如果您对新特性解读|MySQL8.0索引特性1-函数索引和mysql索引特点感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解新特性解读|MySQL8.0索引特性1-函数索引的各种细节,并对mys
如果您对新特性解读 | MySQL 8.0 索引特性1-函数索引和mysql索引特点感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解新特性解读 | MySQL 8.0 索引特性1-函数索引的各种细节,并对mysql索引特点进行深入的分析,此外还有关于28.读书笔记收获不止Oracle之 函数索引、MySQL 5.5 新特性解读、mysql 启动报错Can''t connect to local MySQL server through socket ''/data/mysql/mysql/mysql.soc...、mysql 安装避坑指南 ,mysql 安装后不能启动, mysql 指定版本安装,mysql 5.7.39版本安装,mysql 5.7.36版本安装的实用技巧。
本文目录一览:- 新特性解读 | MySQL 8.0 索引特性1-函数索引(mysql索引特点)
- 28.读书笔记收获不止Oracle之 函数索引
- MySQL 5.5 新特性解读
- mysql 启动报错Can''t connect to local MySQL server through socket ''/data/mysql/mysql/mysql.soc...
- mysql 安装避坑指南 ,mysql 安装后不能启动, mysql 指定版本安装,mysql 5.7.39版本安装,mysql 5.7.36版本安装
")
新特性解读 | MySQL 8.0 索引特性1-函数索引(mysql索引特点)
原创作者: 杨涛涛
函数索引顾名思义就是加给字段加了函数的索引,这里的函数也可以是表达式。所以也叫表达式索引。
MySQL 5.7 推出了虚拟列的功能,MySQL8.0的函数索引内部其实也是依据虚拟列来实现的。
我们考虑以下几种场景:
1.对比日期部分的过滤条件。
SELECT ...
FROM tb1
WHERE date(time_field1) = current_date;2.两字段做计算。
SELECT ...
FROM tb1
WHERE field2 + field3 = 5;3.求某个字段中间某子串。
SELECT ...
FROM tb1
WHERE substr(field4, 5, 9) = ''actionsky'';4.求某个字段末尾某子串。
SELECT ...
FROM tb1
WHERE RIGHT(field4, 9) = ''actionsky'';5.求JSON格式的VALUE。
SELECT ...
FROM tb1
WHERE CAST(field4 ->> ''$.name'' AS CHAR(30)) = ''actionsky'';以上五个场景如果不用函数索引,改写起来难易不同。不过都要做相关修改,不是过滤条件修正就是表结构变更添加冗余字段加额外索引。
比如第1个场景改写为,
SELECT ...
FROM tb1
WHERE time_field1 >= concat(current_date, '' 00:00:00'')
AND time_field1 <= concat(current_date, ''23:59:59'');再比如第4个场景的改写,
由于是求最末尾的子串,只能添加一个新的冗余字段,并且做相关的计划任务来一定频率的异步更新或者添加触发器来实时更新此字段值。
SELECT ...
FROM tb1
WHERE field4_suffix = ''actionsky'';那我们看到,改写也可以实现,不过这样的SQL就没有标准化而言,后期不能平滑的迁移了。
MySQL 8.0 推出来了函数索引让这些变得相对容易许多。
不过函数索引也有自己的缺陷,就是写法很固定,必须要严格按照定义的函数来写,不然优化器不知所措。
我们来把上面那些场景实例化。
示例表结构,

总记录数
mysql> SELECT COUNT(*)
FROM t_func;
+----------+
| count(*) |
+----------+
| 16384 |
+----------+
1 row in set (0.01 sec)我们把上面几个场景的索引全加上。
mysql > ALTER TABLE t_func ADD INDEX idx_log_time ( ( date( log_time ) ) ),
ADD INDEX idx_u1 ( ( rank1 + rank2 ) ),
ADD INDEX idx_suffix_str3 ( ( RIGHT ( str3, 9 ) ) ),
ADD INDEX idx_substr_str1 ( ( substr( str1, 5, 9 ) ) ),
ADD INDEX idx_str2 ( ( CAST( str2 ->> ''$.name'' AS CHAR ( 9 ) ) ) );
QUERY OK,
0 rows affected ( 1.13 sec ) Records : 0 Duplicates : 0 WARNINGS : 0我们再看下表结构, 发现好几个已经被转换为系统自己的写法了。

MySQL 8.0 还有一个特性,就是可以把系统隐藏的列显示出来。
我们用show extened 列出函数索引创建的虚拟列,

上面5个随机字符串列名为函数索引隐式创建的虚拟COLUMNS。
我们先来看看场景2,两个整形字段的相加,
mysql> SELECT COUNT(*)
FROM t_func
WHERE rank1 + rank2 = 121;
+----------+
| count(*) |
+----------+
| 878 |
+----------+
1 row in set (0.00 sec)看下执行计划,用到了idx_u1函数索引,
mysql> explain SELECT COUNT(*)
FROM t_func
WHERE rank1 + rank2 = 121\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t_func
partitions: NULL
type: ref
possible_keys: idx_u1
key: idx_u1
key_len: 9
ref: const
rows: 878
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
那如果我们稍微改下这个SQL的执行计划,发现此时不能用到函数索引,变为全表扫描了,所以要严格按照函数索引的定义来写SQL。
mysql> explain SELECT COUNT(*)
FROM t_func
WHERE rank1 = 121 - rank2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t_func
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 16089
filtered: 10.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)再来看看场景1的的改写和不改写的性能简单对比,
mysql> SELECT *
FROM t_func
WHERE date(log_time) = ''2019-04-18''
LIMIT 1\G
*************************** 1. row ***************************
id: 2
rank1: 1
str1: test-actionsky-test
str2: {"age": 30, "name": "dell"}
rank2: 120
str3: test-actionsky
log_time: 2019-04-18 10:04:53
1 row in set (0.01 sec)我们把普通的索引加上。
mysql > ALTER TABLE t_func ADD INDEX idx_log_time_normal ( log_time );
QUERY OK,
0 rows affected ( 0.36 sec ) Records : 0 Duplicates : 0 WARNINGS : 0然后改写下SQL看下。
mysql> SELECT *
FROM t_func
WHERE date(log_time) >= ''2019-04-18 00:00:00''
AND log_time < ''2019-04-19 00:00:00''
*************************** 1. row ***************************
id: 2
rank1: 1
str1: test-actionsky-test
str2: {"age": 30, "name": "dell"}
rank2: 120
str3: test-actionsky
log_time: 2019-04-18 10:04:53
1 row in set (0.01 sec)两个看起来没啥差别,我们仔细看下两个的执行计划:
- 普通索引
mysql> explain format=json SELECT *
FROM t_func
WHERE log_time >= ''2019-04-18 00:00:00''
AND log_time < ''2019-04-19 00:00:00''
LIMIT 1\G
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "630.71"
},
"table": {
"table_name": "t_func",
"access_type": "range",
"possible_keys": [
"idx_log_time_normal"
],
"key": "idx_log_time_normal",
"used_key_parts": [
"log_time"
],
"key_length": "6",
"rows_examined_per_scan": 1401,
"rows_produced_per_join": 1401,
"filtered": "100.00",
"index_condition": "((`ytt`.`t_func`.`log_time` >= ''2019-04-18 00:00:00'') and (`ytt`.`t_func`.`log_time` < ''2019-04-19 00:00:00''))",
"cost_info": {
"read_cost": "490.61",
"eval_cost": "140.10",
"prefix_cost": "630.71",
"data_read_per_join": "437K"
},
"used_columns": [
"id",
"rank1",
"str1",
"str2",
"rank2",
"str3",
"log_time",
"cast(`log_time` as date)",
"(`rank1` + `rank2`)",
"right(`str3`,9)",
"substr(`str1`,5,9)",
"cast(json_unquote(json_extract(`str2`,_utf8mb4''$.name'')) as char(9) charset utf8mb4)"
]
}
}
}
1 row in set, 1 warning (0.00 sec)- 函数索引
mysql> explain format=json SELECT COUNT(*)
FROM t_func
WHERE date(log_time) = ''2019-04-18''
LIMIT 1\G
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "308.85"
},
"table": {
"table_name": "t_func",
"access_type": "ref",
"possible_keys": [
"idx_log_time"
],
"key": "idx_log_time",
"used_key_parts": [
"cast(`log_time` as date)"
],
"key_length": "4",
"ref": [
"const"
],
"rows_examined_per_scan": 1401,
"rows_produced_per_join": 1401,
"filtered": "100.00",
"cost_info": {
"read_cost": "168.75",
"eval_cost": "140.10",
"prefix_cost": "308.85",
"data_read_per_join": "437K"
},
"used_columns": [
"log_time",
"cast(`log_time` as date)"
]
}
}
}
1 row in set, 1 warning (0.00 sec)
mysql>从上面的执行计划看起来区别不是很大, 唯一不同的是,普通索引在CPU的计算上消耗稍微大点,见红色字体。
当然,有兴趣的可以大并发的测试下,我这仅仅作为功能性进行一番演示。

28.读书笔记收获不止Oracle之 函数索引
28.读书笔记收获不止Oracle之 函数索引
先来看个例子:
sql> drop table t purge;
Table dropped.
sql> create table t as select * from dba_objects;
Table created.
sql> create index idx_object_id on t(object_id);
Index created.
sql> create index idx_object_name on t(object_name);
Index created.
sql> create index idx_createed on t(created);
Index created.
sql> select count(*) from t;
COUNT(*)
----------
90945
sql> set autotrace traceonly
sql> set linesize 1000
sql> select * from t whereupper(object_name)='T';
Execution Plan
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id| Operation | Name | Rows| Bytes | Cost (%cpu)| Time |
--------------------------------------------------------------------------
| 0| SELECT STATEMENT | |909 | 102K| 426(1)| 00:00:01 |
|* 1| TABLE ACCESS FULL| T |909 | 102K| 426(1)| 00:00:01 |
--------------------------------------------------------------------------
Predicate information (identified byoperation id):
---------------------------------------------------
1- filter(UPPER("OBJECT_NAME")='T')
Statistics
----------------------------------------------------------
1recursive calls
0 dbblock gets
1533 consistent gets
0physical reads
0 redosize
1851 bytes sent via sql*Net toclient
551 bytes received via sql*Net from client
2sql*Net roundtrips to/from client
0sorts (memory)
0sorts (disk)
1 rowsprocessed
走的全表扫描,没有走索引。去掉UPPER函数执行如下
sql> select * from t where object_name='T';
Execution Plan
----------------------------------------------------------
Plan hash value: 603483963
-------------------------------------------------------------------------------------------------------
| Id| Operation | Name | Rows| Bytes | Cost (%cpu)| Time |
-------------------------------------------------------------------------------------------------------
| 0| SELECT STATEMENT | |2 | 230 | 4 (0)|00:00:01 |
| 1| TABLE ACCESS BY INDEX ROWID BATCHED| T |2 | 230 | 4 (0)|00:00:01 |
|* 2| INDEX RANGESCAN | IDX_OBJECT_NAME | 2 || 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------
Predicate information (identified byoperation id):
---------------------------------------------------
2- access("OBJECT_NAME"='T')
Statistics
----------------------------------------------------------
1recursive calls
0 dbblock gets
5consistent gets
2physical reads
0 redosize
1855 bytes sent via sql*Net toclient
551 bytes received via sql*Net from client
2sql*Net roundtrips to/from client
0sorts (memory)
0sorts (disk)
1 rowsprocessed
发现,因为UPPER函数,导致无法使用索引,这个是因为对所有列做运算导致索引无法使用。
如果OBJECT_NAME列不存在小写字母,则SELECT *FROM T WHERE OBJECT_NAME=’T’ 和SELECT *FROM T WHEREUPPER(OBJECT_NAME)=’T’ 是完全等价的。如果还写UPPER就是多此一举又影响性能。
1. 函数索引
如果OBJECT_NAME列的取值真的有大有小,需要UPPER函数来执行,就需要函数索引了。
函数索引的方法很简单,和普通索引的方法类似,区别在于用函数运算替代列名。具体看如下例子:
sql> create index idx_upper_obj_name on t (upper(object_name));
Index created.
sql> select * from t where upper(object_name)='T';
Execution Plan
----------------------------------------------------------
Plan hash value: 2908766729
----------------------------------------------------------------------------------------------------------
| Id| Operation | Name | Rows | Bytes | Cost (%cpu)| Time |
----------------------------------------------------------------------------------------------------------
| 0| SELECT STATEMENT | | 909 | 102K|193 (0)| 00:00:01 |
| 1| TABLE ACCESS BY INDEX ROWID BATCHED| T | 909| 102K| 193(0)| 00:00:01 |
|* 2| INDEX RANGE SCAN | IDX_UPPER_OBJ_NAME | 364 | | 3(0)| 00:00:01 |
----------------------------------------------------------------------------------------------------------
Predicate information (identified byoperation id):
---------------------------------------------------
2- access(UPPER("OBJECT_NAME")='T')
Statistics
----------------------------------------------------------
5recursive calls
0 dbblock gets
7consistent gets
2physical reads
0 redosize
1851 bytes sent via sql*Net toclient
551 bytes received via sql*Net from client
2sql*Net roundtrips to/from client
0sorts (memory)
0sorts (disk)
1 rowsprocessed
使用函数索引了,代价是193,B树索引代价是4,全表扫描代价是426.
来查看索引类型如下:
sql> selectindex_name,index_type from user_indexes where table_name='T';
INDEX_NAME INDEX_TYPE
--------------- ---------------------------
IDX_OBJECT_ID norMAL
IDX_OBJECT_NAME norMAL
IDX_CREATEED norMAL
IDX_UPPER_OBJ_N FUNCTION-BASED norMAL
AME
在大多数情况下,对列进行函数运算的sql写法都是可以转换成对列不做运算的不同写法。
2. 避免列运算1
函数索引在很多情况下,是对列进行运算。函数索引性能介于普通索引和全表扫描之间,能用普通索引就尽量用普通索引。
2.1实验1
sql> set autotrace traceonly
sql> set linesize 1000
sql> select * from t where object_id-10<=30;
39 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id| Operation | Name | Rows | Bytes | Cost (%cpu)| Time |
--------------------------------------------------------------------------
| 0| SELECT STATEMENT | |4547 | 510K| 426(1)| 00:00:01 |
|* 1| TABLE ACCESS FULL| T | 4547 | 510K|426 (1)| 00:00:01 |
--------------------------------------------------------------------------
Predicate information (identified byoperation id):
---------------------------------------------------
1- filter("OBJECT_ID"-10<=30)
Statistics
----------------------------------------------------------
1recursive calls
0 dbblock gets
1535 consistent gets
0physical reads
0 redosize
3725 bytes sent via sql*Net toclient
573 bytes received via sql*Net from client
4sql*Net roundtrips to/from client
0sorts (memory)
0sorts (disk)
39 rowsprocessed
2.2实验2
sql> select * from t where object_id<=40;
39 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1296629646
-----------------------------------------------------------------------------------------------------
| Id| Operation | Name | Rows| Bytes | Cost (%cpu)| Time |
-----------------------------------------------------------------------------------------------------
| 0| SELECT STATEMENT | | 39 | 4485 | 4 (0)| 00:00:01 |
| 1| TABLE ACCESS BY INDEX ROWID BATCHED| T | 39 | 4485 | 4 (0)| 00:00:01 |
|* 2| INDEX RANGE SCAN | IDX_OBJECT_ID | 39 | | 2(0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
Predicate information (identified byoperation id):
---------------------------------------------------
2- access("OBJECT_ID"<=40)
Statistics
----------------------------------------------------------
1recursive calls
0 dbblock gets
9consistent gets
1physical reads
0 redosize
5890 bytes sent via sql*Net toclient
573 bytes received via sql*Net from client
4sql*Net roundtrips to/from client
0sorts (memory)
0sorts (disk)
39 rowsprocessed
同样的结果,不同的写法导致性能差异。
建立索引试试
2.3实验3
Create index idx_object_id_2 on t(object_id -10);
sql> select * from t where object_id-10<=30;
39 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 865720425
-------------------------------------------------------------------------------------------------------
| Id| Operation | Name | Rows| Bytes | Cost (%cpu)| Time |
-------------------------------------------------------------------------------------------------------
| 0| SELECT STATEMENT | |4547 | 510K| 26 (0)|00:00:01 |
| 1| TABLE ACCESS BY INDEX ROWID BATCHED| T |4547 | 510K| 26 (0)|00:00:01 |
|* 2| INDEX RANGE SCAN | IDX_OBJECT_ID_2 | 819 || 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------
Predicate information (identified byoperation id):
---------------------------------------------------
2- access("OBJECT_ID"-10<=30)
Statistics
----------------------------------------------------------
2recursive calls
0 dbblock gets
11consistent gets
1physical reads
0 redosize
3513 bytes sent via sql*Net toclient
573 bytes received via sql*Net from client
4sql*Net roundtrips to/from client
0sorts (memory)
0sorts (disk)
39 rowsprocessed
3. 避免列运算2
sql> select * from t where substr(object_name,1,4)='CLUS';
Execution Plan
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id| Operation | Name | Rows| Bytes | Cost (%cpu)| Time |
--------------------------------------------------------------------------
| 0| SELECT STATEMENT | |6 | 690 | 426(1)| 00:00:01 |
|* 1| TABLE ACCESS FULL| T |6 | 690 | 426(1)| 00:00:01 |
--------------------------------------------------------------------------
Predicate information (identified byoperation id):
---------------------------------------------------
1- filter(SUBSTR("OBJECT_NAME",4)='CLUS')
Note
-----
-dynamic statistics used: dynamic sampling (level=2)
-1 sql Plan Directive used for this statement
Statistics
----------------------------------------------------------
18recursive calls
0 dbblock gets
2308 consistent gets
0physical reads
0 redosize
2049 bytes sent via sql*Net toclient
551 bytes received via sql*Net from client
2sql*Net roundtrips to/from client
1sorts (memory)
0sorts (disk)
3 rowsprocessed
除非建立一个SUBSTR相关函数的索引,否则用不上索引。
不过还可以使用如下命令进行避免
sql> select * from t where object_name like 'CLUS%';
Execution Plan
----------------------------------------------------------
Plan hash value: 603483963
-------------------------------------------------------------------------------------------------------
| Id| Operation | Name | Rows| Bytes | Cost (%cpu)| Time |
-------------------------------------------------------------------------------------------------------
| 0| SELECT STATEMENT | |2 | 290 | 4 (0)|00:00:01 |
| 1| TABLE ACCESS BY INDEX ROWID BATCHED| T |2 | 290 | 4 (0)|00:00:01 |
|* 2| INDEX RANGE SCAN | IDX_OBJECT_NAME | 2 || 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------
Predicate information (identified byoperation id):
---------------------------------------------------
2- access("OBJECT_NAME" LIKE 'CLUS%')
filter("OBJECT_NAME" LIKE 'CLUS%')
Statistics
----------------------------------------------------------
1831 recursive calls
0 dbblock gets
1676 consistent gets
8physical reads
0 redosize
2136 bytes sent via sql*Net toclient
551 bytes received via sql*Net from client
2sql*Net roundtrips to/from client
67sorts (memory)
0sorts (disk)
3 rowsprocessed
4. 避免列运算3
看如下脚本
sql> select * from t where trunc(created)>=TO_DATE('2012-10-02','YYYY-MM-DD') and trunc(created) <=TO_DATE('2012-10-03','YYYY-MM-DD');
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id| Operation | Name | Rows| Bytes | Cost (%cpu)| Time |
--------------------------------------------------------------------------
| 0| SELECT STATEMENT | |227 | 32915 | 428 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T |227 | 32915 | 428 (1)| 00:00:01 |
--------------------------------------------------------------------------
Predicate information (identified byoperation id):
---------------------------------------------------
1- filter(Trunc(INTERNAL_FUNCTION("CREATED"))>=TO_DATE(' 2012-10-02
00:00:00','syyyy-mm-dd hh24:mi:ss') AND
Trunc(INTERNAL_FUNCTION("CREATED"))<=TO_DATE(' 2012-10-0300:00:00',
'syyyy-mm-dd hh24:mi:ss'))
Statistics
----------------------------------------------------------
11recursive calls
0 dbblock gets
1536 consistent gets
117 physical reads
0 redosize
1572 bytes sent via sql*Net toclient
540 bytes received via sql*Net from client
1sql*Net roundtrips to/from client
0sorts (memory)
0sorts (disk)
0 rowsprocessed
没有走索引,不过可以使用相同的办法实现相同的功能如下:
sql> select * from t wherecreated>= TO_DATE('2012-10-02','YYYY-MM-DD') and created < TO_DATE('2012-10-03','YYYY-MM-DD')+1;
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 3369967073
----------------------------------------------------------------------------------------------------
| Id| Operation | Name | Rows| Bytes | Cost (%cpu)| Time |
----------------------------------------------------------------------------------------------------
| 0| SELECT STATEMENT | |143 | 20735 | 5 (0)| 00:00:01 |
| 1| TABLE ACCESS BY INDEX ROWID BATCHED| T |143 | 20735 | 5 (0)| 00:00:01 |
|* 2| INDEX RANGE SCAN | IDX_CREATEED | 143 | | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate information (identified byoperation id):
---------------------------------------------------
2- access("CREATED">=TO_DATE(' 2012-10-02 00:00:00','syyyy-mm-ddhh24:mi:ss') AND
"CREATED"<TO_DATE('2012-10-04 00:00:00','syyyy-mm-dd hh24:mi:ss'))
Statistics
----------------------------------------------------------
11recursive calls
0 dbblock gets
6consistent gets
2physical reads
0 redosize
1572 bytes sent via sql*Net toclient
540 bytes received via sql*Net from client
1sql*Net roundtrips to/from client
0sorts (memory)
0sorts (disk)
0 rowsprocessed
执行就走索引了。

MySQL 5.5 新特性解读
新一代MySQL产品---MySQL5.5 已经面世,较之之前的5.1版本,将获得诸多特性方面的提升,简单总结如下:
1. 默认存储引擎更改为InnoDB
InnoDB作为成熟、高效的事务引擎,目前已经广泛使用,但MySQL5.1之前的版本默认引擎均为MyISAM,此次MySQL5.5终于 做到与时俱进,将默认数据库存储引擎改为InnoDB,并且引进了Innodb plugin 1.0.7。此次更新对数据库的好处是显而易见的:InnoDB的数据恢复时间从过去的一个甚至几个小时,缩短到几分钟(InnoDB plugin 1.0.7,InnoDB plugin 1.1, 恢复时采用红-黑树)。InnoDB Plugin 支持数据压缩存储,节约存储,提高内存命中率,并且支持adaptive flush checkpoint, 可以在某些场合避免数据库出现突发性能瓶颈。
Multi Rollback Segments: 原来InnoDB只有一个Segment,同时只支持1023的并发。现已扩充到128个Segments,从而解决了高并发的限制。
2. 多核性能提升
Metadata Locking (MDL) Framework替换LOCK_open mutex (lock),使得MySQL5.1及过去版本在多核心处理器上的性能瓶颈得到解决,官方表示将继续增强对MySQL多处理器支持,直至MySQL性能 “不受处理器数量的限制”
3. 复制功能(Replication)加强
MySQL复制特性是互联网公司应用非常广泛的特性,作为MySQL最实用最简单的扩展方式,过去的异步复制方式已经有些不上形势,对某些用户 来说“异步复制”意味着极端情况下的数据风险,MySQL5.5将首次支持半同步(semi-sync replication)在MySQL的高可用方案中将产生更多更加可靠的方案。另外Slave fsync tunning;Relay log corruption recovery和Replication Heartbeat也将实现
4. 增强表分区功能
MySQL 5.5的分区对用户绝对是个好消息,更易于使用的增强功能,以及TRUNCATE PARTITION命令都可以为DBA节省大量的时间,有时对最终用户亦如此:
1) 非整数列分区:任何使用过MySQL分区的人应该都遇到过不少问题,特别是面对非整数列分区时,MySQL 5.1只能处理整数列分区,如果你想在日期或字符串列上进行分区,你不得不使用函数对其进行转换。很麻烦,而MySQL 5.5中新增了两类分区方法,RANG和LIST分区法,同时在新的函数中增加了一个COLUMNS关键词。在MySQL 5.1中使用分区另一个让人头痛的问题是date类型(即日期列),你不能直接使用它们,必须使用YEAR或TO_DAYS转换这些列,但在MySQL 5.5中情况发生了很大的变化,现在在日期列上可以直接分区,并且方法也很简单;
2) 多列分区:COLUMNS关键字现在允许字符串和日期列作为分区定义列,同时还允许使用多个列定义一个分区;
3) 可用性增强:truncate分区。分区最吸引人的一个功能是瞬间移除大量记录的能力,DBA都喜欢将历史记录存储到按日期分区的分区表中,这样可以定期 删除过时的历史数据。 但当你需要移除分区中的部分数据时,事情就不是那么简单了,删除分区没有问题,但如果是清空分区,就很头痛了,要移除分区中的所有 数据,但需要保留分区本身,你可以:使用DELETE语句,但我们知道DELETE语句的性能都很差。使用DROP PARTITION语句,紧跟着一个EORGANIZE PARTITIONS语句重新创建分区,但这样做比前一个方法的成本要高出许多。MySQL 5.5引入了TRUNCATE PARTITION,它和DROP PARTITION语句有些类似,但它保留了分区本身,也就是说分区还可以重复利用。TRUNCATE PARTITION应该是DBA工具箱中的必备工具;
4) 更多微调功能:TO_SECONDS:分区增强包有一个新的函数处理DATE和DATETIME列,使用TO_SECONDS函数,你可以将日期/时间列转换成自0年以来的秒数,如果你想使用小于1天的间隔进行分区,那么这个函数就可以帮到你。
5. Insert Buffering 如果在buffer pool中没找到数据,那么直接buffer起来,避免额外的IO;Delete & Purge Buffering 跟插入一样,如果buffer pool中没有命中,先buffer起来,避免额外的IO。
6. Support for Native AIO on Linux
以上的特性在MySQL 5.5的社区版当中都将包括,在MySQL企业版当中,除以上更新之外,Oracle还加强了更多实用的企业级功能,包括:
1. 实现在线物理热备
MySQL 企业版将包含Innodb Hotbackup(这也许是MySQL和InnDB多年之后重新聚首的新亮点),从而一举解决过去MySQL无法进行可靠的在线实时物理备份的问题, InnoDB Hot Backup 不需要你关闭你的服务器也不需要加任何锁或影响其它普通的数据操作,这对MySQL DBA来说应该是一个不错的消息。
2. MySQL Enterprise Monitor 2.2 & Oracle Enterprise Monitor
是的,你没有看错,MySQL将可以被Oracle Enterprise Monitor监控,这是一个实现起来并不复杂,但在过去绝无可能的变化。并且MySQL企业版监控器(MySQL Enterprise Monitor)得到了更大的加强,版本更新至2.2,对MySQL服务器资源占用降低到可以忽略的地步,集成了监控,报警,SQL语句分析和给出优化建 议,MySQL的一些开源监控方案相比之下显得过于简陋,对企业客户来说,MySQL变得更加可靠。
3. MySQL Workbench
过去MySQL的图形界面工具做的实在是令人难以恭维,当然这也给众多MySQL管理工具提供了市场空间,现在Oracle打算将MySQL做 得比SQL-Server更加简单易用,MySQL Workbench是一款专为MySQL设计的ER/数据库建模工具,可以用来设计和创建新的数据库图示,建立数据库文档,以及进行复杂的MySQL 迁移等操作,因此内置workbench将使MySQL使用起来更简便高效。
4. 关于未来的重要提醒:Oracle的管理工具,MySQL也将能够使用,当然MySQL 5.5我们还没看到这个变化,但变化已经在时间表上,MySQL社区版也能够被Oracle管理工具管理,前提你得是Oracle数据库的用户。

mysql 启动报错Can''t connect to local MySQL server through socket ''/data/mysql/mysql/mysql.soc...
1:首先mysql本地连接报错:
Can''t connect to local MySQL server through socket ''/data/mysql/mysql/mysql.sock''(111)
解决:
1:删除 文件:/data/mysql/mysql/mysql.sock
此时又会报错:Can''t connect to local MySQL server through socket ''/var/lib/mysql/mysql.sock'' (2)
进入到目录:/data/mysql2/bin/
使用命令:mysqld start
此时报错:[ERROR] Too many arguments (first extra is ''start'')
于是将命令修改:mysqld --user=mysql
感谢:
https://www.cnblogs.com/invban/p/5824796.html
https://blog.csdn.net/u010416101/article/details/80490536
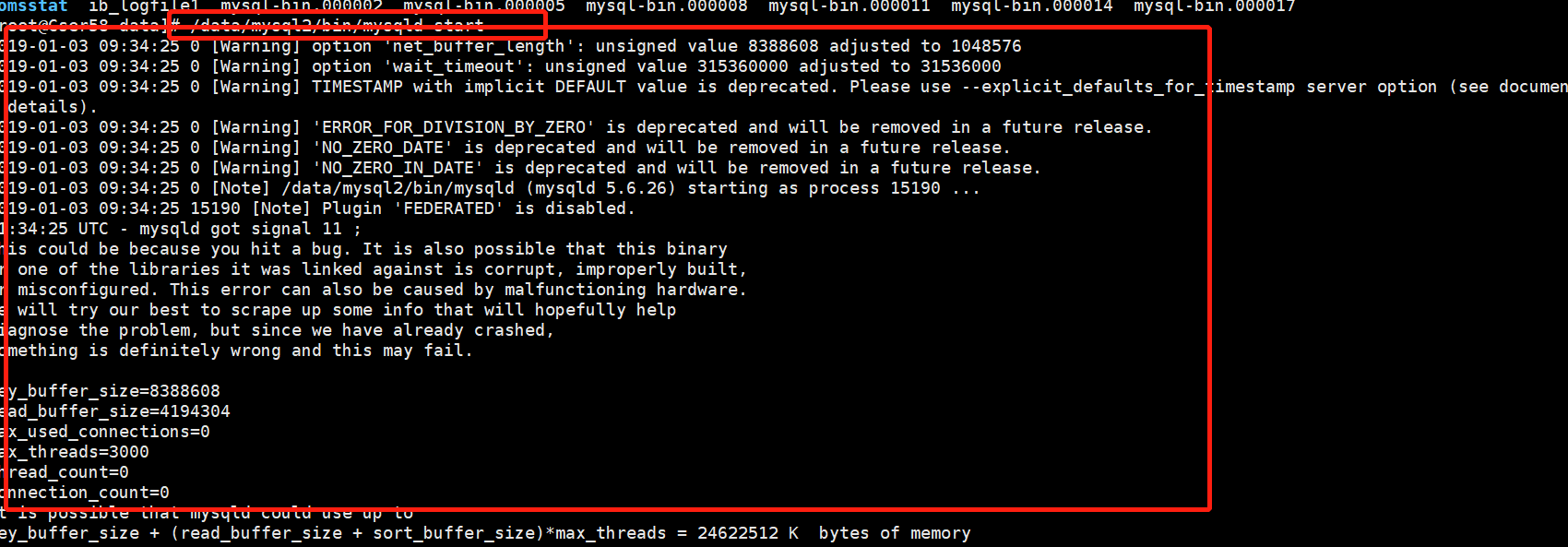

2:19年7月4日,mysql不是自己安装的,也不晓得是怎么安装的.在启动时依然报这个错误,按照前面的方法还是解决不了.
然后我又使用如下命令,启动依然报错
./mysqld --defaults-file=/data/mysql/mysql01/my.cnf --basedir=/data/mysql/mysql01 --datadir=/data/mysql/mysql01/data --user=zabbix 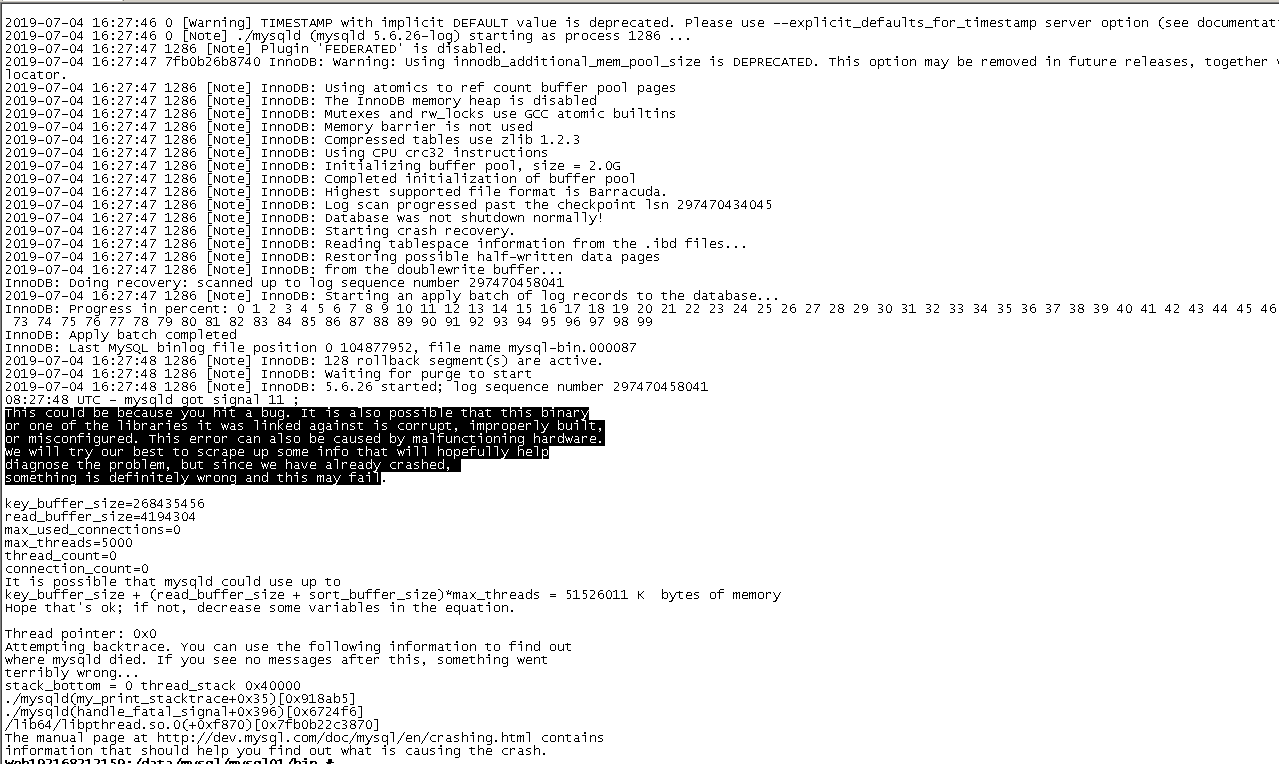

mysql 安装避坑指南 ,mysql 安装后不能启动, mysql 指定版本安装,mysql 5.7.39版本安装,mysql 5.7.36版本安装
MysqL 安装后不能启动,报错如下:请参照本说明第7条的办法解决。
MysqLd.service: Control process exited, code=exited status=1
Please read “Security” section of the manual to find out how to run MysqLd as root
如果MysqL安装遇到了错误如下:请参照第5条的办法解决。
All matches were filtered out by modular filtering for argument: MysqL-community-server
Error: Unable to find a match: MysqL-community-server
具体⽇志错误日志文件:在MysqL 配置⽂件 /etc/my.cnf 中有设置。
log-error=/var/log/MysqLd.log
pid-file=/var/run/MysqLd/MysqLd.pid
1.检查CentOS是否有系统自带的MysqL
yum list installed | grep MysqL
2.如果存在系统自带的MysqL及依赖,则通过 yum remove 将其卸载
卸载后记得执行以下命令删除数据库文件,(删除数据库前请自己确认是否有重要数据库文件!)
rm -rf /var/lib/MysqL #这个是centos下的数据库文件位置
3.CentOS中下载rpm包,并安装本地MysqL源
下载rpm包:yum localinstall MysqL80-community-release-el7-3.noarch.rpm
通过 yum localinstall 安装MysqL源,可以帮助我们解决本地rpm包的依赖问题。
最后,验证是否安装成功:yum repolist all | grep MysqL
wget https://dev.MysqL.com/get/MysqL80-community-release-el7-3.noarch.rpm
rpm -ivh MysqL80-community-release-el7-3.noarch.rpm
yum repolist all | grep MysqL
4.修改默认安装版本为5.7
从上面的图片,我们可以看到,默认是MysqL 8.0可用,我们若想安装MysqL 5.7,则需启用5.7。接下来通过直接修改配置文件来设置启用。
vim /etc/yum.repos.d/MysqL-community.repo
输入上面的命令,在编辑界面,先输入 i 进入编辑模式,将8.0的 enabled 设置为0,将5.7的 enabled 设置为1
5.安装
yum install -y MysqL-community-server
如果遇到了错误
All matches were filtered out by modular filtering for argument: MysqL-community-server
Error: Unable to find a match: MysqL-community-server
解决方法
sudo yum module disable MysqL
重复 yum install -y MysqL-community-server
6.遇到了错误
Public key for MysqL-community-client-5.7.38-1.el7.x86_64.rpm is not installed. Failing package is: MysqL-community-client-5.7.38-1.el7.x86_64
解决方法
sudo rpm --import https://repo.MysqL.com/RPM-GPG-KEY-MysqL-2022
或者这样,我是这样解决的:
yum install MysqL-community-server --nogpgcheck
检查
sudo systemctl status MysqLd
7.启动
sudo systemctl start MysqLd
如果无法启动,可能是以前安装其他版本MysqL有文件残留
先卸载MysqL
yum remove MysqL
yum -y remove MysqL*
然后删除: rm -rf /var/lib/MysqL #删除数据库前请自己确认是否有重要数据库文件!
重新运行安装命令:
yum install MysqL-community-server --nogpgcheck
service MysqLd start
再次启动服务成功!
8.查看临时密码
sudo grep 'temporary password' /var/log/MysqLd.log
9.更改密码
MysqL> ALTER USER 'root'@'localhost' IDENTIFIED BY 'MyNewPass4!';
10.配置
MysqL_secure_installation
ps.直接安装最新版:
sudo dnf -y install @MysqL
登录 创建root管理员和密码
MysqLadmin -u root password 123456
登录: MysqL -u root -p输入密码即可。
忘记密码
service MysqLd stop;
MysqLd_safe --user=root --skip-grant-tables;
这一步骤执行的时候不会出现新的命令行,你需要重新打开一个窗口执行下面的命令
MysqL -u root;
use MysqL ;
update user set password=password("123456") where user="root";
flush privileges;
远程访问 开放防火墙的端口号MysqL
增加权限:MysqL库中的user表新增一条记录Host为“%”,User为“root”。
一般开发测试直接把防火墙关闭
su root
service iptables stop #关闭防火墙
service iptables status #验证是否关闭
chkconfig iptables off #关闭防火墙的开机自动运行
chkconfig –list | grep iptables #验证防火墙的开机自动运行
vim /etc/sysconfig/selinux # 禁用selinux,将SELINUX=disabled
授权用户可以从远程登陆
grant all PRIVILEGES on *.* to root@'%' identified by '123456替换自己的密码';
flush privileges ;
我们今天的关于新特性解读 | MySQL 8.0 索引特性1-函数索引和mysql索引特点的分享就到这里,谢谢您的阅读,如果想了解更多关于28.读书笔记收获不止Oracle之 函数索引、MySQL 5.5 新特性解读、mysql 启动报错Can''t connect to local MySQL server through socket ''/data/mysql/mysql/mysql.soc...、mysql 安装避坑指南 ,mysql 安装后不能启动, mysql 指定版本安装,mysql 5.7.39版本安装,mysql 5.7.36版本安装的相关信息,可以在本站进行搜索。
本文标签:




