对于想了解Python,Pandas:将DataFrame的内容写入文本文件的读者,本文将是一篇不可错过的文章,我们将详细介绍python将dataframe写入excel,并且为您提供关于panda
对于想了解Python,Pandas:将DataFrame的内容写入文本文件的读者,本文将是一篇不可错过的文章,我们将详细介绍python将dataframe写入excel,并且为您提供关于pandas-19 DataFrame读取写入文件的方法、pandas:DataFrame的属性和pandas文件的操作、Python / Pandas:如何将字符串列表与DataFrame列匹配、Python Pandas -- DataFrame的有价值信息。
本文目录一览:- Python,Pandas:将DataFrame的内容写入文本文件(python将dataframe写入excel)
- pandas-19 DataFrame读取写入文件的方法
- pandas:DataFrame的属性和pandas文件的操作
- Python / Pandas:如何将字符串列表与DataFrame列匹配
- Python Pandas -- DataFrame
")
Python,Pandas:将DataFrame的内容写入文本文件(python将dataframe写入excel)
我有这样的熊猫DataFrame
X Y Z Value 0 18 55 1 70 1 18 55 2 67 2 18 57 2 75 3 18 58 1 35 4 19 54 2 70我想将此数据写入如下所示的文本文件:
18 55 1 70 18 55 2 67 18 57 2 75 18 58 1 35 19 54 2 70我已经尝试过类似的东西
f = open(writePath, ''a'')f.writelines([''\n'', str(data[''X'']), '' '', str(data[''Y'']), '' '', str(data[''Z'']), '' '', str(data[''Value''])])f.close()但它不起作用。这该怎么做?
答案1
小编典典您可以只使用np.savetxt和访问np属性.values:
np.savetxt(r''c:\data\np.txt'', df.values, fmt=''%d'')产量:
18 55 1 7018 55 2 6718 57 2 7518 58 1 3519 54 2 70或to_csv:
df.to_csv(r''c:\data\pandas.txt'', header=None, index=None, sep='' '', mode=''a'')请注意,np.savetxt您必须传递通过追加模式创建的文件句柄。

pandas-19 DataFrame读取写入文件的方法
pandas-19 DataFrame读取写入文件的方法
DataFrame有非常丰富的IO方法,比如DataFrame读写csv文件excel文件等等,操作很简单。下面在代码中标记出来一些常用的读写操作方法,需要的时候查询一下该方法就可以了。
df1.to_csv(‘df1.csv’) # 默认会把 index 也当成一列写入到文件中 df1.to_csv(‘df2.csv’, index=False) # 如果不想显示索引,可以添加第二个参数 index = False df1.to_json(‘df1.csv’) 写入到json文件 df1.to_excel(‘df1.xlsx’) 写入到excel文件
更多例子参考如下:
import pandas as pd
from pandas import Series, DataFrame
import webbrowser
link = ''http://pandas.pydata.org/pandas-docs/version/0.20/io.html''
webbrowser.open(link)
df1 = pd.read_clipboard()
print(df1)
''''''
Format Type Data Description Reader Writer
0 text CSV read_csv to_csv
1 text JSON read_json to_json
2 text HTML read_html to_html
3 text Local clipboard read_clipboard to_clipboard
4 binary MS Excel read_excel to_excel
5 binary HDF5 Format read_hdf to_hdf
6 binary Feather Format read_feather to_feather
7 binary Msgpack read_msgpack to_msgpack
8 binary Stata read_stata to_stata
9 binary SAS read_sas
10 binary Python Pickle Format read_pickle to_pickle
11 SQL SQL read_sql to_sql
12 SQL Google Big Query read_gbq to_gbq
''''''
df1.to_csv(''df1.csv'') # 默认会把 index 也当成一列写入到文件中
df1.to_csv(''df2.csv'', index=False) # 如果不想显示索引,可以添加第二个参数 index = False
print(df1.to_json())
df1.to_excel(''df1.xlsx'')

pandas:DataFrame的属性和pandas文件的操作
先将模块导入文件中
import pandas as pd1、DataFrame的属性
df = pd.DataFrame(
data={
"name": ["zs", "ls", "ww", "zl"],
"age": [18, 19, 29, 11],
"score": [92.5, 93, 97, 65]
},
index=["stu_1", "stu_2", "stu_3", "stu_4"]
)创建一个df
将df和df的类型打印看看:

(1)df的索引属性
print("获取df 的行索引名称:\n", df.index)
print("获取df 的列索引名称:\n", df.columns)
(2)df的values属性
print("获取df 的values:\n", df.values)
print("获取df 的values的类型:\n", type(df.values))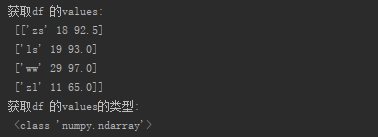
(3)df的形状和维度属性
print("获取df 的形状:\n", df.shape)
print("获取df 的维度:\n", df.ndim)
(4)df的元素个数和元素数据类型
print("获取df 的元素个数:\n", df.size)
print("获取df 的元素数据类型:\n", df.dtypes)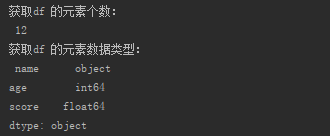
2、pandas文件的操作
(1)使用read_table()方法读取文件
info = pd.read_table(
filepath_or_buffer="./meal_order_info.csv",
sep=",",
header="infer", # 自动识别
# header=None, # 不指定列名
# header=0, # 指定第0行位 列索引名称
encoding="ansi",
# index_col= 0 # 把第0列设置为行索引名称
# nrows=3,
# usecols=[0,1],
# names=["01","07"], # 可以自己设置列名
# usecols=["info_id","emp_id"]
)csv文件:以逗号“,”为分割符的文本文件,filepath_or_buffer:文件路径+文件名,sep/delimiter:分隔符,header="infer":自动识别索引列名称,names:可以自行指定列名称,index_col:可以指定哪一列、哪几列作为行索引名称,usecol:可以自行获取指定的列,encoding:设置编码,nrows:可以指定读取的行数
(2)使用read_csv()方法读取文件
info = pd.read_csv("./meal_order_info.csv",encoding="ansi")具体参数参考read_table()方法
(3)使用read_excel()方法读取文件
users = pd.read_excel(
"./users.xlsx",
sheetname=0,
parse_cols=[0, 1], # 在某些版本起作用,
)使用read_excel()方法读取excel文件(.xlsx、.xls结尾),参数1:文件路径+文件名,sheetname:表的序号,index_col:可以指定哪一列、哪几列作为行索引名称,parse_cols:读取指定的列
(4)使用to_csv()方法保存文件
info.to_csv("./info_save.csv",index=False,mode="a")info:DataFrame变量,index:是否保存索引,mode:保存的模式

Python / Pandas:如何将字符串列表与DataFrame列匹配
我想比较两个columnnDescription和Employer。我想查看是否Employer在该Description列中找到任何关键字。我已将该Employer列分解为单词,并转换为列表。现在,我想看看这些单词中是否有相应的Description列。
输入样例:
print(df.head(25)) Date Description Amount AutoNumber \0 3/17/2015 WW120 TFR?FR xxx8690 140.00 49246 2 3/13/2015 JX154 TFR?FR xxx8690 150.00 49246 5 3/6/2015 CANSEL SURVEY E PAY 1182.08 49246 9 3/2/2015 UE200 TFR?FR xxx8690 180.00 49246 10 2/27/2015 JH401 TFR?FR xxx8690 400.00 49246 11 2/27/2015 CANSEL SURVEY E PAY 555.62 49246 12 2/25/2015 HU204 TFR?FR xxx8690 200.00 49246 13 2/23/2015 UQ263 TFR?FR xxx8690 102.00 49246 14 2/23/2015 UT460 TFR?FR xxx8690 200.00 49246 15 2/20/2015 CANSEL SURVEY E PAY 1222.05 49246 17 2/17/2015 UO414 TFR?FR xxx8690 250.00 49246 19 2/11/2015 HI540 TFR?FR xxx8690 130.00 49246 20 2/11/2015 HQ010 TFR?FR xxx8690 177.00 49246 21 2/10/2015 WU455 TFR?FR xxx8690 200.00 49246 22 2/6/2015 JJ500 TFR?FR xxx8690 301.00 49246 23 2/6/2015 CANSEL SURVEY E PAY 1182.08 49246 24 2/5/2015 IR453 TFR?FR xxx8690 168.56 49246 26 2/2/2015 RQ574 TFR?FR xxx8690 500.00 49246 27 2/2/2015 UT022 TFR?FR xxx8690 850.00 49246 28 12/31/2014 HU521 TFR?FR xxx8690 950.17 49246 Employer 0 Cansel Survey Equipment 2 Cansel Survey Equipment 5 Cansel Survey Equipment 9 Cansel Survey Equipment 10 Cansel Survey Equipment 11 Cansel Survey Equipment 12 Cansel Survey Equipment 13 Cansel Survey Equipment 14 Cansel Survey Equipment 15 Cansel Survey Equipment 17 Cansel Survey Equipment 19 Cansel Survey Equipment 20 Cansel Survey Equipment 21 Cansel Survey Equipment 22 Cansel Survey Equipment 23 Cansel Survey Equipment 24 Cansel Survey Equipment 26 Cansel Survey Equipment 27 Cansel Survey Equipment 28 Cansel Survey Equipment我尝试过类似的方法,但似乎不起作用。
df[''Text_Search''] = df[''Employer''].apply(lambda x: x.split(" "))df[''Match''] = np.where(df[''Description''].str.contains("|".join(df[''Text_Search''])), "Yes", "No")我想要的输出如下所示:
Date Description Amount AutoNumber \0 3/17/2015 WW120 TFR?FR xxx8690 140.00 49246 2 3/13/2015 JX154 TFR?FR xxx8690 150.00 49246 5 3/6/2015 CANSEL SURVEY E PAY 1182.08 49246 9 3/2/2015 UE200 TFR?FR xxx8690 180.00 49246 10 2/27/2015 JH401 TFR?FR xxx8690 400.00 49246 11 2/27/2015 CANSEL SURVEY E PAY 555.62 49246 12 2/25/2015 HU204 TFR?FR xxx8690 200.00 49246 13 2/23/2015 UQ263 TFR?FR xxx8690 102.00 49246 14 2/23/2015 UT460 TFR?FR xxx8690 200.00 49246 15 2/20/2015 CANSEL SURVEY E PAY 1222.05 49246 17 2/17/2015 UO414 TFR?FR xxx8690 250.00 49246 19 2/11/2015 HI540 TFR?FR xxx8690 130.00 49246 20 2/11/2015 HQ010 TFR?FR xxx8690 177.00 49246 21 2/10/2015 WU455 TFR?FR xxx8690 200.00 49246 22 2/6/2015 JJ500 TFR?FR xxx8690 301.00 49246 23 2/6/2015 CANSEL SURVEY E PAY 1182.08 49246 24 2/5/2015 IR453 TFR?FR xxx8690 168.56 49246 26 2/2/2015 RQ574 TFR?FR xxx8690 500.00 49246 27 2/2/2015 UT022 TFR?FR xxx8690 850.00 49246 28 12/31/2014 HU521 TFR?FR xxx8690 950.17 49246 29 12/30/2014 WZ553 TFR?FR xxx8690 200.00 49246 32 12/29/2014 JW173 TFR?FR xxx8690 300.00 49246 33 12/24/2014 CANSEL SURVEY E PAY 1219.21 49246 34 12/24/2014 CANSEL SURVEY E PAY 434.84 49246 36 12/23/2014 WT002 TFR?FR xxx8690 160.00 49246 Employer Text_Search Match 0 Cansel Survey Equipment [Cansel, Survey, Equipment] No 2 Cansel Survey Equipment [Cansel, Survey, Equipment] No 5 Cansel Survey Equipment [Cansel, Survey, Equipment] Yes 9 Cansel Survey Equipment [Cansel, Survey, Equipment] No 10 Cansel Survey Equipment [Cansel, Survey, Equipment] No 11 Cansel Survey Equipment [Cansel, Survey, Equipment] Yes 12 Cansel Survey Equipment [Cansel, Survey, Equipment] No 13 Cansel Survey Equipment [Cansel, Survey, Equipment] No 14 Cansel Survey Equipment [Cansel, Survey, Equipment] No 15 Cansel Survey Equipment [Cansel, Survey, Equipment] Yes 17 Cansel Survey Equipment [Cansel, Survey, Equipment] No 19 Cansel Survey Equipment [Cansel, Survey, Equipment] No 20 Cansel Survey Equipment [Cansel, Survey, Equipment] No 21 Cansel Survey Equipment [Cansel, Survey, Equipment] No 22 Cansel Survey Equipment [Cansel, Survey, Equipment] No 23 Cansel Survey Equipment [Cansel, Survey, Equipment] Yes 24 Cansel Survey Equipment [Cansel, Survey, Equipment] No 26 Cansel Survey Equipment [Cansel, Survey, Equipment] No 27 Cansel Survey Equipment [Cansel, Survey, Equipment] No 28 Cansel Survey Equipment [Cansel, Survey, Equipment] No 29 Cansel Survey Equipment [Cansel, Survey, Equipment] No 32 Cansel Survey Equipment [Cansel, Survey, Equipment] No 33 Cansel Survey Equipment [Cansel, Survey, Equipment] Yes 34 Cansel Survey Equipment [Cansel, Survey, Equipment] Yes 36 Cansel Survey Equipment [Cansel, Survey, Equipment] No答案1
小编典典这是使用个人的可读解决方案search_func:
def search_func(row): matches = [test_value in row["Description"].lower() for test_value in row["Text_Search"]] if any(matches): return "Yes" else: return "No"然后按行应用此函数:
# create example datadf = pd.DataFrame({"Description": ["CANSEL SURVEY E PAY", "JX154 TFR?FR xxx8690"], "Employer": ["Cansel Survey Equipment", "Cansel Survey Equipment"]})print(df) Description Employer0 CANSEL SURVEY E PAY Cansel Survey Equipment1 JX154 TFR?FR xxx8690 Cansel Survey Equipment# create text searches and match columndf["Text_Search"] = df["Employer"].str.lower().str.split()df["Match"] = df.apply(search_func, axis=1)# show resultprint(df) Description Employer Text_Search Match0 CANSEL SURVEY E PAY Cansel Survey Equipment [cansel, survey, equipment] Yes1 JX154 TFR?FR xxx8690 Cansel Survey Equipment [cansel, survey, equipment] No
Python Pandas -- DataFrame
pandas.DataFrame
-
class
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)[source] -
Two-dimensional size-mutable, potentially heterogeneous tabular data structure with labeled axes (rows and columns). Arithmetic operations align on both row and column labels. Can be thought of as a dict-like container for Series objects. The primary pandas data structure
Parameters: data : numpy ndarray (structured or homogeneous), dict, or DataFrame
Dict can contain Series, arrays, constants, or list-like objects
index : Index or array-like
Index to use for resulting frame. Will default to np.arange(n) if no indexing information part of input data and no index provided
columns : Index or array-like
Column labels to use for resulting frame. Will default to np.arange(n) if no column labels are provided
dtype : dtype, default None
Data type to force. Only a single dtype is allowed. If None, infer
copy : boolean, default False
Copy data from inputs. Only affects DataFrame / 2d ndarray input
See also
-
DataFrame.from_records - constructor from tuples, also record arrays
-
DataFrame.from_dict - from dicts of Series, arrays, or dicts
-
DataFrame.from_items - from sequence of (key, value) pairs
pandas.read_csv,pandas.read_table,pandas.read_clipboard1. 先来个小菜
基于dictionary创建
from pandas import Series, DataFrame import pandas as pd import numpy as np d = {''col1'':[1,2],''col2'':[3,4]} df = pd.DataFrame(data=d) print(df) print(df.dtypes) # col1 col2 #0 1 3 #1 2 4 #col1 int64 #col2 int64 #dtype: object基于Numy的ndarrary
df2 = pd.DataFrame(np.random.randint(low=0, high=10, size=(5, 5)),columns=[''a'', ''b'', ''c'', ''d'', ''e'']) print (df2) # a b c d e #0 0 2 4 7 0 #1 6 7 3 4 1 #2 5 3 3 8 7 #3 0 9 4 3 4 #4 7 4 7 0 0 -
关于Python,Pandas:将DataFrame的内容写入文本文件和python将dataframe写入excel的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于pandas-19 DataFrame读取写入文件的方法、pandas:DataFrame的属性和pandas文件的操作、Python / Pandas:如何将字符串列表与DataFrame列匹配、Python Pandas -- DataFrame等相关内容,可以在本站寻找。
本文标签:




