在本文中,您将会了解到关于hivemysql初始化的新资讯,同时我们还将为您解释hive初始化mysql失败的相关在本文中,我们将带你探索hivemysql初始化的奥秘,分析hive初始化mysql失
在本文中,您将会了解到关于hive mysql 初始化的新资讯,同时我们还将为您解释hive初始化mysql失败的相关在本文中,我们将带你探索hive mysql 初始化的奥秘,分析hive初始化mysql失败的特点,并给出一些关于define 解析依赖,判断状态,初始化/触发加载 --------require 同步加载(直接返回)/异步加载(创建匿名模块,判断状态,初始化/触发加载)、hive (01)、基于 hadoop 集群的数据仓库 Hive 搭建实践、hive (06)、数据仓库 Hive 用户图形接口 HWI 的配置、HIVE - 执行 hive 的几种方式,和把 HIVE 保存到本地的几种方式的实用技巧。
本文目录一览:- hive mysql 初始化(hive初始化mysql失败)
- define 解析依赖,判断状态,初始化/触发加载 --------require 同步加载(直接返回)/异步加载(创建匿名模块,判断状态,初始化/触发加载)
- hive (01)、基于 hadoop 集群的数据仓库 Hive 搭建实践
- hive (06)、数据仓库 Hive 用户图形接口 HWI 的配置
- HIVE - 执行 hive 的几种方式,和把 HIVE 保存到本地的几种方式
")
hive mysql 初始化(hive初始化mysql失败)
原文链接:https://juejin.im/post/59c3f8f75188255be81f91d9#heading-17
Apache Hive-2.3.0 快速搭建与使用
Hive 简介
Hive 是一个基于 hadoop 的开源数据仓库工具,用于存储和处理海量结构化数据。它把海量数据存储于 hadoop 文件系统,而不是数据库,但提供了一套类数据库的数据存储和处理机制,并采用 HQL (类 SQL )语言对这些数据进行自动化管理和处理。我们可以把 Hive 中海量结构化数据看成一个个的表,而实际上这些数据是分布式存储在 HDFS 中的。 Hive 经过对语句进行解析和转换,最终生成一系列基于 hadoop 的 map/reduce 任务,通过执行这些任务完成数据处理。
Hive 诞生于 facebook 的日志分析需求,面对海量的结构化数据, Hive 以较低的成本完成了以往需要大规模数据库才能完成的任务,并且学习门槛相对较低,应用开发灵活而高效。
Hive 自 2009.4.29 发布第一个官方稳定版 0.3.0 至今,不过一年的时间,正在慢慢完善,网上能找到的相关资料相当少,尤其中文资料更少,本文结合业务对 Hive 的应用做了一些探索,并把这些经验做一个总结,所谓前车之鉴,希望读者能少走一些弯路。
准备工作
环境
JDK:1.8
Hadoop Release:2.7.4
centos:7.3
node1(master) 主机: 192.168.252.121
node2(slave1) 从机: 192.168.252.122
node3(slave2) 从机: 192.168.252.123
node4(mysql) 从机: 192.168.252.124
复制代码依赖环境
安装**Apache Hive**前提是要先安装hadoop集群,并且hive只需要在hadoop的namenode节点集群里安装即可(需要在有的namenode上安装),可以不在datanode节点的机器上安装。还需要说明的是,虽然修改配置文件并不需要把hadoop运行起来,但是本文中用到了hadoop的hdfs命令,在执行这些命令时你必须确保hadoop是正在运行着的,而且启动hive的前提也需要hadoop在正常运行着,所以建议先把hadoop集群启动起来。
安装**MySQL** 用于存储 Hive 的元数据(也可以用 Hive 自带的嵌入式数据库 Derby,但是 Hive 的生产环境一般不用 Derby),这里只需要安装 MySQL 单机版即可,如果想保证高可用的化,也可以部署 MySQL 主从模式;
Hadoop
Hadoop-2.7.4 集群快速搭建
MySQL 随意任选其一
CentOs7.3 安装 MySQL 5.7.19 二进制版本
搭建 MySQL 5.7.19 主从复制,以及复制实现细节分析
安装
下载解压
su hadoop
cd /home/hadoop/
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3.0/apache-hive-2.3.0-bin.tar.gz
tar -zxvf apache-hive-2.3.0-bin.tar.gz
mv apache-hive-2.3.0-bin hive-2.3.0
复制代码环境变量
如果是对所有的用户都生效就修改vi /etc/profile 文件 如果只针对当前用户生效就修改 vi ~/.bahsrc 文件
sudo vi /etc/profile
复制代码#hive
export PATH=${HIVE_HOME}/bin:$PATH
export HIVE_HOME=/home/hadoop/hive-2.3.0/ 复制代码使环境变量生效,运行 source /etc/profile使/etc/profile文件生效
Hive 配置 Hadoop HDFS
复制 hive-site.xml
cd /home/hadoop/hive-2.3.0/conf
cp hive-default.xml.template hive-site.xml
复制代码新建 hdfs 目录
使用 hadoop 新建 hdfs 目录,因为在 hive-site.xml 中有默认如下配置:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
复制代码进入 hadoop 安装目录 执行hadoop命令新建/user/hive/warehouse目录,并授权,用于存储文件
cd /home/hadoop/hadoop-2.7.4
bin/hadoop fs -mkdir -p /user/hive/warehouse
bin/hadoop fs -mkdir -p /user/hive/tmp
bin/hadoop fs -mkdir -p /user/hive/log
bin/hadoop fs -chmod -R 777 /user/hive/warehouse
bin/hadoop fs -chmod -R 777 /user/hive/tmp
bin/hadoop fs -chmod -R 777 /user/hive/log
复制代码用以下命令检查目录是否创建成功
bin/hadoop fs -ls /user/hive
复制代码修改 hive-site.xml
搜索hive.exec.scratchdir,将该name对应的value修改为/user/hive/tmp
<property>
<name>hive.exec.scratchdir</name> <value>/user/hive/tmp</value> </property> 复制代码搜索hive.querylog.location,将该name对应的value修改为/user/hive/log/hadoop
<property>
<name>hive.querylog.location</name> <value>/user/hive/log/hadoop</value> <description>Location of Hive run time structured log file</description> </property> 复制代码搜索javax.jdo.option.connectionURL,将该name对应的value修改为MySQL的地址
<property>
<name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.252.124:3306/hive?createDatabaseIfNotExist=true</value> <description> JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database. </description> </property> 复制代码搜索javax.jdo.option.ConnectionDriverName,将该name对应的value修改为MySQL驱动类路径
<property>
<name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> 复制代码搜索javax.jdo.option.ConnectionUserName,将对应的value修改为MySQL数据库登录名
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
复制代码搜索javax.jdo.option.ConnectionPassword,将对应的value修改为MySQL数据库的登录密码
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>mima</value>
<description>password to use against metastore database</description>
</property>
复制代码创建 tmp 文件
mkdir /home/hadoop/hive-2.3.0/tmp
复制代码并在 hive-site.xml 中修改
把{system:java.io.tmpdir} 改成 /home/hadoop/hive-2.3.0/tmp
把 {system:user.name} 改成 {user.name}
新建 hive-env.sh
cp hive-env.sh.template hive-env.sh
vi hive-env.sh
HADOOP_HOME=/home/hadoop/hadoop-2.7.4/
export HIVE_CONF_DIR=/home/hadoop/hive-2.3.0/conf
export HIVE_AUX_JARS_PATH=/home/hadoop/hive-2.3.0/lib
复制代码下载 mysql 驱动包
cd /home/hadoop/hive-2.3.0/lib
wget http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.38/mysql-connector-java-5.1.38.jar
复制代码初始化 mysql
MySQL数据库进行初始化
首先确保 mysql 中已经创建 hive 库
cd /home/hadoop/hive-2.3.0/bin
./schematool -initSchema -dbType mysql
复制代码如果看到如下,表示初始化成功
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
复制代码查看 mysql 数据库
/usr/local/mysql/bin/mysql -uroot -p
复制代码mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| hive |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
复制代码mysql> use hive;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+---------------------------+
| Tables_in_hive |
+---------------------------+
| AUX_TABLE |
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| COMPACTION_QUEUE |
| COMPLETED_COMPACTIONS |
| COMPLETED_TXN_COMPONENTS |
| DATABASE_PARAMS |
| DBS |
| DB_PRIVS |
| DELEGATION_TOKENS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| HIVE_LOCKS |
| IDXS |
| INDEX_PARAMS |
| KEY_CONSTRAINTS |
| MASTER_KEYS |
| NEXT_COMPACTION_QUEUE_ID |
| NEXT_LOCK_ID |
| NEXT_TXN_ID |
| NOTIFICATION_LOG |
| NOTIFICATION_SEQUENCE |
| NUCLEUS_TABLES |
| PARTITIONS |
| PARTITION_EVENTS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| PART_COL_PRIVS |
| PART_COL_STATS |
| PART_PRIVS |
| ROLES |
| ROLE_MAP |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SKEWED_COL_NAMES |
| SKEWED_COL_VALUE_LOC_MAP |
| SKEWED_STRING_LIST |
| SKEWED_STRING_LIST_VALUES |
| SKEWED_VALUES |
| SORT_COLS |
| TABLE_PARAMS |
| TAB_COL_STATS |
| TBLS |
| TBL_COL_PRIVS |
| TBL_PRIVS |
| TXNS |
| TXN_COMPONENTS |
| TYPES |
| TYPE_FIELDS |
| VERSION |
| WRITE_SET |
+---------------------------+
57 rows in set (0.00 sec)
复制代码启动 Hive
简单测试
启动Hive
cd /home/hadoop/hive-2.3.0/bin
./hive
复制代码创建 hive 库
hive> create database ymq;
OK
Time taken: 0.742 seconds
复制代码选择库
hive> use ymq;
OK
Time taken: 0.036 seconds
复制代码创建表
hive> create table test (mykey string,myval string);
OK
Time taken: 0.569 seconds
复制代码插入数据
hive> insert into test values("1","www.ymq.io");
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. Query ID = hadoop_20170922011126_abadfa44-8ebe-4ffc-9615-4241707b3c03 Total jobs = 3 Launching Job 1 out of 3 Number of reduce tasks is set to 0 since there''s no reduce operator Starting Job = job_1506006892375_0001, Tracking URL = http://node1:8088/proxy/application_1506006892375_0001/ Kill Command = /home/hadoop/hadoop-2.7.4//bin/hadoop job -kill job_1506006892375_0001 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2017-09-22 01:12:12,763 Stage-1 map = 0%, reduce = 0% 2017-09-22 01:12:20,751 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.24 sec MapReduce Total cumulative CPU time: 1 seconds 240 msec Ended Job = job_1506006892375_0001 Stage-4 is selected by condition resolver. Stage-3 is filtered out by condition resolver. Stage-5 is filtered out by condition resolver. Moving data to directory hdfs://node1:9000/user/hive/warehouse/ymq.db/test/.hive-staging_hive_2017-09-22_01-11-26_242_8022847052615616955-1/-ext-10000 Loading data to table ymq.test MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Cumulative CPU: 1.24 sec HDFS Read: 4056 HDFS Write: 77 SUCCESS Total MapReduce CPU Time Spent: 1 seconds 240 msec OK Time taken: 56.642 seconds 复制代码查询数据
hive> select * from test;
OK
1 www.ymq.io
Time taken: 0.253 seconds, Fetched: 1 row(s)
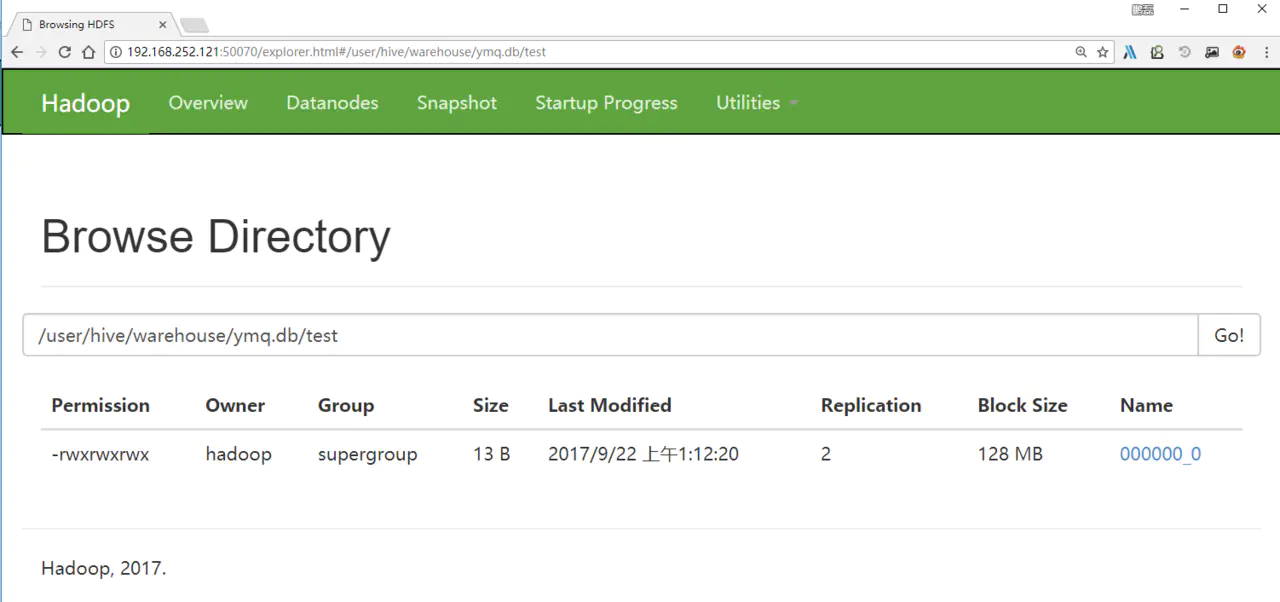
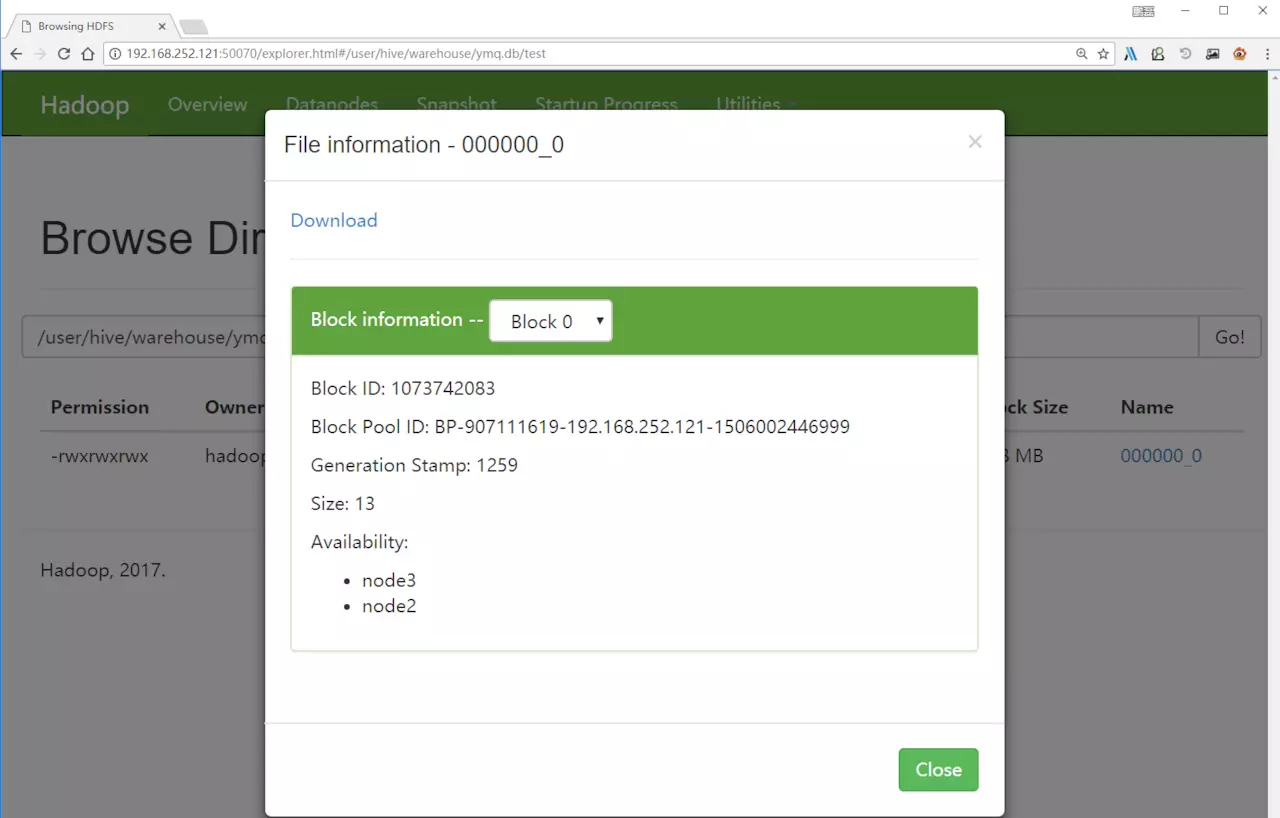
复制代码页面数据
在界面上查看刚刚写入的hdfs数据
/异步加载(创建匿名模块,判断状态,初始化/触发加载)")
define 解析依赖,判断状态,初始化/触发加载 --------require 同步加载(直接返回)/异步加载(创建匿名模块,判断状态,初始化/触发加载)
define
(1)获取依赖 AMD/CMD
(2)触发回调 onScriptLoad
(3)解析依赖
已加载:触发回调
未加载:创建module,监听,触发加载
检查module状态
require 创建匿名模块,加载依赖
、基于 hadoop 集群的数据仓库 Hive 搭建实践")
hive (01)、基于 hadoop 集群的数据仓库 Hive 搭建实践
在前面 hadoop 的一系列文中,我们对 hadoop 有了初步的认识和使用,以及可以搭建完整的集群和开发简单的 MapReduce 项目,下面我们开始学习基于 Hadoop 的数据仓库 Apache Hive,将结构化的数据文件映射为一张数据库表,将 sql 语句转换为 MapReduce 任务进行运行的实践,hadoop 系列深入学习的文章还会继续。
一、Apache Hive 简介
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。 其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
二、Apache Hive 场景
Hive 构建在基于静态批处理的 Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百 MB 的数据集上执行查询一般有分钟级的时间延迟。因此,
Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守 Hadoop MapReduce 的作业执行模型,Hive 将用户的 HiveQL 语句通过解释器转换为 MapReduce 作业提交到 Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
Hive 是一种底层封装了 Hadoop 的数据仓库处理工具,使用类 SQL 的 HiveQL 语言实现数据查询,所有 Hive 的数据都存储在 Hadoop 兼容的文件系统(例如,Amazon S3、HDFS)中。Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到 HDFS 中 Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。Hive 的设计特点如下:
1. 支持索引,加快数据查询。
2. 不同的存储类型,例如,纯文本文件、HBase 中的文件。
3. 将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
4. 可以直接使用存储在 Hadoop 文件系统中的数据。
5. 内置大量用户函数 UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展 UDF 函数来完成内置函数无法实现的操作。
6. 类 SQL 的查询方式,将 SQL 查询转换为 MapReduce 的 job 在 Hadoop 集群上执行。
三、环境准备
1.hadoop 集群环境
2.mysql 数据库服务
3.mysql 数据库驱动
下载地址:https://dev.mysql.com/downloads/connector/j/
4.Apache Hive 安装包
官网地址:https://hive.apache.org/
下载地址:http://www.apache.org/dyn/closer.cgi/hive/

环境说明:
和 hadoop 的主节点公用机器:
192.168.1.10 Master 主节点
192.168.1.50 Mysql 数据库服务
四、安装准备
1. 使用 FTP 上传 Hive 程序包到机器上
2. 解压上传的 hive 程序包
3. 删除程序包修改目录名称
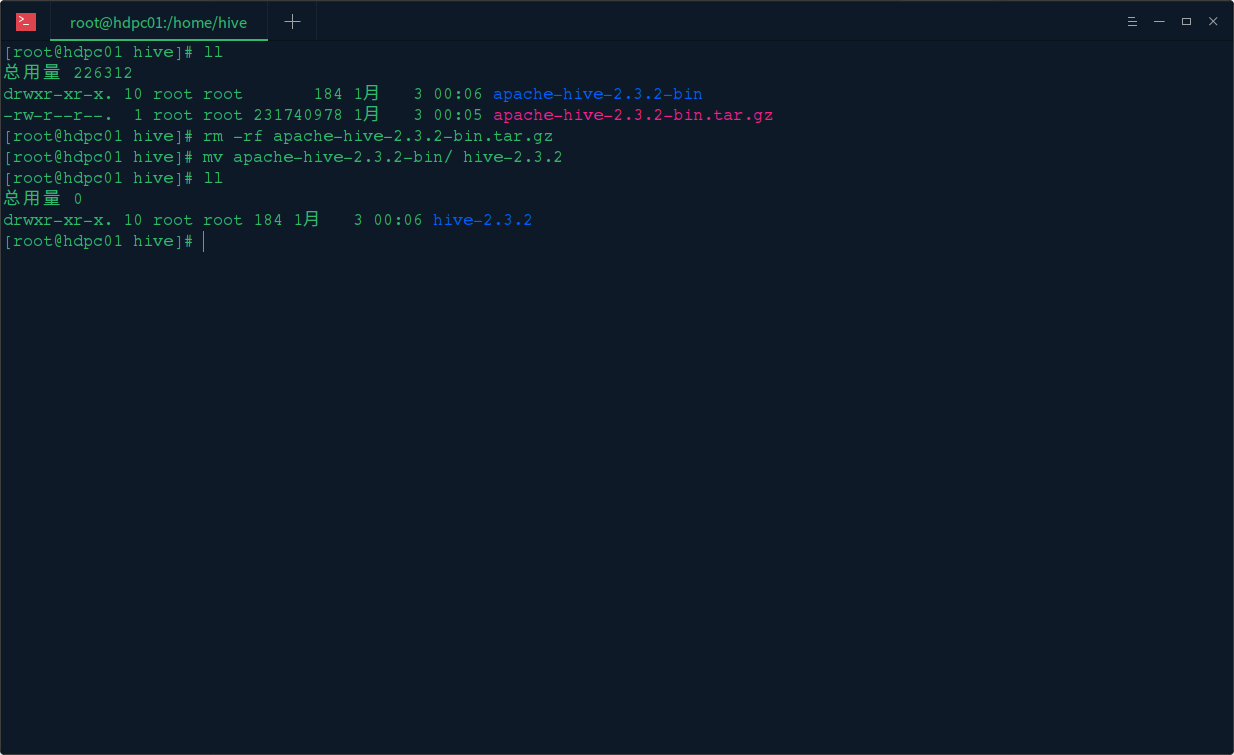
五、安装过程
1. 环境变量配置
执行 vi /etc/profile 输入以下 hive 的环境变量
export HIVE_HOME=/home/hive/hive-2.3.2
export PATH=$HIVE_HOME/bin:$PATH
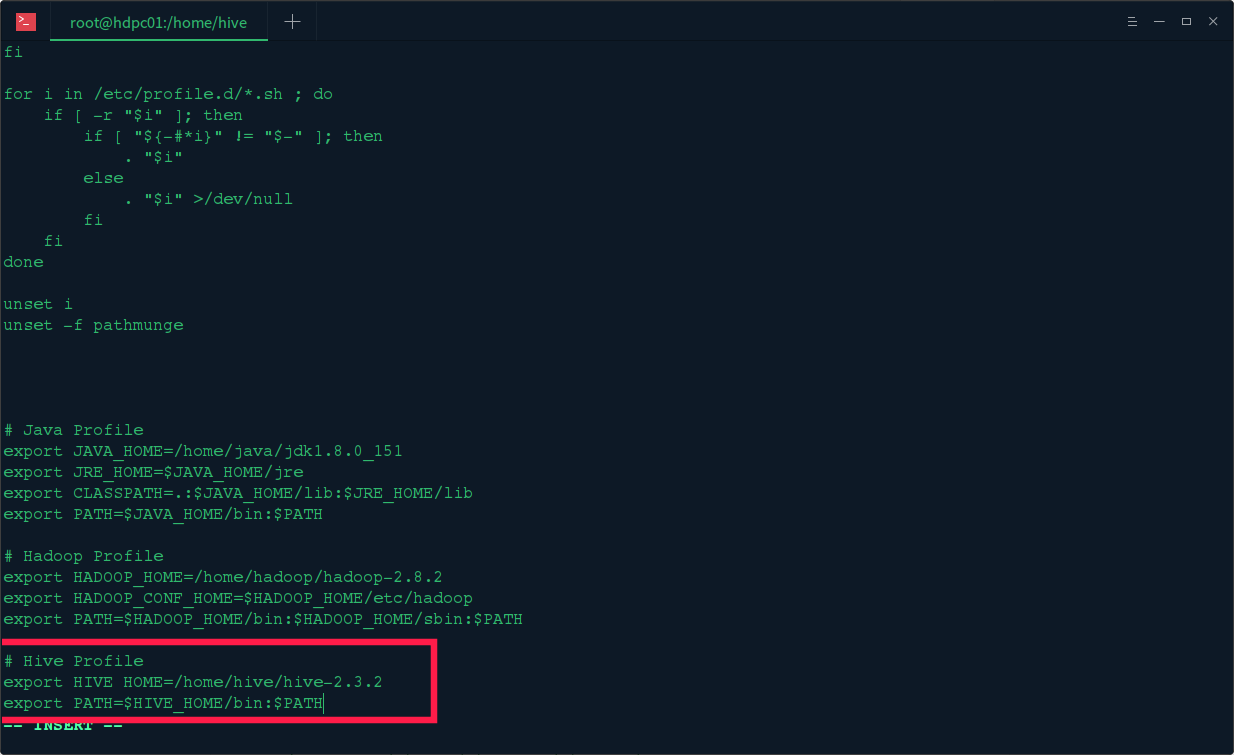
执行 source /etc/profile 使其立即生效
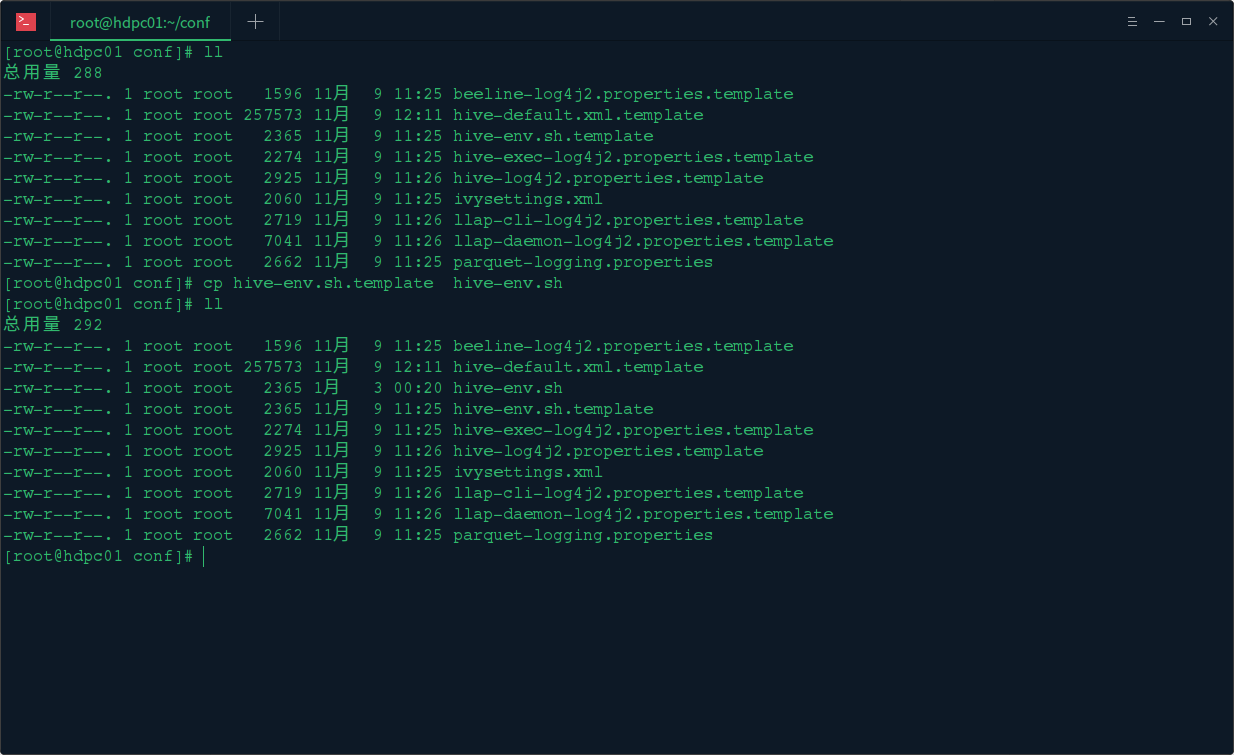
2. 修改 hive 脚本文件
修改 hive-env.sh 脚本文件,首先 cp hive-env.sh.template hive-env.sh
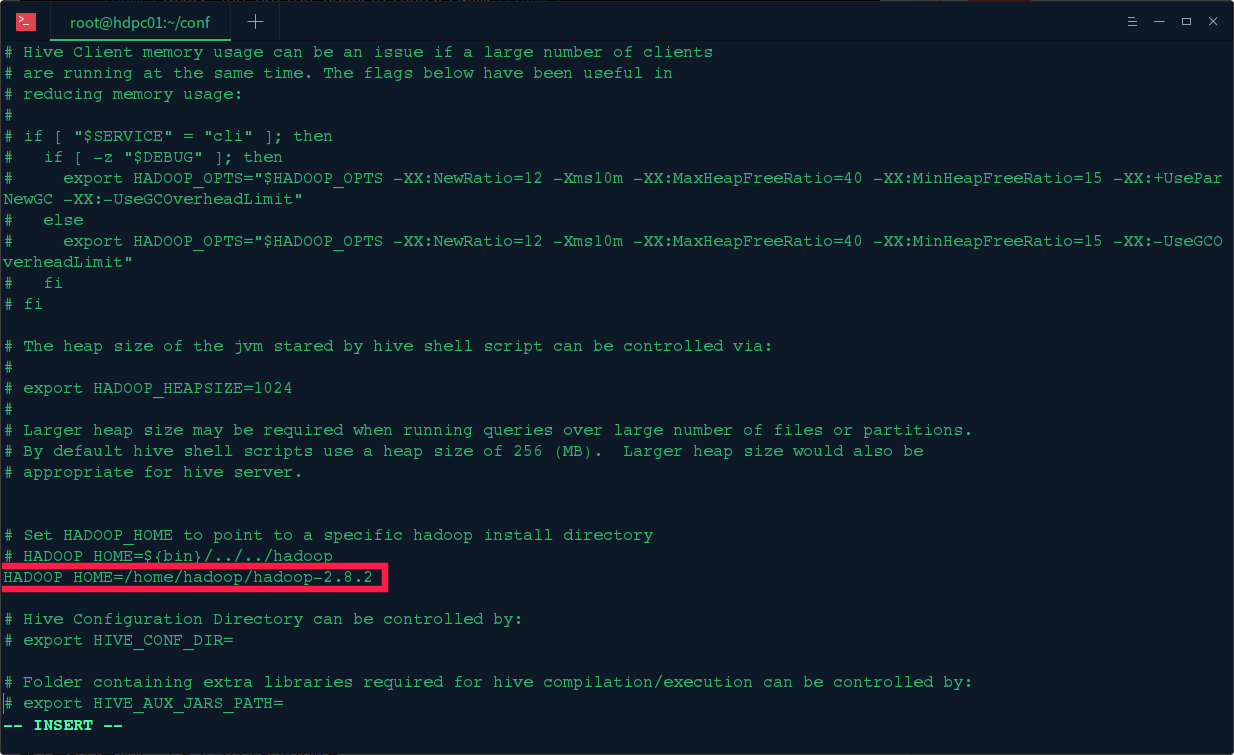
然后编辑 vi hive-env.sh 脚本,HADOOP_HOME=/home/hadoop/hadoop-2.8.2
修改 hive-site.xml 配置文件,首先 cp hive-default.xml.template hive-site.xml
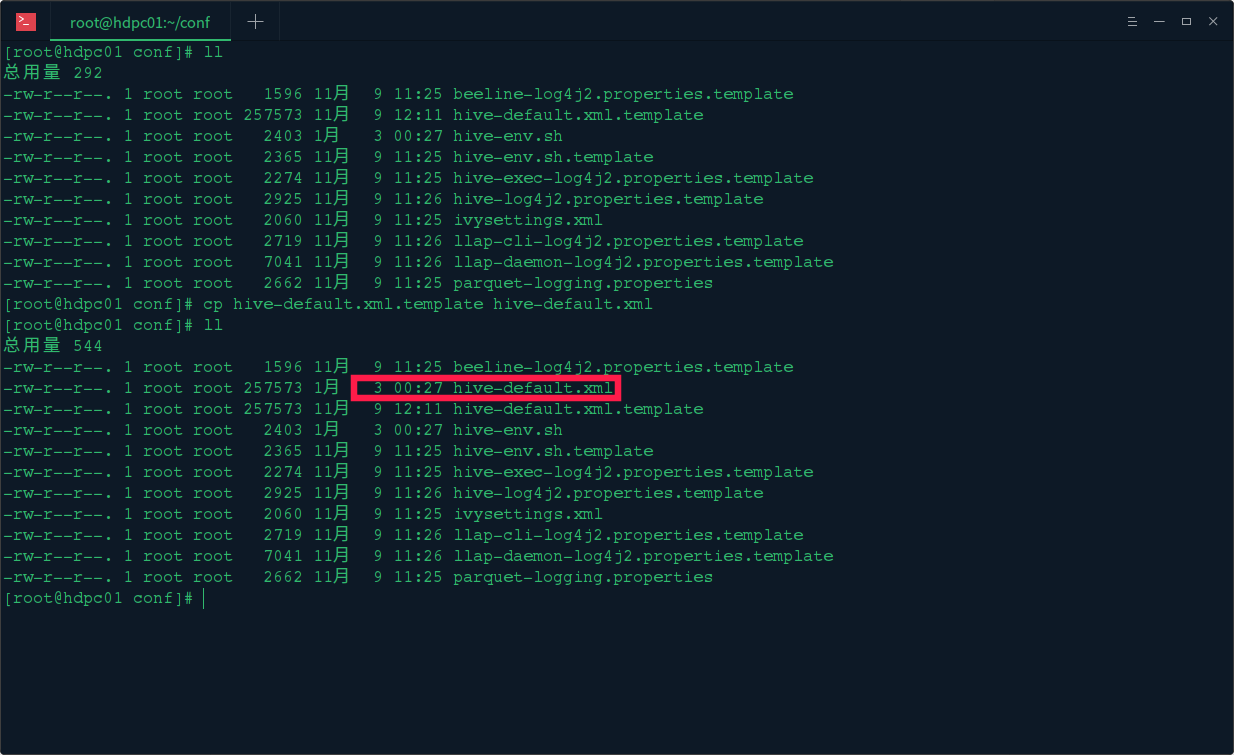
然后编辑 vi hive-site.xml 配置文件,配置 mysql 元数据库信息
<configuration>
<!-- 源数据存储数据库地址 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hdpc05:3306/hive?createDatabaseIfNotExist=true&characterEncoding=utf8&useSSL=true</value>
</property>
<!-- 源数据存储数据库驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- 源数据存储数据库用户 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- 源数据存储数据库密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- 自动创建 Schema-->
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<!-- 自动创建 Tables-->
<property>
<name>datanucleus.autoCreateTables</name>
<value>true</value>
</property>
<!-- 自动创建 Columns-->
<property>
<name>datanucleus.autoCreateColumns</name>
<value>true</value>
</property>
<!-- 设置 hive 仓库的 HDFS 上的位置 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 资源临时文件存放位置 -->
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hive/hive-2.3.2/tmp/resources</value>
</property>
<!-- 修改日志位置 -->
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hive/hive-2.3.2/logs/HiveJobsLog</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hive/hive-2.3.2/logs/ResourcesLog</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/home/hive/hive-2.3.2/logs/HiveRunLog</value>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/home/hive/hive-2.3.2/logs/OpertitionLog</value>
</property>
<!-- 配置 HWI 接口 -->
<property>
<name>hive.hwi.war.file</name>
<value>/home/hive/hive-2.3.2/lib/hive-hwi-2.1.1.jar</value>
</property>
<property>
<name>hive.hwi.listen.host</name>
<value>hdpc01</value>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
</property>
<!--thrift 服务配置 -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hdpc01</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.http.port</name>
<value>10001</value>
</property>
<property>
<name>hive.server2.thrift.http.path</name>
<value>cliservice</value>
</property>
<!--HiveServer2 的 WEBUI-->
<property>
<name>hive.server2.webui.host</name>
<value>hdpc01</value>
</property>
<property>
<name>hive.server2.webui.port</name>
<value>10002</value>
</property>
<property>
<name>hive.scratch.dir.permission</name>
<value>755</value>
</property>
</configuration>
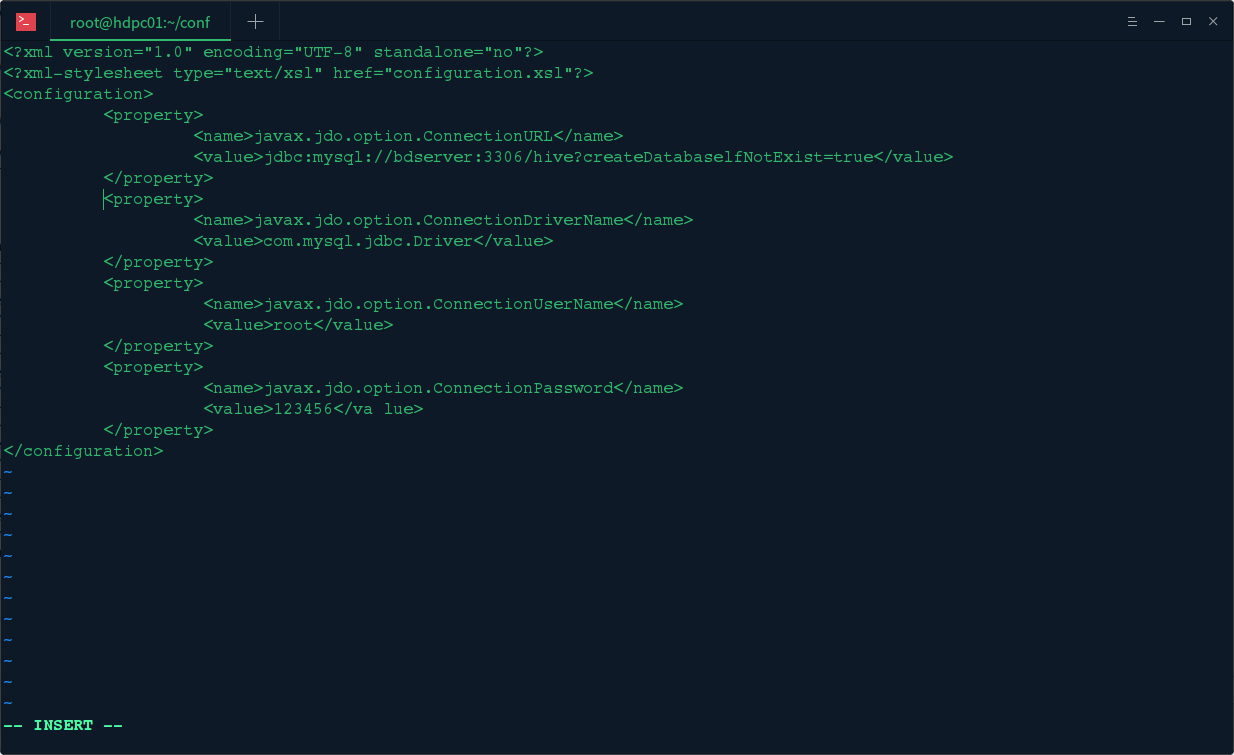
由于 hive 是默认将元数据保存在本地内嵌的 Derby 数据库中,但是这种做法缺点也很明显,Derby 不支持多会话连接,因此本文将选择 mysql 作为元数据存储,以上就是配置 Hive 使用 mysq 作为元数据的配置,mysql 数据库服务本文已经搭建完成,可参考《Linux 开发环境搭建之 MySQL 安装配置 》
3. 配置日志地址 hive-log4j.properties 文件
cp hive-log4j.properties.template hive-log4j.properties
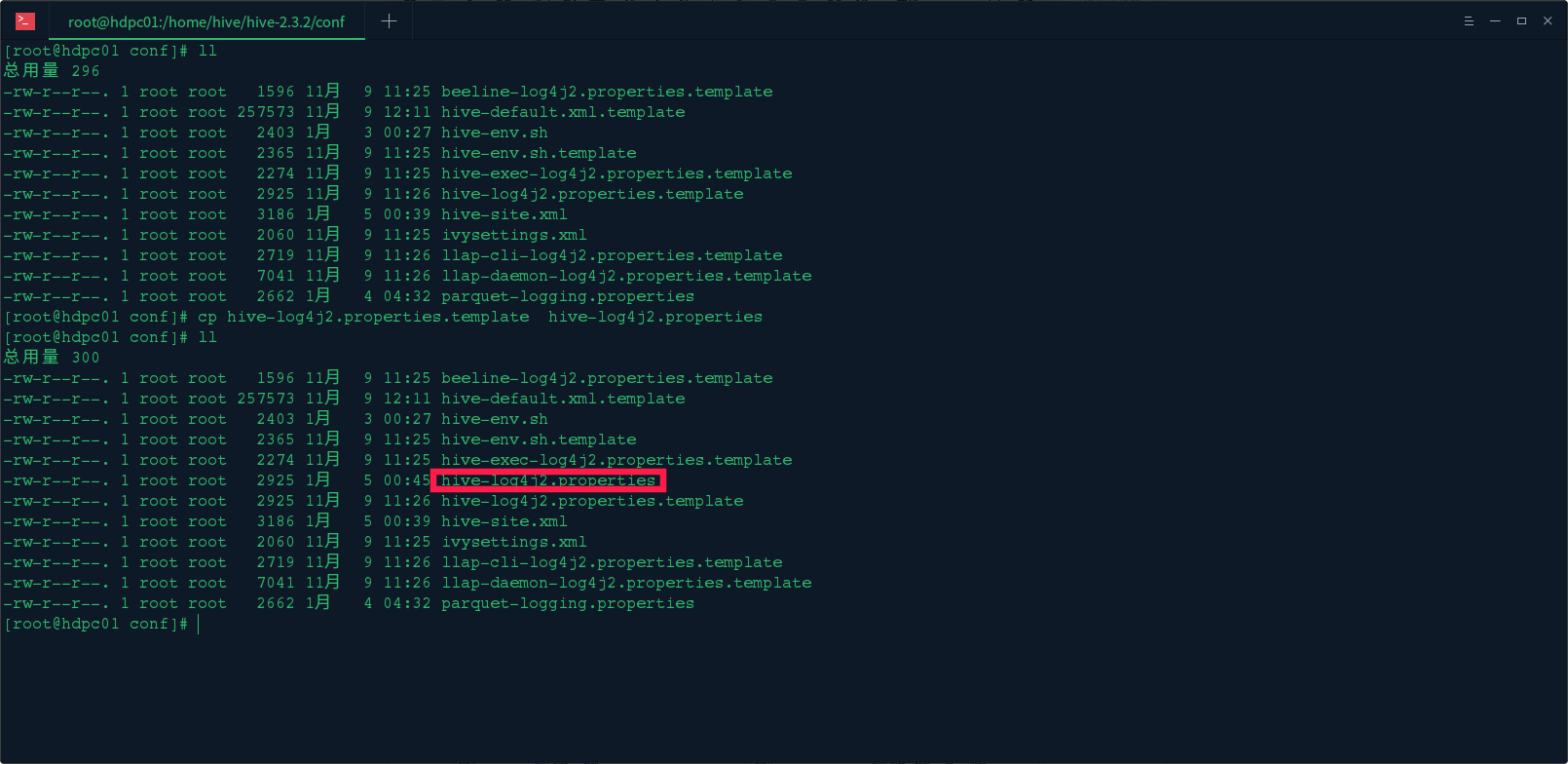
然后 vi hive-log4j.properties,将 hive.log 日志的位置改为 hive 下的 tmp 目录下:
property.hive.log.dir = /home/hive/hive-2.3.2/logs/${sys:user.name}


4. 上传数据库驱动
将下载的 mysql 数据库驱动上传到 hive 的 lib 目录下面
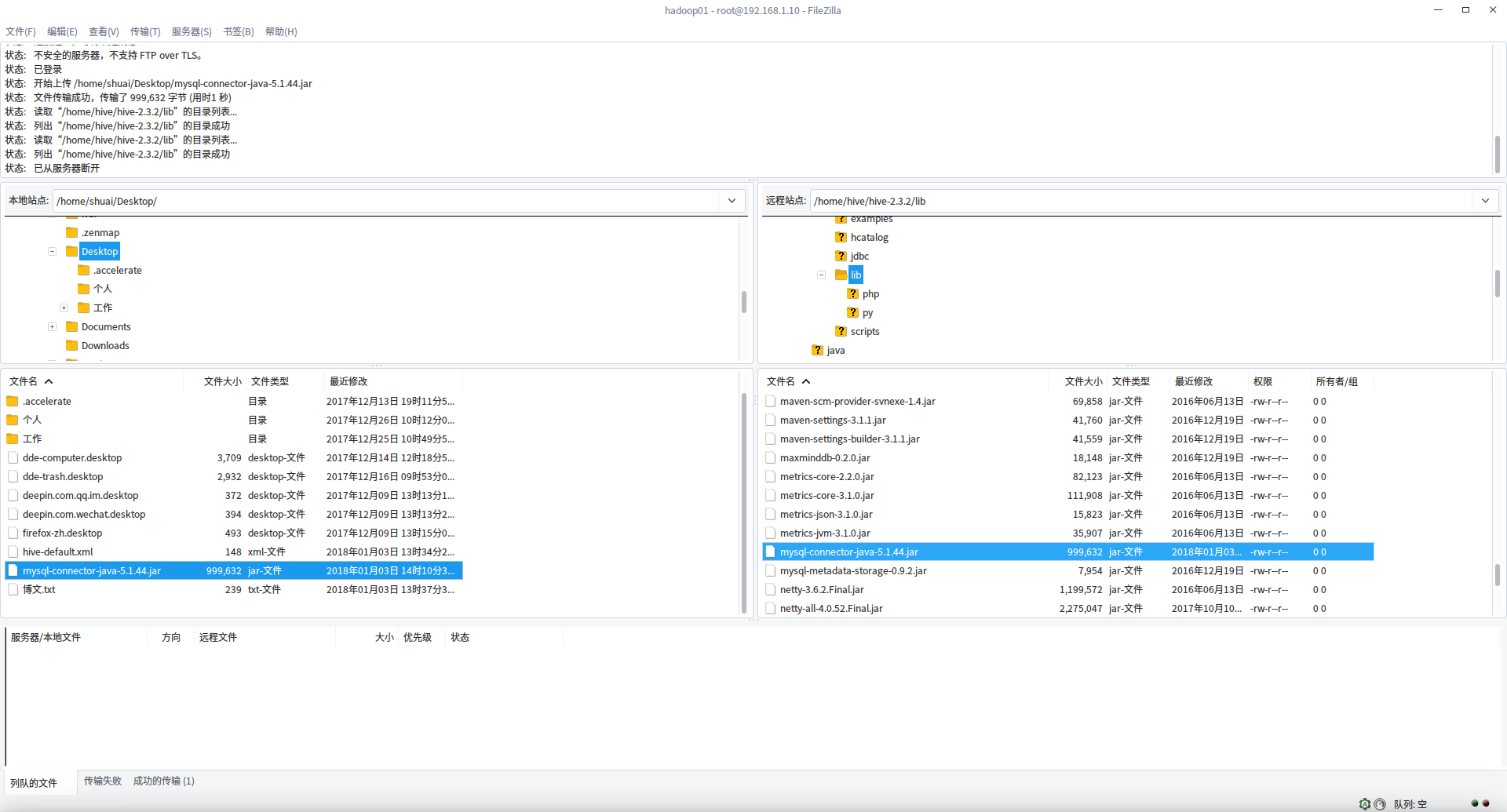
5.Jar 的拷贝
将 hive 下的新版本 jline 的 JAR 包 hive/lib/jline-2.12.jar 拷贝到 hadoop/share/hadoop/yarn/lib/
将 JAVA_HOME/lib 目录下的 tools.jar 到 hive/lib 目录下
6. 在主节点 hosts 文件中配置元数据主机地址
192.168.1.50 hdpc05
六、验证服务
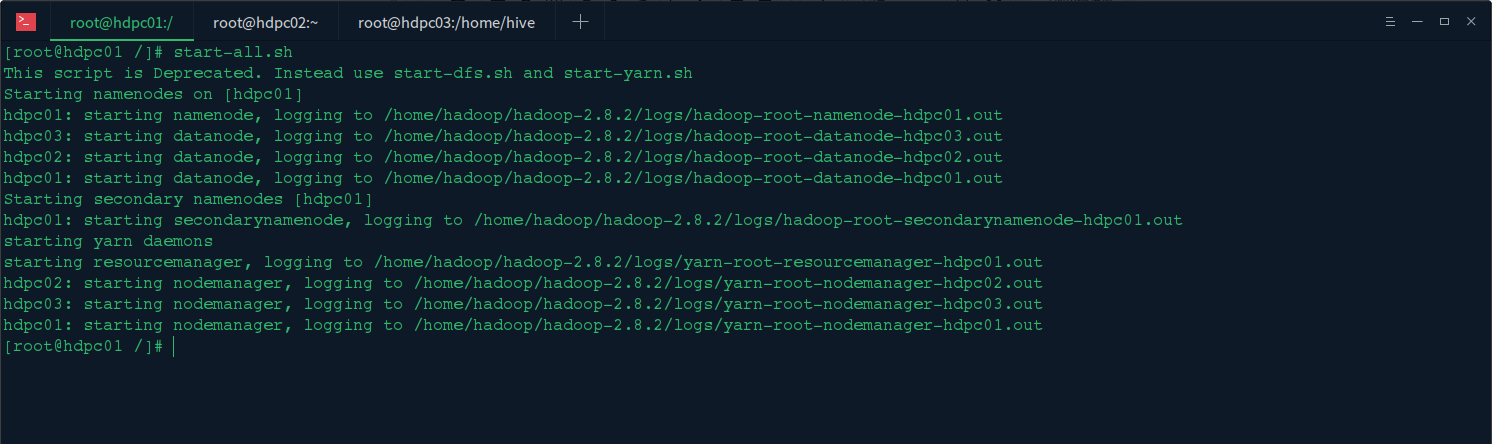
1. 启动 hadoop 集群
在主节点上启动 hadoop 集群 start-all.sh
2. 启动元数据存储服务 mysql 服务
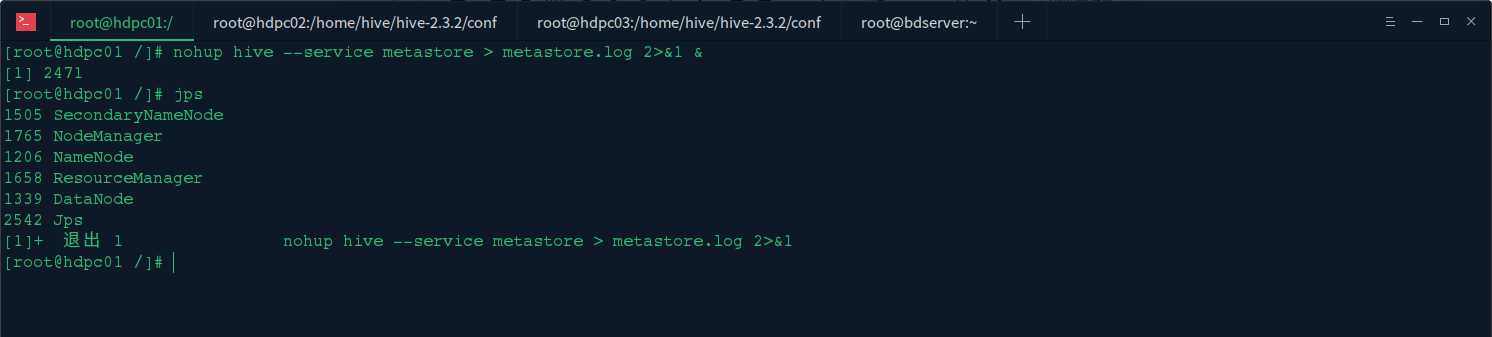
远程连接我们的 mysql 主机,然后启动 MYSQL 服务 (如果设置了自启动,则此步骤可以忽略)

启动 hive 服务端程序 hive --service metastore
查看 metastore 服务是否启动 nohup hive --service metastore > metastore.log 2>&1 &
查看 hive 服务是否启动 nohup hive --service hiveserver2 > hiveserver2.log 2>&1 &
3. 启动 hive 服务
使用 jps -ml 查看启动的服务进程:
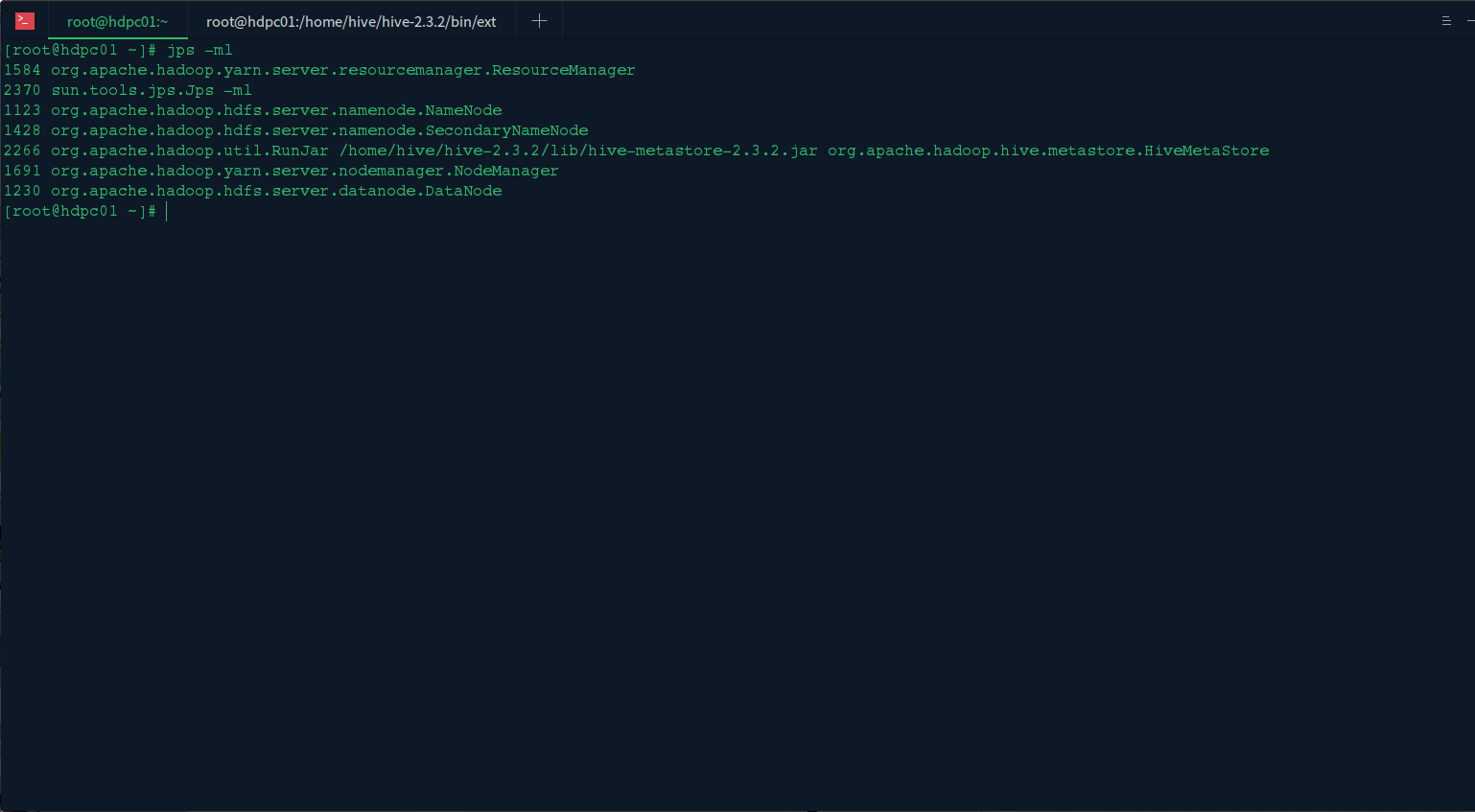
4. 验证 hive 服务
在主节点执行 hive 命令,然后在终端执行 show databases;

七、问题反馈
1. 使用 hive 服务时报如下错误:
Thu Jan 04 00:18:55 EST 2018 WARN: Establishing SSL connection without server''s identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn''t set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to ''false''. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
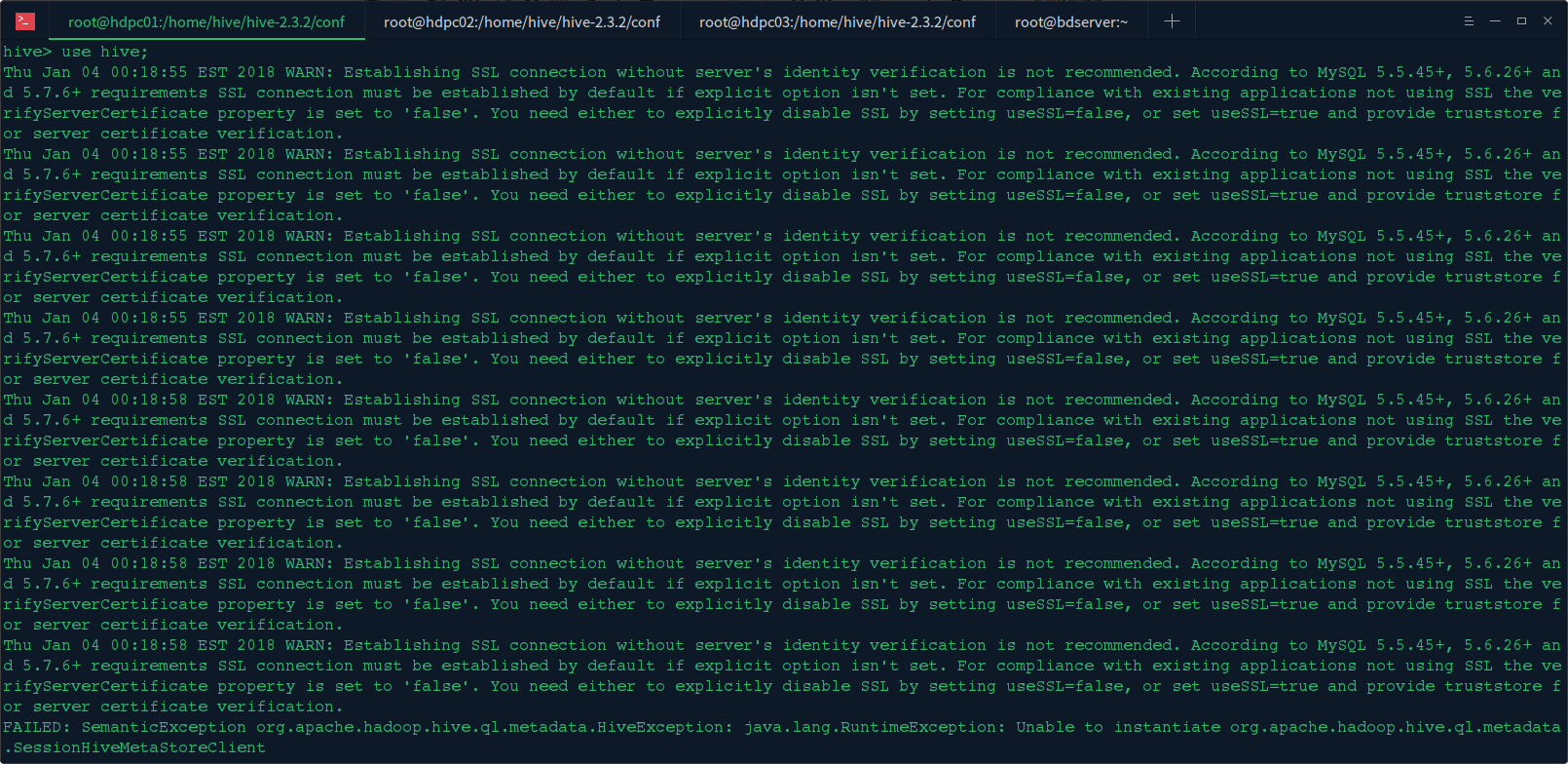
是因为 MySQL 5.5.45+, 5.6.26+ and 5.7.6 + 版本上都要求使用 ssl 去连接,因此我们需要在连接时使用 useSSL=true
2. 启动 hive 报如下错误:
Exception in thread "main" java.lang.RuntimeException: org.xml.sax.SAXParseException; systemId: file:/home/hive/hive-2.3.2/conf/hive-site.xml; lineNumber: 6; columnNumber: 93; The reference to entity "useSSL" must end with the '';'' delimiter.
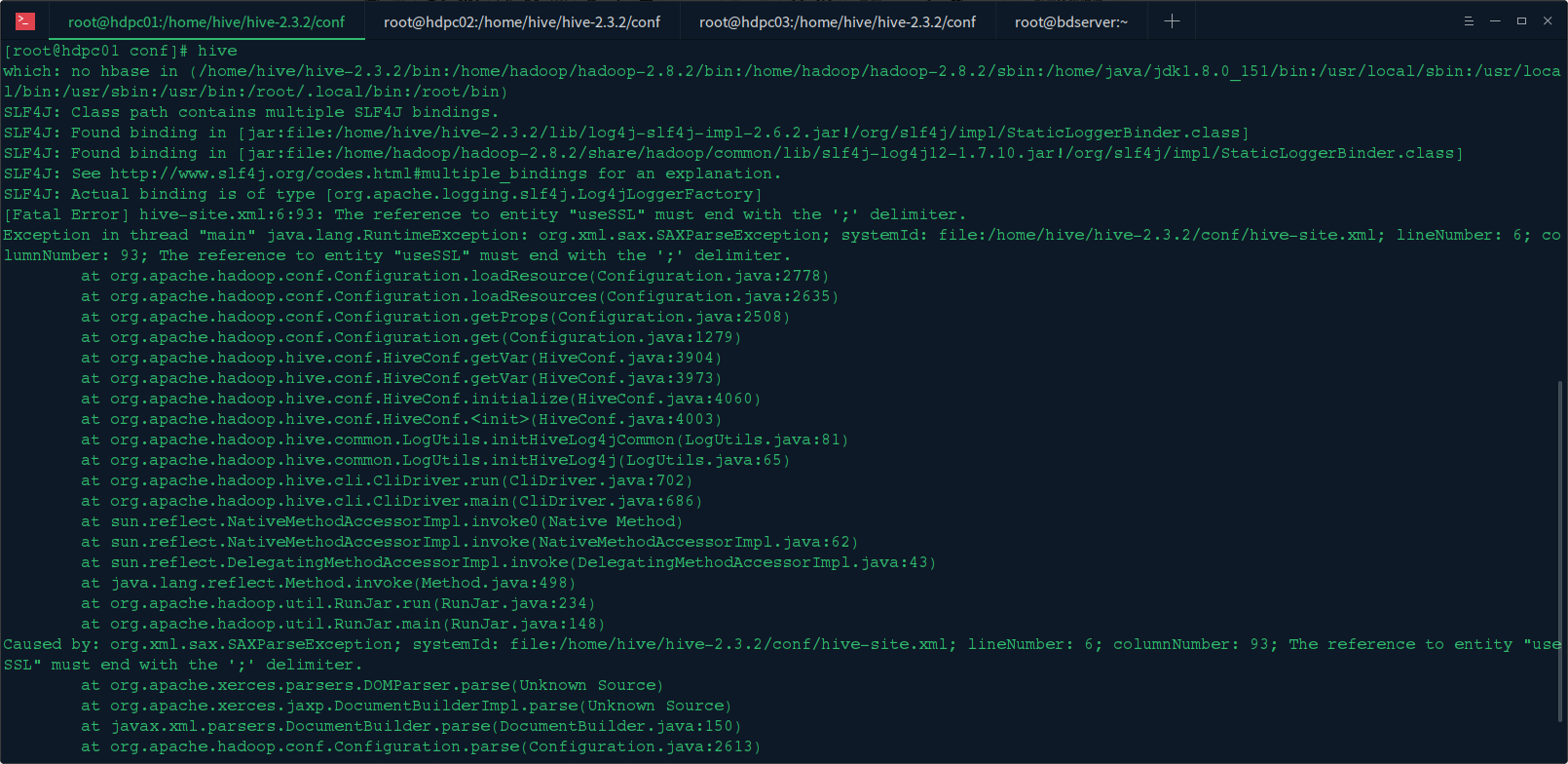
因为在 xml 文件中 & 符号 需要转义 这个根据转义规则更改 & 为 & 于是便解决了
3. 使用 hive 连接元数据库报如下错误:
FAILED:SemanticExceptionorg.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: Unable to instantiate
org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
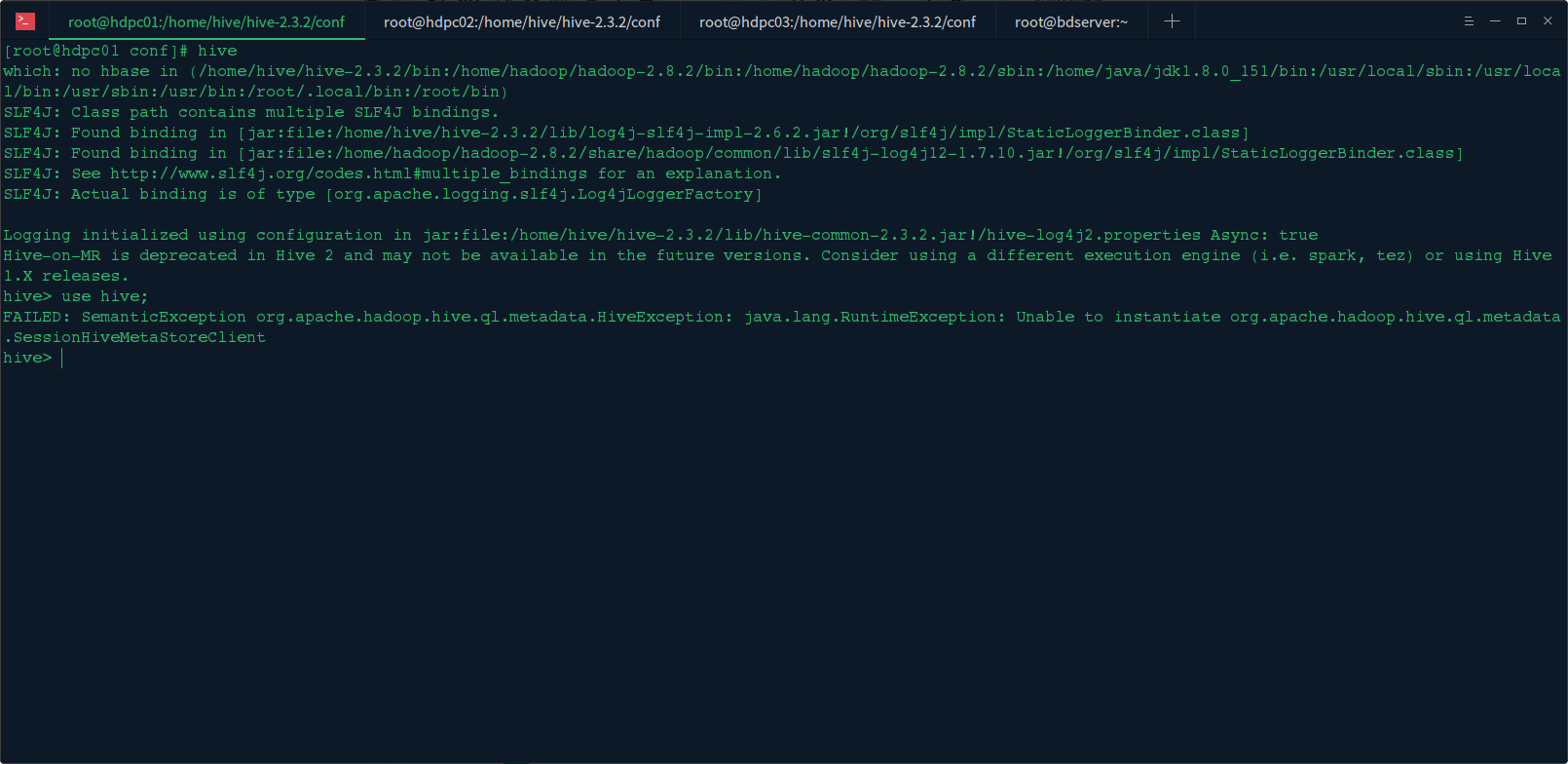
问题找到了,原来 Hive2 需要 hive 元数据库初始化,我们在终端执行:schematool -dbType mysql -initSchema
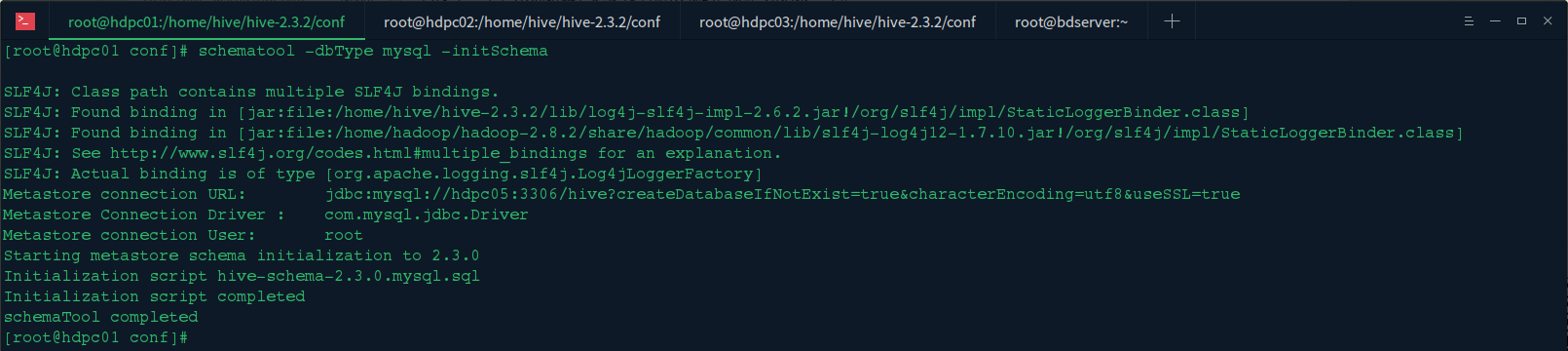
八、总结
本文主要是对 hive 数据仓库集群的搭建实践,在过程中遇到很多问题,在上名的问题中也都列了出来,还有问题的解决办法,hive 的 Metastore 服务配置一般有三种方式,后面我们会有专门的一片文章来说明这三种方式,本文中使用的是第三种方式,这种方式也是生产环境中的使用方式。
、数据仓库 Hive 用户图形接口 HWI 的配置")
hive (06)、数据仓库 Hive 用户图形接口 HWI 的配置
在之前的文中我们配置了一个 hive 监控的 web 界面的服务,主要用于查看当前 HiveServer2 服务链接的会话、服务日志、配置参数等信息,这个服务更像是一个 hive 提供的监控服务,本文我们将配置 HWI (Hive Web Interface) hive 用户图形接口,这是 hive 三种用户接口中的其中之一,可以在 web 界面上对 hive 服务进行操作
一、环境准备
1.hadoop 集群
2.hive 完整的服务(2.3.2)
3.hive 元数据存储服务 (mysql)
4.hive src 源码包
二、配置准备
hwi 服务配置的前提需要我们手动打 hwi 服务的 war 包,然后将 war 包部署在 hive 服务下,配置完成就可使用了,首先我们要下载 hive src 源码包,下载地址:http://mirror.bit.edu.cn/apache/hive/
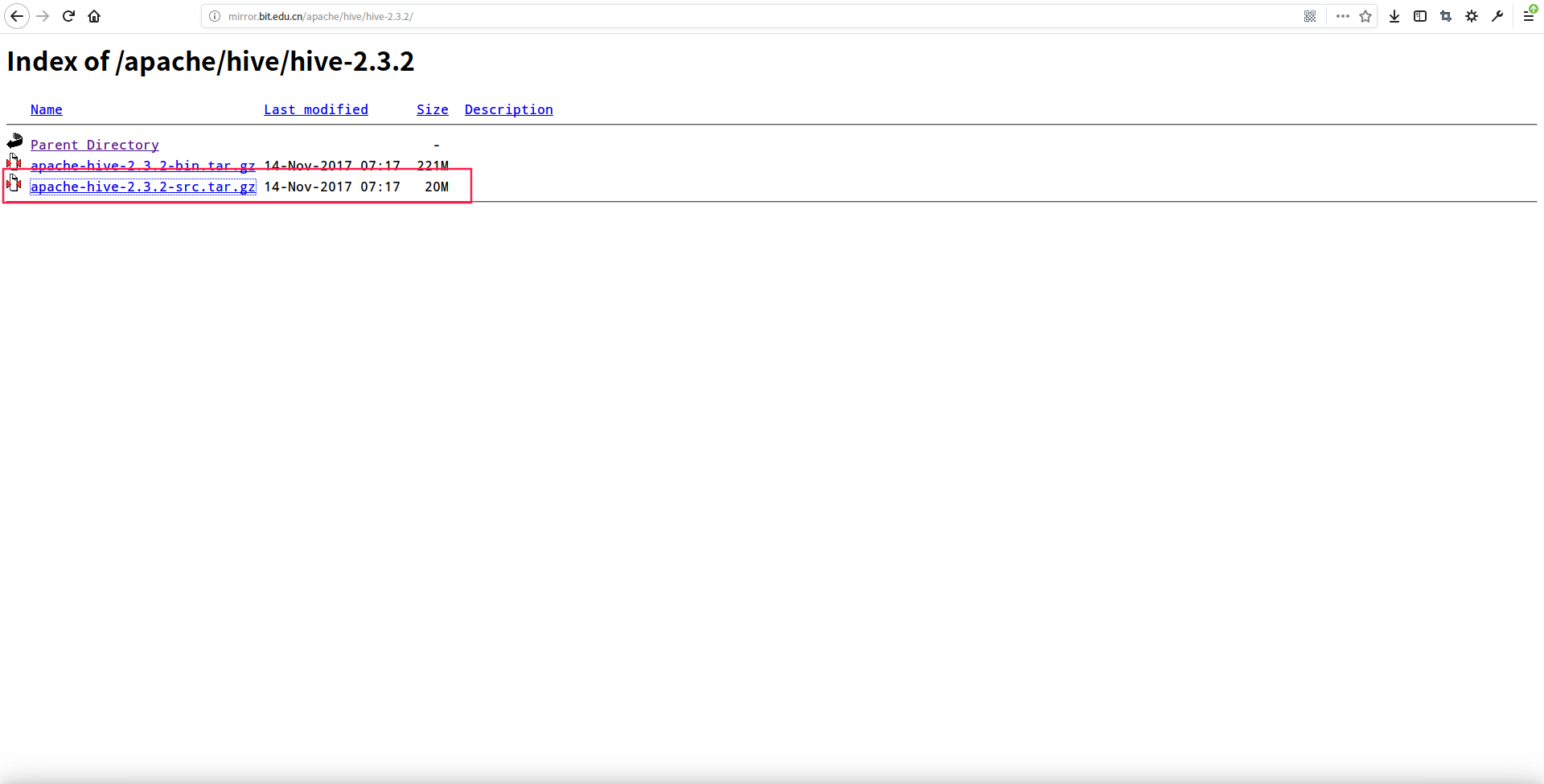
下载 apache-hive-2.3.2-src.tar.gz 包到本地,我们解压源码包,在包中没有发现 hwi 服务的代码目录,于是使用 2.2.0 版本打 war 包:
jar -cvf hive-hwi.war ./*

上传打的 war 包到 lib 下
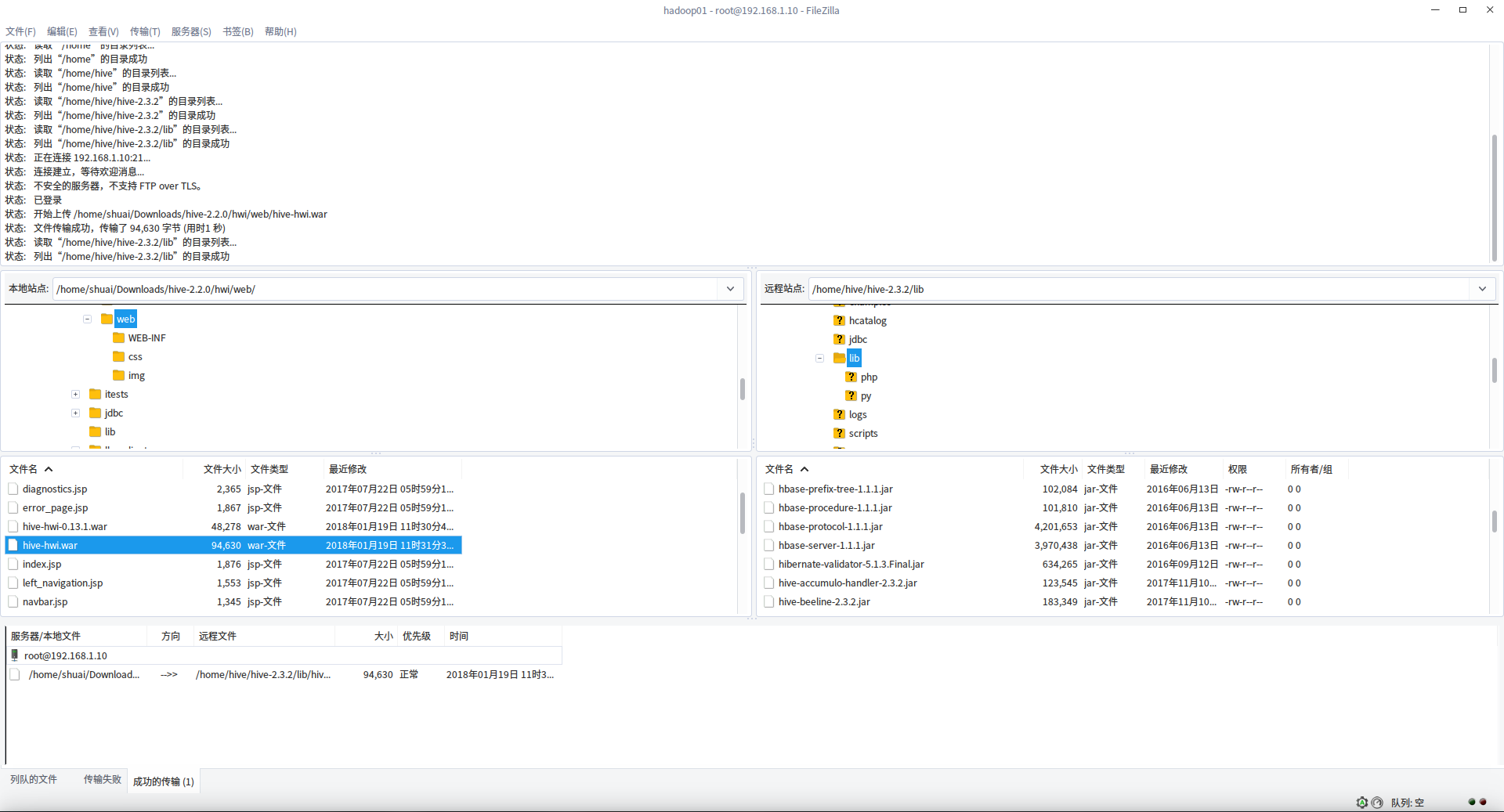
修改 hive-site.xml
<!-- 配置 HWI 接口 -->
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi.war</value>
</property>
<property>
<name>hive.hwi.listen.host</name>
<value>hdpc01</value>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
</property>
启动 hadoop 集群后,输入 hive --service hwi 启动 hwi 服务,提示:service hwi not found 通过查询资料,我们发现 2.3.2 次版本已经不支持 hwi 服务了
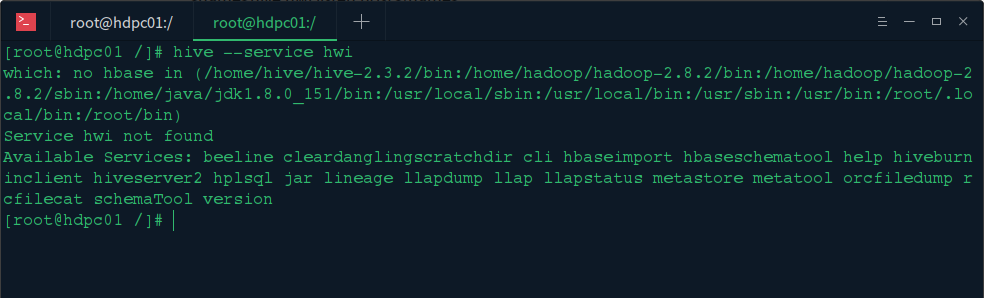
注意:2.2.0 及以前的版本 HWI 服务可以按以上办法配置,2.3.2 已经取消此服务
三、总结
由于 hive 在 2.2.0 以前的版本,官方网站是提供了 hive-hwi 服务的 web 源码包源码的,后面的版本是不提供了,而且 hwi 的服务也取消了,个人觉的现在公司使用 hue 集成 hive 使用的比较多,而且功能更加强大,因此官方取消了 hwi 服务。本文也是在实践配置 hwi 服务的时候发现的,所有在后面还有使用 hue 集成 hive 的文章,文中要是出现不对的地方,请大家评论或者私信指出。

HIVE - 执行 hive 的几种方式,和把 HIVE 保存到本地的几种方式

HIVE - 执行 hive 的几种方式,和把 HIVE 保存到本地的几种方式
网上相关教程很多,这里我主要是简单总结下几种常用的方法,方便日后查询。
第一种,在 bash 中直接通过 hive -e 命令,并用 > 输出流把执行结果输出到制定文件
hive -e "select * from student where sex = ''男''" > /tmp/output.txt
第二种,在 bash 中直接通过 hive -f 命令,执行文件中一条或者多条 sql 语句。并用 > 输出流把执行结果输出到制定文件
hive -f exer.sql > /tmp/output.txt 文件内容 select * from student where sex = ''男''; select count(*) from student;
第三种,在 hive 中输入 hive-sql 语句,通过使用 INSERT OVERWRITE LOCAL DIRECTORY 结果到本地系统和 HDFS 文件系统
语法一致,只是路径不同
insert overwrite local directory "/tmp/out" > select cno,avg(grade) from sc group by(cno);
insert overwrite directory ''hdfs://server71:9000/user/hive/warehouse/mystudent'' select * from student1;
以上是三种,包含了 3 执行 hive-sql 的方法。结果保存到本地的方法前两种都属于 linxu BASH 自带的方法。第三种才是 HIVE 本身的导出数据的方法。
第四种,就是基本的 SQL 语法,从一个表格中抽取数据,直接插入另外一个表格。参考 SQL 语法即可。
insert overwrite table student3 select sno,sname,sex,sage,sdept from student3 where year=''1996'';
http://blog.csdn.net/zhuce1986/article/details/39586189
我们今天的关于hive mysql 初始化和hive初始化mysql失败的分享已经告一段落,感谢您的关注,如果您想了解更多关于define 解析依赖,判断状态,初始化/触发加载 --------require 同步加载(直接返回)/异步加载(创建匿名模块,判断状态,初始化/触发加载)、hive (01)、基于 hadoop 集群的数据仓库 Hive 搭建实践、hive (06)、数据仓库 Hive 用户图形接口 HWI 的配置、HIVE - 执行 hive 的几种方式,和把 HIVE 保存到本地的几种方式的相关信息,请在本站查询。
本文标签:




