针对Mysql-Navicat更改查询语句保存路径报错Connectionisbeingused和navicat修改查询结果这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展HowMemory
针对Mysql-Navicat 更改查询语句保存路径报错 Connection is being used和navicat修改查询结果这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展How Memory is being used、Lost connection to MySQL server during query ([Errno 104] Connection reset by peer)、Navicat for mysql 1130 错误 用 Navicat 连接远程 MYSQL:报错 ERROR 1130、Navicat for MySQL 和 Navicat Premium 之间的区别等相关知识,希望可以帮助到你。
本文目录一览:- Mysql-Navicat 更改查询语句保存路径报错 Connection is being used(navicat修改查询结果)
- How Memory is being used
- Lost connection to MySQL server during query ([Errno 104] Connection reset by peer)
- Navicat for mysql 1130 错误 用 Navicat 连接远程 MYSQL:报错 ERROR 1130
- Navicat for MySQL 和 Navicat Premium 之间的区别
")
Mysql-Navicat 更改查询语句保存路径报错 Connection is being used(navicat修改查询结果)
对于习惯于使用 oracle 的 plsql 工具的小伙伴来说 navicat 是有那么一点点不太一样,在 pl/sql 里面一个查询语句保存为.sql 文件简直是随心所欲,想保存在哪里就保存在哪里,而且是一个.sql 文件都可以保存在任意位置的,甚至我完全可以相信,只要问出这个问题的小伙伴一定是长时间的 pl/sql 使用者,navicat 中它保存.sql 文件是一个固定的位置,你修改了也是另存为一个固定位置,以后你不管有多少个.sql 文件都是保存在这个固定的位置,如下图所示进行更改
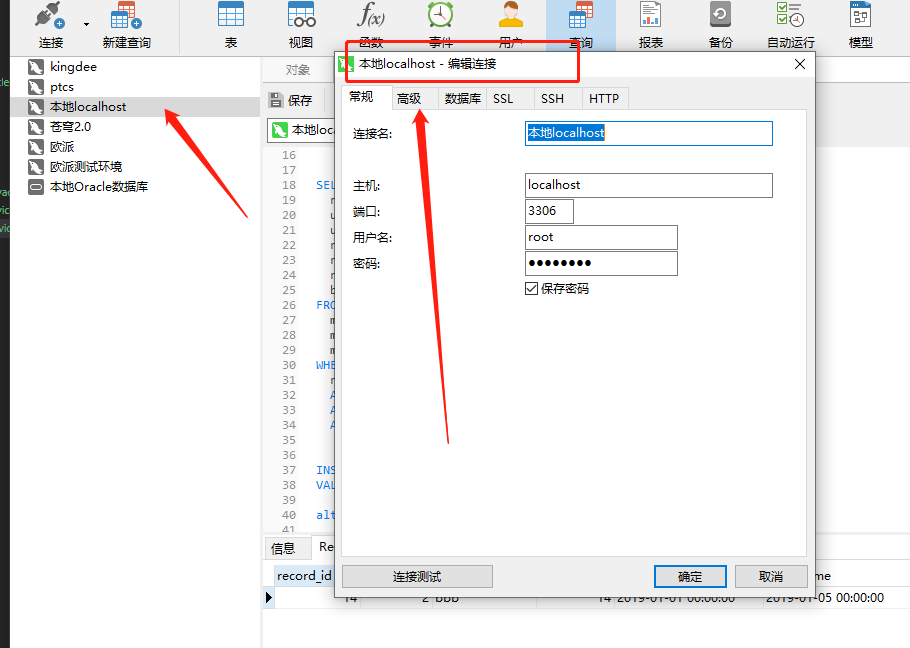

但在保存时就会出现如下图所示的 bConnection is being used
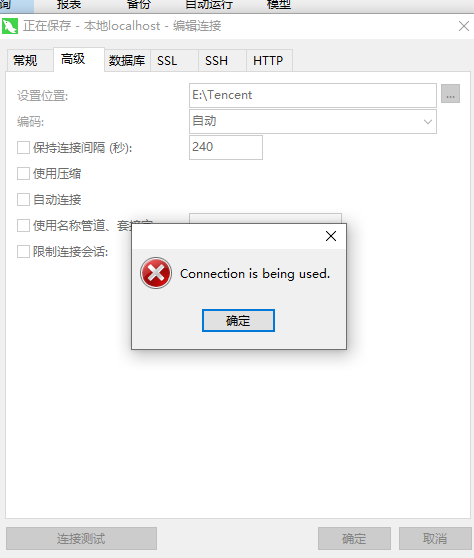
- 要解决这个问题也非常简单,只需要将你原始目录下保存的.sql 文件及其父目录一起剪切到另一位置后,重启 navicat 后再次执行上述步骤即可解决
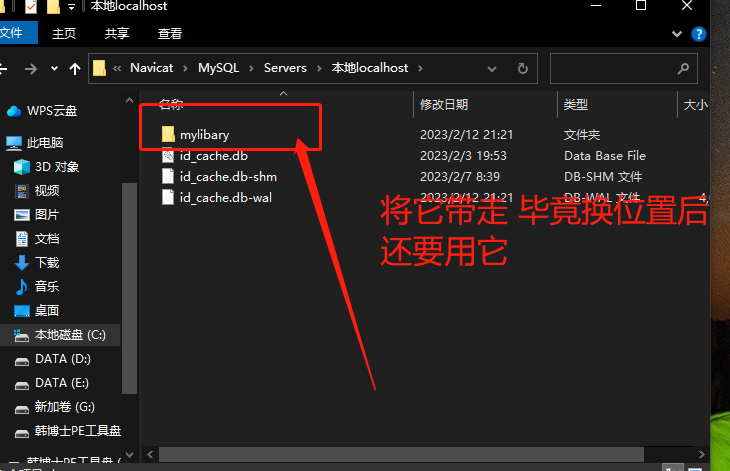
如下图所示再次操作上述步骤则可更改保存位置了,而你只需要将刚刚移动的文件放进你新更改的位置则可打开以前的.sql 文件了
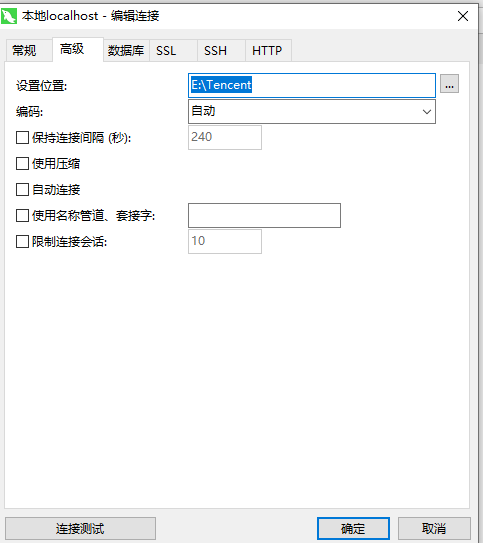
以上就是我关于 Mysql-Navicat 更改查询语句保存路径报错 Connection is being used 知识点的整理与总结的全部内容,希望对你有帮助。。。。。。。
分割线
扩展知识
分割线
博主为咯学编程:父母不同意学编程,现已断绝关系;恋人不同意学编程,现已分手;亲戚不同意学编程,现已断绝来往;老板不同意学编程,现已失业三十年。。。。。。如果此博文有帮到你欢迎打赏,金额不限。。。


How Memory is being used
To determine what plans are in the cache and how often they''re used we can use sys.dm_os_memory_cache_counters dm view .
SELECT TOP 6
LEFT([name], 20) as [name],
LEFT([type], 20) as [type],
[single_pages_kb] + [multi_pages_kb] AS cache_kb,
[entries_count]
FROM sys.dm_os_memory_cache_counters
order by single_pages_kb + multi_pages_kb DESChere :
CACHESTORE_OBJCP are compiled plans for stored procedures, functions and triggers.
CACHESTORE_SQLCP are cached SQL statements or batches that aren''t in stored procedures, functions and triggers. This includes any dynamic SQL or raw SELECT statements sent to the server.
CACHESTORE_PHDR These are algebrizer trees for views, constraints and defaults. An algebrizer tree is the parsed SQL text that resolves the table and column names.
(you will find these counters in DBCC Memorystatus as well.Infact DBCC Memory Status uses this dm)
Generally you will find that CACHESTORE_SQLCP > CACHESTORE_OBJCP , but if the ratio of one to another is very high then we can say that there are more adhoc plans being run then Stored procedures.
That is the reason the sal statements are going in to Plan cache.
You can also monitor the number of data pages in the plan cache using Performance Monitor (PerfMon) using SQLServer:Plan Cache object with the Cache Pages counter. There are instances for SQL Plans (CACHESTORE_SQLCP), Object Plans (CACHESTORE_OBJCP) and Bound Trees (CACHESTORE_PHDR). This will give you the same picture ..for e.g. under bound tree : multiply cache pages by 8. you will get the same output as in dbcc memorystatus and the dm we used above.
After this to know the querry we can use sys.dm_exec_cached_plans and sys.dm_exec_sql_text dm views to find the queries
select TOP 100
objtype,
usecounts,
p.size_in_bytes/1024 ''IN KB'',
LEFT([sql].[text], 100) as [text]
from sys.dm_exec_cached_plans p
outer apply sys.dm_exec_sql_text (p.plan_handle) sql
ORDER BY usecounts DESCNow , SQL Server memory is primarily used to store data (buffer) and query plans (cache).
We will try to find what tables and indexes are in the buffer memory of your server you can use sys.dm_os_buffer_descriptors DMV.
Further , the query below can give us total currrent size of buffer pool .
select count(*) AS Buffered_Page_Count
,count(*) * 8192 / (1024 * 1024) as Buffer_Pool_MB
from sys.dm_os_buffer_descriptorsAfter we have found the Bufferpool size , we can see which database is using more memory by runnig the query below .
SELECT LEFT(CASE database_id
WHEN 32767 THEN ''ResourceDb''
ELSE db_name(database_id)
END, 20) AS Database_Name,
count(*)AS Buffered_Page_Count,
count(*) * 8192 / (1024 * 1024) as Buffer_Pool_MB
FROM sys.dm_os_buffer_descriptors
GROUP BY db_name(database_id) ,database_id
ORDER BY Buffered_Page_Count DESCAnd then we can go further at object level to see what all objects are consuming memory (and how much) .We can use the query below in each database we wish to :
SELECT TOP 25
obj.[name],
i.[name],
i.[type_desc],
count(*)AS Buffered_Page_Count ,
count(*) * 8192 / (1024 * 1024) as Buffer_MB
-- ,obj.name ,obj.index_id, i.[name]
FROM sys.dm_os_buffer_descriptors AS bd
INNER JOIN
(
SELECT object_name(object_id) AS name
,index_id ,allocation_unit_id, object_id
FROM sys.allocation_units AS au
INNER JOIN sys.partitions AS p
ON au.container_id = p.hobt_id
AND (au.type = 1 OR au.type = 3)
UNION ALL
SELECT object_name(object_id) AS name
,index_id, allocation_unit_id, object_id
FROM sys.allocation_units AS au
INNER JOIN sys.partitions AS p
ON au.container_id = p.hobt_id
AND au.type = 2
) AS obj
ON bd.allocation_unit_id = obj.allocation_unit_id
LEFT JOIN sys.indexes i on i.object_id = obj.object_id AND i.index_id = obj.index_id
WHERE database_id = db_id()
GROUP BY obj.name, obj.index_id , i.[name],i.[type_desc]
ORDER BY Buffered_Page_Count DESC
![Lost connection to MySQL server during query ([Errno 104] Connection reset by peer)](http://www.gvkun.com/zb_users/upload/2025/04/110b995c-64ad-495e-b5cd-8e4299fa80ff1745468870049.jpg "Lost connection to MySQL server during query ([Errno 104] Connection reset by peer)")
Lost connection to MySQL server during query ([Errno 104] Connection reset by peer)
Can''t connect to MySQL server Lost connection to MySQL server during query · Issue #269 · PyMySQL/PyMySQL https://github.com/PyMySQL/PyMySQL/issues/269
zappjones commented on Jan 30 2015
| Hey all - I was able to track down my issue with the help of amazon engineers. The default somaxconn value for an amazon RDS instance is 128 and they bumped it up to 1024 for us. After the change we''ve been good. Here''s a little bit more explanation:
https://computing.llnl.gov/linux/slurm/high_throughput.html |
Linux Clusters Overview https://computing.llnl.gov/tutorials/linux_clusters/

Navicat for mysql 1130 错误 用 Navicat 连接远程 MYSQL:报错 ERROR 1130
update mysql.user set host = ''%'' where user =''root'';
select host, user from mysql.user;

Navicat for MySQL 和 Navicat Premium 之间的区别
首先两款软件都可以用来管理数据库链接 MySQL 和 MariaDB
相对于新手或者前端工程师使用 Navicat for MySQL 就够了,功能相对于 Navicat Premium 比较少
Navicat for MySQL 是一套管理和开发 MySQL 或 MariaDB 的理想解决方案,支持单一程序,可同时连接到 MySQL 和 MariaDB。这个功能齐备的前端软件为数据库管理、开发和维护提供了直观而强大的图形界面,给 MySQL 或 MariaDB 新手以及专业人士提供了一组全面的工具。
而 Navicat premium 是一款数据库管理工具,是一个可多重连线资料库的管理工具,它可以让你以单一程式同时连线到 MySQL、SQLite、Oracle 及 PostgreSQL 资料库,让管理不同类型的资料库更加的方便。
在这里插入图片描述
Navicat Premium 功能多较 Navicat for MySQL 强大,熟悉之后建议使用 Navicat Premium
下载地址:http://www.navicat.com.cn/download/navicat-premium
原文:https://blog.csdn.net/weixin_43888402/article/details/86544201
本文同步分享在 博客 “lxw1844912514”(CSDN)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与 “OSC 源创计划”,欢迎正在阅读的你也加入,一起分享。
关于Mysql-Navicat 更改查询语句保存路径报错 Connection is being used和navicat修改查询结果的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于How Memory is being used、Lost connection to MySQL server during query ([Errno 104] Connection reset by peer)、Navicat for mysql 1130 错误 用 Navicat 连接远程 MYSQL:报错 ERROR 1130、Navicat for MySQL 和 Navicat Premium 之间的区别等相关知识的信息别忘了在本站进行查找喔。
本文标签:




