在本文中,我们将带你了解debezium、kafkaconnector解析mysqlbinlog到kafak在这篇文章中,我们将为您详细介绍debezium、kafkaconnector解析mysql
在本文中,我们将带你了解debezium、kafka connector 解析 mysql binlog 到 kafak在这篇文章中,我们将为您详细介绍debezium、kafka connector 解析 mysql binlog 到 kafak的方方面面,并解答kafka数据到mysql常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的Apache Kafak 概念、ARTS打卡计划第二周-Tips-mysql-binlog-connector-java的使用、canal+kafka 订阅 Mysql binlog 将数据异构到 elasticsearch (或其他存储方式)、Debezium MySQL Source Connector 是否支持 mysql ldap 可插拔认证。
本文目录一览:- debezium、kafka connector 解析 mysql binlog 到 kafak(kafka数据到mysql)
- Apache Kafak 概念
- ARTS打卡计划第二周-Tips-mysql-binlog-connector-java的使用
- canal+kafka 订阅 Mysql binlog 将数据异构到 elasticsearch (或其他存储方式)
- Debezium MySQL Source Connector 是否支持 mysql ldap 可插拔认证
")
debezium、kafka connector 解析 mysql binlog 到 kafak(kafka数据到mysql)
目的: 需要搭建一个可以自动监听MySQL数据库的变化,将变化的数据捕获处理,此处只讲解如何自动捕获mysql 中数据的变化
使用的技术
debezium :https://debezium.io/documentation/reference/1.0/connectors/mysql.html
kafka: http://kafka.apache.org/
zookeeper : http://zookeeper.apache.org/
mysql 5.7 https://www.mysql.com/
一、思路
需要一台 Centos 7.x 的虚拟机 ,zk、debezium、kafka、confluent 运行在 虚拟机上 ,mysql 运行在 windows 系统上,虚拟机监听 window 环境下的 mysql 数据变化
二、MySQL 环境准备
首先需要找到 mysql 的配置文件:my.ini ,我的路径是:C:\ProgramData\MySQL\MySQL Server 5.7 ,因为监听基础是基于 mysql binlog ,需要开启binlog ,添加如下配置
log_bin =D:\mysql-binlog\mysql-bin
binlog_format=Row
server-id=223344
binlog_row_image = full
expire_logs_days = 10
binlog_rows_query_log_events = on重启 mysql 服务
net stop mysql57
net start mysql57此处,MySQL binlog 即开启,可以简单的验证,cmd 窗口 mysql -u root -p 登录 mysql
show binary logs;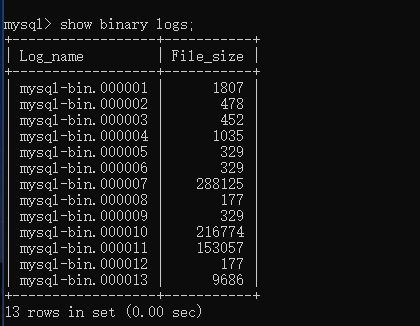
可以看到文件内容,即mysql 变化的二进制文件。到此处,MySQL准备就绪。
二、zookeeper 、 kafka 准备
下载 zookeeper-3.4.14.tar.gz 、kafka_2.12-2.2.0.tar
mkdir -p /usr/local/software/zookeeper
mkdir -p /usr/local/software/kafka
mkdir -p /usr/local/software/confluent准备好路径,并将安装包移入该目录,并解压
mv zookeeper-3.4.14.tar.gz /usr/local/software/zookeeper
mv kafka_2.12-2.2.0.tar
进入 zookeeper /usr/local/software/zookeeper/zookeeper-3.4.14/conf目录,修改 zoo.cfg (原名 zoo_sample.cfg)内容
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs进入 dataDir 目录,创建文件 myid ,并添加内容: 1
此处,zk 的配置修改结束。开启配置 kafka 路径是:/usr/local/software/kafka/kafka_2.12-2.2.0/config, 修改 server.properties
broker.id=1
listeners=PLAINTEXT://192.168.91.25:9092
advertised.listeners=PLAINTEXT://192.168.91.25:9092
log.dirs=/opt/data/kafka-logs
host.name=192.168.91.25
zookeeper.connect=localhost:2181三、debezium配置
此处需要 debezium connector 对 mysql 的 jar 包,下载地址:https://debezium.io/releases/1.0/
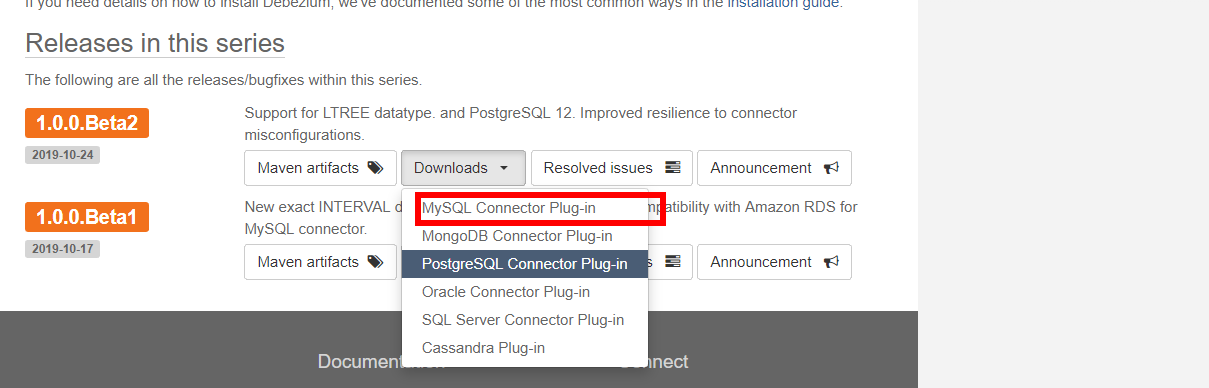
将下载好的 plugs 上传到虚拟机,解压后名称是: debezium-connector-mysql
移动到: /usr/local/share/kafka/plugins 目录下,如果没有该目录则手动创建

依赖的 jar 包下载好后,配置 kafka 目录中conf connector
目录: /usr/local/software/kafka/kafka_2.12-2.2.0/conf/connect-standalone.properties
bootstrap.servers=本机IP:9092
plugin.path=/usr/local/share/kafka/plugins此外,在kafka 根目录下 创建文件: msyql.properties ,内容
name=mysql
connector.class=io.debezium.connector.mysql.MySqlConnector
database.hostname=192.168.3.125
database.port=3306
database.user=root
database.password=123456
database.server.id=112233
database.server.name=test
database.whitelist=orders,users
database.history.kafka.bootstrap.servers=192.168.91.25:9092
database.history.kafka.topic=history.test
include.schema.changes=true
include.query=true
# options: adaptive_time_microseconds(default)adaptive(deprecated) connect()
time.precision.mode=connect
# options: precise(default) double string
decimal.handling.mode=string
# options: long(default) precise
bigint.unsigned.handling.mode=long四、启动服务
01.启动zk
cd /usr/local/software/zookeeper/zookeeper-3.4.14zkServer.sh start
02.启动kafka
cd /usr/local/software/kafka/kafka_2.12-2.2.0./bin/kafka-server-start.sh -daemon config/server.properties03.启动kafka connector
cd /usr/local/software/kafka/kafka_2.12-2.2.0./bin/connect-standalone.sh config/connect-standalone.properties mysql.properties04.查看 topic ,在新的端口查看
./bin/kafka-topics.sh --list --zookeeper localhost:2181五、指定监听的数据库/表
在 postman 中模拟 post 请求,以 json 格式传递参数:表示 监听 shiro数据库
{
"name": "shiro",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "192.168.3.125",
"database.port": "3306",
"database.user": "root",
"database.password": "123456",
"database.server.id": "184054",
"database.server.name": "my",
"database.whitelist": "shiro",
"database.history.kafka.bootstrap.servers": "192.168.91.25:9092",
"database.history.kafka.topic": "history.shiro",
"include.schema.changes": "true"
}}重新查看topic
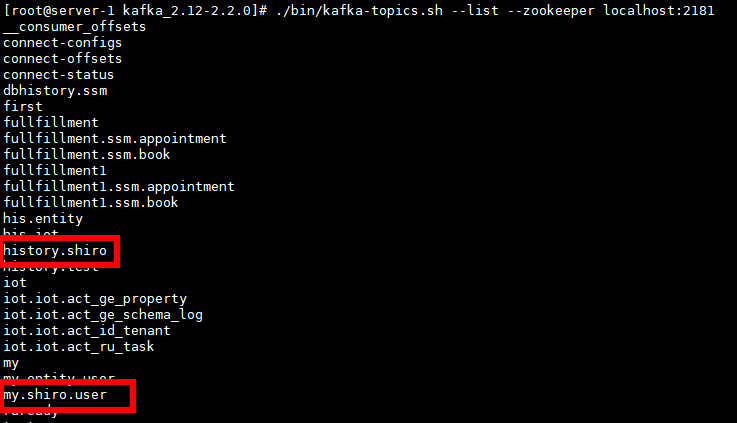
在新端口启动 kafka 消费者,消费my.shiro.user
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my.shiro.user --from-beginningJava客户端消费者代码


package kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
/**
* Created by baizhuang on 2019/10/25 10:39.
*/
public class MyConsumer {
public static void main(String []args){
//1.创建 kafka 生产者配置信息。
Properties properties = new Properties();
//2.指定 kafka 集群
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.91.25:9092");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000");
//key,value 反序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
properties.put("group.id","test");
KafkaConsumer<String,String> consumer = new KafkaConsumer<String,String>(properties);
consumer.subscribe(Arrays.asList("my.shiro.user"));
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(100);
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.key() + "-----" + consumerRecord.value());
}
}
}
}Java 客户端生产者代码


package kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* Created by baizhuang on 2019/10/24 16:58.
*/
public class MyProducer {
public static void main(String []args){
//1.创建 kafka 生产者配置信息。
Properties properties = new Properties();
//2.指定 kafka 集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.91.25:9092");
//3.
properties.put("acks","all");
//4.重试次数
properties.put("retries",0);
//5.批次大小
properties.put("batch.size",16384);
//6.等待时间
properties.put("linger.ms",1);
//7.RecordAccumlate 缓冲区大小
properties.put("buffer.memory",33554432);
//key ,value 序列化
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//9.创建生产者
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
for(int i=0;i<10;i++){
//10.发送
String key = String.valueOf(i);
String value = "第"+key+"条消息";
producer.send(new ProducerRecord<String, String>("mytopic",key,value));
System.out.println("msg:"+i);
}
producer.close();
}
}启动消费者,修改 shiro 数据库的user 表,Java客户端消费者与 linux 消费者均可动态的显示变化的数据


Apache Kafak 概念
Kafak 是基于发布订阅的消息系统。是一个分布式,可分区,冗余备份的持久化的消息系统。主要用户处理活跃的流式数据。
几个重要基本的概念:
1.Topic :主题,特指 Kafak 处理的消息源的不同分类。
2.Partition: Topic 物理上的分区,一个 Topic 可以分为多个 partition. 每个 Partition 都有一个有序的队列。Partition 中的每个消息都会分配一个有序的 id (offset).
replicas:Partition 的副本集,保证 partition 的高可用。
leader:repliocas 中的一个角色,producer 和 consumer 只和 Leader 交互。
followers:replicas 中的一个角色,从 leader 中的复制数据,作为副本,一旦 leader 挂掉,从他的 followers 中选出一个新的 leader 继续提供服务。
3.Message: 消息,通信的基本单位,每个 Producer 可以向一个 Topic 发送消息
4.Producer: 消息和数据的生产者
5.Consumer:消息和数据的消费者
6.Broker :缓存代理,kafak 集群中一台或者多台机器统称 broker。
7.Zookeeper: 通过 Zookeeper 来存储进群的 topic,partition 等信息。
Kafak 为什么要将 topic 进行分区:
1.Topic 是逻辑概念,面向的是 producer 和 consumer, 而 partition 是物理概念。
如果 Topic 不进行分区,而将 Topic 内所有的消息都存储在一个 broker, 那么关于该 Topic 的所有读写都将由一个 borker 处理,吞吐量很容易有瓶颈。
2. 有了 Partition 概念以后,假设一个 topic 被分为 10 个 partition,kafak 会根据一定算法将 10 个 Partition 尽可能分配到不同的 broker.
3. 当 partition 发布消息时,producer 客户端可以采用 random,key-hash 轮询等算法选定 partition
4. 当 consumer 消费消息时候,Consumer 客户端可以采用 range,轮询等算法分配 partition, 从而在不同的 broker 拉取对应的 Partition 的 leader 分区。
所以,在 partition 机制可以极大的提高系统的吞吐量,并且使得系统具有良好的水平扩展能力。
Kafak 的消息发送和消费的基本流程:
1.Producer:根据指定的 partition 方法 (random,hash 等),将消息发送给指定 topic 的 partition.
producer 采用 push 进行模式将消息发布到 Broker,每条消息将 append 到 partition 中,属于顺序写磁盘。Producer 会将消息发送到到 broker 时候,会根据分区算法将其存储到哪一个 partition。
写入流程:
1.Producer 先从 zk 中找到 partition 的 leader。
2.producer 将数据发送给 leader。
3.leader 将消息写入本地 log。
4.followers 从 leader 中 pull 消息,写入本地 log 向 leader 发送 ack。
5.leader 收到所有的 ISR 中的 replicas 的 cas 后,增加 HW,并像 producer 发送 ack。
Producer 的消费发送模式:通过 producer.type 进行配置
1. 默认同步 sync。 可以保证消息的可靠性
2. 可以设置成为异步 async。可以是 producer 以 batch 的形似 push 数据。这样极大提高了 Brokder 性能。
2.Kafak 集群:接收到 producer 发送过来的消息,将其持久化到硬盘,并保留消息指定时长。
物理上将 Topic 分为多个 partition, 每个 partition 物理上对应一个文件夹(文件夹存储改 partition 的所有消息和索引文件)
3.Consumer:从 kafak 集群 pull 数据,并控制获取消息的 offset. 至于消费的进度,可手动或者自动提交给 kafak 集群。pull 模式可以自主控制消费的速率,同时 Consumer 可以控制消费方式,可批量消费也可以逐条消费。同时还能选择不同的提交方式。
一个消息只能被 group 内的一个 comsumer 所消费,且 consumer 消费消息时不关注 offset, 最后一个 offset 有 zk 保存。下次消费时,该 group 中的 Consumer 将从 offset 记录的位置开始消费。
注意:1. 如果消费线程大于 Partition 数量,有些线程将收不到消息。
2. 如果 partition 数量大于消费线程数,那么一个线程将会接收多个 partition 的消息。
3. 如果一个消费线程消费多个 partition,则无法保证你接受到消息的顺序,而一个 partition 内的消息是有序的。
Kafak 提交便宜了
1. 消费者为什么需要提交偏移量?
消费者崩溃或者新增消费者,出发 rebance, 完成再均衡之后,消费者会分配到新的分区 partition。
2. 偏移量可能带来的问题?
如果提交的偏移量小于客户端实际消费的最后一个消息的偏移量,会导致消息被重复消费
如果提交的偏移量大于客户端消费的最后一个消息的偏移量,会导致消息丢失。
3. 提交偏移量的方式
自动或者手动 offset 两种策略。
enable.auto.commit 设置成 true(默认为 true),那么每过 5s,消费者自动把从 poll () 方法接收到的最大的偏移量提交
提交的时间间隔由 auto.commit.interval.ms 控制,默认是 5s
Kafka 提供了异步提交(commitAsync)及同步提交(commitSync)两种手动提交的方式。
同步: consumer.commitSync ();
异步: consumer.commitAsync (new OffsetCommitCallback () {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (null == exception) {
// TODO 表示偏移量成功提交
System.out.println ("提交成功");
} else {
// TODO 表示提交偏移量发生了异常,根据业务进行相关处理
System.out.println ("发生了异常");
}
}
});
Kafak 的数据存储模型:
Kafak 的每个 topic 下面的所有消息都是以 Partition 的方式存储在多个节点上。同时在 kafak 的机器上,每个 partition 其实会对应一个日志目录,在目录下面上会对应多个日志分段 (LogSegment)。
LogSegment 文件由两部分组成,分别为.index 文件和.log 文件,分别用来存储索引和数据。这两个文件的命名规则为:Partition 全局的第一个 segment 从 0 开始,后续每个 segment 文件为上一个 segment 文件最后最后一条消息的 offset 值。
Kafak 如何读取 offset 数据:
如果我们要读取 911 条数据
首先:第一步,找到他属于哪一段,根据二分查找找到属于他的文件,找到 0000900.index 和 0000900.log 之后。
然后,去.index 中查找(911-900)=11 这个索引或者小于 11 最近的索引,在这里 通过二分查找我们找到的索引是 [10,1367]
10 表示,第 10 条消息开始。1367 表示,在.log 的第 1367 字节开始。
然后,我们通过这条索引的物理位置 1367,开始往后查找,直到找到 911 条数据。
大多数情况下,只需按照顺序读即可。而在顺序读中,操作系统会对内存和磁盘之间添加 page cahe,也就是我们平常见的预读操作,所以我们顺序读时候速度很快。但是 Kafak 有个问题,就是分区过多,那么日志分段也会很多,写的时候由于是批量写,其实就是会变成随机写了。
为何不以 partition 为最小存储单位,可以想象当 producer 不停的发送消息,必然会引起 partition 文件的不同扩张,将对消息文件的维护以及已经消费的消息的清理带来严重的影响。

ARTS打卡计划第二周-Tips-mysql-binlog-connector-java的使用
最近发现一个挺不错的框架mysql-binlog-connector-java,可以实时监控binlog的变化。
首先检查mysql的binlog是否开启,在开启的情况下:
引入依赖
<dependency>
<groupId>com.github.shyiko</groupId>
<artifactId>mysql-binlog-connector-java</artifactId>
<version>0.18.1</version>
</dependency>然后使用如下代码可以测试:
public class App
{
public static void main( String[] args ) throws IOException
{
BinaryLogClient client = new BinaryLogClient("xxx", 3306, "xxx", "xxx");
EventDeserializer eventDeserializer = new EventDeserializer();
eventDeserializer.setCompatibilityMode(
EventDeserializer.CompatibilityMode.DATE_AND_TIME_AS_LONG,
EventDeserializer.CompatibilityMode.CHAR_AND_BINARY_AS_BYTE_ARRAY
);
client.setEventDeserializer(eventDeserializer);
client.registerEventListener(new EventListener() {
@Override
public void onEvent(Event event) {
System.out.println(event);
EventData data = event.getData();
if (data instanceof UpdateRowsEventData) {
System.out.println("Update--------------");
System.out.println(data.toString());
} else if (data instanceof WriteRowsEventData) {
System.out.println("Write---------------");
System.out.println(data.toString());
} else if (data instanceof DeleteRowsEventData) {
System.out.println("Delete--------------");
System.out.println(data.toString());
}
}
});
client.connect();
}
}
实际在使用的时候,这个框架提供列名称表名称不太好用,这个时候需要https://github.com/ngocdaothanh/mydit ,这个是一个将mysql同步到mongdb的,其中一些样例代码可以很方便的获取mysql的元数据。")
canal+kafka 订阅 Mysql binlog 将数据异构到 elasticsearch (或其他存储方式)
canal 本质就是 "冒充" 从库,通过订阅 mysql bin-log 来获取数据库的更改信息。
mysql 配置 (my.cnf)
mysql 需要配置 my.cnf 开启 bin-log 日志并且将 bin-log 日志格式设置为 row, 同时为了防止 bin-log 日志占用过多磁盘,可以设置一下过期时间,
[mysqld]
log-bin=mysql-bin # 打开binlog
binlog-format=ROW # ROW格式
server_id=1 # mysql Replication 需要设置 在mysql集群里唯一
expire_logs_days=7 # binlog文件保存7天
max_binlog_size = 500m # 每个binlog日志文件大小
canal 配置
除了 kafka 之外,canal 还支持将数据库修改的消息投递到 rocketMQ, 或者不经过消息队列直接投递到 canal 的客户端,然后再在客户端实现自己的代码 (如写入其他存储 / 其他消息队列) , 但是只能选其一。而如果选择 canal 客户端的方式,一个 canal server 也只能将消息投递到一个 canal client。
但是可以开启多个 canal 服务端和客户端 (同一个实例,即对 mysql 来说只算是一个从库), 他们通过 zookeeper 保证只有一个服务端和客户端是有效的,其他只是作为 HA 的冗余。
然后需要修改 canal 目录下 (以下为近最小配置)
conf/example/instance.properties
## mysql serverId
canal.instance.mysql.slaveId = 1234
# 数据库address
canal.instance.master.address = 127.0.0.1:3306
# 数据库账号密码
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
# 需要订阅的数据库.表名 默认全部
canal.instance.filter.regex = .\*\\\\..\* # 去掉转义符其实就是 .*\..*
# topic名 固定
canal.mq.topic=canal
# 动态topic
# canal.mq.dynamicTopic=mytest,.*,mytest.user,mytest\\..*,.*\\..*
# 库名.表名: 唯一主键,多个表之间用逗号分隔
# canal.mq.partitionHash=mytest.person:id,mytest.role:id
其中动态 topic 和 主键 hash 看上去有点难理解,去看其他人的博客找到的解释和例子如下
动态 topic
canal 1.1.3 版本之后,支持配置格式:schema 或 schema.table,多个配置之间使用逗号分隔
例子 1:test.test 指定匹配的单表,发送到以 test_test 为名字的 topic 上 例子 2:.\…* 匹配所有表,每个表都会发送到各自表名的 topic 上 例子 3:test 指定匹配对应的库,一个库的所有表都会发送到库名的 topic 上 例子 4:test.* 指定匹配的表达式,针对匹配的表会发送到各自表名的 topic 上 例子 5:test,test1.test1,指定多个表达式,会将 test 库的表都发送到 test 的 topic 上,test1.test1 的表发送到对应的 test1_test1 topic 上,其余的表发送到默认的 canal.mq.topic 值 支持指定 topic 名称匹配,配置格式:topicName:schema 或 schema.table,多个配置之间使用逗号分隔,多组之间使用;分隔
例子:test:test,test1.test1;test2:test2,test3.test1 针对匹配的表会发送到指定的 topic 上 ———————————————— 版权声明:本文为 CSDN 博主「BillowX_」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/weixin_35852328/article/details/87600871
主键
canal 1.1.3 版本之后,支持配置格式:schema.table:pk1^pk2,多个配置之间使用逗号分隔
例子 1:test.test:pk1^pk2 指定匹配的单表,对应的 hash 字段为 pk1 + pk2 例子 2:.\…:id 正则匹配,指定所有正则匹配的表对应的 hash 字段为 id 例子 3:.\…:pkpkpk 正则匹配,指定所有正则匹配的表对应的 hash 字段为表主键 (自动查找) 例子 4: 匹配规则啥都不写,则默认发到 0 这个 partition 上 例子 5:.\…* ,不指定 pk 信息的正则匹配,将所有正则匹配的表,对应的 hash 字段为表名 按表 hash: 一张表的所有数据可以发到同一个分区,不同表之间会做散列 (会有热点表分区过大问题) 例子 6: test.test:id,.\…* , 针对 test 的表按照 id 散列,其余的表按照 table 散列 注意:大家可以结合自己的业务需求,设置匹配规则,多条匹配规则之间是按照顺序进行匹配 (命中一条规则就返回) ———————————————— 版权声明:本文为 CSDN 博主「BillowX_」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/weixin_35852328/article/details/87600871
最后实现消费 kafka 上 canal topic 上消息的代码
这里以 go 为例,可以写入到 elasticsearch/redis/ 其他
package main
import (
"bytes"
"context"
"encoding/json"
"fmt"
"github.com/Shopify/sarama"
"github.com/elastic/go-elasticsearch/esapi"
"github.com/elastic/go-elasticsearch/v6"
"os"
)
var esClient *elasticsearch.Client
func init() {
var err error
config := elasticsearch.Config{}
config.Addresses = []string{"http://127.0.0.1:9200"}
esClient, err = elasticsearch.NewClient(config)
checkErr(err)
}
type Msg struct {
Data []struct {
Id string `json:"id"`
A string `json:"a"`
} `json:"data"`
Type string `json:"type"`
DataBase string `json:"database"`
Table string `json:"table"`
}
func checkErr(err error) {
if err != nil {
fmt.Println(err)
os.Exit(-1)
}
}
type Consumer struct{}
func (c *Consumer) Setup(sarama.ConsumerGroupSession) error {
return nil
}
func (c *Consumer) Cleanup(sarama.ConsumerGroupSession) error {
return nil
}
func (consumer *Consumer) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for message := range claim.Messages() {
// fmt.Printf("Message claimed: value = %s, timestamp = %v, topic = %s", string(message.Value), message.Timestamp, message.Topic)
msg := &Msg{}
err := json.Unmarshal(message.Value, msg)
checkErr(err)
if msg.DataBase == "test" && msg.Table == "tbltest" {
if msg.Type == "INSERT" {
for k, _ := range msg.Data {
// 写elasticsearch 逻辑
body := map[string]interface{}{
"id": msg.Data[k].Id,
"a": msg.Data[k].A,
}
jsonBody, _ := json.Marshal(body)
req := esapi.IndexRequest{
Index: msg.DataBase,
DocumentID: msg.Table + "_" + msg.Data[k].Id,
Body: bytes.NewReader(jsonBody),
}
res, err := req.Do(context.Background(), esClient)
checkErr(err)
fmt.Println(res.String())
res.Body.Close()
session.MarkMessage(message, "")
}
}
}
}
return nil
}
func main() {
consumer := &Consumer{}
config := sarama.NewConfig()
config.Version = sarama.MaxVersion
client, err := sarama.NewConsumerGroup([]string{"127.0.0.1:9092"}, "tg", config)
checkErr(err)
ctx := context.Background()
client.Consume(ctx, []string{"canal"}, consumer)
}

Debezium MySQL Source Connector 是否支持 mysql ldap 可插拔认证
如何解决Debezium MySQL Source Connector 是否支持 mysql ldap 可插拔认证?
Debezium MysqL Source Connector 是否支持 MysqL ldap 可插拔认证?
https://dev.mysql.com/doc/refman/8.0/en/ldap-pluggable-authentication.html
解决方法
在 gitter 上从 Debezium 用户组得到答案
Jiri Pechanec 07:14 @ranlupovich 嗨,不,它不受支持,因为用于处理 binlog 的库不支持它
关于debezium、kafka connector 解析 mysql binlog 到 kafak和kafka数据到mysql的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于Apache Kafak 概念、ARTS打卡计划第二周-Tips-mysql-binlog-connector-java的使用、canal+kafka 订阅 Mysql binlog 将数据异构到 elasticsearch (或其他存储方式)、Debezium MySQL Source Connector 是否支持 mysql ldap 可插拔认证的相关信息,请在本站寻找。
本文标签:




