最近很多小伙伴都在问php-每个帐户或几个大表动态创建mysql表和php创建一个用户数据表这两个问题,那么本篇文章就来给大家详细解答一下,同时本文还将给你拓展C#动态创建数据库三(MySQL)、My
最近很多小伙伴都在问php-每个帐户或几个大表动态创建mysql表和php创建一个用户数据表这两个问题,那么本篇文章就来给大家详细解答一下,同时本文还将给你拓展C# 动态创建数据库三(MySQL)、MySQL中的数据动态创建方法、Mysql入门创建mysql表分区的方法、mysql动态创建表等相关知识,下面开始了哦!
本文目录一览:- php-每个帐户或几个大表动态创建mysql表(php创建一个用户数据表)
- C# 动态创建数据库三(MySQL)
- MySQL中的数据动态创建方法
- Mysql入门创建mysql表分区的方法
- mysql动态创建表
")
php-每个帐户或几个大表动态创建mysql表(php创建一个用户数据表)
什么是更优化的数据库设计方式?
我正在构建一个应用程序,不同的公司在这里注册并添加他们的用户并使用该应用程序.每个帐户最多需要10张桌子.例如
table1,table2,table3..table10
这是我当前正在做的事情,有10个表并将所有帐户中的所有信息存储到这些表中.但是我只有一个主意,那就是横向扩展我的数据库设计.所以这个想法是,只要有人创建公司帐户,我的应用程序就会动态创建这些表,如下所示:
c_31_table1,c_31_table2,c_31_table3 … c_31_table10
加入公司的示例帐户ID在哪里31?我的假设是因为sql仅在垂直方向上增加,否则它将随着时间的流逝而变慢,将来每个表大约有4万条记录或更多.因此,这种方法将使数据库的垂直长度减小,而水平扩展.
此技术是一种好的优化技术吗?
解决方法:
通常不是一个好主意.每种情况都不同.有了这个,您将不会从查询缓存中受益(太多).您的查询将需要更多的工作(不是很多).存储的proc,func和event需要CONCAT,PREPARE,EXECUTE和DEALLOCATE PREPARE.
在出现问题之前,适当的索引编制和多租户应成为您的工作重点,这可能要花费很长时间.在开发过程中,我将重点介绍EXPLAIN输出.分析您的代码.始终进行概要分析.找出例程运行缓慢的地方并进行修复.
您所提议的解决方案将使您大吃一惊.他们不容易清理自己.而且,即使偶尔,DDL调用也不便宜.
如果我在一个突然想要命名表格的地方工作
c_31_table1, c_31_table2, c_31_table3...c_31_table10
我会退出.
")
C# 动态创建数据库三(MySQL)
前面有说明使用EF动态新建数据库与表,数据库使用的是SQL SERVER2008的,在使用MYSQL的时候还是有所不同
一、添加 EntityFramework.dll ,System.Data.Entity.dll ,MySql.Data, MySql.Data.Entity.EF6
注意:Entity Framework5.0.0(好像最新的6.X是不支持mysql的)
二、添加dll文件,可以使用“管理NuGet程序包”或者“Nuget程序包管理控制台”添加
与 控制台平台添加
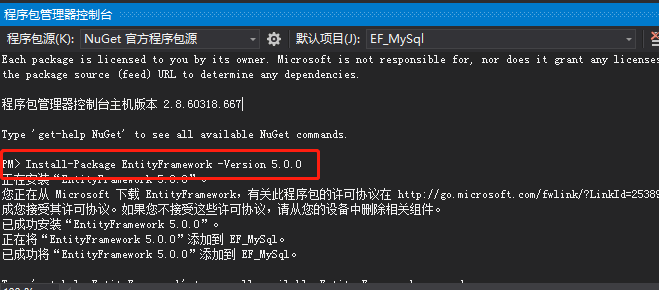
以下为控制台平台安装dll语句
EntityFramework.dll : Install-Package EntityFramework -Version 5.0.0
MySql.Data : Install-Package MySql.Data -Version 6.9.12
MySql.Data.Entity:Install-Package MySql.Data.Entity -Version 6.9.12
三、在app.config文件中添加connectionStrings
源文件
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
<section name="entityFramework" type="System.Data.Entity.Internal.ConfigFile.EntityFrameworkSection, EntityFramework, Version=6.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" requirePermission="false" />
<!-- For more information on Entity Framework configuration, visit http://go.microsoft.com/fwlink/?LinkID=237468 -->
</configSections>
<entityFramework>
<defaultConnectionFactory type="System.Data.Entity.Infrastructure.SqlConnectionFactory, EntityFramework" />
<providers>
<provider invariantName="System.Data.SqlClient" type="System.Data.Entity.SqlServer.SqlProviderServices, EntityFramework.SqlServer" />
<provider invariantName="MySql.Data.MySqlClient" type="MySql.Data.MySqlClient.MySqlProviderServices, MySql.Data.Entity.EF6, Version=6.9.12.0, Culture=neutral, PublicKeyToken=c5687fc88969c44d"></provider>
</providers>
</entityFramework>
<system.data>
<DbProviderFactories>
<remove invariant="MySql.Data.MySqlClient" />
<add name="MySQL Data Provider" invariant="MySql.Data.MySqlClient" description=".Net Framework Data Provider for MySQL" type="MySql.Data.MySqlClient.MySqlClientFactory, MySql.Data, Version=6.9.12.0, Culture=neutral, PublicKeyToken=c5687fc88969c44d" />
</DbProviderFactories>
</system.data>
<connectionStrings>
<!--<add name="conncodefirst" connectionString="server=127.0.0.1;port=3306;uid=root;pwd=repower;database=code" providerName="MySql.Data.MySqlClient"/>-->
<add name="conncodefirst" connectionString="server=127.0.0.1;user id=root;password=repower;database=code" providerName="MySql.Data.MySqlClient" />
</connectionStrings>
</configuration>四、添加类
[Table("Student")]
public class Student
{
public Student()
{
}
[Key]
public int StudentID { get; set; }
public string StudentName { get; set; }
public DateTime AddTime { get; set; }
}
[Table("Standard")]
public class Standard
{
public Standard()
{
}
public int StandardId { get; set; }
public string StandardName { get; set; }
public DateTime AddTime { get; set; }
}
添加SchoolContext 继承DbContext
[DbConfigurationType(typeof(MySql.Data.Entity.MySqlEFConfiguration))]
public class SchoolContext : DbContext
{
public SchoolContext()
: base("name=conncodefirst")
{
}
static SchoolContext()
{
DbConfiguration.SetConfiguration(new MySql.Data.Entity.MySqlEFConfiguration());
}
public DbSet<Student> Students { get; set; }
public DbSet<Standard> Standards { get; set; }
//protected override void OnModelCreating(DbModelBuilder modelBuilder)
//{
// base.OnModelCreating(modelBuilder);
//}
}
最后调用
SchoolContext dbCOntext = new SchoolContext();
//dbCOntext.Database.
bool flag = dbCOntext.Database.CreateIfNotExists();
Student stud = new Student() { StudentName = "New Student", AddTime = DateTime.Now };
dbCOntext.Students.Add(stud);
dbCOntext.SaveChanges();结果


MySQL中的数据动态创建方法
随着现代web应用的发展,大量的数据需要被处理和存储。
1.使用INSERT语句
INSERT语句是MySQL中最基本的创建数据的方法。它可以在一个表中插入一行或多行数据。在这个例子中,我们将插入一行数据到名为mytable的表中。
INSERT INTO mytable (column1, column2, column3) VALUES (value1, value2, value3);
其中mytable是表的名称,column1, column2, 和column3是表的列名,而value1、value2、和value3则是要插入的值。如果想插入多行数据,只需在VALUES关键字后面加上更多的值即可。
2.使用LOAD DATA INFILE语句
如果我们有一个文件,其中包含了要插入到数据库中的各种数据,那么可以使用LOAD DATA INFILE语句来动态创建数据。该语句将文件的内容读入MySQL中,并将其插入到指定的表中。
LOAD DATA INFILE ''data.txt'' INTO TABLE mytable FIELDS TERMINATED BY '','' LINES TERMINATED BY '' '';
在以上示例中,data.txt是我们要导入的文件名,mytable是要插入的表的名称。关键字FIELDS TERMINATED BY和LINES TERMINATED BY分别指定了文件字段的分隔符和每行数据的分隔符。
3.使用INSERT INTO SELECT语句
INSERT INTO SELECT语句允许在同一或不同的表之间动态地复制数据。通过该语句,我们可以从一个表中选择特定的数据,并将其插入到同一或另一个表中。
INSERT INTO mytable (column1, column2, column3) SELECT column1, column2, column3 FROM myothertable WHERE condition;
在以上示例中,我们将从名为myothertable的表中选择指定的列和特定的行,并将它们插入到mytable中。
4.使用INSERT INTO SELECT UNION语句
如果我们需要连接两个表,可以使用INSERT INTO SELECT UNION语句。这将允许我们选择两个表中的特定数据,并将它们一起插入到一个表中。
INSERT INTO mytable (column1, column2, column3) SELECT column1, column2, column3 FROM myfirsttable WHERE condition UNION SELECT column1, column2, column3 FROM mysecondtable WHERE condition;
在以上示例中,我们将从两个表中选择指定的列和特定的行,并将它们连接起来插入到mytable中。
5.使用INSERT INTO VALUES语句
最后,我们可以使用INSERT INTO VALUES语句来创建动态数据。与INSERT INTO语句类似,我们可以在表中插入一行或多行数据。
INSERT INTO mytable (column1, column2, column3) VALUES (value1, value2, value3), (value4, value5, value6), (value7, value8, value9);
在以上示例中,我们向mytable表中插入了三行数据,每行具有三个值。
总结
在MySQL中,我们可以使用多种方法来动态地创建数据。INSERT语句是最基本的方法,而LOAD DATA INFILE语句和INSERT INTO SELECT语句可以在导入和迁移数据时提供帮助。INSERT INTO SELECT UNION语句可以在将两个表中的数据连接一起时使用。最后,INSERT INTO VALUES语句也是一个创建数据的好方法。将以上方法结合使用可以实现更复杂的数据创建和导入。
以上就是MySQL中的数据动态创建方法的详细内容,更多请关注php中文网其它相关文章!

Mysql入门创建mysql表分区的方法
《MysqL入门创建MysqL表分区的方法》要点:
本文介绍了MysqL入门创建MysqL表分区的方法,希望对您有用。如果有疑问,可以联系我们。
表分区的测试使用,主要内容来自于其他博客文章以及MysqL5.1的参考手册
MysqL测试版本:MysqL5.5.28
MysqL物理存储文件(有MysqL配置的datadir决定存储路径)格式简介
数据库engine为MYISAM
frm表结构文件,myd表数据文件,myi表索引文件.
INNODB engine对应的表物理存储文件
innodb的数据库的物理文件结构为:
.frm文件
.ibd文件和.ibdata文件:
这两种文件都是存放innodb数据的文件,之所以用两种文件来存放innodb的数据,是因为innodb的数据存储方式能够通过配置来决定是使用共享表空间存放存储数据,还是用独享表空间存放存储数据.
独享表空间存储方式使用.ibd文件,并且每个表一个ibd文件
共享表空间存储方式使用.ibdata文件,所有表共同使用一个ibdata文件
创建分区
分区的一些优点包括:
・ 与单个磁盘或文件系统分区相比,可以存储更多的数据.
・ 对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据.相反地,在某些情况下,添加新数据的过程又可以通过为那些新数据专门增加一个新的分区,来很方便地实现.
通常和分区有关的其他优点包括下面列出的这些.MysqL 分区中的这些功能目前还没有实现,但是在我们的优先级列表中,具有高的优先级;我们希望在5.1的生产版本中,能包括这些功能.
・ 一些查询可以得到极大的优化,这主要是借助于满足一个给定WHERE 语句的数据可以只保存在一个或多个分区内,这样在查找时就不用查找其他剩余的分区.因为分区可以在创建了分区表后进行修改,所以在第一次配置分区方案时还不曾这么做时,可以重新组织数据,来提高那些常用查询的效率.
・ 涉及到例如SUM() 和 COUNT()这样聚合函数的查询,可以很容易地进行并行处理.这种查询的一个简单例子如 “SELECT salesperson_id,COUNT(orders) as order_total FROM sales GROUP BY salesperson_id;”.通过“并行”,这意味着该查询可以在每个分区上同时进行,最终结果只需通过总计所有分区得到的结果.
・ 通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量.
简而言之就是 数据管理优化,查询更快,数据查询并行
检测MysqL是否支持分区
MysqL> show variables like
"%partition%";
+-------------------+-------+
| Variable_name   | Value |
+-------------------+-------+
| have_partitioning | YES  |
+-------------------+-------+
1 row in set
RANGE 分区:基于属于一个给定连续区间的列值,把多行分配给分区.
DROP TABLE IF EXISTS `p_range`;
CREATE TABLE `p_range` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` char(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=9 DEFAULT CHARSET=utf8
/*!50100 PARTITION BY RANGE (id)
(PARTITION p0 VALUES LESS THAN (8) ENGINE = MyISAM) */;





