在本文中,您将会了解到关于SQLServer:如何模仿oracle保持density_rank查询?的新资讯,同时我们还将为您解释oraclesqlmod的相关在本文中,我们将带你探索SQLServe
在本文中,您将会了解到关于SQL Server:如何模仿oracle保持density_rank查询?的新资讯,同时我们还将为您解释oracle sql mod的相关在本文中,我们将带你探索SQL Server:如何模仿oracle保持density_rank查询?的奥秘,分析oracle sql mod的特点,并给出一些关于mssql sqlserver 分组排序函数 row_number、rank、dense_rank 用法简介及说明、MySQL中是否有任何功能,如Oracle的density_rank()和row_number()?、oracle RANK() dense_rank()、Oracle SQL – DENSE_RANK的实用技巧。
本文目录一览:- SQL Server:如何模仿oracle保持density_rank查询?(oracle sql mod)
- mssql sqlserver 分组排序函数 row_number、rank、dense_rank 用法简介及说明
- MySQL中是否有任何功能,如Oracle的density_rank()和row_number()?
- oracle RANK() dense_rank()
- Oracle SQL – DENSE_RANK
")
SQL Server:如何模仿oracle保持density_rank查询?(oracle sql mod)
我有一个Oracle查询
select max(m.id), m.someId keep (DENSE_RANK FIRST ORDER BY m.UpdateDate desc) from MyTable m groupBy m.someId对于这样的数据:
id UpdateDate someId1 20-01-2012 102 20-01-2012 103 01-01-2012 104 10-02-2012 205 01-02-2012 206 01-04-2012 30会完全返回我:
2 104 206 30因此,对于每个someId,它都会搜索最新的updateDate并确实返回相应的id。(如果最新日期有多个ID,则采用最新ID)。
但是对于SQL Server,此查询将以相同的方式工作吗?我是说这个建筑keep (dense_rank first order by ..)?
答案1
小编典典我认为您的特定查询不会运行SQL Server。但是您可以通过执行以下操作获得相同的结果:
SELECT id, SomeIdFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY someId ORDER BY UpdateDate DESC, id DESC) Corr FROM MyTable) AWHERE Corr = 1
mssql sqlserver 分组排序函数 row_number、rank、dense_rank 用法简介及说明
在实际的项目开发中,我们经常使用分组函数,对组内数据进行群组后,然后进行组内排序:
如:
1:取出一个客户一段时间内,最大订单数的行记录
2: 取出一个客户一段时间内,最后一次销售记录的行记录
————————————————
下文将讲述三个分组函数 row_number rank dense_rank 的用法,
以上三个函数的功能为:返回行数据在” 分组数据内” 的排列值
1:row_number () over () 函数简介
row_number () over (partition by [分组列] order by [排序列])
分组列:这里放入我们需要群组的列,可以为一列 也可以为多列,之间采用逗号分隔
排序列:分组后,排序依据列
通过 row_number () over () 排序后,依次生成分组后,行数据在分组内的排序值 (1,2,3 …)
2:rank () over (partition by [分组列] order by [排序列]) 函数简介
分组列和排序列同上
rank 的群组内的排名方法为 如果出现两个相同的排序列时,那么下一个排序值为会自动加一
(1,1,3…)
3:dense_rank () over (partition by [分组列] order by [排序列]) 函数简介
分组列和排序列同上
dense_rank 的群组内的排名方法为 如果出现两个相同的排序列时,那么下一个排序值不会出现跳跃
例 (1,1,2,3 ..)
——————————————————
例:
create table A ([姓名] nvarchar(20),[订单数] int,[订单日期] datetime )
go
insert into A ([姓名],[订单数],[订单日期]) values (''www.maomao365.com'',1900,''2014-5-6'')
insert into A ([姓名],[订单数],[订单日期]) values (''www.maomao365.com'',1800,''2018-5-6'')
insert into A ([姓名],[订单数],[订单日期]) values (''www.maomao365.com'',1800,''2018-5-6'')
insert into A ([姓名],[订单数],[订单日期]) values (''小张'',100,''2013-5-6'')
insert into A ([姓名],[订单数],[订单日期]) values (''小明'',2600,''2013-1-6'')
insert into A ([姓名],[订单数],[订单日期]) values (''小明'',1800,''2013-5-6'')
insert into A ([姓名],[订单数],[订单日期]) values (''小李'',888,''2017-3-6'')
go
/*row_number 返回分组后的连续排序,不会出现重复的排序值*/
select row_number() over(partition by [姓名] order by [订单日期] desc ) as keyId,* from A
/*rank 返回分组后的连续排序,会出现跳跃排序值*/
select rank() over(partition by [姓名] order by [订单日期] desc ) as keyId,* from A
/*dense_rank 返回分组后的连续排序,不会出现跳跃排序值,但是会出现重复的排序值*/
select dense_rank() over(partition by [姓名] order by [订单日期] desc ) as keyId,* from A
go
truncate table A
drop table A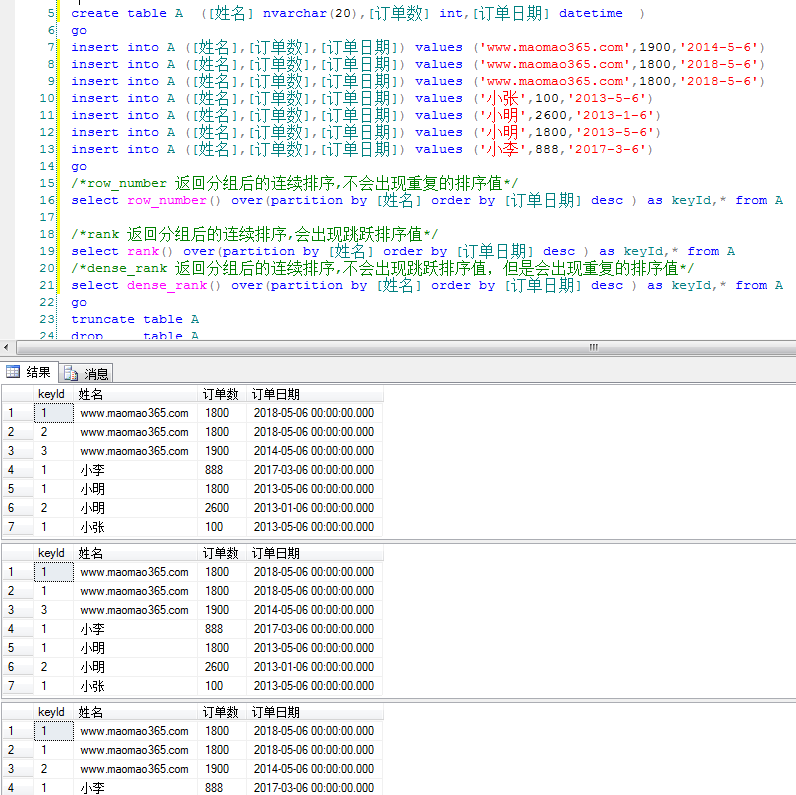
转载:http://www.maomao365.com/?p=5771
和row_number()?")
MySQL中是否有任何功能,如Oracle的density_rank()和row_number()?
有没有像MySQL中的任何功能dense_rank()和row_number()像甲骨文和其他DBMS提供的?
我想在查询中生成一个ID,但是在MySQL中这些功能不存在。还有其他选择吗?
 dense_rank()")
oracle RANK() dense_rank()
【语法】RANK ( ) OVER ( [query_partition_clause] order_by_clause )
dense_RANK ( ) OVER ( [query_partition_clause] order_by_clause )
【功能】聚合函数RANK 和 dense_rank 主要的功能是计算一组数值中的排序值。
【参数】dense_rank与rank()用法相当,
【区别】dence_rank在并列关系是,相关等级不会跳过。rank则跳过
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。
【说明】Oracle分析函数
【示例】
聚合函数RANK 和 dense_rank 主要的功能是计算一组数值中的排序值。
在9i版本之前,只有分析功能(analytic ),即从一个查询结果中计算每一行的排序值,是基于order_by_clause子句中的value_exprs指定字段的。
其语法为:
RANK ( ) OVER ( [query_partition_clause] order_by_clause )
在9i版本新增加了合计功能(aggregate),即对给定的参数值在设定的排序查询中计算出其排序值。这些参数必须是常数或常值表达式,且必须和ORDER BY子句中的字段个数、位置、类型完全一致。
其语法为:
RANK ( expr [, expr]... ) WITHIN GROUP
( ORDER BY
expr [ DESC | ASC ] [NULLS { FIRST | LAST }]
[, expr [ DESC | ASC ] [NULLS { FIRST | LAST }]]...
)
例子1:
有表Table内容如下
COL1 COL2
1 1
2 1
3 2
3 1
4 1
4 2
5 2
5 2
6 2
分析功能:列出Col2分组后根据Col1排序,并生成数字列。比较实用于在成绩表中查出各科前几名的信息。
SELECT a.*,RANK() OVER(PARTITION BY col2 ORDER BY col1) "Rank" FROM table a;
结果如下:
COL1 COL2 Rank
1 1 1
2 1 2
3 1 3
4 1 4
3 2 1
4 2 2
5 2 3
5 2 3
6 2 5
例子2:
TABLE:A (科目,分数)
数学,80
语文,70
数学,90
数学,60
数学,100
语文,88
语文,65
语文,77
现在我想要的结果是:(即想要每门科目的前3名的分数)
数学,100
数学,90
数学,80
语文,88
语文,77
语文,70
那么语句就这么写:
select * from (select rank() over(partition by 科目 order by 分数 desc) rk,a.* from a) t
where t.rk<=3;
例子3:
合计功能:计算出数值(4,1)在Orade By Col1,Col2排序下的排序值,也就是col1=4,col2=1在排序以后的位置
SELECT RANK(4,3) WITHIN GROUP (ORDER BY col1,col2) "Rank" FROM table;
结果如下:
Rank
4
dense_rank与rank()用法相当,但是有一个区别:dence_rank在并列关系是,相关等级不会跳过。rank则跳过
例如:表
A B C
a liu wang
a jin shu
a cai kai
b yang du
b lin ying
b yao cai
b yang 99
例如:当rank时为:
select m.a,m.b,m.c,rank() over(partition by a order by b) liu from test3 m
A B C LIU
a cai kai 1
a jin shu 2
a liu wang 3
b lin ying 1
b yang du 2
b yang 99 2
b yao cai 4
而如果用dense_rank时为:
select m.a,m.b,m.c,dense_rank() over(partition by a order by b) liu from test3 m
A B C LIU
a cai kai 1
a jin shu 2
a liu wang 3
b lin ying 1
b yang du 2
b yang 99 2
b yao cai 3

Oracle SQL – DENSE_RANK
Row_ID Client_ID Status_ID From_date To_date 1 123456 4 20/12/2007 18:02 20/12/2007 18:07 2 789087 4 20/12/2007 18:02 20/12/2007 18:07 3 789087 4 20/12/2007 18:07 20/12/2007 18:50 4 789087 4 20/12/2007 18:50 21/12/2007 10:38 5 123456 4 20/12/2007 18:07 20/12/2007 18:50 6 123456 4 20/12/2007 18:50 21/12/2007 10:38 7 123456 4 21/12/2007 10:38 21/12/2007 16:39 8 789087 4 21/12/2007 10:38 21/12/2007 17:54 9 789087 4 21/12/2007 17:54 21/12/2007 18:32 10 789087 4 21/12/2007 18:32 22/12/2007 06:48 11 123456 5 21/12/2007 16:39 12 789087 5 22/12/2007 06:48 22/12/2007 10:53 13 789087 4 22/12/2007 10:53 22/12/2007 11:51 14 789087 5 22/12/2007 11:51
在通过Client_ID然后通过From_date将数据按升序排列之后,我的目标是在每次将状态与前一行进行比较时,该客户端的状态发生变化时添加计算的Rank_ID.我想要的Rank_ID所需的值如下所示:
Row_ID Client_ID Status_ID From_date To_date Rank_ID 1 123456 4 20/12/2007 18:02 20/12/2007 18:07 1 5 123456 4 20/12/2007 18:07 20/12/2007 18:50 1 6 123456 4 20/12/2007 18:50 21/12/2007 10:38 1 7 123456 4 21/12/2007 10:38 21/12/2007 16:39 1 11 123456 5 21/12/2007 16:39 2 2 789087 4 20/12/2007 18:02 20/12/2007 18:07 3 3 789087 4 20/12/2007 18:07 20/12/2007 18:50 3 4 789087 4 20/12/2007 18:50 21/12/2007 10:38 3 8 789087 4 21/12/2007 10:38 21/12/2007 17:54 3 9 789087 4 21/12/2007 17:54 21/12/2007 18:32 3 10 789087 4 21/12/2007 18:32 22/12/2007 06:48 3 12 789087 5 22/12/2007 06:48 22/12/2007 10:53 4 13 789087 4 22/12/2007 10:53 22/12/2007 11:51 5 14 789087 5 22/12/2007 11:51 6
我试图使用DENSE_RANK作为分析函数,我的“不正确”sql代码在下面
SELECT t1.*,DENSE_RANK () OVER (ORDER BY t1.client_id,t1.status_id) rank_id
FROM (SELECT c.client_ID,c.status_id,c.from_date,c.to_date
FROM client c
ORDER BY c.client_id,c.from_date) t1
ORDER BY t1.client_id,t1.from_date
但是,我遇到的问题是它给出了编写的sql代码,它按如下方式计算Rank_ID:
Row_ID Client_ID Status_ID From_date To_date Rank_ID 1 123456 4 20/12/2007 18:02 20/12/2007 18:07 1 5 123456 4 20/12/2007 18:07 20/12/2007 18:50 1 6 123456 4 20/12/2007 18:50 21/12/2007 10:38 1 7 123456 4 21/12/2007 10:38 21/12/2007 16:39 1 11 123456 5 21/12/2007 16:39 2 2 789087 4 20/12/2007 18:02 20/12/2007 18:07 3 3 789087 4 20/12/2007 18:07 20/12/2007 18:50 3 4 789087 4 20/12/2007 18:50 21/12/2007 10:38 3 8 789087 4 21/12/2007 10:38 21/12/2007 17:54 3 9 789087 4 21/12/2007 17:54 21/12/2007 18:32 3 10 789087 4 21/12/2007 18:32 22/12/2007 06:48 3 12 789087 5 22/12/2007 06:48 22/12/2007 10:53 4 13 789087 4 22/12/2007 10:53 22/12/2007 11:51 3 14 789087 5 22/12/2007 11:51 4
对于记录13,返回的Rank_ID是3(而我想要的是5表示该客户端的状态随该客户端的前一记录的状态而变化)而对于记录14,返回的Rank_ID为4,而我想要6,因为与前一行相比,该客户的状态发生了变化.
我想问题是我的sql通过Client_ID然后通过Status_ID对数据进行排序,因此我可以看出为什么它会产生它给出的答案.问题是无论我对DENSE_RANK行做了什么改变,我都无法得到我想要的答案.
任何帮助,将不胜感激.
解决方法
select client_ID,status_id,from_date,to_date,sum(start_of_group) over (order by client_ID,from_date) + 1 rank
from (SELECT c.client_ID,c.to_date,case when lag(c.client_ID,1,c.client_ID) over (order by c.client_ID,c.from_date) = c.client_ID
and lag(c.status_id,c.status_id) over (order by c.client_ID,c.from_date) = c.status_id
then 0 else 1 end start_of_group
FROM client c)
order by client_ID,from_date
SQLFiddle
关于SQL Server:如何模仿oracle保持density_rank查询?和oracle sql mod的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于mssql sqlserver 分组排序函数 row_number、rank、dense_rank 用法简介及说明、MySQL中是否有任何功能,如Oracle的density_rank()和row_number()?、oracle RANK() dense_rank()、Oracle SQL – DENSE_RANK的相关信息,请在本站寻找。
本文标签:




