如果您对linuxMySQL5.7+keepalived主备服务器自主切换感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于linuxMySQL5.7+keepalived主备
如果您对linux MySQL 5.7+keepalived 主备服务器自主切换感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于linux MySQL 5.7+keepalived 主备服务器自主切换的详细内容,我们还将为您解答linux主备机切换的相关问题,并且为您提供关于61. 集群介绍 keepalived 介绍 keepalived 配置高可用、centos 7 Atlas keepalived 实现高可用 MySQL 5.7 MHA环境读写分离、centos7 Keepalived + Haproxy + MySQL pxc5.6、keepalived + Mysql(主主)实现高可用集群的有价值信息。
本文目录一览:- linux MySQL 5.7+keepalived 主备服务器自主切换(linux主备机切换)
- 61. 集群介绍 keepalived 介绍 keepalived 配置高可用
- centos 7 Atlas keepalived 实现高可用 MySQL 5.7 MHA环境读写分离
- centos7 Keepalived + Haproxy + MySQL pxc5.6
- keepalived + Mysql(主主)实现高可用集群
")
linux MySQL 5.7+keepalived 主备服务器自主切换(linux主备机切换)
一、环境准备
1、关闭防火墙与selinux
systemctl stop firewalld
setenforce 0
sed -i ''s/SELINUX=.*/SELINUX=disabled/g'' /etc/selinux/config
二、mysql5.7.20安装
#MySQL5.6与MySQL5.7的区别在于初始化的时候,其他安装步骤一致
1、创建目录
mkdir -p /data/mysql/{data,logs,tmp}
touch /data/mysql/{mysql.pid,mysql.sock}
2、创建用户
useradd mysql
3、安装依赖包
yum install perl perl-devel perl-Data-Dumper libaio-devel -y
4、下载包
cd /usr/local/src
wget https://cdn.mysql.com/archives/mysql-5.7/mysql-5.7.20-linux-glibc2.12-x86_64.tar.gz
tar zxf mysql-5.7.20-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
cd /usr/local
mv mysql-5.7.20-linux-glibc2.12-x86_64 mysql
chown -R mysql:mysql /usr/local/mysql /data/mysql/
三、配置文件
========================================================
[client]
port = 16205
default-character-set=utf8mb4
socket = /data/mysql/mysql.sock
[mysqld]
user = mysql
port = 16205
server-id = 111
character_set_server=utf8mb4
socket = /data/mysql/mysql.sock
datadir = /data/mysql/data/
pid-file = /data/mysql/mysql.pid
auto-increment-increment = 2 #主主参数,主从可注释(必填)
auto-increment-offset = 1 #主主参数,主从可注释(必填)主:1;从:2
#bind-address = 10.26.25.28
#skip-name-resolve=1
#event_scheduler = on
federated
skip-ssl
secure-file-priv = /home/mysql
disable-partition-engine-check=1
explicit_defaults_for_timestamp=false
max_allowed_packet = 32M
innodb_file_per_table = 1
back_log = 300
max_connections = 8000
max_connect_errors = 1000
table_open_cache = 4096
open_files_limit = 10240
max_allowed_packet = 512M
wait_timeout = 300
interactive_timeout=300
sort_buffer_size = 16M
join_buffer_size = 16M
query_cache_size = 128M
transaction_isolation = REPEATABLE-READ
thread_stack = 512K
innodb_buffer_pool_size = 4G
innodb_data_file_path = ibdata1:512M:autoextend
innodb_flush_log_at_trx_commit = 2
innodb_thread_concurrency = 16
innodb_log_buffer_size = 16M
innodb_log_file_size = 512M
innodb_log_files_in_group = 3
innodb_lock_wait_timeout = 120
binlog-ignore-db=information_schema,mysql,performance_schema #主主参数,主从可注释
#replicate-ignore-db=information_schema,mysql,performance_schema
binlog_format=row
expire_logs_days=10
binlog_cache_size = 7M
log-error = /data/mysql/logs/error.log
log-bin = /data/mysql/logs/mysql_bin.log
log-slave-updates=true #主主参数,主从可注释
#slow log
slow-query-log = 1
long_query_time = 2
slow-query-log-file = /data/mysql/logs/slowquery.log
sql_mode=NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
[mysqld_safe]
pid-file=/data/mysql/mysql.pid
================================================================================
四、初始化
1.MySQL5.7初始化:#注意: 要先初始化,再启动
初始化: bin/mysqld --defaults-file=/etc/my.cnf --basedir=/usr/local/mysql --datadir=/data/mysql/data --user=mysql --initialize
查看随机密码: cat /data/mysql/logs/error.log | grep password(查看后保存密码)
2.启动mysql
bin/mysqld_safe --defaults-file=/etc/my.cnf &
3.修改密码: /usr/local/mysql/bin/mysqladmin -uroot -p password #输入随机密码,再输入两次新密码即可
# 初始化后数据目录包含: mysql、information_schema、sys、performache_schema四个数据库
登录数据库:
/usr/local/mysql/bin/mysql -uroot -p
退出数据库:exit;
五、主从配置
# Master
1、my.cnf
server-id=1111
log-bin=(产生binglog日志。)
2、创建用于主从同步的账号
repl(主从同步用户名)192.168.28.135(从库所在服务器的IP)
mysql> grant replication slave on *.* to ''repl''@''192.168.28.135'' identified by ''a123456'';(a123456表示密码)
Query OK, 0 rows affected, 1 warning (0.06 sec)
mysql> flush privileges;(刷新权限)
Query OK, 0 rows affected (0.02 sec)
3、查看主库当前bin_log文件和Position
mysql> show master status;
+---------------+----------+--------------+--------------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+--------------------------+-------------------+
| binlog.000008 | 25616 | | information_schema,mysql | |
+---------------+----------+--------------+--------------------------+-------------------+
1 row in set (0.00 sec)
#以下是从库操作
登录数据库
/usr/local/mysql/bin/mysql -uroot -p
4、与主库建立连接
mysql> stop slave;(停止同步)
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> change master to master_host=''192.168.28.136'',master_user=''repl'',master_password=''a123456'',master_port=16205,master_log_file=''mysql_bin.000007'',master_log_pos=25616;
Query OK, 0 rows affected, 2 warnings (0.03 sec)
master_host=''192.168.28.136’, (主库所在IP地址)
master_user=''repl'', (主从同步用户名)
master_password=''a.123456'', (主从同步密码)
master_port=16205, (主库对外访问端口号)
master_log_file=''mysql_bin.000007'',(主库配置文件)
master_log_pos=25616; (主库配置文件)
5、start slave;(开启从库同步主库)
6、show slave status;(查看主从同步状态)show slave status\G
。。。。。。
Slave_IO_Running: Yes (IO线程是否正常)
Slave_SQL_Running: Yes (sql线程是否正常)
#这两个参数都为Yes的时候表示主从配置完成
==============================================================================
六、双主配置(就是把主从反过在配一遍)
登录数据库
/usr/local/mysql/bin/mysql -uroot -p
从库:
2、创建用于主从同步的账号
repl(主从同步用户名)192.168.28.135(从库所在服务器的IP)
mysql> grant replication slave on *.* to ''repl1''@''192.168.28.135'' identified by ''a123456'';(a123456表示密码)
Query OK, 0 rows affected, 1 warning (0.06 sec)
mysql> flush privileges;(刷新权限)
Query OK, 0 rows affected (0.02 sec)
3、查看主库当前bin_log文件和Position
mysql> show master status;
+---------------+----------+--------------+--------------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+--------------------------+-------------------+
| binlog.000008 | 25616 | | information_schema,mysql | |
+---------------+----------+--------------+--------------------------+-------------------+
1 row in set (0.00 sec)
#以下是从库操作
4、与主库建立连接
mysql> stop slave;(停止同步)
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> change master to master_host=''192.168.28.135'',master_user=''repl1'',master_password=''a123456'',master_port=16205,master_log_file=''mysql_bin.000008'',master_log_pos=25616;
Query OK, 0 rows affected, 2 warnings (0.03 sec)
master_host=''172.16.1.20’, (主库所在IP地址)
master_user=''repl'', (主从同步用户名)
master_password=''a123456'', (主从同步密码)
master_port=16205, (主库对外访问端口号)
master_log_file=''mysql_bin.000004'',(主库配置文件)
master_log_pos=25618; (主库配置文件)
5、start slave;(开启从库同步主库)
6、show slave status;(查看主从同步状态)show slave status\G
。。。。。。
Slave_IO_Running: Yes (IO线程是否正常)
Slave_SQL_Running: Yes (sql线程是否正常)
#这两个参数都为Yes的时候表示主从配置完成(两台数据库服务器都为YES方为通过,一定要验证!!!!!!!!!!)
。。。。。。
===========================================================================
如遇访问权限问题:以下可以解决
mysql -uroot -p root
mysql->use mysql
mysql->update user set host = ''%'' where user =''root'';
mysql->grant all privileges on *.* to ''root''@''%'' with grant option;
mysql->flush privileges;
mysql->exit;
sudo service mysql restart;
**********************************************************************************************************************************
keepalived部署配置(安装在mysql双主服务器当中)
一、安装keepalived
下载keepalived
官网: https://keepalived.org/download.html
上传并解压keepalived
/home
cd /home/
tar -zxvf keepalived-2.0.18.tar.gz -C /usr/local/src/
进入目录/usr/local/src/keepalived-2.0.18
cd /usr/local/src/keepalived-2.0.18/
检查安装环境
./configure --prefix=/usr/local/keepalived
第一次检查:
configure: error:
!!! OpenSSL is not properly installed on your system. !!!
!!! Can not include OpenSSL headers files. !!!
安装openssl openssl-devel解决问题
yum -y install openssl openssl-devel
第二次检查
*** WARNING - this build will not support IPVS with IPv6. Please install libnl/libnl-3 dev libraries to support IPv6 with IPVS.
安装libnl libnl-devel解决问题
yum -y install libnl libnl-devel
其他问题
configure: error: libnfnetlink headers missing
安装libnfnetlink-devel解决问题
yum -y install libnfnetlink-devel
编译并安装
make && make install
将keepalived添加到系统服务中
拷贝执行文件
cp /usr/local/keepalived/sbin/keepalived /usr/sbin/
将init.d文件拷贝到etc下,加入开机启动项
cp /usr/local/src/keepalived-2.0.18/keepalived/etc/init.d/keepalived /etc/init.d/keepalived
将keepalived文件拷贝到etc下
cp /usr/local/src/keepalived-2.0.18/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
创建keepalived文件夹
mkdir -p /etc/keepalived
将keepalived配置文件拷贝到etc下
cp /usr/local/src/keepalived-2.0.18/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf
添加keepalived到开机启动(看个人可随意)
chkconfig --add keepalived
添加可执行权限
chmod +x /etc/init.d/keepalived
二、部署keepalived双击自主切换(一下配置文件和脚本,两台机器都要重新布)
备份keepalived配置文件
cp keepalived.conf keepalived.conf.back
重新编辑配置文件
vim keepalived.conf
配置文件
===============================================================
! COnfiguration File for keepalived
global_defs {
router_id MASTER-HA #主机标识
#router_id BACKUP #备机标识
script_user root
enable_script_security
}
vrrp_script chk_mysql_port {
script "/etc/keepalived/chk_mysql.sh" #脚本地址和名字,此处调用改脚本
interval 2
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER #主机MASTER、备机BACKUP
interface eth0 #本机的网卡
mcast_src_ip 192.168.28.136 #网卡IP
virtual_router_id 51
priority 101 #主机101,备机小于101便可
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.28.188 #新的IP地址,需要在同机网段内
}
track_script {
chk_mysql_port
}
===============================================================================================
编写脚本
vim chk_mysql.sh
========================================================
#!/bin/bash
#This scripts is check for Mysql Slave status
counter=$(netstat -na|grep "LISTEN"|grep "16205"|wc -l)
if [ "${counter}" -eq 0 ]; then
/etc/init.d/keepalived keepalived stop
killall keepalived
fi
ping 192.168.28.136 -w1 -c1 &>/dev/null
if [ $? -ne 0 ]
then
/etc/init.d/keepalived keepalived stop
killall keepalived
fi
========================================================
添加可执行权限
chmod +x /etc/init.d/keepalived
启动keepalived
/etc/init.d/keepalived start
查看是否启动成功
ps -ef | grep keepalived

启动成功之后会生成一个新的服务器IP地址,可通过新IP直接连接数据库
查看ip地址 ip addr
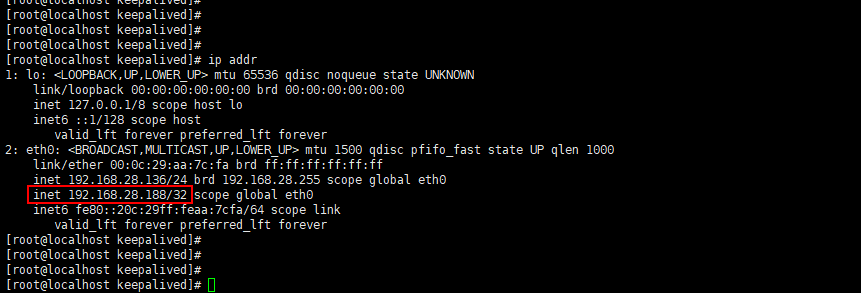
连接数据库地址
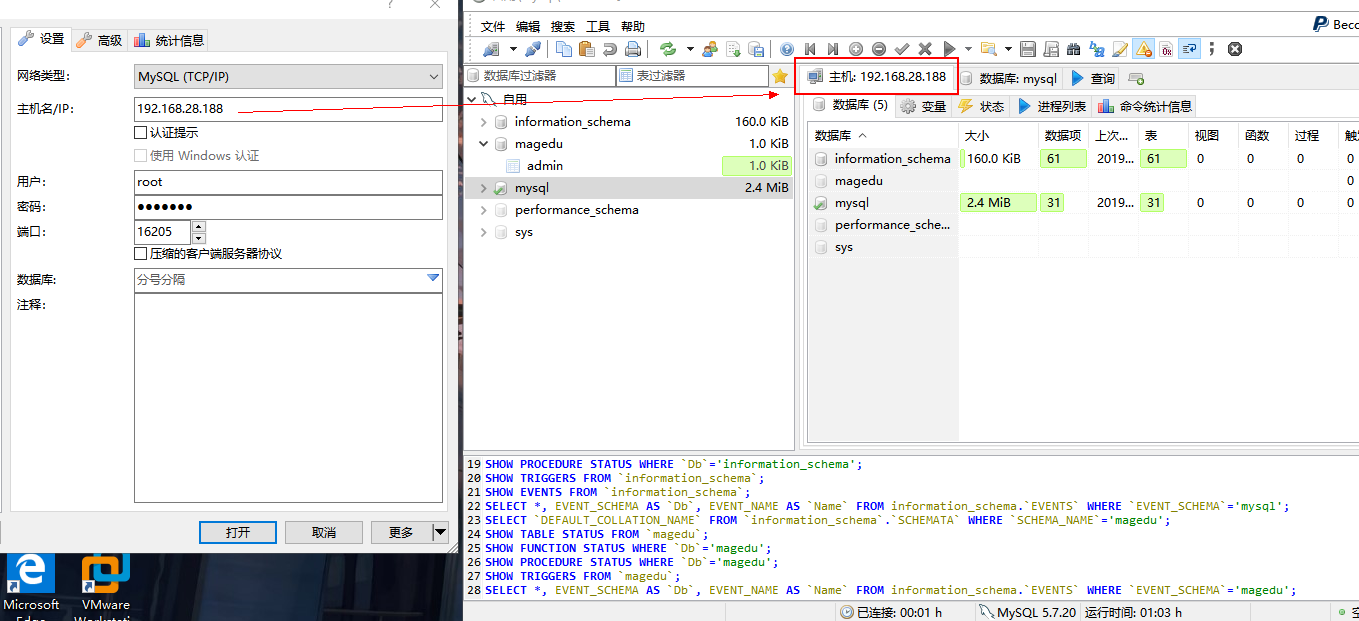
至此,数据库连接成功。
可以自由关闭其中一台数据库服务,keepalived会自动切换到另外一台数据库服务器当中。

61. 集群介绍 keepalived 介绍 keepalived 配置高可用
18.1 集群介绍
18.2 keepalived 介绍
18.3/18.4/18.5 用 keepalived 配置高可用集群
扩展
heartbeat 和 keepalived 比较 http://blog.csdn.net/yunhua_lee/article/details/9788433
DRBD 工作原理和配置 http://502245466.blog.51cto.com/7559397/1298945
mysql+keepalived http://lizhenliang.blog.51cto.com/7876557/1362313
18.1 集群介绍:
有多台机器组成了一个庞大的一台大机器。那么一台机器完不成的任务,可以多台一起
~1. 根据功能划分为两大类:高可用和负载均衡
~2. 高可用集群通常为两台服务器,一台工作,另外一台作为冗余,当提供服务的机器宕机,冗余将接替继续提供服务
一台机器提供服务,如果挂了,那么另一台就出来。这样可以最大化的提供系统可用的效率
很多公司把它可用的效率作为他健壮的标准。在业界一些核心的一些角色,做高可用的衡量标准,比如四个九,就是 99.99%,也就是说这一年百分之 99.99 的时间都是在线的,不允许当机,不允许服务不可用。有的是五个九或者是六个九
那怎么才能做到这么高的使用率、可用性。那实际上我们提供一个高可用的集群出来。一台机器当机,那么另一台机器马上接替服务,切换的时间很短,不到一分钟
~3. 实现高可用的开源软件有:heartbeat、keepalived
heartbeat 有很多 bug 以及不在更新,我们使用 keepalived。keepalived 不但可以实现高可用,还能负载均衡,而且配置简单
~4. 负载均衡集群,需要有一台服务器作为分发器,它负责把用户的请求分发给后端的服务器处理,在这个集群里,除了分发器外,就是给用户提供服务的服务器了,这些服务器数量至少为 2
比如,一开始只有几百人的访问量,随着发展,上升到几万人,一台机器已经满足不了需求,(优化单台机器比如加内存、cpu 等,以及到了瓶颈)那就只能加机器
~5. 实现负载均衡的开源软件有 LVS、keepalived、haproxy、nginx,
商业的有 F5、Netscaler,价格昂贵。优势是有很高的并发量,以及很好的稳定性
如果我们用这种开源的软件,他的稳定性就取决于服务器的稳定性
单机结构
我想大家最最最熟悉的就是单机结构,一个系统业务量很小的时候所有的代码都放在一个项目中就好了,然后这个项目部署在一台服务器上就好了。整个项目所有的服务都由这台服务器提供。这就是单机结构。
那么,单机结构有啥缺点呢?我想缺点是显而易见的,单机的处理能力毕竟是有限的,当你的业务增长到一定程度的时候,单机的硬件资源将无法满足你的业务需求。此时便出现了集群模式,往下接着看。
集群结构
集群模式在程序猿界由各种装逼解释,有的让你根本无法理解,其实就是一个很简单的玩意儿,且听我一一道来。
单机处理到达瓶颈的时候,你就把单机复制几份,这样就构成了一个 “集群”。集群中每台服务器就叫做这个集群的一个 “节点”,所有节点构成了一个集群。每个节点都提供相同的服务,那么这样系统的处理能力就相当于提升了好几倍(有几个节点就相当于提升了这么多倍)。
但问题是用户的请求究竟由哪个节点来处理呢?最好能够让此时此刻负载较小的节点来处理,这样使得每个节点的压力都比较平均。要实现这个功能,就需要在所有节点之前增加一个 “调度者” 的角色,用户的所有请求都先交给它,然后它根据当前所有节点的负载情况,决定将这个请求交给哪个节点处理。这个 “调度者” 有个牛逼了名字 —— 负载均衡服务器。
集群结构的好处就是系统扩展非常容易。如果随着你们系统业务的发展,当前的系统又支撑不住了,那么给这个集群再增加节点就行了。但是,当你的业务发展到一定程度的时候,你会发现一个问题 —— 无论怎么增加节点,貌似整个集群性能的提升效果并不明显了。这时候,你就需要使用微服务结构了。
微服务结构
先来对前面的知识点做个总结。
从单机结构到集群结构,你的代码基本无需要作任何修改,你要做的仅仅是多部署几台服务器,没台服务器上运行相同的代码就行了。但是,当你要从集群结构演进到微服务结构的时候,之前的那套代码就需要发生较大的改动了。所以对于新系统我们建议,系统设计之初就采用微服务架构,这样后期运维的成本更低。但如果一套老系统需要升级成微服务结构的话,那就得对代码大动干戈了。所以,对于老系统而言,究竟是继续保持集群模式,还是升级成微服务架构,这需要你们的架构师深思熟虑、权衡投入产出比。
OK,下面开始介绍所谓的微服务。
微服务就是将一个完整的系统,按照业务功能,拆分成一个个独立的子系统,在微服务结构中,每个子系统就被称为 “服务”。这些子系统能够独立运行在 web 容器中,它们之间通过 RPC 方式通信。
举个例子,假设需要开发一个在线商城。按照微服务的思想,我们需要按照功能模块拆分成多个独立的服务,如:用户服务、产品服务、订单服务、后台管理服务、数据分析服务等等。这一个个服务都是一个个独立的项目,可以独立运行。如果服务之间有依赖关系,那么通过 RPC 方式调用。
https://mp.weixin.qq.com/s?__biz=MzU3MTI5MjcwMQ==&mid=2247483801&idx=1&sn=822ef1066797c9c977d0f0ddfa
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
18.2 keepalived 介绍:
~1. 在这里我们使用 keepalived 来实现高可用集群,因为 heartbeat 在 centos6 上有一些问题,影响实验效果
~2.keepalived 通过 VRRP 协议(Virtual Router Redundancy Protocl)来实现高可用。VRRP 协议中文叫虚拟路由冗余协议
~3. 在这个协议里会将多台功能相同的路由器组成一个小组,这个小组里会有 1 个 master 角色和 N(N>=1)个 backup 角色。
实验中是一台机器而不是路由器
通常情况下,我们为了节省资源,让 N=1。也就是一主一从就可以实现了
~4.master 会通过组播的形式向各个 backup 发送 VRRP 协议的数据包,当 backup 收不到 master 发来的 VRRP 数据包时,就会认为 master 宕机了。此时就需要根据各个 backup 的优先级来决定谁成为新的 mater。
~5.Keepalived 要有三个模块,分别是 core、check 和 vrrp。其中 core 模块为 keepalived 的核心,负责主进程的启动、维护以及全局配置文件的加载和解析,check 模块负责健康检查,vrrp 模块是来实现 VRRP 协议的。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
18.3/18.4/18.5 用 keepalived 配置高可用集群:
用高可用的软件(keepalived)来实现高可用。并且要有一个服务去实现高可用(在这里是 nginx),也就是把 nginx 实现高可用的对象。因为很多企业把 nginx 作为负载均衡器。如果 nginx 挂掉那么后面的 web 服务器及时正常也不能使用,这个是不能出现单点故障的
~~master 上的操作:
~1.
准备两台机器 130 和 132,130 作为 master,132 作为 backup
~2.
两台机器都执行 yum install -y keepalived
~3.
两台机器都安装 nginx,其中 128 上已经编译安装过 nginx,130 上需要 yum 安装 nginx: yum install -y nginx
~4.
设定 vip 为 100。生产环境中公网 IP 就是 VIP
要用 ip add 来查看 ens33 的 IP。用 ifconfig 是看不到的
~5.
编辑 128 上 keepalived 配置文件,/etc/keepalived/keepailved.conf 下是有的,但是我们不用他这个自带的。内容从 https://coding.net/u/aminglinux/p/aminglinux-book/git/blob/master/D21Z/master_keepalived.conf 获取
~6.
128 编辑监控脚本,内容从 https://coding.net/u/aminglinux/p/aminglinux-book/git/blob/master/D21Z/master_check_ng.sh 获取
~7.
给脚本 755 权限
chmod 755 /usr/local/sbin/check_ng.sh
~8.
systemctl start keepalived 130 启动服务
~~backup 上的操作:
~1.
130 上编辑配置文件,内容从 https://coding.net/u/aminglinux/p/aminglinux-book/git/blob/master/D21Z/backup_keepalived.conf 获取
~2.
130 上编辑监控脚本,内容从 https://coding.net/u/aminglinux/p/aminglinux-book/git/blob/master/D21Z/backup_check_ng.sh 获取
~3.
给脚本 755 权限
~4.
130 上也启动服务 systemctl start keepalived
实例:
~~master 上的操作:
[root@axinlinux-01 ~]# yum install -y keepalived master 上安装 keepalived
[root@axinlinux-02 ~]# yum install -y keepalived backup 上安装 keepalived
[root@axinlinux-01 ~]# ps aux |grep nginx master 上检查是否开启 nginx(因为之前编译过 nginx)
[root@axinlinux-02 ~]# rpm -Uvh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm 阿鑫操作的时候,backup 上 yum 安装不了 nginx。后来是缺少 nginx 的源。执行这一条
[root@axinlinux-02 ~]# echo $?
0
[root@axinlinux-02 ~]# yum install -y nginx yum 安装 nginx
[root@axinlinux-01 ~]# vim /etc/keepalived/keepalived.conf #这个就是 keepalived 的内容
[root@axinlinux-01 ~]# > !$ #直接重定向这个文件,使他为空。因为我们不用这个自带的
> /etc/keepalived/keepalived.conf
[root@axinlinux-01 ~]# !vim
vim /etc/keepalived/keepalived.conf
global_defs { #全局的定义参数
notification_email { #出现问题是给那个邮箱发邮件
519321158.qq.com
}
notification_email_from root@aminglinux.com #由哪个邮件发出去
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script chk_nginx { #这个是检测服务是否正常的。就是那个 check 模块
script "/usr/local/sbin/check_ng.sh" #这个是一个 shell 脚本,一会会去写。这个脚本的作用就是检查服务是否正常的,如果不正常要把它启动起来
interval 3 #检测的间断是三秒钟
}
vrrp_instance VI_1 { #定义 master 相关
state MASTER #角色叫 master。(从的话就叫 backup)!这个要跟从不一样
interface ens33 #通过网卡去发 vrrp 协议
virtual_router_id 51 #定义路由器的 ID 是什么 !这个 ID 要保持一致,说明他们是一组
priority 100 #权重(主和从的权重是不一样的) !这个要跟从不一样
advert_int 1
authentication { #认证相关的信息
auth_type PASS #认证的类型是 PASS(密码的形式)
auth_pass aminglinux>com #定义密码的字符串
}
virtual_ipaddress { #定义它的 vip。生产环境中公网 IP 就是 VIP。因为定义了 ens33,用 ip add 去查看他的 IP
两台机器(主和从)正常是主在提供服务。如果主挂了,那么从起来的话肯定要提供服务啊,比如 nginx。那么从提供 nginx,那么我们去访问 nginx 的时候,访问哪个 IP 呢,你把域名解析到哪个 IP 上去呢?假如解析到主上,主都已经挂了,从起来了,那么从的 IP 是什么呢。所以,我们要给他定义一个公有的 IP。主上用的这个 IP,从也要用这个 IP。这个共有 IP 就叫做 vip。这个 IP 是可以随时的下掉去配置的。那这个 VIP 就可以在这定义
正常的话 master 上要启动绑定这个 IP。如果 master 当掉,那么从就要起来绑定这个 IP。那么我们最终解析域名,解析到这个 IP 上,不管是主上还是从上都无所谓了
192.168.188.100
}
track_script { #前面定义的脚本,这里要给他定义一个加载。就是 chk_nginx
chk_nginx
}
}
#!/bin/bash
#时间变量,用于记录日志
d=`date --date today +% Y% m% d_% H:% M:% S` #这个 d 表示时间
#计算 nginx 进程数量
n=`ps -C nginx --no-heading|wc -l`
#如果进程为 0,则启动 nginx,并且再次检测 nginx 进程数量,
#如果还为 0,说明 nginx 无法启动,此时需要关闭 keepalived
if [ $n -eq "0" ]; then
/etc/init.d/nginx start #跟从的启动方式不一样。因为主是编译的,可以这样启动
n2=`ps -C nginx --no-heading|wc -l`
if [ $n2 -eq "0" ]; then
echo "$d nginx down,keepalived will stop" >> /var/log/check_ng.log #如果么有启动起来,错误日志定义到这个里去
systemctl stop keepalived #既然 nginx 没有启动成功,那么 keepalive 也没有意义存在
在高可用集群里有个脑裂的概念。为什么要把主上的 keepalived 杀掉呢。因为这个时候要启动从了。主一停掉 keepalived 那从就要自动起来服务。那如果主和从的 keepalived 都起来,那两者就会争抢资源。比如 VIP 要争抢,那两个机器都监听了 VIP,那域名访问的时候去访问哪个机器呢。那就会出现紊乱。这种情况就叫做脑裂。这是不允许发生的
fi
fi
[root@axinlinux-01 ~]# chmod 755 /usr/local/sbin/check_ng.sh
[root@axinlinux-01 ~]# systemctl start keepalived #开启 keepalived
[root@axinlinux-01 ~]# ps aux |grep keepalived #看一下 keepalived 是否起来
root 2825 0.2 0.0 118656 1396 ? Ss 23:14 0:00 /usr/sbin/keepalived -D
root 2826 0.0 0.1 127520 3304 ? S 23:14 0:00 /usr/sbin/keepalived -D
root 2828 0.2 0.1 127460 2852 ? S 23:14 0:00 /usr/sbin/keepalived -D
root 2877 0.0 0.0 112720 984 pts/0 S+ 23:14 0:00 grep --color=auto keepalived
[root@axinlinux-01 ~]# ps aux |grep nginx #看一下 nginx 是否起来
root 1093 0.0 0.0 45868 1276 ? Ss 21:45 0:00 nginx: master process /usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
nobody 1094 0.0 0.2 48360 4168 ? S 21:45 0:00 nginx: worker process
nobody 1095 0.0 0.2 48360 3908 ? S 21:45 0:00 nginx: worker process
root 2921 0.0 0.0 112724 980 pts/0 S+ 23:15 0:00 grep --color=auto nginx
[root@axinlinux-01 ~]# /etc/init.d/nginx stop #我们做个试验,把 nginx 关掉,看他是否自动起来
Stopping nginx (via systemctl): [ 确定 ]
[root@axinlinux-01 ~]# !ps #自动起来。脚本生效
ps aux |grep nginx
root 3067 0.0 0.0 45868 1280 ? Ss 23:16 0:00 nginx: master process /usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
nobody 3068 0.0 0.2 48360 4164 ? S 23:16 0:00 nginx: worker process
nobody 3069 0.0 0.2 48360 3912 ? S 23:16 0:00 nginx: worker process
root 3074 0.0 0.0 112720 976 pts/0 S+ 23:16 0:00 grep --color=auto nginx
[root@axinlinux-01 ~]# cat /var/log/messages #这是他的日志
[root@axinlinux-01 ~]# systemctl stop firewalld #主从上都要关闭防火墙和 selinux
[root@axinlinux-01 ~]# setenforce 0
~~backup 上的操作:
[root@axinlinux-02 ~]# setenforce 0 #主从都要关闭防火墙和 selinux
[root@axinlinux-02 ~]# getenforce
Permissive
[root@axinlinux-02 ~]# systemctl stop firewalld
[root@axinlinux-02 ~]# vim /etc/keepalived/keepalived.conf #配置从的配置文件
global_defs {
notification_email {
aming@aminglinux.com
}
notification_email_from root@aminglinux.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script chk_nginx {
script "/usr/local/sbin/check_ng.sh" #监控脚本的路径
interval 3
}
vrrp_instance VI_1 {
state BACKUP
interface ens33 #网卡 ens33
virtual_router_id 51
priority 90 #权重 90,要和主不一样,比主低
advert_int 1
authentication {
auth_type PASS
auth_pass aminglinux>com
}
virtual_ipaddress {
192.168.208.100 #vip 跟主保持一样
}
track_script {
chk_nginx
}
[root@axinlinux-02 ~]# vi /usr/local/sbin/check_ng.sh
#时间变量,用于记录日志
d=`date --date today +%Y%m%d_%H:%M:%S`
#计算 nginx 进程数量
n=`ps -C nginx --no-heading|wc -l`
#如果进程为 0,则启动 nginx,并且再次检测 nginx 进程数量,
#如果还为 0,说明 nginx 无法启动,此时需要关闭 keepalived
if [ $n -eq "0" ]; then
systemctl start nginx #在这有跟主不太一样。因为主是源码编译的,使用了 chkconfig 这个工具,可以使用 /etc/init.d/nginx start。从是域名安装的要用 systemctl start nginx
n2=`ps -C nginx --no-heading|wc -l`
if [ $n2 -eq "0" ]; then
echo "$d nginx down,keepalived will stop" >> /var/log/check_ng.log
systemctl stop keepalived
fi
fi
[root@axinlinux-02 ~]# chmod 755 !$ #注意改权限
chmod 755 /usr/local/sbin/check_ng.sh
[root@axinlinux-02 ~]# systemctl start keepalived
[root@axinlinux-02 ~]# ps aux |grep keepalived
root 1700 0.0 0.0 118608 1388 ? Ss 23:41 0:00 /usr/sbin/keepalived -D
root 1701 0.3 0.1 127468 3300 ? S 23:41 0:00 /usr/sbin/keepalived -D
root 1702 0.3 0.1 127408 2836 ? S 23:41 0:00 /usr/sbin/keepalived -D
root 1733 0.0 0.0 112676 992 pts/0 S+ 23:41 0:00 grep --color=auto keepalived
以上 master 和 backup 配置完成。
我们 ip add 看一下 master 的 ens 33 的 IP,用浏览器访问一下

那用 IP 访问的时候他访问哪里去了呢。就是在 nginx 的主虚拟主机 root 的路径:
[root@axinlinux-01 ~]# cat /usr/local/nginx/conf/vhost/aaa.com.conf
server
{
listen 80 default_server;
server_name aaa.com;
index index.html index.htm index.php;
root /data/wwwroot/default; #就是主虚拟主机的 root 路径下的
[root@axinlinux-01 ~]# ls /data/wwwroot/default #也就是这个文件
index.html
[root@axinlinux-01 ~]# cat /data/wwwroot/default/index.html
master master. This is default site. #内容和浏览器的是一样的
我们 ip add 看一下 backup 的 ens 33 的 IP,用浏览器访问一下
因为从的 nginx 是 yum 安装的。他的默认页在:
[root@axinlinux-02 ~]# cat /usr/share/nginx/html/index.html
···
那我们在来访问 vip

访问的是 master 的,所以他的 vip 在 master 这

centos 7 Atlas keepalived 实现高可用 MySQL 5.7 MHA环境读写分离
[TOC]
简介
Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。
它在MySQL官方推出的MySQL-Proxy 0.8.2版本的基础上,修改了大量bug,添加了很多功能特性。而且安装方便。配置的注释写的蛮详细的,都是中文。
主要功能
- 读写分离
- 从库负载均衡
- IP过滤
- 自动分表
- DBA可平滑上下线DB
- 自动摘除宕机的DB
相关链接
- Mysql中间件产品比较:http://songwie.com/articlelist/44
- Atlas的安装:https://github.com/Qihoo360/Atlas/wiki/Atlas的安装
- Atlas功能特点FAQ:https://github.com/Qihoo360/Atlas/wiki/Atlas功能特点FAQ
- Atlas性能特点:https://github.com/Qihoo360/Atlas/wiki/Atlas的性能测试
- Atlas架构:https://github.com/Qihoo360/Atlas/wiki/Atlas的架构
- Atlas+Keepalived:http://sofar.blog.51cto.com/353572/1601552
- Atlas各项功能验证:http://blog.itpub.net/27000195/viewspace-1421262/
环境准备
本次环境主要依赖于 MySQL 高可用架构 之 MHA 这篇文章。
各位可根据自己的环境进行配置修改即可。
Atlas 环境
| 操作系统 | 内核版本 | 主机名 | ip地址 | 角色 |
|---|---|---|---|---|
| centos 7.5 | 5.1.3-1.el7 | master.atlas | 10.0.20.196 | Manager |
| centos 7.5 | 5.1.3-1.el7 | slave.atlas | 10.0.20.197 | node01 mysql-master |
VIP 地址: 10.0.20.198
MySQL 集群环境
| 操作系统 | 内核版本 | 主机名 | MySQL 版本 | ip地址 | 角色 |
|---|---|---|---|---|---|
| centos 7.5 | 5.1.3-1.el7 | manager.mha | MySQL 5.7.18 | 10.0.20.200 | Manager |
| centos 7.5 | 5.1.3-1.el7 | node01.mha | MySQL 5.7.18 | 10.0.20.201 | node01 mysql-master |
| centos 7.5 | 5.1.3-1.el7 | node02.mha | MySQL 5.7.18 | 10.0.20.202 | node02 mysql-slave |
| centos 7.5 | 5.1.3-1.el7 | node03.mha | MySQL 5.7.18 | 10.0.20.203 | node03 mysql-slave |
| centos 7.5 | 5.1.3-1.el7 | node04.mha | MySQL 5.7.18 | 10.0.20.204 | node04 mysql-slave |
主库VIP 地址: 10.0.20.199
Atlas 安装 和 配置
安装和配置
atlas,master和slave的配置要完全相同,一下操作在master和slave上均要操作
[root@master ~]# cd /opt/soft/
[root@master soft]# wget https://github.com/Qihoo360/Atlas/releases/download/2.2.1/Atlas-2.2.1.el6.x86_64.rpm
[root@master soft]# ls
Atlas-2.2.1.el6.x86_64.rpm
[root@master soft]# rpm -ivh Atlas-2.2.1.el6.x86_64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:Atlas-2.2.1-1 ################################# [100%]
[root@master soft]# rpm -qa | grep Atlas
Atlas-2.2.1-1.x86_64
安装完成后,会在/usr/local/mysql-proxy/下生成四个目录
[root@master soft]# ll /usr/local/mysql-proxy/
total 0
drwxr-xr-x 2 root root 75 Jun 18 09:50 bin
drwxr-xr-x 2 root root 22 Jun 18 09:50 conf
drwxr-xr-x 3 root root 331 Jun 18 09:50 lib
drwxr-xr-x 2 root root 6 Dec 17 2014 log
在bin下有三个可执行文件
[root@master soft]# ll /usr/local/mysql-proxy/bin/
total 44
-rwxr-xr-x 1 root root 9696 Dec 17 2014 encrypt
-rwxr-xr-x 1 root root 23564 Dec 17 2014 mysql-proxy
-rwxr-xr-x 1 root root 1552 Dec 17 2014 mysql-proxyd
-rw-r--r-- 1 root root 6 Dec 17 2014 VERSION
bin目录下放的都是可执行文件
- “encrypt”是用来生成MySQL密码加密的,在配置的时候会用到
- “mysql-proxy”是MySQL自己的读写分离代理
- “mysql-proxyd”是360弄出来的,后面有个“d”,服务的启动、重
剩下三个目录分别是:
- conf目录下放的是配置文件 “test.cnf”只有一个文件,用来配置代理的,可以使用vim来编辑
- lib目录下放的是一些包,以及Atlas的依赖
- log目录下放的是日志,如报错等错误信息的记录
为数据库的密码加密
在配置文件中,填写的数据库的密码不是明文的,而是可以通过自带的加密工具加密后得到的内容填写进去,这里使用的最简单的123456密码测试
[root@master soft]# /usr/local/mysql-proxy/bin/encrypt 123456
/iZxz+0GRoA=
修改配置文件
[root@master conf]# cat test.cnf
[mysql-proxy]
#带#号的为非必需的配置项目
#管理接口的用户名
admin-username = user
#管理接口的密码
admin-password = pwd
#Atlas后端连接的MySQL主库的IP和端口,可设置多项,用逗号分隔
proxy-backend-addresses = 10.0.20.199:3306
#Atlas后端连接的MySQL从库的IP和端口,@后面的数字代表权重,用来作负载均衡,若省略则默认为1,可设置多项,用逗号分隔
proxy-read-only-backend-addresses = 10.0.20.202:3306@1,10.0.20.203:3306@1,10.0.20.204:3306@1
#用户名与其对应的加密过的MySQL密码,密码使用PREFIX/bin目录下的加密程序encrypt加密,下行的user1和user2为示例,将其替换为你的MySQL的用户名和加密密码!
pwds = java:Q6gAt5tl+GUa8s/oWZlMvQ==, root:/iZxz+0GRoA=
#设置Atlas的运行方式,设为true时为守护进程方式,设为false时为前台方式,一般开发调试时设为false,线上运行时设为true,true后面不能有空格。
daemon = true
#设置Atlas的运行方式,设为true时Atlas会启动两个进程,一个为monitor,一个为worker,monitor在worker意外退出后会自动将其重启,设为false时只有worker,没有monitor,一般开发调试时设为false,线上运行时设为true,true后面不能有空格。
keepalive = true
#工作线程数,对Atlas的性能有很大影响,可根据情况适当设置
event-threads = 16
#日志级别,分为message、warning、critical、error、debug五个级别
log-level = message
#日志存放的路径
log-path = /usr/local/mysql-proxy/log
#SQL日志的开关,可设置为OFF、ON、REALTIME,OFF代表不记录SQL日志,ON代表记录SQL日志,REALTIME代表记录SQL日志且实时写入磁盘,默认为OFF
#sql-log = OFF
#慢日志输出设置。当设置了该参数时,则日志只输出执行时间超过sql-log-slow(单位:ms)的日志记录。不设置该参数则输出全部日志。
sql-log-slow = 10
#实例名称,用于同一台机器上多个Atlas实例间的区分
instance = dev
#Atlas监听的工作接口IP和端口
proxy-address = 0.0.0.0:3306
#Atlas监听的管理接口IP和端口
admin-address = 0.0.0.0:2345
#分表设置,此例中person为库名,mt为表名,id为分表字段,3为子表数量,可设置多项,以逗号分隔,若不分表则不需要设置该项
#tables = person.mt.id.3
#默认字符集,设置该项后客户端不再需要执行SET NAMES语句
#charset = utf8
#允许连接Atlas的客户端的IP,可以是精确IP,也可以是IP段,以逗号分隔,若不设置该项则允许所有IP连接,否则只允许列表中的IP连接
#client-ips = 127.0.0.1, 192.168.1
#Atlas前面挂接的LVS的物理网卡的IP(注意不是虚IP),若有LVS且设置了client-ips则此项必须设置,否则可以不设置
#lvs-ips = 192.168.1.1
启动
[root@master conf]# /usr/local/mysql-proxy/bin/mysql-proxyd dev start
OK: MySQL-Proxy of dev is started
[root@master conf]# ps aux|grep mysql
root 9173 0.0 0.3 65844 7080 ? S 10:45 0:00 /usr/local/mysql-proxy/bin/mysql-proxy --defaults-file=/usr/local/mysql-proxy/conf/dev.cnf
root 9174 0.0 1.2 235972 26032 ? Sl 10:45 0:00 /usr/local/mysql-proxy/bin/mysql-proxy --defaults-file=/usr/local/mysql-proxy/conf/dev.cnf
[root@master conf]# netstat -lntup | grep mysql
tcp 0 0 0.0.0.0:2345 0.0.0.0:* LISTEN 9174/mysql-proxy
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 9174/mysql-proxy
加入开机启动项
[root@master conf]# echo ''/usr/local/mysql-proxy/bin/mysql-proxyd dev start'' >> /etc/rc.local
注意: 这里master配置完成了,slave需要相同一模一样的配置。
Keepalived 安装配置
安装
master 和 slave 节点都需要安装
yum install keepalived -y
master 配置
配置文件
[root@master keepalived]# vim keepalived.conf
! Configuration File for keepalived
global_defs {
router_id mysql_proxy_196
}
vrrp_script chk_atlas_proxy
{
script "/etc/keepalived/che_atlas.sh"
interval 2
weight -2
}
vrrp_instance VI_1 {
state BACKUP
interface bond0
virtual_router_id 151
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.20.198/24 dev bond0 label bond0:1
}
track_script {
chk_atlas_proxy
}
}
che_atlas.sh 脚本
[root@master keepalived]# cat /etc/keepalived/che_atlas.sh
#!/bin/bash
if [ `ps aux|grep mysql | grep -v grep | wc -l` -ne 2 ];then
systemctl stop keepalived
fi
启动master上的keepalived服务
# 启动服务
[root@master keepalived]# systemctl start keepalived
# 开机启动服务
[root@master keepalived]# systemctl enable keepalived
# 关闭服务
[root@master keepalived]# systemctl stop keepalived
# 查看服务状态
[root@master keepalived]# systemctl status keepalived
查看状态:
[root@master keepalived]# ps aux | grep keep
root 8983 0.0 0.0 118700 1956 ? Ss 09:37 0:00 /usr/sbin/keepalived -D
root 8984 0.0 0.2 118700 5580 ? S 09:37 0:00 /usr/sbin/keepalived -D
root 8985 0.0 0.1 118700 3752 ? S 09:37 0:01 /usr/sbin/keepalived -D
root 9449 0.0 0.1 112712 2276 pts/0 S+ 13:35 0:00 grep --color=auto keep
[root@master keepalived]# ip a | grep 20
inet 10.0.20.196/24 brd 10.0.20.255 scope global bond0
inet 10.0.20.198/24 scope global secondary bond0:1
Keepalive 脚本不执行的坑
请查看文章 CentOS 7 Keepalive 脚本不执行解决
slave 配置
[root@slave ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id mysql_proxy_197
}
vrrp_instance VI_1 {
state BACKUP
interface bond0
virtual_router_id 151
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.20.198/24 dev bond0 label bond0:1
}
}
启动slave上的keepalived服务
# 启动服务
[root@slave keepalived]# systemctl start keepalived
# 开机启动服务
[root@master keepalived]# systemctl enable keepalived
查看状态
[root@slave ~]# ps aux | grep keep
root 9082 0.0 0.0 118700 2012 ? Ss 09:36 0:00 /usr/sbin/keepalived -D
root 9083 0.0 0.2 118700 5476 ? S 09:36 0:00 /usr/sbin/keepalived -D
root 9084 0.0 0.1 118700 3656 ? S 09:36 0:00 /usr/sbin/keepalived -D
root 9484 0.0 0.1 112712 2188 pts/0 S+ 13:36 0:00 grep --color=auto keep
测试宕机
手动停止master上的 atlas服务,查看keepalive的服务状态以及vip飘移是否正常
停止Atlas服务
[root@master keepalived]# /usr/local/mysql-proxy/bin/mysql-proxyd dev stop
OK: MySQL-Proxy of dev is stopped
查看Master日志:
Jun 18 15:17:30 master systemd: Stopping LVS and VRRP High Availability Monitor...
Jun 18 15:17:30 master Keepalived[10367]: Stopping
Jun 18 15:17:30 master Keepalived_vrrp[10369]: VRRP_Instance(VI_1) sent 0 priority
Jun 18 15:17:30 master Keepalived_vrrp[10369]: VRRP_Instance(VI_1) removing protocol VIPs.
Jun 18 15:17:30 master Keepalived_healthcheckers[10368]: Stopped
Jun 18 15:17:31 master Keepalived_vrrp[10369]: Stopped
Jun 18 15:17:31 master Keepalived[10367]: Stopped Keepalived v1.3.5 (03/19,2017), git commit v1.3.5-6-g6fa32f2
Jun 18 15:17:31 master systemd: Stopped LVS and VRRP High Availability Monitor.
查看slave状态
[root@slave keepalived]# ip a | grep 20
inet 10.0.20.197/24 brd 10.0.20.255 scope global bond0
inet 10.0.20.198/24 scope global secondary bond0:1
VIP已经被Slave接管

centos7 Keepalived + Haproxy + MySQL pxc5.6
拓扑图
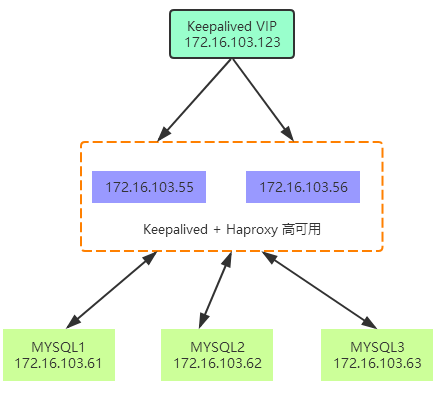
应用通过 VIP 连接到 Haproxy,Haproxy 通过 http 代理分发请求到后端 3 台 MySQL pxc。
Keepalived 可以有效防止 Haproxy 单点故障。
MySQL PXC
PXC 的优点:
- 服务高可用
- 数据同步复制 (并发复制), 几乎无延迟;
- 多个可同时读写节点,可实现写扩展,不过最好事先进行分库分表,让各个节点分别写不同的表或者库,避免让 galera 解决数据冲突;
- 新节点可以自动部署,部署操作简单;
- 数据严格一致性,尤其适合电商类应用;
- 完全兼容 MySQL;
PXC 局限性:
- 只支持 InnoDB 引擎;
- 所有表都要有主键;
- 不支持 LOCK TABLE 等显式锁操作;
- 锁冲突、死锁问题相对更多;
- 不支持 XA;
- 集群吞吐量 / 性能取决于短板;
- 新加入节点采用 SST 时代价高;
- 存在写扩大问题;
- 如果并发事务量很大的话,建议采用 InfiniBand 网络,降低网络延迟;
安装
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm -y
yum install Percona-XtraDB-Cluster-56 -y
pxc1 配置文件
cat <<EOF> /etc/my.cnf
[mysqld]
##general set
#bind-address=172.19.11.21
port=5001
datadir=/mysql_data/smy_node1/
socket=/mysql_data/smy_node1/mysql-smy.sock
pid-file=/mysql_data/smy_node1/mysql-smy.pid
log-error=/mysql_data/smy_node1/mysql-smy.err
server_id=1
##wsrep set
wsrep_provider=/usr/lib64/libgalera_smm.so
wsrep_cluster_name = smy1
wsrep_node_name = smy_node1
wsrep_node_address=172.16.103.61:5020
#wsrep_cluster_address=gcomm://127.0.0.1:4567,127.0.0.1:5020
wsrep_cluster_address=gcomm://172.16.103.61:5020,172.16.103.62:5020,172.16.103.63:5020
wsrep_provider_options = "base_port=5020;"
##sst syc method
wsrep_sst_method=xtrabackup-v2
##sst user and password
wsrep_sst_auth="smydba:smy2016"
##transaction cache for Galera replication,larger size,bigger chance to use ist
wsrep_provider_options="gcache.size=32G;gcache.page_size=1G"
##replication transactions threads for client
wsrep_slave_threads=6
##change it to RSU,when big change like alter table ,change column name, add index happened, otherwise it will infute the whole cluster,
wsrep_OSU_method=TOI
##new db parameters
skip-name-resolve
skip-host-cache
character-set-server=utf8
##character-set-server=utf8mb4
default_storage_engine=InnoDB
binlog_format=ROW
log-slave-updates=on
innodb_autoinc_lock_mode=2
###men cache,up tp 60% of whole physical memory,change it when deploy to production env
innodb_buffer_pool_size=32G
###each log file
innodb_log_file_size=256M
innodb_log_files_in_group=2
###each table in a seprate storage file
innodb_file_per_table=1
###log buffer
innodb_flush_log_at_trx_commit=2
##too small will cause commit error
max_allowed_packet=20M
##it will first read cache,then go to open table
table_open_cache=1024
##increase sort by
sort_buffer_size=4M
join_buffer_size=8M
##increase table sequence scan
read_buffer_size=10M
##1g->8
thread_cache_size=320
tmp_table_size=512M
wait_timeout=108000
max_connections = 2000
##log set
slow_query_log=1
slow_query_log_file = slow.log
general_log=Off
long_query_time=3
##other set
event_scheduler=1
##lower_case_table_names=1
max_connect_errors=1844674407370954751
#innodb_data_file_path = ibdata1:1G:autoextend
EOF
主节点启动方式
systemctl start mysql@bootstrap.service
增加 sst 同步用户
登录修改初始密码:
SET PASSWORD = PASSWORD(‘Lcsmy,123’);
ALTER USER ''root''@''localhost'' PASSWORD EXPIRE NEVER;
FLUSH PRIVILEGES;
创建同步账号:
grant all on *.* to smydba@''%'' identified by ''smy2016'';
systemctl start mysql@bootstrap.service
pxc2 配置文件
cat <<EOF> /etc/my.cnf
[mysqld]
##general set
#bind-address=172.19.11.21
port=5001
datadir=/mysql_data/smy_node2/
socket=/mysql_data/smy_node2/mysql-smy.sock
pid-file=/mysql_data/smy_node2/mysql-smy.pid
log-error=/mysql_data/smy_node2/mysql-smy.err
server_id=2
##wsrep set
wsrep_provider=/usr/lib64/libgalera_smm.so
wsrep_cluster_name = smy1
wsrep_node_name = smy_node2
wsrep_node_address=172.16.103.62:5020
#wsrep_cluster_address=gcomm://127.0.0.1:4567,127.0.0.1:5020
wsrep_cluster_address=gcomm://172.16.103.61:5020,172.16.103.62:5020,172.16.103.63:5020
wsrep_provider_options = "base_port=5020;"
##sst syc method
wsrep_sst_method=xtrabackup-v2
##sst user and password
wsrep_sst_auth="smydba:smy2016"
##transaction cache for Galera replication,larger size,bigger chance to use ist
wsrep_provider_options="gcache.size=32G;gcache.page_size=1G"
##replication transactions threads for client
wsrep_slave_threads=6
##change it to RSU,when big change like alter table ,change column name, add index happened, otherwise it will infute the whole cluster,
wsrep_OSU_method=TOI
##new db parameters
skip-name-resolve
skip-host-cache
character-set-server=utf8
##character-set-server=utf8mb4
default_storage_engine=InnoDB
binlog_format=ROW
log-slave-updates=on
innodb_autoinc_lock_mode=2
###men cache,up tp 60% of whole physical memory,change it when deploy to production env
innodb_buffer_pool_size=32G
###each log file
innodb_log_file_size=256M
innodb_log_files_in_group=2
###each table in a seprate storage file
innodb_file_per_table=1
###log buffer
innodb_flush_log_at_trx_commit=2
##too small will cause commit error
max_allowed_packet=20M
##it will first read cache,then go to open table
table_open_cache=1024
##increase sort by
sort_buffer_size=4M
join_buffer_size=8M
##increase table sequence scan
read_buffer_size=10M
##1g->8
thread_cache_size=320
tmp_table_size=512M
wait_timeout=108000
max_connections = 2000
##log set
slow_query_log=1
slow_query_log_file = slow.log
general_log=Off
long_query_time=3
##other set
event_scheduler=1
##lower_case_table_names=1
max_connect_errors=1844674407370954751
#innodb_data_file_path = ibdata1:1G:autoextend
EOF
pxc3 配置文件
cat <<EOF> /etc/my.cnf
[mysqld]
##general set
#bind-address=172.19.11.21
port=5001
datadir=/mysql_data/smy_node3/
socket=/mysql_data/smy_node3/mysql-smy.sock
pid-file=/mysql_data/smy_node3/mysql-smy.pid
log-error=/mysql_data/smy_node3/mysql-smy.err
server_id=3
##wsrep set
wsrep_provider=/usr/lib64/libgalera_smm.so
wsrep_cluster_name = smy1
wsrep_node_name = smy_node3
wsrep_node_address=172.16.103.63:5020
#wsrep_cluster_address=gcomm://127.0.0.1:4567,127.0.0.1:5020
wsrep_cluster_address=gcomm://172.16.103.61:5020,172.16.103.62:5020,172.16.103.63:5020
wsrep_provider_options = "base_port=5020;"
##sst syc method
wsrep_sst_method=xtrabackup-v2
##sst user and password
wsrep_sst_auth="smydba:smy2016"
##transaction cache for Galera replication,larger size,bigger chance to use ist
wsrep_provider_options="gcache.size=32G;gcache.page_size=1G"
##replication transactions threads for client
wsrep_slave_threads=6
##change it to RSU,when big change like alter table ,change column name, add index happened, otherwise it will infute the whole cluster,
wsrep_OSU_method=TOI
##new db parameters
skip-name-resolve
skip-host-cache
character-set-server=utf8
##character-set-server=utf8mb4
default_storage_engine=InnoDB
binlog_format=ROW
log-slave-updates=on
innodb_autoinc_lock_mode=2
###men cache,up tp 60% of whole physical memory,change it when deploy to production env
innodb_buffer_pool_size=32G
###each log file
innodb_log_file_size=256M
innodb_log_files_in_group=2
###each table in a seprate storage file
innodb_file_per_table=1
###log buffer
innodb_flush_log_at_trx_commit=2
##too small will cause commit error
max_allowed_packet=20M
##it will first read cache,then go to open table
table_open_cache=1024
##increase sort by
sort_buffer_size=4M
join_buffer_size=8M
##increase table sequence scan
read_buffer_size=10M
##1g->8
thread_cache_size=320
tmp_table_size=512M
wait_timeout=108000
max_connections = 2000
##log set
slow_query_log=1
slow_query_log_file = slow.log
general_log=Off
long_query_time=3
##other set
event_scheduler=1
##lower_case_table_names=1
max_connect_errors=1844674407370954751
#innodb_data_file_path = ibdata1:1G:autoextend
EOF
启动 pxc2、3 节点
systemctl start mysql.service
集群状态与维护
状态
每个节点登录执行 show status like ''wsrep_cluster%''; 查看状态
mysql> show status like ''wsrep_cluster%'';
+--------------------------+--------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------+
| wsrep_cluster_weight | 3 |
| wsrep_cluster_conf_id | 21 |
| wsrep_cluster_size | 3 |
| wsrep_cluster_state_uuid | a8abd132-f3cd-11e8-8bc3-e335b42a66e9 |
| wsrep_cluster_status | Primary |
+--------------------------+--------------------------------------+
5 rows in set (0.00 sec) |
维护
启动:
集群第一次启动:
第一个节点启动:
systemctl start mysql@bootstrap.service
其他节点启动:
systemctl start mysql
若有节点异常宕机,且集群依然有其他节点正常运行,则再次启动时,使用命令:
systemctl start mysql
关闭:
第一个节点关闭:
systemctl stop mysql@bootstrap.service
其他节点关闭:
systemctl stop mysql
Haproxy
安装
yum install haproxy -y
配置文件
cat <<EOF> /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2 info
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 10000
user root
group root
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
defaults
mode http
log global
option dontlognull
option redispatch
retries 3
timeout http-request 5m
timeout queue 5m
timeout connect 5m
timeout client 5m
timeout server 5m
timeout check 10s
maxconn 10000
listen pxc_cluster
bind 0.0.0.0:5500
mode tcp
balance roundrobin
server pxc_1 172.16.103.61:5001 weight 1 check port 5001 inter 1s rise 2 fall 2
server pxc_2 172.16.103.62:5001 weight 1 check port 5001 inter 1s rise 2 fall 2
server pxc_3 172.16.103.63:5001 weight 1 check port 5001 inter 1s rise 2 fall 2
listen stats
mode http
bind 0.0.0.0:8888
stats enable
stats uri /stats
stats auth admin:admin
EOF
启动、开机启动
systemctl start haproxy
systemctl enable haproxy
keepalived
安装
yum install keepalived -y
配置文件如下:
cat <<EOF> /etc/keepalived/keepalived.conf
global_defs {
router_id pxc_db1 #备份节点改为pxc_db2
}
#检测haproxy是否正常服务脚本,若haproxy挂机,则自动启动
vrrp_script chk_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 2
weight 20
}
# VIP1
vrrp_instance VI_1 {
state BACKUP
interface enp2s1 #配置当前为当前所使用的网卡
lvs_sync_daemon_inteface enp2s1 #配置当前为当前所使用的网卡
virtual_router_id 240 #配置id为1-255,在同一个局域网内不能重复,同一个集群使用同一个id
priority 100 #备份节点上将100改为90
nopreempt #当前节点启动不抢占已经工作的节点
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
#(配置虚拟IP,成为对外服务IP)
172.16.103.123 dev enp2s1 scope global #设置vip,该vip不被实际机器使用
#(如果有多个VIP,继续换行填写.)
}
track_script {
chk_haproxy
}
}
EOF
检测 Haproxy 进程脚本
cat <<EOF> /etc/keepalived/check_haproxy.sh
#!/bin/bash
systemctl status haproxy &> /dev/null || systemctl restart haproxy &> /dev/null
if [ $? -ne 0 ]; then
systemctl stop keepalived &> /dev/null
fi
EOF
添加执行权限
chmod + x /etc/keepalived/check_haproxy.sh
启动、开机启动
systemctl start keepalived
systemctl enable keepalived
实现高可用集群")
keepalived + Mysql(主主)实现高可用集群
Master1 192.168.20.145
Master2 192.168.20.146
安装mysql
mysql安装脚本:
#!/bin/bash
yum -y install cmake
tar zxvf mysql-5.5.34.tar.gz
cd mysql-5.5.34
cmake -DCMAKE_INSTALL_PREFIX=/work/mysql5.5 -DMYSQL_UNIX_ADDR=/usr/local/mysql/mysql.sock -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci -DWITH_MYISAM_STORAGE_ENGINE=1 -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_MEMORY_STORAGE_ENGINE=1 -DWITH_READLINE=1 -DENABLED_LOCAL_INFILE=1 -DMYSQL_DATADIR=/data/mysql/3306/data/ -DMYSQL_USER=mysql -DMYSQL_TCP_PORT=3306
make && make install && echo "install MYSQL ok"
chmod +w /work/mysql5.5/
chown -R mysql:mysql /work/mysql5.5/
mkdir -p /data/mysql/3306/data
chown -R mysql:mysql /data/mysql/
/work/mysql5.5/scripts/mysql_install_db --basedir=/work/mysql5.5/ --datadir=/data/mysql/3306/data/ --user=mysql
cp support-files/my-medium.cnf /etc/my.cnf
cp support-files/mysql.server /etc/init.d/mysql
chmod +x /etc/init.d/mysql
sed -i ''37a\basedir = /work/mysql5.5'' /etc/my.cnf
sed -i ''38a\datadir = /data/mysql/3306/data'' /etc/my.cnf
sed -i ''39a\log-error = /data/mysql/3306/mysql_error.log'' /etc/my.cnf
sed -i ''40a\pid-file = /data/mysql/3306/mysql.pid'' /etc/my.cnf
chkconfig --add mysql
chkconfig mysql on
service mysql start
锁库进行数据同步,配置主主复制
Master 2
server-id = 1
log-bin=mysql-bin
log-slave-updates
Master 2
log-bin=mysql-bin
binlog_format=mixed
server-id = 2
relay-log=relay-bin
relay-log-index=relay-bin.index
log-slave-updates
首先配置主从同步,
主:show master status\G;
从:change master to master_host=''192.168.20.146'',master_user=''slave001'',master_password=''tl@123 '',master_log_file=''mysql-bin.000002'',master_log_pos=107,MASTER_CONNECT_RETRY=10;
start slave
show slave status\G;
两台主机互相为主
wget http://www.keepalived.org/software/keepalived-1.2.7.tar.gz
tar zxvf keepalived-1.2.7.tar.gz
cd keepalived-1.2.7
./configure --prefix=/usr/local/keepalived --with-kernel-dir=/usr/src/kernels/2.6.32-279.el6.x86_64
make && make install
cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/rc.d/init.d/
cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
cp /usr/local/keepalived/sbin/keepalived /usr/sbin/
chkconfig keepalived on
mkdir /etc/keepalived
vim /etc/keepalived/keepalived.conf
global_defs {
notification_email {
mengtao10@163.com
}
#当主、备份设备发生改变时,通过邮件通知
notification_email_from lzyangel@126.com
smtp_server stmp.163.com
smtp_connect_timeout 30
router_id MySQL-ha
}
vrrp_instance VI_1{
# 在初始化状态下定义为主设备
state BACKUP
# 注意网卡接口
interface eth0
virtual_router_id 51
# 优先级,另一台改为90
priority 100
advert_int 1
# 不主动抢占资源
nopreempt
authentication {
# 认证方式,可以是PASS或AH两种认证方式
auth_type PASS
# 认证密码
auth_pass 1111
}
virtual_ipaddress {
# 虚拟IP地址,随着state的变化而增加删除
192.168.20.111
}
}
virtual_server 192.168.20.111 3306 {
# 每个2秒检查一次real_server状态
delay_loop 2
# LVS算法
lb_algo wrr
# LVS模式
lb_kind DR
# 会话保持时间
persistence_timeout 60
protocol TCP
real_server 192.168.20.146 3306 {
# 权重
weight 3
# 检测到服务down后执行的脚本
notify_down /etc/rc.d/keepalived.sh
TCP_CHECK {
# 连接超时时间
connect_timeout 10
# 重连次数
nb_get_retry 3
# 重连间隔时间
delay_before_retry 3
# 健康检查端口
connect_port 3306
}
}
}
另外一台主机参考此配置
在主的master1上编写检测服务down后所要执行的脚本
vim /etc/rc.d/keepalived.sh
#!/bin/bash
#环境变量
PATH=/bin:/usr/bin:/sbin:/usr/sbin:/work/mysql5.5/bin/; export PATH
sleep 5
#mysql_id(存活=1 死掉=0)
mysql_id=ps -C mysqld --noheader | wc -l
#判断mysql_id如果死掉,则重启mysql一次,若仍然无法启动mysql,则杀掉keepalived进程实现VIP切换
if [ $mysql_id -eq 0 ]
then
service mysql restart
sleep 5
if [ $mysql_id -eq 0 ]
then
/etc/init.d/keepalived stop
fi
fi
Master 2 上的脚本:
vim /etc/rc.d/keepalived.sh
#!/bin/bash
/etc/init.d/keepalived stop
分别在两台机器上启动keepalived 和 此脚本,那台mysql首先开启,那台就是当做master来使用
可以看到虚拟ip已经绑定到优先级高的主机上了
进行连接测试是没有问题,
尝试修改mysql的配置,然后观察结束掉mysql进程,虚拟ip会直通切换到另外一台主机去
关于linux MySQL 5.7+keepalived 主备服务器自主切换和linux主备机切换的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于61. 集群介绍 keepalived 介绍 keepalived 配置高可用、centos 7 Atlas keepalived 实现高可用 MySQL 5.7 MHA环境读写分离、centos7 Keepalived + Haproxy + MySQL pxc5.6、keepalived + Mysql(主主)实现高可用集群等相关知识的信息别忘了在本站进行查找喔。
本文标签:




