这篇文章主要围绕NoSQL解决方案比较和MongoDBvsRedis,TokyoCabinet,andBerkeleyDB展开,旨在为您提供一份详细的参考资料。我们将全面介绍NoSQL解决方案比较的优
这篇文章主要围绕NoSQL解决方案比较和MongoDB vs Redis, Tokyo Cabinet, and Berkeley DB展开,旨在为您提供一份详细的参考资料。我们将全面介绍NoSQL解决方案比较的优缺点,解答MongoDB vs Redis, Tokyo Cabinet, and Berkeley DB的相关问题,同时也会为您带来105道BAT最新Java面试题(MySQL+Redis+nginx+ookeeper+MongoDB)、Cassandra vs MongoDB vs CouchDB vs Redis vs Ria...、centos 安装nodebb(mongodb)、docker 一些软件的简单安装(nginx tomcat Redis mongodb)的实用方法。
本文目录一览:- NoSQL解决方案比较(MongoDB vs Redis, Tokyo Cabinet, and Berkeley DB)(nosql和mongodb)
- 105道BAT最新Java面试题(MySQL+Redis+nginx+ookeeper+MongoDB)
- Cassandra vs MongoDB vs CouchDB vs Redis vs Ria...
- centos 安装nodebb(mongodb)
- docker 一些软件的简单安装(nginx tomcat Redis mongodb)
(nosql和mongodb)")
NoSQL解决方案比较(MongoDB vs Redis, Tokyo Cabinet, and Berkeley DB)(nosql和mongodb)
Nosql解决方案比较
NoSQL Solution: Evaluation and Comparison: MongoDB vs Redis,Tokyo Cabinet,and Berkeley DB
你也许认为这是Nosql (Not Only sql)广告宣传的另一个博客。
是,这的确是。
但是如果这个时候你仍就为寻找一个可行的Nosql解决方案而苦恼,读完这篇后你就知道该做什么了。
当我以前参与Perfect Market的内容处理平台时,我拼命地尝试寻找一个极端快速(从延时和处理时间上)和可扩展的Nosql数据库方案,去支持简单地键/值查询。
在开始前我预定义了需求:
- 快速数据插入(Fast data insertion)。有些数据集可能包含上亿的行(KV键值对),虽然每行数据很小,但如果数据插入很慢,那将这个数据集传入数据库将需要花几天时间,这是不可接受的。
- 大数据集上的快速随机读取(Extermely fast random reads on large datesets)。
- 在所有数据集上的一致的读写速度。这个意思是说,读写速度不能因为数据如何保持和index如何组织就在某个数据量上拥有很好的值,读写速度应该在所有的数据量上均衡。
- 有效的数据存储。原始的数据大小和数据被导入数据库中的大小应该相差不大。
- 很好的扩展性。我们在EC2的内容处理节点可能产生大量的并发线程访问数据节点,这需要数据节点能很好的扩展。同时,不是所有的数据集是只读的,某些数据节点必须在合适的写负载下很好的扩展。
- 容易维护。我们的内容处理平台利用了本地和EC2资源。在不同的环境里,同时打包代码,设置数据,和运行不同类型的节点是不容易的。预期的方案必须很容易维护,以便满足高自动化的内容处理系统。
- 拥有网络接口。只用于库文件的方案是不充足的。
- 稳定。必须的。
我开始寻找时毫无偏见,因为我从未严格地使用过Nosql产品。经过同事的推荐,并且阅读了一堆的博客后,验证的旅程开始于Tokyo Cabinet,然后是Berkeley DB库,MemcacheDB,Project Voldemort,Redis,MongoDB。
其实还存在很多流行的可选项,比如Cassandra,HBase,CouchDB…还有很多你能列出来的,但我们没没有必要去尝试,因为我们选择的那些已经工作得很好。结果出来相当的不错,这个博客共享了我测试的一些细节。
为了解释选择了哪个以及为什么选择这个,我采纳了同事Jay Budzik(CTO)的建议,创建了一张表来比较所有方案在每一个需求上的情况。虽然这张表是一个事后的事情,但它展示了基本原理,同时也会对处于决策的人们带来帮助。
请注意这个表不是100%的客观和科学。它结合了测试结果和我的直觉推导。很有趣,我开始验证时没有偏见,但测试完所有的后,我也许有了一点偏心(特别是基于我的测试用例)。
另一个需要注意的是这里的磁盘访问是I/O密集性工作负载里最慢的一个操作。相对于内存访问, 这是毫秒与纳秒的关系。为了处理包含上亿行的数据集合,你最好给你的机器配置足够的内存。如果你的机器只有4G内存而你想处理50GB的数据且期望较好的 速度,那你要么摇晃你的机器,要么用个更好的,否则只能扔到下面所有的方案,因为它们都不会工作。
看了这张表,你也许能猜到我选了哪个方案。不要着急,让我详细说明每一个方案。
Tokyo Cabinet (TC)是一个非常好的方案也是我第一个验证的。我现在仍然很喜欢它,虽然这不是我最后选择的。它的质量惊人的高。哈希表数据库对于小数据集(低于2千万行)惊人的快,水平扩展能力也很好。TC的问题是当数据量增加时,读写的性能下降的特别快。
Berkeley DB(BDB)和MemcacheDB(BDB的远程接口)是一个较老的结合物。如果你熟悉BDB,并且不是非常依赖速度和功能集合,比如你愿意等几天去加载大数据集到数据库里并且你接受一般但不优秀的读速度,你仍可以使用它。对于我们,事实是它花了太长的时间来加载初始数据。
Project Voldemort是唯一一个基于Java和云计算的方案。在验证前我有很高的期望,但是结果却有点失望,原因是:
- BDB Java版本让我的数据膨胀得太厉害(大概是1比4,而TC只有1比1.3)。基本上存储效率非常低。对于大数据集,它就是灾难。
- 当数据变得很大的时候,插入速度降低得很快。
- 当大数据集被加载时偶尔由于无法预测的异常而崩溃。
当数据膨胀得太厉害并且偶尔系统崩溃时,数据加载还没有完成。只有四分之一的数据被传播,它读速度还可以但不出色。在这个时候我想我最好放弃它。否则,除了上面列的那些需要优化,JVM可能让我操更多的心让我的头发灰的更多,虽然我已经为Sun工作了五年。
Redis是一个极好的缓存解决方案,我们也采用了它。Redis将所有的哈希表存在内存里,背后有一个线程按 照预设的时间定时将哈希表中的快照存到磁盘上。如果系统重启,它可以从磁盘上加载快照到内存,就像启动时保温的缓存。它要花几分钟来恢复20GB的数据, 当然也依赖你的磁盘速度。这是一个非常好的主意,Redis有一个合适的实现。
但是在我们的用例里,它工作得并不好。后台的保存程序仍妨碍了我们,特别是当哈希表变得更大时。我担心它会负面地影响读速度。使用logging style persistence而不是保存整个快照,可以减缓这些数据转存的影响,但是数据大小将会膨胀,如果太频繁,将最终影响恢复时间。单线程模式听起来不是 可伸缩的,虽然在我的测试里它水平方向扩展的很好:支持几百个并发读。
另一个事情干扰我的是Redis的整个数据集必须适合物理内存。这点使得它不容易被管理,象在我们这样在不同的产品周期造成的多样化的环境里。Redis最近的版本可能减轻了这方面的问题。
MongoDB是至今我最喜欢的,在我所验证的所有解决方案中,它是胜出者,我们的产品也正在使用。
MongoDB提供了不同寻常的插入速度,可能原因是延迟写入和快速文件扩展(每个集合结构有多个文件)。只要你拥有足够的内存,上亿的数据行能在 几小时内插入,而不是几天。我应该在这提供确切的数据,但数据太具体(与我们的项目有关)不见得对别人有帮助。但相信我,MongoDB提供了非常快的大 数据量插入操作。
MongoDB使用内存映射文件,它一般花纳秒级的时间来解决微小的页面错误,让文件系统缓存的页面映射到MongoDB的内存空间。相比于其它方 案,MongoDB不会和页面缓存竞争,因为它使用和只读块相同的内存。在其它方案里,如果你分配给太多的内存给工具自身,那盒子里的页面缓存就变得很 少,并且一般来说想让工具的缓存完全地预热不是很容易,或者没有一个有效地方法(你绝对不想事先去从数据库里读取每一行)。
对于MongoDB,可以非常容易地做一些简单的技巧让所有的数据加载到页面缓存。一旦在这个状态,MongoDB就很像Redis,在随机读上有较好的性能。
在我另一个测试中,200并发客户在大数据集(上亿行数据)做持续的随机读取,MongoDB表现了总体上的400,000QPS。测试中,数据在 页面缓存里预热(事先加载)。在随后的测试中,MongoDB同样显示了在适度的写负载下拥有非常好的随机读取速度。在相对来说一个大的负载下,我们压缩 了数据然后将它存入MongoDB,这样就减少了数据大小所以更多的东西能放入内存。
MongoDB提供了一个方便的客户端工具(类似MysqL的),非常好用。它也提供了高级的查询功能,处理大型文档的功能,但是我们还没有用到这 些。MongoDB非常稳定,基本不需要维护,处理你可能要监控数据量增大时的内存使用情况。MongoDB对不同的语言有很好的客户端API支持,这使 得它很容易使用。我不用列举它所有的功能,但我想你会得到你想要的。
虽然MongoDB方案可以满足大多数Nosql的需求,但它不是唯一的一个。如果你只需要处理小数据量,Tokyo Cabinet最合适。如果你需要处理海量数据(PB千兆兆)并拥有很多机器,而且延时不是个问题,你也不强求极好的响应时间,那么Cassandra和 HBase都可以胜任。
最后,如果你仍需要考虑事务处理,那就不要弄Nosql, 直接用Oracle。
引自 Jun Xu ofhttp://perfectmarket.com/blog/not_only_nosql_review_solution_evaluation_guide_chart
引自: http://www.distream.org/?p=10
")
105道BAT最新Java面试题(MySQL+Redis+nginx+ookeeper+MongoDB)





Cassandra vs MongoDB vs CouchDB vs Redis vs Ria...
(Yes it''s a long title, since people kept asking me to write about this and that too :) I do when it has a point.)
While SQL databases are insanely useful tools, their monopoly in the last decades is coming to an end. And it''s just time: I can''t even count the things that were forced into relational databases, but never really fitted them. (That being said, relational databases will always be the best for the stuff that has relations.)
But, the differences between NoSQL databases are much bigger than ever was between one SQL database and another. This means that it is a bigger responsibility on software architects to choose the appropriate one for a project right at the beginning.
In this light, here is a comparison of Cassandra, Mongodb, CouchDB, Redis, Riak, Couchbase (ex-Membase), Hypertable, ElasticSearch, Accumulo, VoltDB, Kyoto Tycoon, Scalaris, Neo4j and HBase:
The most popular ones
MongoDB (2.2)
- Written in: C++
- Main point: Retains some friendly properties of SQL. (Query, index)
- License: AGPL (Drivers: Apache)
- Protocol: Custom, binary (BSON)
- Master/slave replication (auto failover with replica sets)
- Sharding built-in
- Queries are javascript expressions
- Run arbitrary javascript functions server-side
- Better update-in-place than CouchDB
- Uses memory mapped files for data storage
- Performance over features
- Journaling (with --journal) is best turned on
- On 32bit systems, limited to ~2.5Gb
- An empty database takes up 192Mb
- GridFS to store big data + metadata (not actually an FS)
- Has geospatial indexing
- Data center aware
Best used: If you need dynamic queries. If you prefer to define indexes, not map/reduce functions. If you need good performance on a big DB. If you wanted CouchDB, but your data changes too much, filling up disks.
For example: For most things that you would do with MySQL or PostgreSQL, but having predefined columns really holds you back.
Riak (V1.2)
- Written in: Erlang & C, some JavaScript
- Main point: Fault tolerance
- License: Apache
- Protocol: HTTP/REST or custom binary
- Stores blobs
- Tunable trade-offs for distribution and replication
- Pre- and post-commit hooks in JavaScript or Erlang, for validation and security.
- Map/reduce in JavaScript or Erlang
- Links & link walking: use it as a graph database
- Secondary indices: but only one at once
- Large object support (Luwak)
- Comes in "open source" and "enterprise" editions
- Full-text search, indexing, querying with Riak Search
- In the process of migrating the storing backend from "Bitcask" to Google''s "LevelDB"
- Masterless multi-site replication replication and SNMP monitoring are commercially licensed
Best used: If you want something Dynamo-like data storage, but no way you''re gonna deal with the bloat and complexity. If you need very good single-site scalability, availability and fault-tolerance, but you''re ready to pay for multi-site replication.
For example: Point-of-sales data collection. Factory control systems. Places where even seconds of downtime hurt. Could be used as a well-update-able web server.
CouchDB (V1.2)
- Written in: Erlang
- Main point: DB consistency, ease of use
- License: Apache
- Protocol: HTTP/REST
- Bi-directional (!) replication,
- continuous or ad-hoc,
- with conflict detection,
- thus, master-master replication. (!)
- MVCC - write operations do not block reads
- Previous versions of documents are available
- Crash-only (reliable) design
- Needs compacting from time to time
- Views: embedded map/reduce
- Formatting views: lists & shows
- Server-side document validation possible
- Authentication possible
- Real-time updates via ''_changes'' (!)
- Attachment handling
- thus, CouchApps (standalone js apps)
Best used: For accumulating, occasionally changing data, on which pre-defined queries are to be run. Places where versioning is important.
For example: CRM, CMS systems. Master-master replication is an especially interesting feature, allowing easy multi-site deployments.
Redis (V2.4)
- Written in: C/C++
- Main point: Blazing fast
- License: BSD
- Protocol: Telnet-like
- Disk-backed in-memory database,
- Currently without disk-swap (VM and Diskstore were abandoned)
- Master-slave replication
- Simple values or hash tables by keys,
- but complex operations like ZREVRANGEBYSCORE.
- INCR & co (good for rate limiting or statistics)
- Has sets (also union/diff/inter)
- Has lists (also a queue; blocking pop)
- Has hashes (objects of multiple fields)
- Sorted sets (high score table, good for range queries)
- Redis has transactions (!)
- Values can be set to expire (as in a cache)
- Pub/Sub lets one implement messaging (!)
Best used: For rapidly changing data with a foreseeable database size (should fit mostly in memory).
For example: Stock prices. Analytics. Real-time data collection. Real-time communication. And wherever you used memcached before.
Clones of Google''s Bigtable
HBase (V0.92.0)
- Written in: Java
- Main point: Billions of rows X millions of columns
- License: Apache
- Protocol: HTTP/REST (also Thrift)
- Modeled after Google''s BigTable
- Uses Hadoop''s HDFS as storage
- Map/reduce with Hadoop
- Query predicate push down via server side scan and get filters
- Optimizations for real time queries
- A high performance Thrift gateway
- HTTP supports XML, Protobuf, and binary
- Jruby-based (JIRB) shell
- Rolling restart for configuration changes and minor upgrades
- Random access performance is like MySQL
- A cluster consists of several different types of nodes
Best used: Hadoop is probably still the best way to run Map/Reduce jobs on huge datasets. Best if you use the Hadoop/HDFS stack already.
For example: Search engines. Analysing log data. Any place where scanning huge, two-dimensional join-less tables are a requirement.
Cassandra (1.2)
- Written in: Java
- Main point: Best of BigTable and Dynamo
- License: Apache
- Protocol: Thrift & custom binary CQL3
- Tunable trade-offs for distribution and replication (N, R, W)
- Querying by column, range of keys (Requires indices on anything that you want to search on)
- BigTable-like features: columns, column families
- Can be used as a distributed hash-table, with an "SQL-like" language, CQL (but no JOIN!)
- Data can have expiration (set on INSERT)
- Writes can be much faster than reads (when reads are disk-bound)
- Map/reduce possible with Apache Hadoop
- All nodes are similar, as opposed to Hadoop/HBase
- Cross-datacenter replication
Best used: When you write more than you read (logging). If every component of the system must be in Java. ("No one gets fired for choosing Apache''s stuff.")
For example: Banking, financial industry (though not necessarily for financial transactions, but these industries are much bigger than that.) Writes are faster than reads, so one natural niche is data analysis.
Hypertable (0.9.6.5)
- Written in: C++
- Main point: A faster, smaller HBase
- License: GPL 2.0
- Protocol: Thrift, C++ library, or HQL shell
- Implements Google''s BigTable design
- Run on Hadoop''s HDFS
- Uses its own, "SQL-like" language, HQL
- Can search by key, by cell, or for values in column families.
- Search can be limited to key/column ranges.
- Sponsored by Baidu
- Retains the last N historical values
- Tables are in namespaces
- Map/reduce with Hadoop
Best used: If you need a better HBase.
For example: Same as HBase, since it''s basically a replacement: Search engines. Analysing log data. Any place where scanning huge, two-dimensional join-less tables are a requirement.
Accumulo (1.4)
- Written in: Java and C++
- Main point: A BigTable with Cell-level security
- License: Apache
- Protocol: Thrift
- Another BigTable clone, also runs of top of Hadoop
- Cell-level security
- Bigger rows than memory are allowed
- Keeps a memory map outside Java, in C++ STL
- Map/reduce using Hadoop''s facitlities (ZooKeeper & co)
- Some server-side programming
Best used: If you need a different HBase.
For example: Same as HBase, since it''s basically a replacement: Search engines. Analysing log data. Any place where scanning huge, two-dimensional join-less tables are a requirement.
Special-purpose
Neo4j (V1.5M02)
- Written in: Java
- Main point: Graph database - connected data
- License: GPL, some features AGPL/commercial
- Protocol: HTTP/REST (or embedding in Java)
- Standalone, or embeddable into Java applications
- Full ACID conformity (including durable data)
- Both nodes and relationships can have metadata
- Integrated pattern-matching-based query language ("Cypher")
- Also the "Gremlin" graph traversal language can be used
- Indexing of nodes and relationships
- Nice self-contained web admin
- Advanced path-finding with multiple algorithms
- Indexing of keys and relationships
- Optimized for reads
- Has transactions (in the Java API)
- Scriptable in Groovy
- Online backup, advanced monitoring and High Availability is AGPL/commercial licensed
Best used: For graph-style, rich or complex, interconnected data. Neo4j is quite different from the others in this sense.
For example: For searching routes in social relations, public transport links, road maps, or network topologies.
ElasticSearch (0.20.1)
- Written in: Java
- Main point: Advanced Search
- License: Apache
- Protocol: JSON over HTTP (Plugins: Thrift, memcached)
- Stores JSON documents
- Has versioning
- Parent and children documents
- Documents can time out
- Very versatile and sophisticated querying, scriptable
- Write consistency: one, quorum or all
- Sorting by score (!)
- Geo distance sorting
- Fuzzy searches (approximate date, etc) (!)
- Asynchronous replication
- Atomic, scripted updates (good for counters, etc)
- Can maintain automatic "stats groups" (good for debugging)
- Still depends very much on only one developer (kimchy).
Best used: When you have objects with (flexible) fields, and you need "advanced search" functionality.
For example: A dating service that handles age difference, geographic location, tastes and dislikes, etc. Or a leaderboard system that depends on many variables.
The "long tail"
(Not widely known, but definitely worthy ones)
Couchbase (ex-Membase) (2.0)
- Written in: Erlang & C
- Main point: Memcache compatible, but with persistence and clustering
- License: Apache
- Protocol: memcached + extensions
- Very fast (200k+/sec) access of data by key
- Persistence to disk
- All nodes are identical (master-master replication)
- Provides memcached-style in-memory caching buckets, too
- Write de-duplication to reduce IO
- Friendly cluster-management web GUI
- Connection proxy for connection pooling and multiplexing (Moxi)
- Incremental map/reduce
- Cross-datacenter replication
Best used: Any application where low-latency data access, high concurrency support and high availability is a requirement.
For example: Low-latency use-cases like ad targeting or highly-concurrent web apps like online gaming (e.g. Zynga).
Scalaris (0.5)
- Written in: Erlang
- Main point: Distributed P2P key-value store
- License: Apache
- Protocol: Proprietary & JSON-RPC
- In-memory (disk when using Tokyo Cabinet as a backend)
- Uses YAWS as a web server
- Has transactions (an adapted Paxos commit)
- Consistent, distributed write operations
- From CAP, values Consistency over Availability (in case of network partitioning, only the bigger partition works)
Best used: If you like Erlang and wanted to use Mnesia or DETS or ETS, but you need something that is accessible from more languages (and scales much better than ETS or DETS).
For example: In an Erlang-based system when you want to give access to the DB to Python, Ruby or Java programmers.
VoltDB (2.8.4.1)
- Written in: Java
- Main point: Fast transactions and repidly changing data
- License: GPL 3
- Protocol: Proprietary
- In-memory relational database.
- Can export data into Hadoop
- Supports ANSI SQL
- Stored procedures in Java
- Cross-datacenter replication
Best used: Where you need to act fast on massive amounts of incoming data.
For example: Point-of-sales data analysis. Factory control systems.
Kyoto Tycoon (0.9.56)
- Written in: C++
- Main point: A lightweight network DBM
- License: GPL
- Protocol: HTTP (TSV-RPC or REST)
- Based on Kyoto Cabinet, Tokyo Cabinet''s successor
- Multitudes of storage backends: Hash, Tree, Dir, etc (everything from Kyoto Cabinet)
- Kyoto Cabinet can do 1M+ insert/select operations per sec (but Tycoon does less because of overhead)
- Lua on the server side
- Language bindings for C, Java, Python, Ruby, Perl, Lua, etc
- Uses the "visitor" pattern
- Hot backup, asynchronous replication
- background snapshot of in-memory databases
- Auto expiration (can be used as a cache server)
Best used: When you want to choose the backend storage algorithm engine very precisely. When speed is of the essence.
For example: Caching server. Stock prices. Analytics. Real-time data collection. Real-time communication. And wherever you used memcached before.
Of course, all these systems have much more features than what''s listed here. I only wanted to list the key points that I base my decisions on. Also, development of all are very fast, so things are bound to change.
Discussion on Hacker News
Shameless plug: I''m a freelance software architect (resume), have a look at my services!
P.s.: And no, there''s no date on this review. There are version numbers, since I update the databases one by one, not at the same time. And believe me, the basic properties of databases don''t change that much.
")
centos 安装nodebb(mongodb)
安装mongodb 参考:https://docs.mongodb.com/manual/tutorial/install-mongodb-on-red-hat/ 1、修改yum的base源,在最后加上:
[mongodb-org-3.2] name=MongoDB Repository baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.2/x86_64/ gpgcheck=1 enabled=1 gpgkey=https://www.mongodb.org/static/pgp/server-3.2.asc
2、yum 安装 yum install -y mongodb-org 启动 sudo service mongod start 设置服务自启动 chkconfig mongod on
安装nodebb 参考:https://docs.nodebb.org/en/latest/configuring/databases/mongo.html 1、git clone git://github.com/NodeBB/NodeBB.git nodebb 2、安装必要模块 $ cd nodebb $ npm install 3、设置mongo数据库和用户名 $ mongo
use nodebb db.createUser( { user: “nodebb”, pwd: “<Enter in a secure password>”, roles: [ “readWrite” ] } ) 4、初始设置nodebb,启动 $ cd /path/to/nodebb $ node app --setup $ ./nodebb start
")
docker 一些软件的简单安装(nginx tomcat Redis mongodb)
1.nginx 的安装
1.1. mkdir nginx (创建一个 nginx 文件,用了安装 nginx)、
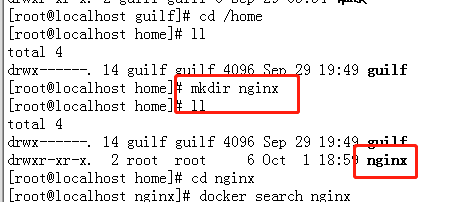
1.2
docker search nginx (搜索)docker pull nginx (下载)
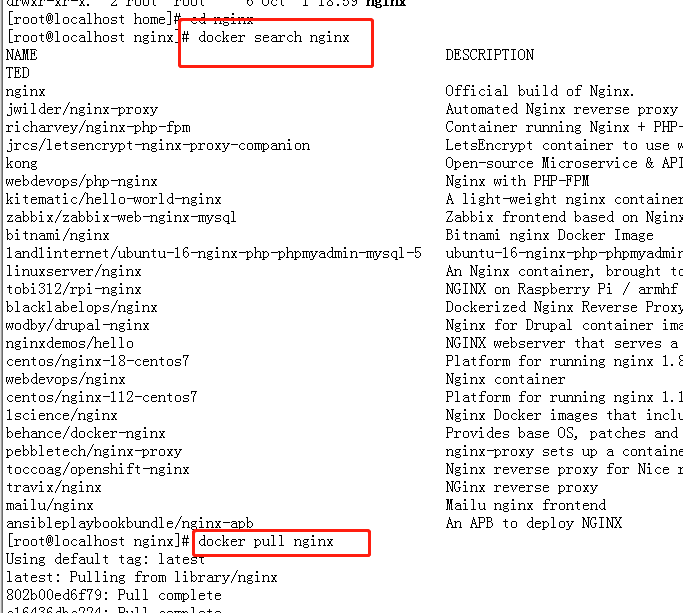
1.4 docker images nginx (查看镜像)

1.3 docker run -p 80:80 --name mynginx1 -v $PWD/www:/www -v $PWD/logs:/wwwlogs -d nginx(启动)
(下面一个要配好文件路径,我没配置,所以用上面一个了)
docker run -p 80:80 --name mynginx -v $PWD/www:/www -v $PWD/conf/nginx.conf:/etc/nginx/nginx.conf -v $PWD/logs:/wwwlogs -d nginx 命令说明:-
-p 80:80:将容器的 80 端口映射到主机的 80 端口
-
--name mynginx:将容器命名为 mynginx
-
-v $PWD/www:/www:将主机中当前目录下的 www 挂载到容器的 /www
-
-v $PWD/conf/nginx.conf:/etc/nginx/nginx.conf:将主机中当前目录下的 nginx.conf 挂载到容器的 /etc/nginx/nginx.conf
-
-v $PWD/logs:/wwwlogs:将主机中当前目录下的 logs 挂载到容器的 /wwwlogs
查看容器启动情况 docker ps

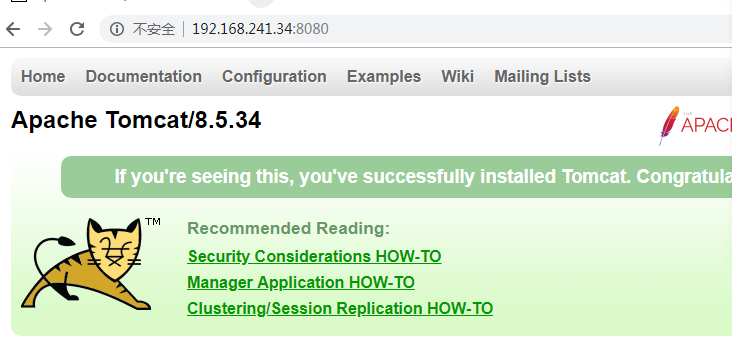
1.5 查看页面
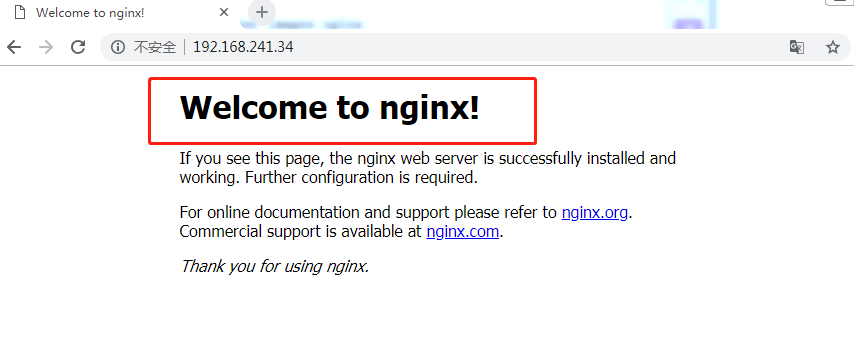
2.tomcat
2.1 mkdir tomcat (创建 tomcat 包)
2.2
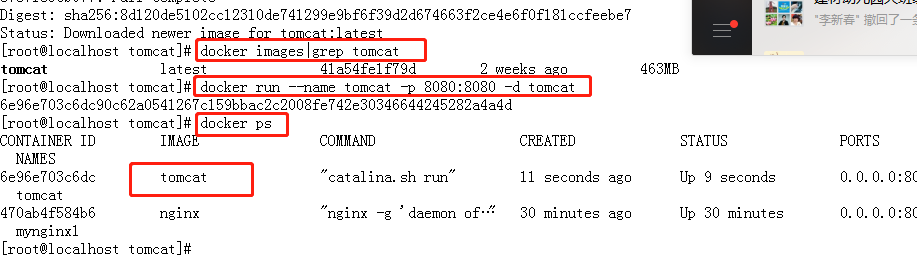
docker search tomcat (查找)
docker pull tomcat (安装)
docker images|grep tomcat(查找镜像)
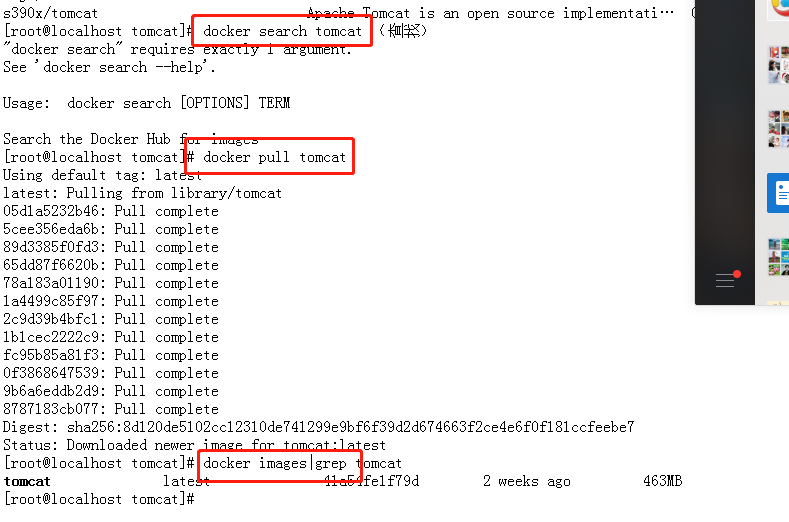
2.3
docker run --name tomcat -p 8080:8080 -d tomcat (启动)
(下面也是启动,只是要制定路径)docker run --name tomcat -p 8080:8080 -v $PWD/test:/usr/local/tomcat/webapps/test -d tomcat
3.redis
mkdir redis
docker search redisdocker pull redis:3.2
docker images redis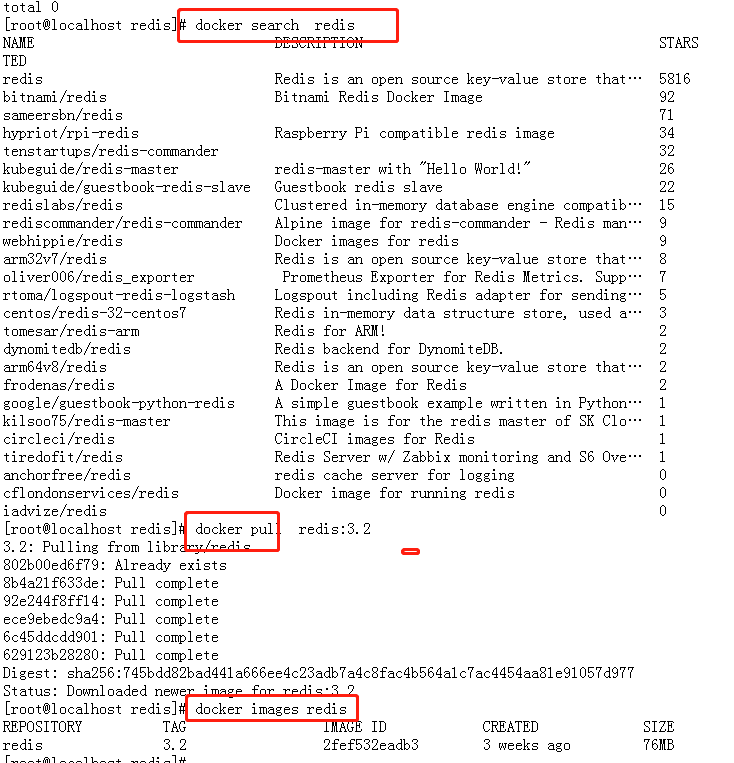
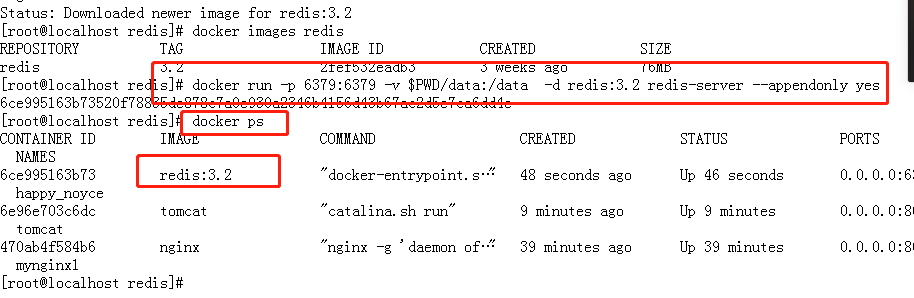
docker run -p 6379:6379 -v $PWD/data:/data -d redis:3.2 redis-server --appendonly yes
命令说明:
-p 6379:6379 : 将容器的 6379 端口映射到主机的 6379 端口
-v $PWD/data:/data : 将主机中当前目录下的 data 挂载到容器的 /data
redis-server --appendonly yes : 在容器执行 redis-server 启动命令,并打开 redis 持久化配置
查看容器启动情况 docker ps
docker exec -it 6ce995163b73 redis-cliinfo
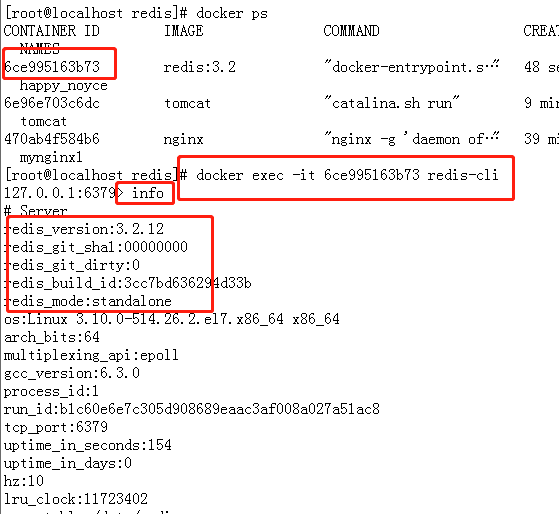
然后可以进行 redis 的一些操作了

4.MongoDB
mkdir mongodb
docker search mongo
docker pull mongodocker images mongo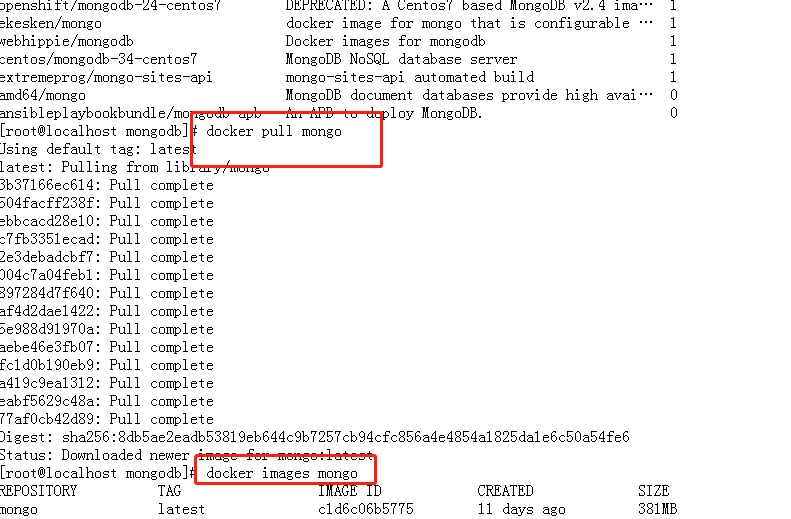
docker run -p 27017:27017 -v $PWD/db:/data/db -d mongo:3.2命令说明:
-p 27017:27017 : 将容器的 27017 端口映射到主机的 27017 端口
-v $PWD/db:/data/db : 将主机中当前目录下的 db 挂载到容器的 /data/db,作为 mongo 数据存储目录
查看容器启动情况 docker ps
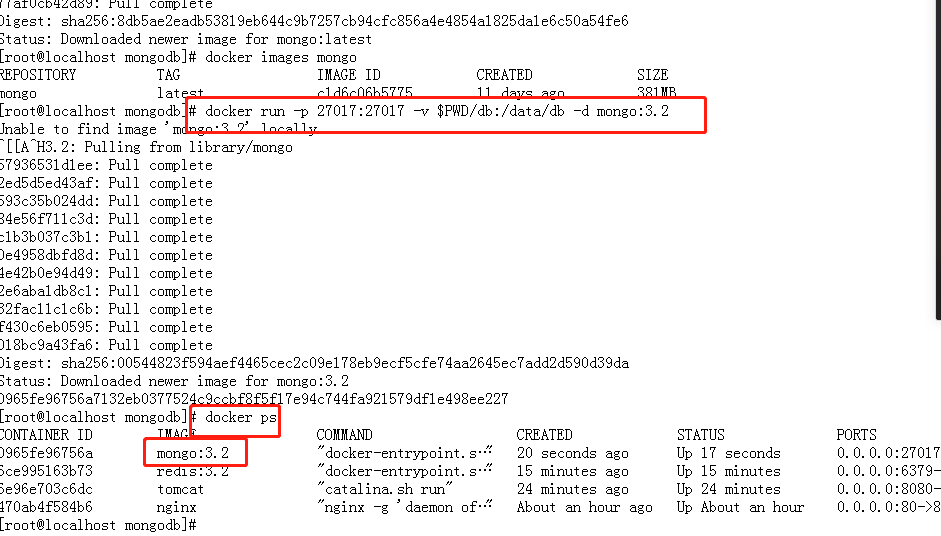
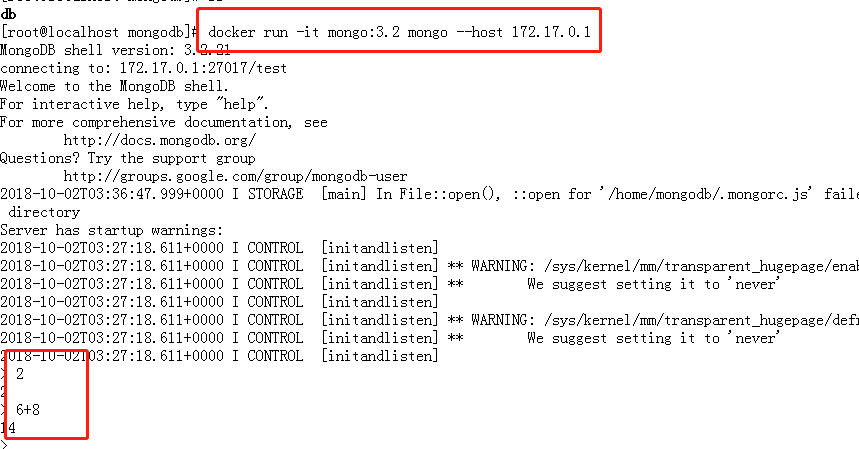
使用mongo镜像执行mongo 命令连接到刚启动的容器,主机IP为172.17.0.1
docker run -it mongo:3.2 mongo --host 172.17.0.1
关于NoSQL解决方案比较和MongoDB vs Redis, Tokyo Cabinet, and Berkeley DB的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于105道BAT最新Java面试题(MySQL+Redis+nginx+ookeeper+MongoDB)、Cassandra vs MongoDB vs CouchDB vs Redis vs Ria...、centos 安装nodebb(mongodb)、docker 一些软件的简单安装(nginx tomcat Redis mongodb)等相关内容,可以在本站寻找。
本文标签:




