如帖子中的发帖人、回复人这些信息都在user数据库中。未拆分前可能一次联表查询就能获取当前帖子的回复、发帖人、回复人等所有信息,拆分后因为跨数据库无法联表查询,只能多次查询获得最终数据。
所以总结起来,分库的目的是降低单台服务器负载,切分原则是根据业务紧密程度拆分,缺点是跨数据库无法联表查询。
分表
分表的原因
当数据量超大的时候,B-Tree索引就无法起作用了。除非是索引覆盖查询,否则数据库服务器需要根据索引扫描的结果回表,查询所有符合条件的记录,如果数据量巨大,这将产生大量随机I/O,随之,数据库的响应时间将大到不可接受的程度。另外,索引维护(磁盘空间、I/O操作)的代价也非常高。
垂直分表
原因:
1.根据MySQL索引实现原理及相关优化策略的内容我们知道Innodb主索引叶子节点存储着当前行的所有信息,所以减少字段可使内存加载更多行数据,有利于查询。
2.受限于操作系统中的文件大小限制。
切分原则:
把不常用或业务逻辑不紧密或存储内容比较多的字段分到新的表中可使表存储更多数据。。
水平分表
原因:
1.随着数据量的增大,table行数巨大,查询的效率越来越低。
2.同样受限于操作系统中的文件大小限制,数据量不能无限增加,当到达一定容量时,需要水平切分以降低单表(文件)的大小。
切分原则: 增量区间或散列或其他业务逻辑。
使用哪种切分方法要根据实际业务逻辑判断。
比如对表的访问多是近期产生的新数据,历史数据访问较少,可以考虑根据时间增量把数据按照一定时间段(比如每年)切分。
如果对表的访问较均匀,没有明显的热点区域,则可以考虑用范围(比如每500w一个表)或普通Hash或一致性Hash来切分。
全局主键问题:
原本依赖数据库生成主键(比如自增)的表在拆分后需要自己实现主键的生成,因为一般拆分规则是建立在主键上的,所以在插入新数据时需要确定主键后才能找到存储的表。
实际应用中也已经有了比较成熟的方案。比如对于自增列做主键的表,flickr的全局主键生成方案很好的解决了性能和单点问题,具体实现原理可以参考这个帖子。除此之外,还有类似于uuid的全局主键生成方案,比如达达参考的Instagram的ID生成器。
一致性Hash:
使用一致性Hash切分比普通的Hash切分可扩展性更强,可以实现拆分表的添加和删除。一致性Hash的具体原理可以参考这个帖子,如果拆分后的表存储在不同服务器节点上,可以跟帖子一样对节点名或ip取Hash;如果拆分后的表存在一个服务器中则可对拆分后的表名取Hash。
---------------------
作者:Jef冒牌绅士
来源:CSDN
原文:https://blog.csdn.net/longjef/article/details/53115519
版权声明:本文为博主原创文章,转载请附上博文链接!

mysql分库分区分表
分表:
分表分为水平分表和垂直分表。
水平分表原理:
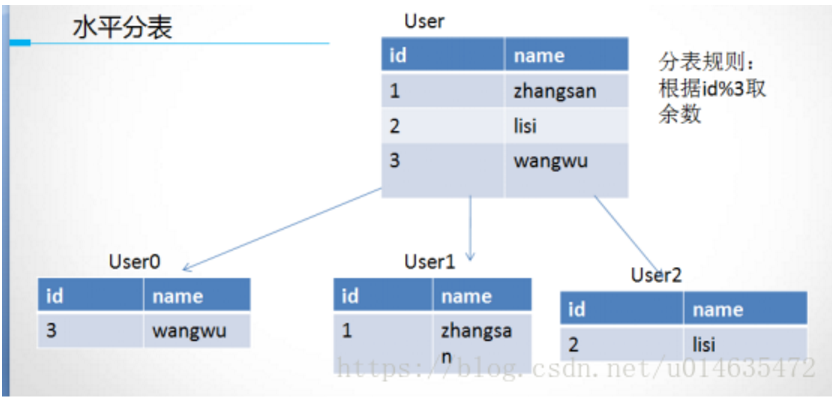
分表策略通常是用户ID取模,如果不是整数,可以首先将其进行hash获取到整。
水平分表遇到的问题:
1. 跨表直接连接查询无法进行
2. 我们需要统计数据的时候
3. 如果数据持续增长,达到现有分表的瓶颈,需要增加分表,此时会出现数据重新排列的情况
解决方案建议:
1. 第1,2点可以通过增加汇总的冗余表,虽然数据量很大,但是可以用于后台统计或者查询时效性比较底的情况,而且我们可以提前算好某个时间点或者时间段的数据
2. 第3点解决建议:
1. 可以开始的时候,就分析大概的数据增长率,来大概确定未来某段时间内的数据总量,从而提前计算出未来某段时间内需要用到的分表的个数
2. 考虑表分区,在逻辑上面还是一个表名,实际物理存储在不同的物理地址上
3. 分库
垂直拆分原则:
1. 把大字段独立存储到一张表中
2. 把不常用的字段单独拿出来存储到一张表
3. 把经常在一起使用的字段可以拿出来单独存储到一张表

垂直拆分标准:
1.表的体积大于2G并且行数大于1千万
2.表中包含有text,blob,varchar(1000)以上
3.数据有时效性的,可以单独拿出来归档处理
/*表的体积计算*/
CREATE TABLE `test1` (
id bigint(20) not null auto_increment,
detail varchar(2000),
createtime datetime,
validity int default ''0'',
primary key (id)
);
1000万 bigint 8字节 varchar 2000 字节 datetime 8字节 validity 4字节
(8+2000+8+4) * 10000000 = 20200000000 字节 == 18G
分表后体积:
CREATE TABLE `test1` (
id int not null auto_increment,
createtime timestamp,
validity tinyint default 0,
primary key (id)
);
(4+4+1) * 10000000 = 0.08G
分库策略与分表策略的实现很相似,最简单的都是可以通过取模的方式进行路由。
分库也可以按照业务分库,比如订单表和库存表在两个库,要注意处理好跨库事务。
分表和分库 同时实现。
分库分表的策略相对于前边两种复杂一些,一种常见的路由策略如下:
1、中间变量 = user_id%(库数量*每个库的表数量);
2、库序号 = 取整(中间变量/每个库的表数量);
3、表序号 = 中间变量%每个库的表数量;
例如:数据库有256 个,每一个库中有1024个数据表,用户的user_id=262145,按照上述的路由策略,可得:
1、中间变量 = 262145%(256*1024)= 1;
2、库序号 = 取整(1/1024)= 0;
3、表序号 = 1%1024 = 1;
这样的话,对于user_id=262145,将被路由到第0个数据库的第1个表中。
表分区:
就是将一个数据量比较大的表,用某种方法把数据从物理上分成若干个小表来存储(类似水平分表),从逻辑来看还是一个大表。分表最大分1024,一般分100左右比较适合。
使用场景:
对于这种数据库比较多,但是并发不是很多的情况下,可以采用表分区。
对于数据量比较大的,但是并发也比较高的情况下,可以采用分表和分区相结合。
/*range分区*/
create table test_range(
id int not null default 0
)engine=myisam default charset=utf8
partition by range(id)(
partition p1 values less than (3),
partition p2 values less than (5),
partition p3 values less than maxvalue
);
/*hash分区*/
create table test_hash(
id int not null default 0
)engine=innodb default charset=utf8
partition by hash(id) partitions 10;
/*线性hash分区*/
create table test_linear(
id int not null default 0
)engine=innodb default charset=utf8
partition by linear hash(id) partitions 10;
/* list分区*/
create table test_list(
id int not null
) engine=innodb default charset=utf8
partition by list(id)(
partition p0 values in (3,5),
partition p1 values in (2,6,7,9)
);
/* key 分区 */
CREATE TABLE test_key (
col1 INT NOT NULL
)
PARTITION BY linear KEY (col1)
PARTITIONS 10;
普通的hash分区 增加风区后,需要重新计算
线性hash分区(了解) 增加分区后,还是在原来的分区
线性hash 相对于 hash分区 没有那么均匀
Key分区用的比较少,也是hash分区
关于mysql分表分库的应用场景和设计方式和mysql分表分库技术 实现的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于mysql 分表分库策略、mysql主从不同步如何做,mysql 主主,mysql一主多从,cobar实现mysql分库分表、mysql分库 分表、mysql分库分区分表等相关内容,可以在本站寻找。
本文标签:




