在这里,我们将给大家分享关于02分布式NOSQLHBASE-JAVAAPI操作HBase的知识,让您更了解分布式数据库hbase的本质,同时也会涉及到如何更有效地01分布式NOSQLHBASEHBas
在这里,我们将给大家分享关于02分布式NOSQL HBASE - JAVA API 操作HBase的知识,让您更了解分布式数据库hbase的本质,同时也会涉及到如何更有效地01分布式NOSQL HBASE HBase 概述和数据模型、03分布式NOSQL HBASE - mapreduce批量读取HBase的数据、04分布式NOSQL HBASE - HBase过滤器、05分布式NOSQL HBASE - Coprocessor协调器的内容。
本文目录一览:- 02分布式NOSQL HBASE - JAVA API 操作HBase(分布式数据库hbase)
- 01分布式NOSQL HBASE HBase 概述和数据模型
- 03分布式NOSQL HBASE - mapreduce批量读取HBase的数据
- 04分布式NOSQL HBASE - HBase过滤器
- 05分布式NOSQL HBASE - Coprocessor协调器
")
02分布式NOSQL HBASE - JAVA API 操作HBase(分布式数据库hbase)
(原文地址:http://www.jb51.cc/cata/500599,转载麻烦带上原文地址。hadoop hive hbasemahout storm spark kafka flume,等连载中,做个爱分享的人)
HBase,可以使用shell界面管理数据,也提供java api 来操作Hbase上的表的数据。所有Column均以二进制格式存储,所以在api中要不断的类型转换。
//1 准备HBase上下文 HBaseAdmin 和user表对象hTable
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.rootdir","hdfs://rdc:9000/HRoot");
conf.set("hbase.zookeeper.quorum","p1");
Configuration conf= HBaseConfiguration.create();
HConnection conn= HConnectionManager.createConnection(conf);
HTableInterface userTable = conn.getTable("user");
//2查->Get,HBase只能根据ROW KEY 做随机查。默认是没有二级索引的。相当于只能 SELECT u.name FROM user u where u.id = 2; 不能对非主键的查询 SELECT u.name FROM user u where u.name = "rdc";
String id = "1"; //row key行键
String columnFamily = "info"; //列镞
String colume = "name"; //列名
Get get = new Get(id.getBytes());
final Result result = hTable.get(get);
byte[] valBytes = result.getValue(columnFamily .getBytes(),colume getBytes());
String value = new String(value); // value 相当于sql语句 SELECT u.name FROM user u where u.id = 1,的结果
//2增->Put ,使用Put 一列一列的加。sql: insert into user(name) values("mosi")
//3改->Put ,使用Put 一列一列的改。sql:update user set name "mosi"
Put put = new Put(id.getBytes());
put.add(columnFamily .getBytes(), colume getBytes(),"mosi".getBytes());
hTable.put(put);//和java的map一样。为空新增,不为空覆盖。
//4删 -》sql: delete from user where id = 1
Delete delete = new Delete(id.getBytes());
hTable.delete(delete);
//5 扫描,HBASE还提供scan方式根据rowkey范围扫描,不指定rowkey范围,则为全表扫描 。一次网络连接获取 批量数据缓存在客户端内存中。相对应GET来说。节省网络的连接次数。
// sql: SELECT * FROM user u
Scan scan = new Scan();
final ResultScanner scanner = hTable.getScanner(scan);
for (Result result : scanner) {
final byte[] value = result.getValue(columnFamily .getBytes(),colume.getBytes());
}

01分布式NOSQL HBASE HBase 概述和数据模型
(HBase数据模型-百度百科)
1:Row Key: 行键,Table的主键,Table中的记录默认按照Row Key升序排序
2:Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number
3:Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以 二进制格式存储,用户需要自行进行类型转换。

03分布式NOSQL HBASE - mapreduce批量读取HBase的数据
(原文地址:http://www.jb51.cc/cata/500599,转载麻烦带上原文地址。hadoop hive hbasemahout storm spark kafka flume,等连载中,做个爱分享的人)
1:如果有一大票数据比如1000万条,或者批量的 插入HBase的表中,HBase提供的java API 中的PUT方法,一条接一条记录的插入方式效率上就非常慢。
2:如果要 取出HBase一个表里的1000万条数据。用GET一条一条的来,效率也是可想而知,scan的方法批量取出1000万条记录没什么问题,但问题是这个api是在单机上运行的,取庞大的数据效率就有问题了
为解决这种大规模数据的 get 和put 操作的效率问题,HBase提供org.apache.hadoop.hbase.mapreduce这个包,基于hadoop上的mapreduce分布式读取HBase表的解决方案,中国山东找蓝翔 。
2 关键类
1 Class TableMapper<KEYOUT,VALUEOUT>
- java.lang.Object
- org.apache.hadoop.mapreduce.Mapper<ImmutableBytesWritable,Result,KEYOUT,VALUEOUT>
- org.apache.hadoop.hbase.mapreduce.TableMapper<KEYOUT,VALUEOUT>
- org.apache.hadoop.hbase.mapreduce.TableMapper<KEYOUT,VALUEOUT>
- Type Parameters:KEYOUT - The type of the key.VALUEOUT - The type of the value.
2 Class TableReducer<KEYIN,VALUEIN,KEYOUT>
- java.lang.Object
- org.apache.hadoop.mapreduce.Reducer<KEYIN,org.apache.hadoop.io.Writable>
- org.apache.hadoop.hbase.mapreduce.TableReducer<KEYIN,KEYOUT>
- org.apache.hadoop.hbase.mapreduce.TableReducer<KEYIN,KEYOUT>
- Type Parameters:KEYIN - The type of the input key.VALUEIN - The type of the input value.KEYOUT - The type of the output key.
3 批量存(put)取(get) hbase的表
//1 mapreduce 批量读出 表中所有的id 和 name字段的值。
class HBaseMap extends TableMapper<Text,Text> { @Override
protected void map(ImmutableBytesWritable key,Result value,Context context)
throws IOException,InterruptedException {
Text keyText = new Text(new String( key.get()));
String family = "info";
String qualifier = "name";
byte[] nameValueBytes = value.getValue( family.getBytes(),qualifier
.getBytes());
Text valueText = new Text(new String(nameValueBytes));
context.write(valueText,keyText);
}
}
//2 mapreduce 批量插入 name 和id。
class HBaseReduce extends TableReducer<Text,Text,ImmutableBytesWritable> {
@Override
protected void reduce(Text key,Iterable<Text> value,InterruptedException {
String family = "info";
String qualifier = "name";
String keyString = key.toString();
Put put = new Put(keyString.getBytes());
for (Text val : values) {
put.add( family.getBytes(), qualifier.getBytes(),val.toString()
.getBytes());
}
}
}
最后用hadoop的Job api执行这两个mapreduce。打成jar包。放到hadoop上跑。批量存取hbase的数据

04分布式NOSQL HBASE - HBase过滤器
(原文地址:http://www.jb51.cc/cata/500599,转载麻烦带上原文地址。hadoop hive hbasemahout storm spark kafka flume,等连载中,做个爱分享的人)
HBase 提供scan 方式来做批量数据扫描。并提供filter机制提供更为精准的数据过滤。并且过滤过程在服务端进行。scan通过setFilter添加过滤器,实现分页、多条件查询等需求。
org.apache.hadoop.hbase.filter.FilterBase 。过滤器的基类,HBase提供了十几个实现类,分别做不同类型的过滤功能。各个过滤器还有各种不一样的过滤条件比较器。过滤功能相当的多。
1、Comparision Filters (比较类型,对行健,列镞等进行比较)
1.1 RowFilter
1.2 FamilyFilter
1.3 QualifierFilter
1.4 ValueFilter
1.5 DependentColumnFilter
2、Dedicated Filters (特殊用途类型,如分页等用途)
2.1 SingleColumnValueFilter (对列的数据过滤)
2.2 SingleColumnValueExcludeFilter
2.3 PrefixFilter
2.4 PageFilter(分页)
2.5 KeyOnlyFilter
2.6 FirstKeyOnlyFilter
2.7 TimestampsFilter
2.8 RandomrowFilter
3、Decorating Filters(Decorating )
3.1SkipFilter
3.2 WhileMatchFilters
// 过滤器,为scan设置过滤器 。 sql: SELECT * FROM user u where id <> 2;
Scan scan = new Scan();
CompareOp compareOp = CompareOp.NO_OP; // != 比较符;
WritableByteArrayComparable comparable = new BinaryComparator(rowkey.getBytes()) //二进制比较器;
RowFilter rowFilter = new RowFilter(compareOp,comparable); //rowkey 过滤器
scan .setFilter(rowFilter);
final ResultScanner scanner = hTable.getScanner(scan);
for (Result result : scanner) {
final byte[] value = result.getValue(columnFamily .getBytes(),colume.getBytes()); }

05分布式NOSQL HBASE - Coprocessor协调器
(原文地址:http://www.jb51.cc/cata/500599,转载麻烦带上原文地址。hadoop hive hbasemahout storm spark kafka flume,等连载中,做个爱分享的人)
1 那么问题又来了????
1:如果要对HBase的User表,做一些sum,orderby等常用的聚合怎么搞。1:如果javaapi 全部读出来,表太大时显然这种方案不合适,2,mapreduce 分布式的批量读出再算,但是当数据小的时候,mr任务要消耗的资源大,有点牛刀。
为解决这种 sum,orderby等常用的聚合聚合操作的,HBase的org.apache.hadoop.hbase.coprocessor 协处理器机智,提供在服务端region运行代码的机制,的解决方案,如GET 操作,直接在服务端执行。并不需要把结果返回回来。中国山东找蓝翔。
2:假设我们在user表执行DELETE 或者GET等操作之后,要做操作日志
HBase的org.apache.hadoop.hbase.coprocessor 协处理器也能处理这样的需求。
2 协处理器概述
HBase有全表,和单表两种作用域的协处理器,以及 observer和endpoint两种调用方式的协处理器,observer为hbase 的GET,PUT,SCAN,DELETE等操作提供了Hook钩子,类似于onClick do,适合在表的某些操作前后的需求。endpoint是一个服务端的方法,我们要使用时,通过rpc可以直接调用,适合做聚合。
3.1 协处理器observer模式关键API
3.2 协处理器endpoint(RPC)模式关键API
3.2.1服务端类关键接口
//接受到请求后,真正执行的方法。
实现com.google.protobuf.Service里的接口
//初始化获取env对象。
public void start(coprocessorEnvironment env) throws IOException {}
//结束时关闭相关资源
public void stop(coprocessorEnvironment env) throws IOException{}
3.2.2客户端端类关键接口
//发起请求
coprocessorService(java.lang.class,byte[],org.apache.hadoop.hbase.client.coprocessor.Batch.Call)]coprocessorService[/url](Class<T> service,byte[] startKey,byte[] endKey,org.apache.hadoop.hbase.client.coprocessor.Batch.Call<T,R> callable)
//执行rpc请求的时候,真正执行的代码,在服务端执行。
public Long call(TestEndpoint.CountService counter)
4.1 协处理器observer模式程序
有空再补充
4.2 协处理器endpoint(RPC)模式程序 有空再补充
关于02分布式NOSQL HBASE - JAVA API 操作HBase和分布式数据库hbase的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于01分布式NOSQL HBASE HBase 概述和数据模型、03分布式NOSQL HBASE - mapreduce批量读取HBase的数据、04分布式NOSQL HBASE - HBase过滤器、05分布式NOSQL HBASE - Coprocessor协调器的相关信息,请在本站寻找。
在本文中,我们将为您详细介绍01分布式NOSQL HBASE HBase 概述和数据模型的相关知识,并且为您解答关于分布式数据库hbase的疑问,此外,我们还会提供一些关于02分布式NOSQL HBASE - JAVA API 操作HBase、03分布式NOSQL HBASE - mapreduce批量读取HBase的数据、04分布式NOSQL HBASE - HBase过滤器、05分布式NOSQL HBASE - Coprocessor协调器的有用信息。
本文目录一览:- 01分布式NOSQL HBASE HBase 概述和数据模型(分布式数据库hbase)
- 02分布式NOSQL HBASE - JAVA API 操作HBase
- 03分布式NOSQL HBASE - mapreduce批量读取HBase的数据
- 04分布式NOSQL HBASE - HBase过滤器
- 05分布式NOSQL HBASE - Coprocessor协调器
")
01分布式NOSQL HBASE HBase 概述和数据模型(分布式数据库hbase)
(HBase数据模型-百度百科)
1:Row Key: 行键,Table的主键,Table中的记录默认按照Row Key升序排序
2:Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number
3:Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以 二进制格式存储,用户需要自行进行类型转换。

02分布式NOSQL HBASE - JAVA API 操作HBase
(原文地址:http://www.jb51.cc/cata/500599,转载麻烦带上原文地址。hadoop hive hbasemahout storm spark kafka flume,等连载中,做个爱分享的人)
HBase,可以使用shell界面管理数据,也提供java api 来操作Hbase上的表的数据。所有Column均以二进制格式存储,所以在api中要不断的类型转换。
//1 准备HBase上下文 HBaseAdmin 和user表对象hTable
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.rootdir","hdfs://rdc:9000/HRoot");
conf.set("hbase.zookeeper.quorum","p1");
Configuration conf= HBaseConfiguration.create();
HConnection conn= HConnectionManager.createConnection(conf);
HTableInterface userTable = conn.getTable("user");
//2查->Get,HBase只能根据ROW KEY 做随机查。默认是没有二级索引的。相当于只能 SELECT u.name FROM user u where u.id = 2; 不能对非主键的查询 SELECT u.name FROM user u where u.name = "rdc";
String id = "1"; //row key行键
String columnFamily = "info"; //列镞
String colume = "name"; //列名
Get get = new Get(id.getBytes());
final Result result = hTable.get(get);
byte[] valBytes = result.getValue(columnFamily .getBytes(),colume getBytes());
String value = new String(value); // value 相当于sql语句 SELECT u.name FROM user u where u.id = 1,的结果
//2增->Put ,使用Put 一列一列的加。sql: insert into user(name) values("mosi")
//3改->Put ,使用Put 一列一列的改。sql:update user set name "mosi"
Put put = new Put(id.getBytes());
put.add(columnFamily .getBytes(), colume getBytes(),"mosi".getBytes());
hTable.put(put);//和java的map一样。为空新增,不为空覆盖。
//4删 -》sql: delete from user where id = 1
Delete delete = new Delete(id.getBytes());
hTable.delete(delete);
//5 扫描,HBASE还提供scan方式根据rowkey范围扫描,不指定rowkey范围,则为全表扫描 。一次网络连接获取 批量数据缓存在客户端内存中。相对应GET来说。节省网络的连接次数。
// sql: SELECT * FROM user u
Scan scan = new Scan();
final ResultScanner scanner = hTable.getScanner(scan);
for (Result result : scanner) {
final byte[] value = result.getValue(columnFamily .getBytes(),colume.getBytes());
}

03分布式NOSQL HBASE - mapreduce批量读取HBase的数据
(原文地址:http://www.jb51.cc/cata/500599,转载麻烦带上原文地址。hadoop hive hbasemahout storm spark kafka flume,等连载中,做个爱分享的人)
1:如果有一大票数据比如1000万条,或者批量的 插入HBase的表中,HBase提供的java API 中的PUT方法,一条接一条记录的插入方式效率上就非常慢。
2:如果要 取出HBase一个表里的1000万条数据。用GET一条一条的来,效率也是可想而知,scan的方法批量取出1000万条记录没什么问题,但问题是这个api是在单机上运行的,取庞大的数据效率就有问题了
为解决这种大规模数据的 get 和put 操作的效率问题,HBase提供org.apache.hadoop.hbase.mapreduce这个包,基于hadoop上的mapreduce分布式读取HBase表的解决方案,中国山东找蓝翔 。
2 关键类
1 Class TableMapper<KEYOUT,VALUEOUT>
- java.lang.Object
- org.apache.hadoop.mapreduce.Mapper<ImmutableBytesWritable,Result,KEYOUT,VALUEOUT>
- org.apache.hadoop.hbase.mapreduce.TableMapper<KEYOUT,VALUEOUT>
- org.apache.hadoop.hbase.mapreduce.TableMapper<KEYOUT,VALUEOUT>
- Type Parameters:KEYOUT - The type of the key.VALUEOUT - The type of the value.
2 Class TableReducer<KEYIN,VALUEIN,KEYOUT>
- java.lang.Object
- org.apache.hadoop.mapreduce.Reducer<KEYIN,org.apache.hadoop.io.Writable>
- org.apache.hadoop.hbase.mapreduce.TableReducer<KEYIN,KEYOUT>
- org.apache.hadoop.hbase.mapreduce.TableReducer<KEYIN,KEYOUT>
- Type Parameters:KEYIN - The type of the input key.VALUEIN - The type of the input value.KEYOUT - The type of the output key.
3 批量存(put)取(get) hbase的表
//1 mapreduce 批量读出 表中所有的id 和 name字段的值。
class HBaseMap extends TableMapper<Text,Text> { @Override
protected void map(ImmutableBytesWritable key,Result value,Context context)
throws IOException,InterruptedException {
Text keyText = new Text(new String( key.get()));
String family = "info";
String qualifier = "name";
byte[] nameValueBytes = value.getValue( family.getBytes(),qualifier
.getBytes());
Text valueText = new Text(new String(nameValueBytes));
context.write(valueText,keyText);
}
}
//2 mapreduce 批量插入 name 和id。
class HBaseReduce extends TableReducer<Text,Text,ImmutableBytesWritable> {
@Override
protected void reduce(Text key,Iterable<Text> value,InterruptedException {
String family = "info";
String qualifier = "name";
String keyString = key.toString();
Put put = new Put(keyString.getBytes());
for (Text val : values) {
put.add( family.getBytes(), qualifier.getBytes(),val.toString()
.getBytes());
}
}
}
最后用hadoop的Job api执行这两个mapreduce。打成jar包。放到hadoop上跑。批量存取hbase的数据

04分布式NOSQL HBASE - HBase过滤器
(原文地址:http://www.jb51.cc/cata/500599,转载麻烦带上原文地址。hadoop hive hbasemahout storm spark kafka flume,等连载中,做个爱分享的人)
HBase 提供scan 方式来做批量数据扫描。并提供filter机制提供更为精准的数据过滤。并且过滤过程在服务端进行。scan通过setFilter添加过滤器,实现分页、多条件查询等需求。
org.apache.hadoop.hbase.filter.FilterBase 。过滤器的基类,HBase提供了十几个实现类,分别做不同类型的过滤功能。各个过滤器还有各种不一样的过滤条件比较器。过滤功能相当的多。
1、Comparision Filters (比较类型,对行健,列镞等进行比较)
1.1 RowFilter
1.2 FamilyFilter
1.3 QualifierFilter
1.4 ValueFilter
1.5 DependentColumnFilter
2、Dedicated Filters (特殊用途类型,如分页等用途)
2.1 SingleColumnValueFilter (对列的数据过滤)
2.2 SingleColumnValueExcludeFilter
2.3 PrefixFilter
2.4 PageFilter(分页)
2.5 KeyOnlyFilter
2.6 FirstKeyOnlyFilter
2.7 TimestampsFilter
2.8 RandomrowFilter
3、Decorating Filters(Decorating )
3.1SkipFilter
3.2 WhileMatchFilters
// 过滤器,为scan设置过滤器 。 sql: SELECT * FROM user u where id <> 2;
Scan scan = new Scan();
CompareOp compareOp = CompareOp.NO_OP; // != 比较符;
WritableByteArrayComparable comparable = new BinaryComparator(rowkey.getBytes()) //二进制比较器;
RowFilter rowFilter = new RowFilter(compareOp,comparable); //rowkey 过滤器
scan .setFilter(rowFilter);
final ResultScanner scanner = hTable.getScanner(scan);
for (Result result : scanner) {
final byte[] value = result.getValue(columnFamily .getBytes(),colume.getBytes()); }

05分布式NOSQL HBASE - Coprocessor协调器
(原文地址:http://www.jb51.cc/cata/500599,转载麻烦带上原文地址。hadoop hive hbasemahout storm spark kafka flume,等连载中,做个爱分享的人)
1 那么问题又来了????
1:如果要对HBase的User表,做一些sum,orderby等常用的聚合怎么搞。1:如果javaapi 全部读出来,表太大时显然这种方案不合适,2,mapreduce 分布式的批量读出再算,但是当数据小的时候,mr任务要消耗的资源大,有点牛刀。
为解决这种 sum,orderby等常用的聚合聚合操作的,HBase的org.apache.hadoop.hbase.coprocessor 协处理器机智,提供在服务端region运行代码的机制,的解决方案,如GET 操作,直接在服务端执行。并不需要把结果返回回来。中国山东找蓝翔。
2:假设我们在user表执行DELETE 或者GET等操作之后,要做操作日志
HBase的org.apache.hadoop.hbase.coprocessor 协处理器也能处理这样的需求。
2 协处理器概述
HBase有全表,和单表两种作用域的协处理器,以及 observer和endpoint两种调用方式的协处理器,observer为hbase 的GET,PUT,SCAN,DELETE等操作提供了Hook钩子,类似于onClick do,适合在表的某些操作前后的需求。endpoint是一个服务端的方法,我们要使用时,通过rpc可以直接调用,适合做聚合。
3.1 协处理器observer模式关键API
3.2 协处理器endpoint(RPC)模式关键API
3.2.1服务端类关键接口
//接受到请求后,真正执行的方法。
实现com.google.protobuf.Service里的接口
//初始化获取env对象。
public void start(coprocessorEnvironment env) throws IOException {}
//结束时关闭相关资源
public void stop(coprocessorEnvironment env) throws IOException{}
3.2.2客户端端类关键接口
//发起请求
coprocessorService(java.lang.class,byte[],org.apache.hadoop.hbase.client.coprocessor.Batch.Call)]coprocessorService[/url](Class<T> service,byte[] startKey,byte[] endKey,org.apache.hadoop.hbase.client.coprocessor.Batch.Call<T,R> callable)
//执行rpc请求的时候,真正执行的代码,在服务端执行。
public Long call(TestEndpoint.CountService counter)
4.1 协处理器observer模式程序
有空再补充
4.2 协处理器endpoint(RPC)模式程序 有空再补充
今天关于01分布式NOSQL HBASE HBase 概述和数据模型和分布式数据库hbase的讲解已经结束,谢谢您的阅读,如果想了解更多关于02分布式NOSQL HBASE - JAVA API 操作HBase、03分布式NOSQL HBASE - mapreduce批量读取HBase的数据、04分布式NOSQL HBASE - HBase过滤器、05分布式NOSQL HBASE - Coprocessor协调器的相关知识,请在本站搜索。
以上就是给各位分享NoSQL数据库的类型,其中也会对nosql数据库的类型包括进行解释,同时本文还将给你拓展AWS Around---NoSql数据库的不同类型、NoSQL 数据库的类型、nosql-redis-网络资料学习-05-nosql数据库的四大分类、NoSQL数据库的主主备份等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- NoSQL数据库的类型(nosql数据库的类型包括)
- AWS Around---NoSql数据库的不同类型
- NoSQL 数据库的类型
- nosql-redis-网络资料学习-05-nosql数据库的四大分类
- NoSQL数据库的主主备份
")
NoSQL数据库的类型(nosql数据库的类型包括)
Nosql纪元
当下已经存在很多的Nosql数据库,比如MongoDB、Redis、Riak、HBase、Cassandra等等。每一个都拥有以下几个特性中的一个:
- 不再使用sql语言,比如MongoDB、Cassandra就有自己的查询语言
- 通常是开源项目
- 为集群运行而生
- 弱结构化——不会严格的限制数据结构类型
Nosql数据库的类型
Nosql可以大体上分为4个种类:Key-value、document-oriented、Column-Family Databases以及 Graph-Oriented Databases。下面就一览这些类型的特性:
一、 键值(Key-Value)数据库
键值数据库就像在传统语言中使用的哈希表。你可以通过key来添加、查询或者删除数据,鉴于使用主键访问,所以会获得不错的性能及扩展性。
产品:Riak、Redis、Memcached、Amazon’s Dynamo、Project Voldemort
有谁在使用:GitHub (Riak)、BestBuy (Riak)、Twitter (Redis和Memcached)、StackOverFlow (Redis)、 Instagram (Redis)、Youtube (Memcached)、Wikipedia(Memcached)
适用的场景
储存用户信息,比如会话、配置文件、参数、购物车等等。这些信息一般都和ID(键)挂钩,这种情景下键值数据库是个很好的选择。
不适用场景
1.取代通过键查询,而是通过值来查询。Key-Value数据库中根本没有通过值查询的途径。
2.需要储存数据之间的关系。在Key-Value数据库中不能通过两个或以上的键来关联数据。
3.事务的支持。在Key-Value数据库中故障产生时不可以进行回滚。
二、 面向文档(document-oriented)数据库
面向文档数据库会将数据以文档的形式储存。每个文档都是自包含的数据单元,是一系列数据项的集合。每个数据项都有一个名称与对应的值,值既可以是简单的数据类型,如字符串、数字和日期等;也可以是复杂的类型,如有序列表和关联对象。数据存储的最小单位是文档,同一个表中存储的文档属性可以是不同的,数据可以使用XML、JSON或者JSONB等多种形式存储。
产品:MongoDB、CouchDB、RavendB
有谁在使用:SAP (MongoDB)、Codecademy (MongoDB)、Foursquare (MongoDB)、NBC News (RavendB)
1.日志。企业环境下,每个应用程序都有不同的日志信息。document-oriented数据库并没有固定的模式,所以我们可以使用它储存不同的信息。
2.分析。鉴于它的弱模式结构,不改变模式下就可以储存不同的度量方法及添加新的度量。
在不同的文档上添加事务。document-oriented数据库并不支持文档间的事务,如果对这方面有需求则不应该选用这个解决方案。
三、 列存储(Wide Column Store/Column-Family)数据库
列存储数据库将数据储存在列族(column family)中,一个列族存储经常被一起查询的相关数据。举个例子,如果我们有一个Person类,我们通常会一起查询他们的姓名和年龄而不是薪资。这种情况下,姓名和年龄就会被放入一个列族中,而薪资则在另一个列族中。
产品:Cassandra、HBase
有谁在使用:Ebay (Cassandra)、Instagram (Cassandra)、NASA (Cassandra)、Twitter (Cassandra and HBase)、Facebook (HBase)、Yahoo!(HBase)
1.日志。因为我们可以将数据储存在不同的列中,每个应用程序可以将信息写入自己的列族中。
2.博客平台。我们储存每个信息到不同的列族中。举个例子,标签可以储存在一个,类别可以在一个,而文章则在另一个。
1.如果我们需要ACID事务。Vassandra就不支持事务。
2.原型设计。如果我们分析Cassandra的数据结构,我们就会发现结构是基于我们期望的数据查询方式而定。在模型设计之初,我们根本不可能去预测它的查询方式,而一旦查询方式改变,我们就必须重新设计列族。
四、 图(Graph-Oriented)数据库
图数据库允许我们将数据以图的方式储存。实体会被作为顶点,而实体之间的关系则会被作为边。比如我们有三个实体,Steve Jobs、Apple和Next,则会有两个“Founded by”的边将Apple和Next连接到Steve Jobs。
产品:Neo4J、Infinite Graph、OrientDB
有谁在使用:Adobe (Neo4J)、Cisco (Neo4J)、T-Mobile (Neo4J)
1.在一些关系性强的数据中
2.推荐引擎。如果我们将数据以图的形式表现,那么将会非常有益于推荐的制定
不适合的数据模型。图数据库的适用范围很小,因为很少有操作涉及到整个图。

AWS Around---NoSql数据库的不同类型
Nosql类型
有四种常见的 Nosql 数据库类型:列式、文档、图形和内存键值。通常,这些数据库在存储、访问和结构化数据的方式上有所差异,但都针对不同的使用案例和应用程序进行了优化。
- 列式数据库针对读取和写入数据列(而不是数据行)进行了优化。适用于数据库表的列式存储是分析查询性能的一大要素,因为它极大地降低了整体磁盘 I/O 要求,并减少了您需要从磁盘加载的数据量。
- 文档数据库旨在将半结构化数据存储为文档,通常采用 JSON 或 XML 格式。与传统关系数据库不同的是,每个 Nosql 文档的架构是不同的,可让您更加灵活地整理和存储应用程序数据并减少可选值所需的存储。
- 图形数据库可存储顶点以及称为边缘的直接链路。图形数据库可以在 sql 和 Nosql 数据库上构建。顶点和边缘可以拥有各自的相关属性。
- 内存键值存储是针对读取密集型应用程序工作负载(例如社交网络、游戏、媒体共享和 Q&A 门户)或计算密集型工作负载(例如推荐引擎)进行了优化的 Nosql 数据库。内存缓存可将重要数据存储在内存中以实现低延迟访问,从而提高应用程序性能
sql 与 Nosql 术语比较
|
sql
|
MongoDB (Nosql) | DynamoDB (Nosql) | Cassandra (Nosql) | Couchbase (Nosql) |
|
表
|
集合 | 数据存储桶 | ||
| 行 | 文档 | 项目 | 文档 | |
| 列 | 字段 | 属性 | 字段 | |
| 主键 | 对象 ID | 文档 ID | ||
| 索引 | 二级索引 | 索引 | ||
| 视图 | 全局二级索引 | 具体化视图 | 视图 | |
| 嵌套表或对象 | 嵌入文档 | 映射 | 映射 | |
| 数组 | 列表 | 列表 |

NoSQL 数据库的类型
一、 键值(Key-Value)数据库
键值数据库就像在传统语言中使用的哈希表。你可以通过 key 来添加、查询或者删除数据,鉴于使用主键访问,所以会获得不错的性能及扩展性。
产品:Riak、Redis、Memcached、Amazon’s Dynamo、Project Voldemort
有谁在使用:GitHub (Riak)、BestBuy (Riak)、Twitter (Redis 和 Memcached)、StackOverFlow (Redis)、 Instagram (Redis)、Youtube (Memcached)、Wikipedia(Memcached)
适用的场景
储存用户信息,比如会话、配置文件、参数、购物车等等。这些信息一般都和 ID(键)挂钩,这种情景下键值数据库是个很好的选择。
不适用场景
1. 取代通过键查询,而是通过值来查询。Key-Value 数据库中根本没有通过值查询的途径。
2. 需要储存数据之间的关系。在 Key-Value 数据库中不能通过两个或以上的键来关联数据。
3. 事务的支持。在 Key-Value 数据库中故障产生时不可以进行回滚。
二、 面向文档(Document-Oriented)数据库
面向文档数据库会将数据以文档的形式储存。每个文档都是自包含的数据单元,是一系列数据项的集合。每个数据项都有一个名称与对应的值,值既可以是简单的数据类型,如字符串、数字和日期等;也可以是复杂的类型,如有序列表和关联对象。数据存储的最小单位是文档,同一个表中存储的文档属性可以是不同的,数据可以使用 XML、JSON 或者 JSONB 等多种形式存储。
产品:MongoDB、CouchDB、RavenDB
有谁在使用:SAP (MongoDB)、Codecademy (MongoDB)、Foursquare (MongoDB)、NBC News (RavenDB)
适用的场景
1. 日志。企业环境下,每个应用程序都有不同的日志信息。Document-Oriented 数据库并没有固定的模式,所以我们可以使用它储存不同的信息。
2. 分析。鉴于它的弱模式结构,不改变模式下就可以储存不同的度量方法及添加新的度量。
不适用场景
在不同的文档上添加事务。Document-Oriented 数据库并不支持文档间的事务,如果对这方面有需求则不应该选用这个解决方案。
三、 列存储(Wide Column Store/Column-Family)数据库
列存储数据库将数据储存在列族(column family)中,一个列族存储经常被一起查询的相关数据。举个例子,如果我们有一个 Person 类,我们通常会一起查询他们的姓名和年龄而不是薪资。这种情况下,姓名和年龄就会被放入一个列族中,而薪资则在另一个列族中。
产品:Cassandra、HBase
有谁在使用:Ebay (Cassandra)、Instagram (Cassandra)、NASA (Cassandra)、Twitter (Cassandra and HBase)、Facebook (HBase)、Yahoo!(HBase)
适用的场景
1. 日志。因为我们可以将数据储存在不同的列中,每个应用程序可以将信息写入自己的列族中。
2. 博客平台。我们储存每个信息到不同的列族中。举个例子,标签可以储存在一个,类别可以在一个,而文章则在另一个。
不适用场景
1. 如果我们需要 ACID 事务。Vassandra 就不支持事务。
2. 原型设计。如果我们分析 Cassandra 的数据结构,我们就会发现结构是基于我们期望的数据查询方式而定。在模型设计之初,我们根本不可能去预测它的查询方式,而一旦查询方式改变,我们就必须重新设计列族。
四、 图(Graph-Oriented)数据库
图数据库允许我们将数据以图的方式储存。实体会被作为顶点,而实体之间的关系则会被作为边。比如我们有三个实体,Steve Jobs、Apple 和 Next,则会有两个 “Founded by” 的边将 Apple 和 Next 连接到 Steve Jobs。
产品:Neo4J、Infinite Graph、OrientDB
有谁在使用:Adobe (Neo4J)、Cisco (Neo4J)、T-Mobile (Neo4J)
适用的场景
1. 在一些关系性强的数据中
2. 推荐引擎。如果我们将数据以图的形式表现,那么将会非常有益于推荐的制定
不适用场景
不适合的数据模型。图数据库的适用范围很小,因为很少有操作涉及到整个图

nosql-redis-网络资料学习-05-nosql数据库的四大分类
nosql数据库的四大分类
1、NoSql数据库的四大分类
kv、列值、文档、图

## 1.1 kv 键值 ##
应用举例(16年数据)
- 新浪:BerkeleyDB+redis
- 美团:redis+tair
- 阿里、百度:memcache+redis
- 列表项目
1.2 文档型数据库(bson格式比较多)
例如
- CouchDB
- MongoDB
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩 展的高性能数据存储解决方案。MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
1.3 列存储数据库
例如
- Cassandra
- HBase
1.4 图关系型数据库
它不是放图形的,放的是关系比如:朋友圈社交网络、广告推荐系统,社交网络,推荐系统等。专注于构建关系图谱例如:
- Neo4J
- InfoGrid

NoSQL数据库的主主备份
《Nosql数据库的主主备份》要点:
本文介绍了Nosql数据库的主主备份,希望对您有用。如果有疑问,可以联系我们。
翻译 | 贺雨言
Tarantool DBMS的高性能应该很多人都听说过,包含其丰富的工具套件和某些特定功能.比如,它拥有一个非常强大的on-disk存储引擎Vinyl,并且知道怎样处理JSON文档.然而,大部分文章往往忽略了一个关键点:通常,Tarantool仅仅被视为存储器,而实际上其最大特点是能够在存储器内部写代码,从而高效处理数据.如果你想知道我和igorcoding是怎样在Tarantool内部建立一个系统的,请继续往下看.
如果你用过Mail.Ru电子邮件服务,你应该知道它可以从其他账号收集邮件.如果支持OAuth协议,那么在收集其他账号的邮件时,我们就不必要让用户提供第三方服务凭证了,而是用OAuth令牌来代替.此外,Mail.Ru Group有很多项目要求通过第三方服务授权,并且必要用户的OAuth令牌才能处理某些应用.因此,我们决定建立一个存储和更新令牌的服务.
我猜大家都知道OAuth令牌是什么样的,闭上眼睛回忆一下,OAuth结构由以下3-4个字段组成:

拜访令牌(access_token)——允许你执行动作、获取用户数据、下载用户的好友列表等等;
更新令牌(refresh_token)——让你重新获取新的access_token,不限次数;
过期时间(expires_in)——令牌到期时间戳或任何其他预定义时间,如果你的access_token到期了,你就不能继续拜访所需的资源.
现在我们看一下服务的简单框架.设想有一些前端可以在我们的服务上写入和读出令牌,还有一个独立的更新器,一旦令牌到期,就可以通过更新器从OAuth服务提供商获取新的拜访令牌.

如上图所示,数据库的结构也十分简单,由两个数据库节点(主和从)组成,为了说明两个数据库节点分别位于两个数据中心,二者之间由一条垂直的虚线隔开,其中一个数据中心包含主数据库节点及其前端和更新器,另一个数据中心包含从数据库节点及其前端,以及拜访主数据库节点的更新器.
面临的困难
我们面临的主要问题在于令牌的使用期(一个小时).详细了解这个项目之后,也许有人会问“在一小时内更新1000万条记录,这真的是高负载服务吗?如果我们用一个数除一下,结果大约是3000rps”.然而,如果因为数据库维护或故障,甚至服务器故障(一切皆有可能)导致一部分记录没有得到更新,那事情将会变得比拟麻烦.比如,如果我们的服务(主数据库)因为某些原因持续中断15分钟,就会导致25%的服务中断(四分之一的令牌变成无效,不能再继续使用);如果服务中断30分钟,将会有一半的数据不能得到更新;如果中断1小时,那么所有的令牌都将失效.假设数据库瘫痪一个小时,我们重启系统,然后整个1000万条令牌都需要进行快速更新.这算不算高负载服务呢?
一开始一切都还进展地比拟顺利,但是两年后,我们进行了逻辑扩展,增加了几个指标,并且开始执行一些辅助逻辑…….总之,Tarantool耗尽了cpu资源.尽管所有资源都是递耗资源,但这样的结果确实让我们大吃一惊.
幸运的是,系统管理员帮我们安装了当时库存中内存最大的cpu,解决了我们随后6个月的cpu需求.但这只是权宜之计,我们必须想出一个解决方法.当时,我们学习了一个新版的Tarantool(我们的系统是用Tarantool 1.5写的,这个版本除了在Mail.Ru Group,其他地方基本没用过).Tarantool 1.6大力提倡主主备份,于是我们想:为什么不在连接主主备份的三个数据中心分别建立一个数据库备份呢?这听起来是个不错的计划.

三个主机、三个数据中心和三个更新器,都分别连接自己的主数据库.即使一个或者两个主机瘫痪了,系统仍然照常运行,对吧?那么这个方案的缺点是什么呢?缺点就是,我们将一个OAuth服务提供商的哀求数量有效地增加到了三倍,也就是说,有多少个副本,我们就要更新几乎相同数量的令牌,这样不行.最直接的解决办法就是,想办法让各个节点自己决定谁是leader,那样就只需要更新存储在leader上的节点了.
选择leader节点
选择leader节点的算法有很多,其中有一个算法叫paxos,相当复杂,不知道怎样简化,于是我们决定用Raft代替.Raft是一个非常通俗易懂的算法,谁能通信就选谁做leader,一旦通信连接失败或者其他因素,就重新选leader.具体实施方法如下:

Tarantool外部既没有Raft也没有paxos,但是我们可以使用net.Box内置模式,让所有节点连接成一个网状网(即每一个节点连接剩下所有节点),然后直接在这些连接上用Raft算法选出leader节点.最后,所有节点要么成为leader节点,要么成为follower节点,或者二者都不是.
如果你觉得Raft算法实施起来有困难,下面的Lua代码可以帮到你:

现在我们给远程服务器发送哀求(其他Tarantool副本)并计算来自每一个节点的票数,如果我们有一个quorum,我们就选定了一个leader,然后发送heartbeats,告诉其他节点我们还活着.如果我们在选举中失败了,我们可以发起另一场选举,一段时间之后,我们又可以投票或被选为leader.
只要我们有一个quorum,选中一个leader,我们就可以将更新器指派给所有节点,但是只准它们为leader服务.
这样我们就规范了流量,由于任务是由单一的节点派出,因此每一个更新器获得大约三分之一的任务,有了这样的设置,我们可以失去任何一台主机,因为如果某台主机出故障了,我们可以发起另一个选举,更新器也可以切换到另一个节点.然而,和其他分布式系统一样,有好几个问题与quorum有关.
“废弃”节点
如果各个数据中心之间失去联系了,那么我们必要有一些适当的机制去维持整个系统正常运转,还必要有一套机制能恢复系统的完整性.Raft成功地做到了这两点:

假设Dataline数据中心掉线了,那么该位置的节点就变成了“废弃”节点,也就是说该节点就看不到其他节点了,集群中的其他节点可以看到这个节点丢失了,于是引发了另一个选举,然后新的集群节点(即上级节点)被选为leader,整个系统仍然坚持运转,因为各个节点之间仍然坚持一致性(大半部分节点仍然互相可见).
那么问题来了,与丢失的数据中心有关的更新器怎么样了呢?Raft说明书没有给这样的节点一个单独的名字,通常,没有quorum的节点和不能与leader联系的节点会被闲置下来.然而,它可以本身建立网络连接然后更新令牌,一般来说,令牌都是在连接模式时更新,但是,也许用一个连接“废弃”节点的更新器也可以更新令牌.一开始我们并不确定这样做有意义,这样不会导致冗余更新吗?
这个问题我们必要在实施系统的过程中搞清楚.我们的第一个想法是不更新:我们有一致性、有quorum,丢失任何一个成员,我们都不应该更新.但是后来我们有了另一个想法,我们看一下Tarantool中的主主备份,假设有两个主节点和一个变量(key)X=1,我们同时在每一个节点上给这个变量赋一个新值,一个赋值为2,另一个赋值为3,然后,两个节点互相交换备份日志(就是X变量的值).在一致性上,这样实施主主备份是很糟糕的(无意冒犯Tarantool开发者).

如果我们必要严格的一致性,这样是行不通的.然而,回忆一下我们的OAuth令牌是由以下两个重要因素组成:
更新令牌,本色上永久有效;
拜访令牌,有效期为一个小时;
我们的更新器有一个refresh函数,可以从一个更新令牌获取任意数量的拜访令牌,一旦发布,它们都将保持一个小时内有效.
我们考虑一下以下场景:两个follower节点正在和一个leader节点交互,它们更新自己的令牌,接收第一个拜访令牌,这个拜访令牌被复制,于是现在每一个节点都有这个拜访令牌,连接中断了,所以,其中一个follower节点变成了“废弃”节点,它没有quorum,既看不到leader也看不到其他follower,然而,我们允许我们的更新器去更新位于“废弃”节点上的令牌,如果“废弃”节点没有连接网络,那么整个方案都将停止运行.尽管如此,如果发生简单的网络拆分,更新器还是可以维持正常运行.
一旦网络拆分结束,“废弃”节点重新加入集群,就会引发另一场选举或者数据交换.注意,第二和第三个令牌一样,也是“好的”.
原始的集群成员恢复之后,下一次更新将只在一个节点上发生,然后备份.换句话来说,当集群拆分之后,被拆分的各个部分各自独立更新,但是一旦重新整合,数据一致性也因此恢复.通常,需要N/2+1个活动节点(对于一个3节点集群,就是需要2个活动节点)去保持集群正常运转.尽管如此,对我们而言,即使只有1个活动节点也足够了,它会发送尽可能多的外部哀求.
重申一下,我们已经讨论了哀求数量逐渐增加的情况,在网络拆分或节点中断时期,我们能够提供一个单一的活动节点,我们会像平时一样更新这个节点,如果出现绝对拆分(即当一个集群被分成最大数量的节点,每一个节点有一个网络连接),如上所述,OAuth服务提供商的哀求数量将提升至三倍.但是,由于这个事件发生的时间相对短暂,所以情况不是太糟,我们可不希望一直工作在拆分模式.通常情况下,系统处于有quorum和网络连接,并且所有节点都启动运行的状态.
分片
还有一个问题没有解决:我们已经达到了cpu上限,最直接的解决方法就是分片.

假设我们有两个数据库分片,每一个都有备份,有一个这样的函数,给定一些key值,就可以计算出哪一个分片上有所必要的数据.如果我们通过电子邮件分片,一部分地址存储在一个分片上,另一部分地址存储在另一个分片上,我们很清楚我们的数据在哪里.
有两种办法可以分片.一种是客户端分片,我们选择一个返回分片数量的连续的分片函数,比如CRC32、Guava或Sumbur,这个函数在所有客户端的实现方式都一样.这种办法的一个明显优势在于数据库对分片一无所知,你的数据库正常运转,然后分片就发生了.
然而,这种办法也存在一个很严重的缺陷.一开始,客户端非常繁忙.如果你想要一个新的分片,你需要把分片逻辑加进客户端,这里的最大的问题是,可能一些客户端在使用这种模式,而另一些客户端却在使用另一种完全不同的模式,而数据库本身却不知道有两种不同的分片模式.
我们选择另一种办法—数据库内部分片,这种情况下,数据库代码变得更加复杂,但是为了折中我们可以使用简单的客户端,每一个连接数据库的客户端被路由到任意节点,由一个特殊函数计算出哪一个节点应该被连接、哪一个节点应该被控制.前面提到,由于数据库变得更加复杂,因此为了折中,客户端就变得更加简单了,但是这样的话,数据库就要对其数据全权负责.此外,最困难的事就是重新分片,如果你有一大堆客户端无法更新,相比之下,如果数据库负责管理自己的数据,那重新分片就会变得非常简单.
具体怎样实施呢?

六边形代表Tarantool实体,有3个节点组成分片1,另一个3节点集群作为分片2,如果我们将所有节点互相连接,结果会怎样呢?根据Raft,我们可以知道每一个集群的状态,谁是leader服务器谁是follower服务器也一目了然,由于是集群内连接,我们还可以知道其他分片(例如它的leader分片或者follower分片)的状态.总的来说,如果拜访第一个分片的用户发现这并不是他需要的分片,我们很清楚地知道应该指导他往哪里走.
我们来看一些简单的例子:
假设用户向驻留在第一个分片上的key发出哀求,该哀求被第一个分片上的某一个节点接收,这个节点知道谁是leader,于是将哀求重新路由到分片leader,反过来,分片leader对这个key进行读或写,并且将结果反馈给用户.
第二个场景:用户的哀求到达第一个分片中的相同节点,但是被哀求的key却在第二个分片上,这种情况也可以用类似的方法处理,第一个分片知道第二个分片上谁是leader,然后把哀求送到第二个分片的leader进行转发和处理,再将结果返回给用户.
这个方案十分简单,但也存在必定的缺陷,其中最大的问题就是连接数,在二分片的例子中,每一个节点连接到其他剩下的节点,连接数是6*5=30,如果再加一个3节点分片,那么连接数就增加到72,这会不会有点多呢?
我们该如何解决这个问题呢?我们只需要增加一些Tarantool实例,我们叫它代理,而不叫分片或数据库,用代理去解决所有的分片问题:包括计算key值和定位分片领导.另一方面,Raft集群保持自包含,只在分片内部工作.当用户拜访代理时,代理计算出所需要的分片,如果需要的是leader,就对用户作相应的重定向,如果不是leader,就将用户重定向至分片内的任意节点.

由此产生的复杂性是线性的,取决于节点数量.现在一共3个节点,每个节点3个分片,连接数少了几倍.
代理方案的设计考虑到了进一步规模扩展(当分片数量大于2时),当只有2个分片时,连接数不变,但是当分片数量增加时,连接数会剧减.分片列表存储在Lua配置文件中,如果想要获取新列表,我们只必要重载代码就好了.
综上所述,首先,我们进行主主备份,应用Raft算法,然后加入分片和代理,最后我们得到的是一个单块,一个集群,所以说,目前这个方案看上去是比拟简单的.
剩下的就是只读或只写令牌的的前端了,我们有更新器可以更新令牌,获得更新令牌后把它传到OAuth服务提供商,然后写一个新的拜访令牌.
前面说过我们的一些辅助逻辑耗尽了cpu资源,现在我们将这些辅助资源移到另一个集群上.
辅助逻辑主要和地址簿有关,给定一个用户令牌,就会有一个对应的地址簿,地址簿上的数据量和令牌一样,为了不耗尽一台机器上的cpu资源,我们显然需要一个与副原形同的集群,只需要加一堆更新地址簿的更新器就可以了(这个任务比较少见,因此地址簿不会和令牌一起更新).
最后,通过整合这两个集群,我们得到一个相对简单的完整结构:

令牌更新队列
为什么我们本可以使用标准队列却还要用本身的队列呢?这和我们的令牌更新模型有关.令牌一旦发布,有效期就是一个小时,当令牌快要到期时,需要进行更新,而令牌更新必须在某个特定的时间点之前完成.

假设系统中断了,但是我们有一堆已到期的令牌,而在我们更新这些令牌的同时,又有其他令牌陆续到期,虽然我们最后肯定能全部更新完,但是如果我们先更新那些即将到期的(60秒内),再用剩下的资源去更新已经到期的,是不是会更合理一些?(优先级别最低的是还有4-5分钟才到期的令牌)
用第三方软件来实现这个逻辑并不是件容易的事,对于Tarantool来说却不费吹灰之力.看一个简单的方案:在Tarantool中有一个存储数据的元组,这个元组的一些ID设置了基础key值,为了得到我们必要的队列,我们只必要添加两个字段:status(队列令牌状态)和time(到期时间或其他预定义时间).

现在我们考虑一下队列的两个主要功能—put和take.put就是写入新数据.给定一些负载,put时本身设置好status和time,然后写数据,这就是建立一个新的元组.
至于take,是指建立一个基于索引的迭代器,挑出那些等待办理的任务(处于就绪状态的任务),然后核查一下是不是该接收这些任务了,或者这些任务是否已经到期了.如果没有任务,take就切换到wait模式.除了内置Lua,Tarantool还有一些所谓的通道,这些通道本质上是互联光纤同步原语.任何光纤都可以建立一个通道然后说“我在这等着”,剩下的其他光纤可以唤醒这个通道然后给它发送信息.
等待中的函数(等待发布任务、等待指定时间或其他)建立一个通道,给通道贴上适当的标签,将通道放置在某个地方,然后进行监听.如果我们收到一个紧急的更新令牌,put会给通道发出通知,然后take接收更新任务.
Tarantool有一个特殊的功能:如果一个令牌被意外发布,或者一个更新令牌被take接收,或者只是出现接收任务的现象,以上三种情况Tarantool都可以跟踪到客户端中断.我们将每一个连接与指定给该连接的任务联系起来,并将这些映射关系坚持在会话保存中.假设由于网络中断导致更新过程失败,而且我们不知道这个令牌是否会被更新并被写回到数据库.于是,客户端发生中断了,搜索与失败过程相关的所有任务的会话保存,然后自动将它们释放.随后,任意已发布的任务都可以用同一个通道给另一个put发送信息,该put会快速接收和执行任务.
实际上,具体实施方案并不必要太多代码:

Put只是接收用户想要插入队列的所有数据,并将其写入某个空间,如果是一个简单的索引式FIFO队列,设置好状态和当前时间,然后返回该任务.
接下来要和take有点关系了,但仍然比拟简单.我们建立一个迭代器,等待接收新任务.Taken函数只需要将任务标记成“已接收”,但有一点很重要,taken函数还能记住哪个任务是由哪个进程接收的.On_disconnect函数可以发布某个特定连接,或者发布由某个特定用户接收的所有任务.
是否有可选方案
当然有.我们本可以使用任意数据库,不管我们选用什么数据库,我们都要建立一个队列用来处理外部系统、处理更新等等问题.我们不能仅仅按需更新令牌,因为那样会产生不可预估的工作量,不管怎样,我们需要坚持我们的系统充满活力,但是那样,我们就要将延期的任务也插入队列,并且保证数据库和队列之间的一致性,我们还要被迫使用一个quorum的容错队列.此外,如果我们把数据同时放在RAM和一个(考虑到工作量)可能要放入内存的队列中,那么我们就要消耗更多资源.
在我们的方案中,数据库存储令牌,队列逻辑只必要占用7个字节(每个元组只必要7个额外的字节,就可以搞定队列逻辑!),如果使用其他的队列形式,必要占用的空间就多得多了,大概是内存容量的两倍.
总结
首先,我们解决了连接中断的问题,这个问题十分常见,使用上述的系统让我们解脱了这个困扰.
分片赞助我们扩展内存,我们将连接数从二次方减少到了线性,优化了业务任务的队列逻辑:如果发生延期,更新我们所能更新的一切令牌,这些延期并非都是我们的故障引起的,有可能是Google、Microsoft或者其他服务端对OAuth服务提供商进行改造,然后导致我们这边出现大量的未更新的令牌.
去数据库内部运算吧,走近数据,你将拥有方便、高效、可扩展和灵活的运算体验!
《Nosql数据库的主主备份》是否对您有启发,欢迎查看更多与《Nosql数据库的主主备份》相关教程,学精学透。小编PHP学院为您提供精彩教程。
关于NoSQL数据库的类型和nosql数据库的类型包括的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于AWS Around---NoSql数据库的不同类型、NoSQL 数据库的类型、nosql-redis-网络资料学习-05-nosql数据库的四大分类、NoSQL数据库的主主备份的相关知识,请在本站寻找。
本文将介绍The NoSQL System的详细情况,。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于/usr/include/boost/system/error_code.hpp:208:链接时未定义对`boost :: system :: get_system_category()的引用、Azure 函数的 Cosmos DB 输入绑定无法将 System.String 转换为 System.Guid、c# – 如何将System.Diagnostics.Trace和System.Diagnostics.Debug消息记录到NLog文件?、CentOS7 mysql 连接不上 :[ERROR] InnoDB: The innodb_system data file ''ibdata1'' must be writable的知识。
本文目录一览:- The NoSQL System
- /usr/include/boost/system/error_code.hpp:208:链接时未定义对`boost :: system :: get_system_category()的引用
- Azure 函数的 Cosmos DB 输入绑定无法将 System.String 转换为 System.Guid
- c# – 如何将System.Diagnostics.Trace和System.Diagnostics.Debug消息记录到NLog文件?
- CentOS7 mysql 连接不上 :[ERROR] InnoDB: The innodb_system data file ''ibdata1'' must be writable

The NoSQL System
不同于大多数其他的项目在这本书中,Nosql 不是一种工具,但生态系统组成的几个免费和相互竞争的工具。烙上 Nosql 外号的工具提供了用于存储数据的基于 sql 的关系数据库系统替代方案。若要了解使用 Nosql,我们必须理解可用的工具的空间,看看如何的每一个设计探索的空间数据存储的可能性。
如果你正在考虑使用 Nosql 存储系统,你先要了解的选项,Nosql 系统跨越了广阔的空间。Nosql 系统废除了许多传统的关系数据库系统,舒适,后面一个数据库系统的边界通常封装的业务现在留给应用程序设计人员。这就要求你带上这顶帽子的系统架构师,需要更深入地了解如何构建这样的系统。 13.1.什么是在一个名称?
在界定 Nosql 的空间,让我们先尝试定义名称。字面上看,Nosql 系统给用户不是 sql 的查询接口。Nosql 社区通常需要一个更具包容性的看法,建议使用 Nosql 系统提供替代传统的关系数据库,并允许开发者在设计使用不只一个 sql 接口的项目。在某些情况下,您可能使用 Nosql 的替代方法,替换关系型数据库和在其他你会聘请您在应用程序开发中遇到的不同问题的混合和匹配方法。
在进 Nosql 的世界之前,让我们了解一下 sql 和关系模型适合您的需要,和别人 Nosql 系统可能在哪一个更好的适合的情况。 13.1.1。 sql 和关系模型
sql 是查询数据的声明性语言。声明性语言,是其中一个程序员指定他们想要的系统来做,而不是程序上定义的系统应该怎么做。一些例子包括: 找到的记录为员工 39,投影出只有雇员姓名和电话号码,从他们的整个记录,筛选员工记录那些在会计工作,在每个部门、 员工或参加与经理人表的雇员表中的数据。
到第一近似值,sql 允许你想要问这些问题不加思索的数据在磁盘上,哪个指数,用来访问数据,布局方式或什么算法用来处理数据。大多数关系数据库的一个重要的建筑部分是查询优化器,决定哪些许多的逻辑上等效的查询计划,要执行最快回答查询。这些优化往往比平均的数据库用户,但他们有时没有足够的信息,或者有太简单了系统模型,以产生最有效的执行。
关系数据库,它是在实践中使用的最常见的数据库,请按照关系数据模型。在此模型中,不同的真实世界的实体存储在不同的表中。例如,所有的员工可能会存储在雇员表,和所有部门可能都存储在一个部门表。每个表中的行具有各种属性存储在列中。例如,员工可能有雇员 id、 薪金、 出生日期和第一个/最后一个名字。上述每个属性将存储在列中的雇员表。
关系模型去手中用 sql 语句。简单的 sql 查询,如滤波器、 检索所有记录一些的测试匹配的字段 (例如,雇员 id = 3 或工资 > 美元 20000)。更复杂的构造原因数据库做一些额外的工作,例如将数据从多个表 (例如,什么是哪个员工 3 工程部门的名称吗?) 联接。其他复杂的构造,例如聚合 (例如,什么是我的员工的平均工资?) 可能会导致全表扫描。
关系数据模型定义了与它们之间的严格关系高度结构化的实体。此模型与 sql 的查询将允许复杂数据遍历没有太多自定义的发展。这种建模的复杂性和查询虽然有其局限性,: ? 1 2 3
复杂性会导致不可预测性。sql 的表现力,使每个查询的成本和因而工作量的成本原因所面临的挑战。虽然简单的查询语言可能更为复杂的应用程序逻辑,他们使它易于提供数据存储系统,只有简单的请求作出回应。 有许多方法,模型存在的问题。关系数据模型是严格: 分配给每个表的架构在每行中指定的数据。如果我们存储更少的结构化的数据或行更多的差异,它们存储的列中,关系的模型可能会不必要地限制。同样地,应用程序开发人员可能无法找到关系模型适合每种类型的数据建模。例如,大量的应用程序逻辑写在面向对象的语言,包括高级概念 suc
Unlike most of the other projects in this book,Nosql is not a tool,but an ecosystem composed of several complimentary and competing tools. The tools branded with the Nosql monicker provide an alternative to sql-based relational database systems for storing data. To understand Nosql,we have to understand the space of available tools,and see how the design of each one explores the space of data storage possibilities.
If you are considering using a Nosql storage system,you should first understand the wide space of options that Nosql systems span. Nosql systems do away with many of the Traditional comforts of relational database systems,and operations which were typically encapsulated behind the system boundary of a database are Now left to application designers. This requires you to take on the hat of a systems architect,which requires a more in-depth understanding of how such systems are built. 13.1. What's in a Name?
In defining the space of Nosql,let's first take a stab at defining the name. Taken literally,a Nosql system presents a query interface to the user that is not sql. The Nosql community generally takes a more inclusive view,suggesting that Nosql systems provide alternatives to Traditional relational databases,and allow developers to design projects which use Not Only a sql interface. In some cases,you might replace a relational database with a Nosql alternative,and in others you will employ a mix-and-match approach to different problems you encounter in application development.
Before diving into the world of Nosql,let's explore the cases where sql and the relational model suit your needs,and others where a Nosql system might be a better fit. 13.1.1. sql and the Relational Model
sql is a declarative language for querying data. A declarative language is one in which a programmer specifies what they want the system to do,rather than procedurally defining how the system should do it. A few examples include: find the record for employee 39,project out only the employee name and phone number from their entire record,filter employee records to those that work in accounting,count the employees in each department,or join the data from the employees table with the managers table.
To a first approximation,sql allows you to ask these questions without thinking about how the data is laid out on disk,which indices to use to access the data,or what algorithms to use to process the data. A significant architectural component of most relational databases is a query optimizer,which decides which of the many logically equivalent query plans to execute to most quickly answer a query. These optimizers are often better than the average database user,but sometimes they do not have enough information or have too simple a model of the system in order to generate the most efficient execution.
Relational databases,which are the most common databases used in practice,follow the relational data model. In this model,different real-world entities are stored in different tables. For example,all employees might be stored in an Employees table,and all departments might be stored in a Departments table. Each row of a table has varIoUs properties stored in columns. For example,employees might have an employee id,salary,birth date,and first/last names. Each of these properties will be stored in a column of the Employees table.
The relational model goes hand-in-hand with sql. Simple sql queries,such as filters,retrieve all records whose field matches some test (e.g.,employeeid = 3,or salary > $20000). More complex constructs cause the database to do some extra work,such as joining data from multiple tables (e.g.,what is the name of the department in which employee 3 works?). Other complex constructs such as aggregates (e.g.,what is the average salary of my employees?) can lead to full-table scans.
The relational data model defines highly structured entities with strict relationships between them. Querying this model with sql allows complex data traversals without too much custom development. The complexity of such modeling and querying has its limits,though:
Complexity leads to unpredictability. sql's expressiveness makes it challenging to reason about the cost of each query,and thus the cost of a workload. While simpler query languages might complicate application logic,they make it easier to provision data storage systems,which only respond to simple requests. There are many ways to model a problem. The relational data model is strict: the schema assigned to each table specifies the data in each row. If we are storing less structured data,or rows with more variance in the columns they store,the relational model may be needlessly restrictive. Similarly,application developers might not find the relational model perfect for modeling every kind of data. For example,a lot of application logic is written in object-oriented languages and includes high-level concepts such as lists,queues,and sets,and some programmers would like their persistence layer to model this. If the data grows past the capacity of one server,then the tables in the database will have to be partitioned across computers. To avoid JOINs having to cross the network in order to get data in different tables,we will have to denormalize it. Denormalization stores all of the data from different tables that one might want to look up at once in a single place. This makes our database look like a key-lookup storage system,leaving us wondering what other data models might better suit the data.
It's generally not wise to discard many years of design considerations arbitrarily. When you consider storing your data in a database,consider sql and the relational model,which are backed by decades of research and development,offer rich modeling capabilities,and provide easy-to-understand guarantees about complex operations. Nosql is a good option when you have a specific problem,such as large amounts of data,a massive workload,or a difficult data modeling decision for which sql and relational databases might not have been optimized. 13.1.2. Nosql Inspirations
The Nosql movement finds much of its inspiration in papers from the research community. While many papers are at the core of design decisions in Nosql systems,two stand out in particular.
Google's BigTable [CDG+06] presents an interesting data model,which facilitates sorted storage of multi-column historical data. Data is distributed to multiple servers using a hierarchical range-based partitioning scheme,and data is updated with strict consistency (a concept that we will eventually define in Section 13.5).
Amazon's Dynamo [DHJ+07] uses a different key-oriented distributed datastore. Dynamo's data model is simpler,mapping keys to application-specific blobs of data. The partitioning model is more resilient to failure,but accomplishes that goal through a looser data consistency approach called eventual consistency.
We will dig into each of these concepts in more detail,but it is important to understand that many of them can be mixed and matched. Some Nosql systems such as HBase1 sticks closely to the BigTable design. Another Nosql system named Voldemort2 replicates many of Dynamo's features. Still other Nosql projects such as Cassandra3 have taken some features from BigTable (its data model) and others from Dynamo (its partitioning and consistency schemes). 13.1.3. characteristics and Considerations
Nosql systems part ways with the hefty sql standard and offer simpler but piecemeal solutions for architecting storage solutions. These systems were built with the belief that in simplifying how a database operates over data,an architect can better predict the performance of a query. In many Nosql systems,complex query logic is left to the application,resulting in a data store with more predictable query performance because of the lack of variability in queries
Nosql systems part with more than just declarative queries over the relational data. Transactional semantics,consistency,and durability are guarantees that organizations such as banks demand of databases. Transactions provide an all-or-nothing guarantee when combining several potentially complex operations into one,such as deducting money from one account and adding the money to another. Consistency ensures that when a value is updated,subsequent queries will see the updated value. Durability guarantees that once a value is updated,it will be written to stable storage (such as a hard drive) and recoverable if the database crashes.
Nosql systems relax some of these guarantees,a decision which,for many non-banking applications,can provide acceptable and predictable behavior in exchange for improved performance. These relaxations,combined with data model and query language changes,often make it easier to safely partition a database across multiple machines when the data grows beyond a single machine's capability.
Nosql systems are still very much in their infancy. The architectural decisions that go into the systems described in this chapter are a testament to the requirements of varIoUs users. The biggest challenge in summarizing the architectural features of several open source projects is that each one is a moving target. Keep in mind that the details of individual systems will change. When you pick between Nosql systems,you can use this chapter to guide your thought process,but not your feature-by-feature product selection.
As you think about Nosql systems,here is a roadmap of considerations:
Data and query model: Is your data represented as rows,objects,data structures,or documents? Can you ask the database to calculate aggregates over multiple records? Durability: When you change a value,does it immediately go to stable storage? Does it get stored on multiple machines in case one crashes? Scalability: Does your data fit on a single server? Do the amount of reads and writes require multiple disks to handle the workload? Partitioning: For scalability,availability,or durability reasons,does the data need to live on multiple servers? How do you kNow which record is on which server? Consistency: If you've partitioned and replicated your records across multiple servers,how do the servers coordinate when a record changes? Transactional semantics: When you run a series of operations,some databases allow you to wrap them in a transaction,which provides some subset of ACID (Atomicity,Consistency,Isolation,and Durability) guarantees on the transaction and all others currently running. Does your business logic require these guarantees,which often come with performance tradeoffs? Single-server performance: If you want to safely store data on disk,what on-disk data structures are best-geared toward read-heavy or write-heavy workloads? Is writing to disk your bottleneck? Analytical workloads: We're going to pay a lot of attention to lookup-heavy workloads of the kind you need to run a responsive user-focused web application. In many cases,you will want to build dataset-sized reports,aggregating statistics across multiple users for example. Does your use-case and toolchain require such functionality?
While we will touch on all of these consideration,the last three,while equally important,see the least attention in this chapter. 13.2. Nosql Data and Query Models
The data model of a database specifies how data is logically organized. Its query model dictates how the data can be retrieved and updated. Common data models are the relational model,key-oriented storage model,or varIoUs graph models. Query languages you might have heard of include sql,key lookups,and MapReduce. Nosql systems combine different data and query models,resulting in different architectural considerations. 13.2.1. Key-based Nosql Data Models
Nosql systems often part with the relational model and the full expressivity of sql by restricting lookups on a dataset to a single field. For example,even if an employee has many properties,you might only be able to retrieve an employee by her ID. As a result,most queries in Nosql systems are key lookup-based. The programmer selects a key to identify each data item,and can,for the most part,only retrieve items by performing a lookup for their key in the database.
In key lookup-based systems,complex join operations or multiple-key retrieval of the same data might require creative uses of key names. A programmer wishing to look up an employee by his employee ID and to look up all employees in a department might create two key types. For example,the key employee:30 would point to an employee record for employee ID 30,and employee_departments:20 might contain a list of all employees in department 20. A join operation gets pushed into application logic: to retrieve employees in department 20,an application first retrieves a list of employee IDs from key employee_departments:20,and then loops over key lookups for each employee:ID in the employee list.
The key lookup model is beneficial because it means that the database has a consistent query pattern—the entire workload consists of key lookups whose performance is relatively uniform and predictable. Profiling to find the slow parts of an application is simpler,since all complex operations reside in the application code. On the flip side,the data model logic and business logic are Now more closely intertwined,which muddles abstraction.
Let's quickly touch on the data associated with each key. VarIoUs Nosql systems offer different solutions in this space. Key-Value Stores
The simplest form of Nosql store is a key-value store. Each key is mapped to a value containing arbitrary data. The Nosql store has no kNowledge of the contents of its payload,and simply delivers the data to the application. In our Employee database example,one might map the key employee:30 to a blob containing JSON or a binary format such as Protocol Buffers4,Thrift5,or Avro6 in order to encapsulate the information about employee 30.
If a developer uses structured formats to store complex data for a key,she must operate against the data in application space: a key-value data store generally offers no mechanisms for querying for keys based on some property of their values. Key-value stores shine in the simplicity of their query model,usually consisting of set,get,and delete primitives,but discard the ability to add simple in-database filtering capabilities due to the opacity of their values. Voldemort,which is based on Amazon's Dynamo,provides a distributed key-value store. BDB7 offers a persistence library that has a key-value interface. Key-Data Structure Stores
Key-data structure stores,made popular by Redis8,assign each value a type. In Redis,the available types a value can take on are integer,string,list,set,and sorted set. In addition to set/get/delete,type-specific commands,such as increment/decrement for integers,or push/pop for lists,add functionality to the query model without drastically affecting performance characteristics of requests. By providing simple type-specific functionality while avoiding multi-key operations such as aggregation or joins,Redis balances functionality and performance. Key-Document Stores
Key-document stores,such as CouchDB9,MongoDB10,and Riak11,map a key to some document that contains structured information. These systems store documents in a JSON or JSON-like format. They store lists and dictionaries,which can be embedded recursively inside one-another.
MongoDB separates the keyspace into collections,so that keys for Employees and Department,for example,do not collide. CouchDB and Riak leave type-tracking to the developer. The freedom and complexity of document stores is a double-edged sword: application developers have a lot of freedom in modeling their documents,but application-based query logic can become exceedingly complex. BigTable Column Family Stores
HBase and Cassandra base their data model on the one used by Google's BigTable. In this model,a key identifies a row,which contains data stored in one or more Column Families (CFs). Within a CF,each row can contain multiple columns. The values within each column are timestamped,so that several versions of a row-column mapping can live within a CF.
Conceptually,one can think of Column Families as storing complex keys of the form (row ID,CF,column,timestamp),mapping to values which are sorted by their keys. This design results in data modeling decisions which push a lot of functionality into the keyspace. It is particularly good at modeling historical data with timestamps. The model naturally supports sparse column placement since row IDs that do not have certain columns do not need an explicit NULL value for those columns. On the flip side,columns which have few or no NULL values must still store the column identifier with each row,which leads to greater space consumption.
Each project data model differs from the original BigTable model in varIoUs ways,but Cassandra's changes are most notable. Cassandra introduces the notion of a supercolumn within each CF to allow for another level of mapping,modeling,and indexing. It also does away with a notion of locality groups,which can physically store multiple column families together for performance reasons. 13.2.2. Graph Storage
One class of Nosql stores are graph stores. Not all data is created equal,and the relational and key-oriented data models of storing and querying data are not the best for all data. Graphs are a fundamental data structure in computer science,and systems such as HypergraphDB12 and Neo4J13 are two popular Nosql storage systems for storing graph-structured data. Graph stores differ from the other stores we have discussed thus far in almost every way: data models,data traversal and querying patterns,physical layout of data on disk,distribution to multiple machines,and the transactional semantics of queries. We can not do these stark differences justice given space limitations,but you should be aware that certain classes of data may be better stored and queried as a graph. 13.2.3. Complex Queries
There are notable exceptions to key-only lookups in Nosql systems. MongoDB allows you to index your data based on any number of properties and has a relatively high-level language for specifying which data you want to retrieve. BigTable-based systems support scanners to iterate over a column family and select particular items by a filter on a column. CouchDB allows you to create different views of the data,and to run MapReduce tasks across your table to facilitate more complex lookups and updates. Most of the systems have bindings to Hadoop or another MapReduce framework to perform dataset-scale analytical queries. 13.2.4. Transactions
Nosql systems generally prioritize performance over transactional semantics. Other sql-based systems allow any set of statements—from a simple primary key row retrieval,to a complicated join between several tables which is then subsequently averaged across several fields—to be placed in a transaction.
These sql databases will offer ACID guarantees between transactions. Running multiple operations in a transaction is Atomic (the A in ACID),meaning all or none of the operations happen. Consistency (the C) ensures that the transaction leaves the database in a consistent,uncorrupted state. Isolation (the I) makes sure that if two transactions touch the same record,they will do without stepping on each other's feet. Durability (the D,covered extensively in the next section),ensures that once a transaction is committed,it's stored in a safe place.
ACID-compliant transactions keep developers sane by making it easy to reason about the state of their data. Imagine multiple transactions,each of which has multiple steps (e.g.,first check the value of a bank account,then subtract $60,then update the value). ACID-compliant databases often are limited in how they can interleave these steps while still providing a correct result across all transactions. This push for correctness results in often-unexpected performance characteristics,where a slow transaction might cause an otherwise quick one to wait in line.
Most Nosql systems pick performance over full ACID guarantees,but do provide guarantees at the key level: two operations on the same key will be serialized,avoiding serIoUs corruption to key-value pairs. For many applications,this decision will not pose noticeable correctness issues,and will allow quick operations to execute with more regularity. It does,however,leave more considerations for application design and correctness in the hands of the developer.
Redis is the notable exception to the no-transaction trend. On a single server,it provides a MULTI command to combine multiple operations atomically and consistently,and a WATCH command to allow isolation. Other systems provide lower-level test-and-set functionality which provides some isolation guarantees. 13.2.5. Schema-free Storage
A cross-cutting property of many Nosql systems is the lack of schema enforcement in the database. Even in document stores and column family-oriented stores,properties across similar entities are not required to be the same. This has the benefit of supporting less structured data requirements and requiring less performance expense when modifying schemas on-the-fly. The decision leaves more responsibility to the application developer,who Now has to program more defensively. For example,is the lack of a lastname property on an employee record an error to be rectified,or a schema update which is currently propagating through the system? Data and schema versioning is common in application-level code after a few iterations of a project which relies on sloppy-schema Nosql systems. 13.3. Data Durability
Ideally,all data modifications on a storage system would immediately be safely persisted and replicated to multiple locations to avoid data loss. However,ensuring data safety is in tension with performance,and different Nosql systems make different data durability guarantees in order to improve performance. Failure scenarios are varied and numerous,and not all Nosql systems protect you against these issues.
A simple and common failure scenario is a server restart or power loss. Data durability in this case involves having moved the data from memory to a hard disk,which does not require power to store data. Hard disk failure is handled by copying the data to secondary devices,be they other hard drives in the same machine (RAID mirroring) or other machines on the network. However,a data center might not survive an event which causes correlated failure (a tornado,for example),and some organizations go so far as to copy data to backups in data centers several hurricane widths apart. Writing to hard drives and copying data to multiple servers or data centers is expensive,so different Nosql systems Trade off durability guarantees for performance. 13.3.1. Single-server Durability
The simplest form of durability is a single-server durability,which ensures that any data modification will survive a server restart or power loss. This usually means writing the changed data to disk,which often bottlenecks your workload. Even if you order your operating system to write data to an on-disk file,the operating system may buffer the write,avoiding an immediate modification on disk so that it can group several writes together into a single operation. Only when the fsync system call is issued does the operating system make a best-effort attempt to ensure that buffered updates are persisted to disk.
Typical hard drives can perform 100-200 random accesses (seeks) per second,and are limited to 30-100 MB/sec of sequential writes. Memory can be orders of magnitudes faster in both scenarios. Ensuring efficient single-server durability means limiting the number of random writes your system incurs,and increasing the number of sequential writes per hard drive. Ideally,you want a system to minimize the number of writes between fsync calls,maximizing the number of those writes that are sequential,all the while never telling the user their data has been successfully written to disk until that write has been fsynced. Let's cover a few techniques for improving performance of single-server durability guarantees. Control fsync Frequency
Memcached14 is an example of a system which offers no on-disk durability in exchange for extremely fast in-memory operations. When a server restarts,the data on that server is gone: this makes for a good cache and a poor durable data store.
Redis offers developers several options for when to call fsync. Developers can force an fsync call after every update,which is the slow and safe choice. For better performance,Redis can fsync its writes every N seconds. In a worst-case scenario,the you will lose last N seconds worth of operations,which may be acceptable for certain uses. Finally,for use cases where durability is not important (maintaining coarse-grained statistics,or using Redis as a cache),the developer can turn off fsync calls entirely: the operating system will eventually flush the data to disk,but without guarantees of when this will happen. Increase Sequential Writes by Logging
Several data structures,such as B+Trees,help Nosql systems quickly retrieve data from disk. Updates to those structures result in updates in random locations in the data structures' files,resulting in several random writes per update if you fsync after each update. To reduce random writes,systems such as Cassandra,HBase,Redis,and Riak append update operations to a sequentially-written file called a log. While other data structures used by the system are only periodically fsynced,the log is frequently fsynced. By treating the log as the ground-truth state of the database after a crash,these storage engines are able to turn random updates into sequential ones.
While Nosql systems such as MongoDB perform writes in-place in their data structures,others take logging even further. Cassandra and HBase use a technique borrowed from BigTable of combining their logs and lookup data structures into one log-structured merge tree. Riak provides similar functionality with a log-structured hash table. CouchDB has modified the Traditional B+Tree so that all changes to the data structure are appended to the structure on physical storage. These techniques result in improved write throughput,but require a periodic log compaction to keep the log from growing unbounded. Increase Throughput by Grouping Writes
Cassandra groups multiple concurrent updates within a short window into a single fsync call. This design,called group commit,results in higher latency per update,as users have to wait on several concurrent updates to have their own update be ackNowledged. The latency bump comes at an increase in throughput,as multiple log appends can happen with a single fsync. As of this writing,every HBase update is persisted to the underlying storage provided by the Hadoop distributed File System (HDFS)15,which has recently seen patches to allow support of appends that respect fsync and group commit. 13.3.2. Multi-server Durability
Because hard drives and machines often irreparably fail,copying important data across machines is necessary. Many Nosql systems offer multi-server durability for data.
Redis takes a Traditional master-slave approach to replicating data. All operations executed against a master are communicated in a log-like fashion to slave machines,which replicate the operations on their own hardware. If a master fails,a slave can step in and serve the data from the state of the operation log that it received from the master. This configuration might result in some data loss,as the master does not confirm that the slave has persisted an operation in its log before ackNowledging the operation to the user. CouchDB facilitates a similar form of directional replication,where servers can be configured to replicate changes to documents on other stores.
MongoDB provides the notion of replica sets,where some number of servers are responsible for storing each document. MongoDB gives developers the option of ensuring that all replicas have received updates,or to proceed without ensuring that replicas have the most recent data. Many of the other distributed Nosql storage systems support multi-server replication of data. HBase,which is built on top of HDFS,receives multi-server durability through HDFS. All writes are replicated to two or more HDFS nodes before returning control to the user,ensuring multi-server durability.
Riak,Cassandra,and Voldemort support more configurable forms of replication. With subtle differences,all three systems allow the user to specify N,the number of machines which should ultimately have a copy of the data,and W<N,the number of machines that should confirm the data has been written before returning control to the user.
To handle cases where an entire data center goes out of service,multi-server replication across data centers is required. Cassandra,and Voldemort have rack-aware configurations,which specify the rack or data center in which varIoUs machines are located. In general,blocking the user's request until a Remote Server has ackNowledged an update incurs too much latency. Updates are streamed without confirmation when performed across wide area networks to backup data centers. 13.4. Scaling for Performance
Having just spoken about handling failure,let's imagine a rosier situation: success! If the system you build reaches success,your data store will be one of the components to feel stress under load. A cheap and dirty solution to such problems is to scale up your existing machinery: invest in more RAM and disks to handle the workload on one machine. With more success,pouring money into more expensive hardware will become infeasible. At this point,you will have to replicate data and spread requests across multiple machines to distribute load. This approach is called scale out,and is measured by the horizontal scalability of your system.
The ideal horizontal scalability goal is linear scalability,in which doubling the number of machines in your storage system doubles the query capacity of the system. The key to such scalability is in how the data is spread across machines. Sharding is the act of splitting your read and write workload across multiple machines to scale out your storage system. Sharding is fundamental to the design of many systems,namely Cassandra,Voldemort,and Riak,and more recently MongoDB and Redis. Some projects such as CouchDB focus on single-server performance and do not provide an in-system solution to sharding,but secondary projects provide coordinators to partition the workload across independent installations on multiple machines.
Let's cover a few interchangeable terms you might encounter. We will use the terms sharding and partitioning interchangeably. The terms machine,server,or node refer to some physical computer which stores part of the partitioned data. Finally,a cluster or ring refers to the set of machines which participate in your storage system.
Sharding means that no one machine has to handle the write workload on the entire dataset,but no one machine can answer queries about the entire dataset. Most Nosql systems are key-oriented in both their data and query models,and few queries touch the entire dataset anyway. Because the primary access method for data in these systems is key-based,sharding is typically key-based as well: some function of the key determines the machine on which a key-value pair is stored. We'll cover two methods of defining the key-machine mapping: hash partitioning and range partitioning. 13.4.1. Do Not Shard Until You Have To
Sharding adds system complexity,and where possible,you should avoid it. Let's cover two ways to scale without sharding: read replicas and caching. Read Replicas
Many storage systems see more read requests than write requests. A simple solution in these cases is to make copies of the data on multiple machines. All write requests still go to a master node. Read requests go to machines which replicate the data,and are often slightly stale with respect to the data on the write master.
If you are already replicating your data for multi-server durability in a master-slave configuration,as is common in Redis,CouchDB,or MongoDB,the read slaves can shed some load from the write master. Some queries,such as aggregate summaries of your dataset,which might be expensive and often do not require up-to-the-second freshness,can be executed against the slave replicas. Generally,the less stringent your demands for freshness of content,the more you can lean on read slaves to improve read-only query performance. Caching
Caching the most popular content in your system often works surprisingly well. Memcached dedicates blocks of memory on multiple servers to cache data from your data store. Memcached clients take advantage of several horizontal scalability tricks to distribute load across Memcached installations on different servers. To add memory to the cache pool,just add another Memcached host.
Because Memcached is designed for caching,it does not have as much architectural complexity as the persistent solutions for scaling workloads. Before considering more complicated solutions,think about whether caching can solve your scalability woes. Caching is not solely a temporary band-aid: Facebook has Memcached installations in the range of tens of terabytes of memory!
Read replicas and caching allow you to scale up your read-heavy workloads. When you start to increase the frequency of writes and updates to your data,you will also increase the load on the master server that contains all of your up-to-date data. For the rest of this section,we will cover techniques for sharding your write workload across multiple servers. 13.4.2. Sharding Through Coordinators
The CouchDB project focuses on the single-server experience. Two projects,Lounge and BigCouch,facilitate sharding CouchDB workloads through an external proxy,which acts as a front end to standalone CouchDB instances. In this design,the standalone installations are not aware of each other. The coordinator distributes requests to individual CouchDB instances based on the key of the document being requested.
Twitter has built the notions of sharding and replication into a coordinating framework called Gizzard16. Gizzard takes standalone data stores of any type—you can build wrappers for sql or Nosql storage systems—and arranges them in trees of any depth to partition keys by key range. For fault tolerance,Gizzard can be configured to replicate data to multiple physical machines for the same key range. 13.4.3. Consistent Hash Rings
Good hash functions distribute a set of keys in a uniform manner. This makes them a powerful tool for distributing key-value pairs among multiple servers. The academic literature on a technique called consistent hashing is extensive,and the first applications of the technique to data stores was in systems called distributed hash tables (DHTs). Nosql systems built around the principles of Amazon's Dynamo adopted this distribution technique,and it appears in Cassandra,and Riak. Hash Rings by Example [A distributed Hash Table Ring]
figure 13.1: A distributed Hash Table Ring
Consistent hash rings work as follows. Say we have a hash function H that maps keys to uniformly distributed large integer values. We can form a ring of numbers in the range [1,L] that wraps around itself with these values by taking H(key) mod L for some relatively large integer L. This will map each key into the range [1,L]. A consistent hash ring of servers is formed by taking each server's unique identifier (say its IP address),and applying H to it. You can get an intuition for how this works by looking at the hash ring formed by five servers (A-E) in figure 13.1.
There,we picked L = 1000. Let's say that H(A) mod L = 7,H(B) mod L = 234,H(C) mod L = 447,H(D) mod L = 660,and H(E) mod L = 875. We can Now tell which server a key should live on. To do this,we map all keys to a server by seeing if it falls in the range between that server and the next one in the ring. For example,A is responsible for keys whose hash value falls in the range [7,233],and E is responsible for keys in the range [875,6] (this range wraps around on itself at 1000). So if H('employee30') mod L = 899,it will be stored by server E,and if H('employee31') mod L = 234,it will be stored on server B. Replicating Data
Replication for multi-server durability is achieved by passing the keys and values in one server's assigned range to the servers following it in the ring. For example,with a replication factor of 3,keys mapped to the range [7,233] will be stored on servers A,B,and C. If A were to fail,its neighbors B and C would take over its workload. In some designs,E would replicate and take over A's workload temporarily,since its range would expand to include A's. Achieving Better distribution
While hashing is statistically effective at uniformly distributing a keyspace,it usually requires many servers before it distributes evenly. Unfortunately,we often start with a small number of servers that are not perfectly spaced apart from one-another by the hash function. In our example,A's key range is of length 227,whereas E's range is 132. This leads to uneven load on different servers. It also makes it difficult for servers to take over for one-another when they fail,since a neighbor suddenly has to take control of the entire range of the Failed server.
To solve the problem of uneven large key ranges,many DHTs including Riak create several `virtual' nodes per physical machine. For example,with 4 virtual nodes,server A will act as server A_1,A_2,A_3,and A_4. Each virtual node hashes to a different value,giving it more opportunity to manage keys distributed to different parts of the keyspace. Voldemort takes a similar approach,in which the number of partitions is manually configured and usually larger than the number of servers,resulting in each server receiving a number of smaller partitions.
Cassandra does not assign multiple small partitions to each server,resulting in sometimes uneven key range distributions. For load-balancing,Cassandra has an asynchronous process which adjusts the location of servers on the ring depending on their historic load. 13.4.4. Range Partitioning
In the range partitioning approach to sharding,some machines in your system keep Metadata about which servers contain which key ranges. This Metadata is consulted to route key and range lookups to the appropriate servers. Like the consistent hash ring approach,this range partitioning splits the keyspace into ranges,with each key range being managed by one machine and potentially replicated to others. Unlike the consistent hashing approach,two keys that are next to each other in the key's sort order are likely to appear in the same partition. This reduces the size of the routing Metadata,as large ranges are compressed to [start,end] markers.
In adding active record-keeping of the range-to-server mapping,the range partitioning approach allows for more fine-grained control of load-shedding from heavily loaded servers. If a specific key range sees higher traffic than other ranges,a load manager can reduce the size of the range on that server,or reduce the number of shards that this server serves. The added freedom to actively manage load comes at the expense of extra architectural components which monitor and route shards. The BigTable Way
Google's BigTable paper describes a range-partitioning hierarchical technique for sharding data into tablets. A tablet stores a range of row keys and values within a column family. It maintains all of the necessary logs and data structures to answer queries about the keys in its assigned range. Tablet servers serve multiple tablets depending on the load each tablet is experiencing.
Each tablet is kept at a size of 100-200 MB. As tablets change in size,two small tablets with adjoining key ranges might be combined,or a large tablet might be split in two. A master server analyzes tablet size,load,and tablet server availability. The master adjusts which tablet server serves which tablets at any time. [BigTable-based Range Partitioning]
figure 13.2: BigTable-based Range Partitioning
The master server maintains the tablet assignment in a Metadata table. Because this Metadata can get large,the Metadata table is also sharded into tablets that map key ranges to tablets and tablet servers responsible for those ranges. This results in a three-layer hierarchy traversal for clients to find a key on its hosting tablet server,as depicted in figure 13.2.
Let's look at an example. A client searching for key 900 will query server A,which stores the tablet for Metadata level 0. This tablet identifies the Metadata level 1 tablet on server 6 containing key ranges 500-1500. The client sends a request to server B with this key,which responds that the tablet containing keys 850-950 is found on a tablet on server C. Finally,the client sends the key request to server C,and gets the row data back for its query. Metadata tablets at level 0 and 1 may be cached by the client,which avoids putting undue load on their tablet servers from repeat queries. The BigTable paper explains that this 3-level hierarchy can accommodate 261 bytes worth of storage using 128MB tablets. Handling Failures
The master is a single point of failure in the BigTable design,but can go down temporarily without affecting requests to tablet servers. If a tablet server fails while serving tablet requests,it is up to the master to recognize this and re-assign its tablets while requests temporarily fail.
In order to recognize and handle machine failures,the BigTable paper describes the use of Chubby,a distributed locking system for managing server membership and liveness. ZooKeeper17 is the open source implementation of Chubby,and several Hadoop-based projects utilize it to manage secondary master servers and tablet server reassignment. Range Partitioning-based Nosql Projects
HBase employs BigTable's hierarchical approach to range-partitioning. Underlying tablet data is stored in Hadoop's distributed filesystem (HDFS). HDFS handles data replication and consistency among replicas,leaving tablet servers to handle requests,update storage structures,and initiate tablet splits and compactions.
MongoDB handles range partitioning in a manner similar to that of BigTable. Several configuration nodes store and manage the routing tables that specify which storage node is responsible for which key ranges. These configuration nodes stay in sync through a protocol called two-phase commit,and serve as a hybrid of BigTable's master for specifying ranges and Chubby for highly available configuration management. Separate routing processes,which are stateless,keep track of the most recent routing configuration and route key requests to the appropriate storage nodes. Storage nodes are arranged in replica sets to handle replication.
Cassandra provides an order-preserving partitioner if you wish to allow fast range scans over your data. Cassandra nodes are still arranged in a ring using consistent hashing,but rather than hashing a key-value pair onto the ring to determine the server to which it should be assigned,the key is simply mapped onto the server which controls the range in which the key naturally fits. For example,keys 20 and 21 would both be mapped to server A in our consistent hash ring in figure 13.1,rather than being hashed and randomly distributed in the ring.
Twitter's Gizzard framework for managing partitioned and replicated data across many back ends uses range partitioning to shard data. Routing servers form hierarchies of any depth,assigning ranges of keys to servers below them in the hierarchy. These servers either store data for keys in their assigned range,or route to yet another layer of routing servers. Replication in this model is achieved by sending updates to multiple machines for a key range. Gizzard routing nodes manage Failed writes in different manner than other Nosql systems. Gizzard requires that system designers make all updates idempotent (they can be run twice). When a storage node fails,routing nodes cache and repeatedly send updates to the node until the update is confirmed. 13.4.5. Which Partitioning Scheme to Use
Given the hash- and range-based approaches to sharding,which is preferable? It depends. Range partitioning is the obvIoUs choice to use when you will frequently be performing range scans over the keys of your data. As you read values in order by key,you will not jump to random nodes in the network,which would incur heavy network overhead. But if you do not require range scans,which sharding scheme should you use?
Hash partitioning gives reasonable distribution of data across nodes,and random skew can be reduced with virtual nodes. Routing is simple in the hash partitioning scheme: for the most part,the hash function can be executed by clients to find the appropriate server. With more complicated rebalancing schemes,finding the right node for a key becomes more difficult.
Range partitioning requires the upfront cost of maintaining routing and configuration nodes,which can see heavy load and become central points of failure in the absence of relatively complex fault tolerance schemes. Done well,range-partitioned data can be load-balanced in small chunks which can be reassigned in high-load situations. If a server goes down,its assigned ranges can be distributed to many servers,rather than loading the server's immediate neighbors during downtime. 13.5. Consistency
Having spoken about the virtues of replicating data to multiple machines for durability and spreading load,it's time to let you in on a secret: keeping replicas of your data on multiple machines consistent with one-another is hard. In practice,replicas will crash and get out of sync,replicas will crash and never come back,networks will partition two sets of replicas,and messages between machines will get delayed or lost. There are two major approaches to data consistency in the Nosql ecosystem. The first is strong consistency,where all replicas remain in sync. The second is eventual consistency,where replicas are allowed to get out of sync,but eventually catch up with one-another. Let's first get into why the second option is an appropriate consideration by understanding a fundamental property of distributed computing. After that,we'll jump into the details of each approach. 13.5.1. A Little Bit About CAP
Why are we considering anything short of strong consistency guarantees over our data? It all comes down to a property of distributed systems architected for modern networking equipment. The idea was first proposed by Eric Brewer as the CAP Theorem,and later proved by Gilbert and Lynch [GL02]. The theorem first presents three properties of distributed systems which make up the acronym CAP:
Consistency: do all replicas of a piece of data always logically agree on the same version of that data by the time you read it? (This concept of consistency is different than the C in ACID.) Availability: Do replicas respond to read and write requests regardless of how many replicas are inaccessible? Partition tolerance: Can the system continue to operate even if some replicas temporarily lose the ability to communicate with each other over the network?
The theorem then goes on to say that a storage system which operates on multiple computers can only achieve two of these properties at the expense of a third. Also,we are forced to implement partition-tolerant systems. On current networking hardware using current messaging protocols,packets can be lost,switches can fail,and there is no way to kNow whether the network is down or the server you are trying to send a message to is unavailable. All Nosql systems should be partition-tolerant. The remaining choice is between consistency and availability. No Nosql system can provide both at the same time.
Opting for consistency means that your replicated data will not be out of sync across replicas. An easy way to achieve consistency is to require that all replicas ackNowledge updates. If a replica goes down and you can not confirm data updates on it,then you degrade availability on its keys. This means that until all replicas recover and respond,the user can not receive successful ackNowledgment of their update operation. Thus,opting for consistency is opting for a lack of round-the-clock availability for each data item.
Opting for availability means that when a user issues an operation,replicas should act on the data they have,regardless of the state of other replicas. This may lead to diverging consistency of data across replicas,since they weren't required to ackNowledge all updates,and some replicas may have not noted all updates.
The implications of the CAP theorem lead to the strong consistency and eventual consistency approaches to building Nosql data stores. Other approaches exist,such as the relaxed consistency and relaxed availability approach presented in Yahoo!'s PNUTS [CRS+08] system. None of the open source Nosql systems we discuss has adopted this technique yet,so we will not discuss it further. 13.5.2. Strong Consistency
Systems which promote strong consistency ensure that the replicas of a data item will always be able to come to consensus on the value of a key. Some replicas may be out of sync with one-another,but when the user asks for the value of employee30:salary,the machines have a way to consistently agree on the value the user sees. How this works is best explained with numbers.
Say we replicate a key on N machines. Some machine,perhaps one of the N,serves as a coordinator for each user request. The coordinator ensures that a certain number of the N machines has received and ackNowledged each request. When a write or update occurs to a key,the coordinator does not confirm with the user that the write occurred until W replicas confirm that they have received the update. When a user wants to read the value for some key,the coordinator responds when at least R have responded with the same value. We say that the system exemplifies strong consistency if R+W>N.
Putting some numbers to this idea,let's say that we're replicating each key across N=3 machines (call them A,and C). Say that the key employee30:salary is initially set to the value $20,000,but we want to give employee30 a raise to $30,000. Let's require that at least W=2 of A,or C ackNowledge each write request for a key. When A and B confirm the write request for (employee30:salary,$30,000),the coordinator lets the user kNow that employee30:salary is safely updated. Let's assume that machine C never received the write request for employee30:salary,so it still has the value $20,000. When a coordinator gets a read request for key employee30:salary,it will send that request to all 3 machines:
If we set R=1,and machine C responds first with $20,our employee will not be very happy. However,if we set R=2,the coordinator will see the value from C,wait for a second response from A or B,which will conflict with C's outdated value,and finally receive a response from the third machine,which will confirm that $30,000 is the majority opinion.
So in order to achieve strong consistency in this case,we need to set R=2} so that R+W3}.
What happens when W replicas do not respond to a write request,or R replicas do not respond to a read request with a consistent response? The coordinator can timeout eventually and send the user an error,or wait until the situation corrects itself. Either way,the system is considered unavailable for that request for at least some time.
Your choice of R and W affect how many machines can act strangely before your system becomes unavailable for different actions on a key. If you force all of your replicas to ackNowledge writes,then W=N,and write operations will hang or fail on any replica failure. A common choice is R + W = N + 1,the minimum required for strong consistency while still allowing for temporary disagreement between replicas. Many strong consistency systems opt for W=N and R=1,since they then do not have to design for nodes going out of sync.
HBase bases its replicated storage on HDFS,a distributed storage layer. HDFS provides strong consistency guarantees. In HDFS,a write cannot succeed until it has been replicated to all N (usually 2 or 3) replicas,so W = N. A read will be satisfied by a single replica,so R = 1. To avoid bogging down write-intensive workloads,data is transferred from the user to the replicas asynchronously in parallel. Once all replicas ackNowledge that they have received copies of the data,the final step of swapping the new data in to the system is performed atomically and consistently across all replicas. 13.5.3. Eventual Consistency
Dynamo-based systems,which include Voldemort,allow the user to specify N,R,and W to their needs,even if R + W <= N. This means that the user can achieve either strong or eventual consistency. When a user picks eventual consistency,and even when the programmer opts for strong consistency but W is less than N,there are periods in which replicas might not see eye-to-eye. To provide eventual consistency among replicas,these systems employ varIoUs tools to catch stale replicas up to speed. Let's first cover how varIoUs systems determine that data has gotten out of sync,then discuss how they synchronize replicas,and finally bring in a few dynamo-inspired methods for speeding up the synchronization process. Versioning and Conflicts
Because two replicas might see two different versions of a value for some key,data versioning and conflict detection is important. The dynamo-based systems use a type of versioning called vector clocks. A vector clock is a vector assigned to each key which contains a counter for each replica. For example,if servers A,and C are the three replicas of some key,the vector clock will have three entries,(N_A,N_B,N_C),initialized to (0,0).
Each time a replica modifies a key,it increments its counter in the vector. If B modifies a key that prevIoUsly had version (39,1,5),it will change the vector clock to (39,2,5). When another replica,say C,receives an update from B about the key's data,it will compare the vector clock from B to its own. As long as its own vector clock counters are all less than the ones delivered from B,then it has a stale version and can overwrite its own copy with B's. If B and C have clocks in which some counters are greater than others in both clocks,say (39,5) and (39,6),then the servers recognize that they received different,potentially unreconcilable updates over time,and identify a conflict. Conflict Resolution
Conflict resolution varies across the different systems. The Dynamo paper leaves conflict resolution to the application using the storage system. Two versions of a shopping cart can be merged into one without significant loss of data,but two versions of a collaboratively edited document might require human reviewer to resolve conflict. Voldemort follows this model,returning multiple copies of a key to the requesting client application upon conflict.
Cassandra,which stores a timestamp on each key,uses the most recently timestamped version of a key when two versions are in conflict. This removes the need for a round-trip to the client and simplifies the API. This design makes it difficult to handle situations where conflicted data can be intelligently merged,as in our shopping cart example,or when implementing distributed counters. Riak allows both of the approaches offered by Voldemort and Cassandra. CouchDB provides a hybrid: it identifies a conflict and allows users to query for conflicted keys for manual repair,but deterministically picks a version to return to users until conflicts are repaired. Read Repair
If R replicas return non-conflicting data to a coordinator,the coordinator can safely return the non-conflicting data to the application. The coordinator may still notice that some of the replicas are out of sync. The Dynamo paper suggests,and Cassandra,Riak,and Voldemort implement,a technique called read repair for handling such situations. When a coordinator identifies a conflict on read,even if a consistent value has been returned to the user,the coordinator starts conflict-resolution protocols between conflicted replicas. This proactively fixes conflicts with little additional work. Replicas have already sent their version of the data to the coordinator,and faster conflict resolution will result in less divergence in the system. Hinted Handoff
Cassandra,and Voldemort all employ a technique called hinted handoff to improve write performance for situations where a node temporarily becomes unavailable. If one of the replicas for a key does not respond to a write request,another node is selected to temporarily take over its write workload. Writes for the unavailable node are kept separately,and when the backup node notices the prevIoUsly unavailable node become available,it forwards all of the writes to the newly available replica. The Dynamo paper utilizes a 'sloppy quorum' approach and allows the writes accomplished through hinted handoff to count toward the W required write ackNowledgments. Cassandra and Voldemort will not count a hinted handoff against W,and will fail a write which does not have W confirmations from the originally assigned replicas. Hinted handoff is still useful in these systems,as it speeds up recovery when an unavailable node returns. Anti-Entropy
When a replica is down for an extended period of time,or the machine storing hinted handoffs for an unavailable replica goes down as well,replicas must synchronize from one-another. In this case,Cassandra and Riak implement a Dynamo-inspired process called anti-entropy. In anti-entropy,replicas exchange Merkle Trees to identify parts of their replicated key ranges which are out of sync. A Merkle tree is a hierarchical hash verification: if the hash over the entire keyspace is not the same between two replicas,they will exchange hashes of smaller and smaller portions of the replicated keyspace until the out-of-sync keys are identified. This approach reduces unnecessary data transfer between replicas which contain mostly similar data. Gossip
Finally,as distributed systems grow,it is hard to keep track of how each node in the system is doing. The three Dynamo-based systems employ an age-old high school technique kNown as gossip to keep track of other nodes. Periodically (every second or so),a node will pick a random node it once communicated with to exchange kNowledge of the health of the other nodes in the system. In providing this exchange,nodes learn which other nodes are down,and kNow where to route clients in search of a key. 13.6. A Final Word
The Nosql ecosystem is still in its infancy,and many of the systems we've discussed will change architectures,designs,and interfaces. The important takeaways in this chapter are not what each Nosql system currently does,but rather the design decisions that led to a combination of features that make up these systems. Nosql leaves a lot of design work in the hands of the application designer. Understanding the architectural components of these systems will not only help you build the next great Nosql amalgamation,but also allow you to use current versions responsibly. 13.7. AckNowledgments
I am grateful to Jackie Carter,Mihir Kedia,and the anonymous reviewers for their comments and suggestions to improve the chapter. This chapter would also not be possible without the years of dedicated work of the Nosql community. Keep building! Footnotes
http://hbase.apache.org/ http://project-voldemort.com/ http://cassandra.apache.org/ http://code.google.com/p/protobuf/ http://thrift.apache.org/ http://avro.apache.org/ http://www.oracle.com/technetwork/database/berkeleydb/overview/index.html http://redis.io/ http://couchdb.apache.org/ http://www.mongodb.org/ http://www.basho.com/products_riak_overview.PHP http://www.hypergraphdb.org/index http://neo4j.org/ http://memcached.org/ http://hadoop.apache.org/hdfs/ http://github.com/twitter/gizzard http://hadoop.apache.org/zookeeper/
的引用")
/usr/include/boost/system/error_code.hpp:208:链接时未定义对`boost :: system :: get_system_category()的引用
如何解决/usr/include/boost/system/error_code.hpp:208:链接时未定义对`boost :: system :: get_system_category()的引用?
似乎它链接到/ usr / include / boost中预装的Boost库,而不是我在主目录中构建的那些库。我怎样才能告诉它使用我建造的那台。我试图添加“ -lboost_filesystem -lboost_system”,但没有帮助。
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

Azure 函数的 Cosmos DB 输入绑定无法将 System.String 转换为 System.Guid
如何解决Azure 函数的 Cosmos DB 输入绑定无法将 System.String 转换为 System.Guid?
我有以下 Azure 函数
[FunctionName("AllProducts")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous,"get",Route = null)] HttpRequest req,[CosmosDB(
databaseName: "marketplace",collectionName: "products",sqlQuery = "SELECT * FROM product",ConnectionStringSetting = "CosmosDbConnectionString")] IEnumerable<Product> products,ILogger log)
{
...some magic here
}
它在带有 Azure Functions 运行时 3.x 的 .NET Core 3.1 上运行。
Product.ID 属性是 Guid。当我向函数发送请求时,我得到 500 并在日志流中看到以下消息:
执行“AllProducts”(失败, Id=147b3de4-c6f1-445c-80ba-28e75a25ed31,持续时间=48ms)无法施放 或从 System.String 转换为 System.Guid。
有没有办法在不改变模型的情况下从字符串转换为 guid?
模型类如下:
public class Product
{
public Guid Id { get; set; }
[required]
public string Name { get; set; }
[required]
public string Description { get; set; }
public bool IsAvailable { get; set; }
[ForeignKey("User")]
public string OwnerName { get; set; }
public User Owner { get; set; }
}
解决方法
请确保您的 Id 属性与文档的自动生成的 id 属性没有冲突。 您可以将文档中的属性更改为PropertyID,并进行相应的序列化
public class Product
{
[JsonProperty("PropertyID")]
public Guid Id { get; set; }
}
CosmosDB 为每个文档自动生成 ID。在我的例子中,自动生成的 ID 看起来像 <Discriminator>|<Auto-generated guid>。这使得绑定无法解析它作为 guid 收到的 ID。我将 Product.ID 属性更改为 Product.ProductID,然后它开始工作。

c# – 如何将System.Diagnostics.Trace和System.Diagnostics.Debug消息记录到NLog文件?
I followed this article to use the NLogTraceListener
那篇文章将System.Net和System.Net.sockets分流到日志文件中.我尝试了它,它的工作原理.我看到System.Net和System.Net.sockets消息被记录到文件中. This SO article描述了相同的 – 它的工作原理.
什么不起作用是将我自己的消息从我自己的命名空间和类记录到日志文件中.
System.Diagnostics.Debug.WriteLine("This won't end up in the log file");
System.Diagnostics.Trace.WriteLine("This won't end up in the log file");
我已经尝试将源名称从我的应用程序更改为名称空间.没工作.我无法让自己的WriteLines登录到该文件.它们仍出现在Visual Studio输出窗口中.
例如:
<system.diagnostics>
<sources>
<source name="MyAppNamespace" switchValue="All">
<listeners>
<add name="nlog" />
</listeners>
</source>
</sources>
<sharedListeners>
<add name="nlog" type="NLog.NLogTraceListener,NLog" />
</sharedListeners>
</system.diagnostics>
显式NLog调用正好记录到日志文件中:
NLog.LogManager.GetCurrentClassLogger().Trace("This Works");
解决方法
尝试:
<system.diagnostics>
<trace>
<listeners>
<add name="nlog" type="NLog.NLogTraceListener,NLog" />
</listeners>
</trace>
</system.diagnostics>
或者使用您配置的TraceSource,例如:
TraceSource source = new TraceSource("MyAppNamespace");
source.TraceEvent(TraceEventType.Warning,2,"File Test not found");
![CentOS7 mysql 连接不上 :[ERROR] InnoDB: The innodb_system data file ''ibdata1'' must be writable](http://www.gvkun.com/zb_users/upload/2025/02/160a8918-74d3-4957-9bf8-65bddb7df5e41738810437862.jpg "CentOS7 mysql 连接不上 :[ERROR] InnoDB: The innodb_system data file ''ibdata1'' must be writable")
CentOS7 mysql 连接不上 :[ERROR] InnoDB: The innodb_system data file ''ibdata1'' must be writable
mysql一直连接不上我的数据库,输入密码也进不去mysql.
报连接不上服务的错误。
Can ''t connect to local MySQL server through socket ''/tmp/mysql.sock ''(2)
我就查看了一下mysql的日志

cat /var/log/mysqld.log

看到了文件没有权限的错误
可以修改下该文件的读写权限或目录下所有文件的权限
解决方案:

这就可以进入mysql了
关于The NoSQL System的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于/usr/include/boost/system/error_code.hpp:208:链接时未定义对`boost :: system :: get_system_category()的引用、Azure 函数的 Cosmos DB 输入绑定无法将 System.String 转换为 System.Guid、c# – 如何将System.Diagnostics.Trace和System.Diagnostics.Debug消息记录到NLog文件?、CentOS7 mysql 连接不上 :[ERROR] InnoDB: The innodb_system data file ''ibdata1'' must be writable等相关知识的信息别忘了在本站进行查找喔。
对于关于一些NoSQL感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍关于一些古代家庭礼仪的故事,并为您提供关于iOS-关于一些取整方式、nosql – 我缺少一些关于文档数据库?、NoSQL入门------关于NoSQL、NoSQL架构实践(一)以NoSQL为辅_MySQL的有用信息。
本文目录一览:- 关于一些NoSQL(关于一些古代家庭礼仪的故事)
- iOS-关于一些取整方式
- nosql – 我缺少一些关于文档数据库?
- NoSQL入门------关于NoSQL
- NoSQL架构实践(一)以NoSQL为辅_MySQL
")
关于一些NoSQL(关于一些古代家庭礼仪的故事)
对于一些大数据高负载,高并发的站点,做优化,会偏向与去做Nosql。
现在公司的项目使用到KT(即Kyoto Cabinet(DBM) + Kyoto Tycoon(网络层))
这是一个非常厉害的Nosql,存储和读取速度很快。
使用Nosql对数据处理、统计等不方便?我们会写一个进程,每一秒都在运行,只要Nosql有更新就会同步更新到MysqL数据库,这样我们对一些统计,就直接在MysqL上面对数据处理。
以下是别人总结的一些出色的Nosql(本人只用过memcache、redis、kt)
出自:http://www.cnblogs.com/skyme/archive/2012/07/26/2609835.html
1、MongoDB
介绍
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。主要解决的是海量数据的访问效率问题,为WEB应用提供可扩展的高性能数据存储解决方案。当数据量达到50GB以上的时候,MongoDB的数据库访问速度是MysqL的10倍以上。MongoDB的并发读写效率不是特别出色,根据官方提供的性能测试表明,大约每秒可以处理0.5万~1.5万次读写请求。MongoDB还自带了一个出色的分布式文件系统GridFS,可以支持海量的数据存储。
MongoDB也有一个Ruby的项目MongoMapper,是模仿Merb的DataMapper编写的MongoDB接口,使用起来非常简单,几乎和DataMapper一模一样,功能非常强大。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
所谓“面向集合”(Collenction-Orented),意思是数据被分组存储在数据集中,被称为一个集合(Collenction)。每个 集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库(RDBMS)里的表(table),不同的是它不需要定 义任何模式(schema)。
模式自由(schema-free),意味着对于存储在mongodb数据库中的文件,我们不需要知道它的任何结构定义。如果需要的话,你完全可以把不同结构的文件存储在同一个数据库里。
存储在集合中的文档,被存储为键-值对的形式。键用于唯一标识一个文档,为字符串类型,而值则可以是各中复杂的文件类型。我们称这种存储形式为BSON(Binary Serialized dOcument Format)。
MongoDB服务端可运行在Linux、Windows或OS X平台,支持32位和64位应用,默认端口为27017。推荐运行在64位平台,因为MongoDB在32位模式运行时支持的最大文件尺寸为2GB。
MongoDB把数据存储在文件中(默认路径为:/data/db),为提高效率使用内存映射文件进行管理。
特性
它的特点是高性能、易部署、易使用,存储数据非常方便。主要功能特性有:
面向集合存储,易存储对象类型的数据。
模式自由。
支持动态查询。
支持完全索引,包含内部对象。
支持查询。
支持复制和故障恢复。
使用高效的二进制数据存储,包括大型对象(如视频等)。
自动处理碎片,以支持云计算层次的扩展性。
支持RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
文件存储格式为BSON(一种JSON的扩展)。
可通过网络访问。
官方网站
http://www.mongodb.org/
2、CouchDB
Apache CouchDB 是一个面向文档的数据库管理系统。它提供以 JSON 作为数据格式的 REST 接口来对其进行操作,并可以通过视图来操纵文档的组织和呈现。 CouchDB 是 Apache 基金会的顶级开源项目。
CouchDB是用Erlang开发的面向文档的数据库系统,其数据存储方式类似Lucene的Index文件格式。CouchDB最大的意义在于它是一个面向Web应用的新一代存储系统,事实上,CouchDB的口号就是:下一代的Web应用存储系统。
主要功能特性有:
CouchDB是分布式的数据库,他可以把存储系统分布到n台物理的节点上面,并且很好的协调和同步节点之间的数据读写一致性。这当然也得以于Erlang无与伦比的并发特性才能做到。对于基于web的大规模应用文档应用,然的分布式可以让它不必像传统的关系数据库那样分库拆表,在应用代码层进行大量的改动。
CouchDB是面向文档的数据库,存储半结构化的数据,比较类似lucene的index结构,特别适合存储文档,因此很适合CMS,电话本,地址本等应用,在这些应用场合,文档数据库要比关系数据库更加方便,性能更好。
CouchDB支持REST API,可以让用户使用JavaScript来操作CouchDB数据库,也可以用JavaScript编写查询语句,我们可以想像一下,用AJAX技术结合CouchDB开发出来的CMS系统会是多么的简单和方便。其实CouchDB只是Erlang应用的冰山一角,在最近几年,基于Erlang的应用也得到的蓬勃的发展,特别是在基于web的大规模,分布式应用领域,几乎都是Erlang的优势项目。
官方网站
http://couchdb.apache.org/
3、Hbase
HBase是一个分布式的、面向列的开源数据库,该技术来源于Chang et al所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库.另一个不同的是HBase基于列的而不是基于行的模式。
HBase � Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。 HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。
HBase访问接口
Native Java API,最常规和高效的访问方式,适合Hadoop MapReduce Job并行批处理HBase表数据
HBase Shell,HBase的命令行工具,最简单的接口,适合HBase管理使用
Thrift Gateway,利用Thrift序列化技术,支持C++,PHP,Python等多种语言,适合其他异构系统在线访问HBase表数据
REST Gateway,支持REST 风格的Http API访问HBase,解除了语言限制
Pig,可以使用Pig Latin流式编程语言来操作HBase中的数据,和Hive类似,本质最终也是编译成MapReduce Job来处理HBase表数据,适合做数据统计
Hive,当前Hive的Release版本尚没有加入对HBase的支持,但在下一个版本Hive 0.7.0中将会支持HBase,可以使用类似sql语言来访问HBase
主要功能特性有:
支持数十亿行X上百万列
采用分布式架构 Map/reduce
对实时查询进行优化
高性能 Thrift网关
通过在server端扫描及过滤实现对查询操作预判
支持 XML,Protobuf,和binary的HTTP
基于 Jruby( JIRB)的shell
对配置改变和较小的升级都会重新回滚
不会出现单点故障
堪比MysqL的随机访问性能
官方网站
http://hbase.apache.org/
4、cassandra
Cassandra是一个混合型的非关系的数据库,类似于Google的BigTable。其主要功能比Dynomite(分布式的Key-Value存储系统)更丰富,但支持度却不如文档存储MongoDB(介于关系数据库和非关系数据库之间的开源产品,是非关系数据库当中功能最丰富,最像关系数据库的。支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。)Cassandra最初由Facebook开发,后转变成了开源项目。它是一个网络社交云计算方面理想的数据库。以Amazon专有的完全分布式的Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型。P2P去中心化的存储。很多方面都可以称之为Dynamo 2.0。
和其他数据库比较,有几个突出特点:
模式灵活 :使用Cassandra,像文档存储,你不必提前解决记录中的字段。你可以在系统运行时随意的添加或移除字段。这是一个惊人的效率提升,特别是在大型部 署上。
真正的可扩展性 :Cassandra是纯粹意义上的水平扩展。为给集群添加更多容量,可以指向另一台电脑。你不必重启任何进程,改变应用查询,或手动迁移任何数据。
多数据中心识别 :你可以调整你的节点布局来避免某一个数据中心起火,一个备用的数据中心将至少有每条记录的完全复制。
一些使Cassandra提高竞争力的其他功能:
范围查询 :如果你不喜欢全部的键值查询,则可以设置键的范围来查询。
列表数据结构 :在混合模式可以将超级列添加到5维。对于每个用户的索引,这是非常方便的。
分布式写操作 :有可以在任何地方任何时间集中读或写任何数据。并且不会有任何单点失败。
官方网站
http://cassandra.apache.org/
5、Hypertable
Hypertable是一个开源、高性能、可伸缩的数据库,它采用与Google的Bigtable相似的模型。在过去数年中,Google为在 PC集群 上运行的可伸缩计算基础设施设计建造了三个关键部分。第一个关键的基础设施是Google File System(GFS),这是一个高可用的文件系统,提供了一个全局的命名空间。它通过跨机器(和跨机架)的文件数据复制来达到高可用性,并因此免受传统 文件存储系统无法避免的许多失败的影响,比如电源、内存和网络端口等失败。第二个基础设施是名为Map-Reduce的计算框架,它与GFS紧密协作,帮 助处理收集到的海量数据。第三个基础设施是Bigtable,它是传统数据库的替代。Bigtable让你可以通过一些主键来组织海量数据,并实现高效的 查询。Hypertable是Bigtable的一个开源实现,并且根据我们的想法进行了一些改进。
主要功能特点:
负载均衡的处理
版本控制和一致性
可靠性
分布为多个节点
http://hypertable.org/
6、Redis
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
性能测试结果:
SET操作每秒钟 110000 次,GET操作每秒钟 81000 次,服务器配置如下:
Linux 2.6,Xeon X3320 2.5Ghz.
stackoverflow 网站使用 Redis 做为缓存服务器。
特点
安全性
主从复制
运行异常快
支持 sets(同时也支持 union/diff/inter)
支持列表(同时也支持队列;阻塞式 pop操作)
支持哈希表(带有多个域的对象)
支持排序 sets(高得分表,适用于范围查询)
Redis支持事务
支持将数据设置成过期数据(类似快速缓冲区设计)
Pub/Sub允许用户实现消息机制
http://redis.io/
7、Tokyo Cabinet/Tokyo Tyant
Tokyo Cabinet(TC)和Tokyo Tyrant(TT)的开发者是日本人Mikio Hirabayashi,主要用于日本最大的SNS网站mixi.jp。TC出现的时间最早,现在已经是一个非常成熟的项目,也是Key-Value数据库领域最大的热点,现在广泛应用于网站。TC是一个高性能的存储引擎,而TT提供了多线程高并发服务器,性能也非常出色,每秒可以处理4万~5万次读写操作。
TC除了支持Key-Value存储之外,还支持Hashtable数据类型,因此很像一个简单的数据库表,并且还支持基于Column的条件查询、分页查询和排序功能,基本上相当于支持单表的基础查询功能,所以可以简单地替代关系数据库的很多操作,这也是TC受到大家欢迎的主要原因之一。有一个Ruby项目miyazakiresistance将TT的Hashtable的操作封装成和ActiveRecord一样的操作,用起来非常高效。
TC/TT在Mixi的实际应用当中,存储了2000万条以上的数据,同时支撑了上万个并发连接,是一个久经考验的项目。TC在保证了极高的并发读写性能的同时,还具有可靠的数据持久化机制,同时还支持类似关系数据库表结构的Hashtable以及简单的条件、分页和排序操作,是一个很优越的Nosql数据库。
TC的主要缺点是,在数据量达到上亿级别以后,并发写数据性能会大幅度下降,开发人员发现在TC里面插入1.6亿条2KB~20KB数据的时候,写入性能开始急剧下降。即当数据量达到上亿条的时候,TC性能便开始大幅度下降,从TC作者自己提供的Mixi数据来看,至少上千万条数据量的时候还没有遇到这么明显的写入性能瓶颈。
http://fallabs.com/tokyocabinet/
8、Flare
TC是日本第一大SNS网站mixi.jp开发的,而Flare是日本第二大SNS网站green.jp开发的。简单地说,Flare就是给TC添加了scale(可扩展)功能。它替换了TT部分,自己另外给TC写了网络服务器。Flare的主要特点就是支持scale能力,它在网络服务端之前添加了一个Node Server,用来管理后端的多个服务器节点,因此可以动态添加数据库服务节点、删除服务器节点,也支持Failover。如果你的使用场景必须让TC可以scale,那么可以考虑Flare。
flare唯一的缺点就是他只支持memcached协议,因此当你使用flare的时候,就不能使用TC的table数据结构了,只能使用TC的key-value数据结构存储。
没找到相关的介绍。
http://flare.prefuse.org/
9、Berkeley DB
Berkeley DB (DB)是一个高性能的,嵌入数据库编程库,和C语言,C++,Java,Perl,Python,PHP,Tcl以及其他很多语言都有绑定。Berkeley DB可以保存任意类型的键/值对,而且可以为一个键保存多个数据。Berkeley DB可以支持数千的并发线程同时操作数据库,支持最大256TB的数据,广泛 用于各种操作系统包括大多数Unix类操作系统和Windows操作系统以及实时操作系统。
Berkeley DB最初开发的目的是以新的HASH访问算法来代替旧的hsearch函数和大量的dbm实现(如AT&T的dbm,Berkeley的 ndbm,GNU项目的gdbm),Berkeley DB的第一个发行版在1991年出现,当时还包含了B+树数据访问算法。在1992年,BSD UNIX第4.4发行版中包含了Berkeley DB1.85版。基本上认为这是Berkeley DB的第一个正式版。在1996年中期,Sleepycat软件公司成立,提供对Berkeley DB的商业支持。在这以后,Berkeley DB得到了广泛的应用,成为一款独树一帜的嵌入式数据库系统。2006年Sleepycat公司被Oracle 公司收购,Berkeley DB成为Oracle数据库家族的一员,Sleepycat原有开发者继续在Oracle开发Berkeley DB,Oracle继续原来的授权方式并且加大了对Berkeley DB的开发力度,继续提升了Berkeley DB在软件行业的声誉。Berkeley DB的当前最新发行版本是4.7.25。
主要特点:
访问速度快
省硬盘空间
http://www.oracle.com/us/products/database/overview/index.html?origref=https://www.jb51.cc/berkeley+db
10、memcachedb
MemcacheDB是一个分布式、key-value形式的持久存储系统。它不是一个缓存组件,而是一个基于对象存取的、可靠的、快速的持久存储引擎。协议跟memcache一致(不完整),所以很多memcached客户端都可以跟它连接。MemcacheDB采用Berkeley DB作为持久存储组件,故很多Berkeley DB的特性的他都支持。
MemcacheDB是一个分布式、key-value形式的持久存储系统。它不是一个缓存组件,而是一个基于对象存取的、可靠的、快速的持久存储引擎。 协议跟memcache一致(不完整),所以很多memcached客户端都可以跟它连接。MemcacheDB采用Berkeley DB作为持久存储组件,故很多Berkeley DB的特性的他都支持。 我们是站在巨人的肩膀上的。MemcacheDB的前端缓存是Memcached 前端:memcached的网络层 后端:BerkeleyDB存储
写速度:从本地服务器通过memcache客户端(libmemcache)set2亿条16字节长的key,10字节长的Value的记录,耗时 16572秒,平均速度12000条记录/秒。
读速度:从本地服务器通过memcache客户端(libmemcache)get100万条16字节长的key,10字节长的Value的记录,耗 时103秒,平均速度10000条记录/秒。 ・支持的memcache命令
http://memcachedb.org/
11、Memlink
Memlink 是天涯社区开发的一个高性能、持久化、分布式的Key-list/queue数据引擎。正如名称中的memlink所示,所有数据都建构在内存中,保证了 系统的高性能 (大约是redis几倍),同时使用了redo-log技术保证数据的持久化。Memlink还支持主从复制、读写分离、List过滤操作等功能。
与Memcached不同的是,它的value是一个list/queue。并且提供了诸如持久化,分布式的功能。听起来有点像Redis,但它号称比Redis更好,在很多Redis做得还不好的地方进行了改进和完善。提供的客户端开发包包括c,python,PHP,java 四种语言。
特点:
内存数据引擎,性能极为高效
List块链结构,精简内存,优化查找效率
Node数据项可定义,支持多种过滤操作
支持redo-log,数据持久化,非Cache模式
分布式,主从同步
http://code.google.com/p/memlink/
12、db4o
“利用表格存储对象,就像是将汽车开回家,然后拆成零件放进车库里,早晨可以再把汽车装配起来。但是人们不禁要问,这是不是泊车的最有效的方法呢。” � Esther Dyson db4o 是一个开源的纯面向对象数据库引擎,对于 Java 与 .NET 开发者来说都是一个简单易用的对象持久化工具,使用简单。同时,db4o 已经被第三方验证为具有优秀性能的面向对象数据库, 下面的基准测试图对 db4o 和一些传统的持久方案进行了比较。db4o 在这次比较中排名第二,仅仅落后于JDBC。通过图 1 的基准测试结果,值得我们细细品味的是采用 Hibernate/HsqlDB 的方案和 JDBC/HsqlDB 的方案在性能方面有着显著差距,这也证实了业界对 Hibernate 的担忧。而 db4o 的优异性能,让我们相信: 更 OO 并不一定会牺牲性能。
同时,db4o 的一个特点就是无需 DBA 的管理,占用资源很小,这很适合嵌入式应用以及 Cache 应用, 所以自从 db4o 发布以来,迅速吸引了大批用户将 db4o 用于各种各样的嵌入式系统,包括流动软件、医疗设备和实时控制系统。 db4o 由来自加州硅谷的开源数据库公司 db4objects 开发并负责商业运营和支持。db4o 是基于 GPL 协议。db4objects 于 2004 年在 CEO Christof Wittig 的领导下组成,资金背景包括 Mark Leslie 、 Veritas 软件公司 CEO 、 Vinod Khosla ( Sun 公司创始人之一)、 Sun 公司 CEO 在内的硅谷高层投资人组成。毫无疑问,今天 db4objects 公司是硅谷炙手可热的技术创新者之一。
db4o 的目标是提供一个功能强大的,适合嵌入的数据库引擎,可以工作在设备,移动产品,桌面以及服务器等各种平台。主要特性如下: 开源模式。与其他 ODBMS 不同,db4o 为开源软件,通过开源社区的力量驱动开发 db4o 产品。 原生数据库。db4o 是 100% 原生的面向对象数据库,直接使用编程语言来操作数据库。程序员无需进行 OR 映射来存储对象,大大节省了程序员在存储数据的开发时间。 高性能。 下图为 db4o 官方公布的基准测试数据,db4o 比采用 Hibernate/MysqL 方案在某些测试线路上速度高出 44 倍之多!并且安装简单,仅仅需要 400Kb 左右的 .jar 或 .dll 库文件。在接下来的系列文章中,我们将只关注在 Java 平台的应用,但是实际上 db4o 毫无疑问会很好地在 .NET平台工作。
图:官方测试数据
易嵌入。使用 db4o 仅需引入 400 多 k 的 jar 文件或是 dll 文件,内存消耗极小。 零管理。使用 db4o 无需 DBA,实现零管理。 支持多种平台。db4o 支持从 Java 1.1 到 Java 5.0,此外还支持 .NET 、 CompactFramework 、 Mono 等 .NET 平台,也可以运行在 CDC 、 PersonalProfile 、 Symbian 、 Savaje 以及 Zaurus 这种支持反射的 J2ME 方言环境中,还可以运行在 CLDC 、 MIDP 、 RIM/BlackBerry 、 Palm OS 这种不支持反射的 J2ME 环境中。 或许开发者会问,如果现有的应用环境已经有了关系型数据库怎么办?没关系,db4o 的 dRS(db4o Replication System)可实现 db4o 与关系型数据库的双向同步(复制),如图 3 。 dRS 是基于 Hibernate 开发,目前的版本是 1.0 ,并运行在 Java 1.2 或更高版本平台上,基于 dRS 可实现 db4o 到 Hibernate/RDBMS 、 db4o 到 db4o 以及 Hibernate/RDBMS 到 Hibernate/RDBMS 的双向复制。dRS 模型如图
图:DRS模型
http://www.db4o.com/china/
13、Versant
Versant Object Database (V/OD) 提供强大的数据管理,面向 C++,Java or .NET 的对象模型,支持大并发和大规模数据集合。
Versant对象数据库是一个对象数据库管理系统(ODBMS:Object Database Management System)。它主要被用在复杂的、分布式的和异构的环境中,用来减少开发量和提高性能。尤其当程序是使用Java和(或)C++语言编写的时候,尤其有用。
它是一个完整的,电子基础设施软件,简化了事务的构建和部署的分布式应用程序。
作为一个卓越的数据库产品,Versant ODBMS在设计时的目标就是为了满足客户在异类处理平台和企业级信息系统中对于高性能、可量测性、可靠性和兼容性方面的需求。
Versant对象数据库已经在为企业业务应用提供可靠性、完整性和高性能方面获得了建树,Versant ODBMS所表现出的高效的多线程架构、internal parallelism 、平稳的Client-Server结构和高效的查询优化,都体现了其非常卓越的性能和可扩展性。
Versant对象数据库包括Versant ODBMS,C++和Java语言接口,XML工具包和异步复制框架。
一、强有力的优势
Versant Object Database8.0,适用于应用环境中包含复杂对象模型的数据库,其设计目标是能够处理这些应用经常需要的导航式访问,无缝的数据分发,和企业级的规模。
对于很多应用程序而言,最具挑战性的方面是控制业务模型本身的内在复杂性。 电信基础设施,交通运输网络,仿真,金融工具以及其它领域的复杂性必须得到支持, 而且这种支持复杂性的方式还要能够随着环境和需求变化而不断地改进应用程序。 这些应用程序的重点是领域和这些领域的逻辑。 复杂的设计应当以对象模型为基础。将技术需求例如持久性(和sql)与领域模型混合在一起的架构会带来灾难性的后果。
Versant对象数据库使您可以使用那些只含有域行为信息的对象,而不用考虑持久性。同时,Versant对象数据库还能提供跨多个数据库的无缝的数据分发,高并发性,细粒度锁,顶级性能, 以及通过复制和其它技术提供的高可用性。现代Java中的对象关系映射工具已经简化了很多映射的问题, 但是它们还不能提供Versant所能提供的无缝数据分发的功能和高性能。
二、主要特性
C++、Java及.NET 的透明对象持久
支持对象持久标准,如JDO
跨多数据库的无缝数据分发
企业级的高可用性选项
动态模式更新
管理工作量少(或不需要)
端到端的对象支持架构
细粒度并发控制
多线程,多会话
支持国际字符集
高速数据采集
三、优势
对象层次结构的快速存储、检索和浏览
性能高于关系型数据库10 倍以上
减少开发时间
四、8.0的新特性
增强的多核线性扩展能力
增强的数据库管理工具(监控、数据库检查、数据重组)
支持基于LINQ的.NET绑定机制
支持.NET和JDO应用的FTS基于“Black Box”工具的数据库活动记录与分析
五、Versant对象数据库特性
Versant支持缓慢模式更新,这意味着当被使用时,对象才会从旧的模式转为新的模式,就不需要映射了。所有这些都支持数据库模式的更新与敏捷开发。
客户端与一个或多个数据库进行无缝交互。单个的数据库无缝地联合在一起,使您能够给数据分区,提高读写能力,增大总体的数据库的大小。这些数据库上的数据分发是透明的。它们被结合在一起形成一个
无缝的数据库,提供巨大的可扩展性。
并发控制
对象级锁确保只有在两个应用程序试图更新同一对象时才会有冲突的发生,这与基于页的锁机制不同。基于页的锁机制可能会导致并发热点的假象。
透明的C++对象持久性
C++对象,STL类,标准C++集合如字典,映射,映射的映射,诸如此类,以原样保存在数据库中。状态变化在后台被自动追踪。当相关的事务提交后,所有的变化将会被自动发送到数据库。因此就能形成一种非常自然的,低干扰的编程风格,这样,就能实现应用程序的快速开发,同时当需求发生变化时,应用程序就能够灵活地修改。
透明的Java对象持久性
V/OD的JVI & JDO 2.0 API 提供了透明的简单对象(POJO)的持久性,包括 Java 2 持久类,接口,以及任何用户定义的类。状态变化
在后台被自动追踪。事务提交后,自动把所有变化写入数据库。因此,对于托管和非托管部署,您都能获得轻量级的编程风格。
可完全嵌入Versant 可以被嵌入到应用程序中,数据库规模可以达到TB 级别。
并且可以自主运行,不需要任何管理。
六、企业级的特性
对象端到端
对象端到端意味着你的应用对象存在于客户端,网络上,以及数据库中。与关系型数据库不同的是,对象在内存中和数据库中的表示之间不需要任何映射或转换。
应用的客户端缓存透明地缓存对象以提高速度。数据库支持对象,它能执行查询,建立索引,使应用能够平衡它和数据库间的进程执行。XA的支持使与其它事务数据源协调成为可能。
七、V/OD 8数据库体系架构
高可用性
通过在线进行数据库管理实现数据库的高可用性。
容错服务器
容错服务器选项可以在Versant数据库的硬件或是软件出现故障的时候,自动进行失效转移和数据恢复。容错服务器使用的是在两个数据库实例之间进行同步复制,一旦出现故障,容错服务器也会支持透明重同步。
异步数据复制
异步数据复制选项支持多个对象服务器之间的主从异步复制和点对点异步复制。可以使用异步数据复制将数据复制到一个分布式恢复站点或者将数据在多个本地的对象数据库之间进行复制,以提高性能和可靠性。
高可用性备份
高可用性数据备份选项使Versant可以使用EMC Symmetrix或其它企业级存储系统的磁盘镜像的特性,来对很大的数据卷进行在线备份,同时又不会影响到可用性。
在线再组织
Versant 数据库再组织选项为了会删除大量对象的应用而设计的。它使用户能够收回数据库中未使用的空间,同时使数据库保持正常运作,增加可用空间,改善数据库的性能。
八、为什么要使用Versant面向对象数据库?
通过缩短研发时间来加速上市
对象关系映射代码可能占用了你的应用的40%或更多。有了Versant面向对象数据库,映射代码就不再需要了。
极大地提高了性能和数据吞吐能力
当应用中涉及到复杂的内存对象模式,尤其是关联访问时,对象数据库要比映射到关系数据库表现得更好。例如,当应用程序需要从对象数据库里检索一个对象时,只要执行单条查询即可找到该对象。当映射到一个关系数据库时,如果对象包含多对多关联,那么就必须通过一个或多个连接才能检索到关联表中的数据。使用了对象数据库,对于一般复杂性的对象的检索,速度则提高了三倍,对于复杂性很高的对象的检索,例如多对多关联,搜索的速度则提高了三十倍。而对于集合的集合和递归联系,检索的速度有可能提高五十倍。
根据需求的变化,快速改进应用
今天,商业进程、结构和应用要求的变化的速度使得适应变化的能力变得极为重要。对象关系映射和其它适用于刚性存储结构的方法,让变化变得困难。而Versant对象数据库极大的提升了你的应用满足当前和未来的商业需求的能力。
投资回报率
当用户遇到了复杂的对象模型和大的数据集,对象数据库就是首选的解决方案。对象数据库主要的优点在于,它能够缩小代码的规模,降低研发成本,缩短上市的时间,减少或根本没有管理的要求以及降低购置硬件和服务器软件许可证的成本。性能上的优势还可以大大降低高负载动作应用所消耗的成本。大型的关系数据库成本高非常昂贵,还需要昂贵的硬件支持
http://www.versant.com/index.aspx
14、Neo4j
Neo4j是一个嵌入式,基于磁盘的,支持完整事务的Java持久化引擎,它在图像中而不是表中存储数据。Neo4j提供了大规模可扩展性,在一台机器上可以处理数十亿节点/关系/属性的图像,可以扩展到多台机器并行运行。相对于关系数据库来说,图形数据库善于处理大量复杂、互连接、低结构化的数据,这些数据变化迅速,需要频繁的查询――在关系数据库中,这些查询会导致大量的表连接,因此会产生性能上的问题。Neo4j重点解决了拥有大量连接的传统RDBMS在查询时出现的性能衰退问题。通过围绕图形进行数据建模,Neo4j会以相同的速度遍历节点与边,其遍历速度与构成图形的数据量没有任何关系。此外,Neo4j还提供了非常快的图形算法、推荐系统和OLAP风格的分析,而这一切在目前的RDBMS系统中都是无法实现的。
Neo是一个网络――面向网络的数据库――也就是说,它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络上而不是表中。网络(从数学角度叫做图)是一个灵活的数据结构,可以应用更加敏捷和快速的开发模式。
你可以把Neo看作是一个高性能的图引擎,该引擎具有成熟和健壮的数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中――但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
由于使用了“面向网络的数据库”,人们对Neo充满了好奇。在该模型中,以“节点空间”来表达领域数据――相对于传统的模型表、行和列来说,节点空间是很多节点、关系和属性(键值对)构成的网络。关系是第一级对象,可以由属性来注解,而属性则表明了节点交互的上下文。网络模型完美的匹配了本质上就是继承关系的问题域,例如语义Web应用。Neo的创建者发现继承和结构化数据并不适合传统的关系数据库模型:
1.对象关系的不匹配使得把面向对象的“圆的对象”挤到面向关系的“方的表”中是那么的困难和费劲,而这一切是可以避免的。
2.关系模型静态、刚性、不灵活的本质使得改变schemas以满足不断变化的业务需求是非常困难的。由于同样的原因,当开发小组想应用敏捷软件开发时,数据库经常拖后腿。
3.关系模型很不适合表达半结构化的数据――而业界的分析家和研究者都认为半结构化数据是信息管理中的下一个重头戏。
4.网络是一种非常高效的数据存储结构。人脑是一个巨大的网络,万维网也同样构造成网状,这些都不是巧合。关系模型可以表达面向网络的数据,但是在遍历网络并抽取信息的能力上关系模型是非常弱的。
虽然Neo是一个比较新的开源项目,但它已经在具有1亿多个节点、关系和属性的产品中得到了应用,并且能满足企业的健壮性和性能的需求:
完全支持JTA和JTS、2PC分布式ACID事务、可配置的隔离级别和大规模、可测试的事务恢复。这些不仅仅是口头上的承诺:Neo已经应用在高请求的24/7环境下超过3年了。它是成熟、健壮的,完全达到了部署的门槛。
Neo4j是一个用Java实现、完全兼容ACID的图形数据库。数据以一种针对图形网络进行过优化的格式保存在磁盘上。Neo4j的内核是一种极快的图形引擎,具有数据库产品期望的所有特性,如恢复、两阶段提交、符合XA等。
Neo4j既可作为无需任何管理开销的内嵌数据库使用;也可以作为单独的服务器使用,在这种使用场景下,它提供了广泛使用的REST接口,能够方便地集成到基于PHP、.NET和JavaScript的环境里。但本文的重点主要在于讨论Neo4j的直接使用。
Neo4j的典型数据特征:
数据结构不是必须的,甚至可以完全没有,这可以简化模式变更和延迟数据迁移。
可以方便建模常见的复杂领域数据集,如CMS里的访问控制可被建模成细粒度的访问控制表,类对象数据库的用例、TripleStores以及其他例子。
典型使用的领域如语义网和RDF、LinkedData、GIS、基因分析、社交网络数据建模、深度推荐算法以及其他领域。
围绕内核,Neo4j提供了一组可选的组件。其中有支持通过元模型构造图形结构、SAIL - 一种SparQL兼容的RDF TripleStore实现或一组公共图形算法的实现。
高性能?
要给出确切的性能基准数据很难,因为它们跟底层的硬件、使用的数据集和其他因素关联很大。自适应规模的Neo4j无需任何额外的工作便可以处理包含数十亿节点、关系和属性的图。它的读性能可以很轻松地实现每毫秒(大约每秒1-2百万遍历步骤)遍历2000关系,这完全是事务性的,每个线程都有热缓存。使用最短路径计算,Neo4j在处理包含数千个节点的小型图时,甚至比MysqL快1000倍,随着图规模的增加,差距也越来越大。
这其中的原因在于,在Neo4j里,图遍历执行的速度是常数,跟图的规模大小无关。不象在RDBMS里常见的联结操作那样,这里不涉及降低性能的集合操作。Neo4j以一种延迟风格遍历图 - 节点和关系只有在结果迭代器需要访问它们的时候才会被遍历并返回,对于大规模深度遍历而言,这极大地提高了性能。
写速度跟文件系统的查找时间和硬件有很大关系。Ext3文件系统和SSD磁盘是不错的组合,这会导致每秒大约100,000写事务操作。
http://neo4j.org/
15、BaseX
BaseX 是一个XML数据库,用来存储紧缩的XML数据,提供了高效的 XPath 和 XQuery 的实现,还包括一个前端操作界面。
BaseX一个比较显著地优点是有了GUI,界面中有查询窗口,可采用XQuery查询相关数据库中的XML文件;也有能够动态展示xml文件层次和节点关系的图。但我感觉也就这点好处了,编程时和GUI无关了。
和Xindice相比,BaseX更能支持大型XML文档的存储,而Xindice对大型xml没有很好的支持,为管理中小型文档的集合而设计。
BaseX 是一个XML数据库,用来存储紧缩的XML数据,提供了高效的 XPath 和 XQuery 的实现,还包括一个前端操作界面。
http://basex.org/

iOS-关于一些取整方式
1. 直接转化
float k = 1.6;
int a = (int)k;
NSLog(@"a = %d",a);输出结果是1,(int) 是强制类型转化,直接丢弃浮点数的小数部分。
2. floor 函数取整(向下取整)
float k = 1.6;
int a = floor(k);
NSLog(@"a = %d",a);输出结果是1,floor ( )方法是向下取整,对于正数来说是舍弃浮点数部分,对于复数来说,舍弃浮点数部分后再减1。(求最大的整数但不大于本身)
3. ceil 函数取整(向上取整)
float k = 1.3;
int a = ceil(k);
NSLog(@"a = %d",a);输出结果是2,ceil ( )方法是向上取整,对于正数来说是舍弃浮点数部分并加1,对于复数来说就是舍弃浮点数部分。(求最小的整数但不小于本身)
4. round 函数取整(四舍五入取整)
float k = 1.6;
int a = round(k);
NSLog(@"a = %d",a);输出结果是2,round ( )方法是四舍五入取整。(求本身的四舍五入)

nosql – 我缺少一些关于文档数据库?
假设您正在实施商店应用程序,并且要存储在数据库产品中,所有这些产品都有一个唯一的类别。在关系数据库中,这将通过具有两个表(产品和类别表)来实现,并且产品表将具有将引用具有正确类别条目的类别表中的行的字段(可能称为“category_id”)。这有几个好处,包括不重复的数据。
这也意味着,如果您拼写类别名称,例如,您可以更新类别表,然后它是固定的,因为这是唯一的值存在的地方。
但在文档数据库中,这不是它的工作原理。你完全反规范化,这意味着在“产品”文档中,你实际上会有一个包含实际类别字符串的值,导致大量的数据重复,并且错误更难以纠正。考虑这更多,不是也意味着运行查询像“给我所有产品这个类别”可能导致结果没有完整性。
当然,这方面的方法是重新实现文档数据库中的整个“category_id”事情,但是当我到达这一点在我的想法,我意识到我应该留在关系数据库,而不是重新实现它们。
这使我相信我缺少一些关键的文档数据库,导致我走这条不正确的路径。所以我想把它堆栈溢出,我错过了什么?
You completely denormalize,meaning in the “products” document,you would actually have a value holding the actual category string,leading to lots of repetition of data […]
真,反规范意味着存储附加数据。它还意味着更少的集合(sql中的表),从而导致数据片段之间的关系较少。每个单个文档可以包含否则将来自多个sql表的信息。
现在,如果您的数据库分布在多个服务器上,查询单个服务器而不是多个服务器更有效率。使用文档数据库的非规范化结构,更有可能您只需要查询单个服务器以获取所需的所有数据。使用sql数据库,有可能您的相关数据分布在多个服务器上,使查询效率低下。
[…] and errors are much more difficult to correct.
也是真的。大多数Nosql解决方案不保证诸如参照完整性之类的事物,这是sql数据库常见的。因此,您的应用程序负责维护数据之间的关系。然而,因为文档数据库中的关系量非常小,所以它不会听起来那么难。
文档数据库的一个优点是它是无模式的。您可以随时定义文档的内容;您不会像使用sql数据库那样绑定到预定义的一组表和列。
现实世界的例子
如果您在sql数据库之上构建CMS,则可以为每个CMS内容类型分别创建一个表,也可以为具有通用列的单个表存储所有类型的内容。使用单独的表,你会有很多表。只要考虑所有的连接表,你需要为每个内容类型的标签和注释。使用单个通用表,您的应用程序负责正确管理所有数据。此外,您的数据库中的原始数据很难更新,在CMS应用程序之外是毫无意义的。
使用文档数据库,您可以将每种类型的CMS内容存储在单个集合中,同时在每个文档中保持强烈定义的结构。您还可以在文档中存储所有标签和注释,使数据检索非常高效。这种效率和灵活性有一个代价:您的应用程序更负责管理数据的完整性。另一方面,与sql数据库相比,使用文档数据库扩展的价格要低得多。
建议
正如你所看到的,sql和Nosql解决方案都有优点和缺点。作为大卫already pointed out,每种类型都有它的用途。我建议您分析您的需求并创建两个数据模型,一个用于sql解决方案,一个用于文档数据库。然后选择最适合的解决方案,保持可扩展性。

NoSQL入门------关于NoSQL
转载地址:http://blog.csdn.net/testcs_dn/article/details/51225843
关于Nosql的专栏申请了可能快一年了,也没有填充一篇文章,今天看到,还是先写一篇放进去吧。现在应用Nosql的人也非常多了,大家可能都不再陌生了,中文方面的资料已经漫天飞舞了。但是查看知乎中Nosql 相关话题的回答数却寥寥无几。可能是大家都更多的去关注相关实际技术的应用了,而忽略了这一概念的本质。
什么是Nosql?
百度百科中:Nosql,泛指非关系型的数据库。中文名:非关系型数据库,外文名:Nosql=Not Only sql
看Wikipedia中:ANoSQL(originally referring to "non sql" or "non relational")database provides a mechanism forstorageandretrievalof data which is modeled in means other than the tabular relations used inrelational databases.
Nosql(最初指的"非 sql"或"非关系")数据库提供了一种机制用于存储和检索模型中的数据,不同于关系数据库中使用的表格关系的方式。
再看Wiki中参考的NoSQL终极指南(nosql-database.org)中说的:Nosql DEFinitioN:
Next Generation Databases mostly addressing some of the points: beingnon-relational,distributed,open-sourceandhorizontally scalable.
Nosql的定义:下一代数据库主要是解决一些要点:非关系型,分布式的,开放源码和支持横向扩展。
The original intention has beenmodern web-scale databases. The movement began early 2009 and is growing rapidly. Often more characteristics apply such as:schema-free,easy replication support,simple API,eventually consistent/BASE(not ACID),ahuge amount of dataand more. So the misleading term"nosql" (the community Now translates it mostly with "not only sql") should be seen as an alias to something like the deFinition above.
初衷是现代网络规模的数据库。
该运动始于2009年初,并正在迅速增长。
通常都支持的特性(共同特征),如:无架构开放架构(不需要预定义模式),易于复制,简单的API,最终一致/ 基础(不支持ACID特性),支持海量数据存储。
所以,误导性术语“的Nosql”(现在社会把它翻译大多为“不仅是sql”),应被视为类似于上面的定义的别名。
前世今生
Nosql最近几年才火起来,并且快速增长,那么它从什么时候开始有的呢?
Such databases have existed since the late 1960s,but did not obtain the "Nosql" moniker until a surge of popularity in the early twenty-first century。
早啦,从60年代后期这样的数据库已经存在,但并没有取得“Nosql”的绰号。
只是以前的应用场景更适合使用关系型的数据库,所以Nosql类型的数据库不被大多数人需要,不被大多数人所知。
Nosql一词最早出现于1998年,它是Carlo Strozzi开发的一个轻量、开源、不提供sql功能的关系型数据库(他认为,由于Nosql悖离传统关系数据库模型,因此,它应该有一个全新的名字,比如“norEL”或与之类似的名字)。
2009年,Last.fm的Johan OskaRSSon发起了一次关于分布式开源数据库的讨论,来自Rackspace的Eric Evans再次提出了Nosql的概念,这时的Nosql主要指非关系型、分布式、不提供ACID的数据库设计模式。
2009年在亚特兰大举行的“no:sql(east)”讨论会是一个里程碑,其口号是"select fun,profit from real_world where relational=false;"。因此,对Nosql最普遍的解释是“非关系型的”,强调键值存储和文档数据库的优点,而不是单纯地反对关系型数据库。
诞生的原因
随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。Nosql数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
键值(Key-Value)存储数据库
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。[3] 举例如:Tokyo Cabinet/Tyrant,Redis,Voldemort,Oracle BDB.列存储数据库。
这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。如:Cassandra,HBase,Riak.文档型数据库
文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可 以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。如:CouchDB,MongoDb. 国内也有文档型数据库SequoiaDB,已经开源。图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。[2] 如:Neo4J,InfoGrid,Infinite Graph.因此,我们总结NoSQL数据库在以下的这几种情况下比较适用:1、数据模型比较简单;2、需要灵活性更强的IT系统;3、对数据库性能要求较高;4、不需要高度的数据一致性;5、对于给定key,比较容易映射复杂值的环境。
·简单数据模型。不同于分布式数据库,大多数NoSQL系统采用更加简单的数据模型,这种数据模型中,每个记录拥有唯一的键,而且系统只需支持单记录级别的原子性,不支持外键和跨记录的关系。这种一次操作获取单个记录的约束极大地增强了系统的可扩展性,而且数据操作就可以在单台机器中执行,没有分布式事务的开销。
·元数据和应用数据的分离。NoSQL数据管理系统需要维护两种数据:元数据和应用数据。元数据是用于系统管理的,如数据分区到集群中节点和副本的映射数据。应用数据就是用户存储在系统中的商业数据。系统之所以将这两类数据分开是因为它们有着不同的一致性要求。若要系统正常运转,元数据必须是一致且实时的,而应用数据的一致性需求则因应用场合而异。因此,为了达到可扩展性,NoSQL系统在管理两类数据上采用不同的策略。还有一些NoSQL系统没有元数据,它们通过其他方式解决数据和节点的映射问题。
·弱一致性。NoSQL系统通过复制应用数据来达到一致性。这种设计使得更新数据时副本同步的开销很大,为了减少这种同步开销,弱一致性模型如最终一致性和时间轴一致性得到广泛应用。
通过这些技术,NoSQL能够很好地应对海量数据的挑战。相对于关系型数据库,NoSQL数据存储管理系统的主要优势有:
·避免不必要的复杂性。关系型数据库提供各种各样的特性和强一致性,但是许多特性只能在某些特定的应用中使用,大部分功能很少被使用。NoSQL系统则提供较少的功能来提高性能。
·高吞吐量。一些NoSQL数据系统的吞吐量比传统关系数据管理系统要高很多,如Google使用MapReduce每天可处理20PB存储在Bigtable中的数据。
·高水平扩展能力和低端硬件集群。NoSQL数据系统能够很好地进行水平扩展,与关系型数据库集群方法不同,这种扩展不需要很大的代价。而基于低端硬件的设计理念为采用NoSQL数据系统的用户节省了很多硬件上的开销。
·避免了昂贵的对象-关系映射。许多NoSQL系统能够存储数据对象,这就避免了数据库中关系模型和程序中对象模型相互转化的代价。
主要缺点
虽然NoSQL数据库提供了高扩展性和灵活性,但是它也有自己的缺点,主要有:
·数据模型和查询语言没有经过数学验证。SQL这种基于关系代数和关系演算的查询结构有着坚实的数学保证,即使一个结构化的查询本身很复杂,但是它能够获取满足条件的所有数据。由于NoSQL系统都没有使用SQL,而使用的一些模型还未有完善的数学基础。这也是NoSQL系统较为混乱的主要原因之一。
·不支持ACID特性。这为NoSQL带来优势的同时也是其缺点,毕竟事务在很多场合下还是需要的,ACID特性使系统在中断的情况下也能够保证在线事务能够准确执行。
- ACID,指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。一个支持事务(Transaction)的数据库,必需要具有这四种特性,否则在事务过程(Transactionprocessing)当中无法保证数据的正确性,交易过程极可能达不到交易方的要求。
·没有统一的查询模型。Nosql系统一般提供不同查询模型,这一定程度上增加了开发者的负担。
结束语
Nosql最初或许只是一个噱头,但随着Web 2.0的举起,对非关系型数据库的需求迅猛增加,随之相关的数据库如雨后春笋般快速成长起来,而这时做为与关系型数据库对立的或者说在它们之上的一个群体,用什么来代表呢?Nosql闪亮登场。
参考:
百度百科词条:NoSQL
Wikipedia:大数据管理系统:NoSQL数据库前世今生
)
以NoSQL为辅_MySQL")
NoSQL架构实践(一)以NoSQL为辅_MySQL
(一)NoSQL作为镜像
不改变原有的以mysql作为存储的架构,使用nosql作为辅助镜像存储,用nosql的优势辅助提升性能。

图 1 -NoSQL为镜像(代码完成模式 )
//写入数据的示例伪代码 //data为我们要存储的数据对象 data.title=”title”; data.name=”name”; data.time=”2009-12-01 10:10:01”; data.from=”1”; id=DB.Insert(data);//写入MySQL数据库 NoSQL.Add(id,data);//以写入MySQL产生的自增id为主键写入NoSQL数据库
如果有数据一致性要求,可以像如下的方式使用
//写入数据的示例伪代码 //data为我们要存储的数据对象 bool status=false; DB.startTransaction();//开始事务 id=DB.Insert(data);//写入MySQL数据库 if(id>0){ status=NoSQL.Add(id,data);//以写入MySQL产生的自增id为主键写入NoSQL数据库 } if(id>0 && status==true){ DB.commit();//提交事务 }else{ DB.rollback();//不成功,进行回滚 }上面的代码看起来可能觉得有点麻烦,但是只需要在DB类或者ORM层做一个统一的封装,就能实现重用了,其他代码都不用做任何的修改。
这种架构在原有基于MySQL数据库的架构上增加了一层辅助的NoSQL存储,代码量不大,技术难度小,却在可扩展性和性能上起到了非常大的作用。只需要程序在写入MySQL数据库后,同时写入到NoSQL数据库,让MySQL和NoSQL拥有相同的镜像数据,在某些可以根据主键查询的地方,使用高效的NoSQL数据库查询,这样就节省了MySQL的查询,用NoSQL的高性能来抵挡这些查询。

图 2 -NoSQL为镜像(同步模式)
这种不通过程序代码,而是通过MySQL把数据同步到NoSQL中,这种模式是上面一种的变体,是一种对写入透明但是具有更高技术难度一种模式。这种模式适用于现有的比较复杂的老系统,通过修改代码不易实现,可能引起新的问题。同时也适用于需要把数据同步到多种类型的存储中。
MySQL到NoSQL同步的实现可以使用MySQL UDF函数,MySQL binlog的解析来实现。可以利用现有的开源项目来实现,比如:
- MySQL memcached UDFs:从通过UDF操作Memcached协议。
- 国内张宴开源的mysql-udf-http:通过UDF操作http协议。
有了这两个MySQL UDF函数库,我们就能通过MySQL透明的处理Memcached或者Http协议,这样只要有兼容Memcached或者Http协议的NoSQL数据库,那么我们就能通过MySQL去操作以进行同步数据。再结合lib_mysqludf_json,通过UDF和MySQL触发器功能的结合,就可以实现数据的自动同步。
(二)MySQL和NoSQL组合
MySQL中只存储需要查询的小字段,NoSQL存储所有数据。

图 3 -MySQL和NoSQL组合
//写入数据的示例伪代码 //data为我们要存储的数据对象 data.title=”title”; data.name=”name”; data.time=”2009-12-01 10:10:01”;data.from=”1”;bool status=false; DB.startTransaction();//开始事务 id=DB.Insert(“INSERT INTO table (from) VALUES(data.from)”);//写入MySQL数据库,只写from需要where查询的字段 if(id>0){ status=NoSQL.Add(id,data);//以写入MySQL产生的自增id为主键写入NoSQL数据库 } if(id>0 && status==true){ DB.commit();//提交事务 }else{ DB.rollback();//不成功,进行回滚 }把需要查询的字段,一般都是数字,时间等类型的小字段存储于MySQL中,根据查询建立相应的索引,其他不需要的字段,包括大文本字段都存储在NoSQL中。在查询的时候,我们先从MySQL中查询出数据的主键,然后从NoSQL中直接取出对应的数据即可。
这种架构模式把MySQL和NoSQL的作用进行了融合,各司其职,让MySQL专门负责处理擅长的关系存储,NoSQL作为数据的存储。它有以下优点:
- 节省MySQL的IO开销。由于MySQL只存储需要查询的小字段,不再负责存储大文本字段,这样就可以节省MySQL存储的空间开销,从而节省MySQL的磁盘IO。我们曾经通过这种优化,把MySQL一个40G的表缩减到几百M。
- 提高MySQl Query Cache缓存命中率。我们知道query cache缓存失效是表级的,在MySQL表一旦被更新就会失效,经过这种字段的分离,更新的字段如果不是存储在MySQL中,那么对query cache就没有任何影响。而NoSQL的Cache往往都是行级别的,只对更新的记录的缓存失效。
- 提升MySQL主从同步效率。由于MySQL存储空间的减小,同步的数据记录也减小了,而部分数据的更新落在NoSQL而不是MySQL,这样也减少了MySQL数据需要同步的次数。
- 提高MySQL数据备份和恢复的速度。由于MySQL数据库存储的数据的减小,很容易看到数据备份和恢复的速度也将极大的提高。
- 比以前更容易扩展。NoSQL天生就容易扩展。经过这种优化,MySQL性能也得到提高。
比如手机凤凰网就是这种架构 http://www.cnblogs.com/sunli/archive/2010/12/20/imcp.html
关于关于一些NoSQL和关于一些古代家庭礼仪的故事的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于iOS-关于一些取整方式、nosql – 我缺少一些关于文档数据库?、NoSQL入门------关于NoSQL、NoSQL架构实践(一)以NoSQL为辅_MySQL等相关内容,可以在本站寻找。
本篇文章给大家谈谈【BDTC先睹为快】介文清:NoSQL解决12306遇到的新问题,以及介文汲 百科的知识点,同时本文还将给你拓展12306凌晨可以买票吗 12306夜间维护怎么买票、12306是分批放票吗 铁路12306放票机制介绍、12306火车票怎么提前加购 铁路12306预填购票信息方法一览、12306网站不能登陆怎么办 打不开12306网站的原因及解决方法等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- 【BDTC先睹为快】介文清:NoSQL解决12306遇到的新问题(介文汲 百科)
- 12306凌晨可以买票吗 12306夜间维护怎么买票
- 12306是分批放票吗 铁路12306放票机制介绍
- 12306火车票怎么提前加购 铁路12306预填购票信息方法一览
- 12306网站不能登陆怎么办 打不开12306网站的原因及解决方法
")
【BDTC先睹为快】介文清:NoSQL解决12306遇到的新问题(介文汲 百科)

12306凌晨可以买票吗 12306夜间维护怎么买票
【导读】12306凌晨可以买票吗,下面就是小编整理的网络知识百科,来看看吧!
大家好,我是191路由器网小编,上述问题将由我为大家讲解。
12306凌晨不可以买票。
12306(中国铁路客户服务中心)是由中国铁路总公司于2010年1月30日推出的铁路客户服务网站。客户通过登录网站,可以查询旅客列车时刻表票价、列车正晚点、车票余票、售票代售点、货物运价、车辆技术参数以及有关客货运规章。自2015年起,铁路客票系统启用部分新功能,启用网上购票“选座功能”。2017年3月10日,开通团体票预定业务;11月23日,微信支付服务功能上线。12306网站于2010年1月30日(2010年春运首日)开通并进行了试运行。用户在该网站可查询列车时刻、票价、余票、代售点、正晚点等信息。售票系统在北京时间每天23:00至次日7:00进入维护,期间不提供服务。2011年1月19日(2011年春运首日),中华人民共和国18个 铁路局(公司)所在地也分别成立了铁路客户服务中心,并公布了服务热线。

总结
以上是小编为你收集整理的12306凌晨可以买票吗 12306夜间维护怎么买票全部内容。
如果觉得小编网站内容还不错,欢迎将小编网站推荐给好友。

12306是分批放票吗 铁路12306放票机制介绍
在火车票高峰期,如何平衡供求矛盾,提高用户购票成功率?本文将聚焦于12306分批放票这一机制。分批放票是一种将车票分批次释放给用户的销售方式,旨在缓解售票压力,增加购票机会。php小编百草将在下文中详细探讨12306是否采用分批放票以及如何把握最佳购票时机。

12306是分批放票吗
12306平时售票通常都是一次性放票的。遇上节假日出行高峰会采用分批次放票。

放票的时间以及数量会根据车次、站点、时间等因素来判定,如果玩家在第一批次中没有抢到票,可以等后续的放票时间再购买。
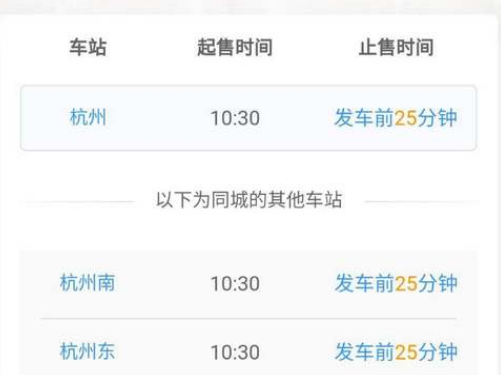
春运期间人流量大,12306是一定会分批放票的,大家可以通过候补订票来提升抢票成功率。
候补方法:
1、打开铁路12306app,进入首页,选择出发地点。
2、选择席位,点击候补。
3、点击右下角候补订单。
4、点击下一步。
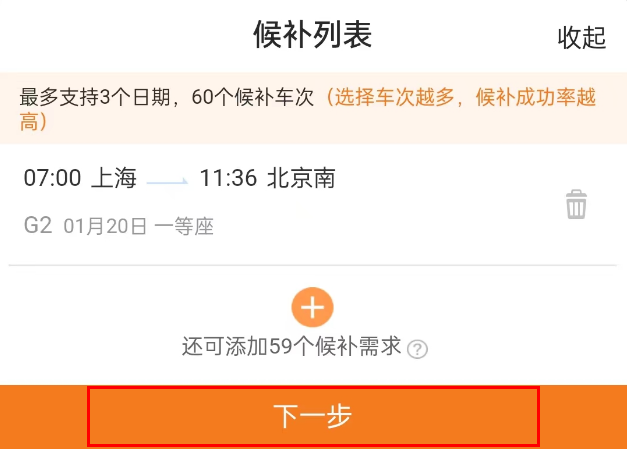
5、根据需求,设置是否开启接受新增列车(开启后可以提升候补成功概率)。
以上就是12306是分批放票吗 铁路12306放票机制介绍的详细内容,更多请关注php中文网其它相关文章!

12306火车票怎么提前加购 铁路12306预填购票信息方法一览
各位乘客,是否因 12306 购票高峰期填单耽误,错失车票而烦恼?php小编西瓜为您带来便捷购票攻略,免除您手忙脚乱的困扰!通过提前填写购票信息,您可在购票时迅速提交订单,大大缩短购票流程,提升购票成功率。接下来,我们将详细介绍具体的操作步骤,助您一票在手,尽享旅程!

12306火车票怎么提前加购
提前车票加购的方法就是预填购票信息。
具体操作如下:
1、选择出发站和到达站,点击查询车票。
2、选择未来的购票日期,找到购票信息预填,点击去填写。
3、选择车次及席别,点击底部完成。
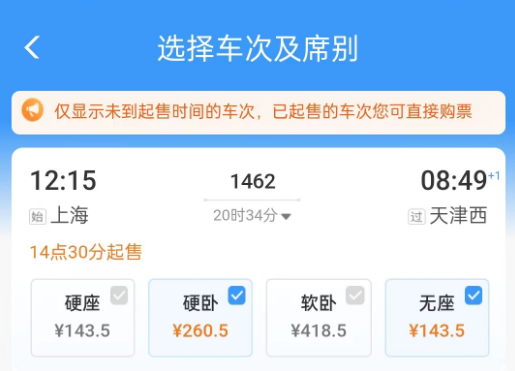
4、添加乘车人,点击底部确认。
以上就是12306火车票怎么提前加购 铁路12306预填购票信息方法一览的详细内容,更多请关注php中文网其它相关文章!

12306网站不能登陆怎么办 打不开12306网站的原因及解决方法
有用户反映一直无法登陆12306网站,这是怎么回事呢?12306网站的验证码是最出名的了,但是也经常会出现无法登陆网站的情况,如何解决这个问题呢?下文将给大家分析12306网站不能登陆的原因及其解决方法。
解决方法:
一、12306网站问题
12306确实是个“神奇”的网站,投资几个亿,12年、13年春运期间登录不上也算是“正常”的事情了,同时抢票的人太多。登录上了算你的运气好。
12306为什么取消了您的登录?
14年春运前据说又投了几个亿,登录不上的情况大有好转。好景不长,自动刷票、黄牛抢票软件横行,也就是说,以前一个人最多也就放票那会同时多人多电脑多帐号抢票,就算他们有耐心平均一天抢上1个小时吧。而14年春运间,大家都在全天全自动刷票,每5秒刷一下,就算平均一天刷个16个小时,想想给12306增加了多少负担。明白12306为什么取消了你的登录吧!
你刷得过于频繁了,每个帐号都刷了个三四万次了,若不取消,12306也做得太不到位了。哈哈!不过,现在12306确实做得还很不到位,能自动刷票时还是刷票有保障。
二、个人网络问题,用上尽可能快的网络
1、首先确保自己电脑能正常浏览网站,看看网易、腾讯等网站是否能正常浏览,速度快不快?若网络异常,网页都打不开,尽快修复网络问题;
2、确保网速正常,建议用360宽带测速器测试网络是否达到申请的带宽(运营商不同,或低或高);
3、若网速异常,建议用360加速球监测网速;
4、关闭12306后,发现还有大量下载上传,采用360流量防火墙,禁止占用网络带宽的程序/服务上传下载;
5、若禁止掉占用网络带宽的程序/服务后,再测网速还是异常;
若是多人共享网络,找管理员沟通处理,若允许,可以考虑先禁用其他的电脑上传下载。若是一人独享网络,还是达不到相应速度,找运营商处理,很多运营商给你的速度根本达不到你申请的速度。
三、电脑问题,用上尽可能快的电脑
1、首先,我们要用上尽可能高配置的电脑;若你电脑还是什么赛扬的处理器,春运间你用它能抢到票,那你就可以去买彩票了,说不准中奖机率更高。
2、其次,抢票前要优化电脑。尽可能关闭其它程序,并退出系统托盘里的其它程序/服务。
最后,笔者建议用户在登录12306的时候,清理以下缓存,另外再按下Ctrl+F5刷新一下再登录网站,这样就可以确保用户使用12306网站更加流畅,少有出现12306登陆不上的情况。
其他浏览器相关问题:
电脑浏览器主页被篡改怎么办 浏览器主页无法修改解决方法
Win10系统360浏览器一直无法打开QQ空间网页的解决方法
360浏览器怎么切换极速模式和兼容模式
我们今天的关于【BDTC先睹为快】介文清:NoSQL解决12306遇到的新问题和介文汲 百科的分享已经告一段落,感谢您的关注,如果您想了解更多关于12306凌晨可以买票吗 12306夜间维护怎么买票、12306是分批放票吗 铁路12306放票机制介绍、12306火车票怎么提前加购 铁路12306预填购票信息方法一览、12306网站不能登陆怎么办 打不开12306网站的原因及解决方法的相关信息,请在本站查询。
如果您对什么时候使用NoSQL和什么时候使用远光灯感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解什么时候使用NoSQL的各种细节,并对什么时候使用远光灯进行深入的分析,此外还有关于$ this-> close();什么时候使用、Java中什么时候使用extends,什么时候使用implements?、jquery中什么时候使用attr(),什么时候使用prop()?、mysql innodb 什么时候使用表锁的实用技巧。
本文目录一览:- 什么时候使用NoSQL(什么时候使用远光灯)
- $ this-> close();什么时候使用
- Java中什么时候使用extends,什么时候使用implements?
- jquery中什么时候使用attr(),什么时候使用prop()?
- mysql innodb 什么时候使用表锁
")
什么时候使用NoSQL(什么时候使用远光灯)
1) 数据库表schema经常变化
比如在线商城,维护产品的属性经常要增加字段,这就意味着ORMapping层的代码和配置要改,如果该表的数据量过百万,新增字段会带来额外开销(重建索引等)。Nosql应用在这种场景,可以极大提升DB的可伸缩性,开发人员可以将更多的精力放在业务层。
2)数据库表字段是复杂数据类型
对于复杂数据类型,比如sql Sever提供了可扩展性的支持,像xml类型的字段。很多用过的同学应该知道,该字段不管是查询还是更改,效率非常一般。主要原因是是DB层对xml字段很难建高效索引,应用层又要做从字符流到dom的解析转换。Nosql以json方式存储,提供了原生态的支持,在效率方便远远高于传统关系型数据库。
3)高并发数据库请求
此类应用常见于web2.0的网站,很多应用对于数据一致性要求很低,而关系型数据库的事务以及大表join反而成了"性能杀手"。在高并发情况下,sql与no-sql的性能对比由于环境和角度不同一直是存在争议的,并不是说在任何场景,no-sql总是会比sql快。有篇article和大家分享下,http://artur.ejsmont.org/blog/content/insert-performance-comparison-of-nosql-vs-sql-servers
4)海量数据的分布式存储
海量数据的存储如果选用大型商用数据,如Oracle,那么整个解决方案的成本是非常高的,要花很多钱在软硬件上。Nosql分布式存储,可以部署在廉价的硬件上,是一个性价比非常高的解决方案。Mongo的auto-sharding已经运用到了生产环境。http://www.mongodb.org/display/DOCS/Sharding
并不是说Nosql可以解决一切问题,像ERP系统、BI系统,在大部分情况还是推荐使用传统关系型数据库。主要的原因是此类系统的业务模型复杂,使用Nosql将导致系统的维护成本增加。
为什么要使用Nosql
Nosql概念
随着web2.0的快速发展,非关系型、分布式数据存储得到了快速的发展,它们不保证关系数据的ACID特性。NoSQL概念在2009年被提了出来。Nosql最常见的解释是“non-relational”,“Not Only sql”也被很多人接受。(“Nosql”一词最早于1998年被用于一个轻量级的关系数据库的名字。)
Nosql被我们用得最多的当数key-value存储,当然还有其他的文档型的、列存储、图型数据库、xml数据库等。在Nosql概念提出之前,这些数据库就被用于各种系统当中,但是却很少用于web互联网应用。比如cdb、qdbm、bdb数据库。
传统关系数据库的瓶颈
传统的关系数据库具有不错的性能,高稳定型,久经历史考验,而且使用简单,功能强大,同时也积累了大量的成功案例。在互联网领域,MysqL成为了绝对靠前的王者,毫不夸张的说,MysqL为互联网的发展做出了卓越的贡献。
在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。在那个时候,更多的都是静态网页,动态交互类型的网站不多。
到了最近10年,网站开始快速发展。火爆的论坛、博客、sns、微博逐渐引领web领域的潮流。在初期,论坛的流量其实也不大,如果你接触网络比较早,你可能还记得那个时候还有文本型存储的论坛程序,可以想象一般的论坛的流量有多大。
Memcached+MysqL
后来,随着访问量的上升,几乎大部分使用MysqL架构的网站在数据库上都开始出现了性能问题,web程序不再仅仅专注在功能上,同时也在追求性能。程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构和索引。开始比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大的时候,多台web机器通过文件缓存不能共享,大量的小文件缓存也带了了比较高的IO压力。在这个时候,Memcached就自然的成为一个非常时尚的技术产品。
Memcached作为一个独立的分布式的缓存服务器,为多个web服务器提供了一个共享的高性能缓存服务,在Memcached服务器上,又发展了根据hash算法来进行多台Memcached缓存服务的扩展,然后又出现了一致性hash来解决增加或减少缓存服务器导致重新hash带来的大量缓存失效的弊端。当时,如果你去面试,你说你有Memcached经验,肯定会加分的。
MysqL主从读写分离
由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。MysqL的master-slave模式成为这个时候的网站标配了。
分表分库
随着web2.0的继续高速发展,在Memcached的高速缓存,MysqL的主从复制,读写分离的基础之上,这时MysqL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发MysqL应用开始使用InnoDB引擎代替MyISAM。同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。这个时候,分表分库成了一个热门技术,是面试的热门问题也是业界讨论的热门技术问题。也就在这个时候,MysqL推出了还不太稳定的表分区,这也给技术实力一般的公司带来了希望。虽然MysqL推出了MysqL Cluster集群,但是由于在互联网几乎没有成功案例,性能也不能满足互联网的要求,只是在高可靠性上提供了非常大的保证。
MysqL的扩展性瓶颈
在互联网,大部分的MysqL都应该是IO密集型的,事实上,如果你的MysqL是个cpu密集型的话,那么很可能你的MysqL设计得有性能问题,需要优化了。大数据量高并发环境下的MysqL应用开发越来越复杂,也越来越具有技术挑战性。分表分库的规则把握都是需要经验的。虽然有像淘宝这样技术实力强大的公司开发了透明的中间件层来屏蔽开发者的复杂性,但是避免不了整个架构的复杂性。分库分表的子库到一定阶段又面临扩展问题。还有就是需求的变更,可能又需要一种新的分库方式。
MysqL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000万4KB大小的文本就接近40GB的大小,如果能把这些数据从MysqL省去,MysqL将变得非常的小。
关系数据库很强大,但是它并不能很好的应付所有的应用场景。MysqL的扩展性差(需要复杂的技术来实现),大数据下IO压力大,表结构更改困难,正是当前使用MysqL的开发人员面临的问题。
NOsql的优势
易扩展
Nosql数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
大数据量,高性能
Nosql数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。一般MysqL使用Query Cache,每次表的更新Cache就失效,是一种大粒度的Cache,在针对web2.0的交互频繁的应用,Cache性能不高。而Nosql的Cache是记录级的,是一种细粒度的Cache,所以Nosql在这个层面上来说就要性能高很多了。
灵活的数据模型
Nosql无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。这点在大数据量的web2.0时代尤其明显。
高可用
Nosql在不太影响性能的情况,就可以方便的实现高可用的架构。比如Cassandra,HBase模型,通过复制模型也能实现高可用。
总结
Nosql数据库的出现,弥补了关系数据(比如MysqL)在某些方面的不足,在某些方面能极大的节省开发成本和维护成本。
MysqL和Nosql都有各自的特点和使用的应用场景,两者的紧密结合将会给web2.0的数据库发展带来新的思路。让关系数据库关注在关系上,Nosql关注在存储上。
关系数据库还是NoSQL数据库
在过去,我们只需要学习和使用一种数据库技术,就能做几乎所有的数据库应用开发。因为成熟稳定的关系数据库产品并不是很多,而供你选择的免费版本就更加少了,所以互联网领域基本上都选择了免费的MysqL数据库。在高速发展的WEB2.0时代,我们发现关系数据库在性能、扩展性、数据的快速备份和恢复、满足需求的易用性上并不总是能很好的满足我们的需要,我们越来越趋向于根据业务场景选择合适的数据库,以及进行多种数据库的融合运用。几年前的一篇文章《One Size Fits All - An Idea Whose Time Has Come and Gone》就已经阐述了这个观点。
当我们在讨论是否要使用Nosql的时候,你还需要理解Nosql也是分很多种类的,在Nosql百花齐放的今天,Nosql的正确选择比选择关系数据库还具有挑战性。虽然Nosql的使用很简单,但是选择却是个麻烦事,这也正是很多人在观望的一个原因。
Nosql的分类
| 类型 |
部分代表 | 特点 |
| Hbase Cassandra Hypertable |
顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 | |
| MongoDB CouchDB |
文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有有机会对某些字段建立索引,实现关系数据库的某些功能。 | |
| Tokyo Cabinet / Tyrant Berkeley DB MemcacheDB Redis |
可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) | |
| Neo4J FlockDB |
图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 | |
| db4o Versant |
通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 | |
| Berkeley DB XML BaseX |
高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 |
Nosql还是关系数据库
如果关系数据库在你的应用场景中,完全能够很好的工作,而你又是非常善于使用和维护关系数据库的,那么我觉得你完全没有必要迁移到Nosql上面,除非你是个喜欢折腾的人。如果你是在金融,电信等以数据为王的关键领域,目前使用的是Oracle数据库来提供高可靠性的,除非遇到特别大的瓶颈,不然也别贸然尝试Nosql。
选择合适的Nosql
- 数据结构特点。包括结构化、半结构化、字段是否可能变更、是否有大文本字段、数据字段是否可能变化。
- 写入特点。包括insert比例、update比例、是否经常更新数据的某一个小字段、原子更新需求。
- 查询特点。包括查询的条件、查询热点的范围。比如用户信息的查询,可能就是随机的,而新闻的查询就是按照时间,越新的越频繁。
Nosql和关系数据库结合
所以,我们一般会把Nosql和关系数据库进行结合使用,各取所长,需要使用关系特性的时候我们使用关系数据库,需要使用Nosql特性的时候我们使用Nosql数据库,各得其所。
举个简单的例子吧,比如用户评论的存储,评论大概有主键id、评论的对象aid、评论内容content、用户uid等字段。我们能确定的是评论内容content肯定不会在数据库中用where content=’’查询,评论内容也是一个大文本字段。那么我们可以把主键id、评论对象aid、用户id存储在数据库,评论内容存储在Nosql,这样数据库就节省了存储content占用的磁盘空间,从而节省大量IO,对content也更容易做Cache。
//从MysqL中查询出评论主键id列表 commentIds=DB.query("SELECT id FROM comments where aid='评论对象id' LIMIT 0,20"); //根据主键id列表,从Nosql取回评论实体数据 CommentsList=Nosql.get(commentIds);
Nosql代替MysqL
Nosql作为缓存服务器
Nosql数据库一般都具有非常高的性能,在大多数场景下面,你不必再考虑在代码层为Nosql构建一层Memcached缓存。Nosql数据本身在Cache上已经做了相当多的优化工作。
Memcached这类内存缓存服务器缓存的数据大小受限于内存大小,如果用Nosql来代替Memcached来缓存数据库的话,就可以不再受限于内存大小。虽然可能有少量的磁盘IO读写,可能比Memcached慢一点,但是完全可以用来缓存数据库的查询操作。
规避风险
现在业内很多公司的做法就是数据的备份。在往Nosql里面存储数据的时候还会往MysqL里面存储一份。Nosql数据库本身也需要进行备份(冷备和热备)。或者可以考虑使用两种Nosql数据库,出现问题后可以进行切换(避免出现digg使用Cassandra的悲剧)。
总结
本文只是简单的从MysqL和Nosql的角度分析如何选择,以及进行融合使用。其实在选择Nosql的时候,你可能还会碰到关于CAP原则,最终一致性,BASE思想的考虑。因为使用MysqL架构的时候,你也会碰到上面的问题,所以这里没有阐述。
;什么时候使用")
$ this-> close();什么时候使用
如何解决$ this-> close();什么时候使用?
所有这些使每次我使用include(''conn / conn.PHP'');这是我的数据库连接。假如我说$ conn-> close(),我有一个if语句是正确的;在else语句之后,如下所示?
我的意思是说,因为我不再需要使用数据库连接,所以我将其关闭。
IF($something == true){
// do some code here related to the databse
}else{
$conn->close();
echo "something went wrong please try again";
}
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

Java中什么时候使用extends,什么时候使用implements?
1.Extends 是实现单继承一个类的关键字,通过使用extends来显示的指明当前类继承的父类,只要那个类不是声明final或者那个类定义为abstract的就能继承。基本声明格式是
[修饰符] class 子类名 extends 父类名{
类体
}
2.Java的继承机制只能提供单一继承,所以就以java的interface来代替c++的多重继承,通过使用implements来在类中实现接口,implements可以实现多个接口,只要中间用逗号分开就行了,
[修饰符] class <类名> [extends 父类名] [implements 接口列表]{
类体
}
,什么时候使用prop()?")
jquery中什么时候使用attr(),什么时候使用prop()?
有人给 Multiple Select 插件 提了问题:
setSelects doesn''t work in Firefox when using jquery 1.9.0 一直都在用 jQuery 1.8.3 的版本,没有尝试过 jQuery 1.9.0 的版本。
于是,开始调试代码,在 1.9.0 的版本中:
<input><script>
$(function() {
$('input').click(function() {
$(this).attr('checked');
});
});
</script>点击 checkbox,结果都是 undefined
而在 1.8.3 的版本中,结果是 checked 和 undefined
到这里,问题答案找到了,就是使用 attr() 方法的问题,于是查看官方文档, 才知道从 jQuery 1.6 开始新增了一个方法 prop(),但是一直都没有使用过。
从中文意思看,两者分别是获取/设置 attributes 和 properties 的方法,那么为什么还要增加 prop() 方法呢?
Before jQuery 1.6, the .attr() method sometimes took property values into account when retrieving some attributes, which could cause inconsistent behavior.
因为在 jQuery 1.6 之前,使用 attr() 有时候会出现不一致的行为。
那么,什么时候使用attr(),什么时候使用prop()?
To retrieve and change DOM properties such as the checked, selected, or disabled state of form elements, use the .prop() method.
根据官方的建议:具有 true 和 false 两个属性的属性,如 checked, selected 或者 disabled 使用prop(),其他的使用 attr()
到此,将 attr(''checked'') 改成 prop(''checked'') 即可修复提的 issues 了。
等等,貌似问题还没真正解决,为什么开头例子中 jQuery 1.8.3 和 1.9.0 使用 attr() 会有所区别呢?
想知道他们的区别,最好的办法还是看他们的源代码:
1.8.3 attr():
attr: function( elem, name, value, pass ) { var ret, hooks, notxml,
nType = elem.nodeType; // don''t get/set attributes on text, comment and attribute nodes
if ( !elem || nType === 3 || nType === 8 || nType === 2 ) { return;
} if ( pass && jQuery.isFunction( jQuery.fn[ name ] ) ) { return jQuery( elem )[ name ]( value );
} // Fallback to prop when attributes are not supported
if ( typeof elem.getAttribute === "undefined" ) { return jQuery.prop( elem, name, value );
}
notxml = nType !== 1 || !jQuery.isXMLDoc( elem ); // All attributes are lowercase
// Grab necessary hook if one is defined
if ( notxml ) {
name = name.toLowerCase();
hooks = jQuery.attrHooks[ name ] || ( rboolean.test( name ) ? boolHook : nodeHook );
} if ( value !== undefined ) { if ( value === null ) {
jQuery.removeAttr( elem, name ); return;
} else if ( hooks && "set" in hooks && notxml && (ret = hooks.set( elem, value, name )) !== undefined ) { return ret;
} else {
elem.setAttribute( name, value + "" ); return value;
}
} else if ( hooks && "get" in hooks && notxml && (ret = hooks.get( elem, name )) !== null ) { return ret;
} else {
ret = elem.getAttribute( name ); // Non-existent attributes return null, we normalize to undefined
return ret === null ?
undefined :
ret;
}
}1.9.0 attr():
attr: function( elem, name, value, pass ) {
var ret, hooks, notxml,
nType = elem.nodeType;
// don''t get/set attributes on text, comment and attribute nodes
if ( !elem || nType === 3 || nType === 8 || nType === 2 ) {
return;
}
if ( pass && jQuery.isFunction( jQuery.fn[ name ] ) ) {
return jQuery( elem )[ name ]( value );
}
// Fallback to prop when attributes are not supported
if ( typeof elem.getAttribute === "undefined" ) {
return jQuery.prop( elem, name, value );
}
notxml = nType !== 1 || !jQuery.isXMLDoc( elem );
// All attributes are lowercase
// Grab necessary hook if one is defined
if ( notxml ) {
name = name.toLowerCase();
hooks = jQuery.attrHooks[ name ] || ( rboolean.test( name ) ? boolHook : nodeHook );
}
if ( value !== undefined ) {
if ( value === null ) {
jQuery.removeAttr( elem, name );
return;
} else if ( hooks && "set" in hooks && notxml && (ret = hooks.set( elem, value, name )) !== undefined ) {
return ret;
} else {
elem.setAttribute( name, value + "" );
return value;
}
} else if ( hooks && "get" in hooks && notxml && (ret = hooks.get( elem, name )) !== null ) {
return ret;
} else {
ret = elem.getAttribute( name );
// Non-existent attributes return null, we normalize to undefined
return ret === null ?
undefined :
ret;
}
}1.8.3 和 1.9.0 的 prop() 是一样的:
prop: function( elem, name, value ) {
var ret, hooks, notxml,
nType = elem.nodeType;
// don''t get/set properties on text, comment and attribute nodes
if ( !elem || nType === 3 || nType === 8 || nType === 2 ) {
return;
}
notxml = nType !== 1 || !jQuery.isXMLDoc( elem );
if ( notxml ) {
// Fix name and attach hooks
name = jQuery.propFix[ name ] || name;
hooks = jQuery.propHooks[ name ];
}
if ( value !== undefined ) {
if ( hooks && "set" in hooks && (ret = hooks.set( elem, value, name )) !== undefined ) {
return ret;
} else {
return ( elem[ name ] = value );
}
} else {
if ( hooks && "get" in hooks && (ret = hooks.get( elem, name )) !== null ) {
return ret;
} else {
return elem[ name ];
}
}
}首先,我们看下 attr() 和 prop() 的区别:
attr() 里面,最关键的两行代码
elem.setAttribute( name, value + "" ); ret = elem.getAttribute( name );
很明显的看出来,使用的 DOM 的 API setAttribute() 和 getAttribute() 方法操作的属性元素节点。
prop() 里面,最关键的两行代码
return ( elem[ name ] = value );return elem[ name ];
可以理解为 document.getElementById(el)[name] = value,这是转化成 element 的一个属性。
对比调试 1.9.0 和 1.8.3 的 attr() 方法,发现两者的区别在于
hooks.get( elem, name ))
返回的值不一样,具体的实现:
1.8.3 中
boolHook = {
get: function( elem, name ) {
// Align boolean attributes with corresponding properties
// Fall back to attribute presence where some booleans are not supported
var attrNode,
property = jQuery.prop( elem, name );
return property === true || typeof property !== "boolean" && ( attrNode = elem.getAttributeNode(name) ) && attrNode.nodeValue !== false ?
name.toLowerCase() :
undefined;
}
}1.9.0 中
boolHook = { get: function( elem, name ) {
var
// Use .prop to determine if this attribute is understood as boolean
prop = jQuery.prop( elem, name ),
// Fetch it accordingly
attr = typeof prop === "boolean" && elem.getAttribute( name ),
detail = typeof prop === "boolean" ?
getSetInput && getSetAttribute ?
attr != null :
// oldIE fabricates an empty string for missing boolean attributes
// and conflates checked/selected into attroperties
ruseDefault.test( name ) ?
elem[ jQuery.camelCase( "default-" + name ) ] :
!!attr :
// fetch an attribute node for properties not recognized as boolean
elem.getAttributeNode( name );
return detail && detail.value !== false ?
name.toLowerCase() :
undefined;
}
}由此可见,1.9.0 开始不建议使用 attr() 来对具有 true 和 false 两个属性的属性进行操作了。
那么我们的结论是:
具有 true 和 false 两个属性的属性,如 checked, selected 或者 disabled 使用prop(),其他的使用 attr(),具体见下表:
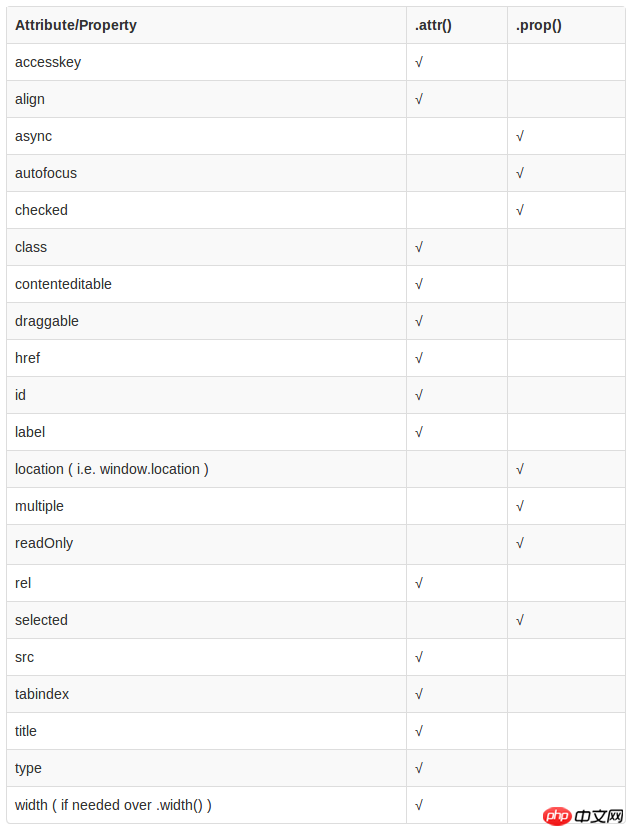
以上就是 jquery中什么时候使用attr(),什么时候使用prop()?的详细内容,更多请关注php中文网其它相关文章!

mysql innodb 什么时候使用表锁
什么时候使用表锁
对于InnoDB表,在绝大部分情况下都应该使用行级锁,因为事务和行锁往往是我们之所以选择InnoDB表的理由。但在个另特殊事务中,也可以考虑使用表级锁。
- 第一种情况是:事务需要更新大部分或全部数据,表又比较大,如果使用默认的行锁,不仅这个事务执行效率低,而且可能造成其他事务长时间锁等待和锁冲突,这种情况下可以考虑使用表锁来提高该事务的执行速度。
- 第二种情况是:事务涉及多个表,比较复杂,很可能引起死锁,造成大量事务回滚。这种情况也可以考虑一次性锁定事务涉及的表,从而避免死锁、减少数据库因事务回滚带来的开销。
当然,应用中这两种事务不能太多,否则,就应该考虑使用MyISAM表。
在InnoDB下 ,使用表锁要注意以下两点。
(1)使用LOCK TALBES虽然可以给InnoDB加表级锁,但必须说明的是,表锁不是由InnoDB存储引擎层管理的,而是由其上一层MySQL Server负责的,仅当autocommit=0、innodb_table_lock=1(默认设置)时,InnoDB层才能知道MySQL加的表锁,MySQL Server才能感知InnoDB加的行锁,这种情况下,InnoDB才能自动识别涉及表级锁的死锁;否则,InnoDB将无法自动检测并处理这种死锁。
(2)在用LOCAK TABLES对InnoDB锁时要注意,要将AUTOCOMMIT设为0,否则MySQL不会给表加锁;事务结束前,不要用UNLOCAK TABLES释放表锁,因为UNLOCK TABLES会隐含地提交事务;COMMIT或ROLLBACK产不能释放用LOCAK TABLES加的表级锁,必须用UNLOCK TABLES释放表锁,正确的方式见如下语句。
例如,如果需要写表t1并从表t读,可以按如下做:
| 1 2 3 4 5 |
|
今天关于什么时候使用NoSQL和什么时候使用远光灯的讲解已经结束,谢谢您的阅读,如果想了解更多关于$ this-> close();什么时候使用、Java中什么时候使用extends,什么时候使用implements?、jquery中什么时候使用attr(),什么时候使用prop()?、mysql innodb 什么时候使用表锁的相关知识,请在本站搜索。
在本文中,我们将为您详细介绍【BDTC先睹为快】介文清:使用NoSQL技术解决新问题的相关知识,此外,我们还会提供一些关于2021 OSCAR 开源产业大会来了!八大亮点先睹为快、Apple 9 月新产品先睹为快、C# 7.1 先睹为快(第一部分)、DockerCon 大会第一天回顾,三大新功能先睹为快!的有用信息。
本文目录一览:- 【BDTC先睹为快】介文清:使用NoSQL技术解决新问题
- 2021 OSCAR 开源产业大会来了!八大亮点先睹为快
- Apple 9 月新产品先睹为快
- C# 7.1 先睹为快(第一部分)
- DockerCon 大会第一天回顾,三大新功能先睹为快!

【BDTC先睹为快】介文清:使用NoSQL技术解决新问题

2021 OSCAR 开源产业大会来了!八大亮点先睹为快
近几年开源技术快速发展,在云计算、大数据、人工智能等领域逐渐形成技术主流。今年,「开源」首次被明确列入国民经济和社会发展五年规划纲要,在国家战略层面得到支持,开源已然成为大势所趋。
但是,开源并非易事。它涉及安全性、社区治理、技术运维、法律合规等方方面面的事项,需要企业、社区、开源基金会、开发者等的持续协作与努力。
如何进一步探索我国开源生态发展模式,推动开源技术在中国市场落地?如何提升企业的开源治理能力?如何推动开源生态健康有序发展,促进我国开源产业快速、健康发展?为解决这些问题,中国信息通信研究院将主办“2021 OSCAR 开源产业大会”,邀请百位开源领域技术专家共同探讨开源的未来。

本次大会由中国信息通信研究院主办,云计算开源产业联盟承办,云计算标准与开源推进委员会、金融行业开源技术应用社区支持,SegmentFault 思否、中国 IDC 圈、开源社、开源之道协办,将于 2021 年 9 月 17 日正式召开。大会亮点多多,我们先睹为快!
亮点一:可信开源治理标准与评估结果
开源存在安全和合规性等风险,企业纷纷构建内部开源治理体系,同时面临开源治理工具的选择问题。因此,中国信息通信研究院从 2019 年开始,针对企业开源治理能力发布了一系列的规范和标准,以帮助企业规范开源软件的使用,提升企业的开源治理能力。
据悉,该评估体系分别面向开源发起企业、开源产品企业和开源使用企业。在经过多轮测试和可信评估之后,本次大会将正式发布可信开源评估结果,包括:可信开源治理、可信开源供应链、可信开源项目、可信开源社区、可信开源治理工具。
亮点二:全新发布《开源生态白皮书 (2021)》
随着整个社会加速数字化、网络化、智能化,开源已经成为大势所趋。而随着开源产业繁荣兴起,开源生态也备受关注。
为了让国内用户更好地理解和使用开源技术,中国信息通信研究院去年正式发布了业内首个《开源生态白皮书 (2020)》,对开源生态发展概况进行了整体介绍,并重点围绕开源布局、开源运营、开源治理、行业开源、开源风险、开源技术等开源领域热点话题进行探讨。
今年,中国信息通信研究院将全新发布《开源生态白皮书 (2021)》,新增过去一年的开源生态新动向,并对开源生态的未来发展做出展望。
本次大会将对《白皮书》进行详细解读,为企业及用户带来最权威的开源应用和实践指南,企业和用户也将有机会全方位了解开源技术带来的机遇与挑战,以及开源治理的实际案例。
亮点三:发布中国信通院开源治理平台 V3.0 版本
在开源技术发展迅猛的当下,开源软件已经基本覆盖重要基础软件领域,在金融、电信、工业互联网等行业应用广泛。但是我国也面临着知识产权问题复杂、开源风险突出,开源生态信息不全面等一系列问题。
为了缓解这些问题,中国信息通信研究院推出了开源治理平台,从 “开源风险检测” 和“开源生态监测”两大方面入手,帮助企业检测开源许可证、开源漏洞等风险,降低因使用开源而造成的违规现象,同时通过持续监测开源项目的社区活跃度等信息为企业提供开源项目选型参考,形成了全方位的综合性开源治理平台。会上将重磅发布中国信通院开源治理平台 V3.0 版本。
亮点四:发布业内首个《操作系统开放生态白皮书》
操作系统是最基本也最重要的基础性系统软件,越来越多的操作系统选择开源这一方向。
国内早期开源生态发展主要集中在应用侧开发软件领域,近年来国内企业逐渐侧重基础软件领域进行开源项目布局,涌现出多个操作系统开源项目。
中国信息通信研究院发布业内首个《操作系统开放生态白皮书》,对操作系统的开放生态概况进行总结与概述,并着重探讨了操作系统在开源开放时所面临的问题和可能的解决方案。
亮点五:发布业内首个《开源社区白皮书》
在开源的发展过程中,开源社区无疑扮演了极其重要的角色。开源社区为众多开发者提供自由学习交流的空间,在推动开源软件发展的过程中起着巨大作用。
然而,开源社区的治理面临着许多问题。如何吸引开发者和用户,并让他们对社区做出贡献?如何聚集核心贡献者进行项目的维护、开发和管理?
为此,中国信息通信研究院联合 PingCAP 发布业内首个《开源社区白皮书》,帮助大家深入了解开源社社区,揭示开源社区发展和治理过程中的难题。本次大会还将对《白皮书》进行详细解读,帮助开发者、企业等组织了解开源社区。
亮点六:发布《金融行业开源白皮书》
开源迅猛发展,传统行业也在积极跟进,并形成特色开源社区。浦发银行联合中国信通院于 2018 年成立金融行业开源技术应用社区(FINOC),关注金融行业开源软件使用与治理问题。
但是,作为对安全性要求极高的行业,金融行业采用开源技术面临着更为严苛的监管要求,在知识产权、信息安全方面应最小化风险。
在此次大会上,中国信息通信研究院将联合浦发银行重磅发布《金融行业开源白皮书》,并进行详细解读,帮助大家更深入地了解金融行业的开源发展现状。
亮点七:OSCAR 开源尖峰案例
为了更好地推动开源技术在中国市场的落地,鼓励企业和厂商使用开源,推动开源技术在中国市场的落地,鼓励企业或个人进一步探索我国开源技术发展模式,大会特设立 “OSCAR 开源尖峰案例” 评选。 评选共分为 “开源人物”、“开源社区及开源项目”、“开源企业及开源用户”、“开源技术创新” 四项。
本次大会将现场揭晓获得开源产业界 “OSCAR” 奖项的企业、个人和项目!
亮点八:六大分论坛,聚焦开源治理、开源社区、开源知识产权与安全、云原生、开源文化、开源商业化
除了精彩纷呈的主论坛,本次大会还开设六大分论坛:开源治理论坛、开源项目与开源社区论坛、开源知识产权和安全论坛、云原生开源论坛、开源文化论坛和开源之商论坛,邀请行业专家和大咖进行干货分享。
此外,大会还围绕 “金融开源应用社区” 和“电信开源应用社区”设置了一场闭门会议。来自金融和电信开源社区的开发者、企业人员将共同探讨行业和开源话题。
百位开源领域技术专家、众多企业开源生态从业者与开发者汇聚一堂,2021 OSCAR 开源产业大会等你来!
企业合作:徐琳(linda@sifou.com,152-6620-3210)

Apple 9 月新产品先睹为快
八月对苹果来说是一个平静的月份,因为它通常是。但九月很可能会被 Apple 产品发布所淹没,其中包括今年最重要的几款产品。

iPhone 13

触手可及的产品、赚钱的工具、苹果整个年度计划的焦点。是的,我们将在 9 月收到一组新 iPhone。
我们相当肯定 Apple 将在 9 月中旬的一次活动中发布四款新手机,其中最小的机型在销售不佳的一年中幸存下来,并与 iPhone 13、13 一起以 iPhone 13 mini 的形式出现Pro 和 13 Pro Max。然而,苹果可能会避免使用不幸的数字 13,而是将这些新手机命名为 12s 系列,或者完全放弃编号。
新手机将采用超快的A15 处理器芯片、更薄的刘海、120Hz 屏幕和广泛的相机改进。
Apple Watch 7

当发布新的 iPhone 时,新的 Apple Watch 通常不会落后太多——尽管今年可能会看到这一传统的一个例外。
苹果一直计划在 9 月中旬的一次活动中同时发布 iPhone 13 和 Apple Watch Series 7。但新表的复杂设计造成了生产问题,Series 7 有可能会延期。
可能是 Apple 仍然同时发布了手机和手表,但手表的发货日期要晚一些。但该公司可能会选择将手表推迟到今年秋天的晚些时候举行。(第三种选择是苹果的供应商解决生产问题,我们都想知道这有什么大不了的。这通常是这些头痛的结果。)
然而,每当 Series 7 到来时,等待都是值得的。我们期待彻底的重新设计,包括更平坦的边缘、更大的屏幕和新的颜色。它还将拥有更快的处理器和更长的电池寿命。
Airpods 3

我们一直在等待新的 AirPods 耳塞。(我指定了耳塞,因为我们确实在 2020 年 12 月获得了AirPods Max,但它们实际上并不重要。)标准 AirPods 上次更新是在 2019 年 3 月,AirPods Pro 于 2019 年 10 月问世。
我们漫长的等待终于在 2021 年 9 月结束了吗?看起来是这样,虽然仅适用于 AirPods 3;第二代 AirPods Pro要到明年才会出现。
标准 AirPods 将采用新的设计和功能集,使它们更接近 Pro 型号。根据 Pro 版本,AirPods 3 会更短,而且我们可能还会获得新的硅胶耳塞。硅胶头补充了 Pro 型号的主动降噪功能,这不太可能在更便宜的型号上重复,但硅胶头仍然可以实现更好的被动隔离。
充电盒也将看起来更像当前的 AirPods Pro。
")
C# 7.1 先睹为快(第一部分)
自 2003 年以来,Microsoft 首次考虑对 C# 使用带小数点后位数的版本。当前暂定下一个版本是 C# 7.1,其中有望包括:异步 Main 函数(Async Main)、默认表达式(Default Expression)、推导元组名(Infer Tuple Names)和使用泛型的模式匹配(Pattern-matching with Generics)等。
异步 Main 函数
最让测试异步代码的开发人员沮丧的,无疑是控制台应用当前不支持异步入口点(EntryPoint)。虽然变通方法是编写多行样板代码,但是这样的模式依赖于对方法的非正常使用,难于理解。例如:
ublic static void Main()
{
MainAsync().GetAwaiter().GetResult();
}
private static async Task MainAsync()
{
... // 程序主代码。
}为解决这个问题,在 “异步 Main 函数建议” 中,添加了如下四个新的函数签名,罗列了可能的入口点。
static Task Main()
static Task
Main()
static Task Main(string[])
static Task
Main(string[])
如果代码中不存在另一个非异步 Main 函数,那么只要给出一个上述的入口点函数,编译器就会生成所需的样板代码。唯一的限制是需要向后兼容。
Microsoft 曾考虑允许 “async void Main ()”,但是这种做法会使编译器更复杂,并且 Microsoft 总体上并不鼓励在事件处理器之外使用 “async void”。
默认值(即 Nothing)
VB 没有表示 “null” 的关键字,这是 C# 和 VB 间的一个微妙的差别。但是 VB 有一个关键字 “Nothing”。在语言技术规范中,对该关键字给出了如下说明:
Nothing 是一个特殊的常值。它没有类型,可转换为类型系统中的任意类型,也包括类型参数。在转换为某个特定类型后,它等价于该类型的默认值。
C# 当前使用 “default (T)” 模式实现同一效果,但略为繁琐,尤其是类的名字很长时。C# 7.1 中将提供一个 “默认常值”(Default Literal),其描述为:
这一类型的表达式可通过常值转换为默认值或 null 值,隐式地转换为 any 类型。
该类型向默认常值的推理与向 null 常值推理的工作机制一样,除非允许 any 类型(不只是引用类型)。
在可以使用 null 的地方,通常也可以使用默认常值。这一做法被看成是 C# 建议中的一个倒退,可能因为人们通常会对两个非常类似的方法完成同一件事大皱眉头。在设计会议纪要中,就有人提出疑问:
我们是否正在挑起类型之争?
一个使用默认常值的例子如下:
ImmutableArray
x = default;
return default;
void Method(ImmutableArray
arrayOpt = default)
var x = new[] { default, ImmutableArray.Create(y) };
const int x = default;
if (x == default)
if (x is default)
y = default as RefType //编译器告警:总是null。
int i = default
下面例子给出的是对默认常值的非法使用:
const int? y = default;
if (default == default)
if (default is T)
var i = default
throw default后者无疑是一个 C# 设计上的奇特构件。在设计会议纪要中,给出了如下说法:
在 C# 中,允许开发人员抛出 null。这会引发一个运行时错误,进而导致抛出一个 NullReferenceException 异常。因此,抛出 NullReferenceException 并非正大光明的,而是一种丑陋的模式。
完全没有理由允许抛出默认值。我们并不认为用户会感觉这是可行的,或是了解它的工作机制。
Microsoft 并未引入默认常值,而是考虑通过扩展 “null” 实现同一效果。因为在 VB 中 “nothing” 和 “null” 是两个不同的关键词,所以在 VB 中可以这样做。即使不使用关键字,VB 中也具有 null 的概念。因此,开发人员可以看到 “NothingReferenceException” 这样的异常。
在 C# 中,开发人员可能常会有这样的一个疑问:“null 是否表示的是实际的空值,或是表示了可能为空值也可能不为空值的默认值?” 我们认为,这是一个令人非常困惑的问题。
在本文的第二部分中,我们将介绍元组和模式匹配。
原文地址:http://www.infoq.com/cn/news/2017/06/CSharp-7.1-a
.NET 社区新闻,深度好文,微信中搜索 dotNET 跨平台或扫描二维码关注



")







