以上就是给各位分享Python内存管理说明,其中也会对python内存管理进行解释,同时本文还将给你拓展FasterCPython公布面向Python3.13的计划:优化解释器和内存管理、Python
以上就是给各位分享Python内存管理说明,其中也会对python 内存管理进行解释,同时本文还将给你拓展Faster CPython 公布面向 Python 3.13 的计划:优化解释器和内存管理、Python re模块+内存管理、python 内存管理、Python 内存管理和回收等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- Python内存管理说明(python 内存管理)
- Faster CPython 公布面向 Python 3.13 的计划:优化解释器和内存管理
- Python re模块+内存管理
- python 内存管理
- Python 内存管理和回收
")
Python内存管理说明(python 内存管理)
#coding=utf8
''''''
变量和内存管理细节:
1、变量无须事先声明
2、变量无须指定类型
3、程序员不用关心内存管理
4、变量名会被"回收"
5、del语句能够直接释放资源
''''''
from audioop import add
''''''
Python中无需显示声明变量,变量在第一次被赋值时自动声明。
变量只有被创建和赋值后才能被使用。
''''''
#print var #变量var没有定义
var=45
#变量一旦被赋值,就可以通过变量名来访问它
print var
''''''
Python中不但变量名无需实现声明。
对象的类型和内存占用都是运行时确定的。
Python解释承担了内存管理的复杂任务。
''''''
''''''
Python使用引用计数来保持追踪内存中的对象。
Python内部记录着所有使用中的对象有多少引用。
一个内部跟踪变量,称为一个引用计数器。
每个对象拥有引用的个数,称为引用计数。
当对象被创建时,就创建了一个引用计数,当对象不在需要时,引用计数为0,就会被垃圾回收。
''''''
''''''
当对象被创建并赋值给变量时,该对象的引用计数就被设置为1。
当同一个对象的引用又被赋值给其它变量时,
或作为参数传递给函数、方法或实例时,
或者被赋值为一个窗口对象的成员时,
该对象的一个新的引用,或者称作别名,
就被创建(则该对象的引用计数自动加1)。
''''''
Float=3.14 #创建一个浮点对象并将其引用赋值
Some=Float #创建一个指向同一对象的别名Some。Float对象的引用计数加1。
add(Float,Float) #作为参数传递给函数(新的本地引用),引用计数加1。
List=[123,Float] #称为容器对象的一个元素,引用计数加1。
''''''
当对象的引用被销毁时,引用计数会减小。
当引用离开其作用范围时,所有的局部变量都被自动销毁,对象的引用计数页随之减少。
''''''
def add(x,y): #局部变量x,y,当离开函数时,x,y被自动销毁
return x+y
''''''
当变量被赋值给另外一个对象时,原对象的引用计数会自动减1。
''''''
foo=''xyz'' #创建一个字符串对象并将其引用赋值
bar=foo #创建一个指向同一对象的别名bar。引用计数加1。
foo=123 #把整数对象赋值给变量,字符串引用计数减1。
''''''
使用del删除一个变量,也会造成对象引用计数减少;
当一个对象被移出一个窗口对象时,也会造成对象引用计数减少;
''''''
del Some #对象的别名被显示销毁
List.remove(Float) #对象被从一个窗口中移除
del List #窗口对象本身被销毁
''''''
del语句会删除对象的一个引用,语法格式如下:
del obj1[,obj2[,... objN]]
执行一个del语句会产生两个结果:
从现在的命名空间中删除obj、对象的引用计数减1
''''''
''''''
执行del语句会删除对象的最后一个引用,
也就是对象的引用计数减为0,
这会导致该对象从此“无法访问”或“无法抵达”。
该对象就成为垃圾回收机制的回收对象。
任何追踪或调试程序会给一个对象增加一个额外的引用,
这会推迟该对象被回收的时间。
''''''
''''''
不再被使用的内存会被一种称为垃圾收集的机制释放。
垃圾收集器是一块独立的代码,它用来寻址引用计数为0的对象。
它也负责检查虽然引用计数大于0但也应该被销毁的对象。
''''''
''''''
Python的垃圾收集器实际上是一个引用计数器和一个循环垃圾收集器。
用来防止循环引用的产生。
''''''
Faster CPython 公布面向 Python 3.13 的计划:优化解释器和内存管理
2020 年秋,CPython 核心开发者 Mark Shannon 提出了关于 Python 的几个性能改进。这个提议被称为 “香农计划” (Shannon Plan)。Shannon 随后创建了 Faster Cpython 项目,他希望在 4 年的时间里,通过多个版本的更新将 Python 的速度提升 5 倍。
不久之后微软正式加入该计划,该公司支持包括 Mark Shannon、Guido van Rossum 在内的开发人员,致力于「Faster CPython」项目的研究。
近日,Mark Shannon 和 Michael Droettboom 介绍了面向 Python 3.13 的计划。
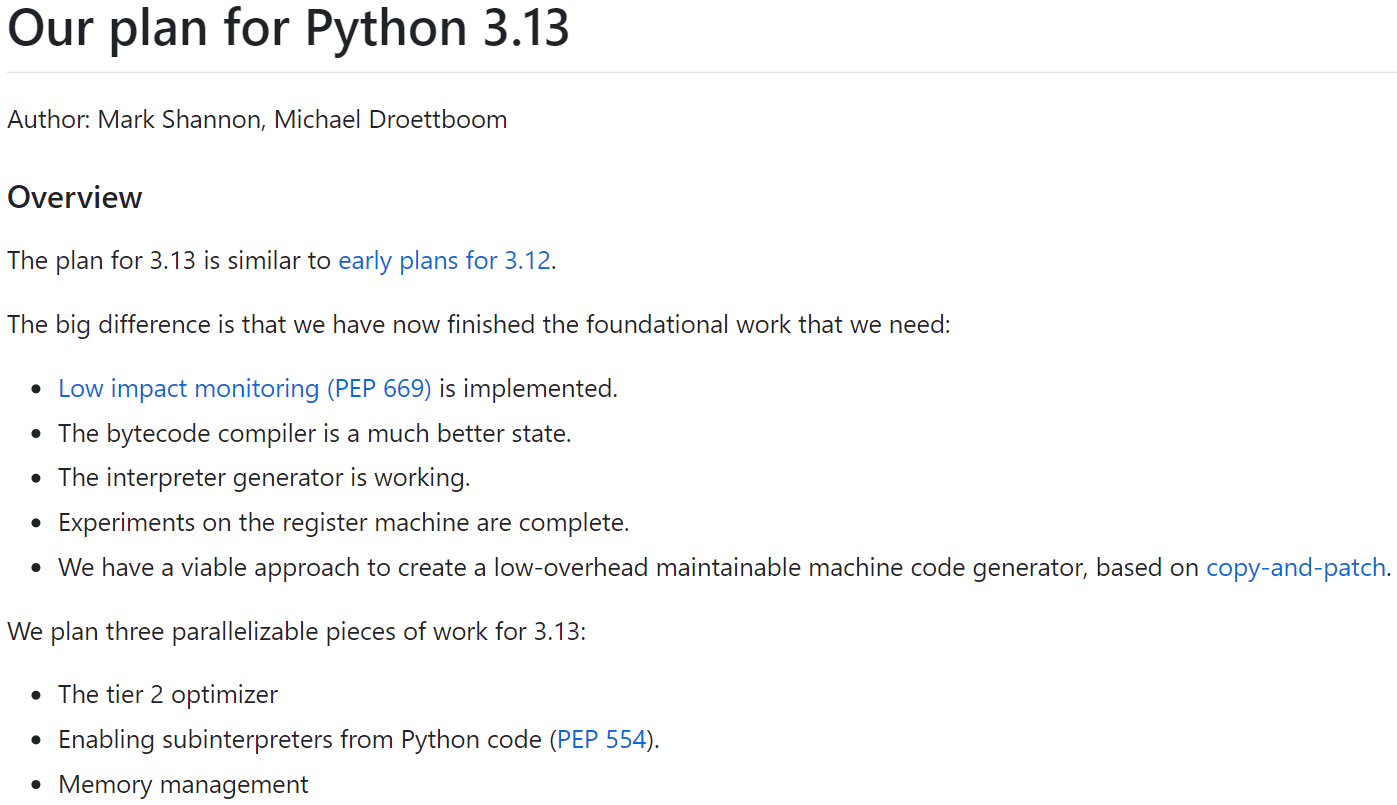
他们提出了三个可并行推进的工作:
- 推出 Tier 2 优化器
- 从 Python 代码中启用子解释器 (PEP 554)
- 优化内存管理
Tier 2 优化器的目标是将花在解释器上的时间减少至少 50%,其工作计划大致如下:
- 让 Tier 2 解释器运转起来
- 生成 superblocks
- 实现基本的 superblock 管理功能
至于从 Python 代码中启用子解释器,这项工作建立在 Python 3.12 中 per-interpreter GIL 的基础上,方便 Python 程序员利用 Python 代码子解释器中更好的并行性(无需编写 C 扩展)。
目前已有针对这项工作的草案:PEP 554。首先需要更新并推动早日获得批准,以便在必要时改变方向。
最后,关于优化内存管理方面。性能分析数据显示,内存管理和循环 GC 花费了相当多的时间。目前的计划是:
- 通过改进数据结构来减少分配
- 花费更少的时间进行循环 GC
延伸阅读
- 微软 Faster CPython 团队:为 Python 社区增添价值
- Python 之父汇报进展:CPython 3.11 比 3.10 快 25%

Python re模块+内存管理
今日内容:
-
1.垃圾回收机制
-
2.re模块
一、垃圾回收机制
在计算机中,不能被程序访问到的数,称之为垃圾
1.1 引用计数
引用计数用来记录值的内存地址被记录的次数
每引用一次就对标记 +1 操作
每释放一次就对标记 -1 操作
当内存中的值的引用计数为 0 时,该值就会被系统的垃圾回收机制回收
1.2 引用计数的问题
# 例子
ls1 = [666]
ls2 = [888]
ls1.append(ls2)
ls2.append(ls1)
打印结果:
[666, [888, [...]]]
[888, [666, [...]]]
# 首先该语句不会执行错误,但是不会一直执行下去,
# python解释器会对结果进行处理
# ps:内存中,赋值操作只是将值的内存地址给拷贝给了变量名
# 通过查找内存地址指向的内容将值找出来。
1.3 标记删除
标记:
标记的过程其实就是,遍历所有的GCRoots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,存放到新的内存空间中
删除:
删除的过程将遍历堆中所有的对象,将之前所有的内容全部清除
1.4 分代回收
分代:指的是根据存活时间来为变量划分不同等级(也就是不同的代)
新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,
如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,
当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),
假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,
节省了扫描的总时间,接下来,青春代中的对象,
也会以同样的方式被移动到老年代中。
也就是等级(代)越高,被垃圾回收机制扫描的频率越低
回收:依然是使用引用计数作为回收的依据
2.正则表达式
2.1 什么是正则
正则就是带语法的字符串,用来匹配目标字符串得到想要的字符串结果
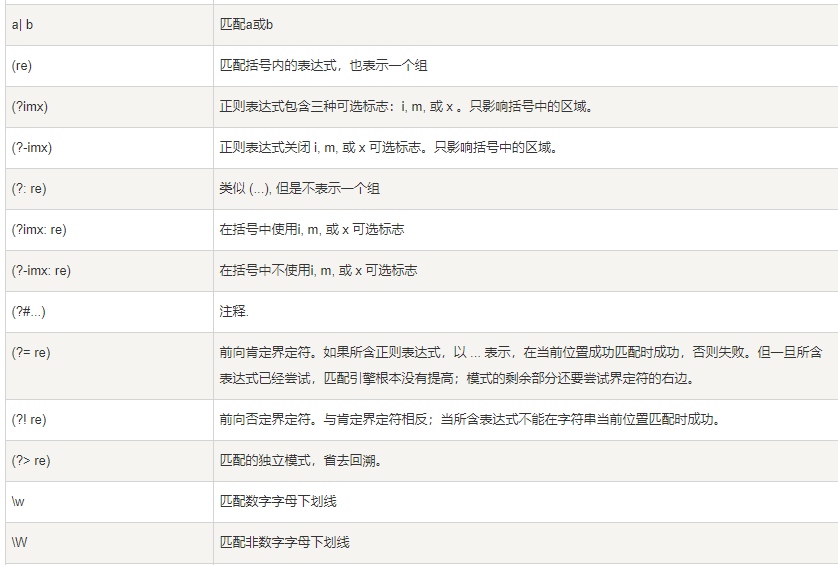
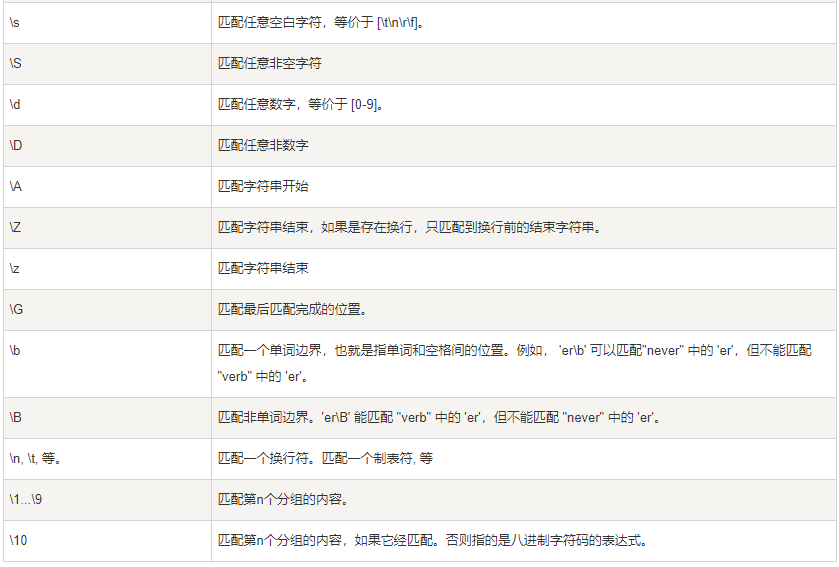
2.2 语法:
1.单个字符
\d == [0-9]
\D == [^0-9]
\w == 字母+数字+_
[0-9A-Za-z] == 所有字母+数字
. == 匹配所有单个字符(刨除换行)
import re
str1 = ''sfio29ia77y12飞范7发哦''
# 匹配单个字符
print(re.findall(r''a'', str1))
# [''a'']
# 匹配数字 == ''\d''
print(re.findall(r''[0-9]'', str1))
# [''2'', ''9'', ''7'', ''7'', ''1'', ''2'', ''7'']
# 匹配非数字 效果等同于 ''\D''
print(re.findall(r''[^0-9]'', str1))
# [''s'', ''f'', ''i'', ''o'', ''i'', ''a'', ''y'', ''飞'', ''范'', ''发'', ''哦'']
print(re.findall(r''\D'', str1))
# [''s'', ''f'', ''i'', ''o'', ''i'', ''a'', ''y'', ''飞'', ''范'', ''发'', ''哦'']
# 匹配字母+数字+_
print(re.findall(r''\w'', str1))
# [''s'', ''f'', ''i'', ''o'', ''2'', ''9'', ''i'', ''a'', ''7'', ''7'', ''y'', ''1'', ''2'', ''飞'', ''范'', ''7'', ''发'', ''哦'']
# 匹配所有字母+数字
print(re.findall(r''[0-9A-Za-z]'', str1))
# [''s'', ''f'', ''i'', ''o'', ''2'', ''9'', ''i'', ''a'', ''7'', ''7'', ''y'', ''1'', ''2'', ''7'']
# 匹配所有单个字符(刨除换行)
print(re.findall(r''.'', str1))
# [''s'', ''f'', ''i'', ''o'', ''2'', ''9'', ''i'', ''a'', ''7'', ''7'', ''y'', ''1'', ''2'', ''飞'', ''范'', ''7'', ''发'', ''哦'']
# 2.多个字符
# zo* == zo{0,}
# zo+ == zo{1,}
# zo? == zo{0,1}
import re
str2 = ''sfizzjioa201jiszzzzzji45fzzja545ijf''
# 匹配多个zz
print(re.findall(r''zz*'', str2))
print(re.findall(r''zz{0,}'', str2))
# [''zz'', ''zzzzz'', ''zz'']
# [''zz'', ''zzzzz'', ''zz'']
# 匹配一次或多次zz
print(re.findall(r''zz+'', str2))
print(re.findall(r''zz{1,}'', str2))
# [''zz'', ''zzzzz'', ''zz'']
# [''zz'', ''zzzzz'', ''zz'']
# 匹配0个或多个zz
print(re.findall(r''zz?'', str2))
print(re.findall(r''zz{0,1}'', str2))
# [''zz'', ''zz'', ''zz'', ''z'', ''zz'']
# [''zz'', ''zz'', ''zz'', ''z'', ''zz'']
# 3.多行
# ^: 以什么开头 $: 以什么结尾,结合 flags=re.M 可以按\n来完成多行匹配
# re.S:将\n也能被.匹配 re.I:不区分大小写
"""
"""
import re
str3 = ''zhangsJIansHUfhn54\nlisi''
# ^ 以什么开头
print(re.findall("^zhang", str3, flags=re.M))
# [''zhang'']
# 4.分组
# 1.从左往右数数 ( 进行编号,自己的分组从1开始,group(0)代表匹配到的目标整体
# 2.(?: ... ):取消所属分组,()就是普通(),可以将里面的信息作为整体包裹,但不产生分组
import re
regexp = re.compile(''(?:(http://)(.+)/)'') # 生成正则对象
target = regexp.match(''http://www.baidu.com/'')
print(target.group(2)) # www.baidu.com
# 5.拆分
print(re.split(''\s'', ''12ssw 456\n789\t000''))
# [''12ssw'', ''456'', ''789'', ''000'']
# 6.替换
# 1.不参与匹配的原样带下
# 2.参与匹配的都会被替换为指定字符串
# 3.在指定字符串值\num拿到具体分组
# 4.其他字符串信息都是原样字符串
print(re.sub(''([a-z]+)(\d+)(.{2})'', r''\2\1'', ''《abc123你好》''))
# 《123abc》


python 内存管理
def func3():
pass
str="1"
mum=1
flo=1.1
print(func3)
print(hex(id(func3)))
print(id(func3))
print(id(str))
print(id(flo))
print(id(mum))
#运行反馈
<function func3 at 0x0000000000B8E730> #此16进制转换为10进制即为11724592
0xb8e730
12117808 #十进制
1697584 #字符串的id总比函数的id小,而且应该有一个固定的界限
1352016 #浮点型的id总比字符串的id小
1761673680 #整型在相对遥远的地方
http://www.cnblogs.com/vamei/p/3232088.html Python深入06 Python的内存管理

Python 内存管理和回收
Python对内存的管理要从三个方面来说
对象的引用机制
Pyhton的内部使用引用计数,来保持内存中的对象,所有对象都有引用计数。
引用计数增加:
一个对象分配一个新名称
将其放入一个容器中(列表、元素或字典)
引用减少的情况
使用del语句将对象的别名显式的销毁
对象的一个别名被赋值给其他对象
对象从一个窗口对象中移除,或,窗口对象本身被销毁
一个本地引用离开了它的作用域
注:获取引用对象:通过sys.getrefcount( )函数获取某个引用的引用数,函数参数实际上创建了一个临时的引用。因此,getrefcount( )所得到的结果,会比期望多1。
垃圾回收
当一个对象的引用计数归零时,它将被垃圾回收机制处理掉。
python的自动垃圾回收
当分配对象的次数和取消分配对象的次数的差值高于某个阈值时,垃圾回收才会启动。
分代回收
python分代回收基本策略:Pyhton认为存活时间越久的对象,越不可能在后面的程序中变成垃圾。(在垃圾回收的过程中,减少“长寿”对象的扫描频率)。
1 Python将所有的对象分为0, 1, 2三代。所有新建的对象都是0代对象。
2 当某一代对象经历过垃圾回收,依然存活,那么它就被归入下一代对象。
3 每次垃圾回收启动时,一定会扫描所有0代对象。如果0代对象经过一定次数 垃圾回收,那么就会启动0代和1代的扫描清理。
4 当1代经历一定次数的垃圾回收后,那么会启动对0,1,2,即对所有对象进行扫描。
5 对于函数set_threshold(),返回(700, 10, 10),700为分配对象和取消分配对象的差值,当差值大于700时,启动垃圾回收;
6 每10次0代垃圾回收,会配合1次1代回收
内存池机制
Python的内存垃圾回收机制,将不用的内存放到内存池而不是返回给操作系统。
1 为了加速Python的执行效率,Python引入内存池机制,用于管理对小块内存的管理和释放。
对于所有小于256个字节的对象都使用pymalloc实现的分配器;而大于这个长度的对象则使用系统的malloc。
2 对于Python对象,如整数、浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。如果你分配又释放了大量的整数,用于缓存这些整数的内存不能再分配给浮点数
我们今天的关于Python内存管理说明和python 内存管理的分享就到这里,谢谢您的阅读,如果想了解更多关于Faster CPython 公布面向 Python 3.13 的计划:优化解释器和内存管理、Python re模块+内存管理、python 内存管理、Python 内存管理和回收的相关信息,可以在本站进行搜索。
本文标签:




