在本文中,我们将为您详细介绍MySQL8.0.29instantDDL数据腐化问题分析的相关知识,并且为您解答关于mysqlddl语句的疑问,此外,我们还会提供一些关于A2-03-01.DDL-Man
在本文中,我们将为您详细介绍MySQL 8.0.29 instant DDL 数据腐化问题分析的相关知识,并且为您解答关于mysql ddl语句的疑问,此外,我们还会提供一些关于A2-03-01.DDL-Manage Database in MySQL、A2-03-02.DDL-Understanding MySQL Table Types, or Storage Engines、A2-03-03.DDL-MySQL Data Types、A2-03-06.DDL-MySQL UNIQUE Constraint的有用信息。
本文目录一览:- MySQL 8.0.29 instant DDL 数据腐化问题分析(mysql ddl语句)
- A2-03-01.DDL-Manage Database in MySQL
- A2-03-02.DDL-Understanding MySQL Table Types, or Storage Engines
- A2-03-03.DDL-MySQL Data Types
- A2-03-06.DDL-MySQL UNIQUE Constraint
")
MySQL 8.0.29 instant DDL 数据腐化问题分析(mysql ddl语句)
- 前言
- Instant add or drop column 的主线逻辑
- 表定义的列顺序与 row 存储列顺序阐述
- 引入 row 版本的必要性
- 数据腐化问题
- 原因分析
- Bug 重现与解析
- MySQL8.0.30 修复方案
前言
DDL 相对于数据库的 DML 之类的其他操作,相对来说是比较耗时、相对重型的操作;因此对业务的影比较严重。MySQL 从 5.6 版本开始一直在持续改进其 DDL 性能:引入了 online DDL,inplace DDL,instant DDL 等实用性极强的功能, DDL 目前对业务的影响持续降低。
MySQL 8.0.29 引入了 instant add/drop column 功能,支持在任意位置添加 column, drop column 也不需要表数据的任何形式的移动, 只需要修改表的元数据就可以完成 add/drop column,所以 instant add/drop column 的操作是轻型操作,速度快,资源需求量少。
ALTER table drop column a, ALGORITHM=INSTANT;
8.0.29 引入了新的 alter 算法 INSTANT。
但是这个新功能目前很不稳定,导致的问题比较多;而且通常都比较严重:数据损坏,或者数据库无法启动等。
本文是分析其中的一个问题: 对表进行 instant drop 后,进行 update ,之后数据库停机,而后数据库无法启动。
为分析这个问题, 我们会从 instant add/drop column 在 Innodb 的实现原理与细节方面来阐述这个数据腐化 bug 的具体原因。
Instant add or drop column 的主线逻辑
因为这个功能的 WorkLog 无法从官方获取,所以无法得到准确的设计出发点,通过阅读相关代码,得出要实现这个功能,必须要处理以下关键点:
-
因为要支持在任意位置添加 / 删除列,同时不会更改表数据文件,所以表的逻辑定义与 row 的实际存储形式需要映射关系,不再是所见即所得的一一对应的关系。即为了实现这样功能:
-
- 表中列的定义顺序与表中行数据 (row) 的存储顺序是不同的。
- 同时对同一个 table 可以做多次 instant DDL, 所以需要引入版本机制,在表的数据文件中,不同 row 对应的表定义可能是不同的,需要在 row 中记住表定义的 version。
以上可以认为是该功能的设计原则与实现的主线逻辑。
表定义的列顺序与 row 存储列顺序阐述
在引入这个功能之前, create table 时列定义的顺序与列在 InnoDB 中存储的顺序是一致的。(这里我们不用考虑 InnoDB 添加系统隐藏列)
Instant add/drop column 要实现的亮点功能是在表定义的任意位置添加或者减少 column,同时做这样的操作的时候,能够做到不需要重构表数据。
我们称 column 在表定义中出现的顺序为逻辑顺序 ;
而 column 在行数据的存储顺序为物理顺序。
要做到修改表定义,而不重构表数据,就必须将逻辑顺序与物理顺序解耦:不能再像 MySQL 8.0.29 之前的版本那样,逻辑顺序与物理顺序是完全一致的;而从 8.0.29 开始通过表的元数据保存了逻辑顺序与物理顺序的映射关系。这种映射关系的构建与维护构成了 instant add/drop column 的基础.
如下图简单阐述了逻辑 / 物理顺序的关系。

引入 row 版本的必要性
对于同一张表,Instant add/drop DDL 可以执行多次;每一次执行后,逻辑 / 物理顺序的映射关系就发生变化;同时 instant add/drop DDL 并不需要做表数据的重构操作;因此可以得出经过多次 instant add/drop DDL,InnoDB 存储的行数据与表定义存在多种逻辑 / 物理顺序映射关系:比如说,在 ibd 文件中,前十行数据对应原始的表定义,接下来的十行可能对应着 instant add column 后的数据,再接下来的十行,可能对应着 instant drop column 后的数据。
为了管理这种形式的逻辑 / 物理,在 InnoDB 中,为每一行实际存储的数据引入了版本号的概念:每个版本号对应着一个逻辑 / 物理映射关系。
为存储这个版本信息,InnoDB 中,row 的信息头记录的格式有稍微的变化:

如上图所示,在 row 的 extra 中存储了其对应的版本号, 同时在 row header 中有标志位指示出了是否存在版本号信息。
根据版本号获取相应的映射关系,就可以正确的解析行数据。
目前版本号最大支持到 64, instant add/drop column 到达这个限制后报错;其后如果还需要 instant add/drop column DDL 操作,可能需要做一次能够触发 table rebuild 操作才可以。
数据腐化问题
由 instant add/drop column 引入了多个数据腐化问题,其中一个问题可以从:
[PS-8292] MySQL 8.0.29 fails to perform crash recovery - Percona JIRA(https://jira.percona.com/browse/PS-8292) 查看。
这个问题简单来说:在对表进行 instant drop 后,进行 update 操作,之后 MySQL server 重启,在启动阶段恢复之前的 update 操作会引发 assert 崩溃 (debug 版本的情况下)。
从代码上看,这个 bug 可能会造成数据的静默错误 (数据完全错乱而且不报任何错误),而不仅仅是崩溃这一种现象。
通过对 core 文件的简单分析,造成该问题的大概原因如下:
在通过 redo 做恢复的时候,字段的逻辑顺序与物理存储顺序之间的映射关系不对 (错位) 导致的。在恢复期间可能会找不到对应的字段,或者更新了错误的字段。
原因分析
从原始的问题看,这个是发生在 InnoDB 启动恢复阶段。这一阶段离不开 redo log 的参与。前面介绍 instant add/drop 设计要点的时候,那些列出的要点,可以认为是在在 DDL 期间的工作以及编码的基本逻辑;那么在完成 instant DDL 时候, 在 DML 的时候也需要将必要的信息写入 redo log 才能做到 recovery。
- 为支持 instant add/drop column,redo log 记录的格式发生了变化,因为代码 bug,导致在解析 redo log 做恢复的时候,得到的字段信息错误,导致数据腐化。
- 问题表现出来可能是:恢复始终无法执行,数据库无法启动;还可能是恢复到错误的数据,数据库能够启动。
因为 redo log 的种类较多,信息也比较繁杂,这里我们只关注问题本身中出现的 update 相关的 redo log ,进而较多的关注 update redo log 与该问题相关的字段信息。
下图简要的阐述了 update redo log 相关内容:
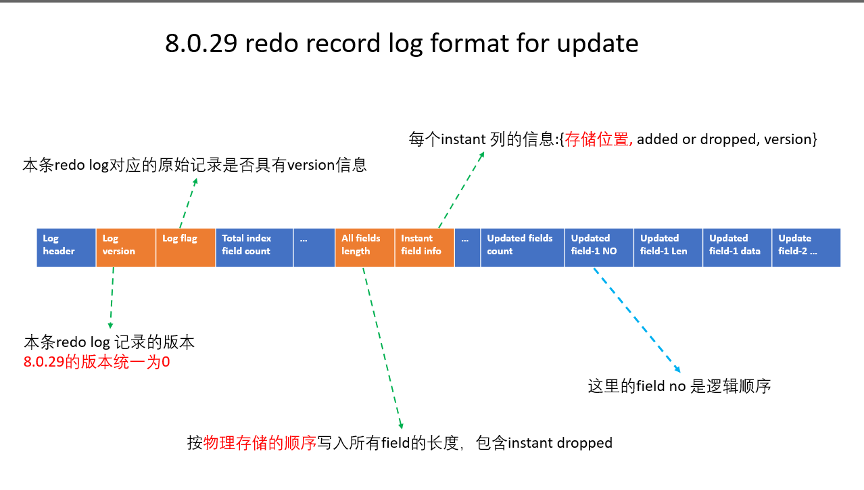
到这里,可以看到 在 MySQL 8.0.29 中,update redo log 引入了 instant column 的物理逻辑顺序。
下面从 InnoDB 的恢复流程跟踪问题发生的原因,其中主要需要关注的是恢复过程中的表 (索引) 定义。
- 应用 redo log 是在数据库启动阶段最开始就执行,此时数据字典无法打开,获取不到待恢复表的定义信息
- 但是此时需要表的定义信息去解析 redo log 中的相关数据
- 此时就会根据 redo log 中记录的长度信息,以及记录长度的顺序构建临时的表定义,此时仅仅是为了恢复,并不需要精确的表定义,此时只需要知道 field 的长度和位置即可。
- 同时如果 redo log 中如果有 instant DDL 的信息,那么也会用这些信息去修改临时构建的表定义:这是问题发生的初始错误的地方。
- 恢复过程中,构建出的临时表实际上表中列的逻辑顺序,这是符合正常运行的需求的。
- 但是实际上 8.0.29 中字段长度的记录顺序是按字段 (列) 的物理存储顺序写入的。
- 如果带有 instant DDL 的信息,那么修改表定义时就会按物理顺序去修改逻辑顺序的表定义,这样会修改到非预期的字段,导致错误发生!
Bug 重现与解析
CREATE TABLE `tb1` (
`col1` VARCHAR(10) NOT NULL,
`col2` char(13),
`col3` varchar(11),
PRIMARY KEY (`col1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO tb1 VALUES (''4000'',''50'',''100'');
--echo # the FIRST INSTANT ALTER
ALTER TABLE tb1 DROP COLUMN col2, LOCK=DEFAULT;
INSERT INTO tb1 VALUES( ''4545'', ''52'' );
UPDATE tb1 SET col3 = ''46'' WHERE col1 = ''4545'';
--echo # crash and restart 1
--source include/kill_and_restart_mysqld.inc
CHECK TABLE tb1;
DROP TABLE tb1;
以上 MySQL MTR 测例可以重现 InnoDB 启动恢复期间始终 core 的问题。我们从这个例子出发,结合上面解释的 instant drop DDL 代码行为看看问题是如何一步步发生的。
- 首先说明一下,在测例运行期间逻辑顺序与物理顺序的变化。 如下图所示稍微展示了 table 的逻辑定于与 InnoDB row 存储的以下细节。这里注意的是 被 dropped column 仍然会以隐藏列的形式存在于表定于中:因为 drop 之前存在的 row 还是需要这样信息解析字段。

-
结合 redo log 的恢复过程看看问题发生的第一现场。这里针对这个测例摘取相关 redo log 的部分信息:

2.1 按照字段长度列表(8.0.29 中是物理顺序写入的列表)创建的专门用于恢复的表,类似于: create table dummy_table (d1:10, d2:13, d3:11)
2.2 按照 instant 字段信息修改 dummy 表:按照 physical pos=1 去修改后,结果类似于:create table dummy_table (d1:10, d2:13 [dropped], d3:11)
2.3 期望的正确的表应该类似于:create table dummy_table (d1:10, d3:11, d2:13 [dropped]);
2.4 Redo log 中的 Field_no=1, 去恢复时期望用到的是 #2.3 的表,但是过程中创建的是 #2.2 中错误的表,这样当 Field_no=1 去恢复数据时,会错误的发现对应的 field (column) 已经 dropped, 导致 core!
MySQL8.0.30 修复方案
知道了问题发生的原因,修复起来就比较简单了:
-
MySQL 8.0.30 的代码修复方案
-
- Redo log 中字段的长度列表,按照字段的逻辑顺序写入,不再按存储顺序写入。
- 在 redo log 的 instant column 信息中也包含了字段的逻辑位置。
- Redo log 的记录本身的版本设置为 1 ,与 8.0.29 的版本为 0 ,做出差别。
- 8.0.30 的修复代码本身也是不能正确解析 8.0.29 产生的 redo log ,只是根据版本号检测出 8.0.29 redo log,进而报错防止数据进一步恶化。实际上 8.0.29 的 redo log ,在 instant DDL 后,是不可能正确解析的,因为没有逻辑 / 物理的映射关系。
-
修复的逻辑比较简单:
-
-
Redo log 中字段的长度列表,按照字段的逻辑顺序写入:
保证在恢复阶段构建的临时表是按正确的逻辑定义顺序构建的。
-
在 redo log 的 instant column 信息中也包含字段的逻辑位置:
保证在更新临时表的字段时,按照逻辑顺序,不会出现错误更新的情况。
-
下面是 MySQL 8.0.30 update redo log 相关字段信息:
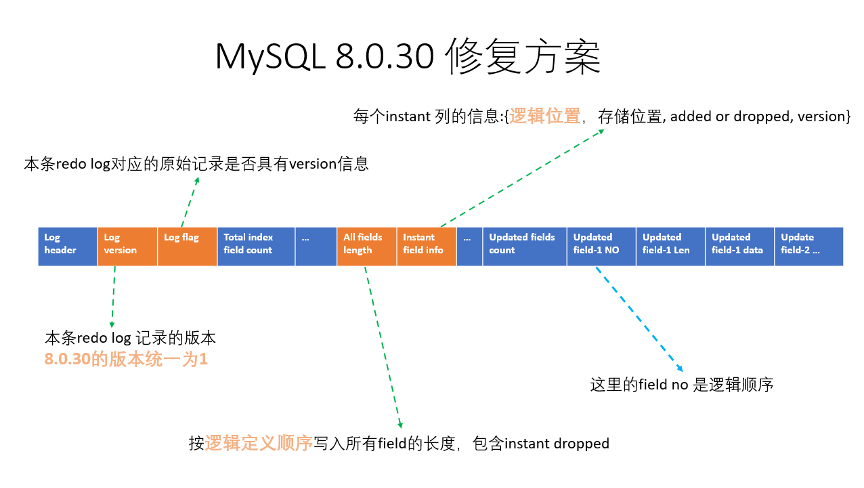
从上图可以看出,MySQL 8.0.30 redo log 中已经不存储物理位置相关的信息了,全部是逻辑位置相关的信息;这样就和 MySQL 8.0.29 redo log 这种有问题的记录方式是昙花一现了。
附带的这个测例可以重现数据的静默错误 (恢复过程没问题, 但是数据实际上错了)
CREATE TABLE `tb2` ( `c1` char(4) NOT NULL, `c2` char(4), `c3` char(4), PRIMARY KEY (`c1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
begin;
INSERT INTO tb2 VALUES (''1000'',''2000'',''3000'');
commit;
--echo # the FIRST INSTANT ALTER
ALTER TABLE tb2 add COLUMN c4 char(4) after c1, LOCK=DEFAULT;
INSERT INTO tb2 VALUES (''1001'',''4001'', ''2001'', ''3001'');
SELECT * FROM tb2;
UPDATE tb2 set c4=''4002'' WHERE c1=''1001'';
--echo # crash and restart 1
--source include/kill_and_restart_mysqld.inc
select * from tb2;
CHECK TABLE tb2;
需要把这个测例放到 innodb test case suite 中。
Enjoy GreatSQL :)
关于 GreatSQL
GreatSQL 是由万里数据库维护的 MySQL 分支,专注于提升 MGR 可靠性及性能,支持 InnoDB 并行查询特性,是适用于金融级应用的 MySQL 分支版本。
相关链接: GreatSQL 社区 Gitee GitHub Bilibili
GreatSQL 社区:

社区有奖建议反馈: https://greatsql.cn/thread-54-1-1.html
社区博客有奖征稿详情: https://greatsql.cn/thread-100-1-1.html
社区 2022 年度勋章获奖名单: https://greatsql.cn/thread-184-1-1.html
(对文章有疑问或者有独到见解都可以去社区官网提出或分享哦~)
技术交流群:
微信 & QQ 群:
QQ 群:533341697
微信群:添加 GreatSQL 社区助手(微信号:wanlidbc )好友,待社区助手拉您进群。

A2-03-01.DDL-Manage Database in MySQL
转载自:http://www.mysqltutorial.org/mysql-create-drop-database.aspx
Manage Database in MySQL
Summary: in this tutorial, you will learn how to manage databases in MySQL. You will learn how to create new databases, remove existing databases, and display all databases in the MySQL database server.
Let’s start creating a new database in MySQL.
Creating Database
Before doing anything else with the data, you need to create a database. A database is a container of data. It stores contacts, vendors, customers or any kind of data that you can think of. In MySQL, a database is a collection of objects that are used to store and manipulate data such as tables, database views, triggers, stored procedures, etc.
To create a database in MySQL, you use the CREATE DATABASE statement as follows:
|
1
|
CREATE DATABASE [IF NOT EXISTS] database_name;
|
Let’s examine the CREATE DATABASE statement in greater detail:
- Followed by the
CREATE DATABASEstatement is database name that you want to create. It is recommended that the database name should be as meaningful and descriptive as possible. - The
IF NOT EXISTSis an optional clause of the statement. TheIF NOT EXISTSclause prevents you from an error of creating a new database that already exists in the database server. You cannot have 2 databases with the same name in a MySQL database server.
For example, to create classicmodels database, you can execute the CREATE DATABASE statement as follows:
|
1
|
CREATE DATABASE classicmodels;
|
After executing this statement, MySQL returns a message to notify that the new database has been created successfully or not.
Displaying Databases
The SHOW DATABASES statement displays all databases in the MySQL database server. You can use the SHOW DATABASES statement to check the database that you’ve created or to see all the databases on the database server before you create a new database, for example:
|
1
|
SHOW DATABASES;
|

We have three databases in the MySQL database server. The information_schema and mysql are the default databases that are available when we install MySQL, and the classicmodels is the new database that we have created.
Selecting a database to work with
Before working with a particular database, you must tell MySQL which database you want to work with by using the USE statement.
|
1
|
USE database_name;
|
You can select the classicmodels sample database using the USE statement as follows:
|
1
|
USE classicmodels;
|
From now all operations such as querying data, create new tables or calling stored procedures which you perform, will take effects on the current database i.e., classicmodels .
Removing Databases
Removing database means you delete the database physically. All the data and associated objects inside the database are permanently deleted and this cannot be undone. Therefore, it is very important to execute this query with extra cautions.
To delete a database, you use the DROP DATABASE statement as follows:
|
1
|
DROP DATABASE [IF EXISTS] database_name;
|
Followed the DROP DATABASE is the database name that you want to remove. Similar to the CREATE DATABASE statement, the IF EXISTS is an optional part of the statement to prevent you from removing a database that does not exist in the database server.
If you want to practice with the DROP DATABASE statement, you can create a new database, make sure that it is created, and remove it. Let’s look at the following queries:
|
1
2
3
|
CREATE DATABASE IF NOT EXISTS temp_database;
SHOW DATABASES;
DROP DATABASE IF EXISTS temp_database;
|
The sequence of three statements is as follows:
- First, we created a database named
temp_databaseusing theCREATE DATABASEstatement. - Second, we displayed all databases using the
SHOW DATABASESstatement. - Third, we removed the
temp_databaseusing theDROP DATABASEstatement.
In this tutorial, you’ve learned various statements to manage databases in MySQL including creating a new database, removing an existing database, selecting a database to work with, and displaying all databases in a MySQL database server.

A2-03-02.DDL-Understanding MySQL Table Types, or Storage Engines
转载自:http://www.mysqltutorial.org/understand-mysql-table-types-innodb-myisam.aspx
Understanding MySQL Table Types, or Storage Engines
Summary: in this tutorial, you will learn various MySQL table types or storage engines. It is essential to understand the features of each table type in MySQL so that you can use them effectively to maximize the performance of your databases.
MySQL provides various storage engines for its tables as below:
- MyISAM
- InnoDB
- MERGE
- MEMORY (HEAP)
- ARCHIVE
- CSV
- FEDERATED
Each storage engine has its own advantages and disadvantages. It is crucial to understand each storage engine features and choose the most appropriate one for your tables to maximize the performance of the database. In the following sections, we will discuss each storage engine and its features so that you can decide which one to use.
MyISAM
MyISAM extends the former ISAM storage engine. The MyISAM tables are optimized for compression and speed. MyISAM tables are also portable between platforms and operating systems.
The size of MyISAM table can be up to 256TB, which is huge. In addition, MyISAM tables can be compressed into read-only tables to save spaces. At startup, MySQL checks MyISAM tables for corruption and even repairs them in a case of errors. The MyISAM tables are not transaction-safe.
Before MySQL version 5.5, MyISAM is the default storage engine when you create a table without specifying the storage engine explicitly. From version 5.5, MySQL uses InnoDB as the default storage engine.
InnoDB
The InnoDB tables fully support ACID-compliant and transactions. They are also optimal for performance. InnoDB table supports foreign keys, commit, rollback, roll-forward operations. The size of an InnoDB table can be up to 64TB.
Like MyISAM, the InnoDB tables are portable between different platforms and operating systems. MySQL also checks and repairs InnoDB tables, if necessary, at startup.
MERGE
A MERGE table is a virtual table that combines multiple MyISAM tables that have a similar structure into one table. The MERGE storage engine is also known as the MRG_MyISAM engine. The MERGE table does not have its own indexes; it uses indexes of the component tables instead.
Using MERGE table, you can speed up performance when joining multiple tables. MySQL only allows you to perform SELECT, DELETE, UPDATE and INSERT operations on the MERGE tables. If you use DROP TABLE statement on a MERGE table, only MERGE specification is removed. The underlying tables will not be affected.
Memory
The memory tables are stored in memory and use hash indexes so that they are faster than MyISAM tables. The lifetime of the data of the memory tables depends on the uptime of the database server. The memory storage engine is formerly known as HEAP.
Archive
The archive storage engine allows you to store a large number of records, which for archiving purpose, into a compressed format to save disk space. The archive storage engine compresses a record when it is inserted and decompress it using the zlib library as it is read.
The archive tables only allow INSERT and SELECT statements. The ARCHIVE tables do not support indexes, so it is required a full table scanning for reading rows.
CSV
The CSV storage engine stores data in comma-separated values (CSV) file format. A CSV table brings a convenient way to migrate data into non-SQL applications such as spreadsheet software.
CSV table does not support NULL data type. In addition, the read operation requires a full table scan.
FEDERATED
The FEDERATED storage engine allows you to manage data from a remote MySQL server without using the cluster or replication technology. The local federated table stores no data. When you query data from a local federated table, the data is pulled automatically from the remote federated tables.
Choosing MySQL Table Types
You can download the following checklist to choose the most appropriate storage engine, or table type, based on various criteria.
MySQL Storage Engine Feature Summary
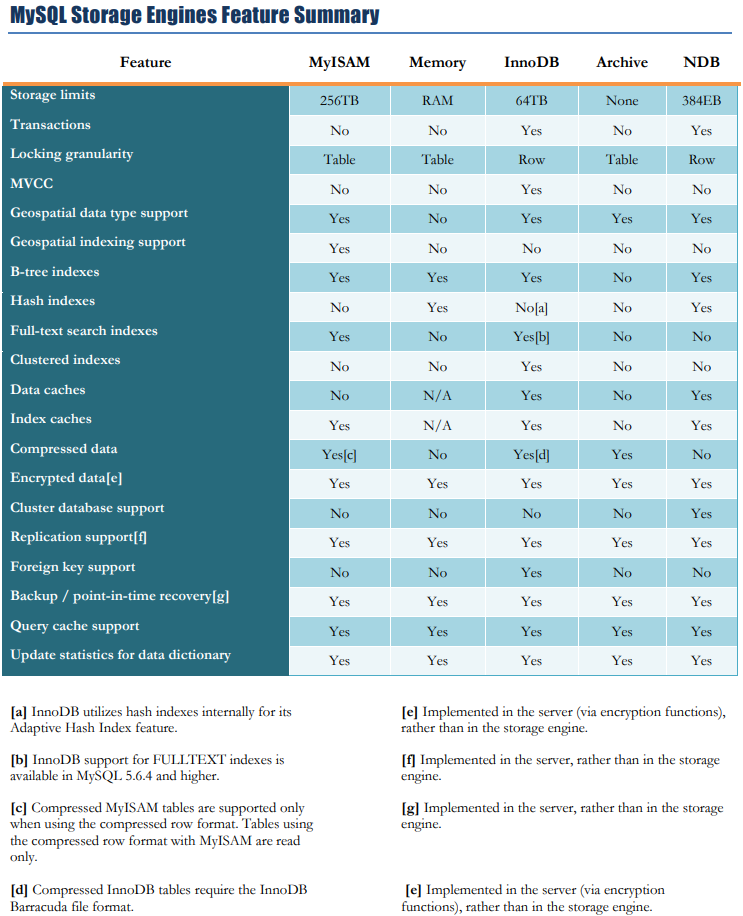
In this tutorial, you have learned various storage engines or table types available in MySQL.

A2-03-03.DDL-MySQL Data Types
转载自:http://www.mysqltutorial.org/mysql-data-types.aspx
MySQL Data Types
Summary: in this tutorial, you will learn about MySQL data types and how to use them effectively in designing database in MySQL.
A database table contains multiple columns with specific data types such as numeric or string. MySQL provides more data types other than just numeric or string. Each data type in MySQL can be determined by the following characteristics:
- The kind of values it represents.
- The space that takes up and whether the values is a fixed-length or variable length.
- The values of the data type can be indexed or not.
- How MySQL compares the values of a specific data type.

Download MySQL Data Types Overview
MySQL numeric data types
In MySQL, you can find all SQL standard numeric types including exact number data type and approximate numeric data types including integer, fixed-point and floating point. In addition, MySQL also hasBIT data type for storing bit values. Numeric types can be signed or unsigned except for the BIT type.
The following table shows the summary of numeric types in MySQL:
| Numeric Types | Description |
|---|---|
TINYINT |
A very small integer |
SMALLINT |
A small integer |
MEDIUMINT |
A medium-sized integer |
INT |
A standard integer |
BIGINT |
A large integer |
DECIMAL |
A fixed-point number |
FLOAT |
A single-precision floating point number |
DOUBLE |
A double-precision floating point number |
BIT |
A bit field |
MySQL Boolean data type
MySQL does not have the built-in BOOLEANor BOOL data type. To represent Boolean values, MySQL uses the smallest integer type which isTINYINT(1). In other words, BOOLEAN and BOOL are synonyms for TINYINT(1).
MySQL String data types
In MySQL, a string can hold anything from plain text to binary data such as images or files. Strings can be compared and searched based on pattern matching by using the LIKE operator, regular expression, and full-text search.
The following table shows the string data types in MySQL:
| String Types | Description |
|---|---|
CHAR |
A fixed-length nonbinary (character) string |
VARCHAR |
A variable-length non-binary string |
BINARY |
A fixed-length binary string |
VARBINARY |
A variable-length binary string |
TINYBLOB |
A very small BLOB (binary large object) |
BLOB |
A small BLOB |
MEDIUMBLOB |
A medium-sized BLOB |
LONGBLOB |
A large BLOB |
TINYTEXT |
A very small non-binary string |
TEXT |
A small non-binary string |
MEDIUMTEXT |
A medium-sized non-binary string |
LONGTEXT |
A large non-binary string |
ENUM |
An enumeration; each column value may be assigned one enumeration member |
SET |
A set; each column value may be assigned zero or more SET members |
MySQL date and time data types
MySQL provides types for date and time as well as the combination of date and time. In addition, MySQL supports timestamp data type for tracking the changes in a row of a table. If you just want to store the year without date and month, you can use the YEAR data type.
The following table illustrates the MySQL date and time data types:
| Date and Time Types | Description |
|---|---|
DATE |
A date value in CCYY-MM-DD format |
TIME |
A time value in hh:mm:ss format |
DATETIME |
A date and time value inCCYY-MM-DD hh:mm:ssformat |
TIMESTAMP |
A timestamp value in CCYY-MM-DD hh:mm:ss format |
YEAR |
A year value in CCYY or YY format |
MySQL spatial data types
MySQL supports many spatial data types that contain various kinds of geometrical and geographical values as shown in the following table:
| Spatial Data Types | Description |
|---|---|
GEOMETRY |
A spatial value of any type |
POINT |
A point (a pair of X-Y coordinates) |
LINESTRING |
A curve (one or more POINT values) |
POLYGON |
A polygon |
GEOMETRYCOLLECTION |
A collection of GEOMETRYvalues |
MULTILINESTRING |
A collection of LINESTRINGvalues |
MULTIPOINT |
A collection of POINTvalues |
MULTIPOLYGON |
A collection of POLYGONvalues |
JSON data type
MySQL supported a native JSON data type since version 5.7.8 that allows you to store and manage JSON documents more efficiently. The native JSON data type provides automatic validation of JSON documents and optimal storage format.
In this tutorial, you have learned various MySQL data types that help you determine which data type you should use for columns when you create tables.

A2-03-06.DDL-MySQL UNIQUE Constraint
转载自:http://www.mysqltutorial.org/mysql-unique-constraint/
MySQL UNIQUE Constraint
Summary: in this tutorial, you will learn about MySQL UNIQUE constraint to enforce the uniqueness of the values in a column or a group of columns.
Introduction to MySQL UNIQUE constraint
Sometimes, you want to enforce the uniqueness value in a column e.g., the phones of the suppliers in the suppliers table must be unique, or the combination of the supplier name and address must not be duplicate.
To enforce this rule, you need to use the UNIQUE constraint.
The UNIQUE constraint is either column constraint or table constraint that defines a rule that constrains values in a column or a group of columns to be unique.
To add the UNIQUE constraint to a column, you use the following syntax:
|
1
2
3
|
CREATE TABLE table_1(
column_name_1 data_type UNIQUE,
);
|
Or you can define the UNIQUE constraint as the table constraint as follows:
|
1
2
3
4
5
6
|
CREATE TABLE table_1(
...
column_name_1 data_type,
...
UNIQUE(column_name_1)
);
|
If you insert or update a value that causes a duplicate value in the column_name_1 column, MySQL will issue an error message and reject the change.
In case you want to enforce unique values across columns, you must define the UNIQUE constraint as the table constraint and separate the each column by a comma:
|
1
2
3
4
5
6
7
8
|
CREATE TABLE table_1(
...
column_name_1 data_type,
column_name_2 data type,
...
UNIQUE(column_name_1,column_name_2)
);
|
MySQL will use the combination of the values in both column_name_1 and column_name_2 columns to evaluate the uniqueness.
If you want to assign a specific name to a UNIQUE constraint, you use the CONSTRAINT clause as follows:
|
1
2
3
4
5
6
7
|
CREATE TABLE table_1(
...
column_name_1 data_type,
column_name_2 data type,
...
CONSTRAINT constraint_name UNIQUE(column_name_1,column_name_2)
);
|
MySQL UNIQUE constraint example
The following statement creates a new table named suppliers with the two UNIQUE constraints:
|
1
2
3
4
5
6
7
|
CREATE TABLE IF NOT EXISTS suppliers (
supplier_id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
phone VARCHAR(12) NOT NULL UNIQUE,
address VARCHAR(255) NOT NULL,
CONSTRAINT uc_name_address UNIQUE (name , address)
);
|
The first UNIQUE constraint is applied on the phone column. It means that every supplier must have a distinct phone number. In other words, no two suppliers have the same phone number.
The second UNIQUE constraint has a name uc_name_address that enforces the uniqueness of values in the name and address columns. It means suppliers can have the same name or address, but cannot have the same name and address.
Let’s insert some rows into the suppliers table to test the UNIQUE constraint.
The following statement inserts a row into to the suppliers table.
|
1
2
|
INSERT INTO suppliers(name, phone, address)
VALUES(''ABC Inc'', ''408-908-2476'',''4000 North 1st Street, San Jose, CA, USA'');
|
|
1
|
1
row(s) affected
|
We try to insert a different supplier but has the phone number that already exists in the supplierstable.
|
1
2
|
INSERT INTO suppliers(name, phone, address)
VALUES(''XYZ Corporation'', ''408-908-2476'',''4001 North 1st Street, San Jose, CA, USA'');
|
MySQL issued an error:
|
1
|
Error
Code: 1062. Duplicate entry ''408-908-2476'' for key ''phone''
|
Let’s change the phone number to a different one and execute the insert statement again.
|
1
2
|
INSERT INTO suppliers(name, phone, address)
VALUES(''XYZ Corporation'', ''408-908-2567'',''400 North 1st Street, San Jose, CA, USA'');
|
|
1
|
1
row(s) affected
|
Now we execute the following INSERT statement to insert a row with the values in the name and address columns that already exists.
|
1
2
|
INSERT INTO suppliers(name, phone, address)
VALUES(''XYZ Corporation'', ''408-908-102'',''400 North 1st Street, San Jose, CA, USA'');
|
MySQL issued an error.
|
1
|
Error
Code: 1062. Duplicate entry ''XYZ Corporation-400 North 1st Street, San Jose, CA, USA'' for key ''name''
|
Because the UNIQUE constraint uc_name_address was violated.
Managing MySQL UNIQUE constraints
When you add a unique constraint to a table MySQL creates a corresponding BTREE index to the database. The following SHOW INDEX statement displays all indexes created on the suppliers table.
|
1
|
SHOW INDEX FROM classicmodels.suppliers;
|

As you see, there are two BTREE indexes corresponding to the two UNIQUE constraints created.
To remove a UNIQUE constraint, you use can use DROP INDEX or ALTER TABLE statement as follows:
|
1
|
DROP INDEX index_name ON table_name;
|
|
1
2
|
ALTER TABLE table_name
DROP INDEX index_name;
|
For example, to remove the uc_name_address constraint on the suppliers table, you the following statement:
|
1
|
DROP INDEX uc_name_address ON suppliers;
|
Execute the SHOW INDEX statement again to verify if the uc_name_unique constraint has been removed.
|
1
|
SHOW INDEX FROM classicmodels.suppliers;
|

What if you want to add a UNIQUE constraint to a table that already exists?
To do this, you use the ALTER TABLE statement as follows:
|
1
2
|
ALTER TABLE table_name
ADD CONSTRAINT constraint_name UNIQUE (column_list);
|
For example, to add the uc_name_address UNIQUE constraint back to the suppliers table, you use the following statement:
|
1
2
|
ALTER TABLE suppliers
ADD CONSTRAINT uc_name_address UNIQUE (name,address);
|

Note that the combination of values in the name and address columns must be unique in order to make the statement execute successfully.
In this tutorial, you have learned how to use the MySQL UNIQUE constraint to enforce the uniqueness of values in a column or a group of columns in a table.
Related Tutorials
- MySQL NOT NULL Constraint
今天关于MySQL 8.0.29 instant DDL 数据腐化问题分析和mysql ddl语句的介绍到此结束,谢谢您的阅读,有关A2-03-01.DDL-Manage Database in MySQL、A2-03-02.DDL-Understanding MySQL Table Types, or Storage Engines、A2-03-03.DDL-MySQL Data Types、A2-03-06.DDL-MySQL UNIQUE Constraint等更多相关知识的信息可以在本站进行查询。
本文标签:




