关于MySQL分组聚合group_concat+substr_index和mysql分组聚合函数的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于DAX第七篇:分组聚合、javaAPI操作E
关于MySQL 分组聚合 group_concat + substr_index和mysql分组聚合函数的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于DAX 第七篇:分组聚合、javaAPI 操作 ES 分组聚合、MySQL (15)----- 运算符和优先级查询结果拼接处理及 CONCAT ()、CONCAT_WAS () 和 GROUP_CONCAT () 函数的使用、MySQL -- 行转列 -- GROUP_CONCAT -- MAX(CASE WHEN THEN)等相关知识的信息别忘了在本站进行查找喔。
本文目录一览:- MySQL 分组聚合 group_concat + substr_index(mysql分组聚合函数)
- DAX 第七篇:分组聚合
- javaAPI 操作 ES 分组聚合
- MySQL (15)----- 运算符和优先级查询结果拼接处理及 CONCAT ()、CONCAT_WAS () 和 GROUP_CONCAT () 函数的使用
- MySQL -- 行转列 -- GROUP_CONCAT -- MAX(CASE WHEN THEN)
")
MySQL 分组聚合 group_concat + substr_index(mysql分组聚合函数)
场景:
给予一张商品售卖表,表中数据为商品的售卖记录,假设表中数据是定时脚本插入的,每个时间段的商品售卖数量不同,根据此表找各个商品的最多售卖数量的数据。
1、数据表
CREATE TABLE `goods_sell` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`goods_id` int(10) unsigned NOT NULL DEFAULT ''0'',
`sell_num` int(10) unsigned NOT NULL DEFAULT ''0'',
`create_time` int(10) unsigned NOT NULL DEFAULT ''0'',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb42、数据内容
mysql> select * from goods_sell;
+----+----------+----------+-------------+
| id | goods_id | sell_num | create_time |
+----+----------+----------+-------------+
| 1 | 1 | 5 | 1420520010 |
| 2 | 2 | 10 | 1420520000 |
| 3 | 1 | 10 | 1410520000 |
| 4 | 1 | 5 | 1510520000 |
| 5 | 2 | 6 | 1510521000 |
| 6 | 3 | 15 | 1510621000 |
+----+----------+----------+-------------+
6 rows in set (0.00 sec)剖析其要求,也就是说,要用 1 条 sql
找出 goods_id 为 1 的 id 为 4 的数据
找出 goods_id 为 2 的 id 为 2 的数据
找出 goods_id 为 3 的 id 为 6 的数据
3、怎么做呢?
这时就可以用 MySQL 的分组聚合,GROUP_CONCAT 和 SUBSTRING_INDEX 一起使用。
#查找各个商品售卖最多的一条记录,此时 group_concat () 中一定要 order by 排序。要不然截取第一个数据就不对了。
select id,goods_id,
SUBSTRING_INDEX(GROUP_CONCAT(sell_num order by sell_num desc),'','',1) sell_num_max,
create_time
from goods_sell group by goods_id order by create_time DESC;
+----+----------+--------------+-------------+
| id | goods_id | sell_num_max | create_time |
+----+----------+--------------+-------------+
| 6 | 3 | 15 | 1510621000 |
| 1 | 1 | 10 | 1420520010 |
| 2 | 2 | 10 | 1420520000 |
+----+----------+--------------+-------------+
3 rows in set (0.00 sec)不使用 SUBSTRING_INDEX 的话,查出来的数据是:
select id,goods_id, GROUP_CONCAT(sell_num order by sell_num desc) sell_num_list, create_time from good;
+----+----------+---------------+-------------+
| id | goods_id | sell_num_list | create_time |
+----+----------+---------------+-------------+
| 6 | 3 | 15 | 1510621000 |
| 1 | 1 | 10,5,5 | 1420520010 |
| 2 | 2 | 10,6 | 1420520000 |
+----+----------+---------------+-------------+
3 rows in set (0.00 sec)所以用 SUBSTRING_INDEX 截取最前面的一个数据。
文档参考:
https://www.cnblogs.com/zhwbqd/p/4205821.html
https://blog.csdn.net/m0_37797991/article/details/80511855
https://baijiahao.baidu.com/s?id=1595349117525189591&wfr=spider&for=pc

DAX 第七篇:分组聚合
DAX 有三个用于生成分组聚合数据的函数,这三个函数有两个共同的特征:分组列和扩展列。
- 分组列是用于分组的列,只能来源于基础表中已存的列,分组列可以来源于同一个表,也可以来源于相关的列。
- 扩展列是由 name 和 expression 对构成的,name 是字符串,expression 是包含聚合函数的表达式。
在分组列和扩展列上,这三个函数有各自独特的处理方式。
一,SUMMARIZE
SUMMARIZE 函数对相互关联的 Table 按照特定的一个字段(分组列)或多个字段,进行分组聚合。由于分组列是唯一的,通过 SUMMARIZE 函数,可以获得多列的唯一值构成的二维表:
SUMMARIZE(<table>, <groupBy_columnName>[, <groupBy_columnName>]…[, <name>, <expression>]…)参数注释:
- table:必需参数,表示主表,可以是任何返回表的表达式。
- groupBy_columnName:可选参数,表示分组列,该列必须是 table 参数中的列,或者相关联表中的列。分组列必须使用列的完全限定名,格式是 table [column],分组列可以有 0 个,1 个或多个。
- name、expression:可选参数,表示自定义的汇总列 / 扩展列,该参数对总是成对出现的,name 是 expression 计算结果的名称,expression 用于计算列的聚合值。
该函数的返回值是一个汇总表,汇总表包含分组列和自定义的扩展列。
1,获得多列的唯一值
分组列是唯一的,可以不返回汇总列,而只返回分组列,这样得到的表是多列的唯一值。
SUMMARIZE(ResellerSales
, DateTime[CalendarYear]
, ProductCategory[ProductCategoryName]
) 2,获得汇总数据
例如,对数据表 ResellerSales ,按照字段 DateTime [CalendarYear] 和 ProductCategory [ProductCategoryName] 分组,计算 ResellerSales [SalesAmount] 和 ResellerSales [DiscountAmount] 的加和 。
SUMMARIZE(ResellerSales
, DateTime[CalendarYear]
, ProductCategory[ProductCategoryName]
, "Sales Amount", SUM(ResellerSales[SalesAmount])
, "Discount Amount", SUM(ResellerSales[DiscountAmount])
) 该函数利用 ResellerSales 和 DateTime、ProductCategory 之间的关系,得到关联表数据(是一个中间临时表),按照 DateTime [CalendarYear] 和 ProductCategory [ProductCategoryName] 对关联之后的数据进行分组,分别计算销售和折扣的加和。
注意,ResellerSales 和 DateTime,ResellerSales 和 ProductCategory 必须显式存在关系,否则,不能用于分组列中。
3,分组聚合的作用
第一是作为中间临时表,为后续的计算提供数据;第二是用于创建新表,在 Modeling 菜单中,通过 “New Table” 从 DAX 表达式中创建新的 Table:

参考文档:SUMMARIZE – groupping in data models (DAX – Power Pivot, Power BI)
4,ROLLUP 选项
ROLLUP 函数用于对分组列进行上卷操作,该函数用于预定义多个分组集:
SUMMARIZE(<table>, <groupBy_columnName>[, <groupBy_columnName>]…[, ROLLUP(<groupBy_columnName>[,< groupBy_columnName>…])][, <name>, <expression>]…)作用类似于 TSQL 的 rollup 函数,例如,对于 group by rollup(a,b) ,其表示的分组集是 group by (), group by (a), group by (a,b)。
5,ROLLUPGROUP 选项
ROLLUPGROUP 函数用于计算小计组。如果把 ROLLUPGROUP 来代替 ROLLUP 函数,那么 ROLLUPGROUP 通过向 groupBy_columnName 列的结果添加汇总行来产生和 ROLLUP 相同的结果。 但是,在 ROLLUP 语法中添加 ROLLUPGROUP()可用于防止汇总行中的部分小计。例如,ROLLUP (ROLLUPGROUP (A,B)),分组集是 (A,B) 和 ():
SUMMARIZE(ResellerSales_USD
, ROLLUP(ROLLUPGROUP( DateTime[CalendarYear], ProductCategory[ProductCategoryName]))
, "Sales Amount (USD)", SUM(ResellerSales_USD[SalesAmount_USD])
, "Discount Amount (USD)", SUM(ResellerSales_USD[DiscountAmount])
) 6,ISSUBTOTAL 选项
只能用于 SUMMRIZE 函数中,用于检查该列是否为小计组。
SUMMARIZE(<table>, <groupBy_columnName>[, <groupBy_columnName>]…[, ROLLUP(<groupBy_columnName>[,< groupBy_columnName>…])][, <name>, {<expression>|ISSUBTOTAL(<columnName>)}]…)例如,使用该函数检查 CalendarYear 和 ProductCategoryName 是否为小计组:
SUMMARIZE(ResellerSales_USD
, ROLLUP( DateTime[CalendarYear], ProductCategory[ProductCategoryName])
, "Sales Amount (USD)", SUM(ResellerSales_USD[SalesAmount_USD])
, "Discount Amount (USD)", SUM(ResellerSales_USD[DiscountAmount])
, "Is Sub Total for DateTimeCalendarYear", ISSUBTOTAL(DateTime[CalendarYear])
, "Is Sub Total for ProductCategoryName", ISSUBTOTAL(ProductCategory[ProductCategoryName])
)二,SUMMARIZECOLUMNS
该函数也用于分组聚合,和 SUMMARIZE 函数的差异在于分组列之间的关系是非必需的,分组列之间执行的交叉连接或自动存在。
SUMMARIZECOLUMNS( <groupBy_columnName> [, < groupBy_columnName >]…, [<filterTable>]…[, <name>, <expression>]…)参数注释:
- groupBy_columnName:分组列,该列必须使用列的完全限定名,格式是 base_table [column],该列必须是基础表中的现存列,分组列可以有 0 个,1 个或多个。多个分组列之间的表不要求必须有关系,对于不同表,分组列之间是交叉连接(cross-join);对于相同表,分组列之间使用的是自动存在(auto-existed)。
- filterTable:可选参数,对分组列所在的基础表进行过滤, 过滤器表中存在的值用于在执行交叉连接 / 自动存在之前进行过滤。
- name、expression:可选参数,表示自定义的汇总列,该参数对总是成对出现的,name 是 expression 计算结果的名称,expression 用于计算列的聚合值。
返回值是汇总表,包含分组列和自定义列,返回的数据行中,至少包含一个非空值,如果在一个数据行中,所有 expression 的结果都是 BLANK/NULL,那么该行不包含在汇总表中。
1,分组字段进行笛卡尔乘积
以下 DAX 按照 SalesTerritory 的字段 Category 和 Customer 的 Education 字段进行分组,并对 Customer 表进行过滤:
SUMMARIZECOLUMNS ( ''SalesTerritory''[Category], ''Customer'' [Education], FILTER(''Customer'', ''Customer''[First Name] = “Alicia”) )对过滤之后的数据进行汇总计算,返回的结果是 Category 和 Eduction 的笛卡尔乘积。
2,IGNORE 选项
把包含 NULL/BLANK 的行过滤掉
SUMMARIZECOLUMNS(<groupBy_columnName>[, < groupBy_columnName >]…, [<filterTable>]…[, <name>, IGNORE(…)]…)例如,如果 Sum (Sales [Qty] ) 中包含一个 NULL/BLANK,那么把该行从结果集中移除:
SUMMARIZECOLUMNS( Sales[CustomerId], "Total Qty", IGNORE( SUM( Sales[Qty] ) ), “BlankIfTotalQtyIsNot3”, IF( SUM( Sales[Qty] )=3, 3 ) )3,其他选项
- NONVISUAL()
- ROLLUPADDISSUBTOTAL()
- ROLLUPGROUP()
三,GROUPBY
GROUPBY 函数除了不能再扩展列中使用 CALCULATE 函数之外,和 SUMMARIZE 的用法相同:
GROUPBY (<table>, [<groupBy_columnName1>]..., [<name>, <expression>]… )expression 参数中不能使用 CALCULATE 函数,CURRENTGROUP 函数只能用于最顶层的表扫描(Table Scan)操作。
GROUPBY 函数执行的操作是:
- #1:从指定的表(以及 “to-one” 方向的所有相关表)开始
- #2:按照所有的 GroupBy 列创建分组,每一个分组代表一组数据行
- #3:对于每一个分组,评估要增加的扩展列(Extension column)。与 SUMMARIZE 函数不同,不执行隐含的 CALCULATE,并且不把该组放入到过滤器上下文中。
在该函数中,可以调用 CURRENTGROUP 函数:
CURRENTGROUP()该函数只能用于 GROUPBY 函数的 expression 参数中,表示当前分组。 CURRENTGROUP 函数不带参数,仅支持作为以下聚合函数之一的第一个参数:AverageX,CountAX,CountX,GeoMeanX,MaxX,MinX,ProductX,StDevX.S,StDevX.P,SumX,VarX.S,VarX.P。举个例子,对 Sales 表,按照 Country 和 Category 进行分组,计算每个分组中 Price * Qty 的乘积之和。
GROUPBY (
Sales,
Geography[Country],
Product[Category],
“Total Sales”, SUMX( CURRENTGROUP(), Sales[Price] * Sales[Qty])
)
参考文档:
SUMMARIZE
SUMMARIZECOLUMNS
GROUPBY
DAX function reference

javaAPI 操作 ES 分组聚合
连接 es 的客户端使用的 TransportClient
SearchRequestBuilder requestBuilder = transportClient.prepareSearch(indies).setTypes(TYPE_NAME);
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
AggregationBuilder groupByType = AggregationBuilders.terms("分组别名").field("分组字段");
AggregationBuilder sumDownOutputSum = AggregationBuilders.sum("聚合别名").field("聚合字段");
//sub是子聚合
requestBuilder.setQuery(boolQueryBuilder).addAggregation(groupByType.subAggregation(sumDownOutputSum));
SearchResponse response = requestBuilder.get();
Terms terms = response.getAggregations().get("groupByType");
for (Terms.Bucket bucket : terms.getBuckets()) {
Map<String, Object> resMap = new HashMap<>();
Sum downOutputSum = bucket.getAggregations().get("downOutputSum");
double value = downOutputSum.getValue();
Object key = bucket.getKey();
//key 是分组字段
//value是聚合value
}----- 运算符和优先级查询结果拼接处理及 CONCAT ()、CONCAT_WAS () 和 GROUP_CONCAT () 函数的使用")
MySQL (15)----- 运算符和优先级查询结果拼接处理及 CONCAT ()、CONCAT_WAS () 和 GROUP_CONCAT () 函数的使用
本文测试用例的数据表 tb_goods:

1、CONCAT () 函数
【1】功能:将多个字符串连接成一个字符串。
【2】语法:concat(str1, str2,...)
返回结果为连接参数产生的字符串,如果有任何一个参数为 null,则返回值为 null。
测试 SQL:
SELECT
CONCAT(A.id, A.brand ) AS goods
FROM
tb_goods A
WHERE A.id < ''1057740''
ORDER BY
A.id
查询结果:

【3】语法:concat (str1, seperator,str2,seperator,...)
返回结果为连接参数产生的字符串。如有任何一个参数为 NULL ,则返回值为 NULL。可以有一个或多个参数。
测试 SQL:
SELECT
CONCAT(A.id, ''_'', A.price, ''_'', A.brand ) AS goods
FROM
tb_goods A
WHERE A.id < ''1057740''
ORDER BY
A.id
查询结果:

2、CONCAT_WAS () 函数
【1】功能:和 concat () 一样,将多个字符串连接成一个字符串,但是可以一次性指定分隔符(concat_ws 就是 concat with separator)
【2】语法:concat_ws (separator, str1, str2, ...)
说明:
- 第一个参数指定分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。
- 如果分隔符为 NULL,则结果为 NULL。
- 函数会忽略任何分隔符参数后的 NULL 值。但是 CONCAT_WS () 不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
测试 SQL:
SELECT
CONCAT_WS(''_'', A.id, A.price, A.brand ) AS goods
FROM
tb_goods A
WHERE A.id < ''1057740''
ORDER BY
A.id
查询结果:

注意:如果把分割符指定为 null,则使用 CONCAT_WAS () 函数获得的结果将全部为 null。
测试 SQL:
SELECT
CONCAT_WS(null, A.id, A.price, A.brand ) AS goods
FROM
tb_goods A
WHERE A.id < ''1057740''
ORDER BY
A.id
查询结果:

3、GROUP_CONCAT () 函数
在有 group by 的查询语句中,select 指定的字段要么就包含在 group by 语句的后面,作为分组的依据,要么就包含在聚合函数中。
查询商品表内品牌和价格,测试 SQL:
SELECT
A.brand as brand,
A.price as price
FROM
tb_goods A
ORDER BY
A.id
查询结果:

但是这样同一个组织出现多次,看上去非常不直观。有没有更直观的方法,既让每个组织 id 都只出现一次,又能够显示所有的名字相同的品牌?
—— 使用 group_concat () 函数
【1】功能:将 group by 产生的同一个分组中的值连接起来,返回一个字符串结果。
【2】语法:group_concat ([distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '' 分隔符 ''] )
说明:通过使用 distinct 可以排除重复值;如果希望对结果中的值进行排序,可以使用 order by 子句;separator 是一个字符串值,缺省为一个逗号。
测试 SQL
SELECT
GROUP_CONCAT(A.brand),
A.price AS price
FROM
tb_goods A
ORDER BY
A.price
查询结果:
![]()
注意:
- 通过使用 distinct 可以排除重复值;
- 如果希望对结果中的值进行排序,可以使用 order by 子句;
- separator 是一个字符串值,它被用于插入到结果值中。缺省为一个逗号 (","),可以通过指定 separator "" 完全地移除这个分隔符。
- 可以通过变量 group_concat_max_len 设置一个最大的长度。在运行时执行的句法如下: SET [SESSION | GLOBAL] group_concat_max_len = unsigned_integer;
- 如果最大长度被设置,结果值被剪切到这个最大长度。如果分组的字符过长,可以对系统参数进行设置:SET @@global.group_concat_max_len=40000;
愿你就像早晨八九点钟的太阳,活力十足,永远年轻。
")
MySQL -- 行转列 -- GROUP_CONCAT -- MAX(CASE WHEN THEN)
列转行: 多列转多行
行转列:多行转多列
以下转自:https://www.cnblogs.com/ClassNotFoundException/p/6860615.html
列转行:利用max(case when then)
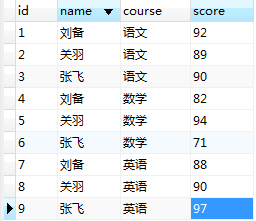

SELECT
`name`,
MAX(
CASE
WHEN course=''语文'' THEN
score
END
) AS 语文,
MAX(
CASE
WHEN course=''数学'' THEN
score
END
) AS 数学,
MAX(
CASE
WHEN course=''英语'' THEN
score
END
) AS 英语
FROM
student
GROUP BY `name`
;
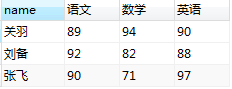
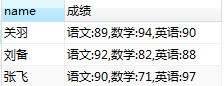
合并字段显示:利用group_cancat(course,”:”,”score”)

SELECT
`name`,
GROUP_CONCAT(course, ":", score) AS 成绩
FROM
student
GROUP BY
`name`;
-- -- -- -- -- -- -- --- - -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --- - -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --- - -- -- -- -- -- -- -- -- -- -- -- -- -
-- 合并字段显示 : 去重、排序
SELECT rid,GROUP_CONCAT(DISTINCT gid ORDER BY gid)
FROM gt_lighting.res_lights
GROUP BY rid;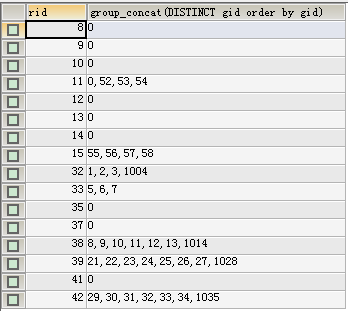
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
多来点面试题:
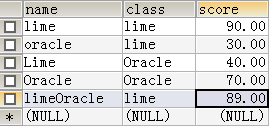
计算各班级及格人数:
SELECT class,SUM(CASE WHEN score >= 60 THEN 1 END) AS ''及格'',SUM(CASE WHEN score < 60 THEN 1 END) AS ''不及格''
FROM gradeTable
GROUP BY class;或者:

SELECT succ.class,succ.su AS ''及格'',fail.fa AS ''不及格'' FROM
(
SELECT class,COUNT(1) AS su
FROM gradeTable
WHERE score >= 60
GROUP BY class
) AS succ,
(
SELECT class,COUNT(1) AS fa
FROM gradeTable
WHERE score < 60
GROUP BY class
) AS fail
WHERE succ.class = fail.class;
Console :
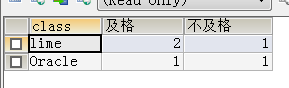
啦啦啦
关于MySQL 分组聚合 group_concat + substr_index和mysql分组聚合函数的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于DAX 第七篇:分组聚合、javaAPI 操作 ES 分组聚合、MySQL (15)----- 运算符和优先级查询结果拼接处理及 CONCAT ()、CONCAT_WAS () 和 GROUP_CONCAT () 函数的使用、MySQL -- 行转列 -- GROUP_CONCAT -- MAX(CASE WHEN THEN)的相关信息,请在本站寻找。
本文标签:




