在本文中,我们将带你了解SQL:GROUPBY之后的SUM在这篇文章中,我们将为您详细介绍SQL:GROUPBY之后的SUM的方方面面,并解答sqlgroupbysum常见的疑惑,同时我们还将给您一些
在本文中,我们将带你了解SQL:GROUP BY之后的SUM在这篇文章中,我们将为您详细介绍SQL:GROUP BY之后的SUM的方方面面,并解答sql group by sum常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的$ group by之后的动态键、C#LINQ to Objects:Group By / Sum帮助、group by 之后的筛选、groupby之后基于0或1的百分比。
本文目录一览:- SQL:GROUP BY之后的SUM(sql group by sum)
- $ group by之后的动态键
- C#LINQ to Objects:Group By / Sum帮助
- group by 之后的筛选
- groupby之后基于0或1的百分比
")
SQL:GROUP BY之后的SUM(sql group by sum)
样品表
CustomerId | VoucherId | CategoryId | StartDate | EndDate
-------------------------------------------------------------
10 | 1 | 1 | 2013-09-01| 2013-09-30
10 | 1 | 2 | 2013-09-01| 2013-09-30
11 | 2 | 1 | 2013-09-01| 2013-11-30
11 | 2 | 2 | 2013-09-01| 2013-11-30
11 | 2 | 3 | 2013-09-01| 2013-11-30
10 | 3 | 1 | 2013-10-01| 2013-12-31
10 | 3 | 2 | 2013-10-01| 2013-12-31
11 | 4 | 1 | 2013-12-01| 2014-04-30
在上面的示例记录中,我想找出客户凭证涵盖的总月数
我需要形式的输出
CustomerId | Months
--------------------
10 | 4
11 | 8
问题在于,凭证可以有多行用于不同的CategoryIds …
我计算出凭证涵盖的月份为DATEDIFF(MM,StartDate,EndDate)+1 …
当我应用SUM(DATEDIFF(MM,StartDate,EndDate))GROUP BY
VoucherId,StartDate,EndDate时,由于VoucherId的多行,我给出了错误的结果。
我得到这样的东西…
CustomerId | Months
--------------------
10 | 8
11 | 14
在这种情况下CategoryId是无用的
谢谢

$ group by之后的动态键
我有以下收藏
{ "_id" : ObjectId("5b18d14cbc83fd271b6a157c"), "status" : "pending", "description" : "You have to complete the challenge...",}{ "_id" : ObjectId("5b18d31a27a37696ec8b5773"), "status" : "completed", "description" : "completed...",}{ "_id" : ObjectId("5b18d31a27a37696ec8b5775"), "status" : "pending", "description" : "pending...",}{ "_id" : ObjectId("5b18d31a27a37696ec8b5776"), "status" : "inProgress", "description" : "inProgress...",}我需要分组status并动态获取其中的所有密钥status
[ { "completed": [ { "_id": "5b18d31a27a37696ec8b5773", "status": "completed", "description": "completed..." } ] }, { "pending": [ { "_id": "5b18d14cbc83fd271b6a157c", "status": "pending", "description": "You have to complete the challenge..." }, { "_id": "5b18d31a27a37696ec8b5775", "status": "pending", "description": "pending..." } ] }, { "inProgress": [ { "_id": "5b18d31a27a37696ec8b5776", "status": "inProgress", "description": "inProgress..." } ] }]答案1
小编典典并不是说我认为这是个好主意,主要是因为我根本看不到任何“聚合”,是在将“分组”添加到数组后,您可以$push通过"status"分组键将所有类似的内容添加到数组中,然后转换为键在文档的$replaceRoot使用$arrayToObject:
db.collection.aggregate([ { "$group": { "_id": "$status", "data": { "$push": "$$ROOT" } }}, { "$group": { "_id": null, "data": { "$push": { "k": "$_id", "v": "$data" } } }}, { "$replaceRoot": { "newRoot": { "$arrayToObject": "$data" } }}])返回值:
{ "inProgress" : [ { "_id" : ObjectId("5b18d31a27a37696ec8b5776"), "status" : "inProgress", "description" : "inProgress..." } ], "completed" : [ { "_id" : ObjectId("5b18d31a27a37696ec8b5773"), "status" : "completed", "description" : "completed..." } ], "pending" : [ { "_id" : ObjectId("5b18d14cbc83fd271b6a157c"), "status" : "pending", "description" : "You have to complete the challenge..." }, { "_id" : ObjectId("5b18d31a27a37696ec8b5775"), "status" : "pending", "description" : "pending..." } ]}如果
您实际上事先进行了“汇总”,那可能就可以了,但是在任何实际大小的集合上,所有要做的就是将整个集合强行放入一个文档中,这很可能会超出BSON限制(16MB),所以我只是不建议在此步骤之前,甚至尝试不进行“分组”操作。
坦白地说,以下相同的代码可以完成相同的操作,并且没有聚合技巧,也没有BSON限制问题:
var obj = {};// Using forEach as a premise for representing "any" cursor iteration formdb.collection.find().forEach(d => { if (!obj.hasOwnProperty(d.status)) obj[d.status] = []; obj[d.status].push(d);})printjson(obj);或更短:
var obj = {};// Using forEach as a premise for representing "any" cursor iteration formdb.collection.find().forEach(d => obj[d.status] = [ ...(obj.hasOwnProperty(d.status)) ? obj[d.status] : [], d ])printjson(obj);聚合用于“数据精简”,而任何简单地“重塑结果”却不实际减少从服务器返回的数据的方法通常都可以通过客户端代码更好地处理。无论您做什么,仍将返回所有数据,并且游标的客户端处理的开销要小得多。而且没有限制。

C#LINQ to Objects:Group By / Sum帮助
public class Extract
{
// Notable fields in TRANSACTION are: String mBatchNo,String mAmount
private List<Transaction> Transactions;
public void testTransactions()
{
// Sum of amounts grouped by batch number
var sGroup = from t in Transactions
group t by t.mBatchNo into g
select new { batchNo = g.Key,totalAmount = g.Max(a => (Int32.Parse(a.mAmount)))};
}
}
此时,我通过locals窗口进入代码查看,看看我的结果集是针对我导入到此对象的文件进行检查的.
文件中的最后一批有3条记录,每条记录100个,可以看到钻入到事务列表对象中.但是向下钻取到sGroup结果会发现同一批次总数为100(应为300).我在这个查询中搞砸了什么?
请注意,我已将其存储为字符串,因为我们在8字符字段的左侧填零.出于出口原因,我决定将其存储为字符串.虽然这可以(也可能会)改变,但它没有回答我的问题:如何使这个查询通过BatchNo将总和聚合成集合?
解决方法
Sum而不是
Max:
var sGroup = from t in Transactions
group t by t.mBatchNo into g
select new {
batchNo = g.Key,totalAmount = g.Sum(a => (int.Parse(a.mAmount))) // Sum,not Max
};
我还建议,如果您的mAmount字段存储为字符串,则使用比int.Parse更强大的方法(因为如果字符串不是有效整数,例如,如果它是空白的话,那将抛出异常).像这样的东西:
int ParSEOrZero(string text)
{
int value;
if (int.TryParse(text,out value))
return value;
else
return 0;
}
var sGroup = from t in Transactions
group t by t.mBatchNo into g
select new {
batchNo = g.Key,totalAmount = g.Sum(ParSEOrZero) // blanks will be treated as 0
};

group by 之后的筛选
目标:实现sql查询,查询某个属性最大(或第几到第几)的行所有信息()
举例:首先需要一张我们进行查询的数据库表:user表
查询出:男和女年龄最大的人的全部信息
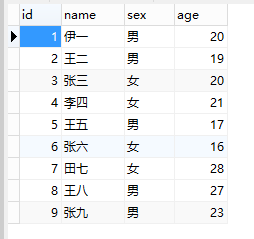
方法一:
解决方案:分别查出男女的第n条开始的,m条记录
(select * from `user`
where sex="男"
order by age desc
limit n,m)
union all
(select * from `user`
where sex="女"
order by age desc
limit n,m)方法一只限于这种情况,如果将性别换成人的属性(鼠牛羊)来查询最大的信息就不合理了,总不能union十几次吧
方法二:
查询出男女的最大年龄,再通过表连接进行查询其他信息
(select * from user)a
(select sex,max(age) from user group by sex)b
select * from (b left join a on b.sex=a.sex and b.age=a.age)这里即使将sex换成属性(鼠牛羊)也可以直接查出来了
问题是这里使用了group by 就没办法使用limit了,所以就只能查询最大年龄(或最小年龄的信息)
问题怎么才是查询多条记录呢?

groupby之后基于0或1的百分比
让我们尝试groupby().transform():
df['result'] = df['col3'] * df.groupby(['col1','col2'])['col3'].transform('mean')
我们今天的关于SQL:GROUP BY之后的SUM和sql group by sum的分享就到这里,谢谢您的阅读,如果想了解更多关于$ group by之后的动态键、C#LINQ to Objects:Group By / Sum帮助、group by 之后的筛选、groupby之后基于0或1的百分比的相关信息,可以在本站进行搜索。
本文标签:




