针对如何计算python中正态累积分布函数的反函数?和python正态分布反函数这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展excel怎么获得标准正态累计分布函数的反函数值_excel中
针对如何计算python中正态累积分布函数的反函数?和python 正态分布反函数这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展excel怎么获得标准正态累计分布函数的反函数值_excel中NORMSINV函数使用教程、numpy的bincount函数的反函数、Python Sklearn-如何计算P值、Python-转置/解压缩功能(zip的反函数)?等相关知识,希望可以帮助到你。
本文目录一览:- 如何计算python中正态累积分布函数的反函数?(python 正态分布反函数)
- excel怎么获得标准正态累计分布函数的反函数值_excel中NORMSINV函数使用教程
- numpy的bincount函数的反函数
- Python Sklearn-如何计算P值
- Python-转置/解压缩功能(zip的反函数)?
")
如何计算python中正态累积分布函数的反函数?(python 正态分布反函数)
如何计算Python中正态分布的累积分布函数(CDF)的反函数?
我应该使用哪个库?可能是卑鄙的?
答案1
小编典典NORMSINV(在注释中提到)是标准正态分布的CDF的倒数。使用scipy,您可以使用对象的ppf方法进行计算scipy.stats.norm。首字母缩写词ppf代表
百分比点函数
,它是 分位数函数的 另一个名称。
In [20]: from scipy.stats import normIn [21]: norm.ppf(0.95)Out[21]: 1.6448536269514722检查它是否与CDF相反:
In [34]: norm.cdf(norm.ppf(0.95))Out[34]: 0.94999999999999996默认情况下,norm.ppf使用mean = 0和stddev =
1,这是“标准”正态分布。您可以通过分别指定loc和scale参数来使用不同的均值和标准差。
In [35]: norm.ppf(0.95, loc=10, scale=2)Out[35]: 13.289707253902945如果您看一下的源代码scipy.stats.norm,就会发现该ppf方法最终会调用scipy.special.ndtri。因此,要计算标准正态分布的CDF的倒数,可以直接使用该函数:
In [43]: from scipy.special import ndtriIn [44]: ndtri(0.95)Out[44]: 1.6448536269514722
excel怎么获得标准正态累计分布函数的反函数值_excel中NORMSINV函数使用教程
标准正态累计分布函数反函数详解在数据分析中,计算标准正态累计分布函数的反函数值是常见需求。php小编香蕉特此带来 excel 中 normsinv 函数 的使用教程,为您详解如何轻松获得标准正态累计分布函数的反函数值。本教程将一步步引导您认识 normsinv 函数的语法、用法和注意事项,帮助您高效解决实际问题。继续阅读,深入了解这一 excel 函数的强大功能。
1、打开表格,点击要返回答案的单元格。
2、在菜单栏中选择【公式-插入函数】。
3、打开函数下拉列表,在选择类别中选择【统计】。
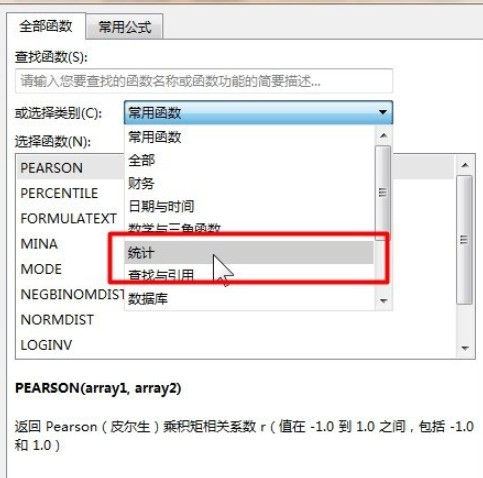
4、在插入函数对话框中的选择函数中找到【NORMSINV】。

5、输入相应的参数值。
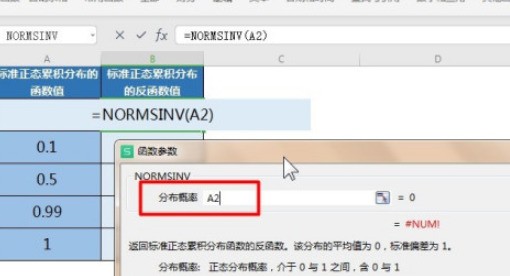
6、然后鼠标放置第一个单元格右下角双击即可返回标准正态累积分布函数的反函数。
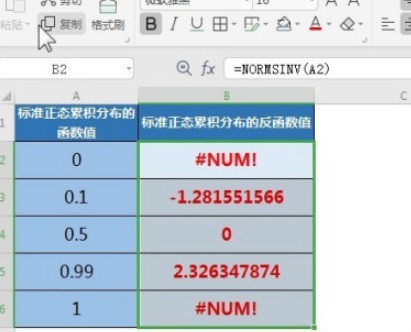
以上就是excel怎么获得标准正态累计分布函数的反函数值_excel中NORMSINV函数使用教程的详细内容,更多请关注php中文网其它相关文章!

numpy的bincount函数的反函数
给定一个整数计数数组,c我如何将其转换为一个整数数组,inds使之np.all(np.bincount(inds) == c)为真?
例如:
>>> c = np.array([1,3,2,2])
>>> inverse_bincount(c) # <-- what I need
array([0,1,3])
上下文:我试图跟踪多组数据的位置,同时一次对所有数据执行计算。我将所有数据连接在一起以进行批处理,但是我需要一个索引数组来提取结果。
当前解决方法:
def inverse_bincount(c):
return np.array(list(chain.from_iterable([i]*n for i,n in enumerate(c))))

Python Sklearn-如何计算P值
这可能是一个简单的问题,但是我正在尝试使用分类器(用于分类问题)或回归器(用于回归)来计算特征的p值。有人可以建议每种情况的最佳方法是什么,并提供示例代码吗?我只想查看每个功能的p值,而不是按照文档中的说明保持功能的k最佳/百分位。
谢谢
答案1
小编典典只需X, y直接进行意义测试。使用20news和的示例chi2:
>>> from sklearn.datasets import fetch_20newsgroups_vectorized>>> from sklearn.feature_selection import chi2>>> data = fetch_20newsgroups_vectorized()>>> X, y = data.data, data.target>>> scores, pvalues = chi2(X, y)>>> pvaluesarray([ 4.10171798e-17, 4.34003018e-01, 9.99999996e-01, ..., 9.99999995e-01, 9.99999869e-01, 9.99981414e-01])?")
Python-转置/解压缩功能(zip的反函数)?
如何解决Python-转置/解压缩功能(zip的反函数)??
zip是它自己的逆!前提是你使用特殊的*运算符。
>>> zip(*[(''a'', 1), (''b'', 2), (''c'', 3), (''d'', 4)])
[(''a'', ''b'', ''c'', ''d''), (1, 2, 3, 4)]
它的工作方式是通过调用zip参数:
zip((''a'', 1), (''b'', 2), (''c'', 3), (''d'', 4))
…除了参数zip直接传递(转换为元组后)外,因此不必担心参数数量太大。
解决方法
我有一个2项元组的列表,我想将它们转换为2个列表,其中第一个包含每个元组中的第一项,第二个包含第二项。
例如:
original = [(''a'',1),(''b'',2),(''c'',3),(''d'',4)]
# and I want to become...
result = ([''a'',''b'',''c'',''d''],[1,2,3,4])
有内置的功能吗?
关于如何计算python中正态累积分布函数的反函数?和python 正态分布反函数的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于excel怎么获得标准正态累计分布函数的反函数值_excel中NORMSINV函数使用教程、numpy的bincount函数的反函数、Python Sklearn-如何计算P值、Python-转置/解压缩功能(zip的反函数)?等相关内容,可以在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

