在本文中,我们将给您介绍关于高性能可扩展mysql笔记的详细内容,并且为您解答三Hash分区、RANGE分区、LIST分区的相关问题,此外,我们还将为您提供关于'range(y.shape[1])'在
在本文中,我们将给您介绍关于高性能可扩展 mysql 笔记的详细内容,并且为您解答三Hash 分区、RANGE 分区、LIST 分区的相关问题,此外,我们还将为您提供关于'range(y.shape[1])'在“for i in range(dataset2.shape[1]):”中是什么意思?、015. 数据分布算法:hash+ 一致性 hash + redis cluster 的 hash slot、ACM-ICPC 2018 南京赛区网络预赛 Skr 马拉车 + 字符串 hash+hash 表、Consistent-Hash(一致性 hash)- 从 sofa-registry 谈起的知识。
本文目录一览:- 高性能可扩展 mysql 笔记(三)Hash 分区、RANGE 分区、LIST 分区(mysql hash分区表)
- 'range(y.shape[1])'在“for i in range(dataset2.shape[1]):”中是什么意思?
- 015. 数据分布算法:hash+ 一致性 hash + redis cluster 的 hash slot
- ACM-ICPC 2018 南京赛区网络预赛 Skr 马拉车 + 字符串 hash+hash 表
- Consistent-Hash(一致性 hash)- 从 sofa-registry 谈起
Hash 分区、RANGE 分区、LIST 分区(mysql hash分区表)")
高性能可扩展 mysql 笔记(三)Hash 分区、RANGE 分区、LIST 分区(mysql hash分区表)
个人博客网:https://wushaopei.github.io/ (你想要这里多有)
一、MySQL 分区表操作
1、定义:数据库表分区是数据库基本设计规范之一,分区表在物理上表现为多个文件,在逻辑上表现为一个表;
2、表分区的弊端: 要谨慎选择分区键,错误的操作可能导致跨分区查询效率降低。
建议 采用物理分表的方式管理大数据。
3、确认 MySQL 服务器是否支持分区表
使用 SHOW PLUGINS;在 mysql 命令行查看是否具有分区表的功能:

查询结果中的 "partition | ACTIVE | STORAGE ENGINE | NULL | GPL " 这一行代表当前数据库可以进行数据库分区表操作。
4、普通数据库表的物理结构与分区表的物理结构的区别:

左边为普通表的物理结构,右边为分区后的数据库表物理结构。
一、Hash 分区表 (按 HASH 分区)
1、HASH 分区的特点
根据 MOD(分区键,分区数)的值把数据行存储到表的不同分区中,使数据可以平均的分布在各个分区中。
注意: HASH 分区的键值必须是一个 INT 类型的值,或是通过函数可以转为 INT 类型。
2、创建 HASH 分区:
use hash;
CREATE TABLE `hash`.`customer_login_log`( customer_id int UNSIGNED not null, login_time TIMESTAMP, login_ip int UNSIGNED, login_type TINYINT NOT NULL ) PARTITION by hash(login_ip) PARTITIONS 6;查看 customer_login_log 分区表物理结构:
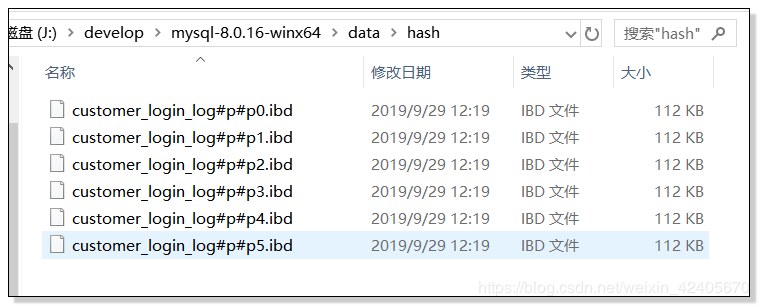
customer_login_log 普通非分区表物理结构:

向 HASH 分区表 customer_login_log 中插入数据:
INSERT INTO customer_login_log(customer_id,login_time,login_ip,login_type)
VALUES (1,now(),11111,1);查看分区表数据:

二、RANGE 分区表(按范围分区)
1、RANGE 分区特点:
RANGE 分区 是根据分区键值的范围把数据行存储到表的不同分区中,并且 多个分区的范围要连续,但是不能重叠。
注意: 默认情况下使用 VALUES LESS THAN 属性,即每个分区不包括指定的那个值
2、创建 RANGE 分区表:
create table `customer_login_log`(
`customer_id` int(10) UNSIGNED not null, `login_time` TIMESTAMP not null, `login_ip` int(10) UNSIGNED not null, `login_type` TINYINT(4) NOT NULL ) ENGINE=INNODB PARTITION BY RANGE( customer_id)( PARTITION P0 VALUES LESS THAN (10000), PARTITION P1 VALUES LESS THAN (20000), PARTITION P2 VALUES LESS THAN (30000), PARTITION P3 VALUES LESS THAN MAXVALUE )
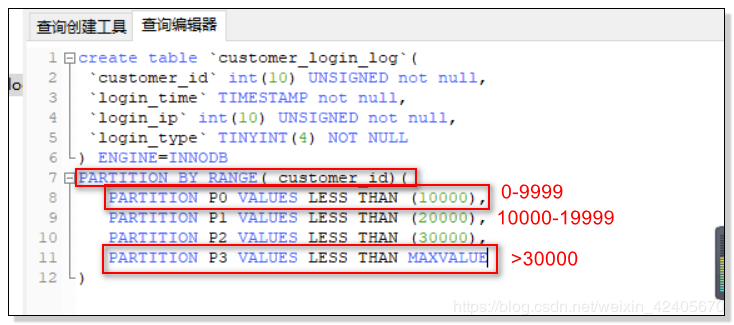
分区范围说明:
当插入的数据为 30000 到 40000 分区范围的数据时,没有创建分区范围为 40000 的分区的情况下,会返回错误提示;但,当存在图中 p3 分区的 MAXVALUE 这一分区时,所以没有指明分区范围的数据都会被插入到 p3 中
3、RANGE 分区的使用场景
- 分区键为日期或是时间类型
- 所有查询中都包括分区键
- 定期按分区范围清理历史数据
三、List 分区(按分区键取值分区)
1、LIST 分区的特点
定义: LIST 分区按分区键取值的列表进行分区,并且同范围分区一样,各分区的列表只不能重复
注意:每一行数据必须能找到对应 分区列表,否则数据插入失败
2、创建 LIST 分区表:
create table `customer_login_log_list`(
`customer_id` int(10) UNSIGNED not null, `login_time` TIMESTAMP not null, `login_ip` int(10) UNSIGNED not null, `login_type` TINYINT(4) NOT NULL ) ENGINE=INNODB PARTITION BY LIST (login_type)( PARTITION P0 VALUES IN (1,3,5,7,9), PARTITION P1 VALUES IN (2,4,6,8) )插入包含未建立分区的分区键的值,会返回错误:
INSERT INTO customer_login_log_list(customer_id,login_time,login_ip,login_type)VALUES(100,now(),1,10) 错误截图:
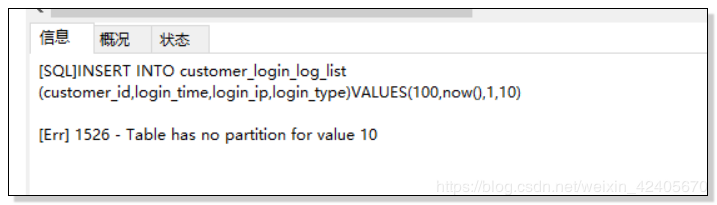
根据 login_type 的值进行分区 p0 存储 login_type 为 1,3,5,7,9;p1 存储 login_type 为 2,4,6,8 的数据,而插入的数据的 login_type 为 10,不包含在 p0 或 p1 的 login_type 范围中,所以插入失败,返回错误提示。
!['range(y.shape[1])'在“for i in range(dataset2.shape[1]):”中是什么意思?](http://www.gvkun.com/zb_users/upload/2025/04/6e34b6fb-1f77-4f73-89eb-e941044c374c1745551420930.jpg "'range(y.shape[1])'在“for i in range(dataset2.shape[1]):”中是什么意思?")
'range(y.shape[1])'在“for i in range(dataset2.shape[1]):”中是什么意思?
如何解决''range(y.shape[1])''在“for i in range(dataset2.shape[1]):”中是什么意思?
我想从外行的角度找出上面提到的这段代码是如何工作的? 对于上下文,此代码包含 Numpy、Seaborn、Pandas 和 matplotlib。
下面是代码行:
dataset2 = dataset.drop(columns = [''entry_id'',''pay_schedule'',''e_signed''])fig = plt.figure(figsize=(15,12))plt.suptitle(''Histograms of Numerical Columns'',fontsize=20)**for i in range(dataset2.shape[1]):**plt.subplot(6,3,i + 1)f = plt.gca()f.set_title(dataset2.columns.values[i])
解决方法
pd.shape 将为您提供数据帧中存在的 rows 和 columns 的数量。
其中,df.shape[0] 将为您提供数据帧中存在的 total rows。
并且,df.shape[1] 会给你数据帧中存在的 columns 的数量。
示例:
,
df = pd.DataFrame({''Date'':[''10/2/2011'',''11/2/2011'',''12/2/2011''],''Phrases'':[''I have a cool family'',''I like avocados'',''I would like to go to school'']})dfOut[26]:Date Phrases0 10/2/2011 I have a cool family1 11/2/2011 I like avocados2 12/2/2011 I would like to go to schooldf.shapeOut[27]: (3,2)df.shape[0] #number of rowsOut[28]: 3df.shape[1] #number of columnsOut[29]: 2
.shape 返回一个元组(行数,列数)。因此 dataset.shape[1] 是列数。 i in range(dataset.shape[1]) 只是从 0 到列数迭代。

015. 数据分布算法:hash+ 一致性 hash + redis cluster 的 hash slot
[toc]
讲解分布式数据存储的核心算法,数据分布的算法
hash 算法 -> 一致性 hash 算法(memcached) -> redis cluster 的 hash slot 算法
用不同的算法,就决定了在多个 master 节点的时候,数据如何分布到这些节点上去,解决这个问题
看到这里的时候,已经明白了,可能是通过 key 去路由到多个 master 上的
redis cluster 介绍
- 自动将数据进行分片,每个 master 上放一部分数据
- 提供内置的高可用支持,部分 master 不可用时,还是可以继续工作的
在 redis cluster 架构下,每个 redis 要放开两个端口号,比如一个是 6379,另外一个就是加 10000 的端口号,比如 16379
16379 端口号是用来进行节点间通信的,通过 cluster bus(集群总线)。cluster bus 的通信是用来进行故障检测,配置更新,故障转移授权
cluster bus 用了另外一种二进制的协议,主要用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间
最老土的 hash 算法和弊端(大量缓存重建)
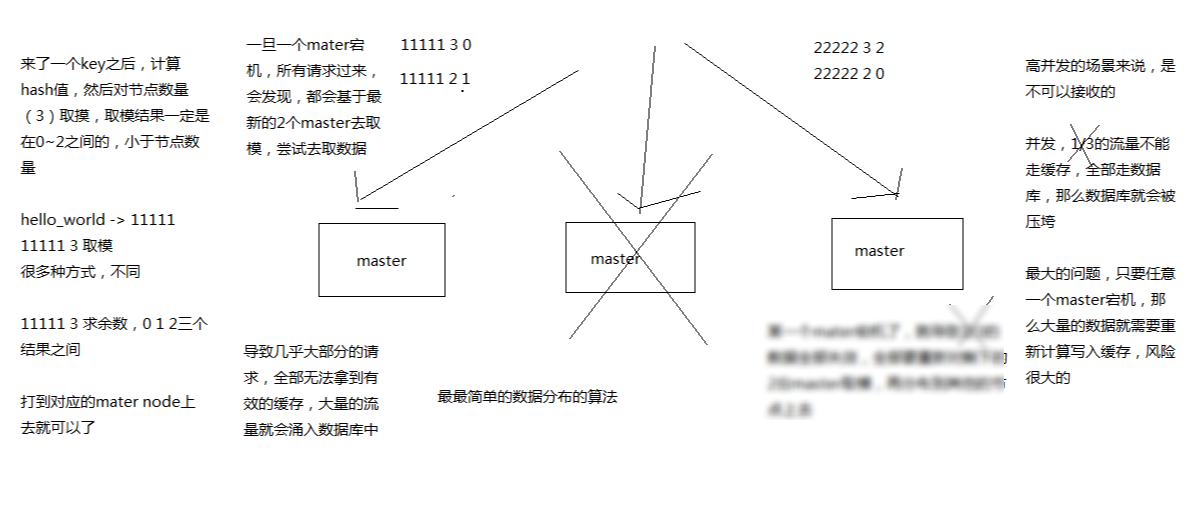
的确它的最大弊端就是,增加或者减少节点的时候,基本上所有数据都要重建路由
一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡)
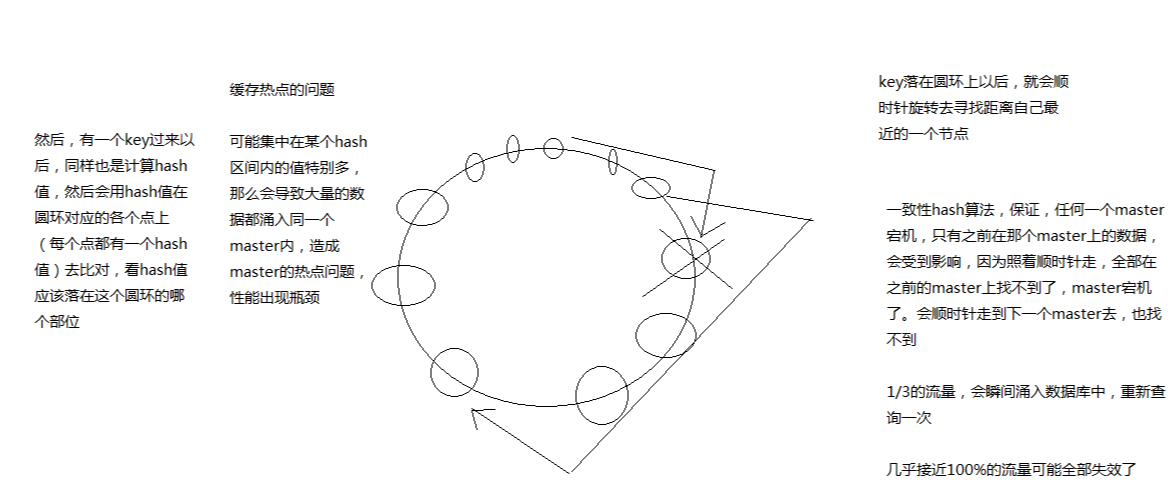
- 优点:自动缓存迁移
- 缺点:缓存热点问题
一致性 hash 的严重问题是缓存热点,关键字是 区间,因为它是一个环,顺时针找可用节点,所以只要节点够多,就能更均匀的均衡负载。
所以出现了虚拟节点,来解决这个缺点
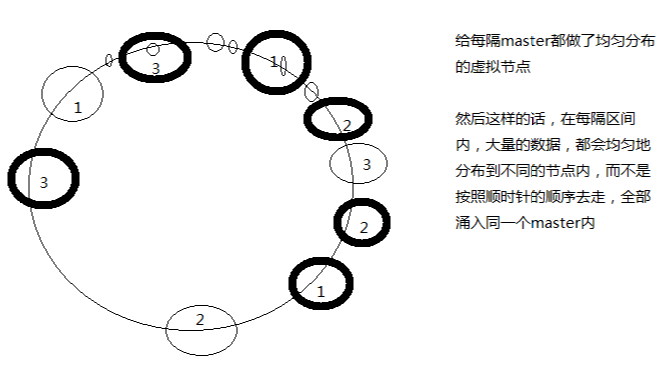
如上图,假设只有 3 个物理节点,但是在这个环上,分布了若干个虚拟节点(最后指向的是物理节点)
对于数据落在 1-3 这个区间
- 无虚拟节点:顺时针向右,全部导向了节点 3
- 有虚拟节点:顺时针向右,被多个虚拟节点分割,可能会遇上节点 1、2、3 。这样就负载均衡了
redis cluster 的 hash slot 算法
redis cluster 有固定的 16384 个 hash slot,对每个 key 计算 CRC16 值,然后对 16384 取模,可以获取 key 对应的 hash slot
redis cluster 中每个 master 都会持有部分 slot,比如有 3 个 master,那么可能每个 master 持有 5000 多个 hash slot
hash slot 让 node 的增加和移除很简单:
- 增加一个 master,就将其他 master 的 hash slot 移动部分过去
- 减少一个 master,就将它的 hash slot 移动到其他 master 上去
移动 hash slot 的成本是非常低的
客户端的 api,可以对指定的数据,让他们走同一个 hash slot,通过 hash tag 来实现

如上图,思路与一致性 hash 是一样的。通过更过的 hash slot,将路由分布得更均匀。 当一台机器挂掉之后,会在极短的时间内,将挂掉的 hash slot 分配给其他两个物理节点
可以看成是 -> hash slot -> 机器,hash slot 数量固定,不一一对应机器,动态分配的。
## 参考
- 中华石杉:亿级流量电商详情页系统实战(第二版):缓存架构 + 高可用服务架构 + 微服务架构 -Mrcode 笔记本

ACM-ICPC 2018 南京赛区网络预赛 Skr 马拉车 + 字符串 hash+hash 表
题目链接:Skr
题意,求不同的回文串的和。
题解:马拉车的时候当找到一个新的回文串时,判断这个回文串的 hash 值是否在 hashmap 中,没有就加入然后 ans 加上这段值,有就不管
#include<bits/stdc++.h>
#define ll long long
#define ull unsigned long long
using namespace std;
const int base=23;
const int N=2e6+100;
const int mod=1e9+7;
struct hash
{
char s[N];
ull h[N],qp[N];
ll p[N],len,val[N];
void init()
{
h[0]=val[0]=0;
qp[0]=p[0]=1;
len=strlen(s+1);
for(int i=1;i<=len;i++)
{
p[i]=p[i-1]*10%mod;
qp[i]=qp[i-1]*base;
h[i]=h[i-1]*base+s[i];
val[i]=(1LL*val[i-1]*10%mod+s[i]-''0'')%mod;
}
}
ull get_hash(int l,int r)
{
return h[r]-h[l-1]*qp[r-l+1];
}
int get_val(int l,int r)
{
return ((val[r]-val[l-1]*p[r-l+1]%mod)%mod+mod)%mod;
}
}ac;
int mx,len[N],x;
ll ans;
const int HASH = 1000007;
const int maxn=1e7+7;
struct hashmap{
ll a[maxn];
int head[HASH],nxt[maxn],sz;
void init(){
memset(head,-1,sizeof(head));
sz = 0;
}
bool find(ull val){
int tmp = (val%HASH + HASH) % HASH;
for(int i = head[tmp] ; ~i ; i = nxt[i]){
if(val == a[i]) return true;
}
return false;
}
void add(ull val){
int tmp = (val%HASH + HASH) % HASH;
if(find(val)) return;
a[sz] = val;
nxt[sz] = head[tmp];
head[tmp] = sz ++;
}
}ap;
void ins(int l,int r)
{
ull h=ac.get_hash(l,r);
if(!ap.find(h))
{
ap.add(h);
ans+=ac.get_val(l,r);
ans%=mod;
}
}
int main(){
scanf("%s",ac.s+1);
ac.init();
ap.init();
//int mx=0,x=0;
for(int i=1;i<=ac.len;i++)
{
ins(i,i);
if(mx>i)len[i]=min(mx-i,len[2*x-i]);
while(i+len[i]+1<=ac.len&&ac.s[i+len[i]+1]==ac.s[i-len[i]-1])
{
ins(i-len[i]-1,i+len[i]+1);
len[i]++;
}
if(i+len[i]>mx)
{
mx=i+len[i];x=i;
}
}
mx=x=0;
memset(len,0,sizeof len);
ap.init();
for(int i=2;i<=ac.len;i++)
{
if(mx>i)len[i]=min(mx-i+1,len[2*x-i]);
while(i+len[i]<=ac.len&&ac.s[i+len[i]]==ac.s[i-len[i]-1])
{
ins(i-len[i]-1,i+len[i]);
len[i]++;
}
if(i+len[i]-1>mx)
{
mx=i+len[i]-1;x=i;
}
}
printf("%lld\n",ans);
return 0;
}
- 从 sofa-registry 谈起")
Consistent-Hash(一致性 hash)- 从 sofa-registry 谈起
SOFARegistry 简介
SOFARegistry 是蚂蚁金服开源的一个生产级、高时效、高可用的服务注册中心
功能特性
* 支持服务发布与服务订阅
* 支持服务变更时的主动推送
* 丰富的 REST 接口
* 采用分层架构及数据分片,支持海量连接及海量数据
* 支持多副本备份,保证数据高可用
* 基于 SOFABolt 通信框架,服务上下线秒级通知
* AP 架构,保证网络分区下的可用性
sofa-registry 地址:https://github.com/sofastack/sofa-registry
从服务的注册与发现谈起
其支持服务发布与服务订阅功能,依赖一致性 hash 算法,其简介:参见:https://www.jianshu.com/p/e968c081f563
在解决分布式系统中负载均衡的问题时候可以使用 Hash 算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡的作用。 但是普通的余数 hash(hash (比如用户 id)% 服务器机器数)算法伸缩性很差,当新增或者下线服务器机器时候,用户 id 与服务器的映射关系会大量失效。一致性 hash 则利用 hash 环对其进行了改进。
核心代码参见:代码地址:[ConsistentHash.java](https://github.com/sofastack/sofa- registry/blob/master/server/consistency/src/main/java/com/alipay/sofa/registry/consistency/hash/ConsistentHash.java "ConsistentHash.java")
private final SortedMap<Integer, T> circle = new TreeMap<>();
/**
* This returns the closest node for the object. If the object is the node it
* should be an exact hit, but if it is a value traverse to find closest
* subsequent node.
* @param key the key
* @return node for
*/
public T getNodeFor(Object key) {
if (circle.isEmpty()) {
return null;
}
int hash = hashFunction.hash(key);
T node = circle.get(hash);
if (node == null) {
// inexact match -- find the next value in the circle
SortedMap<Integer, T> tailMap = circle.tailMap(hash);
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
node = circle.get(hash);
}
return node;
}
获取大于该 node 节点对应 hash 值的的 hash 环(tailMap 方法)信息,即 tailMap
- 若 tailMap 不为空,则获取最近的一个 node 节点(firstKey () 方法)
- 若 tailMap 为空,则获取 hash 环的第一个 node 节点(firstKey () 方法)
tailMap(K fromKey) 方法用于返回此映射,其键大于或等于fromKey的部分视图。
返回的映射受此映射支持,因此改变返回映射反映在此映射中,反之亦然。
虚拟节点
新的节点尝试注册进来,会调用 addNode(T node)方法,同时会有虚拟节点存在
/**
* Add a new node to the consistent hash
*
* This is not thread safe.
* @param node the node
*/
private void addNode(T node) {
realNodes.add(node);
for (int i = 0; i < numberOfReplicas; i++) {
// The string addition forces each replica to have different hash
circle.put(hashFunction.hash(node.getNodeName() + SIGN + i), node);
}
}
TODO
关于高性能可扩展 mysql 笔记和三Hash 分区、RANGE 分区、LIST 分区的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于'range(y.shape[1])'在“for i in range(dataset2.shape[1]):”中是什么意思?、015. 数据分布算法:hash+ 一致性 hash + redis cluster 的 hash slot、ACM-ICPC 2018 南京赛区网络预赛 Skr 马拉车 + 字符串 hash+hash 表、Consistent-Hash(一致性 hash)- 从 sofa-registry 谈起等相关知识的信息别忘了在本站进行查找喔。
本文标签:




