本篇文章给大家谈谈python代理脚本实现期望数据与实际数据的比对(V1.0),以及python求期望代码的知识点,同时本文还将给你拓展.net–IronPython与原始Python的比较.我对第一
本篇文章给大家谈谈python 代理脚本实现期望数据与实际数据的比对 (V1.0),以及python求期望代码的知识点,同时本文还将给你拓展.net – IronPython与原始Python的比较.我对第一个有什么期望?、2.3 Hive 的数据类型讲解及实际项目中如何使用 python 脚本对数据进行 ETL、jfinal 执行sql语句获取的数据与实际数据有差异、PHP 调用python 脚本实现python功能等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- python 代理脚本实现期望数据与实际数据的比对 (V1.0)(python求期望代码)
- .net – IronPython与原始Python的比较.我对第一个有什么期望?
- 2.3 Hive 的数据类型讲解及实际项目中如何使用 python 脚本对数据进行 ETL
- jfinal 执行sql语句获取的数据与实际数据有差异
- PHP 调用python 脚本实现python功能
(python求期望代码)")
python 代理脚本实现期望数据与实际数据的比对 (V1.0)(python求期望代码)
1. 需要引用的包如下:
from BaseHTTPServer import BaseHTTPRequestHandler
from SocketServer import ThreadingTCPServer
import gzip
from StringIO import StringIO
import logging
import os
from readDataToDic import GenExceptData2.readDataToDic 包
该包可以从我的博客链接:http://blog.csdn.net/henni_719/article/details/75007233,复制下来,在下面我附上该包最新的代码:
#coding=utf8
import csv
import logging
import os
''''''
Author:ewang
Data:2017/07/12
该模块的主要功能函数:
readDataToList():把csv中的数据,数据项以字典类型存储在列表中。
getAllServiceId():获取所有的serviceId列表
printListData():输出数据list中的每项数据
createDataDic():创建一个数据字典表,以serviceId为key,相同的数据项列表为value
printDicData():输出数据字典中的每项数据
''''''
PATH=lambda p:os.path.abspath(os.path.join(
os.path.dirname(__file__), p))
logging.basicConfig(level=logging.DEBUG,
format=''%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s'',
datefmt=''%a, %d %b %Y %H:%M:%S'',
filename=PATH(''../Log/readDate.log''),
filemode=''w'')
class GenExceptData(object):
def __init__(self,filePah=PATH("../LastCSV/20170510174450.csv")):
try:
#存放csv中读取的数据
self.mdbuffer=[]
#打开csv文件,设置读的权限
csvHand=open(filePah,"r")
#创建读取csv文件句柄
readcsv=csv.reader(csvHand)
#把csv的数据读取到mdbuffer中
for row in readcsv:
self.mdbuffer.append(row)
#把数据穿件为为字典类型的
except Exception,e:
logging.error("Read Excel error:"+e)
finally:
#关闭csv文件
csvHand.close()
def readDataToList(self):
try:
#在数组最后添加一个空白行
#该行的作用是为了成功获取最后一条json数据
#在数组endLine添加空白字符
endLine=[" " for num in range(len(self.mdbuffer[1])) if num>=0]
#把以空字符的endLine添加到末尾
self.mdbuffer.append(endLine)
#获取mdbuffer中的元素个数
rowNumber=len(self.mdbuffer)
#设置当前行号
currentrow=1
#设置json数据的属性值
propertyJson={}
#读取列表中的元素
dataList=[]
try:
for row in range(1,rowNumber):
#创建一个临时变量用来存取一次循环的属性键值
temp={}
#获取列表中一个元素
item=self.mdbuffer[row]
#获取当前元素,当前元素代表的是每个
#事件起始的位置
currentItem=self.mdbuffer[currentrow]
#获取serviceId并进行解码
serviceId= currentItem[2].decode("gbk")
#获取属性并进行解码,把解码的值存入propertyName
propertyName=item[3].decode("gbk")
#获取属性值并进行解码,把解码的值存入propertyValue
propertyValue=item[4].decode("gbk")
try:
#判断埋点事件与serviceId是否相等
if item[0]==currentItem[0] and item[2]==currentItem[2]:
#把serviceId方式字典propertyJson中
propertyJson["serviceId"]=serviceId
#把属性/值对放入temp字典中
temp[propertyName]=propertyValue
#调用字典的update函数,把temp中的键值对
#添加到 propertyJson字典中
propertyJson.update(temp)
#使用continue,如果为if条件为true则循环执行if语句模块
continue
else:
#把行号设置为当前行
currentrow=row
#把当前的属性解码放入propertyName
propertyName=currentItem[3].decode("gbk")
#把当前的属性值解码放入propertyName
propertyValue=currentItem[4].decode("gbk")
#把serviceId方式字典propertyJson中
propertyJson["serviceId"]=serviceId
#把属性/值对放入propertyJson字典中
propertyJson[propertyName]=propertyValue
#propertyJsonList.append(propertyJson)
dataList.append(propertyJson)
''''''
在这说下:
propertyJson.clear()与propertyJson={}的区别:
propertyJson.clear()是删除字典的值,不创建引用,会改变字典本身的值;
propertyJson={}是创建新的引用,字典的中的值不发现变化;
如果想让 self.dataDic.append(propertyJson)该语句执行成功,而且添加每次循环的值,
需要使用propertyJson={}方法;
如果使用propertyJson.clear(),只会把最后一次propertyJson存储的值,添加到self.dataDic中
''''''
propertyJson={}
except Exception,e:
logging.error("Get Property Json Error:" +e)
#print "Get Property Json Error:",e
except Exception,e:
logging.error("Get Date Error:"+e)
#print "Get Date Error:",e
#返回dataList
return dataList
except Exception,e:
#把信息写入日志中
logging.error("Reading Data TO Dic Error:"+e)
#print "Reading Data TO Dic Error:",e
def getAllServiceId(self):
try:
#调用readDataToList函数创建一个数据list
dataList=self.readDataToList()
#把数据list中的所有serviceId放入表serList中
serList=[item["serviceId"] for item in dataList if item["serviceId"] ]
#对serList中的数据去重,分为两步:
#第一步把列表转换成集合:set(serList)
#第二步:把集合转换为list:list(set(serList))
#集合和list的区别:集合中的数据是唯一性,不存在相同部分
serList=list(set(serList))
#返回serList
return serList
except Exception,e:
logging.error("Create ServiceId List Error:"+e)
#print "Create ServiceId List Error:"+e
#输出list中的数据信息
def printListData(self):
try:
#调用readDataToList方法获取dataList列表
dataList=self.readDataToList()
#对列表中的数据执行for循环
#并输出类似与json样式的数据
for item in dataList:
print "{"
#输出键值对
for key,val in item.items():
print "\t",key,":",val,","
print "}"
#设置以#格式的分隔符
print "#"*50
except Exception,e:
logging.error("OutPut List Data Error:"+e)
#print "OutPut List Data Error:"+e
#创建一个数据字典
def createDataDic(self):
try:
#定义个数据字典变量
dataDic={}
#调用函数readDataToList创建一个dataList表
dataList=self.readDataToList()
#调用getAllServiceId获取serviceId列表
serviceIdList=self.getAllServiceId()
#判断列表中是否有元素,如果有执行if语句
if len(serviceIdList)>0 and len(dataList)>0:
#对serviceIdList进行循环,以serviceId作为key
for serviceId in serviceIdList:
#创建一个list用来存放serviceId相同的数据项
sameServiceidJosnList=[]
#对数据列表执行循环
for item in dataList:
#获取字典中键为serviceId值,放入变量中
itemServiceId=item["serviceId"]
#如果值不为空,执行if语句
if itemServiceId:
#判断serviceId与数据项中serviceId的值是否相等
#如果相等执行if语句块
if serviceId==itemServiceId:
#把数据项加入sameServiceidJosnList列表中
sameServiceidJosnList.append(item)
else:
logging.debug("ServiceId is null")
#print "ServiceId is null"
#给字典赋值,以serviceId作为key,
#serviceId相同的数据项列表作为值
dataDic[serviceId]=sameServiceidJosnList
else:
logging.debug("seriviceIdList or dataList is null")
#print "seriviceIdList or dataList is null"
#返回字典类型的数据
return dataDic
except Exception,e:
logging.error("Create Data Dictionary Error:"+e)
#print "Create Data Dictionary Error:",e
#打印字典信息
def printDicData(self):
try:
#调用createDataDic创建dataDic字典
dataDic=self.createDataDic()
#对字典中的数据进行循环,获取键值对
for serviceId,dataitem in dataDic.items():
print "{"
print "\t",serviceId,":","["
#由于值是列表,列表中的数据项类型是字典类型
#每一数据项是哈希表
for item in dataitem:
print "\t\t{"
#输出哈希表中的数据
for key,val in item.items():
print "\t\t\t",key,":",val,","
print "\t\t},"
print"\t]"
print "}\n"
print "#"*50
except Exception,e:
logging.error("OutPut Dictionary Data Error:"+e)
#print "OutPut Dictionary Data Error:"+e
def getDicDataValue(self,serviceId="pageview"):
try:
dataDic=self.createDataDic()
if serviceId:
return dataDic[serviceId]
except Exception,e:
logging.error("Get Dic Data Error:"+e)
#print "Get Dic Data Error:",e
def test():
filepath="../LastCSV/20170510174450.csv"
gen =GenExceptData(filepath)
gen.printDicData()
print gen.getDicDataValue()
if __name__=="__main__":
test()3. 代理脚本编写
通过 BaseHTTPRequestHandler 对该类的继承,代理脚本:proxyHandler.py,该脚本较之前的代码进行了优化,运行速度更快,代码更简洁,可以参考之前的链接:http://blog.csdn.net/henni_719/article/details/70445196
proxyHandler.py:
#coding=utf8
from BaseHTTPServer import BaseHTTPRequestHandler
from SocketServer import ThreadingTCPServer
import gzip
from StringIO import StringIO
import logging
import os
from readDataToDic import GenExceptData
PATH=lambda p:os.path.abspath(os.path.join(
os.path.dirname(__file__), p))
logging.basicConfig(level=logging.DEBUG,
format=''%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s'',
datefmt=''%a, %d %b %Y %H:%M:%S'',
filename=PATH(''../Log/proxy.log''),
filemode=''w'')
class proxyHandler(BaseHTTPRequestHandler):
exceptData=GenExceptData()
def do_POST(self):
while True:
try:
path = self.path
if path.split("/")[-1] =="statistics":
#获取post提交的数据
self.datas =gzip.GzipFile(fileobj=StringIO(self.rfile.read())).read()
self.wfile.write(self.datas)
logging.debug(self.datas)
self.cmpJsonKey()
self.printJsonProps()
except Exception,e:
logging.error(e)
finally:
self.finish()
def do_CONNECT(self):
pass
def do_GET(self):
pass
def getJsonProps(self):
try:
#通过eval函数将datas的str类型转换为dict类型
self.datas=eval(self.datas)
#获取字典datas对应属性events的值
#类型为字典类型
events=self.datas["events"][0]
#获取字典events对应属性props的值
#类型为字典类型
props=events["props"]
#删除props字典与期望数据不同的部分
if props["appName"]: del props["appName"]
if props["x_xmly_resource"]:del props["x_xmly_resource"]
if props["x_xmly_tid"]:del props["x_xmly_tid"]
return props
logging.debug(props)
except Exception,e:
logging.error("Get Props Error:"+e)
def printJsonProps(self):
try:
props=self.getJsonProps()
try:
if props:
#获取所有的键,并把键值进行排序
Mdpro=sorted(props.keys())
if Mdpro:
print "{"
for index in Mdpro:
#判断属性值是否是数字
#如果不是数字进行转码
if not isinstance(props[index], int):
props[index]=props[index].decode("utf8")
print "\t",index,":",props[index],","
logging.debug(index+":"+props[index])
print "}"
except Exception,e:
logging.error("Create Props Error:"+e)
except Exception,e:
logging.error("Output Props Error:"+e)
def cmpJsonKey(self):
dataKeys=self.exceptData.getAllServiceId()
props=self.getJsonProps()
realJsonKeys=sorted(props.keys())
if props["serviceId"] in dataKeys:
#print props["serviceId"]
itemList=self.exceptData.getDicDataValue(props["serviceId"])
for item in itemList:
exceptJsonKeys=sorted(item.keys())
print "exceptKey",exceptJsonKeys
print "realKey",realJsonKeys
if cmp(realJsonKeys,exceptJsonKeys)==0:
print exceptJsonKeys
#return True
break
def test():
host=''127.0.0.1''
port=8888
try:
server = ThreadingTCPServer((host, port), proxyHandler)
print ''Welcome to the Server HTTP On %s Port %d...'' %(host,port)
server.serve_forever()
except KeyboardInterrupt,e:
logging.error(e)
#print ''^C received, shutting down server''
server.socket.close()
if __name__ == ''__main__'':
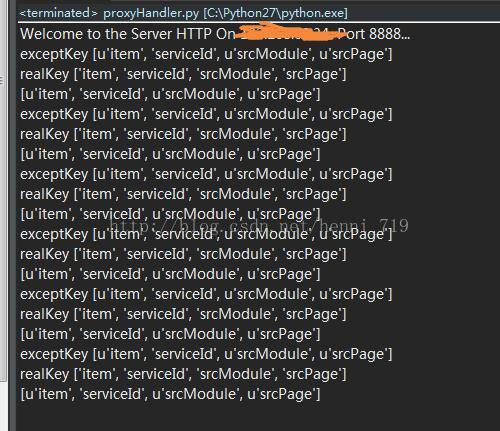
test()4. 运行结果:

.net – IronPython与原始Python的比较.我对第一个有什么期望?
我希望学习Python,但我整天都在.Net作为C#开发人员工作,所以我决定下载并安装IronPython和集成的IronPython工作室.它与原始Python有何不同或相似之处?作为.Net开发人员,我可以期望在.Net环境中运行传统的Python脚本没有问题,或者这只是旧的迁移乌托邦?我能期待什么?
提前致谢.
编辑:Dic. 2009年 – IronPython最近升级到2.6.如果可能,请升级您的答案.
cpython和IronPython之间的差异(和Jython,就其而言,它与IronPython应用了与JVM相同的概念 – Jim Hugunin在他搬到微软之前很久就是Jython的创始人,在那里他发起了IronPython,两个项目现在都茁壮成长)主要是垃圾收集和线程化:IronPython和Jython依赖于他们的底层平台(因此,你得到了标记和清除垃圾收集和免费线程),cpython自己推出(因此,它主要是引用计数GC,带有mark-and – 偶尔扫描一下来解决引用循环,并且线程受全局解释器锁的阻碍).
一个编码良好的Python脚本不依赖于有问题的实现细节(它从不假设GC立即发生,从不假设操作在线程下是原子的,除了少数,如Queue.Queue的方法,明确记录为),但当然有大量的脚本在野外,是草率的.例如:
data = open('x.txt').read()
这会使文件对象保持打开状态,直到它被垃圾收集为止;在引用计数环境中,集合立即发生(因此文件尽快关闭),在标记和扫描环境中并非如此(因此使用此类结构的进程通常会错误地保留一些文件,可能是许多文件,无用地打开比他们需要的更长的时间,浪费系统资源& c).
所以,适当的Python编码是:
# needed in 2.5,unneeded but innocuous in 2.6
from __future__ import with_statement
with open('x.txt') as f: data = f.read()
这确保了在每个实现中立即关闭文件(with语句非常方便;-).
这不会影响您对Python的学习,也不会妨碍重复使用正确编码的Python代码,但是如果您想重用编码很简单的Python代码(特别是在长时间运行的服务器,服务,守护进程和放大器中) ; c)您将来可能需要对其进行一些收紧.那么,顺便说一句,那些想要使用更新更好的cpython版本的人,比如Unladen Swallow& c,一旦这些版本实现更好的垃圾收集机制,摆脱GIL和其他增强功能;希望这已经将Python社区的“文化”改变为更正确,更少草率的编码,但当然还有大量旧的草率代码,所以需要一些小心;-).

2.3 Hive 的数据类型讲解及实际项目中如何使用 python 脚本对数据进行 ETL
一、hive Data Types
https://cwiki. apache. org/confluence/display/HiveLanguageManual+Types
Numeric Types
· TINYINT(1-byte signed integer, from-128 to 127)
· SMALLINT(2-byte signed integer, from-32,768 to 32,767)
· INT(4-byte signed integer, from-2,147,483,648 to 2,147,483,647)
· BIGINT(8-byte signed integer, from-9,223,372,036,854,775,808 to9
· FLOAT(4-byte single precision floating point number)
· DOUBLE(8-byte double precision floating point number)
· DECIMAL
· Introduced in Hive 0.11.0 with a precision of 38 digits
· Hive 0.13.0 introduced user definable precision and scale
Date/Time Types
· TIMESTAMP(Note: Only available starting with Hive 0.8.0)
· DATE(Note: Only available starting with Hive 0.12.0)
String Types
· STRING
· VARCHAR(Note: Only available starting with Hive 0.12.0)
· CHAR(Note: Only available starting with Hive 0.13.0)
Misc Types
· BOOLEAN
· BINARY(Note: Only available starting with Hive 0.8.0)
Complex Types
· arrays: ARRAY<data_type>(Note: negative values and non-constant expressions are allowed as of Hive 0.14.)
· maps: MAP<primitivetype, data_type>(Note: negative values and non-constant expressions are allowed as of Hive 0.14.)
· structs: STRUCT<col_name: datatype [ COMENT col_comment],..>
· union: UNIONTYPE<datatype, data_type,..>(Note: Only available starting with Hive 0.7.0.)二、Primitive Types
·Types are associated with the columns in the tables.The following Primitive types are
supported:
·Integers
·TINYINT-1 byte integer
·SMALLINT-2 byte integer
·INT-4 byte integer
·BIGINT-8 byte integer
·Boolean type
·BOOLEAN-TRUE/FALSE
·Floating point numbers
·FLOAT-single precision
·DOUBLE-Double precision
·String type
·STRING-sequence of characters in a specified character set
https://cwiki.apache.org/confluence/display/Hive/Tutorial三、python 脚本对数据进行 ETL 流程
1)table, load E
2)select, python T
3)sub table L

jfinal 执行sql语句获取的数据与实际数据有差异
以下mysql 语句执行是没有问题的,但是在jfinal中执行,其中int_out.int_quantity, int_out.out_quantity获取的值有异常
SELECT int_out.sn, int_out.operation_date, item.id, item.code, item.name, item.url, item.image_url, item.price, int_out.int_quantity, int_out.out_quantity FROM ((SELECT sn, operation_date, item_id, quantity int_quantity, @out_quantity out_quantity FROM t_storage_item LEFT JOIN t_storage ON t_storage_item.storage_id=t_storage.id) UNION ALL (SELECT sn, operation_date, item_id, @int_quantity int_quantity, quantity out_quantity FROM t_outbound_item LEFT JOIN t_outbound ON t_outbound_item.outbound_id=t_outbound.id)) int_out LEFT JOIN (SELECT item.id, item.code, item_language.name, item.url, image.url image_url, item.market_price price FROM t_item item LEFT JOIN t_item_language item_language ON item.item_language_id=item_language.id LEFT JOIN t_image image ON item.image_id=image.id) item ON int_out.item_id=item.id WHERE 1=1 AND int_out.item_id=2209 ORDER BY int_out.operation_date DESC
获取数据结果示例:
"id":2209,"operation_date":"2014-06-13","sn":"STO1406101746090158946","price":100.0,"image_url":"\/UPLOAD\/2927\/20140401\/1759318591354.jpg","name":"Donod D611 QVGA LCM Phone Coolsandchipset Dual sims dual standby","int_quantity":{},"code":"CP20140402020S","out_quantity":null,"url":"donod-d611-qvga-lcm-phone-coolsand-chipset-dual-sims-dual-standby"
其中int_quantity本应该是1,但是现在是{},求助。
@JFinal

PHP 调用python 脚本实现python功能
本人需要使用php调用
所以使用php中的exec函数。
在exec中第一个参数后添加 2>&1。如果python运行错误,将会把出错信息传递给$arr变量,然后就可以将arr变量的值输出到web端,以便差错。
<?php exec("/usr/bin/python test_english.py $firstname $secondname 2>&1",$arr,$ret);
print ("<xmp>");
print_r($arr);
print ("</xmp>");
echo "<br>" . $ret . "<br>"; ?>
因为本人在python中调用Image.TrueType函数获取字体,结果报出_imaging C module error in python PIL这个错误。只好先全部卸载之前PIL库,然后按照这篇文章mac装PIL库,将PIL库重新装一遍。
以上就介绍了PHP 调用python 脚本实现python功能,包括了方面的内容,希望对PHP教程有兴趣的朋友有所帮助。
今天关于python 代理脚本实现期望数据与实际数据的比对 (V1.0)和python求期望代码的讲解已经结束,谢谢您的阅读,如果想了解更多关于.net – IronPython与原始Python的比较.我对第一个有什么期望?、2.3 Hive 的数据类型讲解及实际项目中如何使用 python 脚本对数据进行 ETL、jfinal 执行sql语句获取的数据与实际数据有差异、PHP 调用python 脚本实现python功能的相关知识,请在本站搜索。
本文标签:




